- 浏览: 2687424 次
- 来自: 杭州
-

文章分类
- 全部博客 (1188)
- webwork (4)
- 网摘 (18)
- java (103)
- hibernate (1)
- Linux (85)
- 职业发展 (1)
- activeMQ (2)
- netty (14)
- svn (1)
- webx3 (12)
- mysql (81)
- css (1)
- HTML (6)
- apache (3)
- 测试 (2)
- javascript (1)
- 储存 (1)
- jvm (5)
- code (13)
- 多线程 (12)
- Spring (18)
- webxs (2)
- python (119)
- duitang (0)
- mongo (3)
- nosql (4)
- tomcat (4)
- memcached (20)
- 算法 (28)
- django (28)
- shell (1)
- 工作总结 (5)
- solr (42)
- beansdb (6)
- nginx (3)
- 性能 (30)
- 数据推荐 (1)
- maven (8)
- tonado (1)
- uwsgi (5)
- hessian (4)
- ibatis (3)
- Security (2)
- HTPP (1)
- gevent (6)
- 读书笔记 (1)
- Maxent (2)
- mogo (0)
- thread (3)
- 架构 (5)
- NIO (5)
- 正则 (1)
- lucene (5)
- feed (4)
- redis (17)
- TCP (6)
- test (0)
- python,code (1)
- PIL (3)
- guava (2)
- jython (4)
- httpclient (2)
- cache (3)
- signal (1)
- dubbo (7)
- HTTP (4)
- json (3)
- java socket (1)
- io (2)
- socket (22)
- hash (2)
- Cassandra (1)
- 分布式文件系统 (5)
- Dynamo (2)
- gc (8)
- scp (1)
- rsync (1)
- mecached (0)
- mongoDB (29)
- Thrift (1)
- scribe (2)
- 服务化 (3)
- 问题 (83)
- mat (1)
- classloader (2)
- javaBean (1)
- 文档集合 (27)
- 消息队列 (3)
- nginx,文档集合 (1)
- dboss (12)
- libevent (1)
- 读书 (0)
- 数学 (3)
- 流程 (0)
- HBase (34)
- 自动化测试 (1)
- ubuntu (2)
- 并发 (1)
- sping (1)
- 图形 (1)
- freemarker (1)
- jdbc (3)
- dbcp (0)
- sharding (1)
- 性能测试 (1)
- 设计模式 (2)
- unicode (1)
- OceanBase (3)
- jmagick (1)
- gunicorn (1)
- url (1)
- form (1)
- 安全 (2)
- nlp (8)
- libmemcached (1)
- 规则引擎 (1)
- awk (2)
- 服务器 (1)
- snmpd (1)
- btrace (1)
- 代码 (1)
- cygwin (1)
- mahout (3)
- 电子书 (1)
- 机器学习 (5)
- 数据挖掘 (1)
- nltk (6)
- pool (1)
- log4j (2)
- 总结 (11)
- c++ (1)
- java源代码 (1)
- ocr (1)
- 基础算法 (3)
- SA (1)
- 笔记 (1)
- ml (4)
- zokeeper (0)
- jms (1)
- zookeeper (5)
- zkclient (1)
- hadoop (13)
- mq (2)
- git (9)
- 问题,io (1)
- storm (11)
- zk (1)
- 性能优化 (2)
- example (1)
- tmux (1)
- 环境 (2)
- kyro (1)
- 日志系统 (3)
- hdfs (2)
- python_socket (2)
- date (2)
- elasticsearch (1)
- jetty (1)
- 树 (1)
- 汽车 (1)
- mdrill (1)
- 车 (1)
- 日志 (1)
- web (1)
- 编译原理 (1)
- 信息检索 (1)
- 性能,linux (1)
- spam (1)
- 序列化 (1)
- fabric (2)
- guice (1)
- disruptor (1)
- executor (1)
- logback (2)
- 开源 (1)
- 设计 (1)
- 监控 (3)
- english (1)
- 问题记录 (1)
- Bitmap (1)
- 云计算 (1)
- 问题排查 (1)
- highchat (1)
- mac (3)
- docker (1)
- jdk (1)
- 表达式 (1)
- 网络 (1)
- 时间管理 (1)
- 时间序列 (1)
- OLAP (1)
- Big Table (0)
- sql (1)
- kafka (1)
- md5 (1)
- springboot (1)
- spring security (1)
- Spring Boot (3)
- mybatis (1)
- java8 (1)
- 分布式事务 (1)
- 限流 (1)
- Shadowsocks (0)
- 2018 (1)
- 服务治理 (1)
- 设计原则 (1)
- log (0)
- perftools (1)
最新评论
-
siphlina:
课程——基于Python数据分析与机器学习案例实战教程分享网盘 ...
Python机器学习库 -
san_yun:
leibnitz 写道hi,我想知道,无论在92还是94版本, ...
hbase的行锁与多版本并发控制(MVCC) -
leibnitz:
hi,我想知道,无论在92还是94版本,更新时(如Puts)都 ...
hbase的行锁与多版本并发控制(MVCC) -
107x:
不错,谢谢!
Latent Semantic Analysis(LSA/ LSI)算法简介 -
107x:
不错,谢谢!
Python机器学习库
一、问题的由来
URL就是网址,只要上网,就一定会用到。

