GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。本文数一数GB18030中的汉字,也顺便看看其它标准中的汉字。
1 Unicode中的汉字
在Unicode 5.0的99089个字符中,有71226个字符与汉字有关。它们的分布如下:
| Block名称 |
开始码位 |
结束码位 |
字符数 |
| CJK统一汉字 |
4E00 |
9FBB |
20924 |
|
| CJK统一汉字扩充A |
3400 |
4DB5 |
6582 |
|
| CJK统一汉字扩充B |
20000 |
2A6D6 |
42711 |
|
| CJK兼容汉字 |
F900 |
FA2D |
302 |
|
| CJK兼容汉字 |
FA30 |
FA6A |
59 |
|
| CJK兼容汉字 |
FA70 |
FAD9 |
106 |
| CJK兼容汉字补充 |
2F800 |
2FA1D |
542 |
如果不算兼容汉字,Unicode目前支持的汉字总数是20924+6582+42711=70217。
这里有一个细节。在早期的Unicode版本中,CJK统一汉字区的范围是0x4E00-0x9FA5,也就是我们经常提到的20902个汉字。当前版本的Unicode增加了22个字符,码位是0x9FA6-0x9FBB。它们是:
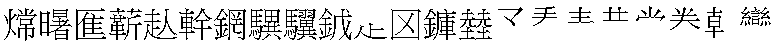
那么GB18030是否支持这22个字符?后面还会讨论。
2 GB2312
1980年的GB2312一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
这6763个汉字在Unicode中不是连续的,分布在CJK统一汉字字符区(0x4E00-0x9FA5)的20902个汉字中。
3 GBK
1995年的汉字扩展规范GBK1.0收录了21886个符号,包括21003个汉字和883个其它符号。
这21003汉字包括CJK统一汉字区的20902个汉字。余下的101个汉字包括:
-
增补汉字和部首80个,包括28个部首和52个汉字。GBK编码是从FE50-FE7E,FE80-FEA0。下图标注了Unicode编码。
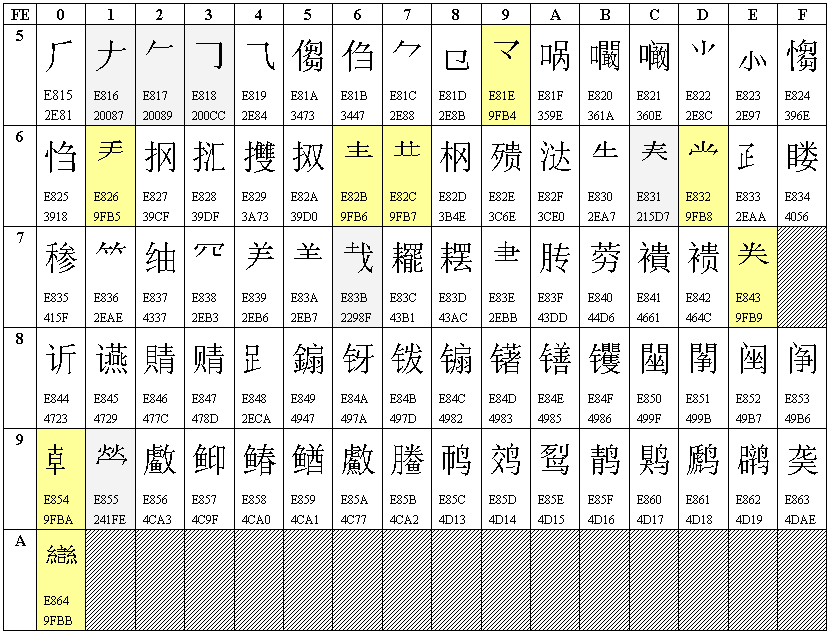
在制定GBK时,Unicode中还没有这些字符,所以使用了专用区的码位,这80个字符的码位是0xE815-0xE864。后来,Unicode将52个汉字收录到“CJK统一汉字扩充A”。28个部首中有14个部首被收录到“CJK部首补充区”。所以在上图中,这些字符都有两个Unicode编码。
上图中淡黄色背景的8个部首被收录到“CJK统一汉字区”的新增区域,即前面提到的0x9FA6-0x9FBB。还有6个淡灰色背景的部首被Unicode收录到“CJK统一汉字扩充B”(网友slt指正)。
请注意,淡黄色和淡灰色的14个字符按照GB18030还是应该映射到PUA码位。这14个字符与非PUA码位的映射关系只是网友找出来的,不是标准规定的。如果按照GBK编码,这80个字符应该全部映射到PUA码位。GB18030将其中66个字符映射到了非PUA码位。不过在Windows中,简体中文区域的默认代码页还是GBK,不是GB18030。
