
原文:http://blog.csdn.net/derekjiang/article/details/9126185
Trident是在storm基础上,一个以realtime 计算为目标的高度抽象。 它在提供处理大吞吐量数据能力的同时,也提供了低延时分布式查询和有状态流式处理的能力。 如果你对Pig和Cascading这种高级批量处理工具很了解的话,那么应该毕竟容易理解Trident,因为他们之间很多的概念和思想都是类似的。Tident提供了 joins, aggregations, grouping, functions, 以及 filters等能力。除此之外,Trident 还提供了一些专门的原语,从而在基于数据库或者其他存储的前提下来应付有状态的递增式处理。
举例说明
让我们一起来看一个Trident的例子。在这个例子中,我们主要做了两件事情:
- 从一个流式输入中读取语句病计算每个单词的个数
- 提供查询给定单词列表中每个单词当前总数的功能
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"),
spout.setCycle(true);
这个spout会循环输出列出的那些语句到sentence stream当中,下面的代码会以这个stream作为输入并计算每个单词的个数:
TridentTopology topology = new TridentTopology();
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);
让我们一起来读一下这段代码。我们首先创建了一个TridentTopology对象。TridentTopology类相应的接口来构造Trident计算过程中的所有内容。我们在调用了TridentTopology类的newStream方法时,传入了一个spout对象,spout对象会从外部读取数据并输出到当前topology当中,从而在topology中创建了一个新的数据流。在这个例子中,我们使用了上面定义的FixedBatchSpout对象。输入数据源同样也可以是如Kestrel或者Kafka这样的队列服务。Trident会再Zookeeper中保存一小部分状态信息来追踪数据的处理情况,而在代码中我们指定的字符串“spout1”就是Zookeeper中用来存储metadata信息的Znode节点
Trident在处理输入stream的时候会把输入转换成若干个tuple的batch来处理。比如说,输入的sentence stream可能会被拆分成如下的batch:
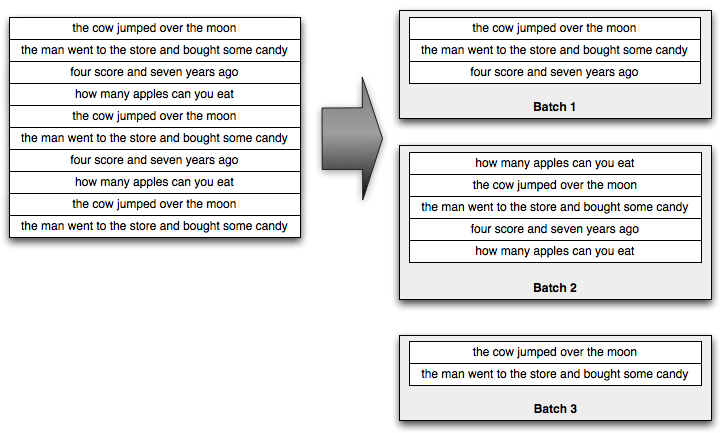
一般来说,这些小的batch中的tuple可能会在数千或者数百万这样的数量级,这完全取决于你的输入的吞吐量。
Trident提供了一系列非常成熟的批量处理的API来处理这些小batch. 这些API和你在Pig或者Cascading中看到的非常类似, 你可以做group by's, joins, aggregations, 运行 functions, 执行 filters等等。当然,独立的处理每个小的batch并不是非常有趣的事情,所以Trident提供了很多功能来实现batch之间的聚合的结果并可以将这些聚合的结果存储到内存,Memcached, Cassandra或者是一些其他的存储中。同时,Trident还提供了非常好的功能来查询实时状态。这些实时状态可以被Trident更新,同时它也可以是一个独立的状态源。
回到我们的这个例子中来,spout输出了一个只有单一字段“sentence”的数据流。在下一行,topology使用了Split函数来拆分stream中的每一个tuple,Split函数读取输入流中的“sentence”字段并将其拆分成若干个word tuple。每一个sentence tuple可能会被转换成多个word tuple,比如说"the cow jumped over the moon" 会被转换成6个 "word" tuples. 下面是Split的定义:
public class Split extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
如你所见,真的很简单。它只是简单的根据空格拆分sentence,并将拆分出的每个单词作为一个tuple输出。
topology的其他部分计算单词的个数并将计算结果保存到了持久存储中。首先,word stream被根据“word”字段进行group操作,然后每一个group使用Count聚合器进行持久化聚合。persistentAggregate会帮助你把一个状态源聚合的结果存储或者更新到存储当中。在这个例子中,单词的数量被保持在内存中,不过我们可以很简单的把这些数据保存到其他的存储当中,如 Memcached, Cassandra等。如果我们要把结果存储到Memcached中,只是简单的使用下面这句话替换掉persistentAggregate就可以,这当中的"serverLocations"是Memcached cluster的主机和端口号列表:
.persistentAggregate(MemcachedState.transactional(serverLocations), new Count(), new Fields("count"))
MemcachedState.transactional()
persistentAggregate存储的数据就是所有batch聚合的结果。
Trident非常酷的一点就是它是完全容错的,拥有者有且只有一次处理的语义。这就让你可以很轻松的使用Trident来进行实时数据处理。Trident会把状态以某种形式保持起来,当有错误发生时,它会根据需要来恢复这些状态。
persistentAggregate方法会把数据流转换成一个TridentState对象。在这个例子当中,TridentState对象代表了所有的单词的数量。我们会使用这个TridentState对象来实现在计算过程中的进行分布式查询。
下面这部分实现了一个低延时的单词数量的分布式查询。这个查询以一个用空格分割的单词列表为输入,并返回这些单词当天的个数。这些查询是想普通的RPC调用那样被执行的,要说不同的话,那就是他们在后台是并行执行的。下面是执行查询的一个例子:
DRPCClient client = new DRPCClient("drpc.server.location", 3772);
System.out.println(client.execute("words", "cat dog the man");
// prints the JSON-encoded result, e.g.: "[[5078]]"
如你所见,除了这是并发执行在storm cluster上之外,这看上去就是一个正常的RPC调用。这样的简单查询的延时通常在10毫秒左右。当然,更负责的DRPC调用可能会占用更长的时间,尽管延时很大程度上是取决于你给计算分配了多少资源。
这个分布式查询的实现如下所示:
topology.newDRPCStream("words")
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
我们仍然是使用TridentTopology对象来创建DRPC stream,并且我们将这个函数命名为“words”。这个函数名会作为第一个参数在使用DRPC Client来执行查询的时候用到。
每个DRPC请求会被当做只有一个tuple的batch来处理。在处理的过程中,以这个输入的单一tuple来表示这个请求。这个tuple包含了一个叫做“args”的字段,在这个字段中保存了客户端提供的查询参数。在这个例子中,这个参数是一个以空格分割的单词列表。
首先,我们使用Splict功能把入参拆分成独立的单词。然后对“word” 进行group by操作,之后就可以使用stateQuery来在上面代码中创建的TridentState对象上进行查询。stateQuery接受一个数据源(在这个例子中,就是我们的topolgoy所计算的单词的个数)以及一个用于查询的函数作为输入。在这个例子中,我们使用了MapGet函数来获取每个单词的出现个数。由于DRPC stream是使用跟TridentState完全同样的group方式(按照“word”字段进行group),每个单词的查询会被路由到TridentState对象管理和更新这个单词的分区去执行。
接下来,我们用FilterNull这个过滤器把从未出现过的单词给去掉,并使用Sum这个聚合器将这些count累加起来。最终,Trident会自动把这个结果发送回等待的客户端。
Trident在如何最大程度的保证执行topogloy性能方面是非常智能的。在topology中会自动的发生两件非常有意思的事情:
- 读取和更新状态的操作 (比如说 persistentAggregate 和 stateQuery) 会自动的是batch的形式操作状态。 如果有20次更新需要被同步到存储中,Trident会自动的把这些操作汇总到一起,只做一次读一次写,而不是进行20次读20次写的操作。因此你可以在很方便的执行计算的同时,保证了非常好的性能。
- Trident的聚合器已经是被优化的非常好了的。Trident并不是简单的把一个group中所有的tuples都发送到同一个机器上面进行聚合,而是在发送之前已经进行过一次部分的聚合。打个比方,Count聚合器会先在每个partition上面进行count,然后把每个分片count汇总到一起就得到了最终的count。这个技术其实就跟MapReduce里面的combiner是一个思想。
让我们再来看一下Trident的另外一个例子。
Reach
