from:http://www.aboutyun.com/thread-11858-1-1.html
еәҸиЁҖ
ScalaжҳҜTwitterдҪҝз”Ёзҡ„дё»иҰҒеә”з”Ёзј–зЁӢиҜӯиЁҖд№ӢдёҖгҖӮеҫҲеӨҡжҲ‘们зҡ„еҹәзЎҖжһ¶жһ„йғҪжҳҜз”ЁScalaеҶҷзҡ„пјҢ
жҲ‘们д№ҹжңүдёҖдәӣеӨ§зҡ„еә“ж”ҜжҢҒжҲ‘们дҪҝз”ЁгҖӮScalaжҳҜдёҖй—Ёй«ҳж•Ҳ并且еәһеӨ§(large)зҡ„иҜӯиЁҖпјҢз»ҸйӘҢж•ҷдјҡжҲ‘们еңЁе®һи·өдёӯиҰҒйқһеёёе°ҸеҝғгҖӮ е®ғжңүд»Җд№Ҳйҷ·йҳұпјҹе“Әдәӣзү№жҖ§жҲ‘们еә”иҜҘжӢҘжҠұпјҢе“Әдәӣеә”иҜҘйҒҝејҖпјҹжҲ‘们д»Җд№Ҳж—¶еҖҷйҮҮз”ЁвҖңзәҜеҮҪж•°ејҸйЈҺж јвҖқпјҢд»Җд№Ҳж—¶еҖҷеә”иҜҘйҒҝе…ҚпјҹжҚўеҸҘиҜқиҜҙпјҡжҲ‘们еҸ‘зҺ°е“ӘдәӣеҸҜд»Ҙй«ҳж•Ҳзҡ„дҪҝз”Ёиҝҷй—ЁиҜӯиЁҖзҡ„ең°ж–№пјҹжң¬жҢҮеҚ—иҜ•еӣҫжҠҠжҲ‘们зҡ„з»ҸйӘҢжҸҗзӮјжҲҗзҹӯж–ҮпјҢжҸҗдҫӣдёҖзі»еҲ—жңҖдҪіе®һи·өгҖӮжҲ‘们дҪҝз”ЁScalaдё»иҰҒеҲӣе»әдёҖдәӣеӨ§е®№йҮҸеҲҶеёғејҸзі»з»ҹжңҚеҠЎвҖ”вҖ”жҲ‘们зҡ„е»әи®®д№ҹеҒҸеҗ‘дәҺжӯӨвҖ”вҖ”дҪҶиҝҷйҮҢзҡ„еӨ§еӨҡе»әи®®д№ҹеә”иҜҘиҮӘ然зҡ„йҖӮз”Ёе…¶д»–зі»з»ҹгҖӮиҝҷдёҚжҳҜжі•еҲҷпјҢдҪҶжңүиҝқдәҺе®ғзҡ„еҒҡжі•йЎ»жңүи¶іеӨҹзҡ„зҗҶз”ұгҖӮ
В
ScalaжҸҗдҫӣеҫҲеӨҡе·Ҙе…·дҪҝиЎЁиҫҫејҸеҸҜд»ҘеҫҲз®ҖжҙҒгҖӮж•Ізҡ„е°‘иҜ»зҡ„е°ұе°‘пјҢиҜ»зҡ„е°‘е°ұиғҪиҜ»зҡ„еҝ«пјҢз®ҖжҙҒдҪҝд»Јз Ғжӣҙжё…жҷ°гҖӮ然иҖҢз®ҖжҙҒд№ҹжҳҜдёҖжҠҠй’қеҷЁ(blunt tool)д№ҹеҸҜиғҪиө·еҲ°зӣёеҸҚзҡ„ж•ҲжһңпјҡеңЁиҖғиҷ‘жӯЈзЎ®жҖ§д№ӢеҗҺпјҢд№ҹиҰҒдёәиҜ»иҖ…зқҖжғігҖӮ
В
йҰ–е…ҲпјҢз”ЁScalaзј–зЁӢпјҢдҪ дёҚжҳҜеңЁеҶҷJavaпјҢHaskellжҲ–PythonпјӣScalaзЁӢеәҸдёҚеғҸиҝҷе…¶дёӯзҡ„д»»дҪ•дёҖз§ҚгҖӮдёәдәҶй«ҳж•Ҳзҡ„дҪҝз”ЁиҜӯиЁҖпјҢдҪ еҝ…йЎ»з”Ёе…¶жңҜиҜӯиЎЁиҫҫдҪ зҡ„й—®йўҳгҖӮ ејәеҲ¶жҠҠJavaзЁӢеәҸиҪ¬жҲҗScalaзЁӢеәҸжҳҜж— з”Ёзҡ„пјҢеӣ дёәеӨ§еӨҡж•°жғ…еҶөдёӢе®ғдјҡдёҚеҰӮеҺҹжқҘзҡ„гҖӮ
В
иҝҷдёҚжҳҜеҜ№Scalaзҡ„дёҖзҜҮд»Ӣз»ҚпјҢжҲ‘们еҒҮе®ҡиҜ»иҖ…зҶҹжӮүиҝҷй—ЁиҜӯиЁҖгҖӮиҝҷе„ҝжңүдәӣеӯҰд№ Scalaзҡ„иө„жәҗпјҡ
иҝҷжҳҜдёҖзҜҮвҖңжҙ»зҡ„вҖқж–ҮжЎЈпјҢжҲ‘们дјҡжӣҙж–°е®ғ,д»ҘеҸҚжҳ жҲ‘们еҪ“еүҚзҡ„жңҖдҪіе®һи·өпјҢдҪҶж ёеҝғзҡ„жҖқжғідёҚеӨӘеҸҜиғҪдјҡеҸҳпјҡ ж°ёиҝңйҮҚи§ҶеҸҜиҜ»жҖ§пјӣеҶҷжіӣеҢ–зҡ„д»Јз ҒдҪҶдёҚиҰҒеңЁзүәзүІжё…жҷ°еәҰпјӣ еҲ©з”Ёз®ҖеҚ•зҡ„иҜӯиЁҖзү№жҖ§зҡ„еЁҒеҠӣпјҢдҪҶйҒҝе…ҚжҷҰ涩йҡҫжҮӮпјҲе°Өе…¶жҳҜзұ»еһӢзі»з»ҹпјүгҖӮжңҖйҮҚиҰҒзҡ„пјҢжҖ»иҰҒж„ҸиҜҶеҲ°дҪ жүҖеҒҡзҡ„еҸ–иҲҚгҖӮдёҖй—ЁжҲҗзҶҹзҡ„(sophisticated)иҜӯиЁҖйңҖиҰҒеӨҚжқӮзҡ„е®һзҺ°пјҢеӨҚжқӮжҖ§еҸҲдә§з”ҹдәҶеӨҚжқӮжҖ§пјҡжҺЁзҗҶпјҢиҜӯд№үпјҢзү№жҖ§д№Ӣй—ҙзҡ„дәӨдә’пјҢд»ҘеҸҠдёҺдҪ еҗҲдҪңиҖ…д№Ӣй—ҙзҡ„зҗҶи§ЈгҖӮеӣ жӯӨеӨҚжқӮжҖ§жҳҜдёәжҲҗзҶҹжүҖдәӨзҡ„зЁҺвҖ”вҖ”дҪ еҝ…йЎ»зЎ®дҝқж•Ҳз”Ёи¶…иҝҮе®ғзҡ„жҲҗжң¬гҖӮ
зҺ©зҡ„ж„үеҝ«гҖӮ
ж јејҸеҢ–
д»Јз Ғж јејҸеҢ–зҡ„规иҢғ вҖ“ еҸӘиҰҒе®ғ们е®һз”ЁпјҢ并дёҚйҮҚиҰҒгҖӮе®ғзҡ„е®ҡд№үеҪўејҸжІЎжңүе…ҲеӨ©зҡ„еҘҪдёҺеқҸпјҢеҮ д№ҺжҜҸдёӘдәәйғҪжңүиҮӘе·ұзҡ„еҒҸеҘҪгҖӮ然иҖҢпјҢеҜ№дәҺдёҖиҮҙзҡ„еә”з”ЁйҮҮз”ЁеҗҢдёҖж јејҸеҢ–规еҲҷзҡ„жҖ»дјҡеўһеҠ еҸҜиҜ»жҖ§гҖӮе·Із»ҸзҶҹжӮүжҹҗз§Қзү№е®ҡйЈҺж јзҡ„иҜ»иҖ…дёҚеҝ…йқһиҰҒеҺ»жҺҢжҸЎеҸҰдёҖеҘ—еҪ“ең°д№ жғҜпјҢжҲ–иҜ‘и§ЈеҸҰдёҖдёӘи§’иҗҪйҮҢзҡ„иҜӯиЁҖиҜӯжі•гҖӮ
иҝҷеҜ№ScalaжқҘиҜҙд№ҹзү№еҲ«йҮҚиҰҒпјҢеӣ дёәе®ғзҡ„иҜӯжі•й«ҳеәҰзҡ„йҮҚеҸ гҖӮдёҖдёӘдҫӢеӯҗжҳҜж–№жі•и°ғз”Ёпјҡж–№жі•и°ғз”ЁеҸҜд»Ҙз”ЁвҖң.вҖқеҗҺиҫ№и·ҹеңҶжӢ¬еҸ·пјҢжҲ–дёҚдҪҝз”ЁвҖң.вҖқеҗҺиҫ№з”Ёз©әж јеҠ дёҚеёҰеңҶжӢ¬еҸ·(й’ҲеҜ№з©әе…ғжҲ–дёҖе…ғж–№жі•)ж–№ејҸи°ғз”ЁгҖӮжӯӨеӨ–пјҢдёҚеҗҢйЈҺж јзҡ„ж–№жі•и°ғз”ЁжҸӯйңІдәҶе®ғ们еңЁиҜӯжі•дёҠдёҚеҗҢзҡ„еҲҶжӯ§(ambiguities)гҖӮеҪ“然дёҖиҮҙзҡ„еә”з”Ёж…ҺйҮҚзҡ„йҖүжӢ©дёҖз»„ж јејҸеҢ–规еҲҷпјҢеҜ№дәәе’ҢжңәеҷЁжқҘиҜҙйғҪдјҡж¶ҲйҷӨеӨ§йҮҸзҡ„жӯ§д№үгҖӮ
з©әж ј
з”ЁдёӨдёӘз©әж јзј©иҝӣгҖӮйҒҝе…ҚжҜҸиЎҢй•ҝеәҰи¶…иҝҮ100еҲ—гҖӮеңЁдёӨдёӘж–№жі•гҖҒзұ»гҖҒеҜ№иұЎе®ҡд№үд№Ӣй—ҙдҪҝз”ЁдёҖдёӘз©әзҷҪиЎҢгҖӮ
е‘ҪеҗҚеҜ№дҪңз”Ёеҹҹиҫғзҹӯзҡ„еҸҳйҮҸдҪҝз”ЁзҹӯеҗҚеӯ—пјҡis, js е’Ң ksзӯүеҸҜеҮәзҺ°еңЁеҫӘзҺҜдёӯгҖӮеҜ№дҪңз”Ёеҹҹиҫғй•ҝзҡ„еҸҳйҮҸдҪҝз”Ёй•ҝеҗҚеӯ—пјҡеӨ–йғЁAPIsеә”иҜҘз”Ёй•ҝзҡ„пјҢдёҚйңҖеҠ д»ҘиҜҙжҳҺдҫҝеҸҜзҗҶи§Јзҡ„еҗҚеӯ—гҖӮдҫӢеҰӮпјҡFuture.collect иҖҢйқһ Future.allдҪҝз”ЁйҖҡз”Ёзҡ„зј©еҶҷпјҢйҒҝејҖйҡҗз§ҳйҡҫжҮӮзҡ„зј©еҶҷпјҡдҫӢеҰӮжҜҸдёӘдәәйғҪзҹҘйҒ“ ok,err, defnзӯүзј©еҶҷзҡ„ж„ҸжҖқпјҢиҖҢsfriжҳҜдёҚеёёз”Ёзҡ„гҖӮдёҚиҰҒеңЁдёҚеҗҢз”ЁйҖ”ж—¶йҮҚз”ЁеҗҢж ·зҡ„еҗҚеӯ—пјҡдҪҝз”Ёval(жіЁпјҡScalaдёӯзҡ„дёҚеҸҜеҸҳзұ»еһӢ)йҒҝе…Қз”Ё `еЈ°жҳҺдҝқз•ҷеӯ—еҸҳйҮҸпјҡз”Ёtypжӣҝд»Ј `type`з”Ёдё»еҠЁиҜӯжҖҒ(active)жқҘе‘ҪеҗҚжңүеүҜдҪңз”Ёзҡ„ж“ҚдҪңпјҡuser.activate()иҖҢйқһ user.setActive()еҜ№жңүиҝ”еӣһеҖјзҡ„ж–№жі•з”ЁеҸҜжҸҸиҝ°зҡ„еҗҚеӯ—пјҡsrc.idDefined иҖҢйқһsrc.definedgettersдёҚйҮҮз”ЁеүҚзјҖgetпјҡз”ЁgetжҳҜеӨҡдҪҷзҡ„: site.countиҖҢйқһsite.getCountдёҚеҝ…йҮҚеӨҚе·Із»Ҹиў«packageжҲ–objectе°ҒиЈ…иҝҮзҡ„еҗҚеӯ—пјҡдҪҝз”Ёпјҡ
- object User {
- В В def get(id: Int): Option[User]
- }
иҖҢйқһпјҡ
- object User {
- В В def getUser(id: Int): Option[User]
- }
зӣёжҜ” get ж–№жі• getUser ж–№жі•дёӯзҡ„UserжҳҜеӨҡдҪҷзҡ„пјҢ并дёҚиғҪжҸҗдҫӣйўқеӨ–зҡ„дҝЎжҒҜгҖӮ
Imports
еҜ№importиЎҢжҢүеӯ—жҜҚйЎәеәҸжҺ’еәҸпјҡиҝҷеҜ№и§Ҷи§үдёҠзҡ„жЈҖжҹҘеҫҲж–№дҫҝпјҢеҜ№иҮӘеҠЁж“ҚдҪңд№ҹеҫҲз®ҖеҚ•гҖӮеҪ“д»ҺдёҖдёӘеҢ…дёӯеј•е…ҘеӨҡдёӘж—¶пјҢз”ЁиҠұжӢ¬еҸ·пјҡimport com.twitter.concurrent.{Broker, Offer}еҪ“еј•е…Ҙи¶…иҝҮ6дёӘж—¶дҪҝз”ЁйҖҡй…Қз¬Ұпјҡe.g.: import com.twitter.concurrent._
дёҚиҰҒиҪ»зҺҮзҡ„дҪҝз”Ё: дёҖдәӣеҢ…еҜје…ҘдәҶеӨӘеӨҡзҡ„еҗҚеӯ—еҪ“еј•е…ҘйӣҶеҗҲзҡ„ж—¶еҖҷпјҢз”Ёimport scala.collections.immutable(дёҚеҸҜеҸҳйӣҶеҗҲ)жҲ–scala.collections.mutable(еҸҜеҸҳйӣҶеҗҲ)дҝ®йҘ°йӣҶеҗҲзұ»еҗҚеҸҜеҸҳйӣҶеҗҲе’ҢдёҚеҸҜеҸҳйӣҶеҗҲжңүеҗҢж ·зҡ„зұ»еҗҚ.дҝ®йҘ°еҗҚи®©иҜ»иҖ…иғҪжҳҺзЎ®зҹҘйҒ“дҪҝз”Ёзҡ„жҳҜе“ӘдёӘеҸҳдҪ“(variant)(e.g. вҖңimmutable.MapвҖң)дёҚиҰҒдҪҝз”ЁжқҘиҮӘе…¶е®ғеҢ…зҡ„зӣёеҜ№еј•з”ЁпјҡйҒҝе…Қ
- import com.twitter
- import concurrent
иҖҢеә”иҜҘз”Ёжё…жҷ°зҡ„пјҡ
- import com.twitter.concurrent
(иҜ‘жіЁпјҢе®һйҷ…дёҠйқўзҡ„importдёҚиғҪзј–иҜ‘йҖҡиҝҮпјҢ第дәҢдёӘimportеә”иҜҘдёәпјҡimport twitter.concurrent еҚіimportдёҖдёӘеҢ…е®һйҷ…жҳҜе®ҡд№үдәҶиҝҷдёӘеҢ…зҡ„еҲ«еҗҚгҖӮ)
е°Ҷimportж”ҫеңЁж–Ү件зҡ„еӨҙйғЁпјҡиҜ»иҖ…еҸҜд»ҘеңЁдёҖдёӘең°ж–№еҸӮиҖғжүҖжңүзҡ„еј•з”ЁгҖӮиҠұжӢ¬еҸ·
иҠұжӢ¬еҸ·з”ЁдәҺеҲӣе»әеӨҚеҗҲиЎЁиҫҫејҸпјҢеӨҚеҗҲиЎЁиҫҫејҸзҡ„иҝ”еӣһеҖјжҳҜжңҖеҗҺдёҖдёӘиЎЁиҫҫејҸгҖӮйҒҝе…ҚеҜ№з®ҖеҚ•зҡ„иЎЁиҫҫејҸйҮҮз”ЁиҠұжӢ¬еҸ·пјӣеҶҷжҲҗпјҡ
В
иҖҢдёҚжҳҜпјҡ
- def square(x: Int) = {
- В В x * x
- }
е°Ҫз®Ўе®ғз”ЁеңЁеҢәеҲҶж–№жі•дҪ“зҡ„иҜӯеҸҘжһ„жҲҗеҫҲиҜұдәәгҖӮ第дёҖз§ҚйҖүжӢ©жӣҙе°‘еҮҢд№ұпјҢжӣҙе®№жҳ“иҜ»гҖӮйҒҝе…ҚиҜӯеҸҘдёҠзҡ„з№Ғж–ҮзјӣиҠӮпјҢйҷӨйқһйңҖиҰҒйҳҗжҳҺгҖӮ
жЁЎејҸеҢ№й…Қ
е°ҪеҸҜиғҪзӣҙжҺҘеңЁеҮҪж•°е®ҡд№үзҡ„ең°ж–№дҪҝз”ЁжЁЎејҸеҢ№й…ҚгҖӮдҫӢеҰӮпјҢдёӢйқўзҡ„еҶҷжі• matchеә”иҜҘиў«жҠҳеҸ иө·жқҘ(collapse)
- list map { item =>
- В В item match {
- В В В В case Some(x) => x
- В В В В case None => default
- В В }
- }
з”ЁдёӢйқўзҡ„еҶҷжі•жӣҝд»Јпјҡ
- list map {
- В В case Some(x) => x
- В В case None => default
- }
е®ғеҫҲжё…жҷ°зҡ„иЎЁиҫҫдәҶ listдёӯзҡ„е…ғзҙ йғҪиў«жҳ е°„пјҢй—ҙжҺҘзҡ„ж–№ејҸи®©дәәдёҚе®№жҳ“жҳҺзҷҪгҖӮ
жіЁйҮҠ
дҪҝз”Ё
ScalaDocжҸҗдҫӣAPIж–ҮжЎЈгҖӮз”ЁдёӢйқўзҡ„йЈҺж јпјҡ
- /**
- В В * ServiceBuilder builds services
- В В * ...
- В В */
иҖҢйқһж ҮеҮҶзҡ„ScalaDocйЈҺж јпјҡ
- /** ServiceBuilder builds services
- В В * ...
