
гҖҗеҺҹж–Үпјҡhttp://blog.codinglabs.org/articles/consistent-hashing.htmlгҖ‘
ж‘ҳиҰҒ
жң¬ж–Үе°Ҷдјҡд»Һе®һйҷ…еә”з”ЁеңәжҷҜеҮәеҸ‘пјҢд»Ӣз»ҚдёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүеҸҠе…¶еңЁеҲҶеёғејҸзі»з»ҹдёӯзҡ„еә”з”ЁгҖӮйҰ–е…Ҳжң¬ж–ҮдјҡжҸҸиҝ°дёҖдёӘеңЁж—ҘеёёејҖеҸ‘дёӯз»ҸеёёдјҡйҒҮеҲ°зҡ„й—®йўҳеңәжҷҜпјҢеҖҹжӯӨд»Ӣз»ҚдёҖиҮҙжҖ§е“ҲеёҢз®—жі•д»ҘеҸҠиҝҷдёӘз®—жі•еҰӮдҪ•и§ЈеҶіжӯӨй—®йўҳпјӣ жҺҘдёӢжқҘдјҡеҜ№иҝҷдёӘз®—жі•иҝӣиЎҢзӣёеҜ№иҜҰз»Ҷзҡ„жҸҸиҝ°пјҢ并讨и®әдёҖдәӣеҰӮиҷҡжӢҹиҠӮзӮ№зӯүдёҺжӯӨз®—жі•еә”з”Ёзӣёе…ізҡ„иҜқйўҳгҖӮ
еҲҶеёғејҸзј“еӯҳй—®йўҳ
еҒҮи®ҫжҲ‘们жңүдёҖдёӘзҪ‘з«ҷпјҢжңҖиҝ‘еҸ‘зҺ°йҡҸзқҖжөҒйҮҸеўһеҠ пјҢжңҚеҠЎеҷЁеҺӢеҠӣи¶ҠжқҘи¶ҠеӨ§пјҢд№ӢеүҚзӣҙжҺҘиҜ»еҶҷж•°жҚ®еә“зҡ„ж–№ејҸдёҚеӨӘз»ҷеҠӣдәҶпјҢдәҺжҳҜжҲ‘们жғіеј•е…ҘMemcachedдҪңдёәзј“еӯҳжңәеҲ¶гҖӮзҺ°еңЁжҲ‘们дёҖе…ұжңүдёүеҸ°жңәеҷЁеҸҜд»ҘдҪңдёәMemcachedжңҚеҠЎеҷЁпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
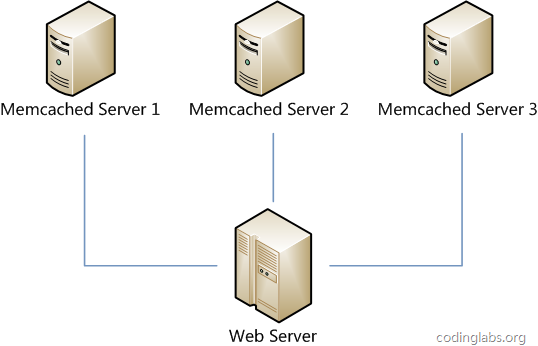
еҫҲжҳҫ然пјҢжңҖз®ҖеҚ•зҡ„зӯ–з•ҘжҳҜе°ҶжҜҸдёҖж¬ЎMemcachedиҜ·жұӮйҡҸжңәеҸ‘йҖҒеҲ°дёҖеҸ°MemcachedжңҚеҠЎеҷЁпјҢдҪҶжҳҜиҝҷз§Қзӯ–з•ҘеҸҜиғҪдјҡеёҰжқҘдёӨдёӘй—®йўҳпјҡдёҖжҳҜеҗҢдёҖд»Ҫж•°жҚ® еҸҜиғҪиў«еӯҳеңЁдёҚеҗҢзҡ„жңәеҷЁдёҠиҖҢйҖ жҲҗж•°жҚ®еҶ—дҪҷпјҢдәҢжҳҜжңүеҸҜиғҪжҹҗж•°жҚ®е·Із»Ҹиў«зј“еӯҳдҪҶжҳҜи®ҝй—®еҚҙжІЎжңүе‘ҪдёӯпјҢеӣ дёәж— жі•дҝқиҜҒеҜ№зӣёеҗҢkeyзҡ„жүҖжңүи®ҝй—®йғҪиў«еҸ‘йҖҒеҲ°зӣёеҗҢзҡ„жңҚеҠЎеҷЁгҖӮеӣ жӯӨпјҢйҡҸжңәзӯ–з•Ҙж— и®әжҳҜж—¶й—ҙж•ҲзҺҮиҝҳжҳҜз©әй—ҙж•ҲзҺҮйғҪйқһеёёдёҚеҘҪгҖӮ
иҰҒи§ЈеҶідёҠиҝ°й—®йўҳеҸӘйңҖеҒҡеҲ°еҰӮдёӢдёҖзӮ№пјҡдҝқиҜҒеҜ№зӣёеҗҢkeyзҡ„и®ҝй—®дјҡиў«еҸ‘йҖҒеҲ°зӣёеҗҢзҡ„жңҚеҠЎеҷЁгҖӮеҫҲеӨҡж–№жі•еҸҜд»Ҙе®һзҺ°иҝҷдёҖзӮ№пјҢжңҖеёёз”Ёзҡ„ж–№жі•жҳҜи®Ўз®—е“ҲеёҢгҖӮдҫӢеҰӮеҜ№дәҺжҜҸж¬Ўи®ҝй—®пјҢеҸҜд»ҘжҢүеҰӮдёӢз®—жі•и®Ўз®—е…¶е“ҲеёҢеҖјпјҡ