下一个例子是一个纯粹的DRPC topology。这个topology会计算一个给定URL的reach。那么什么事reach呢,这里我们将reach定义为有多少个独立用户在Twitter上面expose了一个给定的URL,那么我们就把这个数量叫做这个URL的reach。要计算reach,你需要tweet过这个URL的所有人,然后找到所有follow这些人的人,并将这些follower去重,最后就得到了去重后的follower的数量。如果把计算reach的整个过程都放在一台机器上面,就太勉强了,因为这会需要进行数千次数据库调用以及上一次的tuple的读取。如果使用Storm和Trident,你就可以把这些计算步骤在整个cluster中进行并发。
这个topology会读取两个state源。一个用来保存URL以及tweet这个URL的人的关系的数据库。还有一个保持人和他的follower的关系的数据库。topology的定义如下:
TridentState urlToTweeters =
topology.newStaticState(getUrlToTweetersState());
TridentState tweetersToFollowers =
topology.newStaticState(getTweeterToFollowersState());
topology.newDRPCStream("reach")
.stateQuery(urlToTweeters, new Fields("args"), new MapGet(), new Fields("tweeters"))
.each(new Fields("tweeters"), new ExpandList(), new Fields("tweeter"))
.shuffle()
.stateQuery(tweetersToFollowers, new Fields("tweeter"), new MapGet(), new Fields("followers"))
.parallelismHint(200)
.each(new Fields("followers"), new ExpandList(), new Fields("follower"))
.groupBy(new Fields("follower"))
.aggregate(new One(), new Fields("one"))
.parallelismHint(20)
.aggregate(new Count(), new Fields("reach"));
这个topology使用newStaticState方法创建了TridentState对象来代表一种外部存储。使用这个TridentState对象,我们就可以在这个topology上面进行动态查询了。和所有的状态源一样,在数据库上面的查找会自动被批量执行,从而最大程度的提升效率。
这个topology的定义是非常直观的 - 只是一个简单的批量处理job。首先,查询urlToTweeters数据库来得到tweet过这个URL的人员列表。这个查询会返回一个列表,因此我们使用ExpandList函数来把每一个反悔的tweeter转换成一个tuple。
接下来,我们来获取每个tweeter的follower。我们使用shuffle来把要处理的tweeter分布到toplology运行的每一个worker中并发去处理。然后查询follower数据库从而的到每个tweeter的follower。你可以看到我们为topology的这部分分配了很大的并行度,这是因为这部分是整个topology中最耗资源的计算部分。
然后我们在follower上面使用group by操作进行分组,并对每个组使用一个聚合器。这个聚合器只是简单的针对每个组输出一个tuple “One”,再count “One” 从而的到不同的follower的数量。“One”聚合器的定义如下:
public class One implements CombinerAggregator<Integer> {
public Integer init(TridentTuple tuple) {
return 1;
}
public Integer combine(Integer val1, Integer val2) {
return 1;
}
public Integer zero() {
return 1;
}
}
这是一个"汇总聚合器", 它会在传送结果到其他worker汇总之前进行局部汇总,从而来最大程度上提升性能。Sum也是一个汇总聚合器,因此以Sum作为topology的最终操作是非常高效的。
接下来让我们一起来看看Trident的一些细节。
Fields and tuples