-
CJK兼容汉字区挑选出来的21个汉字。见下表:
| 汉字 |
GBK编码 |
Unicode编码 |
| 郎 |
FD9C |
F92C |
| 凉 |
FD9D |
F979 |
| 秊 |
FD9E |
F995 |
| 裏 |
FD9F |
F9E7 |
| 隣 |
FDA0 |
F9F1 |
| 兀 |
FE40 |
FA0C |
| 嗀 |
FE41 |
FA0D |
| 﨎 |
FE42 |
FA0E |
| 﨏 |
FE43 |
FA0F |
| 﨑 |
FE44 |
FA11 |
| 﨓 |
FE45 |
FA13 |
| 﨔 |
FE46 |
FA14 |
| 礼 |
FE47 |
FA18 |
| 﨟 |
FE48 |
FA1F |
| 蘒 |
FE49 |
FA20 |
| 﨡 |
FE4A |
FA21 |
| 﨣 |
FE4B |
FA23 |
| 﨤 |
FE4C |
FA24 |
| 﨧 |
FE4D |
FA27 |
| 﨨 |
FE4E |
FA28 |
| 﨩 |
FE4F |
FA29 |
4 GB18030-2000
4.1 字汇
GB18030-2000的字汇部分是这样写的:
本标准收录的字符分别以单字节、双字节和四字节编码。
5.1 单字节部分
本标准中,单字节的部分收录了GB 11383的0x00到0x7F全部128个字符及单字节编码的欧元符号。
5.2 双字节部分
本标准中,双字节的部分收录内容如下:
GB 13000.1的全部CJK统一汉字字符。
GB 13000.1的CJK兼容区挑选出来的21个汉字。
GB 13000.1中收录而GB 2312未收录的我国台湾地区使用的图形字符139个。
GB 13000.1收录的其它字符31个。
GB 2312中的非汉字符号。
GB 12345 的竖排标点符号19个。
GB 2312未收录的10个小写罗马数字。
GB 2312未收录的带音调的汉语拼音字母5个以及ɑ 和ɡ 。
汉字数字“〇”。
表意文字描述符13个。
增补汉字和部首/构件80个。
双字节编码的欧元符号。
5.3 四字节部分
本标准的四字节的部分,收录了上述双字节字符之外的,包括CJK统一汉字扩充A在内的GB 13000.1 中的全部字符。
4.2 汉字
如下表所示,GB18030-2000收录了27533个汉字:
| 类别 |
码位范围 |
码位数 |
字符数 |
字符类型 |
| 双字节部分 |
第一字节 0xB0-0xF7
第二字节 0xA1-0xFE |
6768 |
6763 |
汉字 |
第一字节0x81-0xA0
第二字节0x40-0xFE |
6080 |
6080 |
汉字 |
第一字节0xAA-0xFE
第二字节0x40-0xA0 |
8160 |
8160 |
汉字 |
| 四字节部分 |
第一字节0x81-0x82
第二字节0x30-0x39
第三字节0x81-0xFE
第四字节0x30-0x39 |
6530 |
6530 |
CJK统一汉字扩充A |
27533就是6763+6080+8160+6530。双字节部分的6763+6080+8160=21003个汉字就是GBK的21003个汉字。
在Unicode中,CJK统一汉字扩充A有6582个汉字,为什么这里只有6530个汉字?
