实际上,HashSet 和 HashMap 之间有很多相似之处,对于 HashSet 而言,系统采用 Hash 算法决定集合元素的存储位置,这样可以保证能快速存、取集合元素;对于 HashMap 而言,系统 key-value 当成一个整体进行处理,系统总是根据 Hash 算法来计算 key-value 的存储位置,这样可以保证能快速存、取 Map 的 key-value 对。
在介绍集合存储之前需要指出一点:虽然集合号称存储的是 Java 对象,但实际上并不会真正将 Java 对象放入 Set 集合中,只是在 Set 集合中保留这些对象的引用而言。也就是说:Java 集合实际上是多个引用变量所组成的集合,这些引用变量指向实际的 Java 对象。
HashMap 的存储实现
当程序试图将多个 key-value 放入 HashMap 中时,以如下代码片段为例:
HashMap<String , Double> map = new HashMap<String , Double>();
map.put("语文" , 80.0);
map.put("数学" , 89.0);
map.put("英语" , 78.2);
|
HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。
当程序执行 map.put("语文" , 80.0); 时,系统将调用"语文"的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。
我们可以看 HashMap 类的 put(K key , V value) 方法的源代码:
public V put(K key, V value)
{
// 如果 key 为 null,调用 putForNullKey 方法进行处理
if (key == null)
return putForNullKey(value);
// 根据 key 的 keyCode 计算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在对应 table 中的索引
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素
for (Entry<K,V> e = table[i]; e != null; e = e.next)
{
Object k;
// 找到指定 key 与需要放入的 key 相等(hash 值相同
// 通过 equals 比较放回 true)
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果 i 索引处的 Entry 为 null,表明此处还没有 Entry
modCount++;
// 将 key、value 添加到 i 索引处
addEntry(hash, key, value, i);
return null;
}
|
上面程序中用到了一个重要的内部接口:Map.Entry,每个 Map.Entry 其实就是一个 key-value 对。从上面程序中可以看出:当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑 Entry 中的 value,仅仅只是根据 key 来计算并决定每个 Entry 的存储位置。这也说明了前面的结论:我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可。
上面方法提供了一个根据 hashCode() 返回值来计算 Hash 码的方法:hash(),这个方法是一个纯粹的数学计算,其方法如下:
static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
|
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 Hash 码值总是相同的。接下来程序会调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
static int indexFor(int h, int length)
{
return h & (length-1);
}
|
这个方法非常巧妙,它总是通过 h &(table.length -1) 来得到该对象的保存位置——而 HashMap 底层数组的长度总是 2 的 n 次方,这一点可参看后面关于 HashMap 构造器的介绍。
当 length 总是 2 的倍数时,h & (length-1) 将是一个非常巧妙的设计:假设 h=5,length=16, 那么 h & length - 1 将得到 5;如果 h=6,length=16, 那么 h & length - 1 将得到 6 ……如果 h=15,length=16, 那么 h & length - 1 将得到 15;但是当 h=16 时 , length=16 时,那么 h & length - 1 将得到 0 了;当 h=17 时 , length=16 时,那么 h & length - 1 将得到 1 了……这样保证计算得到的索引值总是位于 table 数组的索引之内。
根据上面 put 方法的源代码可以看出,当程序试图将一个 key-value 对放入 HashMap 中时,程序首先根据该 key 的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的 value,但 key 不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。
当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置。当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false)。
上面程序中还调用了 addEntry(hash, key, value, i); 代码,其中 addEntry 是 HashMap 提供的一个包访问权限的方法,该方法仅用于添加一个 key-value 对。下面是该方法的代码:
void addEntry(int hash, K key, V value, int bucketIndex)
{
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex]; // ①
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到 2 倍。
resize(2 * table.length); // ②
}
|
上面方法的代码很简单,但其中包含了一个非常优雅的设计:系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序①号代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。
回页首
Hash 算法的性能选项
根据上面代码可以看出,在同一个 bucket 存储 Entry 链的情况下,新放入的 Entry 总是位于 bucket 中,而最早放入该 bucket 中的 Entry 则位于这个 Entry 链的最末端。
上面程序中还有这样两个变量:
- size:该变量保存了该 HashMap 中所包含的 key-value 对的数量。
- threshold:该变量包含了 HashMap 能容纳的 key-value 对的极限,它的值等于 HashMap 的容量乘以负载因子(load factor)。
从上面程序中②号代码可以看出,当 size++ >= threshold 时,HashMap 会自动调用 resize 方法扩充 HashMap 的容量。每扩充一次,HashMap 的容量就增大一倍。
上面程序中使用的 table 其实就是一个普通数组,每个数组都有一个固定的长度,这个数组的长度就是 HashMap 的容量。HashMap 包含如下几个构造器:
- HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
- HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
- HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
当创建一个 HashMap 时,系统会自动创建一个 table 数组来保存 HashMap 中的 Entry,下面是 HashMap 中一个构造器的代码:
// 以指定初始化容量、负载因子创建 HashMap
public HashMap(int initialCapacity, float loadFactor)
{
// 初始容量不能为负数
if (initialCapacity < 0)
throw new IllegalArgumentException(
"Illegal initial capacity: " +
initialCapacity);
// 如果初始容量大于最大容量,让出示容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 负载因子必须大于 0 的数值
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException(
loadFactor);
// 计算出大于 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
// 设置容量极限等于容量 * 负载因子
threshold = (int)(capacity * loadFactor);
// 初始化 table 数组
table = new Entry[capacity]; // ①
init();
}
|
上面代码中粗体字代码包含了一个简洁的代码实现:找出大于 initialCapacity 的、最小的 2 的 n 次方值,并将其作为 HashMap 的实际容量(由 capacity 变量保存)。例如给定 initialCapacity 为 10,那么该 HashMap 的实际容量就是 16。
程序①号代码处可以看到:table 的实质就是一个数组,一个长度为 capacity 的数组。
对于 HashMap 及其子类而言,它们采用 Hash 算法来决定集合中元素的存储位置。当系统开始初始化 HashMap 时,系统会创建一个长度为 capacity 的 Entry 数组,这个数组里可以存储元素的位置被称为“桶(bucket)”,每个 bucket 都有其指定索引,系统可以根据其索引快速访问该 bucket 里存储的元素。
无论何时,HashMap 的每个“桶”只存储一个元素(也就是一个 Entry),由于 Entry 对象可以包含一个引用变量(就是 Entry 构造器的的最后一个参数)用于指向下一个 Entry,因此可能出现的情况是:HashMap 的 bucket 中只有一个 Entry,但这个 Entry 指向另一个 Entry ——这就形成了一个 Entry 链。如图 1 所示:
图 1. HashMap 的存储示意
回页首
HashMap 的读取实现
当 HashMap 的每个 bucket 里存储的 Entry 只是单个 Entry ——也就是没有通过指针产生 Entry 链时,此时的 HashMap 具有最好的性能:当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。看 HashMap 类的 get(K key) 方法代码:
public V get(Object key)
{
// 如果 key 是 null,调用 getForNullKey 取出对应的 value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 直接取出 table 数组中指定索引处的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
// 搜索该 Entry 链的下一个 Entr
e = e.next) // ①
{
Object k;
// 如果该 Entry 的 key 与被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
}
|
从上面代码中可以看出,如果 HashMap 的每个 bucket 里只有一个 Entry 时,HashMap 可以根据索引、快速地取出该 bucket 里的 Entry;在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据 Hash 算法来决定其存储位置;当需要取出一个 Entry 时,也会根据 Hash 算法找到其存储位置,直接取出该 Entry。由此可见:HashMap 之所以能快速存、取它所包含的 Entry,完全类似于现实生活中母亲从小教我们的:不同的东西要放在不同的位置,需要时才能快速找到它。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
掌握了上面知识之后,我们可以在创建 HashMap 时根据实际需要适当地调整 load factor 的值;如果程序比较关心空间开销、内存比较紧张,可以适当地增加负载因子;如果程序比较关心时间开销,内存比较宽裕则可以适当的减少负载因子。通常情况下,程序员无需改变负载因子的值。
如果开始就知道 HashMap 会保存多个 key-value 对,可以在创建时就使用较大的初始化容量,如果 HashMap 中 Entry 的数量一直不会超过极限容量(capacity * load factor),HashMap 就无需调用 resize() 方法重新分配 table 数组,从而保证较好的性能。当然,开始就将初始容量设置太高可能会浪费空间(系统需要创建一个长度为 capacity 的 Entry 数组),因此创建 HashMap 时初始化容量设置也需要小心对待。
回页首
HashSet 的实现
对于 HashSet 而言,它是基于 HashMap 实现的,HashSet 底层采用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,查看 HashSet 的源代码,可以看到如下代码:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
// 使用 HashMap 的 key 保存 HashSet 中所有元素
private transient HashMap<E,Object> map;
// 定义一个虚拟的 Object 对象作为 HashMap 的 value
private static final Object PRESENT = new Object();
...
// 初始化 HashSet,底层会初始化一个 HashMap
public HashSet()
{
map = new HashMap<E,Object>();
}
// 以指定的 initialCapacity、loadFactor 创建 HashSet
// 其实就是以相应的参数创建 HashMap
public HashSet(int initialCapacity, float loadFactor)
{
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity)
{
map = new HashMap<E,Object>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy)
{
map = new LinkedHashMap<E,Object>(initialCapacity
, loadFactor);
}
// 调用 map 的 keySet 来返回所有的 key
public Iterator<E> iterator()
{
return map.keySet().iterator();
}
// 调用 HashMap 的 size() 方法返回 Entry 的数量,就得到该 Set 里元素的个数
public int size()
{
return map.size();
}
// 调用 HashMap 的 isEmpty() 判断该 HashSet 是否为空,
// 当 HashMap 为空时,对应的 HashSet 也为空
public boolean isEmpty()
{
return map.isEmpty();
}
// 调用 HashMap 的 containsKey 判断是否包含指定 key
//HashSet 的所有元素就是通过 HashMap 的 key 来保存的
public boolean contains(Object o)
{
return map.containsKey(o);
}
// 将指定元素放入 HashSet 中,也就是将该元素作为 key 放入 HashMap
public boolean add(E e)
{
return map.put(e, PRESENT) == null;
}
// 调用 HashMap 的 remove 方法删除指定 Entry,也就删除了 HashSet 中对应的元素
public boolean remove(Object o)
{
return map.remove(o)==PRESENT;
}
// 调用 Map 的 clear 方法清空所有 Entry,也就清空了 HashSet 中所有元素
public void clear()
{
map.clear();
}
...
}
|
由上面源程序可以看出,HashSet 的实现其实非常简单,它只是封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。
HashSet 的绝大部分方法都是通过调用 HashMap 的方法来实现的,因此 HashSet 和 HashMap 两个集合在实现本质上是相同的。
掌握上面理论知识之后,接下来看一个示例程序,测试一下自己是否真正掌握了 HashMap 和 HashSet 集合的功能。
class Name
{
private String first;
private String last;
public Name(String first, String last)
{
this.first = first;
this.last = last;
}
public boolean equals(Object o)
{
if (this == o)
{
return true;
}
if (o.getClass() == Name.class)
{
Name n = (Name)o;
return n.first.equals(first)
&& n.last.equals(last);
}
return false;
}
}
public class HashSetTest
{
public static void main(String[] args)
{
Set<Name> s = new HashSet<Name>();
s.add(new Name("abc", "123"));
System.out.println(
s.contains(new Name("abc", "123")));
}
}
|
上面程序中向 HashSet 里添加了一个 new Name("abc", "123") 对象之后,立即通过程序判断该 HashSet 是否包含一个 new Name("abc", "123") 对象。粗看上去,很容易以为该程序会输出 true。
实际运行上面程序将看到程序输出 false,这是因为 HashSet 判断两个对象相等的标准除了要求通过 equals() 方法比较返回 true 之外,还要求两个对象的 hashCode() 返回值相等。而上面程序没有重写 Name 类的 hashCode() 方法,两个 Name 对象的 hashCode() 返回值并不相同,因此 HashSet 会把它们当成 2 个对象处理,因此程序返回 false。
由此可见,当我们试图把某个类的对象当成 HashMap 的 key,或试图将这个类的对象放入 HashSet 中保存时,重写该类的 equals(Object obj) 方法和 hashCode() 方法很重要,而且这两个方法的返回值必须保持一致:当该类的两个的 hashCode() 返回值相同时,它们通过 equals() 方法比较也应该返回 true。通常来说,所有参与计算 hashCode() 返回值的关键属性,都应该用于作为 equals() 比较的标准。
如下程序就正确重写了 Name 类的 hashCode() 和 equals() 方法,程序如下:
class Name
{
private String first;
private String last;
public Name(String first, String last)
{
this.first = first;
this.last = last;
}
// 根据 first 判断两个 Name 是否相等
public boolean equals(Object o)
{
if (this == o)
{
return true;
}
if (o.getClass() == Name.class)
{
Name n = (Name)o;
return n.first.equals(first);
}
return false;
}
// 根据 first 计算 Name 对象的 hashCode() 返回值
public int hashCode()
{
return first.hashCode();
}
public String toString()
{
return "Name[first=" + first + ", last=" + last + "]";
}
}
public class HashSetTest2
{
public static void main(String[] args)
{
HashSet<Name> set = new HashSet<Name>();
set.add(new Name("abc" , "123"));
set.add(new Name("abc" , "456"));
System.out.println(set);
}
}
|
上面程序中提供了一个 Name 类,该 Name 类重写了 equals() 和 toString() 两个方法,这两个方法都是根据 Name 类的 first 实例变量来判断的,当两个 Name 对象的 first 实例变量相等时,这两个 Name 对象的 hashCode() 返回值也相同,通过 equals() 比较也会返回 true。
程序主方法先将第一个 Name 对象添加到 HashSet 中,该 Name 对象的 first 实例变量值为"abc",接着程序再次试图将一个 first 为"abc"的 Name 对象添加到 HashSet 中,很明显,此时没法将新的 Name 对象添加到该 HashSet 中,因为此处试图添加的 Name 对象的 first 也是" abc",HashSet 会判断此处新增的 Name 对象与原有的 Name 对象相同,因此无法添加进入,程序在①号代码处输出 set 集合时将看到该集合里只包含一个 Name 对象,就是第一个、last 为"123"的 Name 对象。
基础
如先前所提到的,类图的目的是显示建模系统的类型。在大多数的 UML 模型中这些类型包括:
UML 为这些类型起了一个特别的名字:“分类器”。通常地,你可以把分类器当做类,但在技术上,分类器是更为普遍的术语,它还是引用上面的其它三种类型为好。
类名
类的 UML 表示是一个长方形,垂直地分为三个区,如图 1 所示。顶部区域显示类的名字。中间的区域列出类的属性。底部的区域列出类的操作。当在一个类图上画一个类元素时,你必须要有顶端的区域,下面的二个区域是可选择的(当图描述仅仅用于显示分类器间关系的高层细节时,下面的两个区域是不必要的)。图 1 显示一个航线班机如何作为 UML 类建模。正如我们所能见到的,名字是 Flight,我们可以在中间区域看到Flight类的3个属性:flightNumber,departureTime 和 flightDuration。在底部区域中我们可以看到Flight类有两个操作:delayFlight 和 getArrivalTime。

