
1 倒排索引
1.1 倒排索引
"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
1.2 应用场景
通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的文档或者是标识文档的ID号,或者是指文档所在位置的URL,如图6.1-1所示。
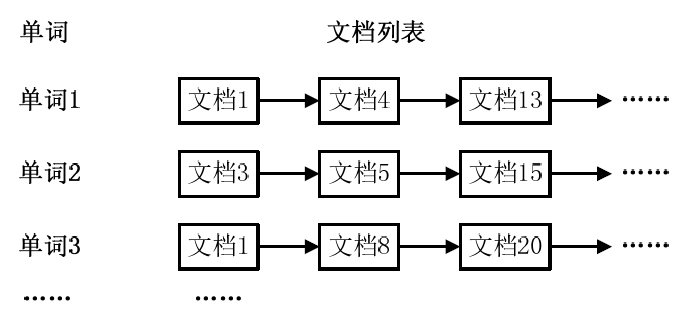
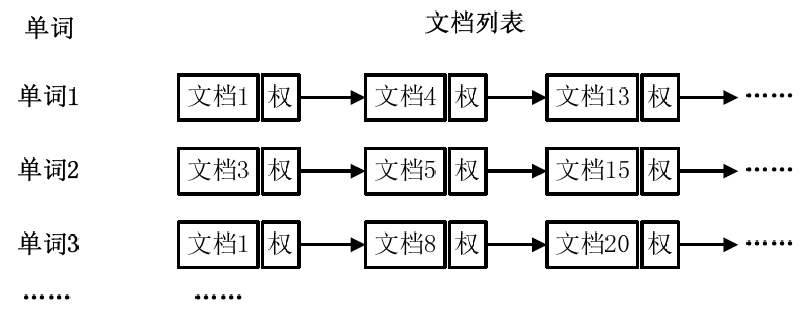
从上图可以看出,单词1出现在{文档1,文档4,文档13,……}中,单词2出现在{文档3,文档5,文档15,……}中,而单词3出现在{文档1,文档8,文档20,……}中。在实际应用中,还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相关度,如下图所示。
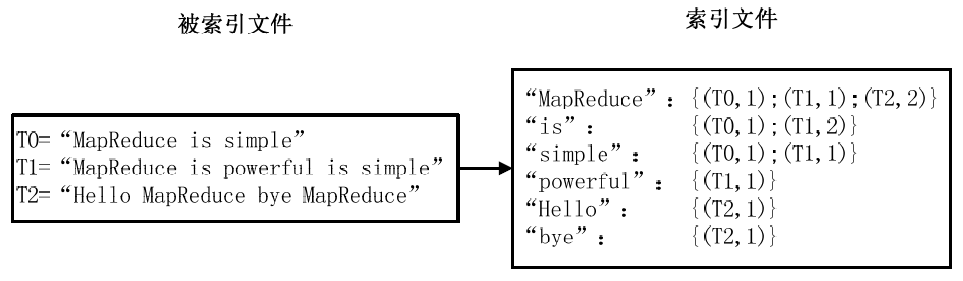
最常用的是使用词频作为权重,即记录单词在文档中出现的次数。以英文为例,如下图所示,索引文件中的"MapReduce"一行表示:"MapReduce"这个单词在文本T0中出现过1次,T1中出现过1次,T2中出现过2次。当搜索条件为"MapReduce"、"is"、"Simple"时,对应的集合为:{T0,T1,T2}∩{T0,T1}∩{T0,T1}={T0,T1},即文档T0和T1包含了所要索引的单词,而且只有T0是连续的。
更复杂的权重还可能要记录单词在多少个文档中出现过,以实现TF-IDF(Term Frequency-Inverse Document Frequency)算法,或者考虑单词在文档中的位置信息(单词是否出现在标题中,反映了单词在文档中的重要性)等。
1.3 设计思路
实现"倒排索引"只要关注的信息为:单词、文档URL及词频,如图3-11所示。但是在实现过程中,索引文件的格式与图6.1-3会略有所不同,以避免重写OutPutFormat类。下面根据MapReduce的处理过程给出倒排索引的设计思路。
1)Map过程
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词、文档URL和词频,如下图所示。
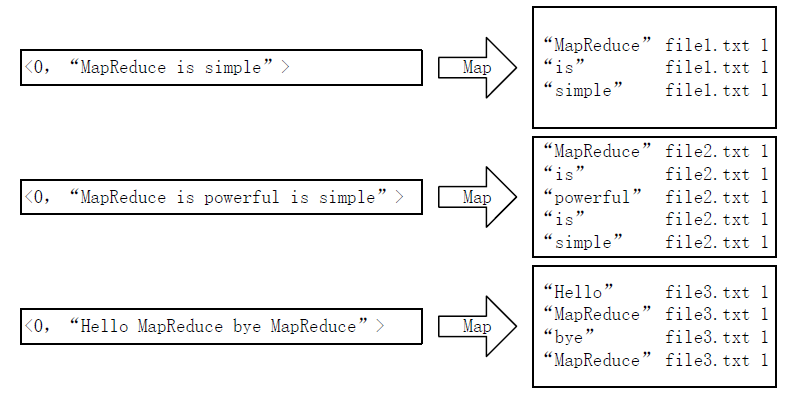
这里存在两个问题:第一,<key,value>对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值;第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
这里讲单词和URL组成key值(如"MapReduce:file1.txt"),将词频作为value,这样做的好处是可以利用MapReduce框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
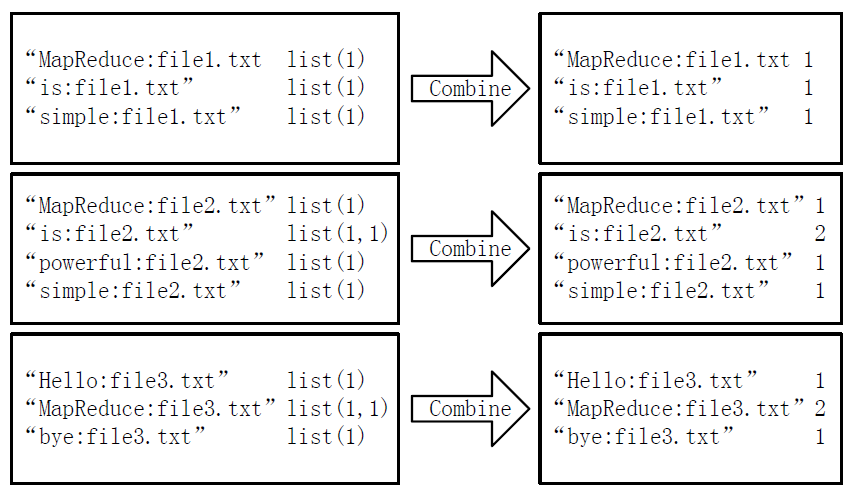
2)Combine过程
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档中的词频,如下图所示。如果直接将下图所示的输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词作为key值,URL和词频组成value值(如"file1.txt:1")。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。
