sichunli_030
- жөҸи§Ҳ: 649666 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

ж–Үз« еҲҶзұ»
- е…ЁйғЁеҚҡе®ў (820)
- javaејҖеҸ‘ (110)
- ж•°жҚ®еә“ (56)
- javascript (30)
- з”ҹжҙ»гҖҒе“ІзҗҶ (17)
- jquery (36)
- жқӮи°Ҳ (15)
- linux (62)
- spring (52)
- kafka (11)
- httpеҚҸи®® (22)
- жһ¶жһ„ (18)
- ZooKeeper (18)
- eclipse (13)
- ngork (2)
- dubboжЎҶжһ¶ (6)
- Mybatis (10)
- зј“еӯҳ (28)
- maven (20)
- MongoDB (3)
- и®ҫи®ЎжЁЎејҸ (3)
- shiro (10)
- taokeeper (1)
- й”Ғе’ҢеӨҡзәҝзЁӢ (3)
- Tomcat7йӣҶзҫӨ (12)
- Nginx (34)
- nodejs (1)
- MDC (1)
- Netty (7)
- solr (15)
- JSON (8)
- rabbitmq (32)
- disconf (7)
- PowerDesigne (0)
- Spring Boot (31)
- ж—Ҙеҝ—зі»з»ҹ (6)
- erlang (2)
- Swagger (3)
- жөӢиҜ•е·Ҙе…· (3)
- docker (17)
- ELK (2)
- TCCеҲҶеёғејҸдәӢеҠЎ (2)
- marathon (12)
- phpMyAdmin (12)
- git (3)
- Atomix (1)
- Calico (1)
- Lua (7)
- жіӣи§Јжһҗ (2)
- OpenResty (2)
- spring mvc (19)
- еүҚз«Ҝ (3)
- spring cloud (15)
- Netflix (1)
- zipkin (3)
- JVM еҶ…еӯҳжЁЎеһӢ (5)
- websocket (1)
- Eureka (4)
- apollo (2)
- idea (2)
- go (1)
- дёҡеҠЎ (0)
- ideaејҖеҸ‘е·Ҙе…· (1)
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2024-12 ( 1)
- 2024-02 ( 1)
- 2024-01 ( 1)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
sichunli_030пјҡ
еҜ№дәҺйў‘з№Ғи°ғз”Ёзҡ„иҜқпјҢе»әи®®йҮҮз”ЁиҝһжҺҘжұ жңәеҲ¶
й…ҚзҪ®TOMCATеҸҠhttpClientзҡ„keepaliveд»Ҙй«ҳж•ҲеҲ©з”Ёй•ҝиҝһжҺҘ -
11жғіеҝө99дёҚи§Ғпјҡ
дҪ еҘҪпјҢжҲ‘зңӢдёҚеӨӘжҮӮгҖӮеҒҮеҰӮжҲ‘зҡ„йЎ№зӣ®дёӯдјҡйў‘з№Ғи°ғз”ЁrestжҺҘеҸЈпјҢжҳҜиҰҒз”Ё ...
й…ҚзҪ®TOMCATеҸҠhttpClientзҡ„keepaliveд»Ҙй«ҳж•ҲеҲ©з”Ёй•ҝиҝһжҺҘ
ZooKeeperеҶ…йғЁжңүдёҖдёӘin-memory DBпјҢиЎЁзӨәдёәдёҖдёӘж ‘еҪўз»“жһ„гҖӮжҜҸдёӘж ‘иҠӮзӮ№з§°дёәZnode(зӣёе…ізҡ„д»Јз ҒеңЁDataTree.javaе’ҢDataNode.javaдёӯ)
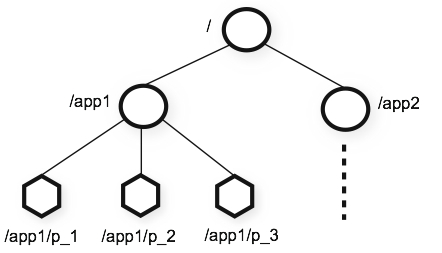
е®ўжҲ·з«ҜеҸҜд»ҘиҝһжҺҘеҲ°zookeeperйӣҶзҫӨдёӯзҡ„д»»ж„ҸдёҖеҸ°гҖӮ
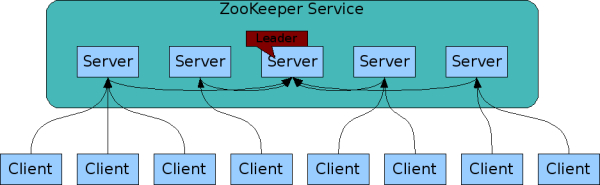
еҜ№дәҺиҜ»иҜ·жұӮпјҢзӣҙжҺҘиҝ”еӣһжң¬ең°znodeж•°жҚ®гҖӮеҶҷж“ҚдҪңеҲҷиҪ¬жҚўдёәдёҖдёӘдәӢеҠЎпјҢ并иҪ¬еҸ‘еҲ°йӣҶзҫӨзҡ„LeaderеӨ„зҗҶгҖӮZookeeperжҸҗдәӨдәӢеҠЎдҝқиҜҒеҶҷж“ҚдҪң(жӣҙж–°)еҜ№дәҺzookeeperйӣҶзҫӨжүҖжңүжңәеҷЁйғҪжҳҜдёҖиҮҙзҡ„гҖӮ