图 1: Flight类的类图
类属性列表
类的属性节(中部区域)在分隔线上列出每一个类的属性。属性节是可选择的,要是一用它,就包含类的列表显示的每个属性。该线用如下格式:
继续我们的Flight类的例子,我们可以使用属性类型信息来描述类的属性,如表 1 所示。
表 1:具有关联类型的Flight类的属性名字
属性名称
属性类型
|
| flightNumber |
Integer |
| departureTime |
Date |
| flightDuration |
Minutes |
|
在业务类图中,属性类型通常与单位相符,这对于图的可能读者是有意义的(例如,分钟,美元,等等)。然而,用于生成代码的类图,要求类的属性类型必须限制在由程序语言提供的类型之中,或包含于在系统中实现的、模型的类型之中。
在类图上显示具有默认值的特定属性,有时是有用的(例如,在银行账户应用程序中,一个新的银行账户会以零为初始值)。UML 规范允许在属性列表节中,通过使用如下的记号作为默认值的标识:
name : attribute type = default value
|
举例来说:
显示属性默认值是可选择的;图 2 显示一个银行账户类具有一个名为 balance的类型,它的默认值为0。

图 2:显示默认为0美元的balance属性值的银行账户类图。
类操作列表
类操作记录在类图长方形的第三个(最低的)区域中,它也是可选择的。和属性一样,类的操作以列表格式显示,每个操作在它自己线上。操作使用下列记号表现:
name(parameter list) : type of value returned
|
下面的表 2 中Flight类操作的映射。
表 2:从图 2 映射的Flight类的操作
操作名称返回参数值类型
| delayFlight |
| Name |
Type |
| numberOfMinutes |
Minutes |
|
N/A |
| getArrivalTime |
N/A |
Date |
|
图3显示,delayFlight 操作有一个Minutes类型的输入参数 -- numberOfMinutes。然而,delayFlight 操作没有返回值。 1 当一个操作有参数时,参数被放在操作的括号内;每个参数都使用这样的格式:“参数名:参数类型”。

图 3:Flight类操作参数,包括可选择的“in”标识。
当文档化操作参数时,你可能使用一个可选择的指示器,以显示参数到操作的输入参数、或输出参数。这个可选择的指示器以“in”或“out”出现,如图3中的操作区域所示。一般来说,除非将使用一种早期的程序编程语言,如Fortran ,这些指示器可能会有所帮助,否则它们是不必要的。然而,在 C++和Java中,所有的参数是“in”参数,而且按照UML规范,既然“in”是参数的默认类型,大多数人将会遗漏输入/输出指示器。
继承
在面向对象的设计中一个非常重要的概念,继承,指的是一个类(子类)继承另外的一个类(超类)的同一功能,并增加它自己的新功能(一个非技术性的比喻,想象我继承了我母亲的一般的音乐能力,但是在我的家里,我是唯一一个玩电吉他的人)的能力。为了在一个类图上建模继承,从子类(要继承行为的类)拉出一条闭合的,单键头(或三角形)的实线指向超类。考虑银行账户的类型:图 4 显示 CheckingAccount 和 SavingsAccount 类如何从 BankAccount 类继承而来。

图 4: 继承通过指向超类的一条闭合的,单箭头的实线表示。
在图 4 中,继承关系由每个超类的单独的线画出,这是在IBM Rational Rose和IBM Rational XDE中使用的方法。然而,有一种称为 树标记的备选方法可以画出继承关系。当存在两个或更多子类时,如图 4 中所示,除了继承线象树枝一样混在一起外,你可以使用树形记号。图 5 是重绘的与图 4 一样的继承,但是这次使用了树形记号。

图 5: 一个使用树形记号的继承实例
抽象类及操作
细心的读者会注意到,在图 4 和 图5 中的图中,类名BankAccount和withdrawal操作使用斜体。这表示,BankAccount 类是一个抽象类,而withdrawal方法是抽象的操作。换句话说,BankAccount 类使用withdrawal规定抽象操作,并且CheckingAccount 和 SavingsAccount 两个子类都分别地执行它们各自版本的操作。
然而,超类(父类)不一定要是抽象类。标准类作为超类是正常的。
关联
当你系统建模时,特定的对象间将会彼此关联,而且这些关联本身需要被清晰地建模。有五种关联。在这一部分中,我将会讨论它们中的两个 -- 双向的关联和单向的关联,而且我将会在Beyond the basics部分讨论剩下的三种关联类型。请注意,关于何时该使用每种类型关联的详细讨论,不属于本文的范围。相反的,我将会把重点集中在每种关联的用途,并说明如何在类图上画出关联。
双向(标准)的关联
关联是两个类间的联接。关联总是被假定是双向的;这意味着,两个类彼此知道它们间的联系,除非你限定一些其它类型的关联。回顾一下Flight 的例子,图 6 显示了在Flight类和Plane类之间的一个标准类型的关联。

图 6:在一个Flight类和Plane类之间的双向关联的实例
一个双向关联用两个类间的实线表示。在线的任一端,你放置一个角色名和多重值。图 6 显示Flight与一个特定的Plane相关联,而且Flight类知道这个关联。因为角色名以Plane类表示,所以Plane承担关联中的“assignedPlane”角色。紧接于Plane类后面的多重值描述0...1表示,当一个Flight实体存在时,可以有一个或没有Plane与之关联(也就是,Plane可能还没有被分配)。图 6 也显示Plane知道它与Flight类的关联。在这个关联中,Flight承担“assignedFlights”角色;图 6 的图告诉我们,Plane实体可以不与flight关联(例如,它是一架全新的飞机)或与没有上限的flight(例如,一架已经服役5年的飞机)关联。
由于对那些在关联尾部可能出现的多重值描述感到疑惑,下面的表3列出了一些多重值及它们含义的例子。
表 3: 多重值和它们的表示
表示
含义
| 可能的多重值描述 |
|
| 0..1 |
0个或1个 |
| 1 |
只能1个 |
| 0..* |
0个或多个 |
| * |
0个或多个 |
| 1..* |
1个或我个 |
| 3 |
只能3个 |
| 0..5 |
0到5个 |
| 5..15 |
5到15个 |
|
单向关联
在一个单向关联中,两个类是相关的,但是只有一个类知道这种联系的存在。图 7 显示单向关联的透支财务报告的一个实例。

图 7: 单向关联一个实例:OverdrawnAccountsReport 类 BankAccount 类,而 BankAccount 类则对关联一无所知。
一个单向的关联,表示为一条带有指向已知类的开放箭头(不关闭的箭头或三角形,用于标志继承)的实线。如同标准关联,单向关联包括一个角色名和一个多重值描述,但是与标准的双向关联不同的时,单向关联只包含已知类的角色名和多重值描述。在图 7 中的例子中,OverdrawnAccountsReport 知道 BankAccount 类,而且知道 BankAccount 类扮演“overdrawnAccounts”的角色。然而,和标准关联不同,BankAccount 类并不知道它与 OverdrawnAccountsReport 相关联。 2
软件包
不可避免,如果你正在为一个大的系统或大的业务领域建模,在你的模型中将会有许多不同的分类器。管理所有的类将是一件令人生畏的任务;所以,UML 提供一个称为 软件包的组织元素。软件包使建模者能够组织模型分类器到名字空间中,这有些象文件系统中的文件夹。把一个系统分为多个软件包使系统变成容易理解,尤其是在每个软件包都表现系统的一个特定部分时。 3
在图中存在两种方法表示软件包。并没有规则要求使用哪种标记,除了用你个人的判断:哪种更便于阅读你画的类图。两种方法都是由一个较小的长方形(用于定位)嵌套在一个大的长方形中开始的,如图 8 所示。但是建模者必须决定包的成员如何表示,如下:
- 如果建模者决定在大长方形中显示软件包的成员,则所有的那些成员 4 需要被放置在长方形里面。另外,所有软件包的名字需要放在软件包的较小长方形之内(如图 8 的显示)。
- 如果建模者决定在大的长方形之外显示软件包成员,则所有将会在图上显示的成员都需要被置于长方形之外。为了显示属于软件包的分类器属于,从每个分类器画一条线到里面有加号的圆周,这些圆周粘附在软件包之上(图9)。

图 8:在软件包的长方形内显示软件包成员的软件包元素例子

图 9:一个通过连接线表现软件包成员的软件包例子
了解基础重要性
在 UML 2 中,了解类图的基础更为重要。这是因为类图为所有的其他结构图提供基本的构建块。如组件或对象图(仅仅是举了些例子)。
回页首
超过基础
到此为止,我已经介绍了类图的基础,但是请继续往下读!在下面的部分中,我将会引导你到你会使用的类图的更重要的方面。这些包括UML 2 规范中的接口,其它的三种关联类型,可见性和其他补充。
接口
在本文的前面,我建议你以类来考虑分类器。事实上,分类器是一个更为一般的概念,它包括数据类型和接口。
关于何时、以及如何高效地在系统结构图中使用数据类型和接口的完整讨论,不在本文的讨论范围之内。既然这样,我为什么要在这里提及数据类型和接口呢?你可能想在结构图上模仿这些分类器类型,在这个时候,使用正确的记号来表示,或者至少知道这些分类器类型是重要的。不正确地绘制这些分类器,很有可能将使你的结构图读者感到混乱,以后的系统将不能适应需求。
一个类和一个接口不同:一个类可以有它形态的真实实例,然而一个接口必须至少有一个类来实现它。在 UML 2 中,一个接口被认为是类建模元素的特殊化。因此,接口就象类那样绘制,但是长方形的顶部区域也有文本“interface”,如图 10 所示。 5

图 10:Professor类和Student类实现Person接口的类图实例
在图 10 中显示的图中,Professor和Student类都实现了Person的接口,但并不从它继承。我们知道这一点是由于下面两个原因:1) Person对象作为接口被定义 -- 它在对象的名字区域中有“interface”文本,而且我们看到由于Professor和Student对象根据画类对象的规则(在它们的名字区域中没有额外的分类器文本)标示,所以它们是 类对象。 2) 我们知道继承在这里没有被显示,因为与带箭头的线是点线而不是实线。如图 10 所示,一条带有闭合的单向箭头的点 线意味着实现(或实施);正如我们在图 4 中所见到的,一条带有闭合单向箭头的实线表示继承。
更多的关联
在上面,我讨论了双向关联和单向关联。现在,我将会介绍剩下的三种类型的关联。
关联类
在关联建模中,存在一些情况下,你需要包括其它类,因为它包含了关于关联的有价值的信息。对于这种情况,你会使用 关联类 来绑定你的基本关联。关联类和一般类一样表示。不同的是,主类和关联类之间用一条相交的点线连接。图 11 显示一个航空工业实例的关联类。

图 11:增加关联类 MileageCredit
在图 11 中显示的类图中,在Flight类和 FrequentFlyer 类之间的关联,产生了称为 MileageCredit的关联类。这意味当Flight类的一个实例关联到 FrequentFlyer 类的一个实例时,将会产生 MileageCredit 类的一个实例。
聚合
聚合是一种特别类型的关联,用于描述“总体到局部”的关系。在基本的聚合关系中, 部分类 的生命周期独立于 整体类 的生命周期。
举例来说,我们可以想象,车 是一个整体实体,而 车轮 轮胎是整辆车的一部分。轮胎可以在安置到车时的前几个星期被制造,并放置于仓库中。在这个实例中,Wheel类实例清楚地独立地Car类实例而存在。然而,有些情况下, 部分 类的生命周期并 不 独立于 整体 类的生命周期 -- 这称为合成聚合。举例来说,考虑公司与部门的关系。 公司和部门 都建模成类,在公司存在之前,部门不能存在。这里Department类的实例依赖于Company类的实例而存在。
让我们更进一步探讨基本聚合和组合聚合。
基本聚合
有聚合关系的关联指出,某个类是另外某个类的一部分。在一个聚合关系中,子类实例可以比父类存在更长的时间。为了表现一个聚合关系,你画一条从父类到部分类的实线,并在父类的关联末端画一个未填充棱形。图 12 显示车和轮胎间的聚合关系的例子。

图 12: 一个聚合关联的例子
组合聚合
组合聚合关系是聚合关系的另一种形式,但是子类实例的生命周期依赖于父类实例的生命周期。在图13中,显示了Company类和Department类之间的组合关系,注意组合关系如聚合关系一样绘制,不过这次菱形是被填充的。

