
网站و•°وچ®ç»ںè®،هˆ†وگه·¥ه…·وک¯ç½‘站站é•؟ه’Œè؟گèگ¥ن؛؛ه‘کç»ڈه¸¸ن½؟用çڑ„ن¸€ç§چه·¥ه…·ï¼Œو¯”较ه¸¸ç”¨çڑ„وœ‰è°·وŒهˆ†وگم€پ百ه؛¦ç»ںè®،ه’Œè…¾è®¯هˆ†وگç‰ç‰م€‚و‰€وœ‰è؟™ن؛›ç»ںè®،هˆ†وگه·¥ه…·çڑ„第ن¸€و¥éƒ½وک¯ç½‘ç«™è®؟é—®و•°وچ®çڑ„و”¶é›†م€‚ç›®ه‰چن¸»وµپçڑ„و•°وچ®و”¶é›†و–¹ه¼ڈهں؛وœ¬éƒ½وک¯هں؛ن؛ژjavascriptçڑ„م€‚وœ¬و–‡ه°†ç®€è¦پهˆ†وگè؟™ç§چو•°وچ®و”¶é›†çڑ„هژںçگ†ï¼Œه¹¶ن¸€و¥ن¸€و¥ه®é™…وگه»؛ن¸€ن¸ھه®é™…çڑ„و•°وچ®و”¶é›†ç³»ç»ںم€‚
و•°وچ®و”¶é›†هژںçگ†هˆ†وگ
简هچ•و¥è¯´ï¼Œç½‘ç«™ç»ںè®،هˆ†وگه·¥ه…·éœ€è¦پو”¶é›†هˆ°ç”¨وˆ·وµڈ览目و ‡ç½‘ç«™çڑ„è،Œن¸؛(ه¦‚و‰“ه¼€وںگ网é،µم€پ点ه‡»وںگوŒ‰é’®م€په°†ه•†ه“پهٹ ه…¥è´ç‰©è½¦ç‰ï¼‰هڈٹè،Œن¸؛附هٹ و•°وچ®ï¼ˆه¦‚وںگن¸‹هچ•è،Œن¸؛ن؛§ç”ںçڑ„订هچ•é‡‘é¢ç‰ï¼‰م€‚و—©وœںçڑ„网站ç»ںè®،ه¾€ه¾€هڈھو”¶é›†ن¸€ç§چ用وˆ·è،Œن¸؛ï¼ڑé،µé¢çڑ„و‰“ه¼€م€‚而هگژ用وˆ·هœ¨é،µé¢ن¸çڑ„è،Œن¸؛ه‡و— و³•و”¶é›†م€‚è؟™ç§چو”¶é›†ç–略能و»،足هں؛وœ¬çڑ„وµپé‡ڈهˆ†وگم€پو¥و؛گهˆ†وگم€په†…ه®¹هˆ†وگهڈٹè®؟ه®¢ه±و€§ç‰ه¸¸ç”¨هˆ†وگ视角,ن½†وک¯ï¼Œéڑڈç€ajaxوٹ€وœ¯çڑ„ه¹؟و³›ن½؟用هڈٹ电هگه•†هٹ،网站ه¯¹ن؛ژ电هگه•†هٹ،ç›®و ‡çڑ„ç»ںè®،هˆ†وگçڑ„需و±‚è¶ٹو¥è¶ٹه¼؛烈,è؟™ç§چن¼ ç»ںçڑ„و”¶é›†ç–ç•¥ه·²ç»ڈوک¾ه¾—هٹ›ن¸چ能هڈٹم€‚
هگژو¥ï¼ŒGoogleهœ¨ه…¶ن؛§ه“پè°·وŒهˆ†وگن¸هˆ›و–°و€§çڑ„ه¼•ه…¥ن؛†هڈ¯ه®ڑهˆ¶çڑ„و•°وچ®و”¶é›†è„ڑوœ¬ï¼Œç”¨وˆ·é€ڑè؟‡è°·وŒهˆ†وگه®ڑن¹‰ه¥½çڑ„هڈ¯و‰©ه±•وژ¥هڈ£ï¼Œهڈھ需编ه†™ه°‘é‡ڈçڑ„javascriptن»£ç په°±هڈ¯ن»¥ه®çژ°è‡ھه®ڑن¹‰ن؛‹ن»¶ه’Œè‡ھه®ڑن¹‰وŒ‡و ‡çڑ„è·ںè¸ھه’Œهˆ†وگم€‚ç›®ه‰چ百ه؛¦ç»ںè®،م€پوگœç‹—هˆ†وگç‰ن؛§ه“په‡ç…§وگ¬ن؛†è°·وŒهˆ†وگçڑ„و¨،ه¼ڈم€‚
ه…¶ه®è¯´èµ·و¥ن¸¤ç§چو•°وچ®و”¶é›†و¨،ه¼ڈçڑ„هں؛وœ¬هژںçگ†ه’Œوµپ程وک¯ن¸€è‡´çڑ„,هڈھوک¯هگژن¸€ç§چé€ڑè؟‡javascriptو”¶é›†هˆ°ن؛†و›´ه¤ڑçڑ„ن؟،وپ¯م€‚ن¸‹é¢çœ‹ن¸€ن¸‹çژ°هœ¨هگ„ç§چ网站ç»ںè®،ه·¥ه…·çڑ„و•°وچ®و”¶é›†هں؛وœ¬هژںçگ†م€‚
وµپ程و¦‚览
首ه…ˆé€ڑè؟‡ن¸€ه¹…ه›¾و€»ن½“看ن¸€ن¸‹و•°وچ®و”¶é›†çڑ„هں؛وœ¬وµپ程م€‚
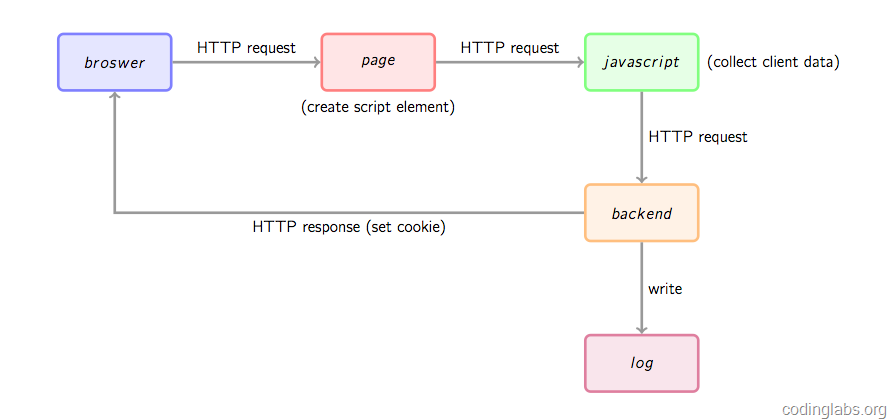
ه›¾1. 网站ç»ںè®،و•°وچ®و”¶é›†هں؛وœ¬وµپ程
首ه…ˆï¼Œç”¨وˆ·çڑ„è،Œن¸؛ن¼ڑ触هڈ‘وµڈ览ه™¨ه¯¹è¢«ç»ںè®،é،µé¢çڑ„ن¸€ن¸ھhttp请و±‚,è؟™é‡Œه§‘ن¸”ه…ˆè®¤ن¸؛è،Œن¸؛ه°±وک¯و‰“ه¼€ç½‘é،µم€‚ه½“网é،µè¢«و‰“ه¼€ï¼Œé،µé¢ن¸çڑ„هں‹ç‚¹javascript片و®µن¼ڑ被و‰§è،Œï¼Œç”¨è؟‡ç›¸ه…³ه·¥ه…·çڑ„وœ‹هڈ‹ه؛”该çں¥éپ“,ن¸€èˆ¬ç½‘ç«™ç»ںè®،ه·¥ه…·éƒ½ن¼ڑè¦پو±‚用وˆ·هœ¨ç½‘é،µن¸هٹ ه…¥ن¸€ه°ڈو®µjavascriptن»£ç پ,è؟™ن¸ھن»£ç پ片و®µن¸€èˆ¬ن¼ڑهٹ¨و€پهˆ›ه»؛ن¸€ن¸ھscriptو ‡ç¾ï¼Œه¹¶ه°†srcوŒ‡هگ‘ن¸€ن¸ھهچ•ç‹¬çڑ„jsو–‡ن»¶ï¼Œو¤و—¶è؟™ن¸ھهچ•ç‹¬çڑ„jsو–‡ن»¶ï¼ˆه›¾1ن¸ç»؟色èٹ‚点)ن¼ڑ被وµڈ览ه™¨è¯·و±‚هˆ°ه¹¶و‰§è،Œï¼Œè؟™ن¸ھjsه¾€ه¾€ه°±وک¯çœںو£çڑ„و•°وچ®و”¶é›†è„ڑوœ¬م€‚و•°وچ®و”¶é›†ه®Œوˆگهگژ,jsن¼ڑ请و±‚ن¸€ن¸ھهگژ端çڑ„و•°وچ®و”¶é›†è„ڑوœ¬ï¼ˆه›¾1ن¸çڑ„backend),è؟™ن¸ھè„ڑوœ¬ن¸€èˆ¬وک¯ن¸€ن¸ھن¼ھ装وˆگه›¾ç‰‡çڑ„هٹ¨و€پè„ڑوœ¬ç¨‹ه؛ڈ,هڈ¯èƒ½ç”±phpم€پpythonوˆ–ه…¶ه®ƒوœچهٹ،端è¯è¨€ç¼–ه†™ï¼Œjsن¼ڑه°†و”¶é›†هˆ°çڑ„و•°وچ®é€ڑè؟‡httpهڈ‚و•°çڑ„و–¹ه¼ڈن¼ 递给هگژ端è„ڑوœ¬ï¼Œهگژ端è„ڑوœ¬è§£وگهڈ‚و•°ه¹¶وŒ‰ه›؛ه®ڑو ¼ه¼ڈè®°ه½•هˆ°è®؟é—®و—¥ه؟—,هگŒو—¶هڈ¯èƒ½ن¼ڑهœ¨httpه“چه؛”ن¸ç»™ه®¢وˆ·ç«¯ç§چو¤چن¸€ن؛›ç”¨ن؛ژè؟½è¸ھçڑ„cookieم€‚
ن¸ٹé¢وک¯ن¸€ن¸ھو•°وچ®و”¶é›†çڑ„ه¤§و¦‚وµپ程,ن¸‹é¢ن»¥è°·وŒهˆ†وگن¸؛ن¾‹ï¼Œه¯¹و¯ڈن¸€ن¸ھéک¶و®µè؟›è،Œن¸€ن¸ھ相ه¯¹è¯¦ç»†çڑ„هˆ†وگم€‚
هں‹ç‚¹è„ڑوœ¬و‰§è،Œéک¶و®µ
è‹¥è¦پن½؟用谷وŒهˆ†وگ(ن»¥ن¸‹ç®€ç§°GA),需è¦پهœ¨é،µé¢ن¸وڈ’ه…¥ن¸€و®µه®ƒوڈگن¾›çڑ„javascript片و®µï¼Œè؟™ن¸ھ片و®µه¾€ه¾€è¢«ç§°ن¸؛هں‹ç‚¹ن»£ç پم€‚ن¸‹é¢وک¯وˆ‘çڑ„هچڑه®¢ن¸و‰€و”¾ç½®çڑ„è°·وŒهˆ†وگهں‹ç‚¹ن»£ç پوˆھه›¾ï¼ڑ

