NFAеј•ж“ҺеҢ№й…ҚеҺҹзҗҶ
1 дёәд»Җд№ҲиҰҒдәҶи§Јеј•ж“ҺеҢ№й…ҚеҺҹзҗҶ
дёҖдёӘдёӘйҹіз¬ҰжқӮд№ұж— з« зҡ„з»„еҗҲеңЁдёҖиө·пјҢеј№еҘҸеҮәзҡ„жҲ–и®ёе°ұжҳҜеҷӘйҹіпјҢеҗҢж ·зҡ„йҹіз¬Ұз»ҸиҝҮдҪңжӣІе®¶зҡ„жүӢпјҢе°ұеҸҜд»Ҙи°ұеҮәйқһеёёеҠЁеҗ¬зҡ„д№җжӣІпјҢдёҖдёӘжј”еҘҸиҖ…еҗҢж ·еҸҜд»Ҙз…§зқҖд№җи°ұеҘҸеҮәеҠЁеҗ¬зҡ„д№җжӣІпјҢдҪҶд»–/еҘ№жҲ–и®ёдёҚзҹҘйҒ“иҜҘеҰӮдҪ•еҺ»ж”№еҸҳйҹіз¬Ұзҡ„з»„еҗҲпјҢдҪҝеҫ—д№җжӣІжӣҙеҠЁеҗ¬гҖӮ
дҪңдёәжӯЈеҲҷзҡ„дҪҝз”ЁиҖ…д№ҹдёҖж ·пјҢдёҚжҮӮжӯЈеҲҷеј•ж“ҺеҺҹзҗҶзҡ„жғ…еҶөдёӢпјҢеҗҢж ·еҸҜд»ҘеҶҷеҮәж»Ўи¶ійңҖжұӮзҡ„жӯЈеҲҷпјҢдҪҶжҳҜдёҚзҹҘйҒ“еҺҹзҗҶпјҢеҚҙеҫҲйҡҫеҶҷеҮәй«ҳж•Ҳдё”жІЎжңүйҡҗжӮЈзҡ„жӯЈеҲҷгҖӮжүҖд»ҘеҜ№дәҺз»ҸеёёдҪҝз”ЁжӯЈеҲҷпјҢжҲ–жҳҜжңүе…ҙи¶Јж·ұе…ҘеӯҰд№ жӯЈеҲҷзҡ„дәәпјҢиҝҳжҳҜжңүеҝ…иҰҒдәҶи§ЈдёҖдёӢжӯЈеҲҷеј•ж“Һзҡ„еҢ№й…ҚеҺҹзҗҶзҡ„гҖӮ
2 жӯЈеҲҷиЎЁиҫҫејҸеј•ж“Һ
жӯЈеҲҷеј•ж“ҺеӨ§дҪ“дёҠеҸҜеҲҶдёәдёҚеҗҢзҡ„дёӨзұ»пјҡDFAе’ҢNFAпјҢиҖҢNFAеҸҲеҹәжң¬дёҠеҸҜд»ҘеҲҶдёәдј з»ҹеһӢNFAе’ҢPOSIX NFAгҖӮ
DFADeterministic finite automaton зЎ®е®ҡеһӢжңүз©·иҮӘеҠЁжңә
NFA Non-deterministic finite automatonгҖҖйқһзЎ®е®ҡеһӢжңүз©·иҮӘеҠЁжңә
Traditional NFA
POSIX NFA
DFAеј•ж“Һеӣ дёәдёҚйңҖиҰҒеӣһжәҜпјҢжүҖд»ҘеҢ№й…Қеҝ«йҖҹпјҢдҪҶдёҚж”ҜжҢҒжҚ•иҺ·з»„пјҢжүҖд»Ҙд№ҹе°ұдёҚж”ҜжҢҒеҸҚеҗ‘еј•з”Ёе’Ң$numberиҝҷз§Қеј•з”Ёж–№ејҸпјҢзӣ®еүҚдҪҝз”ЁDFAеј•ж“Һзҡ„иҜӯиЁҖе’Ңе·Ҙе…·дё»иҰҒжңүawkгҖҒegrepе’Ң lexгҖӮ
POSIX NFAдё»иҰҒжҢҮз¬ҰеҗҲPOSIXж ҮеҮҶзҡ„NFAеј•ж“ҺпјҢе®ғзҡ„зү№зӮ№дё»иҰҒжҳҜжҸҗдҫӣlongest-leftmostеҢ№й…ҚпјҢд№ҹе°ұжҳҜеңЁжүҫеҲ°жңҖе·Ұдҫ§жңҖй•ҝеҢ№й…Қд№ӢеүҚпјҢе®ғе°Ҷ继з»ӯеӣһжәҜгҖӮеҗҢDFAдёҖж ·пјҢйқһиҙӘе©ӘжЁЎејҸжҲ–иҖ…иҜҙеҝҪз•Ҙдјҳе…ҲйҮҸиҜҚеҜ№дәҺPOSIX NFAеҗҢж ·жҳҜжІЎжңүж„Ҹд№үзҡ„гҖӮ
еӨ§еӨҡж•°иҜӯиЁҖе’Ңе·Ҙе…·дҪҝз”Ёзҡ„жҳҜдј з»ҹеһӢзҡ„NFAеј•ж“ҺпјҢе®ғжңүдёҖдәӣDFAдёҚж”ҜжҢҒзҡ„зү№жҖ§пјҡ
гҖҖгҖҖжҚ•иҺ·з»„гҖҒеҸҚеҗ‘еј•з”Ёе’Ң$numberеј•з”Ёж–№ејҸпјӣ
гҖҖгҖҖзҺҜи§Ҷ(LookaroundпјҢ(?<=вҖҰ)гҖҒ(?<!вҖҰ)гҖҒ(?=вҖҰ)гҖҒ(?!вҖҰ))пјҢжҲ–иҖ…жңүзҡ„жңүж–Үз« еҸ«еҒҡйў„жҗңзҙўпјӣ
гҖҖгҖҖеҝҪз•ҘдјҳеҢ–йҮҸиҜҚпјҲ??гҖҒ*?гҖҒ+?гҖҒ{m,n}?гҖҒ{m,}?пјүпјҢжҲ–иҖ…жңүзҡ„ж–Үз« еҸ«еҒҡйқһиҙӘе©ӘжЁЎејҸпјӣ
гҖҖгҖҖеҚ жңүдјҳе…ҲйҮҸиҜҚпјҲ?+гҖҒ*+гҖҒ++гҖҒ{m,n}+гҖҒ{m,}+пјҢзӣ®еүҚд»…Javaе’ҢPCREж”ҜжҢҒпјүпјҢеӣәеҢ–еҲҶз»„(?>вҖҰ)гҖӮ