图 13: 一个组合关系的例子
在图 13 中的关系建模中,一个Company类实例至少总有一个Department类实例。因为关系是组合关系,当Company实例被移除/销毁时,Department实例也将自动地被移除/销毁。组合聚合的另一个重要功能是部分类只能与父类的实例相关(举例来说,我们例子中的Company类)。
反射关联
现在我们已经讨论了所有的关联类型。就如你可能注意到的,我们的所有例子已经显示了两个不同类之间的关系。然而,类也可以使用反射关联与它本身相关联。起先,这可能没有意义,但是记住,类是抽象的。图 14 显示一个Employee类如何通过manager / manages角色与它本身相关。当一个类关联到它本身时,这并不意味着类的实例与它本身相关,而是类的一个实例与类的另一个实例相关。

图 14:一个反射关联关系的实例
图 14 描绘的关系说明一个Employee实例可能是另外一个Employee实例的经理。然而,因为“manages”的关系角色有 0..*的多重性描述;一个雇员可能不受任何其他雇员管理。
可见性
在面向对象的设计中,存在属性及操作可见性的记号。UML 识别四种类型的可见性:public,protected,private及package。
UML 规范并不要求属性及操作可见性必须显示在类图上,但是它要求为每个属性及操作定义可见性。为了在类图上的显示可见性,放置可见性标志于属性或操作的名字之前。虽然 UML 指定四种可见性类型,但是实际的编程语言可能增加额外的可见性,或不支持 UML 定义的可见性。表4显示了 UML 支持的可见性类型的不同标志。
表 4:UML 支持的可见性类型的标志
标志
可见性类型
|
| + |
Public |
| # |
Protected |
| - |
Private |
| ~ |
Package |
|
现在,让我们看一个类,以说明属性及操作的可见性类型。在图 15 中,所有的属性及操作都是public,除了 updateBalance 操作。updateBalance 操作是protected。

图 15:一个 BankAccount 类说明它的属性及操作的可见性
回页首
UML 2 补充
既然我们已经覆盖了基础和高级主题,我们将覆盖一些由UML 1. x增加的类图的新记号。
实例
当一个系统结构建模时,显示例子类实例有时候是有用的。为了这种结构建模,UML 2 提供 实例规范 元素,它显示在系统中使用例子(或现实)实例的值得注意的信息。
实例的记号和类一样,但是取代顶端区域中仅有的类名,它的名字是经过拼接的:
Instance Name : Class Name
|
举例来说:
因为显示实例的目的是显示值得注意的或相关的信息,没必要在你的模型中包含整个实体属性及操作。相反地,仅仅显示感兴趣的属性及其值是完全恰当的。如图16所描述。

图 16:Plane类的一个实例例子(只显示感兴趣的属性值)
然而,仅仅表现一些实例而没有它们的关系不太实用;因此,UML 2 也允许在实体层的关系/关联建模。绘制关联与一般的类关系的规则一样,除了在建模关联时有一个附加的要求。附加的限制是,关联关系必须与类图的关系相一致,而且关联的角色名字也必须与类图相一致。它的一个例子显示于图 17 中。在这个例子中,实例是图 6 中类图的例子实例。

图 17:图 6 中用实例代替类的例子
图 17 有Flight类的二个实例,因为类图指出了在Plane类和Flight类之间的关系是 0或多。因此,我们的例子给出了两个与NX0337 Plane实例相关的Flight实例。
角色
建模类的实例有时比期望的更为详细。有时,你可能仅仅想要在一个较多的一般层次做类关系的模型。在这种情况下,你应该使用 角色 记号。角色记号类似于实例记号。为了建立类的角色模型,你画一个方格,并在内部放置类的角色名及类名,作为实体记号,但是在这情况你不能加下划线。图 18 显示一个由图 14 中图描述的雇员类扮演的角色实例。在图 18 中,我们可以认为,即使雇员类与它本身相关,关系确实是关于雇员之间扮演经理及团队成员的角色。

图 18:一个类图显示图14中扮演不同角色的类
注意,你不能在纯粹类图中做类角色的建模,即使图 18显示你可以这么做。为了使用角色记号,你将会需要使用下面讨论的内部结构记号。
内部的结构
UML 2 结构图的更有用的功能之一是新的内部结构记号。它允许你显示一个类或另外的一个分类器如何在内部构成。这在 UML 1. x 中是不可能的,因为记号限制你只能显示一个类所拥有的聚合关系。现在,在 UML 2 中,内部的结构记号让你更清楚地显示类的各个部分如何保持关系。
让我们看一个实例。在图 18 中我们有一个类图以表现一个Plane类如何由四个引擎和两个控制软件对象组成。从这个图中省略的东西是显示关于飞机部件如何被装配的一些信息。从图 18 的图,你无法说明,是每个控制软件对象控制两个引擎,还是一个控制软件对象控制三个引擎,而另一个控制一个引擎。

图 19: 只显示对象之间关系的类图
绘制类的内在结构将会改善这种状态。开始时,你通过用二个区域画一个方格。最顶端的区域包含类名字,而较低的区域包含类的内部结构,显示在它们父类中承担不同角色的部分类,角色中的每个部分类也关系到其它类。图 19 显示了Plane类的内部结构;注意内部结构如何澄清混乱性。