Trident的数据模型就是TridentTuple - 一个有名的值的列表。在一个topology中,tuple是在一系列的处理操作(operation)中增量生成的。operation一般以一组子弹作为输入并输出一组功能字段。Operation的输入字段经常是输入tuple的一个子集,而功能字段则是operation的输出。
看一下如下这个例子。假定你有一个叫做“stream”的stream,它包含了“x”,"y"和"z"三个字段。为了运行一个读取“y”作为输入的过滤器MyFilter,你可以这样写:
stream.each(new Fields("y"), new MyFilter())
假定MyFilter的实现是这样的:
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(0) < 10;
}
}
这会保留所有“y”字段小于10的tuples。TridentTuple传个MyFilter的输入将只有字段“y”。这里需要注意的是,当选择输入字段时,Trident会自动投影tuple的一个子集,这个操作是非常高效的。
让我们一起看一下“功能字段”是怎样工作的。假定你有如下这个功能:
public class AddAndMultiply extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int i1 = tuple.getInteger(0);
int i2 = tuple.getInteger(1);
collector.emit(new Values(i1 + i2, i1 * i2));
}
}
这个函数接收两个数作为输入并输出两个新的值:“和”和“乘积”。假定你有一个stream,其中包含“x”,"y"和"z"三个字段。你可以这样使用这个函数:
stream.each(new Fields("x", "y"), new AddAndMultiply(), new Fields("added", "multiplied"));
输出的功能字段被添加到输入tuple中。因此这个时候,每个tuple中将会有5个字段"x", "y", "z", "added", 和 "multiplied". "added" 和"multiplied"对应于AddAndMultiply输出的第一和第二个字段。
另外,我们可以使用聚合器来用输出字段来替换输入tuple。如果你有一个stream包含字段"val1"和"val2",你可以这样做:
stream.aggregate(new Fields("val2"), new Sum(), new Fields("sum"))
output stream将会只包含一个叫做“sum”的字段,这个sum字段就是“val2”的累积和。
在group之后的stream上,输出将会是被group的字段以及聚合器输出的字段。举例如下:
stream.groupBy(new Fields("val1"))
.aggregate(new Fields("val2"), new Sum(), new Fields("sum"))
在这个例子中,输出将包含字段"val1" 和 "sum".
State
在实时计算领域的一个主要问题就是怎么样来管理状态并能轻松应对错误和重试。消除错误的影响是非常重要的,因为当一个节点死掉,或者一些其他的问题出现时,那行batch需要被重新处理。问题是-你怎样做状态更新来保证每一个消息被处理且只被处理一次?
这是一个很棘手的问题,我们可以用接下来的例子进一步说明。假定你在做一个你的stream的计数聚合,并且你想要存储运行时的count到一个数据库中去。如果你只是存储这个count到数据库中,并且想要进行一次更新,我们是没有办法知道同样的状态是不是以前已经被update过了的。这次更新可能在之前就尝试过,并且已经成功的更新到了数据库中,不过在后续的步骤中失败了。还有可能是在上次更新数据库的过程中失败的,这些你都不知道。
Trident通过做下面两件事情来解决这个问题:
- 每一个batch被赋予一个唯一标识id“transaction id”。如果一个batch被重试,它将会拥有和之前同样的transaction id
- 状态更新是以batch为单位有序进行的。也就是说,batch 3的状态更新必须等到batch 2的状态更新成功之后才可以进行。
有了这2个原则,你就可以达到有且只有一次更新的目标。你可以将transaction id和count一起以原子的方式存到数据库中。当更新一个count的时候,需要判断数据库中当前batch的transaction id。如果跟要更新的transaction id一样,就跳过这次更新。如果不同,就更新这个count。
当然,你不需要在topology中手动处理这些逻辑。这些逻辑已经被封装在Stage的抽象中并自动进行。你的Stage object也不需要自己去实习transaction id的跟踪操作。如果你想了解更多的关于如何实现一个Stage以及在容错过程中的一些取舍问题,可以参照这篇文章.
