1 概述
贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。
属于贪婪模式的量词,也叫做匹配优先量词,包括:
“{m,n}”、“{m,}”、“?”、“*”和“+”。
在一些使用NFA引擎的语言中,在匹配优先量词后加上“?”,即变成属于非贪婪模式的量词,也叫做忽略优先量词,包括:
“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。
从正则语法的角度来讲,被匹配优先量词修饰的子表达式使用的就是贪婪模式,如“(Expression)+”;被忽略优先量词修饰的子表达式使用的就是非贪婪模式,如“(Expression)+?”。
对于贪婪模式,各种文档的叫法基本一致,但是对于非贪婪模式,有的叫懒惰模式或惰性模式,有的叫勉强模式,其实叫什么无所谓,只要掌握原理和用法,能够运用自如也就是了。个人习惯使用贪婪与非贪婪的叫法,所以文中都会使用这种叫法进行介绍。
2 贪婪与非贪婪模式匹配原理
对于贪婪与非贪婪模式,可以从应用和原理两个角度进行理解,但如果想真正掌握,还是要从匹配原理来理解的。
先从应用的角度,回答一下“什么是贪婪与非贪婪模式?”
2.1 从应用角度分析贪婪与非贪婪模式
2.1.1 什么是贪婪与非贪婪模式
先看一个例子
举例:
源字符串:aa<div>test1</div>bb<div>test2</div>cc
正则表达式一:<div>.*</div>
匹配结果一:<div>test1</div>bb<div>test2</div>
正则表达式二:<div>.*?</div>
匹配结果二:<div>test1</div>(这里指的是一次匹配结果,所以没包括<div>test2</div>)
根据上面的例子,从匹配行为上分析一下,什是贪婪与非贪婪模式。
正则表达式一采用的是贪婪模式,在匹配到第一个“</div>”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串,匹配到第二个“</div>”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“<div>test1</div>bb<div>test2</div>”。当然,实际的匹配过程并不是这样的,后面的匹配原理会详细介绍。
仅从应用角度分析,可以这样认为,贪婪模式,就是在整个表达式匹配成功的前提下,尽可能多的匹配,也就是所谓的“贪婪”,通俗点讲,就是看到想要的,有多少就捡多少,除非再也没有想要的了。
正则表达式二采用的是非贪婪模式,在匹配到第一个“</div>”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“<div>test1</div>”。
仅从应用角度分析,可以这样认为,非贪婪模式,就是在整个表达式匹配成功的前提下,尽可能少的匹配,也就是所谓的“非贪婪”,通俗点讲,就是找到一个想要的捡起来就行了,至于还有没有没捡的就不管了。
2.1.2 关于前提条件的说明
在上面从应用角度分析贪婪与非贪婪模式时,一直提到的一个前提条件就是“整个表达式匹配成功”,为什么要强调这个前提,我们看下下面的例子。
正则表达式三:<div>.*</div>bb
匹配结果三:<div>test1</div>bb
修饰“.”的仍然是匹配优先量词“*”,所以这里还是贪婪模式,前面的“<div>.*</div>”仍然可以匹配到“<div>test1</div>bb<div>test2</div>”,但是由于后面的“bb”无法匹配成功,这时“<div>.*</div>”必须让出已匹配的“bb<div>test2</div>”,以使整个表达式匹配成功。这时整个表达式匹配的结果为“<div>test1</div>bb”,“<div>.*</div>”匹配的内容为“<div>test1</div>”。可以看到,在“整个表达式匹配成功”的前提下,贪婪模式才真正的影响着子表达式的匹配行为,如果整个表达式匹配失败,贪婪模式只会影响匹配过程,对匹配结果的影响无从谈起。