h = Hash(key) % 3
е…¶дёӯHashжҳҜдёҖдёӘд»Һеӯ—з¬ҰдёІеҲ°жӯЈж•ҙж•°зҡ„е“ҲеёҢжҳ е°„еҮҪж•°гҖӮиҝҷж ·пјҢеҰӮжһңжҲ‘们е°ҶMemcached ServerеҲҶеҲ«зј–еҸ·дёә0гҖҒ1гҖҒ2пјҢйӮЈд№Ҳе°ұеҸҜд»Ҙж №жҚ®дёҠејҸе’Ңkeyи®Ўз®—еҮәжңҚеҠЎеҷЁзј–еҸ·hпјҢ然еҗҺеҺ»и®ҝй—®гҖӮ
иҝҷдёӘж–№жі•иҷҪ然解еҶідәҶдёҠйқўжҸҗеҲ°зҡ„дёӨдёӘй—®йўҳпјҢдҪҶжҳҜеӯҳеңЁдёҖдәӣе…¶е®ғзҡ„й—®йўҳгҖӮеҰӮжһңе°ҶдёҠиҝ°ж–№жі•жҠҪиұЎпјҢеҸҜд»Ҙи®ӨдёәйҖҡиҝҮпјҡ
h = Hash(key) % N
иҝҷдёӘз®—ејҸи®Ўз®—жҜҸдёӘkeyзҡ„иҜ·жұӮеә”иҜҘиў«еҸ‘йҖҒеҲ°е“ӘеҸ°жңҚеҠЎеҷЁпјҢе…¶дёӯNдёәжңҚеҠЎеҷЁзҡ„еҸ°ж•°пјҢ并且жңҚеҠЎеҷЁжҢүз…§0 вҖ“ (N-1)зј–еҸ·гҖӮ
иҝҷдёӘз®—жі•зҡ„й—®йўҳеңЁдәҺе®№й”ҷжҖ§е’Ңжү©еұ•жҖ§дёҚеҘҪгҖӮжүҖи°“е®№й”ҷжҖ§жҳҜжҢҮеҪ“зі»з»ҹдёӯжҹҗдёҖдёӘжҲ–еҮ дёӘжңҚеҠЎеҷЁеҸҳеҫ—дёҚеҸҜз”Ёж—¶пјҢж•ҙдёӘзі»з»ҹжҳҜеҗҰеҸҜд»ҘжӯЈзЎ®й«ҳж•ҲиҝҗиЎҢпјӣиҖҢжү©еұ•жҖ§жҳҜжҢҮеҪ“еҠ е…Ҙж–°зҡ„жңҚеҠЎеҷЁеҗҺпјҢж•ҙдёӘзі»з»ҹжҳҜеҗҰеҸҜд»ҘжӯЈзЎ®й«ҳж•ҲиҝҗиЎҢгҖӮ
зҺ°еҒҮи®ҫжңүдёҖеҸ°жңҚеҠЎеҷЁе®•жңәдәҶпјҢйӮЈд№ҲдёәдәҶеЎ«иЎҘз©әзјәпјҢиҰҒе°Ҷе®•жңәзҡ„жңҚеҠЎеҷЁд»Һзј–еҸ·еҲ—иЎЁдёӯ移йҷӨпјҢеҗҺйқўзҡ„жңҚеҠЎеҷЁжҢүйЎәеәҸеүҚ移дёҖдҪҚ并е°Ҷе…¶зј–еҸ·еҖјеҮҸдёҖпјҢжӯӨж—¶жҜҸдёӘkeyе°ұ иҰҒжҢүh = Hash(key) % (N-1)йҮҚж–°и®Ўз®—пјӣеҗҢж ·пјҢеҰӮжһңж–°еўһдәҶдёҖеҸ°жңҚеҠЎеҷЁпјҢиҷҪ然еҺҹжңүжңҚеҠЎеҷЁзј–еҸ·дёҚз”Ёж”№еҸҳпјҢдҪҶжҳҜиҰҒжҢүh = Hash(key) % (N+1)йҮҚж–°и®Ўз®—е“ҲеёҢеҖјгҖӮеӣ жӯӨзі»з»ҹдёӯдёҖж—ҰжңүжңҚеҠЎеҷЁеҸҳжӣҙпјҢеӨ§йҮҸзҡ„keyдјҡиў«йҮҚе®ҡдҪҚеҲ°дёҚеҗҢзҡ„жңҚеҠЎеҷЁд»ҺиҖҢйҖ жҲҗеӨ§йҮҸзҡ„зј“еӯҳдёҚе‘ҪдёӯгҖӮиҖҢиҝҷз§Қжғ…еҶөеңЁеҲҶеёғејҸзі»з»ҹдёӯжҳҜйқһ еёёзіҹзі•зҡ„гҖӮ
дёҖдёӘи®ҫи®ЎиүҜеҘҪзҡ„еҲҶеёғејҸе“ҲеёҢж–№жЎҲеә”иҜҘе…·жңүиүҜеҘҪзҡ„еҚ•и°ғжҖ§пјҢеҚіжңҚеҠЎиҠӮзӮ№зҡ„еўһеҮҸдёҚдјҡйҖ жҲҗеӨ§йҮҸе“ҲеёҢйҮҚе®ҡдҪҚгҖӮдёҖиҮҙжҖ§е“ҲеёҢз®—жі•е°ұжҳҜиҝҷж ·дёҖз§Қе“ҲеёҢж–№жЎҲгҖӮ
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•