- В В */
дёҚиҰҒиҜүиҜёдәҺASCIIз ҒиүәжңҜжҲ–е…¶д»–еҸҜи§ҶеҢ–дҝ®йҘ°гҖӮз”Ёж–ҮжЎЈи®°еҪ•APIsдҪҶдёҚиҰҒж·»еҠ дёҚеҝ…иҰҒзҡ„жіЁйҮҠгҖӮеҰӮжһңдҪ еҸ‘зҺ°дҪ иҮӘе·ұж·»еҠ жіЁйҮҠи§ЈйҮҠдҪ зҡ„д»Јз ҒиЎҢдёәпјҢе…Ҳй—®й—®иҮӘе·ұжҳҜеҗҰеҸҜд»Ҙи°ғж•ҙз»“жһ„д»Ҙи®©е®ғжҳҺжҳҫзҡ„еҸҜд»ҘзңӢеҮәеҒҡдәҶд»Җд№ҲгҖӮзӣёеҜ№дәҺвҖңit works, obviouslyвҖқ жӣҙеҒҸеҗ‘дәҺвҖңobviously it worksвҖқ
зұ»еһӢе’ҢжіӣеһӢ
зұ»еһӢзі»з»ҹзҡ„йҰ–иҰҒзӣ®зҡ„жҳҜжЈҖжөӢзЁӢеәҸй”ҷиҜҜпјҢзұ»еһӢзі»з»ҹжңүж•Ҳзҡ„жҸҗдҫӣдәҶдёҖдёӘйқҷжҖҒжЈҖжөӢзҡ„жңүйҷҗеҪўејҸпјҢе…Ғи®ёжҲ‘们代з ҒдёӯжҳҺзЎ®жҹҗз§Қзұ»еһӢзҡ„еҸҳйҮҸ并且编иҜ‘еҷЁеҸҜд»ҘйӘҢиҜҒгҖӮзұ»еһӢзі»з»ҹеҪ“然д№ҹжҸҗдҫӣдәҶе…¶д»–еҘҪеӨ„пјҢдҪҶй”ҷиҜҜжЈҖжөӢжҳҜд»–еӯҳеңЁзҡ„зҗҶз”ұ(Raison dвҖҷГӘtre)
жҲ‘们еҜ№зұ»еһӢзі»з»ҹзҡ„дҪҝз”ЁеҸҚжҳ дәҶиҝҷдёҖзӣ®ж ҮпјҢдҪҶйңҖиҰҒз•ҷеҝғиҜ»иҖ…пјҡжҳҺжҷәзҡ„дҪҝз”Ёзұ»еһӢеҸҜд»ҘеўһеҠ жё…жҷ°еәҰпјҢиҖҢиҝҮдәҺиҒӘжҳҺеҸӘдјҡдҪҝдәәиҝ·жғ‘пјҲиҜ‘жіЁпјҡеә”иҜҘжҳҜжҢҮиҝҮеҲҶдҪҝз”ЁScalaзҡ„зұ»еһӢжҺЁж–ӯиҖҢзңҒз•ҘдәҶеӨӘеӨҡзұ»еһӢеЈ°жҳҺпјүгҖӮ
Scalaзҡ„ејәеӨ§зұ»еһӢзі»з»ҹжҳҜеӯҰжңҜжҺўзҙўе’Ңе®һи·өе…ұеҗҢжқҘжәҗ(eg.Type level programming in Scala) гҖӮдҪҶиҝҷжҳҜдёҖдёӘиҝ·дәәзҡ„еӯҰжңҜиҜқйўҳ,иҝҷдәӣжҠҖжңҜеҫҲе°‘еңЁеә”з”Ёе’ҢжӯЈејҸдә§е“Ғд»Јз ҒдёӯдҪҝз”ЁгҖӮе®ғ们еә”иҜҘйҒҝе…ҚгҖӮ
иҝ”еӣһзұ»еһӢжіЁи§Ј(annotation)
Scalaе…Ғи®ёзңҒз•Ҙиҝ”еӣһзұ»еһӢпјҢиҖҢжіЁи§ЈжҸҗдҫӣдәҶеҫҲеҘҪзҡ„ж–ҮжЎЈпјҡиҝҷеҜ№publicж–№жі•зү№еҲ«йҮҚиҰҒгҖӮиҖҢдёҖдёӘж–№жі•дёҚйңҖиҰҒеҜ№еӨ–жҡҙйңІе№¶дё”е®ғзҡ„иҝ”еӣһеҖјзұ»еһӢжҳҜжҳҫиҖҢжҳ“и§Ғзҡ„пјҢеҲҷеҸҜд»ҘзӣҙжҺҘзңҒз•ҘгҖӮ
еңЁдҪҝз”Ёж··е…Ҙ(mixin)е®һдҫӢеҢ–еҜ№иұЎж—¶иҝҷдёҖзӮ№е°Өе…¶йҮҚиҰҒпјҢScalaзј–иҜ‘еҷЁдёәиҝҷдәӣеҲӣйҖ дәҶеҚ•зұ»гҖӮдҫӢеҰӮпјҡ
- trait Service
- def make() = new Service {
- В В def getId = 123
- }
дёҠйқўзҡ„makeдёҚйңҖиҰҒе®ҡд№үиҝ”еӣһзұ»еһӢдёәServiceпјӣзј–иҜ‘еҷЁдјҡеҲӣе»әдёҖдёӘеҠ е·ҘиҝҮзҡ„зұ»еһӢ: Object with Service{def getId:Int}. (иҜ‘жіЁ:withжҳҜScalaйҮҢзҡ„mixinзҡ„иҜӯжі•)иҖҢдёҚеҝ…з”ЁдёҖдёӘжҳҫејҸзҡ„жіЁи§Јпјҡ
- def make(): Service = new Service{}
зҺ°еңЁдҪңиҖ…дёҚеҝ…ж”№еҸҳmakeж–№жі•зҡ„е…¬ејҖзұ»еһӢиҖҢйҡҸж„Ҹзҡ„ж··е…Ҙ(mix in) жӣҙеӨҡзҡ„зү№иҙЁ(traits)пјҢдҪҝеҗ‘еҗҺе…је®№еҫҲе®№жҳ“е®һзҺ°гҖӮ
еҸҳеһӢ
еҸҳеһӢ(Variance)еҸ‘з”ҹеңЁжіӣеһӢдёҺеӯҗзұ»еһӢеҢ–(subtyping)з»“еҗҲзҡ„ж—¶еҖҷгҖӮдёҺе®№еҷЁзұ»еһӢзҡ„еӯҗзұ»еһӢеҢ–жңүе…іпјҢе®ғ们е®ҡд№үдәҶеҜ№жүҖеҢ…еҗ«зҡ„зұ»еһӢеҰӮдҪ•еӯҗзұ»еһӢеҢ–гҖӮеӣ дёәScalaжңүеЈ°жҳҺзӮ№еҸҳеһӢ(declaration site variance)жіЁйҮҠпјҢе…¬е…ұеә“зҡ„дҪңиҖ…вҖ”вҖ”зү№еҲ«жҳҜйӣҶеҗҲвҖ”вҖ”еҝ…йЎ»жңүдё°еҜҢзҡ„жіЁйҮҠеҷЁгҖӮиҝҷдәӣжіЁйҮҠеҜ№е…ұдә«д»Јз Ғзҡ„еҸҜз”ЁжҖ§еҫҲйҮҚиҰҒпјҢдҪҶж»Ҙз”Ёд№ҹдјҡеҫҲеҚұйҷ©гҖӮ
дёҚеҸҜеҸҳ(invariants)жҳҜScalaзұ»еһӢзі»з»ҹдёӯй«ҳзә§йғЁеҲҶпјҢдҪҶд№ҹжҳҜеҝ…йЎ»зҡ„дёҖйқўпјҢеә”иҜҘдҪҝз”Ёе№ҝжіӣзҡ„(并且жӯЈзЎ®зҡ„)пјҢе®ғжңүеҠ©дәҺеӯҗзұ»еһӢеҢ–зҡ„еә”з”ЁгҖӮ
дёҚеҸҜеҸҳ(Immutable)йӣҶеҗҲеә”иҜҘжҳҜеҚҸеҸҳзҡ„(covariant)гҖӮж–№жі•жҺҘеҸ—зҡ„зұ»еһӢеә”иҜҘйҖӮеҪ“зҡ„йҷҚзә§(downgrade)пјҡ
- trait Collection[+T] {
- В В def add[U >: T](other: U): Collection[U]
- }
еҸҜеҸҳ(mutable)йӣҶеҗҲеә”иҜҘжҳҜдёҚеҸҜеҸҳзҡ„(invariant). еҚҸеҸҳеҜ№дәҺеҸҜеҸҳйӣҶеҗҲжҳҜе…ёеһӢж— ж•Ҳзҡ„гҖӮиҖғиҷ‘пјҡ
- trait HashSet[+T] {
- В В def add[U >: T](item: U)
- }
дёӢйқўзҡ„зұ»еһӢеұӮзә§пјҡ
- trait Mammal
- trait Dog extends Mammal
- trait Cat extends Mammal
еҰӮжһңжҲ‘зҺ°еңЁжңүдёҖдёӘзӢ—(dog)зҡ„ HashSetпјҡ
еҪ“е®ғдёәдёҖдёӘе“әд№іеҠЁзү©зҡ„SetпјҢеўһеҠ дёҖеҸӘзҢ«(cat)
- val mammals: HashSet[Mammal] = dogs
- mammals.add(new Cat{})
иҝҷе°ҶдёҚеҶҚжҳҜдёҖдёӘеҸӘеӯҳеӮЁзӢ—(dog)зҡ„HashSetпјҒ
зұ»еһӢеҲ«еҗҚ
дҪҝз”Ёзұ»еһӢеҲ«еҗҚеҪ“е®ғ们жҸҗдҫӣдәҶдҫҝжҚ·зҡ„е‘ҪеҗҚжҲ–йҳҗжҳҺж„Ҹеӣҫж—¶пјҢдҪҶеҜ№дәҺиҮӘи§ЈйҮҠзұ»еһӢдёҚиҰҒдҪҝз”Ёзұ»еһӢеҲ«еҗҚгҖӮжҜ”еҰӮ
жҜ”дёӢйқўе®ҡд№үзҡ„еҲ«еҗҚIntMarkerжӣҙжё…жҷ°
- type IntMaker = () => Int
- IntMaker
дҪҶпјҢдёӢйқўзҡ„еҲ«еҗҚ:
- class ConcurrentPool[K, V] {
- В В type Queue = ConcurrentLinkedQueue[V]
- В В type MapВ В = ConcurrentHashMap[K, Queue]
- В В ...
- }
жңүеҠ©дәҺдәӨжөҒзҡ„зӣ®зҡ„并дҪҝеҫ—жӣҙеҠ з®ҖзҹӯгҖӮ
еҪ“дҪҝз”Ёзұ»еһӢеҲ«еҗҚзҡ„ж—¶еҖҷдёҚиҰҒдҪҝз”Ёеӯҗзұ»еһӢеҢ–(subtyping)
- trait SocketFactory extends (SocketAddress => Socket)
SocketFactory жҳҜдёҖдёӘз”ҹдә§Socketзҡ„ж–№жі•гҖӮдҪҝз”ЁдёҖдёӘзұ»еһӢеҲ«еҗҚжӣҙеҘҪпјҡ
- type SocketFactory = SocketAddress => Socket
жҲ‘们зҺ°еңЁеҸҜд»ҘеҜ№ SocketFactoryзұ»еһӢзҡ„еҖј жҸҗдҫӣеҮҪж•°еӯ—йқўйҮҸ(function literals) ,д№ҹеҸҜд»ҘдҪҝз”ЁеҮҪж•°з»„еҗҲпјҡ
- val addrToInet: SocketAddress => Long
- val inetToSocket: Long => Socket
-
- val factory: SocketFactory = addrToInet andThen inetToSocket
зұ»еһӢеҲ«еҗҚйҖҡиҝҮз”Ё package object е°ҶеҗҚеӯ—з»‘е®ҡеңЁйЎ¶еұӮ:
- package com.twitter
- package object net {
- В В type SocketFactory = (SocketAddress) => Socket
- }
жіЁж„Ҹзұ»еһӢеҲ«еҗҚдёҚжҳҜж–°зұ»еһӢвҖ”вҖ”他们зӯүд»·дәҺеңЁиҜӯжі•дёҠзҡ„з”ЁеҲ«еҗҚд»ЈжӣҝдәҶеҺҹзұ»еһӢгҖӮ
йҡҗејҸиҪ¬жҚў
йҡҗејҸиҪ¬жҚўжҳҜзұ»еһӢзі»з»ҹйҮҢдёҖдёӘејәеӨ§зҡ„еҠҹиғҪпјҢдҪҶеә”еҪ“и°Ёж…Һзҡ„дҪҝз”ЁгҖӮе®ғ们жңүеӨҚжқӮзҡ„и§ЈеҶіи§„еҲҷдёәйҡҫдҪ вҖ”вҖ”йҖҡиҝҮз®ҖеҚ•зҡ„иҜҚжі•жЈҖжҹҘвҖ”вҖ”йўҶдјҡе®һйҷ…еҸ‘з”ҹдәҶд»Җд№ҲгҖӮеңЁдёӢйқўзҡ„еңәжҷҜдҪҝз”ЁйҡҗејҸиҪ¬жҚўжҳҜOKзҡ„пјҡ
- жү©еұ•жҲ–еўһеҠ дёҖдёӘScalaйЈҺж јзҡ„йӣҶеҗҲ
- йҖӮй…ҚжҲ–жү©еұ•дёҖдёӘеҜ№иұЎ(pimp my libraryжЁЎејҸпјүпјҲиҜ‘жіЁеҸӮи§Ғпјҡhttp://www.artima.com/weblogs/viewpost.jsp?thread=179766)
- йҖҡиҝҮжҸҗдҫӣзәҰжқҹиҜҒжҚ®жқҘеҠ ејәзұ»еһӢе®үе…ЁгҖӮ(Use to enhance type safety by providing constraint evidence)
- To provide type evidence (typeclassingпјҢдёҚзҹҘжҖҺд№Ҳзҝ»иҜ‘пјҢhaskellдёӯзҡ„жҰӮеҝөпјҢдё»иҰҒйҖҡиҝҮйҡҗејҸиҪ¬жҚўжқҘе®һзҺ°)
- For Manifests (жіЁпјҡManifest[T]еҢ…еҗ«зұ»еһӢTзҡ„иҝҗиЎҢж—¶дҝЎжҒҜ)
еҰӮжһңдҪ еҸ‘зҺ°иҮӘе·ұеңЁз”ЁйҡҗејҸиҪ¬жҚўпјҢжҖ»иҰҒй—®й—®иҮӘе·ұжҳҜеҗҰдёҚдҪҝз”Ёиҝҷз§Қж–№ејҸд№ҹеҸҜд»ҘиҫҫеҲ°зӣ®зҡ„гҖӮ
дёҚиҰҒдҪҝз”ЁйҡҗејҸиҪ¬жҚўеҜ№дёӨдёӘзӣёдјјзҡ„ж•°жҚ®зұ»еһӢеҒҡиҮӘеҠЁиҪ¬жҚў(дҫӢеҰӮпјҢжҠҠlistиҪ¬жҚўдёәstream);жҳҫзӨәзҡ„еҒҡжӣҙеҘҪпјҢеӣ дёәзұ»еһӢжңүдёҚеҗҢзҡ„иҜӯж„ҸпјҢиҜ»иҖ…еә”иҜҘж„ҸиҜҶеҲ°иҝҷз§Қеҗ«д№үгҖӮ иҜ‘жіЁпјҡ 1пјүдёҖдәӣеҚ•иҜҚзҡ„ж„Ҹд№үдёҚеҗҢпјҢдҪҶзҝ»иҜ‘дёәдёӯж–Үж—¶еҸҜиғҪз”Ёзҡ„зӣёдјјзҡ„иҜҚиҜӯпјҢжҜ”еҰӮmutableпјҢ Immutable иҝҷдёӨдёӘзҝ»иҜ‘дёәеҸҜеҸҳе’ҢдёҚеҸҜеҸҳпјҢе®ғ们жҳҜжҢҮж•°жҚ®зҡ„еҸҜеҸҳдёҺдёҚеҸҜеҸҳгҖӮ variance, invariant д№ҹзҝ»иҜ‘дёә еҸҜеҸҳе’ҢдёҚеҸҜеҸҳпјҢпјҲvarianceд№ҹзҝ»иҜ‘дёәвҖңеҸҳеһӢвҖқпјүпјҢе®ғ们жҳҜжҢҮзұ»еһӢзҡ„еҸҜеҸҳдёҺдёҚеҸҜеҸҳгҖӮvarianceжҢҮж”ҜжҢҒеҚҸеҸҳжҲ–йҖҶеҸҳзҡ„зұ»еһӢпјҢinvariantеҲҷзӣёеҸҚгҖӮ
йӣҶеҗҲ
ScalaжңүдёҖдёӘйқһеёёйҖҡз”ЁпјҢдё°еҜҢпјҢејәеӨ§пјҢеҸҜз»„еҗҲзҡ„йӣҶеҗҲеә“пјӣйӣҶеҗҲжҳҜй«ҳйҳ¶зҡ„(high level)并жҡҙйңІдәҶдёҖеӨ§еҘ—ж“ҚдҪңж–№жі•гҖӮеҫҲеӨҡйӣҶеҗҲзҡ„еӨ„зҗҶе’ҢиҪ¬жҚўеҸҜд»Ҙиў«иЎЁиҫҫзҡ„з®ҖжҙҒеҸҲеҸҜиҜ»пјҢдҪҶзІ—еҝғзҡ„з”Ёе®ғзҡ„еҠҹиғҪд№ҹеҜјиҮҙзӣёеҸҚзҡ„з»“жһңгҖӮжҜҸдёӘScalaзЁӢеәҸе‘ҳеә”иҜҘйҳ…иҜ» йӣҶеҗҲи®ҫи®Ўж–ҮжЎЈпјӣйҖҡиҝҮе®ғеҸҜд»ҘеҫҲеҘҪзҡ„жҙһеҜҹйӣҶеҗҲеә“пјҢ并дәҶи§Ји®ҫи®ЎеҠЁжңәгҖӮ
жҖ»дҪҝз”ЁжңҖз®ҖеҚ•зҡ„йӣҶеҗҲжқҘж»Ўи¶ідҪ зҡ„йңҖжұӮ
еұӮзә§
йӣҶеҗҲеә“еҫҲеӨ§пјҡйҷӨдәҶзІҫеҝғи®ҫи®Ўзҡ„еұӮзә§(Hierarchy)вҖ”вҖ”ж №жҳҜ Traversable[T] вҖ”вҖ” еӨ§еӨҡж•°йӣҶеҗҲйғҪжңүдёҚеҸҜеҸҳ(immutable)е’ҢеҸҜеҸҳ(mutable)дёӨз§ҚеҸҳдҪ“гҖӮж— и®әе…¶еӨҚжқӮжҖ§пјҢдёӢйқўзҡ„еӣҫиЎЁеҢ…еҗ«дәҶеҸҜеҸҳе’ҢдёҚеҸҜеҸҳйӣҶеҗҲеұӮзә§зҡ„йҮҚиҰҒе·®ејӮгҖӮ
<ignore_js_op>
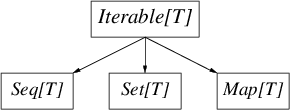
coll.png (2.57 KB, дёӢиҪҪж¬Ўж•°: 0)
дёӢиҪҪйҷ„件 В дҝқеӯҳеҲ°зӣёеҶҢ
2015-3-9 01:02 дёҠдј
В
Iterable[T] жҳҜжүҖжңүеҸҜйҒҚеҺҶзҡ„йӣҶеҗҲпјҢе®ғжҸҗдҫӣдәҶиҝӯд»Јзҡ„ж–№жі•(foreach)гҖӮSeq[T] жҳҜжңүеәҸйӣҶеҗҲпјҢSet[T]жҳҜж•°еӯҰдёҠзҡ„йӣҶеҗҲ(ж— еәҸдё”дёҚйҮҚеӨҚ)пјҢMap[T]жҳҜе…іиҒ”ж•°з»„пјҢд№ҹжҳҜж— еәҸзҡ„гҖӮ
йӣҶеҗҲзҡ„дҪҝз”Ё
дјҳе…ҲдҪҝз”ЁдёҚеҸҜеҸҳйӣҶеҗҲ.дёҚеҸҜеҸҳйӣҶеҗҲйҖӮз”ЁдәҺеӨ§еӨҡж•°жғ…еҶөпјҢи®©зЁӢеәҸжҳ“дәҺзҗҶи§Је’ҢжҺЁж–ӯпјҢеӣ дёәе®ғ们жҳҜеј•з”ЁйҖҸжҳҺзҡ„( referentially transparent )еӣ жӯӨзјәзңҒд№ҹжҳҜзәҝзЁӢе®үе…Ёзҡ„гҖӮ
дҪҝз”ЁеҸҜеҸҳйӣҶеҗҲж—¶пјҢжҳҺзЎ®зҡ„еј•з”ЁеҸҜеҸҳйӣҶеҗҲзҡ„е‘ҪеҗҚз©әй—ҙгҖӮдёҚиҰҒз”ЁдҪҝз”Ёimport scala.collection.mutable._ 然еҗҺеј•з”Ё Set пјҢеә”иҜҘз”ЁдёӢйқўзҡ„ж–№ејҸжӣҝд»Јпјҡ
- import scala.collections.mutable
- val set = mutable.Set()
иҝҷж ·жӣҙжҳҺзЎ®еңЁдҪҝз”ЁдёҖдёӘеҸҜеҸҳйӣҶеҗҲгҖӮ
дҪҝз”ЁйӣҶеҗҲзұ»еһӢзјәзңҒзҡ„жһ„йҖ еҮҪж•°гҖӮжҜҸеҪ“дҪ йңҖиҰҒдёҖдёӘжңүеәҸзҡ„еәҸеҲ—(дёҚйңҖиҰҒй“ҫиЎЁиҜӯд№ү)пјҢз”Ё Seq() зӯүиҜёеҰӮжӯӨзұ»зҡ„ж–№жі•жһ„йҖ пјҡ
- val seq = Seq(1, 2, 3)
- val set = Set(1, 2, 3)
- val map = Map(1 -> "one", 2 -> "two", 3 -> "three")
иҝҷз§ҚйЈҺж јд»ҺиҜӯж„ҸдёҠеҲҶзҰ»дәҶйӣҶеҗҲдёҺе®ғзҡ„е®һзҺ°пјҢи®©йӣҶеҗҲеә“дҪҝз”ЁжӣҙйҖӮеҪ“зҡ„зұ»еһӢпјҡдҪ йңҖиҰҒMapпјҢиҖҢдёҚжҳҜеҝ…йЎ»дёҖдёӘзәўй»‘ж ‘(Red-Black TreeпјҢжіЁпјҡзәўй»‘ж ‘TreeMapжҳҜMapзҡ„е®һзҺ°иҖ…)
жӯӨеӨ–пјҢй»ҳи®Өзҡ„жһ„йҖ еҮҪж•°йҖҡеёёдҪҝз”Ёдё“жңүзҡ„иЎЁиҫҫејҸпјҢдҫӢеҰӮпјҡMap() е°ҶдҪҝз”Ёжңү3дёӘжҲҗе‘ҳзҡ„еҜ№иұЎ(дё“з”Ёзҡ„Map3зұ»)жқҘжҳ е°„3дёӘkeysгҖӮ
дёҠйқўзҡ„жҺЁи®әжҳҜпјҡеңЁдҪ иҮӘе·ұзҡ„ж–№жі•е’Ңжһ„йҖ еҮҪж•°йҮҢпјҢйҖӮеҪ“зҡ„жҺҘеҸ—жңҖе®Ҫжіӣзҡ„йӣҶеҗҲзұ»еһӢгҖӮйҖҡеёёеҸҜд»ҘеҪ’з»“дёәдёҖдёӘ: Iterable, Seq, Set, жҲ– Map.еҰӮжһңдҪ зҡ„ж–№жі•йңҖиҰҒдёҖдёӘ sequenceпјҢдҪҝз”Ё Seq[T]пјҢиҖҢдёҚжҳҜList[T]
йЈҺж ј
еҮҪж•°ејҸзј–зЁӢйј“еҠұдҪҝз”ЁжөҒж°ҙзәҝиҪ¬жҚўе°ҶдёҖдёӘдёҚеҸҜеҸҳзҡ„йӣҶеҗҲеЎ‘йҖ дёәжғіиҰҒзҡ„з»“жһңгҖӮиҝҷеёёеёёдјҡжңүйқһеёёз®ҖжҳҺзҡ„ж–№жЎҲпјҢдҪҶд№ҹе®№жҳ“иҝ·жғ‘иҜ»иҖ…вҖ”вҖ”еҫҲйҡҫйўҶжӮҹдҪңиҖ…зҡ„ж„ҸеӣҫпјҢжҲ–и·ҹиёӘжүҖжңүйҡҗеҗ«зҡ„дёӯй—ҙз»“жһңгҖӮдҫӢеҰӮпјҢжҲ‘们жғіиҰҒд»ҺдёҖз»„жҠ•зҘЁз»“жһң(иҜӯиЁҖпјҢзҘЁж•°)дёӯз»ҹи®ЎдёҚеҗҢзЁӢеәҸиҜӯиЁҖзҡ„зҘЁж•°е№¶жҢүз…§еҫ—зҘЁзҡ„йЎәеәҸжҳҫзӨәпјҡ
- val votes = Seq(("scala", 1), ("java", 4), ("scala", 10), ("scala", 1), ("python", 10))
- val orderedVotes = votes
- В В .groupBy(_._1)
- В В .map { case (which, counts) =>
- В В В В (which, counts.foldLeft(0)(_ + _._2))
- В В }.toSeq
- В В .sortBy(_._2)
- В В .reverse
дёҠйқўзҡ„д»Јз Ғз®ҖжҙҒ并且жӯЈзЎ®пјҢдҪҶеҮ д№ҺжҜҸдёӘиҜ»иҖ…йғҪдёҚеҘҪзҗҶи§ЈдҪңиҖ…зҡ„еҺҹжң¬ж„ҸеӣҫгҖӮдёҖдёӘзӯ–з•ҘжҳҜеЈ°жҳҺдёӯй—ҙз»“жһңе’ҢеҸӮж•°пјҡ
- val votesByLang = votes groupBy { case (lang, _) => lang }
- val sumByLang = votesByLang map { case (lang, counts) =>
- В В val countsOnly = counts map { case (_, count) => count }
- В В (lang, countsOnly.sum)
- }
- val orderedVotes = sumByLang.toSeq
- В В .sortBy { case (_, count) => count }
- В В .reverse
д»Јз Ғд№ҹеҗҢж ·з®ҖжҙҒпјҢдҪҶжӣҙжё…жҷ°зҡ„иЎЁиҫҫдәҶиҪ¬жҚўзҡ„еҸ‘з”ҹ(йҖҡиҝҮе‘ҪеҗҚдёӯй—ҙеҖј)пјҢе’ҢжӯЈеңЁж“ҚдҪңзҡ„ж•°жҚ®зҡ„з»“жһ„(йҖҡиҝҮе‘ҪеҗҚеҸӮж•°)гҖӮеҰӮжһңдҪ жӢ…еҝғиҝҷз§ҚйЈҺж јжұЎжҹ“дәҶе‘ҪеҗҚз©әй—ҙпјҢз”ЁеӨ§жӢ¬еҸ·{}жқҘе°ҶиЎЁиҫҫејҸеҲҶз»„:
- val orderedVotes = {
- В В val votesByLang = ...