еј•ж“Һй—ҙзҡ„еҢәеҲ«дёҚжҳҜжң¬ж–Үзҡ„йҮҚзӮ№пјҢд»…еҒҡз®ҖиҰҒзҡ„д»Ӣз»ҚпјҢжңүе…ҙи¶Јзҡ„еҸҜеҸӮиҖғзӣёе…іж–ҮзҢ®гҖӮ
3 йў„еӨҮзҹҘиҜҶ
3.1 еӯ—з¬ҰдёІз»„жҲҗ
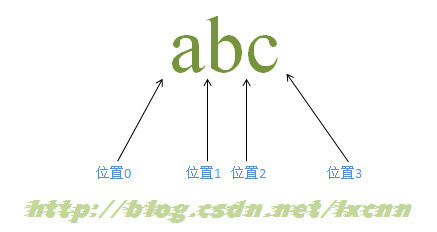
еҜ№дәҺеӯ—з¬ҰдёІвҖңabcвҖқиҖҢиЁҖпјҢеҢ…жӢ¬дёүдёӘеӯ—з¬Ұе’ҢеӣӣдёӘдҪҚзҪ®гҖӮ
3.2 еҚ жңүеӯ—з¬Ұе’Ңйӣ¶е®ҪеәҰ
жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…ҚиҝҮзЁӢдёӯпјҢеҰӮжһңеӯҗиЎЁиҫҫејҸеҢ№й…ҚеҲ°зҡ„жҳҜеӯ—з¬ҰеҶ…е®№пјҢиҖҢйқһдҪҚзҪ®пјҢ并被дҝқеӯҳеҲ°жңҖз»Ҳзҡ„еҢ№й…Қз»“жһңдёӯпјҢйӮЈд№Ҳе°ұи®ӨдёәиҝҷдёӘеӯҗиЎЁиҫҫејҸжҳҜеҚ жңүеӯ—з¬Ұзҡ„пјӣеҰӮжһңеӯҗиЎЁиҫҫејҸеҢ№й…Қзҡ„д»…д»…жҳҜдҪҚзҪ®пјҢжҲ–иҖ…еҢ№й…Қзҡ„еҶ…容并дёҚдҝқеӯҳеҲ°жңҖз»Ҳзҡ„еҢ№й…Қз»“жһңдёӯпјҢйӮЈд№Ҳе°ұи®ӨдёәиҝҷдёӘеӯҗиЎЁиҫҫејҸжҳҜйӣ¶е®ҪеәҰзҡ„гҖӮ
еҚ жңүеӯ—з¬ҰжҳҜдә’ж–Ҙзҡ„пјҢйӣ¶е®ҪеәҰжҳҜйқһдә’ж–Ҙзҡ„гҖӮд№ҹе°ұжҳҜдёҖдёӘеӯ—з¬ҰпјҢеҗҢдёҖж—¶й—ҙеҸӘиғҪз”ұдёҖдёӘеӯҗиЎЁиҫҫејҸеҢ№й…ҚпјҢиҖҢдёҖдёӘдҪҚзҪ®пјҢеҚҙеҸҜд»ҘеҗҢж—¶з”ұеӨҡдёӘйӣ¶е®ҪеәҰзҡ„еӯҗиЎЁиҫҫејҸеҢ№й…ҚгҖӮ
3.3 жҺ§еҲ¶жқғе’Ңдј еҠЁ
жӯЈеҲҷзҡ„еҢ№й…ҚиҝҮзЁӢпјҢйҖҡеёёжғ…еҶөдёӢйғҪжҳҜз”ұдёҖдёӘеӯҗиЎЁиҫҫејҸпјҲеҸҜиғҪдёәдёҖдёӘжҷ®йҖҡеӯ—з¬ҰгҖҒе…ғеӯ—з¬ҰжҲ–е…ғеӯ—з¬ҰеәҸеҲ—з»„жҲҗпјүеҸ–еҫ—жҺ§еҲ¶жқғпјҢд»Һеӯ—з¬ҰдёІзҡ„жҹҗдёҖдҪҚзҪ®ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢдёҖдёӘеӯҗиЎЁиҫҫејҸејҖе§Ӣе°қиҜ•еҢ№й…Қзҡ„дҪҚзҪ®пјҢжҳҜд»ҺеүҚдёҖеӯҗиЎЁиҫҫеҢ№й…ҚжҲҗеҠҹзҡ„з»“жқҹдҪҚзҪ®ејҖе§Ӣзҡ„гҖӮеҰӮжӯЈеҲҷиЎЁиҫҫејҸпјҡ
(еӯҗиЎЁиҫҫејҸдёҖ)(еӯҗиЎЁиҫҫејҸдәҢ)
еҒҮи®ҫ(еӯҗиЎЁиҫҫејҸдёҖ)дёәйӣ¶е®ҪеәҰиЎЁиҫҫејҸпјҢз”ұдәҺе®ғеҢ№й…ҚејҖе§Ӣе’Ңз»“жқҹзҡ„дҪҚзҪ®жҳҜеҗҢдёҖдёӘпјҢеҰӮдҪҚзҪ®0пјҢйӮЈд№Ҳ(еӯҗиЎЁиҫҫејҸдәҢ)жҳҜд»ҺдҪҚзҪ®0ејҖе§Ӣе°қиҜ•еҢ№й…Қзҡ„гҖӮ
еҒҮи®ҫ(еӯҗиЎЁиҫҫејҸдёҖ)дёәеҚ жңүеӯ—з¬Ұзҡ„иЎЁиҫҫејҸпјҢз”ұдәҺе®ғеҢ№й…ҚејҖе§Ӣе’Ңз»“жқҹзҡ„дҪҚзҪ®дёҚжҳҜеҗҢдёҖдёӘпјҢеҰӮеҢ№й…ҚжҲҗеҠҹејҖе§ӢдәҺдҪҚзҪ®0пјҢз»“жқҹдәҺдҪҚзҪ®2пјҢйӮЈд№Ҳ(еӯҗиЎЁиҫҫејҸдәҢ)жҳҜд»ҺдҪҚзҪ®2ејҖе§Ӣе°қиҜ•еҢ№й…Қзҡ„гҖӮ
иҖҢеҜ№дәҺж•ҙдёӘиЎЁиҫҫејҸжқҘиҜҙпјҢйҖҡеёёжҳҜз”ұеӯ—з¬ҰдёІдҪҚзҪ®0ејҖе§Ӣе°қиҜ•еҢ№й…Қзҡ„гҖӮеҰӮжһңеңЁдҪҚзҪ®0ејҖе§Ӣзҡ„е°қиҜ•пјҢеҢ№й…ҚеҲ°еӯ—з¬ҰдёІжҹҗдёҖдҪҚзҪ®ж—¶ж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеӨұиҙҘпјҢйӮЈд№Ҳеј•ж“ҺдјҡдҪҝжӯЈеҲҷеҗ‘еүҚдј еҠЁпјҢж•ҙдёӘиЎЁиҫҫејҸд»ҺдҪҚзҪ®1ејҖе§ӢйҮҚж–°е°қиҜ•еҢ№й…ҚпјҢдҫқжӯӨзұ»жҺЁпјҢзӣҙеҲ°жҠҘе‘ҠеҢ№й…ҚжҲҗеҠҹжҲ–е°қиҜ•еҲ°жңҖеҗҺдёҖдёӘдҪҚзҪ®еҗҺжҠҘе‘ҠеҢ№й…ҚеӨұиҙҘгҖӮ
