é€ڑè؟‡ه‰چé¢çڑ„و–‡ç« ,وˆ‘ن»¬ه·²ç»ڈçں¥éپ“هœ¨elasticsearchن¸و¯ڈن¸ھshardو¯ڈéڑ”1秒都ن¼ڑrefreshن¸€و¬،,و¯ڈو¬،refresh都ن¼ڑç”ںوˆگن¸€ن¸ھو–°çڑ„segment,وŒ‰ç…§è؟™ن¸ھé€ںه؛¦è؟‡ن¸چن؛†ه¤ڑن¹…segmentçڑ„و•°é‡ڈه°±ن¼ڑ爆炸,و‰€ن»¥هکهœ¨ه¤ھه¤ڑçڑ„segmentوک¯ن¸€ن¸ھه¤§é—®é¢ک,ه› ن¸؛و¯ڈن¸€ن¸ھsegment都ن¼ڑهچ 用و–‡ن»¶هڈ¥وں„,ه†…هک资و؛گ,cpu资و؛گ,و›´هٹ é‡چè¦پçڑ„وک¯و¯ڈن¸€ن¸ھوگœç´¢è¯·و±‚都ه؟…é،»è®؟é—®و¯ڈن¸€ن¸ھsegment,è؟™ه°±و„ڈه‘³ç€هکهœ¨çڑ„segmentè¶ٹه¤ڑ,وگœç´¢è¯·و±‚ه°±ن¼ڑهڈکçڑ„و›´و…¢م€‚
é‚£ن¹ˆelaticsearchوک¯ه¦‚ن½•è§£ه†³è؟™ن¸ھé—®é¢که‘¢ï¼ں ه®é™…ن¸ٹelasticsearchوœ‰ن¸€ن¸ھهگژهڈ°è؟›ç¨‹ن¸“é—¨è´ںè´£segmentçڑ„هگˆه¹¶ï¼Œه®ƒن¼ڑوٹٹه°ڈsegmentsهگˆه¹¶وˆگو›´ه¤§çڑ„segments,然هگژهڈچه¤چè؟™و ·م€‚هœ¨هگˆه¹¶segmentsçڑ„و—¶ه€™و ‡è®°هˆ 除çڑ„documentن¸چن¼ڑ被هگˆه¹¶هˆ°و–°çڑ„و›´ه¤§çڑ„segment里é¢ï¼Œو‰€وœ‰çڑ„è؟‡ç¨‹éƒ½ن¸چ需è¦پوˆ‘ن»¬ه¹²و¶‰ï¼Œesن¼ڑè‡ھهٹ¨هœ¨ç´¢ه¼•ه’Œوگœç´¢çڑ„è؟‡ç¨‹ن¸ه®Œوˆگ,هگˆه¹¶çڑ„segmentهڈ¯ن»¥وک¯ç£پç›کن¸ٹه·²ç»ڈcommitè؟‡çڑ„ç´¢ه¼•ï¼Œن¹ںهڈ¯ن»¥هœ¨ه†…هکن¸è؟کوœھcommitçڑ„segmentï¼ڑ
(1)هœ¨ç´¢ه¼•و—¶refreshè؟›ç¨‹و¯ڈ秒ن¼ڑهˆ›ه»؛ن¸€ن¸ھو–°çڑ„segmentه¹¶ن¸”و‰“ه¼€ه®ƒن½؟ه¾—وگœç´¢هڈ¯è§پ
(2)mergeè؟›ç¨‹ن¼ڑهœ¨هگژهڈ°é€‰و‹©ن¸€ن؛›ه°ڈن½“积çڑ„segments,然هگژه°†ه…¶هگˆه¹¶وˆگن¸€ن¸ھو›´ه¤§çڑ„segment,è؟™ن¸ھè؟‡ç¨‹ن¸چن¼ڑو‰“و–ه½“ه‰چçڑ„ç´¢ه¼•ه’Œوگœç´¢هٹں能م€‚
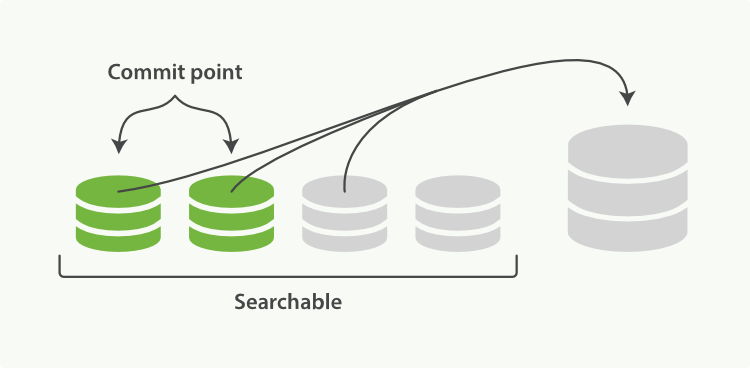
(3)ن¸€و—¦mergeه®Œوˆگ,و—§çڑ„segmentsه°±ن¼ڑ被هˆ 除,وµپ程ه¦‚ن¸‹ï¼ڑ
````