- В В ...
- }
жҖ§иғҪ
й«ҳйҳ¶йӣҶеҗҲеә“пјҲйҖҡеёёд№ҹдјҙйҡҸй«ҳйҳ¶жһ„йҖ )дҪҝжҺЁзҗҶжҖ§иғҪжӣҙеҠ еӣ°йҡҫпјҡдҪ и¶ҠеҒҸзҰ»зӣҙжҺҘжҢҮзӨәи®Ўз®—жңәвҖ”вҖ”еҚіе‘Ҫд»ӨејҸйЈҺж јвҖ”вҖ”е°ұи¶ҠйҡҫеҮҶзЎ®йў„жөӢдёҖж®өд»Јз Ғзҡ„жҖ§иғҪеҪұе“ҚгҖӮ然иҖҢжҺЁзҗҶжӯЈзЎ®жҖ§йҖҡеёёеҫҲе®№жҳ“пјӣеҸҜиҜ»жҖ§д№ҹжҳҜеҠ ејәзҡ„гҖӮеңЁjavaиҝҗиЎҢж—¶дҪҝз”ЁScalaдҪҝеҫ—жғ…еҶөжӣҙеҠ еӨҚжқӮпјҢScalaеҜ№дҪ йҡҗи—ҸдәҶиЈ…з®ұ(boxing)/жӢҶз®ұ(unboxing)ж“ҚдҪңпјҢеҸҜиғҪеј•еҸ‘дёҘйҮҚзҡ„жҖ§иғҪжҲ–еҶ…еӯҳз©әй—ҙй—®йўҳгҖӮ
еңЁе…іжіЁдәҺдҪҺеұӮж¬Ўзҡ„з»ҶиҠӮд№ӢеүҚ,зЎ®дҝқдҪ дҪҝз”Ёзҡ„йӣҶеҗҲйҖӮеҗҲдҪ гҖӮ зЎ®дҝқдҪ зҡ„ж•°жҚ®з»“жһ„жІЎжңүдёҚжңҹжңӣзҡ„жёҗиҝӣеӨҚжқӮеәҰгҖӮеҗ„з§ҚScalaйӣҶеҗҲзҡ„еӨҚжқӮжҖ§жҸҸиҝ°еңЁ
иҝҷе„ҝгҖӮ
жҖ§иғҪдјҳеҢ–зҡ„第дёҖжқЎеҺҹеҲҷжҳҜзҗҶи§ЈдҪ зҡ„еә”з”Ёдёәд»Җд№Ҳиҝҷд№Ҳж…ўгҖӮдёҚиҰҒдҪҝз”Ёз©әж•°жҚ®ж“ҚдҪңгҖӮеңЁжү§иЎҢеүҚеҲҶжһҗ
[1]дҪ зҡ„еә”з”ЁгҖӮе…іжіЁзҡ„第дёҖзӮ№жҳҜзғӯеҫӘзҺҜ(hot loops) е’ҢеӨ§ж•°жҚ®з»“жһ„.иҝҮеәҰе…іжіЁдјҳеҢ–йҖҡеёёжҳҜжөӘиҙ№зІҫеҠӣгҖӮи®°дҪҸKnuth(й«ҳеҫ·зәі)зҡ„ж јиЁҖпјҡвҖңиҝҮж—©дјҳеҢ–жҳҜдёҮжҒ¶д№ӢжәҗвҖқгҖӮ
еҰӮжһңжҳҜйңҖиҰҒжӣҙй«ҳжҖ§иғҪжҲ–иҖ…з©әй—ҙж•ҲзҺҮзҡ„еңәжҷҜпјҢйҖҡеёёжӣҙйҖӮеҗҲдҪҝз”ЁдҪҺзә§зҡ„йӣҶеҗҲгҖӮеҜ№еӨ§еәҸеҲ—дҪҝз”Ёж•°з»„жӣҝд»ЈеҲ—иЎЁ(List) (дёҚеҸҜеҸҳVectorжҸҗдҫӣдәҶдёҖдёӘжҢҮз§°йҖҸжҳҺзҡ„иҪ¬жҚўеҲ°ж•°з»„зҡ„жҺҘеҸЈ) пјҢ并иҖғиҷ‘дҪҝз”Ёbuffersжӣҝд»ЈзӣҙжҺҘеәҸеҲ—зҡ„жһ„йҖ жқҘжҸҗй«ҳжҖ§иғҪгҖӮ
JavaйӣҶеҗҲ
дҪҝз”Ё scala.collection.JavaConverters дёҺjavaйӣҶеҗҲдәӨдә’гҖӮжңүдёҖзі»еҲ—зҡ„йҡҗејҸзҡ„з”ЁдәҺJavaдёҺScalaзҡ„иҪ¬жҚўгҖӮжңүеҠ©дәҺиҜ»иҖ…пјҢдҪҝз”ЁдёӢйқўзҡ„ж–№ејҸзЎ®дҝқиҪ¬жҚўжҳҜжҳҫејҸзҡ„пјҡ
- import scala.collection.JavaConverters._
-
- val list: java.util.List[Int] = Seq(1,2,3,4).asJava
- val buffer: scala.collection.mutable.Buffer[Int] = list.asScala
并еҸ‘
зҺ°д»ЈжңҚеҠЎжҳҜй«ҳеәҰ并еҸ‘зҡ„вҖ”вҖ” жңҚеҠЎеҷЁйҖҡеёёжҳҜеңЁ10вҖ“100з§’еҶ…并еҲ—дёҠеҚғдёӘеҗҢж—¶ж“ҚдҪңвҖ”вҖ”еӨ„зҗҶйҡҗеҗ«зҡ„еӨҚжқӮжҖ§жҳҜеҲӣдҪңеҒҘеЈ®зі»з»ҹиҪҜ件зҡ„дёӯеҝғдё»йўҳгҖӮ
*зәҝзЁӢжҸҗдҫӣдәҶдёҖз§ҚиЎЁиҫҫ并еҸ‘зҡ„ж–№ејҸпјҡе®ғ们з»ҷдҪ зӢ¬з«Ӣзҡ„пјҢе Ҷе…ұдә«зҡ„(heap-sharing)з”ұж“ҚдҪңзі»з»ҹи°ғеәҰзҡ„жү§иЎҢдёҠдёӢж–ҮгҖӮ然иҖҢпјҢеңЁjavaйҮҢзәҝзЁӢзҡ„еҲӣе»әжҳҜжҳӮиҙөзҡ„пјҢжҳҜдёҖз§Қеҝ…йЎ»жүҳз®Ўзҡ„иө„жәҗпјҢйҖҡеёёеҖҹеҠ©дәҺзәҝзЁӢжұ гҖӮиҝҷеҜ№зЁӢеәҸе‘ҳеҲӣйҖ дәҶйўқеӨ–зҡ„еӨҚжқӮпјҢд№ҹйҖ жҲҗй«ҳеәҰзҡ„иҖҰеҗҲпјҡеҫҲйҡҫд»ҺжүҖдҪҝз”Ёзҡ„еҹәзЎҖиө„жәҗдёӯеҲҶзҰ»еә”з”ЁйҖ»иҫ‘гҖӮ
иҝҷз§ҚеӨҚжқӮеәҰе°Өе…¶жҳҺжҳҫеҪ“еҲӣе»әй«ҳеәҰеҲҶж•Ј(fan-out)зҡ„жңҚеҠЎж—¶пјҡ жҜҸдёӘиҫ“е…ҘиҜ·жұӮеҜјиҮҙдёҖеӨ§жү№еҜ№еҸҰдёҖеұӮзі»з»ҹзҡ„иҜ·жұӮгҖӮеңЁиҝҷдәӣзі»з»ҹдёӯпјҢзәҝзЁӢжұ еҝ…йЎ»иў«жүҳз®Ўд»Ҙдҫҝж №жҚ®жҜҸдёҖеұӮиҜ·жұӮзҡ„жҜ”дҫӢжқҘе№іиЎЎпјҡз®ЎзҗҶдёҚе–„зҡ„зәҝзЁӢжұ дјҡжё—е…ҘеҲ°еҸҰдёҖдёӘйҮҢ(bleeds into another)гҖӮ
дёҖдёӘеҒҘеЈ®зі»з»ҹеҝ…йЎ»иҖғиҷ‘и¶…ж—¶е’ҢеҸ–ж¶ҲпјҢдёӨиҖ…йғҪйңҖиҰҒеј•е…ҘеҸҰдёҖдёӘвҖңжҺ§еҲ¶вҖқзәҝзЁӢпјҢдҪҝй—®йўҳжӣҙеҠ еӨҚжқӮгҖӮжіЁж„ҸиӢҘзәҝзЁӢеҫҲе»үд»·иҝҷдәӣй—®йўҳд№ҹе°Ҷдјҡиў«еүҠејұпјҡдёҚеҶҚйңҖиҰҒдёҖдёӘзәҝзЁӢжұ пјҢи¶…ж—¶зҡ„зәҝзЁӢе°Ҷиў«дёўејғпјҢдёҚеҶҚйңҖиҰҒйўқеӨ–зҡ„иө„жәҗз®ЎзҗҶгҖӮ
еӣ жӯӨпјҢиө„жәҗз®ЎзҗҶеҚұе®ідәҶжЁЎеқ—гҖӮ
Future
дҪҝз”ЁFutureз®ЎзҗҶ并еҸ‘гҖӮе®ғ们е°Ҷ并еҸ‘ж“ҚдҪңд»Һиө„жәҗз®ЎзҗҶйҮҢи§ЈиҖҰеҮәжқҘпјҡдҫӢеҰӮпјҢFinagle(иҜ‘жіЁпјҡtwitterзҡ„дёҖдёӘжЎҶжһ¶)д»Ҙжңүж•Ҳзҡ„ж–№ејҸеңЁе°‘йҮҸзәҝзЁӢдёҠе®һзҺ°еӨҚз”Ё(multiplexes)гҖӮScalaжңүдёҖдёӘиҪ»йҮҸзә§зҡ„й—ӯеҢ…еӯ—йқўиҜӯжі•(literal syntax)пјҢжүҖд»ҘFuturesеј•е…ҘдәҶеҫ®дёҚеҸҜеҜҹзҡ„иҜӯжі•ејҖй”ҖпјҢе®ғ们жҲҗдёәеҫҲеӨҡзЁӢеәҸе‘ҳзҡ„第дәҢжң¬иғҪ(second nature)
Futuresе…Ғи®ёзЁӢеәҸе‘ҳз”ЁдёҖз§ҚеЈ°жҳҺйЈҺж јпјҢеҸҜжү©е……зҡ„пјҢжңүеӨ„зҗҶеӨұиҙҘеҺҹеҲҷзҡ„пјҢжқҘиЎЁиҫҫ并еҸ‘и®Ўз®—гҖӮиҝҷдәӣзү№жҖ§дҪҝжҲ‘们зӣёдҝЎе®ғ们е°Өе…¶йҖӮеҗҲеңЁеҮҪж•°ејҸеҸҳжҲҗдёӯз”ЁпјҢиҝҷд№ҹжҳҜйј“еҠұдҪҝз”Ёзҡ„йЈҺж јгҖӮ
*жӣҙж„ҝж„Ҹж”№йҖ futureдёәиҮӘе·ұеҲӣе»әзҡ„гҖӮFutureзҡ„иҪ¬жҚў(transformations)зЎ®дҝқеӨұиҙҘдјҡдј ж’ӯпјҢеҸҜд»ҘйҖҡиҝҮдҝЎеҸ·еҸ–ж¶ҲпјҢеҜ№дәҺзЁӢеәҸе‘ҳжқҘиҜҙдёҚеҝ…иҖғиҷ‘javaеҶ…еӯҳжЁЎеһӢзҡ„еҗ«д№үгҖӮз”ҡиҮідёҖдёӘд»”з»Ҷзҡ„зЁӢеәҸе‘ҳдјҡеҶҷеҮәдёӢйқўзҡ„д»Јз ҒпјҢйЎәеәҸзҡ„еҸ‘еҮә10ж¬ЎRPCиҜ·жұӮжү“еҚ°з»“жһңпјҡ
В
- val p = new Promise[List[Result]]
- var results: List[Result] = Nil
- def collect() {
- В В doRpc() onSuccess { result =>
- В В В В results = result :: results
- В В В В if (results.length < 10)
- В В В В collect()
- В В В В else
- В В В В p.setValue(results)
- В В } onFailure { t =>
- В В В В p.setException(t)
- В В }
- }
-
- collect()
- p onSuccess { results =>
- В В printf("Got results %s\n", results.mkString(", "))
- }
В
зЁӢеәҸе‘ҳдёҚеҫ—дёҚзЎ®дҝқRPCеӨұиҙҘжҳҜеҸҜдј ж’ӯзҡ„пјҢд»Јз Ғж•ЈеёғеңЁжҺ§еҲ¶жөҒзЁӢдёӯпјӣзіҹзі•зҡ„жҳҜпјҢд»Јз ҒжҳҜй”ҷиҜҜзҡ„пјҒ жІЎжңүеЈ°жҳҺresultsжҳҜvolatileпјҢжҲ‘们дёҚиғҪзЎ®дҝқresultsжҜҸж¬Ўиҝӯд»ЈдјҡдҝқжҢҒеүҚдёҖж¬ЎеҖјгҖӮJavaеҶ…еӯҳжЁЎеһӢжҳҜдёҖдёӘзӢЎзҢҫзҡ„йҮҺе…ҪпјҢе№ёеҘҪжҲ‘们еҸҜд»ҘйҒҝејҖиҝҷдәӣйҷ·йҳұпјҢйҖҡиҝҮз”ЁеЈ°жҳҺејҸйЈҺж ј(
- def collect(results: List[Result] = Nil): Future[List[Result]] =
- В В doRpc() flatMap { result =>
- В В В В if (results.length < 9)
- В В В В collect(result :: results)
- В В В В else
- В В В В result :: results
- В В }
-
- collect() onSuccess { results =>
- В В printf("Got results %s\n", results.mkString(", "))
- }
жҲ‘们用flatMapйЎәеәҸзҡ„ж“ҚдҪңпјҢжҠҠжҲ‘们еӨ„зҗҶдёӯзҡ„з»“жһңйў„иҝҪеҠ (prepend)еҲ°listдёӯгҖӮиҝҷжҳҜдёҖдёӘйҖҡз”Ёзҡ„еҮҪж•°ејҸзј–зЁӢзҡ„д№ иҜӯзҡ„FuturesиҜ‘жң¬гҖӮиҝҷжҳҜжӯЈзЎ®зҡ„пјҢдёҚд»…йңҖиҰҒзҡ„вҖңе’’иҜӯвҖқ(boilerplate)еҸҜд»ҘеҮҸе°‘пјҢжҳ“еҮәй”ҷзҡ„еҸҜиғҪжҖ§д№ҹдјҡеҮҸе°‘пјҢ并且иҜ»иө·жқҘжӣҙеҘҪгҖӮ
*Futureз»„еҗҲеӯҗ(combinators)зҡ„дҪҝз”ЁгҖӮеҪ“ж“ҚдҪңеӨҡдёӘfuturesж—¶пјҢFuture.select,Future.join,е’ҢFuture.collectеә”иҜҘиў«з»„еҗҲзј–еҶҷеҮәйҖҡз”ЁжЁЎејҸгҖӮ
йӣҶеҗҲ
并еҸ‘йӣҶеҗҲзҡ„дё»йўҳе……ж»ЎзқҖж„Ҹи§ҒгҖҒеҫ®еҰҷ(subtleties)гҖҒж•ҷжқЎгҖҒжҒҗжғ§/дёҚзЎ®е®ҡ/жҖҖз–‘(FUD)гҖӮеңЁеӨ§еӨҡе®һйҷ…еңәжҷҜйғҪдёҚеӯҳеңЁй—®йўҳпјҡжҖ»жҳҜе…Ҳз”ЁжңҖз®ҖеҚ•,жңҖж— иҒҠпјҢжңҖж ҮеҮҶзҡ„йӣҶеҗҲи§ЈеҶій—®йўҳгҖӮ еңЁдҪ зҹҘйҒ“дёҚиғҪдҪҝз”ЁsynchronizedеүҚдёҚиҰҒеҺ»з”ЁдёҖдёӘ并еҸ‘йӣҶеҗҲпјҡJVMжңүзқҖеӨҚжқӮиҖҒз»ғзҡ„жүӢж®өжқҘеҲ¶йҖ еҗҢжӯҘж¬әйӘ—(synchronization cheap)пјҢжүҖд»Ҙе®ғзҡ„ж•ҲзҺҮиғҪи®©дҪ жғҠ讶гҖӮ
еҰӮжһңдёҖдёӘдёҚеҸҜеҸҳ(immutable)йӣҶеҗҲеҸҜиЎҢпјҢе°ұе°ҪеҸҜиғҪз”ЁдёҚеҸҜеҸҳйӣҶеҗҲвҖ”вҖ”е®ғ们жҳҜжҢҮз§°йҖҸжҳҺзҡ„(referentially transparent)пјҢжүҖд»Ҙе®ғ们用еңЁе№¶еҸ‘дёҠдёӢж–Үзҡ„зҗҶз”ұжҳҜз®ҖеҚ•гҖӮдёҚеҸҜеҸҳйӣҶеҗҲзҡ„ж”№еҸҳйҖҡеёёз”Ёжӣҙж–°еј•з”ЁеҲ°еҪ“еүҚеҖј(дёҖдёӘvarеҚ•е…ғжҲ–дёҖдёӘAtomicReference)гҖӮеҝ…йЎ»е°ҸеҝғжӯЈзЎ®зҡ„еә”з”ЁпјҡеҺҹеӯҗеһӢзҡ„(atomics)еҝ…йЎ»йҮҚиҜ•(retried)пјҢеҸҳйҮҸ(varзұ»еһӢзҡ„)еҝ…йЎ»еЈ°жҳҺдёәvolatileд»ҘдҝқиҜҒе®ғ们еҸ‘еёғ(published)еҲ°е®ғ们зҡ„зәҝзЁӢгҖӮ
еҸҜеҸҳзҡ„并еҸ‘йӣҶеҗҲжңүзқҖеӨҚжқӮзҡ„иҜӯд№үпјҢеҲ©з”ЁjavaеҶ…еӯҳжЁЎеһӢзҡ„еҫ®еҰҷзҡ„дёҖйқўпјҢжүҖд»ҘеңЁдҪ дҪҝз”ЁеүҚзЎ®е®ҡдҪ зҗҶи§Је®ғзҡ„еҗ«д№үвҖ”вҖ”е°Өе…¶еҜ№дәҺеҸ‘еёғжӣҙж–°(ж–°е…¬ејҖж–№жі•)гҖӮеҗҢжӯҘзҡ„йӣҶеҗҲеҗҢж ·еҶҷиө·жқҘжӣҙеҘҪпјҡеғҸgetOrElseUpdateж“ҚдҪңдёҚиғҪеӨҹ被并еҸ‘йӣҶеҗҲжӯЈзЎ®зҡ„е®һзҺ°пјҢеҲӣе»әеӨҚеҗҲ(composite)йӣҶеҗҲе°Өе…¶е®№жҳ“еҮәй”ҷгҖӮ
жҺ§еҲ¶з»“жһ„