4 жӯЈеҲҷиЎЁиҫҫејҸз®ҖеҚ•еҢ№жң¬иҝҮзЁӢ
4.1 еҹәзЎҖеҢ№й…ҚиҝҮзЁӢ
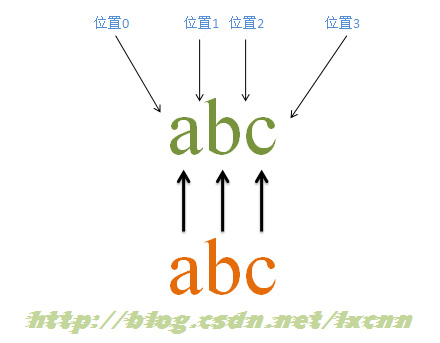
жәҗеӯ—з¬ҰдёІпјҡabc
жӯЈеҲҷиЎЁиҫҫејҸпјҡabc
еҢ№й…ҚиҝҮзЁӢпјҡ
йҰ–е…Ҳз”ұеӯ—з¬ҰвҖңaвҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢд»ҺдҪҚзҪ®0ејҖе§ӢеҢ№й…ҚпјҢз”ұвҖңaвҖқжқҘеҢ№й…ҚвҖңaвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷеӯ—з¬ҰвҖңbвҖқпјӣз”ұдәҺвҖңaвҖқе·Іиў«вҖңaвҖқеҢ№й…ҚпјҢжүҖд»ҘвҖңbвҖқд»ҺдҪҚзҪ®1ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢз”ұвҖңbвҖқжқҘеҢ№й…ҚвҖңbвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖңcвҖқпјӣз”ұвҖңcвҖқжқҘеҢ№й…ҚвҖңcвҖқпјҢеҢ№й…ҚжҲҗеҠҹгҖӮ
жӯӨж—¶жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе®ҢжҲҗпјҢжҠҘе‘ҠеҢ№й…ҚжҲҗеҠҹгҖӮеҢ№й…Қз»“жһңдёәвҖңabcвҖқпјҢејҖе§ӢдҪҚзҪ®дёә0пјҢз»“жқҹдҪҚзҪ®дёә3гҖӮ
4.2 еҗ«жңүеҢ№й…Қдјҳе…ҲйҮҸиҜҚзҡ„еҢ№й…ҚиҝҮзЁӢвҖ”вҖ”еҢ№й…ҚжҲҗеҠҹпјҲдёҖпјү
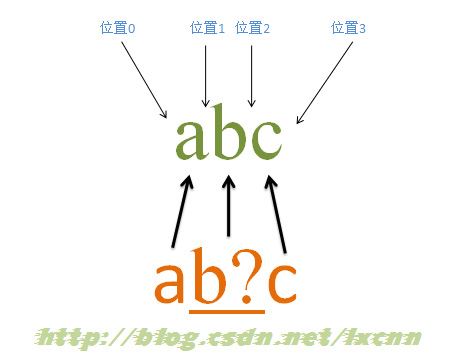
жәҗеӯ—з¬ҰдёІпјҡabc
жӯЈеҲҷиЎЁиҫҫејҸпјҡab?c
йҮҸиҜҚвҖң?вҖқеұһдәҺеҢ№й…Қдјҳе…ҲйҮҸиҜҚпјҢеңЁеҸҜеҢ№й…ҚеҸҜдёҚеҢ№й…Қж—¶пјҢдјҡе…ҲйҖүжӢ©е°қиҜ•еҢ№й…ҚпјҢеҸӘжңүиҝҷз§ҚйҖүжӢ©дјҡдҪҝж•ҙдёӘиЎЁиҫҫејҸж— жі•еҢ№й…ҚжҲҗеҠҹж—¶пјҢжүҚдјҡе°қиҜ•и®©еҮәеҢ№й…ҚеҲ°зҡ„еҶ…е®№гҖӮиҝҷйҮҢзҡ„йҮҸиҜҚвҖң?вҖқжҳҜз”ЁжқҘдҝ®йҘ°еӯ—з¬ҰвҖңbвҖқзҡ„пјҢжүҖд»ҘвҖңb?вҖқжҳҜдёҖдёӘж•ҙдҪ“гҖӮ
еҢ№й…ҚиҝҮзЁӢпјҡ
йҰ–е…Ҳз”ұеӯ—з¬ҰвҖңaвҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢд»ҺдҪҚзҪ®0ејҖе§ӢеҢ№й…ҚпјҢз”ұвҖңaвҖқжқҘеҢ№й…ҚвҖңaвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷеӯ—з¬ҰвҖңb?вҖқпјӣз”ұдәҺвҖң?вҖқжҳҜеҢ№й…Қдјҳе…ҲйҮҸиҜҚпјҢжүҖд»Ҙдјҡе…Ҳе°қиҜ•иҝӣиЎҢеҢ№й…ҚпјҢз”ұвҖңb?вҖқжқҘеҢ№й…ҚвҖңbвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖңcвҖқпјҢеҗҢж—¶и®°еҪ•дёҖдёӘеӨҮйҖүзҠ¶жҖҒпјӣз”ұвҖңcвҖқжқҘеҢ№й…ҚвҖңcвҖқпјҢеҢ№й…ҚжҲҗеҠҹгҖӮи®°еҪ•зҡ„еӨҮйҖүзҠ¶жҖҒдёўејғгҖӮ
жӯӨж—¶жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе®ҢжҲҗпјҢжҠҘе‘ҠеҢ№й…ҚжҲҗеҠҹгҖӮеҢ№й…Қз»“жһңдёәвҖңabcвҖқпјҢејҖе§ӢдҪҚзҪ®дёә0пјҢз»“жқҹдҪҚзҪ®дёә3гҖӮ