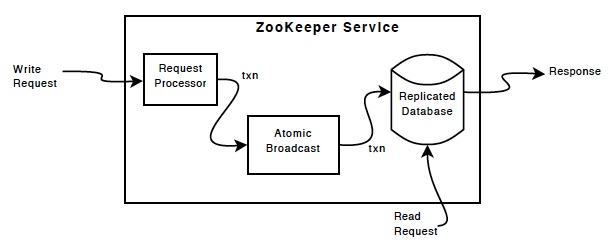
ZooKeeperдёӯжҸҗдәӨдәӢеҠЎзҡ„еҚҸ议并дёҚжҳҜPaxosпјҢиҖҢжҳҜз”ұдәҢйҳ¶ж®өжҸҗдәӨеҚҸи®®ж”№зј–зҡ„ZABеҚҸи®®гҖӮ
ZabеҸҜд»Ҙж»Ўи¶ід»ҘдёӢзү№жҖ§
Reliable deliveryпјҡеҰӮжһңж¶ҲжҒҜmиў«дёҖдёӘserverйҖ’дәӨ(commit)дәҶпјҢйӮЈд№Ҳmд№ҹе°ҶжңҖз»Ҳиў«жүҖжңүserverйҖ’дәӨгҖӮ
Total orderпјҡеҰӮжһңserverеңЁйҖ’дәӨbд№ӢеүҚйҖ’дәӨдәҶaпјҢйӮЈд№ҲжүҖжңүйҖ’дәӨдәҶaгҖҒbзҡ„serverд№ҹдјҡеңЁйҖ’дәӨbд№ӢеүҚйҖ’дәӨaгҖӮ
Casual orderпјҡеҜ№дәҺдёӨдёӘйҖ’дәӨдәҶзҡ„ж¶ҲжҒҜaгҖҒbпјҢеҰӮжһңaеӣ жһңе…ізі»дјҳе…ҲдәҺ(causally precedes)bпјҢйӮЈд№Ҳaе°ҶеңЁbд№ӢеүҚйҖ’дәӨгҖӮ
第дёүжқЎзҡ„еӣ жһңдјҳе…ҲжҢҮзҡ„жҳҜеҗҢдёҖдёӘеҸ‘йҖҒиҖ…еҸ‘йҖҒзҡ„дёӨдёӘж¶ҲжҒҜaе…ҲдәҺbеҸ‘йҖҒпјҢжҲ–иҖ…дёҠдёҖдёӘleaderеҸ‘йҖҒзҡ„ж¶ҲжҒҜaе…ҲдәҺеҪ“еүҚleaderеҸ‘йҖҒзҡ„ж¶ҲжҒҜгҖӮ
ZabеҚҸи®®дёӯServerжңүдёӨдёӘжЁЎејҸпјҡbroadcastжЁЎејҸгҖҒrecoveryжЁЎејҸ(Leaderе®•жңәжҲ–followerдёҚжһ„жҲҗquorum)
LeaderеңЁејҖе§Ӣbroadcastд№ӢеүҚпјҢеҝ…йЎ»жңүдёҖдёӘеҗҢжӯҘжӣҙж–°иҝҮзҡ„followerзҡ„quorum(еӨҡж•°жҙҫ)гҖӮ
ServerеңЁLeaderжңҚеҠЎжңҹй—ҙжҒўеӨҚеңЁзәҝж—¶пјҢе°Ҷиҝӣе…ҘrecoveryжЁЎејҸпјҢдёҺLeaderиҝӣиЎҢеҗҢжӯҘгҖӮ
BroadcastжЁЎејҸдҪҝз”ЁдәҢйҳ¶ж®өжҸҗдәӨпјҢдҪҶжҳҜз®ҖеҢ–дәҶеҚҸи®®пјҢдёҚйңҖиҰҒabortгҖӮfollowerиҰҒд№ҲackпјҢиҰҒд№ҲжҠӣејғLeaderпјҢеӣ дёәzookeeperдҝқиҜҒдәҶжҜҸж¬ЎеҸӘжңүдёҖдёӘLeaderгҖӮеҸҰеӨ–д№ҹдёҚйңҖиҰҒзӯүеҫ…жүҖжңүServerзҡ„ACKпјҢеҸӘйңҖиҰҒдёҖдёӘquorumеә”зӯ”е°ұеҸҜд»ҘдәҶгҖӮ
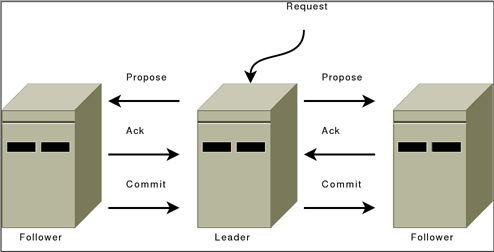
Follower收еҲ°proposalеҗҺпјҢеҶҷеҲ°зЈҒзӣҳ(е°ҪеҸҜиғҪжү№еӨ„зҗҶ)пјҢиҝ”еӣһACKгҖӮ
Leader收еҲ°еӨ§еӨҡж•°ACKеҗҺпјҢе№ҝж’ӯCOMMITж¶ҲжҒҜпјҢиҮӘе·ұд№ҹdeliverиҜҘж¶ҲжҒҜгҖӮ
Follower收еҲ°COMMITд№ӢеҗҺпјҢdeliverиҜҘж¶ҲжҒҜгҖӮ
然иҖҢпјҢиҝҷдёӘз®ҖеҢ–зҡ„дәҢйҳ¶ж®өжҸҗдәӨдёҚиғҪеӨ„зҗҶLeaderеӨұж•Ҳзҡ„жғ…еҶөпјҢжүҖд»ҘеўһеҠ дәҶrecoveryжЁЎејҸгҖӮеҲҮжҚўLeaderж—¶пјҢйңҖиҰҒи§ЈеҶідёӢйқўдёӨдёӘй—®йўҳгҖӮ
Never forget delivered messages
LeaderеңЁCOMMITжҠ•йҖ’еҲ°д»»дҪ•дёҖеҸ°followerд№ӢеүҚе®•жңәпјҢеҸӘжңүе®ғиҮӘе·ұcommitдәҶгҖӮж–°Leaderеҝ…йЎ»дҝқиҜҒиҝҷдёӘдәӢеҠЎд№ҹеҝ…йЎ»commitгҖӮ
Let go of messages that are skipped
