
NFA引擎匹配原理
1 为什么要了解引擎匹配原理
一个个音符杂乱无章的组合在一起,弹奏出的或许就是噪音,同样的音符经过作曲家的手,就可以谱出非常动听的乐曲,一个演奏者同样可以照着乐谱奏出动听的乐曲,但他/她或许不知道该如何去改变音符的组合,使得乐曲更动听。
作为正则的使用者也一样,不懂正则引擎原理的情况下,同样可以写出满足需求的正则,但是不知道原理,却很难写出高效且没有隐患的正则。所以对于经常使用正则,或是有兴趣深入学习正则的人,还是有必要了解一下正则引擎的匹配原理的。
2 正则表达式引擎
正则引擎大体上可分为不同的两类:DFA和NFA,而NFA又基本上可以分为传统型NFA和POSIX NFA。
DFA Deterministic finite automaton 确定型有穷自动机
NFA Non-deterministic finite automaton 非确定型有穷自动机
Traditional NFA
POSIX NFA
DFA引擎因为不需要回溯,所以匹配快速,但不支持捕获组,所以也就不支持反向引用和$number这种引用方式,目前使用DFA引擎的语言和工具主要有awk、egrep 和 lex。
POSIX NFA主要指符合POSIX标准的NFA引擎,它的特点主要是提供longest-leftmost匹配,也就是在找到最左侧最长匹配之前,它将继续回溯。同DFA一样,非贪婪模式或者说忽略优先量词对于POSIX NFA同样是没有意义的。
大多数语言和工具使用的是传统型的NFA引擎,它有一些DFA不支持的特性:
捕获组、反向引用和$number引用方式;
环视(Lookaround,(?<=…)、(?<!…)、(?=…)、(?!…)),或者有的有文章叫做预搜索;
忽略优化量词(??、*?、+?、{m,n}?、{m,}?),或者有的文章叫做非贪婪模式;
占有优先量词(?+、*+、++、{m,n}+、{m,}+,目前仅Java和PCRE支持),固化分组(?>…)。
引擎间的区别不是本文的重点,仅做简要的介绍,有兴趣的可参考相关文献。
3 预备知识
3.1 字符串组成
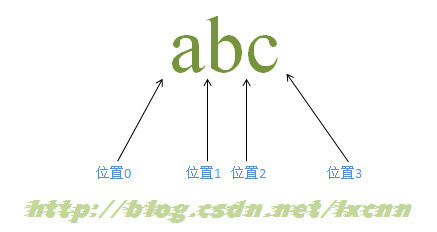
对于字符串“abc”而言,包括三个字符和四个位置。
3.2 占有字符和零宽度
正则表达式匹配过程中,如果子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的。
占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。
3.3 控制权和传动
正则的匹配过程,通常情况下都是由一个子表达式(可能为一个普通字符、元字符或元字符序列组成)取得控制权,从字符串的某一位置开始尝试匹配,一个子表达式开始尝试匹配的位置,是从前一子表达匹配成功的结束位置开始的。如正则表达式:
(子表达式一)(子表达式二)
假设(子表达式一)为零宽度表达式,由于它匹配开始和结束的位置是同一个,如位置0,那么(子表达式二)是从位置0开始尝试匹配的。
假设(子表达式一)为占有字符的表达式,由于它匹配开始和结束的位置不是同一个,如匹配成功开始于位置0,结束于位置2,那么(子表达式二)是从位置2开始尝试匹配的。
而对于整个表达式来说,通常是由字符串位置0开始尝试匹配的。如果在位置0开始的尝试,匹配到字符串某一位置时整个表达式匹配失败,那么引擎会使正则向前传动,整个表达式从位置1开始重新尝试匹配,依此类推,直到报告匹配成功或尝试到最后一个位置后报告匹配失败。