一个Stage可以采用任何策略来存储状态。它可以存储到一个外部的数据库,也可以在内存中保持状态并备份到HDFS中。Stage并不需要永久的保持状态。比如说,你有一个内存版的Stage实现,它保存最近X个小时的数据并丢弃老的数据。可以把 Memcached integration 作为例子来看看State的实现.
Execution of Trident topologies
Trident的topology会被编译成尽可能高效的Storm topology。只有在需要对数据进行repartition的时候(如groupby或者shuffle)才会把tuple通过network发送出去,如果你有一个trident如下:
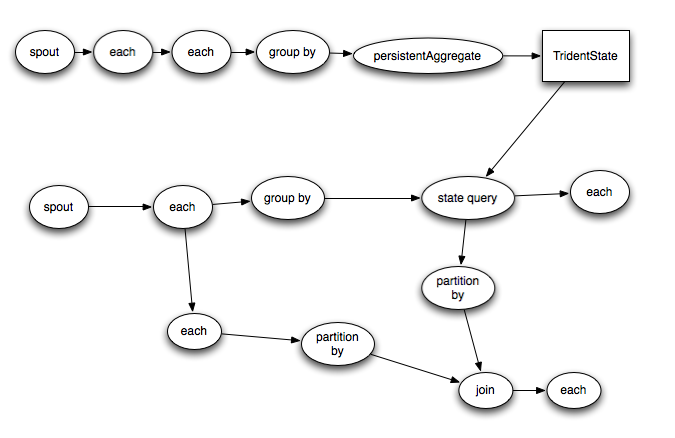
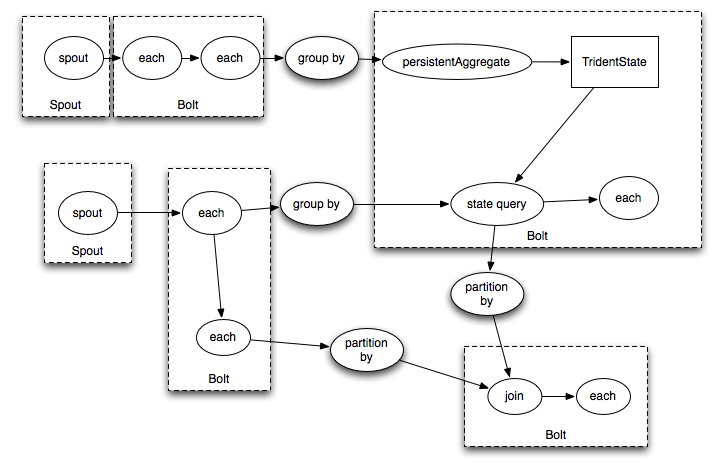
它将会被编译成如下的storm topology:
Conclusion
Trident使得实时计算更加优雅。你已经看到了如何使用Trident的API来完成大吞吐量的流式计算,状态维护,低延时查询等等功能。Trident让你在获取最大性能的同时,以更自然的一种方式进行实时计算。



相关推荐
Storm入门教程 之Storm原理和概念详解,出自Storm流计算从入门到精通之技术篇,Storm入门视频教程用到技术:Storm集群、Zookeeper集群等,涉及项目:网站PV、UV案例实战、其他案例; Storm视频教程亮点: 1、Storm...
而Trident是Storm的一个高级API,提供了可靠且精确一次的消息处理语义,常用于大规模实时数据处理任务,如日志分析、网站点击流分析、社交媒体数据处理等。本实战案例将重点介绍如何使用Storm Trident来计算网站的...
Storm视频教程通过含3个Storm完整项目,均为企业实际项目,其中一个是完全由Storm Trident开发。本课程每个技术均采用最新稳定版本,学完后可以从Kafka到Storm项目开发及HighCharts图表开发一个人搞定!涨工资?身价...
**Storm Trident:分布式流处理框架详解** Storm Trident是Twitter开源的、基于Apache Storm的一个高级抽象,它提供了一种更强大且高效的方式来处理实时数据流。Trident的核心理念是将数据流划分为一系列的小批量...
