lucene + hadoop 分布式搜索运行框架 Nut 1.0a8
[url]http://code.google.com/p/nutla/ [/url]
Nut开发环境搭建(虚拟机下hadoop0.20.2+zookeeper3.3.1+hbase0.20.6开发环境的搭建)
http://www.blogjava.net/nianzai/
http://code.google.com/p/nutla/
1、概述
不管程序性能有多高,机器处理能力有多强,都会有其极限。能够快速方便的横向与纵向扩展是Nut设计最重要的原则。
Nut是一个Lucene+Hadoop分布式搜索框架,能对千G以上索引提供7*24小时搜索服务。在服务器资源足够的情况下能达到每秒处理100万次的搜索请求。
Nut开发环境:jdk1.6.0.21+lucene3.0.2+eclipse3.6.1+hadoop0.20.2+zookeeper3.3.1+hbase0.20.6+memcached+linux
2、特新
a、热插拔
b、可扩展
c、高负载
d、易使用,与现有项目无缝集成
e、支持排序
f、7*24服务
g、失败转移
3、搜索流程
Nut由Index、Search、Client、Cache和DB五部分构成。(Cache默认使用memcached,DB默认使用hbase)
Client处理用户请求和对搜索结果排序。Search对请求进行搜索,Search上只放索引,数据存储在DB中,Nut将索引和存储分离。Cache缓存的是搜索条件和结果文档id。DB存储着数据,Client根据搜索排序结果,取出当前页中的文档id从DB上读取数据。
用户发起搜索请求给由Nut Client构成的集群,由某个Nut Client根据搜索条件查询Cache服务器是否有该缓存,如果有缓存根据缓存的文档id直接从DB读取数据,如果没有缓存将随机选择一组搜索服务器组(Search Group i),将查询条件同时发给该组搜索服务器组里的n台搜索服务器,搜索服务器将搜索结果返回给Nut Client由其排序,取出当前页文档id,将搜索条件和当前文档id缓存,同时从DB读取数据。
4、索引流程
Hadoop Mapper/Reducer 建立索引。再将索引从HDFS分发到各个索引服务器。
对索引的更新分为两种:删除和添加(更新分解为删除和添加)。
a、删除
在HDFS上删除索引,将生成的*.del文件分发到所有的索引服务器上去或者对HDFS索引目录删除索引再分发到对应的索引服务器上去。
b、添加
新添加的数据用另一台服务器来生成。
删除和添加步骤可按不同定时策略来实现。
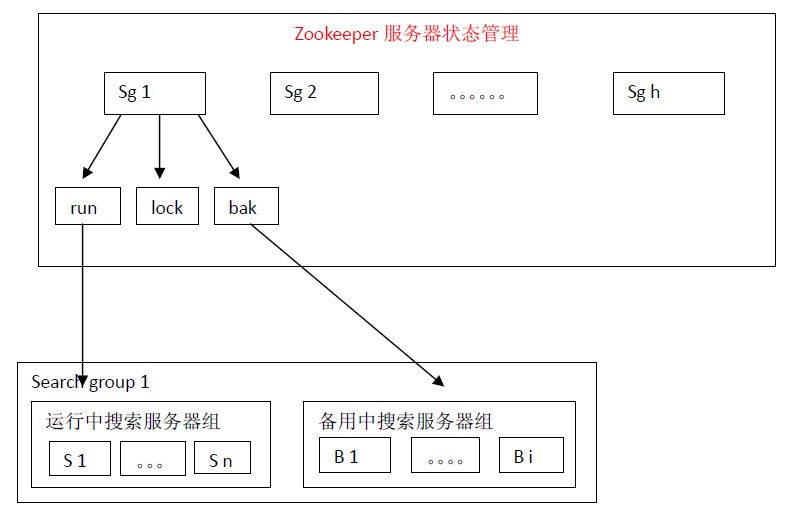
5、Zookeeper服务器状态管理策略
在架构设计上通过使用多组搜索服务器可以支持每秒处理100万个搜索请求。
每组搜索服务器能处理的搜索请求数在1万—1万5千之间。如果使用100组搜索服务器,理论上每秒可处理100万个搜索请求。
假如每组搜索服务器有100份索引放在100台正在运行中搜索服务器(run)上,那么将索引按照如下的方式放在备用中搜索服务器(bak)上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一台备用搜索服务器上。那么每份索引会存在3台机器中(1份正在运行中,2份备份中)。
尽管这样设计每份索引会存在3台机器中,仍然不是绝对安全的。假如运行中的index 1,index 2,index 3同时宕机的话,那么就会有一份索引搜索服务无法正确启用。这样设计,作者认为是在安全性和机器资源两者之间一个比较适合的方案。
备用中的搜索服务器会定时检查运行中搜索服务器的状态。一旦发现与自己索引对应的服务器宕机就会向lock申请分布式锁,得到分布式锁的服务器就将自己加入到运行中搜索服务器组,同时从备用搜索服务器组中删除自己,并停止运行中搜索服务器检查服务。
为能够更快速的得到搜索结果,设计上将搜索服务器分优先等级。通常是将最新的数据放在一台或几台内存搜索服务器上。通常情况下前几页数据能在这几台搜索服务器里搜索到。如果在这几台搜索服务器上没有数据时再向其他旧数据搜索服务器上搜索。
优先搜索等级的逻辑是这样的:9最大为搜索全部服务器并且9不能作为level标识。当搜索等级level为1,搜索优先级为1的服务器,当level为2时搜索优先级为1和2的服务器,依此类推。