非贪婪模式也存在同样的问题,来看下面的例子。
正则表达式四:<div>.*?</div>cc
匹配结果四:<div>test1</div>bb<div>test2</div>cc
这里采用的是非贪婪模式,前面的“<div>.*?</div>”仍然是匹配到“<div>test1</div>”为止,此时后面的“cc”无法匹配成功,要求“<div>.*?</div>”必须继续向右尝试匹配,直到匹配内容为“<div>test1</div>bb<div>test2</div>”时,后面的“cc”才能匹配成功,整个表达式匹配成功,匹配的内容为“<div>test1</div>bb<div>test2</div>cc”,其中“<div>.*?</div>”匹配的内容为“<div>test1</div>bb<div>test2</div>”。可以看到,在“整个表达式匹配成功”的前提下,非贪婪模式才真正的影响着子表达式的匹配行为,如果整个表达式匹配失败,非贪婪模式无法影响子表达式的匹配行为。
2.1.3 贪婪还是非贪婪——应用的抉择
通过应用角度的分析,已基本了解了贪婪与非贪婪模式的特性,那么在实际应用中,究竟是选择贪婪模式,还是非贪婪模式呢,这要根据需求来确定。
对于一些简单的需求,比如源字符为“aa<div>test1</div>bb”,那么取得div标签,使用贪婪与非贪婪模式都可以取得想要的结果,使用哪一种或许关系不大。
但是就2.1.1中的例子来说,实际应用中,一般一次只需要取得一个配对出现的div标签,也就是非贪婪模式匹配到的内容,贪婪模式所匹配到的内容通常并不是我们所需要的。
那为什么还要有贪婪模式的存在呢,从应用角度很难给出满意的解答了,这就需要从匹配原理的角度去分析贪婪与非贪婪模式。
2.2 从匹配原理角度分析贪婪与非贪婪模式
如果想真正了解什么是贪婪模式,什么是非贪婪模式,分别在什么情况下使用,各自的效率如何,那就不能仅仅从应用角度分析,而要充分了解贪婪与非贪婪模式的匹配原理。
2.2.1 从基本匹配原理谈起
NFA引擎基本匹配原理参考:正则基础之——NFA引擎匹配原理。
这里主要针对贪婪与非贪婪模式涉及到的匹配原理进行介绍。先看一下贪婪模式简单的匹配过程。
源字符串:"Regex"
正则表达式:".*"
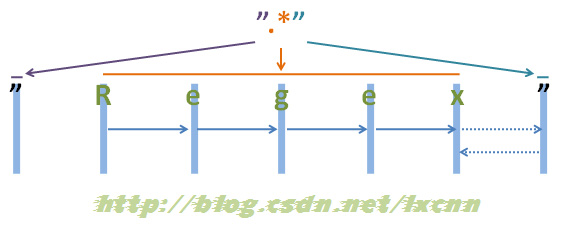
图2-1
注:为了能够看清晰匹配过程,上面的空隙留得较大,实际源字符串为“”Regex””,下同。
来看一下匹配过程。首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.*”。
“.*”取得控制权后,由于“*”是匹配优先量词,在可匹配可不匹配的情况下,优先尝试匹配。从位置1处的“R”开始尝试匹配,匹配成功,继续向右匹配,匹配位置2处的“e”,匹配成功,继续向右匹配,直到匹配到结尾的“””,匹配成功,由于此时已匹配到字符串的结尾,所以“.*”结束匹配,将控制权交给正则表达式最后的“"”。
“"”取得控制权后,由于已经在字符串结束位置,匹配失败,向前查找可供回溯的状态,控制权交给“.*”,由“.*”让出一个字符,也就是字符串结尾处的“””,再把控制权交给正则表达式最后的“"”,由“"”匹配字符串结尾处的“"”,匹配成功。
此时整个正则表达式匹配成功,其中“.*”匹配的内容为“Regex”,匹配过程中进行了一次回溯。
接下来看一下非贪婪模式简单的匹配过程。
源字符串:"Regex"
正则表达式:".*?"
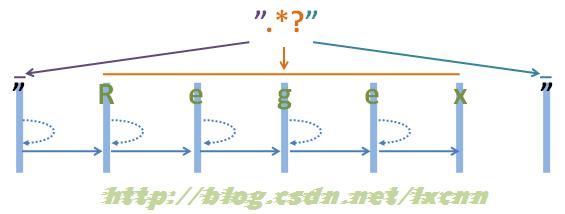
图2-2
看一下非贪婪模式的匹配过程。首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.*?”。
“.*?”取得控制权后,由于“*?”是忽略优先量词,在可匹配可不匹配的情况下,优先尝试不匹配,由于“*”等价于“{0,}”,所以在忽略优先的情况下,可以不匹配任何内容。从位置1处尝试忽略匹配,也就是不匹配任何内容,将控制权交给正则表达式最后的“””。
“"”取得控制权后,从位置1处尝试匹配,由“"”匹配位置1处的“R”,匹配失败,向前查找可供回溯的状态,控制权交给“.*?”,由“.*?”吃进一个字符,匹配位置1处的“R”,再把控制权交给正则表达式最后的“"”。
“"”取得控制权后,从位置2处尝试匹配,由“"”匹配位置1处的“e”,匹配失败,向前查找可供回溯的状态,重复以上过程,直到由“.*?”匹配到“x”为止,再把控制权交给正则表达式最后的“"”。
“"”取得控制权后,从位置6处尝试匹配,由“"”匹配字符串最后的“"”,匹配成功。
此时整个正则表达式匹配成功,其中“.*?”匹配的内容为“Regex”,匹配过程中进行了五次回溯。
2.2.2 贪婪还是非贪婪——匹配效率的抉择
通过匹配原理的分析,可以看到,在匹配成功的情况下,贪婪模式进行了更少的回溯,而回溯的过程,需要进行控制权的交接,让出已匹配内容或匹配未匹配内容,并重新尝试匹配,在很大程度上降低匹配效率,所以贪婪模式与非贪婪模式相比,存在匹配效率上的优势。
但2.2.1中的例子,仅仅是一个简单的应用,读者看到这里时,是否会存在这样的疑问,贪婪模式就一定比非贪婪模式匹配效率高吗?答案是否定的。
举例:
需求:取得两个“"”中的子串,其中不能再包含“"”。
正则表达式一:".*"
正则表达式二:".*?"
情况一:当贪婪模式匹配到更多不需要的内容时,可能存在比非贪婪模式更多的回溯。比如源字符串为“The word "Regex" means regular expression.”。
情况二:贪婪模式无法满足需求。比如源字符串为“The phrase "regular expression" is called "Regex" for short.”。
对于情况一,正则表达式一采用的贪婪模式,“.*”会一直匹配到字符串结束位置,控制权交给最后的“””,匹配不成功后,再进行回溯,由于多匹配的内容“means regular expression.”远远超过需匹配内容本身,所以采用正则表达式一时,匹配效率会比使用正则表达式二的非贪婪模式低。
对于情况二,正则表达式一匹配到的是“"regular expression" is called "Regex"”,连需求都不满足,自然也谈不上什么匹配效率的高低了。
以上两种情况是普遍存在的,那么是不是为了满足需求,又兼顾效率,就只能使用非贪婪模式了呢?当然不是,根据实际情况,变更匹配优先量词修饰的子表达式,不但可以满足需求,还可以提高匹配效率。
源字符串:"Regex"
给出正则表达式三:"[^"]*"
看一下正则表达式三的匹配过程。
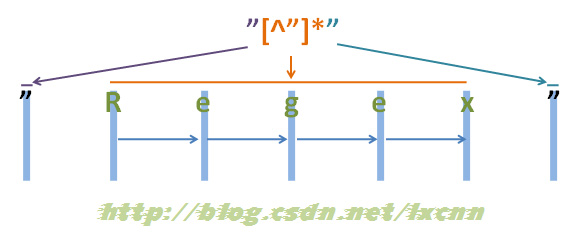
图2-3
首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“[^"]*”。