一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址 “http://www.abc.com”,但是没有希腊字母的网址“http://www.aβγ.com”(读作阿尔法-贝塔-伽玛.com)。这是 因为网络标准RFC 1738 做了硬性规定:
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致“URL编码”成为了一个混乱的领域。
下面就让我们看看,“URL编码”到底有多混乱。我会依次分析四种不同的情况,在每一种情况中,浏览器的URL编码方法都不一样。把它们的差异解释清楚之后,我再说如何用Javascript找到一个统一的编码方法。
二、情况1:网址路径中包含汉字
打开IE(我用的是8.0版),输入网址“http://zh.wikipedia.org/wiki/春节 ”。注意,“春节”这两个字此时是网址路径的一部分。

查看HTTP请求的头信息,会发现IE实际查询的网址是“http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82 ”。也就是说,IE自动将“春节”编码成了“%E6%98%A5%E8%8A%82”。
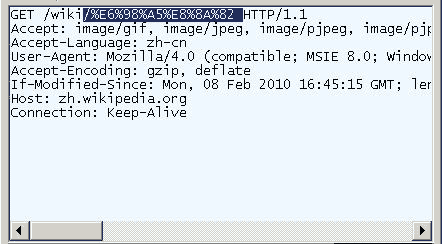
我们知道,“春”和“节”的utf-8编码分别是“E6 98 A5”和“E8 8A 82”,因此,“%E6%98%A5%E8%8A%82”就是按照顺序,在每个字节前加上%而得到的。(具体的转码方法,请参考我写的《字符编码笔记》 。)
在Firefox中测试,也得到了同样的结果。所以,结论1就是,网址路径的编码,用的是utf-8编码。
三、情况2:查询字符串包含汉字
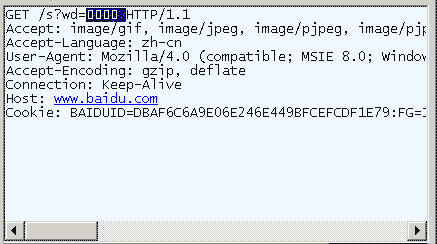
在IE中输入网址“http://www.baidu.com/s?wd=春节 ”。注意,“春节”这两个字此时属于查询字符串,不属于网址路径,不要与情况1混淆。