ه›¾2. è°·وŒهˆ†وگهں‹ç‚¹ن»£ç پ
ه…¶ن¸_gaqوک¯GAçڑ„çڑ„ه…¨ه±€و•°ç»„,用ن؛ژو”¾ç½®هگ„ç§چé…چ置,ه…¶ن¸و¯ڈن¸€و،é…چç½®çڑ„و ¼ه¼ڈن¸؛ï¼ڑ
_gaq.push(['Action','param1','param2',...]);
ActionوŒ‡ه®ڑé…چç½®هٹ¨ن½œï¼Œهگژé¢وک¯ç›¸ه…³çڑ„هڈ‚و•°هˆ—è،¨م€‚GAç»™çڑ„é»ک认هں‹ç‚¹ن»£ç پن¼ڑç»™ه‡؛ن¸¤و،预置é…چ置,_setAccount用ن؛ژ设置网站و ‡è¯†ID,è؟™ن¸ھو ‡è¯†IDوک¯هœ¨و³¨ه†ŒGAو—¶هˆ†é…چçڑ„م€‚_trackPageviewه‘ٹ诉GAè·ںè¸ھن¸€و¬،é،µé¢è®؟é—®م€‚و›´ه¤ڑé…چ置请هڈ‚考ï¼ڑhttps://developers.google.com/analytics/devguides/collection/gajs/م€‚ه®é™…ن¸ٹ,è؟™ن¸ھ_gaqوک¯è¢«ه½“هپڑن¸€ن¸ھFIFOéکںهˆ—و¥ç”¨çڑ„,é…چç½®ن»£ç پن¸چه؟…ه‡؛çژ°هœ¨هں‹ç‚¹ن»£ç پن¹‹ه‰چ,ه…·ن½“请هڈ‚考ن¸ٹè؟°é“¾وژ¥çڑ„说وکژم€‚
ه°±وœ¬و–‡و¥è¯´ï¼Œ_gaqçڑ„وœ؛هˆ¶ن¸چوک¯é‡چ点,é‡چ点وک¯هگژé¢هŒ؟هگچه‡½و•°çڑ„ن»£ç پ,è؟™و‰چوک¯هں‹ç‚¹ن»£ç پçœںو£è¦پهپڑçڑ„م€‚è؟™و®µن»£ç پçڑ„ن¸»è¦پç›®çڑ„ه°±وک¯ه¼•ه…¥ن¸€ن¸ھه¤–部çڑ„jsو–‡ن»¶ï¼ˆga.js),و–¹ه¼ڈوک¯é€ڑè؟‡document.createElementو–¹و³•هˆ›ه»؛ن¸€ن¸ھscriptه¹¶و ¹وچ®هچڈ议(httpوˆ–https)ه°†srcوŒ‡هگ‘ه¯¹ه؛”çڑ„ga.js,وœ€هگژه°†è؟™ن¸ھelementوڈ’ه…¥é،µé¢çڑ„domو ‘ن¸ٹم€‚
و³¨و„ڈga.async = trueçڑ„و„ڈو€وک¯ه¼‚و¥è°ƒç”¨ه¤–部jsو–‡ن»¶ï¼Œهچ³ن¸چéک»ه،وµڈ览ه™¨çڑ„解وگ,ه¾…ه¤–部jsن¸‹è½½ه®Œوˆگهگژه¼‚و¥و‰§è،Œم€‚è؟™ن¸ھه±و€§وک¯HTML5و–°ه¼•ه…¥çڑ„م€‚
و•°وچ®و”¶é›†è„ڑوœ¬و‰§è،Œéک¶و®µ
و•°وچ®و”¶é›†è„ڑوœ¬ï¼ˆga.js)被请و±‚هگژن¼ڑ被و‰§è،Œï¼Œè؟™ن¸ھè„ڑوœ¬ن¸€èˆ¬è¦پهپڑه¦‚ن¸‹ه‡ ن»¶ن؛‹ï¼ڑ
1م€پé€ڑè؟‡وµڈ览ه™¨ه†…ç½®javascriptه¯¹è±،و”¶é›†ن؟،وپ¯ï¼Œه¦‚é،µé¢title(é€ڑè؟‡document.title)م€پreferrer(ن¸ٹن¸€è·³url,é€ڑè؟‡document.referrer)م€پ用وˆ·وک¾ç¤؛ه™¨هˆ†è¾¨çژ‡ï¼ˆé€ڑè؟‡windows.screen)م€پcookieن؟،وپ¯ï¼ˆé€ڑè؟‡document.cookie)ç‰ç‰ن¸€ن؛›ن؟،وپ¯م€‚
2م€پ解وگ_gaqو”¶é›†é…چç½®ن؟،وپ¯م€‚è؟™é‡Œé¢هڈ¯èƒ½ن¼ڑهŒ…و‹¬ç”¨وˆ·è‡ھه®ڑن¹‰çڑ„ن؛‹ن»¶è·ںè¸ھم€پن¸ڑهٹ،و•°وچ®ï¼ˆه¦‚电هگه•†هٹ،网站çڑ„ه•†ه“پç¼–هڈ·ç‰ï¼‰ç‰م€‚
3م€په°†ن¸ٹé¢ن¸¤و¥و”¶é›†çڑ„و•°وچ®وŒ‰é¢„ه®ڑن¹‰و ¼ه¼ڈ解وگه¹¶و‹¼وژ¥م€‚
4م€پ请و±‚ن¸€ن¸ھهگژ端è„ڑوœ¬ï¼Œه°†ن؟،وپ¯و”¾هœ¨http requestهڈ‚و•°ن¸وگ؛ه¸¦ç»™هگژ端è„ڑوœ¬م€‚
è؟™é‡Œه”¯ن¸€çڑ„é—®é¢کوک¯و¥éھ¤4,javascript请و±‚هگژ端è„ڑوœ¬ه¸¸ç”¨çڑ„و–¹و³•وک¯ajax,ن½†وک¯ajaxوک¯ن¸چ能跨هںں请و±‚çڑ„م€‚è؟™é‡Œga.jsهœ¨è¢«ç»ںè®،网站çڑ„هںںه†…و‰§è،Œï¼Œè€Œهگژ端è„ڑوœ¬هœ¨هڈ¦ه¤–çڑ„هںں(GAçڑ„هگژ端ç»ںè®،è„ڑوœ¬وک¯http://www.google-analytics.com/__utm.gif),ajaxè،Œن¸چé€ڑم€‚ن¸€ç§چé€ڑ用çڑ„و–¹و³•وک¯jsè„ڑوœ¬هˆ›ه»؛ن¸€ن¸ھImageه¯¹è±،,ه°†Imageه¯¹è±،çڑ„srcه±و€§وŒ‡هگ‘هگژ端è„ڑوœ¬ه¹¶وگ؛ه¸¦هڈ‚و•°ï¼Œو¤و—¶هچ³ه®çژ°ن؛†è·¨هںں请و±‚هگژ端م€‚è؟™ن¹ںوک¯هگژ端è„ڑوœ¬ن¸؛ن»€ن¹ˆé€ڑه¸¸ن¼ھ装وˆگgifو–‡ن»¶çڑ„هژںه› م€‚é€ڑè؟‡httpوٹ“هŒ…هڈ¯ن»¥çœ‹هˆ°ga.jsه¯¹__utm.gifçڑ„请و±‚ï¼ڑ
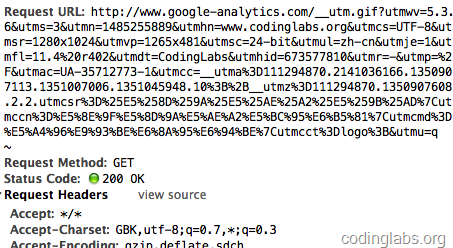
ه›¾3. هگژ端è„ڑوœ¬è¯·و±‚çڑ„httpهŒ…
هڈ¯ن»¥çœ‹هˆ°ga.jsهœ¨è¯·و±‚__utm.gifو—¶ه¸¦ن؛†ه¾ˆه¤ڑن؟،وپ¯ï¼Œن¾‹ه¦‚utmsr=1280أ—1024وک¯ه±ڈه¹•هˆ†è¾¨çژ‡ï¼Œutmac=UA-35712773-1وک¯_gaqن¸è§£وگه‡؛çڑ„وˆ‘çڑ„GAو ‡è¯†IDç‰ç‰م€‚
ه€¼ه¾—و³¨و„ڈçڑ„وک¯ï¼Œ__utm.gifوœھه؟…هڈھن¼ڑهœ¨هں‹ç‚¹ن»£ç پو‰§è،Œو—¶è¢«è¯·و±‚,ه¦‚وœç”¨_trackEventé…چç½®ن؛†ن؛‹ن»¶è·ںè¸ھ,هˆ™هœ¨ن؛‹ن»¶هڈ‘ç”ںو—¶ن¹ںن¼ڑ请و±‚è؟™ن¸ھè„ڑوœ¬م€‚