еҮҪж•°ејҸйЈҺж јзҡ„зЁӢеәҸеҖҫеҗ‘дәҺйңҖиҰҒжӣҙе°‘зҡ„дј з»ҹзҡ„жҺ§еҲ¶з»“жһ„пјҢ并且дҪҝз”ЁеЈ°жҳҺејҸйЈҺж јеҶҷзҡ„зЁӢеәҸиҜ»иө·жқҘжӣҙеҘҪгҖӮиҝҷйҖҡеёёж„Ҹе‘ізқҖжү“з ҙдҪ зҡ„йҖ»иҫ‘пјҢжӢҶеҲҶеҲ°иӢҘе№ІдёӘе°Ҹзҡ„ж–№жі•жҲ–еҮҪж•°пјҢз”Ёз”ЁеҢ№й…ҚиЎЁиҫҫејҸ(match expression)жҠҠ他们зІҳеңЁдёҖиө·гҖӮеҮҪж•°ејҸзЁӢеәҸд№ҹеҖҫеҗ‘дәҺжӣҙеӨҡйқўеҗ‘иЎЁиҫҫејҸ(expression-oriented)пјҡжқЎд»¶еҲҶж”ҜжҳҜеҗҢдёҖзұ»еһӢзҡ„еҖји®Ўз®—пјҢforиЎЁиҫҫејҸ(for-comprehension)пјҢйҖ’еҪ’йғҪжҳҜеҸёз©әи§ҒжғҜзҡ„гҖӮ
йҖ’еҪ’
*з”ЁйҖ’еҪ’жңҜиҜӯжқҘиЎЁиҫҫдҪ зҡ„й—®йўҳеёёеёёдјҡжҳҜз®ҖеҢ–зҡ„пјҢеҰӮжһңеә”з”ЁдәҶе°ҫйҖ’еҪ’дјҳеҢ–(еҸҜд»ҘйҖҡиҝҮ@tailrecжіЁйҮҠжЈҖжөӢ)пјҢзј–иҜ‘еҷЁз”ҡиҮідјҡе°ҶдҪ зҡ„д»Јз ҒиҪ¬жҚўдёәжӯЈеёёзҡ„еҫӘзҺҜгҖӮеҜ№жҜ”дёҖдёӘж ҮеҮҶзҡ„е‘Ҫд»ӨејҸзүҲжң¬зҡ„е ҶжҺ’еәҸ(fix-down):
В
- def fixDown(heap: Array[T], m: Int, n: Int): Unit = {
- В В var k: Int = m
- В В while (n >= 2*k) {
- В В В В var j = 2*k
- В В В В if (j < n && heap(j) < heap(j + 1))
- В В В В j += 1
- В В В В if (heap(k) >= heap(j))
- В В В В return
- В В В В else {
- В В В В swap(heap, k, j)
- В В В В k = j
- В В В В }
- В В }
- }
В
жҜҸж¬Ўиҝӣе…ҘwhileеҫӘзҺҜпјҢжҲ‘们е·ҘдҪңеңЁеүҚдёҖж¬Ўиҝӯд»Јж—¶жұЎжҹ“иҝҮзҡ„зҠ¶жҖҒгҖӮжҜҸдёӘеҸҳйҮҸзҡ„еҖјжҳҜйӮЈдёҖеҲҶж”ҜжүҖиҝӣе…ҘеҮҪж•°пјҢеҪ“жүҫеҲ°жӯЈзЎ®зҡ„дҪҚзҪ®ж—¶дјҡеңЁеҫӘзҺҜдёӯreturnгҖӮ (ж•Ҹй”җзҡ„иҜ»иҖ…дјҡеңЁDijkstraзҡ„
вҖңGo ToеЈ°жҳҺжҳҜжңүе®ізҡ„вҖқдёҖж–ҮжүҫеҲ°зӣёдјјзҡ„и§ӮзӮ№)
иҖғиҷ‘е°ҫйҖ’еҪ’зҡ„е®һзҺ°
[2]:
В
- @tailrec
- final def fixDown(heap: Array[T], i: Int, j: Int) {
- В В if (j < i*2) return
-
- В В val m = if (j == i*2 || heap(2*i) < heap(2*i+1)) 2*i else 2*i + 1
- В В if (heap(m) < heap(i)) {
- В В В В swap(heap, i, m)
- В В В В fixDown(heap, m, j)
- В В }
- }
В
жҜҸж¬Ўиҝӯд»ЈйғҪжҳҜдёҖдёӘжҳҺзЎ®е®ҡд№үзҡ„жё…зҷҪеҺҶеҸІзҡ„еҸҳйҮҸпјҢ并且没жңүеј•з”ЁеҚ•е…ғпјҡеҲ°еӨ„йғҪжҳҜдёҚеҸҳзҡ„(invariants)гҖӮжӣҙе®№жҳ“е®һзҺ°пјҢд№ҹе®№жҳ“йҳ…иҜ»гҖӮд№ҹжІЎжңүжҖ§иғҪж–№йқўзҡ„жғ©зҪҡпјҡ既然方法жҳҜе°ҫйҖ’еҪ’пјҢзј–иҜ‘еҷЁдјҡиҪ¬жҚўдёәж ҮеҮҶзҡ„е‘Ҫд»ӨејҸзҡ„еҫӘзҺҜгҖӮ
иҝ”еӣһ(Return)
并дёҚжҳҜиҜҙе‘Ҫд»ӨејҸз»“жһ„жІЎжңүд»·еҖјгҖӮеңЁеҫҲеӨҡдҫӢеӯҗдёӯе®ғ们еҫҲйҖӮеҗҲдәҺжҸҗеүҚз»Ҳжӯўи®Ўз®—иҖҢйқһеҜ№жҜҸдёӘеҸҜиғҪз»Ҳжӯўзҡ„зӮ№еӯҳеңЁдёҖдёӘжқЎд»¶еҲҶж”Ҝпјҡзҡ„зЎ®еңЁдёҠйқўзҡ„fixDownеҮҪж•°пјҢдёҖдёӘreturnз”ЁдәҺжҸҗеүҚз»ҲжӯўеҰӮжһңжҲ‘们已з»ҸеңЁе Ҷзҡ„з»“е°ҫгҖӮ
ReturnsеҸҜд»Ҙз”ЁдәҺеҲҮж–ӯеҲҶж”Ҝе»әз«ӢдёҚеҸҳйҮҸ(establish invariants)гҖӮиҝҷеё®еҠ©дәҶиҜ»иҖ…еҮҸе°‘дәҶеөҢеҘ—пјҢ并且容жҳ“е®һзҺ°еҗҺз»ӯзҡ„д»Јз Ғзҡ„жӯЈзЎ®жҖ§гҖӮиҝҷе°Өе…¶йҖӮз”ЁдәҺеҚ«иҜӯеҸҘ(guard clauses)пјҡ
- def compare(a: AnyRef, b: AnyRef): Int = {
- В В if (a eq b)
- В В В В return 0
-
- В В val d = System.identityHashCode(a) compare System.identityHashCode(b)
- В В if (d != 0)
- В В В В return d
-
- В В // slow path..
- }
дҪҝз”ЁreturnеўһеҠ дәҶеҸҜиҜ»жҖ§
- def suffix(i: Int) = {
- В В ifВ В В В (i == 1) return "st"
- В В else if (i == 2) return "nd"
- В В else if (i == 3) return "rd"
- В В elseВ В В В В В В В return "th"
- }
дёҠйқўжҳҜй’ҲеҜ№е‘Ҫд»ӨејҸиҜӯиЁҖзҡ„пјҢеңЁScalaдёӯйј“еҠұзңҒз•Ҙreturn
- def suffix(i: Int) =
- В В ifВ В В В (i == 1) "st"
- В В else if (i == 2) "nd"
- В В else if (i == 3) "rd"
- В В elseВ В В В В В В В "th"
дҪҶдҪҝз”ЁжЁЎејҸеҢ№й…ҚжӣҙеҘҪпјҡ
- def suffix(i: Int) = i match {
- В В case 1 => "st"
- В В case 2 => "nd"
- В В case 3 => "rd"
- В В case _ => "th"
- }
жіЁж„ҸпјҢreturnдјҡжңүйҡҗжҖ§жҲҗжң¬пјҡеҪ“еңЁй—ӯеҢ…еҶ…йғЁдҪҝз”Ёж—¶гҖӮ
- seq foreach { elem =>
- В В if (elem.isLast)
- В В В В return
-
- В В // process...
- }
еңЁеӯ—иҠӮз ҒеұӮе®һзҺ°ж—¶дјҡеҢ…еҗ«дёҖдёӘејӮеёёзҡ„жҚ•иҺ·/еЈ°жҳҺ(catching/throwing)еҜ№пјҢз”ЁеңЁйў‘з№Ғзҡ„жү§иЎҢзҡ„д»Јз ҒдёӯпјҢдјҡжңүжҖ§иғҪеҪұе“ҚгҖӮ
forеҫӘзҺҜе’ҢforжҺЁеҜј
forеҜ№еҫӘзҺҜе’ҢиҒҡйӣҶжҸҗдҫӣдәҶз®ҖжҙҒе’ҢиҮӘ然зҡ„иЎЁиҫҫгҖӮ е®ғеңЁжүҒе№іеҢ–(flattening)еҫҲеӨҡеәҸеҲ—ж—¶зү№еҲ«жңүз”ЁгҖӮforиҜӯжі•йҖҡиҝҮеҲҶй…Қе’ҢжҙҫеҸ‘й—ӯеҢ…йҡҗи—ҸдәҶеә•еұӮзҡ„жңәеҲ¶гҖӮиҝҷдјҡеҜјиҮҙж„ҸеӨ–зҡ„ејҖй”Җе’ҢиҜӯд№үпјӣдҫӢеҰӮпјҡ
- for (item <- container) {
- В В if (item != 2) return
- }
еҰӮжһңе®№еҷЁе»¶иҝҹи®Ўз®—(delays computation)дјҡеј•иө·иҝҗиЎҢж—¶й”ҷиҜҜпјҢдҪҝиҝ”еӣһдёҚеңЁжң¬ең°дёҠдёӢж–Ү (making the return nonlocal)
еӣ дёәиҝҷдәӣеҺҹеӣ пјҢеёёеёёжӣҙеҸҜеҸ–зҡ„жҳҜзӣҙжҺҘи°ғз”Ёforeach, flatMap, mapе’Ңfilter вҖ”вҖ” еңЁжё…жҘҡзҡ„ж—¶еҖҷдҪҝз”ЁforгҖӮ
requireе’Ңж–ӯиЁҖ(assert)
иҰҒжұӮ(require)е’Ңж–ӯиЁҖ(assert)йғҪиө·еҲ°еҸҜжү§иЎҢж–ҮжЎЈзҡ„дҪңз”ЁгҖӮдёӨиҖ…йғҪеңЁзұ»еһӢзі»з»ҹдёҚиғҪиЎЁиҫҫжүҖжұӮиҰҒзҡ„дёҚеҸҳйҮҸ(invariants)зҡ„еңәжҷҜйҮҢжңүз”ЁгҖӮ assertз”ЁдәҺд»Јз ҒеҒҮи®ҫзҡ„дёҚеҸҳйҮҸ(invariants) дҫӢеҰӮпјҡ(иҜ‘жіЁпјҢдёҚеҸҳйҮҸ invariant жҳҜжҢҮзұ»еһӢдёҚеҸҜеҸҳпјҢеҚідёҚж”ҜжҢҒеҚҸеҸҳжҲ–йҖҶеҸҳзҡ„зұ»еһӢеҸҳйҮҸ)
- val stream = getClass.getResourceAsStream("someclassdata")
- assert(stream != null)
зӣёеҸҚпјҢrequireз”ЁдәҺиЎЁиҫҫAPIеҘ‘зәҰпјҡ
- def fib(n: Int) = {
- В В require(n > 0)
- В В ...
- }
еҮҪж•°ејҸзј–зЁӢ
value-oriented зј–зЁӢжңүеҫҲеӨҡдјҳеҠҝпјҢзү№еҲ«жҳҜз”ЁеңЁдёҺеҮҪж•°ејҸзј–зЁӢз»“жһ„зӣёз»“еҗҲгҖӮиҝҷз§ҚйЈҺж јејәи°ғйҖҡиҝҮзҠ¶жҖҒеҸҳеҢ–жқҘиҪ¬жҚўvaluesпјҢз”ҹжҲҗзҡ„д»Јз ҒжҳҜжҢҮз§°йҖҸжҳҺзҡ„(referentially transparent)пјҢжҸҗдҫӣдәҶжӣҙејәзҡ„дёҚеҸҳеһӢ(invariants)пјҢеӣ жӯӨе®№жҳ“е®һзҺ°гҖӮCaseзұ»(д№ҹиў«зҝ»иҜ‘дёәж ·жң¬зұ»)пјҢжЁЎејҸеҢ№й…ҚпјҢи§Јжһ„з»‘е®ҡ(destructuring bindings)пјҢзұ»еһӢжҺЁж–ӯпјҢиҪ»йҮҸзә§зҡ„й—ӯеҢ…е’Ңж–№жі•еҲӣе»әиҜӯжі•йғҪжҳҜиҝҷдёҖиЎҢзҡ„е·Ҙе…·гҖӮ
Caseзұ»жЁЎжӢҹд»Јж•°ж•°жҚ®зұ»еһӢ
Caseзұ»еҸҜжЁЎжӢҹд»Јж•°ж•°жҚ®зұ»еһӢ(ADT)зј–з Ғпјҡе®ғ们еҜ№еӨ§йҮҸзҡ„ж•°жҚ®з»“жһ„иҝӣиЎҢе»әжЁЎж—¶жңүз”ЁпјҢз”ЁејәдёҚеҸҳзұ»еһӢ(invariants)жҸҗдҫӣдәҶз®ҖжҙҒзҡ„д»Јз ҒгҖӮе°Өе…¶еңЁз»“еҗҲжЁЎејҸеҢ№й…Қжғ…еҶөдёӢгҖӮжЁЎејҸеҢ№й…Қе®һзҺ°дәҶе…Ёйқўи§ЈжһҗжҸҗдҫӣжӣҙејәеӨ§зҡ„йқҷжҖҒдҝқжҠӨгҖӮ (иҜ‘жіЁпјҡADTsжҳҜAlgebraic Data Typeд»Јж•°ж•°жҚ®зұ»еһӢзҡ„зј©еҶҷпјҢе…ідәҺиҝҷдёӘжҰӮеҝөи§ҒжҲ‘зҡ„еҸҰдёҖзҜҮblog)
дёӢйқўжҳҜз”Ёcaseзұ»жЁЎжӢҹд»Јж•°ж•°жҚ®зұ»еһӢзҡ„жЁЎејҸ
- sealed trait Tree[T]
- case class Node[T](left: Tree[T], right: Tree[T]) extends Tree[T]
- case class Leaf[T](value: T) extends Tree[T]
зұ»еһӢ Tree[T] жңүдёӨдёӘжһ„йҖ еҮҪеҷЁпјҡNodeе’ҢLeafгҖӮе®ҡд№үзұ»еһӢдёәsealed(е°Ғй—ӯзұ»)е…Ғи®ёзј–иҜ‘еҷЁеҪ»еә•зҡ„еҲҶжһҗ(иҝҷжҳҜй’ҲеҜ№жЁЎејҸеҢ№й…Қзҡ„пјҢеҸӮиҖғProgramming in Scala)еӣ дёәжһ„йҖ еҷЁе°ҶдёҚиғҪд»ҺеӨ–йғЁжәҗж–Ү件дёӯж·»еҠ гҖӮ
дёҺжЁЎејҸеҢ№й…ҚдёҖеҗҢпјҢиҝҷдёӘе»әжЁЎдҪҝеҫ—д»Јз Ғз®ҖжҙҒ并且жҳҫ然жҳҜжӯЈзЎ®зҡ„(obviously correct)
В
- def findMin[T <: Ordered[T]](tree: Tree[T]) = tree match {
- В В case Node(left, right) => Seq(findMin(left), findMin(right)).min
- В В case Leaf(value) => value
- }
В
дёҖдәӣйҖ’еҪ’з»“жһ„пјҢеҰӮж ‘зҡ„з»„жҲҗжҳҜе…ёеһӢзҡ„ADTs(д»Јж•°ж•°жҚ®зұ»еһӢ)еә”з”ЁпјҢе®ғ们зҡ„з”ЁеӨ„йўҶеҹҹжӣҙеӨ§гҖӮ disjoint,unionsзү№еҲ«е®№жҳ“зҡ„з”ЁADTsе»әжЁЎпјӣиҝҷдәӣйў‘з№ҒеҸ‘з”ҹеңЁзҠ¶жҖҒжңәдёҠ(state machines)гҖӮ
Options
Optionзұ»еһӢжҳҜдёҖдёӘе®№еҷЁпјҢз©ә(None)жҲ–ж»Ў(Some(value))дәҢйҖүдёҖгҖӮе®ғжҸҗдҫӣдәҶдҪҝз”Ёnullзҡ„еҸҰдёҖз§Қе®үе…ЁйҖүжӢ©пјҢеә”иҜҘе°ҪеҸҜиғҪзҡ„жӣҝд»ЈnullгҖӮе®ғжҳҜдёҖдёӘйӣҶеҗҲ(жңҖеӨҡеҸӘжңүдёҖдёӘе…ғзҙ )并用йӣҶеҗҲж“ҚжүҖдҝ®йҘ°пјҢе°ҪйҮҸз”ЁOptionгҖӮ
з”Ё var username: Option[String] = None вҖҰ username = Some(вҖңfoobarвҖқ)
д»Јжӣҝ
- var username: String = null
- ...