图 20:Plane类的内部结构例子。
在图 20 中Plane有两个 ControlSoftware 对象,而且每个控制二个引擎。在图左边上的 ControlSoftware(control1)控制引擎 1 和 2 。在图右边的 ControlSoftware(control2)控制引擎 3 和 4 。
回页首
结论
至少存在两个了解类图的重要理由。第一个是它显示系统分类器的静态结构;第二个理由是图为UML描述的其他结构图提供了基本记号。开发者将会认为类图是为他们特别建立的;但是其他的团队成员将发现它们也是有用的。业务分析师可以用类图,为系统的业务远景建模。正如我们将会在本系列关于 UML 基础的文章中见到的,其他的图 -- 包括活动图,序列图和状态图——参考类图中的类建模和文档化。
关于“UML 基础”的本系列的后面的元件图。
一、什么是注释
说起注释,得先提一提什么是元数据(metadata)。所谓元数据就是数据的数据。也就是说,元数据是描述数据的。就象数据表中的字段一样,每个字段描述了这个字段下的数据的含义。而J2SE5.0中提供的注释就是java源代码的元数据,也就是说注释是描述java源代码的。在J2SE5.0中可以自定义注释。使用时在@后面跟注释的名字。
二、J2SE5.0中预定义的注释
在J2SE5.0的java.lang包中预定义了三个注释。它们是Override、Deprecated和SuppressWarnings。下面分别解释它们的含义。
1.Override注释:仅用于方法(不可用于类、包的生命或其他),指明注释的方法将覆盖超类中的方法(如果覆盖父类的方法而没有注
释就无法编译该类),注释还能确保注释父类方法的拼写是正确(错误的编写,编译器不认为是子类的新方法,而会报错)
2.@Deprecated注释:对不应再使用的方法进行注释,与正在声明为过时的方法放在同一行。使用被 Deprecated注释的方法,编译器会
提示方法过时警告(”Warring”)
3.@SuppressWarnings注释:单一注释,可以通过数组提供变量,变量值指明要阻止的特定类型警告(忽略某些警告)。数组中的变量指明要阻止的警告@SuppressWarnings(value={”unchecked”,”fallthrough”}))
三、自定义注释@interface
@interface:注释声明,定义注释类型(与默认的Override等三种注释类型类似)。请看下面实例:
注释类1:
package a.test;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface FirstAnno {
String value() default "FirstAnno";
}
注释类2:
package a.test;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface SecondAnnotation {
// 注释中含有两个参数
String name() default "Hrmzone";
String url() default "hrmzone.cn";
}
注释类3:
package a.test;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Kitto {
String value() default "kitto";
}
使用类:
package a.test;
@FirstAnno("http://hrmzone.cn")
public class Anno {
@Kitto("测试")
private String test = "";
// 不赋值注释中的参数,使用默认参数
@SecondAnnotation()
public String getDefault() {
return "get default Annotation";
}
@SecondAnnotation(name="desktophrm",url="desktophrm.com")
public String getDefine() {
return "get define Annotation";
}
}
测试类:
package a.test;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
public class AnnoTest {
public static void main(String[] args) throws ClassNotFoundException {
// 要使用到反射中的相关内容
Class c = Class.forName("a.test.Anno");
Method[] method = c.getMethods();
boolean flag = c.isAnnotationPresent(FirstAnno.class);
if (flag) {
FirstAnno first = (FirstAnno) c.getAnnotation(FirstAnno.class);
System.out.println("First Annotation:" + first.value() + "\n");
}
List<Method> list = new ArrayList<Method>();
for (int i = 0; i < method.length; i++) {
list.add(method[i]);
}
for (Method m : list) {
SecondAnnotation anno = m.getAnnotation(SecondAnnotation.class);
if(anno == null)
continue;
System.out.println("second annotation's\nname:\t" + anno.name()
+ "\nurl:\t" + anno.url());
}
List<Field> fieldList = new ArrayList<Field>();
for(Field f : c.getDeclaredFields()){//访问所有字段
Kitto k = f.getAnnotation(Kitto.class);
System.out.println("----kitto anno: " + k.value());
}
}
}
结合源文件中注释,想必对注释的应用有所了解。下面深入了解。
深入注释:
@Target:指定程序元定义的注释所使用的地方,它使用了另一个类:ElementType,是一个枚举类定义了注释类型可以应用到不同的程序元素以免使用者误用。看看java.lang.annotation 下的源代码:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Target {
ElementType[] value();
}
ElementType是一个枚举类型,指明注释可以使用的地方,看看ElementType类:
public enum ElementType {
TYPE, // 指定适用点为 class, interface, enum
FIELD, // 指定适用点为 field
METHOD, // 指定适用点为 method
PARAMETER, // 指定适用点为 method 的 parameter
CONSTRUCTOR, // 指定适用点为 constructor
LOCAL_VARIABLE, // 指定使用点为 局部变量
ANNOTATION_TYPE, //指定适用点为 annotation 类型
PACKAGE // 指定适用点为 package
}
@Retention:这个元注释和java编译器处理注释的注释类型方式相关,告诉编译器在处理自定义注释类型的几种不同的选择,需要使用RetentionPolicy枚举类。此枚举类只有一个成员变量,可以不用指明成名名称而赋值,看Retention的源代码:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Retention {
RetentionPolicy value();
}
类中有个RetentionPolicy类,也是一个枚举类,具体看代码:
public enum RetentionPolicy {
SOURCE, // 编译器处理完Annotation后不存储在class中
CLASS, // 编译器把Annotation存储在class中,这是默认值
RUNTIME // 编译器把Annotation存储在class中,可以由虚拟机读取,反射需要
}
@Documented:是一个标记注释,表示注释应该出现在类的javadoc中,因为在默认情况下注释时不包括在javadoc中的。
所以如果花费了大量的时间定义一个注释类型,并想描述注释类型的作用,可以使用它。
注意他与@Retention(RetentionPolicy.RUNTIME)配合使用,因为只有将注释保留在编译后的类文件中由虚拟机加载,
然后javadoc才能将其抽取出来添加至javadoc中。
@Inherited:将注释同样继承至使用了该注释类型的方法中(表达有点问题,就是如果一个方法使用了的注释用了@inherited,
那么其子类的该方法同样继承了该注释)
注意事项:
1.所有的Annotation自动继承java.lang.annotation接口
2.自定义注释的成员变量访问类型只能是public、default;(所有的都能访问,源作者没用到函数:getDeclaredFields而已)
3.成员变量的只能使用基本类型(byte、short、int、char、long、double、float、boolean和String、Enum、Class、annotations以及该类型的数据)(没有限制,大家可以修改测试一下,就清楚)
4.如果只有一个成员变量,最好将参数名称设为value,赋值时不用制定名称而直接赋值
5.在实际应用中,还可以使用注释读取和设置Bean中的变量。
1 前言 2
2 总纲 2
3 降龙十八掌 3
第一掌 避免对列的操作 3
第二掌 避免不必要的类型转换 4
第三掌 增加查询的范围限制 4
第四掌 尽量去掉”IN”、”OR” 4
第五掌 尽量去掉 “<>” 5
第六掌 去掉Where子句中的IS NULL和IS NOT NULL 5
第七掌 索引提高数据分布不均匀时查询效率 5
第八掌 利用HINT强制指定索引 6
第九掌 屏蔽无用索引 6
第十掌 分解复杂查询,用常量代替变量 7
第十一掌 like子句尽量前端匹配 7
第十二掌 用Case语句合并多重扫描 7
第十三掌 使用nls_date_format 8
第十四掌 使用基于函数的索引 8
第十五掌 基于函数的索引要求等式匹配 9
第十六掌 使用分区索引 9
第十七掌 使用位图索引 9
第十八掌 决定使用全表扫描还是使用索引 9
4 总结 10
1 前言
客服业务受到SQL语句的影响非常大,在规模比较大的局点,往往因为一个小的SQL语句不够优化,导致数据库性能急剧下降,小型机idle所剩无几,应用 服务器断连、超时,严重影响业务的正常运行。因此,称低效的SQL语句为客服业务的‘恶龙’并不过分。数据库的优化方法有很多种,在应用层来说,主要是基 于索引的优化。本次秘笈根据实际的工作经验,在研发原来已有的方法的基础上,进行了一些扩充,总结了基于索引的SQL语句优化的降龙十八掌,希望有一天你 能用其中一掌来驯服客服业务中横行的‘恶龙’。
2 总纲
l 建立必要的索引
这次传授的降龙十八掌,总纲只有一句话:建立必要的索引,这就是后面降龙十八掌的内功基础。这一点看似容易实际却很难。难就难在如何判断哪些索引是必要 的,哪些又是不必要的。判断的最终标准是看这些索引是否对我们的数据库性能有所帮助。具体到方法上,就必须熟悉数据库应用程序中的所有SQL语句,从中统 计出常用的可能对性能有影响的部分SQL,分析、归纳出作为Where条件子句的字段及其组合方式;在这一基础上可以初步判断出哪些表的哪些字段应该建立 索引。其次,必须熟悉应用程序。必须了解哪些表是数据操作频繁的表;哪些表经常与其他表进行连接;哪些表中的数据量可能很大;对于数据量大的表,其中各个 字段的数据分布情况如何;等等。对于满足以上条件的这些表,必须重点关注,因为在这些表上的索引,将对SQL语句的性能产生举足轻重的影响。不过下面还是 总结了一下降龙十八掌内功的入门基础,建立索引常用的规则如下:
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
以上是一些普遍的建立索引时的判断依据。一言以蔽之,索引的建立必须慎重,对每个索引的必要性都应该经过仔细分析,要有建立的依据。因为太多的索引与不充 分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。 另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更 大。
3 降龙十八掌
第一掌 避免对列的操作
任何对列的操作都可能导致全表扫描,这里所谓的操作包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等式的右边,甚至去掉函数。
例1:下列SQL条件语句中的列都建有恰当的索引,但30万行数据情况下执行速度却非常慢:
select * from record where substrb(CardNo,1,4)=’5378′(13秒)
select * from record where amount/30< 1000(11秒)
select * from record where to_char(ActionTime,’yyyymmdd’)=’19991201′(10秒)
由于where子句中对列的任何操作结果都是在SQL运行时逐行计算得到的,因此它不得不进行表扫描,而没有使用该列上面的索引;如果这些结果在查询编译时就能得到,那么就可以被SQL优化器优化,使用索引,避免表扫描,因此将SQL重写如下:
select * from record where CardNo like ‘5378%’(< 1秒)
select * from record where amount < 1000*30(< 1秒)
select * from record where ActionTime= to_date (’19991201′ ,’yyyymmdd’)(< 1秒)
差别是很明显的!
第二掌 避免不必要的类型转换
需要注意的是,尽量避免潜在的数据类型转换。如将字符型数据与数值型数据比较,ORACLE会自动将字符型用to_number()函数进行转换,从而导致全表扫描。
例2:表tab1中的列col1是字符型(char),则以下语句存在类型转换:
select col1,col2 from tab1 where col1>10,
应该写为: select col1,col2 from tab1 where col1>’10′。
第三掌 增加查询的范围限制
增加查询的范围限制,避免全范围的搜索。
例3:以下查询表record 中时间ActionTime小于2001年3月1日的数据:
select * from record where ActionTime < to_date (’20010301′ ,’yyyymm’)
查询计划表明,上面的查询对表进行全表扫描,如果我们知道表中的最早的数据为2001年1月1日,那么,可以增加一个最小时间,使查询在一个完整的范围之内。修改如下: select * from record where
ActionTime < to_date (’20010301′ ,’yyyymm’)
and ActionTime > to_date (’20010101′ ,’yyyymm’)
后一种SQL语句将利用上ActionTime字段上的索引,从而提高查询效率。把’20010301′换成一个变量,根据取值的机率,可以有一半以上的 机会提高效率。同理,对于大于某个值的查询,如果知道当前可能的最大值,也可以在Where子句中加上 “AND 列名< MAX(最大值)”。
第四掌 尽量去掉”IN”、”OR”
含有”IN”、”OR”的Where子句常会使用工作表,使索引失效;如果不产生大量重复值,可以考虑把子句拆开;拆开的子句中应该包含索引。
例4: select count(*) from stuff where id_no in(’0′,’1′)(23秒)
可以考虑将or子句分开:
select count(*) from stuff where id_no=’0′
select count(*) from stuff where id_no=’1′
然后再做一个简单的加法,与原来的SQL语句相比,查询速度更快。
第五掌 尽量去掉 “<>”
尽量去掉 “<>”,避免全表扫描,如果数据是枚举值,且取值范围固定,则修改为”OR”方式。
例5:
UPDATE SERVICEINFO SET STATE=0 WHERE STATE<>0;
以上语句由于其中包含了”<>”,执行计划中用了全表扫描(TABLE ACCESS FULL),没有用到state字段上的索引。实际应用中,由于业务逻辑的限制,字段state为枚举值,只能等于0,1或2,而且,值等于=1,2的很 少,因此可以去掉”<>”,利用索引来提高效率。
修改为:UPDATE SERVICEINFO SET STATE=0 WHERE STATE = 1 OR STATE = 2 。进一步的修改可以参考第4种方法。
第六掌 去掉Where子句中的IS NULL和IS NOT NULL
Where字句中的IS NULL和IS NOT NULL将不会使用索引而是进行全表搜索,因此需要通过改变查询方式,分情况讨论等方法,去掉Where子句中的IS NULL和IS NOT NULL。
第七掌 索引提高数据分布不均匀时查询效率
索引的选择性低,但数据的值分布差异很大时,仍然可以利用索引提高效率。A、数据分布不均匀的特殊情况下,选择性不高的索引也要创建。
表ServiceInfo中数据量很大,假设有一百万行,其中有一个字段DisposalCourseFlag,取值范围为枚举值:[0,1,2,3, 4,5,6,7]。按照前面说的索引建立的规则,“选择性不高的字段不应该建立索引,该字段只有8种取值,索引值的重复率很高,索引选择性明显很低,因此 不建索引。然而,由于该字段上数据值的分布情况非常特殊,具体如下表:
取值范围 1~5 6 7
占总数据量的百分比 1% 98% 1%
而且,常用的查询中,查询DisposalCourseFlag<6 的情况既多又频繁,毫无疑问,如果能够建立索引,并且被应用,那么将大大提高这种情况的查询效率。因此,我们需要在该字段上建立索引。
第八掌 利用HINT强制指定索引
在ORACLE优化器无法用上合理索引的情况下,利用HINT强制指定索引。
继续上面7的例子,ORACLE缺省认定,表中列的值是在所有数据行中均匀分布的,也就是说,在一百万数据量下,每种 DisposalCourseFlag值各有12.5万数据行与之对应。假设SQL搜索条件DisposalCourseFlag=2,利用 DisposalCourseFlag列上的索引进行数据搜索效率,往往不比全表扫描的高,ORACLE因此对索引“视而不见”,从而在查询路径的选择 中,用其他字段上的索引甚至全表扫描。根据我们上面的分析,数据值的分布很特殊,严重的不均匀。为了利用索引提高效率,此时,一方面可以单独对该字段或该 表用analyze语句进行分析,对该列搜集足够的统计数据,使ORACLE在查询选择性较高的值时能用上索引;另一方面,可以利用HINT提示,在 SELECT关键字后面,加上“/*+ INDEX(表名称,索引名称)*/”的方式,强制ORACLE优化器用上该索引。
比如: select * from serviceinfo where DisposalCourseFlag=1 ;
上面的语句,实际执行中ORACLE用了全表扫描,加上蓝色提示部分后,用到索引查询。如下:
select /*+ INDEX(SERVICEINFO,IX_S_DISPOSALCOURSEFLAG) */ *
from serviceinfo where DisposalCourseFlag=1;
请注意,这种方法会加大代码维护的难度,而且该字段上索引的名称被改变之后,必须要同步所有指定索引的HINT代码,否则HINT提示将被ORACLE忽略掉。
第九掌 屏蔽无用索引
继续上面8的例子,由于实际查询中,还有涉及到DisposalCourseFlag=6的查询,而此时如果用上该字段上的索引,将是非常不明智的,效率 也极低。因此这种情况下,我们需要用特殊的方法屏蔽该索引,以便ORACLE选择其他字段上的索引。比如,如果字段为数值型的就在表达式的字段名后,添加 “+ 0”,为字符型的就并上空串:“||”"”
如: select * from serviceinfo where DisposalCourseFlag+ 0 = 6 and workNo = ‘36′ 。
不过,不要把该用的索引屏蔽掉了,否则同样会产生低效率的全表扫描。
第十掌 分解复杂查询,用常量代替变量
对于复杂的Where条件组合,Where中含有多个带索引的字段,考虑用IF语句分情况进行讨论;同时,去掉不必要的外来参数条件,减低复杂度,以便在不同情况下用不同字段上的索引。
继续上面9的例子,对于包含
Where (DisposalCourseFlag < v_DisPosalCourseFlag) or (v_DisPosalCourseFlag is null) and ….的查询,(这里v_DisPosalCourseFlag为一个输入变量,取值范围可能为[NULL,0,1,2,3,4,5,6,7]),可以 考虑分情况用IF语句进行讨论,类似:
IF v_DisPosalCourseFlag =1 THEN
Where DisposalCourseFlag = 1 and ….
ELSIF v_DisPosalCourseFlag =2 THEN
Where DisposalCourseFlag = 2 and ….
。。。。。。
第十一掌 like子句尽量前端匹配
因为like参数使用的非常频繁,因此如果能够对like子句使用索引,将很高的提高查询的效率。
例6:select * from city where name like ‘%S%’
以上查询的执行计划用了全表扫描(TABLE ACCESS FULL),如果能够修改为:
select * from city where name like ‘S%’
那么查询的执行计划将会变成(INDEX RANGE SCAN),成功的利用了name字段的索引。这意味着Oracle SQL优化器会识别出用于索引的like子句,只要该查询的匹配端是具体值。因此我们在做like查询时,应该尽量使查询的匹配端是具体值,即使用 like ‘S%’。
第十二掌 用Case语句合并多重扫描
我们常常必须基于多组数据表计算不同的聚集。例如下例通过三个独立查询:
例8:1)select count(*) from emp where sal<1000;
2)select count(*) from emp where sal between 1000 and 5000;
3)select count(*) from emp where sal>5000;
这样我们需要进行三次全表查询,但是如果我们使用case语句:
select
count (sale when sal <1000
then 1 else null end) count_poor,
count (sale when between 1000 and 5000
then 1 else null end) count_blue_collar,
count (sale when sal >5000
then 1 else null end) count_poor
from emp;
这样查询的结果一样,但是执行计划只进行了一次全表查询。
第十三掌 使用nls_date_format
例9:
select * from record where to_char(ActionTime,’mm’)=’12′
这个查询的执行计划将是全表查询,如果我们改变nls_date_format,
SQL>alert session set nls_date_formate=’MM’;
现在重新修改上面的查询:
select * from record where ActionTime=’12′
这样就能使用actiontime上的索引了,它的执行计划将是(INDEX RANGE SCAN)。
第十四掌 使用基于函数的索引
前面谈到任何对列的操作都可能导致全表扫描,例如:
select * from emp where substr(ename,1,2)=’SM’;
但是这种查询在客服系统又经常使用,我们可以创建一个带有substr函数的基于函数的索引,
create index emp_ename_substr on eemp ( substr(ename,1,2) );
这样在执行上面的查询语句时,这个基于函数的索引将排上用场,执行计划将是(INDEX RANGE SCAN)。
第十五掌 基于函数的索引要求等式匹配
上面的例子中,我们创建了基于函数的索引,但是如果执行下面的查询:
select * from emp where substr(ename,1,1)=’S’
得到的执行计划将还是(TABLE ACCESS FULL),因为只有当数据列能够等式匹配时,基于函数的索引才能生效,这样对于这种索引的计划和维护的要求都很高。请注意,向表中添加索引是非常危险的 操作,因为这将导致许多查询执行计划的变更。然而,如果我们使用基于函数的索引就不会产生这样的问题,因为Oracle只有在查询使用了匹配的内置函数时 才会使用这种类型的索引。
第十六掌 使用分区索引
在用分析命令对分区索引进行分析时,每一个分区的数据值的范围信息会放入Oracle的数据字典中。Oracle可以利用这个信息来提取出那些只与SQL查询相关的数据分区。
例如,假设你已经定义了一个分区索引,并且某个SQL语句需要在一个索引分区中进行一次索引扫描。Oracle会仅仅访问这个索引分区,而且会在这个分区上调用一个此索引范围的快速全扫描。因为不需要访问整个索引,所以提高了查询的速度。
第十七掌 使用位图索引
位图索引可以从本质上提高使用了小于1000个唯一数据值的数据列的查询速度,因为在位图索引中进行的检索是在RAM中完成的,而且也总是比传统的B树索引的速度要快。对于那些少于1000个唯一数据值的数据列建立位图索引,可以使执行效率更快。
第十八掌 决定使用全表扫描还是使用索引
和所有的秘笈一样,最后一招都会又回到起点,最后我们来讨论一下是否需要建立索引,也许进行全表扫描更快。在大多数情况下,全表扫描可能会导致更多的物理 磁盘输入输出,但是全表扫描有时又可能会因为高度并行化的存在而执行的更快。如果查询的表完全没有顺序,那么一个要返回记录数小于10%的查询可能会读取 表中大部分的数据块,这样使用索引会使查询效率提高很多。但是如果表非常有顺序,那么如果查询的记录数大于40%时,可能使用全表扫描更快。因此,有一个 索引范围扫描的总体原则是:
1)对于原始排序的表 仅读取少于表记录数40%的查询应该使用索引范围扫描。反之,读取记录数目多于表记录数的40%的查询应该使用全表扫描。
2)对于未排序的表 仅读取少于表记录数7%的查询应该使用索引范围扫描。反之,读取记录数目多于表记录数的7%的查询应该使用全表扫描。
4 总结
以上的招式,是完全可以相互结合同时运用的。而且各种方法之间相互影响,紧密联系。这种联系既存在一致性,也可能带来冲突,当冲突发生时,需要根据实际情况进行选择,没有固定的模式。最后决定SQL优化功力的因素就是对ORACLE内功的掌握程度了。
另外,值得注意的是:随着时间的推移和数据的累计与变化,ORACLE对SQL语句的执行计划也会改变,比如:基于代价的优化方法,随着数据量的增大,优 化器可能错误的不选择索引而采用全表扫描。这种情况可能是因为统计信息已经过时,在数据量变化很大后没有及时分析表;但如果对表进行分析之后,仍然没有用 上合理的索引,那么就有必要对SQL语句用HINT提示,强制用合理的索引。但这种HINT提示也不能滥用,因为这种方法过于复杂,缺乏通用性和应变能 力,同时也增加了维护上的代价;相对来说,基于函数右移、去掉“IN ,OR ,<> ,IS NOT NULL ”、分解复杂的SQL语句等等方法,却是“放之四海皆准”的,可以放心大胆的使用。
同时,优化也不是“一劳永逸”的,必须随着情况的改变进行相应的调整。当数据库设计发生变化,包括更改表结构:字段和索引的增加、删除或改名等;业务逻辑发生变化:如查询方式、取值范围发生改变等等。在这种情况下,也必须对原有的优化进行调整,以适应效率上的需求。
1 什么是单点登陆
单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。
较大的企业内部,一般都有很多的业务支持系统为其提供相应的管理和IT服务。例如财务系统为财务人员提供财务的管理、计算和报表服务;人事系统为人事部门 提供全公司人员的维护服务;各种业务系统为公司内部不同的业务提供不同的服务等等。这些系统的目的都是让
计算机来进行复杂繁琐的计算工作,来替代人力的手 工劳动,提高工作效率和质量。这些不同的系统往往是在不同的时期建设起来的,运行在不同的平台上;也许是由不同厂商开发,使用了各种不同的技术和标准。如 果举例说国内一著名的IT公司(名字隐去),内部共有60多个业务系统,这些系统包括两个不同版本的SAP的ERP系统,12个不同类型和版本的数据库系 统,8个不同类型和版本的操作系统,以及使用了3种不同的防火墙技术,还有数十种互相不能兼容的协议和标准,你相信吗?不要怀疑,这种情况其实非常普遍。 每一个应用系统在运行了数年以后,都会成为不可替换的企业IT架构的一部分,如下图所示。