Leaderдә§з”ҹжҹҗдёӘproposalпјҢдҪҶжҳҜеңЁе®•жңәд№ӢеүҚпјҢжІЎжңүfollowerзңӢеҲ°иҝҷдёӘproposalгҖӮиҜҘserverжҒўеӨҚж—¶пјҢеҝ…йЎ»дёўејғиҝҷдёӘproposalгҖӮ
ж–°LeaderеңЁproposeж–°ж¶ҲжҒҜд№ӢеүҚпјҢеҝ…йЎ»дҝқиҜҒдәӢеҠЎж—Ҙеҝ—дёӯзҡ„жүҖжңүж¶ҲжҒҜйғҪproposed并且committedгҖӮ
дёәдәҶдҝқиҜҒfollowerзңӢеҲ°жңүproposalпјҢд»ҘеҸҠйҖ’дәӨзҡ„ж¶ҲжҒҜпјҢLeaderеҗ‘followerеҸ‘йҖҒfollowerжІЎжңүи§ҒиҝҮзҡ„PROPOSALпјҢд»ҘеҸҠжңҖеҗҺжҸҗдәӨзҡ„ж¶ҲжҒҜзҡ„зј–еҸ·д№ӢеүҚзҡ„COMMITгҖӮ
еӣ дёәProposalжҳҜдҝқеӯҳеңЁfollowerзҡ„дәӢеҠЎж—Ҙеҝ—дёӯпјҢ并且йЎәеәҸжңүдҝқиҜҒпјҢеӣ жӯӨCOMMITзҡ„йЎәеәҸд№ҹжҳҜзЎ®е®ҡзҡ„гҖӮи§ЈеҶізҡ„第дёҖдёӘй—®йўҳгҖӮ
дёҠдёӘжІЎжңүжҠҠproposalеҸ‘йҖҒеҮәеҺ»зҡ„LeaderйҮҚеҗҜеҗҺпјҢж–°Leaderе°Ҷе‘ҠиҜүе®ғжҲӘж–ӯдәӢеҠЎж—Ҙеҝ—пјҢдёҖзӣҙжҲӘж–ӯеҲ°followerзҡ„epochеҜ№еә”зҡ„жңҖеҗҺдёҖдёӘcommitдҪҚзҪ®гҖӮ
е…ідәҺZABзҡ„иҜҰз»ҶиҜҒжҳҺеҸҜд»ҘеҸӮиҖғZab - High-performance broadcast for primary-backup systems
еҸӮиҖғ:http://blog.csdn.net/m_vptr/article/details/9325405
е®ўжҲ·з«ҜеҸҜд»ҘиҝһжҺҘеҲ°zookeeperйӣҶзҫӨдёӯзҡ„д»»ж„ҸдёҖеҸ°гҖӮ
еҜ№дәҺиҜ»иҜ·жұӮпјҢзӣҙжҺҘиҝ”еӣһжң¬ең°znodeж•°жҚ®гҖӮеҶҷж“ҚдҪңеҲҷиҪ¬жҚўдёәдёҖдёӘдәӢеҠЎпјҢ并иҪ¬еҸ‘еҲ°йӣҶзҫӨзҡ„LeaderеӨ„зҗҶгҖӮZookeeperжҸҗдәӨдәӢеҠЎдҝқиҜҒеҶҷж“ҚдҪң(жӣҙж–°)еҜ№дәҺzookeeperйӣҶзҫӨжүҖжңүжңәеҷЁйғҪжҳҜдёҖиҮҙзҡ„гҖӮ
ZooKeeperдёӯжҸҗдәӨдәӢеҠЎзҡ„еҚҸ议并дёҚжҳҜPaxosпјҢиҖҢжҳҜз”ұдәҢйҳ¶ж®өжҸҗдәӨеҚҸи®®ж”№зј–зҡ„ZABеҚҸи®®гҖӮ
ZabеҸҜд»Ҙж»Ўи¶ід»ҘдёӢзү№жҖ§
Reliable deliveryпјҡеҰӮжһңж¶ҲжҒҜmиў«дёҖдёӘserverйҖ’дәӨ(commit)дәҶпјҢйӮЈд№Ҳmд№ҹе°ҶжңҖз»Ҳиў«жүҖжңүserverйҖ’дәӨгҖӮ
Total orderпјҡеҰӮжһңserverеңЁйҖ’дәӨbд№ӢеүҚйҖ’дәӨдәҶaпјҢйӮЈд№ҲжүҖжңүйҖ’дәӨдәҶaгҖҒbзҡ„serverд№ҹдјҡеңЁйҖ’дәӨbд№ӢеүҚйҖ’дәӨaгҖӮ
Casual orderпјҡеҜ№дәҺдёӨдёӘйҖ’дәӨдәҶзҡ„ж¶ҲжҒҜaгҖҒbпјҢеҰӮжһңaеӣ жһңе…ізі»дјҳе…ҲдәҺ(causally precedes)bпјҢйӮЈд№Ҳaе°ҶеңЁbд№ӢеүҚйҖ’дәӨгҖӮ
第дёүжқЎзҡ„еӣ жһңдјҳе…ҲжҢҮзҡ„жҳҜеҗҢдёҖдёӘеҸ‘йҖҒиҖ…еҸ‘йҖҒзҡ„дёӨдёӘж¶ҲжҒҜaе…ҲдәҺbеҸ‘йҖҒпјҢжҲ–иҖ…дёҠдёҖдёӘleaderеҸ‘йҖҒзҡ„ж¶ҲжҒҜaе…ҲдәҺеҪ“еүҚleaderеҸ‘йҖҒзҡ„ж¶ҲжҒҜгҖӮ
ZabеҚҸи®®дёӯServerжңүдёӨдёӘжЁЎејҸпјҡbroadcastжЁЎејҸгҖҒrecoveryжЁЎејҸ(Leaderе®•жңәжҲ–followerдёҚжһ„жҲҗquorum)
LeaderеңЁејҖе§Ӣbroadcastд№ӢеүҚпјҢеҝ…йЎ»жңүдёҖдёӘеҗҢжӯҘжӣҙж–°иҝҮзҡ„followerзҡ„quorum(еӨҡж•°жҙҫ)гҖӮ