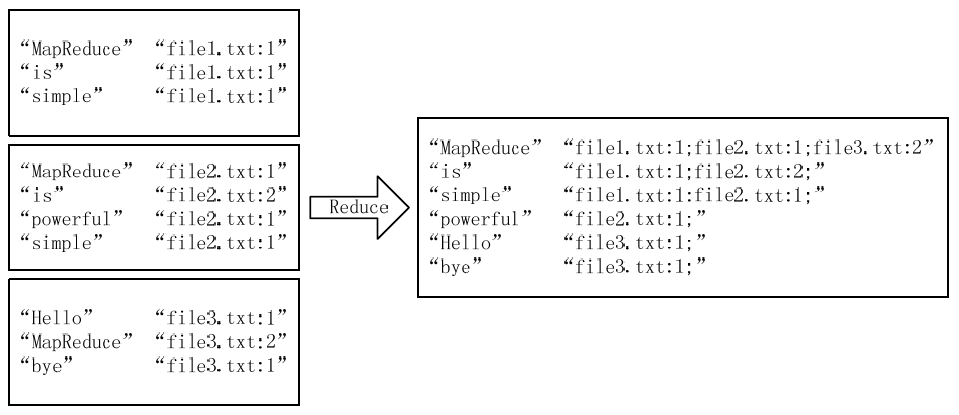
3)Reduce过程
经过上述两个过程后,Reduce过程只需将相同key值的value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。如下图所示:
4)需要解决的问题
本实例设计的倒排索引在文件数目上没有限制,但是单词文件不宜过大(具体值与默认HDFS块大小及相关配置有关),要保证每个文件对应一个split。否则,由于Reduce过程没有进一步统计词频,最终结果可能会出现词频未统计完全的单词。可以通过重写InputFormat类将每个文件为一个split,避免上述情况。或者执行两次MapReduce,第一次MapReduce用于统计词频,第二次MapReduce用于生成倒排索引。除此之外,还可以利用复合键值对等实现包含更多信息的倒排索引。
1.4 程序代码
程序代码如下所示:
|
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class InvertedIndex { public static class Map extends Mapper<Object, Text, Text, Text> { private Text keyInfo = new Text(); // 存储单词和URL组合 private Text valueInfo = new Text(); // 存储词频 private FileSplit split; // 存储Split对象 // 实现map函数 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // 获得<key,value>对所属的FileSplit对象 split = (FileSplit) context.getInputSplit(); StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { // key值由单词和URL组成,如"MapReduce:file1.txt" int splitIndex = split.getPath().toString().indexOf("file"); keyInfo.set(itr.nextToken() + ":" + split.getPath().toString().substring(splitIndex)); // 词频初始化为1 valueInfo.set("1"); context.write(keyInfo, valueInfo); } } } public static class Combine extends Reducer<Text, Text, Text, Text> { private Text info = new Text(); // 实现reduce函数 public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 统计词频 int sum = 0; for (Text