- username = "foobar"
еүҚдёҖз§Қжӣҙе®үе…ЁпјҡOptionзұ»еһӢйқҷжҖҒзҡ„ејәеҲ¶usernameеҝ…йЎ»еҜ№з©ә(emptyness)еҒҡжЈҖжөӢгҖӮ
еҜ№дёҖдёӘOptionеҖјеҒҡжқЎд»¶еҲӨж–ӯеә”иҜҘз”Ёforeach
- if (opt.isDefined)
- В В operate(opt.get)
дёҠйқўзҡ„д»Јз Ғеә”иҜҘз”ЁдёӢйқўзҡ„ж–№ејҸжӣҝд»Јпјҡ
- opt foreach { value =>
- В В operate(value)}
йЈҺж јзңӢиө·жқҘжңүдәӣеҸӨжҖӘпјҢдҪҶжҸҗдҫӣдәҶжӣҙеӨҡзҡ„е®үе…Ёе’Ңз®ҖжҙҒгҖӮеҰӮжһңдёӨз§Қжғ…еҶөйғҪжңү(Optionзҡ„NoneжҲ–Some)пјҢз”ЁжЁЎејҸеҢ№й…Қ
- opt match {
- В В case Some(value) => operate(value)
- В В case None => defaultAction()
- }
еҰӮжһңйғҪзјәе°‘зјәзңҒеҖјпјҢз”ЁgetOrElseж–№жі•пјҡ
- operate(opt getOrElse defaultValue)
дёҚиҰҒиҝҮеәҰдҪҝз”ЁOptionпјҡ еҰӮжһңжңүдёҖдёӘжҳҺзЎ®зҡ„зјәзңҒеҖјвҖ”вҖ”дёҖдёӘNullеҜ№иұЎвҖ”вҖ”зӣҙжҺҘз”ЁNullиҖҢдёҚеҝ…з”ЁOption
OptionиҝҳжңүдёҖдёӘж–№дҫҝзҡ„жһ„йҖ еҷЁз”ЁдәҺеҢ…иЈ…з©әеҖј(nullable value)
- Option(getClass.getResourceAsStream("foo"))
еҫ—еҲ°дёҖдёӘ Option[InputStream] еҒҮе®ҡз©әеҖј(None)ж—¶getResourceAsStreamдјҡиҝ”еӣһnull
жЁЎејҸеҢ№й…Қ
жЁЎејҸеҢ№й…Қ(x match { вҖҰ) еңЁScalaд»Јз Ғдёӯж— еӨ„дёҚеңЁпјҡз”ЁдәҺеҗҲ并жқЎд»¶жү§иЎҢгҖҒи§Јжһ„(destructuring) гҖҒеңЁжһ„йҖ дёӯйҖ еһӢгҖӮдҪҝз”ЁеҘҪжЁЎејҸеҢ№й…ҚеҸҜд»ҘеўһеҠ зЁӢеәҸзҡ„жҳҺжҷ°е’Ңе®үе…ЁгҖӮ дҪҝз”ЁжЁЎејҸеҢ№й…Қе®һзҺ°зұ»еһӢиҪ¬жҚўпјҡ
- obj match {
- В В case str: String => ...
- В В case addr: SocketAddress => ...
жЁЎејҸеҢ№й…ҚиҒ”еҗҲдҪҝз”Ёи§Јжһ„(destructuring)ж—¶ж•ҲжһңжңҖеҘҪпјҲдҫӢеҰӮдҪ иҰҒеҢ№й…Қcaseзұ»пјүпјӣдёӢйқўзҡ„еҶҷжі•
- animal match {
- В В case dog: Dog => "dog (%s)".format(dog.breed)
- В В case _ => animal.species
- В В }
еә”иҜҘиў«жӣҝд»Јдёәпјҡ
- animal match {
- В В case Dog(breed) => "dog (%s)".format(breed)
- В В case other => other.species
- }
еҶҷиҮӘе®ҡд№үзҡ„жҠҪеҸ–еҷЁ(extractor)ж—¶еҝ…йЎ»жңүеҸҢйҮҚжһ„йҖ еҷЁпјҢеҗҰеҲҷеҸҜиғҪжҳҜдёҚйҖӮеҗҲзҡ„гҖӮ(иҜ‘жіЁпјҡиҝҷеҸҘиҜқжІЎзҗҶи§ЈпјҢеҸҜиғҪдҪңиҖ…жҳҜжғіиҜҙapplyж–№жі•дёҺunapplyзҡ„еҜ№з§°жҖ§)
еҜ№жқЎд»¶жү§иЎҢдёҚиҰҒз”ЁжЁЎејҸеҢ№й…ҚпјҢй»ҳи®Өзҡ„ж–№жі•жӣҙжңүж„Ҹд№үгҖӮйӣҶеҗҲеә“зҡ„ж–№жі•йҖҡеёёиҝ”еӣһOptionsпјҢйҒҝе…Қпјҡ
- val x = list match {
- В В case head :: _ => head
- В В case Nil => default
- }
еӣ дёә
- val x = list.headOption getOrElse default
жӣҙзҹӯ并且жӣҙиғҪиЎЁиҫҫзӣ®зҡ„
еҒҸеҮҪж•°
ScalaжҸҗдҫӣдәҶе®ҡд№үеҒҸеҮҪж•°(PartialFunction)зҡ„иҜӯжі•еҝ«жҚ·пјҡ
- val pf: PartialFunction[Int, String] = {
- В В case i if i%2 == 0 => "even"
- }
е®ғ们д№ҹеҸҜиғҪз”ұ orElse з»„жҲҗ:
- val tf: (Int => String) = pf orElse { case _ => "odd"}
-
- tf(1) == "odd"
- tf(2) == "even"
еҒҸеҮҪж•°еҮәзҺ°еңЁеҫҲеӨҡеңәжҷҜпјҢ并被жңүж•Ҳзҡ„зј–з Ғдёә PartialFunctionпјҢдҫӢеҰӮ ж–№жі•еҸӮж•°пјҡ
- trait Publisher[T] {
- В В def subscribe(f: PartialFunction[T, Unit])
- }
-
- val publisher: Publisher[Int] = ..
- publisher.subscribe {
- В В case i if isPrime(i) => println("found prime", i)
- В В case i if i%2 == 0 => count += 2
- В В /* ignore the rest */
- }
жҲ–еңЁиҝ”еӣһдёҖдёӘOptionзҡ„жғ…еҶөдёӢпјҡ
- // Attempt to classify the the throwable for logging.
- type Classifier = Throwable => Option[java.util.logging.Level]
еҸҜд»ҘжӣҙеҘҪзҡ„з”ЁPartialFunctionиЎЁиҫҫ
- type Classifier = PartialFunction[Throwable, java.util.Logging.Level]
еӣ дёәе®ғжҸҗдҫӣдәҶжӣҙеҘҪзҡ„еҸҜз»„еҗҲжҖ§пјҡ
- val classifier1: Classifier
- val classifier2: Classifier
-
- val classifier = classifier1 orElse classifier2 orElse { _ => java.util.Logging.Level.FINEST }
и§Јжһ„з»‘е®ҡ
и§Јжһ„з»‘е®ҡдёҺжЁЎејҸеҢ№й…Қжңүе…і,е®ғ们用дәҶзӣёеҗҢзҡ„жңәеҲ¶пјҢдҪҶеҸҜеә”з”ЁеңЁеҪ“еҢ№й…ҚеҸӘжңүдёҖз§ҚйҖүйЎ№зҡ„ж—¶еҖҷ (д»Ҙе…ҚдҪ жҺҘеҸ—ејӮеёёзҡ„еҸҜиғҪ). и§Јжһ„з»‘е®ҡзү№еҲ«йҖӮз”ЁдәҺе…ғз»„(tuple)е’Ңж ·жң¬зұ»(case class).
- val tuple = ('a', 1)
- val (char, digit) = tuple
-
- val tweet = Tweet("just tweeting", Time.now)
- val Tweet(text, timestamp) = tweet
жғ°жҖ§иөӢеҖј
еҪ“дҪҝз”Ёlazyдҝ®йҘ°дёҖдёӘvalжҲҗе‘ҳж—¶пјҢе…¶иөӢеҖјжғ…еҶөжҳҜеңЁйңҖиҰҒж—¶жүҚиөӢеҖјзҡ„(by need) еӣ дёәScalaдёӯжҲҗе‘ҳдёҺж–№жі•жҳҜзӯүд»·зҡ„пјҲйҷӨдәҶprivate[this]жҲҗе‘ҳпјү
- lazy val field = computation()
зӣёеҪ“дәҺдёӢйқўзҡ„з®ҖеҶҷ:
- var _theField = None
- def field = if (_theField.isDefined) _theField.get else {
- В В _theField = Some(computation())
- В В _theField.get
- }
д№ҹе°ұжҳҜиҜҙпјҢе®ғеңЁйңҖиҰҒж—¶и®Ўз®—з»“жһң并дјҡи®°дҪҸз»“жһңпјҢеңЁиҝҷз§Қзӣ®зҡ„ж—¶дҪҝз”ЁlazyжҲҗе‘ҳпјӣдҪҶеҪ“иҜӯж„ҸдёҠйңҖиҰҒжғ°жҖ§иөӢеҖјж—¶(by semantics)пјҢиҰҒйҒҝе…ҚдҪҝз”Ёжғ°жҖ§иөӢеҖјпјҢиҝҷз§Қжғ…еҶөдёӢпјҢжңҖеҘҪжҳҫејҸиөӢеҖјеӣ дёәе®ғдҪҝеҫ—жҲҗжң¬жЁЎеһӢжҳҜжҳҺзЎ®зҡ„пјҢ并且еүҜдҪңз”Ёиў«дёҘж јзҡ„жҺ§еҲ¶гҖӮ
LazyжҲҗе‘ҳжҳҜзәҝзЁӢе®үе…Ёзҡ„гҖӮ
дј еҗҚи°ғз”Ё
ж–№жі•еҸӮж•°еҸҜд»ҘжҢҮе®ҡдёәдј еҗҚеҸӮж•° (by-name) ж„Ҹе‘ізқҖеҸӮж•°дёҚжҳҜз»‘е®ҡеҲ°дёҖдёӘеҖјпјҢиҖҢжҳҜйңҖиҰҒеҸҚеӨҚи®Ўз®—зҡ„гҖӮиҝҷдёҖзү№жҖ§йңҖиҰҒе°ҸеҝғдҪҝз”Ёпјӣ и°ғз”ЁиҖ…жҢүз…§дј еҖј(by-value)иҜӯжі•жңҹеҫ…зҡ„иҜқдјҡж„ҹеҲ°жғҠ讶гҖӮиҝҷдёҖзү№жҖ§зҡ„еҠЁжңәжҳҜжһ„йҖ иҜӯжі•иҮӘ然зҡ„ DSLsвҖ”вҖ”дҪҝж–°зҡ„жҺ§еҲ¶з»“жһ„зңӢиө·жқҘжӣҙеғҸжң¬ең°иҜӯиЁҖзү№еҫҒгҖӮ
еҸӘеңЁдёӢйқўзҡ„жҺ§еҲ¶з»“жһ„дёӯдҪҝз”Ёдј еҗҚи°ғз”Ё, и°ғз”ЁиҖ…жҳҺжҳҫдј йҖ’зҡ„жҳҜдёҖж®өд»Јз Ғеқ—(block)иҖҢйқһдёҖдёӘзЎ®е®ҡзҡ„и®Ўз®—з»“жһңгҖӮдј еҗҚеҸӮж•°еҝ…йЎ»ж”ҫеңЁеҸӮж•°еҲ—иЎЁзҡ„жңҖеҗҺдёҖдҪҚгҖӮеҪ“дҪҝз”Ёдј еҗҚи°ғз”Ёж—¶пјҢзЎ®дҝқж–№жі•еҗҚз§°и®©и°ғз”ЁиҖ…жҳҺжҳҫзҡ„ж„ҹзҹҘеҲ°ж–№жі•еҸӮж•°жҳҜдј еҗҚеҸӮж•°гҖӮ
еҪ“дҪ жғіиҰҒдёҖдёӘеҖјиў«и®Ўз®—еӨҡж¬ЎпјҢзү№еҲ«жҳҜиҝҷдёӘи®Ўз®—дјҡеј•иө·еүҜдҪңз”Ёж—¶пјҢдҪҝз”ЁжҳҫејҸеҮҪж•°пјҡ
- class SSLConnector(mkEngine: () => SSLEngine)
иҝҷж ·ж„ҸеӣҫеҫҲжҳҺзЎ®пјҢи°ғз”ЁиҖ…дёҚдјҡж„ҹеҲ°жғҠеҘҮгҖӮ
flatMap
flatMapвҖ”вҖ”з»“еҗҲдәҶmap е’Ң flatten вҖ”вҖ” иҰҒзү№еҲ«е°ҸеҝғпјҢе®ғжңүзқҖйҡҫд»ҘзҗўзЈЁзҡ„еЁҒеҠӣе’ҢејәеӨ§зҡ„е®һз”ЁжҖ§гҖӮзұ»дјје®ғзҡ„е…„ејҹ mapпјҢе®ғд№ҹжҳҜз»ҸеёёеңЁйқһдј з»ҹзҡ„йӣҶеҗҲдёӯдҪҝз”Ёзҡ„пјҢдҫӢеҰӮ Future , Option.е®ғзҡ„иЎҢдёәз”ұе®ғзҡ„зӯҫеҗҚжҸӯзӨәпјӣеҜ№дәҺдёҖдәӣе®№еҷЁ Container[A]
- flatMap[B](f: A => Container[B]): Container[B]
В
flatMapеҜ№йӣҶеҗҲдёӯзҡ„жҜҸдёӘе…ғзҙ и°ғз”ЁдәҶ еҮҪж•° f дә§з”ҹдёҖдёӘж–°зҡ„йӣҶеҗҲпјҢе°Ҷе®ғ们全йғЁ flatten еҗҺж”ҫе…Ҙз»“жһңдёӯ
дҫӢеҰӮпјҢиҺ·еҸ–дёӨдёӘеӯ—з¬Ұзҡ„жүҖжңүжҺ’еҲ—пјҢзӣёеҗҢзҡ„еӯ—з¬ҰдёҚиғҪеҮәзҺ°дёӨж¬Ў
- val chars = 'a' to 'z'
- val perms = chars flatMap { a =>
- В В chars flatMap { b =>
- В В В В if (a != b) Seq("%c%c".format(a, b))
- В В В В else Seq()
- В В }
- }
зӯүд»·дәҺдёӢйқўиҝҷж®өжӣҙз®ҖжҙҒзҡ„ for-comprehension пјҲеҹәжң¬е°ұжҳҜй’ҲеҜ№дёҠйқўзҡ„иҜӯжі•зі–пјү
- val perms = for {
- В В a <- chars
- В В b <- chars
- В В if a != b
- } yield "%c%c".format(a, b)
flatMapеңЁеӨ„зҗҶOptionsж—¶йў‘з№ҒдҪҝз”ЁвҖ”вҖ” е®ғе°Ҷoptionsй“ҫеҗҲ并дёәдёҖдёӘпјҢ
- val host: Option[String] = ..
- val port: Option[Int] = ..
-
- val addr: Option[InetSocketAddress] =
- В В host flatMap { h =>
- В В В В port map { p =>
- В В В В new InetSocketAddress(h, p)
- В В В В }
- В В }
д№ҹеҸҜд»ҘдҪҝз”Ёжӣҙз®ҖжҙҒзҡ„forжқҘе®һзҺ°пјҡ
- val addr: Option[InetSocketAddress] = for {
- В В h <- host
- В В p <- port
- } yield new InetSocketAddress(h, p)
йқўеҗ‘еҜ№иұЎзҡ„зј–зЁӢ
Scalaзҡ„еҚҡеӨ§еҫҲеӨ§зЁӢеәҰдёҠеңЁдәҺе®ғзҡ„еҜ№иұЎзі»з»ҹгҖӮScalaдёӯжүҖжңүзҡ„еҖјйғҪжҳҜеҜ№иұЎпјҢе°ұиҝҷдёҖж„Ҹд№үиҖҢиЁҖScalaжҳҜй—ЁзәҜзІ№зҡ„иҜӯиЁҖпјӣеҹәжң¬зұ»еһӢе’Ңз»„еҗҲзұ»еһӢжІЎжңүеҢәеҲ«гҖӮScalaд№ҹжҸҗдҫӣдәҶmixinзҡ„зү№жҖ§е…Ғи®ёжӣҙеӨҡжӯЈдәӨзҡ„гҖҒз»ҶзІ’еәҰзҡ„жһ„йҖ дёҖдәӣеңЁзј–иҜ‘ж—¶еҸ—зӣҠдәҺйқҷжҖҒзұ»еһӢжЈҖжөӢзҡ„еҸҜиў«зҒөжҙ»з»„иЈ…зҡ„жЁЎеқ—гҖӮ mixinзі»з»ҹзҡ„иғҢеҗҺеҠЁжңәд№ӢдёҖжҳҜж¶ҲйҷӨдј з»ҹзҡ„дҫқиө–жіЁе…ҘгҖӮиҝҷз§ҚвҖң组件йЈҺж ј(component style)вҖқзј–зЁӢзҡ„й«ҳжҪ®жҳҜжҳҜ
the cake pattern.
дҫқиө–жіЁе…Ҙ
еңЁжҲ‘们用жқҘпјҢеҸ‘зҺ°Scalaжң¬иә«еҲ йҷӨдәҶеҫҲеӨҡз»Ҹе…ё(жһ„йҖ еҮҪж•°)дҫқиө–жіЁе…Ҙзҡ„иҜӯжі•ејҖй”ҖпјҢжҲ‘们жӣҙж„ҝж„Ҹе°ұиҝҷж ·з”Ё: е®ғжӣҙжё…жҷ°пјҢдҫқиө–д»Қ然йҖҡиҝҮзұ»еһӢзј–з ҒпјҢзұ»жһ„йҖ иҜӯжі•жҳҜеҰӮжӯӨеҫ®дёҚи¶ійҒ“иҖҢеҸҳеҫ—иҪ»иҖҢжҳ“дёҫгҖӮжңүдәӣж— иҒҠпјҢз®ҖеҚ•пјҢдҪҶжңүж•ҲгҖӮеҜ№жЁЎеқ—еҢ–зј–зЁӢж—¶дҪҝз”Ёдҫқиө–жіЁе…ҘпјҢзү№еҲ«жҳҜпјҢз»„еҗҲдјҳдәҺ继жүҝвҖ”иҝҷдҪҝеҫ—зЁӢеәҸжӣҙеҠ жЁЎеқ—еҢ–е’ҢеҸҜжөӢиҜ•зҡ„гҖӮеҪ“йҒҮеҲ°йңҖиҰҒ继жүҝзҡ„жғ…еҶөпјҢй—®й—®иҮӘе·ұпјҡеңЁиҜӯиЁҖзјәд№ҸеҜ№з»§жүҝж”ҜжҢҒзҡ„жғ…еҶөдёӢеҰӮдҪ•жһ„йҖ зЁӢеәҸпјҹзӯ”жЎҲеҸҜиғҪжҳҜд»ӨдәәдҝЎжңҚзҡ„гҖӮ
дҫқиө–жіЁе…Ҙе…ёеһӢзҡ„дҪҝз”ЁеҲ° trait
- trait TweetStream {
- В В def subscribe(f: Tweet => Unit)
- }
- class HosebirdStream extends TweetStream ...
- class FileStream extends TweetStream ..