查看HTTP请求的头信息,会发现IE将“春节”转化成了一个乱码。
切换到十六进制方式,才能清楚地看到,“春节”被转成了“B4 BA BD DA”。
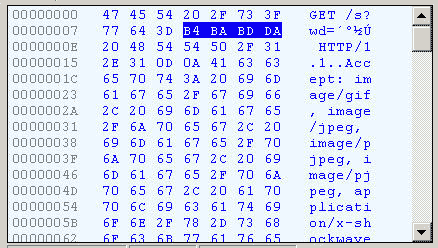
我们知道,“春”和“节”的GB2312编码(我的操作系统“Windows XP”中文版的默认编码)分别是“B4 BA”和“BD DA”。因此,IE实际上就是将查询字符串,以GB2312编码的格式发送出去。
Firefox的处理方法,略有不同。它发送的HTTP Head是“wd=%B4%BA%BD%DA”。也就是说,同样采用GB2312编码,但是在每个字节前加上了%。
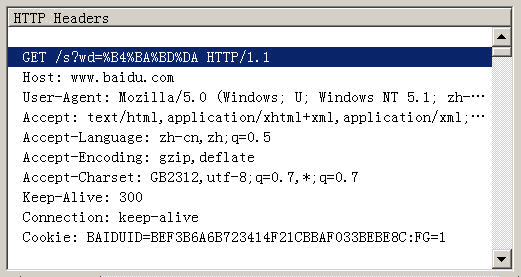
所以,结论2就是,查询字符串的编码,用的是操作系统的默认编码。
四、情况3:Get方法生成的URL包含汉字
前面说的是直接输入网址的情况,但是更常见的情况是,在已打开的网页上,直接用Get或Post方法发出HTTP请求。
根据台湾中兴大学吕瑞麟老师的试验 ,这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
举例来说,百度是GB2312编码,Google是UTF-8编码。因此,从它们的搜索框中搜索同一个词“春节”,生成的查询字符串是不一样的。
百度生成的是%B4%BA%BD%DA,这是GB2312编码。
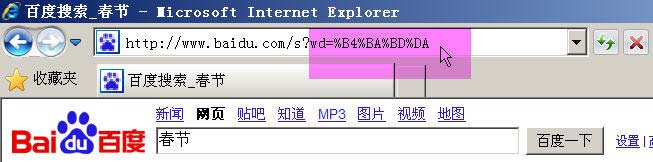
Google生成的是%E6%98%A5%E8%8A%82,这是UTF-8编码。
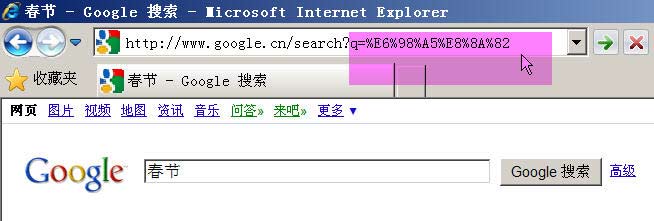
所以,结论3就是,GET和POST方法的编码,用的是网页的编码。
五、情况4:Ajax调用的URL包含汉字
前面三种情况都是由浏览器发出HTTP请求,最后一种情况则是由Javascript生成HTTP请求,也就是Ajax调用。还是根据吕瑞麟老师的文章,在这种情况下,IE和Firefox的处理方式完全不一样。
举例来说,有这样两行代码:
url = url + "?q=" +document.myform.elements[0].value; // 假定用户在表单中提交的值是“春节”这两个字
http_request.open('GET', url, true);
那么,无论网页使用什么字符集,IE传送给服务器的总是“q=%B4%BA%BD%DA”,而Firefox传送给服务器的总是“q=%E6%98%A5%E8%8A%82”。也就是说,在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是采用utf-8编码。这就是我们的结论4。
六、Javascript函数:escape()
好了,到此为止,四种情况都说完了。
假定前面你都看懂了,那么此时你应该会感到很头痛。因为,实在太混乱了。不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果。如果程序员要把每一种结果都考虑进去,是不是太恐怖了?有没有办法,能够保证客户端只用一种编码方法向服务器发出请求?
回答是有的,就是使用Javascript先对URL编码,然后再向服务器提交,不要给浏览器插手的机会。因为Javascript的输出总是一致的,所以就保证了服务器得到的数据是格式统一的。
Javascript语言用于编码的函数,一共有三个,最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了,但是由于历史原因,很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果 是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。

它的具体规则是,除了ASCII字母、数字、标点符号“@ * _ + - . /”以外,对其他所有字符进行编码。在\u0000到\u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是unescape()。
所以,“Hello World”的escape()编码就是“Hello%20World”。因为空格的Unicode值是20(十六进制)。

还有两个地方需要注意。
首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出,默认都是Unicode字符。这一点对下面两个函数也适用。