三叉戟教程实用的Storm Trident教程本教程以的的出色为基础。 流浪者的设置基于Taylor Goetz的。 Hazelcast状态代码基于wurstmeister的。 看看随附的。本教程的结构浏览Part * .java,了解Trident的基础知识使用...
《Storm Trident API 使用详解》 Storm Trident API 是 Apache Storm 框架中用于构建实时大数据处理应用程序的关键组件。它的核心概念是"Stream",一种无界的数据序列,它被分割成一系列批次(Batch),以便在...
### 大数据开发高级就业指导课程——Storm及Trident理论与实战 #### 一、Storm并发机制 在Storm中,为了提高数据处理的性能和效率,设计了一套完整的并发机制。这一机制涉及到Topology的组件配置、并发度设置等多...
Trident是一种构建在Twitter的开源分布式实时数据处理框架Storm之上的抽象层,它提供了高级的数据处理功能,特别适合大规模实时流数据的处理。在大数据领域,传统的Hadoop框架擅长批量数据处理,但不适用于实时需求...
storm_trident_state storm trident自定义state的实现,实现了3种插入数据库的持久化方法,事务,不透明事务,不透明分区事务 下载下面,运行:mvn eclipse:eclipse即可在eclipse使用此项目。
Trident是Storm的一个高级接口,用于构建强一致性的流处理应用。在项目中,Trident被用来实现更复杂的处理逻辑,如分区和状态管理。在"项目1-地区销售额-Trident代码开发一"中,初步建立了Trident拓扑结构,而在...
三叉戟《风暴蓝图:分布式实时计算模式》一书的源码和翻译=============(已完成,待校对)(未开始)(已完成,待校对)(已完成,待校对)(未开始)(未开始)(进行中)(未开始)(未开始)(未开始)
- **Storm Trident项目**:特别值得一提的是,其中一个项目是完全使用Storm Trident开发完成的。Storm Trident作为Storm的一个高级API,提供了更高级别的抽象和事务支持,使得复杂的数据处理变得更加简单和可靠。 *...
《storm实时数据处理》通过丰富的实例,系统讲解Storm的基础知识和实时数据处理的最佳实践方法,内容涵盖Storm本地开发环境搭建、日志流数据处理、Trident、分布式远程过程调用、Topology在不同编程语言中的实现方法...
5. ** Trident API**:Trident是Storm提供的高级API,它支持精确一次的语义,可以更方便地构建复杂的实时处理任务。 6. **Zookeeper整合**:Storm利用Zookeeper进行集群协调,保证系统的稳定运行。 7. **Java编程*...
#### 一、配置Storm + Trident的最佳实践 Apache Storm 是一个用于实时数据处理的强大框架,而Trident是其提供的一个高级API层,它提供了更强大的容错能力和易于理解的编程模型。为了充分发挥Storm + Trident的能力...
Storm流计算项目(文档中含有视频下载地址和解压密码),内容包含 storm、trident、kafka、hbase、cdh、hightcharts 等内容
三叉戟的例子一组用 Storm Trident 编写的应用程序。应用用法建造$ git clone git@github.com:mayconbordin/trident-examples.git$ cd trident-examples/$ mvn -P < profile> package 使用local配置文件以本地模式...
- **Trident**: Storm 0.9 引入的 Trident 是一个高级抽象层,提供了更强大的容错保障和精确一次处理语义。Trident 将数据流分割为一系列小的、可管理的事务。 - **检查点(Checkpointing)**: 通过定期保存状态,...
PDF版资料通常包括教程、用户手册、技术文档等,帮助用户深入理解和应用Storm。这些资料可能涵盖以下关键知识点: 1. **Storm架构**:Storm由多个组件构成,如Nimbus(主控节点)、Supervisor(工作节点)、Worker...
"storm学习入门《Getting started with Storm》中英文版" 指的是一个关于Apache Storm的初学者教程资源,包含了该技术的入门介绍。Apache Storm是一个开源的分布式实时计算系统,用于处理流数据,即持续不断的数据流...