4 正则表达式简单匹配过程
4.1 基础匹配过程
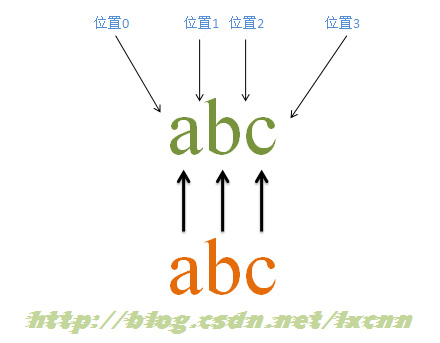
源字符串:abc
正则表达式:abc
匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b”;由于“a”已被“a”匹配,所以“b”从位置1开始尝试匹配,由“b”来匹配“b”,匹配成功,控制权交给“c”;由“c”来匹配“c”,匹配成功。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“abc”,开始位置为0,结束位置为3。
4.2 含有匹配优先量词的匹配过程——匹配成功(一)
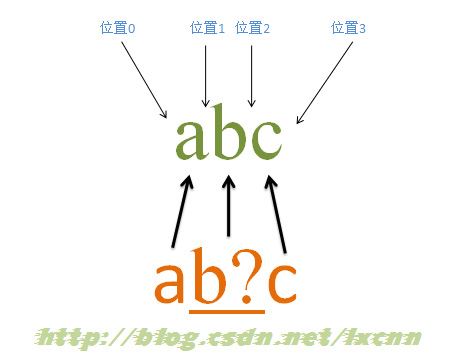
源字符串:abc
正则表达式:ab?c
量词“?”属于匹配优先量词,在可匹配可不匹配时,会先选择尝试匹配,只有这种选择会使整个表达式无法匹配成功时,才会尝试让出匹配到的内容。这里的量词“?”是用来修饰字符“b”的,所以“b?”是一个整体。
匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b?”;由于“?”是匹配优先量词,所以会先尝试进行匹配,由“b?”来匹配“b”,匹配成功,控制权交给“c”,同时记录一个备选状态;由“c”来匹配“c”,匹配成功。记录的备选状态丢弃。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“abc”,开始位置为0,结束位置为3。
4.3 含有匹配优先量词的匹配过程——匹配成功(二)
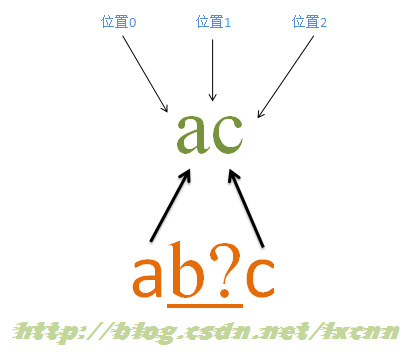
源字符串:ac
正则表达式:ab?c
匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b?”;先尝试进行匹配,由“b?”来匹配“c”,同时记录一个备选状态,匹配失败,此时进行回溯,找到备选状态,“b?”忽略匹配,让出控制权,把控制权交给“c”;由“c”来匹配“c”,匹配成功。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“ac”,开始位置为0,结束位置为2。其中“b?”不匹配任何内容。
4.4 含有匹配优先量词的匹配过程——匹配失败
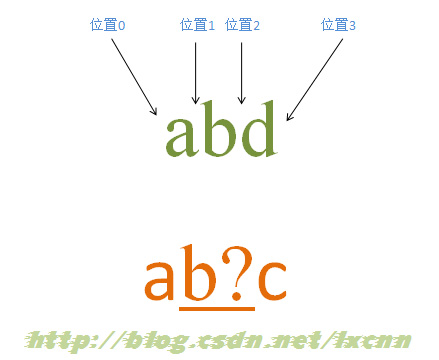
源字符串:abd
正则表达式:ab?c
匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b?”;先尝试进行匹配,由“b?”来匹配“b”,同时记录一个备选状态,匹配成功,控制权交给“c”;由“c”来匹配“d”,匹配失败,此时进行回溯,找到记录的备选状态,“b?”忽略匹配,即“b?”不匹配“b”,让出控制权,把控制权交给“c”;由“c”来匹配“b”,匹配失败。此时第一轮匹配尝试失败。
正则引擎使正则向前传动,由位置1开始尝试匹配,由“a”来匹配“b”,匹配失败,没有备选状态,第二轮匹配尝试失败。
继续向前传动,直到在位置3尝试匹配失败,匹配结束。此时报告整个表达式匹配失败。