“[^"]*”取得控制权后,由于“*”是匹配优先量词,在可匹配可不匹配的情况下,优先尝试匹配。从位置1处的“R”开始尝试匹配,匹配成功,继续向右匹配,匹配位置2处的“e”,匹配成功,继续向右匹配,直到匹配到“x”,匹配成功,再匹配结尾的“””时,匹配失败,将控制权交给正则表达式最后的“"”。
“””取得控制权后,匹配字符串结尾处的“””,匹配成功。
此时整个正则表达式匹配成功,其中“[^"]*”匹配的内容为“Regex”,匹配过程中没有进行回溯。
将量词修饰的子表达式由范围较大的“.”,换成了排除型字符组“[^"]”,使用的仍是贪婪模式,很完美的解决了需求和效率问题。当然,由于这一匹配过程没有进行回溯,所以也不需要记录回溯状态,这样就可以使用固化分组,对正则做进一步的优化。
给出正则表达式四:"(?>[^"]*)"
固化分组并不是所有语言都支持的,如.NET支持,而Java就不支持,但是在Java中却可以使用更简单的占有优先量词来代替:"[^"]*+"。
3 贪婪还是非贪婪模式——再谈匹配效率
一般来说,贪婪与非贪婪模式,如果量词修饰的子表达式相同,比如“.*”和“.*?”,它们的应用场景通常是不同的,所以效率上一般不具有可比性。
而对于改变量词修饰的子表达式,以满足需求时,比如把“.*”改为“[^"]*”,由于修饰的子表达式已不同,也不具有直接的可对比性。但是在相同的子表达式,又都可以满足需求的情况下,比如“[^"]*”和“[^"]*?”,贪婪模式的匹配效率通常要高些。
同时还有一个事实就是,非贪婪模式可以实现的,通过优化量词修饰的子表达式的贪婪模式都可以实现,而贪婪模式可以实现的一些优化效果,却未必是非贪婪模式可以实现的。
贪婪模式还有一点优势,就是在匹配失败时,贪婪模式可以更快速的报告失败,从而提升匹配效率。下面将全面考察贪婪与非贪婪模式的匹配效率。
3.1 效率提升——演进过程
在了解了贪婪与非贪婪模式的匹配基本原理之后,我们再来重新看一下正则效率提升的演进过程。
需求:取得两个“"”中的子串,其中不能再包含“"”。
源字符串:The phrase "regular expression" is called "Regex" for short.
正则表达式一:".*"
正则表达式一匹配的内容为“"regular expression" is called "Regex"”,不符合要求。
提出正则表达式二:".*?"
首先“"”取得控制权,由位置0位开始尝试匹配,直到位置11处匹配成功,控制权交给“.*?”,匹配过程同2.2.1中非贪婪模式的匹配过程。“.*?”匹配的内容为“Regex”,匹配过程中进行了四次回溯。
如何消除回溯带来的匹配效率的损失,就是使用更小范围的子表达式,采用贪婪模式,提出正则表达式三:"[^"]*"
首先“"”取得控制权,由位置0位开始尝试匹配,直到位置11处匹配成功,控制权交给“[^"]*”,匹配过程同2.2.2节中非贪婪模式的匹配过程。“[^"]*”匹配的内容为“Regex”,匹配过程中没有进行回溯。
3.2 效率提升——更快的报告失败
以上讨论的是匹配成功的演进过程,而对于一个正则表达式,在匹配失败的情况下,如果能够以最快的速度报告匹配失败,也会提升匹配效率,这或许是我们设计正则过程中最容易忽略的。而在源字符串数据量非常大,或正则表达式比较复杂的情况下,是否能够快速报告匹配失败,将对匹配效率产生直接的影响。
下面将构建匹配失败的正则表达式,对匹配过程进行分析。
以下匹配过程分析中,源字符串统一为:The phrase "regular expression" is called "Regex" for short.