ServerеңЁLeaderжңҚеҠЎжңҹй—ҙжҒўеӨҚеңЁзәҝж—¶пјҢе°Ҷиҝӣе…ҘrecoveryжЁЎејҸпјҢдёҺLeaderиҝӣиЎҢеҗҢжӯҘгҖӮ
BroadcastжЁЎејҸдҪҝз”ЁдәҢйҳ¶ж®өжҸҗдәӨпјҢдҪҶжҳҜз®ҖеҢ–дәҶеҚҸи®®пјҢдёҚйңҖиҰҒabortгҖӮfollowerиҰҒд№ҲackпјҢиҰҒд№ҲжҠӣејғLeaderпјҢеӣ дёәzookeeperдҝқиҜҒдәҶжҜҸж¬ЎеҸӘжңүдёҖдёӘLeaderгҖӮеҸҰеӨ–д№ҹдёҚйңҖиҰҒзӯүеҫ…жүҖжңүServerзҡ„ACKпјҢеҸӘйңҖиҰҒдёҖдёӘquorumеә”зӯ”е°ұеҸҜд»ҘдәҶгҖӮ
Follower收еҲ°proposalеҗҺпјҢеҶҷеҲ°зЈҒзӣҳ(е°ҪеҸҜиғҪжү№еӨ„зҗҶ)пјҢиҝ”еӣһACKгҖӮ
Leader收еҲ°еӨ§еӨҡж•°ACKеҗҺпјҢе№ҝж’ӯCOMMITж¶ҲжҒҜпјҢиҮӘе·ұд№ҹdeliverиҜҘж¶ҲжҒҜгҖӮ
Follower收еҲ°COMMITд№ӢеҗҺпјҢdeliverиҜҘж¶ҲжҒҜгҖӮ
然иҖҢпјҢиҝҷдёӘз®ҖеҢ–зҡ„дәҢйҳ¶ж®өжҸҗдәӨдёҚиғҪеӨ„зҗҶLeaderеӨұж•Ҳзҡ„жғ…еҶөпјҢжүҖд»ҘеўһеҠ дәҶrecoveryжЁЎејҸгҖӮеҲҮжҚўLeaderж—¶пјҢйңҖиҰҒи§ЈеҶідёӢйқўдёӨдёӘй—®йўҳгҖӮ
Never forget delivered messages
LeaderеңЁCOMMITжҠ•йҖ’еҲ°д»»дҪ•дёҖеҸ°followerд№ӢеүҚе®•жңәпјҢеҸӘжңүе®ғиҮӘе·ұcommitдәҶгҖӮж–°Leaderеҝ…йЎ»дҝқиҜҒиҝҷдёӘдәӢеҠЎд№ҹеҝ…йЎ»commitгҖӮ
Let go of messages that are skipped
Leaderдә§з”ҹжҹҗдёӘproposalпјҢдҪҶжҳҜеңЁе®•жңәд№ӢеүҚпјҢжІЎжңүfollowerзңӢеҲ°иҝҷдёӘproposalгҖӮиҜҘserverжҒўеӨҚж—¶пјҢеҝ…йЎ»дёўејғиҝҷдёӘproposalгҖӮ
ж–°LeaderеңЁproposeж–°ж¶ҲжҒҜд№ӢеүҚпјҢеҝ…йЎ»дҝқиҜҒдәӢеҠЎж—Ҙеҝ—дёӯзҡ„жүҖжңүж¶ҲжҒҜйғҪproposed并且committedгҖӮ
дёәдәҶдҝқиҜҒfollowerзңӢеҲ°жңүproposalпјҢд»ҘеҸҠйҖ’дәӨзҡ„ж¶ҲжҒҜпјҢLeaderеҗ‘followerеҸ‘йҖҒfollowerжІЎжңүи§ҒиҝҮзҡ„PROPOSALпјҢд»ҘеҸҠжңҖеҗҺжҸҗдәӨзҡ„ж¶ҲжҒҜзҡ„зј–еҸ·д№ӢеүҚзҡ„COMMITгҖӮ
еӣ дёәProposalжҳҜдҝқеӯҳеңЁfollowerзҡ„дәӢеҠЎж—Ҙеҝ—дёӯпјҢ并且йЎәеәҸжңүдҝқиҜҒпјҢеӣ жӯӨCOMMITзҡ„йЎәеәҸд№ҹжҳҜзЎ®е®ҡзҡ„гҖӮи§ЈеҶізҡ„第дёҖдёӘй—®йўҳгҖӮ
дёҠдёӘжІЎжңүжҠҠproposalеҸ‘йҖҒеҮәеҺ»зҡ„LeaderйҮҚеҗҜеҗҺпјҢж–°Leaderе°Ҷе‘ҠиҜүе®ғжҲӘж–ӯдәӢеҠЎж—Ҙеҝ—пјҢдёҖзӣҙжҲӘж–ӯеҲ°followerзҡ„epochеҜ№еә”зҡ„жңҖеҗҺдёҖдёӘcommitдҪҚзҪ®гҖӮ
е…ідәҺZABзҡ„иҜҰз»ҶиҜҒжҳҺеҸҜд»ҘеҸӮиҖғZab - High-performance broadcast for primary-backup systems
еҸӮиҖғ:http://blog.csdn.net/m_vptr/article/details/9325405
еҲҶдә«еҲ°пјҡ


- 2016-07-29 14:29
- жөҸи§Ҳ 686
- иҜ„и®ә(0)
- еҲҶзұ»:ејҖжәҗиҪҜ件
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
Zookeeperзҡ„еӣӣеӯ—е‘Ҫд»Ө
2017-05-18 20:39 566http://www.cnblogs.com/wuxl360/ ... -