这是因为在GBK时代,双字节部分已经收录过CJK统一汉字扩充A的52个汉字,所以还余6530个汉字。
5 GB18030-2005
5.1 字汇
GB18030-2005的字汇部分是这样写的:
本标准收录的字符分别以单字节、双字节或四字节编码。
5.1 单字节部分
本标准中,单字节的部分收录了GB/T 11383-1989的0x00到0x7F全部128个字符。
5.2 双字节部分
本标准中,双字节的部分收录内容如下:
GB 13000.1-1993的全部CJK统一汉字字符。见附录A。
GB 13000.1-1993的CJK兼容区挑选出来的21个汉字。见附录A。
GB 13000.1-1993中收录而GB 2312未收录的我国台湾地区使用的图形字符139个。见附录A。
GB 13000.1-1993收录的其它字符31个。见附录A。
GB 2312中的非汉字符号。见附录A。
GB 12345 的竖排标点符号19个。见附录A。
GB 2312未收录的10个小写罗马数字。见附录A。
GB 2312未收录的带音调的汉语拼音字母5个以及ɑ 和ɡ 。见附录A。
汉字数字“〇”。 见附录A。
表意文字描述符13个。见附录A和附录B。
对GB 13000.1-1993增补的汉字和部首/构件80个。见附录A和附录C。
双字节编码的欧元符号。见附录A。
5.3 四字节部分
本标准的四字节的部分,收录了上述双字节字符之外的,GB 13000的CJK统一汉字扩充A、CJK统一汉字扩充B和已经在GB13000中编码的我国少数民族文字的字符。见附录D。
GB18030-2005最主要的变化是增加了CJK统一汉字扩充B。它还去掉了单字节编码的欧元符号(0x80)。
5.2 汉字
如下表所示,GB18030-2005收录了70244个汉字:
| 类别 |
码位范围 |
码位数 |
字符数 |
字符类型 |
| 双字节部分 |
第一字节 0xB0-0xF7
第二字节 0xA1-0xFE |
6768 |
6763 |
汉字 |
第一字节0x81-0xA0
第二字节0x40-0xFE |
6080 |
6080 |
汉字 |
第一字节0xAA-0xFE
第二字节0x40-0xA0 |
8160 |
8160 |
汉字 |
| 四字节部分 |
第一字节0x81-0x82
第二字节0x30-0x39
第三字节0x81-0xFE
第四字节0x30-0x39 |
6530 |
6530 |
CJK统一汉字扩充A |
第一字节0x95-0x98
第二字节0x30-0x39
第三字节0x81-0xFE
第四字节0x30-0x39 |
42711 |
42711 |
CJK统一汉字扩充B |
70244就是6763+6080+8160+6530+42711。
6 结束语
GB2312有6763个汉字,GBK有21003个汉字,GB18030-2000有27533个汉字,GB18030-2005有70244个汉字。
Unicode 5.0中,如果不算兼容区,目前有70217个汉字。让我们比较一下Unicode的70217汉字和GB18030-2005中的70244汉字:
| GB18030-2005 |
Unicode 5.0 |
对应的Unicode编码 |
| CJK统一汉字的20902汉字 |
CJK统一汉字的20902汉字 |
0x4E00-0x9FA5 |
| CJK统一汉字扩充A的6582汉字 |
CJK统一汉字扩充A的6582汉字 |
0x3400-0x4DB5 |
| CJK统一汉字扩充B的42711汉字 |
CJK统一汉字扩充B的42711汉字 |
0x20000-0x2A6D6 |
| CJK部首补充区的14个部首 |
未计入 |
2E81, 2E84, 2E88, 2E8B, 2E8C, 2E97, 2EA7, 2EAA, 2EAE, 2EB3, 2EB6, 2EB7, 2EBB, 2ECA |
| CJK兼容汉字区的21个汉字 |
未计入 |
F92C, F979, F995, F9E7, F9F1, FA0C, FA0D, FA0E, FA0F, FA11, FA13, FA14, FA18, FA1F, FA20, FA21, FA23, FA24, FA27, FA28, FA29 |
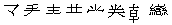 |
CJK统一汉字区新增了这8个字符 |
0x9FB4-0x9FBB |
| 未计入 |
CJK统一汉字区新增的14个字符 |
0x9FA6-0x9FB3 |
因为GB18030映射了Unicode的所有码位,所以CJK统一汉字区新增的0x9FA6-0x9FB3这14个字符在GB18030中都有对应的码位。不过GB18030没有明确收录这些字符。
附录1 GB18030的汉字编码表
我整理了GB18030的汉字编码表,需要的朋友可以下载。以下是其中的简要说明:
简要说明
将表1(21003)和表2(6530)合起来就是GB18030-2000要求的27533个汉字
将表1(21003)、表2(6530)和表3(42711)合起来就是GB18030-2005要求的70244个汉字
Unicode的扩充A本来有6582个汉字,因为GB18030的双字节区已经收录过Unicode扩充A的52个汉字,所以GB18030四字节区扩充A只有6530个汉字。表4列出了这52个汉字。
GBK增补的80个字符本来是放在PUA区的。后来又被Unicode收录。所以既可以用PUA区的编码表示,也可以用非PUA编码表示。如下表所示。
分享到:





相关推荐
GBK是在GB2312基础上的扩展,增加了对GBK18030之前其他编码系统的兼容,包括BIG5(用于繁体中文)和GB2312不涵盖的一些少数民族文字,共收录了20902个汉字和符号,是GB2312的一个广泛使用的扩展版本。 转换码表是...
