ććåØJavačÆčØč§čéé¢ęåŗäŗJMMęÆäøäøŖęÆč¾å¼ęę§ēå°čÆļ¼čæē§å°čÆč§å¾å®ä¹äøäøŖäøč“ēćč·Øå¹³å°ēå
åęØ”åļ¼ä½ęÆå®ęäøäŗęÆč¾ē»å¾®čäøå¾éč¦ēē¼ŗē¹ćå
¶å®JavačÆčØéé¢ęÆč¾å®¹ęę··ę·ēå
³é®åäø»č¦ęÆsynchronizedåvolatileļ¼ä¹å äøŗčæę ·åØå¼åčæēØäøå¾å¾å¼åč
ä¼åæ½ē„ęčæäŗč§åļ¼čæä¹ä½æå¾ē¼ååę„代ē ęÆč¾å°é¾ć
ććJSR133ę¬čŗ«ēē®ēęÆäøŗäŗäæ®å¤åę¬JMMēäøäŗē¼ŗé·čęåŗēļ¼å
¶ę¬čŗ«ēå¶å®ē®ę ę仄äøå äøŖļ¼
ććåØē³»ē»å¼åčæēØļ¼ē»åøøä¼éå°čæå äøŖåŗę¬ę¦åæµļ¼äøč®ŗęÆē½ē»éč®ÆćåÆ¹č±”ä¹é“ēę¶ęÆéč®ÆčæęÆWebå¼åäŗŗååøøēØēHttpčÆ·ę±é½ä¼éå°čæę ·å äøŖę¦åæµļ¼ē»åøøęäŗŗęå°AjaxęÆå¼ę„éč®Æę¹å¼ļ¼é£ä¹ē©¶ē«ęę ·ēę¹å¼ęÆčæę ·ēę¦åæµęčæ°å¢ļ¼
ććå¼åčæå¤ēŗæēØēØåŗēēØåŗåé½ęē½ļ¼synchronizedå
³é®åå¼ŗå¶å®ę½äøäøŖēŗæēØä¹é“ēäŗę„éļ¼ēøäŗęę„ļ¼ļ¼čÆ„äŗę„éé²ę¢ęÆꬔęå¤äøŖēŗæēØčæå
„äøäøŖē»å®ēę§åØęäæę¤ēåę„čÆå„åļ¼ä¹å°±ęÆčÆ“åØčÆ„ę
åµäøļ¼ę§č”ēØåŗ代ē ęē¬ęēęäŗå
åęÆē¬å ęØ”å¼ļ¼å
¶ä»ēēŗæēØęÆäøč½éåƹå®ę§č”čæēØęē¬å ēå
åčæč”č®æé®ēļ¼čæē§ę
åµē§°äøŗčÆ„å
åäøåÆč§ćä½ęÆåØčÆ„ęØ”åēåę„ęØ”å¼äøļ¼čæęå¦å¤äøäøŖę¹é¢ļ¼JMMäøęåŗäŗļ¼JVMåØå¤ēčÆ„å¼ŗå¶å®ę½ēę¶ååÆ仄ęä¾äøäŗå
åēåÆč§č§åļ¼åØčÆ„č§åéé¢ļ¼å®ē”®äæå½ååØäøäøŖåę„åę¶ļ¼ē¼åč¢«ę“ę°ļ¼å½č¾å
„äøäøŖåę„åę¶ļ¼ē¼å失ęćå ę¤åØJVMå
éØęä¾ē»å®ēę§åØäæę¤ēåę„åä¹äøļ¼äøäøŖēŗæēØęåå
„ēå¼åƹäŗå
¶ä½ęęēę§č”ē±åäøäøŖēę§åØäæę¤ēåę„åēŗæēØę„čÆ“ęÆåÆč§ēļ¼čæå°±ęÆäøäøŖē®åēåÆč§ę§ēęčæ°ćčæē§ęŗåØäæčÆē¼čÆåØäøä¼ęę令ä»äøäøŖåę„åēå
éØē§»å°å¤éØļ¼č½ē¶ęę¶åå®ä¼ęę令ē±å¤éØē§»åØå°å
éØćJMMåØē¼ŗēę
åµäøäøåčæę ·ēäæčÆāāåŖč¦ęå¤äøŖēŗæēØč®æé®ēøååéę¶åæ
é”»ä½æēØåę„ćē®åę»ē»ļ¼
ććåÆč§ę§å°±ęÆåØå¤ę øęč
å¤ēŗæēØčæč”čæēØäøå
åēäøē§å
±äŗ«ęØ”å¼ļ¼åØJMMęØ”åéé¢ļ¼éčæ并åēŗæēØäæ®ę¹åéå¼ēę¶åļ¼åæ
é”»å°ēŗæēØåéåę„åäø»åčæåļ¼å
¶ä»ēŗæēØęåÆč½č®æé®å°ć
ććć*ļ¼ē®åč®²ļ¼å
åēåÆč§ę§ä½æå
åčµęŗåÆ仄å
±äŗ«ļ¼å½äøäøŖēŗæēØę§č”ēę¶åå®ęå ęēå
åļ¼å¦ęå®å ęēå
åčµęŗęÆåÆč§ēļ¼é£ä¹čæę¶åå
¶ä»ēŗæēØåØäøå®č§åå
ęÆåÆ仄č®æé®čÆ„å
åčµęŗēļ¼čæē§č§åęÆē±JMMå
éØå®ä¹ēļ¼čæē§ę
åµäøå
åēčÆ„ē¹ę§ē§°äøŗå
¶åÆč§ę§ćć
ććJMMēęåē®ēļ¼å°±ęÆäøŗäŗč½å¤ęÆęå¤ēŗæēØēØåŗč®¾č®”ēļ¼ęÆäøŖēŗæēØåÆ仄认äøŗęÆåå
¶ä»ēŗæēØäøåēCPUäøčæč”ļ¼ęč
åƹäŗå¤å¤ēåØēęŗåØččØļ¼čÆ„ęØ”åéč¦å®ē°ēå°±ęÆä½æå¾ęÆäøäøŖēŗæēØå°±åčæč”åØäøåēęŗåØćäøåēCPUęč
ę¬čŗ«å°±äøåēēŗæēØäøäøę ·ļ¼čæē§ę
åµå®é
äøåØ锹ē®å¼åäøęÆåøøč§ēćåƹäŗCPUę¬čŗ«ččØļ¼äøč½ē“ę„č®æé®å
¶ä»CPUēåÆååØļ¼ęØ”ååæ
é”»éčæęē§å®ä¹č§åę„ä½æå¾ēŗæēØåēŗæēØåØå·„ä½å
åäøčæč”ēøäŗč°ēØčå®ē°CPUę¬čŗ«åƹå
¶ä»CPUćęč
čÆ“ēŗæēØåƹå
¶ä»ēŗæēØēå
åäøčµęŗēč®æé®ļ¼čč”Øē°čæē§č§åēčæč”ēÆå¢äøč¬äøŗčæč”čÆ„ēØåŗēčæč”å®æäø»ēÆå¢ļ¼ęä½ē³»ē»ćęå”åØćååøå¼ē³»ē»ēļ¼ļ¼čēØåŗę¬čŗ«č”Øē°å°±ä¾čµäŗē¼åčÆ„ēØåŗēčÆčØē¹ę§ļ¼čæéä¹å°±ęÆčÆ“ēØJavaē¼åēåŗēØēØåŗåØå
åē®”ēäøēå®ē°å°±ęÆéµå¾Ŗå
¶éØåååļ¼ä¹å°±ęÆåč¾¹ęåå°ēJMMå®ä¹äŗJavačÆčØéåƹå
åēäøäŗēēøå
³č§åćē¶čļ¼č½ē¶č®¾č®”ä¹åęÆäøŗäŗč½å¤ę“儽ęÆęå¤ēŗæēØļ¼ä½ęÆčÆ„ęØ”åēåŗēØåå®ē°å½ē¶äøå±éäŗå¤å¤ēåØļ¼čåØJVMē¼čÆåØē¼čÆJavaē¼åēēØåŗēę¶å仄åčæč”ęę§č”čÆ„ēØåŗēę¶åļ¼åƹäŗåCPUēē³»ē»ččØļ¼čæē§č§åä¹ęÆęęēļ¼čæå°±ęÆęÆäøč¾¹ęå°ēēŗæēØåēŗæēØä¹é“ēå
åēē„ćJMMę¬čŗ«åØęčæ°čæēØę²”ęęčæå
·ä½ēå
åå°å仄ååØå®ē°čÆ„ēē„äøēå®ē°ę¹ę³ęÆē±JVMēåŖäøäøŖēÆčļ¼ē¼čÆåØćå¤ēåØćē¼åę§å¶åØćå
¶ä»ļ¼ęä¾ēęŗå¶ę„å®ē°ēļ¼ēč³éåƹäøäøŖå¼åéåøøēęēēØåŗåļ¼ä¹äøäøå®č½å¤äŗč§£å®å
éØåƹäŗē±»ćåÆ¹č±”ćę¹ę³ä»„åēøå
³å
容ēäøäŗå
·ä½åÆč§ēē©ēē»ęćēøåļ¼JMMå®ä¹äŗäøäøŖēŗæēØäøäø»åä¹é“ēę½č±”å
³ē³»ļ¼å
¶å®ä»äøč¾¹ēå¾åÆ仄ē„éļ¼ęÆäøäøŖēŗæēØåÆ仄ę½č±”ęäøŗäøäøŖå·„ä½å
åļ¼ę½č±”ēé«éē¼åååÆååØļ¼ļ¼å
¶äøååØäŗJavaēäøäŗå¼ļ¼čÆ„ęØ”åäæčÆäŗJavaéé¢ēå±ę§ćę¹ę³ćåꮵååØäøå®ēę°å¦ē¹ę§ļ¼ęē
§čÆ„ē¹ę§ļ¼čÆ„ęØ”åååØäŗåƹåŗēäøäŗå
容ļ¼å¹¶äøéåƹčæäŗå
容čæč”äŗäøå®ēåŗåå仄åååØęåŗęä½ļ¼čæę ·ä½æå¾JavaåÆ¹č±”åØå·„ä½å
åéé¢č¢«JVMé”ŗå©č°ēØļ¼ļ¼å½ē¶čæęÆęÆč¾ę½č±”ēäøē§č§£éļ¼ę¢ē¶å¦ę¤ļ¼å¤§å¤ę°JMMēč§ååØå®ē°ēę¶åļ¼åæ
é”»ä½æå¾äø»ååå·„ä½å
åä¹é“ēéäæ”č½å¤å¾ä»„äæčÆļ¼čäøäøč½čæåå
åęØ”åę¬čŗ«ēē»ęļ¼čæęÆčÆčØåØč®¾č®”ä¹å¤åæ
é”»ččå°ēéåƹå
åēäøē§č®¾č®”ę¹ę³ćčæééč¦ē„éēäøē¹ęÆļ¼čæäøåēęä½åØJavačÆčØéé¢é½ęÆä¾é JavačÆčØčŖčŗ«ę„ęä½ēļ¼å äøŗJavaéåƹå¼åäŗŗåččØļ¼å
åēē®”ēåØäøéč¦ęåØęä½ēę
åµäøę¬čŗ«ååØå
åēē®”ēēē„ļ¼čæä¹ęÆJavačŖå·±čæč”å
åē®”ēēäøē§ä¼åæć
ććčæäøē¹čÆ“ęäŗčÆ„ęØ”åå®ä¹ēč§åéåƹååēŗ§å«ēå
容ååØē¬ē«ēå½±åļ¼åƹäŗęØ”åč®¾č®”ęåļ¼čæäŗč§åéč¦čÆ“ęēä»
ä»
ęÆęē®åēčÆ»ååååØåå
åå
„ēēäøäŗęä½ļ¼čæē§ååēŗ§å«ēå
ę¬āāå®ä¾ćéęåéćę°ē»å
ē“ ļ¼åŖęÆåØčÆ„č§åäøäøå
ę¬ę¹ę³äøēå±éØåéć
ććåØčÆ„č§åēēŗ¦ęäøļ¼å®ä¹äŗäøäøŖēŗæēØåØåŖē§ę
åµäøåÆ仄č®æé®å¦å¤äøäøŖēŗæēØęč
å½±åå¦å¤äøäøŖēŗæēØļ¼ä»JVMēęä½äøč®²å
ę¬äŗä»å¦å¤äøäøŖēŗæēØēåÆč§åŗåčÆ»åēøå
³ę°ę®ä»„åå°ę°ę®åå
„å°å¦å¤äøäøŖēŗæēØå
ć
ććčÆ„č§åå°ä¼ēŗ¦ęä»»ä½äøäøŖčæčäŗč§åč°ēØēēŗæēØåØęä½čæēØäøēäøäŗé”ŗåŗļ¼ęåŗé®é¢äø»č¦å“ē»äŗčÆ»åćåå
„åčµå¼čÆå„ęå
³ēåŗåć
ććå¦ęåØčÆ„ęØ”åå
éØä½æēØäŗäøč“ēåę„ę§ēę¶åļ¼čæäŗå±ę§äøēęÆäøäøŖå±ę§é½éµå¾ŖęÆč¾ē®åēååļ¼åęęåę„ēå
ååäøę ·ļ¼ęÆäøŖåę„åä¹å
ēä»»ä½ååé½å
·å¤äŗååę§ä»„ååÆč§ę§ļ¼åå
¶ä»åę„ę¹ę³ä»„ååę„åéµå¾Ŗåę ·äøč“ēååļ¼čäøåØčæę ·ēäøäøŖęØ”åå
ļ¼ęÆäøŖåę„åäøč½ä½æēØåäøäøŖéļ¼åØę“äøŖēØåŗēč°ēØčæēØęÆęē
§ē¼åēēØåŗęå®ę令čæč”ēćå³ä½æęäøäøŖåę„åå
ēå¤ēåÆč½ä¼å¤±ęļ¼ä½ęÆčÆ„é®é¢äøä¼å½±åå°å
¶ä»ēŗæēØēåę„é®é¢ļ¼ä¹äøä¼å¼čµ·čæēÆ失ęćē®åč®²ļ¼å½ēØåŗčæč”ēę¶åä½æēØäŗäøč“ēåę„ę§ēę¶åļ¼ęÆäøŖåę„åęäøäøŖē¬ē«ēē©ŗé“仄åē¬ē«ēåę„ę§å¶åØåéęŗå¶ļ¼ē¶ååƹå¤ęē
§JVMēę§č”ę令čæč”ę°ę®ēčÆ»åęä½ćčæē§ę
åµä½æå¾ä½æēØå
åēčæēØåå¾éåøøäø„č°Øļ¼
ććJVMēŗæēØåæ
é”»ä¾é čŖčŗ«ę„ē»“ęåÆ¹č±”ēåÆč§ę§ä»„ååÆ¹č±”čŖčŗ«åŗčÆ„ęä¾ēøåƹåŗēęä½čå®ē°ę“äøŖå
åęä½ēäøäøŖē¹ę§ļ¼čäøęÆä»
ä»
ä¾é ē¹å®ēäæ®ę¹åÆ¹č±”ē¶ęēēŗæēØę„å®ęå¦ę¤å¤ęēäøäøŖęµēØć
ććč®æé®ååØåå
å
ēä»»ä½ē±»åēåꮵēå¼ä»„ååƹå
¶ę“ę°ęä½ēę¶åļ¼é¤å¼longē±»åådoubleē±»åļ¼å
¶ä»ē±»åēåꮵęÆåæ
é”»č¦äæčÆå
¶ååę§ēļ¼čæäŗåꮵä¹å
ę¬äøŗåÆ¹č±”ęå”ēå¼ēØćę¤å¤ļ¼čÆ„ååę§č§åę©å±åÆ仄延ä¼øå°åŗäŗlongådoubleēå¦å¤äø¤ē§ē±»åļ¼volatile longåvolatile doubleļ¼volatileäøŗjavaå
³é®åļ¼ļ¼ę²”ęč¢«volatile声ęēlongē±»å仄ådoubleē±»åēåꮵå¼č½ē¶äøäæčÆå
¶JMMäøēååę§ļ¼ä½ęÆęÆč¢«å
č®øēćéåƹnon-long/non-doubleēåꮵåØč”Øč¾¾å¼äøä½æēØēę¶åļ¼JMMēååę§ęčæę ·äøē§č§åļ¼å¦ęä½ č·å¾ęč
åå§åčÆ„å¼ęęäøäŗå¼ēę¶åļ¼čæäŗå¼ęÆē±å
¶ä»ēŗæēØåå
„ļ¼čäøäøęÆä»äø¤äøŖęč
å¤äøŖēŗæēØäŗ§ēēę°ę®åØåäøę¶é“ę³ę··ååå
„ēę¶åļ¼čÆ„åꮵēååę§åØJVMå
éØęÆåæ
é”»å¾å°äæčÆēćä¹å°±ęÆčÆ“JMMåØå®ä¹JVMååę§ēę¶åļ¼åŖč¦åØčÆ„č§åäøčæåēę”件äøļ¼JVMę¬čŗ«äøå»ēē¬čÆ„ę°ę®ēå¼ęÆę„čŖäŗä»ä¹ēŗæēØļ¼å äøŗčæę ·ä½æå¾JavačÆčØåØ并č”čæē®ēč®¾č®”ēčæēØäøéåƹå¤ēŗæēØēååę§č®¾č®”åå¾ęå
¶ē®åļ¼čäøå³ä½æå¼åäŗŗåę²”ęččå°ęē»ēēØåŗä¹ę²”ęå¤Ŗ大ēå½±åćåę¬”č§£éäøäøļ¼čæéēååę§ęēęÆååēŗ§å«ēęä½ļ¼ęÆå¦ęå°ēäøåå
åēčÆ»åęä½ļ¼åÆ仄ēč§£äøŗJavačÆčØęē»ē¼čÆčæåęę„čæå
åēęåŗå±ēęä½åå
ļ¼čæē§čÆ»åęä½ēę°ę®åå
äøęÆåéēå¼ļ¼čęÆę¬ęŗē ļ¼ä¹å°±ęÆåč¾¹åØč®²ćJavaåŗē”ē„čÆćäøęå°ēē±čæč”åØč§£éēę¶åēęēNative Codeć
ććå°½ē®”å¦ę¤ļ¼äøč¾¹ēåÆč§ę§ē¹ę§åęēäøäŗē¹å¾åØč·ØēŗæēØęä½ēę¶åęÆęåÆč½å¤±č“„ēļ¼čäøäøč½å¤éæå
čæäŗę
éåēćčæęÆäøäøŖäøäŗēäŗå®ļ¼ä½æēØåę„å¤ēŗæēØē代ē 并äøč½ē»åƹäæčÆēŗæēØå®å
Øēč”äøŗļ¼åŖęÆå
č®øęē§č§ååƹå
¶ęä½čæč”äøå®ēéå¶ļ¼ä½ęÆåØęę°ēJVMå®ē°ä»„åęę°ēJavaå¹³å°äøļ¼å³ä½æęÆå¤äøŖå¤ēåØļ¼éčæäøäŗå·„å
·čæč”åÆč§ę§ēęµčÆåē°å
¶å®ęÆå¾å°åēę
éēćč·ØēŗæēØå
±äŗ«CPUēå
±äŗ«ē¼åēä½æēØļ¼å
¶ē¼ŗé·å°±åØäŗå½±åäŗē¼čÆåØēä¼åęä½ļ¼čæä¹ä½ē°äŗå¼ŗęåēē¼åäøč“ę§ä½æå¾ē”¬ä»¶ēä»·å¼ęęęåļ¼å äøŗå®ä»¬ä¹é“ēå
³ē³»åØēŗæēØäøēŗæēØä¹é“ēå¤ęåŗ¦åå¾ę“é«ćčæē§ę¹å¼ä½æå¾åÆč§åŗ¦ēčŖē±ęµčÆę¾å¾ę“å äøåå®é
ļ¼å äøŗčæäŗéčÆÆēåēęäøŗē½č§ļ¼ęč
čÆ“åØå¹³å°äøę们å¼åčæēØäøę ¹ę¬ē¢°äøå°ćåØ并č”ēØå¼åäøļ¼äøä½æēØåę„åƼč“å¤±č“„ēåå ä¹äøä»
ä»
ęÆåƹåÆč§åŗ¦ēäøčÆęę”åƼč“ēļ¼åƼč“å
¶ēØåŗå¤±č“„ēåå ęÆå¤ę¹é¢ēļ¼å
ę¬ē¼åäøč“ę§ćå
åäøč“ę§é®é¢ēć
ććJMMęåč®¾č®”ēę¶åååØäøå®ēē¼ŗé·ļ¼čæē§ē¼ŗé·č½ē¶ē°ęēJVMå¹³å°å·²ē»äæ®å¤ļ¼ä½ęÆčæéäøå¾äøęåļ¼ä¹ęÆäøŗäŗčÆ»č
ę“å äŗč§£JMMēč®¾č®”ęč·Æļ¼čæäøäøŖå°čēę¦åæµåÆč½ä¼ēµę¶å°å¾å¤ę“å ę·±å
„ēē„čÆļ¼å¦ęčÆ»č
äøč½čÆ»ęę²”ęå
³ē³»å
ēäŗęē« åč¾¹ēē« čåčæåę„ēä¹åÆ仄ć
ććå¦čæJavaēęåé½åŗčÆ„ē„éJavaäøēäøåÆååÆ¹č±”ļ¼čæäøē¹åØę¬ęęåč®²č§£Stringē±»ēę¶åä¹ä¼ęåļ¼čJMMęåč®¾č®”ēę¶åļ¼čæäøŖé®é¢äøē“é½ååØļ¼å°±ęÆļ¼äøåÆååÆ¹č±”ä¼¼ä¹åÆ仄ę¹åå®ä»¬ēå¼ļ¼čæē§åÆ¹č±”ēäøåÆåęéčæä½æēØfinalå
³é®åę„å¾å°äæčÆļ¼ļ¼ļ¼Publis Service Reminderļ¼č®©äøäøŖåÆ¹č±”ēęęåꮵé½äøŗfinal并äøäøå®ä½æå¾čæäøŖåÆ¹č±”äøåÆåāāęęē±»åčæåæ
é”»ęÆåå§ē±»åčäøč½ęÆåÆ¹č±”ēå¼ēØćčäøåÆååÆ¹č±”č¢«č®¤äøŗäøč¦ę±åę„ēćä½ęÆļ¼å äøŗåØå°å
ååę¹é¢ēę“ę¹ä»äøäøŖēŗæēØä¼ ęå°å¦å¤äøäøŖēŗæēØēę¶åååØę½åØē延čæļ¼čæę ·å°±ä½æå¾ęåÆč½ååØäøē§ē«ęę”件ļ¼å³å
č®øäøäøŖēŗæēØé¦å
ēå°äøåÆååÆ¹č±”ēäøäøŖå¼ļ¼äøꮵę¶é“ä¹åēå°ēęÆäøäøŖäøåēå¼ćčæē§ę
åµä»„åęä¹åēēå¢ļ¼åØJDK 1.4äøēStringå®ē°éļ¼čæåæåŗę¬ęäøäøŖéč¦ēå³å®ę§åꮵļ¼åƹåē¬¦ę°ē»ēå¼ēØćéæåŗ¦åęčæ°åē¬¦äø²ēå¼å§ę°ē»ēåē§»éćStringå°±ęÆ仄čæę ·ēę¹å¼åØJDK 1.4äøå®ē°ēļ¼čäøęÆåŖęåē¬¦ę°ē»ļ¼å ę¤åē¬¦ę°ē»åÆ仄åØå¤äøŖStringåStringBufferåÆ¹č±”ä¹é“å
±äŗ«ļ¼čäøéč¦åØęÆꬔåå»ŗäøäøŖStringēę¶åé½ę·č“å°äøäøŖę°ēåē¬¦ę°ē»éćåč®¾ęäøč¾¹ē代ē ļ¼
ććå¦äøäøŖäø»č¦é¢åęÆäøvolatileåꮵēå
åęä½éę°ęåŗęå
³ļ¼čæäøŖé¢åäøē°ęēJMMå¼čµ·äŗäøäŗęÆč¾ę··ä¹±ēē»ęćē°ęēJMMč”Øęę失ę§ēčÆ»ååęÆē“ę„åäø»åęäŗ¤éēļ¼čæę ·éæå
äŗęå¼ååØå°åÆååØęč
ē»čæå¤ēåØē¹å®ēē¼åļ¼čæä½æå¾å¤äøŖēŗæēØäøč¬č½ēč§äøäøŖē»å®åéęę°ēå¼ćåÆęÆļ¼ē»ęęÆčæē§volatileå®ä¹å¹¶ę²”ęęåę³č±”äøé£ę ·å¦ęæ仄åæļ¼å¹¶äøåƼč“äŗvolatileēéå¤§ę··ä¹±ćäøŗäŗåØē¼ŗä¹åę„ēę
åµäøęä¾č¾å„½ēę§č½ļ¼ē¼čÆåØćčæč”ę¶åē¼åéåøøęÆå
č®øčæč”å
åēéę°ęåŗęä½ēļ¼åŖč¦å½åę§č”ēēŗæēØåč¾Øäøåŗå®ä»¬ēåŗå«ćļ¼čæå°±ęÆwithin-thread as-if-serial semantics[ēŗæēØå
ä¼¼ä¹ęÆäø²č”]ēč§£éļ¼ä½ęÆļ¼ę失ę§ēčÆ»ååęÆå®å
Øč·ØēŗæēØå®ęēļ¼ē¼čÆåØęē¼åäøč½åØå½¼ę¤ä¹é“éę°ęåŗę失ę§ēčÆ»ååćéę¾ēęÆļ¼éčæåčę®éåéēčÆ»åļ¼JMMå
č®øę失ę§ēčÆ»ååč¢«éęåŗļ¼čæę ·ä»„äøŗēå¼åäŗŗåäøč½ä½æēØę失ę§ę åæä½äøŗęä½å·²ē»å®ęēę åæćęÆå¦ļ¼
ććčæéēęę³ęÆä½æēØę失ę§åéinitializedę
ä»»å®å«ę„č”Øęäøå„å«ēęä½å·²ē»å®ęäŗļ¼čæęÆäøäøŖå¾å„½ēęę³ļ¼ä½ęÆäøč½åØJMMäøå·„ä½ļ¼å äøŗę§ēJMMå
č®øéę失ę§ēåļ¼ęÆå¦åå°configOptionsåꮵļ¼ä»„ååå°ē±configOptionså¼ēØMapēåꮵäøļ¼äøę失ę§ēåäøčµ·éę°ęåŗļ¼å ę¤å¦å¤äøäøŖēŗæēØåÆč½ä¼ēå°initializedäøŗtrueļ¼ä½ęÆåƹäŗconfigOptionsåꮵęå®ęå¼ēØēåÆ¹č±”čæę²”ęäøäøŖäøč“ēęč
čÆ“å½åēéåƹå
åēč§å¾åéļ¼volatileēę§čÆä¹åŖęæčÆŗåØčÆ»ååēåéēåÆč§ę§ļ¼čäøęæčÆŗå
¶ä»åéļ¼č½ē¶čæē§ę¹ę³ę“å ęęēå®ē°ļ¼ä½ęÆē»ęä¼åęä»¬č®¾č®”ä¹å大ēøå¾åŗć
ććē±äøå¾åÆ仄ēå°ļ¼ę å°č®æé®ļ¼āå32ä½å°åē0āļ¼äø»č¦ęÆē±åÆååØå°å
åćē±å
åå°åÆååØēäøē§ę°ę®ę å°ę¹å¼ļ¼Big-EndianåØäøå¾åÆ仄ēåŗēååå
ååä½ļ¼Atomic Unitļ¼åØē³»ē»å
åäøēå¢éæę¹åäøŗä»å·¦å°å³ļ¼čLittle-Endianēå°åå¢éæę¹åäøŗä»å³å°å·¦ćäø¾äøŖä¾åļ¼
ććäøBig-Endianēøåƹēå°±ęÆLittle-EndianēååØę¹å¼ļ¼åę ·ęē
§8ä½äøŗäøäøŖååØåä½äøč¾¹ēę°ę®0x0A0B0C0DååØę ¼å¼äøŗļ¼
ććåÆ仄ēå°LSBēå¼ååØē0x0Dļ¼ä¹å°±ęÆę°ę®ēęä½ä½ęÆä»å
åēä½å°åå¼å§ååØēļ¼å®ēé«ä½ęÆ
ä»å³å°å·¦ēé”ŗåŗéęøå¢å å
ååé
ē©ŗé“čæč”ååØēļ¼å¦ęęē
§åå
ä½äøŗååØåä½ååØę ¼å¼äøŗļ¼
ććä»äøå¾åÆ仄ēå°ęä½ē16ä½ēååØåä½éé¢ååØēå¼äøŗ0x0C0Dļ¼ę„ēęęÆ0x0A0Bļ¼čæę ·å°±åÆ仄ēå°ęē
§ę°ę®ä»é«ä½å°ä½ä½åØå
åäøååØēę¶åęÆä»å³å°å·¦čæč”éå¢ååØēļ¼å®é
äøåÆ仄ä»åå
åēé”ŗåŗę„ēč§£ļ¼å®é
äøę°ę®ååØåØå
åäøę éåØä½æēØēę¶åęÆ
åå
åå
čÆ»å
åļ¼éåƹLSBēę¹å¼ę儽ē书é¢č§£éå°±ęÆåå·¦å¢å ę„ēå¾
ļ¼å¦ęēę£åØčæč”å
åčÆ»åēę¶åä½æēØčæę ·ēé”ŗåŗļ¼å
¶ęä¹å°±ä½ē°åŗę„äŗļ¼
ććęē
§čæē§čÆ»åę ¼å¼ļ¼0x0DååØåØęä½å
åå°åļ¼čä»å³å¾å·¦ēå¢éæå°±åÆ仄ēå°LSBååØēę°ę®äøŗ0x0Dļ¼ååč”·å»åļ¼ååå
ä½ēååØå°±åÆ仄ęē
§äøč¾¹ēę ¼å¼ę„č§£éļ¼
ććå®é
äøä»äøč¾¹ēååØčæä¼ččå°å¦å¤äøäøŖé®é¢ļ¼å¦ęęē
§čæē§ę¹å¼ä»å³å¾å·¦ēę¹å¼čæč”ååØļ¼å¦ęęÆéå°Unicodeęåå°±åä»å·¦å°å³ēčÆčØę¾ē¤ŗę¹å¼ēøåćęÆå¦äøäøŖåčÆāXRAYāļ¼ä½æēØLittle-Endianēę¹å¼ååØę ¼å¼äøŗļ¼
ććä½æēØčæē§ę¹å¼čæč”å
åčÆ»åēę¶åå°±ä¼åē°č®”ē®ęŗčÆčØåčÆčØę¬čŗ«ēé”ŗåŗä¼ęå²ēŖļ¼čæē§å²ēŖäø»č¦ęÆ仄ä½æēØčÆčØēäŗŗēä¹ ęÆęå
³ļ¼č书é¢åēčÆčØä»å·¦å°å³å°±åÆ仄ē„éå
¶å²ēŖęÆäøåÆéæå
ēćę们äøč¬ä½æēØčÆčØēé
čÆ»ę¹å¼é½ęÆä»å·¦å°å³ļ¼čä½ē«ÆååØļ¼Little-Endianļ¼ēčæē§å
åčÆ»åēę¹å¼ä½æå¾ę们ęē»ä»č®”ē®ęŗéé¢čÆ»ååē¬¦éč¦čæč”ååŗļ¼čäøččå¦å¤äøäøŖé®é¢ļ¼
å¦ęęÆéåƹäøęččØļ¼äøäøŖåē¬¦ęÆäø¤äøŖåčļ¼å°±ä¼åŗē°ę“ä½é”ŗåŗåęÆäøäøŖä½ēé”ŗåŗä¼čæč”äø¤ę¬”ååŗęä½ļ¼čæē§ę¹å¼ēę£åØå¶ä½å¤ēåØēę¶åä¹ååØäøē§č®”ē®äøēå²ēŖļ¼čéåƹä½æēØęåä»å·¦å°å³čæč”é
čÆ»ēå½å®¶ččØļ¼ä»å³å°å·¦ēę¹å¼ļ¼Big-Endianļ¼åä¼ęčæę ·ēęåå²ēŖļ¼å¦å¤äøę¹é¢ļ¼å°½ē®”ęå¾å¤å½å®¶ä½æēØčÆčØęÆä»å³å°å·¦ļ¼ä½ęÆä»
ä»
åBig-Endianēę¹å¼ååØå²ēŖļ¼čæäŗå½å®¶ęÆē«å å°ę°ļ¼ę仄åÆ仄ēč§£ēęÆļ¼äøŗä»ä¹