-
- class TweetCounter(stream: TweetStream) {
- В В stream.subscribe { tweet => count += 1 }
- }
иҝҷжҳҜеёёи§Ғзҡ„жіЁе…Ҙе·ҘеҺӮ вҖ” з”ЁдәҺдә§з”ҹе…¶д»–еҜ№иұЎзҡ„еҜ№иұЎгҖӮеңЁиҝҷдәӣдҫӢеӯҗдёӯпјҢжӣҙйқ’зқҗз”Ёз®ҖеҚ•зҡ„еҮҪж•°иҖҢйқһдё“жңүзҡ„е·ҘеҺӮзұ»еһӢгҖӮ
- class FilteredTweetCounter(mkStream: Filter => TweetStream) {
- В В mkStream(PublicTweets).subscribe { tweet => publicCount += 1 }
- В В mkStream(DMs).subscribe { tweet => dmCount += 1 }
- }
Trait
дҫқиө–жіЁе…ҘдёҚеҰЁзўҚдҪҝз”Ёе…¬е…ұжҺҘеҸЈпјҢжҲ–еңЁtraitдёӯе®һзҺ°е…¬е…ұд»Јз ҒгҖӮжҒ°жҒ°зӣёеҸҚвҖ”жӯЈжҳҜеӣ дёәд»ҘдёӢеҺҹеӣ иҖҢй«ҳеәҰйј“еҠұдҪҝз”ЁtraitпјҡдёҖдёӘе…·дҪ“зҡ„зұ»еҸҜд»Ҙе®һзҺ°еӨҡжҺҘеҸЈ(traits)пјҢе…¬е…ұзҡ„д»Јз ҒеҸҜд»ҘйҖҡиҝҮиҝҷдәӣзұ»еӨҚз”ЁгҖӮ
дҝқжҢҒtraitsз®Җзҹӯ并且жҳҜжӯЈдәӨзҡ„пјҡдёҚиҰҒжҠҠеҲҶзҰ»зҡ„еҠҹиғҪж··еңЁдёҖдёӘtraitйҮҢпјҢиҖғиҷ‘е°ҶжңҖе°Ҹзҡ„зӣёе…ізҡ„ж„Ҹеӣҫж”ҫеңЁдёҖиө·гҖӮдҫӢеҰӮпјҢжғіиұЎдёҖдёӢдҪ иҰҒеҒҡдёҖдәӣIOзҡ„ж“ҚдҪңпјҡ
- trait IOer {
- В В def write(bytes: Array[Byte])
- В В def read(n: Int): Array[Byte]
- }
еҲҶзҰ»дёӨдёӘиЎҢдёәпјҡ
- trait Reader {
- В В def read(n: Int): Array[Byte]
- }
- trait Writer {
- В В def write(bytes: Array[Byte])
- }
еҸҜд»Ҙе°Ҷе®ғ们д»Ҙж··е…Ҙ(mix)зҡ„ж–№ејҸе®һзҺ°дёҖдёӘIOer : new Reader with Writer
жҺҘеҸЈжңҖе°ҸеҢ–дҝғдҪҝжӣҙеҘҪзҡ„жӯЈдәӨе’Ңжӣҙжё…жҷ°зҡ„жЁЎеқ—еҢ–гҖӮ
еҸҜи§ҒжҖ§
ScalaжңүеҫҲдё°еҜҢзҡ„еҸҜи§ҒжҖ§дҝ®йҘ°гҖӮдҪҝз”ЁиҝҷдәӣеҸҜи§ҒжҖ§дҝ®йҘ°еҫҲйҮҚиҰҒпјҢе®ғ们е®ҡд№үдәҶе“Әдәӣжһ„жҲҗе…¬ејҖAPIгҖӮе…¬ејҖAPIsеә”иҜҘйҷҗеҲ¶пјҢжүҖд»Ҙз”ЁжҲ·дёҚдјҡж— ж„Ҹдёӯдҫқиө–е®һзҺ°з»ҶиҠӮ并йҷҗеҲ¶дәҶдҪңиҖ…зҡ„иғҪеҠӣжқҘдҝ®ж”№е®ғ们: е®ғ们еҜ№дәҺеҘҪзҡ„жЁЎеқ—еҢ–и®ҫи®ЎжҳҜиҮіе…ійҮҚиҰҒзҡ„гҖӮдёҖиҲ¬жқҘиҜҙпјҢжү©еұ•е…¬ејҖAPIsжҜ”收缩公ејҖзҡ„APIsе®№жҳ“зҡ„еӨҡгҖӮе·®еҠІзҡ„жіЁйҮҠд№ҹиғҪеҚұе®іеҲ°дҪ д»Јз Ғеҗ‘еҗҺзҡ„дәҢиҝӣеҲ¶е…је®№жҖ§гҖӮ
private[this]
дёҖдёӘзұ»зҡ„жҲҗе‘ҳж Үи®°дёәз§Ғжңүзҡ„пјҢ
В
е®ғеҜ№иҝҷдёӘзұ»зҡ„жүҖжңүе®һдҫӢжқҘиҜҙйғҪжҳҜеҸҜи§Ғзҡ„пјҲдҪҶеҜ№е…¶еӯҗзұ»дёҚеҸҜи§ҒпјүгҖӮеӨ§еӨҡжғ…еҶөпјҢдҪ жғіиҰҒзҡ„жҳҜ private[this] гҖӮ
- private[this] val x: Int = ..
В
иҝҷдёӘдҝ®йҘ°йҷҗеҲ¶дәҶе®ғеҸӘеҜ№еҪ“еүҚзү№е®ҡзҡ„е®һдҫӢеҸҜи§ҒгҖӮScalaзј–иҜ‘еҷЁдјҡжҠҠprivate[this]зҝ»иҜ‘дёәдёҖдёӘеӯ—ж®өи®ҝй—®(еӣ дёәи®ҝй—®д»…йҷҗдәҺйқҷжҖҒе®ҡд№үзҡ„зұ»)жңүж—¶еҸҜеўһеҠ жҖ§иғҪдјҳеҢ–гҖӮ
еҚ•дҫӢзұ»еһӢ
еңЁScalaдёӯеҲӣе»әеҚ•дҫӢзұ»еһӢжҳҜеҫҲеёёи§Ғзҡ„пјҢдҫӢеҰӮпјҡ
- def foo() = new Foo with Bar with Baz {
- В В ...
- }
В
еңЁиҝҷз§Қжғ…еҶөдёӢпјҢеҸҜд»ҘйҖҡиҝҮеЈ°жҳҺиҝ”еӣһзұ»еһӢжқҘйҷҗеҲ¶еҸҜи§ҒжҖ§пјҡ
- def foo(): Foo with Bar = new Foo with Bar with Baz {
- В В ...
- }
В
foo()ж–№жі•зҡ„и°ғз”ЁиҖ…дјҡзңӢеҲ°д»Ҙжңүйҷҗи§Ҷеӣҫзҡ„иҝ”еӣһе®һдҫӢ(Foo with Bar)
з»“жһ„зұ»еһӢ
дёҚиҰҒеңЁжӯЈеёёжғ…еҶөдёӢдҪҝз”Ёз»“жһ„зұ»еһӢгҖӮз»“жһ„зұ»еһӢжңүзқҖдҫҝеҲ©дё”ејәеӨ§зҡ„зү№жҖ§пјҢдҪҶдёҚе№ёзҡ„жҳҜеңЁJVMдёҠзҡ„е®һзҺ°дёҚжҳҜеҫҲй«ҳж•ҲгҖӮ 然иҖҢвҖ”вҖ”з”ұдәҺе®һзҺ°зҡ„жҖӘзҷ–вҖ”вҖ”е®ғжҸҗеҜ№жү§иЎҢеҸҚе°„(reflection)дҫӣдәҶеҫҲеҘҪзҡ„йҖҹи®°гҖӮ
- val obj: AnyRef
- obj.asInstanceOf[{def close()}].close()
еһғеңҫеӣһ收
жҲ‘们еҜ№з”ҹдә§жЁЎејҸзҡ„еә”з”ЁиҠұдәҶеҫҲеӨҡж—¶й—ҙжқҘи°ғж•ҙеһғеңҫеӣһ收гҖӮеһғеңҫеӣһ收зҡ„е…іжіЁзӮ№дёҺjavaеӨ§иҮҙзӣёдјјпјҢе°Ҫз®ЎдёҖдәӣжғҜз”Ёзҡ„Scalaд»Јз ҒжҜ”иө·жғҜз”Ёзҡ„javaд»Јз Ғдјҡе®№жҳ“дә§з”ҹжӣҙеӨҡ(зҹӯжҡӮзҡ„)еһғеңҫвҖ”вҖ”еҮҪж•°ејҸйЈҺж јзҡ„еүҜдә§е“ҒгҖӮHotspotзҡ„еҲҶд»Јеһғеңҫ收йӣҶйҖҡеёёдҪҝиҝҷдёҚжҲҗй—®йўҳпјҢеӣ дёәзҹӯжҡӮзҡ„(short-lived)еһғеңҫеңЁеӨ§еӨҡжғ…еҪўдёӢдјҡиў«жңүж•Ҳзҡ„йҮҠж”ҫжҺүгҖӮ
еңЁи°ҲGCи°ғдјҳиҜқйўҳеүҚпјҢе…ҲзңӢзңӢ
иҝҷдёӘз”ұAttilaдёҫдҫӢиҜҙжҳҺжҲ‘们еңЁGCж–№йқўзҡ„дёҖдәӣз»ҸйӘҢзҡ„д»Ӣз»ҚгҖӮ
Scalaеӣәжңүзҡ„й—®йўҳпјҢдҪ иғҪеӨҹзј“и§ЈGCзҡ„ж–№жі•жҳҜдә§з”ҹжӣҙе°‘зҡ„еһғеңҫпјӣдҪҶдёҚиҰҒеңЁжІЎжңүж•°жҚ®зҡ„жғ…еҶөдёӢиЎҢеҠЁгҖӮйҷӨйқһдҪ еҒҡдәҶжҹҗдәӣжҳҺжҳҫзҡ„жҒ¶еҢ–гҖӮдҪҝз”Ёеҗ„з§Қjavaзҡ„profilingе·Ҙе…·вҖ”вҖ”жҲ‘们жӢҘжңүзҡ„еҢ…жӢ¬
heapsterе’Ң
gcprofгҖӮ
Java е…је®№жҖ§
еҪ“жҲ‘们еҶҷзҡ„Scalaд»Јз Ғиў«javaи°ғз”Ёж—¶пјҢжҲ‘们иҰҒзЎ®дҝқд»ҺjavaжқҘз”Ёд»Қз„¶д№ жғҜгҖӮиҝҷеёёеёёдёҚйңҖиҰҒйўқеӨ–зҡ„еҠӘеҠӣвҖ”вҖ”classе’ҢtraitжҳҺзЎ®зҡ„зӯүд»·дәҺjavaзҡ„дёӯзҡ„еҜ№еә”зұ»еһӢ вҖ”вҖ” дҪҶжңүж—¶йңҖиҰҒжҸҗдҫӣзӢ¬з«Ӣзҡ„Java ApiгҖӮдёҖз§Қж„ҹеҸ—дҪ зҡ„еә“дёӯзҡ„java apiеҘҪзҡ„ж–№ејҸжҳҜз”ЁjavaеҶҷеҚ•е…ғжөӢиҜ•(еҸӘжҳҜдёәдәҶе…је®№жҖ§);иҝҷд№ҹзЎ®дҝқдәҶдҪ зҡ„еә“дёӯзҡ„javaи§ҶеӣҫдҝқжҢҒзЁіе®ҡпјҢеңЁиҝҷдёҖзӮ№дёҠдёҚдјҡйҡҸзқҖж—¶й—ҙеӣ Scalaзј–иҜ‘еҷЁзҡ„жіўеҠЁиҖҢеҪұе“ҚгҖӮ
еҢ…еҗ«йғЁеҲҶе®һзҺ°зҡ„TraitдёҚиғҪзӣҙжҺҘиў«javaдҪҝз”Ёпјҡ ж”№дёә extends дёҖдёӘжҠҪиұЎзұ»
- // дёҚиғҪзӣҙжҺҘиў«javaдҪҝз”Ё
- trait Animal {
- В В def eat(other: Animal)
- В В def eatMany(animals: Seq[Animal) = animals foreach(eat(_))
- }
-
- // ж”№дёәиҝҷж ·:
- abstract class JavaAnimal extends Animal
Twitterж ҮеҮҶеә“
TwitterжңҖйҮҚиҰҒзҡ„ж ҮеҮҶеә“жҳҜ
Util е’Ң
FinagleгҖӮUtil еҸҜд»ҘзҗҶи§ЈдёәScalaе’ҢJavaзҡ„ж ҮеҮҶеә“жү©еұ•пјҢжҸҗдҫӣдәҶж ҮеҮҶеә“дёӯжІЎжңүзҡ„еҠҹиғҪжҲ–жӣҙеҗҲйҖӮзҡ„е®һзҺ°гҖӮFinagle жҳҜжҲ‘们зҡ„RPCзі»з»ҹпјҢж ёеҝғеҲҶеёғејҸзі»з»ҹ组件гҖӮ
Future
Futuresе·Із»ҸеңЁе№¶еҸ‘дёҖиҠӮдёӯз®ҖеҚ•и®Ёи®әиҝҮгҖӮжңүдёҖдёӘдёӯеҝғжңәеҲ¶жқҘеҚҸи°ғејӮжӯҘеӨ„зҗҶпјҢжё—йҖҸеңЁжҲ‘们代з Ғеә“дёӯпјҢеҢ…жӢ¬ж ёеҝғзҡ„FinagleгҖӮFuturesе…Ғи®ёз»„еҗҲ并еҸ‘дәӢ件пјҢз®ҖеҢ–дәҶй«ҳ并еҸ‘ж“ҚдҪңгҖӮжңүеҠ©дәҺе®ғ们еңЁJVMдёҠй«ҳж•Ҳзҡ„е®һзҺ°гҖӮ
Twitterзҡ„futureжҳҜејӮжӯҘзҡ„пјҢжүҖд»Ҙеҹәжң¬дёҠд»»дҪ•ж“ҚдҪң(йҳ»еЎһж“ҚдҪң)еҸҜд»Ҙsuspendе®ғзҡ„зәҝзЁӢзҡ„жү§иЎҢпјӣзҪ‘з»ңIOе’ҢзЈҒзӣҳIOжҳҜе°ұжҳҜдҫӢеӯҗвҖ”вҖ”еҝ…йЎ»з”ұзі»з»ҹеӨ„зҗҶпјҢе®ғдёәз»“жһңжҸҗдҫӣfutureгҖӮFinagleдёәзҪ‘з»ңIOжҸҗдҫӣдәҶиҝҷж ·дёҖз§Қзі»з»ҹгҖӮ
Futueжё…жҷ°з®ҖеҚ•пјҡе®ғ们жҢҒжңүдёҖдёӘе°ҡжңӘе®ҢжҲҗиҝҗз®—з»“жһңзҡ„ promise гҖӮе®ғ们жҳҜдёҖдёӘз®ҖеҚ•зҡ„е®№еҷЁвҖ”вҖ”дёҖдёӘеҚ дҪҚз¬ҰгҖӮдёҖж¬Ўи®Ўз®—еҪ“然еҸҜиғҪдјҡеӨұиҙҘпјҢиҝҷз§ҚзҠ¶еҶөеҝ…йЎ»иў«зј–з ҒпјҡдёҖдёӘFutureеҸҜд»Ҙжңү3з§ҚзҠ¶жҖҒпјҡ pending, failed, completedгҖӮ
й—ІиҜқ: з»„еҗҲ(composition)
и®©жҲ‘们йҮҚж–°е®Ўи§ҶжҲ‘们жүҖиҜҙзҡ„з»„еҗҲпјҡе°Ҷз®ҖеҚ•зҡ„组件еҗҲжҲҗдёҖдёӘжӣҙеӨҚжқӮзҡ„гҖӮеҮҪж•°з»„еҗҲзҡ„дёҖдёӘжқғеЁҒзҡ„дҫӢеӯҗпјҡз»ҷе®ҡеҮҪж•° f е’Ң gпјҢз»„еҗҲеҮҪж•° (gВ°f)(x) = g(f(x)) вҖ”вҖ”з»“жһңе…ҲеҜ№ xдҪҝз”ЁfеҮҪж•°пјҢ然еҗҺеңЁдҪҝз”ЁgеҮҪж•°вҖ”вҖ”з”ЁScalaжқҘеҶҷпјҡ
- val f = (i: Int) => i.toString
- val g = (s: String) => s+s+s
- val h = g compose fВ В // : Int => String
-
- scala> h(123)
- res0: java.lang.String = 123123123
В
еӨҚеҗҲеҮҪж•°hпјҢжҳҜдёӘж–°зҡ„еҮҪж•°пјҢз”ұд№ӢеүҚе®ҡд№үзҡ„fе’ҢgеҮҪж•°еҗҲжҲҗгҖӮ
В
FutureжҳҜдёҖз§ҚйӣҶеҗҲзұ»еһӢвҖ”вҖ”е®ғжҳҜдёӘеҢ…еҗ«0жҲ–1дёӘе…ғзҙ зҡ„е®№еҷЁвҖ”вҖ”дҪ еҸҜд»ҘеҸ‘зҺ°д»–们жңүж ҮеҮҶзҡ„йӣҶеҗҲж–№жі•пјҲegпјҡmap, filter, foreachпјүгҖӮеӣ дёәFutureзҡ„еҖјжҳҜ延иҝҹзҡ„пјҢз»“жһңеә”з”Ёиҝҷдәӣж–№жі•дёӯзҡ„д»»дҪ•дёҖз§Қеҝ…然д№ҹ延иҝҹпјӣеңЁ
- val result: Future[Int]
- val resultStr: Future[String] = result map { i => i.toString }
еҮҪж•° { i => i.toString } дёҚдјҡиў«и°ғз”ЁпјҢзӣҙеҲ°intеҖјеҸҜз”ЁпјӣиҪ¬жҚўйӣҶеҗҲзҡ„resultStrеңЁеҸҜз”Ёд№ӢеүҚд№ҹдёҖзӣҙжҳҜеҫ…е®ҡзҠ¶жҖҒгҖӮ
ListеҸҜд»Ҙиў« flattenпјҡ
- val listOfList: List[List[Int]] = ..
- val list: List[Int] = listOfList.flatten
иҝҷеҜ№futureд№ҹжҳҜжңүж„Ҹд№үзҡ„пјҡ
- val futureOfFuture: Future[Future[Int]] = ..
- val future: Future[Int] = futureOfFuture.flatten
еӣ дёәfutureжҳҜ延иҝҹзҡ„пјҢflattenзҡ„е®һзҺ°вҖ”вҖ”з«ӢеҚіиҝ”еӣһвҖ”вҖ”дёҚеҫ—дёҚиҝ”еӣһдёҖдёӘзӯүеҫ…еӨ–йғЁfuture (Future[Future[Int]) е®ҢжҲҗзҡ„future (Future[Future[Int]]).еҰӮжһңеӨ–йғЁfutureеӨұиҙҘпјҢеҶ…йғЁflattened futureд№ҹе°ҶеӨұиҙҘгҖӮ
Future (зұ»дјјList) д№ҹе®ҡд№үдәҶflatMapпјӣFuture[A] е®ҡд№үж–№жі•flatMapзҡ„зӯҫеҗҚ
- flatMap[B](f: A => Future[B]): Future[B]
еҰӮеҗҢз»„еҗҲ map е’Ң flattenпјҢжҲ‘们еҸҜд»Ҙиҝҷж ·е®һзҺ°пјҡ
- def flatMap[B](f: A => Future[B]): Future[B] = {
- В В val mapped: Future[Future[B]] = this map f
- В В val flattened: Future[B] = mapped.flatten
- В В flattened
- }
иҝҷжҳҜдёҖз§ҚжңүеЁҒеҠӣзҡ„з»„еҗҲгҖӮдҪҝз”ЁflatMapжҲ‘们еҸҜд»Ҙе®ҡд№үдёҖдёӘ Future жҳҜдёӨдёӘFutureеәҸеҲ—зҡ„з»“жһңгҖӮ第дәҢдёӘfuture зҡ„и®Ўз®—еҹәдәҺ第дёҖдёӘзҡ„з»“жһңгҖӮжғіиұЎжҲ‘们йңҖиҰҒ2ж¬ЎRPCи°ғз”ЁжқҘйӘҢиҜҒдёҖдёӘз”ЁжҲ·иә«д»ҪпјҢжҲ‘们еҸҜд»Ҙз”ЁдёӢйқўзҡ„ж–№ејҸз»„еҗҲж“ҚдҪңпјҡ
В
- def getUser(id: Int): Future[User]
- def authenticate(user: User): Future[Boolean]
-
- def isIdAuthed(id: Int): Future[Boolean] =
- В В getUser(id) flatMap { user => authenticate(user) }
В
иҝҷз§Қз»„еҗҲзұ»еһӢзҡ„дёҖдёӘйўқеӨ–зҡ„еҘҪеӨ„жҳҜй”ҷиҜҜеӨ„зҗҶжҳҜеҶ…зҪ®зҡ„пјҡеҰӮжһңgetUser(..)жҲ–authenticate(..)жІЎжңүйўқеӨ–зҡ„й”ҷиҜҜеӨ„зҗҶд»Јз Ғ future д»Һ isAuthred(..)иҝ”еӣһж—¶е°ҶдјҡеӨұиҙҘгҖӮ
йЈҺж ј
Futureеӣһи°ғж–№жі•(respond, onSuccess, onFailure, ensure) иҝ”еӣһдёҖдёӘж–°зҡ„й“ҫеҲ°е®ғparentзҡ„Future,гҖӮиҝҷдёӘFutureиў«дҝқиҜҒеҸӘжңүеңЁе®ғparentе®ҢжҲҗеҗҺжүҚе®ҢжҲҗпјҢдҪҝз”ЁжЁЎејҸеҰӮдёӢпјҡ
В
- acquireResource() onSuccess { value =>
- В В computeSomething(value)
- } ensure {
- В В freeResource()
- }
В
freeResource() иў«дҝқиҜҒеҸӘжңүеңЁ computeSomethingд№ӢеҗҺжүҚжү§иЎҢпјҢ е…Ғи®ёжЁЎжӢҹ try-finally жЁЎејҸгҖӮ
дҪҝз”Ё onSuccessжӣҝд»Ј foreach вҖ”вҖ” е®ғдёҺ onFailure ж–№жі•еҜ№з§°пјҢе‘ҪеҗҚзҡ„ж„ҸеӣҫжӣҙжҳҺзЎ®пјҢ并且д№ҹе…Ғи®ё chainingгҖӮ
ж°ёиҝңйҒҝе…ҚзӣҙжҺҘеҲӣе»әPromiseе®һдҫӢпјҡ еҮ д№ҺжҜҸдёҖдёӘд»»еҠЎйғҪеҸҜд»ҘйҖҡиҝҮдҪҝз”Ёйў„е®ҡд№үзҡ„з»„еҗҲеӯҗе®ҢжҲҗгҖӮиҝҷдәӣз»„еҗҲеӯҗзЎ®дҝқй”ҷиҜҜе’ҢеҸ–ж¶ҲжҳҜеҸҜдј ж’ӯзҡ„, йҖҡеёёйј“еҠұзҡ„ж•°жҚ®жөҒйЈҺж јзҡ„зј–зЁӢпјҢдёҚеҶҚйңҖиҰҒеҗҢжӯҘе’ҢvolatilityеЈ°жҳҺгҖӮ
з”Ёе°ҫйҖ’еҪ’йЈҺж јзј–еҶҷзҡ„д»Јз ҒдёҚеҶҚйҒӯеҸ—е Ҷж Ҳз©әй—ҙжі„жјҸпјҢе…Ғи®ёд»Ҙж•°жҚ®жөҒйЈҺж јй«ҳж•Ҳзҡ„е®һзҺ°еҫӘзҺҜпјҡ
- case class Node(parent: Option[Node], ...)
