
参考:http://blog.csdn.net/shirdrn/article/details/4634119
NameNode节点是就是HDFS的大脑。想了解HDFS文件系统,必须了解大脑结构。 咱们就从NameNode节点开始。NameNode类中,关于HDFS文件系统的存储和管理都交给了FSNamesystem负责。下面介绍一下 FSNamesystem的逻辑组成和类图。
1. FSNameSystem层次结构
一些概念
INode: 它用来存放文件及目录的基本信息:名称,父节点、修改时间,访问时间以及UGI信息等。
INodeFile: 继承自INode,除INode信息外,还有组成这个文件的Blocks列表,重复因子,Block大小
INodeDirectory:继承自INode,此外还有一个INode列表来组成文件或目录树结构
Block(BlockInfo):组成文件的物理存储,有BlockId,size ,以及时间戳
BlocksMap: 保存数据块到INode和DataNode的映射关系
FSDirectory:保存文件树结构,HDFS整个文件系统是通过FSDirectory来管理
FSImage:保存的是文件系统的目录树
FSEditlog: 文件树上的操作日志
FSNamesystem: HDFS文件系统管理
这些概念之间的层次关系:
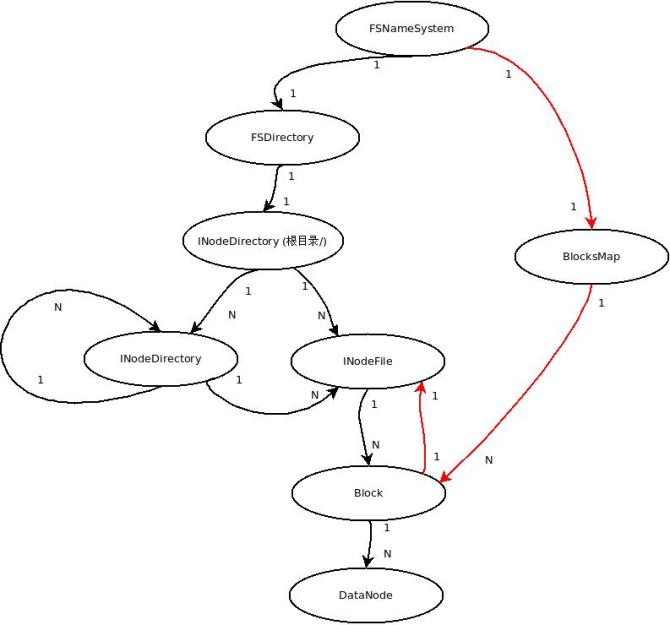
我们都知道,在NameNode内存中存在两张很重要的映射表:
1. 文件系统的命名空间(文件目录树) 主要是 文件和Block映射关系 (保存在FSDirectory)
2. Block 和 INodeFile & DataNode的映射关系 (保存在FSNamesystem)
在上图中,左边黑线部分是1 数据结构的层次关系;红线部分是 2 关系的层次结构
(其中block & DataNode这个共用)
下面详细的介绍上图所表示的关系:
文件系统 FSNamesystem
FSNamesystem 主要有两个对象:文件系统(FSDirectory)根节点rootDir 和BlocksMap映射表 (Block -> { INode, datanodes, self ref } )
文件系统目录FSDirectory
保存文件目录结构(INodeDirectory树),实现FSImage和FSEditLog操作实现。
INode ( INodeFile & INodeDirectory )
在HDFS中,无论目录还是文件,都是INode。INode有两个派生类INodeFile和INodeDirectory。
INodeFile是INode文件类,INodeDirectory是INode目录类。每一 INodeDirectory孩子节点都是由INodeDirectory目录或INodeFile文件列表构成。这样就形成了一棵INode树形结构。
NameNode内存中保存着HDFS整个文件系统形成的树,这棵树保存在FSDirectory对象内。
Block & BlocksMap & BlockInfo
HDFS物理存储单元是Block(缺省的Block大小为64M),每个Block会有几个副本(缺省是3个),这些Block都是存储在不同数据节点上的。映射关系保存在BlocksMap。
Block & INodeFile
每个INodeFile都有一个Block列表组成。每一个block有多个副本(缺省3个副本), 各副本保存在不同的数据节点上。 这样在文件与Block和DataNode之间形成一个映射关系表。这张关系表就保存在FSDirectory对象 .