随着企业的发展,业务系统的数量在不断的增加,老的系统却不能轻易的替换,这会带来很多的开销。其一是管理上的开销,需要维护的系统越来越多。很多系统的 数据是相互冗余和重复的,数据的不一致性会给管理工作带来很大的压力。业务和业务之间的相关性也越来越大,例如公司的计费系统和财务系统,财务系统和人事 系统之间都不可避免的有着密切的关系。
为了降低管理的消耗,最大限度的重用已有投资的系统,很多企业都在进行着企业应用集成(EAI)。企业应用集成可以在不同层面上进行:例如在数据存储层面 上的“数据大集中”,在传输层面上的“通用数据交换平台”,在应用层面上的“业务流程整合”,和用户界面上的“通用企业门户”等等。事实上,还用一个层面 上的集成变得越来越重要,那就是“身份认证”的整合,也就是“单点登录”。
通常来说,每个单独的系统都会有自己的安全体系和身份认证系统。整合以前,进入每个系统都需要进行登录,这样的局面不仅给管理上带来了很大的困难,在安全方面也埋下了重大的隐患。下面是一些著名的调查公司显示的统计数据:
- 用户每天平均16分钟花在身份验证任务上 - 资料来源:IDS
- 频繁的IT用户平均有21个密码 - 资料来源:NTA Monitor Password Survey
- 49%的人写下了其密码,而67%的人很少改变它们
- 每79秒出现一起身份被窃事件 - 资料来源:National Small Business Travel Assoc
- 全球欺骗损失每年约12B - 资料来源:Comm Fraud Control Assoc
- 到2007年,身份管理市场将成倍增长至$4.5B - 资料来源:IDS
使用“单点登录”整合后,只需要登录一次就可以进入多个系统,而不需要重新登录,这不仅仅带来了更好的用户体验,更重要的是降低了安全的风险和管理的消耗。请看下面的统计数据:
- 提高IT效率:对于每1000个受管用户,每用户可节省$70K
- 帮助台呼叫减少至少1/3,对于10K员工的公司,每年可以节省每用户$75,或者合计$648K
- 生产力提高:每个新员工可节省$1K,每个老员工可节省$350 - 资料来源:Giga
- ROI回报:7.5到13个月 - 资料来源:Gartner
另外,使用“单点登录”还是
SOA时代的需求之一。在面向服务的架构中,服务和服务之间,程序和程序之间的通讯大量存在,服务之间的安全认证是SOA应用的难点之一,应此建立“单点登录”的系统体系能够大大简化SOA的安全问题,提高服务之间的合作效率。
2 单点登陆的技术实现机制 随着SSO技术的流行,SSO的产品也是满天飞扬。所有著名的软件厂商都提供了相应的解决方案。在这里我并不想介绍自己公司(
SunMicrosystems)的产品,而是对SSO技术本身进行解析,并且提供自己开发这一类产品的方法和简单演示。有关我写这篇文章的目的,请参考我的博 客(
http://yuwang881.blog.sohu.com/3184816.html)。
单点登录的机制其实是比较简单的,用一个现实中的例子做比较。颐和园是北京著名的旅游景点,也是我常去的地方。在颐和园内部有许多独立的景点,例如“苏州 街”、“佛香阁”和“德和园”,都可以在各个景点门口单独买票。很多游客需要游玩所有德景点,这种买票方式很不方便,需要在每个景点门口排队买票,钱包拿 进拿出的,容易丢失,很不安全。于是绝大多数游客选择在大门口买一张通票(也叫套票),就可以玩遍所有的景点而不需要重新再买票。他们只需要在每个景点门 口出示一下刚才买的套票就能够被允许进入每个独立的景点。
单点登录的机制也一样,如下图所示,当用户第一次访问应用系统1的时候,因为还没有登录,会被引导到认证系统中进行登录(1);根据用户提供的登录信息, 认证系统进行身份效验,如果通过效验,应该返回给用户一个认证的凭据--ticket(2);用户再访问别的应用的时候(3,5)就会将这个ticket 带上,作为自己认证的凭据,应用系统接受到请求之后会把ticket送到认证系统进行效验,检查ticket的合法性(4,6)。如果通过效验,用户就可 以在不用再次登录的情况下访问应用系统2和应用系统3了。

从上面的视图可以看出,要实现SSO,需要以下主要的功能:
- 所有应用系统共享一个身份认证系统。
统一的认证系统是SSO的前提之一。认证系统的主要功能是将用户的登录信息和用户信息库相比较,对用户进行登录认证;认证成功后,认证系统应该生成统一的认证标志(ticket),返还给用户。另外,认证系统还应该对ticket进行效验,判断其有效性。
- 所有应用系统能够识别和提取ticket信息
要实现SSO的功能,让用户只登录一次,就必须让应用系统能够识别已经登录过的用户。应用系统应该能对ticket进行识别和提取,通过与认证系统的通讯,能自动判断当前用户是否登录过,从而完成单点登录的功能。
上面的功能只是一个非常简单的SSO架构,在现实情况下的SSO有着更加复杂的结构。有两点需要指出的是:
- 单一的用户信息数据库并不是必须的,有许多系统不能将所有的用户信息都集中存储,应该允许用户信息放置在不同的存储中,如下图所示。事实上,只要统一认证系统,统一ticket的产生和效验,无论用户信息存储在什么地方,都能实现单点登录。

- 统一的认证系统并不是说只有单个的认证服务器,如下图所示,整个系统可以存在两个以上的认证服务器,这些服务器甚至可以是不同的产品。认证服务器 之间要通过标准的通讯协议,互相交换认证信息,就能完成更高级别的单点登录。如下图,当用户在访问应用系统1时,由第一个认证服务器进行认证后,得到由此 服务器产生的ticket。当他访问应用系统4的时候,认证服务器2能够识别此ticket是由第一个服务器产生的,通过认证服务器之间标准的通讯协议 (例如SAML)来交换认证信息,仍然能够完成SSO的功能。
 3 WEB-SSO的实现
3 WEB-SSO的实现 随着互联网的高速发展,
WEB应用几乎统治了绝大部分的软件应用系统,因此WEB-SSO是SSO应用当中最为流行。WEB-SSO有其自身的特点和优 势,实现起来比较简单易用。很多商业软件和
开源软件都有对WEB-SSO的实现。其中值得一提的是OpenSSO (
https://opensso.dev.java.net),为用
Java实现WEB-SSO提供架构指南和服务指南,为用户自己来实现WEB-SSO提供了理论的依据和实现的方法。
为什么说WEB-SSO比较容易实现呢?这是有WEB应用自身的特点决定的。
众所周知,Web协议(也就是HTTP)是一个无状态的协议。一个Web应用由很多个Web页面组成,每个页面都有唯一的URL来定义。用户在浏览器的地 址栏输入页面的URL,浏览器就会向Web
Server去发送请求。如下图,浏览器向Web服务器发送了两个请求,申请了两个页面。这两个页面的请求是分别使用了两个单独的HTTP连接。所谓无状 态的协议也就是表现在这里,浏览器和Web服务器会在第一个请求完成以后关闭连接通道,在第二个请求的时候重新建立连接。Web服务器并不区分哪个请求来 自哪个客户端,对所有的请求都一视同仁,都是单独的连接。这样的方式大大区别于传统的(Client/Server)C/S结构,在那样的应用中,客户端 和服务器端会建立一个长时间的专用的连接通道。正是因为有了无状态的特性,每个连接资源能够很快被
其他客户端所重用,一台Web服务器才能够同时服务于成 千上万的客户端。

但是我们通常的应用是有状态的。先不用提不同应用之间的SSO,在同一个应用中也需要保存用户的登录身份信息。例如用户在访问页面1的时候进行了登录,但 是刚才也提到,客户端的每个请求都是单独的连接,当客户再次访问页面2的时候,如何才能告诉Web服务器,客户刚才已经登录过了呢?浏览器和服务器之间有 约定:通过使用cookie技术来维护应用的状态。Cookie是可以被Web服务器设置的字符串,并且可以保存在浏览器中。如下图所示,当浏览器访问了 页面1时,web服务器设置了一个cookie,并将这个cookie和页面1一起返回给浏览器,浏览器接到cookie之后,就会保存起来,在它访问页 面2的时候会把这个cookie也带上,Web服务器接到请求时也能读出cookie的值,根据cookie值的内容就可以判断和恢复一些用户的信息状 态。

Web-SSO完全可以利用Cookie结束来完成用户登录信息的保存,将浏览器中的Cookie和上文中的Ticket结合起来,完成SSO的功能。
为了完成一个简单的SSO的功能,需要两个部分的合作:
- 统一的身份认证服务。
- 修改Web应用,使得每个应用都通过这个统一的认证服务来进行身份效验。
3.1 Web SSO 的样例 根据上面的原理,我用
J2EE的技术(
JSP和Servlet)完成了一个具有Web-SSO的简单样例。样例包含一个身份认证的服务器和两个简单的 Web应用,使得这两个 Web应用通过统一的身份认证服务来完成Web-SSO的功能。此样例所有的源代码和二进制代码都可以从网站地址
http://gceclub.sun.com.cn/wangyu/下载。
样例下载、安装部署和运行指南:
- Web-SSO的样例是由三个标准Web应用组成,压缩成三个zip文件,从http://gceclub.sun.com.cn/wangyu/web-sso/中下载。其中SSOAuth(http://gceclub.sun.com.cn/wangyu/web-sso/SSOAuth.zip)是身份认证服务;SSOWebDemo1(http://gceclub.sun.com.cn/wangyu/web-sso/SSOWebDemo1.zip)和SSOWebDemo2(http://gceclub.sun.com.cn/wangyu/web-sso/SSOWebDemo2.zip) 是两个用来演示单点登录的Web应用。这三个Web应用之所以没有打成war包,是因为它们不能直接部署,根据读者的部署环境需要作出小小的修改。样例部 署和运行的环境有一定的要求,需要符合Servlet2.3以上标准的J2EE容器才能运行(例如Tomcat5,Sun Application Server 8, Jboss 4等)。另外,身份认证服务需要JDK1.5的运行环境。之所以要用JDK1.5是因为笔者使用了一个线程安全的高性能的Java集合类 “ConcurrentMap”,只有在JDK1.5中才有。
- 这三个Web应用完全可以单独部署,它们可以分别部署在 不同的机器,不同的操作系统和不同的J2EE的产品上,它们完全是标准的和平台无关的应用。但是有一个限制,那两台部署应用(demo1、demo2)的 机器的域名需要相同,这在后面的章节中会解释到cookie和domain的关系以及如何制作跨域的WEB-SSO
解压缩SSOAuth.zip文件,在/WEB-INF/下的web.xml中请修改“domainname”的属性以反映实际的应用部署情况, domainname需要设置为两个单点登录的应用(demo1和demo2)所属的域名。这个domainname和当前SSOAuth服务部署的机器 的域名没有关系。我缺省设置的是“.sun.com”。如果你部署demo1和demo2的机器没有域名,请输入IP地址或主机名(如 localhost),但是如果使用IP地址或主机名也就意味着demo1和demo2需要部署到一台机器上了。设置完后,根据你所选择的J2EE容器, 可能需要将SSOAuth这个目录压缩打包成war文件。用“jar -cvf SSOAuth.war SSOAuth/”就可以完成这个功能。
- 解压缩SSOWebDemo1和SSOWebDemo2文件,分别在它们/WEB-INF/下找到web.xml文件,请修改其中的几个初始化参数
<init-param>
<param-name>SSOServiceURL</param-name>
<param-value>http://wangyu.prc.sun.com:8080/SSOAuth/SSOAuth</param-value>
</init-param>
<init-param>
<param-name>SSOLoginPage</param-name>
<param-value>http://wangyu.prc.sun.com:8080/SSOAuth/login.jsp</param-value>
</init-param>
- 将其中的SSOServiceURL和SSOLoginPage修改成部署SSOAuth应用的机器名、端口号以及根路径(缺省是 SSOAuth)以反映实际的部署情况。设置完后,根据你所选择的J2EE容器,可能需要将SSOWebDemo1和SSOWebDemo2这两个目录压 缩打包成两个war文件。用“jar -cvf SSOWebDemo1.war SSOWebDemo1/”就可以完成这个功能。
- 请输入第一个web应用的测试URL(test.jsp),例如http://wangyu.prc.sun.com:8080/SSOWebDemo1/test.jsp,如果是第一次访问,便会自动跳转到登录界面,如下图。