value : values) { sum += Integer.parseInt(value.toString()); } int splitIndex = key.toString().indexOf(":"); // 重新设置value值由URL和词频组成 info.set(key.toString().substring(splitIndex + 1) + ":" + sum); // 重新设置key值为单词 key.set(key.toString().substring(0, splitIndex)); context.write(key, info); } } public static class Reduce extends Reducer<Text, Text, Text, Text> { private Text result = new Text(); // 实现reduce函数 public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 生成文档列表 String fileList = new String(); for (Text value : values) { fileList += value.toString() + ";"; } result.set(fileList); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("mapred.job.tracker", "192.168.1.2:9001"); String[] ioArgs = new String[] { "index_in", "index_out" }; String[] otherArgs = new GenericOptionsParser(conf, ioArgs) .getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: Inverted Index <in> <out>"); System.exit(2); } Job job = new Job(conf, "Inverted Index"); job.setJarByClass(InvertedIndex.class); // 设置Map、Combine和Reduce处理类 job.setMapperClass(Map.class); job.setCombinerClass(Combine.class); job.setReducerClass(Reduce.class); // 设置Map输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); // 设置Reduce输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); // 设置输入和输出目录 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |



相关推荐
在这个实例中,我们将详细探讨如何使用MapReduce实现倒排索引。 首先,我们来看`Mapper`类。`InvertedIndexMapper`是Map阶段的核心,它负责将输入数据拆分成键值对(K1, V1)并转换为新的键值对(K2, V2)。在这个...