4.5 含有忽略优先量词的匹配过程——匹配成功
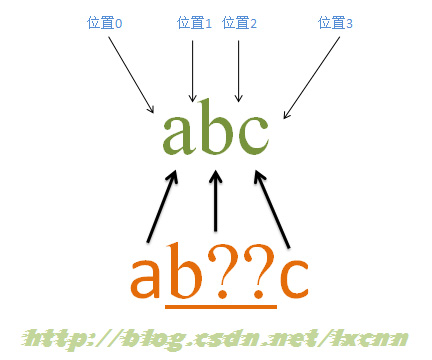
源字符串:abc
正则表达式:ab??c
量词“??”属于忽略优先量词,在可匹配可不匹配时,会先选择不匹配,只有这种选择会使整个表达式无法匹配成功时,才会尝试进行匹配。这里的量词“??”是用来修饰字符“b”的,所以“b??”是一个整体。
匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b??”;先尝试忽略匹配,即“b??”不进行匹配,同时记录一个备选状态,控制权交给“c”;由“c”来匹配“b”,匹配失败,此时进行回溯,找到记录的备选状态,“b??”尝试匹配,即“b??”来匹配“b”,匹配成功,把控制权交给“c”;由“c”来匹配“c”,匹配成功。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“abc”,开始位置为0,结束位置为3。其中“b??”匹配字符“b”。
4.6 零宽度匹配过程
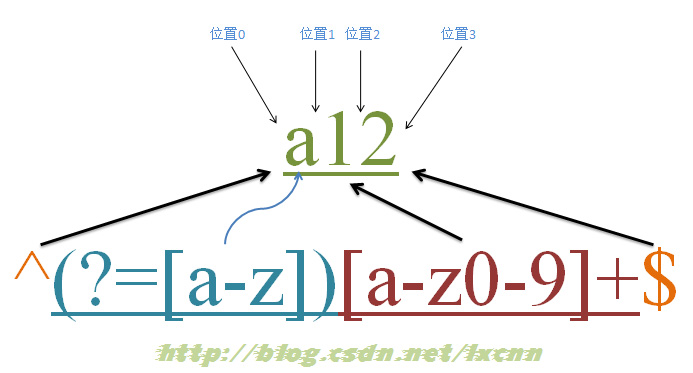
源字符串:a12
正则表达式:^(?=[a-z])[a-z0-9]+$
元字符“^”和“$”匹配的只是位置,顺序环视“(?=[a-z])”只进行匹配,并不占有字符,也不将匹配的内容保存到最终的匹配结果,所以都是零宽度的。
这个正则的意义就是匹配由字母或数字组成的,第一个字符是字母的字符串。
匹配过程:
首先由元字符“^”取得控制权,从位置0开始匹配,“^”匹配的就是开始位置“位置0”,匹配成功,控制权交给顺序环视“(?=[a-z])”;
“(?=[a-z])”要求它所在位置右侧必须是字母才能匹配成功,零宽度的子表达式之间是不互斥的,即同一个位置可以同时由多个零宽度子表达式匹配,所以它也是从位置0尝试进行匹配,位置0的右侧是字符“a”,符合要求,匹配成功,控制权交给“[a-z0-9]+”;
因为“(?=[a-z])”只进行匹配,并不将匹配到的内容保存到最后结果,并且“(?=[a-z])”匹配成功的位置是位置0,所以“[a-z0-9]+”也是从位置0开始尝试匹配的,“[a-z0-9]+”首先尝试匹配“a”,匹配成功,继续尝试匹配,可以成功匹配接下来的“1”和“2”,此时已经匹配到位置3,位置3的右侧已没有字符,这时会把控制权交给“$”;
元字符“$”从位置3开始尝试匹配,它匹配的是结束位置,也就是“位置3”,匹配成功。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“a12”,开始位置为0,结束位置为3。其中“^”匹配位置0,“(?=[a-z])”匹配位置0,“[a-z0-9]+”匹配字符串“a12”,“$”匹配位置3。



相关推荐
本文件“正则基础之——NFA引擎匹配原理.rar”将深入探讨NFA的工作机制。 首先,我们需要理解NFA的基本概念。NFA是一种有向图,每个节点代表一个状态,边则表示状态间的转换。在NFA中,一个输入字符可以引发多个...
正则基础之——NFA引擎匹配原理 在正则表达式中,了解引擎匹配原理是非常重要的。就像音乐家一样,一个人可以演奏出动听的乐曲,但是如果不知道如何去改变音符的组合,乐曲就不会变得更动听。同样,在使用正则...