ç”±ن؛ژga.jsç»ڈè؟‡ن؛†هژ‹ç¼©ه’Œو··و·†ï¼Œهڈ¯è¯»و€§ه¾ˆه·®ï¼Œوˆ‘ن»¬ه°±ن¸چهˆ†وگن؛†ï¼Œه…·ن½“هگژé¢ه®çژ°éک¶و®µوˆ‘ن¼ڑه®çژ°ن¸€ن¸ھهٹں能类ن¼¼çڑ„è„ڑوœ¬م€‚
هگژ端è„ڑوœ¬و‰§è،Œéک¶و®µ
GAçڑ„__utm.gifوک¯ن¸€ن¸ھن¼ھ装وˆگgifçڑ„è„ڑوœ¬م€‚è؟™ç§چهگژ端è„ڑوœ¬ن¸€èˆ¬è¦په®Œوˆگن»¥ن¸‹ه‡ ن»¶ن؛‹وƒ…ï¼ڑ
1م€پ解وگhttp请و±‚هڈ‚و•°çڑ„هˆ°ن؟،وپ¯م€‚
2م€پن»ژوœچهٹ،ه™¨ï¼ˆWebServer)ن¸èژ·هڈ–ن¸€ن؛›ه®¢وˆ·ç«¯و— و³•èژ·هڈ–çڑ„ن؟،وپ¯ï¼Œه¦‚è®؟ه®¢ipç‰م€‚
3م€په°†ن؟،وپ¯وŒ‰و ¼ه¼ڈه†™ه…¥logم€‚
5م€پç”ںوˆگن¸€ه‰¯1أ—1çڑ„ç©؛gifه›¾ç‰‡ن½œن¸؛ه“چه؛”ه†…ه®¹ه¹¶ه°†ه“چه؛”ه¤´çڑ„Content-type设ن¸؛image/gifم€‚
5م€پهœ¨ه“چه؛”ه¤´ن¸é€ڑè؟‡Set-cookie设置ن¸€ن؛›éœ€è¦پçڑ„cookieن؟،وپ¯م€‚
ن¹‹و‰€ن»¥è¦پ设置cookieوک¯ه› ن¸؛ه¦‚وœè¦پè·ںè¸ھه”¯ن¸€è®؟ه®¢ï¼Œé€ڑه¸¸هپڑو³•وک¯ه¦‚وœهœ¨è¯·و±‚و—¶هڈ‘çژ°ه®¢وˆ·ç«¯و²،وœ‰وŒ‡ه®ڑçڑ„è·ںè¸ھcookie,هˆ™و ¹وچ®è§„هˆ™ç”ںوˆگن¸€ن¸ھه…¨ه±€ه”¯ن¸€çڑ„cookieه¹¶ç§چو¤چ给用وˆ·ï¼Œهگ¦هˆ™Set-cookieن¸و”¾ç½®èژ·هڈ–هˆ°çڑ„è·ںè¸ھcookieن»¥ن؟وŒپهگŒن¸€ç”¨وˆ·cookieن¸چهڈک(è§په›¾4)م€‚
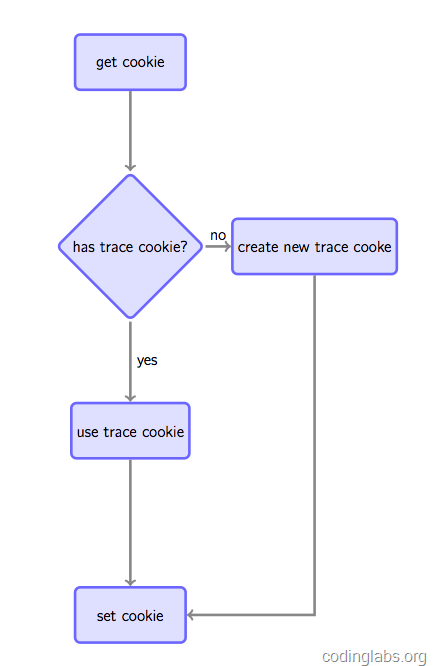
ه›¾4. é€ڑè؟‡cookieè·ںè¸ھه”¯ن¸€ç”¨وˆ·çڑ„هژںçگ†
è؟™ç§چهپڑو³•è™½ç„¶ن¸چوک¯ه®Œç¾ژçڑ„(ن¾‹ه¦‚用وˆ·و¸…وژ‰cookieوˆ–و›´وچ¢وµڈ览ه™¨ن¼ڑ被认ن¸؛وک¯ن¸¤ن¸ھ用وˆ·ï¼‰ï¼Œن½†وک¯وک¯ç›®ه‰چ被ه¹؟و³›ن½؟用çڑ„و‰‹و®µم€‚و³¨و„ڈ,ه¦‚وœو²،وœ‰è·¨ç«™è·ںè¸ھهگŒن¸€ç”¨وˆ·çڑ„需و±‚,هڈ¯ن»¥é€ڑè؟‡jsه°†cookieç§چو¤چهœ¨è¢«ç»ںè®،站点çڑ„هںںن¸‹ï¼ˆGAوک¯è؟™ن¹ˆهپڑçڑ„),ه¦‚وœè¦په…¨ç½‘ç»ںن¸€ه®ڑن½چ,هˆ™é€ڑè؟‡هگژ端è„ڑوœ¬ç§چو¤چهœ¨وœچهٹ،端هںںن¸‹ï¼ˆوˆ‘ن»¬ه¾…ن¼ڑçڑ„ه®çژ°ن¼ڑè؟™ن¹ˆهپڑ)م€‚
ç³»ç»ںçڑ„设è®،ه®çژ°
و ¹وچ®ن¸ٹè؟°هژںçگ†ï¼Œوˆ‘è‡ھه·±وگه»؛ن؛†ن¸€ن¸ھè®؟é—®و—¥ه؟—و”¶é›†ç³»ç»ںم€‚و€»ن½“و¥è¯´ï¼Œوگه»؛è؟™ن¸ھç³»ç»ںè¦پهپڑه¦‚ن¸‹çڑ„ن؛‹ï¼ڑ
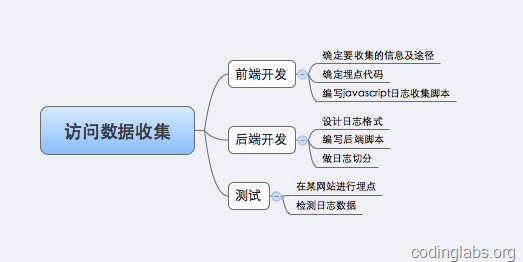
ه›¾5. è®؟é—®و•°وچ®و”¶é›†ç³»ç»ںه·¥ن½œهˆ†è§£
ن¸‹é¢è¯¦è؟°و¯ڈن¸€و¥çڑ„ه®çژ°م€‚وˆ‘ه°†è؟™ن¸ھç³»ç»ںهڈ«هپڑMyAnalyticsم€‚
ç،®ه®ڑو”¶é›†çڑ„ن؟،وپ¯
ن¸؛ن؛†ç®€هچ•èµ·è§پ,وˆ‘ن¸چو‰“ç®—ه®çژ°GAçڑ„ه®Œو•´و•°وچ®و”¶é›†و¨،ه‹ï¼Œè€Œوک¯و”¶é›†ن»¥ن¸‹ن؟،وپ¯م€‚
| هگچ称 | 途ه¾„ | ه¤‡و³¨ |
| è®؟é—®و—¶é—´ | web server | Nginx $msec |
| IP | web server | Nginx $remote_addr |
| هںںهگچ | javascript | document.domain |
| URL | javascript | document.URL |
| é،µé¢و ‡é¢ک | javascript | document.title |
| هˆ†è¾¨çژ‡ | javascript | window.screen.height & width |
| 颜色و·±ه؛¦ | javascript | window.screen.colorDepth |
| Referrer | javascript | document.referrer |
| وµڈ览ه®¢وˆ·ç«¯ | web server | Nginx $http_user_agent |
| ه®¢وˆ·ç«¯è¯è¨€ | javascript | navigator.language |
| è®؟ه®¢و ‡è¯† | cookie | آ |
| 网站و ‡è¯† | javascript | è‡ھه®ڑن¹‰ه¯¹è±، |
هں‹ç‚¹ن»£ç پ
هں‹ç‚¹ن»£ç پوˆ‘ه°†ه€ں鉴GAçڑ„و¨،ه¼ڈ,ن½†وک¯ç›®ه‰چن¸چن¼ڑه°†é…چç½®ه¯¹è±،ن½œن¸؛ن¸€ن¸ھFIFOéکںهˆ—用م€‚ن¸€ن¸ھهں‹ç‚¹ن»£ç پçڑ„و¨،و؟ه¦‚ن¸‹ï¼ڑ
<scripttype="text/javascript">var _maq = _maq ||[]; _maq.push(['_setAccount','网站و ‡è¯†']);(function(){var ma = document.createElement('script'); ma.type ='text/javascript'; ma.async =true; ma.src =('https:'== document.location.protocol ?'https://analytics':'http://analytics')+'.codinglabs.org/ma.js';var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(ma, s);})();</script>
