
关系型数据库曾经在网站和企业应用中都是占统治地位的结构化数据存储技术。自从上世纪70年代关系型数据诞生,一直到本世纪初,关系型数据库和SQL语言几乎是结构化数据存储和访问的唯一选择。这几乎是一个奇迹 - 想象一下, 同一时期,硬件技术,软件开发技术变化可以用天翻地覆来形容。而这个领域几乎没有发生革命性的改变。
变革起初发生在数据访问层面上。 如早期的EJB体系中的实体Bean,到SSH中的Hibernate等。但这些领域的进展只是为了避免数据库厂商的锁定,为了把关系型的数据更方便映射到面向对象的世界里等等这些原因。 关系型数据库基本上还统治着整个数据存储领域。
同时,一些针对数据分析领域的OLAP数据库开始出现,如TD, Sybase IQ等。这些数据库针对分析型的场景做了一些改变,甚至底层的存储方式发生了很大的变化(如列式存储),但是逻辑对象的组织和访问的语言,仍然极大程度上兼容了OLTP关系型数据库。
随着大数据时代的到来,这种折衷式的妥协方案逐渐变得无法应对了。数据库领域开始了激烈的蜕变,至今这个变化仍然在进行中。可以确定的是,我们再也无法回到用一种工具,一种技术去解决所有数据存储领域的问题的时代了。 取而代之的是,架构师需要细致地思考数据应用的场景,从众多的方案中仔细的筛选,找出最贴合场景的选择。甚至,从零开始为你的场景去构建一个合适的数据存储方案。
这个系列会过一遍主流的NoSQL数据库,从而能够理解每类数据库适用的场景,试图解决的问题,蕴含的数据结构,以及它们不擅长的领域。
Big Table (Google)
1 数据结构
谷歌的Big Table最初的设计为了存储 “稀疏的,分布式的,持久的多维的Sorted Map”。这个Sorted Map以行键,列键(列簇名+列名), 和时间戳来索引,定位出存储的具体内容。 在Big Table里所有的数据以Bytes Array的形式存储。
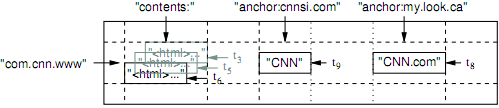
行
Row key 最长可以到64KB。记录按字典顺序保存,并且动态被分成“数据片” (Tablet)。数据片是Bigtable中数据分布和负载平衡的最小单位。客户端应用可以通过仔细设计选择row key,使得需要经常访问的多条记录存放在一起,这样在行范围读取的时候,只需要读取比较少的数据片就可以完成。 比如上图的例子里, row key 被设计成反过来的域名。这样同一个二级域名下的访问记录就会存放在一起。
字段的个数是基本上可以认为是无限的。字段按列簇组织在一起。Bigtable中加入列簇的主要考虑是值的稀疏性。因为Bigtable是按列存储的,而列的值可能是稀疏的,而且列的数目非常多,如果只按照列来组织存储的话,可能会形成很多个小文件。而分布式文件系统对小文件的管理成本是比较高的。因此bigtable 引入列簇的概念,把同一个列簇的列存储在一起。
具体来说,列簇有以下的特性:
- 列簇是访问权限控制的单元
- 列簇中的列存储相同类型,或者类似类型的数据
- 列簇中的数据是在一起被压缩存储的
- 列簇必须预先定义 (而列不需要)
- 列簇名必须是可打印字符串(而列名可以是任意字符串)
- 列簇应该是有限个的,并且很少被修改。
时间戳
时间戳是64位整数,在bigtable中用来区分数据的不同版本。时间戳可以由数据库自动生成,也可以由应用自行指定。数据的存储按照时间戳的倒序排列,因此最近的版本会被最先读到。Bigtable支持指定数据最多有多少个版本,或者数据的生存时间。过期的数据有自动的垃圾回收机制删除。应用程序不需要维护数据的删除问题。
2 API
Big table 不提供SQL接口。只提供编程访问接口。
读操作 提供按row key查询,按row key范围查询, 按列簇过滤,按时间戳过滤,以及列的迭代器。
写操作 包括创建记录,更新记录,删除记录。也有批量写接口(但是不保证事务性)
管理操作 管理集群,表,列簇,权限等
服务器端 代码执行 支持在服务器端脚本的执行。可以进行数据的过滤, 表达式转换,数据聚合等操作。
Map reduce Hbase表可以作为map reduce的输出和输入
3 组件依赖
Bigtable 依赖于这些组件GFS (对应于开源界的HDFS),Chubby(对于开源界的ZooKeeper), 大规模集群管理系统 (开源界的如Yarn, Meos差不多都是这个领域)。对于这些依赖的组件,此处不做展开。
4 实现细节
4.1 系统组件
- 数据片服务器