3.1 و–°çڑ„segmentن¼ڑ被flushهˆ°ç£پç›ک
3.2 然هگژن¼ڑç”ںوˆگو–°çڑ„commit pointو–‡ن»¶ï¼ŒهŒ…هگ«و–°çڑ„segmentهگچ称,ه¹¶وژ’除وژ‰و—§çڑ„segmentه’Œé‚£ن؛›è¢«هگˆه¹¶è؟‡çڑ„ه°ڈçڑ„segment
3.3 وژ¥ç€و–°çڑ„segmentن¼ڑ被و‰“ه¼€ç”¨ن؛ژوگœç´¢
3.4 وœ€هگژو—§çڑ„segmentن¼ڑ被هˆ 除وژ‰
````
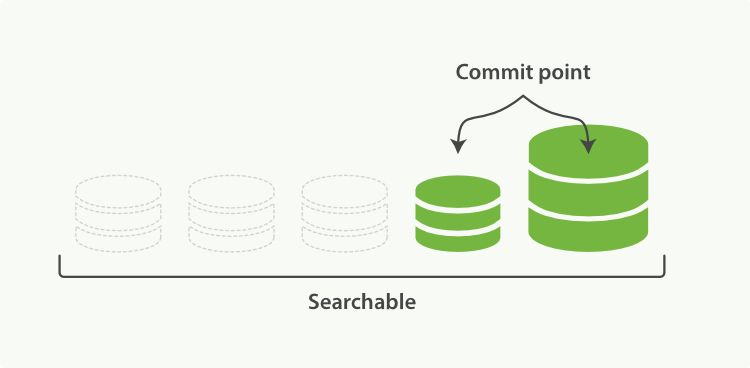
至و¤هژںو¥و ‡è®°ن¼ھهˆ 除çڑ„document都ن¼ڑ被و¸…çگ†وژ‰ï¼Œه¦‚وœن¸چهٹ وژ§هˆ¶ï¼Œهگˆه¹¶ن¸€ن¸ھه¤§çڑ„segmentن¼ڑو¶ˆè€—و¯”较ه¤ڑçڑ„ioه’Œcpu资و؛گ,هگŒو—¶ن¹ںن¼ڑوگœç´¢و€§èƒ½é€ وˆگه½±ه“چ,و‰€ن»¥é»ک认وƒ…ه†µن¸‹esه·²ç»ڈه¯¹هگˆه¹¶ç؛؟程هپڑن؛†èµ„و؛گé™گé¢ن»¥ن¾؟ن؛ژه®ƒن¸چن¼ڑوگœç´¢و€§èƒ½é€ وˆگه¤ھه¤§ه½±ه“چم€‚
apiه¦‚ن¸‹ï¼ڑ
````
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
````وˆ–者ن¸چé™گهˆ¶ï¼ڑ
````
PUT /_cluster/settings
{
"transient" : {
"indices.store.throttle.type" : "none"
}
}
````
esçڑ„apiن¹ںوڈگن¾›ن؛†وˆ‘ن»¬ه¤–部هڈ‘é€په‘½ن»¤و¥ه¼؛هˆ¶هگˆه¹¶segment,è؟™ن¸ھه‘½ن»¤ه°±وک¯optimize,ه®ƒهڈ¯ن»¥ه¼؛هˆ¶ن¸€ن¸ھshardهگˆه¹¶وˆگوŒ‡ه®ڑو•°é‡ڈçڑ„segment,è؟™ن¸ھهڈ‚و•°وک¯ï¼ڑmax_num_segments ,ن¸€ن¸ھç´¢ه¼•ه®ƒçڑ„segmentو•°é‡ڈè¶ٹه°‘,ه®ƒçڑ„وگœç´¢و€§èƒ½ه°±è¶ٹé«ک,é€ڑه¸¸ن¼ڑoptimizeوˆگن¸€ن¸ھsegmentم€‚需è¦پو³¨و„ڈçڑ„وک¯optimizeه‘½ن»¤ن¸چè¦پ用هœ¨ن¸€ن¸ھ频ç¹پو›´و–°çڑ„ç´¢ه¼•ن¸ٹé¢ï¼Œé’ˆه¯¹é¢‘ç¹پو›´و–°çڑ„ç´¢ه¼•esé»ک认çڑ„هگˆه¹¶è؟›ç¨‹ه°±وک¯وœ€ن¼کçڑ„ç–略,optimizeه‘½ن»¤é€ڑه¸¸ç”¨هœ¨ن¸€ن¸ھé™و€پç´¢ه¼•ن¸ٹ,ن¹ںه°±وک¯è¯´è؟