在开发stm32时,从网上接收到utf8的数据流中包含汉字,如果要正确的在串口中打印汉字的话,就要把utf8(一个汉字3字节)转为GB2312(一个汉字2字节),这个过程不能直接转化,因为GB2312只有和16位的Unicode有映射,...
- **编码演变**:从GB2312到GBK再到GB18030,可以看出汉字编码标准随着技术进步和社会需求的发展不断扩展和完善。GB18030作为最新且最全面的标准,不仅支持了大量的汉字和图形符号,还考虑了与国际标准Unicode的兼容...
"汉字编码表.txt"和"Unicode、GB2312、GBK和GB18030中的汉字_janvyking999的空间_百度空间.txt"这两个文本文件可能包含了汉字在不同编码中的对应信息,供开发者参考和使用。 在实际开发中,理解和掌握这些编码标准...
在表中,星号(*)标记的字符是只在GBK编码中定义的字符,表示这个字符在GB2312中没有对应。比如,U+0020表示空格,而“a1e3±”则对应于GBK中的字符±。另外,“a8b5)”表示GBK中的字符“ǖ”。 需要注意的是,由于...
总的来说,GB18030与Unicode转换表是跨平台、跨语言数据交换的重要工具,理解并掌握其工作原理和使用方法,对于IT从业人员来说具有重要意义,特别是在处理中文字符集的项目中。通过深入学习和应用这个转换表,我们...
GB2312,全称“汉字国标交换码”,是中国大陆的国家标准汉字编码,主要用来表示简体中文。它包含6763个常用汉字和682个非汉字图形符号,适用于一般中文信息处理和交换。 然而,Unity Web Player作为一个基于Web的...
例如,在GB2312中,低位字节的范围通常是A1到FE,在GBK中则是A1到F7。每个汉字或符号在字符集中都对应着一个唯一的机内码。 字符集的使用涉及到字符的存储和编码,以确保计算机系统能够识别和处理汉字信息。无论是...
本文将从头讲解编码的故事,包括 Unicode、Ascii、utf-8、GB2312、GBK 等编码标准的由来和发展。 首先,让我们从基本的概念开始。计算机使用字节来存储信息,而字节是由 8 个可以开合的晶体管组合成的。这些字节...
GB18030,全称是《信息技术 中文编码扩展规范》,是中国国家标准,旨在扩大GB2312和GBK编码的覆盖范围,以支持更多的汉字和其他中文字符。GB18030编码标准包含了大约27,500多个汉字,包括简体和繁体,以及一些少数...
标题和描述中提到的"编码转换器 绿色版 gb2312 gbk utf-8 万能转换"是一个软件工具,它能够帮助用户将文本文件从一种编码格式转换到另一种,尤其是GB2312、GBK和UTF-8这三种常见的中文编码格式。 1. **编码系统**:...
GBK兼容GB2312,不仅包含GB2312中的所有汉字,还增加了包括繁体字、少数民族文字、符号等在内的20902个字符,总计20480个不同的编码位置,大大扩展了汉字的表示范围,为中文信息处理提供了更广阔的空间。 在“GBK_...
GB 2312、GB 13000、GBK、GB18030 是中国国家标准,用于中文字符集编码,解决了中文应用系统需要大量汉字的问题,满足了政府机关内部工作、政府机关的网上工作、电子商务、以及其他网上服务行业的需要。
GB18030不仅包含了GBK中的所有汉字,还增加了大量其他语言字符,如藏文、蒙古文等。GB18030采用了单字节、双字节和四字节的编码方式,能够表示超过27000个不同的字符。 在实际应用中,由于历史原因,某些系统或软件...
为此,后来又出现了GB18030编码,它进一步扩大了字符集,包含了GB2312和GBK的所有字符,并且加入了Unicode的部分内容。 在提供的文件中,"gb2312.pdf"可能包含对GB2312编码的详细介绍,包括其编码规则和使用场景;...
GB18030是正式国家标准,是GBK或GB2312的超集。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。 这里是一个Excle版本的码表,罗列出码元及对应的GBK编码和Unicode编码,是研究编码的...
总之,“unicode编码gb2312全字库16X16”是一个兼顾Unicode和GBK编码,适用于16x16点阵显示的汉字资源,对于需要处理中文字符的开发者来说,它是一个实用且全面的工具,有助于解决多编码环境下的显示问题。
本文将深入探讨标题中提及的几个关键概念:GB2312、GB 13000、GBK、GB18030以及Unicode,同时也会涉及它们与GBK和Unicode之间的转换以及字库资料的相关知识。 首先,让我们从GB2312开始,它是中华人民共和国国家...