因此,我建议你先了解正则表达式NFA引擎的匹配原理。想要整理一份易懂易描述的话,的确要费些时间,但不知道这篇内容会不会达到我预期的效果。慢慢完善吧~(注:这是我2010年写的,现在拿过来,有时间将自己做为读者...
2. **改进NFA到DFA转换**:将原有的单个跳转字符和跳转字符区间合并到有序数组列表,以缩短转换时间并提升基于NFA匹配的执行效率。 3. **内存管理**:面对百万级的正则表达式,需要研究如何压缩自动机的内存占用,...
在计算机科学领域,形式语言与自动机理论是理论计算的基础之一。NFA,全称“不确定的有限自动机”(Non-deterministic Finite Automaton),是自动机理论中的一个重要概念。本篇主要围绕NFA的概念、特点以及在Java中...
使用正则表达式匹配文本... 38 向更实用的程序前进... 40 成功匹配的副作用... 40 错综复杂的正则表达式... 43 暂停片刻... 49 使用正则表达式修改文本... 50 例子:公函生成程序... 50 举例:修整股票价格....
1. 匹配算法:正则表达式引擎通常使用两种匹配算法——DFA(确定有限状态自动机)和NFA(非确定有限状态自动机)。DFA效率高,但不支持所有正则表达式特性;NFA支持更多特性,但可能需要更多步骤。 2. 编译与解析:...
非确定性有限状态自动机(NFA)是一种计算模型,用于匹配正则表达式或识别特定的字符串模式。NFA由一系列状态和边构成,每个状态可以通过读取输入字符或者不读取任何字符来转移到另一个状态。与确定性有限状态自动机...
NFA是非确定性的,意味着在给定状态下,对于相同的输入符号,它可以进入多个不同的状态,这使得NFA在处理某些正则表达式时更为灵活。然而,NFA在实际应用中并不常见,因为它可能导致多个无效的词法单元匹配。 相比...
这通常涉及到构建一个NFA,使其能够接受与给定正则表达式匹配的所有字符串。这一过程可以使用多种算法实现,其中一种常见的方式是基于Thompson构造法。 Thompson构造法的基本思想是为正则表达式的每个元素(如字符...
- NFA则是通过正则表达式来匹配文本串,它会尝试多个路径直到找到匹配的结果。 - NFA的缺点是速度相对较慢,因为它需要反复尝试不同的匹配路径;优点是可以提供更多的功能和灵活性。 这两种算法的不同之处体现在...
在本项目中,你需要理解基础的正则表达式语法,如字符类(如[a-z]表示小写字母)、量词(如*、+、?表示重复次数)、分组以及选择符(|)等。 2. **自动机理论**:自动机主要有几种类型,包括确定有限状态自动机...
本文将深入探讨正则表达式中的一个重要概念——回溯,以及它与两种不同的匹配机制:非确定型有穷自动机(NFA)和确定型有穷自动机(DFA)的关系。 在正则表达式中,回溯是一种搜索策略,当遇到多个可能的匹配路径时...
综上所述,《程序设计语言——编译原理》第二章和第三章的内容深入探讨了编译器设计的基础理论,特别是文法分析和自动机理论,这对于理解和开发现代编程语言和编译器系统具有重要意义。通过学习这些核心概念,开发者...
#### 正则表达式到NFA的转换——Thompson构造法 Thompson构造法是一种将正则表达式转换为NFA的算法,具体步骤如下: 1. **分解元素**:将正则表达式r分解为其组成元素,针对每个元素构建基本的NFA结构。 - 对于空...
.NET的正则表达式引擎采用了传统的非确定有限自动机(NFA)实现方式,因此在设计上遵循了Chapters 4、5和6中介绍的基本原理和技术,这些章节涵盖了正则表达式的高级概念和技术。这确保了.NET引擎能够处理复杂的正则...
在正则表达式的匹配过程中,NFA 引擎通常会尝试各种可能的匹配路径,如果匹配失败,就会回溯到之前的某个点重新开始匹配。固化分组通过阻止某些匹配分支的回溯,提高了匹配速度。 - **语法**:`(?>PATTERN)`。 - **...