- 浏览: 409624 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
-
秦时明月黑:
深入浅出,楼主很有功底
hive编译部分的源码结构 -
tywo45:
感觉好多错误,但还是支持!
HDFS+MapReduce+Hive+HBase十分钟快速入门 -
xbbHistory:
解析的很棒!!
Linux-VFS -
darrendu:
执行这个命令,bin/hadoop fs -ls /home/ ...
Hadoop示例程序WordCount运行及详解 -
moudaen:
请问楼主,我执行总后一条语句时,执行的是自带的1.sql,你当 ...
TPC-H on Hive
Hive 是Apache Hadoop 项目下的一个子项目,是一个底层用Map/Reduce实现的查询引擎,具体的介绍可以查看Hive的wiki 。
入口
Hive有三种用户接口:CLI、Client(JDBC、ODBC、thrift或其他)和WebUI,如下图所示: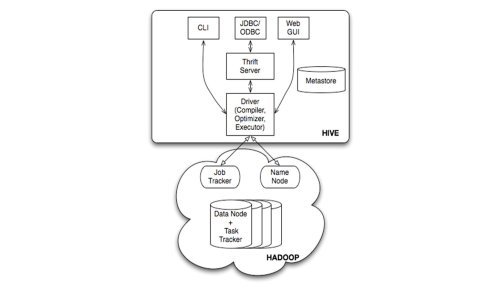
图1 Hive的入口
这些用户接口的工作是将用户输入的HQL语句解析成单条命令传递给Driver(包括用户配置,CLI还包括Session信息)。
Driver模块的工作是将HQL语句转化为MapReduce调用,包括主要的三个阶段:
编译:Compile,生成执行计划
优化:Optimize,优化执行计划(当前的Hive实现是在执行前做一次唯一的优化,没有反馈的过程,这使得优化工作只能是rule-based,做不到cost-based)。
执行:Execute,将执行计划提交给Hadoop。
本文主要记录的是Compile过程。
语义解析器
Compile过程的输入是抽象语法树(AST),输出是执行计划。这一过程由Driver调用,但是主要的逻辑在语义解析器中。语义解析器继承自BaseSemanticAnalyser,对每一种HQL命令,有对应的语义解析器类,包括下列:
表1 HQL命令对应的语义解析器
类 HQL命令类别 Task DCLSemanticAnalyzer DCL (taobao dist only) DCLTask DDLSemanticAnalyzer DDL DDLTask ExplainSemanticAnalyzer Explain ExplainTask FunctionSemanticAnalyzer FunctionTask LoadSemanticAnalyzer Load CopyTask MoveTask SemanticAnalyzer DML FetchTask ConditionalTask MapRedTask UserSemanticAnalyzer UserTask
语义解析器的工厂类SemanticAnalyzerFactory负责分发解析任务,它按照AST根节点的类别生成对应的解析器。
语义解析器部分的类图: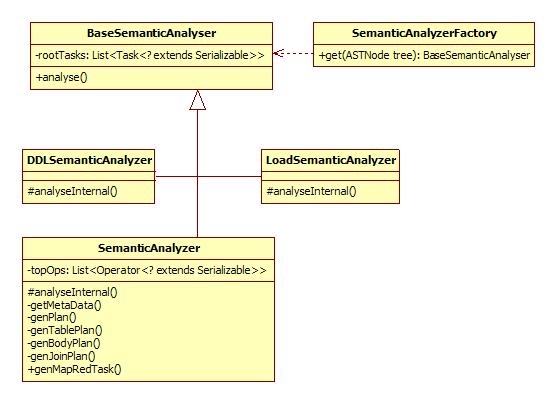
生成Operator树
下面以一个select语句为例解析Compile的过程:SELECT
s.name name, count(o.amount) sum_order, sum(o.amount) sum_amount
FROM t_sale s LEFT OUTER JOIN t_order o ON (s.id = o.sale_id)
GROUP BY s.id, s.name
如上所述,select语句由SemanticAnalyzer解析。其他的语义解析器较为简单略去不讲。这一查询语句的AST画出来类似这样:
Operator抽象了Hive中的一次操作。首先看一下上面的命令的执行计划
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-2 depends on stages: Stage-1
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-1
Map Reduce
Alias -> Map Operator Tree:
s
TableScan
alias: s
Reduce Output Operator
key expressions:
expr: id
type: int
sort order: +
Map-reduce partition columns:
expr: id
type: int
tag: 0
value expressions:
expr: id
type: int
expr: name
type: string
o
TableScan
alias: o
Reduce Output Operator
key expressions:
expr: sale_id
type: int
sort order: +
Map-reduce partition columns:
expr: sale_id
type: int
tag: 1
value expressions:
expr: amount
type: int
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join0 to 1
condition expressions:
0 {VALUE._col0} {VALUE._col1}
1 {VALUE._col4}
outputColumnNames: _col0, _col1, _col7
Select Operator
expressions:
expr: _col0
type: int
expr: _col1
type: string
expr: _col7
type: int
outputColumnNames: _col0, _col1, _col7
Group By Operator
aggregations:
expr: count(_col7)
expr: sum(_col7)
keys:
expr: _col0
type: int
expr: _col1
type: string
mode: hash
outputColumnNames: _col0, _col1, _col2, _col3