- 使用系统自带的三个帐号之一登录(例如,用户名:wangyu,密码:wangyu),便能成功的看到test.jsp的内容:显示当前用户名和欢迎信息。

- 请接着在同一个浏览器中输入第二个web应用的测试URL(test.jsp),例如http://wangyu.prc.sun.com:8080/SSOWebDemo2/test.jsp。你会发现,不需要再次登录就能看到test.jsp的内容,同样是显示当前用户名和欢迎信息,而且欢迎信息中明确的显示当前的应用名称(demo2)。
 3.2 WEB-SSO代码讲解 3.2.1身份认证服务代码解析
3.2 WEB-SSO代码讲解 3.2.1身份认证服务代码解析 Web-SSO的源代码可以从网站地址
http://gceclub.sun.com.cn/wangyu/web-sso/websso_src.zip下 载。身份认证服务是一个标准的web应用,包括一个名为SSOAuth的Servlet,一个login.jsp文件和一个failed.html。身份 认证的所有服务几乎都由SSOAuth的Servlet来实现了;login.jsp用来显示登录的页面(如果发现用户还没有登录过); failed.html是用来显示登录失败的信息(如果用户的用户名和密码与信息数据库中的不一样)。
SSOAuth的代码如下面的列表显示,结构非常简单,先看看这个Servlet的主体部分:
package DesktopSSO;
import java.io.*;
import java.net.*;
import java.text.*;
import java.util.*;
import java.util.concurrent.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class SSOAuth extends HttpServlet {
static private ConcurrentMap accounts;
static private ConcurrentMap SSOIDs;
String cookiename="WangYuDesktopSSOID";
String domainname;
public void init(ServletConfig config) throws ServletException {
super.init(config);
domainname= config.getInitParameter("domainname");
cookiename = config.getInitParameter("cookiename");
SSOIDs = new ConcurrentHashMap();
accounts=new ConcurrentHashMap();
accounts.put("wangyu", "wangyu");
accounts.put("paul", "paul");
accounts.put("carol", "carol");
}
protected void processRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
PrintWriter ut = response.getWriter();
String action = request.getParameter("action");
String result="failed";
if (action==null) {
handlerFromLogin(request,response);
} else if (action.equals("authcookie")){
String myCookie = request.getParameter("cookiename");
if (myCookie != null) result = authCookie(myCookie);
out.print(result);
out.close();
} else if (action.equals("authuser")) {
result=authNameAndPasswd(request,response);
out.print(result);
out.close();
} else if (action.equals("logout")) {
String myCookie = request.getParameter("cookiename");
logout(myCookie);
out.close();
}
}
.....
}
从代码很容易看出,SSOAuth就是一个简单的Servlet。其中有两个静态成员变量:accounts和SSOIDs,这两个成员变量都使用了 JDK1.5中线程安全的MAP类: ConcurrentMap,所以这个样例一定要JDK1.5才能运行。Accounts用来存放用户的用户名和密码,在init()的方法中可以看到我 给系统添加了三个合法的用户。在实际应用中,accounts应该是去数据库中或LDAP中获得,为了简单起见,在本样例中我使用了 ConcurrentMap在内存中用程序创建了三个用户。而SSOIDs保存了在用户成功的登录后所产生的cookie和用户名的对应关系。它的功能显 而易见:当用户成功登录以后,再次访问别的系统,为了鉴别这个用户请求所带的cookie的有效性,需要到SSOIDs中检查这样的映射关系是否存在。
在主要的请求处理方法processRequest()中,可以很清楚的看到SSOAuth的所有功能。
- 如果用户还没有登录过,是第一次登录本系统,会被跳转到login.jsp页面(在后面会解释如何跳转)。用户在提供了用户名和密码以后,就会用handlerFromLogin()这个方法来验证。
- 如果用户已经登录过本系统,再访问别的应用的时候,是不需要再次登录的。因为浏览器会将第一次登录时产生的cookie和请求一起发送。效验cookie的有效性是SSOAuth的主要功能之一。
- SSOAuth还能直接效验非login.jsp页面过来的用户名和密码的效验请求。这个功能是用于非web应用的SSO,这在后面的桌面SSO中会用到。
- SSOAuth还提供logout服务。
下面看看几个主要的功能函数:
private void handlerFromLogin(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String username = request.getParameter("username");
String password = request.getParameter("password");
String pass = (String)accounts.get(username);
if ((pass==null)||(!pass.equals(password)))
getServletContext().getRequestDispatcher("/failed.html").forward(request, response);
else {
String gotoURL = request.getParameter("goto");
String newID = createUID();
SSOIDs.put(newID, username);
Cookie wangyu = new Cookie(cookiename, newID);
wangyu.setDomain(domainname);
wangyu.setMaxAge(60000);
wangyu.setValue(newID);
wangyu.setPath("/");
response.addCookie(wangyu);
System.out.println("login success, goto back url:" + gotoURL);
if (gotoURL != null) {
PrintWriter ut = response.getWriter();
response.sendRedirect(gotoURL);
out.close();
}
}
}
handlerFromLogin()这个方法是用来处理来自login.jsp的登录请求。它的逻辑很简单:将用户输入的用户名和密码与预先设定好的用 户集合(存放在accounts中)相比较,如果用户名或密码不匹配的话,则返回登录失败的页面(failed.html),如果登录成功的话,需要为用 户当前的session创建一个新的ID,并将这个ID和用户名的映射关系存放到SSOIDs中,最后还要将这个ID设置为浏览器能够保存的cookie 值。
登录成功后,浏览器会到哪个页面呢?那我们回顾一下我们是如何使用身份认证服务的。一般来说我们不会直接访问身份服务的任何URL,包括 login.jsp。身份服务是用来保护其他应用服务的,用户一般在访问一个受SSOAuth保护的Web应用的某个URL时,当前这个应用会发现当前的 用户还没有登录,便强制将也页面转向SSOAuth的login.jsp,让用户登录。如果登录成功后,应该自动的将用户的浏览器指向用户最初想访问的那 个URL。在handlerFromLogin()这个方法中,我们通过接收“goto”这个参数来保存用户最初访问的URL,成功后便重新定向到这个页 面中。
另外一个要说明的是,在设置cookie的时候,我使用了一个setMaxAge(6000)的方法。这个方法是用来设置cookie的有效期,单位是 秒。如果不使用这个方法或者参数为负数的话,当浏览器关闭的时候,这个cookie就失效了。在这里我给了很大的值(1000分钟),导致的行为是:当你 关闭浏览器(或者关机),下次再打开浏览器访问刚才的应用,只要在1000分钟之内,就不需要再登录了。我这样做是下面要介绍的桌面SSO中所需要的功 能。
其他的方法更加简单,这里就不多解释了。
3.2.2具有SSO功能的web应用源代码解析 要实现WEB-SSO的功能,只有身份认证服务是不够的。这点很显然,要想使多个应用具有单点登录的功能,还需要每个应用本身的配合:将自己的身份认证的 服务交给一个统一的身份认证服务-SSOAuth。SSOAuth服务中提供的各个方法就是供每个加入SSO的Web应用来调用的。
再转载点内容:
昨天和几位朋友探讨到了这个话题,发现虽然单点登录,或者叫做独立的passport登录虽然已经有了很多实现方法,但是能真正了解并实现的人却并不太多,所以些下此文,希望从原理到实现,能让大家了解的多一些
至于什么是单点登录,举个例子,如果你登录了msn messenger,访问hotmail邮件就不用在此登录。
一般单点登录都需要有一个独立的登录站点,一般具有独立的域名,专门的进行注册,登录,注销等操作
我们为了讨论方便,把这个登录站点叫做站点P,设其Url为http://passport.yizhu2000.com,需要提供服务的站点设为A和B,跨站点单点登录是指你在A网站进行登录后,使用B网站的服务就不需要再登录
从技术角度讲单点登录分为:
跨子域单点登录
所谓跨子域登录,A,B站点和P站点位于同一个域下面,比如A站点为http://blog.yizhu2000.com B站点为http://forum.yizhu2000.com,他们和登录站点P的关系可以看到,都是属于同一个父域,yizhu2000.com,不同的是子域不同,一个为blog,一个为forum,一个是passport
我们先看看最常用的非跨站点普通登录的情况,一般登录验证通过后,一般会将你的用户名和一些用户信息,通过某一密钥进行加密,写在本地,也就是一个加密的cookie,我们把这个cookie叫做--票(ticket)。
需要判断用户是否登录的页面,需要读取这个ticket,并从其中解密出用户信息,如果ticket不存在,或者无法解密,意味着用户没有登录,或者登录信息不正确,这时就要跳转到登录页面进行登录,在这里加密的作用有两个,一是防止用户信息被不怀好意者看到,二是保证ticket不会被伪造,后者其实更为重要,加密后,各个应用需要采用与加密同样的密钥进行解密,如果不知道密钥,就不能伪造出ticket,
(注:加密和解密的密钥有可能不同,取决于采用什么加密算法,如果是对称加密,则为同一密钥,如果是非对称,就不同了,一般用私钥加密,公钥解密,但是无论怎样,密钥都只有内部知道,这样伪造者既无法伪造也无法解密ticket)
跨子域的单点登录,和上述普通登录的过程没有什么不同,唯一不同的是写cookie时,由于登录站点P和应用A处于不同的子域,P站写入的cookie的域为passport.yizhu2000.net,而A站点为forum.yizhu2000.net,A在判断用户登录时无法读到P站点的ticket
解决方法非常简单,当Login完成后P站点写ticket的时候,只需把cookie的域设为他们共同的父域,yizhu2000.net就可以了:cookie.domain="yizhu2000.net",A站点自然就可以读到这个ticket了
ASP。Net的form验证本身实现了这个机制,大家可以参考http://blog.csdn.net/octverve/archive/2007/09/22/1796338.aspx
ASP.NET身份验证信息跨域共享状态
在ASP.NET 2.0 中只需修改web.config文件即可,修改方法如下:
<authentication mode="Forms">
<forms name=".ASPNETFORM" domain="imneio.com" loginUrl="/login.aspx" defaultUrl="/default.aspx" protection="All" timeout="30" path="/" requireSSL="false" slidingExpiration="true" enableCrossAppRedirects="false" cookieless="UseDeviceProfile" />
</authentication>
domain指定了cookie保存的域,只要保存的是 abc.com形式或者.abc.com的形式,那么其二级域名都可以共享此cookie。
此外,web.config标签中的<sessionState >也做相应修改,mode改为StateServer或者SqlServer,那么里面的session信息也就全部可以共享了。
StateServer需要在服务中开启“asp.net状态服务”的服务。
http://www.imneio.com/2007/11/17/aspnetnote1/,以上斜体内容摘自此链接
完全跨单点域登录
完全跨域登录,是指A,B站点和P站点没有共同的父域,比如A站点为forum.yizhu1999.net,B站点为blog.yizhu1998.net,大家可以参考微软旗下的几个站点http://www.live.com,www.hotmail.com,这两个站点就没有共同的父域,而仍然可以共用登录,怎样才能实现呢?请参考下图,由于这种情况ticket比较复杂,我们暂时把P站点创建的的ticket叫做P-ticket,而A站点创建的ticket叫A-ticket,B的为B-ticket
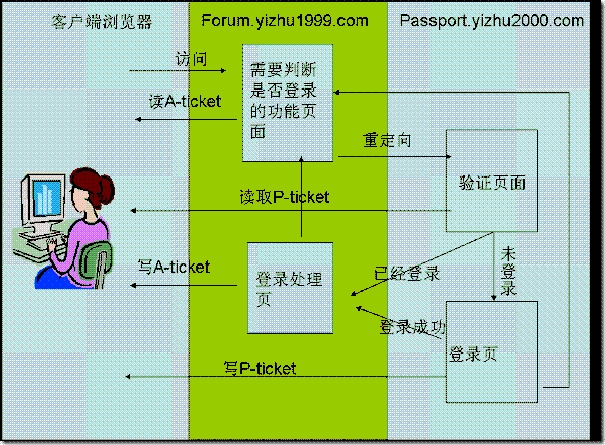
由于站点A(forum.yizhu1999.com)不能读取到由站点P(passport.yizhu2000.com)创建的加密ticket,所以当用户访问A站点上需要登录才能访问的资源时,A站点会首先查看是否有A-ticket,如果没有,证明用户没有在A站点登录过,不过并不保证用户没有在B站点登录,(重复一下,既然是单点登录,当然无论你在A,B任意一个站点登录过,另外一个站点都要可以访问),请求会被重定向到p站点的验证页面,验证页面读取P-ticket,如果没有,或者解密不成功,就需要重定向登录页面,登录页面完成登录后,写一个加密cookie,也就是P-ticket,并且重定向到A站点的登录处理页,并把加密的用户信息作为参数传递给这个页面,这个页面接收登录页的用户信息,解密后也要写一个cookie,也就是A-ticket,今后用户再次访问A站点上需要登录权限才能访问的资源时,只需要检查这个A-cookie是否存在就可以了