4.3 еҗ«жңүеҢ№й…Қдјҳе…ҲйҮҸиҜҚзҡ„еҢ№й…ҚиҝҮзЁӢвҖ”вҖ”еҢ№й…ҚжҲҗеҠҹпјҲдәҢпјү
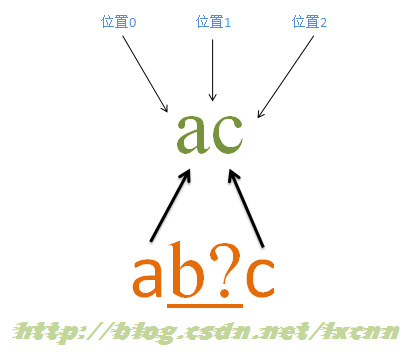
жәҗеӯ—з¬ҰдёІпјҡac
жӯЈеҲҷиЎЁиҫҫејҸпјҡab?c
еҢ№й…ҚиҝҮзЁӢпјҡ
йҰ–е…Ҳз”ұеӯ—з¬ҰвҖңaвҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢд»ҺдҪҚзҪ®0ејҖе§ӢеҢ№й…ҚпјҢз”ұвҖңaвҖқжқҘеҢ№й…ҚвҖңaвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷеӯ—з¬ҰвҖңb?вҖқпјӣе…Ҳе°қиҜ•иҝӣиЎҢеҢ№й…ҚпјҢз”ұвҖңb?вҖқжқҘеҢ№й…ҚвҖңcвҖқпјҢеҗҢж—¶и®°еҪ•дёҖдёӘеӨҮйҖүзҠ¶жҖҒпјҢеҢ№й…ҚеӨұиҙҘпјҢжӯӨж—¶иҝӣиЎҢеӣһжәҜпјҢжүҫеҲ°еӨҮйҖүзҠ¶жҖҒпјҢвҖңb?вҖқеҝҪз•ҘеҢ№й…ҚпјҢи®©еҮәжҺ§еҲ¶жқғпјҢжҠҠжҺ§еҲ¶жқғдәӨз»ҷвҖңcвҖқпјӣз”ұвҖңcвҖқжқҘеҢ№й…ҚвҖңcвҖқпјҢеҢ№й…ҚжҲҗеҠҹгҖӮ
жӯӨж—¶жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе®ҢжҲҗпјҢжҠҘе‘ҠеҢ№й…ҚжҲҗеҠҹгҖӮеҢ№й…Қз»“жһңдёәвҖңacвҖқпјҢејҖе§ӢдҪҚзҪ®дёә0пјҢз»“жқҹдҪҚзҪ®дёә2гҖӮе…¶дёӯвҖңb?вҖқдёҚеҢ№й…Қд»»дҪ•еҶ…е®№гҖӮ
4.4 еҗ«жңүеҢ№й…Қдјҳе…ҲйҮҸиҜҚзҡ„еҢ№й…ҚиҝҮзЁӢвҖ”вҖ”еҢ№й…ҚеӨұиҙҘ
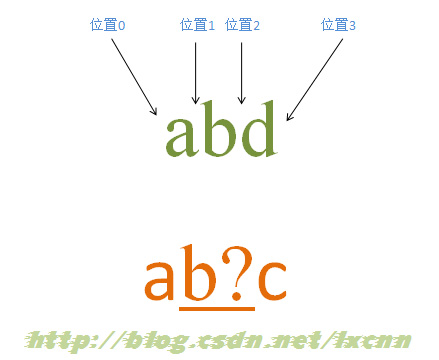
жәҗеӯ—з¬ҰдёІпјҡabd
жӯЈеҲҷиЎЁиҫҫејҸпјҡab?c
еҢ№й…ҚиҝҮзЁӢпјҡ
йҰ–е…Ҳз”ұеӯ—з¬ҰвҖңaвҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢд»ҺдҪҚзҪ®0ејҖе§ӢеҢ№й…ҚпјҢз”ұвҖңaвҖқжқҘеҢ№й…ҚвҖңaвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷеӯ—з¬ҰвҖңb?вҖқпјӣе…Ҳе°қиҜ•иҝӣиЎҢеҢ№й…ҚпјҢз”ұвҖңb?вҖқжқҘеҢ№й…ҚвҖңbвҖқпјҢеҗҢж—¶и®°еҪ•дёҖдёӘеӨҮйҖүзҠ¶жҖҒпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖңcвҖқпјӣз”ұвҖңcвҖқжқҘеҢ№й…ҚвҖңdвҖқпјҢеҢ№й…ҚеӨұиҙҘпјҢжӯӨж—¶иҝӣиЎҢеӣһжәҜпјҢжүҫеҲ°и®°еҪ•зҡ„еӨҮйҖүзҠ¶жҖҒпјҢвҖңb?вҖқеҝҪз•ҘеҢ№й…ҚпјҢеҚівҖңb?вҖқдёҚеҢ№й…ҚвҖңbвҖқпјҢи®©еҮәжҺ§еҲ¶жқғпјҢжҠҠжҺ§еҲ¶жқғдәӨз»ҷвҖңcвҖқпјӣз”ұвҖңcвҖқжқҘеҢ№й…ҚвҖңbвҖқпјҢеҢ№й…ҚеӨұиҙҘгҖӮжӯӨ时第дёҖиҪ®еҢ№й…Қе°қиҜ•еӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“ҺдҪҝжӯЈеҲҷеҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®1ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢз”ұвҖңaвҖқжқҘеҢ№й…ҚвҖңbвҖқпјҢеҢ№й…ҚеӨұиҙҘпјҢжІЎжңүеӨҮйҖүзҠ¶жҖҒпјҢ第дәҢиҪ®еҢ№й…Қе°қиҜ•еӨұиҙҘгҖӮ
继з»ӯеҗ‘еүҚдј еҠЁпјҢзӣҙеҲ°еңЁдҪҚзҪ®3е°қиҜ•еҢ№й…ҚеӨұиҙҘпјҢеҢ№й…Қз»“жқҹгҖӮжӯӨж—¶жҠҘе‘Ҡж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеӨұиҙҘгҖӮ
4.5 еҗ«жңүеҝҪз•Ҙдјҳе…ҲйҮҸиҜҚзҡ„еҢ№й…ҚиҝҮзЁӢвҖ”вҖ”еҢ№й…ҚжҲҗеҠҹ
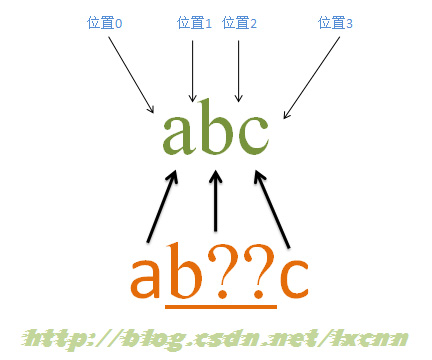
жәҗеӯ—з¬ҰдёІпјҡabc
жӯЈеҲҷиЎЁиҫҫејҸпјҡab??c
йҮҸиҜҚвҖң??вҖқеұһдәҺеҝҪз•Ҙдјҳе…ҲйҮҸиҜҚпјҢеңЁеҸҜеҢ№й…ҚеҸҜдёҚеҢ№й…Қж—¶пјҢдјҡе…ҲйҖүжӢ©дёҚеҢ№й…ҚпјҢеҸӘжңүиҝҷз§ҚйҖүжӢ©дјҡдҪҝж•ҙдёӘиЎЁиҫҫејҸж— жі•еҢ№й…ҚжҲҗеҠҹж—¶пјҢжүҚдјҡе°қиҜ•иҝӣиЎҢеҢ№й…ҚгҖӮиҝҷйҮҢзҡ„йҮҸиҜҚвҖң??вҖқжҳҜз”ЁжқҘдҝ®йҘ°еӯ—з¬ҰвҖңbвҖқзҡ„пјҢжүҖд»ҘвҖңb??вҖқжҳҜдёҖдёӘж•ҙдҪ“гҖӮ
еҢ№й…ҚиҝҮзЁӢпјҡ
йҰ–е…Ҳз”ұеӯ—з¬ҰвҖңaвҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢд»ҺдҪҚзҪ®0ејҖе§ӢеҢ№й…ҚпјҢз”ұвҖңaвҖқжқҘеҢ№й…ҚвҖңaвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷеӯ—з¬ҰвҖңb??вҖқпјӣе…Ҳе°қиҜ•еҝҪз•ҘеҢ№й…ҚпјҢеҚівҖңb??вҖқдёҚиҝӣиЎҢеҢ№й…ҚпјҢеҗҢж—¶и®°еҪ•дёҖдёӘеӨҮйҖүзҠ¶жҖҒпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖңcвҖқпјӣз”ұвҖңcвҖқжқҘеҢ№й…ҚвҖңbвҖқпјҢеҢ№й…ҚеӨұиҙҘпјҢжӯӨж—¶иҝӣиЎҢеӣһжәҜпјҢжүҫеҲ°и®°еҪ•зҡ„еӨҮйҖүзҠ¶жҖҒпјҢвҖңb??вҖқе°қиҜ•еҢ№й…ҚпјҢеҚівҖңb??вҖқжқҘеҢ№й…ҚвҖңbвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҠҠжҺ§еҲ¶жқғдәӨз»ҷвҖңcвҖқпјӣз”ұвҖңcвҖқжқҘеҢ№й…ҚвҖңcвҖқпјҢеҢ№й…ҚжҲҗеҠҹгҖӮ
жӯӨж—¶жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе®ҢжҲҗпјҢжҠҘе‘ҠеҢ№й…ҚжҲҗеҠҹгҖӮеҢ№й…Қз»“жһңдёәвҖңabcвҖқпјҢејҖе§ӢдҪҚзҪ®дёә0пјҢз»“жқҹдҪҚзҪ®дёә3гҖӮе…¶дёӯвҖңb??вҖқеҢ№й…Қеӯ—з¬ҰвҖңbвҖқгҖӮ
4.6 йӣ¶е®ҪеәҰеҢ№й…ҚиҝҮзЁӢ
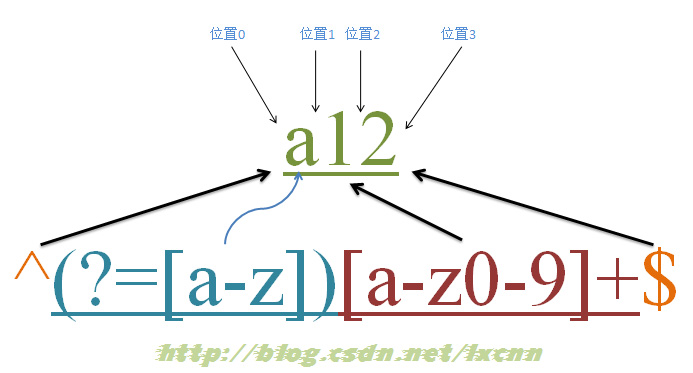
жәҗеӯ—з¬ҰдёІпјҡa12
жӯЈеҲҷиЎЁиҫҫејҸпјҡ^(?=[a-z])[a-z0-9]+$
е…ғеӯ—з¬ҰвҖң^вҖқе’ҢвҖң$вҖқеҢ№й…Қзҡ„еҸӘжҳҜдҪҚзҪ®пјҢйЎәеәҸзҺҜи§ҶвҖң(?=[a-z])вҖқеҸӘиҝӣиЎҢеҢ№й…ҚпјҢ并дёҚеҚ жңүеӯ—з¬ҰпјҢд№ҹдёҚе°ҶеҢ№й…Қзҡ„еҶ…е®№дҝқеӯҳеҲ°жңҖз»Ҳзҡ„еҢ№й…Қз»“жһңпјҢжүҖд»ҘйғҪжҳҜйӣ¶е®ҪеәҰзҡ„гҖӮ
иҝҷдёӘжӯЈеҲҷзҡ„ж„Ҹд№үе°ұжҳҜеҢ№й…Қз”ұеӯ—жҜҚжҲ–ж•°еӯ—з»„жҲҗзҡ„пјҢ第дёҖдёӘеӯ—з¬ҰжҳҜеӯ—жҜҚзҡ„еӯ—з¬ҰдёІгҖӮ
еҢ№й…ҚиҝҮзЁӢпјҡ
йҰ–е…Ҳз”ұе…ғеӯ—з¬ҰвҖң^вҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢд»ҺдҪҚзҪ®0ејҖе§ӢеҢ№й…ҚпјҢвҖң^вҖқеҢ№й…Қзҡ„е°ұжҳҜејҖе§ӢдҪҚзҪ®вҖңдҪҚзҪ®0вҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷйЎәеәҸзҺҜи§ҶвҖң(?=[a-z])вҖқпјӣ