其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
七、Javascript函数:encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
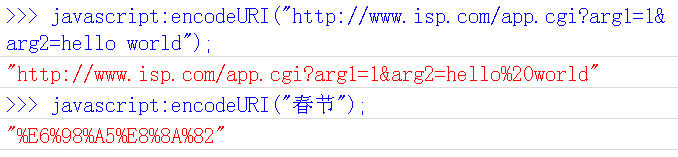
它对应的解码函数是decodeURI()。

需要注意的是,它不对单引号'编码。
八、Javascript函数:encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。
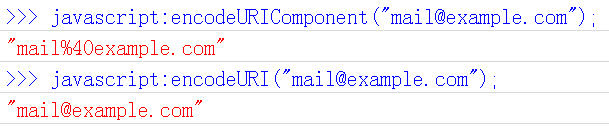
它对应的解码函数是decodeURIComponent()。
(完)


发表评论

-
Raft
2018-07-12 14:20 802前言 上篇文章说解决问题要分而治之,先把分片的问题解决了再 ... -
java uuid
2017-09-14 18:18 583在java中产生uuid的方式是使用java.util.UU ... -
JAVA 编码规范
2017-09-06 11:34 456https://google.github.io/style ... -
mac 入门
2015-12-01 16:28 642http://foocoder.com/blog/wo-zai ... -
java 反编译工具gad
2014-05-09 12:04 1000java 反编译工具gad,备个份。 -
java 代码大全(code book)
2014-04-29 10:59 1114参考这里: http://www.java2s.com/C ... -
SQL语法解析器JSQLParser
2014-02-09 19:53 2194SQL 语法解释器jsqlparser 是用java ... -
BufferedInputStream 深入研究。
2013-11-19 13:26 14591. BufferedInputStream的基本原理 ... -
java 启动脚本
2013-08-22 19:08 1003java 启动脚本 #!/bin/bash cmd=&q ... -
CRLF escape
2013-08-06 17:51 1228最近需要对用户输入的CRLF即(\r\n)做escape, ... -
安全的自增类
2013-07-22 18:16 1015java中一个计数器如果超过MAX_VALUE再自增会如何? ... -
solr日志被block的问题
2013-05-23 16:48 1286"catalina-exec-22386" ... -
beanMapper
2013-01-13 22:43 917实在被一堆get,set搞烦了,周末写了一个beanMappe ... -
java instanceof ,isInstance(),isAssignableFrom之前的差异
2013-01-06 11:00 977public class ItemQuery { ... -
通过gzip对字符串压缩
2012-12-22 18:10 3160通过GZIPOutputStream,GZIPInputStr ... -
spring的FactoryBean机制
2012-11-20 16:18 1276spring可以通过的FactoryBean的形式把一个Fac ... -
HashMap cpu占用 100%
2012-11-10 22:22 1838今天在重现出HashMap cpu占用100%了,只 ... -
文字扫描工具--java.util.Scanner
2012-11-10 14:33 1139A simple text scanner which c ... -
一个隐形的java int溢出
2012-11-06 22:17 1157故事的背景: 笔者最近在做一个类SNS的项目, ... -
Java网络编程--Socket编程
2012-11-03 23:07 1046原文:http://blog.sina.com.c ...
相关推荐
根据提供的文件信息,关于URL编码的详细知识点如下: 首先,URL编码问题的由来是与网络标准RFC1738紧密相关的。RFC1738规定了URL中哪些字符是允许的,哪些是需要编码的。标准规定只允许使用字母、数字、少数特殊...
URL编码,全称为统一资源定位符(Uniform Resource Locator)编码,是互联网上用于标识资源的一种标准格式。在HTTP协议中,URL是访问网络资源的重要途径,但有些字符在URL中直接使用时可能会引起问题,因此需要进行...