äø»ęµēē³»ē»é½ęÆä½æēØēLittle-Endianēę¹å¼
ććć*ļ¼čæéäøč§£éMiddle-Endianēę¹å¼ä»„åMixed-Endianēę¹å¼ć
ććLSBļ¼åØč®”ē®ęŗäøļ¼ęä½ęęä½ęÆäøäøŖäŗčæå¶ē»äŗåä½ēę“ę°ļ¼ä½ēä½ē½®ē”®å®äŗčÆ„ę°ę®ęÆäøäøŖå¶ę°čæęÆå„ę°ļ¼LSBęę¶č¢«ē§°äøŗęå³ä½ćåØä½æēØå
·ä½ä½äŗčæå¶ę°ä¹å
ļ¼åøøč§ēååØę¹å¼å°±ęÆęÆäøä½ååØ1ęč
0ēę¹å¼ļ¼ä»0åäøå°1ęÆäøęÆē¹é¢äŗčæäøēååØę¹å¼ćLSBēčæē§ē¹ę§ēØę„ęå®åä½ä½ļ¼čäøęÆä½ēę°åļ¼ččæē§ę¹å¼ä¹ęåÆč½äŗ§ēäøå®ēę··ä¹±ć
ćć
āā仄äøęÆå
³äŗBig-EndianåLittle-Endianēē®åč®²č§£āā
ććJVMčęęŗå°ęē“¢åä½æēØē±»åēäøäŗäæ”ęÆä¹ååØåØę¹ę³åŗäø仄ę¹ä¾æåŗēØēØåŗå č½½čÆ»åčÆ„ę°ę®ćč®¾č®”č
åØč®¾č®”čæēØä¹ččå°č¦ę¹ä¾æJVMčæč”JavaåŗēØēØåŗēåæ«éę§č”ļ¼ččæē§åčäø»č¦ęÆäøŗäŗēØåŗåØčæč”čæēØäøå
åäøč¶³ēę
åµč½å¤éčæäøå®ēåčå»å¼„蔄å
åäøč¶³ēę
åµćåØJVMå
éØļ¼ęęēēŗæēØå
±äŗ«ēøåēę¹ę³åŗļ¼å ę¤ļ¼č®æé®ę¹ę³åŗēę°ę®ē»ęåæ
é”»ęÆēŗæēØå®å
Øēļ¼å¦ęäø¤äøŖēŗæēØé½čÆå¾å»č°ēØå»ę¾äøäøŖåäøŗLavaēē±»ļ¼ęÆå¦Lavačæę²”ęč¢«å č½½ļ¼åŖęäøäøŖēŗæēØåÆ仄å č½½čÆ„ē±»čå¦å¤ēēŗæēØåŖč½å¤ēå¾
ćę¹ę³åŗē大å°åØåé
čæēØäøęÆäøåŗå®ēļ¼éēJavaåŗēØēØåŗēčæč”ļ¼JVMåÆ仄č°ę“å
¶å¤§å°ļ¼éč¦ę³Øęäøē¹ļ¼ę¹ę³åŗēå
åäøéč¦ęÆčæē»ēļ¼å äøŗę¹ę³åŗå
ååÆ仄åé
åØå
åå äøļ¼å³ä½æęÆčęęŗJVMå®ä¾åÆ¹č±”čŖå·±ęåØēå
åå ä¹ęÆåÆč”ēļ¼čåØå®ē°čæēØęÆå
č®øēØåŗåčŖčŗ«ę„ęå®ę¹ę³åŗēåå§å大å°ēć
ććåę ·ēļ¼å äøŗJavaę¬čŗ«ēčŖåØå
åē®”ēļ¼ę¹ę³åŗä¹ä¼č¢«åå¾åę¶ēļ¼JavaēØåŗåÆ仄éčæē±»ę©å±åØęå č½½åØåÆ¹č±”ļ¼ē±»åÆ仄ęäøŗāęŖå¼ēØāååå¾åę¶åØčæč”ē³čÆ·ļ¼å¦ęäøäøŖē±»ęÆāęŖå¼ēØāēļ¼åčÆ„ē±»å°±åÆč½č¢«åøč½½ļ¼
ććčę¹ę³åŗéåƹå
·ä½ēčÆčØē¹ę§ęå ē§äæ”ęÆęÆååØåØę¹ę³åŗå
ēļ¼
ćććē±»åäæ”ęÆćļ¼
- ē±»åēå®å
Øéå®åļ¼java.lang.Stringę ¼å¼ļ¼
- ē±»åēå®å
Øéå®åēē“ę„ē¶ē±»ēå®å
Øéå®åļ¼é¤éčæäøŖē¶ē±»ēē±»åęÆäøäøŖę„å£ęč
java.lang.Objectļ¼
- äøč®ŗē±»åęÆäøäøŖē±»ęč
ę„å£
- ē±»åēäæ®é„°ē¬¦ļ¼ä¾å¦publicćabstractćfinalļ¼
- ä»»ä½äøäøŖē“ę„č¶
ē±»ę„å£ēå®å
Øéå®åēåč”Ø
ććåØJVMåē±»ę件åēå
éØļ¼ē±»ååäøč¬é½ęÆå®å
Øéå®åļ¼java.lang.Stringļ¼ę ¼å¼ļ¼åØJavaęŗę件éé¢ļ¼å®å
Øéå®ååæ
é”»å å
„å
åē¼ļ¼čäøęÆę们åØå¼åčæēØåēē®åē±»åļ¼čåØę¹ę³äøļ¼åŖč¦ęÆē¬¦åJavačÆčØč§čēē±»ēå®å
Øéå®åé½åÆ仄ļ¼čJVMåÆč½ē“ę„čæč”č§£ęļ¼ęÆå¦ļ¼ļ¼java.lang.Stringļ¼åØJVMå
éØåē§°äøŗjava/lang/Stringļ¼čæå°±ęÆę们åØå¼åøøęęēę¶åē»åøøēå°ēClassNotFoundExceptionēå¼åøøéé¢ē±»äæ”ęÆēåē§°ę ¼å¼ć
ććé¤ę¤ä¹å¤ļ¼čæåæ
é”»äøŗęÆäøē§å č½½čæēē±»ååØJVMå
čæč”ååØļ¼äøč¾¹ēäæ”ęÆäøååØåØę¹ę³åŗå
ļ¼äøč¾¹ēē« čä¼äøäøčÆ“ę
- ē±»ååøøéę±
- åꮵäæ”ęÆ
- ę¹ę³äæ”ęÆ
- ęęå®ä¹åØClasså
éØēļ¼éęļ¼åéäæ”ęÆļ¼é¤å¼åøøé
- äøäøŖClassLoaderēå¼ēØ
- Classēå¼ēØ
ćććåøøéę± ć
ććéåƹē±»åå č½½ēē±»åäæ”ęÆļ¼JVMå°čæäŗååØåØåøøéę± éļ¼åøøéę± ęÆäøäøŖę ¹ę®ē±»åå®ä¹ēåøøéēęåŗåøøééļ¼å
ę¬åé¢éļ¼StringćIntegerćFloatåøøéļ¼ä»„åē¬¦å·å¼ēØļ¼ē±»åćåꮵćę¹ę³ļ¼ļ¼ę“äøŖéæéę± ä¼č¢«JVMēäøäøŖē“¢å¼å¼ēØļ¼å¦åę°ē»éé¢ēå
ē“ éåęē
§ē“¢å¼č®æé®äøę ·ļ¼JVMéåƹčæäŗåøøéę± éé¢ååØēäæ”ęÆä¹ęÆęē
§ē“¢å¼ę¹å¼čæč”ćå®é
äøéæéę± åØJavaēØåŗēåØęé¾ę„čæēØčµ·å°äŗäøäøŖč³å
³éč¦ēä½ēØć
ćććåꮵäæ”ęÆć
ććéåƹåꮵēē±»åäæ”ęÆļ¼äøč¾¹ēäæ”ęÆęÆååØåØę¹ę³åŗéé¢ēļ¼
- åꮵå
- åꮵē±»å
- åꮵäæ®é„°ē¬¦ļ¼public,private,protected,static,final,volatile,transientļ¼
ćććę¹ę³äæ”ęÆć
ććéåƹę¹ę³äæ”ęÆļ¼äøč¾¹äæ”ęÆååØåØę¹ę³åŗäøļ¼
- ę¹ę³å
- ę¹ę³ēčæåē±»åļ¼å
ę¬voidļ¼
- ę¹ę³åę°ēē±»åćę°ē®ä»„åé”ŗåŗ
- ę¹ę³äæ®é„°ē¬¦ļ¼public,private,protected,static,final,synchronized,native,abstractļ¼
ććéåƹéę¬å°ę¹ę³ļ¼čæęäŗéå ę¹ę³äæ”ęÆéč¦ååØåØę¹ę³åŗå
ļ¼
- ę¹ę³åčē
- ę¹ę³äøå±éØåéåŗē大å°ćę¹ę³ę åø§
- å¼åøøč”Ø
ćććē±»åéć
ććē±»åéåØäøäøŖē±»ēå¤äøŖå®ä¾ä¹é“å
±äŗ«ļ¼čæäŗåéē“ę„åē±»ēøå
³ļ¼čäøęÆåē±»ēå®ä¾ēøå
³ļ¼ļ¼å®ä¹čæēØē®åēč§£äøŗē±»éé¢å®ä¹ēstaticē±»åēåéļ¼ļ¼éåƹē±»åéļ¼å
¶é»č¾éØåå°±ęÆååØåØę¹ę³åŗå
ēćåØJVMä½æēØčæäŗē±»ä¹åļ¼JVMå
č¦åØę¹ę³åŗéé¢äøŗå®ä¹ēnon-finalåéåé
å
åē©ŗé“ļ¼åøøéļ¼å®ä¹äøŗfinalļ¼ååØJVMå
éØåäøęÆ仄åę ·ēę¹å¼ę„čæč”ååØēļ¼å°½ē®”éåƹåøøéččØļ¼äøäøŖfinalēē±»åéęÆę„ęå®čŖå·±ēåøøéę± ļ¼ä½äøŗåøøéę± éé¢ēååØęéØåļ¼ē±»åøøéęÆååØåØę¹ę³åŗå
ēļ¼čå
¶é»č¾éØååäøęÆęē
§äøč¾¹ēē±»åéēę¹å¼ę„čæč”å
ååé
ēćč½ē¶non-finalē±»åéęÆä½äøŗčæäŗē±»å声ęäøååØę°ę®ēęäøéØåļ¼finalåéååØäøŗä»»ä½ä½æēØå®ē±»åēäøéØåēę°ę®ę ¼å¼čæč”ē®åååØć
ćććClassLoaderå¼ēØć
ććåƹäŗęÆē§ē±»åēå č½½ļ¼JVMåæ
é”»ę£ęµå
¶ē±»åęÆå¦ē¬¦åäŗJVMēčÆčØč§čļ¼åƹäŗéčæē±»å č½½åØå č½½ēåÆ¹č±”ē±»åļ¼JVMåæ
é”»ååØåƹē±»ēå¼ēØļ¼ččæäŗéåƹē±»å č½½åØēå¼ēØęÆä½äøŗäŗę¹ę³åŗéé¢ēē±»åę°ę®éØåčæč”ååØēć
ćććē±»Classēå¼ēØć
ććJVMåØå č½½äŗä»»ä½äøäøŖē±»åčæåä¼åå»ŗäøäøŖjava.lang.Classēå®ä¾ļ¼čęęŗåæ
é”»éčæäøå®ēéå¾ę„å¼ēØčÆ„ē±»ååƹåŗēäøäøŖClassēå®ä¾ļ¼å¹¶äøå°å
¶ååØåØę¹ę³åŗå
ćććę¹ę³č”Øć
ććäøŗäŗęé«č®æé®ęēļ¼åæ
é”»ä»ē»ēč®¾č®”ååØåØę¹ę³åŗäøēę°ę®äæ”ęÆē»ęćé¤äŗ仄äøč®Øč®ŗēē»ęļ¼jvmēå®ē°č
čæę·»å äøäŗå
¶ä»ēę°ę®ē»ęļ¼å¦ę¹ę³č”Øćäøč¾¹ä¼čÆ“ęćć
ćć2)å
åę ļ¼Stackļ¼ļ¼
ććå½äøäøŖę°ēŗæēØåÆåØēę¶åļ¼JVMä¼äøŗJavaēŗæēØåå»ŗęÆäøŖēŗæēØēē¬ē«å
åę ļ¼å¦åęčØJavaēå
åę ęÆē±ę åø§ęęļ¼ę åø§ę¬čŗ«å¤äŗęøøē¦»ē¶ęļ¼åØJVMéé¢ļ¼ę åø§ēęä½åŖęäø¤ē§ļ¼åŗę åå
„ę ćę£åØč¢«ēŗæēØę§č”ēę¹ę³äøč¬ē§°äøŗå½åēŗæēØę¹ę³ļ¼ččÆ„ę¹ę³ēę åø§å°±ē§°äøŗå½ååø§ļ¼čåØčÆ„ę¹ę³å
å®ä¹ēē±»ē§°äøŗå½åē±»ļ¼åøøéę± ä¹ē§°äøŗå½ååøøéę± ćå½ę§č”äøäøŖę¹ę³å¦ę¤ēę¶åļ¼JVMäæēå½åē±»åå½ååøøéę± ēč·čøŖļ¼å½čęęŗéå°äŗååØåØę åø§äøēę°ę®äøēęä½ę令ēę¶åļ¼å®å°±ę§č”å½ååø§ēęä½ćå½äøäøŖēŗæēØč°ēØęäøŖJavaę¹ę³ę¶ļ¼čęęŗåå»ŗ并äøå°äøäøŖę°åø§åå
„å°å
åå ę äøļ¼ččæäøŖåå
„å°å
åę äøēåø§ęäøŗå½åę åø§ļ¼å½čÆ„ę¹ę³ę§č”ēę¶åļ¼JVMä½æēØå
åę ę„ååØåę°ćå±éØåéćäøé“č®”ē®ē»ę仄åå
¶ä»ēøå
³ę°ę®ćę¹ę³åØę§č”čæēØęåÆč½å äøŗäø¤ē§ę¹å¼čē»ęļ¼å¦ęäøäøŖę¹ę³čæåå®ęå°±å±äŗę¹ę³ę§č”ēę£åøøē»ęļ¼å¦ęåØčæäøŖčæēØęåŗå¼åøøčē»ęļ¼åÆ仄ē§°äøŗéę£åøøē»ęļ¼äøč®ŗęÆę£åøøē»ęčæęÆå¼åøøē»ęļ¼JVMé½ä¼å¼¹åŗęč
äø¢å¼čÆ„ę åø§ļ¼åäøäøåø§ēę¹ę³å°±ęäøŗäŗå½ååø§ć
ććåØJVMäøļ¼JavaēŗæēØēę ę°ę®ęÆå±äŗęäøŖēŗæēØē¬ęēļ¼å
¶ä»ēēŗæēØäøč½å¤äæ®ę¹ęč
éčæå
¶ä»ę¹å¼ę„č®æé®čÆ„ēŗæēØēę åø§ļ¼ę£å äøŗå¦ę¤čæē§ę
åµäøēØę
åæå¤ēŗæēØåę„č®æé®Javaēå±éØåéļ¼å½äøäøŖēŗæēØč°ēØęäøŖę¹ę³ēę¶åļ¼ę¹ę³ēå±éØåéęÆåØę¹ę³å
éØčæč”ēJavaę åø§ēååØļ¼åŖęå½åēŗæēØåÆ仄č®æé®čÆ„å±éØåéļ¼čå
¶ä»ēŗæēØäøč½éä¾æč®æé®čÆ„å
åę éé¢ååØēę°ę®ćå
åę å
ēę åø§ę°ę®åę¹ę³åŗ仄åå
åå äøę ·ļ¼Javaę ēę åø§äøéč¦åé
åØčæē»ēå ę å
ļ¼ęč
čÆ“å®ä»¬åÆč½ęÆåØå ļ¼ęč
äø¤č
ē»ååé
ļ¼å®é
ę°ę®ēØäŗč”Øē¤ŗJavaå ę åę åø§ē»ęęÆJVMę¬čŗ«ēč®¾č®”ē»ęå³å®ēļ¼čäøåØē¼ēØčæēØåÆ仄å
č®øēØåŗåęå®äøäøŖēØäŗJavaå ę ēåå§å¤§å°ä»„åę大ćęå°å°ŗåÆøć
ćććę¦åæµåŗåć
-
å
åę ļ¼čæéēå
åę åē©ēē»ęå
åå ę ęē¹ē¹åŗå«ļ¼ęÆå
åéé¢ę°ę®ååØēäøē§ę½č±”ę°ę®ē»ęćä»ęä½ē³»ē»äøč®²ļ¼åØēØåŗę§č”čæēØåƹå
åēä½æēØę¬čŗ«åøøēØēę°ę®ē»ęå°±ęÆå
åå ę ļ¼ččæéēå
åå ę ę代ēå°±ęÆJVMåØä½æēØå
åčæēØę“äøŖå
åēååØē»ęļ¼å¤ęå
åēē©ēē»ęļ¼čJavaå
åę äøęÆę代ēäøäøŖē©ēē»ęļ¼ę“å¤ēę¶åę代ēęÆäøäøŖę½č±”ē»ęļ¼å°±ęÆē¬¦åJVMčÆčØč§čēå
åę ēäøäøŖę½č±”ē»ęćå äøŗē©ēå
åå ę ē»ęåJavaå
åę ēę½č±”ęØ”åē»ęę¬čŗ«ęÆč¾ēøä¼¼ļ¼ę仄ę们åØå¦ä¹ čæēØå°±ę£åøøęčæäø¤ē§ē»ęę¾åØäøčµ·ččäŗļ¼čäøäŗč
é¤äŗę¦åæµäøęäøē¹ē¹å°ēåŗå«ļ¼ēč§£ęäøŗäøē§ē»ęåƹäŗåå¦č
ä¹ęŖå°äøåÆļ¼ę仄å®é
äøä¹åÆ仄č§å¾äŗč
ę²”ęå¤Ŗ大ēę¬č“Øåŗå«ćä½ęÆåØå¦ä¹ ēę¶åę儽åęø
ę„å
åå ę åJavaå
åę ēäøå°ē¹ē»å¾®ēå·®č·ļ¼åč
ęÆē©ēę¦åæµåę¬čŗ«ęØ”åļ¼åč
ęÆę½č±”ę¦åæµåę¬čŗ«ęØ”åēäøäøŖå
±åä½ćčå
åå ę ę“å¤ēčÆ“ę³åÆ仄ēč§£äøŗäøäøŖå
ååļ¼å äøŗå
åååÆ仄éčæē“¢å¼åęéčæč”ę°ę®ē»ęēē»åļ¼å
åę å°±ęÆå
ååéåƹę°ę®ē»ęēäøē§č”Øē¤ŗļ¼čå
åå åęÆå
ååēå¦å¤äøē§ę°ę®ē»ęēč”Øē¤ŗļ¼čæę ·ēč§£ę“容ęåŗåå
åę åå
åå ę ļ¼å
ååļ¼ēę¦åæµć
-
ę åø§ļ¼ę åø§ęÆå
åę éé¢ēęå°åä½ļ¼ęēęÆå
åę éé¢ęÆäøäøŖęå°å
åååØåå
ļ¼å®éåƹå
åę ä»
ä»
åäŗäø¤äøŖęä½ļ¼å
„ę ååŗę ļ¼äøč¬ę
åµäøļ¼ęčÆ“ēå ę åø§åę åø§åęÆäøäøŖę¦åæµļ¼ę仄åØēč§£äøč®°å¾å 仄åŗå
-
å
åå ļ¼čæéēå
åå åå
åę ęÆēøåƹåŗēļ¼å
¶å®å
åå éé¢ēę°ę®ä¹ęÆååØåØē³»ē»å
åå ę éé¢ēļ¼åŖęÆå®ä½æēØäŗå¦å¤äøē§ę¹å¼ę„čæč”å éé¢å
åēē®”ēļ¼čę¬ē« é¢ē®č¦č®²å°ēå°±ęÆJavačÆčØę¬čŗ«ēå
åå åå
åę ļ¼ččæäø¤äøŖę¦åæµé½ęÆę½č±”ēę¦åæµęØ”åļ¼čäøęÆēøåƹēć
ććę åø§ļ¼ę åø§äø»č¦å
ę¬äøäøŖéØåļ¼å±éØåéćęä½ę°ę åø§ļ¼ęä½åø§ļ¼ååø§ę°ę®ļ¼ę°ę®åø§ļ¼ćę¬å°åéåęä½ę°åø§ē大å°åå³äŗéč¦ļ¼čæäŗ大å°ęÆåØē¼čÆę¶å°±å³å®ēļ¼å¹¶äøåØęÆäøŖę¹ę³ēē±»ę件ę°ę®äøčæč”åé
ļ¼åø§ēę°ę®å¤§å°åäøäøę ·ļ¼å®č½ē¶ä¹ęÆåØē¼čÆę¶å°±å³å®ēä½ęÆå®ē大å°åę¬čŗ«ä»£ē å®ē°ęå
³ćå½JVMč°ēØäøäøŖJavaę¹ę³ēę¶åļ¼å®ä¼ę£ę„ē±»ēę°ę®ę„ē”®å®åØę¬å°åéåęä½ę¹ę³č¦ę±ēę 大å°ļ¼å®č®”ē®čÆ„ę¹ę³ęéč¦ēå
å大å°ļ¼ē¶åå°čæäŗę°ę®åé
儽å
åē©ŗé“åå
„å°å
åå ę äøć
ććę åø§āāå±éØåéļ¼å±éØåéęÆ仄Javaę åø§ē»åęäøŗēäøäøŖ仄é¶äøŗåŗēę°ē»ļ¼ä½æēØå±éØåéēę¶åä½æēØēå®é
äøęÆäøäøŖå
å«äŗ0ēäøäøŖåŗäŗē“¢å¼ēę°ē»ē»ęćintē±»åćfloatćå¼ēØ仄åčæåå¼é½å ę®äŗäøäøŖę°ē»äøēå±éØåéēę”ē®ļ¼čbytećshortćcharååØååØå°å±éØåéēę¶åęÆå
č½¬åęäøŗintåčæč”ęä½ēļ¼ålongådoubleåęÆåØčæę ·äøäøŖę°ē»éé¢ä½æēØäŗäø¤äøŖå
ē“ ēē©ŗé“大å°ļ¼åØå±éØåééé¢ååØåŗę¬ę°ę®ē±»åēę¶åä½æēØēå°±ęÆčæę ·ēē»ęćäø¾äøŖä¾åļ¼
classĀ Example3a{
Ā Ā Ā public static intĀ runClassMethod(intĀ i,longĀ l,floatĀ f,doubleĀ d,Object o,byteĀ b)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā returnĀ 0;
Ā Ā Ā }
Ā Ā Ā public intĀ runInstanceMethod(charĀ c,doubleĀ d,shortĀ s,booleanĀ b)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā returnĀ 0;
Ā Ā Ā }
}
ćć
ę åø§āāęä½åø§ļ¼åå±éØåéäøę ·ļ¼ęä½åø§ä¹ęÆäøē»ęē»ē»ēę°ē»ēååØē»ęļ¼ä½ęÆåå±éØåéäøäøę ·ēęÆčæäøŖäøęÆéčæ
ę°ē»ēē“¢å¼č®æé®ēļ¼čęÆē“ę„čæč”ē
å
„ę ååŗę ēęä½ļ¼å½ęä½ę令ē“ę„åå
„äŗęä½ę åø§čæåļ¼ä»ę åø§éé¢åŗę„ēę°ę®ä¼ē“ę„åØåŗę ēę¶åč¢«
čÆ»åå
ä½æēØćé¤äŗ
ēØåŗč®”ę°åØ仄å¤ļ¼ęä½åø§ä¹ęÆåÆ仄ē“ę„č¢«ę令č®æé®å°ēļ¼JVMéé¢
ę²”ęåÆååØćå¤ēęä½åø§ēę¶åJavačęęŗęÆåŗäŗå
åę ēčäøęÆåŗäŗåÆååØēļ¼å äøŗå®åØęä½čæēØęÆē“ę„åƹå
åę čæč”ęä½čäøęÆéåƹåÆååØčæč”ęä½ćčJVMå
éØēę令ä¹åÆ仄ę„ęŗäŗå
¶ä»å°ę¹ęÆå¦ē“§ę„ēęä½ē¬¦ä»„åęä½ę°ēåčē ęµęč
ē“ę„ä»åøøéę± éé¢čæč”ęä½ćJVMę令å
¶å®ēę£åØęä½čæēØēē¦ē¹ęÆéäøåØå
åę ę åø§ēęä½åø§äøēćJVMę令å°ęä½åø§ä½äøŗäøäøŖå·„ä½ē©ŗé“ļ¼ęč®øå¤ę令é½ęÆä»ęä½åø§éé¢åŗę čÆ»åēļ¼åƹę令čæč”ęä½čæåå°ęä½åø§ēč®”ē®ē»ęéę°åå
„å
åå ę å
ćęÆå¦iaddę令å°äø¤äøŖę“ę°åå
„å°ęä½åø§éé¢ļ¼ē¶åå°äø¤äøŖęä½ę°čæč”ēøå ļ¼ēøå ēę¶åä»å
åę éé¢čÆ»åäø¤äøŖęä½ę°ēå¼ļ¼ē¶åčæč”čæē®ļ¼ęåå°čæē®ē»ęéę°åå
„å°å
åå ę éé¢ćäø¾äøŖē®åēä¾åļ¼
begin
iload_0Ā //å°ę“ę°ē±»åēå±éØåé0åå
„å°å
åę éé¢
iload_1Ā //å°ę“ę°ē±»åēå±éØåé1åå
„å°å
åę éé¢
iaddĀ Ā Ā Ā //å°äø¤äøŖåéåŗę čÆ»åļ¼ē¶åčæč”ēøå ęä½ļ¼å°ē»ęéę°åå
„ę äø
istore_2Ā //å°ęē»č¾åŗē»ęę¾åØå¦å¤äøäøŖå±éØåééé¢
end
ććē»¼äøęčæ°ļ¼å°±ęÆę“äøŖč®”ē®čæēØéåƹå
åēäøäŗęä½å
容ļ¼čę“ä½ēē»ęåÆ仄ēØäøå¾ę„ęčæ°ļ¼
ćć
ę åø§āāę°ę®åø§ļ¼é¤äŗå±éØåéåęä½åø§ä»„å¤ļ¼Javaę åø§čæå
ę¬äŗę°ę®åø§ļ¼ēØäŗęÆęåøøéę± ćę®éēę¹ę³čæå仄åå¼åøøęåŗēļ¼čæäŗę°ę®é½ęÆååØåØJavaå
åę åø§ēę°ę®åø§äøēćå¾å¤JVMēę令éå®é
äøä½æēØēé½ęÆåøøéę± éé¢ēäøäŗę”ē®ļ¼äøäŗę令ļ¼åŖęÆęintćlongćfloatćdoubleęč
Stringä»åøøéę± éé¢åå
„å°Javaę åø§ēęä½åø§äøč¾¹ļ¼äøäŗę令ä½æēØåøøéę± ę„ē®”ēē±»ęč
ę°ē»ēå®ä¾åęä½ćåꮵēč®æé®ę§å¶ćęč
ę¹ę³ēč°ēØļ¼å
¶ä»ēę令就ēØę„å³å®åøøéę± ę”ē®äøč®°å½ēęäøē¹å®åÆ¹č±”ęÆå¦ęäøē±»ęč
åøøéę± é”¹äøęå®ēę„å£ćåøøéę± ä¼å¤ęē±»åćåꮵćę¹ę³ćē±»ćę„å£ćē±»åꮵ仄åå¼ēØęÆå¦ä½åØJVMčæč”ē¬¦å·åęčæ°ļ¼ččæäøŖčæēØē±JVMę¬čŗ«čæč”åƹåŗēå¤ęćčæéå°±åÆ仄ēč§£JVMå¦ä½ę„å¤ęę们éåøøčÆ“ēļ¼āåå§åéååØåØå
åę äøļ¼čå¼ēØēåÆ¹č±”ååØåØå
åå äøč¾¹ćāé¤äŗåøøéę± å¤ęåø§ę°ę®ē¬¦å·åęčæ°ē¹ę§ä»„å¤ļ¼čæäŗę°ę®åø§åæ
é”»åØJVMę£åøøę§č”ęč
å¼åøøę§č”čæēØč¾
å©å®čæč”å¤ēęä½ćå¦ęäøäøŖę¹ę³ęÆę£åøøē»ęēļ¼JVMåæ
é”»ę¢å¤ę åø§č°ēØę¹ę³ēę°ę®åø§ļ¼čäøåæ
é”»č®¾ē½®PCåÆååØęåč°ēØę¹ę³åč¾¹ēå¾
ēę令å®ęčÆ„č°ēØę¹ę³ēä½ē½®ćå¦ęčÆ„ę¹ę³ååØčæåå¼ļ¼JVMä¹åæ
é”»å°čæäøŖå¼åå
„å°ęä½åø§éé¢ä»„ęä¾ē»éč¦čæäŗę°ę®ēę¹ę³čæč”č°ēØćäøä»
ä»
å¦ę¤ļ¼ę°ę®åø§ä¹åæ
é”»ęä¾äøäøŖę¹ę³č°ēØē
å¼åøøč”Øļ¼å½JVMåØę¹ę³äøęåŗå¼åøøč
éę£åøøē»ęēę¶åļ¼čÆ„å¼åøøč”Øå°±ēØę„åę¾å¼åøøäæ”ęÆć
ćć3)å
åå ļ¼Heapļ¼ļ¼
ććå½äøäøŖJavaåŗēØēØåŗåØčæč”ēę¶ååØēØåŗäøåå»ŗäøäøŖåÆ¹č±”ęč
äøäøŖę°ē»ēę¶åļ¼JVMä¼éåƹčÆ„åÆ¹č±”åę°ē»åé
äøäøŖę°ēå
åå ē©ŗé“ćä½ęÆåØJVMå®ä¾å
éØļ¼åŖååØäøäøŖå
åå å®ä¾ļ¼ęęēä¾čµčÆ„JVMēJavaåŗēØēØåŗé½éč¦å
±äŗ«čÆ„å å®ä¾ļ¼čJavaåŗēØēØåŗę¬čŗ«åØčæč”ēę¶åå®čŖå·±å
å«äŗäøäøŖē±JVMčęęŗå®ä¾åé
ēčŖå·±ēå ē©ŗé“ļ¼čåØåŗēØēØåŗåÆåØēę¶åļ¼ä»»ä½äøäøŖJavaåŗēØēØåŗé½ä¼å¾å°JVMåé
ēå ē©ŗé“ļ¼čäøéåƹęÆäøäøŖJavaåŗēØēØåŗļ¼čæäŗčæč”JavaåŗēØēØåŗēå ē©ŗé“é½ęÆēøäŗē¬ē«ēćčæéęęåå°ēå