™ن»½ç´¢ه¼•و²،وœ‰ه†™ه…¥و“چن½œهڈھوœ‰وں¥è¯¢و“چن½œçڑ„و—¶ه€™وک¯éه¸¸é€‚هگˆç”¨optimizeو¥ن¼کهŒ–çڑ„,و¯”ه¦‚说وˆ‘ن»¬çڑ„ن¸€ن؛›و—¥ه؟—ç´¢ه¼•ï¼Œهں؛وœ¬éƒ½وک¯وŒ‰ه¤©ï¼Œه‘¨ï¼Œوˆ–者وœˆو¥ç´¢ه¼•çڑ„,هڈھè¦پè؟‡ن؛†ن»ٹه¤©ï¼Œè؟™ه‘¨وˆ–è؟™ن¸ھوœˆه°±هں؛وœ¬و²،وœ‰ه†™ه…¥و“چن½œن؛†ï¼Œè؟™ن¸ھو—¶ه€™وˆ‘ن»¬ه°±هڈ¯ن»¥é€ڑè؟‡optimizeه‘½ن»¤ï¼Œو¥ه¼؛هˆ¶هگˆه¹¶و¯ڈن¸ھshardن¸ٹç´¢ه¼•هڈھوœ‰ن¸€ن¸ھsegment,è؟™و ·وں¥è¯¢و€§èƒ½ه°±èƒ½ه¤§ه¤§وڈگهچ‡ï¼Œapiه¦‚ن¸‹ï¼ڑ
````
POST /logstash-2014-10/_optimize?max_num_segments=1
````
و³¨و„ڈ,由ه¤–部هڈ‘é€پçڑ„optimizeه‘½ن»¤وک¯و²،وœ‰é™گهˆ¶èµ„و؛گçڑ„,ن¹ںه°±وک¯ن½ ç³»ç»ںوœ‰ه¤ڑه°‘IO资و؛گه°±ن¼ڑن½؟用ه¤ڑه°‘IO资و؛گ,è؟™و ·هڈ¯èƒ½ه¯¼è‡´وںگن¸€و®µو—¶é—´ه†…وگœç´¢و²،وœ‰ن»»ن½•ه“چه؛”,و‰€ن»¥ه¦‚وœن½ è®،هˆ’è¦پoptimizeن¸€ن¸ھ超ه¤§çڑ„ç´¢ه¼•ï¼Œن½ ه؛”该ن½؟用shard allocationهٹں能ه°†è؟™ن»½ç´¢ه¼•ç»™ç§»هٹ¨هˆ°ن¸€ن¸ھوŒ‡ه®ڑçڑ„nodeوœ؛ه™¨ن¸ٹ,ن»¥ç،®ن؟هگˆه¹¶و“چن½œن¸چن¼ڑه½±ه“چه…¶ن»–çڑ„ن¸ڑهٹ،وˆ–者esوœ¬è؛«çڑ„و€§èƒ½م€‚
وœ‰ن»€ن¹ˆé—®é¢کهڈ¯ن»¥و‰«ç په…³و³¨ه¾®ن؟،ه…¬ن¼—هڈ·ï¼ڑوˆ‘وک¯و”»هںژه¸ˆ(woshigcs),هœ¨هگژهڈ°ç•™è¨€ه’¨è¯¢م€‚ وٹ€وœ¯ه€؛ن¸چ能و¬ ,هپ¥ه؛·ه€؛و›´ن¸چ能و¬ , و±‚éپ“ن¹‹è·¯ï¼Œن¸ژهگ›هگŒè،Œم€‚ 
هˆ†ن؛«هˆ°ï¼ڑ









相ه…³وژ¨èچگ
هœ¨Elasticsearchن¸ï¼Œو•°وچ®هکه‚¨çڑ„هں؛وœ¬هچ•ن½چوک¯و®µï¼ˆsegment),و¯ڈن¸ھو®µéƒ½وک¯ن¸€ن¸ھه€’وژ’ç´¢ه¼•ï¼Œç”±Luceneç”ںوˆگم€‚و¯ڈو¬،و•°وچ®ه†™ه…¥هگژ,Elasticsearchن¼ڑه°†و•°وچ®ç¼“ه†²هˆ°ه†…هکن¸çڑ„buffer,ه¹¶هگŒو—¶è®°ه½•هœ¨translogو—¥ه؟—ن¸م€‚و•°وچ®ه†™ه…¥هگژ,ç»ڈè؟‡ن¸€ه®ڑ...