з®—жі•з®Җиҝ°
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүжңҖж—©еңЁи®әж–ҮгҖҠConsistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide WebгҖӢдёӯиў«жҸҗеҮәгҖӮз®ҖеҚ•жқҘиҜҙпјҢдёҖиҮҙжҖ§е“ҲеёҢе°Ҷж•ҙдёӘе“ҲеёҢеҖјз©әй—ҙз»„з»ҮжҲҗдёҖдёӘиҷҡжӢҹзҡ„еңҶзҺҜпјҢеҰӮеҒҮи®ҫжҹҗе“ҲеёҢеҮҪж•°Hзҡ„еҖјз©әй—ҙдёә0 - 232-1пјҲеҚіе“ҲеёҢеҖјжҳҜдёҖдёӘ32дҪҚж— з¬ҰеҸ·ж•ҙеҪўпјүпјҢж•ҙдёӘе“ҲеёҢз©әй—ҙзҺҜеҰӮдёӢпјҡ
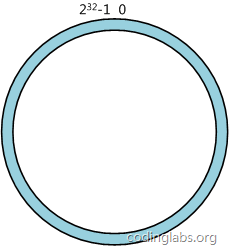
ж•ҙдёӘз©әй—ҙжҢүйЎәж—¶й’Ҳж–№еҗ‘з»„з»ҮгҖӮ0е’Ң232-1еңЁйӣ¶зӮ№дёӯж–№еҗ‘йҮҚеҗҲгҖӮ
дёӢдёҖжӯҘе°Ҷеҗ„дёӘжңҚеҠЎеҷЁдҪҝз”ЁHиҝӣиЎҢдёҖдёӘе“ҲеёҢпјҢе…·дҪ“еҸҜд»ҘйҖүжӢ©жңҚеҠЎеҷЁзҡ„ipжҲ–дё»жңәеҗҚдҪңдёәе…ій”®еӯ—иҝӣиЎҢе“ҲеёҢпјҢиҝҷж ·жҜҸеҸ°жңәеҷЁе°ұиғҪзЎ®е®ҡе…¶еңЁе“ҲеёҢзҺҜдёҠзҡ„дҪҚзҪ®пјҢиҝҷйҮҢеҒҮи®ҫе°ҶдёҠж–ҮдёӯдёүеҸ°жңҚеҠЎеҷЁдҪҝз”Ёipең°еқҖе“ҲеёҢеҗҺеңЁзҺҜз©әй—ҙзҡ„дҪҚзҪ®еҰӮдёӢпјҡ
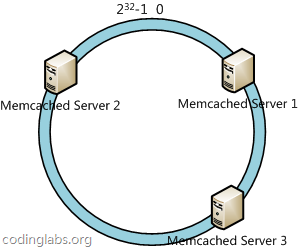
жҺҘдёӢжқҘдҪҝз”ЁеҰӮдёӢз®—жі•е®ҡдҪҚж•°жҚ®и®ҝй—®еҲ°зӣёеә”жңҚеҠЎеҷЁпјҡе°Ҷж•°жҚ®keyдҪҝз”ЁзӣёеҗҢзҡ„еҮҪж•°Hи®Ўз®—еҮәе“ҲеёҢеҖјhпјҢйҖҡж №жҚ®hзЎ®е®ҡжӯӨж•°жҚ®еңЁзҺҜдёҠзҡ„дҪҚзҪ®пјҢд»ҺжӯӨдҪҚзҪ®жІҝзҺҜйЎәж—¶й’ҲвҖңиЎҢиө°вҖқпјҢ第дёҖеҸ°йҒҮеҲ°зҡ„жңҚеҠЎеҷЁе°ұжҳҜе…¶еә”иҜҘе®ҡдҪҚеҲ°зҡ„жңҚеҠЎеҷЁгҖӮ
дҫӢеҰӮжҲ‘们жңүAгҖҒBгҖҒCгҖҒDеӣӣдёӘж•°жҚ®еҜ№иұЎпјҢз»ҸиҝҮе“ҲеёҢи®Ўз®—еҗҺпјҢеңЁзҺҜз©әй—ҙдёҠзҡ„дҪҚзҪ®еҰӮдёӢпјҡ
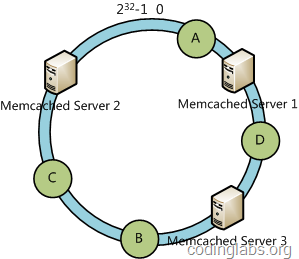
ж №жҚ®дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҢж•°жҚ®Aдјҡиў«е®ҡдёәеҲ°Server 1дёҠпјҢDиў«е®ҡдёәеҲ°Server 3дёҠпјҢиҖҢBгҖҒCеҲҶеҲ«иў«е®ҡдёәеҲ°Server 2дёҠгҖӮ
е®№й”ҷжҖ§дёҺеҸҜжү©еұ•жҖ§еҲҶжһҗ
дёӢйқўеҲҶжһҗдёҖиҮҙжҖ§е“ҲеёҢз®—жі•зҡ„е®№й”ҷжҖ§е’ҢеҸҜжү©еұ•жҖ§гҖӮзҺ°еҒҮи®ҫServer 3е®•жңәдәҶпјҡ
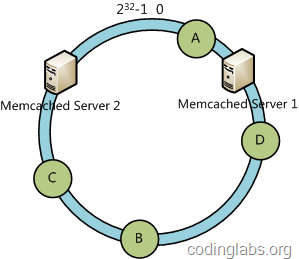
