
MapReduce工作流程
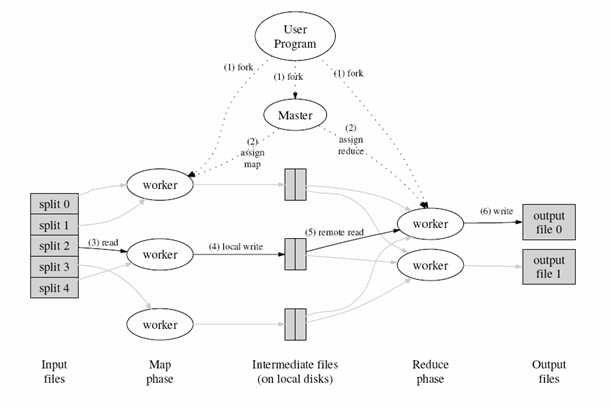
1.将输入源(Inputfiles)切割成不同的片段,每个片段的大小通常在16M-64M之间(可通过参数配置),然后启动云端程序。
2.MapReduce程序基于master/slaves方式部署,在云端机器中选中一台机器运行master程序,职责包括:调度任务分配给slaves,监听任务的执行情况。
3.在图形中,slave的体现形式为worker,当worker接到Map任务时,会读取输入源片段,从中解析出Key/Value键值对,并作为参数传递到用户自定义的Map功能函数之中,Map功能函数的输出值同样为Key/Value键值对,这些键值对会临时缓存在内存里面。
4.缓存之后,程序会定期将缓存的键值对写入本地硬盘(执行如图所示的local write操作),并且把存储地址传回给master,以便master记录它们的位置用以执行Reduce操作。
5.当worker被通知执行Reduce操作时,master会把相应的Map输出数据所存储的地址也发送给该worker,以便其通过远程调用来获取这些数据。得到这些数据之后,reduce worker会把具有相同Key值的记录组织到一起来达到排序的效果。
6.Reduce Worker会把排序后的数据作为参数传递到用户自定义的Reduce功能函数之中,而函数的输出结果会持久化存储到output file中去。
7.当所有的Map任务和Reduce任务结束之后,Master会重新唤醒用户主程序,至此,一次MapReduce操作调用完成。
2.2、HDFS组件结构
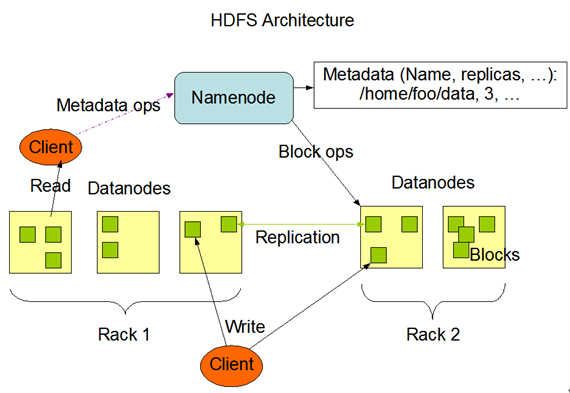
同MapReduce部署结构类似,HDFS同样具备master/slaves主仆结构
1.如图所示中,NameNode充当master角色,职责包括:管理文档系统的命名空间(namespace);调节客户端访问到需要的文件(存储在DateNode中的文件)
注:namespace—映射文件系统的目录结构
2.DataNodes充当slaves角色,通常情况下,一台机器只部署一个Datenode,用来存储MapReduce程序需要的数据
Namenode会定期从DataNodes那里收到Heartbeat和Blockreport反馈
Heartbeat反馈用来确保DataNode没有出现功能异常;
Blockreport包含DataNode所存储的Block集合
2.3、hadoop资源
1 http://wiki.apache.org/nutch/NutchHadoopTutorial基于Nutch和Hadoop完成分布式采集和分布式查询
http://wiki.apache.org/nutch/MapReduce
使用MapReduce进行排序
http://www.cnblogs.com/koalaer/archive/2012/04/16/MapReduce_Combiner.htmlMapReduce 算法设计
http://blog.csdn.net/cuirong1986/article/details/8443841MapReduce Design Patterns(chapter 1)(一)



相关推荐
实验的总结与思考部分,强调了实验的目标在于理解和掌握MapReduce编程思想,了解MapReduce作业的执行流程,以及如何使用MapReduce Java API进行编程。此外,还包括在Hadoop集群上运行程序,利用Web界面和Shell命令...