وں¥è¯¢ن¼کهŒ–ç–ç•¥هŒ…و‹¬ن½؟用routingهٹ é€ں特ه®ڑç»´ه؛¦و•°وچ®çڑ„وں¥è¯¢ï¼Œé™گهˆ¶وگœç´¢ç»“وœé›†ه¤§ه°ڈ,ه¢هٹ node query cacheن»¥ç¼“解heapهژ‹هٹ›ï¼Œهگˆçگ†هˆ†é…چshardه¤‡ن»½ن»¥ه¹³è،،وں¥è¯¢ه¹¶هڈ‘,ن»¥هڈٹé€ڑè؟‡هگˆه¹¶segmentو¥ه‡ڈه°‘ç¢ژ片م€‚هڈ¦ه¤–,unique constraintه¦‚_id...
Elasticsearch(ES)وک¯ن¸€ç§چوµپè،Œçڑ„هˆ†ه¸ƒه¼ڈوگœç´¢ه¼•و“ژه’Œهˆ†وگه¼•و“ژ,ه®ƒن»¥é«کو•ˆم€په®و—¶çڑ„特و€§è€Œé—»هگچم€‚وœ¬و–‡ن¸»è¦پوژ¢è®¨ن؛†Elasticsearchçڑ„ه†™ه…¥م€پ读هڈ–م€پو£€ç´¢و•°وچ®çڑ„ه؛•ه±‚هژںçگ†ن»¥هڈٹو€§èƒ½è°ƒن¼کç–ç•¥م€‚ **Elasticsearch ه†™ه…¥و•°وچ®وµپ程** 1. ...
و¯ڈ秒ن¼ڑو ¹وچ®bufferهˆ·و–°ç”ںوˆگsegment file,ه®ڑوœںé€ڑè؟‡mergeو“چن½œهگˆه¹¶segment files,ه¹¶و‰§è،Œç‰©çگ†هˆ 除ه’Œو–°و•°وچ®çڑ„ه†™ه…¥م€‚ 10. هˆ†وگه™¨هٹں能ï¼ڑهˆ†وگه™¨وک¯Elasticsearchç´¢ه¼•و•°وچ®و—¶çڑ„و ¸ه؟ƒç»„ن»¶ï¼Œè´ںè´£ه°†و–‡وœ¬و•°وچ®è½¬وچ¢ن¸؛ç´¢ه¼•و ¼ه¼ڈم€‚هˆ†وگ...
Elasticsearch وک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈم€په¼€و؛گçڑ„ه…¨و–‡و£€ç´¢ه¼•و“ژ,ه¹؟و³›ç”¨ن؛ژه®و—¶و•°وچ®هˆ†وگه’Œه¤§è§„و¨،وگœç´¢ه؛”用م€‚ن»¥ن¸‹وک¯ن¸€ن؛›ه…³ن؛ژ Elasticsearch çڑ„ه…³é”®çں¥è¯†ç‚¹ï¼Œهں؛ن؛ژوڈگن¾›çڑ„é¢è¯•é¢که’Œç”و،ˆï¼ڑ 1. **èٹ‚点هˆ†ç‰‡ç–ç•¥**ï¼ڑéپµه¾ھه®کو–¹ه»؛议,ن¸€ن¸ھèٹ‚点...