File Output Operator
compressed: false
GlobalTableId: 0
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Stage: Stage-2
Map Reduce
Alias -> Map Operator Tree:
hdfs://hdpnn.cm3:9000/group/tbdev/shaojie/hive-tmp/1908438422/10002
Reduce Output Operator
key expressions:
expr: _col0
type: int
expr: _col1
type: string
sort order: ++
Map-reduce partition columns:
expr: _col0
type: int
expr: _col1
type: string
tag: -1
value expressions:
expr: _col2
type: bigint
expr: _col3
type: bigint
Reduce Operator Tree:
Group By Operator
aggregations:
expr: count(VALUE._col0)
expr: sum(VALUE._col1)
keys:
expr: KEY._col0
type: int
expr: KEY._col1
type: string
mode: mergepartial
outputColumnNames: _col0, _col1, _col2, _col3
Select Operator
expressions:
expr: _col1
type: string
expr: _col2
type: bigint
expr: _col3
type: bigint
outputColumnNames: _col0, _col1, _col2
File Output Operator
compressed: true
GlobalTableId: 0
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Stage: Stage-0
Fetch Operator
limit: -1
可以看到,上面的查询语句包含FilterOperator、SelectOperator等多个Operator,且Operator节点之间构成一颗Operator树。以后我们还会多次回顾这个执行计划。
PS:严格意义上的Operator节点之间的关系构成的结构是一个图。用树结构来描述语法是很自然的,例如AST,但树结构不足以描述语义,示例的
SELECT命令中,需要两次扫描表的操作,join操作需要基于扫描表的结果进行,这在Operator树中描述为“JoinOperator的父节点
为t_order表TableScan和t_sale表TableScan(多个父节点)”。
除了上述情况外,Operator树一般是退化为链表的树形结构,例外是所有的子查询又会是一颗子树。
SemanticAnalyzer通过一系列genXXXPlan方法来生成这颗Operator树。


发表评论

-
hive serde
2011-04-13 15:34 2934一、背景 1、当进程在进行远程通信时,彼此可以发送各种类型的 ... -
hive 用mysql存储元信息
2011-01-22 15:22 1431http://www.tech126.com/hive-m ... -
hive编译部分的源码结构
2011-01-13 16:47 2644很少在博客里写翻译的东西, 这次例外. 原文在这儿 . ... -
hive执行作业时reduce任务个数设置为多少合适?
2011-01-12 15:31 2589Hive怎样决定reducer个数? Hadoop ... -
hive 源码结构分析(编译器)
2011-01-06 16:52 6702Hive 是将 SQL 语句转换成 h ... -
hive中关于partition的操作
2011-01-06 10:51 2378hive > create table mp (a s ... -
hive mapjoin
2010-12-15 21:35 2185insert overwrite table cross ... -
Hive QL
2010-12-15 10:47 1730Hive 的官方文档中对查 ... -
hive数据模型
2010-12-06 19:48 2699Hive 中所有的数据都存储在 HDFS 中 ... -
SequenceFile的压缩和分片
2010-12-06 19:43 2467Compressed Data Storage Kee ... -
hive的一些资料整理
2010-12-06 16:23 1585解释器、编译器、优� ... -
hive的存储格式
2010-12-06 13:05 2468hive有textFile,SequenceFile,RCFi ... -
TPC-H on Hive
2010-12-03 17:40 41561)下载TPC-H的代码,用来 ... -
hive show table显示不出表的问题
2010-12-03 11:30 5542问题:在hive中运行 show table时,以前存在的表显 ... -
hive运行实例
2010-12-02 21:18 1901实际示例 创建一个表 CREATE TABLE u_dat ... -
源码编译hive
2010-12-02 19:00 3601hive -hiveconf hive.root.logger ... -
hive报Invalid maximum heap size: -Xmx4096m错误解决方法
2010-11-29 10:25 2495mongodb@krusiting-laptop:~/hive ... -
Hive Installation and Configuration
2010-11-25 20:13 741http://wiki.apache.org/hadoop/H ...
