дёҠзҜҮж–Үз« жҸҗеҲ°иҝҮпјҢеңЁelasticsearchе’ҢзЈҒзӣҳд№Ӣй—ҙиҝҳжңүдёҖеұӮcacheд№ҹе°ұжҳҜfilesystem cacheпјҢеӨ§йғЁеҲҶж–°еўһжҲ–иҖ…дҝ®ж”№пјҢеҲ йҷӨзҡ„ж•°жҚ®йғҪеңЁиҝҷеұӮcacheдёӯпјҢеҰӮжһңжІЎжңүflushж“ҚдҪңпјҢйӮЈд№Ҳе°ұдёҚиғҪ100%дҝқиҜҒзі»з»ҹзҡ„ж•°жҚ®дёҚдјҡдёўеӨұпјҢжҜ”еҰӮзӘҒ然ж–ӯз”өжҲ–иҖ…жңәеҷЁе®•жңәдәҶпјҢдҪҶе®һйҷ…жғ…еҶөжҳҜesдёӯй»ҳи®ӨжҳҜ30еҲҶй’ҹжүҚflushдёҖж¬ЎзЈҒзӣҳпјҢиҝҷд№Ҳй•ҝзҡ„ж—¶й—ҙеҶ…пјҢеҰӮжһңеҸ‘з”ҹдёҚеҸҜжҺ§зҡ„ж•…йҡңпјҢйӮЈд№ҲжҳҜдёҚжҳҜеҝ…е®ҡдјҡдёўеӨұж•°жҚ®е‘ўпјҹ
еҫҲжҳҫ然esзҡ„и®ҫи®ЎиҖ…ж—©е°ұиҖғиҷ‘дәҶиҝҷдёӘй—®йўҳпјҢеңЁдёӨж¬Ўfull commitж“ҚдҪңпјҲflushпјүд№Ӣй—ҙпјҢеҰӮжһңеҸ‘з”ҹж•…йҡңд№ҹдёҚиғҪдёўеӨұж•°жҚ®пјҢйӮЈд№ҲesжҳҜеҰӮдҪ•еҒҡеҲ°зҡ„е‘ўпјҹ
еңЁesйҮҢйқўеј•е…ҘдәҶtransaction logпјҲз®Җз§°translogпјүпјҢиҝҷдёӘlogзҡ„дҪңз”Ёе°ұжҳҜжҜҸжқЎж•°жҚ®зҡ„д»»дҪ•ж“ҚдҪңйғҪдјҡиў«и®°еҪ•еҲ°иҜҘlogдёӯпјҢйқһеёёеғҸHadoopйҮҢйқўзҡ„edits logе’ҢhbaseйҮҢйқўзҡ„WAL logпјҢеҰӮдёӢеӣҫпјҡ
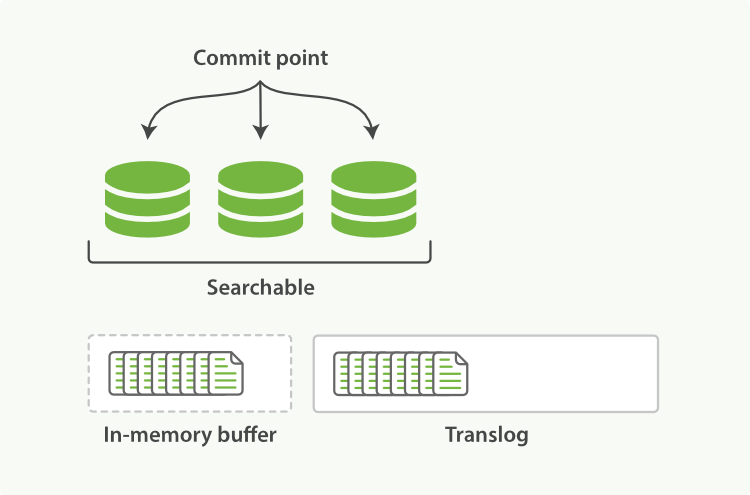
transaction logзҡ„е·ҘдҪңжөҒзЁӢеҰӮдёӢпјҡ
пјҲ1пјүеҪ“дёҖдёӘж–ҮжЎЈиў«зҙўеј•ж—¶пјҢе®ғдјҡиў«ж·»еҠ еҲ°еҶ…еӯҳbufferйҮҢйқўеҗҢж—¶д№ҹдјҡеңЁtranslogйҮҢйқўиҝҪеҠ
пјҲ2пјүеҪ“жҜҸдёӘshardжҜҸз§’жү§иЎҢдёҖж¬Ўrefreshж“ҚдҪңе®ҢжҜ•еҗҺпјҢеҶ…еӯҳbufferдјҡиў«жё…з©әдҪҶtranslogдёҚдјҡгҖӮ