当用户访问B站点时,会重复上面的过程,监测到没有B-ticket,就会重定向到P站点的验证页面,去检查P-ticket,如果没有,就登录,有则返回B的登录处理页面写B-ticket
注销的时候需要删除P-ticket和A-ticket
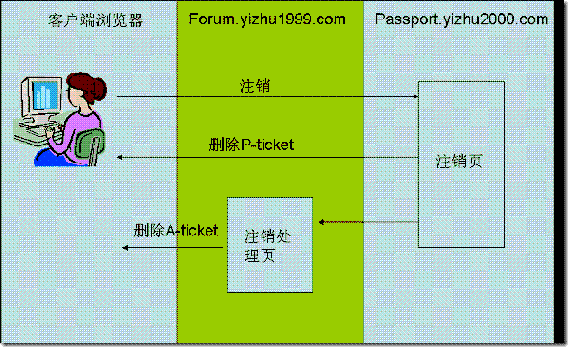
怎么删除cookie:本来以为这个不是问题,不过还是有朋友问道,简单的说其实是创建一个和你要删除的cookie同名的cookie,并把cookie的expire设为当前时间之前的某个时间,不过在跨子域的删除cookie时有一点要注意:必须要把cookie的域设置为父域,在本文中为yizhu2000.com
为了保证各个环节的传输的安全性,最好使用https连接
很多人对二级缓存都不太了解,或者是有错误的认识,我一直想写一篇文章介绍一下hibernate的二级缓存的,今天终于忍不住了。
我的经验主要来自hibernate2.1版本,基本原理和3.0、3.1是一样的,请原谅我的顽固不化。
hibernate的session提供了一级缓存,每个session,对同一个id进行两次load,不会发送两条sql给数据库,但是session关闭的时候,一级缓存就失效了。
二级缓存是SessionFactory级别的全局缓存,它底下可以使用不同的缓存类库,比如ehcache、oscache等,需要设置hibernate.cache.provider_class,我们这里用ehcache,在2.1中就是
hibernate.cache.provider_class=net.sf.hibernate.cache.EhCacheProvider
如果使用查询缓存,加上
hibernate.cache.use_query_cache=true
缓存可以简单的看成一个Map,通过key在缓存里面找value。
Class的缓存
对于一条记录,也就是一个PO来说,是根据ID来找的,缓存的key就是ID,value是POJO。无论list,load还是 iterate,只要读出一个对象,都会填充缓存。但是list不会使用缓存,而iterate会先取数据库select id出来,然后一个id一个id的load,如果在缓存里面有,就从缓存取,没有的话就去数据库load。假设是读写缓存,需要设置:
<cache usage="read-write"/>
如果你使用的二级缓存实现是ehcache的话,需要配置ehcache.xml
<cache name="com.xxx.pojo.Foo" maxElementsInMemory="500" eternal="false" timeToLiveSeconds="7200" timeToIdleSeconds="3600" overflowToDisk="true" />
其中eternal表示缓存是不是永远不超时,timeToLiveSeconds是缓存中每个元素(这里也就是一个POJO)的超时时间,如果eternal="false",超过指定的时间,这个元素就被移走了。timeToIdleSeconds是发呆时间,是可选的。当往缓存里面put 的元素超过500个时,如果overflowToDisk="true",就会把缓存中的部分数据保存在硬盘上的临时文件里面。
每个需要缓存的class都要这样配置。如果你没有配置,hibernate会在启动的时候警告你,然后使用defaultCache的配置,这样多个class会共享一个配置。
当某个ID通过hibernate修改时,hibernate会知道,于是移除缓存。
这样大家可能会想,同样的查询条件,第一次先list,第二次再iterate,就可以使用到缓存了。实际上这是很难的,因为你无法判断什么时候是第一次,而且每次查询的条件通常是不一样的,假如数据库里面有100条记录,id从1到100,第一次list的时候出了前50个id,第二次 iterate的时候却查询到30至70号id,那么30-50是从缓存里面取的,51到70是从数据库取的,共发送1+20条sql。所以我一直认为 iterate没有什么用,总是会有1+N的问题。
(题外话:有说法说大型查询用list会把整个结果集装入内存,很慢,而iterate只select id比较好,但是大型查询总是要分页查的,谁也不会真的把整个结果集装进来,假如一页20条的话,iterate共需要执行21条语句,list虽然选择若干字段,比iterate第一条select id语句慢一些,但只有一条语句,不装入整个结果集hibernate还会根据数据库方言做优化,比如使用mysql的limit,整体看来应该还是 list快。)
如果想要对list或者iterate查询的结果缓存,就要用到查询缓存了
查询缓存
首先需要配置hibernate.cache.use_query_cache=true
如果用ehcache,配置ehcache.xml,注意hibernate3.0以后不是net.sf的包名了
<cache name="net.sf.hibernate.cache.StandardQueryCache"
maxElementsInMemory="50" eternal="false" timeToIdleSeconds="3600"
timeToLiveSeconds="7200" overflowToDisk="true"/>
<cache name="net.sf.hibernate.cache.UpdateTimestampsCache"
maxElementsInMemory="5000" eternal="true" overflowToDisk="true"/>
然后
query.setCacheable(true);//激活查询缓存
query.setCacheRegion("myCacheRegion");//指定要使用的cacheRegion,可选
第二行指定要使用的cacheRegion是myCacheRegion,即你可以给每个查询缓存做一个单独的配置,使用setCacheRegion来做这个指定,需要在ehcache.xml里面配置它:
<cache name="myCacheRegion" maxElementsInMemory="10" eternal="false" timeToIdleSeconds="3600" timeToLiveSeconds="7200" overflowToDisk="true" />
如果省略第二行,不设置cacheRegion的话,那么会使用上面提到的标准查询缓存的配置,也就是net.sf.hibernate.cache.StandardQueryCache
对于查询缓存来说,缓存的key是根据hql生成的sql,再加上参数,分页等信息(可以通过日志输出看到,不过它的输出不是很可读,最好改一下它的代码)。
比如hql:
from Cat c where c.name like ?
生成大致如下的sql:
select * from cat c where c.name like ?
参数是"tiger%",那么查询缓存的key*大约*是这样的字符串(我是凭记忆写的,并不精确,不过看了也该明白了):
select * from cat c where c.name like ? , parameter:tiger%
这样,保证了同样的查询、同样的参数等条件下具有一样的key。
现在说说缓存的value,如果是list方式的话,value在这里并不是整个结果集,而是查询出来的这一串ID。也就是说,不管是list方法还是iterate方法,第一次查询的时候,它们的查询方式很它们平时的方式是一样的,list执行一条sql,iterate执行1+N条,多出来的行为是它们填充了缓存。但是到同样条件第二次查询的时候,就都和iterate的行为一样了,根据缓存的key去缓存里面查到了value,value是一串id,然后在到class的缓存里面去一个一个的load出来。这样做是为了节约内存。
可以看出来,查询缓存需要打开相关类的class缓存。list和iterate方法第一次执行的时候,都是既填充查询缓存又填充class缓存的。
这里还有一个很容易被忽视的重要问题,即打开查询缓存以后,即使是list方法也可能遇到1+N的问题!相同条件第一次list的时候,因为查询缓存中找不到,不管class缓存是否存在数据,总是发送一条sql语句到数据库获取全部数据,然后填充查询缓存和class缓存。但是第二次执行的时候,问题就来了,如果你的class缓存的超时时间比较短,现在class缓存都超时了,但是查询缓存还在,那么list方法在获取id串以后,将会一个一个去数据库load!因此,class缓存的超时时间一定不能短于查询缓存设置的超时时间!如果还设置了发呆时间的话,保证class缓存的发呆时间也大于查询的缓存的生存时间。这里还有其他情况,比如class缓存被程序强制evict了,这种情况就请自己注意了。
另外,如果hql查询包含select字句,那么查询缓存里面的value就是整个结果集了。
当hibernate更新数据库的时候,它怎么知道更新哪些查询缓存呢?
hibernate在一个地方维护每个表的最后更新时间,其实也就是放在上面net.sf.hibernate.cache.UpdateTimestampsCache所指定的缓存配置里面。
当通过hibernate更新的时候,hibernate会知道这次更新影响了哪些表。然后它更新这些表的最后更新时间。每个缓存都有一个生成时间和这个缓存所查询的表,当hibernate查询一个缓存是否存在的时候,如果缓存存在,它还要取出缓存的生成时间和这个缓存所查询的表,然后去查找这些表的最后更新时间,如果有一个表在生成时间后更新过了,那么这个缓存是无效的。
可以看出,只要更新过一个表,那么凡是涉及到这个表的查询缓存就失效了,因此查询缓存的命中率可能会比较低。
Collection缓存
需要在hbm的collection里面设置
<cache usage="read-write"/>
假如class是Cat,collection叫children,那么ehcache里面配置
<cache name="com.xxx.pojo.Cat.children"
maxElementsInMemory="20" eternal="false" timeToIdleSeconds="3600" timeToLiveSeconds="7200"
overflowToDisk="true" />
Collection的缓存和前面查询缓存的list一样,也是只保持一串id,但它不会因为这个表更新过就失效,一个collection缓存仅在这个collection里面的元素有增删时才失效。
这样有一个问题,如果你的collection是根据某个字段排序的,当其中一个元素更新了该字段时,导致顺序改变时,collection缓存里面的顺序没有做更新。
缓存策略
只读缓存(read-only):没有什么好说的
读/写缓存(read-write):程序可能要的更新数据
不严格的读/写缓存(nonstrict-read-write):需要更新数据,但是两个事务更新同一条记录的可能性很小,性能比读写缓存好
事务缓存(transactional):缓存支持事务,发生异常的时候,缓存也能够回滚,只支持jta环境,这个我没有怎么研究过
读写缓存和不严格读写缓存在实现上的区别在于,读写缓存更新缓存的时候会把缓存里面的数据换成一个锁,其他事务如果去取相应的缓存数据,发现被锁住了,然后就直接取数据库查询。
在hibernate2.1的ehcache实现中,如果锁住部分缓存的事务发生了异常,那么缓存会一直被锁住,直到60秒后超时。
不严格读写缓存不锁定缓存中的数据。
使用二级缓存的前置条件
你的hibernate程序对数据库有独占的写访问权,其他的进程更新了数据库,hibernate是不可能知道的。你操作数据库必需直接通过 hibernate,如果你调用存储过程,或者自己使用jdbc更新数据库,hibernate也是不知道的。hibernate3.0的大批量更新和删除是不更新二级缓存的,但是据说3.1已经解决了这个问题。
这个限制相当的棘手,有时候hibernate做批量更新、删除很慢,但是你却不能自己写jdbc来优化,很郁闷吧。
SessionFactory也提供了移除缓存的方法,你一定要自己写一些JDBC的话,可以调用这些方法移除缓存,这些方法是:
void evict(Class persistentClass)
Evict all entries from the second-level cache.
void evict(Class persistentClass, Serializable id)
Evict an entry from the second-level cache.
void evictCollection(String roleName)
Evict all entries from the second-level cache.
void evictCollection(String roleName, Serializable id)
Evict an entry from the second-level cache.
void evictQueries()
Evict any query result sets cached in the default query cache region.
void evictQueries(String cacheRegion)
Evict any query result sets cached in the named query cache region.
不过我不建议这样做,因为这样很难维护。比如你现在用JDBC批量更新了某个表,有3个查询缓存会用到这个表,用evictQueries (String cacheRegion)移除了3个查询缓存,然后用evict(Class persistentClass)移除了class缓存,看上去好像完整了。不过哪天你添加了一个相关查询缓存,可能会忘记更新这里的移除代码。如果你的 jdbc代码到处都是,在你添加一个查询缓存的时候,还知道其他什么地方也要做相应的改动吗?
----------------------------------------------------
总结:
不要想当然的以为缓存一定能提高性能,仅仅在你能够驾驭它并且条件合适的情况下才是这样的。hibernate的二级缓存限制还是比较多的,不方便用jdbc可能会大大的降低更新性能。在不了解原理的情况下乱用,可能会有1+N的问题。不当的使用还可能导致读出脏数据。
如果受不了hibernate的诸多限制,那么还是自己在应用程序的层面上做缓存吧。
在越高的层面上做缓存,效果就会越好。就好像尽管磁盘有缓存,数据库还是要实现自己的缓存,尽管数据库有缓存,咱们的应用程序还是要做缓存。因为底层的缓存它并不知道高层要用这些数据干什么,只能做的比较通用,而高层可以有针对性的实现缓存,所以在更高的级别上做缓存,效果也要好些吧。
什么是Spring 的 IOC 容器呢 ? 可以说 BeanFactory 就是 我们看到的Spring IoC容器.
如何初始化 SPRING 的 IOC 容器 ?
一共三种方法 :
1 :

Resource resource =
new FileSystemResource("beans.xml");
BeanFactory factory =
new XmlBeanFactory(resource);
2:
ClassPathResource resource =
new ClassPathResource("beans.xml");
BeanFactory factory =
new XmlBeanFactory(resource);
3:

ApplicationContext context =
new ClassPathXmlApplicationContext(
new String[]
{"applicationContext.xml", "applicationContext-part2.xml"});
BeanFactory factory = (BeanFactory) context;
详细展开 :
一 :org.springframework.core.io包中主要是各样的Resource类

补充UML 知识 :
1:类名是斜体的表示是抽象类,正体的表示普通类
2 :

3 :