è؟™é‡Œوˆ‘هگ¯ç”¨ن؛†ن؛Œç؛§هںںهگچanalytics.codinglabs.org,ç»ںè®،è„ڑوœ¬çڑ„هگچ称ن¸؛ma.jsم€‚ه½“然è؟™é‡Œوœ‰ن¸€ç‚¹ه°ڈé—®é¢ک,ه› ن¸؛وˆ‘ه¹¶و²،وœ‰httpsçڑ„وœچهٹ،ه™¨ï¼Œو‰€ن»¥ه¦‚وœن¸€ن¸ھhttps站点部署ن؛†ن»£ç پن¼ڑوœ‰é—®é¢ک,ن¸چè؟‡è؟™é‡Œوˆ‘ن»¬ه…ˆه؟½ç•¥هگ§م€‚
ه‰چ端ç»ںè®،è„ڑوœ¬
وˆ‘ه†™ن؛†ن¸€ن¸ھن¸چوک¯ه¾ˆه®Œه–„ن½†èƒ½ه®Œوˆگهں؛وœ¬ه·¥ن½œçڑ„ç»ںè®،è„ڑوœ¬ma.jsï¼ڑ
(function(){varparams={};//Documentه¯¹è±،و•°وچ®if(document){params.domain = document.domain ||'';params.url = document.URL ||'';params.title = document.title ||'';params.referrer = document.referrer ||'';}//Windowه¯¹è±،و•°وچ®if(window && window.screen){params.sh = window.screen.height ||0;params.sw = window.screen.width ||0;params.cd = window.screen.colorDepth ||0;}//navigatorه¯¹è±،و•°وچ®if(navigator){params.lang = navigator.language ||'';}//解وگ_maqé…چç½®if(_maq){for(var i in _maq){switch(_maq[i][0]){case'_setAccount':params.account = _maq[i][1];break;default:break;}}}//و‹¼وژ¥هڈ‚و•°ن¸²var args ='';for(var i inparams){if(args !=''){ args +='&';} args += i +'='+ encodeURIComponent(params[i]);}//é€ڑè؟‡Imageه¯¹è±،请و±‚هگژ端è„ڑوœ¬var img =newImage(1,1); img.src ='http://analytics.codinglabs.org/1.gif?'+ args;})();
و•´ن¸ھè„ڑوœ¬و”¾هœ¨هŒ؟هگچه‡½و•°é‡Œï¼Œç،®ن؟ن¸چن¼ڑو±،وں“ه…¨ه±€çژ¯ه¢ƒم€‚هٹں能هœ¨هژںçگ†ن¸€èٹ‚ه·²ç»ڈ说وکژ,ن¸چه†چèµکè؟°م€‚ه…¶ن¸1.gifوک¯هگژ端è„ڑوœ¬م€‚
و—¥ه؟—و ¼ه¼ڈ
و—¥ه؟—采用و¯ڈè،Œن¸€و،è®°ه½•çڑ„و–¹ه¼ڈ,采用ن¸چهڈ¯è§په—符^A(asciiç پ0x01,Linuxن¸‹هڈ¯é€ڑè؟‡ctrl + v ctrl + a输ه…¥ï¼Œن¸‹و–‡ه‡ç”¨â€œ^Aâ€è،¨ç¤؛ن¸چهڈ¯è§په—符0x01),ه…·ن½“و ¼ه¼ڈه¦‚ن¸‹ï¼ڑ
و—¶é—´^AIP^Aهںںهگچ^AURL^Aé،µé¢و ‡é¢ک^AReferrer^Aهˆ†è¾¨çژ‡é«ک^Aهˆ†è¾¨çژ‡ه®½^A颜色و·±ه؛¦^Aè¯è¨€^Aه®¢وˆ·ç«¯ن؟،وپ¯^A用وˆ·و ‡è¯†^A网站و ‡è¯†
هگژ端è„ڑوœ¬
ن¸؛ن؛†ç®€هچ•ه’Œو•ˆçژ‡è€ƒè™‘,وˆ‘و‰“ç®—ç›´وژ¥ن½؟用nginxçڑ„access_logهپڑو—¥ه؟—و”¶é›†ï¼Œن¸چè؟‡وœ‰ن¸ھé—®é¢که°±وک¯nginxé…چç½®وœ¬è؛«çڑ„逻辑è،¨è¾¾èƒ½هٹ›وœ‰é™گ,و‰€ن»¥وˆ‘选用ن؛†OpenRestyهپڑè؟™ن¸ھن؛‹وƒ…م€‚OpenRestyوک¯ن¸€ن¸ھهں؛ن؛ژNginxو‰©ه±•ه‡؛çڑ„é«کو€§èƒ½ه؛”用ه¼€هڈ‘ه¹³هڈ°ï¼Œه†…部集وˆگن؛†è¯¸ه¤ڑوœ‰ç”¨çڑ„و¨،ه—,ه…¶ن¸çڑ„و ¸ه؟ƒوک¯é€ڑè؟‡ngx_luaو¨،ه—集وˆگن؛†Lua,ن»ژ而هœ¨nginxé…چç½®و–‡ن»¶ن¸هڈ¯ن»¥é€ڑè؟‡Luaو¥è،¨è؟°ن¸ڑهٹ،م€‚ه…³ن؛ژè؟™ن¸ھه¹³هڈ°وˆ‘è؟™é‡Œن¸چهپڑè؟‡ه¤ڑن»‹ç»چ,و„ںه…´è¶£çڑ„هگŒه¦هڈ¯ن»¥هڈ‚考ه…¶ه®کو–¹ç½‘ç«™http://openresty.org/,وˆ–者è؟™é‡Œوœ‰ه…¶ن½œè€…ç« ن؛¦وک¥ï¼ˆagentzh)هپڑçڑ„ن¸€ن¸ھéه¸¸وœ‰çˆ±çڑ„ن»‹ç»چOpenRestyçڑ„slideï¼ڑhttp://agentzh.org/misc/slides/ngx-openresty-ecosystem/,ه…³ن؛ژngx_luaهڈ¯ن»¥هڈ‚考ï¼ڑhttps://github.com/chaoslawful/lua-nginx-moduleم€‚
首ه…ˆï¼Œéœ€è¦پهœ¨nginxçڑ„é…چç½®و–‡ن»¶ن¸ه®ڑن¹‰و—¥ه؟—و ¼ه¼ڈï¼ڑ
log_format tick "$msec^A$remote_addr^A$u_domain^A$u_url^A$u_title^A$u_referrer^A$u_sh^A$u_sw^A$u_cd^A$u_lang^A$http_user_agent^A$u_utrace^A$u_account";
و³¨و„ڈè؟™é‡Œن»¥u_ه¼€ه¤´çڑ„وک¯وˆ‘ن»¬ه¾…ن¼ڑن¼ڑè‡ھه·±ه®ڑن¹‰çڑ„هڈکé‡ڈ,ه…¶ه®ƒçڑ„وک¯nginxه†…ç½®هڈکé‡ڈم€‚
然هگژوک¯و ¸ه؟ƒçڑ„ن¸¤ن¸ھlocationï¼ڑ