一个bigtable 系统有多个数据片(tablet)服务器。每个数据片服务器负责管理一些数据片,包括对这些数据片的读写,数据片过大的时候的拆分,数据片过小的时候的合并等。 数据片服务器可以灵活的增加与减少。
- 客户端库
应用通过客户端库来和bigtable系统进行交互。客户端负责数据库服务器的查找,和数据片服务器直接交互,提供数据的读写,并把服务器的响应返回给应用。
- 主服务器
主服务器有着多种职责。首先它管理数据片和数据片服务器。它把数据片分配给数据片服务器,发现新的数据片服务器,移除死掉的数据片服务器,并平衡数据片服务器的负载。其次,它负责管理bigtable的schema,包括表的创建和列簇的创建。最后它负责删除和过期文件的垃圾回收处理。尽管主服务器承担很多职责,它的负责是很轻的,因为客户端库负责自己查找数据片的位置信息。 因此,大多数客户端始终不会和主服务器交互。主服务器是单点,因此一般会有备的主服务器。
4.2 数据片位置信息
之前提到过,表动态地被划分到数据片,而数据片分布在多个数据片服务器上。 数据片服务器可以随时增加,也可能随时减少。因此,bigtable必须有一个管理和查询数据片位置信息的方式。这样,主服务器才能重新平衡数据片,客户端库才能发现是哪一个数据片服务器管理想要查询的数据。下图说明了数据片信息是如何被管理的。
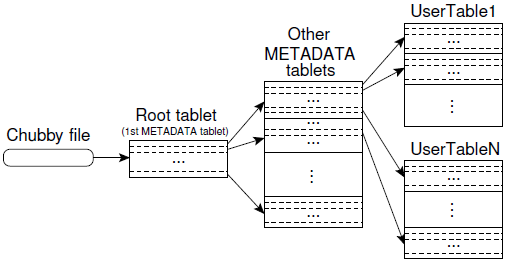
数据片的位置信息是保存在一个叫METADATA的数据片中。这个数据片在运行期间是被完全读入保持在内存中的。这个表被分隔为特殊的第一个数据片(根数据片)和其余的任意数目个非根数据片。非根数据片包含了所有的用户表的数据片信息。而根数据片包含了所有的非根METADATA数据片。根数据片的位置保存在Chubby命名空间中的一个文件中。数据片的位置信息用表的标识符(表名)和数据片的最后一条记录来描述。假设一行元数据记录的大小占用1KB的内存,假设元数据片的大小为128M, 那么这个体系可以描述( 128M/1K * 128M/1K = 2^32 >10亿)个数据片信息。其总体占用内存为(128M/1K+1)*128M = 128G。
客户端在访问数据的时候,是不需要扫描所有的的METADATA数据片的。而是说,它会缓存数据片信息。如果缓存的数据片信息失效,它会在这个三层结构中上移一层寻找新的(分裂或合并后的)数据片信息。为了进一步优化性能,当客户端获取METADATA数据片信息时,它总会读取一批数据片,而不是仅仅一个数据片。
4.3 主服务器,数据片服务器和数据片生命周期
数据片生命周期 数据片由主服务器创建,删除,被分配给某个具体的数据片服务器。每个数据片最多同时被分配给一个数据片服务器。主服务器当发现一个相对空闲的数据片服务器时,也会将其重新分配给空闲的数据片服务器。主服务会主动合并数据片,或者数据片服务器会分裂数据片并通知主服务器。 关于数据片的详细结构,参考下面数据片详情部分。
数据片服务器的生命周期 当一个数据片服务器启动时,它在Chubby上创建一个唯一的文件锁。主服务器会持续监控Chubby文件锁的状态从而知道数据片服务器是否存活。如果主服务器发现一个数据片服务器不再持有这个锁,那么它会认为这个数据片服务器已经不可用,并且删掉这个锁。然后,分配给这个数据片服务器的数据片标记为待分配的数据片。一个数据片服务器如果发现它丢失了Chubby上的文件锁,那么它会停止服务并自杀。如果数据片服务器被管理员停止时,它也会主动释放Chubby上的锁,这样主服务器可以尽早发现并重新分配数据片。
主服务器的生命周期 当主服务器启动时,它也会在Chubby上放置一个文件锁,用来防止其他的服务器获得主服务器资格。假如主服务器无法稳定持有这个锁(网络延时),那么主服务器会自杀,因为一旦它无法和Chubby很好通讯,那么它也无法管理好数据片服务器。因此,主服务器和Chubby的网络必须良好。
除了在Chubby上的注册, 主服务器启动时还会做一下的事情:
- 扫描Chubby,发现存活的数据片服务器。
- 和数据片服务器对话,获得每个数据片服务器服务的数据皮
- 扫描METADATA数据片,构建表的列表和数据片列表。
- 通过2和3,推导出未分配数据片列表。
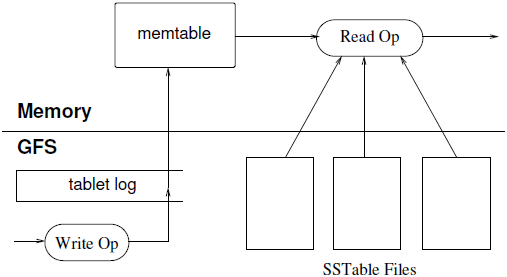
4.4 数据片详解



相关推荐