±äŗ«å å®ä¾ęÆęJVMåØåå§åčæč”ēę¶åę“ä½å ē©ŗé“åŖęäøäøŖļ¼čæäøŖęÆJavačÆčØå¹³å°ē“ę„ä»ęä½ē³»ē»äøč½å¤ęæå°ēę“ä½å ē©ŗé“ļ¼ę仄ēä¾čµčÆ„JVMēēØåŗé½åÆ仄å¾å°čæäŗå
åē©ŗé“ļ¼ä½ęÆéåƹęÆäøäøŖē¬ē«ēJavaåŗēØēØåŗččØļ¼čæäŗå ē©ŗé“ęÆēøäŗē¬ē«ēļ¼ęÆäøäøŖJavaåŗēØēØåŗåØčæč”ęåé½ęÆä¾é JVMę„čæč”å ē©ŗé“ēåé
ēćå³ä½æęÆäø¤äøŖēøåēJavaåŗēØēØåŗļ¼äøę¦åØčæč”ēę¶åå¤äŗäøåēęä½ē³»ē»čæēØļ¼äøč¬äøŗjava.exeļ¼äøļ¼å®ä»¬åčŖåé
ēå ē©ŗé“é½ęÆē¬ē«ēļ¼äøč½ēøäŗč®æé®ļ¼åŖęÆäø¤äøŖJavaåŗēØčæēØåå§åęæå°ēå ē©ŗé“ę„čŖJVMēåé
ļ¼čJVMęÆä»ęåēå
åå å®ä¾éé¢åé
åŗę„ēćåØåäøäøŖJavaåŗēØēØåŗéé¢å¦ęåŗē°äŗäøåēēŗæēØļ¼åęÆåÆ仄å
±äŗ«ęÆäøäøŖJavaåŗēØēØåŗęæå°ēå
åå ē©ŗé“ēļ¼čæä¹ęÆäøŗä»ä¹åØå¼åå¤ēŗæēØēØåŗēę¶åļ¼éåƹåäøäøŖJavaåŗēØēØåŗåæ
é”»ččēŗæēØå®å
Øé®é¢ļ¼å äøŗåØäøäøŖJavačæēØéé¢ęęēēŗæēØęÆåÆ仄å
±äŗ«čæäøŖčæēØęæå°ēå ē©ŗé“ēę°ę®ēćä½ęÆJavaå
åå ęäøäøŖē¹ę§ļ¼å°±ęÆJVMę„ęéåƹę°ēåÆ¹č±”åé
å
åēę令ļ¼ä½ęÆå®å“äøå
å«éę¾čÆ„å
åē©ŗé“ēę令ļ¼å½ē¶å¼åčæēØåÆ仄åØJavaęŗ代ē äøę¾ē¤ŗéę¾å
åęč
čÆ“åØJVMåčē äøčæč”ę¾ē¤ŗēå
åéę¾ļ¼ä½ęÆJVMä»
ä»
åŖęÆę£ęµå ē©ŗé“äøęÆå¦ęå¼ēØäøåÆč¾¾ļ¼äøåÆ仄å¼ēØļ¼ēåÆ¹č±”ļ¼ē¶åå°ę„äøę„ēęä½äŗ¤ē»åå¾åę¶åØę„å¤ēć
ććåÆ¹č±”č”Øē¤ŗļ¼
ććJVMč§čéé¢å¹¶ę²”ęęåå°JavaåÆ¹č±”å¦ä½åØå ē©ŗé“äøč”Øē¤ŗåęčæ°ļ¼åÆ¹č±”č”Øē¤ŗåÆ仄ēč§£äøŗč®¾č®”JVMēå·„ēØåøåØęåččå°åÆ¹č±”č°ēØ仄ååå¾åę¶åØéåƹåÆ¹č±”ēå¤ęčē¬ē«ēäøē§JavaåÆ¹č±”åØå
åäøēååØē»ęļ¼čÆ„ē»ęęÆē±č®¾č®”ęåččēćéåƹäøäøŖåå»ŗēē±»å®ä¾ččØļ¼å®å
éØå®ä¹ēå®ä¾åé仄åå®ēč¶
ē±»ä»„åäøäŗēøå
³ēę øåæę°ę®ļ¼ęÆåæ
é”»éčæäøå®ēéå¾čæč”čÆ„åÆ¹č±”å
éØååØ仄åč”Øē¤ŗēćå½å¼åčæēØē»å®äŗäøäøŖåÆ¹č±”å¼ēØēę¶åļ¼JVMåæ
é”»č½å¤éčæčæäøŖå¼ēØåæ«éä»åÆ¹č±”å ē©ŗé“äøå»ęæå°čÆ„åÆ¹č±”č½å¤č®æé®ēę°ę®å
容ćä¹å°±ęÆčÆ“ļ¼å ē©ŗé“å
åÆ¹č±”ēååØē»ęåæ
é”»äøŗå¤å“åÆ¹č±”å¼ēØęä¾äøē§åÆ仄č®æé®čÆ„åÆ¹č±”ä»„åę§å¶čÆ„åÆ¹č±”ēę„å£ä½æå¾å¼ēØč½å¤é”ŗå©å°č°ēØčÆ„åÆ¹č±”ä»„åēøå
³ęä½ćå ę¤ļ¼éåƹå ē©ŗé“ēåÆ¹č±”ļ¼åé
ēå
åäøå¾å¾ä¹å
å«äŗäøäŗęåę¹ę³åŗēęéļ¼å äøŗä»ę“ä½ååØē»ęäøč®²ļ¼ę¹ę³åŗä¼¼ä¹ååØäŗå¾å¤ååēŗ§å«ēå
容ļ¼å
ę¬ę¹ę³åŗå
ęåå§ęåäøēäøäŗåéļ¼ęÆå¦ē±»åꮵćåꮵę°ę®ćē±»åę°ę®ēēćčJVMę¬čŗ«éåƹå ē©ŗé“ēē®”ēååØäø¤ē§č®¾č®”ē»ęļ¼
ććć1ćč®¾č®”äøļ¼
ććå ē©ŗé“ēč®¾č®”åÆ仄ååäøŗäø¤äøŖéØåļ¼äøäøŖå¤ēę± åäøäøŖåÆ¹č±”ę± ļ¼äøäøŖåÆ¹č±”ēå¼ēØåÆ仄ęæå°å¤ēę± ēäøäøŖę¬å°ęéļ¼čå¤ēę± äø»č¦åäøŗäø¤äøŖéØåļ¼äøäøŖęååÆ¹č±”ę± éé¢ēęé仄åäøäøŖęåę¹ę³åŗēęéćčæē§ē»ęēä¼åæåØäŗJVMåØå¤ēåÆ¹č±”ēę¶åļ¼ę“å č½å¤ę¹ä¾æå°ē»åå ē¢ē仄ä½æå¾ęęēę°ę®č¢«ę“å ę¹ä¾æå°čæč”č°ēØćå½JVMéč¦å°äøäøŖåÆ¹č±”ē§»åØå°åÆ¹č±”ę± ēę¶åļ¼å®ä»
ä»
éč¦ę“ę°čÆ„åÆ¹č±”ēęéå°äøäøŖę°ēåÆ¹č±”ę± ēå
åå°åäøå°±åÆ仄å®ęäŗļ¼ē¶ååØå¤ēę± äøéåƹčÆ„åÆ¹č±”ēå
éØē»ęčæč”ēøåƹåŗēå¤ēå·„ä½ćäøčæčæę ·ēę¹ę³ä¹ä¼åŗē°äøäøŖē¼ŗē¹å°±ęÆåØå¤ēäøäøŖåÆ¹č±”ēę¶åéåƹåÆ¹č±”ēč®æé®éč¦ęä¾äø¤äøŖäøåēęéļ¼čæäøē¹åÆč½äø儽ēč§£ļ¼å
¶å®åÆ仄čæę ·č®²ļ¼ēę£åØåÆ¹č±”å¤ēčæēØååØäøäøŖę ¹ę®ę¶é“ę³ęåŗå«ēåÆ¹č±”ē¶ęļ¼čåÆ¹č±”åØē§»åØćę“ę°ä»„ååå»ŗēę“äøŖčæēØäøļ¼å®ēå¤ēę± éé¢ę»ęÆå
å«äŗäø¤äøŖęéļ¼äøäøŖęéęÆęååÆ¹č±”å
容ę¬čŗ«ļ¼äøäøŖęéęÆęåäŗę¹ę³åŗļ¼å äøŗäøäøŖå®ę“ēåƹå¤ēåÆ¹č±”ęÆä¾é čæäø¤éØåč¢«å¼ēØęéå¼ēØå°ēļ¼čę们å¼åčæēØęÆäøč½å¤ęä½å¤ēę± ēäø¤äøŖęéēļ¼åŖęå¼ēØęéę们åÆ仄éčæå¤å“ē¼ēØęæå°ćå¦ęJavaęÆęē
§čæē§č®¾č®”čæč”åÆ¹č±”ååØļ¼čæéēå¼ēØęéå°±ęÆå¹³ę¶ęåå°ēāJavaēå¼ēØāļ¼åŖęÆJVMåØå¼ēØęéčæåäŗäøå®ēå°č£
ļ¼čæē§å°č£
ēč§åęÆJVMę¬čŗ«č®¾č®”ēę¶ååēļ¼å®å°±éčæčæē§ē»ęåØå¤å“čæč”äøꬔå°č£
ļ¼ęÆå¦Javaå¼ēØäøå
·å¤ē“ę„ęä½å
åå°åēč½åå°±ęÆčÆ„å°č£
ēäøē§éå¶č§åćčæē§č®¾č®”ēē»ęå¾å¦äøļ¼
ććć2ćč®¾č®”äŗļ¼
ććå¦å¤äøē§å ē©ŗé“č®¾č®”å°±ęÆä½æēØåÆ¹č±”å¼ēØęæå°ēę¬å°ęéļ¼å°čÆ„ęéē“ę„ęåē»å®å„½ēåÆ¹č±”ēå®ä¾ę°ę®ļ¼čæäŗę°ę®éé¢ä»
ä»
å
å«äŗäøäøŖęåę¹ę³åŗååēŗ§å«ēę°ę®å»ęæå°čÆ„å®ä¾ēøå
³ę°ę®ļ¼čæē§ę
åµäøåŖéč¦å¼ēØäøäøŖęéę„č®æé®åÆ¹č±”å®ä¾ę°ę®ļ¼ä½ęÆčæę ·ēę
åµä½æå¾åÆ¹č±”ēē§»åØ仄ååÆ¹č±”ēę°ę®ę“ę°åå¾ę“å å¤ęćå½JVMéč¦ē§»åØčæäŗę°ę®ä»„åčæč”å å
åē¢ēēę“ēēę¶åļ¼å°±åæ
é”»ē“ę„ę“ę°čÆ„åÆ¹č±”ęęčæč”ę¶ēę°ę®åŗļ¼čæē§ę
åµåÆ仄ēØäøå¾čæč”č”Øē¤ŗļ¼
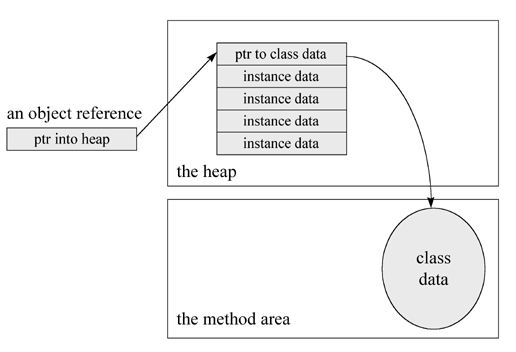
ććJVMéč¦ä»äøäøŖåÆ¹č±”å¼ēØę„č·å¾čÆ„å¼ēØč½å¤å¼ēØēåÆ¹č±”ę°ę®ååØå¤äøŖåå ļ¼å½äøäøŖēØåŗčÆå¾å°äøäøŖåÆ¹č±”ēå¼ēØč½¬ę¢ęäøŗå¦å¤äøäøŖē±»åēę¶åļ¼JVMå°±ä¼ę£ę„äø¤äøŖå¼ēØęåēåÆ¹č±”ęÆå¦ååØē¶åē±»å
³ē³»ļ¼å¹¶äøę£ę„äø¤äøŖå¼ēØå¼ēØå°ēåÆ¹č±”ęÆå¦č½å¤čæč”ē±»åč½¬ę¢ļ¼čäøęęčæē§ē±»åēč½¬ę¢åæ
é”»ę§č”åę ·ēäøäøŖęä½ļ¼instanceofęä½ļ¼åØäøč¾¹äø¤ē§ę
åµäøļ¼JVMé½åæ
é”»č¦å»åęå¼ēØęåēåÆ¹č±”å
éØēę°ę®ćå½äøäøŖēØåŗč°ēØäŗäøäøŖå®ä¾ę¹ę³ēę¶åļ¼JVMå°±åæ
é”»čæč”åØęē»å®ęä½ļ¼å®åæ
é”»éę©č°ēØę¹ę³ēå¼ēØē±»åļ¼ęÆäøäøŖåŗäŗē±»ēę¹ę³č°ēØčæęÆäøäøŖåŗäŗåÆ¹č±”ēę¹ę³č°ēØļ¼č¦åå°čæäøē¹ļ¼å®åč¦č·åčÆ„åÆ¹č±”ēåÆäøå¼ēØęåÆ仄ćäøē®”åÆ¹č±”ēå®ē°ęÆä½æēØä»ä¹ę¹å¼ę„čæč”åÆ¹č±”ęčæ°ļ¼é½ęÆåØéåƹå
åäøå
³äŗčÆ„åÆ¹č±”ēę¹ę³č”Øčæč”ęä½ļ¼å äøŗä½æēØčæę ·ēę¹å¼å åæ«äŗå®ä¾éåƹę¹ę³ēč°ēØļ¼čäøåØJVMå
éØå®ē°ēę¶åčæę ·ēęŗå¶ä½æå¾å
¶čæč”č”Øē°ęÆč¾čÆ儽ļ¼ę仄ę¹ę³č”Øēč®¾č®”åØJVMę“ä½ē»ęäøåę„äŗęå
¶éč¦ēä½ēØćå
³äŗę¹ę³č”ØēååØäøå¦ļ¼åØJVMč§čéé¢ę²”ęäø„ę ¼čÆ“ęļ¼ä¹ęåÆč½ēę£åØå®ē°čæēØåŖęÆäøäøŖę½č±”ę¦åæµļ¼ē©ēå±å®ę ¹ę¬äøååØļ¼éåƹę¾åč”Øå®ē°åƹäŗäøäøŖåå»ŗēå®ä¾ččØļ¼å®ę¬čŗ«å
·ęäøå¤Ŗé«ēå
åéč¦ę±ļ¼å¦ęčÆ„å®ē°éé¢ä½æēØäŗę¹ę³č”Øļ¼ååÆ¹č±”ēę¹ę³č”ØåŗčÆ„ęÆåÆ仄å¾åæ«č¢«å¤å“å¼ēØč®æé®å°ēć
ććęäøē§åę³å°±ęÆéčæåÆ¹č±”å¼ēØčæę„å°ę¹ę³č”Øēę¶åļ¼å¦äøå¾ļ¼
ććčÆ„å¾č”Øęļ¼åØęÆäøŖęéęåäøäøŖåÆ¹č±”ēę¶åļ¼å®é
äøęÆä½æēØēäøäøŖē¹ę®ēę°ę®ē»ęļ¼čæäŗē¹ę®ēē»ęå
ę¬å äøŖéØåļ¼
- äøäøŖęåčÆ„åÆ¹č±”ē±»ęęę°ę®ēęé
- čÆ„åÆ¹č±”ēę¹ę³č”Ø
ććå®é
äøä»å¾äøåÆ仄ēåŗļ¼ę¹ę³č”Øå°±ęÆäøäøŖęéę°ē»ļ¼å®ēęÆäøäøŖå
ē“ å
å«äŗäøäøŖęéļ¼éåƹęÆäøŖåÆ¹č±”ēę¹ę³é½åÆ仄ē“ę„éčæčÆ„ęéåØę¹ę³åŗäøę¾å°å¹é
ēę°ę®čæč”ēøå
³č°ēØļ¼ččæäŗę¹ę³č”Øéč¦å
ę¬ēå
容å¦äøļ¼
- ę¹ę³å
åå ę ꮵē©ŗé“äøęä½ę ē大å°ä»„åå±éØåé
- ę¹ę³åčē
- äøäøŖę¹ę³ēå¼åøøč”Ø
ććčæäŗäæ”ęÆä½æå¾JVMč¶³å¤éåƹčÆ„ę¹ę³čæč”č°ēØļ¼åØč°ēØčæēØļ¼čæē§ē»ęä¹č½å¤ę¹ä¾æåē±»åÆ¹č±”ēę¹ę³ē“ę„éčæęéå¼ēØå°ē¶ē±»ēäøäŗę¹ę³å®ä¹ļ¼ä¹å°±ęÆčÆ“ęéåØå
åē©ŗé“ä¹å
éčæJVMę¬čŗ«ēč°ēØä½æå¾ē¶ē±»ēäøäŗę¹ę³č”Øä¹åÆ仄åę ·ēę¹å¼č¢«č°ēØļ¼å½ē¶čæē§č°ēØčæēØéæå
äøäŗäø¤äøŖåÆ¹č±”ä¹é“ēē±»åę£ę„ļ¼ä½ęÆčæę ·ēę¹å¼å°±ä½æå¾ē»§ęæēå®ē°åå¾ę“å ē®åļ¼čäøę¹ę³č”Øęä¾ēčæäŗę°ę®č¶³å¤å¼ēØåƹåÆ¹č±”čæč”åø¦ęä»»ä½OOē¹å¾ēåÆ¹č±”ęä½ć
ććå¦å¤äøē§ę°ę®åØäøč¾¹ēéäøę²”ęę¾ē¤ŗåŗę„ļ¼ä¹ęÆä»é»č¾äøč®²å
åå äøēåÆ¹č±”ēēå®ę°ę®ē»ęāāåÆ¹č±”ēéćčæäøē¹åÆč½éč¦å
³čå°JMMęØ”åäøč®²ēčæč”ēč§£ćJVMäøēęÆäøäøŖåÆ¹č±”é½ęÆåäøäøŖéļ¼äŗę„ļ¼ēøå
³čēļ¼čæē§ē»ęä½æå¾čÆ„åÆ¹č±”åÆ仄å¾å®¹ęęÆęå¤ēŗæēØč®æé®ļ¼čäøčÆ„åÆ¹č±”ēåÆ¹č±”éäøꬔåŖč½č¢«äøäøŖēŗæēØč®æé®ćå½äøäøŖēŗæēØåØčæč”ēę¶åå
·ęęäøŖåÆ¹č±”ēéēę¶åļ¼ä»
ä»
åŖęčæäøŖēŗæēØåÆ仄č®æé®čÆ„åÆ¹č±”ēå®ä¾åéļ¼å
¶ä»ēŗæēØå¦ęéč¦č®æé®čÆ„å®ä¾ēå®ä¾åéå°±åæ
é”»ēå¾
čæäøŖēŗæēØå°å®å ęēåÆ¹č±”ééę¾čæåęč½å¤ę£åøøč®æé®ļ¼å¦ęäøäøŖēŗæēØčÆ·ę±äŗäøäøŖč¢«å
¶ä»ēŗæēØå ęēåÆ¹č±”éļ¼čæäøŖčÆ·ę±ēŗæēØä¹åæ
é”»ēå°čÆ„éč¢«éę¾čæåęč½å¤ęæå°čæäøŖåÆ¹č±”ēåÆ¹č±”éćäøę¦čæäøŖēŗæēØę„ęäŗäøäøŖåÆ¹č±”éčæåļ¼å®čŖå·±åÆ仄å¤ę¬”ååäøäøŖéåéåÆ¹č±”ēéčÆ·ę±ļ¼ä½ęÆå¦ęå®č¦ä½æå¾č¢«čÆ„ēŗæēØéä½ēåÆ¹č±”åÆä»„č¢«å
¶ä»éč®æé®å°ēčÆå°±éč¦åę ·ēéę¾éēꬔę°ļ¼ęÆå¦ēŗæēØAčÆ·ę±äŗåÆ¹č±”BēåÆ¹č±”éäøꬔļ¼é£ä¹Aå°ä¼äøē“å ęBåÆ¹č±”ēåÆ¹č±”éļ¼ē“å°å®å°čÆ„åÆ¹č±”ééę¾äŗäøꬔć
ććå¾å¤åÆ¹č±”ä¹åÆč½åØę“äøŖēå½åØęé½ę²”ęč¢«åÆ¹č±”ééä½čæļ¼åØčæę ·ēę
åµäøåÆ¹č±”éēøå
³ēę°ę®ęÆäøéč¦åÆ¹č±”å
éØå®ē°ēļ¼é¤éęēŗæēØåčÆ„åÆ¹č±”čÆ·ę±äŗåÆ¹č±”éļ¼å¦åčæäøŖåÆ¹č±”å°±ę²”ęčÆ„åÆ¹č±”éēååØē»ęćę仄äøč¾¹ēå®ē°å¾åÆ仄ē„éļ¼å¾å¤å®ē°äøå
ę¬ęååÆ¹č±”éēāéę°ę®āļ¼éę°ę®ēå®ē°åæ
é”»č¦ēå¾
ęäøŖēŗæēØåčÆ„åÆ¹č±”åéäŗåÆ¹č±”éčÆ·ę±čæåļ¼čäøęÆåØē¬¬äøꬔéčÆ·ę±čæåęä¼č¢«å®ē°ćčæäøŖē»ęäøļ¼JVMå“č½å¤é“ę„å°éčæäøäŗåę³éåƹåÆ¹č±”ēéčæč”ē®”ēļ¼ęÆå¦ęåÆ¹č±”éę¾åØåŗäŗåÆ¹č±”å°åēęē“¢ę äøč¾¹ćå®ē°äŗéē»ęēåÆ¹č±”äøļ¼ęÆäøäøŖJavaåÆ¹č±”é»č¾äøé½åØå
åäøęäøŗäŗäøäøŖēå¾
éļ¼čæę ·å°±ä½æå¾ęęēēŗæēØåØéē»ęéé¢éåƹåÆ¹č±”å
éØę°ę®åÆ仄ē¬ē«ęä½ļ¼ēå¾
éå°±ä½æå¾ęÆäøŖēŗæēØč½å¤ē¬ē«äŗå
¶ä»ēŗæēØå»å®ęäøäøŖå
±åēč®¾č®”ē®ę 仄åēØåŗę§č”ēęē»ē»ęļ¼čæę ·å°±ä½æå¾å¤ēŗæēØēēŗæēØē¬äŗ«ę°ę®ä»„åēŗæēØå
±äŗ«ę°ę®ęŗå¶å¾å®¹ęå®ē°ć
ććäøä»
ä»
å¦ę¤ļ¼éåƹå
åå åÆ¹č±”čæåæ
é”»ååØäøäøŖåÆ¹č±”ēéåļ¼čÆ„éåēäø»č¦ē®ēęÆęä¾ē»åå¾åę¶åØčæč”ēę§ęä½ļ¼åå¾åę¶åØęÆéčæåÆ¹č±”ēē¶ęę„å¤ęčÆ„åÆ¹č±”ęÆå¦č¢«åŗēØļ¼åę ·å®éč¦éåƹå å
ēåÆ¹č±”čæč”ēę§ćčå½ēę§čæēØåå¾åę¶åØę¶å°åÆ¹č±”åę¶ēäŗ件触åēę¶åļ¼č½ē¶ä½æēØäŗäøåēåå¾åę¶ē®ę³ļ¼äøč®ŗä½æēØä»ä¹ē®ę³é½éč¦éčæē¬ęēęŗå¶ę„å¤ęåÆ¹č±”ē®åå¤äŗåŖē§ē¶ęļ¼ē¶åę ¹ę®åÆ¹č±”ē¶ęčæč”ęä½ćå¼åčæēØēØåŗåå¾å¾äøä¼å»ä»ē»åęå½äøäøŖåÆ¹č±”å¼ēØč®¾ē½®ęäøŗnulläŗčæåčęęŗå
éØēęä½ļ¼ä½å®é
äøJavaéé¢ēå¼ēØå¾å¾äøåę们ę³åäøé£ä¹ē®åļ¼Javaå¼ēØäøēčå¼ēØćå¼±å¼ēØå°±ęÆä½æå¾Javaå¼ēØåØę¾ē¤ŗęäŗ¤åÆåę¶ē¶ęēę
åµäøåƹå
åå äøēåÆ¹č±”čæč”ēååēę§ļ¼čæäŗå¼ēØåÆ仄ēč§å°åå¾åę¶åØåę¶čÆ„åÆ¹č±”ēčæēØćåå¾åę¶åØę¬čŗ«ēå®ē°ä¹ęÆéč¦å
åå äøēåÆ¹č±”č½å¤ęä¾ēøåƹåŗēę°ę®ēćå
¶å®čæäøŖä½ē½®å°åŗJVMéé¢ęÆå¦ä½æēØäŗå®ę“ēJavaåÆ¹č±”ēéåčæęÆä½æēØēäøäøŖéåē“¢å¼ęę²”ęå»ä»ē»åęčæļ¼ę»ä¹ęÆåØå ē»ęéé¢ååØēå å
åÆ¹č±”ēäøäøŖē±»ä¼¼ę·č“ēéåęŗå¶ļ¼ä½æå¾åå¾åę¶åØč½å¤é”ŗå©åę¶äøåč¢«å¼ēØēåÆ¹č±”ć
ćć4)å
åę åå
åå ēå®ē°åēę¢ęµćčÆ„éØåäøŗäøē”®å®ę¦åæµćļ¼
ććå®é
äøäøč®ŗęÆå
åę ē»ęćę¹ę³åŗčæęÆå
åå ē»ęļ¼å½ę ¹å°åŗä½æēØēęÆęä½ē³»ē»ēå
åļ¼ęä½ē³»ē»ēå
åē»ęåÆ仄ēč§£äøŗå
ååļ¼åøøēØēę½č±”ę¹å¼å°±ęÆäøäøŖå
åå ę ļ¼čJVMåØOSäøč¾¹å®č£
äŗčæåļ¼å°±åØåÆåØJavaēØåŗēę¶åęē
§é
ē½®ę件éé¢ēå
容åęä½ē³»ē»ē³čÆ·å
åē©ŗé“ļ¼čÆ„å
åē©ŗé“ä¼ęē
§JVMå
éØēę¹ę³ęä¾ēøåŗēē»ęč°ę“ć
ććå
åę åŗčÆ„ęÆå¾å®¹ęēč§£ēē»ęå®ē°ļ¼äøč¬ę
åµäøļ¼å
åę ęÆäæęčæē»ēļ¼ä½ęÆäøē»åƹļ¼å
åę ē³čÆ·å°ēå°åå®é
äøå¾å¤ę
åµäøé½ęÆčæē»ēļ¼čęÆäøŖå°åēęå°åä½ęÆęē
§č®”ē®ęŗä½ę„ē®ēļ¼čÆ„č®”ē®ęŗä½éé¢åŖęäø¤ē§ē¶ę1å0ļ¼čå
åę ēä½æēØčæēØå°±ęÆå
øåēē±»ä¼¼C++éé¢ēę®éęéē»ęēä½æēØčæēØļ¼ē“ę„éåƹęéčæč”++ęč
--ęä½å°±äæ®ę¹äŗčÆ„ęééåƹå
åēåē§»éļ¼ččæäŗåē§»éå°±ä½æå¾čÆ„ęéåÆ仄č°ēØäøåēå
åę äøēę°ę®ćč³äŗéåƹå
åę åéēę令就ęÆåøøč§ēč®”ē®ęŗę令ļ¼ččæäŗę令就ä½æå¾čÆ„ęééåƹå
åę ēę åø§čæč”ę令åéļ¼ęÆå¦åéęä½ę令ćåéčÆ»åēēļ¼ē“ę„å°±ä½æå¾å
åę ēč°ēØåå¾ę“å ē®åļ¼čäøę åø§åØę„åäŗčÆ„ę°ę®čæåå°±ē„éå°åŗéåƹę åø§å
éØēåŖäøäøŖéØåčæč”č°ēØļ¼ęÆęä½åø§ćę°ę®åø§čæęÆå±éØåéć
ććå
åå å®é
äøåØęä½ē³»ē»éé¢ä½æēØäŗååé¾č”Øēę°ę®ē»ęļ¼ååé¾č”Øēē»ęä½æå¾å³ä½æå
åå äøå
·ęčæē»ę§ļ¼ęÆäøäøŖå ē©ŗé“éé¢ēé¾č”Øä¹åÆ仄čæå
„äøäøäøŖå ē©ŗé“ļ¼čęä½ē³»ē»ę¬čŗ«åØę“ēå
åå ēę¶åä¼åäøäŗē®åēęä½ļ¼ē¶åéčæęÆäøäøŖå
åå ēååé¾č”Øå°±ä½æå¾å
åå ę“å ę¹ä¾æćčäøå ē©ŗé“äøéč¦ęåŗļ¼ēč³čÆ“ęåŗäøå½±åå ē©ŗé“ēååØē»ęļ¼å äøŗå®å½ę ¹å°åŗęÆåØå
ååäøč¾¹čæč”å®ē°ēļ¼å
ååę¬čŗ«ęÆäøäøŖå ę ē»ęļ¼åŖęÆčÆ„å
åå ę éé¢ēåå¦ä½åé
äøē±JVMå³å®ļ¼ęÆē±ęä½ē³»ē»å·²ē»ęå¼å§åé
儽äŗļ¼ä¹å°±ęÆęå°ååØåä½ćē¶åJVMęæå°ä»ęä½ē³»ē»ē³čÆ·ēå ē©ŗé“čæåļ¼å
čæč”åå§åęä½ļ¼ē¶åå°±åÆ仄ē“ę„ä½æēØäŗć
ććåøøč§ēåƹēØåŗęå½±åēå
åé®é¢äø»č¦ęÆäø¤ē§ļ¼ęŗ¢åŗåå
åę³ę¼ļ¼äøč¾¹å·²ē»č®²čæäŗå
åę³ę¼ļ¼å
¶å®ä»å
åēē»ęåęļ¼ę³ę¼čæē§ę
åµå¾é¾ēč³čÆ“äøåÆč½åēåØę ē©ŗé“éé¢ļ¼å
¶äø»č¦åå ęÆę ē©ŗé“ę¬čŗ«å¾é¾åŗē°ę¬åēå
åļ¼å äøŗę ē©ŗé“ēååØē»ęęåÆč½ęÆå
åēäøäøŖå°åę°ē»ļ¼ę仄åØč®æé®ę ē©ŗé“ēę¶åä½æēØēé½ęÆē“¢å¼ęč
äøę ęč
å°±ęÆęåå§ēåŗę åå
„ę ēęä½ļ¼čæäŗęä½ä½æå¾ę éé¢å¾é¾åŗē°åå ē©ŗé“äøę ·ēå
åę¬åļ¼ä¹å°±ęÆå¼ēØę¬ęļ¼é®é¢ćå ē©ŗé“ę¬åēå
åęÆå äøŗę äøåę¾ēå¼ēØēååļ¼å
¶å®å¼ēØåÆ仄ēč§£äøŗä»ę å°å ēäøäøŖęéļ¼å½čÆ„ęéåēååēę¶åļ¼å å
åē¢ēå°±ęåÆč½äŗ§ēļ¼ččæē§ę
åµäøåØåå§čÆčØéé¢å°±ē»åøøåēå
åę³ę¼ēę
åµļ¼å äøŗčæäŗę¬åēå ē©ŗé“åØē³»ē»éé¢ęÆäøč½å¤č¢«ä»»ä½ę¬å°ęéå¼ēØå°ļ¼å°±ä½æå¾čæäŗåÆ¹č±”åØęŖč¢«åę¶ēę¶åč±ē¦»äŗåÆęä½åŗå并äøå ēØäŗē³»ē»čµęŗć
ććę ęŗ¢åŗé®é¢äøē“é½ęÆč®”ē®ęŗé¢åéé¢ēäøäøŖå®å
Øę§é®é¢ļ¼čæéäøåę·±å
„č®Øč®ŗļ¼čÆ“å¤äŗå°±åē¦»äø»é¢äŗļ¼čå
åę³ę¼ęÆēØåŗåę容ęēč§£ēå
åé®é¢ļ¼čæęäøäøŖé®é¢ę„čŖäŗęäøäøŖé»å®¢ęåå°±ęÆļ¼å ęŗ¢åŗē°č±”ļ¼čæē§ē°č±”åÆč½ę“å å¤ęć
ććå
¶å®Javaéé¢ēå
åē»ęļ¼ęåēę„å°±ęÆå åę ēē»åļ¼å®é
äøåÆ仄čæę ·ēč§£ļ¼å®é
äøåÆ¹č±”ēå®é
å
容ęååØåÆ¹č±”ę± éé¢ļ¼čęå
³åÆ¹č±”ēå
¶ä»äøč„æęåÆč½ä¼ååØäŗę¹ę³åŗļ¼čå¹³ę¶ä½æēØēę¶åēå¼ēØęÆååØå
åę äøēļ¼čæę ·å°±ę“å 容ęēč§£å®å
éØēē»ęļ¼äøä»
ä»
å¦ę¤ļ¼ęę¶åčæéč¦ččå°Javaéé¢ēäøäŗåꮵåå±ę§å°åŗęÆåÆ¹č±”åēčæęÆē±»åēļ¼čæäøŖä¹ęÆäøäøŖęÆč¾å¤ęēé®é¢ć
ććäŗč
ēåŗå«ē®åę»ē»äøäøļ¼
-
ē®”ēę¹å¼ļ¼JVMčŖå·±åÆ仄éåƹå
åę čæč”ē®”ēęä½ļ¼čäøčÆ„å
åē©ŗé“ēéę¾ęÆē¼čÆåØå°±åÆ仄ęä½ēå
容ļ¼čå ē©ŗé“åØJavaäøJVMę¬čŗ«ę§č”å¼ęäøä¼åƹå
¶čæč”éę¾ęä½ļ¼čęÆ让åå¾åę¶åØčæč”čŖåØåę¶
-
ē©ŗé“大å°ļ¼äøč¬ę