运行说明:在linux终端输入 $ hadoop jar test-1.0-SNAPSHOT.jar WordCount /input/* /MyOutput1/ 后两个参数是hdfs上面【输入】的文本文件目录和【输出】目录。 记得清空输出目录。
《Hadoop倒排索引程序:并行框架下的文本处理技术》 在现代大数据处理领域,Hadoop作为一款开源的并行计算框架,扮演着至关重要的角色。倒排索引,作为一种高效的全文检索技术,被广泛应用于搜索引擎和信息检索系统...
需求 有如下数据 a.txt hello tom hello jim hello kitty hello rose b.txt hello jerry hello jim hello kitty hello jack c.txt hello jerry hello java hello c++ hello c++ 需要输出如下格式: ...1
案例描述:为搜索引擎构建倒排索引,将单词映射到其出现的文档列表。 Map阶段:输出键值对,键为单词,值为文档ID。 Reduce阶段:对每个单词的文档列表进行合并,形成倒排索引。 3. 网络数据分析 案例描述:分析...
在本节中,我们将深入探讨MapReduce的扩展案例,特别是倒排索引的构建,这是一个在大数据处理中常见的任务,特别是在搜索引擎技术中。倒排索引允许快速定位文档中特定关键词的位置,从而提高搜索效率。 首先,我们...
7. 倒排索引总结(Inverted Index Summarizations):这是一个搜索引擎中常用的索引技术,MapReduce可以用来构建倒排索引,提高数据检索的速度。 8. 计数模式(Counting with Counters):计数器是MapReduce中用于...
本书分为多个章节,涵盖了MapReduce的基本概念、算法设计、文本检索中的倒排索引以及图算法等多个方面。 - **第1章:介绍** 本章主要介绍了云计算的概念及其在处理大规模数据集时的重要性和优势,并概述了...
这些数据可能来自网页抓取文档、网络请求日志等,目标是计算各种派生数据,如倒排索引、网页结构的多种表示、每个主机爬取页面的摘要统计以及一天内最频繁查询的集合。虽然这些计算在概念上并不复杂,但输入数据量...
在案例需求中,需要对a.txt、b.txt和c.txt三个源文件建立倒排索引,并将结果输出到倒排索引文件。 实施这个任务时,项目采用了Hadoop作为基础平台,这是一个分布式计算框架,擅长处理和存储大量数据。Hadoop服务的...
为了提取有价值的衍生数据,如倒排索引、网页图结构、页面访问统计等,传统的处理方法在面对庞大的数据量时显得力不逮。MapReduce的诞生正是为了解决这一问题,它提供了一个抽象模型,能够自动并行化计算过程,隐藏...
与正向索引不同,倒排索引以词汇为索引项,每个词汇对应一个文档列表。 - **倒排索引构建**:包括词汇提取、文档标识符分配等步骤。 - **索引压缩**:为了节省存储空间,可以采用不同的编码技术对索引进行压缩。 - ...
Google内部已实现数百个MapReduce程序,每天有超过1000个作业在运行,涉及各种数据处理任务,如文档抓取、倒排索引构建、网络日志分析等。 论文中详细描述了MapReduce的基本编程模型和使用案例,包括其简化编程接口...
实际应用中,谷歌内部已经使用了数百个MapReduce程序,每天执行超过1000个作业,涵盖各种任务,如构建倒排索引、分析网页请求日志、统计页面抓取信息等。 在实现上,MapReduce库处理了数据分片、机器调度、故障恢复...
为了从这些数据中提取有价值的信息,如建立倒排索引、生成Web文档图结构的多种表示形式、统计每台主机爬取的页面数量、识别每天访问量最大的集合等,通常需要处理极大的数据量。尽管这些计算在概念上较为直观,但...
通过MapReduce,Google能够快速响应不断增长的数据处理需求,支持各种衍生数据的计算,如文档倒排索引、网页图结构的表示、页面抓取统计等。 #### 结论与展望 MapReduce作为Google的一项关键技术,不仅极大地简化了...