Table of Contents INTRODUCTION xvii PART I: GETTING STARTED CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 CHAPTER 2: HELLO NOSQL: GETTING INITIAL HANDS-ON EXPERIENCE 21 CHAPTER 3: ...
Big Data, MongoDB not only enables the user in understanding the buzz words “Big Data” and “NoSQL”, it also delves in understanding one of the popular document-based NoSQL databases “MongoDB”....
In Beginning Big Data with Power BI and Excel 2013, you will learn to solve business problems by tapping the power of Microsoft’s Excel and Power BI to import data from NoSQL and SQL databases and ...
Chapter 6: Database and NoSQL Chapter 7: RHadoop Appendix A: Installation of Java Environment Appendix B: Installation of MySQL Appendix C: Installation of Redis Appendix D: Installation of MongoDB ...
4. **Big Table**:Big Table是由Google开发的一种分布式多维度键值存储系统,主要用于存储大规模数据集。它是Google搜索引擎、Gmail等服务背后的基础架构之一,支持高并发和低延迟的数据访问。 5. **SSTable...
This book is also for big data enthusiasts and database developers who have worked with other NoSQL databases and now want to explore HBase as another futuristic scalable database solution in the big...
4. **DBMS (Database Management System)**: 数据库管理系统,用于创建和管理数据库的软件。 5. **DBA (Database Administrator)**: 数据库管理员,负责管理数据库系统的人员。 6. **Table**: 表,数据库中组织数据...
1. **HBase介绍**:HBase是一个分布式、面向列的NoSQL数据库,它是Apache Hadoop生态系统的一部分,灵感来源于Google的BigTable。HBase利用了HDFS(Hadoop Distributed File System)作为其底层存储,为大规模数据集...
HBase,全称为Hadoop Distributed File System Base,是构建在Apache Hadoop文件系统(HDFS)之上的分布式、列式存储的NoSQL数据库,专为处理大规模数据而设计。它在大数据领域扮演着至关重要的角色,尤其在实时查询...
首先,HBase(Hadoop Database)是Apache软件基金会的一个开源项目,它构建于Hadoop之上,是一款面向列的分布式数据库。HBase基于Google的Bigtable模型,提供高可靠性、高性能、可伸缩的存储。其设计目标是处理PB...
Even faster Key/Value store nosql embedded database engine utilizing the new MGIndex data structure with MurMur2 Hashing and WAH Bitmap indexes for duplicates. See Also More like this More by this...
在技术层面,数据库类型呈现出百花齐放的态势,包括关系型数据库、键值存储、NewSQL、Big Table、图数据库和非关系型数据库等。这些技术各自针对不同的应用场景,如OLTP(在线事务处理)、OLAP(在线分析处理)和...