sichunli_030
- 浏览: 649676 次
- 性别:

- 来自: 北京
-

文章分类
- 全部博客 (820)
- java开发 (110)
- 数据库 (56)
- javascript (30)
- 生活、哲理 (17)
- jquery (36)
- 杂谈 (15)
- linux (62)
- spring (52)
- kafka (11)
- http协议 (22)
- 架构 (18)
- ZooKeeper (18)
- eclipse (13)
- ngork (2)
- dubbo框架 (6)
- Mybatis (10)
- 缓存 (28)
- maven (20)
- MongoDB (3)
- 设计模式 (3)
- shiro (10)
- taokeeper (1)
- 锁和多线程 (3)
- Tomcat7集群 (12)
- Nginx (34)
- nodejs (1)
- MDC (1)
- Netty (7)
- solr (15)
- JSON (8)
- rabbitmq (32)
- disconf (7)
- PowerDesigne (0)
- Spring Boot (31)
- 日志系统 (6)
- erlang (2)
- Swagger (3)
- 测试工具 (3)
- docker (17)
- ELK (2)
- TCC分布式事务 (2)
- marathon (12)
- phpMyAdmin (12)
- git (3)
- Atomix (1)
- Calico (1)
- Lua (7)
- 泛解析 (2)
- OpenResty (2)
- spring mvc (19)
- 前端 (3)
- spring cloud (15)
- Netflix (1)
- zipkin (3)
- JVM 内存模型 (5)
- websocket (1)
- Eureka (4)
- apollo (2)
- idea (2)
- go (1)
- 业务 (0)
- idea开发工具 (1)
最新评论
-
sichunli_030:
对于频繁调用的话,建议采用连接池机制
配置TOMCAT及httpClient的keepalive以高效利用长连接 -
11想念99不见:
你好,我看不太懂。假如我的项目中会频繁调用rest接口,是要用 ...
配置TOMCAT及httpClient的keepalive以高效利用长连接
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。Zookeeper是hadoop的一个子项目,其发展历程无需赘述。在分布式应用中,由于工程师不能很好地使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,因此需要有一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。Zookeeper的目的就在于此。本文简单分析zookeeper的工作原理,对于如何使用zookeeper不是本文讨论的重点
1 Zookeeper的基本概念
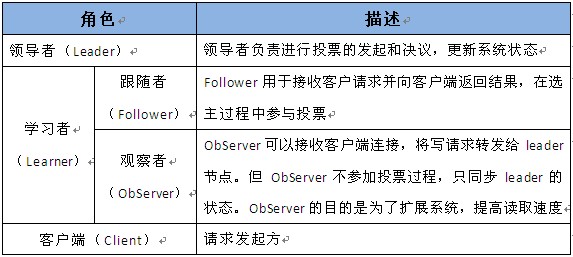
1.1 角色
Zookeeper中的角色主要有以下三类,如下表所示:
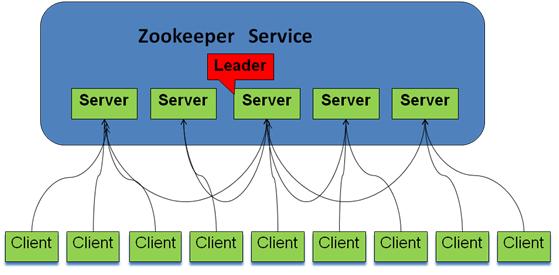
系统模型如图所示:
1.2 设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2 .可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
3 .实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4 .等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6 .顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
2 ZooKeeper的工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
2.1 选主流程
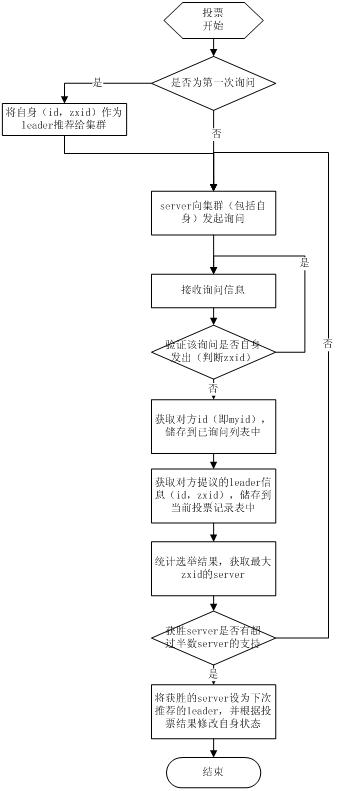
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。先介绍basic paxos流程:
1 .选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2 .选举线程首先向所有Server发起一次询问(包括自己);
3 .选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4. 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5. 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1.
每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。选主的具体流程图如下所示:
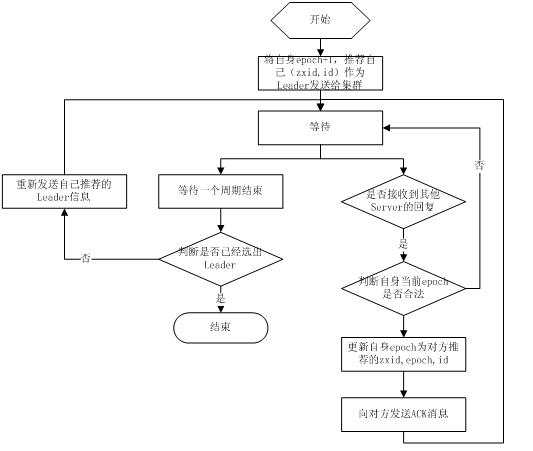
fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。其流程图如下所示:
2.2 同步流程
选完leader以后,zk就进入状态同步过程。
1. leader等待server连接;
2 .Follower连接leader,将最大的zxid发送给leader;
3 .Leader根据follower的zxid确定同步点;
4 .完成同步后通知follower 已经成为uptodate状态;
5 .Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。
流程图如下所示:

2.3 工作流程
2.3.1 Leader工作流程
Leader主要有三个功能:
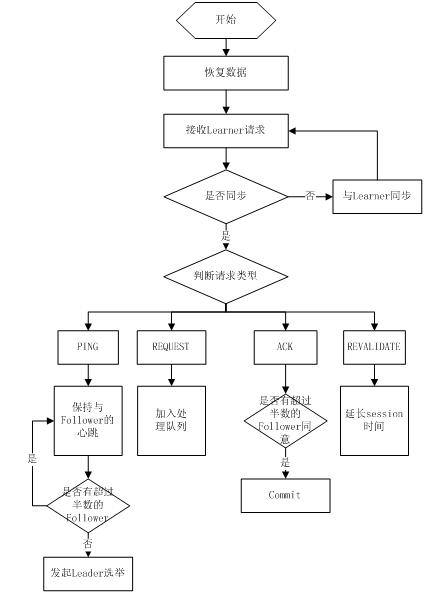
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING消息是指Learner的心跳信息;REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;ACK消息是Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间。
Leader的工作流程简图如下所示,在实际实现中,流程要比下图复杂得多,启动了三个线程来实现功能。
参考:http://cailin.iteye.com/blog/2014486/
1 Zookeeper的基本概念
1.1 角色
Zookeeper中的角色主要有以下三类,如下表所示:
系统模型如图所示:
1.2 设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2 .可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
3 .实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4 .等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6 .顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
2 ZooKeeper的工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
2.1 选主流程
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。先介绍basic paxos流程:
1 .选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2 .选举线程首先向所有Server发起一次询问(包括自己);
3 .选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4. 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5. 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1.
每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。选主的具体流程图如下所示:
fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。其流程图如下所示:
2.2 同步流程
选完leader以后,zk就进入状态同步过程。
1. leader等待server连接;
2 .Follower连接leader,将最大的zxid发送给leader;
3 .Leader根据follower的zxid确定同步点;
4 .完成同步后通知follower 已经成为uptodate状态;
5 .Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。
流程图如下所示:
2.3 工作流程
2.3.1 Leader工作流程
Leader主要有三个功能:
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING消息是指Learner的心跳信息;REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;ACK消息是Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间。
Leader的工作流程简图如下所示,在实际实现中,流程要比下图复杂得多,启动了三个线程来实现功能。
参考:http://cailin.iteye.com/blog/2014486/
分享到:


发表评论

-
Zookeeper的四字命令
2017-05-18 20:39 566http://www.cnblogs.com/wuxl360/ ... -
Zookeeper开源客户端框架Curator简介
2016-10-25 08:43 517ZooKeeper原生的API支持通过注册Watcher来进行 ... -
Curator Framework的基本使用方法
2016-10-21 15:17 1083Curator Framework提供了简化使用zookeep ... -
ZooKeeper学习总结
2016-09-30 15:18 422参考:http://www.tuicool.com/artic ... -
推荐一个zookeeper信息查看工具
2016-08-31 16:01 1703zookeeper信息查看工具 下载地址:https://i ... -
Paxos算法细节详解(一)--通过现实世界描述算法
2016-08-24 16:29 555http://www.cnblogs.com/endsock/ ... -
ZooKeeper学习总结 第一篇:ZooKeeper快速入门
2016-08-22 16:23 435http://www.cnblogs.com/leocook/ ... -
zookeeper客户端curator使用手记
2016-08-09 15:10 471http://www.tuicool.com/articles ... -
Zookeeper的一致性协议:Zab
2016-08-01 09:21 670Zookeeper使用了一种称为Zab(Zookeeper A ... -
ZooKeeper源码阅读(一):ZAB协议
2016-07-29 14:29 687ZooKeeper内部有一个in-memo ... -
Zookeeper基本原理与应用场景
2016-07-28 18:51 326http://blog.csdn.net/yunpiao123 ... -
一步一步理解Paxos算法
2016-07-21 14:34 620背景 Paxos算法是Lamport� ... -
Paxos算法简述
2016-07-21 14:10 396Paxos算法是分布式中一个著名的一致性算法。它的假设前提是, ... -
Zookeeper-Zookeeper leader选举
2016-07-20 09:05 539在上一篇文章中我们大� ... -
部署与管理ZooKeeper(转)
2016-07-19 09:17 382http://www.cnblogs.com/ggjuchen ... -
ZooKeeper原理及使用
2016-08-02 08:27 420ZooKeeper是Hadoop Ecosystem中非常重要 ... -
ZooKeeper Java API
2016-05-22 10:05 896ZooKeeper提供了Java和C的binding. 本文关 ...
相关推荐
### ZooKeeper原理及其在Hadoop和HBase中的应用 #### ZooKeeper概述 ZooKeeper是一个由雅虎开发的开源分布式协调服务系统,旨在为分布式应用提供一致性和可靠性支持。它是Google Chubby系统的开源版本,主要功能...
Zookeeper原理及应用 Zookeeper是一个分布式服务框架,由Apache Hadoop子项目组成,它提供了可靠的协调系统,可以解决分布式环境中的数据管理问题,如统一命名服务、状态同步服务、集群管理、分布式应用配置项的...
ZooKeeper原理与实战 PPT内容
Zookeeper入门及其原理介绍以及一些简单的应用
### 深入分析Zookeeper实现原理 #### 初识Zookeeper 在深入了解Zookeeper之前,我们先简要介绍下Zookeeper以及它所处的分布式环境的一些特点。 **分布式环境的特点:** - **分布性:** 系统由多个通过网络连接的...
《从Paxos到Zookeeper分布式一致性原理与实践》是一本深入探讨分布式系统一致性问题的著作,其中重点讲解了Paxos算法与Zookeeper在实际应用中的理论与实践。Paxos是分布式计算领域中著名的共识算法,为解决分布式...
从Paxos到Zookeeper 分布式一致性原理与实践 倪超,完整版
ZooKeeper技术原理与应用 ZooKeeper是一种分布式协调服务,用于维护和监控存储数据状态的变化,解决分布式集群中应用程序的一致性问题。 ZooKeeper的核心是原子广播机制,保障了各个Server之间的同步。 ZooKeeper...
Zookeeper 搭建和原理学习 Zookeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现。它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理...
" Zookeeper 的通俗原理解释" Zookeeper 是基于 Paxos 算法实现的分布式协调服务,它提供了高可用、高性能、可扩展的解决方案。下面我们将通过一个通俗的例子来解释 Paxos 算法的原理和 Zookeeper 的实现机制。 ...
### 分布式一致性原理与实践:从Paxos到Zookeeper #### 一、引言 随着互联网技术的发展,分布式系统已经成为现代软件架构的核心组成部分。在分布式系统中,多个节点协同工作来完成复杂的任务,而如何确保这些节点...
《Paxos到Zookeeper——分布式一致性原理与实践》是一本深入探讨分布式一致性问题的书籍,对于理解并应用Zookeeper这一关键的分布式协调系统具有重要价值。本书旨在帮助读者掌握分布式环境中的数据一致性原理,并...
ZooKeeper是一个广泛使用的开源分布式协调服务,由雅虎开发,其设计灵感来源于Google的Chubby系统。它的主要目标是为分布式应用...理解并熟练掌握ZooKeeper的工作原理和配置对于构建和维护高可用的分布式系统至关重要。
Apache ZooKeeper 是一个分布式协调服务,它为分布式应用程序提供了一个简单、高效且高度可靠的系统。Zookeeper 提供了命名服务、配置管理、集群同步、分布式锁等核心功能,广泛应用于大数据处理、微服务架构和...
从Paxos到Zookeeper 分布式一致性原理与实践
#### 四、Zookeeper的工作原理 1. **客户端与服务器交互**: - 客户端通过网络连接到任意一台服务器,并与其建立Session。 - Session的维持依赖于心跳包,如果服务器在一定时间内没有接收到客户端的心跳,则认为...
从Paxos到Zookeeper:分布式一致性原理与实践,适合分布式系统各阶段学习,并对分布式架构有深入的理解与提高
### Zookeeper的核心原理 #### 分布式一致性解决方案 Zookeeper本质上是一个分布式数据一致性解决方案。它通过对复杂且容易出错的分布式一致性服务进行封装,形成一套高效可靠的操作原语集合,并通过简单易用的接口...