
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
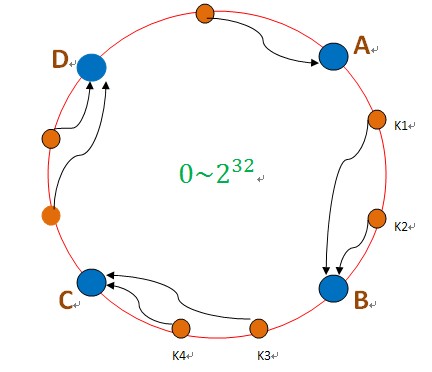
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
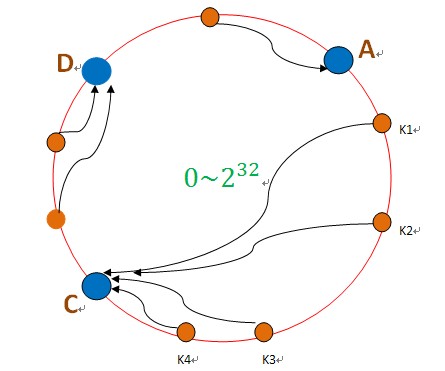
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
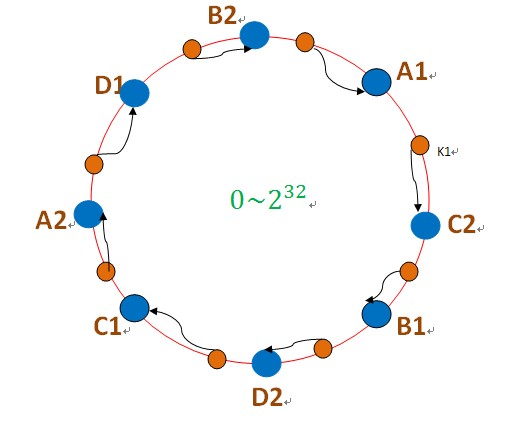
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
- public class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等
- private TreeMap<Long, S> nodes; // 虚拟节点
- private List<S> shards; // 真实机器节点
- private final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数
- public Shard(List<S> shards) {
- super();
- this.shards = shards;
- init();
- }
- private void init() { // 初始化一致性hash环
- nodes = new TreeMap<Long, S>();
- for (int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点
- final S shardInfo = shards.get(i);
- for (int n = 0; n < NODE_NUM; n++)
- // 一个真实机器节点关联NODE_NUM个虚拟节点
- nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
- }
- }
- public S getShardInfo(String key) {
- SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点
- if (tail.size() == 0) {
- return nodes.get(nodes.firstKey());
- }
- return tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息
- }
- /**
- * MurMurHash算法,是非加密HASH算法,性能很高,
- * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
- * 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
- * http://murmurhash.googlepages.com/
- */
- private Long hash(String key) {
- ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
- int seed = 0x1234ABCD;
- ByteOrder byteOrder = buf.order();
- buf.order(ByteOrder.LITTLE_ENDIAN);
- long m = 0xc6a4a7935bd1e995L;
- int r = 47;
- long h = seed ^ (buf.remaining() * m);
- long k;
- while (buf.remaining() >= 8) {
- k = buf.getLong();
- k *= m;
- k ^= k >>> r;
- k *= m;
- h ^= k;
- h *= m;
- }
- if (buf.remaining() > 0) {
- ByteBuffer finish = ByteBuffer.allocate(8).order(
- ByteOrder.LITTLE_ENDIAN);
- // for big-endian version, do this first:
- // finish.position(8-buf.remaining());
- finish.put(buf).rewind();
- h ^= finish.getLong();
- h *= m;
- }
- h ^= h >>> r;
- h *= m;
- h ^= h >>> r;
- buf.order(byteOrder);
- return h;
- }
- }



相关推荐
本压缩包文件"一致性哈希算法演示.rar"包含了一个C#实现的一致性哈希算法演示项目,可以在Visual Studio 2019环境下运行。该项目可以帮助我们理解一致性哈希的工作原理,通过观察不同情况下(如添加或移除节点)数据...
Ketama一致性哈希算法是基于一致性哈希的一种优化实现,主要解决了传统一致性哈希中节点分布不均匀的问题。在Ketama中,每个实际的物理服务器会被映射到多个虚拟节点,通常是100到200个,这些虚拟节点均匀分布在环上...
在这个Java实现中,我们看到的是Ketama一致性哈希算法,这是一种在实践中广泛应用的一致性哈希变体。 Ketama一致性哈希算法由Last.fm的工程师开发,其设计目标是优化分布式哈希表的性能,特别是在处理大量小键值对...