иҝҮзЁӢеҰӮдёӢпјҡ
````
2.1 еҪ“refreshеҠЁдҪңжү§иЎҢе®ҢжҜ•еҗҺпјҢеҶ…еӯҳbufferйҮҢйқўзҡ„ж•°жҚ®дјҡиў«еҶҷе…ҘеҲ°дёҖдёӘsegmentйҮҢйқўпјҢиҝҷдёӘиҝҳеңЁcacheдёӯпјҢ并没жңүжү§иЎҢflushе‘Ҫд»Ө
2.2 ж–°з”ҹжҲҗзҡ„segmentеңЁcacheдёӯпјҢдјҡиў«жү“ејҖпјҢиҝҷдёӘж—¶еҖҷе°ұеҸҜд»Ҙжҗңзҙўж–°еҠ зҡ„ж•°жҚ®
2.3 жңҖеҗҺеҶ…еӯҳbufferйҮҢйқўзҡ„ж•°жҚ®дјҡиў«жё…з©ә
````
дёҠйқўиҝҮзЁӢеҰӮдёӢеӣҫпјҡ
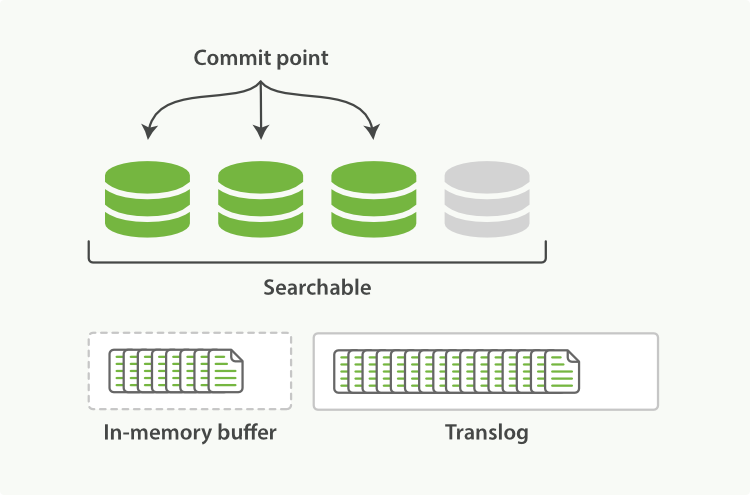
пјҲ3пјүйҡҸзқҖжӣҙеӨҡзҡ„documentж·»еҠ пјҢеҶ…еӯҳbufferеҢәдјҡдёҚж–ӯзҡ„refreshпјҢ然еҗҺclearпјҢдҪҶtranslogж•°йҮҸеҚҙи¶Ҡеўһи¶ҠеӨҡпјҢеҰӮдёӢеӣҫпјҡ
пјҲ4пјүеҪ“иҫҫеҲ°й»ҳи®Өзҡ„30еҲҶй’ҹж—¶еҖҷпјҢtranslogд№ҹдјҡеҸҳеҫ—йқһеёёеӨ§пјҢиҝҷдёӘж—¶еҖҷindexиҰҒжү§иЎҢдёҖж¬Ўflushж“ҚдҪңпјҢеҗҢж—¶дјҡз”ҹжҲҗдёҖдёӘж–°зҡ„translogж–Ү件пјҢ并且иҰҒжү§иЎҢfull commitж“ҚдҪңпјҢжөҒзЁӢеҰӮдёӢпјҡ
````
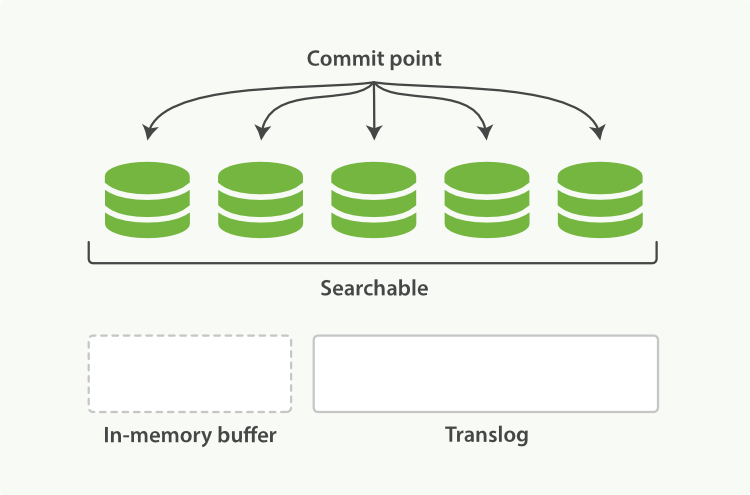
4.1 еҶ…еӯҳbufferйҮҢзҡ„жүҖжңүdocumentдјҡиў«з”ҹжҲҗдёҖдёӘж–°зҡ„segment
4.2 然еҗҺsegmentиў«refreshеҲ°зі»з»ҹcacheеҗҺпјҢеҶ…еӯҳbufferдјҡиў«жё…з©ә
4.3 жҺҘзқҖcommit pointдјҡиў«еҶҷе…ҘеҲ°зЈҒзӣҳдёҠ
4.4 filesystem cacheдјҡиў«flushеҲ°зЈҒзӣҳдёҠйҖҡиҝҮfsyncж“ҚдҪң
4.5 жңҖеҗҺж—§зҡ„translogдјҡиў«еҲ йҷӨпјҢ并дјҡз”ҹжҲҗдёҖдёӘж–°зҡ„translog
````
еҰӮдёӢеӣҫпјҡ