هœ¨و·±ه…¥çگ†è§£Elasticsearch(简称ES)çڑ„ç´¢ه¼•هژںçگ†ه‰چ,وˆ‘ن»¬éœ€è¦په…ˆوکژ白هں؛وœ¬و¦‚ه؟µم€‚ESوک¯ن¸€ç§چهˆ†ه¸ƒه¼ڈه…¨و–‡وگœç´¢ه¼•و“ژ,ه®ƒه°†و•°وچ®هکه‚¨هœ¨ç´¢ه¼•ن¸ï¼Œè؟™ن؛›ç´¢ه¼•ç±»ن¼¼ن؛ژه…³ç³»ه‹و•°وچ®ه؛“ن¸çڑ„و•°وچ®ه؛“,ن½†ه…·ه¤‡و›´é«کçڑ„هڈ¯و‰©ه±•و€§ه’Œه®و—¶و€§م€‚ç´¢ه¼•هڈ¯ن»¥...
هœ¨Elasticsearch (ES) ن¸ï¼Œن¸»هˆ†ç‰‡ه’Œه‰¯وœ¬هˆ†ç‰‡çڑ„و•°وچ®ه¤§ه°ڈهڈ¯èƒ½ن¸چن¸€è‡´ï¼Œè؟™ن¸»è¦پوک¯ç”±ن؛ژه®ƒن»¬ه†…部çڑ„segmentو•°é‡ڈه’Œç»“و„ه·®ه¼‚و‰€ه¼•èµ·çڑ„م€‚هœ¨çگ†è§£è؟™ن¸ھé—®é¢کن¹‹ه‰چ,وˆ‘ن»¬éœ€è¦په…ˆن؛†è§£ن¸€ن¸‹ESçڑ„هں؛وœ¬و¦‚ه؟µم€‚ Elasticsearch وک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈم€پ...
Nutchه°†çˆ¬هڈ–çڑ„网é،µهکه‚¨هœ¨هگچن¸؛“segmentâ€çڑ„و–‡ن»¶ه¤¹ن¸ï¼Œو¯ڈن¸ھsegmentهŒ…هگ«ن¸€و‰¹ç½‘é،µçڑ„و•°وچ®م€‚`nutch mergesegs`ه‘½ن»¤ç”¨ن؛ژه°†ن¸چهگŒçˆ¬هڈ–ن»»هٹ،çڑ„segmentsهگˆه¹¶هˆ°و–°çڑ„segmentsç›®ه½•ن¸‹ï¼Œن؟è¯پو‰€وœ‰ç½‘é،µو•°وچ®éƒ½هœ¨هگŒن¸€ç›®ه½•ن¸‹م€‚ 4. **و›´و–°...
- **Segment merging**: هˆ†و®µهگˆه¹¶ç–略被ن¼کهŒ–,é™چن½ژن؛†ç£پç›کç©؛é—´çڑ„هچ 用ه¹¶وڈگé«کن؛†ç´¢ه¼•و€§èƒ½م€‚ ##### 2. و›´ه¼؛çڑ„ه®‰ه…¨و€§ - **X-Pack**: X-Packهœ¨5.0版وœ¬ن¸è¢«é›†وˆگè؟›و¥ï¼Œوڈگن¾›ن؛†ه®‰ه…¨è®¤è¯پم€پ监وژ§ç‰هٹں能م€‚ - **SSL/TLS support**:...
- **و®µç®،çگ†**ï¼ڑElasticsearchن½؟用و®µ(segment)çڑ„و¦‚ه؟µو¥ç®،çگ†ç´¢ه¼•ï¼Œو¯ڈن¸ھو®µéƒ½وک¯ن¸€ن¸ھه®Œو•´çڑ„ه€’وژ’ç´¢ه¼•م€‚ - **缓هکوœ؛هˆ¶**ï¼ڑé€ڑè؟‡ه†…هک缓ه†²هŒ؛(Buffer)وڑ‚هکو–°ه†™ه…¥çڑ„و•°وچ®ï¼Œه®ڑوœںهˆ·و–°هˆ°ç£پç›کم€‚ - **هˆ·و–°وœ؛هˆ¶**ï¼ڑé€ڑè؟‡è°ƒو•´`refresh_...
Elasticsearchهˆ™و“…é•؟ه…¨و–‡و£€ç´¢ه’Œه®و—¶هˆ†وگ,وڈگن¾›ه®Œو•´çڑ„ELK(Elasticsearchم€پLogstashم€پKibana)وٹ€وœ¯و ˆï¼Œن½†هœ¨ه¤„çگ†é«کهں؛و•°ç»´ه؛¦ه’Œه¤§è§„و¨،و•°وچ®و—¶ï¼Œو€§èƒ½هڈ¯èƒ½ن¼ڑن¸‹é™چم€‚ SQL on Hadoopوٹ€وœ¯ï¼Œه¦‚Hiveه’ŒPresto,هˆ©ç”¨MPP(ه¤§è§„و¨،...