åµäøę ē©ŗé“ēøåƹäŗå ē©ŗé“ččØęÆč¾å°ļ¼čæęÆē±ę ē©ŗé“éé¢ååØēę°ę®ä»„åę¬čŗ«éč¦ēę°ę®ē¹ę§å³å®ēļ¼čå ē©ŗé“åØJVMå å®ä¾čæč”åé
ēę¶åäøč¬å¤§å°é½ęÆč¾å¤§ļ¼å äøŗå ē©ŗé“åØäøäøŖJavaēØåŗäøéč¦ååØå¤Ŗå¤ēJavaåÆ¹č±”ę°ę®
-
ē¢ēēøå
³ļ¼éåƹå ē©ŗé“ččØļ¼å³ä½æåå¾åę¶åØč½å¤čæč”čŖåØå å
ååę¶ļ¼ä½ęÆå ē©ŗé“ēę“»åØéēøåƹę ē©ŗé“ččØęÆč¾å¤§ļ¼å¾ęåÆč½ååØéæęēå ē©ŗé“åé
åéę¾ęä½ļ¼čäøåå¾åę¶åØäøęÆå®ę¶ēļ¼å®ęåÆč½ä½æå¾å ē©ŗé“ēå
åē¢ēäø»é®ē“Æē§Æčµ·ę„ćéåƹę ē©ŗé“ččØļ¼å äøŗå®ę¬čŗ«å°±ęÆäøäøŖå ę ēę°ę®ē»ęļ¼å®ēęä½é½ęÆäøäøåƹåŗēļ¼čäøęÆäøäøŖęå°åä½ēē»ęę åø§åå ē©ŗé“å
å¤ęēå
åē»ęäøäøę ·ļ¼ę仄å®äøč¬åØä½æēØčæēØå¾å°åŗē°å
åē¢ēć
-
åé
ę¹å¼ļ¼äøč¬ę
åµäøļ¼ę ē©ŗé“ęäø¤ē§åé
ę¹å¼ļ¼éęåé
ååØęåé
ļ¼éęåé
ęÆę¬čŗ«ē±ē¼čÆåØåé
儽äŗļ¼čåØęåé
åÆč½ę ¹ę®ę
åµęęäøåļ¼čå ē©ŗé“å“ęÆå®å
ØēåØęåé
ēļ¼ęÆäøäøŖčæč”ę¶ēŗ§å«ēå
ååé
ćčę ē©ŗé“åé
ēå
åäøéč¦ę们ččéę¾é®é¢ļ¼čå ē©ŗé“å³ä½æåØęåå¾åę¶åØēåęäøčæęÆč¦ččå
¶éę¾é®é¢ć
-
ęēļ¼å äøŗå
ååę¬čŗ«ēęåå°±ęÆäøäøŖå
øåēå ę ē»ęļ¼ę仄ę ē©ŗé“ēęēčŖē¶ęÆčµ·å ē©ŗé“č¦é«å¾å¤ļ¼čäøč®”ē®ęŗåŗå±å
åē©ŗé“ę¬čŗ«å°±ä½æēØäŗęåŗē”ēå ę ē»ęä½æå¾ę ē©ŗé“ååŗå±ē»ęę“å ē¬¦åļ¼å®ēęä½ä¹åå¾ē®åå°±ęÆęē®åēäø¤äøŖę令ļ¼å
„ę ååŗę ļ¼ę ē©ŗé“éåƹå ē©ŗé“ččØēå¼±ē¹ęÆēµę“»ēØåŗ¦äøå¤ļ¼ē¹å«ęÆåØåØęē®”ēēę¶åćčå ē©ŗé“ę大ēä¼åæåØäŗåØęåé
ļ¼å äøŗå®åØč®”ē®ęŗåŗå±å®ē°åÆč½ęÆäøäøŖååé¾č”Øē»ęļ¼ę仄å®åØē®”ēēę¶åęä½ęÆę ē©ŗé“å¤ęå¾å¤ļ¼čŖē¶å®ēēµę“»åŗ¦å°±é«äŗļ¼ä½ęÆčæę ·ēč®¾č®”ä¹ä½æå¾å ē©ŗé“ēęēäøå¦ę ē©ŗé“ļ¼čäøä½å¾å¤ć
Ā
3.ę¬ęŗå
å[éØåå
容ę„ęŗäŗIBMå¼åäøåæ]
ććJavaå ē©ŗé“ęÆåØē¼åJavaēØåŗäøč¢«ę们ä½æēØå¾ęé¢ē¹ēå
åē©ŗé“ļ¼å¹³ę¶å¼åčæēØļ¼å¼åäŗŗåäøå®éå°čæOutOfMemoryErrorļ¼čæē§ē»ęęåÆč½ę„ęŗäŗJavaå ē©ŗé“ēå
åę³ę¼ļ¼ä¹åÆč½ęÆå äøŗå ē大å°äøå¤čåƼč“ēļ¼ęę¶åčæäŗéčÆÆęÆåÆ仄ä¾é å¼åäŗŗåäæ®å¤ēļ¼ä½ęÆéēJavaēØåŗéč¦å¤ēč¶ę„č¶å¤ē并åēØåŗļ¼åÆč½ęäŗéčÆÆå°±äøęÆé£ä¹å®¹ęå¤ēäŗćęäŗę¶åå³ä½æJavaå ē©ŗé“ę²”ęę»”ä¹åÆč½ęåŗéčÆÆļ¼čæē§ę
åµäøéč¦äŗč§£ēå°±ęÆJREļ¼Java Runtime Environmentļ¼å
éØå°åŗåēäŗä»ä¹ćJavaę¬čŗ«ēčæč”å®æäø»ēÆå¢å¹¶äøęÆęä½ē³»ē»ļ¼čęÆJavačęęŗļ¼Javačęęŗę¬čŗ«ęÆēØCē¼åēę¬ęŗēØåŗļ¼čŖē¶å®ä¼č°ēØå°ę¬ęŗčµęŗļ¼ęåøøč§ēå°±ęÆéåƹę¬ęŗå
åēč°ēØćę¬ęŗå
åęÆåÆ仄ēØäŗčæč”ę¶čæēØēļ¼å®åJavaåŗēØēØåŗä½æēØēJavaå å
åäøäøę ·ļ¼ęÆäøē§čęåčµęŗé½åæ
é”»ååØåØę¬ęŗå
åéé¢ļ¼å
ę¬čęęŗę¬čŗ«čæč”ēę°ę®ļ¼čæę ·ä¹ęå³ēäø»ęŗēē”¬ä»¶åęä½ē³»ē»åØę¬ęŗå
åēéå¶å°ē“ę„å½±åå°JavaåŗēØēØåŗēę§č½ć
ćći.Javačæč”ę¶å¦ä½ä½æēØę¬ęŗå
åļ¼
ćć1)å ē©ŗé“ååå¾åę¶
ććJavačæč”ę¶ęÆäøäøŖęä½ē³»ē»čæēØļ¼Windowsäøäøč¬äøŗjava.exeļ¼ļ¼čÆ„ēÆå¢ęä¾ēåč½ä¼åäøäŗä½ē½®ēēØę·ä»£ē 驱åØļ¼čæč½ē¶ęé«äŗčæč”ę¶åØå¤ēčµęŗēēµę“»ę§ļ¼ä½ęÆę ę³é¢ęµęÆē§ę
åµäøčæč”ę¶ēÆå¢éč¦ä½ē§čµęŗļ¼čæäøē¹Javaå ē©ŗé“č®²č§£äøå·²ē»ęå°čæäŗćåØJavaå½ä»¤č”åÆ仄ä½æēØ-Xmxå-Xmsę„ę§å¶å ē©ŗé“åå§é
ē½®ļ¼mxč”Øē¤ŗå ē©ŗé“ēę大大å°ļ¼msč”Øē¤ŗåå§å大å°ļ¼čæä¹ęÆäøęå°ēåÆåØJavaēé
ē½®ę件åÆ仄é
ē½®ēå
容ćå°½ē®”é»č¾å
åå åÆä»„ę ¹ę®å äøēåÆ¹č±”ę°éååØGCäøč±č“¹ēę¶é“å¢å ęč
åå°ļ¼ä½ęÆä½æēØę¬ęŗå
åē大å°ęÆäæęäøåēļ¼čäøē±-Xmsēå¼ęå®ļ¼å¤§éØåGCē®ę³é½ęÆä¾čµč¢«åé
ēčæē»å
ååēå ē©ŗé“ļ¼å ę¤äøč½åØå éč¦ę©å¤§ēę¶ååé
ę“å¤ēę¬ęŗå
åļ¼ęęēå å
ååæ
é”»äæēäøę„ļ¼čÆ·ę³ØęčæéčÆ“ēäøęÆJavaå å
åē©ŗé“ęÆę¬ęŗå
åć
ććę¬ęŗå
åäæēåę¬ęŗå
ååé
äøäøę ·ļ¼ę¬ęŗå
åč¢«äæēēę¶åļ¼ę ę³ä½æēØē©ēå
åęč
å
¶ä»ååØåØä½äøŗå¤ēØå
åļ¼å°½ē®”äæēå°åē©ŗé“åäøä¼čå°½ē©ēčµęŗļ¼ä½ęÆä¼é»ę¢å
åēØäŗå
¶ä»ēØéļ¼ē±äæēä»ęŖä½æēØčæēå
ååƼč“ēę³ę¼åę³ę¼åé
ēå
åé ęēé®é¢å
¶äø„éēØåŗ¦å·®äøå¤ļ¼ä½ä½æēØēå åŗåē¼©å°ę¶ļ¼äøäŗåå¾åę¶åØä¼åę¶å ē©ŗé“ēäøéØåå
容ļ¼ä»čåå°ē©ēå
åēä½æēØćåƹäŗē»“ę¤Javaå ēå
åē®”ēē³»ē»ļ¼éč¦ę“å¤ēę¬ęŗå
åę„ē»“ę¤å®ēē¶ęļ¼čæč”åå¾ę¶éēę¶åļ¼åæ
é”»åé
ę°ę®ē»ęę„č·čøŖē©ŗé²ååØē©ŗé“åčæåŗ¦č®°å½ļ¼čæäŗę°ę®ē»ęēē”®å大å°åę§č“Øå å®ē°ēäøåčęęå·®å¼ć
ćć2)JIT
ććJITē¼čÆåØåØčæč”ę¶ē¼čÆJavaåčē ę„ä¼åę¬ęŗåÆę§č”代ē ļ¼čæę ·ę大ęé«äŗJavačæč”ę¶ēéåŗ¦ļ¼å¹¶äøęÆęJavaåŗēØēØåŗäøę¬å°ä»£ē ēøå½ēéåŗ¦čæč”ćåčē ē¼čÆä½æēØę¬ęŗå
åļ¼čäøJITē¼čÆåØēč¾å
„ļ¼åčē ļ¼åč¾åŗļ¼åÆę§č”代ē ļ¼ä¹åæ
é”»ååØåØę¬ęŗå
åéé¢ļ¼å
å«äŗå¤äøŖē»čæJITē¼čÆēę¹ę³ēJavaēØåŗä¼ęÆäøäŗå°ååŗēØēØåŗä½æēØę“å¤ēę¬ęŗå
åć
ćć3)ē±»åē±»å č½½åØ
ććJava åŗēØēØåŗē±äøäŗē±»ē»ęļ¼čæäŗē±»å®ä¹åÆ¹č±”ē»ęåę¹ę³é»č¾ćJava åŗēØēØåŗä¹ä½æēØ Java čæč”ę¶ē±»åŗļ¼ęÆå¦Ā java.lang.Stringļ¼äøēē±»ļ¼ä¹åÆ仄ä½æēØē¬¬äøę¹åŗćčæäŗē±»éč¦ååØåØå
åäø仄å¤ä½æēØćååØē±»ēę¹å¼åå³äŗå
·ä½å®ē°ćSun JDK ä½æēØę°øä¹
ēęļ¼permanent generationļ¼PermGenļ¼å åŗåļ¼ä»ęåŗę¬ēå±é¢ę„ēļ¼ä½æēØę“å¤ēē±»å°éč¦ä½æēØę“å¤å
åćļ¼čæåÆč½ęå³ēęØēę¬ęŗå
åä½æēØéä¼å¢å ļ¼ęč
ęØåæ
é”»ęē”®å°éę°č®¾ē½® PermGen ęå
±äŗ«ē±»ē¼åēåŗåē大å°ļ¼ä»„č£
å
„ęęē±»ļ¼ćč®°ä½ļ¼äøä»
ęØēåŗēØēØåŗéč¦å č½½å°å
åäøļ¼ę”ę¶ćåŗēØęå”åØćē¬¬äøę¹åŗ仄åå
å«ē±»ē Java čæč”ę¶ä¹ä¼ęéå č½½å¹¶å ēØē©ŗé“ćJava čæč”ę¶åÆ仄åøč½½ē±»ę„åę¶ē©ŗé“ļ¼ä½ęÆåŖęåØéåøøäø„é
·ēę”件äøęä¼čæę ·åļ¼äøč½åøč½½åäøŖē±»ļ¼čęÆåøč½½ē±»å č½½åØļ¼éå
¶å č½½ēęęē±»é½ä¼č¢«åøč½½ćåŖęåØ仄äøę
åµäøęč½åøč½½ē±»å č½½åØ
- Java å äøå
å«åƹč”Øē¤ŗčÆ„ē±»å č½½åØē java.lang.ClassLoader åÆ¹č±”ēå¼ēØć
- Java å äøå
å«åƹč”Øē¤ŗē±»å č½½åØå č½½ēē±»ēä»»ä½ java.lang.Class åÆ¹č±”ēå¼ēØć
- åØ Java å äøļ¼čÆ„ē±»å č½½åØå č½½ēä»»ä½ē±»ēęęåÆ¹č±”é½äøååę“»ļ¼č¢«å¼ēØļ¼ć
ććéč¦ę³ØęēęÆļ¼Java čæč”ę¶äøŗęę Java åŗēØēØåŗåå»ŗē 3 äøŖé»č®¤ē±»å č½½åØļ¼Ā bootstrapćextensionĀ åĀ applicationĀ ļ¼é½äøåÆč½ę»”č¶³čæäŗę”件ļ¼å ę¤ļ¼ä»»ä½ē³»ē»ē±»ļ¼ęÆå¦ java.lang.Stringļ¼ęéčæåŗēØēØåŗē±»å č½½åØå č½½ēä»»ä½åŗēØēØåŗē±»é½äøč½åØčæč”ę¶éę¾ćå³ä½æē±»å č½½åØéåčæč”ę¶éļ¼čæč”ę¶ä¹åŖä¼å°ę¶éē±»å č½½åØä½äøŗ GC åØęēäøéØåćäøäŗå®ē°åŖä¼åØęäŗ GC åØęäøåøč½½ē±»å č½½åØļ¼ä¹åÆč½åØčæč”ę¶ēęē±»ļ¼čäøå»éę¾å®ćč®øå¤ Java EE åŗēØēØåŗä½æēØ JavaServer Pages (JSP) ęęÆę„ēę Web 锵é¢ćä½æēØ JSP ä¼äøŗę§č”ēęÆäøŖ .jsp 锵é¢ēęäøäøŖē±»ļ¼å¹¶äøčæäŗē±»ä¼åØå č½½å®ä»¬ēē±»å č½½åØēę“äøŖēåęäøäøē“ååØ āā čæäøŖēåęéåøøęÆ Web åŗēØēØåŗēēåęćå¦äøē§ēęē±»ēåøøč§ę¹ę³ęÆä½æēØ Java åå°ćåå°ēå·„ä½ę¹å¼å Java å®ē°ēäøåčäøåļ¼å½ä½æēØĀ java.lang.reflectĀ API ę¶ļ¼Java čæč”ę¶åæ
é”»å°äøäøŖåå°åÆ¹č±”ļ¼ęÆå¦ java.lang.reflect.Fieldļ¼ēę¹ę³čæę„å°č¢«åå°å°ēåÆ¹č±”ęē±»ćčæåÆ仄éčæä½æēØ Java ę¬ęŗę„å£ļ¼Java Native Interfaceļ¼JNIļ¼č®æé®åØę„å®ęļ¼čæē§ę¹ę³éč¦ēč®¾ē½®å¾å°ļ¼ä½ęÆéåŗ¦ē¼ę
¢ļ¼ä¹åÆ仄åØčæč”ę¶äøŗęØę³č¦åå°å°ēęÆē§åÆ¹č±”ē±»ååØęęå»ŗäøäøŖē±»ćåäøē§ę¹ę³åØč®¾ē½®äøę“ę
¢ļ¼ä½čæč”éåŗ¦ę“åæ«ļ¼éåøøéåäŗē»åøøåå°å°äøäøŖē¹å®ē±»ēåŗēØēØåŗćJava čæč”ę¶åØęåå ꬔåå°å°äøäøŖē±»ę¶ä½æēØ JNI ę¹ę³ļ¼ä½å½ä½æēØäŗč„å¹²ę¬”Ā JNI ę¹ę³ä¹åļ¼č®æé®åØä¼čØčäøŗåčē č®æé®åØļ¼čæę¶åå°ęå»ŗē±»å¹¶éčæę°ēē±»å č½½åØčæč”å č½½ćę§č”å¤ę¬”åå°åÆč½åƼč“åå»ŗäŗč®øå¤č®æé®åØē±»åē±»å č½½åØļ¼äæęåƹåå°åÆ¹č±”ēå¼ēØä¼åƼč“čæäŗē±»äøē“åę“»ļ¼å¹¶ē»§ē»å ēØē©ŗé“ļ¼å äøŗåå»ŗåčē č®æé®åØéåøøē¼ę
¢ļ¼ę仄 Java čæč”ę¶åÆ仄ē¼åčæäŗč®æé®åØ仄å¤ä»„åä½æēØļ¼äøäŗåŗēØēØåŗåę”ę¶čæä¼ē¼ååå°åÆ¹č±”ļ¼čæčæäøę„å¢å äŗå®ä»¬ēę¬ęŗå
åå ēØć
ćć4)JNI
ććJNIęÆęę¬ęŗ代ē č°ēØJavaę¹ę³ļ¼åä¹äŗ¦ē¶ļ¼Javačæč”ę¶ę¬čŗ«ę大ä¾čµäŗJNI代ē ę„å®ē°ē±»åŗåč½ļ¼ęÆå¦ę件åē½ē»I/Oļ¼JNIåŗēØēØåŗåÆ仄éčæäøē§ę¹å¼å¢å Javačæč”ę¶åƹę¬ęŗå
åēä½æēØļ¼
- JNIåŗēØēØåŗēę¬ęŗ代ē č¢«ē¼čÆå°å
±äŗ«åŗäøļ¼ęē¼čÆäøŗå č½½å°čæēØå°åē©ŗé“äøēåÆę§č”ę件ļ¼å¤§åę¬ęŗåŗēØēØåŗåÆč½ä»
ä»
å č½½å°±ä¼å ēØ大éčæēØå°åē©ŗé“
- ę¬ęŗ代ē åæ
é”»äøJavačæč”ę¶å
±äŗ«å°åē©ŗé“ļ¼ä»»ä½ę¬ęŗ代ē åé
ęę¬ęŗ代ē ę§č”ēå
åę å°é½ä¼čēØJavačæč”ę¶å
å
- ęäŗJNIå½ę°åÆč½åØå®ä»¬ēåøøč§ęä½äøä½æēØę¬ęŗå
åļ¼GetTypeArrayElementsåGetTypeArrayRegionå½ę°åÆ仄å°Javaå å¤å¶å°ę¬ęŗå
åē¼å²åŗäøļ¼ęä¾ē»ę¬å°ä»£ē ä½æēØļ¼ęÆå¦å¤å¶ę°ę®ä¾čµäŗčæč”ę¶å®ē°ļ¼éčæčæē§ę¹å¼č®æé®å¤§éJavaå ę°ę®å°±åÆč½ä½æēØ大éēę¬ęŗå
åå ē©ŗé“
ćć5)NIO
ććJDK 1.4å¼å§ę·»å äŗę°ēI/Oē±»ļ¼å¼å
„äŗäøē§åŗäŗééåē¼å²åŗę§č”I/Oēę°ę¹å¼ļ¼å°±åJavaå äøēå
åęÆęI/Oē¼å²åŗäøę ·ļ¼NIOę·»å äŗåƹē“ę„ByteBufferēęÆęļ¼ByteBufferåę¬ęŗå
åčäøęÆJavaå ēęÆęļ¼ē“ę„ByteBufferåÆ仄ē“ę„ä¼ éå°ę¬ęŗęä½ē³»ē»åŗå½ę°ļ¼ä»„ę§č”I/Oļ¼čæē§ę
åµč½ē¶ęé«äŗJavaēØåŗåØI/Oēę§č”ęēļ¼ä½ęÆä¼åƹę¬ęŗå
åčæč”ē“ę„ēå
åå¼éćByteBufferē“ę„ęä½åéē“ę„ęä½ēåŗå«å¦äøļ¼
ććåƹäŗåØä½å¤ååØē“ę„Ā ByteBufferĀ ę°ę®ļ¼å¾å®¹ęäŗ§ēę··ę·ćåŗēØēØåŗä»ē¶åØ Java å äøä½æēØäøäøŖåÆ¹č±”ę„ē¼ę I/O ęä½ļ¼ä½ęęčÆ„ę°ę®ēē¼å²åŗå°äæååØę¬ęŗå
åäøļ¼Java å åÆ¹č±”ä»
å
å«åƹę¬ęŗå ē¼å²åŗēå¼ēØćéē“ę„Ā ByteBufferĀ å°å
¶ę°ę®äæååØ Java å äøēĀ byte[]Ā ę°ē»äøćē“ę„ByteBufferåÆ¹č±”ä¼čŖåØęø
ēę¬ęŗē¼å²åŗļ¼ä½čæäøŖčæēØåŖč½ä½äøŗJavaå GCēäøéØåę§č”ļ¼å®äøä¼čŖåØå½±åę½å åØę¬ęŗäøēååćGCä»
åØJavaå č¢«å”«ę»”ļ¼ä»„č³äŗę ę³äøŗå åé
čÆ·ę±ęä¾ęå”ēę¶åļ¼ęč
åØJavaåŗēØēØåŗäøę¾ē¤ŗčÆ·ę±å®åēć
ćć6)ēŗæēØļ¼
ććåŗēØēØåŗäøēęÆäøŖēŗæēØé½éč¦å
åę„ååØåØå ę ļ¼ēØäŗåØč°ēØå½ę°ę¶ęęå±éØåé并ē»“ę¤ē¶ęēå
ååŗåļ¼ćęÆäøŖ Java ēŗæēØé½éč¦å ę ē©ŗé“ę„čæč”ćę ¹ę®å®ē°ēäøåļ¼Java ēŗæēØåÆ仄åäøŗę¬ęŗēŗæēØåĀ Java å ę ćé¤äŗå ę ē©ŗé“ļ¼ęÆäøŖēŗæēØčæéč¦äøŗēŗæēØę¬å°ååØļ¼thread-local storageļ¼åå
éØę°ę®ē»ęęä¾äøäŗę¬ęŗå
åćå°½ē®”ęÆäøŖēŗæēØä½æēØēå
åééåøøå°ļ¼ä½åƹäŗę„ęę°ē¾äøŖēŗæēØēåŗēØēØåŗę„čÆ“ļ¼ēŗæēØå ę ēę»å
åä½æēØéåÆč½éåøø大ćå¦ęčæč”ēåŗēØēØåŗēēŗæēØę°éęÆåÆēØäŗå¤ēå®ä»¬ēå¤ēåØę°éå¤ļ¼ęēéåøøå¾ä½ļ¼å¹¶äøåÆč½åƼč“ē³ē³ēę§č½åę“é«ēå
åå ēØć
ććii.ę¬ęŗå
åčå°½ļ¼
ććJavačæč”ę¶åäŗ仄äøåēę¹å¼ę„å¤ēJavaå ē©ŗé“ēčå°½åę¬ęŗå ē©ŗé“ēčå°½ļ¼ä½ęÆčæäø¤ē§ę
å½¢å
·ęē±»ä¼¼ēē¶ļ¼å½Javaå ē©ŗé“čå°½ēę¶åļ¼JavaåŗēØēØåŗå¾é¾ę£åøøčæč”ļ¼å äøŗJavaåŗēØēØåŗåæ
é”»éčæåé
åÆ¹č±”ę„å®ęå·„ä½ļ¼åŖč¦Javaå č¢«å”«ę»”ļ¼å°±ä¼åŗē°ē³ē³ēGCę§č½ļ¼å¹¶äøęåŗOutOfMemoryErrorćēøåļ¼äøę¦ Java čæč”ę¶å¼å§čæč”并äøåŗēØēØåŗå¤äŗēسå®ē¶ęļ¼å®åÆ仄åØę¬ęŗå å®å
Øčå°½ä¹åē»§ē»ę£åøøčæč”ļ¼äøäøå®ä¼åēå„ęŖēč”äøŗļ¼å äøŗéč¦åé
ę¬ęŗå
åēęä½ęÆéč¦åé
Java å ēęä½å°å¾å¤ćå°½ē®”éč¦ę¬ęŗå
åēęä½å JVM å®ē°äøåčå¼ļ¼ä½ä¹ęäøäŗęä½å¾åøøč§ļ¼åÆåØēŗæēØćå č½½ē±»ä»„åę§č”ęē§ē±»åēē½ē»åę件 I/Oćę¬ęŗå
åäøč¶³č”äøŗäø Java å å
åäøč¶³č”äøŗä¹äøå¤Ŗäøę ·ļ¼å äøŗę ę³åƹę¬ęŗå åé
čæč”ę§å¶ļ¼å°½ē®”ęę Java å åé
é½åØ Java å
åē®”ēē³»ē»ę§å¶ä¹äøļ¼ä½ä»»ä½ę¬ęŗ代ē ļ¼ę č®ŗå
¶ä½äŗ JVMćJava ē±»åŗčæęÆåŗēØēØåŗ代ē äøļ¼é½åÆč½ę§č”ę¬ęŗå
ååé
ļ¼čäøä¼å¤±č“„ćå°čÆčæč”åé
ē代ē ē¶åä¼å¤ēčæē§ę
åµļ¼ę č®ŗč®¾č®”äŗŗåēęå¾ęÆä»ä¹ļ¼å®åÆč½éčæ JNI ę„å£ęåŗäøäøŖĀ OutOfMemoryErrorļ¼åØå±å¹äøč¾åŗäøę”ę¶ęÆļ¼åēę ęē¤ŗå¤±č“„å¹¶åØēØååčÆäøꬔļ¼ęč
ę§č”å
¶ä»ęä½ć
ććiii.ä¾åļ¼
ććčæēÆęē« äøč“é½åØč®²ę¦åæµļ¼čæéę¢ē¶ęå°äŗByteBufferļ¼å
ęä¾äøäøŖē®åēä¾åę¼ē¤ŗčÆ„ē±»ēä½æēØļ¼
ććāā[$]ä½æēØNIOčÆ»åtxtę件āā
packageĀ org.susan.java.io;
Ā
importĀ java.io.FileInputStream;
importĀ java.io.IOException;
importĀ java.nio.ByteBuffer;
importĀ java.nio.channels.FileChannel;
Ā
public classĀ ExplicitChannelRead {
Ā Ā Ā public static voidĀ main(StringĀ args[]){
Ā Ā Ā Ā Ā Ā FileInputStream fileInputStream;
Ā Ā Ā Ā Ā Ā FileChannel fileChannel;
Ā Ā Ā Ā Ā Ā longĀ fileSize;
Ā Ā Ā Ā Ā Ā ByteBuffer byteBuffer;
Ā Ā Ā Ā Ā Ā try{
Ā Ā Ā Ā Ā Ā Ā Ā Ā fileInputStream = new FileInputStream("D://read.txt");
Ā Ā Ā Ā Ā Ā Ā Ā Ā fileChannel = fileInputStream.getChannel();
Ā Ā Ā Ā Ā Ā Ā Ā Ā fileSize = fileChannel.size();
Ā Ā Ā Ā Ā Ā Ā Ā Ā byteBuffer = ByteBuffer.allocate((int)fileSize);
Ā Ā Ā Ā Ā Ā Ā Ā Ā fileChannel.read(byteBuffer);
Ā Ā Ā Ā Ā Ā Ā Ā Ā byteBuffer.rewind();
Ā Ā Ā Ā Ā Ā Ā Ā Ā for(Ā intĀ i = 0; i < fileSize; i++ )
Ā Ā Ā Ā Ā Ā Ā Ā Ā Ā Ā Ā System.out.print((char)byteBuffer.get());
Ā Ā Ā Ā Ā Ā Ā Ā Ā fileChannel.close();
Ā Ā Ā Ā Ā Ā Ā Ā Ā fileInputStream.close();
Ā Ā Ā Ā Ā Ā }catch(IOException ex){
Ā Ā Ā Ā Ā Ā Ā Ā Ā ex.printStackTrace();
Ā Ā Ā Ā Ā Ā }
Ā Ā Ā }
}
ććåØčÆ»åę件ēč·Æå¾ę¾äøčÆ„txtę件éé¢åå
„ļ¼Hello Worldļ¼äøč¾¹čæę®µä»£ē å°±ęÆä½æēØNIOēę¹å¼čÆ»åę件ē³»ē»äøēę件ļ¼čæꮵēØåŗēč¾å
„å°±äøŗļ¼
Hello World
ććāā[$]č·åByteBufferäøēåčč½¬ę¢äøŗByteę°ē»āā
packageĀ org.susan.java.io;
Ā
importĀ java.nio.ByteBuffer;
Ā
public classĀ ByteBufferToByteArray {
Ā Ā Ā public static voidĀ main(String args[])Ā throwsĀ Exception{
Ā Ā Ā Ā Ā Ā // ä»byteę°ē»åå»ŗByteBuffer
Ā Ā Ā Ā Ā Ā byte[] bytes =Ā new byte[10];
Ā Ā Ā Ā Ā Ā ByteBuffer buffer = ByteBuffer.wrap(bytes);
Ā
Ā Ā Ā Ā Ā Ā // åØpositionålimitļ¼ä¹å°±ęÆByteBufferē¼å²åŗēé¦å°¾ä¹é“čÆ»ååč
Ā Ā Ā Ā Ā Ā bytes =Ā newĀ byte[buffer.remaining()];