вҖң(?=[a-z])вҖқиҰҒжұӮе®ғжүҖеңЁдҪҚзҪ®еҸідҫ§еҝ…йЎ»жҳҜеӯ—жҜҚжүҚиғҪеҢ№й…ҚжҲҗеҠҹпјҢйӣ¶е®ҪеәҰзҡ„еӯҗиЎЁиҫҫејҸд№Ӣй—ҙжҳҜдёҚдә’ж–Ҙзҡ„пјҢеҚіеҗҢдёҖдёӘдҪҚзҪ®еҸҜд»ҘеҗҢж—¶з”ұеӨҡдёӘйӣ¶е®ҪеәҰеӯҗиЎЁиҫҫејҸеҢ№й…ҚпјҢжүҖд»Ҙе®ғд№ҹжҳҜд»ҺдҪҚзҪ®0е°қиҜ•иҝӣиЎҢеҢ№й…ҚпјҢдҪҚзҪ®0зҡ„еҸідҫ§жҳҜеӯ—з¬ҰвҖңaвҖқпјҢз¬ҰеҗҲиҰҒжұӮпјҢеҢ№й…ҚжҲҗеҠҹпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң[a-z0-9]+вҖқпјӣ
еӣ дёәвҖң(?=[a-z])вҖқеҸӘиҝӣиЎҢеҢ№й…ҚпјҢ并дёҚе°ҶеҢ№й…ҚеҲ°зҡ„еҶ…е®№дҝқеӯҳеҲ°жңҖеҗҺз»“жһңпјҢ并且вҖң(?=[a-z])вҖқеҢ№й…ҚжҲҗеҠҹзҡ„дҪҚзҪ®жҳҜдҪҚзҪ®0пјҢжүҖд»ҘвҖң[a-z0-9]+вҖқд№ҹжҳҜд»ҺдҪҚзҪ®0ејҖе§Ӣе°қиҜ•еҢ№й…Қзҡ„пјҢвҖң[a-z0-9]+вҖқйҰ–е…Ҳе°қиҜ•еҢ№й…ҚвҖңaвҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢ继з»ӯе°қиҜ•еҢ№й…ҚпјҢеҸҜд»ҘжҲҗеҠҹеҢ№й…ҚжҺҘдёӢжқҘзҡ„вҖң1вҖқе’ҢвҖң2вҖқпјҢжӯӨж—¶е·Із»ҸеҢ№й…ҚеҲ°дҪҚзҪ®3пјҢдҪҚзҪ®3зҡ„еҸідҫ§е·ІжІЎжңүеӯ—з¬ҰпјҢиҝҷж—¶дјҡжҠҠжҺ§еҲ¶жқғдәӨз»ҷвҖң$вҖқпјӣ
е…ғеӯ—з¬ҰвҖң$вҖқд»ҺдҪҚзҪ®3ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢе®ғеҢ№й…Қзҡ„жҳҜз»“жқҹдҪҚзҪ®пјҢд№ҹе°ұжҳҜвҖңдҪҚзҪ®3вҖқпјҢеҢ№й…ҚжҲҗеҠҹгҖӮ
жӯӨж—¶жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе®ҢжҲҗпјҢжҠҘе‘ҠеҢ№й…ҚжҲҗеҠҹгҖӮеҢ№й…Қз»“жһңдёәвҖңa12вҖқпјҢејҖе§ӢдҪҚзҪ®дёә0пјҢз»“жқҹдҪҚзҪ®дёә3гҖӮе…¶дёӯвҖң^вҖқеҢ№й…ҚдҪҚзҪ®0пјҢвҖң(?=[a-z])вҖқеҢ№й…ҚдҪҚзҪ®0пјҢвҖң[a-z0-9]+вҖқеҢ№й…Қеӯ—з¬ҰдёІвҖңa12вҖқпјҢвҖң$вҖқеҢ№й…ҚдҪҚзҪ®3гҖӮ
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
жң¬ж–Ү件вҖңжӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”NFAеј•ж“ҺеҢ№й…ҚеҺҹзҗҶ.rarвҖқе°Ҷж·ұе…ҘжҺўи®ЁNFAзҡ„е·ҘдҪңжңәеҲ¶гҖӮ йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒзҗҶи§ЈNFAзҡ„еҹәжң¬жҰӮеҝөгҖӮNFAжҳҜдёҖз§Қжңүеҗ‘еӣҫпјҢжҜҸдёӘиҠӮзӮ№д»ЈиЎЁдёҖдёӘзҠ¶жҖҒпјҢиҫ№еҲҷиЎЁзӨәзҠ¶жҖҒй—ҙзҡ„иҪ¬жҚўгҖӮеңЁNFAдёӯпјҢдёҖдёӘиҫ“е…Ҙеӯ—з¬ҰеҸҜд»Ҙеј•еҸ‘еӨҡдёӘ...
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”NFAеј•ж“ҺеҢ№й…ҚеҺҹзҗҶ еңЁжӯЈеҲҷиЎЁиҫҫејҸдёӯпјҢдәҶи§Јеј•ж“ҺеҢ№й…ҚеҺҹзҗҶжҳҜйқһеёёйҮҚиҰҒзҡ„гҖӮе°ұеғҸйҹід№җ家дёҖж ·пјҢдёҖдёӘдәәеҸҜд»Ҙжј”еҘҸеҮәеҠЁеҗ¬зҡ„д№җжӣІпјҢдҪҶжҳҜеҰӮжһңдёҚзҹҘйҒ“еҰӮдҪ•еҺ»ж”№еҸҳйҹіз¬Ұзҡ„з»„еҗҲпјҢд№җжӣІе°ұдёҚдјҡеҸҳеҫ—жӣҙеҠЁеҗ¬гҖӮеҗҢж ·пјҢеңЁдҪҝз”ЁжӯЈеҲҷ...