本项目以“基于NIO-EPOOL模型netty实现的具备一致性哈希算法的NAT端口映射器”为主题,深入探讨了Netty在NAT端口映射中的应用,以及一致性哈希算法在此过程中的作用。 首先,我们来了解NIO(Non-blocking I/O,非...
2. **一致性哈希算法**: - 一致性哈希解决了普通哈希扩容时大量元素移动的问题,特别适用于分布式系统中节点的动态增减。 - 哈希空间被组织成一个固定大小的环,每个节点分配到环上的一个或多个位置,负责其...
一致性哈希算法(Consistent Hashing)是一种常用于分布式系统中的数据分片策略,它有效地解决了数据在多台服务器间均匀分布的问题,同时减少了因节点加入或离开时的数据迁移成本。 首先,一致性哈希的基本原理是将...
标题“获取哈希及获取哈希算法标识demo-java”表明这个示例主要涉及两个关键知识点:一是如何在Java中计算哈希值,二是如何获取哈希算法的标识。下面将详细解释这两个概念: 1. 获取哈希值: Java中的`java....
一致性哈希算法的工作流程如下: 1. 所有节点(包括服务器和数据)被哈希成一个唯一的值,并映射到一个闭合的哈希环上。 2. 当查找一个数据的存储位置时,同样对数据的键进行哈希,然后在哈希环上找到该键对应的点。...
- **分布式系统**:在分布式数据库或一致性哈希中,哈希算法用于确定数据存储的位置。 `java-hash` 工具可能包含了这些常见哈希算法的实现,以及可能的自定义优化,提供了一种便捷的方式来计算和比较哈希值。通过这...
【一致性Hash算法】是一种分布式系统中用于负载均衡的哈希算法。它的主要目的是解决当服务节点增加或减少时,能够尽量少地改变已有的请求分配,以保持系统的稳定性。在传统的哈希算法中,增加或删除一个服务器可能...
本文将探讨一个名为"ufire-springcloud-platform"的项目,该项目是基于一致性哈希算法实现WebSocket分布式扩展的一次尝试,并结合Jenkins、GitHub Hook和Docker Compose实现了自动化持续部署。 1. **一致性哈希算法...
MD5(Message-Digest Algorithm 5)是一种广泛使用的哈希函数,它能够将任意长度的输入数据转换成...同时,也可以扩展这个实现,比如增加对大文件的分块处理,或者与其他哈希算法(如SHA-1、SHA-256)进行比较学习。
在这个简单的实现中,我们将探讨如何用Java语言来模拟一致性哈希的工作原理。 1. **一致性哈希的基本概念** - **哈希环**:一致性哈希将所有可能的哈希值映射到一个闭合的圆环上,每个节点都按照哈希值分布在环上...
在Java中,你可以通过扩展`MessageDigest`类或者使用特定库来实现SM3哈希计算,以确保数据的完整性和一致性。 3. **SM4算法**:SM4是一种分组密码算法,主要用于块加密。它采用了128位的密钥和128位的数据块。在...
这个"java-hash.7z"压缩包包含了一个Java实现的哈希计算工具,这是一份经典的学习资源,可以帮助开发者深入理解哈希算法及其在Java中的应用。 哈希(Hash)函数是一种将任意长度输入(也叫做预映射pre-image)通过...
8. **分布式系统**: 在分布式系统中,如一致性哈希,哈希函数用于确定数据应存储在哪个节点上,以均衡负载并处理节点的增减。 9. **碰撞处理**: 虽然理想情况下哈希函数应确保每个输入都有唯一的哈希值,但实际上...
哈希算法能够确保即使是微小的数据变化也能导致完全不同的哈希值,从而实现数据完整性的验证。 ##### 2.2 特点 - **不可逆性**:无法从哈希值反推出原始数据。 - **唯一性**:不同数据几乎不会产生相同的哈希值。 -...
在这个场景下,我们将深入探讨一致性哈希算法的原理、特点以及在Java和C++中的实现。 一致性哈希算法的基本思想是将哈希空间环绕成一个虚拟的圆环,每个节点都被分配到这个环上的一个或多个位置。当需要将数据映射...
与其他哈希算法相比的优势: 哈希的均匀分布很好的就哈希计算中使用的指令数量而言,比大多数哈希算法要快。用法 String message = "";JenkinsHash jh = new JenkinsHash();int pc = jh.hash32(message.getBytes())...
总结起来,Java-hash.zip提供的工具集可能是为了简化Java环境下的哈希计算任务,包括了多种哈希算法的选择与应用,以及相关的数据处理和结果展示。通过理解和使用这样的工具,开发者可以更高效地完成数据校验、文件...