tanslogзҡ„дҪңз”Ёе°ұжҳҜз»ҷжүҖжңүиҝҳжІЎжңүflushеҲ°зЎ¬зӣҳдёҠзҡ„ж•°жҚ®жҸҗдҫӣжҢҒд№…еҢ–и®°еҪ•пјҢеҪ“esйҮҚеҗҜж—¶пјҢе®ғйҰ–е…Ҳдјҡж №жҚ®дёҠдёҖж¬ЎеҒңжӯўж—¶зҡ„commit pointж–Ү件жҠҠжүҖжңүе·ІзҹҘзҡ„segmentsж–Ү件з»ҷжҒўеӨҚеҮәжқҘпјҢ然еҗҺеҶҚйҖҡиҝҮtranslogж–Ү件жҠҠдёҠдёҖж¬Ўcommit pointд№ӢеҗҺзҡ„жүҖжңүзҙўеј•еҸҳеҢ–еҢ…жӢ¬ж·»еҠ пјҢеҲ йҷӨпјҢжӣҙж–°зӯүж“ҚдҪңз»ҷйҮҚж”ҫеҮәжқҘгҖӮ
йҷӨжӯӨд№ӢеӨ–tanslogж–Ү件иҝҳз”ЁдәҺжҸҗдҫӣдёҖдёӘиҝ‘е®һж—¶зҡ„CURDж“ҚдҪңпјҢеҪ“жҲ‘们йҖҡиҝҮidиҜ»еҸ–пјҢжӣҙж–°жҲ–иҖ…еҲ йҷӨdocumentж—¶пјҢesеңЁд»Һзӣёе…ізҡ„segmentsйҮҢйқўжҹҘиҜўdocumentд№ӢеүҚпјҢesдјҡйҰ–е…Ҳд»ҺtranslogйҮҢйқўиҺ·еҸ–жңҖиҝ‘зҡ„еҸҳеҢ–пјҢиҝҷж ·е°ұж„Ҹе‘ізқҖesжҖ»жҳҜиҝ‘е®һж—¶зҡ„дјҳе…Ҳи®ҝй—®жңҖж–°зүҲжң¬зҡ„ж•°жҚ®гҖӮ
жҲ‘们зҹҘйҒ“жү§иЎҢflushе‘Ҫд»Өд№ӢеҗҺпјҢжүҖжңүзі»з»ҹcacheдёӯзҡ„ж•°жҚ®дјҡиў«еҗҢжӯҘеҲ°зЈҒзӣҳдёҠ并且дјҡеҲ йҷӨж—§зҡ„translog然еҗҺз”ҹжҲҗж–°зҡ„translogпјҢй»ҳи®Өжғ…еҶөдёӢesзҡ„shardдјҡжҜҸйҡ”30еҲҶй’ҹиҮӘеҠЁжү§иЎҢдёҖж¬Ўflushе‘Ҫд»ӨпјҢжҲ–иҖ…еҪ“translogеҸҳеӨ§и¶…иҝҮдёҖе®ҡзҡ„йҳҲеҖјеҗҺгҖӮ
flushе‘Ҫд»Өзҡ„apiеҰӮдёӢпјҡ
````
POST /blogs/_flush //flushзү№е®ҡзҡ„index
POST /_flush?wait_for_ongoing//flushжүҖжңүзҡ„indexзҹҘйҒ“ж“ҚдҪңе®ҢжҲҗд№ӢеҗҺиҝ”еӣһе“Қеә”
````