3.2.1 非贪婪模式匹配失败过程分析

图3-1
构建匹配失败的非贪婪模式的正则表达式:".*?"@
由于最后的“@”的存在,这个正则表达式最后一定是匹配失败的,那么看一下匹配过程。
首先由“"”取得控制权,由位置0处开始尝试匹配,匹配失败,直到图中标示的A处匹配成功,控制权交给“.*?”。
“.*?”取得控制权后,由A后面的位置开始尝试匹配,由于是非贪婪模式,首先忽略匹配,将控制权交给“"”,同时记录一下回溯状态。“"”取得控制权后,由A后面的位置开始尝试匹配,匹配字符“r”失败,查找可供回溯的状态,将控制权交给“.*?”,由“.*?”匹配字符“r”。重复以上过程,直到“.*?”匹配了B处前面的字符“n”,“"”匹配了B处的字符“””,将控制权交给“@”。由“@”匹配接下来的空格“ ”,匹配失败,查找可供回溯的状态,控制权交给“.*?”,由“.*?”匹配空格。继续重复以上匹配过程,直到由“.*?”匹配到字符串结束位置,将控制权交给“"”。由于已经是字符串结束位置,匹配失败,报告整个表达式在位置11处匹配失败,一轮匹配尝试结束。
正则引擎传动装置使正则向前传动,进入下一轮尝试。后续匹配过程与第一轮尝试匹配过程基本类似,可以参考图3-1。
从匹配过程中可以看到,非贪婪模式的匹配失败过程,几乎每一步都伴随着回溯过程,对匹配效率的影响是很大的。
3.2.2 贪婪模式匹配失败过程分析——大范围子表达式
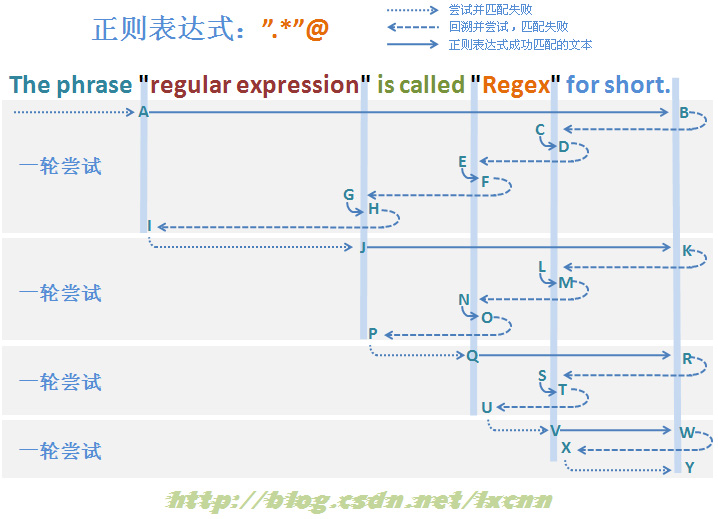
图3-2
PS:以上分析过程图示参考了《精通正则表达式》一书相关章节图示。
构建匹配失败的贪婪模式的正则表达式:".*"@
其中量词修饰的子表达式为匹配范围较大的“.”,由于最后的“@”的存在,这个正则表达式最后也是一定匹配失败的,看一下匹配过程。
首先由“"”取得控制权,由位置0处开始尝试匹配,匹配失败,直
分享到:





相关推荐
在正则表达式的世界里,贪婪与非贪婪模式是两种重要的匹配策略,它们决定了正则表达式在查找匹配时的行为。这两个概念对于任何想要深入理解正则表达式的开发者来说至关重要。 首先,我们来理解一下“贪婪”模式。...
在学习正则表达式的过程中,掌握贪婪与非贪婪模式的区别是基础中的基础。这一知识不仅有助于避免匹配过度或不足的问题,还能在使用正则表达式时提高效率,减少不必要的计算。通过合理运用这两种模式,可以显著提升...
### 正则表达式——递归匹配与非贪婪匹配 #### 一、递归匹配 在正则表达式中,递归匹配是一个重要的概念,它主要用于处理那些具有嵌套结构的数据,例如数学公式中的括号匹配或HTML标签的匹配。 ##### 1.1 嵌套...
贪婪模式(默认)会尽可能多地匹配,非贪婪模式可以通过在数量词后加`?`来实现,如`[a-zA-Z]{3,5}?`。 2. **字符匹配**: - `[ ]`:字符集,匹配其中的任意一个字符。 - `[^ ]`:反向字符集,匹配不在括号内的...