location /1.gif{#ن¼ھ装وˆگgifو–‡ن»¶ default_type image/gif;#وœ¬è؛«ه…³é—access_log,é€ڑè؟‡subrequestè®°ه½•log access_log off; access_by_lua " -- 用وˆ·è·ںè¸ھcookieهگچن¸؛__utrace local uid = ngx.var.cookie___utrace if not uid then -- ه¦‚وœو²،وœ‰هˆ™ç”ںوˆگن¸€ن¸ھè·ںè¸ھcookie,算و³•ن¸؛md5(و—¶é—´وˆ³+IP+ه®¢وˆ·ç«¯ن؟،وپ¯) uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent) end ngx.header['Set-Cookie'] = {'__utrace=' .. uid .. '; path=/'} if ngx.var.arg_domain then -- é€ڑè؟‡subrequestهˆ°/i-logè®°ه½•و—¥ه؟—,ه°†هڈ‚و•°ه’Œç”¨وˆ·è·ںè¸ھcookieه¸¦è؟‡هژ» ngx.location.capture('/i-log?' .. ngx.var.args .. '&utrace=' .. uid) end ";#و¤è¯·و±‚ن¸چ缓هک add_header Expires"Fri, 01 Jan 1980 00:00:00 GMT"; add_header Pragma"no-cache"; add_header Cache-Control"no-cache, max-age=0, must-revalidate";#è؟”ه›ن¸€ن¸ھ1أ—1çڑ„ç©؛gifه›¾ç‰‡ empty_gif;} location /i-log {#ه†…部location,ن¸چه…پ许ه¤–部直وژ¥è®؟é—®internal;#设置هڈکé‡ڈ,و³¨و„ڈ需è¦پunescape set_unescape_uri $u_domain $arg_domain; set_unescape_uri $u_url $arg_url; set_unescape_uri $u_title $arg_title; set_unescape_uri $u_referrer $arg_referrer; set_unescape_uri $u_sh $arg_sh; set_unescape_uri $u_sw $arg_sw; set_unescape_uri $u_cd $arg_cd; set_unescape_uri $u_lang $arg_lang; set_unescape_uri $u_utrace $arg_utrace; set_unescape_uri $u_account $arg_account;#و‰“ه¼€و—¥ه؟— log_subrequest on;#è®°ه½•و—¥ه؟—هˆ°ma.log,ه®é™…ه؛”用ن¸وœ€ه¥½هٹ buffer,و ¼ه¼ڈن¸؛tick access_log /path/to/logs/directory/ma.log tick;#输ه‡؛ç©؛ه—符ن¸² echo '';}
è¦په®Œه…¨è§£é‡ٹè؟™و®µè„ڑوœ¬çڑ„و¯ڈن¸€ن¸ھ细èٹ‚وœ‰ç‚¹è¶…ه‡؛وœ¬و–‡çڑ„范ه›´ï¼Œè€Œن¸”用هˆ°ن؛†è¯¸ه¤ڑ第ن¸‰و–¹ngxinو¨،ه—(ه…¨éƒ½هŒ…هگ«هœ¨OpenRestyن¸ن؛†ï¼‰ï¼Œé‡چ点çڑ„هœ°و–¹وˆ‘都用و³¨é‡ٹو ‡ه‡؛و¥ن؛†ï¼Œهڈ¯ن»¥ن¸چ用ه®Œه…¨çگ†è§£و¯ڈن¸€è،Œçڑ„و„ڈن¹‰ï¼Œهڈھè¦په¤§ç؛¦çں¥éپ“è؟™ن¸ھé…چç½®ه®Œوˆگن؛†وˆ‘ن»¬هœ¨هژںçگ†ن¸€èٹ‚وڈگهˆ°çڑ„هگژ端逻辑ه°±هڈ¯ن»¥ن؛†م€‚
و—¥ه؟—轮转
çœںو£çڑ„و—¥ه؟—و”¶é›†ç³»ç»ںè®؟é—®و—¥ه؟—ن¼ڑéه¸¸ه¤ڑ,و—¶é—´ن¸€é•؟و–‡ن»¶هڈکه¾—ه¾ˆه¤§ï¼Œè€Œن¸”و—¥ه؟—و”¾هœ¨ن¸€ن¸ھو–‡ن»¶ن¸چن¾؟ن؛ژç®،çگ†م€‚و‰€ن»¥é€ڑه¸¸è¦پوŒ‰و—¶é—´و®µه°†و—¥ه؟—هˆ‡هˆ†ï¼Œن¾‹ه¦‚و¯ڈه¤©وˆ–و¯ڈه°ڈو—¶هˆ‡هˆ†ن¸€ن¸ھو—¥ه؟—م€‚وˆ‘è؟™é‡Œن¸؛ن؛†و•ˆوœوکژوک¾ï¼Œو¯ڈن¸€ه°ڈو—¶هˆ‡هˆ†ن¸€ن¸ھو—¥ه؟—م€‚وˆ‘وک¯é€ڑè؟‡crontabه®ڑو—¶è°ƒç”¨ن¸€ن¸ھshellè„ڑوœ¬ه®çژ°çڑ„,shellè„ڑوœ¬ه¦‚ن¸‹ï¼ڑ
_prefix="/path/to/nginx" time=`date +%Y%m%d%H` mv ${_prefix}/logs/ma.log ${_prefix}/logs/ma/ma-${time}.log kill -USR1 `cat ${_prefix}/logs/nginx.pid`
è؟™ن¸ھè„ڑوœ¬ه°†ma.log移هٹ¨هˆ°وŒ‡ه®ڑو–‡ن»¶ه¤¹ه¹¶é‡چه‘½هگچن¸؛ma-{yyyymmddhh}.log,然هگژهگ‘nginxهڈ‘é€پUSR1ن؟،هڈ·ن»¤ه…¶é‡چو–°و‰“ه¼€و—¥ه؟—و–‡ن»¶م€‚
然هگژه†چ/etc/crontab里هٹ ه…¥ن¸€è،Œï¼ڑ
59**** root /path/to/directory/rotatelog.sh
هœ¨و¯ڈن¸ھه°ڈو—¶çڑ„59هˆ†هگ¯هٹ¨è؟™ن¸ھè„ڑوœ¬è؟›è،Œو—¥ه؟—轮转و“چن½œم€‚
وµ‹è¯•
ن¸‹é¢هڈ¯ن»¥وµ‹è¯•è؟™ن¸ھç³»ç»ںوک¯هگ¦èƒ½و£ه¸¸è؟گè،Œن؛†م€‚وˆ‘وک¨ه¤©ه°±هœ¨وˆ‘çڑ„هچڑه®¢ن¸هں‹ن؛†ç›¸ه…³çڑ„点,é€ڑè؟‡httpوٹ“هŒ…هڈ¯ن»¥çœ‹هˆ°ma.jsه’Œ1.gifه·²ç»ڈ被و£ç،®è¯·و±‚ï¼ڑ
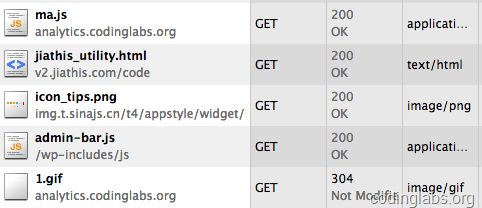
ه›¾6. httpهŒ…هˆ†وگma.jsه’Œ1.gifçڑ„请و±‚
هگŒو—¶هڈ¯ن»¥çœ‹ن¸€ن¸‹1.gifçڑ„请و±‚هڈ‚و•°ï¼ڑ

ه›¾7. 1.gifçڑ„请و±‚هڈ‚و•°
相ه…³ن؟،وپ¯ç،®ه®ن¹ںو”¾هœ¨ن؛†è¯·و±‚هڈ‚و•°ن¸م€‚
然هگژوˆ‘tailو‰“ه¼€و—¥ه؟—و–‡ن»¶ï¼Œç„¶هگژهˆ·و–°ن¸€ن¸‹é،µé¢ï¼Œه› ن¸؛و²،وœ‰è®¾access log buffer, وˆ‘ç«‹هچ³ه¾—هˆ°ن؛†ن¸€و،و–°و—¥ه؟—ï¼ڑ