FSImage & FSEditlog(FSDirectory)
由于目录树(FSDirectory)在NameNode内存中保存,机器也有掉电的时候。若只保存在内存那势必会造成数据的丢失。因此,系统会周期性的保存文件目录树到NameNode本地文件系统,生成FSImage。主要由FSImage和FSEditLog,这两个类负责目录树持久化。
当 HDFS系统非常庞大时,FSImage也会非常大,这样不能文件系统发生任何操作时,就更新到FSImage,所以一段时间内文件系统的操作日志会记录到FSEditLog。到一定时间会把操作日志FSEditLog同步到FSImage,这样就形成完整的文件目录树。
2. FSNameSystem 主要类关系图
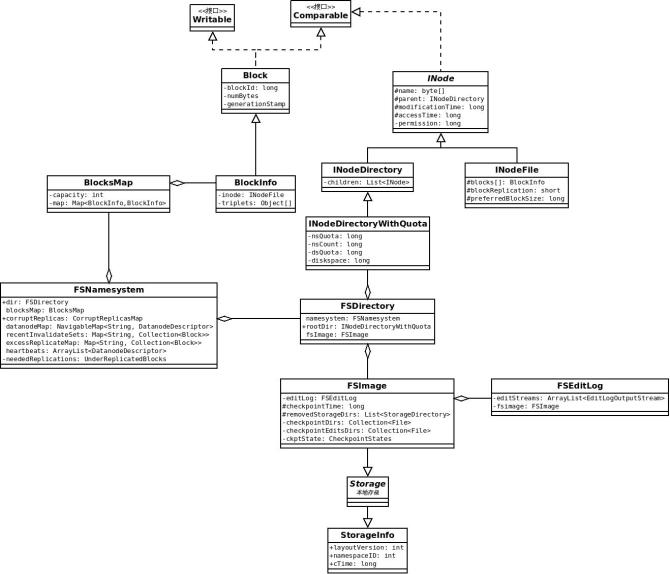
这个类图可以分成三个部分
Bock相关的部分(BlocksMap & BlockInof & Block)
INode相关的部分(INode & INodeDirectory & INodeFile & INodeDirectoryWithQuota)
FSImage & FSEditLog (Storage & StorageInfo)
其中
BlockInfo是Block的加强类,增加了INodeFile的引用和DataNode列表
INodeFirectoryWithQuota 是INodeDirectory的增强类,增加了Quota限制功能
从层次关系图和类图中,可以看出FSNamesystem中各数据结构之间的关系。了解FSNamesystem, 那么HDFS的文件系统就了解了90%。



相关推荐
在HDFS中,NameNode是主节点,负责管理文件系统的元数据,包括文件到数据块的映射以及目录结构。由于NameNode存储的元数据在内存中,因此文件数量受到NameNode内存大小的限制。如果文件数量过多,NameNode可能会成为...
当客户端想要打开一个HDFS文件时,它会调用`DistributedFileSystem.open`方法,传入文件路径和缓冲区大小。这个方法实际上会创建一个`DFSDataInputStream`,内部调用了`DFSClient`的`open`函数。`DFSClient.open`会...
本文将深入剖析HDFS文件读取流程,重点探讨客户端如何打开文件、NameNode的角色以及其内部结构对读取过程的影响。 ##### 1.1 客户端文件打开操作 客户端在HDFS中打开文件的过程始于`DistributedFileSystem.open()`...
第2章 HDFS元数据解析 2.1 概述 2.2 内存元数据结构 2.2.1 INode 2.2.2 Block 2.2.3 BlockInfo和DatanodeDescriptor 2.2.4 小结 2.2.5 代码分析——元数据结构 2.3 磁盘元数据文件 2.4 Format情景分析 2.5 元数据...