### JS实现URL编码转换中文 在Web开发过程中,经常需要处理URL中的特殊字符,特别是中文字符。由于URL传输限制及浏览器解析原因,中文等非ASCII字符需要被编码为特定格式才能在网络上传输。本文将详细介绍如何使用...
标题和描述中提到的“vb url编码解码”是指在Visual Basic(VB)环境中进行URL编码和解码的过程。URL编码,也称为百分号编码,是一种用于将特殊字符转换为适用于URL格式的编码方式,目的是确保这些特殊字符能够正确...
这个文本文件可能包含了一个示例的C代码或关于URL编码的说明。打开文件,可以找到具体的实现方法或者使用指南。可能包含如下内容: ```c void encodeUrl(char* input, char* output) { // ... } ``` 或者是...
C++作为一门强大的系统级编程语言,虽然没有内置的URL编码和解码函数,但开发者可以借助标准库和第三方库来实现这些功能。本文将深入探讨C++中如何进行URL编码和解码。 URL(Uniform Resource Locator)是互联网上...
关于URL编码和解码的知识点: 1. **URL编码**:URL编码是使用百分号(%)加上字符的ASCII值来表示非ASCII字符或URL中不安全的字符。例如,空格通常被编码为`%20`。 2. **PHP内置函数**:PHP提供了`urlencode()`和`...
标题中的“URL编码解码小程序”指的是一个工具或软件,其主要功能是处理URL(统一资源定位符)中的编码问题。URL编码是互联网通信中的一种标准化机制,它确保非ASCII字符或特殊字符在URL中能被正确传输和解析。这是...
URL编码,全称为统一资源定位符(Uniform Resource Locator)编码,是互联网上数据通信的一种标准格式,用于确保数据在传输过程中不受损失或错误地被解释。URL编码的主要目的是解决URL中可能包含的特殊字符,如空格...
URL编码,全称为统一资源定位符(Uniform Resource Locator)编码,是互联网上数据通信的一种标准格式,用于将非ASCII字符转换为可以在URL中安全传输的形式。GBK编码是中国大陆广泛使用的汉字编码标准,它包含了GB...
这个名为“一个简单url编码解码”的项目,就是为新手提供了一个理解和实践URL编码与解码机制的实例。 URL编码是根据RFC 3986标准进行的,主要使用百分号(%)表示非ASCII字符或特殊字符的ASCII十六进制值。例如,...
本文将深入探讨“C#自动识别URL编码”的主题,帮助开发者解决URL编码带来的乱码问题。 URL编码,也称为百分号编码(Percent-encoding),是统一资源定位符(Uniform Resource Locator, URL)的一部分,用于在非...
另外,虽然在大多数情况下,URL编码遵循ASCII标准,但在Unicode环境中,URL编码也可以扩展到包含非ASCII字符,这通常被称为“ Punycode”转换。 在实际开发中,了解并正确使用URL编码和解码不仅能保证数据的完整性...
自己写的,可能有bug,请大家一块学习 环境为PB12 函数(及参数) 作用 arraysort 对一维数组进行排序 decto 将十进制数字转成其它进制字符串 ...urlencode 将指定字符串以进行指定字符集url编码 涨价了,哈哈
URL编码是互联网上的一种标准编码方式,用于将特殊字符转换为可安全传递的ASCII字符串,以便在URL(统一资源定位符)中使用。这个“URL编码转换工具”就是专门为了帮助开发者解决这个问题而设计的。它能够将URL中的...
### URL编码转换:将URL转换为Unicode进行传输 在互联网技术的应用中,URL(Uniform Resource Locator,统一资源定位符)编码转换是一项基本且重要的技术。本文将深入探讨URL编码转换的相关概念、应用场景以及一个...
URL编码遵循统一资源标识符(URI)的规则,其中最常用的是基于百分号(%)的编码方法。每个非ASCII或特殊字符会被替换为"%xy"的形式,其中xy是该字符在UTF-8编码中的两个字节的十六进制表示。例如,空格字符(ASCII...
在IT领域,URL编码是一种常见的数据处理技术,特别是在网络编程中。这个压缩包文件的标题和描述提及了“url加密”和“URL编码”,实际上,它们指的是同一个概念,即URL编码(URL Encoding)。URL编码是根据统一资源...
今天写一个POST程序的时候有一段UNICODE字符串需要进行URL编码后进行提交。但是找遍了精易模块和百度都没有说有这这个命令 让Unicode字符串(易语言里面以字节集表示)直接进行正确的URL编码。所以就自己写了一个...