MapReduce的核心思想是将复杂的大规模数据处理任务分解成一系列可并行执行的小任务,然后在多台计算机(节点)上同时运行,以提高计算效率。 Map阶段是数据处理的第一步,它接收输入数据,将其分割成多个键值对...
### MapReduce基础知识详解 #### 一、MapReduce概述 **MapReduce** 是一种编程模型,最初由Google提出并在Hadoop中实现,用于处理大规模...通过深入理解其工作原理和设计原则,可以更好地利用MapReduce解决实际问题。
MapReduce的核心思想可以分为两个主要阶段:Map阶段和Reduce阶段。Map阶段负责将输入数据分解成多个键值对,并分发到不同的工作节点进行并行处理。Reduce阶段则将Map阶段的结果进行聚合,通过特定的逻辑对结果进行...
MapReduce编程模型基于一个简单的思想:通过map阶段将原始数据分解为键值对,然后在reduce阶段对这些键值对进行聚合。以WordCount为例,map函数将每个文本行中的单词转化为(key, value)对,其中key是单词,value通常...
1.什么是mapreduce 2.编写mapreduce典型demo 3.理解mapreduce核心思想 4.熟练编写mapreduce典型demo
MapReduce是Hadoop生态系统中的核心组件之一,主要用于处理和生成大规模数据集。它的设计目标是简化分布式计算,使得开发者能够专注于...在实际项目中,可以通过编写WordCount这样的简单应用来加深对MapReduce的理解。
同时,许多基于Hadoop生态系统的工具和技术都是围绕MapReduce构建的,这使得MapReduce成为了理解大数据处理领域不可或缺的一部分。 #### 七、总结 MapReduce作为一种高效、可靠的分布式计算模型,为解决大规模数据...
为了更好地理解MapReduce编程模型,可以以WordCount程序为例,该程序统计文本数据中单词出现的频率。在Map阶段,每个Mapper读取文本数据,分割单词并为每个单词生成一个键值对,其中键是单词,值是1。在Reduce阶段,...
MapReduce的核心思想是将大规模数据集分割成小块,然后在多台机器上并行处理这些小块。Map阶段负责将原始数据转化为键值对形式,Reduce阶段则负责聚合这些键值对,进行进一步的计算和汇总。这种设计模式使得...
MapReduce的核心思想是将复杂的大规模数据处理任务分解成两个阶段:Map阶段和Reduce阶段。 - **Map阶段**:在这个阶段,用户定义一个map函数,该函数负责处理输入的键值对,并产生一系列的中间键值对。 - **Reduce...
MapReduce的核心思想是将复杂的并行计算任务分解为两个主要阶段:Map和Reduce,使得开发者能够专注于业务逻辑,而无需深入理解分布式系统的底层细节。 Map阶段是数据的预处理过程,用户定义的Map函数接收输入的键值...
MapReduce的核心思想是将大规模数据集分割成多个小块,并将处理任务分布到大量计算机上执行。这一过程主要包括Map(映射)和Reduce(归约)两个阶段。在Map阶段,原始数据被分割并分配给不同的节点进行初步处理;在...
MapReduce的核心思想是通过将大数据集分割成小块,并在多个计算机节点上进行并行处理,从而实现高效的数据处理。 #### 二、MapReduce工作流程详解 1. **输入切分**:Hadoop将输入文件分割成固定大小的块,每个块...
- **绪论**:MapReduce的核心思想是将大规模数据的处理分解为两个主要操作:Map和Reduce,这两个操作都是以函数式编程中的概念为基础。Map阶段将原始数据分片并应用映射函数,生成中间键值对;Reduce阶段则对这些...
MapReduce是一种分布式计算模型,由Google在2004年提出,主要用于处理和生成大规模数据集。...虽然随着技术的发展,新的计算框架不断涌现,但MapReduce的基本思想和原理仍然是理解和解决大规模数据问题的基础。
MapReduce的核心思想是将复杂的并行计算任务分解为两个主要阶段:Map阶段和Reduce阶段。这两个阶段通过中间结果(Intermediate Key-Value Pairs)进行连接。 1. Map阶段:在Map阶段,原始数据被分割成多个块(通常...
后续出现了如Spark、Flink等新一代计算框架,它们在保留MapReduce思想的同时,引入了更高级的功能,如内存计算和流处理,以解决原生MapReduce的不足。 总的来说,Google的MapReduce论文不仅奠定了现代大数据处理的...
MapReduce 的核心思想是将一个大任务分解成许多小任务来并行处理,然后合并这些结果得到最终的结果。对于矩阵运算这类计算密集型任务来说,MapReduce 提供了一种有效的解决方案。 #### 二、矩阵相乘概述 矩阵相乘是...