"基于Spark Streaming将图片以流的方式写入HDFS分布式文件系统" 这个标题揭示了我们讨论的核心技术栈。首先,Spark Streaming是Apache Spark的一部分,它允许实时处理连续的数据流。这里提到的"图片"是指我们要处理...
《Hadoop技术内幕:深入解析HADOOP COMMON和HDFS架构设计与实现原理》这本书是Hadoop技术领域的一本深入解析之作,它详尽地探讨了Hadoop的两大核心组件——HADOOP COMMON和HDFS(Hadoop Distributed File System)的...
- **获取文件系统实例**:使用`FileSystem.get()`方法获取HDFS文件系统的实例。 - **路径检查与创建**:检查目标路径是否存在,若不存在则创建相应的目录结构。 - **文件名提取**:从完整路径中提取出文件名。 - **...
3. **HDFS文件系统结构解析.doc**:此文档可能进一步阐述了HDFS的架构,包括名称节点、数据节点、数据块等关键组件,以及数据冗余和容错机制。 4. **Hive学习笔记.pdf**:Hive的学习笔记通常会涵盖HQL(Hive Query ...
HDFS是分布式文件系统的一种实现,由Apache Hadoop项目开发,专门设计用于存储和处理大规模数据。它将大型文件分布在多台服务器上,通过副本机制保证数据的可靠性和可用性,非常适合大规模数据分析任务。 在Java中...
元数据是描述数据的数据,在HDFS中,元数据主要由NameNode节点负责管理,它记录了文件系统树形目录结构、文件属性以及每一个文件的块列表等信息。HDFS的元数据管理机制是保证文件系统稳定运行的关键。HDFS为了解决单...
1. **Hadoop HDFS**:Hadoop HDFS是分布式文件系统,用于存储大量数据。它以高容错性和可扩展性为设计目标,使得数据可以在多台机器上分布存储。Java API提供了访问HDFS的接口,例如`org.apache.hadoop.fs....
总之,《Hadoop技术内幕:深入解析HADOOP COMMON和HDFS架构设计与实现原理》这本书将带你全面了解Hadoop生态系统的基础,帮助你更好地理解和优化Hadoop集群,从而在大数据处理领域发挥更大的效能。无论是初学者还是...
1. **数据预处理**:HDFS上的文件可能是CSV、JSON或自定义格式,需要先进行解析和转换,使其符合HBase的表结构。这可能涉及到使用MapReduce或者Spark等工具进行数据清洗和转换。 2. **创建HBase表**:在HBase中创建...
总之,《基于HDFS的云存储服务系统研究》这篇论文全面解析了HDFS在云存储服务中的应用,不仅介绍了其基本特性和工作流程,还对未来发展进行了深入探讨。对于理解和掌握HDFS以及云存储服务的运作原理,具有很高的学术...
1. **层次存储体系**:通过建立多级缓存体系,包括应用程序缓存、HBase的HBlock缓存以及操作系统层面的HDFS文件缓存,Facebook极大提高了数据访问速度,减少了磁盘I/O,增强了系统的响应能力。 2. **容错机制改进**...
在将数据推送到HDFS之前,通常需要清洗、解析或格式化原始数据,使其更适合后续分析或处理。 3. **HDFS消费**:`HdfsConsumer.java`是核心消费者类,负责从Kafka获取数据并将其写入HDFS。这可能涉及到使用Hadoop的`...
GPFS 并行文件系统原理解析 GPFS(General Parallel File System)是 IBM 公司推出的行业领先的并行分布式通用并行集群文件系统。自 1993 年开始研发,1995 年投入商用,GPFS 已经成为了行业领先的文件系统解决方案...
4. **读取HDFS文件**:获取文件的`Path`对象,然后使用`FileSystem`的`open()`方法打开文件。接着,你可以使用`BufferedReader`逐行读取文件内容。 5. **连接HBase**:创建一个`Connection`对象来连接HBase,使用`...
1. **HDFS(Hadoop Distributed File System)**:HDFS是Apache Hadoop项目的核心部分,是一种分布式文件系统,旨在处理和存储大规模的数据集。它的设计目标是高容错性、高吞吐量以及处理PB级别的数据。HDFS将大文件...