温昱说图org.springframework.core.io包中主要是各样的Resource类,Spring的
Resource 接口是为了提供更强的访问底层资源能力的抽象。相当巧妙的地方在于,为何AbstractResource的子类有的override了getFile()而有的没有?这是因为在AbstractResource的getFile()方法设计为抛出异常,如果子类没有重写此方法,说明子类不支持通过绝对路径查找资源的方式,而override的子类则提供自己的实现。这里通过类的层次设计,充分利用继承带来的优点,避免了大量的条件语句。
二 :关于 org.springframework.beans.factory 包 和 org.springframework.context 包:
1 :BeanFactory 是个接口,LifecycleBean 是个类它负责管理bean的生命周期,它实现了4个接口,并且有一个 BeanFactory 类型的变量 owningFactory

补充一下 上文 的 XmlBeanFactory 不是
org.springframework.beans.factory
包下面的 而是
org.springframework.beans.factory.xml
下面的
2 。 ApplicationContext 也是个接口,它继承的 ListableBeanFactory 接口 又 继承 BeanFactory 接口
public interface ApplicationContext extends ListableBeanFactory, HierarchicalBeanFactory, MessageSource, ApplicationEventPublisher, ResourcePatternResolver
{
 }
}
public interface ListableBeanFactory extends BeanFactory {
}
Spring的bean包支持通过编码方式管理和操作bean的基本功能,ApplicationContext则以Framework的方式提供BeanFactory的所有功能。使用
ApplicationContext,你可以让系统加载你的bean,例如:
在Servlet容器初始化ContextLoaderServlet时,通过ContextLoader类加载Spring Framework),而不是使用编码方式来加载。
ApplicationContext接口是context包的基础,位于org.springframework.context包里,提供了BeanFactory的所有功能。除此之外, ApplicationContext为了支持Framework的工作方式,提供了以下的功能:
l.MessageSource,提供了语言信息的国际化支持
2.提供资源(如URL和文件系统)的访问支持
3.为实现了ApplicationListener接口的bean提供了事件传播支持
4.为不同的应用环境提供不同的context,例如支持web应用的XmlWebApplicationContext类
导言
从 Spring 1.1.1 开始, EHCache 就作为一种通用缓存解决方案集成进 Spring 。
我将示范拦截器的例子,它能把方法返回的结果缓存起来。
利用 Spring IoC 配置 EHCache
在 Spring 里配置 EHCache 很简单。你只需一个 ehcache.xml 文件,该文件用于配置 EHCache :
|
<ehcache>
<!—设置缓存文件 .data 的创建路径。
如果该路径是 Java 系统参数,当前虚拟机会重新赋值。
下面的参数这样解释:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径 -->
<diskStore path="java.io.tmpdir"/>
<!—缺省缓存配置。CacheManager 会把这些配置应用到程序中。
下列属性是 defaultCache 必须的:
maxInMemory - 设定内存中创建对象的最大值。
eternal - 设置元素(译注:内存中对象)是否永久驻留。如果是,将忽略超
时限制且元素永不消亡。
timeToIdleSeconds - 设置某个元素消亡前的停顿时间。
也就是在一个元素消亡之前,两次访问时间的最大时间间隔值。
这只能在元素不是永久驻留时有效(译注:如果对象永恒不灭,则
设置该属性也无用)。
如果该值是 0 就意味着元素可以停顿无穷长的时间。
timeToLiveSeconds - 为元素设置消亡前的生存时间。
也就是一个元素从构建到消亡的最大时间间隔值。
这只能在元素不是永久驻留时有效。
overflowToDisk - 设置当内存中缓存达到 maxInMemory 限制时元素是否可写到磁盘
上。
-->
<cache name="org.taha.cache.METHOD_CACHE"
maxElementsInMemory="300"
eternal="false"
timeToIdleSeconds="500"
timeToLiveSeconds="500"
overflowToDisk="true"
/>
</ehcache>
|
拦截器将使用 ”org.taha.cache.METHOD_CACHE” 区域缓存方法返回结果。下面利用 Spring IoC 让 bean 来访问这一区域。
|
<!-- ====================== 缓存 ======================= -->
<bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean">
<property name="configLocation">
<value>classpath:ehcache.xml</value>
</property>
</bean>
<bean id="methodCache" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager">
<ref local="cacheManager"/>
</property>
<property name="cacheName">
<value>org.taha.cache.METHOD_CACHE</value>
</property>
</bean>
|
构建我们的 MethodCacheInterceptor
该拦截器实现 org.aopalliance.intercept.MethodInterceptor 接口。一旦 运行起来 (kicks-in) ,它首先检查被拦截方法是否被配置为可缓存的。这将可选择性的配置想要缓存的 bean 方法。只要调用的方法配置为可缓存,拦截器将为该方法生成 cache key 并检查该方法返回的结果是否已缓存。如果已缓存,就返回缓存的结果,否则再次调用被拦截方法,并缓存结果供下次调用。
org.taha.interceptor.MethodCacheInterceptor
|
/*
* Copyright 2002-2004 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.taha.interceptor;
import java.io.Serializable;
import org.aopalliance.intercept.MethodInterceptor;
import org.aopalliance.intercept.MethodInvocation;
import org.apache.commons.logging.LogFactory;
import org.apache.commons.logging.Log;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.util.Assert;
import net.sf.ehcache.Cache;
import net.sf.ehcache.Element;
/**
* @author <a href=" mailto:irbouh@gmail.com">OmarIrbouh</a>
* @since 2004.10.07
*/
public class MethodCacheInterceptor implements MethodInterceptor, InitializingBean {
private static final Log logger = LogFactory.getLog(MethodCacheInterceptor.class);
private Cache cache;
/**
* 设置缓存名
*/
public void setCache(Cache cache) {
this.cache = cache;
}
/**
* 检查是否提供必要参数。
*/
public void afterPropertiesSet() throws Exception {
Assert.notNull(cache, "A cache is required. Use setCache(Cache) to provide one.");
}
/**
* 主方法
* 如果某方法可被缓存就缓存其结果
* 方法结果必须是可序列化的(serializable)
*/
public Object invoke(MethodInvocation invocation) throws Throwable {
String targetName = invocation.getThis().getClass().getName();
String methodName = invocation.getMethod().getName();
Object[] arguments = invocation.getArguments();
Object result;
logger.debug("looking for method result in cache");
String cacheKey = getCacheKey(targetName, methodName, arguments);
Element element = cache.get(cacheKey);
if (element == null) {
//call target/sub-interceptor
logger.debug("calling intercepted method");
result = invocation.proceed();
//cache method result
logger.debug("caching result");
element = new Element(cacheKey, (Serializable) result);
cache.put(element);
}
return element.getValue();
}
/**
* creates cache key: targetName.methodName.argument0.argument1...
*/
private String getCacheKey(String targetName,
String methodName,
Object[] arguments) {
StringBuffer sb = new StringBuffer();
sb.append(targetName)
.append(".").append(methodName);
if ((arguments != null) && (arguments.length != 0)) {
for (int i=0; i<arguments.length; i++) {
sb.append(".")
.append(arguments[i]);
}
}
return sb.toString();
}
}
|
MethodCacheInterceptor 代码说明了:
-
默认条件下,所有方法返回结果都被缓存了( methodNames 是 null )
-
缓存区利用 IoC 形成
-
cacheKey 的生成还包括方法参数的因素(译注:参数的改变会影响 cacheKey )
使用 MethodCacheInterceptor
下面摘录了怎样配置 MethodCacheInterceptor :
|
<bean id="methodCacheInterceptor" class="org.taha.interceptor.MethodCacheInterceptor">
<property name="cache">
<ref local="methodCache" />
</property>
</bean>
<bean id="methodCachePointCut" class="org.springframework.aop.support.RegexpMethodPointcutAdvisor">
<property name="advice">
<ref local="methodCacheInterceptor"/>
</property>
<property name="patterns">
<list>
<value>.*methodOne</value>
<value>.*methodTwo</value>
</list>
</property>
</bean>
<bean id="myBean" class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target">
<bean class="org.taha.beans.MyBean"/>
</property>
<property name="interceptorNames">
<list>
<value>methodCachePointCut</value>
</list>
</property>
</bean>
|
译注
如果你要缓存的方法是 findXXX,那么正则表达式应该这样写:“.*find.*”。
夏昕所著《 Hibernate 开发指南》,其中他这样描述 EHCache 配置文件的:
<ehcache>
<diskStore path="java.io.tmpdir"/>
<defaultCache
maxElementsInMemory="10000" //Cache中最大允许保存的数据数量
eternal="false" //Cache中数据是否为常量
timeToIdleSeconds="120" //缓存数据钝化时间
timeToLiveSeconds="120" //缓存数据的生存时间
overflowToDisk="true" //内存不足时,是否启用磁盘缓存
/>
</ehcache> |
请注意!引用、转贴本文应注明原译者:Rosen Jiang 以及出处:http://www.blogjava.net/rosen
<!-- EHCache -->
< bean id ="cacheManager" class ="org.springframework.cache.ehcache.EhCacheManagerFactoryBean" >
< property name ="configLocation" >
< value > classpath:ehcache.xml </ value >
</ property >
</ bean >
< bean id ="methodCache" class ="org.springframework.cache.ehcache.EhCacheFactoryBean" >
< property name ="cacheManager" >
< ref local ="cacheManager" />
</ property >
< property name ="cacheName" >
< value > org.taha.cache.METHOD_CACHE </ value >
</ property >
</ bean >
< bean id ="methodCacheInterceptor" class ="com.cdmcs.util.MethodCacheInterceptor" >
< property name ="cache" >
< ref local ="methodCache" />
</ property >
</ bean >
< bean id ="cleanCacheAdvice" class ="com.cdmcs.util.CleanCacheAdvice" >
< property name ="cache" >
< ref local ="methodCache" />
</ property >
</ bean >
< bean id ="advicePointCut" class ="org.springframework.aop.support.RegexpMethodPointcutAdvisor" >
< property name ="advice" >
< ref local ="cleanCacheAdvice" />
</ property >
< property name ="patterns" >
< list >
< value > .*save.* </ value >
< value > .*update.* </ value >
< value > .*delete.* </ value >
< value > .*valid.* </ value >
</ list >
</ property >
</ bean >
< bean id ="methodCachePointCut" class ="org.springframework.aop.support.RegexpMethodPointcutAdvisor" >
< property name ="advice" >
< ref local ="methodCacheInterceptor" />
</ property >
< property name ="patterns" >
< list >
< value > .*find.* </ value >
</ list >
</ property >
</ bean >
<!-- EHCache End -->
< bean id ="supplyDemandService" parent ="baseTransactionProxy" >
< property name ="target" >
< bean class ="com.cdmcs.webbuilder.service.impl.SupplyDemandServiceImpl" autowire ="byName" />
</ property >
< property name ="preInterceptors" >
< list >
< ref bean ="methodCachePointCut" />
< ref bean ="advicePointCut" />
</ list >
</ property >
</ bean >
分享到:






相关推荐
JDK HashMap源码粗略分析 根据10个问题进行阅读探讨
Java HashMap原理分析 Java HashMap是一种基于哈希表的数据结构,它的存储原理是通过将Key-Value对存储在一个数组中,每个数组元素是一个链表,链表中的每个元素是一个Entry对象,Entry对象包含了Key、Value和指向...
hashMap存储分析hashMap存储分析
### HashMap部分源码分析 #### 一、HashMap数据结构 HashMap是一种非常常用的数据结构,在Java中,它提供了基于键值对存储数据的功能。其内部采用了数组加链表(或红黑树)的形式来存储数据。 - **数组**:提供...
HashMap 是 Java 中最常用的集合类之一,它是基于哈希表实现的,提供了高效的数据存取功能。HashMap 的核心原理是将键(key)通过哈希函数转化为数组索引,然后将键值对(key-value pair)存储在数组的对应位置。...
HashMap死循环原因分析 HashMap是Java中常用的数据结构,但是它在多线程环境下可能会出现死循环的问题,使CPU占用率达到100%。这种情况是如何产生的呢?下面我们将从源码中一步一步地分析这种情况是如何产生的。 ...
哈希映射(HashMap)是Java编程语言中广泛使用的数据结构之一,主要提供键值对的存储和查找功能。HashMap的实现基于哈希表的概念,它通过计算对象的哈希码来快速定位数据,从而实现了O(1)的平均时间复杂度。在深入...
面试中,可能会被问及HashMap的性能优化、内存占用分析、以及在特定场景下的选择,如并发环境、内存敏感的应用等。 总结,HashMap是Java编程中的基础工具,掌握其工作原理和常见面试题,不仅能帮助我们应对面试,更...
面试中,HashMap的源码分析与实现是一个常见的考察点,因为它涉及到数据结构、并发处理和性能优化等多个核心领域。本篇文章将深入探讨HashMap的内部工作原理、关键特性以及其在实际应用中的考量因素。 HashMap基于...
用过Java的都知道,里面有个功能强大的数据结构——HashMap,它能提供键与值的对应访问。不过熟悉JS的朋友也会说,JS里面到处都是hashmap,因为每个对象都提供了map[key]的访问形式。
HashMap导致CPU100% 的分析
hashmap的原理啊思想。
在Java编程语言中,`HashMap`和`HashTable`都是实现键值对存储的数据结构,但它们之间存在一些显著的区别,这些区别主要体现在线程安全性、性能、null值处理以及一些方法特性上。以下是对这两个类的详细分析: 1. ...
通过分析源码,开发者可以深入理解哈希表的工作原理,学习如何在易语言中实现高效的数据结构,这对于提升程序性能和优化内存管理至关重要。同时,这也为自定义数据结构或实现其他哈希表相关的功能提供了基础。
比较分析Vector、ArrayList和hashtable hashmap数据结构
hashMap基本工作原理,图解分析,基础Map集合
1.面试必考之HashMap源码分析与实现 伸缩性角度看HashMap的不足