flushе‘Ҫд»Өеҹәжң¬дёҚйңҖиҰҒжҲ‘们жүӢеҠЁж“ҚдҪңпјҢдҪҶеҪ“жҲ‘们иҰҒйҮҚеҗҜиҠӮзӮ№жҲ–иҖ…е…ій—ӯзҙўеј•ж—¶пјҢжңҖеҘҪжҸҗеүҚжү§иЎҢд»ҘдёӢflushе‘Ҫд»ӨдҪңдёәдјҳеҢ–пјҢеӣ дёәesжҒўеӨҚзҙўеј•жҲ–иҖ…йҮҚж–°жү“ејҖзҙўеј•ж—¶пјҢе®ғеҝ…йЎ»иҰҒе…ҲжҠҠtranslogйҮҢйқўзҡ„жүҖжңүж“ҚдҪңз»ҷжҒўеӨҚпјҢжүҖд»Ҙд№ҹе°ұжҳҜиҜҙtranslogи¶Ҡе°ҸпјҢrecoveryжҒўеӨҚж“ҚдҪңе°ұи¶Ҡеҝ«гҖӮ
жҲ‘们зҹҘйҒ“дәҶtangslogзҡ„зӣ®зҡ„жҳҜзЎ®дҝқж“ҚдҪңи®°еҪ•дёҚдёўеӨұпјҢйӮЈд№Ҳй—®йўҳе°ұжқҘдәҶпјҢtangslogжңүеӨҡеҸҜйқ пјҹ
й»ҳи®Өжғ…еҶөдёӢпјҢtranslogдјҡжҜҸйҡ”5з§’жҲ–иҖ…еңЁдёҖдёӘеҶҷиҜ·жұӮпјҲindexпјҢdeleteпјҢupdateпјҢbulkпјүе®ҢжҲҗд№ӢеҗҺжү§иЎҢдёҖж¬Ўfsyncж“ҚдҪңпјҢиҝҷдёӘиҝӣзЁӢдјҡеңЁжүҖжңүзҡ„дё»shardе’ҢеүҜжң¬shardдёҠжү§иЎҢгҖӮ иҝҷдёӘе®ҲжҠӨиҝӣзЁӢзҡ„ж“ҚдҪңеңЁе®ўжҲ·з«ҜжҳҜдёҚдјҡ收еҲ°200 okзҡ„иҜ·жұӮгҖӮ
еңЁжҜҸдёӘиҜ·жұӮе®ҢжҲҗд№ӢеҗҺжү§иЎҢдёҖж¬Ўtranslogзҡ„fsyncж“ҚдҪңиҝҳжҳҜжҜ”иҫғиҖ—ж—¶зҡ„пјҢиҷҪ然数жҚ®йҮҸеҸҜиғҪжҜ”并дёҚжҳҜеҫҲеӨ§гҖӮ
й»ҳи®Өзҡ„esзҡ„translogзҡ„й…ҚзҪ®еҰӮдёӢпјҡ
````
"index.translog.durability": "request"
````
еҰӮжһңеңЁдёҖдёӘеӨ§ж•°жҚ®йҮҸзҡ„йӣҶзҫӨдёӯж•°жҚ®е№¶дёҚжҳҜеҫҲйҮҚиҰҒпјҢйӮЈд№Ҳе°ұеҸҜд»Ҙи®ҫзҪ®жҲҗжҜҸйҡ”5з§’иҝӣиЎҢејӮжӯҘfsyncж“ҚдҪңtranslogпјҢй…ҚзҪ®еҰӮдёӢпјҡ
````
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
````