ZookeeperејҖжәҗе®ўжҲ·з«ҜжЎҶжһ¶Curatorз®Җд»Ӣ
2016-10-25 08:43 517ZooKeeperеҺҹз”ҹзҡ„APIж”ҜжҢҒйҖҡиҝҮжіЁеҶҢWatcherжқҘиҝӣиЎҢ ... -
Curator Frameworkзҡ„еҹәжң¬дҪҝз”Ёж–№жі•
2016-10-21 15:17 1082Curator FrameworkжҸҗдҫӣдәҶз®ҖеҢ–дҪҝз”Ёzookeep ... -
ZooKeeperеӯҰд№ жҖ»з»“
2016-09-30 15:18 421еҸӮиҖғпјҡhttp://www.tuicool.com/artic ... -
жҺЁиҚҗдёҖдёӘzookeeperдҝЎжҒҜжҹҘзңӢе·Ҙе…·
2016-08-31 16:01 1702zookeeperдҝЎжҒҜжҹҘзңӢе·Ҙе…· дёӢиҪҪең°еқҖпјҡhttps://i ... -
Paxosз®—жі•з»ҶиҠӮиҜҰи§Ј(дёҖ)--йҖҡиҝҮзҺ°е®һдё–з•ҢжҸҸиҝ°з®—жі•
2016-08-24 16:29 554http://www.cnblogs.com/endsock/ ... -
ZooKeeperеӯҰд№ жҖ»з»“ 第дёҖзҜҮпјҡZooKeeperеҝ«йҖҹе…Ҙй—Ё
2016-08-22 16:23 435http://www.cnblogs.com/leocook/ ... -
zookeeperеҺҹзҗҶпјҲиҪ¬пјү
2016-08-22 14:02 396ZooKeeperжҳҜдёҖдёӘеҲҶеёғејҸзҡ„п ... -
zookeeperе®ўжҲ·з«ҜcuratorдҪҝз”ЁжүӢи®°
2016-08-09 15:10 470http://www.tuicool.com/articles ... -
Zookeeperзҡ„дёҖиҮҙжҖ§еҚҸи®®пјҡZab
2016-08-01 09:21 669ZookeeperдҪҝз”ЁдәҶдёҖз§Қз§°дёәZabпјҲZookeeper A ... -
Zookeeperеҹәжң¬еҺҹзҗҶдёҺеә”з”ЁеңәжҷҜ
2016-07-28 18:51 326http://blog.csdn.net/yunpiao123 ... -
дёҖжӯҘдёҖжӯҘзҗҶи§ЈPaxosз®—жі•
2016-07-21 14:34 620иғҢжҷҜ Paxosз®—жі•жҳҜLamportд ... -
Paxosз®—жі•з®Җиҝ°
2016-07-21 14:10 396Paxosз®—жі•жҳҜеҲҶеёғејҸдёӯдёҖдёӘи‘—еҗҚзҡ„дёҖиҮҙжҖ§з®—жі•гҖӮе®ғзҡ„еҒҮи®ҫеүҚжҸҗжҳҜпјҢ ... -
Zookeeper-Zookeeper leaderйҖүдёҫ
2016-07-20 09:05 538еңЁдёҠдёҖзҜҮж–Үз« дёӯжҲ‘们еӨ§и ... -
йғЁзҪІдёҺз®ЎзҗҶZooKeeper(иҪ¬)
2016-07-19 09:17 381http://www.cnblogs.com/ggjuchen ... -
ZooKeeperеҺҹзҗҶеҸҠдҪҝз”Ё
2016-08-02 08:27 420ZooKeeperжҳҜHadoop EcosystemдёӯйқһеёёйҮҚиҰҒ ... -
ZooKeeper Java API
2016-05-22 10:05 895ZooKeeperжҸҗдҫӣдәҶJavaе’ҢCзҡ„binding. жң¬ж–Үе…і ...
зӣёе…іжҺЁиҚҗ
еңЁжң¬иҜҫзЁӢдёӯпјҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁZookeeperзҡ„ZABеҚҸи®®е®һзҺ°пјҢ并йҖҡиҝҮжәҗз ҒеҲҶжһҗжқҘзҗҶи§Је…¶еҗҜеҠЁжөҒзЁӢгҖҒеҝ«з…§дёҺдәӢеҠЎж—Ҙеҝ—зҡ„еӯҳеӮЁз»“жһ„гҖӮZookeeperжҳҜдёҖж¬ҫеҲҶеёғејҸеҚҸи°ғжңҚеҠЎпјҢе№ҝжіӣеә”з”ЁдәҺеҲҶеёғејҸзі»з»ҹдёӯпјҢеҰӮHadoopгҖҒHBaseзӯүгҖӮжң¬иҠӮдё»иҰҒе…іжіЁ...