еӣ жӯӨпјҢжҲ‘е»әи®®дҪ е…ҲдәҶи§ЈжӯЈеҲҷиЎЁиҫҫејҸNFAеј•ж“Һзҡ„еҢ№й…ҚеҺҹзҗҶгҖӮжғіиҰҒж•ҙзҗҶдёҖд»Ҫжҳ“жҮӮжҳ“жҸҸиҝ°зҡ„иҜқпјҢзҡ„зЎ®иҰҒиҙ№дәӣж—¶й—ҙпјҢдҪҶдёҚзҹҘйҒ“иҝҷзҜҮеҶ…е®№дјҡдёҚдјҡиҫҫеҲ°жҲ‘йў„жңҹзҡ„ж•ҲжһңгҖӮж…ўж…ўе®Ңе–„еҗ§~пјҲжіЁпјҡиҝҷжҳҜжҲ‘2010е№ҙеҶҷзҡ„пјҢзҺ°еңЁжӢҝиҝҮжқҘпјҢжңүж—¶й—ҙе°ҶиҮӘе·ұеҒҡдёәиҜ»иҖ…...
2. **ж”№иҝӣNFAеҲ°DFAиҪ¬жҚў**пјҡе°ҶеҺҹжңүзҡ„еҚ•дёӘи·іиҪ¬еӯ—з¬Ұе’Ңи·іиҪ¬еӯ—з¬ҰеҢәй—ҙеҗҲ并еҲ°жңүеәҸж•°з»„еҲ—иЎЁпјҢд»Ҙзј©зҹӯиҪ¬жҚўж—¶й—ҙ并жҸҗеҚҮеҹәдәҺNFAеҢ№й…Қзҡ„жү§иЎҢж•ҲзҺҮгҖӮ 3. **еҶ…еӯҳз®ЎзҗҶ**пјҡйқўеҜ№зҷҫдёҮзә§зҡ„жӯЈеҲҷиЎЁиҫҫејҸпјҢйңҖиҰҒз ”з©¶еҰӮдҪ•еҺӢзј©иҮӘеҠЁжңәзҡ„еҶ…еӯҳеҚ з”ЁпјҢ...
еңЁи®Ўз®—жңә科еӯҰйўҶеҹҹпјҢеҪўејҸиҜӯиЁҖдёҺиҮӘеҠЁжңәзҗҶи®әжҳҜзҗҶи®әи®Ўз®—зҡ„еҹәзЎҖд№ӢдёҖгҖӮNFAпјҢе…Ёз§°вҖңдёҚзЎ®е®ҡзҡ„жңүйҷҗиҮӘеҠЁжңәвҖқпјҲNon-deterministic Finite AutomatonпјүпјҢжҳҜиҮӘеҠЁжңәзҗҶи®әдёӯзҡ„дёҖдёӘйҮҚиҰҒжҰӮеҝөгҖӮжң¬зҜҮдё»иҰҒеӣҙз»•NFAзҡ„жҰӮеҝөгҖҒзү№зӮ№д»ҘеҸҠеңЁJavaдёӯ...
дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қж–Үжң¬... 38 еҗ‘жӣҙе®һз”Ёзҡ„зЁӢеәҸеүҚиҝӣ... 40 жҲҗеҠҹеҢ№й…Қзҡ„еүҜдҪңз”Ё... 40 й”ҷз»јеӨҚжқӮзҡ„жӯЈеҲҷиЎЁиҫҫејҸ... 43 жҡӮеҒңзүҮеҲ»... 49 дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸдҝ®ж”№ж–Үжң¬... 50 дҫӢеӯҗпјҡе…¬еҮҪз”ҹжҲҗзЁӢеәҸ... 50 дёҫдҫӢпјҡдҝ®ж•ҙиӮЎзҘЁд»·ж ј....
1. еҢ№й…Қз®—жі•пјҡжӯЈеҲҷиЎЁиҫҫејҸеј•ж“ҺйҖҡеёёдҪҝз”ЁдёӨз§ҚеҢ№й…Қз®—жі•вҖ”вҖ”DFAпјҲзЎ®е®ҡжңүйҷҗзҠ¶жҖҒиҮӘеҠЁжңәпјүе’ҢNFAпјҲйқһзЎ®е®ҡжңүйҷҗзҠ¶жҖҒиҮӘеҠЁжңәпјүгҖӮDFAж•ҲзҺҮй«ҳпјҢдҪҶдёҚж”ҜжҢҒжүҖжңүжӯЈеҲҷиЎЁиҫҫејҸзү№жҖ§пјӣNFAж”ҜжҢҒжӣҙеӨҡзү№жҖ§пјҢдҪҶеҸҜиғҪйңҖиҰҒжӣҙеӨҡжӯҘйӘӨгҖӮ 2. зј–иҜ‘дёҺи§Јжһҗпјҡ...
йқһзЎ®е®ҡжҖ§жңүйҷҗзҠ¶жҖҒиҮӘеҠЁжңәпјҲNFAпјүжҳҜдёҖз§Қи®Ўз®—жЁЎеһӢпјҢз”ЁдәҺеҢ№й…ҚжӯЈеҲҷиЎЁиҫҫејҸжҲ–иҜҶеҲ«зү№е®ҡзҡ„еӯ—з¬ҰдёІжЁЎејҸгҖӮNFAз”ұдёҖзі»еҲ—зҠ¶жҖҒе’Ңиҫ№жһ„жҲҗпјҢжҜҸдёӘзҠ¶жҖҒеҸҜд»ҘйҖҡиҝҮиҜ»еҸ–иҫ“е…Ҙеӯ—з¬ҰжҲ–иҖ…дёҚиҜ»еҸ–д»»дҪ•еӯ—з¬ҰжқҘиҪ¬з§»еҲ°еҸҰдёҖдёӘзҠ¶жҖҒгҖӮдёҺзЎ®е®ҡжҖ§жңүйҷҗзҠ¶жҖҒиҮӘеҠЁжңә...
NFAжҳҜйқһзЎ®е®ҡжҖ§зҡ„пјҢж„Ҹе‘ізқҖеңЁз»ҷе®ҡзҠ¶жҖҒдёӢпјҢеҜ№дәҺзӣёеҗҢзҡ„иҫ“е…Ҙз¬ҰеҸ·пјҢе®ғеҸҜд»Ҙиҝӣе…ҘеӨҡдёӘдёҚеҗҢзҡ„зҠ¶жҖҒпјҢиҝҷдҪҝеҫ—NFAеңЁеӨ„зҗҶжҹҗдәӣжӯЈеҲҷиЎЁиҫҫејҸж—¶жӣҙдёәзҒөжҙ»гҖӮ然иҖҢпјҢNFAеңЁе®һйҷ…еә”з”Ёдёӯ并дёҚеёёи§ҒпјҢеӣ дёәе®ғеҸҜиғҪеҜјиҮҙеӨҡдёӘж— ж•Ҳзҡ„иҜҚжі•еҚ•е…ғеҢ№й…ҚгҖӮ зӣёжҜ”...
- NFAеҲҷжҳҜйҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸжқҘеҢ№й…Қж–Үжң¬дёІпјҢе®ғдјҡе°қиҜ•еӨҡдёӘи·Ҝеҫ„зӣҙеҲ°жүҫеҲ°еҢ№й…Қзҡ„з»“жһңгҖӮ - NFAзҡ„зјәзӮ№жҳҜйҖҹеәҰзӣёеҜ№иҫғж…ўпјҢеӣ дёәе®ғйңҖиҰҒеҸҚеӨҚе°қиҜ•дёҚеҗҢзҡ„еҢ№й…Қи·Ҝеҫ„пјӣдјҳзӮ№жҳҜеҸҜд»ҘжҸҗдҫӣжӣҙеӨҡзҡ„еҠҹиғҪе’ҢзҒөжҙ»жҖ§гҖӮ иҝҷдёӨз§Қз®—жі•зҡ„дёҚеҗҢд№ӢеӨ„дҪ“зҺ°еңЁ...
еңЁжң¬йЎ№зӣ®дёӯпјҢдҪ йңҖиҰҒзҗҶи§ЈеҹәзЎҖзҡ„жӯЈеҲҷиЎЁиҫҫејҸиҜӯжі•пјҢеҰӮеӯ—з¬Ұзұ»пјҲеҰӮ[a-z]иЎЁзӨәе°ҸеҶҷеӯ—жҜҚпјүгҖҒйҮҸиҜҚпјҲеҰӮ*гҖҒ+гҖҒ?иЎЁзӨәйҮҚеӨҚж¬Ўж•°пјүгҖҒеҲҶз»„д»ҘеҸҠйҖүжӢ©з¬ҰпјҲ|пјүзӯүгҖӮ 2. **иҮӘеҠЁжңәзҗҶи®ә**пјҡиҮӘеҠЁжңәдё»иҰҒжңүеҮ з§Қзұ»еһӢпјҢеҢ…жӢ¬зЎ®е®ҡжңүйҷҗзҠ¶жҖҒиҮӘеҠЁжңә...
жң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁжӯЈеҲҷиЎЁиҫҫејҸдёӯзҡ„дёҖдёӘйҮҚиҰҒжҰӮеҝөвҖ”вҖ”еӣһжәҜпјҢд»ҘеҸҠе®ғдёҺдёӨз§ҚдёҚеҗҢзҡ„еҢ№й…ҚжңәеҲ¶пјҡйқһзЎ®е®ҡеһӢжңүз©·иҮӘеҠЁжңәпјҲNFAпјүе’ҢзЎ®е®ҡеһӢжңүз©·иҮӘеҠЁжңәпјҲDFAпјүзҡ„е…ізі»гҖӮ еңЁжӯЈеҲҷиЎЁиҫҫејҸдёӯпјҢеӣһжәҜжҳҜдёҖз§Қжҗңзҙўзӯ–з•ҘпјҢеҪ“йҒҮеҲ°еӨҡдёӘеҸҜиғҪзҡ„еҢ№й…Қи·Ҝеҫ„ж—¶...
з»јдёҠжүҖиҝ°пјҢгҖҠзЁӢеәҸи®ҫи®ЎиҜӯиЁҖвҖ”вҖ”зј–иҜ‘еҺҹзҗҶгҖӢ第дәҢз« е’Ң第дёүз« зҡ„еҶ…е®№ж·ұе…ҘжҺўи®ЁдәҶзј–иҜ‘еҷЁи®ҫи®Ўзҡ„еҹәзЎҖзҗҶи®әпјҢзү№еҲ«жҳҜж–Үжі•еҲҶжһҗе’ҢиҮӘеҠЁжңәзҗҶи®әпјҢиҝҷеҜ№дәҺзҗҶи§Је’ҢејҖеҸ‘зҺ°д»Јзј–зЁӢиҜӯиЁҖе’Ңзј–иҜ‘еҷЁзі»з»ҹе…·жңүйҮҚиҰҒж„Ҹд№үгҖӮйҖҡиҝҮеӯҰд№ иҝҷдәӣж ёеҝғжҰӮеҝөпјҢејҖеҸ‘иҖ…...
#### жӯЈеҲҷиЎЁиҫҫејҸеҲ°NFAзҡ„иҪ¬жҚўвҖ”вҖ”Thompsonжһ„йҖ жі• Thompsonжһ„йҖ жі•жҳҜдёҖз§Қе°ҶжӯЈеҲҷиЎЁиҫҫејҸиҪ¬жҚўдёәNFAзҡ„з®—жі•пјҢе…·дҪ“жӯҘйӘӨеҰӮдёӢпјҡ 1. **еҲҶи§Је…ғзҙ **пјҡе°ҶжӯЈеҲҷиЎЁиҫҫејҸrеҲҶи§Јдёәе…¶з»„жҲҗе…ғзҙ пјҢй’ҲеҜ№жҜҸдёӘе…ғзҙ жһ„е»әеҹәжң¬зҡ„NFAз»“жһ„гҖӮ - еҜ№дәҺз©ә...
.NETзҡ„жӯЈеҲҷиЎЁиҫҫејҸеј•ж“ҺйҮҮз”ЁдәҶдј з»ҹзҡ„йқһзЎ®е®ҡжңүйҷҗиҮӘеҠЁжңәпјҲNFAпјүе®һзҺ°ж–№ејҸпјҢеӣ жӯӨеңЁи®ҫи®ЎдёҠйҒөеҫӘдәҶChapters 4гҖҒ5е’Ң6дёӯд»Ӣз»Қзҡ„еҹәжң¬еҺҹзҗҶе’ҢжҠҖжңҜпјҢиҝҷдәӣз« иҠӮж¶өзӣ–дәҶжӯЈеҲҷиЎЁиҫҫејҸзҡ„й«ҳзә§жҰӮеҝөе’ҢжҠҖжңҜгҖӮиҝҷзЎ®дҝқдәҶ.NETеј•ж“ҺиғҪеӨҹеӨ„зҗҶеӨҚжқӮзҡ„жӯЈеҲҷ...