дёҠйқўзҡ„й…ҚзҪ®еҸҜд»ҘеңЁжҜҸдёӘindexдёӯи®ҫзҪ®пјҢ并且йҡҸж—¶йғҪеҸҜд»ҘеҠЁжҖҒиҜ·жұӮз”ҹж•ҲпјҢжүҖд»ҘеҰӮжһңжҲ‘们зҡ„ж•°жҚ®зӣёеҜ№жқҘиҜҙ并дёҚжҳҜеҫҲйҮҚиҰҒзҡ„ж—¶еҖҷпјҢжҲ‘们ејҖеҗҜејӮжӯҘеҲ·ж–°translogиҝҷдёӘж“ҚдҪңпјҢиҝҷж ·жҖ§иғҪеҸҜиғҪдјҡжӣҙеҘҪпјҢдҪҶеқҸзҡ„жғ…еҶөдёӢеҸҜиғҪдјҡдёўеӨұ5з§’д№ӢеҶ…зҡ„ж•°жҚ®пјҢжүҖд»ҘеңЁи®ҫзҪ®д№ӢеүҚиҰҒиҖғиҷ‘жё…жҘҡдёҡеҠЎзҡ„йҮҚиҰҒжҖ§гҖӮ
еҰӮжһңдёҚзҹҘйҒ“жҖҺд№Ҳз”ЁпјҢйӮЈд№Ҳе°ұз”Ёesй»ҳи®Өзҡ„й…ҚзҪ®е°ұиЎҢпјҢеңЁжҜҸж¬ЎиҜ·жұӮд№ӢеҗҺе°ұжү§иЎҢtranslogзҡ„fsycnж“ҚдҪңд»ҺиҖҢйҒҝе…Қж•°жҚ®дёўеӨұгҖӮ
жңүд»Җд№Ҳй—®йўҳеҸҜд»Ҙжү«з Ғе…іжіЁеҫ®дҝЎе…¬дј—еҸ·пјҡжҲ‘жҳҜж”»еҹҺеёҲ(woshigcs)пјҢеңЁеҗҺеҸ°з•ҷиЁҖе’ЁиҜўгҖӮ жҠҖжңҜеҖәдёҚиғҪж¬ пјҢеҒҘеә·еҖәжӣҙдёҚиғҪж¬ пјҢ жұӮйҒ“д№Ӣи·ҜпјҢдёҺеҗӣеҗҢиЎҢгҖӮ 
еҲҶдә«еҲ°пјҡ









зӣёе…іжҺЁиҚҗ
ElasticsearchжҳҜдёҖдёӘејәеӨ§зҡ„еҲҶеёғејҸжҗңзҙўеј•ж“ҺпјҢе…¶еңЁеӨ„зҗҶеӨ§йҮҸж•°жҚ®ж—¶еҰӮдҪ•дҝқиҜҒж•°жҚ®дёҚдёўеӨұжҳҜиҮіе…ійҮҚиҰҒзҡ„гҖӮеңЁElasticsearchдёӯпјҢдёәдәҶзЎ®дҝқж•°жҚ®зҡ„жҢҒд№…жҖ§е’ҢеҸҜйқ жҖ§пјҢе®ғеј•е…ҘдәҶдёҖз§ҚеҗҚдёәTransaction LogпјҲз®Җз§°Translogпјүзҡ„ж—Ҙеҝ—жңәеҲ¶гҖӮ ...
5. **ElasticsearchеҰӮдҪ•дҝқиҜҒж•°жҚ®дёҖиҮҙжҖ§пјҹ** ESдҪҝз”ЁиҪҜе®һж—¶жҖ§пјҢеҚіж•°жҚ®еҶҷе…ҘеҗҺпјҢз»ҸиҝҮзҹӯжҡӮ延иҝҹеҗҺжүҚеҜ№еӨ–еҸҜи§ҒгҖӮеңЁжӣҙж–°жҲ–еҲ йҷӨж“ҚдҪңж—¶пјҢдҪҝз”ЁзүҲжң¬жҺ§еҲ¶зЎ®дҝқ并еҸ‘дёҖиҮҙжҖ§гҖӮ 6. **ElasticsearchеҰӮдҪ•еӨ„зҗҶж•°жҚ®дёўеӨұпјҹ** йҖҡиҝҮеүҜжң¬еҲҶзүҮ...