йҖҡиҝҮйҳ…иҜ»жәҗз ҒпјҢжҲ‘们еҸҜд»Ҙж·ұе…ҘдәҶи§ЈZooKeeperеҰӮдҪ•еӨ„зҗҶ并еҸ‘гҖҒеҰӮдҪ•иҝӣиЎҢж•°жҚ®еҗҢжӯҘгҖҒеҰӮдҪ•е®һзҺ°WatcherжңәеҲ¶пјҢд»ҘеҸҠеҰӮдҪ•дҝқиҜҒеҲҶеёғејҸдёҖиҮҙжҖ§гҖӮиҝҷеҜ№дәҺжҲ‘们дјҳеҢ–ZooKeeperжҖ§иғҪгҖҒи§ЈеҶіе®һйҷ…й—®йўҳжҲ–ејҖеҸ‘зұ»дјјжңҚеҠЎе…·жңүжһҒй«ҳзҡ„д»·еҖјгҖӮ еңЁ...
ZookeeperжҳҜдёҖдёӘеҲҶеёғејҸзҡ„пјҢејҖж”ҫжәҗз Ғзҡ„еҚҸи°ғжңҚеҠЎпјҢе®ғжҸҗдҫӣдәҶдёҖз§Қз®ҖеҚ•жңүж•Ҳзҡ„еҺҹиҜӯйӣҶпјҢдҪҝеҫ—еҲҶеёғејҸеә”з”ЁиғҪеӨҹеӨ„зҗҶе‘ҪеҗҚжңҚеҠЎгҖҒй…ҚзҪ®з®ЎзҗҶгҖҒйӣҶзҫӨеҗҢжӯҘзӯүй—®йўҳгҖӮZABеҚҸи®®жҳҜZookeeperеңЁж•°жҚ®дёҖиҮҙжҖ§ж–№йқўзҡ„йҮҚиҰҒдҝқйҡңпјҢе®ғзЎ®дҝқдәҶеңЁеҲҶеёғејҸзҺҜеўғ...
гҖҠZookeeperжәҗз ҒеҲҶжһҗгҖӢ ZookeeperжҳҜдёҖж¬ҫеҲҶеёғејҸеҚҸи°ғжңҚеҠЎпјҢе№ҝжіӣеә”з”ЁдәҺеҲҶеёғејҸзі»з»ҹдёӯпјҢжҸҗдҫӣиҜёеҰӮе‘ҪеҗҚжңҚеҠЎгҖҒй…ҚзҪ®з®ЎзҗҶгҖҒйӣҶзҫӨеҗҢжӯҘгҖҒйўҶеҜјиҖ…йҖүдёҫзӯүж ёеҝғеҠҹиғҪгҖӮжң¬ж–Үе°Ҷж·ұе…Ҙеү–жһҗZookeeperзҡ„е·ҘдҪңеҺҹзҗҶпјҢд»ҘеҸҠе…¶еҶ…йғЁе®һзҺ°зҡ„FastLeader...
ZooKeeperжҳҜдёҖдёӘеҲҶеёғејҸзҡ„пјҢејҖж”ҫжәҗз Ғзҡ„еҲҶеёғејҸеә”з”ЁзЁӢеәҸ...йҖҡиҝҮйҳ…иҜ»е’ҢзҗҶи§ЈиҝҷдёӘжіЁйҮҠзүҲзҡ„ZooKeeperжәҗз ҒпјҢејҖеҸ‘иҖ…иғҪеӨҹж·ұе…ҘдәҶи§Је…¶е®һзҺ°з»ҶиҠӮпјҢжӣҙеҘҪең°еҲ©з”Ёе®ғжқҘи§ЈеҶіеҲҶеёғејҸзҺҜеўғдёӯзҡ„й—®йўҳпјҢеҗҢж—¶д№ҹдёәејҖеҸ‘жӣҙй«ҳзә§еҲ«зҡ„еҲҶеёғејҸжңҚеҠЎжҸҗдҫӣеҹәзЎҖгҖӮ
жң¬ж–Үе°Ҷеӣҙз»•вҖңZookeeperжәҗз ҒвҖқиҝҷдёҖдё»йўҳпјҢж·ұеәҰжҺўи®ЁZookeeperзҡ„ж ёеҝғи®ҫи®ЎдёҺе®һзҺ°еҺҹзҗҶгҖӮ дёҖгҖҒZookeeperжһ¶жһ„ ZookeeperйҮҮз”ЁPaxosз®—жі•зҡ„еҸҳз§ҚZABпјҲZookeeper Atomic BroadcastпјүеҚҸи®®жқҘдҝқиҜҒеҲҶеёғејҸдёҖиҮҙжҖ§гҖӮZookeeperйӣҶзҫӨз”ұеӨҡ...
гҖҠZookeeperжәҗз Ғеү–жһҗпјҡж·ұе…ҘзҗҶи§ЈLeaderйҖүдёҫжңәеҲ¶гҖӢжҳҜдёҖзҜҮж·ұеәҰжҺўи®ЁZookeeperеҲҶеёғејҸеҚҸи°ғзі»з»ҹж ёеҝғжңәеҲ¶зҡ„ж–Үз« гҖӮеңЁZookeeperдёӯпјҢLeaderйҖүдёҫжҳҜж•ҙдёӘзі»з»ҹзЁіе®ҡиҝҗиЎҢзҡ„е…ій”®пјҢе®ғдҝқиҜҒдәҶйӣҶзҫӨзҡ„дёҖиҮҙжҖ§е’Ңй«ҳеҸҜз”ЁжҖ§гҖӮжң¬ж–Үе°Ҷд»Һд»ҘдёӢеҮ дёӘ...