### 正则表达式之道 —— Java中的应用与实践 #### 一、引言 正则表达式是一种强大的文本处理工具,它可以帮助开发者快速高效地完成字符串的匹配、搜索、替换等工作。对于Java开发者而言,掌握正则表达式的用法尤...
例如:<H1>Chapter 1 - 介绍正则表达式</H1> 贪婪模式匹配结果:<H1>Chapter 1 - 介绍正则表达式</H1> 非贪婪:如果您只需要匹配开始和介绍H1 标记,下面的非贪婪表达式只匹配。 5. 定位符:定位符能够将正则表达式...
Python中的正则表达式是处理文本模式匹配的强大工具,它允许程序员通过简洁的语法来查找、替换或提取字符串中的特定模式。以下是对正则表达式关键概念的详细解释: 1. **简介**: - 正则表达式是用于描述字符串...
最后,正则表达式还有非贪婪和贪婪两种匹配模式。默认情况下,正则表达式采用贪婪匹配,尽可能多的匹配字符;而加上"?",如"a*"变为"a*?",则会采用非贪婪模式,尽可能少的匹配字符。 "笔记.txt"中可能会涵盖这些...
1. 贪婪与懒惰:默认情况下,正则表达式是贪婪的,会尽可能多地匹配字符。使用`?`可以使匹配变得懒惰,仅匹配最少量的字符。 2. 前瞻和后顾:预查可以确保某部分文本前面或后面存在特定的模式,而不会实际包含这部分...
- **贪婪与懒惰匹配**:控制正则表达式的匹配行为。 - **原子组和递归模式**:解决复杂的嵌套结构匹配问题。 #### 六、学习资源 - **《Mastering Regular Expressions》**:本书由 Jeffrey E.F. Friedl 编写,是...
### 正则表达式的基础语法 #### 概述 正则表达式是一种强大的文本处理工具,可以在字符串中执行复杂的搜索和替换操作。它提供了一种描述字符串模式的方式,这种模式可以用来检查一个字符串是否符合某种特定类型的...
Java通过`java.util.regex`包中的两个核心类——`Pattern`和`Matcher`——提供了对正则表达式的支持。 1. **Pattern** 类:它负责编译正则表达式字符串为模式对象。这个模式对象可以被用来创建多个`Matcher`实例,...
##### **3.4 贪婪与懒惰** - **贪婪匹配**:尽可能多地匹配。 - **懒惰匹配**:尽可能少地匹配。 - 示例:`.*`(贪婪)与 `.*?`(懒惰)。 #### 四、示例应用 ##### **4.1 实战示例** 假设我们需要在一个英文...
在编程领域,C#语言提供了一种强大的工具——正则表达式,用于处理字符串和验证数据格式。正则表达式是一种模式匹配语言,它能够帮助我们有效地检查、查找、替换和提取文本。在C#中,我们可以使用System.Text....
通过阅读这些文档,开发者可以有效地学习如何构建和匹配正则表达式,以及如何利用库提供的高级功能,如捕获组、命名捕获、非贪婪匹配等。 此外,库中包含的调试器工具——MTracer 2.1,是开发和调试正则表达式时的...
贪婪与懒惰是正则表达式中的一种语法,用于指定某个模式的贪婪或懒惰匹配。例如,使用正则表达式.*可以匹配任何字符的任意次重复。 15. 处理选项 处理选项是正则表达式中的一种语法,用于指定某个模式的处理选项。...
### 代替正则——HyperScriptExpression联合开发倡议公告 #### 概述 本文档旨在介绍一项新的编程技术——HyperScriptExpression (以下简称HSE),一种旨在替代传统正则表达式的新型文本处理工具。HSE的设计目标是...
- 使用非贪婪匹配:默认情况下,正则表达式是贪婪的,会匹配尽可能多的字符。使用`?`符号可以设置为非贪婪匹配,只匹配最少的字符。 - 注意性能开销:尽管正则表达式强大,但过度使用可能导致性能下降,尤其是对大...