еҸҜд»ҘзңӢеҲ°жӯӨж—¶AгҖҒCгҖҒBдёҚдјҡеҸ—еҲ°еҪұе“ҚпјҢеҸӘжңүDиҠӮзӮ№иў«йҮҚе®ҡдҪҚеҲ°Server 2гҖӮдёҖиҲ¬зҡ„пјҢеңЁдёҖиҮҙжҖ§е“ҲеёҢз®—жі•дёӯпјҢеҰӮжһңдёҖеҸ°жңҚеҠЎеҷЁдёҚеҸҜз”ЁпјҢеҲҷеҸ—еҪұе“Қзҡ„ж•°жҚ®д»…д»…жҳҜжӯӨжңҚеҠЎеҷЁеҲ°е…¶зҺҜз©әй—ҙдёӯеүҚдёҖеҸ°жңҚеҠЎеҷЁпјҲеҚійЎәзқҖйҖҶж—¶й’Ҳж–№еҗ‘иЎҢиө°йҒҮеҲ°зҡ„第дёҖеҸ°жңҚеҠЎеҷЁпјүд№Ӣй—ҙж•°жҚ®пјҢе…¶е®ғдёҚдјҡеҸ—еҲ°еҪұе“ҚгҖӮ
дёӢйқўиҖғиҷ‘еҸҰеӨ–дёҖз§Қжғ…еҶөпјҢеҰӮжһңжҲ‘们еңЁзі»з»ҹдёӯеўһеҠ дёҖеҸ°жңҚеҠЎеҷЁMemcached Server 4пјҡ
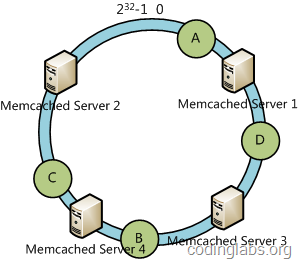
жӯӨж—¶AгҖҒDгҖҒCдёҚеҸ—еҪұе“ҚпјҢеҸӘжңүBйңҖиҰҒйҮҚе®ҡдҪҚеҲ°ж–°зҡ„Server 4гҖӮдёҖиҲ¬зҡ„пјҢеңЁдёҖиҮҙжҖ§е“ҲеёҢз®—жі•дёӯпјҢеҰӮжһңеўһеҠ дёҖеҸ°жңҚеҠЎеҷЁпјҢеҲҷеҸ—еҪұе“Қзҡ„ж•°жҚ®д»…д»…жҳҜж–°жңҚеҠЎеҷЁеҲ°е…¶зҺҜз©әй—ҙдёӯеүҚдёҖеҸ°жңҚеҠЎеҷЁпјҲеҚійЎәзқҖйҖҶж—¶й’Ҳж–№еҗ‘иЎҢиө°йҒҮеҲ°зҡ„第дёҖеҸ°жңҚеҠЎеҷЁпјүд№Ӣй—ҙж•°жҚ®пјҢе…¶е®ғдёҚдјҡеҸ—еҲ°еҪұе“ҚгҖӮ
з»јдёҠжүҖиҝ°пјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•еҜ№дәҺиҠӮзӮ№зҡ„еўһеҮҸйғҪеҸӘйңҖйҮҚе®ҡдҪҚзҺҜз©әй—ҙдёӯзҡ„дёҖе°ҸйғЁеҲҶж•°жҚ®пјҢе…·жңүиҫғеҘҪзҡ„е®№й”ҷжҖ§е’ҢеҸҜжү©еұ•жҖ§гҖӮ
иҷҡжӢҹиҠӮзӮ№
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•еңЁжңҚеҠЎиҠӮзӮ№еӨӘе°‘ж—¶пјҢе®№жҳ“еӣ дёәиҠӮзӮ№еҲҶйғЁдёҚеқҮеҢҖиҖҢйҖ жҲҗж•°жҚ®еҖҫж–ңй—®йўҳгҖӮдҫӢеҰӮжҲ‘们зҡ„зі»з»ҹдёӯжңүдёӨеҸ°жңҚеҠЎеҷЁпјҢе…¶зҺҜеҲҶеёғеҰӮдёӢпјҡ
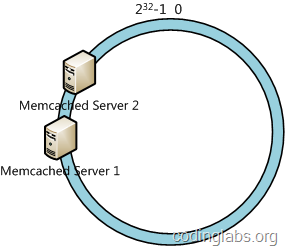
жӯӨж—¶еҝ…然йҖ жҲҗеӨ§йҮҸж•°жҚ®йӣҶдёӯеҲ°Server 1дёҠпјҢиҖҢеҸӘжңүжһҒе°‘йҮҸдјҡе®ҡдҪҚеҲ°Server 2дёҠгҖӮдёәдәҶи§ЈеҶіиҝҷз§Қж•°жҚ®еҖҫж–ңй—®йўҳпјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•еј•е…ҘдәҶиҷҡжӢҹиҠӮзӮ№жңәеҲ¶пјҢеҚіеҜ№жҜҸдёҖдёӘжңҚеҠЎиҠӮзӮ№и®Ўз®—еӨҡдёӘе“ҲеёҢпјҢжҜҸдёӘи®Ўз®—з»“жһңдҪҚзҪ®йғҪж”ҫзҪ®дёҖдёӘжӯӨжңҚеҠЎиҠӮзӮ№пјҢз§°дёәиҷҡжӢҹ иҠӮзӮ№гҖӮе…·дҪ“еҒҡжі•еҸҜд»ҘеңЁжңҚеҠЎеҷЁipжҲ–дё»жңәеҗҚзҡ„еҗҺйқўеўһеҠ зј–еҸ·жқҘе®һзҺ°гҖӮдҫӢеҰӮдёҠйқўзҡ„жғ…еҶөпјҢжҲ‘们еҶіе®ҡдёәжҜҸеҸ°жңҚеҠЎеҷЁи®Ўз®—дёүдёӘиҷҡжӢҹиҠӮзӮ№пјҢдәҺжҳҜеҸҜд»ҘеҲҶеҲ«и®Ўз®— вҖңMemcached Server 1#1вҖқгҖҒвҖңMemcached Server 1#2вҖқгҖҒвҖңMemcached Server 1#3вҖқгҖҒвҖңMemcached Server 2#1вҖқгҖҒвҖңMemcached Server 2#2вҖқгҖҒвҖңMemcached Server 2#3вҖқзҡ„е“ҲеёҢеҖјпјҢдәҺжҳҜеҪўжҲҗе…ӯдёӘиҷҡжӢҹиҠӮзӮ№пјҡ
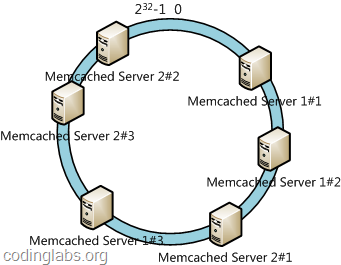
еҗҢж—¶ж•°жҚ®е®ҡдҪҚз®—жі•дёҚеҸҳпјҢеҸӘжҳҜеӨҡдәҶдёҖжӯҘиҷҡжӢҹиҠӮзӮ№еҲ°е®һйҷ…иҠӮзӮ№зҡ„жҳ е°„пјҢдҫӢеҰӮе®ҡдҪҚеҲ°вҖңMemcached Server 1#1вҖқгҖҒвҖңMemcached Server 1#2вҖқгҖҒвҖңMemcached Server 1#3вҖқдёүдёӘиҷҡжӢҹиҠӮзӮ№зҡ„ж•°жҚ®еқҮе®ҡдҪҚеҲ°Server 1дёҠгҖӮиҝҷж ·е°ұи§ЈеҶідәҶжңҚеҠЎиҠӮзӮ№е°‘ж—¶ж•°жҚ®еҖҫж–ңзҡ„й—®йўҳгҖӮеңЁе®һйҷ…еә”з”ЁдёӯпјҢйҖҡеёёе°ҶиҷҡжӢҹиҠӮзӮ№ж•°и®ҫзҪ®дёә32з”ҡиҮіжӣҙеӨ§пјҢеӣ жӯӨеҚідҪҝеҫҲе°‘зҡ„жңҚеҠЎиҠӮзӮ№д№ҹиғҪеҒҡеҲ°зӣёеҜ№еқҮеҢҖзҡ„ж•°жҚ®еҲҶ еёғгҖӮ
жҖ»з»“
зӣ®еүҚдёҖиҮҙжҖ§е“ҲеёҢеҹәжң¬жҲҗдёәдәҶеҲҶеёғејҸзі»з»ҹ组件зҡ„ж ҮеҮҶй…ҚзҪ®пјҢдҫӢеҰӮMemcachedзҡ„еҗ„з§Қе®ўжҲ·з«ҜйғҪжҸҗдҫӣеҶ…зҪ®зҡ„дёҖиҮҙжҖ§е“ҲеёҢж”ҜжҢҒгҖӮжң¬ж–ҮеҸӘжҳҜз®ҖиҰҒд»Ӣз»ҚдәҶиҝҷдёӘз®—жі•пјҢжӣҙж·ұе…Ҙзҡ„еҶ…е®№еҸҜд»ҘеҸӮзңӢи®әж–ҮгҖҠConsistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide WebгҖӢпјҢеҗҢж—¶жҸҗдҫӣдёҖдёӘCиҜӯиЁҖзүҲжң¬зҡ„е®һзҺ°дҫӣеҸӮиҖғгҖӮ



зӣёе…іжҺЁиҚҗ
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯз”ЁдәҺи§ЈеҶіж•°жҚ®еҲҶеҸ‘е’ҢиҙҹиҪҪеқҮиЎЎй—®йўҳзҡ„з®—жі•гҖӮйҡҸзқҖдә’иҒ”зҪ‘жҠҖжңҜзҡ„еҝ«йҖҹеҸ‘еұ•пјҢеҲҶеёғејҸзі»з»ҹе·Із»ҸжҲҗдёәж”Ҝж’‘еӨ§и§„жЁЎжңҚеҠЎзҡ„е…ій”®жҠҖжңҜд№ӢдёҖгҖӮеңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢеӨҡдёӘиҠӮзӮ№йҖҡиҝҮзҪ‘з»ңеҚҸеҗҢе·ҘдҪңпјҢжҸҗдҫӣй«ҳеҸҜз”ЁжҖ§...