posted on 2010-10-27 10:38 nianzai 阅读(1783) 评论(10) 编辑 收藏 所属分类: Nut(lucene + hadoop 分布式运行框架)
评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8 2010-10-28 09:15 qiu768
博主这套框架是否在实际项目中用过? 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8 2010-10-28 09:42 nianzai
Nut目前还是alpha版,因需要有大量的机器所以目前还没有这样的条件来实际使用该框架 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8[未登录] 2010-10-29 10:04 JL
问两个问题:
1. 同步到一组中的每个nut搜索服务器上的索引是相同的吗,就是说是一份大索引?还是说整个系统的索引是这组服务器上索引的并集?
2. 如果直接用搜索服务器去搜索放在hdfs上的索引时,如何解决hdfs上索引更新时的同步问题? 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8 2010-10-29 10:29 nianzai
同一组服务器里服务器上的索引是不相同的,同一组服务器共同构成一个完整的大索引
搜索的时候并不搜索hdfs上的索引,那样性能非常差,是要分发到搜索服务器上的进行本地搜索 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8[未登录] 2010-10-29 12:24 YY
那这样岂不违背了hadoop的设计理念?@nianzai
回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8 2010-10-29 13:23 nianzai
违背了hadoop的设计理念?
不知道为什么这么说? 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8[未登录] 2010-11-25 23:32 keren
请问在搜索的时候,是根据什么来把从M/R里面的结果组装起来的?因为搜索结果是有排序和相似度的。谢谢! 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8[未登录] 2010-11-26 13:06 nianzai
nut并不用M/R来排序,用M/R来排序的话并发是上不来的
nut是通过各个搜索服务器来实现本地搜索再在nut client端进行合并排序 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8 2010-12-03 08:58 zhuweimin
版主的设计的系统和katta有点象,不过katta没有使用Hbase来保存数据和是索引放在一起 回复 更多评论
# re: lucene + hadoop 分布式搜索运行框架 Nut 1.0a8 2010-12-03 14:53 nianzai
katta发布的时候应该是还没有hbase的
nut 和 katta 是有点像,但是 是两个完全不一样的东西 回复 更多评论
新用户注册 刷新评论列表
分享到:





相关推荐
### Lucene + Hadoop 分布式搜索运行框架详解 #### 一、概述 本文档旨在介绍基于Lucene和Hadoop构建的分布式搜索运行框架——Nut。该框架专门为Lucene提供了强大的分布式搜索能力,能够支持7*24小时不间断运行,...
Hadoop是Apache Lucene下的一个子项目,它最初是从Nutch项目中分离出来...Hadoop分布式安装与配置手册 Hadoop权威指南原版 hadoop权威指南中文第二版 Hadoop实战-陆嘉恒 分布式基础学习 用+Hadoop+进行分布式并行编程
基于Hadoop分布式系统的地质环境大数据框架探讨,涉及了地质环境大数据的特性分析,以及提出了一种基于Hadoop生态系统架构的框架。这个框架支持数据清洗转换、分布式数据存储管理、数据挖掘、文本搜索和数据可视化等...
Hadoop 是一个分布式计算框架,用于处理和存储大量数据。在 Nutch 中,Hadoop 负责分布式爬虫的执行和数据处理。Nutch 使用 Hadoop MapReduce 模型来并行处理任务,如网页抓取、解析、索引等。通过 Nutch 脚本,我们...