- def getNode(id: Int): Future[Node] = ...
-
- def getHierarchy(id: Int, nodes: List[Node] = Nil): Future[Node] =
- В В getNode(id) flatMap {
- В В В В case n@Node(Some(parent), ..) => getHierarchy(parent, n :: nodes)
- В В В В case n => Future.value((n :: nodes).reverse)
- В В }
Futureе®ҡд№үеҫҲеӨҡжңүз”Ёзҡ„ж–№жі•пјҡ дҪҝз”Ё Future.value() е’Ң Future.exception() жқҘеҲӣе»әжңӘж»Ўж„Ҹ(pre-satisfied) зҡ„futureгҖӮFuture.collect(), Future.join() е’Ң Future.select() жҸҗдҫӣдәҶз»„еҗҲеӯҗе°ҶеӨҡдёӘfutureеҗҲжҲҗдёҖдёӘ(дҫӢеҰӮпјҡscatter-gatherж“ҚдҪңзҡ„gatherйғЁеҲҶ)гҖӮ
Cancellation
Futureе®һзҺ°дәҶдёҖз§ҚејұеҪўејҸзҡ„еҸ–ж¶ҲгҖӮи°ғз”ЁFuture#cancel дёҚдјҡзӣҙжҺҘз»Ҳжӯўиҝҗз®—пјҢиҖҢжҳҜеҸ‘йҖҒжҹҗдёӘзә§еҲ«зҡ„еҸҜиў«д»»дҪ•еӨ„зҗҶжҹҘиҜўзҡ„и§ҰеҸ‘дҝЎеҸ·пјҢжңҖз»Ҳж»Ўи¶іиҝҷдёӘfutureгҖӮCancellationдҝЎеҸ·жөҒеҗ‘зӣёеҸҚзҡ„ж–№еҗ‘пјҡдёҖдёӘз”ұж¶Ҳиҙ№иҖ…и®ҫзҪ®зҡ„cancellationдҝЎеҸ·пјҢдј ж’ӯеҲ°е®ғзҡ„ж¶Ҳиҙ№иҖ…гҖӮз”ҹдә§иҖ…дҪҝз”Ё Promiseзҡ„onCancellationжқҘзӣ‘еҗ¬дҝЎеҸ·е№¶жү§иЎҢзӣёеә”зҡ„еҠЁдҪңгҖӮ
иҝҷж„Ҹе‘іиҝҷеҸ–ж¶ҲиҜӯж„ҸдёҠдҫқиө–з”ҹдә§иҖ…пјҢжІЎжңүй»ҳи®Өзҡ„е®һзҺ°гҖӮеҸ–ж¶ҲеҸӘжҳҜдёҖдёӘжҸҗзӨәгҖӮ
Local
Utilзҡ„
LocalжҸҗдҫӣдәҶдёҖдёӘдҪҚдәҺзү№е®ҡзҡ„futureжҙҫеҸ‘ж ‘(dispatch tree)зҡ„еј•з”ЁеҚ•е…ғ(cell)гҖӮи®ҫе®ҡдёҖдёӘlocalзҡ„еҖјпјҢдҪҝиҝҷдёӘеҖјеҸҜд»Ҙз”ЁдәҺиў«еҗҢдёҖдёӘзәҝзЁӢзҡ„Future 延иҝҹзҡ„д»»дҪ•и®Ўз®—гҖӮжңүдёҖдәӣзұ»дјјзҡ„зәҝзЁӢ localsпјҢйҷӨдәҶе®ғ们зҡ„иҢғеӣҙдёҚжҳҜдёҖдёӘjavaзәҝзЁӢпјҢиҖҢжҳҜдёҖдёӘ future зәҝзЁӢж ‘гҖӮеңЁ
trait User {В В def name: StringВ В def incrCost(points: Int) } val user = new Local[User] ... user() = currentUser rpc() ensure {В В user().incrCost(10) }
еңЁ ensureеқ—дёӯзҡ„ user() е°ҶеңЁеӣһи°ғиў«ж·»еҠ зҡ„ж—¶еҖҷеј•з”Ё user localзҡ„еҖјгҖӮ
е°ұthread localsжқҘиҜҙпјҢLocalsйқһеёёзҡ„ж–№дҫҝпјҢдҪҶиҰҒйҒҝе…ҚпјҡзЎ®дҝЎйҖҡиҝҮжҳҫејҸдј йҖ’ж•°жҚ®ж—¶й—®йўҳдёҚиғҪиў«е……еҲҶзҡ„и§ЈеҶіпјҢз”ҡиҮіжңүдәӣз№ҒйҮҚзҡ„гҖӮ
Localsжңүж•Ҳзҡ„иў«ж ёеҝғеә“дҪҝз”ЁеңЁйқһеёёеёёи§Ғзҡ„й—®йўҳдёҠвҖ”вҖ”зәҝзЁӢйҖҡиҝҮRPCи·ҹиёӘпјҢдј ж’ӯзӣ‘и§ҶеҷЁпјҢдёәfutureзҡ„еӣһи°ғеҲӣе»әstack tracesвҖ”вҖ”д»»дҪ•е…¶д»–и§ЈеҶіж–№жі•йғҪдҪҝеҫ—з”ЁжҲ·иҙҹжӢ…иҝҮеәҰгҖӮLocalsеңЁеҮ д№Һд»»дҪ•е…¶д»–жғ…еҶөдёӢйғҪдёҚйҖӮеҗҲгҖӮ
Offer/Broker
并еҸ‘зі»з»ҹз”ұдәҺйңҖиҰҒеҚҸи°ғи®ҝй—®ж•°жҚ®е’Ңиө„жәҗиҖҢеҸҳеҫ—еӨҚжқӮгҖӮ
ActorжҸҗеҮәдёҖз§Қз®ҖеҢ–зҡ„зӯ–з•ҘпјҡжҜҸдёҖдёӘactorжҳҜдёҖдёӘиҝһз»ӯзҡ„иҝӣзЁӢ(process),дҝқжҢҒиҮӘе·ұзҡ„зҠ¶жҖҒе’Ңиө„жәҗ,ж•°жҚ®йҖҡиҝҮж¶ҲжҒҜзҡ„ж–№ејҸдёҺе…¶е®ғactorе…ұдә«гҖӮ е…ұдә«ж•°жҚ®йңҖиҰҒactorд№Ӣй—ҙйҖҡдҝЎгҖӮ
Offer/Broker е»әз«ӢдәҺиҝҷ3дёӘйҮҚиҰҒзҡ„ж–№ејҸдёҠпјҡ1пјҢйҖҡдҝЎйҖҡйҒ“(Brokers)жҳҜfirst classвҖ”вҖ”еҚіеҸ‘йҖҒж¶ҲжҒҜйңҖиҰҒйҖҡиҝҮBrokersпјҢиҖҢйқһзӣҙжҺҘеҲ°actorгҖӮ2, Offer/Broker жҳҜдёҖз§ҚеҗҢжӯҘжңәеҲ¶пјҡйҖҡдҝЎдјҡиҜқжҳҜеҗҢжӯҘзҡ„гҖӮ иҝҷж„Ҹе‘іжҲ‘们еҸҜд»Ҙз”Ё BrokerеҒҡдёәеҚҸи°ғжңәеҲ¶пјҡеҪ“иҝӣзЁӢaеҸ‘йҖҒдёҖжқЎдҝЎжҒҜз»ҷиҝӣзЁӢbпјӣaе’ҢbйғҪиҰҒеҜ№зі»з»ҹзҠ¶жҖҒиҫҫжҲҗдёҖиҮҙгҖӮ3, жңҖеҗҺпјҢйҖҡдҝЎеҸҜд»ҘйҖүжӢ©жҖ§зҡ„жү§иЎҢпјҡдёҖдёӘиҝӣзЁӢеҸҜд»ҘжҸҗеҮәеҮ дёӘдёҚеҗҢзҡ„йҖҡдҝЎпјҢе…¶дёӯзҡ„дёҖдёӘе°Ҷиў«иҺ·еҸ–гҖӮ
дёәдәҶд»ҘдёҖз§ҚйҖҡз”Ёзҡ„ж–№ејҸж”ҜжҢҒйҖүжӢ©жҖ§йҖҡдҝЎпјҲд»ҘеҸҠе…¶д»–з»„еҗҲпјү,жҲ‘们йңҖиҰҒе°ҶйҖҡдҝЎзҡ„жҸҸиҝ°е’Ңжү§иЎҢи§ЈиҖҰгҖӮиҝҷжӯЈжҳҜOfferеҒҡзҡ„вҖ”вҖ”е®ғжҳҜдёҖдёӘжҢҒд№…ж•°жҚ®з”ЁдәҺжҸҸиҝ°дёҖж¬ЎйҖҡдҝЎпјӣдёәдәҶжү§иЎҢиҝҷдёӘйҖҡдҝЎпјҲofferжү§иЎҢпјүпјҢжҲ‘们йҖҡиҝҮе®ғзҡ„sync()ж–№жі•еҗҢжӯҘ
- trait Offer[T] {
- В В def sync(): Future[T]
- }
иҝ”еӣһ Future[T] еҪ“йҖҡдҝЎиў«иҺ·еҸ–зҡ„ж—¶еҖҷз”ҹжҲҗдәӨжҚўеҖј
BrokerйҖҡиҝҮofferеҚҸи°ғеҖјзҡ„дәӨжҚўвҖ”вҖ”е®ғжҳҜйҖҡдҝЎзҡ„йҖҡйҒ“пјҡ
- trait Broker[T] {
- В В def send(msg: T): Offer[Unit]
- В В val recv: Offer[T]
- }
жүҖд»ҘпјҢеҪ“еҲӣе»ә2дёӘoffer
- val b: Broker[Int]
- val sendOf = b.send(1)
- val recvOf = b.recv
sendOfе’ҢrecvOfйғҪеҗҢжӯҘ
- // In process 1:
- sendOf.sync()
-
- // In process 2:
- recvOf.sync()
дёӨдёӘofferйғҪиҺ·еҸ–并且еҖј1иў«дәӨжҚўгҖӮ
еҸҜйҖүжӢ©йҖҡдҝЎиў«йҖҡиҝҮOffer.chooseз»‘е®ҡзҡ„еӨҡдёӘofferжү§иЎҢгҖӮ
- def choose[T](ofs: Offer[T]*): Offer[T]
з”ҹжҲҗдёҖдёӘж–°зҡ„offerпјҢеҪ“еҗҢжӯҘзҡ„иҺ·еҸ–зү№е®ҡзҡ„ofsвҖ”вҖ”第дёҖдёӘеҸҜз”ЁгҖӮеҪ“еӨҡдёӘйғҪз«ӢеҚіеҸҜз”Ёж—¶пјҢйҡҸжңәиҺ·еҸ–дёҖдёӘгҖӮ
OfferеҜ№иұЎжңүдәӣдёҖж¬ЎжҖ§зҡ„Offersз”ЁдәҺдёҺжқҘиҮӘBrokerзҡ„Offerжһ„е»әгҖӮ
- Offer.timeout(duration): Offer[Unit]
offerеңЁз»ҷе®ҡж—¶й—ҙеҗҺжҝҖжҙ»гҖӮOffer.neverе°Ҷз”ЁдәҺдёҚдјҡжңүж•ҲпјҢOffer.const(value)еңЁз»ҷе®ҡеҖјеҗҺз«ӢеҚіжңүж•ҲгҖӮйҖҡиҝҮйҖүжӢ©жҖ§йҖҡдҝЎжқҘз»„еҗҲжҳҜйқһеёёжёёжіізҡ„гҖӮдҫӢеҰӮпјҢеңЁдёҖдёӘsendж“ҚдҪңдёӯдҪҝз”Ёи¶…ж—¶пјҡ
- Offer.choose(
- В В Offer.timeout(10.seconds),
- В В broker.send("my value")
- ).sync()
дәә们еҸҜиғҪдјҡжҜ”иҫғ Offer/Broker дёҺ
SynchronousQueueпјҢ他们з»ҶиҠӮдёҠдёҚеҗҢиҖҢйқһйҮҚиҰҒзҡ„ж–№йқўгҖӮOfferеҸҜд»Ҙиў«з»„еҗҲпјҢиҖҢqueueдёҚиғҪгҖӮдҫӢеҰӮпјҢиҖғиҷ‘дёҖз»„queuesпјҢжҸҸиҝ°дёә Brokers:
- val q0 = new Broker[Int]
- val q1 = new Broker[Int]
- val q2 = new Broker[Int]
зҺ°еңЁи®©жҲ‘们дёәreadingеҲӣе»әдёҖдёӘеҗҲ并зҡ„queue
- val anyq: Offer[Int] = Offer.choose(q0.recv, q1.recv, q2.recv)
anyqжҳҜдёҖдёӘе°Ҷд»Һ第дёҖдёӘеҸҜз”Ёзҡ„queueдёӯиҜ»еҸ–зҡ„offerгҖӮжіЁж„Ҹ anyq д»ҚжҳҜеҗҢжӯҘзҡ„вҖ”вҖ”жҲ‘们д»Қ然жӢҘжңүеә•еұӮйҳҹеҲ—зҡ„иҜӯд№үгҖӮиҝҷзұ»з»„еҗҲжҳҜдёҚеҸҜиғҪз”Ёqueueзҡ„гҖӮ
дҫӢеӯҗпјҡдёҖдёӘз®ҖеҚ•зҡ„иҝһжҺҘжұ
иҝһжҺҘжұ еңЁзҪ‘з»ңеә”з”ЁдёӯеҫҲеёёи§ҒпјҢ并且е®ғ们зҡ„е®һзҺ°еёёеёёйңҖиҰҒжҠҖе·§вҖ”вҖ”дҫӢеҰӮпјҢйҖҡеёёйңҖиҰҒи¶…ж—¶жңәеҲ¶еңЁд»Һжұ дёӯиҺ·еҸ–дёҖдёӘиҝһжҺҘзҡ„ж—¶еҖҷпјҢеӣ дёәдёҚеҗҢзҡ„е®ўжҲ·з«ҜжңүдёҚеҗҢзҡ„延иҝҹйңҖжұӮгҖӮжұ зҡ„з®ҖеҚ•еҺҹеҲҷпјҡз»ҙжҠӨдёҖдёӘиҝһжҺҘйҳҹеҲ—пјҢж»Ўи¶ійӮЈдәӣиҝӣе…Ҙзҡ„зӯүеҫ…иҖ…гҖӮдҪҝз”Ёдј з»ҹзҡ„еҗҢжӯҘеҺҹиҜӯпјҢиҝҷйҖҡеёёйңҖиҰҒ2дёӘйҳҹеҲ—(queues)пјҡдёҖдёӘз”ЁдәҺзӯүеҫ…иҖ…(еҪ“жІЎжңүиҝһжҺҘеҸҜз”Ёж—¶)пјҢдёҖдёӘз”ЁдәҺиҝһжҺҘ(еҪ“жІЎжңүзӯүеҫ…иҖ…ж—¶)гҖӮ
дҪҝз”Ё Offer/Brokers пјҢеҸҜд»ҘиЎЁиҫҫзҡ„йқһеёёиҮӘ然пјҡ
В
- class Pool(conns: Seq[Conn]) {
- В В private[this] val waiters = new Broker[Conn]
- В В private[this] val returnConn = new Broker[Conn]
-
- В В val get: Offer[Conn] = waiters.recv
- В В def put(c: Conn) { returnConn ! c }
-
- В В private[this] def loop(connq: Queue[Conn]) {
- В В В В Offer.choose(
- В В В В if (connq.isEmpty) Offer.never else {
- В В В В В В val (head, rest) = connq.dequeue
- В В В В В В waiters.send(head) { _ => loop(rest) }
- В В В В },
- В В В В returnConn.recv { c => loop(connq enqueue c) }
- В В В В ).sync()
- В В }
-
- В В loop(Queue.empty ++ conns)
- }
loopжҖ»жҳҜжҸҗдҫӣдёҖдёӘеҪ’иҝҳзҡ„иҝһжҺҘпјҢдҪҶеҸӘжңүqueueйқһз©әзҡ„ж—¶еҖҷжүҚдјҡsendгҖӮ дҪҝз”ЁжҢҒд№…еҢ–йҳҹеҲ—(persistent queue)жӣҙиҝӣдёҖжӯҘз®ҖеҢ–йҖ»иҫ‘гҖӮдёҺиҝһжҺҘжұ зҡ„жҺҘеҸЈд№ҹжҳҜйҖҡиҝҮOfferпјҢжүҖд»Ҙи°ғз”ЁиҖ…еҰӮжһңж„ҝж„Ҹи®ҫзҪ®timeoutпјҢ他们еҸҜд»ҘйҖҡиҝҮеҲ©з”Ёз»„еҗҲеӯҗ(combinators)жқҘеҒҡпјҡ
- val conn: Future[Option[Conn]] = Offer.choose(
- В В pool.get { conn => Some(conn) },
- В В Offer.timeout(1.second) { _ => None }
- В В ).sync()
е®һзҺ°timeoutдёҚйңҖиҰҒйўқеӨ–зҡ„и®°иҙҰ(bookkeeping)пјӣиҝҷжҳҜеӣ дёәOfferзҡ„иҜӯд№үпјҡеҰӮжһңOffer.timeoutиў«йҖүжӢ©пјҢдёҚдјҡеҶҚжңүofferд»Һжұ дёӯиҺ·еҫ—вҖ”вҖ”иҝһжҺҘжұ е’Ңе®ғзҡ„и°ғз”ЁиҖ…еңЁеҗ„иҮӘwaiterзҡ„brokerдёҠдёҚеҝ…еҗҢж—¶еҗҢж„ҸжҺҘеҸ—е’ҢеҸ‘йҖҒгҖӮ
еҹғжӢүжүҳиүІе°јзӯӣеӯҗ(Sieve of Eratosthenes иҜ‘жіЁпјҡдёҖз§Қз”ЁдәҺзӯӣйҖүзҙ ж•°зҡ„з®—жі•)
еңЁжһ„йҖ 并еҸ‘зЁӢеәҸдҪңдёәдёҖз»„йЎәеәҸзҡ„еҗҢжӯҘйҖҡдҝЎиҝӣзЁӢпјҢе®ғйҖҡеёёеҫҲжңүз”ЁвҖ”вҖ”жңүж—¶зЁӢеәҸиў«еӨ§еӨ§зҡ„з®ҖеҢ–дәҶгҖӮOfferе’ҢBrokerжҸҗдҫӣдәҶдёҖз»„е·Ҙе…·жқҘи®©е®ғз®ҖеҚ•е№¶дёҖиҮҙгҖӮзЎ®е®һпјҢе®ғ们зҡ„еә”з”Ёи¶…и¶ҠдәҶжҲ‘们еҸҜиғҪи®ӨдёәжҳҜз»Ҹ典并еҸ‘жҖ§й—®йўҳвҖ”вҖ”并еҸ‘зј–зЁӢ(дҪҝжңүOffer/Brokerиҫ…еҠ©)жҳҜдёҖз§Қжңүз”Ёзҡ„жһ„е»әе·Ҙе…·пјҢжӯЈеҰӮеӯҗдҫӢзЁӢ(subroutines)пјҢзұ»пјҢе’ҢжЁЎеқ—йғҪжҳҜвҖ”вҖ”жқҘиҮӘCSPзҡ„йҮҚиҰҒжҖқжғігҖӮ
иҝҷйҮҢжңүдёҖдёӘ
еҹғжӢүжүҳиүІе°јзӯӣеӯҗеҸҜд»ҘеҜ№дёҖдёӘж•ҙж•°жөҒ(stream of integers)жһ„йҖ дёәиҝһз»ӯзҡ„еә”з”ЁиҝҮж»ӨеҷЁ гҖӮйҰ–е…ҲпјҢжҲ‘们йңҖиҰҒдёҖдёӘж•ҙж•°зҡ„жәҗ(source of integers)пјҡ
- def integers(from: Int): Offer[Int] = {
- В В val b = new Broker[Int]
- В В def gen(n: Int): Unit = b.send(n).sync() ensure gen(n + 1)
- В В gen(from)
- В В b.recv
- }
integers(n) ж–№жі•з®ҖеҚ•зҡ„жҸҗдҫӣдәҶд»ҺnејҖе§Ӣзҡ„жүҖжңүиҝһз»ӯзҡ„ж•ҙж•°гҖӮ然еҗҺжҲ‘们йңҖиҰҒдёҖдёӘиҝҮж»ӨеҷЁпјҡ
- def filter(in: Offer[Int], prime: Int): Offer[Int] = {
- В В val b = new Broker[Int]
- В В def loop() {
- В В В В in.sync() onSuccess { i =>
- В В В В if (i % prime != 0)
- В В В В В В b.send(i).sync() ensure loop()
- В В В В else
- В В В В В В loop()
- В В В В }
- В В }
- В В loop()
-
- В В b.recv
- }
loop() е·ҘдҪңеҫҲз®ҖеҚ•пјҡд»ҺofдёӯиҜ»еҸ–дёӢдёҖдёӘиҙЁж•°(prime)пјҢ然еҗҺеҜ№ofеә”з”ЁиҝҮж»ӨеҷЁжҺ’йҷӨиҝҷдёӘиҙЁж•°гҖӮloopдёҚж–ӯзҡ„йҖ’еҪ’пјҢжҢҒз»ӯзҡ„иҙЁж•°иў«иҝҮж»ӨпјҢдәҺжҳҜжҲ‘们еҫ—еҲ°дәҶзӯӣйҖүз»“жһңгҖӮжҲ‘们зҺ°еңЁжү“еҚ°еүҚ10000дёӘиҙЁж•°пјҡ
val primes = sieve 0 until 10000 foreach { _ =>В В println(primes.sync()()) }
йҷӨдәҶжһ„йҖ з®ҖеҚ•пјҢ组件жӯЈдәӨпјҢиҝҷз§ҚеҒҡжі•д№ҹз»ҷдҪ дёҖз§ҚжөҒејҸзӯӣеӯҗ(streaming sieve)пјҡдҪ дёҚйңҖиҰҒе…Ҳи®Ўз®—еҮәдҪ ж„ҹе…ҙи¶Јзҡ„иҙЁж•°йӣҶеҗҲпјҢиҝӣдёҖжӯҘжҸҗй«ҳдәҶжЁЎеқ—еҢ–гҖӮ
иҮҙи°ў
жң¬иҜҫзЁӢз”ұTwitterе…¬еҸёScalaзӨҫеҢәиҙЎзҢ®вҖ”вҖ”жҲ‘еёҢжңӣжҲ‘жҳҜдёӘеҝ е®һзҡ„и®°еҪ•иҖ…гҖӮ
Blake Matheny, Nick Kallen, Steve Gury, е’ҢRaghavendra PrabhuжҸҗдҫӣдәҶеҫҲеӨҡжңүз”Ёзҡ„жҢҮеҜје’Ңи®ёеӨҡдјҳз§Җзҡ„е»әи®®гҖӮ
В




зӣёе…іжҺЁиҚҗ
жң¬иҜҫ件жҳҜй’ҲеҜ№ScalaеӯҰд№ иҖ…зІҫеҝғеҮҶеӨҮзҡ„иө„жәҗпјҢж—ЁеңЁеё®еҠ©дҪ ж·ұе…ҘзҗҶи§Је’ҢжҺҢжҸЎScalaзҡ„ж ёеҝғжҰӮеҝөпјҢ并иҝӣдёҖжӯҘзҶҹжӮүеңЁSparkжЎҶжһ¶дёӯзҡ„еә”з”ЁгҖӮ йҰ–е…ҲпјҢжҲ‘们д»Һ"Scalaиҝӣйҳ¶д№Ӣи·Ҝ-part01-еҹәзЎҖ.pdf"ејҖе§ӢпјҢиҝҷйғЁеҲҶеҶ…е®№дё»иҰҒж¶өзӣ–дәҶScalaзҡ„еҹәзЎҖзҹҘиҜҶ...