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жңҖеҲқз”ұйә»зңҒзҗҶе·ҘеӯҰйҷўзҡ„KзӯүдәәжҸҗеҮәпјҢ并被е№ҝжіӣеә”з”ЁдәҺеҲҶеёғејҸзі»з»ҹдёӯпјҢд»Ҙи§ЈеҶіиҠӮзӮ№еҠЁжҖҒеҸҳеҢ–ж—¶ж•°жҚ®дёҖиҮҙжҖ§й—®йўҳгҖӮе…¶ж ёеҝғжҖқжғіжҳҜйҖҡиҝҮеј•е…Ҙе“ҲеёҢзҺҜпјҢе°Ҷж•°жҚ®еҜ№иұЎеқҮеҢҖеҲҶеёғеңЁе“ҲеёҢзҺҜдёҠзҡ„дёҚеҗҢиҠӮзӮ№дёӯпјҢд»ҘжӯӨйҷҚдҪҺиҠӮзӮ№еҸҳжӣҙеҜ№...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜеңЁеҲҶеёғејҸзі»з»ҹдёӯе№ҝжіӣдҪҝз”Ёзҡ„дёҖз§Қж•°жҚ®е®ҡдҪҚз®—жі•пјҢе°Өе…¶йҖӮз”ЁдәҺеҲҶеёғејҸзј“еӯҳзі»з»ҹпјҢеҰӮRedisгҖӮдј з»ҹзҡ„е“ҲеёҢз®—жі•еңЁеҲҶеёғејҸеӯҳеӮЁзі»з»ҹдёӯжңүдёҖдёӘзјәзӮ№пјҢеҚіеҪ“зі»з»ҹжү©еұ•жҲ–зј©еҮҸиҠӮзӮ№ж—¶пјҢж•°жҚ®зҡ„иҝҒ移йҮҸиҝҮеӨ§гҖӮдёҖиҮҙжҖ§е“ҲеёҢз®—жі•йҖҡиҝҮ...
з»јдёҠжүҖиҝ°пјҢжң¬ж–ҮйҖҡиҝҮеҜ№дёҖиҮҙжҖ§е“ҲеёҢз®—жі•еҸҠе…¶еңЁеҲҶеёғејҸж•°жҚ®еә“жү©еұ•дёӯзҡ„еә”з”ЁиҝӣиЎҢж·ұе…Ҙз ”з©¶пјҢжҲҗеҠҹжҸҗеҮәдәҶдёҖз§Қй«ҳж•Ҳжү©еұ•зҡ„ж–№жЎҲгҖӮиҜҘж–№жЎҲйҖҡиҝҮеҗҲзҗҶеҲ©з”Ёйў„з•ҷеӯҗеҲҶеҢәиҜҶеҲ«дҪҚе’ҢCRC32ж ЎйӘҢжҠҖжңҜпјҢжҳҫи‘—жҸҗй«ҳдәҶж•°жҚ®еә“жү©еұ•зҡ„йҖҹеәҰе’ҢиҙЁйҮҸпјҢеҜ№дәҺ...
жң¬ж–Үе°ҶиҜҰз»Ҷд»Ӣз»ҚдёҖиҮҙжҖ§е“ҲеёҢзҡ„жҰӮеҝөгҖҒеҺҹзҗҶд»ҘеҸҠеңЁеҲҶеёғејҸзі»з»ҹдёӯзҡ„еә”з”ЁгҖӮ дёҖиҮҙжҖ§е“ҲеёҢдёәеҲҶеёғејҸзі»з»ҹжҸҗдҫӣдәҶдёҖз§Қй«ҳж•Ҳдё”зҒөжҙ»зҡ„ж•°жҚ®еҲҶеёғжңәеҲ¶гҖӮйҖҡиҝҮжң¬ж–Үзҡ„д»Ӣз»ҚпјҢжҲ‘们еӯҰд№ дәҶдёҖиҮҙжҖ§е“ҲеёҢзҡ„жҰӮеҝөгҖҒеҺҹзҗҶгҖҒеә”з”ЁеңәжҷҜд»ҘеҸҠеҰӮдҪ•е®һзҺ°е®ғгҖӮдёҖиҮҙ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•з”ұDavid KargerзӯүдәәеңЁ1997е№ҙжҸҗеҮәпјҢе®ғжҳҜдёҖз§Қзү№ж®Ҡзҡ„е“ҲеёҢз®—жі•пјҢдё»иҰҒз”ЁдәҺеҲҶеёғејҸзі»з»ҹдёӯе®һзҺ°иҙҹиҪҪеқҮиЎЎгҖӮдёҺдј з»ҹзҡ„е“ҲеёҢз®—жі•дёҚеҗҢпјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•еңЁеӨ„зҗҶиҠӮзӮ№еўһеҮҸж—¶пјҢиғҪеӨҹжңҖе°ҸеҢ–йҮҚж–°еҲҶй…Қж•°жҚ®зҡ„ж•°йҮҸпјҢд»ҺиҖҢжҸҗй«ҳзі»з»ҹ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢпјҲDistributed Hash Table, DHTпјүжҠҖжңҜпјҢе®ғи§ЈеҶідәҶеңЁеҲҶеёғејҸзҺҜеўғдёӯж•°жҚ®еҲҶзүҮе’ҢиҙҹиҪҪеқҮиЎЎзҡ„й—®йўҳгҖӮеңЁдј з»ҹзҡ„е“ҲеёҢз®—жі•дёӯпјҢеҰӮжһңеўһеҠ жҲ–еҮҸе°‘жңҚеҠЎеҷЁиҠӮзӮ№пјҢдјҡеҜјиҮҙеӨ§йҮҸж•°жҚ®йҮҚж–°еҲҶй…ҚпјҢиҖҢдёҖиҮҙжҖ§е“ҲеёҢ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯи§ЈеҶіж•°жҚ®еҲҶзүҮе’ҢиҙҹиҪҪеқҮиЎЎй—®йўҳзҡ„з®—жі•пјҢе®ғдё»иҰҒи§ЈеҶідәҶеңЁеҠЁжҖҒж·»еҠ жҲ–移йҷӨиҠӮзӮ№ж—¶пјҢе°ҪеҸҜиғҪе°‘ең°ж”№еҸҳе·Із»ҸеӯҳеңЁзҡ„ж•°жҚ®еҲҶеёғгҖӮеңЁдә‘и®Ўз®—е’ҢеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹпјҢдёҖиҮҙжҖ§е“ҲеёҢиў«е№ҝжіӣеә”з”ЁпјҢдҫӢеҰӮеңЁеҲҶеёғејҸ...
1. **дёҖиҮҙжҖ§е“ҲеёҢз®—жі•**пјҡдёҖиҮҙжҖ§е“ҲеёҢжҳҜдёҖз§Қи§ЈеҶіеҲҶеёғејҸзі»з»ҹдёӯж•°жҚ®еҲҶеёғй—®йўҳзҡ„з®—жі•пјҢе®ғзҡ„дё»иҰҒзү№зӮ№жҳҜиғҪеӨҹе°ҪеҸҜиғҪең°еҮҸе°‘ж•°жҚ®иҝҒ移гҖӮеңЁWebSocketжңҚеҠЎзҡ„еҲҶеёғејҸжү©еұ•дёӯпјҢдёҖиҮҙжҖ§е“ҲеёҢз”ЁдәҺзЎ®е®ҡжҜҸдёӘиҝһжҺҘеә”иҜҘи·Ҝз”ұеҲ°е“ӘдёӘжңҚеҠЎеҷЁпјҢдҪҝеҫ—еңЁ...
жҖ»зҡ„жқҘиҜҙпјҢKetamaдёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜеҲҶеёғејҸзі»з»ҹдёӯи§ЈеҶіж•°жҚ®еҲҶеёғй—®йўҳзҡ„йҮҚиҰҒе·Ҙе…·пјҢйҖҡиҝҮе·§еҰҷзҡ„и®ҫи®Ўе®һзҺ°дәҶеңЁиҠӮзӮ№еҸҳеҢ–ж—¶е°ҪеҸҜиғҪе°‘зҡ„ж•°жҚ®иҝҒ移пјҢжҸҗй«ҳдәҶзі»з»ҹзҡ„зЁіе®ҡжҖ§е’Ңжү©еұ•жҖ§гҖӮйҖҡиҝҮж·ұе…ҘзҗҶ解并иҝҗз”Ёиҝҷз§Қз®—жі•пјҢжҲ‘们еҸҜд»Ҙжһ„е»әжӣҙеҠ еҒҘеЈ®...
йҖҡиҝҮиҝҗиЎҢжӯӨйЎ№зӣ®пјҢдҪ еҸҜд»ҘзңӢеҲ°йҡҸзқҖиҠӮзӮ№ж•°йҮҸзҡ„еҸҳеҢ–пјҢж•°жҚ®йЎ№зҡ„еҲҶеёғеҰӮдҪ•еҠЁжҖҒи°ғж•ҙпјҢиҝҷжңүеҠ©дәҺж·ұе…ҘзҗҶи§ЈдёҖиҮҙжҖ§е“ҲеёҢз®—жі•еңЁе®һйҷ…еә”з”Ёдёӯзҡ„д»·еҖјгҖӮжӯӨеӨ–пјҢC#иҜӯиЁҖзҡ„е®һзҺ°дҪҝеҫ—д»Јз Ғжҳ“дәҺйҳ…иҜ»е’ҢеӯҰд№ пјҢеҜ№дәҺзҶҹжӮүжҲ–жғіиҰҒеӯҰд№ C#зј–зЁӢзҡ„дәәжқҘиҜҙпјҢиҝҷ...