Lucene是一个强大的全文检索库,而Nutch则是一个完整的网络爬虫框架,两者结合为搜索引擎的构建提供了全面的解决方案。 Lucene是Java编写的一个高性能、可扩展的信息检索库。它提供了索引和搜索文本的API,支持倒排...
Nutch还支持分布式爬取,通过Hadoop等大数据处理框架处理大规模数据,适应海量网页的抓取需求。 三、Lucene+Nutch整合 结合Lucene和Nutch,可以构建一个完整的搜索引擎系统。Nutch负责网络爬虫部分,获取和预处理...
5. 分布式搜索:Nutch支持Hadoop,能够在大规模集群上运行,处理海量数据。 三、Lucene+Nutch整合应用 结合Lucene和Nutch,可以构建一个完整的搜索引擎系统。Nutch负责网络爬取和预处理,提取出有价值的信息;...
1. **爬虫架构**:Nutch采用分布式爬虫设计,利用Hadoop框架处理大规模数据,能有效应对海量网页的抓取和索引。 2. **种子URL管理**:Nutch维护一个种子URL列表,从这些种子URL出发,按照链接关系递归抓取网页。 3...
Lucene本身并不提供一个完整的搜索引擎应用框架,而是作为一个底层库或者服务被广泛应用于各种搜索引擎项目中。其主要特点包括: 1. **高性能**:Lucene经过高度优化,能够实现快速的索引建立和检索。 2. **灵活性*...
数据库技术与分布式计算框架是现代数据处理领域的两大基石,本文将带领读者从基础的数据库出发,逐步深入到分布式计算框架的核心,特别适用于想要从数据存储转移到分布式计算的初学者。 首先,从数据库层面来看,...
Apache Lucene是一个高性能、全文本搜索库,而Hadoop是用于大数据处理的开源框架,两者结合能有效解决大规模数据集上的搜索问题。 首先,我们需要理解Lucene的基本工作原理。Lucene通过建立倒排索引来实现快速文本...
Hadoop 分布式并行编程框架知识点 Hadoop 是一个开源的分布式并行编程框架,由于分布式存储对于分布式编程来说是必不可少的,这个框架中还包含了一个分布式文件系统 HDFS(Hadoop Distributed File System)。...
Lucene和Nutch是两个在搜索引擎领域中极具影响力的开源项目,它们为开发者提供了构建高效、可扩展的全文搜索引擎的基础框架。本篇文章将深入探讨这两个项目的核心技术和应用场景。 Lucene是一个高性能、全文检索库...
[硕士论文]_基于MapReduce的分布式智能搜索引擎框架研究.pdf [硕士论文]_基于Nutch的垂直搜索引擎的分析与实现.pdf 一个例子学懂搜索引擎(lucene).doc 中文搜索引擎技术揭密.doc 九大开源搜索引擎介绍.txt 基于Nutch...
Hadoop作为开源的大数据处理框架,以其分布式、可扩展的特性,为构建大规模的搜索引擎提供了强大的支持。本文将深入探讨如何在Hadoop平台上构建一个分布式搜索引擎,并结合"SearchEngine-master"项目,详细解析其...
- Nutch是一个开源框架,基于Hadoop和Lucene构建。 - 用于大规模网络爬取和全文搜索。 - **2.2.5 用户界面** - 设计友好的用户界面,让用户可以方便地进行搜索操作。 - 支持多种展示形式,如列表、卡片式等。 ...
该系统的设计充分利用了Hadoop的分布式处理能力,结合了Lucene框架的全文索引功能和Solr的企业级检索特性,以及SparkStreaming的实时数据处理优势,形成了一个能够提供企业级智能云检索服务的高效系统。通过这样的...
在这样的背景下,本文提出了基于Hadoop分布式计算平台的设计方案,其中包括利用LIRE(Lucene Image Retrieval)开发包来提取图像特征。LIRE是基于Lucene全文搜索引擎的扩展,专门用于图像内容检索。它能够以分布式的...
首先,Hadoop是一个由Apache软件基金会支持的开源分布式存储与计算框架,其发展起源于Apache Lucene、Apache Nutch以及Google的三大论文:MapReduce、GFS和BigTable。Hadoop生态系统包括Hadoop核心、Hadoop Common、...