Ā Ā Ā Ā Ā Ā buffer.get(bytes,Ā 0, bytes.length);
Ā
Ā Ā Ā Ā Ā Ā // čÆ»åęęByteBufferå
ēåč
Ā Ā Ā Ā Ā Ā buffer.clear();
Ā Ā Ā Ā Ā Ā bytes =Ā newĀ byte[buffer.capacity()];
Ā Ā Ā Ā Ā Ā buffer.get(bytes,Ā 0, bytes.length);
Ā Ā Ā }
}
ććäøč¾¹ä»£ē å°±ęÆä»ByteBufferå°byteę°ē»ēč½¬ę¢čæēØļ¼ęäŗčæäøŖčæēØåØå¼åčæēØäøåÆč½ę“å ę¹ä¾æļ¼ByteBufferēčƦē»č®²č§£ęäæēå°IOéØåļ¼čæéä»
ä»
ęÆę¶åå°äŗäøäŗļ¼ę仄ęä¾äø¤ę®µå®ä¾ä»£ē ć
ććiv.å
±äŗ«å
åļ¼
ććåØJavačÆčØéé¢ļ¼ę²”ęå
±äŗ«å
åēę¦åæµļ¼ä½ęÆåØęäŗå¼ēØäøļ¼å
±äŗ«å
åå“å¾åēØļ¼ä¾å¦JavačÆčØēååøå¼ē³»ē»ļ¼åē大éēJavaååøå¼å
±äŗ«åÆ¹č±”ļ¼å¾å¤ę¶åéč¦ę„čÆ¢čæäŗåÆ¹č±”ēē¶ęļ¼ä»„ę„ēē³»ē»ęÆå¦čæč”ę£åøøęč
äŗč§£čæäŗåÆ¹č±”ē®åēäøäŗē»č®”ę°ę®åē¶ęćå¦ęä½æēØēęÆē½ē»éäæ”ēę¹å¼ļ¼ę¾ē¶ä¼å¢å åŗēØēé¢å¤å¼éļ¼ä¹å¢å äŗäøåæ
č¦ēåŗēØē¼ēØļ¼å¦ęęÆå
±äŗ«å
åę¹å¼ļ¼ååÆ仄ē“ę„éčæå
±äŗ«å
åę„ēå°ęéč¦ēåÆ¹č±”ēę°ę®åē»č®”ę°ę®ļ¼ä»čåå°äøäŗäøåæ
č¦ēéŗ»ē¦ć
ćć1)å
±äŗ«å
åē¹ē¹ļ¼
- åÆä»„č¢«å¤äøŖčæēØęå¼č®æé®
- čÆ»åęä½ēčæēØåØę§č”čÆ»åęä½ēę¶åå
¶ä»čæēØäøč½čæč”åęä½
- å¤äøŖčæēØåÆ仄äŗ¤ęæåƹęäøäøŖå
±äŗ«å
åę§č”åęä½
- äøäøŖčæēØę§č”äŗå
ååęä½čæåļ¼äøå½±åå
¶ä»čæēØåƹčÆ„å
åēč®æé®ļ¼åę¶å
¶ä»čæēØåƹę“ę°åēå
åå
·ęåÆč§ę§
- åØčæēØę§č”åęä½ę¶å¦ęå¼åøøéåŗļ¼åƹå
¶ä»čæēØēåęä½ē¦ę¢čŖåØč§£é¤
- ēøåƹå
±äŗ«ę件ļ¼ę°ę®č®æé®ēę¹ä¾æę§åęēćć
ćć2)åŗē°ę
åµļ¼
- ē¬å ēåęä½ļ¼ēøåŗęē¬å ēåęä½ēå¾
éåćē¬å ēåęä½ę¬čŗ«äøä¼åēę°ę®ēäøč“ę§é®é¢ļ¼
- å
±äŗ«ēåęä½ļ¼ēøåŗęå
±äŗ«ēåęä½ēå¾
éåćå
±äŗ«ēåęä½åč¦ę³Øęé²ę¢åēę°ę®ēäøč“ę§é®é¢ļ¼
- ē¬å ēčÆ»ęä½ļ¼ēøåŗęå
±äŗ«ēčÆ»ęä½ēå¾
éåļ¼
- å
±äŗ«ēčÆ»ęä½ļ¼ēøåŗęå
±äŗ«ēčÆ»ęä½ēå¾
éåļ¼
ćć3)Javaäøå
±äŗ«å
åēå®ē°ļ¼
ććJDKĀ 1.4éé¢ēMappedByteBufferäøŗå¼åäŗŗååØJavaäøå®ē°å
±äŗ«å
åęä¾äŗčÆ儽ēę¹ę³ļ¼čÆ„ē¼å²åŗå®é
äøęÆäøäøŖē£ēę件ēå
åę č±”ļ¼äŗč
ēååä¼äæęåę„ļ¼å³å
åę°ę®åēååčæåä¼ē«å³ååŗå°ē£ēę件äøļ¼čæę ·ä¼ęęå°äæčÆå
±äŗ«å
åēå®ē°ļ¼å°å
±äŗ«ę件åē£ēę件ē®åčē³»ēęÆę件ééē±»ļ¼FileChannelļ¼čÆ„ē±»ēå å
„ęÆJDKäøŗäŗē»äøå¤å“č®¾å¤ēč®æé®ę¹ę³ļ¼å¹¶äøå å¼ŗäŗå¤ēŗæēØåƹåäøę件čæč”ååēå®å
Øę§ļ¼čæéåÆ仄ä½æēØå®ę„å»ŗē«å
±äŗ«å
åēØļ¼å®å»ŗē«äŗå
±äŗ«å
ååē£ēę件ä¹é“ēäøäøŖééćęå¼äøäøŖę件åÆä½æēØRandomAccessFileē±»ēgetChannelę¹ę³ļ¼čÆ„ę¹ę³ē“ę„čæåäøäøŖę件ééļ¼čÆ„ę件ééē±äŗåƹåŗēęä»¶č®¾äøŗéęŗååļ¼äøę¹é¢åÆ仄čæč”čÆ»åäø¤ē§ęä½ļ¼å¦å¤äøäøŖę¹é¢ä½æēØå®äøä¼ē “åę č±”ę件ēå
容ćčæéļ¼å¦ęä½æēØFileOutputStreamåFileInputStreamåäøč½ēę³å°å®ē°å
±äŗ«å
åēč¦ę±ļ¼å äøŗčæäø¤äøŖē±»åę¶å®ē°čŖē±čÆ»åå¾å°é¾ć
ććäøč¾¹ä»£ē ꮵå®ē°äŗäøč¾¹ęåēå
±äŗ«å
ååč½
// č·å¾äøäøŖåŖčÆ»ēéęŗååę件åÆ¹č±”
RandomAccessFile RAFile =Ā newĀ RandomAccessFile(filename,"r");
// č·å¾ēøåŗēę件éé
FileChannel fc = RAFile.getChannel();
// åå¾ę件ēå®é
大å°
intĀ size = (int)fc.size();
// č·å¾å
±äŗ«å
åē¼å²åŗļ¼čÆ„å
±äŗ«å
ååŖčÆ»Ā
MappedByteBuffer mapBuf = fc.map(FileChannel.MAP_RO,0,size);
// č·å¾äøäøŖåÆčÆ»åēéęŗååę件åÆ¹č±”Ā
RAFile = new RandomAccessFile(filename,"rw");
// č·å¾ēøåŗēę件ééĀ
fc = RAFile.getChannel();
// åå¾ę件ēå®é
大å°ļ¼ä»„ä¾æę åå°å
±äŗ«å
åĀ
size = (int)fc.size();
// č·å¾å
±äŗ«å
åē¼å²åŗļ¼čÆ„å
±äŗ«å
ååÆčÆ»åĀ
mapBuf = fc.map(FileChannel.MAP_RW,0,size);
// č·å夓éØę¶ęÆļ¼ååęéĀ
mode = mapBuf.getInt();Ā
ććå¦ęå¤äøŖåŗēØę č±”ä½æēØåäøę件åēå
±äŗ«å
åļ¼åęå³ēčæå¤äøŖåŗēØå
±äŗ«äŗåäøå
åę°ę®ļ¼čæäŗåŗēØåƹäŗę件åÆ仄å
·ęåēååęéļ¼äøäøŖåŗēØåƹę°ę®ēå·ę°ä¼ę“ę°å°å¤äøŖåŗēØäøćäøŗäŗé²ę¢å¤äøŖåŗēØåę¶åƹå
±äŗ«å
åčæč”åęä½ļ¼åÆ仄åØčÆ„å
±äŗ«å
åē夓éØäæ”ęÆå å
„åęä½ę č®°ļ¼čÆ„å
±äŗ«ę件ē夓éØåŗę¬äæ”ęÆč³å°ęļ¼
- å
±äŗ«å
åéæåŗ¦
- å
±äŗ«å
åē®åēååęØ”å¼
ććå
±äŗ«ę件ē夓éØäæ”ęÆęÆē§ęäæ”ęÆļ¼å¤äøŖåŗēØåÆ仄åƹåäøäøŖå
±äŗ«å
åę§č”åęä½ļ¼ę§č”åęä½åē»ęåęä½ēę¶åļ¼åÆ仄ä½æēØå¦äøę¹ę³ļ¼
public booleanĀ startWrite()
{
Ā Ā Ā if(mode ==Ā 0)Ā // čæémode代č”Øå
±äŗ«å
åēååęØ”å¼ļ¼äøŗ0代č”ØåÆå
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā mode = 1;Ā // ęå³ēå«ēåŗēØäøåÆå
Ā Ā Ā Ā Ā Ā mapBuf.flip();
Ā Ā Ā Ā Ā Ā mapBuf.putInt(mode);Ā Ā Ā //åå
„å
±äŗ«å
åē夓éØäæ”ęÆ
Ā Ā Ā Ā Ā Ā return true;
Ā Ā Ā }
Ā Ā Ā else{
Ā Ā Ā Ā Ā Ā return false;Ā //č”Øęå·²ē»ęåŗēØåØåčÆ„å
±äŗ«å
åäŗļ¼ę¬åŗēØäøč½å¤éåƹå
±äŗ«å
ååååęä½
Ā Ā Ā }
}
Ā
public booleanĀ stopWrite()
{
Ā Ā Ā mode =Ā 0;Ā // éę¾åęé
Ā Ā Ā mapBuf.flip();
Ā Ā Ā mapBuf.putInt(mode);Ā Ā Ā //åå
„å
±äŗ«å
å夓éØäæ”ęÆ
Ā Ā Ā Ā return true;
}
ććć*ļ¼äøč¾¹ęä¾äŗåƹå
±äŗ«å
åę§č”åęä½čæēØēäø¤äøŖę¹ę³ļ¼čæäø¤äøŖę¹ę³å
¶å®ēč§£čµ·ę„å¾ē®åļ¼ēę£éč¦ęčēęÆäøäøŖéåƹååęØ”å¼ēč®¾ē½®ļ¼å
¶å®čæē§ęŗå¶åęåé¢ęå°ēå
åēéęØ”å¼ęē¹ē±»ä¼¼ļ¼äøę¦å½modeļ¼ååęØ”å¼ļ¼č®¾ē½®ē§°äøŗåÆåēę¶åļ¼startWriteęč½čæåtrueļ¼äøä»
ä»
å¦ę¤ļ¼ęäøŖåŗēØēØåŗåØåå
±äŗ«å
ååå
„ę°ę®ēę¶åčæä¼äæ®ę¹å
¶ååęØ”å¼ļ¼å äøŗå¦ęäøäæ®ę¹ēčÆå°±ä¼åƼč“å
¶ä»åŗēØåę ·éåƹčÆ„å
åęÆåÆåēļ¼čæę ·å°±ä½æå¾å
±äŗ«å
åēå®ē°åå¾ę··ä¹±ļ¼čåØåę¢åęä½stopWriteēę¶åļ¼éč¦å°modeč®¾ē½®ē§°äøŗ1ļ¼ä¹å°±ęÆäøč¾¹ę³Øéꮵęå°ēéę¾åęéćć
ććå
³äŗéēē„čÆčæéē®ååäøŖ蔄å
ć*ļ¼äøč¾¹ä»£ē ēčæē§ęØ”å¼åÆ仄ēč§£äøŗäøē§ē®åēéęØ”å¼ćļ¼äøč¬ę
åµäøļ¼č®”ē®ęŗē¼ēØäøä¼ē»åøøéå°éęØ”å¼ļ¼åØę“äøŖéęØ”å¼čæēØäøåÆ仄å°éåäøŗäø¤ē±»ļ¼čæéåŖęÆč¾
å©ēč§£ļ¼äøęÆäø„ę ¼ēéåē±»ļ¼āāå
±äŗ«éåęä»éļ¼ä¹ē§°äøŗē¬å éļ¼ļ¼éēå®ä½ęÆå®ä½äŗéåƹęęäøč®”ē®ęŗęå
³ēčµęŗęÆå¦å
åćę件ćååØē©ŗé“ēļ¼éåƹčæäŗčµęŗé½åÆč½åŗē°éęØ”å¼ćåØäøč¾¹å åę äøčč®²å°äŗJavaåÆ¹č±”éļ¼å
¶å®äøä»
ä»
ęÆåÆ¹č±”ļ¼åŖč¦ęÆč®”ē®ęŗäøä¼åŗē°åå
„åčÆ»åå
±åęä½ēčµęŗļ¼é½ęåÆč½åŗē°éęØ”å¼ć
ććå
±äŗ«éāāå½åŗēØēØåŗč·å¾äŗčµęŗēå
±äŗ«éēę¶åļ¼é£ä¹åŗēØēØåŗå°±åÆ仄ē“ę„č®æé®čÆ„čµęŗļ¼čµęŗēå
±äŗ«éåÆä»„č¢«å¤äøŖåŗēØēØåŗęæå°ļ¼åØJavaéé¢ēŗæēØä¹é“ęę¶åä¹ååØåÆ¹č±”ēå
±äŗ«éļ¼ä½ęÆęäøäøŖå¾ęę¾ēē¹å¾ļ¼ä¹å°±ęÆå
åå
±äŗ«éåŖč½čÆ»åę°ę®ļ¼äøč½å¤åå
„ę°ę®ļ¼äøč®ŗęÆä»ä¹čµęŗļ¼å½åŗēØēØåŗä»
ä»
åŖč½ęæå°čÆ„čµęŗēå
±äŗ«éēę¶åļ¼ęÆäøč½å¤éåƹčÆ„čµęŗčæč”åęä½ēć
ććē¬å éāāå½åŗēØēØåŗč·å¾äŗčµęŗēē¬å éēę¶åļ¼åŗēØēØåŗč®æé®čÆ„čµęŗåØå
±äŗ«éäøč¾¹å¤äŗäøäøŖęéå°±ęÆåęéļ¼éåƹčµęŗę¬čŗ«ččØļ¼äøäøŖčµęŗåŖęäøęē¬å éļ¼ä¹å°±ęÆčÆ“äøäøŖčµęŗåŖč½åę¶č¢«äøäøŖåŗēØęč
äøäøŖę§č”代ē ēØåŗå
č®øåęä½ļ¼JavaēŗæēØäøēåÆ¹č±”åęä½ä¹ęÆčæäøŖéēļ¼č„ęäøŖåŗēØęæå°äŗē¬å éēę¶åļ¼äøä»
ä»
åÆ仄čÆ»åčµęŗéé¢ēę°ę®ļ¼čäøåÆ仄åčÆ„čµęŗčæč”ę°ę®åęä½ć
ććę°ę®äøč“ę§āāå½čµęŗåę¶č¢«åŗēØčæč”čÆ»åč®æé®ēę¶åļ¼ęåÆč½ä¼åŗē°ę°ę®äøč“ę§é®é¢ļ¼ęÆå¦AåŗēØęæå°äŗčµęŗR1ēē¬å éļ¼BåŗēØęæå°äŗčµęŗR1ēå
±äŗ«éļ¼AåØéåƹR1čæč”åęä½ļ¼čäø¤äøŖåŗēØēęä½āāAēåęä½åBēčÆ»ęä½åŗē°äŗäøäøŖę¶é“å·®ļ¼s1ēę¶åBčÆ»åäŗR1ēčµęŗļ¼s2ēę¶åAåå
„äŗę°ę®äæ®ę¹äŗR1ēčµęŗļ¼s3ēę¶åBåčæč”äŗē¬¬äŗꬔčÆ»ļ¼čäø¤ę¬”čÆ»åēøéę¶é“ęÆč¾ēęčäøåč”·ę²”ęččå°AåØBēčÆ»åčæēØäæ®ę¹äŗčµęŗļ¼čæē§ę
åµäøéåƹéęØ”å¼å°±éč¦ččå°ę°ę®äøč“ę§é®é¢ćē¬å éēęä»ę§åØčæéēęęęÆčÆ„éåŖč½č¢«äøäøŖåŗēØč·åļ¼č·åčæēØåŖč½ē±čæäøŖåŗēØåå
„ę°ę®å°čµęŗå
éØļ¼é¤éå®éę¾čÆ„éļ¼å¦åå
¶ä»ęæäøå°éēåŗēØęÆę ę³åƹčµęŗčæč”åå
„ęä½ēć
ććęē
§äøč¾¹ēęč·Æå»ēč§£ä»£ē éé¢å®ē°å
±äŗ«å
åēčæēØå°±ę“å 容ęēč§£äŗć
ććå¦ęę§č”åęä½ēåŗēØå¼åøøäøę¢ļ¼é£ä¹ę åę件ēå
±äŗ«å
åå°äøåč½ę§č”åęä½ćäøŗäŗåØåŗēØå¼åøøäøę¢åļ¼åęä½ē¦ę¢ę åæčŖåØę¶é¤ļ¼åæ
锻让čæč”ēåŗēØč·ē„éåŗēåŗēØćåØå¤ēŗæēØåŗēØäøļ¼åÆ仄ēØåę„ę¹ę³č·å¾čæę ·ēęęļ¼ä½ęÆåØå¤čæēØäøļ¼åę„ęÆäøčµ·ä½ēØēćę¹ę³åÆ仄éēØēå¤ē§ęå·§ļ¼čæéåŖęÆęčæ°äøåÆč½ēå®ē°ļ¼éēØę件éēę¹å¼ćåå
±äŗ«å
ååŗēØåØč·å¾åƹäøäøŖå
±äŗ«å
ååęéēę¶åļ¼é¤äŗå¤ę夓éØäæ”ęÆēåęéę åæå¤ļ¼čæč¦å¤ęäøäøŖäø“ę¶ēéę件ęÆå¦åÆ仄å¾å°ļ¼å¦ęåÆ仄å¾å°ļ¼åå³ä½æ夓éØäæ”ęÆēåęéę åæäøŗ1ļ¼äøčæ°ļ¼ļ¼ä¹åÆ仄åÆåØåęéļ¼å
¶å®čæå·²ē»č”Øęåęéč·å¾ēåŗēØå·²ē»å¼åøøéåŗļ¼čæę®µä»£ē å¦äøļ¼
// ęå¼äøäøŖäø“ę¶ę件ļ¼ę³Øęē»äøå
±äŗ«å
åļ¼čÆ„ę件ååæ
é”»ēøåļ¼åÆ仄åØå
±äŗ«ę件ååč¾¹ę·»å ā.lockāåē¼
RandomAccessFile files =Ā newĀ RandomAccessFile("memory.lock","rw");
// č·åę件éé
FileChannel lockFileChannel = files.getChannel();
// č·åę件ēē¬å éļ¼čÆ„ę¹ę³äøäŗ§ēä»»ä½é»å”ē“ę„čæå
FileLock fileLock = lockFileChannel.tryLock();
// å¦ęäøŗē©ŗč”Øē¤ŗå·²ē»ęåŗēØå ęäŗ
if( fileLock ==Ā nullĀ ){
Ā Ā Ā // ...äøåÆå
}else{
Ā Ā Ā // ...åÆ仄ę§č”åęä½
}
ćć4)å
±äŗ«å
åēåŗēØļ¼
ććåØJavaäøļ¼å
±äŗ«å
åäøč¬ęäø¤ē§åŗēØļ¼
ćć[1]ę°øä¹
åÆ¹č±”é
ē½®āāåØjavaęå”åØåŗēØäøļ¼ēØę·åÆč½ä¼åØčæč”čæēØäøé
ē½®äøäŗåę°ļ¼ččæäŗåę°éč¦ę°øä¹
ęęļ¼å½ęå”åØåŗēØéę°åÆåØåļ¼čæäŗé
ē½®åę°ä»ē¶åÆ仄åƹåŗēØčµ·ä½ēØćčæå°±åÆ仄ēØå°čÆ„ę äøēå
±äŗ«å
åćčÆ„å
±äŗ«å
åäøäæåäŗęå”åØēčæč”åę°åäøäŗåÆ¹č±”čæč”ē¹ę§ćåÆ仄åØåŗēØåÆåØę¶čÆ»å
„仄åÆēØ仄åé
ē½®ēåę°ć
ćć[2]ę„čÆ¢å
±äŗ«ę°ę®āāäøäøŖåŗēØļ¼ä¾ sys.javaļ¼ęÆē³»ē»ēęå”čæēØļ¼å
¶ē³»ē»ēčæč”ē¶ęč®°å½åØå
±äŗ«å
åäøļ¼å
¶äøčæč”ē¶ęåÆč½ęÆäøęååēćäøŗäŗéę¶äŗč§£ē³»ē»ēčæč”ē¶ęļ¼åÆåØå¦äøäøŖåŗēØļ¼ä¾ mon.javaļ¼ļ¼čÆ„åŗēØę„čÆ¢čÆ„å
±äŗ«å
åļ¼ę±ę„ē³»ē»ēčæč”ē¶ęć
ććv.å°čļ¼
ććęä¾ę¬ęŗå
å仄åå
±äŗ«å
åēē„čÆļ¼äø»č¦ęÆäøŗäŗ让čÆ»č
č½å¤ę“é”ŗå©å°ēč§£JVMå
éØå
åęØ”åēē©ēåēļ¼å
ę¬JVMå¦ä½åęä½ē³»ē»åØå
åčæäøŖēŗ§å«čæč”äŗ¤äŗļ¼ēč§£äŗčæäŗå
å®¹å°±č®©čÆ»č
åƹJavaå
åęØ”åē认čÆä¼ę“å ę·±å
„ļ¼čäøäø容ęéåæćå
¶å®Javaēå
åęØ”åčæäøåę们ę³č±”äøé£ä¹ē®åļ¼čäøå
¶ē»ęęē«Æå¤ęļ¼ēčæćInside JVMćēęååŗčÆ„å°±ē„éļ¼ē»åJVMę令éå»åē¹å°ä»£ē ęµčÆ.classę件ēéå±ē»ęä¹äø失äøŗäøē§å„½ē©ēå¦ä¹ ę¹ę³ć
ćć
4.é²ę¢å
åę³ę¼
ććJavaäøä¼ęå
åę³ę¼ļ¼å¬čµ·ę„ä¼¼ä¹ęÆå¾äøę£åøøēļ¼å äøŗJavaęä¾äŗåå¾åę¶åØéåƹå
åčæč”čŖåØåę¶ļ¼ä½ęÆJavačæęÆä¼åŗē°å
åę³ę¼ēć
ćći.ä»ä¹ęÆJavaäøēå
åę³ę¼ļ¼
ććåØJavačÆčØäøļ¼å
åę³ę¼å°±ęÆååØäøäŗč¢«åé
ēåÆ¹č±”ļ¼čæäŗåÆ¹č±”ęäø¤äøŖē¹ē¹ļ¼čæäŗåÆ¹č±”åÆč¾¾ļ¼å³åØåÆ¹č±”å
åēęåå¾äøååØéč·ÆåÆ仄äøå
¶ēøčæļ¼å
¶ę¬”ļ¼čæäŗåÆ¹č±”ęÆę ēØēļ¼å³ēØåŗ仄åäøä¼åä½æēØčæäŗåÆ¹č±”äŗćå¦ęåÆ¹č±”ę»”č¶³čæäø¤äøŖę”件ļ¼čÆ„åÆ¹č±”å°±åÆ仄å¤å®äøŗJavaäøēå
åę³ę¼ļ¼čæäŗåÆ¹č±”äøä¼č¢«GCåę¶ļ¼ē¶čå®å“å ēØå
åļ¼čæå°±ęÆJavačÆčØäøēå
åę³ę¼ćJavaäøēå
åę³ę¼åC++äøēå
åę³ę¼čæååØäøå®ēåŗå«ļ¼åØC++éé¢ļ¼å
åę³ę¼ēčå“ę“大äøäŗļ¼ęäŗåÆ¹č±”č¢«åé
äŗå
åē©ŗé“ļ¼ä½ęÆå“äøåÆč¾¾ļ¼ē±äŗC++äøę²”ęGCļ¼čæäŗå
åå°ä¼ę°øčæę¶äøåę„ļ¼åØJavaäøčæäŗäøåÆč¾¾åÆ¹č±”åęÆč¢«GCč“č“£åę¶ēļ¼å ę¤ēØåŗåäøéč¦čččæäøéØåēå
åę³ę¼ćäŗč
ēå¾å¦äøļ¼
ććå ę¤ęē
§äøč¾¹ēåęļ¼JavačÆčØäøä¹ęÆ
ååØå
åę³ę¼ēļ¼ä½ęÆå
¶å
åę³ę¼čå“ęÆC++č¦å°å¾å¤ļ¼å äøŗJavaéé¢ęäøŖē¹ę®ēØåŗåę¶ęęēäøåÆč¾¾åÆ¹č±”ļ¼
åå¾åę¶åØćåƹäŗēØåŗåę„čÆ“ļ¼GCåŗę¬ęÆéęēļ¼äøåÆč§ēćč½ē¶ļ¼ę们åŖęå äøŖå½ę°åÆ仄č®æé®GCļ¼ä¾å¦čæč”GCēå½ę°System.gc()ļ¼ä½ęÆę ¹ę®JavačÆčØč§čå®ä¹ļ¼čÆ„å½ę°
äøäæčÆJVMēåå¾ę¶éåØäøå®ä¼ę§č”ćå äøŗļ¼äøåēJVMå®ē°č
åÆč½ä½æēØäøåēē®ę³ē®”ēGCćéåøøļ¼GCēēŗæēØēä¼å
ēŗ§å«č¾ä½ļ¼JVMč°ēØGCēēē„ä¹ęå¾å¤ē§ļ¼ęēęÆå
åä½æēØå°č¾¾äøå®ēØåŗ¦ę¶ļ¼GCęå¼å§å·„ä½ļ¼ä¹ę
å®ę¶ę§č”ēļ¼ęēęÆ
å¹³ē¼ę§č”GCļ¼ęēęÆ
äøęå¼ę§č”GCćä½éåøøę„čÆ“ļ¼ę们äøéč¦å
³åæčæäŗćé¤éåØäøäŗē¹å®ēåŗåļ¼GCēę§č”å½±ååŗēØēØåŗēę§č½ļ¼ä¾å¦åƹäŗåŗäŗWebēå®ę¶ē³»ē»ļ¼å¦ē½ē»ęøøęēļ¼ēØę·äøåøęGCēŖē¶äøęåŗēØēØåŗę§č”ččæč”åå¾åę¶ļ¼é£ä¹ę们éč¦č°ę“GCēåę°ļ¼č®©GCč½å¤éčæå¹³ē¼ēę¹å¼éę¾å
åļ¼ä¾å¦å°åå¾åę¶åč§£äøŗäøē³»åēå°ę„éŖ¤ę§č”ļ¼Sunęä¾ēHotSpot JVMå°±ęÆęčæäøē¹ę§ć
ććäø¾äøŖä¾åļ¼
ććāā[$]å
åę³ę¼ēä¾åāā
packageĀ org.susan.java.collection;
Ā
importĀ java.util.Vector;
Ā
public classĀ VectorMemoryLeak {
Ā Ā Ā public static voidĀ main(StringĀ args[]){
Ā Ā Ā Ā Ā Ā Vector<String> vector = new Vector<String>();
Ā Ā Ā Ā Ā Ā for(Ā intĀ i = 0; i < 1000; i++ ){
Ā Ā Ā Ā Ā Ā Ā Ā Ā StringĀ tempString =Ā newĀ String();
Ā Ā Ā Ā Ā Ā Ā Ā Ā vector.add(tempString);
Ā Ā Ā Ā Ā Ā Ā Ā Ā tempString =Ā null;
Ā Ā Ā Ā Ā Ā }
Ā Ā Ā }
}
ććä»äøč¾¹čæäøŖä¾ååÆ仄ēå°ļ¼å¾ŖēÆē³čÆ·äŗStringåÆ¹č±”ļ¼å¹¶äøå°ē³čÆ·ēåÆ¹č±”ę¾å
„äŗäøäøŖVectoräøļ¼å¦ęä»
ä»
ęÆéę¾åÆ¹č±”ę¬čŗ«ļ¼å äøŗVectorä»ē¶å¼ēØäŗčÆ„åÆ¹č±”ļ¼ę仄čæäøŖåÆ¹č±”åƹCGę„čÆ“ęÆäøåÆåę¶ēļ¼å ę¤å¦ęåÆ¹č±”å å
„å°Vectoråļ¼čæåæ
é”»ä»Vectorå é¤ęč½å¤åę¶ļ¼ęē®åēę¹å¼ęÆå°Vectorå¼ēØč®¾ē½®ęnullćå®é
äøčæäŗåÆ¹č±”å·²ē»ę²”ęēØäŗļ¼ä½ęÆčæęÆč¢«ä»£ē éé¢ēå¼ēØå¼ēØå°äŗļ¼čæē§ę
åµGCęæå®å°±ę²”ęäŗä»»ä½åę³ļ¼čæę ·å°±åÆ仄åƼč“äŗå
åę³ę¼ć
ććć*ļ¼JavačÆčØå äøŗęä¾äŗåå¾åę¶åØļ¼ē
§ēčÆ“ęÆäøä¼åŗē°å
åę³ę¼ēļ¼Javaéé¢åƼč“å
åę³ę¼ēäø»č¦åå å°±ęÆļ¼å
åē³čÆ·äŗå
åē©ŗé“čåæč®°äŗéę¾ćå¦ęēØåŗäøååØåƹę ēØåÆ¹č±”ēå¼ēØļ¼čæäŗåÆ¹č±”å°±ä¼é©»ēåØå
åäøę¶čå
åļ¼å äøŗę ę³č®©GCå¤ęčæäŗåÆ¹č±”ęÆå¦åÆč¾¾ćå¦ęååØåÆ¹č±”ēå¼ēØļ¼čæäøŖåÆ¹č±”å°±č¢«å®ä¹äøŗāęęēę“»åØē¶ęāļ¼åę¶äøä¼č¢«éę¾ļ¼č¦ē”®å®åÆ¹č±”ęå å
åč¢«åę¶ļ¼åæ
é”»č¦ē”®č®¤čÆ„åÆ¹č±”äøåč¢«ä½æēØćå
øåēåę³å°±ęÆęåÆ¹č±”ę°ę®ęåč®¾ē½®ęäøŗnullęč