жҖ»зҡ„жқҘиҜҙпјҢ"Scalaзј–зЁӢжҢҮеҚ—第дёүзүҲ"жҳҜдёҖжң¬е…ЁйқўиҖҢж·ұе…Ҙзҡ„еӯҰд№ иө„ж–ҷпјҢдёҚд»…йҖӮеҗҲеҲқеӯҰиҖ…е…Ҙй—ЁпјҢд№ҹеҜ№жңүз»ҸйӘҢзҡ„ејҖеҸ‘иҖ…жҸҗдҫӣдәҶдё°еҜҢзҡ„иҝӣйҳ¶еҶ…е®№гҖӮйҖҡиҝҮйҳ…иҜ»иҝҷжң¬д№ҰпјҢдҪ е°ҶиғҪзҶҹз»ғжҺҢжҸЎScalaиҜӯиЁҖпјҢ并жңүиғҪеҠӣеҲ©з”ЁScalaе’ҢSparkжһ„е»әй«ҳж•Ҳзҡ„еӨ§ж•°жҚ®...
е…¶ж¬ЎпјҢзҪ‘з»ңдёҠжңүеӨ§йҮҸзҡ„е…Қиҙ№ScalaеӯҰд№ иө„жәҗеҸҜдҫӣеҸӮиҖғгҖӮжҜ”еҰӮпјҢйҖҡиҝҮgoogleжҗңзҙўвҖңprogramminginscala2ndedition.pdfвҖқпјҢжҲ‘们еҸҜд»ҘжүҫеҲ°гҖҠProgramming in ScalaгҖӢиҝҷжң¬д№Ұзҡ„第дәҢзүҲз”өеӯҗзүҲиө„жәҗгҖӮиҝҷжң¬д№Ұз”ұScalaиҜӯиЁҖзҡ„дё»иҰҒи®ҫи®ЎеёҲе’Ң...
йҖҡиҝҮеӯҰд№ иҝҷдәӣд»Јз Ғжё…еҚ•пјҢиҜ»иҖ…дёҚд»…еҸҜд»Ҙж·ұе…ҘзҗҶи§ЈScalaиҜӯиЁҖжң¬иә«пјҢиҝҳиғҪжҺҢжҸЎеҰӮдҪ•еҲ©з”ЁScalaжһ„е»әе®һйҷ…зҡ„гҖҒй«ҳж•Ҳзҡ„еә”з”ЁзЁӢеәҸпјҢзү№еҲ«жҳҜеҪ“ж¶үеҸҠеҲ°е“Қеә”ејҸзј–зЁӢе’Ңжһ„е»әе·Ҙе…·зҡ„дҪҝз”Ёж—¶пјҢиғҪжӣҙеҘҪең°йҖӮеә”зҺ°д»ЈиҪҜ件ејҖеҸ‘зҡ„йңҖжұӮгҖӮ
иҝҷдёӘ"scalaеӯҰд№ её®еҠ©ж–Ү件"еҢ…еҗ«дәҶScalaзј–зЁӢзҡ„第дёҖеҸ‘иЎҢзүҲпјҢ第е…ӯзүҲжң¬зҡ„иҜҰз»ҶеҶ…е®№пјҢжҳҜеӯҰд№ ScalaиҜӯиЁҖзҡ„е®қиҙөиө„жәҗгҖӮ еңЁ Scala зј–зЁӢдёӯпјҢеҹәзЎҖжҰӮеҝөеҢ…жӢ¬еҸҳйҮҸгҖҒеёёйҮҸгҖҒж•°жҚ®зұ»еһӢпјҲеҰӮеҹәжң¬зұ»еһӢIntгҖҒDoubleгҖҒStringпјҢд»ҘеҸҠзұ»зұ»еһӢе’ҢйӣҶеҗҲ...
еҗҢж—¶пјҢз”ұдәҺScalaжһ„е»әеңЁJavaе№іеҸ°дёҠпјҢдәҶи§ЈJavaеҜ№дәҺScalaеӯҰд№ иҖ…жқҘиҜҙжҳҜйқһеёёжңүеё®еҠ©зҡ„пјҢеӣ дёәеҸҜд»Ҙе°ҶJavaзҡ„з”ҹжҖҒе’Ңе·Іжңүзҡ„зҹҘиҜҶж— зјқиҝҒ移еҲ°ScalaдёҠгҖӮ ж·ұе…ҘеӯҰд№ ScalaпјҢйҷӨдәҶйҳ…иҜ»д№ҰзұҚе’Ңж–ҮжЎЈд№ӢеӨ–пјҢиҝҳйңҖиҰҒеӨ§йҮҸзҡ„е®һи·өгҖӮеҸӮдёҺејҖжәҗйЎ№зӣ®гҖҒ...
жҖ»зҡ„жқҘиҜҙпјҢиҝҷдёӘеҺӢзј©еҢ…жҸҗдҫӣдәҶдёҖдёӘе…Ёйқўзҡ„ScalaеӯҰд№ иө„жәҗйӣҶеҗҲпјҢеҢ…жӢ¬е®ҳж–№APIж–ҮжЎЈгҖҒеҹәзЎҖж•ҷзЁӢе’Ңй’ҲеҜ№JavaејҖеҸ‘иҖ…зҡ„дё“дёҡжҢҮеҚ—пјҢйҖӮеҗҲдёҚеҗҢзЁӢеәҰзҡ„ScalaеӯҰд№ иҖ…гҖӮйҖҡиҝҮж·ұе…ҘеӯҰд№ иҝҷдәӣжқҗж–ҷпјҢејҖеҸ‘иҖ…еҸҜд»ҘзҶҹз»ғжҺҢжҸЎScalaиҜӯиЁҖпјҢд»ҺиҖҢеңЁејҖеҸ‘й«ҳ...
### ејҖеҸ‘дәәе‘ҳзҡ„ScalaжҢҮеҚ— #### дёҖгҖҒеј•иЁҖ гҖҠејҖеҸ‘дәәе‘ҳзҡ„ScalaжҢҮеҚ—гҖӢжҳҜдёҖйғЁдё“дёә...йҖҡиҝҮжң¬д№Ұзҡ„еӯҰд№ пјҢиҜ»иҖ…дёҚд»…иғҪжҺҢжҸЎScalaзҡ„ж ёеҝғжҰӮеҝөе’ҢжҠҖжңҜпјҢиҝҳиғҪдәҶи§ЈеҲ°еҰӮдҪ•е°Ҷе…¶еә”з”ЁдәҺи§ЈеҶіе®һйҷ…й—®йўҳпјҢд»ҺиҖҢжҸҗеҚҮиҮӘе·ұзҡ„зј–зЁӢжҠҖиғҪе’ҢиҒҢдёҡеҸ‘еұ•гҖӮ
ScalaеӯҰд№ жҠҖжңҜж•ҷзЁӢжҳҜдёәеҲқеӯҰиҖ…еҮҶеӨҮзҡ„дёҖжң¬е…Ёйқўзҡ„еӯҰд№ жҢҮеҜјпјҢе®ғдёҚд»…ж¶өзӣ–дәҶScalaзҡ„еҹәзЎҖзҹҘиҜҶзӮ№пјҢиҝҳжіЁйҮҚдәҺе®һи·өеә”з”ЁпјҢйҖҡиҝҮдё°еҜҢзҡ„иҜҫеҗҺд№ йўҳеҠ ж·ұеҜ№ScalaиҜӯиЁҖзҡ„зҗҶи§ЈгҖӮиҝҷжң¬ж•ҷзЁӢеңЁзј–еҶҷж—¶еҸҜиғҪйҮҮз”ЁдәҶеӨ§йҮҸзҡ„е®һдҫӢе’Ңз»ғд№ пјҢд»Ҙеё®еҠ©еҲқеӯҰиҖ…...
### йқўеҗ‘JavaејҖеҸ‘дәәе‘ҳзҡ„ScalaжҢҮеҚ— #### дёҖгҖҒеј•иЁҖ йҡҸзқҖжҠҖжңҜзҡ„дёҚж–ӯеҸ‘еұ•пјҢзј–зЁӢиҜӯиЁҖд№ҹеңЁдёҚж–ӯең°жј”иҝӣгҖӮй•ҝжңҹд»ҘжқҘпјҢJavaдҪңдёәйқўеҗ‘еҜ№иұЎзј–зЁӢзҡ„д»ЈиЎЁжҖ§иҜӯиЁҖпјҢеңЁиҪҜ件ејҖеҸ‘йўҶеҹҹеҚ жҚ®дё»еҜјең°дҪҚгҖӮ然иҖҢпјҢиҝ‘е№ҙжқҘпјҢдёҖз§ҚеҗҚдёәScalaзҡ„ж–°иҜӯиЁҖ...
2. **SCALAзЁӢеәҸи®ҫи®Ў**пјҡиҝҷдёӘж–Ү件еҗҚеҸҜиғҪжҢҮзҡ„жҳҜе…ідәҺScalaзЁӢеәҸи®ҫи®Ўзҡ„ж•ҷжқҗжҲ–жҢҮеҚ—пјҢеҸҜиғҪж¶өзӣ–дәҶд»Һеҹәжң¬иҜӯжі•еҲ°жӣҙеӨҚжқӮзҡ„зј–зЁӢжҠҖе·§пјҢеҰӮй«ҳйҳ¶еҮҪж•°гҖҒдёҚеҸҜеҸҳж•°жҚ®з»“жһ„гҖҒзұ»еһӢжҺЁж–ӯгҖҒзұ»еһӢзұ»гҖҒжЁЎејҸеҢ№й…ҚзӯүгҖӮеңЁJavaиҷҡжӢҹжңәпјҲJVMпјүдёҠиҝҗиЎҢзҡ„...
2. еҮҪж•°ејҸзј–зЁӢпјҡScala д№ҹжҳҜдёҖдёӘжҲҗзҶҹзҡ„еҮҪж•°ејҸиҜӯиЁҖпјҢеҮҪж•°ејҸзј–зЁӢжңүдёӨдёӘжҢҮеҜјжҖқжғіпјҡеҮҪж•°жҳҜеӨҙзӯүеҖјпјҢеҸҜд»Ҙиў«еҪ“дҪңеҸӮж•°дј йҖ’пјҢд№ҹеҸҜд»Ҙиў«еҪ“дҪңиҝ”еӣһеҖјиҝ”еӣһпјӣзЁӢеәҸзҡ„ж“ҚдҪңеә”иҜҘжҠҠиҫ“е…ҘеҖјжҳ е°„дёәиҫ“еҮәеҖјиҖҢдёҚжҳҜе°ұең°дҝ®ж”№гҖӮ 3. йқҷжҖҒзұ»еһӢпјҡScala...
然иҖҢпјҢеӯҰд№ Scalaд№ҹйңҖиҰҒдёҖе®ҡзҡ„жҠ•е…ҘпјҢеӣ дёәе®ғзҡ„иҜӯиЁҖзү№жҖ§иҫғдёәеӨҚжқӮпјҢеҜ№дәҺд№ жғҜдәҶJavaзҡ„ејҖеҸ‘иҖ…жқҘиҜҙпјҢеҸҜиғҪйңҖиҰҒж—¶й—ҙйҖӮеә”гҖӮдҪҶдёҖж—ҰжҺҢжҸЎдәҶScalaпјҢејҖеҸ‘иҖ…е°ҶиғҪеӨҹеҲ©з”Ёе…¶ејәеӨ§зҡ„еҠҹиғҪжқҘжҸҗеҚҮз”ҹдә§еҠӣе’Ңд»Јз ҒиҙЁйҮҸпјҢд»ҺиҖҢеңЁйқўеҜ№еӨҚжқӮзҡ„зј–зЁӢжҢ‘жҲҳ...
гҖҠйқўеҗ‘JavaејҖеҸ‘дәәе‘ҳзҡ„ScalaжҢҮеҚ—гҖӢжҳҜдёҖжң¬дё“дёәзҶҹжӮүJavaзј–зЁӢиҜӯиЁҖзҡ„ејҖеҸ‘иҖ…и®ҫи®Ўзҡ„д№ҰзұҚпјҢж—ЁеңЁеё®еҠ©д»–们зҗҶи§Је’ҢжҺҢжҸЎScalaиҝҷй—ЁејәеӨ§зҡ„еӨҡиҢғејҸзј–зЁӢиҜӯиЁҖгҖӮScalaз»“еҗҲдәҶйқўеҗ‘еҜ№иұЎе’ҢеҮҪж•°ејҸзј–зЁӢзҡ„зү№зӮ№пјҢжҸҗдҫӣдәҶжӣҙй«ҳзҡ„д»Јз ҒжҠҪиұЎиғҪеҠӣе’ҢжҖ§иғҪ...
**Scalaе®һз”ЁжҢҮеҚ—1** жҳҜдёҖжң¬йқўеҗ‘JavaејҖеҸ‘иҖ…пјҢж—ЁеңЁж•ҷжҺҲScalaзј–зЁӢиҜӯиЁҖзҡ„е®һз”ЁжҢҮеҚ—гҖӮдҪңиҖ…ж–ҮеҚЎзү№В·иӢҸеё•жӢү马尼дәҡе§ҶпјҲVenkat SubramaniamпјүжҳҜдёҖдҪҚзҹҘеҗҚзҡ„зј–зЁӢ专家пјҢд»–еңЁAgile Developerе…¬еҸёжӢ…д»»еҲӣе§ӢдәәпјҢ并еңЁдј‘ж–Ҝж•ҰеӨ§еӯҰд»»ж•ҷпјҢ...
гҖҠIBMпјҡйқўеҗ‘JavaејҖеҸ‘дәәе‘ҳзҡ„ScalaжҢҮеҚ—гҖӢжҳҜдёҖжң¬ж—ЁеңЁеё®еҠ©JavaејҖеҸ‘иҖ…иҝҮжёЎеҲ°ScalaиҜӯиЁҖзҡ„е®һз”Ё...йҖҡиҝҮеӯҰд№ ScalaпјҢJavaејҖеҸ‘иҖ…дёҚд»…еҸҜд»ҘжӢ“е®Ҫи§ҶйҮҺпјҢиҝҳиғҪеҲ©з”ЁScalaзҡ„й«ҳзә§зү№жҖ§жқҘи§ЈеҶіеӨҚжқӮзҡ„й—®йўҳпјҢзү№еҲ«жҳҜеңЁеӨ§ж•°жҚ®еӨ„зҗҶе’Ңдә‘и®Ўз®—зҺҜеўғдёӯгҖӮ
д»ҘдёҠеҶ…е®№иҰҶзӣ–дәҶ Scala зј–зЁӢиҜӯиЁҖзҡ„ж ёеҝғзҹҘиҜҶзӮ№пјҢд»Һеҹәжң¬иҜӯжі•еҲ°й«ҳзә§зү№жҖ§пјҢдёәеҲқеӯҰиҖ…жҸҗдҫӣдәҶдёҖдёӘе…Ёйқўзҡ„еӯҰд№ жҢҮеҚ—гҖӮScala жҳҜдёҖй—ЁеҠҹиғҪејәеӨ§дё”зҒөжҙ»зҡ„иҜӯиЁҖпјҢйҖӮеҗҲдәҺжһ„е»әеӨ§еһӢзҡ„гҖҒеӨҚжқӮзҡ„иҪҜ件系з»ҹгҖӮеёҢжңӣиҝҷдәӣзҹҘиҜҶзӮ№иғҪеӨҹеё®еҠ©иҜ»иҖ…жӣҙеҘҪең°...
еҸҰеӨ–пјҢеҺӢзј©еҢ…дёӯиҝҳеҢ…жӢ¬вҖңзҶҹз»ғзҡ„жҺҢжҸЎScalaиҜӯиЁҖзі»еҲ—иҜҫзЁӢ.txtвҖқпјҢиҝҷеҸҜиғҪжҳҜдёҖдёӘиҜҫзЁӢеӨ§зәІжҲ–еӯҰд№ и·Ҝеҫ„пјҢжҢҮеҜјиҜ»иҖ…жҢүйғЁе°ұзҸӯең°еӯҰд№ ScalaпјҢд»ҺеҹәзЎҖеҲ°иҝӣйҳ¶пјҢж¶өзӣ–е®һжҲҳйЎ№зӣ®е’ҢжңҖдҪіе®һи·өгҖӮ жңҖеҗҺпјҢвҖңйҖҡеёёзҡ„Scalaзј–еҶҷ规иҢғ.txtвҖқеҫҲеҸҜиғҪ...
ж №жҚ®з»ҷе®ҡзҡ„ж–Ү件дҝЎжҒҜпјҢд»ҘдёӢжҳҜд»ҺвҖңscalaзј–зЁӢжҢҮеҜјж–ҮжЎЈвҖқдёӯжҸҗзӮјеҮәзҡ„зӣёе…іITзҹҘиҜҶзӮ№пјҡ ### scalaзј–зЁӢеҹәзЎҖ #### дёҖгҖҒScalaиҜӯиЁҖжҰӮиҝ° ScalaжҳҜдёҖз§ҚеӨҡиҢғејҸзј–зЁӢиҜӯиЁҖпјҢз»“еҗҲдәҶйқўеҗ‘еҜ№иұЎзј–зЁӢе’ҢеҮҪж•°ејҸзј–зЁӢзҡ„зү№зӮ№пјҢиҝҗиЎҢеңЁJavaе№іеҸ°...