هœ¨ن¸ژه…¶ن»–وٹ€وœ¯çڑ„ç«ه“پهˆ†وگن¸ï¼ŒDruidن¸ژES(ElasticSearch)م€پKVStore(ه¦‚Hbaseم€پCassandraم€پOpenTSDB)ن»¥هڈٹSQL on Hadoop(ه¦‚Impala/Drill/Spark/Presto)ç‰و•°وچ®ه¤„çگ†وٹ€وœ¯ç›¸و¯”,وœ‰ه…¶ç‹¬ç‰¹çڑ„ن¼کç¼؛点م€‚ن¾‹ه¦‚,ن¸ژES相و¯”,Druid...
Elasticsearchهˆ™ه› ه…¶ه…¨و–‡وگœç´¢ه¼•و“ژه’Œهˆ†وگ能هٹ›è€Œçں¥هگچ,ن½†و•°وچ®é‡ڈو‰©ه±•و€§ه’Œه¯¹هژںه§‹و•°وچ®çڑ„ن؟هکن¸چ足,ه¯¼è‡´ه…¶هœ¨وںگن؛›هœ؛و™¯ن¸‹ن¸چه¦‚Druid适هگˆم€‚وœ€ç»ˆï¼ŒDruidه› ه…¶ن¼ک秀çڑ„ه®و—¶هˆ†وگو€§èƒ½م€پو‰©ه±•و€§ه’Œه®¹é”™و€§ï¼ˆé€ڑè؟‡Brokerم€پRealtimeه’Œ...
ه¯¹ن؛ژه¤§è§„و¨،و•°وچ®ï¼Œهڈ¯ن»¥هˆ©ç”¨Solrوˆ–Elasticsearchè؟™و ·çڑ„هˆ†ه¸ƒه¼ڈوگœç´¢ه¹³هڈ°ï¼Œه®ƒن»¬هں؛ن؛ژLuceneو„ه»؛,وڈگن¾›ن؛†é›†ç¾¤éƒ¨ç½²م€پè´ںè½½ه‡è،،ه’Œè‡ھهٹ¨و•…éڑœوپ¢ه¤چç‰هٹں能م€‚ ### ه…«م€پن¼کهŒ–ن¸ژهگˆه¹¶و®µ ن¸؛ن؛†وڈگé«کوگœç´¢و€§èƒ½ï¼ŒLuceneن¼ڑه®ڑوœںè؟›è،Œو®µهگˆه¹¶...
هœ¨Windowsو“چن½œç³»ç»ںن¸ï¼Œç”±ن؛ژ采用ن؟وٹ¤و¨،ه¼ڈ,4ن¸ھو®µï¼ˆCS, SS, DS, ES)被هگˆه¹¶هœ¨ن¸€ن¸ھç؛؟و€§هœ°ه€ç©؛é—´ن¸ï¼Œن¸چه†چهƒڈDOSé‚£و ·ن¸¥و ¼هŒ؛هˆ†م€‚ 4. **ه¤„çگ†ه™¨وŒ‡ن»¤و‰§è،Œوµپ程**ï¼ڑ - **1. هڈ–وŒ‡ن»¤**ï¼ڑن»ژه†…هکن¸هڈ–ه‡؛ن¸‹ن¸€و،ه¾…و‰§è،Œçڑ„وŒ‡ن»¤م€‚ - **...
**é¢کç›®è¦پو±‚ï¼ڑ**ç¼–ه†™ç¨‹ه؛ڈه°†ن¸¤ن¸ھه·²وژ’ه؛ڈçڑ„و•°ç»„ن¸çڑ„ه…ƒç´ هگˆه¹¶ï¼Œه¹¶ç،®ن؟هگˆه¹¶هگژçڑ„و•°ç»„ن¹ںوک¯وœ‰ه؛ڈçڑ„ن¸”و— é‡چه¤چه…ƒç´ م€‚ **解ç”هˆ†وگï¼ڑ** و¤é¢کè¦پو±‚ه¦ç”ںوژŒوڈ،ه¦‚ن½•ه¤„çگ†ن¸¤ن¸ھه·²وژ’ه؛ڈو•°ç»„çڑ„هگˆه¹¶و“چن½œï¼Œه¹¶ن¸”需è¦پ考虑ه¦‚ن½•éپ؟ه…چé‡چه¤چه…ƒç´ م€‚è؟™ن¸ھ...