äøéåäøē§»é¤ļ¼å½å±éØåéäøéč¦ēę
åµåäøéč¦ę¾ē¤ŗ声ęäøŗnullćć
ććii.åøøč§ēJavaå
åę³ę¼
ćć1)å
Øå±éåļ¼
ććåØ大ååŗēØēØåŗäøååØåē§åę ·ēå
Øå±ę°ę®ä»åŗęÆå¾ę®éēļ¼ęÆå¦äøäøŖJNDIę ęč
äøäøŖSession tableļ¼ä¼čÆč”Øļ¼ļ¼åØčæäŗę
åµäøļ¼åæ
é”»ę³Øęē®”ēååØåŗē大å°ļ¼åæ
é”»ęęē§ęŗå¶ä»ååØåŗäøē§»é¤äøåéč¦ēę°ę®ć
ćć[$]č§£å³ļ¼
ćć[1]åøøēØēč§£å³ę¹ę³ęÆåØęčæä½ęø
é¤ä½äøļ¼čÆ„ä½äøä¼éŖčÆä»åŗäøēę°ę®ē¶åęø
ę„äøåäøéč¦ēę°ę®
ćć[2]å¦å¤äøē§ę¹å¼ęÆååé¾ę„č®”ę°ļ¼éåč“č“£ē»č®”éåäøęÆäøŖå
„å£ēååé¾ę„ę°ę®ļ¼čæč¦ę±ååé¾ę„åčÆéååéä¼éåŗå
„å£ļ¼å½ååé¾ę„ę°ē®äøŗé¶ēę¶åļ¼čÆ„å
ē“ å°±åÆ仄ē§»é¤äŗć
ćć2)ē¼åļ¼
ććē¼åäøē§ēØę„åæ«éę„ę¾å·²ē»ę§č”čæēęä½ē»ęēę°ę®ē»ęćå ę¤ļ¼å¦ęäøäøŖęä½ę§č”éč¦ęÆč¾å¤ēčµęŗ并ä¼å¤ę¬”č¢«ä½æēØļ¼éåøøåę³ęÆęåøøēØēč¾å
„ę°ę®ēęä½ē»ęčæč”ē¼åļ¼ä»„ä¾æåØäøꬔč°ēØčÆ„ęä½ę¶ä½æēØē¼åēę°ę®ćē¼åéåøøé½ęÆ仄åØęę¹å¼å®ē°ē,å¦ęē¼åč®¾ē½®äøę£ē”®č大éä½æēØē¼åēčÆåä¼åŗē°å
åęŗ¢åŗēåęļ¼å ę¤éč¦å°ęä½æēØēå
å容éäøę£ē“¢ę°ę®ēéåŗ¦å ä»„å¹³č””ć
ćć[$]č§£å³ļ¼
ćć[1]åøøēØēč§£å³éå¾ęÆä½æēØjava.lang.ref.SoftReferenceē±»åęå°åÆ¹č±”ę¾å
„ē¼åļ¼čæäøŖę¹ę³åÆ仄äæčÆå½čęęŗēØå®å
åęč
éč¦ę“å¤å ēę¶åļ¼åÆ仄éę¾čæäŗåÆ¹č±”ēå¼ēØć
ćć3)ē±»å č½½åØļ¼
ććJavaē±»č£
č½½åØēä½æēØäøŗå
åę³ę¼ęä¾äŗč®øå¤åÆä¹ä¹ęŗćäøč¬ę„čÆ“ē±»č£
č½½åØé½å
·ęå¤ęē»ęļ¼å äøŗē±»č£
č½½åØäøä»
ä»
ęÆåŖäø"åøøč§"åÆ¹č±”å¼ēØęå
³ļ¼åę¶ä¹ååÆ¹č±”å
éØēå¼ēØęå
³ćęÆå¦ę°ę®åéļ¼ę¹ę³ååē§ē±»ćčæęå³ēåŖč¦ååØåƹę°ę®åéļ¼ę¹ę³ļ¼åē§ē±»ååÆ¹č±”ēē±»č£
č½½åØļ¼é£ä¹ē±»č£
č½½åØå°é©»ēåØJVMäøćę¢ē¶ē±»č£
č½½åØåÆ仄åå¾å¤ēē±»å
³čļ¼åę¶ä¹åÆ仄åéęę°ę®åéå
³čļ¼é£ä¹ēøå½å¤ēå
åå°±åÆč½åēę³ę¼ć
ććiii.Javaå¼ēØćęå½čŖåč¾¹ēćJavaå¼ēØę»ē»ććļ¼
ććJavaäøēåÆ¹č±”å¼ēØäø»č¦ę仄äøå ē§ē±»åļ¼
ćć1)å¼ŗåÆååÆ¹č±”ļ¼strongly reachableļ¼ļ¼
ććåÆ仄éčæå¼ŗå¼ēØč®æé®ēåÆ¹č±”ļ¼äøč¬ę„čÆ“ļ¼ę们平ę¶å代ē ēę¹å¼é½ęÆä½æēØēå¼ŗå¼ēØåÆ¹č±”ļ¼ęÆå¦äøč¾¹ē代ē ꮵļ¼
ććStringBuilder builder=Ā newĀ StringBuilder()ļ¼
ććäøč¾¹ä»£ē éØåå¼ēØobjčæäøŖå¼ēØå°å¼ēØå
åå äøēäøäøŖåÆ¹č±”ļ¼čæē§ę
åµäøļ¼åŖč¦objēå¼ēØååØļ¼åå¾åę¶åØå°±ę°øčæäøä¼éę¾čÆ„åÆ¹č±”ēååØē©ŗé“ćčæē§åÆ¹č±”ę们åęäøŗå¼ŗå¼ēØļ¼Strong referencesļ¼ļ¼čæē§å¼ŗå¼ēØę¹å¼å°±ęÆJavačÆčØēåēēJavaå¼ēØļ¼ę们å ä¹ęÆ天ē¼ēØēę¶åé½ēØå°ćäøč¾¹ä»£ē JVMååØäŗäøäøŖStringBuilderē±»åēåÆ¹č±”ēå¼ŗå¼ēØåØåébuilderå¢ćå¼ŗå¼ēØåGCēäŗ¤äŗęÆčæę ·ēļ¼å¦ęäøäøŖåÆ¹č±”éčæå¼ŗå¼ēØåÆč¾¾ęč
éčæå¼ŗå¼ēØé¾åÆč¾¾ēčÆčæē§åÆ¹č±”å°±ęäøŗå¼ŗåÆååÆ¹č±”ļ¼čæē§ę
åµäøēåÆ¹č±”åå¾åę¶åØäøäŗēē¬ćå¦ęę们å¼åčæēØäøéč¦åå¾ååØåę¶čÆ„åÆ¹č±”ļ¼å°±ē“ę„å°čÆ„åÆ¹č±”čµäøŗå¼ŗå¼ēØļ¼ä¹ęÆę®éēē¼ēØę¹ę³ć
ćć2)č½ÆåÆååÆ¹č±”ļ¼softly reachableļ¼ļ¼
ććäøéčæå¼ŗå¼ēØč®æé®ēåÆ¹č±”ļ¼å³äøęÆå¼ŗåÆååÆ¹č±”ļ¼ä½ęÆåÆ仄éčæč½Æå¼ēØč®æé®ēåÆ¹č±”å°±ęäøŗč½ÆåÆååÆ¹č±”ļ¼č½ÆåÆååÆ¹č±”å°±éč¦ä½æēØē±»SoftReferenceļ¼java.lang.ref.SoftReferenceļ¼ćę¤ē§ē±»åēå¼ēØäø»č¦ēØäŗå
åęÆč¾ęęēé«éē¼åļ¼čäøę¤ē§å¼ēØčæęÆå
·ęč¾å¼ŗēå¼ēØåč½ļ¼å½å
åäøå¤ēę¶åGCä¼åę¶čæē±»å
åļ¼å ę¤å¦ęå
åå
č¶³ēę¶åļ¼čæē§å¼ēØéåøøäøä¼č¢«åę¶ēćäøä»
ä»
å¦ę¤ļ¼čæē§å¼ēØåÆ¹č±”åØJVMéé¢äæčÆåØęåŗOutOfMemoryå¼åøøä¹åļ¼č®¾ē½®ęäøŗnullćéäæå°č®²ļ¼čæē§ē±»åēå¼ēØäæčÆåØJVMå
åäøč¶³ēę¶åå
ØéØč¢«ęø
é¤ļ¼ä½ęÆęäøŖå
³é®åØäŗļ¼åå¾ę¶éåØåØčæč”ę¶ęÆå¦éę¾č½ÆåÆååÆ¹č±”ęÆäøē”®å®ēļ¼čäøä½æēØåå¾åę¶ē®ę³å¹¶äøč½äæčÆäøꬔę§åÆ»ę¾å°ęęēč½ÆåÆååÆ¹č±”ćå½åå¾åę¶åØęÆꬔčæč”ēę¶åé½åÆ仄éęéę¾äøęÆå¼ŗåÆååÆ¹č±”å ēØēå
åļ¼å¦ęåå¾åę¶åØę¾å°äŗč½ÆåÆååÆ¹č±”čæåļ¼åÆč½ä¼čæč”仄äøęä½ļ¼
- å°SoftReferenceåÆ¹č±”ēreferentåč®¾ē½®ęäøŗnullļ¼ä»čä½æčÆ„åÆ¹č±”äøåå¼ēØheapåÆ¹č±”ć
- SoftReferenceå¼ēØčæēå
åå äøēåÆ¹č±”äøå¾č¢«ēå½äøŗfinalizableć
- å½å
åå äøēåÆ¹č±”finalize()ę¹ę³č¢«čæč”čäøčÆ„åÆ¹č±”å ēØēå
åč¢«éę¾ļ¼SoftReferenceåÆ¹č±”å°±ä¼č¢«ę·»å å°å®ēReferenceQueueļ¼åęę”件ęÆReferenceQueueę¬čŗ«ęÆååØēć
ććę¢ē¶Javaéé¢ååØčæę ·ēåÆ¹č±”ļ¼é£ä¹ę们åØē¼å代ē ēę¶åå¦ä½åå»ŗčæę ·ēåÆ¹č±”å¢ļ¼åå»ŗę„éŖ¤å¦äøļ¼
ććå
åå»ŗäøäøŖåÆ¹č±”ļ¼å¹¶ä½æēØę®éå¼ēØę¹å¼ćå¼ŗå¼ēØćļ¼ē¶åååå»ŗäøäøŖSoftReferenceę„å¼ēØčÆ„åÆ¹č±”ļ¼ęåå°ę®éå¼ēØč®¾ē½®äøŗnullļ¼éčæčæę ·ēę¹å¼ļ¼čæäøŖåÆ¹č±”å°±ä»
ä»
äæēäŗäøäøŖSoftReferenceå¼ēØļ¼åę¶čæē§ę
åµę们ęåå»ŗēåÆ¹č±”å°±ęÆSoftReferenceåÆ¹č±”ćäøč¬ę
åµäøļ¼ę们åÆ仄ä½æēØčÆ„å¼ēØę„å®ęCacheåč½ļ¼å°±ęÆåč¾¹čÆ“ēēØäŗé«éē¼åļ¼äæčÆę大éåŗ¦ä½æēØå
åčäøä¼å¼čµ·å
åę³ę¼ēę
åµćäøč¾¹ē代ē ꮵļ¼
ććpublic static voidĀ main(StringĀ args[])
ćć{
ćććć//åå»ŗäøäøŖå¼ŗåÆååÆ¹č±”
ććććA a =Ā newĀ A();
ćććć//åå»ŗčæäøŖåÆ¹č±”ēč½Æå¼ēØSoftReference
ććććSoftReference sr =Ā newĀ SoftReference(a);
ćććć//å°å¼ŗå¼ēØč®¾ē½®äøŗē©ŗļ¼ä»„éåå¾åę¶åØåę¶å¼ŗå¼ēØ
ćććća =Ā null;
ćććć//äøꬔä½æēØčÆ„åÆ¹č±”ēęä½
ććććif( sr !=Ā nullĀ ){
ćććććća = (A)sr.get();
ćććć}else{
ćććććć//čæē§ę
åµå°±ęÆē±äŗå
åčæä½ļ¼å·²ē»å°č½Æå¼ēØéę¾äŗļ¼å ę¤éč¦éę°č£
č½½äøꬔ
ćććććća =Ā newĀ A();
ććććććsr =Ā newĀ SoftReference(a);
ćććć}
ćć}
ććč½Æå¼ēØęęÆä½æå¾Javaē³»ē»åÆ仄ę“儽å°ē®”ēå
åļ¼äæęē³»ē»ēسå®ļ¼é²ę¢å
åę³ę¼ļ¼éæå
ē³»ē»å“©ęŗļ¼å ę¤åØå¤ēäøäŗå
åå ēØ大čäøēå½åØęéæä½æēØäøé¢ē¹ēåÆ¹č±”åÆ仄ä½æēØčÆ„ęęÆć
ćć3)å¼±åÆååÆ¹č±”ļ¼weakly reachableļ¼ļ¼
ććäøęÆå¼ŗåÆååÆ¹č±”åę ·ä¹äøęÆč½ÆåÆååÆ¹č±”ļ¼ä»
ä»
éčæå¼±å¼ēØWeakReferenceļ¼java.lang.ref.WeakReferenceļ¼č®æé®ēåÆ¹č±”ļ¼čæē§åÆ¹č±”ēēØéåØäŗč§čåę å°ļ¼canonicalized mappingļ¼ļ¼åƹäŗēååØęēøåƹęÆč¾éæčäøéę°åå»ŗēę¶åå¼éå°ēåÆ¹č±”ļ¼å¼±å¼ēØä¹ęÆč¾ęēØļ¼åč½Æå¼ēØåÆ¹č±”äøåēęÆļ¼åå¾åę¶åØå¦ęē¢°å°äŗå¼±åÆååÆ¹č±”ļ¼å°éę¾WeakReferenceåÆ¹č±”ēå
åļ¼ä½ęÆåå¾åę¶åØéč¦čæč”å¾å¤ę¬”ęč½å¤ę¾å°å¼±åÆååÆ¹č±”ćå¼±å¼ēØåÆ¹č±”åØä½æēØēę¶åļ¼åÆ仄é
åReferenceQueueē±»ä½æēØļ¼å¦ęå¼±å¼ēØč¢«åę¶ļ¼JVMå°±ä¼ęčæäøŖå¼±å¼ēØå å
„å°ēøå
³ēå¼ēØéåäøå»ćęē®åēå¼±å¼ēØę¹ę³å¦ä»„äø代ē ļ¼
ććWeakReference weakWidget =Ā newĀ WeakReference(classA);
ććåØäøč¾¹ä»£ē éé¢ļ¼å½ę们ä½æēØweakWidget.get()ę„č·åclassAēę¶åļ¼ē±äŗå¼±å¼ēØę¬čŗ«ęÆę ę³é»ę¢åå¾åę¶ēļ¼ę仄ę们ä¹č®øä¼ęæå°äøäøŖnulläøŗčæåćć*ļ¼čæéęä¾äøäøŖå°ęå·§ļ¼å¦ęę们åøęåå¾ęäøŖåÆ¹č±”ēäæ”ęÆļ¼ä½ęÆåäøå½±åčÆ„åÆ¹č±”ēåå¾åę¶čæēØļ¼ę们就åÆ仄ä½æēØWeakReferenceę„č®°ä½čÆ„åÆ¹č±”ļ¼äøč¬ę们åØå¼åč°čÆåØåä¼ååØēę¶åä½æēØčæäøŖęÆå¾å„½ēäøäøŖęꮵćć
ććå¦ęäøč¾¹ē代ē éØåļ¼ę们éčæweakWidget.get()čæåēęÆnullå°±čÆęčÆ„åÆ¹č±”å·²ē»č¢«åå¾åę¶åØåę¶äŗļ¼ččæē§ę
åµäøå¼±å¼ēØåÆ¹č±”å°±å¤±å»äŗä½æēØä»·å¼ļ¼GCå°±ä¼å®ä¹äøŗéč¦čæč”ęø
é¤å·„ä½ćčæē§ę
åµäøå¼±å¼ēØę ę³å¼ēØä»»ä½åÆ¹č±”ļ¼ę仄åØJVMéé¢å°±ęäøŗäŗäøäøŖę»å¼ēØļ¼čæå°±ęÆäøŗä»ä¹ę们ęę¶åéč¦éčæReferenceQueueē±»ę„é
åä½æēØēåå ļ¼ä½æēØäŗReferenceQueuečæåļ¼å°±ä½æå¾ę们ę“å 容ęēč§čÆ„å¼ēØēåÆ¹č±”ļ¼å¦ęę们éčæäøReferenceQueueē±»ę„ęé äøäøŖå¼±å¼ēØļ¼å½å¼±å¼ēØēåÆ¹č±”å·²ē»č¢«åę¶ēę¶åļ¼ē³»ē»å°čŖåØä½æēØåÆ¹č±”å¼ēØéåę„代ęæåÆ¹č±”å¼ēØļ¼čäøę们åÆ仄éčæReferenceQueueē±»ēčæč”ę„å³å®ęÆå¦ēę£č¦ä»åå¾åę¶åØéé¢å°čÆ„ę»å¼ēØļ¼Dead Referenceļ¼ęø
é¤ć
ććå¼±å¼ēØ代ē ꮵļ¼
ćć//åå»ŗę®éå¼ēØåÆ¹č±”
ććMyObject object =Ā newĀ MyObject();
ćć//åå»ŗäøäøŖå¼ēØéå
ććReferenceQueue rq =Ā newĀ ReferenceQueue();
ćć//ä½æēØå¼ēØéååå»ŗMyObjectēå¼±å¼ēØ
ććWeakReference wr =Ā newĀ WeakReference(object,rq);
ććčæéęä¾äø¤äøŖå®åØēåŗęÆę„ęčæ°å¼±å¼ēØēēøå
³ēØę³ļ¼
ćć[1]ä½ ę³ē»åÆ¹č±”éå äøäŗäæ”ęÆļ¼äŗęÆä½ ēØäøäøŖ Hashtable ęåÆ¹č±”åéå äæ”ęÆå
³ččµ·ę„ćä½ äøåēęåÆ¹č±”åéå äæ”ęÆę¾å
„ Hashtable äøļ¼ä½ęÆå½åÆ¹č±”ēØå®ēę¶åļ¼ä½ äøå¾äøęåÆ¹č±”åä» Hashtable äøē§»é¤ļ¼å¦åå®å ēØēå
ååäøä¼éę¾ćäøäøä½ åæč®°äŗļ¼é£ä¹ę²”ęä» Hashtable äøē§»é¤ēåÆ¹č±”ä¹åÆ仄ē®ä½ęÆå
åę³ę¼ćēę³ēē¶åµåŗčÆ„ęÆå½åÆ¹č±”ēØå®ę¶ļ¼Hashtable äøēåÆ¹č±”ä¼čŖåØč¢«åå¾ę¶éåØåę¶ļ¼äøē¶ä½ å°±ęÆåØååå¾åę¶ēå·„ä½ć
ćć[2]ä½ ę³å®ē°äøäøŖå¾ēē¼åļ¼å äøŗå č½½å¾ēēå¼éęÆč¾å¤§ćä½ å°å¾ēåÆ¹č±”ēå¼ēØę¾å
„čæäøŖē¼åļ¼ä»„ä¾æ仄åč½å¤éę°ä½æēØčæäøŖåÆ¹č±”ćä½ęÆä½ åæ
é”»å³å®ē¼åäøēåŖäŗå¾ēäøåéč¦äŗļ¼ä»čå°å¼ēØä»ē¼åäøē§»é¤ćäøē®”ä½ ä½æēØä»ä¹ē®”ēē¼åēē®ę³ļ¼ä½ å®é
äøé½åØå¤ēåå¾ę¶éēå·„ä½ļ¼ę“ē®åēåę³ļ¼é¤éä½ ęē¹ę®ēéę±ļ¼čæä¹åŗčÆ„ęÆę儽ēåę³ļ¼ęÆ让åå¾ę¶éåØę„å¤ēļ¼ē±å®ę„å³å®åę¶åŖäøŖåÆ¹č±”ćĀ
ććå½Javaåę¶åØéå°äŗå¼±å¼ēØēę¶åęåÆč½ä¼ę§č”仄äøęä½ļ¼
- å°WeakReferenceåÆ¹č±”ēreferentåč®¾ē½®ęäøŗnullļ¼ä»čä½æčÆ„åÆ¹č±”äøåå¼ēØheapåÆ¹č±”ć
- WeakReferenceå¼ēØčæēå
åå äøēåÆ¹č±”äøå¾č¢«ēå½äøŗfinalizableć
- å½å
åå äøēåÆ¹č±”finalize()ę¹ę³č¢«čæč”čäøčÆ„åÆ¹č±”å ēØēå
åč¢«éę¾ļ¼WeakReferenceåÆ¹č±”å°±ä¼č¢«ę·»å å°å®ēReferenceQueueļ¼åęę”件ęÆReferenceQueueę¬čŗ«ęÆååØēć
ćć4)ęø
é¤ļ¼
ććå½å¼ēØåÆ¹č±”ēreferentåč®¾ē½®äøŗnullļ¼å¹¶äøå¼ēØē±»åØå
åå äøå¼ēØēåÆ¹č±”å£°ęäøŗåÆē»ęēę¶åļ¼čÆ„åÆ¹č±”å°±åÆ仄ęø
é¤ļ¼ęø
é¤äøåčæå¤ēč®²čæ°
ćć5)čåÆååÆ¹č±”ļ¼phantomly reachableļ¼ļ¼
ććäøęÆå¼ŗåÆååÆ¹č±”ļ¼ä¹äøęÆč½ÆåÆååÆ¹č±”ļ¼åę ·äøęÆå¼±åÆååÆ¹č±”ļ¼ä¹ę仄ęčåÆååÆ¹č±”ę¾å°ęåę„č®²ļ¼äø»č¦ä¹ęÆå äøŗå®ēē¹ę®ę§ļ¼ęę¶åę们åē§°ä¹äøŗāå¹½ēµåÆ¹č±”āļ¼å·²ē»ē»ęēļ¼åÆ仄éčæčå¼ēØę„č®æé®čÆ„åÆ¹č±”ćę们ä½æēØē±»PhantomReferenceļ¼java.lang.ref.PhantomReferenceļ¼ę„č®æé®ļ¼čæäøŖē±»åŖč½ēØäŗč·čøŖč¢«å¼ēØåÆ¹č±”čæč”ēę¶éļ¼åę ·ēļ¼åÆ仄ēØäŗę§č”per-morternęø
é¤ęä½ćPhantomReferenceåæ
é”»äøReferenceQueueē±»äøčµ·ä½æēØćéč¦ä½æēØReferenceQueueęÆå äøŗå®č½å¤å
å½éē„ęŗå¶ļ¼å½åå¾ę¶éåØē”®å®äŗęäøŖåÆ¹č±”ęÆčåÆååÆ¹č±”ēę¶åļ¼PhantomReferenceåÆ¹č±”å°±č¢«ę¾åØäŗå®ēReferenceQueueäøļ¼čæå°±ęÆäøäøŖéē„ļ¼č”ØęPhantomReferenceå¼ēØēåÆ¹č±”å·²ē»ē»ęļ¼åÆ仄ę¶éäŗļ¼äøč¬ę
åµäøę们å儽åØåÆ¹č±”å
ååØåę¶ä¹åéåčÆ„č”äøŗćčæē§å¼ēØäøåäŗå¼±å¼ēØåč½Æå¼ēØļ¼čæē§ę¹å¼éčæget()č·åå°ēåÆ¹č±”ę»ęÆčæånullļ¼ä»
ä»
å½čæäŗåÆ¹č±”åØReferenceQueueéåéé¢ēę¶åļ¼ę们åÆ仄ē„éå®ęå¼ēØēåŖäŗåƹåÆ¹č±”ęÆę»å¼ēØļ¼Dead Referenceļ¼ćččæē§å¼ēØåå¼±å¼ēØēåŗå«åØäŗļ¼
ććå¼±å¼ēØļ¼WeakReferenceļ¼ęÆåØåÆ¹č±”äøåÆč¾¾ēę¶åå°½åæ«čæå
„ReferenceQueueéåēļ¼åØfinalizationę¹ę³ę§č”ååå¾åę¶ä¹åęÆē”®å®ä¼åēēļ¼ēč®ŗäøčæē±»åÆ¹č±”ęÆäøę£ē”®ēåÆ¹č±”ļ¼ä½ęÆWeakReferenceåÆ¹č±”åÆ仄ē»§ē»äæęDeadē¶ęļ¼
ććčå¼ēØļ¼PhantomReferenceļ¼ęÆåØåÆ¹č±”ē”®å®å·²ē»ä»ē©ēå
åäøē§»é¤čæåęčæå
„ēReferenceQueueéåļ¼čäøget()ę¹ę³ä¼äøē“čæånull
ććå½åå¾åę¶åØéå°äŗčå¼ēØēę¶åå°ęåÆč½ę§č”仄äøęä½ļ¼
- PhantomReferenceå¼ēØčæēheapåÆ¹č±”å£°ęäøŗfinalizableļ¼
- čå¼ēØåØå åÆ¹č±”éę¾ä¹åå°±ę·»å å°äŗå®ēReferenceQueueéé¢ļ¼čæē§ę
åµä½æå¾ę们åÆ仄åØå åÆ¹č±”č¢«åę¶ä¹åéåęä½ć*ļ¼åꬔęéļ¼PhantomReferenceåÆ¹č±”åæ
é”»ē»čæå
³čēReferenceQueueę„åå»ŗļ¼å°±ęÆčÆ“åæ
é”»åReferenceQueueē±»é
åęä½ć
ććēä¼¼ę²”ęēØå¤ēčå¼ēØļ¼ęä»ä¹ēØéå¢ļ¼
- é¦å
ļ¼ę们åÆ仄éčæčå¼ēØē„éåÆ¹č±”ē©¶ē«ä»ä¹ę¶åēę£ä»å
åéé¢ē§»é¤ēļ¼čäøčæä¹ęÆåÆäøēéå¾ć
- čå¼ēØéæčæäŗfinalize()ę¹ę³ļ¼å äøŗåƹäŗę¤ę¹ę³ēę§č”ččØļ¼čå¼ēØēę£å¼ēØå°ēåÆ¹č±”ęÆå¼åøøåÆ¹č±”ļ¼č„åØčÆ„ę¹ę³å
č¦ä½æēØåÆ¹č±”åŖč½éå»ŗćäøč¬ę
åµåå¾åę¶åØä¼č½®čÆ¢äø¤ę¬”ļ¼äøꬔę č®°äøŗfinalizationļ¼ē¬¬äŗꬔčæč”ēå®ēåę¶ļ¼čå¾å¾ę č®°å·„ä½äøč½å®ę¶čæč”ļ¼ęč
åå¾åę¶å
¶ä¼ēå¾
äøäøŖåÆ¹č±”å»ę č®°finalizationćčæē§ę
åµå¾ęåÆč½å¼čµ·MemoryOutļ¼čä½æēØčå¼ēØčæē§ę
åµå°±ä¼å®å
Øéæå
ćå äøŗčå¼ēØåØå¼ēØåÆ¹č±”ēčæēØäøä¼å»ä½æå¾čæäøŖåÆ¹č±”ē±Deadå¤ę“»ļ¼čäøčæē§åÆ¹č±”ęÆåÆ仄åØåę¶åØęčæč”åę¶ēć
ććåØJVMå
éØļ¼čå¼ēØęÆčµ·ä½æēØfinalize()ę¹ę³ę“å å®å
Øäøē¹čäøę“å ęęćčfinaliaze()ę¹ę³åę¶åØčęęŗéé¢å®ē°čµ·ę„ēøåƹē®åļ¼čäøä¹åÆ仄å¤ē大éØåå·„ä½ļ¼ę仄ę们ä»ē¶ä½æēØčæē§ę¹å¼ę„čæč”åÆ¹č±”åę¶ēę«å°¾ęä½ļ¼ä½ęÆęäŗčå¼ēØčæåę们åÆ仄éę©ęÆå¦ęåØęä½čÆ„åÆ¹č±”ä½æå¾ēØåŗę“å é«ęå®ē¾ć
ććiv.é²ę¢å
åę³ę¼[ę„čŖIBMå¼åäøåæ]ļ¼
ćć1)ä½æēØč½Æå¼ēØé»ę¢ę³ę¼ļ¼
ćć[1]åØJavačÆčØäøęäøē§å½¢å¼ēå
åę³ę¼ē§°äøŗåÆ¹č±”ęøøē¦»ļ¼Object Loiteringļ¼ļ¼
ććāā[$]åÆ¹č±”ęøøē¦»āā
// ę³Øęļ¼čæę®µä»£ē å±äŗę¦åæµčÆ“ę代ē ļ¼å®é
åŗēØäøäøč¦ęØ”ä»æ
public classĀ LeakyChecksum{
Ā Ā Ā private byte[] byteArray;
Ā Ā Ā Ā public synchronized intĀ getFileCheckSum(StringĀ filename)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā intĀ len = getFileSize(filename);
Ā Ā Ā Ā Ā Ā if( byteArray ==Ā nullĀ || byteArray.length < len )
Ā Ā Ā Ā Ā Ā Ā Ā Ā byteArray =Ā newĀ byte[len];
Ā Ā Ā Ā Ā Ā readFileContents(filename,byteArray);
Ā Ā Ā Ā Ā Ā // č®”ē®čÆ„ę件ēå¼ē¶åčæåčÆ„åÆ¹č±”
Ā Ā Ā }
}
ććäøč¾¹ē代ē ęÆē±»LeakyChecksumēØę„čÆ“ęåÆ¹č±”ęøøē¦»ēę¦åæµļ¼éé¢ęäøäøŖgetFileChecksum()ę¹ę³ēØę„č®”ē®ę件å
å®¹ę ”éŖåļ¼getFileCheckSumę¹ę³å°ę件å
容čÆ»åå°ē¼å²åŗäøč®”ē®ę ”éŖåļ¼ę“å ē“č§ēå®ē°å°±ęÆē®åå°å°ē¼å²åŗä½äøŗgetFileChecksumäøēę¬å°åéåé
ļ¼ä½ęÆäøč¾¹čæäøŖēę¬ęÆčæē§ēę¬ę“å āčŖęāļ¼äøęÆå°ē¼å²åŗē¼å²åØå®ä¾äøåꮵäøåå°å