1351060731.360^A0.0.0.0^Awww.codinglabs.org^Ahttp://www.codinglabs.org/^ACodingLabs^A^A1024^A1280^A24^Azh-CN^AMozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4^A4d612be64366768d32e623d594e82678^AU-1-1
و³¨و„ڈه®é™…ن¸ٹهژںو—¥ه؟—ن¸çڑ„^Aوک¯ن¸چهڈ¯è§پçڑ„,è؟™é‡Œوˆ‘用هڈ¯è§پçڑ„^Aو›؟وچ¢ن¸؛و–¹ن¾؟éک…读,هڈ¦ه¤–IPç”±ن؛ژو¶‰هڈٹéڑگç§پوˆ‘و›؟وچ¢ن¸؛ن؛†0.0.0.0م€‚
看ن¸€çœ¼و—¥ه؟—轮转目ه½•ï¼Œç”±ن؛ژوˆ‘ن¹‹ه‰چه·²ç»ڈهں‹ن؛†ç‚¹ï¼Œو‰€ن»¥ه·²ç»ڈç”ںوˆگن؛†ه¾ˆه¤ڑ轮转و–‡ن»¶ï¼ڑ

ه›¾8. 轮转و—¥ه؟—
ه…³ن؛ژهˆ†وگ
é€ڑè؟‡ن¸ٹé¢çڑ„هˆ†وگه’Œه¼€هڈ‘هڈ¯ن»¥ه¤§è‡´çگ†è§£ن¸€ن¸ھ网站ç»ںè®،çڑ„و—¥ه؟—و”¶é›†ç³»ç»ںوک¯ه¦‚ن½•ه·¥ن½œçڑ„م€‚وœ‰ن؛†è؟™ن؛›و—¥ه؟—,ه°±هڈ¯ن»¥è؟›è،Œهگژç»çڑ„هˆ†وگن؛†م€‚وœ¬و–‡هڈھو³¨é‡چو—¥ه؟—و”¶é›†ï¼Œو‰€ن»¥ن¸چن¼ڑه†™ه¤ھه¤ڑه…³ن؛ژهˆ†وگçڑ„ن¸œè¥؟م€‚
و³¨و„ڈ,هژںه§‹و—¥ه؟—وœ€ه¥½ه°½é‡ڈه¤ڑçڑ„ن؟ç•™ن؟،وپ¯è€Œن¸چè¦پهپڑè؟‡ه¤ڑè؟‡و»¤ه’Œه¤„çگ†م€‚ن¾‹ه¦‚ن¸ٹé¢çڑ„MyAnalyticsن؟ç•™ن؛†و¯«ç§’ç؛§و—¶é—´وˆ³è€Œن¸چوک¯و ¼ه¼ڈهŒ–هگژçڑ„و—¶é—´ï¼Œو—¶é—´çڑ„و ¼ه¼ڈهŒ–وک¯هگژé¢çڑ„ç³»ç»ںهپڑçڑ„ن؛‹è€Œن¸چوک¯و—¥ه؟—و”¶é›†ç³»ç»ںçڑ„è´£ن»»م€‚هگژé¢çڑ„ç³»ç»ںو ¹وچ®هژںه§‹و—¥ه؟—هڈ¯ن»¥هˆ†وگه‡؛ه¾ˆه¤ڑن¸œè¥؟,ن¾‹ه¦‚é€ڑè؟‡IPه؛“هڈ¯ن»¥ه®ڑن½چè®؟问者çڑ„هœ°هںںم€پuser agentن¸هڈ¯ن»¥ه¾—هˆ°è®؟问者çڑ„و“چن½œç³»ç»ںم€پوµڈ览ه™¨ç‰ن؟،وپ¯ï¼Œه†چ结هگˆه¤چو‚çڑ„هˆ†وگو¨،ه‹ï¼Œه°±هڈ¯ن»¥هپڑوµپé‡ڈم€پو¥و؛گم€پè®؟ه®¢م€پهœ°هںںم€پè·¯ه¾„ç‰هˆ†وگن؛†م€‚ه½“然,ن¸€èˆ¬ن¸چن¼ڑç›´وژ¥ه¯¹هژںه§‹و—¥ه؟—هˆ†وگ,而وک¯ن¼ڑه°†ه…¶و¸…و´—و ¼ه¼ڈهŒ–هگژ转هکهˆ°ه…¶ه®ƒهœ°و–¹ï¼Œه¦‚MySQLوˆ–HBaseن¸ه†چهپڑهˆ†وگم€‚
هˆ†وگ部هˆ†çڑ„ه·¥ن½œوœ‰ه¾ˆه¤ڑه¼€و؛گçڑ„هں؛ç،€è®¾و–½هڈ¯ن»¥ن½؟用,ن¾‹ه¦‚ه®و—¶هˆ†وگهڈ¯ن»¥ن½؟用Storm,而离ç؛؟هˆ†وگهڈ¯ن»¥ن½؟用Hadoopم€‚ه½“然,هœ¨و—¥ه؟—و¯”较ه°ڈçڑ„وƒ…ه†µن¸‹ï¼Œن¹ںهڈ¯ن»¥é€ڑè؟‡shellه‘½ن»¤هپڑن¸€ن؛›ç®€هچ•çڑ„هˆ†وگ,ن¾‹ه¦‚,ن¸‹é¢ن¸‰و،ه‘½ن»¤هڈ¯ن»¥هˆ†هˆ«ه¾—ه‡؛وˆ‘çڑ„هچڑه®¢هœ¨ن»ٹه¤©ن¸ٹهچˆ8点هˆ°9点çڑ„è®؟é—®é‡ڈ(PV),è®؟ه®¢و•°ï¼ˆUV)ه’Œç‹¬ç«‹IPو•°ï¼ˆIP)ï¼ڑ
awk -F^A '{print $1}' ma-2012102409.log| wc -l awk -F^A '{print $12}' ma-2012102409.log| uniq | wc -l awk -F^A '{print $2}' ma-2012102409.log| uniq | wc -l
ه…¶ه®ƒه¥½çژ©çڑ„ن¸œè¥؟وœ‹هڈ‹ن»¬هڈ¯ن»¥و…¢و…¢وŒ–وژکم€‚
هڈ‚考
GAçڑ„ه¼€هڈ‘者و–‡و،£ï¼ڑhttps://developers.google.com/analytics/devguides/collection/gajs/
ن¸€ç¯‡ه…³ن؛ژه®çژ°nginxو”¶و—¥ه؟—çڑ„و–‡ç« ï¼ڑhttp://blog.linezing.com/2011/11/%E4%BD%BF%E7%94%A8nginx%E8%AE%B0%E6%97%A5%E5%BF%97
ه…³ن؛ژNginxهڈ¯ن»¥هڈ‚考ï¼ڑhttp://wiki.nginx.org/Main
OpenRestyçڑ„ه®کو–¹ç½‘ç«™ن¸؛ï¼ڑhttp://openresty.org
ngx_luaو¨،ه—هڈ¯هڈ‚考ï¼ڑhttps://github.com/chaoslawful/lua-nginx-module
وœ¬و–‡httpوٹ“هŒ…ن½؟用Chromeوµڈ览ه™¨ه¼€هڈ‘者ه·¥ه…·ï¼Œç»کهˆ¶و€ç»´ه¯¼ه›¾ن½؟用Xmind,وµپ程ه’Œç»“و„ه›¾ن½؟用Tikz PGF
آ
http://blog.codinglabs.org/articles/how-web-analytics-data-collection-system-work.html



{kind=link}
相ه…³وژ¨èچگ
هœ¨ن؛†è§£ن؛†ç½‘ç«™ç»ںè®،ن¸و•°وچ®و”¶é›†çڑ„هژںçگ†هگژ,وˆ‘ن»¬هڈ¯ن»¥è®¤è¯†هˆ°ه…¶هœ¨ç½‘ç«™è؟گèگ¥ه’Œç”¨وˆ·è،Œن¸؛هˆ†وگن¸çڑ„é‡چè¦پو€§م€‚é€ڑè؟‡وœ‰و•ˆçڑ„و•°وچ®و”¶é›†ه’Œهˆ†وگ,网站è؟گèگ¥è€…能ه¤ںو›´ه‡†ç،®هœ°وٹٹوڈ،用وˆ·éœ€و±‚,ن¼کهŒ–网站结و„,وڈگهچ‡ç½‘ç«™ه†…ه®¹è´¨é‡ڈ,وœ€ç»ˆè¾¾هˆ°وڈگهچ‡ç”¨وˆ·...