еңЁе®һйҷ…зҡ„еҲҶеёғејҸзі»з»ҹдёӯпјҢеҰӮCDNзҪ‘з»ңгҖҒеҲҶеёғејҸзј“еӯҳзі»з»ҹзӯүпјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•еҫ—еҲ°дәҶе№ҝжіӣеә”з”ЁгҖӮдҫӢеҰӮпјҢеңЁCDNзҺҜеўғдёӯпјҢйҖҡиҝҮдёҖиҮҙжҖ§е“ҲеёҢз®—жі•еҸҜд»Ҙе°Ҷз”ЁжҲ·иҜ·жұӮи·Ҝз”ұеҲ°жңҖиҝ‘зҡ„жңҚеҠЎеҷЁпјҢдёҚд»…еҮҸе°‘дәҶзҪ‘з»ң延иҝҹпјҢиҝҳе®һзҺ°дәҶиө„жәҗзҡ„й«ҳж•ҲеҲ©з”ЁгҖӮ ##...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүжҳҜдёҖз§Қеёёз”ЁдәҺеҲҶеёғејҸзі»з»ҹдёӯзҡ„ж•°жҚ®еҲҶзүҮзӯ–з•ҘпјҢе®ғжңүж•Ҳең°и§ЈеҶідәҶж•°жҚ®еңЁеӨҡеҸ°жңҚеҠЎеҷЁй—ҙеқҮеҢҖеҲҶеёғзҡ„й—®йўҳпјҢеҗҢж—¶еҮҸе°‘дәҶеӣ иҠӮзӮ№еҠ е…ҘжҲ–зҰ»ејҖж—¶зҡ„ж•°жҚ®иҝҒ移жҲҗжң¬гҖӮ йҰ–е…ҲпјҢдёҖиҮҙжҖ§е“ҲеёҢзҡ„еҹәжң¬еҺҹзҗҶжҳҜе°Ҷ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүжҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯе®һзҺ°иҙҹиҪҪеқҮиЎЎзҡ„з®—жі•пјҢе°Өе…¶еңЁеҲҶеёғејҸзј“еӯҳеҰӮMemcachedе’ҢRedisзӯүеңәжҷҜдёӢе№ҝжіӣдҪҝз”ЁгҖӮе®ғи§ЈеҶідәҶдј з»ҹе“ҲеёҢз®—жі•еңЁиҠӮзӮ№еўһеҮҸж—¶еҜјиҮҙзҡ„еӨ§йҮҸж•°жҚ®иҝҒ移问йўҳпјҢжҸҗй«ҳдәҶзі»з»ҹзҡ„еҸҜз”Ё...
MycatдёҖиҮҙжҖ§е“ҲеёҢз®—жі•е№ҝжіӣеә”з”ЁдәҺеҲҶеёғејҸзј“еӯҳгҖҒиҙҹиҪҪеқҮиЎЎгҖҒж•°жҚ®еә“еҲҶзүҮзӯүеңәжҷҜпјҢзү№еҲ«жҳҜеңЁеӨ§ж•°жҚ®гҖҒй«ҳ并еҸ‘зҡ„дә’иҒ”зҪ‘еә”з”ЁдёӯпјҢиғҪеӨҹжңүж•ҲжҸҗеҚҮзі»з»ҹзҡ„еӨ„зҗҶиғҪеҠӣе’ҢзЁіе®ҡжҖ§гҖӮ жҖ»з»“пјҢMycatзҡ„дёҖиҮҙжҖ§е“ҲеёҢеҲҶзүҮз®—жі•жҳҜе®һзҺ°й«ҳж•ҲеҲҶеёғејҸж•°жҚ®еә“зҡ„...
2. **иҝӣзЁӢй—ҙйҖҡдҝЎ**пјҡеҲҶеёғејҸзі»з»ҹдёӯзҡ„иҠӮзӮ№йңҖиҰҒжңүж•Ҳең°дәӨжҚўдҝЎжҒҜпјҢиҝҷе°ұж¶үеҸҠеҲ°дәҶеҗ„з§ҚиҝӣзЁӢй—ҙйҖҡдҝЎжңәеҲ¶пјҢеҢ…жӢ¬ж¶ҲжҒҜдј йҖ’гҖҒиҝңзЁӢиҝҮзЁӢи°ғз”Ё(RPC)гҖҒз®ЎйҒ“гҖҒеҘ—жҺҘеӯ—зӯүгҖӮзҗҶи§ЈиҝҷдәӣйҖҡдҝЎжңәеҲ¶зҡ„еҺҹзҗҶе’ҢдјҳзјәзӮ№иҮіе…ійҮҚиҰҒгҖӮ 3. **еҲҶеёғејҸдёҖиҮҙжҖ§...
еңЁдәҶи§ЈдёҖиҮҙжҖ§е“ҲеёҢз®—жі•д№ӢеүҚпјҢйңҖиҰҒдәҶи§ЈдёҖдёӘз»Ҹе…ёзҡ„еҲҶеёғејҸзј“еӯҳеә”з”ЁеңәжҷҜгҖӮеҒҮи®ҫпјҢжҲ‘们жңүдёүеҸ°зј“еӯҳжңҚеҠЎеҷЁпјҢз”ЁдәҺзј“еӯҳеӣҫзүҮпјҢжҲ‘们еёҢжңӣиҝҷдәӣеӣҫзүҮиў«еқҮеҢҖзҡ„зј“еӯҳеңЁиҝҷдёүеҸ°жңҚеҠЎеҷЁдёҠпјҢд»Ҙдҫҝе®ғ们иғҪеӨҹеҲҶж‘Ҡзј“еӯҳзҡ„еҺӢеҠӣгҖӮйӮЈд№ҲпјҢжҲ‘们еә”иҜҘжҖҺж ·еҒҡ...