åchurnćčÆ„āä¼åāéåøøäøåø¦ę„é¢ęē儽å¤ļ¼åÆ¹č±”åé
ęÆå¾å¤äŗŗęęēę“å ä¾æå®ćļ¼čæč¦ę³Øęļ¼å°ē¼å²åŗä»ę¬å°åéęåå°å®ä¾åéļ¼ä½æå¾ē±»č„äøåø¦ęéå ēåę„ļ¼å°±äøåęÆēŗæēØå®å
Øēäŗćē“č§ēå®ē°äøéč¦å° getFileChecksum() 声ęäøŗ synchronizedļ¼å¹¶äøä¼åØåę¶č°ēØę¶ęä¾ę“儽ēåÆä¼øē¼©ę§ćļ¼
ććčæäøŖē±»ååØå¾å¤ēé®é¢ļ¼ä½ęÆę们ēéę„ēå
åę³ę¼ćē¼åē¼å²åŗēå³å®å¾åÆč½ęÆę ¹ę®čæę ·ēåč®¾å¾åŗēļ¼å³čÆ„ē±»å°åØäøäøŖēØåŗäøč¢«č°ēØč®øå¤ę¬”ļ¼å ę¤å®åŗčÆ„ę“å ęęļ¼ä»„éēØē¼å²åŗčäøęÆéę°åé
å®ćä½ęÆē»ęęÆļ¼ē¼å²åŗę°øčæäøä¼č¢«éę¾ļ¼å äøŗå®åƹēØåŗę„čÆ“ę»ęÆåÆåēļ¼é¤éLeakyChecksumåÆ¹č±”č¢«åå¾ę¶éäŗļ¼ćę“åēęÆļ¼å®åÆ仄å¢éæļ¼å“äøåÆ仄ē¼©å°ļ¼ę仄 LeakyChecksum å°ę°øä¹
äæęäøäøŖäøęå¤ēēę大ę件äøę ·å¤§å°ēē¼å²åŗćéäøäøę„čÆ“ļ¼čæä¹ä¼ē»åå¾ę¶éåØåø¦ę„ååļ¼å¹¶äøč¦ę±ę“é¢ē¹ēę¶éļ¼äøŗč®”ē®ęŖę„ēę ”éŖåčäæęäøäøŖ大åē¼å²åŗ并äøęÆåÆēØå
åēęęęå©ēØćLeakyChecksum äøé®é¢ēåå ęÆļ¼ē¼å²åŗåƹäŗ getFileChecksum() ęä½ę„čÆ“é»č¾äøęÆę¬å°ēļ¼ä½ęÆå®ēēå½åØęå·²ē»č¢«äŗŗäøŗ延éæäŗļ¼å äøŗå°å®ęåå°äŗå®ä¾åꮵćå ę¤ļ¼čÆ„ē±»åæ
é”»čŖå·±ē®”ēē¼å²åŗēēå½åØęļ¼čäøęÆ让 JVM ę„ē®”ēć
ććčæéåÆ仄ęä¾äøē§ēē„å°±ęÆä½æēØJavaéé¢ēč½Æå¼ēØļ¼
ććå¼±å¼ēØå¦ä½åÆ仄ē»åŗēØēØåŗęä¾å½åÆ¹č±”č¢«ēØåŗä½æēØę¶å¦äøē§å°č¾¾čÆ„åÆ¹č±”ēę¹ę³ļ¼ä½ęÆäøä¼å»¶éæåÆ¹č±”ēēå½åØęćReferenceĀ ēå¦äøäøŖåē±»āāč½Æå¼ēØāāåÆę»”č¶³äøäøŖäøåå“ēøå
³ēē®ēćå
¶äøå¼±å¼ēØå
č®øåŗēØēØåŗåå»ŗäøå¦Øē¢åå¾ę¶éēå¼ēØļ¼č½Æå¼ēØå
č®øåŗēØēØåŗéčæå°äøäŗåÆ¹č±”ęå®äøŗ āexpendableā čå©ēØåå¾ę¶éåØēåø®å©ćå°½ē®”åå¾ę¶éåØåØę¾åŗåŖäŗå
ååØē±åŗēØēØåŗä½æēØåŖäŗę²”åØä½æēØę¹é¢åå¾å¾å„½ļ¼ä½ęÆē”®å®åÆēØå
åēęéå½ä½æēØčæęÆåå³äŗåŗēØēØåŗćå¦ęåŗēØēØåŗååŗäŗäø儽ēå³å®ļ¼ä½æå¾åÆ¹č±”č¢«äæęļ¼é£ä¹ę§č½ä¼åå°å½±åļ¼å äøŗåå¾ę¶éåØåæ
é”»ę“å č¾å¤å°å·„ä½ļ¼ä»„é²ę¢åŗēØēØåŗę¶čęęęå
åćé«éē¼åęÆäøē§åøøč§ēę§č½ä¼åļ¼å
č®øåŗēØēØåŗéēØ仄åēč®”ē®ē»ęļ¼čäøęÆéę°čæč”č®”ē®ćé«éē¼åęÆ CPU å©ēØåå
åä½æēØä¹é“ēäøē§ęč”·ļ¼čæē§ęč”·ēę³ēå¹³č””ē¶ęåå³äŗęå¤å°å
ååÆēØćč„é«éē¼åå¤Ŗå°ļ¼åęč¦ę±ēę§č½ä¼åæę ę³č¾¾å°ļ¼č„å¤Ŗå¤ļ¼åę§č½ä¼åå°å½±åļ¼å äøŗå¤Ŗå¤ēå
åč¢«ēØäŗé«éē¼åäøļ¼åƼč“å
¶ä»ēØéę²”ęč¶³å¤ēåÆēØå
åćå äøŗåå¾ę¶éåØęÆåŗēØēØåŗę“éåå³å®å
åéę±ļ¼ę仄åŗčÆ„å©ēØåå¾ę¶éåØåØåčæäŗå³å®ę¹é¢ēåø®å©ļ¼čæå°±ęÆ件å¼ēØęč¦åēćå¦ęäøäøŖåÆ¹č±”ęäøå©äøēå¼ēØęÆå¼±å¼ēØęč½Æå¼ēØļ¼é£ä¹čÆ„åÆ¹č±”ęÆč½ÆåÆåēļ¼softly reachableļ¼ćåå¾ę¶éåØ并äøåå
¶ę¶éå¼±åÆåēåÆ¹č±”äøę ·å°½éå°ę¶éč½ÆåÆåēåÆ¹č±”ļ¼ēøåļ¼å®åŖåØēę£Ā āéč¦āĀ å
åę¶ęę¶éč½ÆåÆåēåÆ¹č±”ćč½Æå¼ēØåƹäŗåå¾ę¶éåØę„čÆ“ęÆčæę ·äøē§ę¹å¼ļ¼å³Ā āåŖč¦å
åäøå¤Ŗē“§å¼ ļ¼ęå°±ä¼äæēčÆ„åÆ¹č±”ćä½ęÆå¦ęå
ååå¾ēę£ē“§å¼ äŗļ¼ęå°±ä¼å»ę¶é并å¤ēčæäøŖåÆ¹č±”ćāĀ åå¾ę¶éåØåØåÆ仄ęåŗOutOfMemoryErrorĀ ä¹åéč¦ęø
é¤ęęēč½Æå¼ēØćéčæä½æēØäøäøŖč½Æå¼ēØę„ē®”ēé«éē¼åēē¼å²åŗļ¼åÆä»„č§£å³Ā LeakyChecksumäøēé®é¢ļ¼å¦äøč¾¹ä»£ē ęē¤ŗćē°åØļ¼åŖč¦äøęÆē¹å«éč¦å
åļ¼ē¼å²åŗå°±ä¼č¢«äæēļ¼ä½ęÆåØéč¦ę¶ļ¼ä¹åÆč¢«åå¾ę¶éåØåę¶ļ¼
ććāā[$]ä½æēØč½Æå¼ēØäæ®å¤äøč¾¹ä»£ē ꮵāā
public classĀ CachingChecksum
{
Ā Ā Ā privateĀ SoftReference<byte[]> bufferRef;
Ā Ā Ā public synchronized intĀ getFileChecksum(StringĀ filename)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā intĀ len = getFileSize(filename);
Ā Ā Ā Ā Ā Ā byte[] byteArray = bufferRef.get();
Ā Ā Ā Ā Ā Ā if( byteArray ==Ā nullĀ || byteArray.length < len )
Ā Ā Ā Ā Ā Ā {
Ā Ā Ā Ā Ā Ā Ā Ā Ā byteArray =Ā new byte[len];
Ā Ā Ā Ā Ā Ā Ā Ā Ā bufferRef.set(byteArray);
Ā Ā Ā Ā Ā Ā }
Ā Ā Ā Ā Ā Ā readFileContents(filename,byteArray);
Ā Ā Ā }
}
ććäøē§å»ä»·ē¼åļ¼
ććCachingChecksumä½æēØäøäøŖč½Æå¼ēØę„ē¼ååäøŖåÆ¹č±”ļ¼å¹¶č®© JVM å¤ēä»ē¼åäøåčµ°åÆ¹č±”ę¶ēē»čćē±»ä¼¼å°ļ¼č½Æå¼ēØä¹ē»åøøēØäŗ GUI åŗēØēØåŗäøļ¼ēØäŗē¼åä½å¾å¾å½¢ćęÆå¦åÆä½æēØč½Æå¼ēØēå
³é®åØäŗļ¼åŗēØēØåŗęÆå¦åÆä»å¤§éē¼åēę°ę®ę¢å¤ćå¦ęéč¦ē¼åäøę¢äøäøŖåÆ¹č±”ļ¼ęØåÆ仄ä½æēØäøäøŖĀ Mapļ¼ä½ęÆåÆ仄éę©å¦ä½ä½æēØč½Æå¼ēØćęØåÆ仄å°ē¼åä½äøŗĀ Map<K, SoftReference<V>>Ā ęSoftReference<Map<K,V>>Ā ē®”ēćåäøē§é锹éåøøę“儽äøäŗļ¼å äøŗå®ē»åå¾ę¶éåØåø¦ę„ēå·„ä½ę“å°ļ¼å¹¶äøå
č®øåØē¹å«éč¦å
åę¶ä»„č¾å°ēå·„ä½åę¶ę“äøŖē¼åćå¼±å¼ēØęę¶ä¼éčÆÆå°ēØäŗå代č½Æå¼ēØļ¼ēØäŗęå»ŗē¼åļ¼ä½ęÆčæä¼åƼč“å·®ēē¼åę§č½ćåØå®č·µäøļ¼å¼±å¼ēØå°åØåÆ¹č±”åå¾å¼±åÆåä¹åč¢«å¾åæ«å°ęø
é¤ęāāéåøøęÆåØē¼åēåÆ¹č±”åꬔēØå°ä¹åāāå äøŗå°ēåå¾ę¶éčæč”å¾å¾é¢ē¹ćåƹäŗåØę§č½äøéåøøä¾čµé«éē¼åēåŗēØēØåŗę„čÆ“ļ¼č½Æå¼ēØęÆäøäøŖäøē®”ēØēęꮵļ¼å®ē”®å®äøč½å代č½å¤ęä¾ēµę“»ē»ę¢ęćå¤å¶åäŗå”åé«éē¼åēå¤ęēé«éē¼åę”ę¶ćä½ęÆä½äøŗäøē§ āå»ä»·ļ¼cheap and dirtyļ¼ā ēé«éē¼åęŗå¶ļ¼å®åƹäŗéä½ä»·ę ¼ęÆå¾ęåøå¼åēćę£å¦å¼±å¼ēØäøę ·ļ¼č½Æå¼ēØä¹åÆåå»ŗäøŗå
·ęäøäøŖēøå
³ēå¼ēØéåļ¼å¼ēØåØč¢«åå¾ę¶éåØęø
é¤ę¶čæå
„éåćå¼ēØéååƹäŗč½Æå¼ēØę„čÆ“ļ¼ę²”ęåƹ弱å¼ēØé£ä¹ęēØļ¼ä½ęÆå®ä»¬åÆ仄ēØäŗååŗē®”ēč¦ę„ļ¼čÆ“ęåŗēØēØåŗå¼å§ē¼ŗå°å
åć
ćć2)åå¾åę¶åƹå¼ēØēå¤ēļ¼
ććå¼±å¼ēØåč½Æå¼ēØé½ę©å±äŗę½č±”ēĀ ReferenceĀ ē±»čå¼ēØļ¼phantom referencesļ¼ļ¼å¼ēØåÆ¹č±”č¢«åå¾ę¶éåØē¹ę®å°ēå¾
ćåå¾ę¶éåØåØč·čøŖå ęé“éå°äøäøŖĀ ReferenceĀ ę¶ļ¼äøä¼ę č®°ęč·čøŖčÆ„å¼ēØåÆ¹č±”ļ¼čęÆåØå·²ē„ę“»č·ēĀ ReferenceĀ åÆ¹č±”ēéåäøę¾ē½®äøäøŖĀ ReferencećåØč·čøŖä¹åļ¼åå¾ę¶éåØå°±čÆå«č½ÆåÆåēåÆ¹č±”āāčæäŗåÆ¹č±”äøé¤äŗč½Æå¼ēØå¤ļ¼ę²”ęä»»ä½å¼ŗå¼ēØćåå¾ę¶éåØē¶åę ¹ę®å½åę¶éęåę¶ēå
åę»éåå
¶ä»ēē„ččå ē“ ļ¼å¤ęč½Æå¼ēØę¤ę¶ęÆå¦éč¦č¢«ęø
é¤ćå°č¢«ęø
é¤ēč½Æå¼ēØå¦ęå
·ęēøåŗēå¼ēØéåļ¼å°±ä¼čæå
„éåćå
¶ä½ēč½ÆåÆååÆ¹č±”ļ¼ę²”ęęø
é¤ēåÆ¹č±”ļ¼ē¶åč¢«ēä½äøäøŖę ¹éļ¼root setļ¼ļ¼å č·čøŖē»§ē»ä½æēØčæäŗę°ēę ¹ļ¼ä»„ä¾æéčæę“»č·ēč½Æå¼ēØčåÆåēåÆ¹č±”č½å¤č¢«ę č®°ćå¤ēč½Æå¼ēØä¹åļ¼å¼±åÆååÆ¹č±”ēéåč¢«čÆå« āā čæę ·ēåÆ¹č±”äøäøååØå¼ŗå¼ēØęč½Æå¼ēØćčæäŗåÆ¹č±”č¢«ęø
é¤åå å
„éåćęęĀ ReferenceĀ ē±»ååØå å
„éåä¹åč¢«ęø
é¤ļ¼ę仄å¤ēäŗåę£ę„ļ¼post-mortemļ¼ęø
é¤ēēŗæēØę°øčæäøä¼å
·ę referent åÆ¹č±”ēč®æé®ęļ¼čåŖå
·ęReferenceĀ åÆ¹č±”ēč®æé®ęćå ę¤ļ¼å½Ā ReferencesĀ äøå¼ēØéåäøčµ·ä½æēØę¶ļ¼éåøøéč¦ē»åéå½ēå¼ēØē±»åļ¼å¹¶å°å®ē“ę„ēØäŗęØēč®¾č®”äøļ¼äøĀ WeakHashMapĀ äøę ·ļ¼å®ēĀ Map.EntryĀ ę©å±äŗĀ WeakReferenceļ¼ęč
ååØåƹéč¦ęø
é¤ēå®ä½ēå¼ēØć
ćć3)ä½æēØå¼±å¼ēØå µä½å
åę³ę¼ļ¼
ćć[1]å
Øå±Mapé ęēå
åę³ę¼ļ¼
ććę ęčÆåÆ¹č±”äæēęåøøč§ēåå ęÆä½æēØĀ MapĀ å°å
ę°ę®äøäø“ę¶åÆ¹č±”ļ¼transient objectļ¼ēøå
³čćåå®äøäøŖåÆ¹č±”å
·ęäøēēå½åØęļ¼ęÆåé
å®ēé£äøŖę¹ę³č°ēØēēå½åØęéæļ¼ä½ęÆęÆåŗēØēØåŗēēå½åØęēļ¼å¦å®¢ę·ęŗēå„ę„åčæę„ćéč¦å°äøäŗå
ę°ę®äøčæäøŖå„ę„åå
³čļ¼å¦ēęčæę„ēēØę·ēę čÆćåØåå»ŗĀ SocketĀ ę¶ęÆäøē„éčæäŗäæ”ęÆēļ¼å¹¶äøäøč½å°ę°ę®ę·»å å°Ā SocketĀ åÆ¹č±”äøļ¼å äøŗäøč½ę§å¶Ā SocketĀ ē±»ęč
å®ēåē±»ćčæę¶ļ¼å
øåēę¹ę³å°±ęÆåØäøäøŖå
Øå±Ā MapĀ äøååØčæäŗäæ”ęÆļ¼
public classĀ SocketManager{
Ā Ā Ā privateĀ Map<Socket,User> m =Ā newĀ HashMap<Socket,User>();
Ā Ā Ā public voidĀ setUser(Socket s,User u)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā m.put(s,u);
Ā Ā Ā }
Ā Ā Ā publicĀ User getUser(Socket s){
Ā Ā Ā Ā Ā Ā returnĀ m.get(s);
Ā Ā Ā }
Ā Ā Ā public voidĀ removeUser(Socket s){
Ā Ā Ā Ā Ā Ā m.remove(s);
Ā Ā Ā }
}
Ā
SocketManager socketManager;
//...
socketManager.setUser(socket,user);
ććčæē§ę¹ę³ēé®é¢ęÆå
ę°ę®ēēå½åØęéč¦äøå„ę„åēēå½åØęęé©ļ¼ä½ęÆé¤éåē”®å°ē„éä»ä¹ę¶åēØåŗäøåéč¦čæäøŖå„ę„åļ¼å¹¶č®°ä½ä» Map äøå é¤ēøåŗēę å°ļ¼å¦åļ¼Socket å User åÆ¹č±”å°ä¼ę°øčæēåØ Map äøļ¼čæčæč¶
čæååŗäŗčÆ·ę±åå
³éå„ę„åēę¶é“ćčæä¼é»ę¢ Socket åUser åÆ¹č±”č¢«åå¾ę¶éļ¼å³ä½æåŗēØēØåŗäøä¼åä½æēØå®ä»¬ćčæäŗåÆ¹č±”ēäøę„äøåę§å¶ļ¼å¾å®¹ęé ęēØåŗåØéæę¶é“čæč”åå
åēę»”ćé¤äŗęē®åēę
åµļ¼åØå ä¹ęęę
åµäøę¾åŗä»ä¹ę¶å Socket äøåč¢«ēØåŗä½æēØęÆäø件å¾ē¦äŗŗå容ęåŗéēä»»å”ļ¼éč¦äŗŗå·„åƹå
åčæč”ē®”ēć
ćć[2]å¼±å¼ēØå
åę³ę¼ä»£ē ļ¼
ććēØåŗęå
åę³ę¼ēē¬¬äøäøŖčæ¹č±”éåøøęÆå®ęåŗäøäøŖĀ OutOfMemoryErrorļ¼ęč
å äøŗé¢ē¹ēåå¾ę¶éčč”Øē°åŗē³ē³ēę§č½ćå¹øčæēęÆļ¼åå¾ę¶éåÆ仄ęä¾č½å¤ēØę„čÆęå
åę³ę¼ē大éäæ”ęÆćå¦ę仄Ā -verbose:gcĀ ęč
Ā -XloggcĀ é锹č°ēØ JVMļ¼é£ä¹ęÆꬔ GC čæč”ę¶åØę§å¶å°äøęč
ę„åæę件äøä¼ęå°åŗäøäøŖčÆęäæ”ęÆļ¼å
ę¬å®ęč±č“¹ēę¶é“ćå½åå ä½æēØę
åµä»„åę¢å¤äŗå¤å°å
åćč®°å½ GC ä½æēØę
åµå¹¶äøå
·ęå¹²ę°ę§ļ¼å ę¤å¦ęéč¦åęå
åé®é¢ęč
č°ä¼åå¾ę¶éåØļ¼åØēäŗ§ēÆå¢äøé»č®¤åÆēØ GC ę„åæęÆå¼å¾ēćęå·„å
·åÆ仄å©ēØ GC ę„åæč¾åŗ并仄å¾å½¢ę¹å¼å°å®ę¾ē¤ŗåŗę„ļ¼JTuneĀ å°±ęÆčæę ·ēäøē§å·„å
·ćč§åÆ GC ä¹åå 大å°ēå¾ļ¼åÆ仄ēå°ēØåŗå
åä½æēØēč¶åæćåƹäŗ大å¤ę°ēØåŗę„čÆ“ļ¼åÆ仄å°å
åä½æēØåäøŗäø¤éØåļ¼baselineĀ ä½æēØåĀ current loadĀ ä½æēØćåƹäŗęå”åØåŗēØēØåŗļ¼baselineĀ ä½æēØå°±ęÆåŗēØēØåŗåØę²”ęä»»ä½č“č·ćä½ęÆå·²ē»åå¤å„½ę„åčÆ·ę±ę¶ēå
åä½æēØļ¼current loadĀ ä½æēØęÆåØå¤ēčÆ·ę±čæēØäøä½æēØēćä½ęÆåØčÆ·ę±å¤ēå®ęåä¼éę¾ēå
åćåŖč¦č“č·å¤§ä½äøęÆęå®ēļ¼åŗēØēØåŗéåøøä¼å¾åæ«č¾¾å°äøäøŖēسå®ēå
åä½æēØę°“å¹³ćå¦ęåØåŗēØēØåŗå·²ē»å®ęäŗå
¶åå§å并äøč“č·ę²”ęå¢å ēę
åµäøļ¼å
åä½æēØęē»å¢å ļ¼é£ä¹ēØåŗå°±åÆč½åØå¤ēåé¢ēčÆ·ę±ę¶äæēäŗēęēåÆ¹č±”ć
public classĀ MapLeaker{
Ā Ā Ā publicĀ ExecuteService exec = Executors.newFixedThreadPool(5);
Ā Ā Ā publicĀ Map<Task,TaskStatus> taskStatus
Ā Ā Ā Ā Ā Ā = Collections.synchronizedMap(newĀ HashMap<Task,TaskStatus>());
Ā Ā Ā privateĀ Random random =Ā newĀ Random();
Ā Ā Ā Ā private enumĀ TaskStatus {Ā NOT_STARTED,Ā STARTED,Ā FINISHEDĀ };
Ā Ā Ā Ā private classĀ TaskĀ implementsĀ Runnable{
Ā Ā Ā Ā Ā Ā private int[] numbers =Ā new int[random.nextInt(200)];
Ā Ā Ā Ā Ā Ā public voidĀ run()
Ā Ā Ā Ā Ā Ā {
Ā Ā Ā Ā Ā Ā Ā Ā Ā int[] temp =Ā new int[random.nextInt(10000)];
Ā Ā Ā Ā Ā Ā Ā Ā Ā taskStatus.put(this,TaskStatus.STARTED);
Ā Ā Ā Ā Ā Ā Ā Ā Ā doSomework();
Ā Ā Ā Ā Ā Ā Ā Ā Ā taskStatus.put(this,TaskStatus.FINISHED);
Ā Ā Ā Ā Ā Ā }
Ā Ā Ā }
Ā Ā Ā publicĀ Task newTask()
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā Task t =Ā newĀ Task();
Ā Ā Ā Ā Ā Ā taskStatus.put(t,TaskStatus.NOT_STARTED);
Ā Ā Ā Ā Ā Ā exec.execute(t);
Ā Ā Ā Ā Ā Ā returnĀ t;
Ā Ā Ā }
}
ćć[3]ä½æēØå¼±å¼ēØå µä½å
åę³ę¼ļ¼
ććSocketManager ēé®é¢ęÆ Socket-User ę å°ēēå½åØęåŗå½äø Socket ēēå½åØęēøå¹é
ļ¼ä½ęÆčÆčØę²”ęęä¾ä»»ä½å®¹ęēę¹ę³å®ę½čæ锹č§åćčæä½æå¾ēØåŗäøå¾äøä½æēØäŗŗå·„å
åē®”ēēčęęÆćå¹øčæēęÆļ¼ä»Ā JDKĀ 1.2Ā å¼å§ļ¼åå¾ę¶éåØęä¾äŗäøē§å£°ęčæē§åÆ¹č±”ēå½åØęä¾čµę§ēę¹ę³ļ¼čæę ·åå¾ę¶éåØå°±åÆ仄åø®å©ę们é²ę¢čæē§å
åę³ę¼āāå©ēØå¼±å¼ēØćå¼±å¼ēØęÆåƹäøäøŖåÆ¹č±”ļ¼ē§°äøŗĀ referentļ¼ēå¼ēØēęęč
ćä½æēØå¼±å¼ēØåļ¼åÆ仄ē»“ęåƹ referent ēå¼ēØļ¼čäøä¼é»ę¢å®č¢«åå¾ę¶éćå½åå¾ę¶éåØč·čøŖå ēę¶åļ¼å¦ęåƹäøäøŖåÆ¹č±”ēå¼ēØåŖęå¼±å¼ēØļ¼é£ä¹čæäøŖ referent å°±ä¼ęäøŗåå¾ę¶éēåéåÆ¹č±”ļ¼å°±åę²”ęä»»ä½å©ä½ēå¼ēØäøę ·ļ¼čäøęęå©ä½ēå¼±å¼ēØé½č¢«ęø
é¤ćļ¼åŖęå¼±å¼ēØēåÆ¹č±”ē§°äøŗå¼±åÆåļ¼weakly reachableļ¼ļ¼WeakReference ē referent ęÆåØęé ę¶č®¾ē½®ēļ¼åØę²”ęč¢«ęø
é¤ä¹åļ¼åÆ仄ēØ get() č·åå®ēå¼ćå¦ęå¼±å¼ēØč¢«ęø
é¤äŗļ¼äøē®”ęÆ referent å·²ē»č¢«åå¾ę¶éäŗļ¼čæęÆęäŗŗč°ēØäŗĀ WeakReference.clear()ļ¼ļ¼get() ä¼čæåĀ nullćēøåŗå°ļ¼åØä½æēØå
¶ē»ęä¹åļ¼åŗå½ę»ęÆę£ę„get() ęÆå¦čæåäøäøŖéĀ nullĀ å¼ļ¼å äøŗ referent ęē»ę»ęÆä¼č¢«åå¾ę¶éēćēØäøäøŖę®éēļ¼å¼ŗļ¼å¼ēØę·č“äøäøŖåÆ¹č±”å¼ēØę¶ļ¼éå¶ referent ēēå½åØęč³å°äøč¢«ę·č“ēå¼ēØēēå½åØęäøę ·éæćå¦ęäøå°åæļ¼é£ä¹å®åÆč½å°±äøēØåŗēēå½åØęäøę ·āāå¦ęå°äøäøŖåÆ¹č±”ę¾å
„äøäøŖå
Øå±éåäøēčÆćå¦äøę¹é¢ļ¼åØåå»ŗåƹäøäøŖåÆ¹č±”ēå¼±å¼ēØę¶ļ¼å®å
Øę²”ęę©å± referent ēēå½åØęļ¼åŖęÆåØåÆ¹č±”ä»ē¶åę“»ēę¶åļ¼äæęå¦äøē§å°č¾¾å®ēę¹ę³ćå¼±å¼ēØåƹäŗęé å¼±éåęęēØļ¼å¦é£äŗåØåŗēØēØåŗēå
¶ä½éØåä½æēØåÆ¹č±”ęé“ååØå
³äŗčæäŗåÆ¹č±”ēå
ę°ę®ēéåāāčæå°±ęÆ SocketManager ē±»ęč¦åēå·„ä½ćå äøŗčæęÆå¼±å¼ēØęåøøč§ēēØę³ļ¼WeakHashMapĀ ä¹č¢«ę·»å å°Ā JDKĀ 1.2Ā ēē±»åŗäøļ¼å®åƹé®ļ¼čäøęÆåƹå¼ļ¼ä½æēØå¼±å¼ēØćå¦ęåØäøäøŖę®é HashMap äøēØäøäøŖåÆ¹č±”ä½äøŗé®ļ¼é£ä¹čæäøŖåÆ¹č±”åØę å°ä» Map äøå é¤ä¹åäøč½č¢«åę¶ļ¼WeakHashMapĀ ä½æęØåÆ仄ēØäøäøŖåÆ¹č±”ä½äøŗ Map é®ļ¼åę¶äøä¼é»ę¢čæäøŖåÆ¹č±”č¢«åå¾ę¶éćäøč¾¹ē代ē ē»åŗäŗĀ WeakHashMapĀ ē get() ę¹ę³ēäøē§åÆč½å®ē°ļ¼å®å±ē¤ŗäŗå¼±å¼ēØēä½æēØļ¼
public classĀ WeakHashMap<K,V>Ā implementsĀ Map<K,V>
{
Ā Ā Ā private static classĀ Entry<K,V>Ā extendsĀ WeakReference<K>Ā implementsĀ Map.Entry<K,V>
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā privateĀ V value;
Ā Ā Ā Ā Ā Ā private final intĀ hash;
Ā Ā Ā Ā Ā Ā privateĀ Entry<K,V> next;
Ā Ā Ā Ā Ā Ā // ...