гҖҠж·ұе…Ҙи§ЈжһҗZookeeperжәҗз ҒпјҡJavaи§Ҷи§’дёӢзҡ„еҲҶеёғејҸеҚҸи°ғжңәеҲ¶гҖӢ еңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢZookeeperд»Ҙе…¶й«ҳеҸҜз”ЁжҖ§гҖҒејәдёҖиҮҙжҖ§д»ҘеҸҠз®ҖжҙҒзҡ„APIжҲҗдёәдәҶи®ёеӨҡеӨ§еһӢдјҒдёҡзҡ„йҰ–йҖүеҚҸи°ғжңҚеҠЎгҖӮжң¬зҜҮж–Үз« е°ҶеҹәдәҺJavaжәҗз ҒпјҢж·ұе…Ҙеү–жһҗZookeeperзҡ„ж ёеҝғжңәеҲ¶...
гҖҠж·ұе…Ҙи§ЈжһҗZooKeeperжәҗз ҒгҖӢ ZooKeeperжҳҜдёҖж¬ҫеҲҶеёғејҸеҚҸи°ғжңҚеҠЎпјҢз”ұйӣ…иҷҺеҲӣе»ә并ејҖжәҗпјҢзҺ°дёәApacheеҹәйҮ‘дјҡйЎ¶зә§йЎ№зӣ®гҖӮе®ғдёәеҲҶеёғејҸеә”з”ЁжҸҗдҫӣдёҖиҮҙжҖ§жңҚеҠЎпјҢеҰӮе‘ҪеҗҚжңҚеҠЎгҖҒй…ҚзҪ®з®ЎзҗҶгҖҒйӣҶзҫӨеҗҢжӯҘгҖҒеҲҶеёғејҸй”ҒзӯүгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁZooKeeper...
иҜҘйЎ№зӣ®еҗҚдёәвҖңZooKeeperжәҗз ҒEclipseе·ҘзЁӢйЎ№зӣ®вҖқпјҢж„Ҹе‘ізқҖе®ғжҳҜдё“й—ЁдёәEclipse IDEеҮҶеӨҮзҡ„пјҢеҸҜд»ҘзӣҙжҺҘеҜје…ҘиҝӣиЎҢйҳ…иҜ»е’ҢеӯҰд№ пјҢж— йңҖйҖҡиҝҮANTзӯүжһ„е»әе·Ҙе…·зј–иҜ‘гҖӮиҝҷдҪҝеҫ—ејҖеҸ‘иҖ…еҸҜд»ҘжӣҙдҫҝжҚ·ең°еңЁIDEзҺҜеўғдёӯжҹҘзңӢгҖҒи°ғиҜ•е’ҢзҗҶи§Јд»Јз ҒгҖӮ ...
`pyzab` жҳҜдёҖдёӘеҹәдәҺ Python зҡ„ејҖжәҗйЎ№зӣ®пјҢе®ғе®һзҺ°дәҶ Apache ZooKeeper зҡ„ж ёеҝғеҚҸи®®вҖ”вҖ”еҺҹеӯҗе№ҝж’ӯпјҲZABпјүеҚҸи®®гҖӮZAB еҚҸи®®жҳҜеҲҶеёғејҸеҚҸи°ғжңҚеҠЎ ZooKeeper зҡ„еҹәзЎҖпјҢзЎ®дҝқдәҶй«ҳеҸҜз”ЁжҖ§е’Ңж•°жҚ®дёҖиҮҙжҖ§гҖӮеңЁж·ұе…ҘжҺўи®Ё `pyzab` д№ӢеүҚпјҢжҲ‘们...
1. **дёҖиҮҙжҖ§жЁЎеһӢ**пјҡZookeeperйҮҮз”ЁZABпјҲZookeeper Atomic BroadcastпјүеҚҸи®®пјҢзЎ®дҝқеңЁеҲҶеёғејҸзҺҜеўғдёӯж•°жҚ®зҡ„дёҖиҮҙжҖ§гҖӮиҝҷз§ҚејәдёҖиҮҙжҖ§жЁЎеһӢдҪҝеҫ—еӨҡдёӘиҠӮзӮ№дёҠзҡ„ж•°жҚ®дҝқжҢҒеҗҢжӯҘпјҢдёәеҲҶеёғејҸжңҚеҠЎжҸҗдҫӣеҸҜйқ зҡ„ж•°жҚ®ж”ҜжҢҒгҖӮ 2. **еҺҹеӯҗж“ҚдҪң**пјҡ...
Watcherзү№жҖ§жҖ»з»“пјҡдёҖж¬ЎжҖ§гҖҒе®ўжҲ·з«ҜдёІиЎҢжү§иЎҢгҖҒиҪ»йҮҸгҖӮ ZooKeeperзҡ„йқўиҜ•йўҳж¶өзӣ–дәҶеҲҶеёғејҸеҚҸи°ғжңҚеҠЎзҡ„еҹәжң¬жҰӮеҝөгҖҒZooKeeperзҡ„ж–Ү件系з»ҹгҖҒZABеҚҸи®®гҖҒж•°жҚ®иҠӮзӮ№зұ»еһӢе’ҢWatcherжңәеҲ¶зӯүзҹҘиҜҶзӮ№пјҢдёәејҖеҸ‘иҖ…е’Ңжһ¶жһ„еёҲжҸҗдҫӣдәҶзі»з»ҹзҡ„зҹҘиҜҶжһ¶жһ„...