相关推荐
1. 基于存储的授权(Storage Based Authorization in the Metastore Server) 这种授权模型主要在Metastore服务器上进行,允许对元数据进行保护,但并不提供列级别或行级别的精细访问控制。这意味着用户对表的整体...
1. **环境准备**: - Java环境:确保系统已经安装了Java JDK 8或以上版本,因为Hive需要Java环境来编译和运行。 - Maven:Hive的构建工具是Maven,需要确保Maven已安装并且配置好环境变量。 - Hadoop:Hive是建立...
compile lein uberjar scp build/smoker-1.0.0-SNAPSHOT-standalone.jar myserver:~/hive-jars/smoker-standalone.jar 然后在 Hive 中使用它: # on your server, start hive with auxpath hive --auxpath /home/...
HQL解析器 解析HQL获取源表和目标表 开发者 $ git clone https://github.com/FOuR-/HiveParser.git $ cd HiveParser $ sbt clean compile // import ide $ sbt eclipse
- `set hive.optimize.skewjoin.compiletime=true;` 在编译时启用数据倾斜优化,进一步提升优化效果。 8. **Group By优化**: - `set hive.map.aggr=true;` 开启Map端聚合,减少传递给Reduce端的数据量。 - `set...
"Hive 2.1.1-cdh6.2.0 驱动文件"则意味着压缩包还包含了与Hive相关的JDBC驱动,版本为2.1.1,同样适应于CDH 6.2.0。Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询...
<scope>compile 蜂巢版本 目前,该模块适用于 Apache Hive 0.12(版本 0.0.2-SNAPSHOT)和 0.13(版本 0.0.3-SNAPSHOT 及更高版本)。 如果要与其他版本的 Hive 一起使用,则需要修补。 投影下推 RC 和 ORC
2. **SQL 和 Table API**:进一步提升了 SQL 支持,增强了与 JDBC、Hive 等外部系统的集成。 3. **状态后端**:增强了对 RocksDB 状态后端的支持,提供更高效的状态存储和查询。 4. **连接器和格式**:增加了对更多...
地牢爬行者 要从根目录进行编译: mvn clean compile assembly:single 要从根目录运行: java -jar target/hive-rpg-1.0-SNAPSHOT-jar-with-dependencies.jar
mvn clean compile 要运行Hive示例: mvn exec:java -Dexec.mainClass=com.example.ClouderaJDBCHiveExample 和Impala示例: mvn exec:java -Dexec.mainClass=com.example.ClouderaJDBCImpalaExample
1. **获取Spark源代码** Spark的源代码可以通过访问Apache官方网站或使用Git克隆仓库来获取。在终端中输入以下命令克隆Spark的GitHub仓库: ``` git clone https://github.com/apache/spark.git ``` 2. **...
SKARONATOR @ - 帮助我完成 hive 写入 Jeff @ - 法语翻译 Blite - 德语翻译重做 Anarior - 拖车重做 1.) 解压“zip”并将“logistic”文件夹复制到“/MPMissions/DayZ_Epoch.Map”文件夹。 2.) 在您的任务文件夹中...
Pattern p = Pattern.compile("^[\u4e00-\u9fa5]$"); // 正则表达式,用于匹配中文字符 int i = 0, j = 0; int sublength = length - ((endStr == null) ? 0 : endStr.getBytes(charset).length); // 计算实际...
Snappy 压缩算法可以应用于多种数据处理场景,包括 Hadoop、HBase、 Hive 等。 二、 前置条件 在安装 Snappy 压缩算法之前,需要满足以下前置条件: 1. 安装 gcc,版本为 4.4.x,高于 4.4.x 的版本可能会出现不...
3. **编译源码**:进入源码目录,使用Maven的`mvn compile`命令编译源代码,这会生成相应的class文件。 4. **打包成JAR**:使用`mvn package`命令,Maven会将编译后的class文件打包成一个或多个JAR文件,这些JAR...
1. **DataFrame/Dataset增强**:在Spark 2.3.0中,DataFrame和Dataset API进一步完善,支持更多SQL操作,如窗口函数和多级GROUP BY,同时提升了查询优化和性能。 2. **结构化流处理**:这个版本强化了Structured ...