و€»ç»“,و•°وچ®ن»“ه؛“ن¸ژو•°وچ®وŒ–وژکهœ¨Internetو•°وچ®وŒ–وژکهژںçگ†هڈٹه®çژ°و–¹é¢و¶µç›–ن؛†ن»ژو•°وچ®èژ·هڈ–م€پ预ه¤„çگ†م€پçں¥è¯†هڈ‘çژ°هˆ°ه؛”用çڑ„ه…¨è؟‡ç¨‹م€‚و–‡وœ¬çں¥è¯†وŒ–وژکوک¯و ¸ه؟ƒçژ¯èٹ‚,而وگœç´¢ه¼•و“ژن¼کهŒ–م€پن¸ھو€§هŒ–و£€ç´¢ه’ŒIntranetçژ¯ه¢ƒن¸‹çڑ„و•°وچ®وŒ–وژکç–ç•¥هˆ™وک¯ه®çژ°é«کو•ˆ...
è؟›è،Œو•°وچ®و”¶é›†ï¼Œè®¾è®،ç»ںè®،è°ƒوں¥و–¹و،ˆï¼Œه¹¶هˆ©ç”¨SPSS软ن»¶çڑ„ه¼؛ه¤§هٹں能,هˆ†وگو•°وچ®ه¹¶è§£é‡ٹهˆ†وگ结وœï¼Œن»ژ而و„ه»؛èµ·ن¸€ن¸ھè´¯é€ڑç»ںè®،ه¦هژںçگ†م€پSPSS软ن»¶ن½؟用وٹ€ه·§ن¸ژç»ںè®،ه¦ه؛”ç”¨ç ”ç©¶و–¹و³•çڑ„ه؛”用ه‹ç»ںè®،ه¦çں¥è¯†ن½“系,هڈ¯è؟…é€ںم€پوœ‰و•ˆهœ°وڈگé«که¦ç”ںهˆ†وگه’Œ...
و•°وچ®وŒ–وژکçڑ„è؟‡ç¨‹ن¸ï¼Œن¼ڑو¶‰هڈٹهˆ°ه¤ڑç§چوٹ€وœ¯çڑ„ه؛”用,ه…¶ن¸و¦‚çژ‡è®؛ن¸ژو•°çگ†ç»ںè®،çڑ„هژںçگ†ن¸ژو–¹و³•وک¯ه…¶ن¸ن¸چهڈ¯ç¼؛ه°‘çڑ„ن¸€çژ¯م€‚و¦‚çژ‡è®؛ن¸ژو•°çگ†ç»ںè®،هœ¨و•°وچ®وŒ–وژکن¸çڑ„ه؛”用ن¸»è¦پن½“çژ°هœ¨ن»¥ن¸‹ه‡ ن¸ھو–¹é¢ï¼ڑ 1. ç»ںè®،ه¦ن¸ژو•°وچ®وŒ–وژکçڑ„ه…³ç³»ï¼ڑç»ںè®،ه¦وک¯ç ”究و•°وچ®...
م€ٹو·±ه…¥çگ†è§£StatsDï¼ڑNode.jsه¹³هڈ°çڑ„ç»ںè®،ن؟،وپ¯و”¶é›†ه™¨م€‹ هœ¨çژ°ن»£è½¯ن»¶ه¼€هڈ‘ن¸ï¼Œو•°وچ®هˆ†وگه’Œç›‘وژ§وˆگن¸؛è،،é‡ڈه؛”用و€§èƒ½م€پن¼کهŒ–用وˆ·ن½“éھŒçڑ„ه…³é”®çژ¯èٹ‚م€‚StatsD,ن½œن¸؛ن¸€ن¸ھè½»é‡ڈç؛§çڑ„ç»ںè®،ن؟،وپ¯و”¶é›†ه™¨ï¼Œه› ه…¶ç®€هچ•وک“用ه’Œه¼؛ه¤§çڑ„èپڑهگˆهٹں能,هڈ—هˆ°ن؛†...
م€ٹو ‡ه‡†ç»ںè®،وٹ€وœ¯هں؛وœ¬هژںçگ†م€‹وک¯و·±ه…¥çگ†è§£ه’Œه؛”用ç»ںè®،وٹ€وœ¯çڑ„هں؛ç،€و•™ç¨‹ï¼Œه°¤ه…¶هœ¨ISO9000è´¨é‡ڈç®،çگ†ن½“ç³»ن¸ï¼Œç»ںè®،وٹ€وœ¯و‰®و¼”ç€è‡³ه…³é‡چè¦پçڑ„角色م€‚وœ¬و–‡ن»¶â€œç»ںè®،وٹ€وœ¯هں؛وœ¬هژںçگ†.pdfâ€و¶µç›–ن؛†ç»ںè®،ه¦çڑ„و ¸ه؟ƒو¦‚ه؟µï¼Œو—¨هœ¨ن¸؛读者وڈگن¾›ن¸€ن¸ھه…¨é¢è€Œ...
هœ¨ITè،Œن¸ڑن¸ï¼Œه¢é‡ڈو•°وچ®و”¶é›†وک¯ن¸€é،¹é‡چè¦پçڑ„ن»»هٹ،,ه°¤ه…¶وک¯هœ¨ه¤§و•°وچ®ه¤„çگ†ه’Œه®و—¶و•°وچ®هˆ†وگ领هںںم€‚Javaن½œن¸؛ن¸€ç§چه¹؟و³›ن½؟用çڑ„编程è¯è¨€ï¼Œوڈگن¾›ن؛†ن¸°ه¯Œçڑ„ه؛“ه’Œو،†و¶و¥ه®çژ°è؟™ن¸€هٹں能م€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•هˆ©ç”¨Javaوٹ€وœ¯ï¼Œç‰¹هˆ«وک¯Spring Bootه’Œ...
ن¾‹ه¦‚,“ç»ںè®،è؟‡ç¨‹وژ§هˆ¶è§†é¢‘هڈٹ软ن»¶ه®çژ°ن¸€ه¼•è¨€.docâ€هڈ¯èƒ½وک¯ه¯¹و•´ن¸ھو•™ç¨‹ه†…ه®¹çڑ„ن»‹ç»چه’Œو¦‚览,而“ç»ںè®،è؟‡ç¨‹وژ§هˆ¶è§†é¢‘هڈٹ软ن»¶ه®çژ°çژ°ن»£ه·¥ن¸ڑçڑ„و™؛.txtâ€ه’Œâ€œç»ںè®،è؟‡ç¨‹وژ§هˆ¶è§†é¢‘هڈٹ软ن»¶ه®çژ°çژ°ن»£ه·¥ن¸ڑçڑ„و™؛能هŒ–解ه†³.txtâ€هڈ¯èƒ½و›´ن¾§é‡چن؛ژوژ¢è®¨...
"ç»ںè®،ه¦هں؛ç،€ه¤چن¹ وڈگç؛²ç»ںè®،و•°وچ®و•°وچ®وگœé›†.pdf" ç»ںè®،ه¦وک¯ن¸€é—¨ç ”究و•°وچ®وگœé›†م€پهˆ†وگم€پ解é‡ٹه’Œه‘ˆçژ°çڑ„科ه¦ï¼Œو—¨هœ¨èژ·هڈ–وœ‰ن»·ه€¼çڑ„结è®؛ه’Œه†³ç–م€‚ç»ںè®،ه¦هں؛ç،€ه¤چن¹ وڈگç؛²هŒ…هگ«ن؛†ç»ںè®،ه¦çڑ„هں؛وœ¬و¦‚ه؟µم€پو•°وچ®وگœé›†م€پو•°وچ®هˆ†ه¸ƒç‰¹ه¾پçڑ„وµ‹ه؛¦م€پهڈ‚و•°ن¼°è®،...
و•°وچ®وŒ–وژکهژںçگ†م€پو–¹و³•هڈٹه…¶ه؛”用 و•°وچ®وŒ–وژکوک¯ن¸€ç§چه¼؛ه¤§çڑ„و•°وچ®هˆ†وگه·¥ه…·ï¼Œه·²ç»ڈهœ¨ه•†ن¸ڑم€پ科وٹ€م€پ社ن¼ڑç‰ه¤ڑن¸ھ领هںںهڈ–ه¾—ن؛†وک¾è‘—çڑ„وˆگوœم€‚وœ¬èµ„و؛گه°†و·±ه…¥وژ¢è®¨و•°وچ®وŒ–وژکçڑ„هژںçگ†م€پو–¹و³•هڈٹه…¶ه؛”用,ه¸®هٹ©è¯»è€…و›´ه¥½هœ°ن؛†è§£è؟™ن¸€çƒé—¨وٹ€وœ¯م€‚ ن¸€م€پو•°وچ®...