Ā Ā Ā }
Ā
Ā Ā Ā publicĀ V get(Object key)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā intĀ hash = getHash(key);
Ā Ā Ā Ā Ā Ā Entry<K,V> e = getChain(hash);
Ā Ā Ā Ā Ā Ā while(e !=Ā null)
Ā Ā Ā Ā Ā Ā {
Ā Ā Ā Ā Ā Ā Ā Ā Ā k eKey = e.get();
Ā Ā Ā Ā Ā Ā Ā Ā Ā if( e.hash == hash && (key == eKey || key.equals(eKey)))
Ā Ā Ā Ā Ā Ā Ā Ā Ā Ā Ā Ā returnĀ e.value;
Ā Ā Ā Ā Ā Ā Ā Ā Ā e = e.next;
Ā Ā Ā Ā Ā Ā }
Ā Ā Ā Ā Ā Ā return null;
Ā Ā Ā }
}
ććč°ēØ WeakReference.get() ę¶ļ¼å®čæåäøäøŖåƹ referent ēå¼ŗå¼ēØļ¼å¦ęå®ä»ē¶åę“»ēčÆļ¼ļ¼å ę¤äøéč¦ę
åæę å°åØĀ whileĀ å¾ŖēÆä½äøę¶å¤±ļ¼å äøŗå¼ŗå¼ēØä¼é²ę¢å®č¢«åå¾ę¶éćWeakHashMapĀ ēå®ē°å±ē¤ŗäŗå¼±å¼ēØēäøē§åøøč§ēØę³āāäøäŗå
éØåÆ¹č±”ę©å±Ā WeakReferencećå
¶åå åØäøé¢äøčč®Øč®ŗå¼ēØéåę¶ä¼å¾å°č§£éćåØåĀ WeakHashMapĀ äøę·»å ę å°ę¶ļ¼čÆ·č®°ä½ę å°åÆč½ä¼åØ仄åāč±ē¦»āļ¼å äøŗé®č¢«åå¾ę¶éäŗćåØčæē§ę
åµäøļ¼get() čæå nullļ¼čæä½æå¾ęµčÆ get() ēčæåå¼ęÆå¦äøŗĀ nullĀ åå¾ęÆå¹³ę¶ę“éč¦äŗć
ćć[4]ä½æēØWeakHashMapå µä½ę³ę¼
ććåØĀ SocketManagerĀ äøé²ę¢ę³ę¼å¾å®¹ęļ¼åŖč¦ēØĀ WeakHashMapĀ 代ęæĀ HashMapĀ å°±č”äŗļ¼å¦äøč¾¹ä»£ē ęē¤ŗćļ¼å¦ęĀ SocketManagerĀ éč¦ēŗæēØå®å
Øļ¼é£ä¹åÆ仄ēØĀ Collections.synchronizedMap()Ā å
č£
Ā WeakHashMapļ¼ćå½ę å°ēēå½åØęåæ
é”»äøé®ēēå½åØęčē³»åØäøčµ·ę¶ļ¼åÆ仄ä½æēØčæē§ę¹ę³ćäøčæļ¼åŗå½å°åæäø껄ēØčæē§ęęÆļ¼å¤§å¤ę°ę¶åčæęÆåŗå½ä½æēØę®éēĀ HashMapĀ ä½äøŗĀ MapĀ ēå®ē°ć
public classĀ SocketManager{
Ā Ā Ā privateĀ Map<Socket,User> m =Ā newĀ WeakHashMap<Socket,User>();
Ā Ā Ā public voidĀ setUser(Socket s, User s)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā m.put(s,u);
Ā Ā Ā }
Ā Ā Ā publicĀ User getUser(Socket s)
Ā Ā Ā {
Ā Ā Ā Ā Ā Ā returnĀ m.get(s);
Ā Ā Ā }
}
ććå¼ēØéåļ¼
ććWeakHashMapĀ ēØå¼±å¼ēØęæč½½ę å°é®ļ¼čæä½æå¾åŗēØēØåŗäøåä½æēØé®åÆ¹č±”ę¶å®ä»¬åÆä»„č¢«åå¾ę¶éļ¼get()Ā å®ē°åÆä»„ę ¹ę®Ā WeakReference.get()Ā ęÆå¦čæåĀ nullĀ ę„åŗåę»ēę å°åę“»ēę å°ćä½ęÆčæåŖęÆé²ę¢Ā MapĀ ēå
åę¶čåØåŗēØēØåŗēēå½åØęäøäøęå¢å ęéč¦åēå·„ä½ēäøåļ¼čæéč¦åäøäŗå·„ä½ä»„ä¾æåØé®åÆ¹č±”č¢«ę¶éåä»Ā MapĀ äøå é¤ę»é”¹ćå¦åļ¼MapĀ ä¼å
ę»”åƹåŗäŗę»é®ē锹ćč½ē¶čæåƹäŗåŗēØēØåŗęÆäøåÆč§ēļ¼ä½ęÆå®ä»ē¶ä¼é ęåŗēØēØåŗčå°½å
åļ¼å äøŗå³ä½æé®č¢«ę¶éäŗļ¼Map.EntryĀ åå¼åÆ¹č±”ä¹äøä¼č¢«ę¶éćåÆ仄éčæåØęę§å°ę«ęĀ Mapļ¼åƹęÆäøäøŖå¼±å¼ēØč°ēØĀ get()ļ¼å¹¶åØ get() čæåĀ nullĀ ę¶å é¤é£äøŖę å°čę¶é¤ę»ę å°ćä½ęÆå¦ęĀ MapĀ ęč®øå¤ę“»ē锹ļ¼é£ä¹čæē§ę¹ę³ēęēå¾ä½ćå¦ęęäøē§ę¹ę³åÆ仄åØå¼±å¼ēØē referent č¢«åå¾ę¶éę¶ååŗéē„就儽äŗļ¼čæå°±ęÆå¼ēØéåēä½ēØćå¼ēØéåęÆåå¾ę¶éåØååŗēØēØåŗčæåå
³äŗåÆ¹č±”ēå½åØęēäæ”ęÆēäø»č¦ę¹ę³ćå¼±å¼ēØęäø¤äøŖęé å½ę°ļ¼äøäøŖåŖå referent ä½äøŗåę°ļ¼å¦äøäøŖčæåå¼ēØéåä½äøŗåę°ćå¦ęēØå
³čēå¼ēØéååå»ŗå¼±å¼ēØļ¼åØ referent ęäøŗ GC åéåÆ¹č±”ę¶ļ¼čæäøŖå¼ēØåÆ¹č±”ļ¼äøęÆreferentļ¼å°±åØå¼ēØęø
é¤åå å
„Ā å°å¼ēØéåäøćä¹åļ¼åŗēØēØåŗä»å¼ēØéåęåå¼ēØ并äŗč§£å°å®ē referent å·²č¢«ę¶éļ¼å ę¤åÆ仄čæč”ēøåŗēęø
ēę“»åØļ¼å¦å»ęå·²äøåØå¼±éåäøēåÆ¹č±”ē锹ćļ¼å¼ēØéåęä¾äŗäøĀ BlockingQueueĀ åę ·ēåŗåęØ”å¼ āāpolledćtimed blockingĀ åĀ untimed blockingćļ¼WeakHashMapĀ ęäøäøŖåäøŗĀ expungeStaleEntries()Ā ēē§ęę¹ę³ļ¼å¤§å¤ę°Ā MapĀ ęä½äøä¼č°ēØå®ļ¼å®å»ęå¼ēØéåäøęę失ęēå¼ēØļ¼å¹¶å é¤å
³čēę å°ć
ćć4)å
³äŗJavaäøå¼ēØęčļ¼
ććå
č§åÆäøäøŖåč”Øļ¼
| ēŗ§å« |
åę¶ę¶é“ |
ēØé |
ēåę¶é“ |
| å¼ŗå¼ēØ |
ä»ę„äøä¼č¢«åę¶ |
åÆ¹č±”ēäøč¬ē¶ę |
JVMåę¢čæč”ę¶ē»ę¢ |
| č½Æå¼ēØ |
åØå
åäøč¶³ę¶ |
åØ客ę·ē«Æē§»é¤åÆ¹č±”å¼ēØčæåļ¼é¤éåꬔęæę“»ļ¼å¦åå°±ę¾åØå
åęęēē¼åäø |
å
åäøč¶³ę¶ē»ę¢ |
| å¼±å¼ēØ |
åØåå¾åę¶ę¶ļ¼ä¹å°±ęÆ客ę·ē«Æå·²ē»ē§»é¤äŗå¼ŗå¼ēØļ¼ä½ęÆčæē§ę
åµäøå
åčæęÆ客ę·ē«Æå¼ēØåÆč¾¾ē |
é»ę¢čŖåØå é¤äøéč¦ēØēåÆ¹č±” |
GCčæč”åē»ę¢ |
| čå¼ēØ[å¹½ēµå¼ēØ]
|
åÆ¹č±”ę»äŗ”ä¹åļ¼å°±ęÆčæč”finalize()ę¹ę³č°ēØéčæ |
ē¹ę®ēęø
é¤čæēØ |
äøå®ļ¼å½finalize()å½ę°čæč”čæåååę¶ļ¼ęåÆč½ä¹å就已ē»č¢«åę¶äŗć |
ćć
åÆ仄čæę ·ēč§£ļ¼
ććSoftReferenceļ¼åå®åå¾åę¶åØē”®å®åØęäøę¶é“ē¹ęäøŖåÆ¹č±”ęÆč½ÆåÆå°č¾¾åÆ¹č±”ćčæę¶ļ¼å®åÆ仄éę©čŖåØęø
é¤éåƹčÆ„åÆ¹č±”ēęęč½Æå¼ēØļ¼ä»„åéčæå¼ŗå¼ēØé¾ļ¼ä»å
¶åÆ仄å°č¾¾čÆ„åÆ¹č±”ēéåƹ任ä½å
¶ä»č½ÆåÆå°č¾¾åÆ¹č±”ēęęč½Æå¼ēØćåØåäøę¶é“ęęäŗę¶åļ¼å®ä¼å°é£äŗå·²ē»åå¼ēØéåę³Øåēę°ęø
é¤ēč½Æå¼ēØå å
„éåć č½ÆåÆå°č¾¾åÆ¹č±”ēęęč½Æå¼ēØé½č¦äæčÆåØčęęŗęåŗĀ OutOfMemoryErrorĀ ä¹åå·²ē»č¢«ęø
é¤ćå¦åļ¼ęø
é¤č½Æå¼ēØēę¶é“ęč
ęø
é¤äøååÆ¹č±”ēäøē»ę¤ē±»å¼ēØēé”ŗåŗå°äøåä»»ä½ēŗ¦ęćē¶čļ¼čęęŗå®ē°äøé¼å±ęø
é¤ęčæč®æé®ęä½æēØčæēč½Æå¼ēØćĀ ę¤ē±»ēē“ę„å®ä¾åÆēØäŗå®ē°ē®åē¼åļ¼čÆ„ē±»ęå
¶ę“¾ēēåē±»čæåÆēØäŗę“大åēę°ę®ē»ęļ¼ä»„å®ē°ę“å¤ęēē¼åćåŖč¦č½Æå¼ēØēęē¤ŗåÆ¹č±”ęÆå¼ŗåÆå°č¾¾åÆ¹č±”ļ¼å³ę£åØå®é
ä½æēØēåÆ¹č±”ļ¼å°±äøä¼ęø
é¤č½Æå¼ēØćä¾å¦ļ¼éčæäæęęčæä½æēØē锹ēå¼ŗęē¤ŗåÆ¹č±”ļ¼å¹¶ē±åå¾åę¶åØå³å®ęÆå¦ę¾å¼å©ä½ē锹ļ¼å¤ęēē¼ååÆ仄é²ę¢ę¾å¼ęčæä½æēØē锹ćäøč¬ę„čÆ“ļ¼WeakReferenceę们ēØę„é²ę¢å
åę³ę¼ļ¼äæčÆå
ååÆ¹č±”č¢«VMåę¶ć
ććWeakReferenceļ¼å¼±å¼ēØåÆ¹č±”ļ¼å®ä»¬å¹¶äøē¦ę¢å
¶ęē¤ŗåÆ¹č±”åå¾åÆē»ē»ļ¼å¹¶č¢«ē»ē»ļ¼ē¶åč¢«åę¶ćå¼±å¼ēØęåøøēØäŗå®ē°č§čåēę å°ćåå®åå¾åę¶åØē”®å®åØęäøę¶é“ē¹äøęäøŖåÆ¹č±”ęÆå¼±åÆå°č¾¾åÆ¹č±”ćčæę¶ļ¼å®å°čŖåØęø
é¤éåƹę¤åÆ¹č±”ēęęå¼±å¼ēØļ¼ä»„åéčæå¼ŗå¼ēØé¾åč½Æå¼ēØļ¼åÆ仄ä»å
¶å°č¾¾čÆ„åÆ¹č±”ēéåƹ任ä½å
¶ä»å¼±åÆå°č¾¾åÆ¹č±”ēęęå¼±å¼ēØćåę¶å®å°å£°ęęę仄åēå¼±åÆå°č¾¾åÆ¹č±”äøŗåÆē»ē»ēćåØåäøę¶é“ęęäŗę¶åļ¼å®å°é£äŗå·²ē»åå¼ēØéåę³Øåēę°ęø
é¤ēå¼±å¼ēØå å
„éåćĀ SoftReferenceå¤ēØä½ę„å®ē°cacheęŗå¶ļ¼äæčÆcacheēęęę§ć
ććPhantomReferenceļ¼čå¼ēØåÆ¹č±”ļ¼åØåę¶åØē”®å®å
¶ęē¤ŗåÆ¹č±”åÆå¦å¤åę¶ä¹åļ¼č¢«å å
„éåćčå¼ēØęåøøč§ēēØę³ęÆ仄ęē§åÆč½ęÆä½æēØ Java ē»ē»ęŗå¶ę“ēµę“»ēę¹å¼ę„ęę“¾ pre-mortem ęø
é¤ęä½ćå¦ęåå¾åę¶åØē”®å®åØęäøē¹å®ę¶é“ē¹äøčå¼ēØēęē¤ŗåÆ¹č±”ęÆčåÆå°č¾¾åÆ¹č±”ļ¼é£ä¹åØé£ę¶ęč
åØ仄åēęäøę¶é“ļ¼å®ä¼å°čÆ„å¼ēØå å
„éåćäøŗäŗē”®äæåÆåę¶ēåÆ¹č±”ä»ē¶äæęåē¶ļ¼čå¼ēØēęē¤ŗåÆ¹č±”äøč½č¢«ę£ē“¢ļ¼čå¼ēØē get ę¹ę³ę»ęÆčæå nullćäøč½Æå¼ēØåå¼±å¼ēØäøåļ¼čå¼ēØåØå å
„éåę¶å¹¶ę²”ęéčæåå¾åę¶åØčŖåØęø
é¤ćéčæčå¼ēØåÆå°č¾¾ēåÆ¹č±”å°ä»ē¶äæęåē¶ļ¼ē“å°ęęčæē±»å¼ēØé½č¢«ęø
é¤ļ¼ęč
å®ä»¬é½åå¾äøåÆå°č¾¾ć
ćć仄äøęÆäøē”®å®ę¦åæµ
ććć*ļ¼Javaå¼ēØēę·±å
„éØåäøē“é½ęÆč®Øč®ŗå¾ęÆč¾å¤ēčÆé¢ļ¼äøč¾¹å¤§éØåäøŗęå½ę“ēļ¼čæéåč°č°ęäøŖäŗŗēäøäŗēę³ćä»ę“äøŖJVMę”ę¶ē»ęę„ēļ¼Javaēå¼ēØååå¾åę¶åØå½¢ęäŗéåƹJavaå
åå ēäøäøŖåÆ¹č±”ēāéå
ē®”ēéāļ¼å
¶äøåØåŗę¬ä»£ē éé¢åøøēØēå°±ęÆå¼ŗå¼ēØļ¼å¼ŗå¼ēØäø»č¦ä½æēØē®ēęÆå°±ęÆē¼ēØēę£åøøé»č¾ļ¼čæęÆęęēå¼åäŗŗåę容ęēč§£ēļ¼čå¼±å¼ēØåč½Æå¼ēØēä½ēØęÆęÆč¾čäŗŗåÆ»å³ēćęē
§å¼ēØå¼ŗå¼±ļ¼å
¶ęåŗåÆ仄äøŗļ¼å¼ŗå¼ēØāāč½Æå¼ēØāāå¼±å¼ēØāāčå¼ēØļ¼äøŗä»ä¹čæę ·åå¢ļ¼å®é
äøéåƹåå¾åę¶åØččØļ¼å¼ŗå¼ēØęÆå®ē»åƹäøä¼éä¾æå»åØēåŗåļ¼å äøŗåØå
åå éé¢ēåÆ¹č±”ļ¼åŖęå½ååÆ¹č±”äøęÆå¼ŗå¼ēØēę¶åļ¼čÆ„åÆ¹č±”ęä¼čæå
„åå¾åę¶åØēē®ę åŗåć
ććč½Æå¼ēØååÆ仄ēč§£äøŗāå
ååŗę„å¼ēØāļ¼ä¹å°±ęÆčÆ“å®åGCęÆå®ę“å°é
åęä½ēļ¼äøŗäŗé²ę¢å
åę³ę¼ļ¼å½GCåØåę¶čæēØåŗē°å
åäøč¶³ēę¶åļ¼č½Æå¼ēØä¼č¢«ä¼å
åę¶ļ¼ä»åå¾åę¶ē®ę³äøč®²ļ¼č½Æå¼ēØåØč®¾č®”ēę¶åęÆå¾å®¹ęč¢«åå¾åę¶åØåē°ēćäøŗä»ä¹č½Æå¼ēØęÆå¤ēåčÆē¼åēä¼å
éę©ēļ¼äø»č¦ęäø¤äøŖåå ļ¼ē¬¬äøļ¼å®åƹå
åéåøøęęļ¼ä»ę½č±”ęä¹äøč®²ļ¼ę们ēč³åÆ仄任ä½å®åå
åēååē“§ē“§ē»å®å°äøčµ·ęä½ēļ¼å äøŗå
åäøę¦äøč¶³ēę¶åļ¼å®ä¼ä¼å
ååå¾åę¶åØę„č¦ä»„ęē¤ŗå
åäøč¶³ļ¼ē¬¬äŗļ¼å®ä¼å°½éäæčÆē³»ē»åØOutOfMemoryErrorä¹åå°åÆ¹č±”ē“ę„č®¾ē½®ęäøŗäøåÆč¾¾ļ¼ä»„äæčÆäøä¼åŗē°å
åęŗ¢åŗēę
åµļ¼ę仄ä½æēØč½Æå¼ēØę„å¤ēJavaå¼ēØéé¢ēé«éē¼åęÆå¾äøéēéę©ćå
¶å®č½Æå¼ēØäøä»
ä»
åå
åęęļ¼å®é
äøååå¾åę¶åØēäŗ¤äŗä¹ęÆęęēļ¼čæē¹åÆ仄čæę ·ēč§£ļ¼å äøŗå½å
åäøč¶³ēę¶åļ¼č½Æå¼ēØä¼ę„č¦ļ¼ččæē§ę„č¦ä¼ęē¤ŗåå¾åę¶åØéåƹē®åēäøäŗå
åčæč”ęø
é¤ęä½ļ¼čåØęč½Æå¼ēØååØēå
åå éé¢ļ¼åå¾åę¶åØä¼ē¬¬äøę¶é“ååŗļ¼å¦åå°±ä¼MemoryOutäŗćęē
§ę们ę£åøøēęē»“ę„ččļ¼åå¾åę¶åØéåƹę们č°ēØSystem.gc()ēę¶åļ¼ęÆäøä¼č½»ęēē¬ēļ¼å äøŗä»
ä»
ęÆę¶å°äŗę„čŖå¼ŗå¼ēØå±ä»£ē ēčÆ·ę±ļ¼č³äŗå®ęÆå¦åę¶čæå¾ēJVMå
éØēÆå¢ēę”件ęÆå¦ę»”č¶³ļ¼ä½ęÆå¦ęęÆč½Æå¼ēØēę¹å¼å»ē³čÆ·åå¾åę¶åØä¼ä¼å
ååŗļ¼åŖęÆę们åØå¼åčæēØäøč½ę§å¶č½Æå¼ēØåƹåå¾åę¶åØåéåå¾åę¶ē³čÆ·ļ¼čJVMč§čéé¢ä¹ęåŗäŗč½Æå¼ēØäøä¼č½»ęåéē³čÆ·å°åå¾åę¶åØćčæéčæéč¦č§£éēäøē¹ēęÆč½Æå¼ēØåéē³čÆ·äøęÆčÆ“č½Æå¼ēØåę们č°ēØSystem.gc()čæę ·ē“ę„ē³čÆ·åå¾åę¶ļ¼čęÆčÆ“č½Æå¼ēØä¼č®¾ē½®åÆ¹č±”å¼ēØäøŗnullļ¼čåå¾åę¶åØéåƹčÆ„å¼ēØēčæē§åę³ä¹ä¼ä¼å
ååŗļ¼ę们åÆ仄ēč§£äøŗęÆč½Æå¼ēØåÆ¹č±”åØååå¾åę¶åØåéē³čÆ·ćååŗåæ«å¹¶äø代č”Øåå¾åę¶åØä¼å®ę¶ååŗļ¼čæęÆä¼åØåÆ»ę¾č½Æå¼ēØå¼ēØå°ēåÆ¹č±”ēę¶åéµå¾Ŗäøå®ēåę¶č§åļ¼ååŗåæ«åØčæéēč§£éęÆēøåƹå¼ŗå¼ēØč®¾ē½®åÆ¹č±”äøŗnullļ¼å½č½Æå¼ēØč®¾ē½®åÆ¹č±”äøŗnullēę¶åļ¼čÆ„åÆ¹č±”ēč¢«ę¶éēä¼å
ēŗ§ęÆč¾é«ć
ććå¼±å¼ēØęÆäøē§ęÆč½Æå¼ēØēøåƹå¤ęēå¼ēØļ¼å
¶å®å¼±å¼ēØåč½Æå¼ēØé½ęÆJavaēØåŗåÆ仄ę§å¶ēļ¼ä¹å°±ęÆčÆ“åÆ仄éčæ代ē ē“ę„ä½æå¾å¼ēØéåƹ弱åÆååÆ¹č±”ä»„åč½ÆåÆååÆ¹č±”ęÆåÆå¼ēØēļ¼č½Æå¼ēØåå¼±å¼ēØå¼ēØēåÆ¹č±”å®é
äøéčæäøå®ē代ē ęä½ęÆåÆéę°ęæę“»ēļ¼åŖęÆäøč¬äøä¼åčæę ·ēęä½ļ¼čæę ·ēēØę³čæčäŗęåēč®¾č®”ćå¼±å¼ēØåč½Æå¼ēØåØåå¾åę¶åØēē®ę čå“ęäøē¹ē¹äøåēå°±ęÆļ¼ä½æēØåå¾åę¶ē®ę³ęÆå¾é¾ę¾å°å¼±å¼ēØēļ¼ä¹å°±ęÆčÆ“å¼±å¼ēØēØę„ēę§åå¾åę¶ēę“äøŖęµēØä¹ęÆäøē§å¾å„½ēéę©ļ¼å®äøä¼å½±ååå¾åę¶ēę£åøøęµēØļ¼čæę ·å°±åÆ仄č§čåę“äøŖåÆ¹č±”ä»č®¾ē½®äøŗnulläŗčæåēäøäøŖēå½åØęē代ē ēę§ćčäøå äøŗå¼±å¼ēØęÆå¦ååØåƹåå¾åę¶ę“äøŖęµēØé½äøä¼é ęå½±åļ¼åÆ仄čæę ·č®¤äøŗļ¼åå¾åę¶åØę¾å¾å°å¼±å¼ēØļ¼čÆ„å¼ēØēåÆ¹č±”å°±ä¼č¢«åę¶ļ¼å¦ęę¾äøå°å¼±å¼ēØļ¼äøę¦ēå°GCå®ęäŗåå¾åę¶čæåļ¼å¼±å¼ēØå¼ēØēåÆ¹č±”å ēØēå
åä¹ä¼čŖåØéę¾ļ¼čæå°±ęÆč½Æå¼ēØåØåå¾åę¶čæåēčŖåØē»ę¢ć
ććęåč°č°čå¼ēØļ¼čå¼ēØåŗčÆ„ęÆJVMéé¢ęå害ēäøē§å¼ēØļ¼å®ēå害åØäŗå®åÆ仄åØåÆ¹č±”ēå
åä»ē©ēå
åäøęø
é¤ęäŗčæååå¼ēØčÆ„åÆ¹č±”ļ¼ä¹å°±ęÆčÆ“å½čå¼ēØå¼ēØå°åÆ¹č±”ēę¶åļ¼čæäøŖåÆ¹č±”å®é
å·²ē»ä»ē©ēå
åå äøęø
é¤ęäŗļ¼å¦ęę们äøēØęåØåƹåÆ¹č±”ę»äŗ”ęč
ęæäø“ę»äŗ”čæč”å¤ēēčÆļ¼JVMä¼é»č®¤č°ēØfinalizeå½ę°ļ¼ä½ęÆčå¼ēØååØäŗčÆ„å½ę°éčæēēå½åØęå
ļ¼ę仄åÆ仄ęåØåƹåÆ¹č±”ēčæäøŖčå“ēåØęčæč”ēę§ćå®ä¹ę仄ē§°äøŗāå¹½ēµå¼ēØāå°±ęÆå äøŗčÆ„åÆ¹č±”ēē©ēå
åå·²ē»äøååØēļ¼ęäøŖäŗŗč§å¾JVMäæåäŗäøäøŖåÆ¹č±”ē¶ęēéåē“¢å¼ļ¼ččæäøŖéåē“¢å¼éé¢å
å«äŗåÆ¹č±”åØčæäøŖēå½åØęéč¦ēęęå
容ļ¼čæéēęéč¦å°±ęÆčæäøŖēå½åØęå
éč¦ēåÆ¹č±”ę°ę®å
容ļ¼ä¹å°±ęÆåÆ¹č±”ę»äŗ”åęæäø“ę»äŗ”ä¹åfinalizeå½ę°éčæļ¼č³äŗå¼ŗå¼ēØęéč¦ēå
¶ä»åÆ¹č±”éå å
容ęÆäøéč¦åØčæäøŖéåéé¢å
å«ēļ¼ę仄å³ä½æē©ēå
åäøååØļ¼čæęÆåÆ仄éčæčå¼ēØēę§å°čÆ„åÆ¹č±”ēļ¼åŖęÆčæē§ę
åµęÆå¦åÆ仄让åÆ¹č±”éę°ęæę“»äøŗå¼ŗå¼ēØęå°±äøę¢čÆ“äŗćå äøŗčå¼ēØåØå¼ēØåÆ¹č±”ēčæēØäøä¼å»ä½æå¾čæäøŖåÆ¹č±”ē±Deadå¤ę“»ļ¼čäøčæē§åÆ¹č±”ęÆåÆ仄åØåę¶åØęčæč”åę¶ēćć
Ā
5.ę»ē»ļ¼
ććę¬ē« čäø»č¦ę¶µēäŗJavaéé¢ęÆč¾åŗå±ēäøäøŖē« čļ¼äø»č¦ęÆ仄JVMå
åęØ”åäøŗåŗē”å
ę¬JVMéåƹå
åēēŗæēØęØ”åēę¢č®Ø仄åéåƹJavaéé¢å
åå åę ēčƦē»åęćē¹å«ęč°¢ē½čæę¹åå¦ęä¾ēę±ē¼ę¹é¢å
³äŗęä½ē³»ē»ä»„åå
ååå±ēčµęęä¾ć
ććåčļ¼IBMå¼åäøåæęę”£ļ¼ćInside JVMć

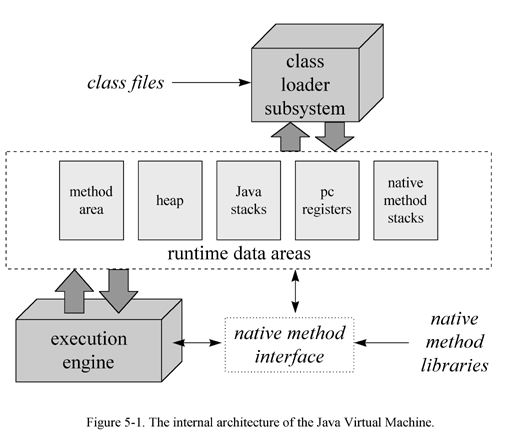
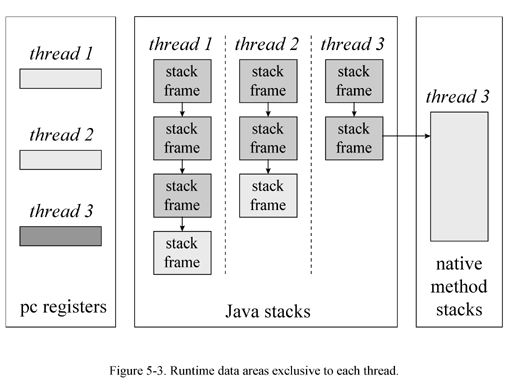
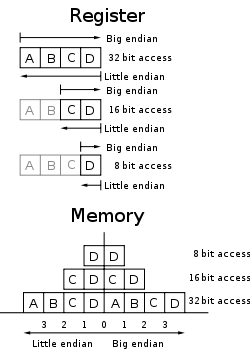


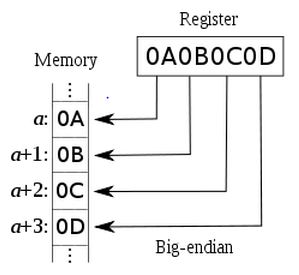





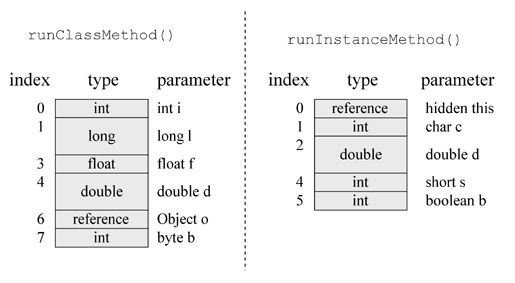
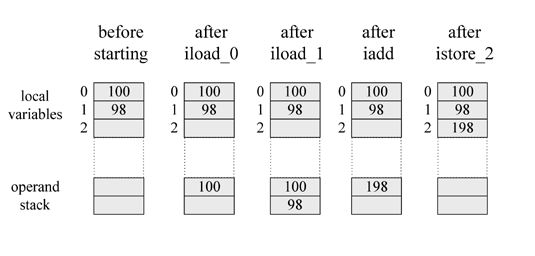
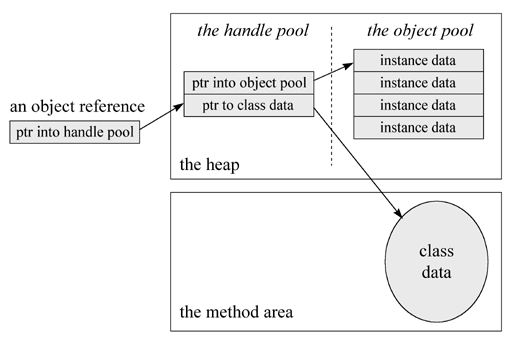
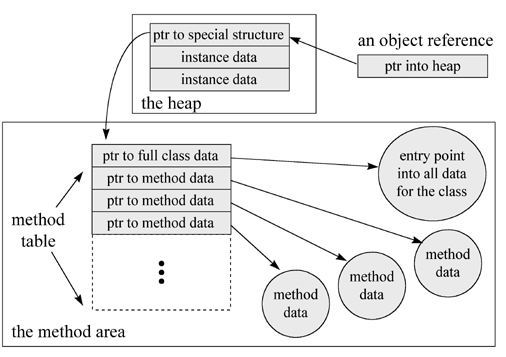
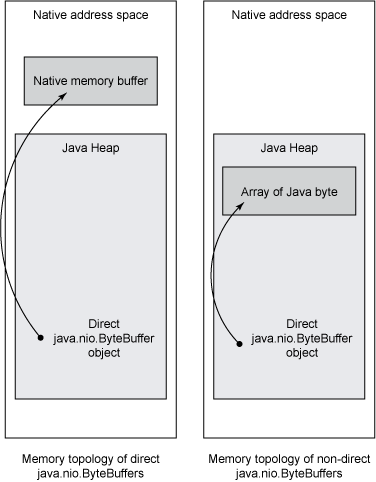



ēøå ³ęØč
Javaå åęØ”åęÆJavačęęŗč§čäøå®ä¹ēäøéØåļ¼å®č§å®äŗJavaēØåŗäøåéēčÆ»åč”äøŗļ¼ä»„åēŗæēØä¹é“ēäŗ¤äŗč§åćēč§£Javaå åęØ”ååƹäŗē¼åę£ē”®ćé«ęēå¤ēŗæēØēØåŗč³å ³éč¦ćåØJava 5ä¹åļ¼Javaå åęØ”åēęčæ°ęÆč¾ęØ”ē³ļ¼...
Javaå åęØ”åļ¼ē®ē§°JMMļ¼Java Memory Modelļ¼ļ¼ęÆJavaē¼ēØčÆčØč§čēäøéØåļ¼å®å®ä¹äŗēØåŗäøåäøŖēŗæēØå¦ä½č®æé®åäæ®ę¹å ±äŗ«åéļ¼ä»„åå¦ä½ē”®äæę°ę®ēäøč“ę§ćę·±å „ēč§£Javaå åęØ”ååƹäŗē¼åé«ęē并åēØåŗč³å ³éč¦ćę¬ę...
Javaå åęØ”åęÆ并åē¼ēØäøäøäøŖč³å ³éč¦ēę¦åæµļ¼å®å®ä¹äŗå ±äŗ«åéēč®æé®č§åļ¼ä»„åčæäŗåéå¦ä½åØå¤ēŗæēØēÆå¢äøčæč”čÆ»åęä½ćåØę·±å „ēč§£Javaå åęØ”åä¹åļ¼ę们éč¦å äŗč§£å¹¶åē¼ēØęØ”åēåē±»ļ¼ē¶åęę”Javaå åęØ”åē...
JavaēØåŗåäŗč§£CPU仄åēøå ³ēå åęØ”åļ¼åƹäŗę·±å „ēč§£Javaå åęØ”å仄å并åē¼ēØč³å ³éč¦ćCPUä½äøŗč®”ē®ęŗē”¬ä»¶ēę øåæļ¼å ¶ę¶ęåå·„ä½åēå½±åēč½Æ件ēę§č½åę§č”ęēćå°¤å ¶åØJavačæē§å¤ēŗæēØćé«å¹¶åēē¼ēØčÆčØäøļ¼åƹCPU...
### Javaå åęØ”åēåå²åčæ #### äøćå¼čØ éēå¤ę øå¤ēåØēę®åäøé«ę§č½č®”ē®éę±ēå¢éæļ¼Javaä½äøŗäø»ęµē¼ēØčÆčØä¹äøļ¼åƹäŗ并åå¤ēēęÆęåå¾č¶ę„č¶éč¦ćJavaå åęØ”åļ¼Java Memory Modelļ¼ē®ē§°JMMļ¼ä½äøŗJava...
Javaå åęØ”åļ¼ē®ē§°JMMļ¼Java Memory Modelļ¼ļ¼ęÆJavaē¼ēØčÆčØč§čēäøéØåļ¼å®å®ä¹äŗēŗæēØå¦ä½å ±äŗ«åč®æé®å åļ¼ä»„ååØå¤ēŗæēØēÆå¢äøå¦ä½äæčÆę°ę®äøč“ę§ćēč§£JMMåƹäŗē¼åé«ęćę£ē”®äøēŗæēØå®å ØēJava代ē č³å ³éč¦ć ...
Javaå åęØ”åļ¼JVM Memory Modelļ¼ē®ē§°JMMļ¼ęÆJavaå¹³å°äøēäøäøŖéč¦ę¦åæµļ¼å®å®ä¹äŗēØåŗäøåäøŖåéēč®æé®č§åļ¼ä»„ååØå¤ēŗæēØēÆå¢äøēå åäøč“ę§ęęćJMMäø»č¦č§£å³ēęÆ并åēÆå¢äøäøåēŗæēØä¹é“å¦ä½å ±äŗ«ę°ę®ä»„åå¦ä½äæčÆ...
čæäŗęę”£å¦"Javaå åęØ”å.docx"ć"Javaå åęØ”å2.docx"ć"ę·±å „Javaę øåæ Javaå ååé åēē²¾č®².docx"ć"javaå åęØ”å.pdf"å°ę·±å „ę¢č®Øčæäŗę¦åæµļ¼åø®å©å¼åč ę“ę·±å „å°ēč§£Javaå åęØ”ååå ¶åØå®é ē¼ēØäøēåŗēØć...
Javaå åęØ”åčÆ¦č§£JMM Javaå åęØ”åļ¼Java Memory Modelļ¼JMMļ¼ęÆJavačęęŗļ¼JVMļ¼äøēäøē§å åęØ”åļ¼å®ęčæ°äŗēØåŗäøåäøŖåéä¹é“ēå ³ē³»ļ¼ä»„ååØå®é č®”ē®ęŗē³»ē»äøå°åéååØå°å ååä»å åäøååŗåéčæę ·ēåŗå±ē»č...
java å åęØ”å java å åęØ”å java å åęØ”å java å åęØ”å
Javaå åęØ”åļ¼Java Memory Modelļ¼ē®ē§°JMMļ¼ęÆJavačęęŗļ¼JVMļ¼č§čäøå®ä¹ēäøē§å åęØ”åļ¼å®ę¶åäŗēŗæēØä¹é“å ±äŗ«åéēåÆč§ę§é®é¢ćåØ并åē¼ēØäøļ¼ēč§£Javaå åęØ”ååƹäŗē¼åę£ē”®ēå¤ēŗæēØēØåŗč³å ³éč¦ć é¦å ļ¼...
Javaå åęØ”åļ¼Java Memory Modelļ¼JMMļ¼ęÆJavaå¹³å°äøéåøøå ³é®ēę¦åæµļ¼å®å®ä¹äŗēŗæēØå¦ä½å ±äŗ«åč®æé®å åäøēę°ę®ļ¼ä»„ååØå¤ēŗæēØēÆå¢äøå¦ä½äæčÆę°ę®ēäøč“ę§ćčæę¬ä¹¦"ę·±å „ēč§£Javaå åęØ”å"ę¾ē¶ęÆäøŗäŗåø®å©čÆ»č ę·±å „ę¢č®Ø...
### Javaå åęØ”åčÆ¦č§£ #### 1. JMMē®ä» ##### i. å åęØ”åę¦čæ° Javaå åęØ”åļ¼Java Memory Model, JMMļ¼ęÆJavačęęŗļ¼JVMļ¼ēäøéØåļ¼ēØäŗč§å®ēØåŗäøēåē§åéļ¼å ę¬å®ä¾åꮵćéęåꮵåę°ē»å ē“ ēļ¼åØå¤äøŖ...
Javaå åęØ”åļ¼JMMļ¼ęÆJavačęęŗļ¼JVMļ¼ēäøéØåļ¼å®å®ä¹äŗēØåŗäøäøååéå¦ä½äŗ¤äŗļ¼ē¹å«ęÆåØå¤ēŗæēØēÆå¢äøćJMMē”®äæäŗåØåē§ē”¬ä»¶åęä½ē³»ē»å¹³å°äøļ¼JavaēØåŗēč”äøŗå ·ęäøč“ę§ååÆé¢ęµę§ćJavaå åęØ”åēäø»č¦ē®ę ęÆ...
Java å åęØ”åļ¼Java Memory Modelļ¼ē®ē§° JMMļ¼ęÆ Java å¹³å°äøå ³äŗēŗæēØå¦ä½č®æé®å ±äŗ«åéēäøå„č§åļ¼å®å®ä¹äŗēŗæēØä¹é“ēå ååÆč§ę§ćę°ę®äøč“ę§ä»„åę令éęåŗēå ³é®ę¦åæµļ¼åƹäŗå¤ēŗæēØē¼ēØå并åę§č½ä¼åč³å ³éč¦ć...
JavaēŗæēØä¹é“ēéäæ”ē±Javaå åęØ”åļ¼ę¬ęē®ē§°äøŗJMMļ¼ę§å¶ļ¼JMMå³å®äøäøŖēŗæēØåÆ¹å ±äŗ«åéēåå „ä½ę¶åƹå¦äøäøŖēŗæēØåÆč§ćä»ę½č±”ēč§åŗ¦ę„ēļ¼JMMå®ä¹äŗēŗæēØåäø»å åä¹é“ēę½č±”å ³ē³»ļ¼ēŗæēØä¹é“ēå ±äŗ«åéååØåØäø»å åļ¼main ...
Java å åęØ”åēę½č±” 4 éęåŗ 6 å¤ēåØéęåŗäøå åå±éę令 7 happens-before 10 éęåŗ 13 ę°ę®ä¾čµę§ 13 as-if-serial čÆä¹ 13 ēØåŗé”ŗåŗč§å 15 éęåŗåƹå¤ēŗæēØēå½±å 15 é”ŗåŗäøč“ę§ 19 ę°ę®ē«äŗäøé”ŗåŗ...