жң¬д№Ұд»ҺеҲҶеёғејҸдёҖиҮҙжҖ§зҡ„зҗҶи®әеҮәеҸ‘пјҢеҗ‘иҜ»иҖ…з®ҖиҰҒд»Ӣз»ҚеҮ з§Қе…ёеһӢзҡ„еҲҶеёғејҸдёҖиҮҙжҖ§еҚҸи®®пјҢд»ҘеҸҠи§ЈеҶіеҲҶеёғејҸдёҖиҮҙжҖ§й—®йўҳзҡ„жҖқи·ҜпјҢе…¶дёӯйҮҚзӮ№и®Іи§ЈдәҶPaxosе’ҢZABеҚҸи®®гҖӮеҗҢж—¶пјҢжң¬д№Ұж·ұе…Ҙд»Ӣз»ҚдәҶеҲҶеёғејҸдёҖиҮҙжҖ§й—®йўҳзҡ„е·Ҙдёҡи§ЈеҶіж–№жЎҲвҖ”вҖ”ZooKeeperпјҢ...
ZooKeeperжҳҜдёҖдёӘеҲҶеёғејҸзҡ„пјҢејҖж”ҫжәҗз Ғзҡ„еҲҶеёғејҸеә”з”ЁзЁӢеәҸеҚҸи°ғжңҚеҠЎпјҢе®ғжҳҜйӣҶзҫӨзҡ„з®ЎзҗҶиҖ…пјҢзӣ‘и§ҶзқҖйӣҶзҫӨдёӯеҗ„дёӘиҠӮзӮ№зҡ„зҠ¶жҖҒж №жҚ®иҠӮзӮ№жҸҗдәӨзҡ„еҸҚйҰҲиҝӣиЎҢдёӢдёҖжӯҘеҗҲзҗҶж“ҚдҪңгҖӮжңҖз»Ҳе°Ҷз®ҖеҚ•жҳ“з”Ёзҡ„жҺҘеҸЈе’ҢжҖ§иғҪй«ҳж•ҲгҖҒеҠҹиғҪзЁіе®ҡзҡ„зі»з»ҹжҸҗдҫӣз»ҷз”ЁжҲ·гҖӮ...
жҜҸдёӘServerйғҪдҝқеӯҳж•ҙдёӘж•°жҚ®ж ‘зҡ„дёҖдёӘеүҜжң¬пјҢ并йҖҡиҝҮPaxosжҲ–ZABпјҲZookeeperеҺҹеӯҗе№ҝж’ӯеҚҸи®®пјүеҚҸи®®иҝӣиЎҢж•°жҚ®еҗҢжӯҘпјҢд»ҘзЎ®дҝқж•°жҚ®дёҖиҮҙжҖ§гҖӮйҖҡеёёпјҢдёәдәҶй«ҳеҸҜз”ЁжҖ§пјҢZookeeperйӣҶзҫӨдјҡй…ҚзҪ®еҘҮж•°дёӘServerиҠӮзӮ№гҖӮ **Zookeeperзҡ„йғЁзҪІжЁЎејҸпјҡ** ...
- ZABпјҲZookeeper Atomic BroadcastпјүеҚҸи®®жҳҜZookeeperзҡ„еҺҹеӯҗе№ҝж’ӯеҚҸи®®пјҢе®ғеҢ…еҗ«дәҶйҖүдёҫз®—жі•гҖӮеҹәжң¬жҖқи·ҜжҳҜйҖҡиҝҮжҜ”иҫғжҜҸдёӘиҠӮзӮ№зҡ„йҖүдёҫдјҳе…Ҳзә§пјҲйҖҡеёёжҳҜжңҚеҠЎеҷЁIDпјүе’ҢжҸҗи®®зҡ„дәӢеҠЎIDжқҘзЎ®е®ҡйўҶеҜјиҖ…гҖӮ - еҪ“еӨҡж•°иҠӮзӮ№еҗҢж„ҸдёҖдёӘиҠӮзӮ№дёә...
гҖҠж·ұе…Ҙи§ЈжһҗZookeeperжәҗз ҒгҖӢ ZookeeperжҳҜдёҖдёӘеҲҶеёғејҸеҚҸи°ғжңҚеҠЎпјҢе№ҝжіӣеә”з”ЁдәҺеҲҶеёғејҸзі»з»ҹдёӯпјҢеҰӮHadoopгҖҒHBaseгҖҒKafkaзӯүгҖӮе®ғжҸҗдҫӣдәҶдёҖз§ҚеҸҜйқ зҡ„ж–№ејҸжқҘз®ЎзҗҶеҲҶеёғејҸзҺҜеўғдёӯзҡ„й…ҚзҪ®дҝЎжҒҜгҖҒе‘ҪеҗҚжңҚеҠЎгҖҒйӣҶзҫӨзҠ¶жҖҒеҗҢжӯҘд»ҘеҸҠеҲҶеёғејҸй”ҒзӯүеҠҹиғҪ...
гҖҠZookeeperжәҗз Ғи§ЈжһҗвҖ”вҖ”еҹәдәҺ3.5.4зүҲжң¬гҖӢ Apache ZooKeeperжҳҜдёҖдёӘеҲҶеёғејҸзҡ„пјҢејҖж”ҫжәҗз Ғзҡ„еҲҶеёғејҸеә”з”ЁзЁӢеәҸеҚҸи°ғжңҚеҠЎпјҢе®ғжҳҜйӣҶзҫӨзҡ„з®ЎзҗҶиҖ…пјҢзӣ‘и§ҶзқҖйӣҶзҫӨдёӯеҗ„дёӘиҠӮзӮ№зҡ„зҠ¶жҖҒж №жҚ®иҠӮзӮ№жҸҗдәӨзҡ„еҸҚйҰҲиҝӣиЎҢдёӢдёҖжӯҘеҗҲзҗҶж“ҚдҪңгҖӮжңҖз»Ҳе°Ҷз®ҖеҚ•...