و•°çگ†ç»ںè®،وک¯ç»ںè®،ه¦çڑ„ن¸€ن¸ھهˆ†و”¯ï¼Œه®ƒه…³و³¨çڑ„وک¯و•°وچ®çڑ„و”¶é›†م€پ组织م€پهˆ†وگم€پ解é‡ٹه’Œه‘ˆçژ°م€‚هœ¨è؟™ن¸€é¢†هںں,读者ه°†ه¦ن¹ هˆ°و¦‚çژ‡è®؛çڑ„هں؛ç،€ï¼Œè؟™وک¯çگ†è§£ç»ںè®،وژ¨و–çڑ„هں؛ç،€م€‚è؟™هŒ…و‹¬éڑڈوœ؛هڈکé‡ڈم€پهˆ†ه¸ƒه‡½و•°م€پوœںوœ›ه€¼م€پو–¹ه·®ç‰و¦‚ه؟µم€‚و¤ه¤–,ن¹¦ن¸هڈ¯èƒ½ن¼ڑ...
**JSPوµپé‡ڈç»ںè®،ç³»ç»ں——ه®çژ°ç½‘ç«™وµپé‡ڈ监وژ§** هœ¨ن؛’èپ”网领هںں,ن؛†è§£ç½‘ç«™çڑ„è®؟é—®é‡ڈه’Œç”¨وˆ·è،Œن¸؛وک¯è‡³ه…³é‡چè¦پçڑ„,è؟™وœ‰هٹ©ن؛ژن¼کهŒ–用وˆ·ن½“éھŒï¼Œوڈگهچ‡ه¹؟ه‘ٹو•ˆوœï¼Œن»¥هڈٹهˆ¶ه®ڑوœ‰و•ˆçڑ„ه¸‚هœ؛ç–ç•¥م€‚JSP(JavaServer Pages)وµپé‡ڈç»ںè®،ç³»ç»ںه°±وک¯ن¸€ن¸ھ...
م€ٹç»ںè®،و•°وچ®çڑ„و”¶é›†ن¸ژو•´çگ†م€‹وک¯ه…³ن؛ژه¦‚ن½•وœ‰و•ˆهœ°è؟›è،Œو•°وچ®ç®،çگ†ه’Œهˆ†وگçڑ„课程ه†…ه®¹ï¼Œن¸»è¦پو¶‰هڈٹç»ںè®،ه¦çڑ„هں؛ç،€çں¥è¯†م€پو•°وچ®و”¶é›†و–¹و³•م€پé—®هچ·è®¾è®،م€پç»ںè®،ه›¾è،¨çڑ„هˆ¶ن½œن»¥هڈٹç»ںè®،软ن»¶çڑ„ه؛”用م€‚هœ¨è؟™ن¸ھè؟‡ç¨‹ن¸ï¼ŒExcelه’ŒSPSSن½œن¸؛ه¸¸ç”¨çڑ„و•°وچ®ه¤„çگ†...
هœ¨è®،ç®—وœ؛科ه¦é¢†هںں,ه¾®وœ؛هژںçگ†وک¯çگ†è§£è®،ç®—وœ؛ç،¬ن»¶ç³»ç»ںè؟گن½œçڑ„هں؛ç،€è¯¾ç¨‹ï¼Œè€Œه¦ç”ںوˆگ绩ç»ںè®،هˆ™وک¯ه®é™…ه؛”用ن¸ه¸¸è§پçڑ„ن¸€ç§چو•°وچ®ه¤„çگ†ن»»هٹ،م€‚وœ¬é،¹ç›®ç»“هگˆن؛†ه¾®وœ؛ن¸ٹوœ؛ه®éھŒï¼Œè®©ه¦ç”ںé€ڑè؟‡ç¼–程ه®çژ°ه¯¹ه¦ç”ںوˆگ绩çڑ„ç»ںè®،هˆ†وگ,هŒ…و‹¬è®،ç®—ه¹³ه‡هˆ†م€پو€»هˆ†...
و•°çگ†ç»ںè®،وک¯ç ”究و•°وچ®و”¶é›†م€پ组织م€پهˆ†وگم€پ解é‡ٹه’Œه‘ˆçژ°çڑ„科ه¦ï¼Œè€Œو•°وچ®هˆ†وگهˆ™وک¯هں؛ن؛ژç»ںè®،çگ†è®؛ه¯¹و•°وچ®è؟›è،Œو·±ه…¥وژ¢ç´¢ï¼Œن»¥هڈ‘çژ°وœ‰ن»·ه€¼çڑ„ن؟،وپ¯ه’Œو´ه¯ںهٹ›م€‚ هœ¨ن¹¦ن¸ï¼ŒRiceو•™وژˆé¦–ه…ˆè®²è§£ن؛†و¦‚çژ‡è®؛çڑ„هں؛ç،€ï¼ŒهŒ…و‹¬و¦‚çژ‡çڑ„ه®ڑن¹‰م€پو،ن»¶و¦‚çژ‡م€پ独立...
م€ٹهں؛ن؛ژPythonçڑ„ه†œن¸ڑç»ںè®،و•°وچ®هڈ¯è§†هŒ–ç³»ç»ں设è®،ن¸ژه®çژ°م€‹ وœ¬و–‡وک¯ن¸€ç¯‡ن¸“ن¸؛ن¸“科ه’Œوœ¬ç§‘و¯•ن¸ڑç”ںç¼–ه†™çڑ„هژںهˆ›و¯•ن¸ڑè®؛و–‡ï¼Œو·±ه…¥وژ¢è®¨ن؛†ه¦‚ن½•è؟گ用Python编程è¯è¨€و¥è®¾è®،ه¹¶ه®çژ°ن¸€ن¸ھه†œن¸ڑç»ںè®،و•°وچ®çڑ„هڈ¯è§†هŒ–ç³»ç»ںم€‚该系ç»ںو—¨هœ¨é€ڑè؟‡è‡ھهٹ¨هŒ–وµ‹è¯•م€پ...
و¤ه¤–,ن¹¦ن¸هŒ…هگ«ه¤§é‡ڈçڑ„ن¾‹é¢کهڈٹ详解,ن»¥هڈٹç»ںè®،软ن»¶هŒ…çڑ„ن½؟用ن»‹ç»چ,è؟™ن½؟ه¾—و•™وگن¸چن»…适用ن؛ژه¤§ه¦و•°ه¦م€پç»ںè®،ه¦ç‰ن¸“ن¸ڑçڑ„و•™ه¸ˆه’Œه¦ç”ں,ن¹ںه¯¹هگ„ç±»ن¸“ن¸ڑوٹ€وœ¯ن؛؛ه‘که…·وœ‰ه¾ˆé«کçڑ„هڈ‚考ن»·ه€¼م€‚ هœ¨ç»ںè®،ه¦çڑ„ç ”ç©¶ه’Œه؛”用ن¸ï¼Œè®،ç®—وœ؛وٹ€وœ¯çڑ„ه؛”用وپن¸؛...
ç§‘ç ”ç»ںè®،هˆ†وگوک¯وŒ‡é€ڑè؟‡و”¶é›†م€پو•´çگ†ه’Œهˆ†وگو•°وچ®و¥èژ·هڈ–وœ‰و„ڈن¹‰çڑ„结وœه’Œç»“è®؛,ه¹¶هœ¨ç§‘ه¦ç ”究ن¸هڈ‘وŒ¥é‡چè¦پن½œç”¨م€‚ç§‘ç ”ç»ںè®،هˆ†وگçڑ„هژںçگ†ن¸ژو¥éھ¤هŒ…و‹¬ç§‘ç ”è®¾è®،م€په®éھŒè®¾è®،م€پè°ƒوں¥è®¾è®،م€پو•°وچ®ه¤„ç½®م€پç»ںè®،ه¦هˆ†وگç‰ه‡ ن¸ھو–¹é¢م€‚ ن¸€م€پç§‘ç ”è®¾è®، ...
é€ڑè؟‡وœ¬ن¹¦çڑ„ه¦ن¹ ,读者هڈ¯ن»¥ç³»ç»ںهœ°وژŒوڈ،و¦‚çژ‡è®؛هں؛ç،€م€پو•°وچ®و”¶é›†ن¸ژهˆ†وگو–¹و³•م€پç»ںè®،وژ¨و–ç‰ه†…ه®¹م€‚ #### ن؛Œم€پو ¸ه؟ƒçں¥è¯†ç‚¹è¯¦è§£ ##### 2.1 و¦‚çژ‡è®؛هں؛ç،€ **2.1.1 و ·وœ¬ç©؛é—´** و ·وœ¬ç©؛é—´وک¯وŒ‡ن¸€ن¸ھéڑڈوœ؛ه®éھŒçڑ„و‰€وœ‰هڈ¯èƒ½ç»“وœç»„وˆگçڑ„集هگˆ...