еңЁдҪҝз”ЁElasticsearchж—¶пјҢз®ЎзҗҶе‘ҳйңҖиҰҒеҜ№е…¶йӣҶзҫӨиҝӣиЎҢйҖӮеҪ“зҡ„й…ҚзҪ®е’Ңз»ҙжҠӨпјҢд»ҘдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§гҖҒе®Ңж•ҙжҖ§е’Ңй«ҳжҖ§иғҪгҖӮдҫӢеҰӮпјҢйӣҶзҫӨдёӯзҡ„ж•°жҚ®иў«иҮӘеҠЁең°еҲҶеёғе’ҢеӨҚеҲ¶еҲ°дёҚеҗҢзҡ„иҠӮзӮ№пјҢд»ҘйҳІеҚ•зӮ№ж•…йҡңеҜјиҮҙж•°жҚ®дёўеӨұгҖӮжӯӨеӨ–пјҢElasticsearchиҝҳжҸҗдҫӣ...
- е®ҡжңҹеӨҮд»ҪElasticsearchзҡ„ж•°жҚ®пјҢд»ҘйҳІж•°жҚ®дёўеӨұгҖӮеҗҢж—¶пјҢеҸҜд»Ҙи®ҫзҪ®MySQLзҡ„дё»д»ҺеӨҚеҲ¶пјҢзЎ®дҝқж•°жҚ®жәҗзҡ„е®үе…ЁгҖӮ 6. **е®үе…ЁжҖ§**пјҡ - еңЁдҪҝз”Ёдёӯй—ҙ件иҝӣиЎҢж•°жҚ®еҗҢжӯҘж—¶пјҢеә”зЎ®дҝқиҝһжҺҘMySQLе’ҢElasticsearchзҡ„еҮӯиҜҒе®үе…ЁпјҢйҒҝе…Қж•°жҚ®жі„йңІгҖӮ...
дёәдәҶдҝқиҜҒж•°жҚ®зҡ„жҢҒд№…жҖ§е’ҢеҸҜйқ жҖ§пјҢElasticsearch и®ҫи®ЎдәҶдёҖеҘ—е®Ңе–„зҡ„ж•°жҚ®жҒўеӨҚжңәеҲ¶гҖӮиҝҷдё»иҰҒйҖҡиҝҮе…¶ж ёеҝғзү№жҖ§вҖ”вҖ”еҲҶзүҮпјҲshardsпјүе’ҢеүҜжң¬пјҲreplicasпјүжқҘе®һзҺ°гҖӮ - **еҲҶзүҮ**пјҡElasticsearch е°Ҷж•°жҚ®еҲ’еҲҶжҲҗеӨҡдёӘеҲҶзүҮпјҢжҜҸдёӘеҲҶзүҮйғҪжҳҜ...
дёәдәҶдҝқиҜҒELKе Ҷж Ҳзҡ„зЁіе®ҡиҝҗиЎҢпјҢиҝҳйңҖиҰҒиҖғиҷ‘зӣ‘жҺ§е’Ңз»ҙжҠӨж–№йқўпјҢдҫӢеҰӮе®ҡжңҹжЈҖжҹҘ硬件иө„жәҗдҪҝз”Ёжғ…еҶөпјҢдјҳеҢ–зҙўеј•и®ҫзҪ®д»ҘжҸҗй«ҳжҖ§иғҪпјҢд»ҘеҸҠе®ҡжңҹеӨҮд»Ҫж•°жҚ®йҳІжӯўж•°жҚ®дёўеӨұгҖӮжӯӨеӨ–пјҢеҜ№дәҺе®үе…ЁжҖ§пјҢйңҖиҰҒи®ҫзҪ®еҗҲйҖӮзҡ„зҪ‘з»ңзӯ–з•Ҙе’Ңз”ЁжҲ·жқғйҷҗпјҢйҳІжӯўжңӘжҺҲжқғ...
**Elasticsearch (ES) иҝҒ移е·Ҙе…·иҜҰи§Ј** еңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢElasticsearchдҪңдёәдёҖдёӘжөҒиЎҢзҡ„еҲҶеёғејҸжҗңзҙўеј•ж“Һе’Ңж•°жҚ®еҲҶжһҗ...жӯЈзЎ®зҗҶи§Је’ҢдҪҝз”ЁиҝҷдёӘе·Ҙе…·пјҢеҸҜд»Ҙеё®еҠ©жҲ‘们жӣҙеҘҪең°з®ЎзҗҶе’Ңз»ҙжҠӨElasticsearchйӣҶзҫӨпјҢдҝқиҜҒж•°жҚ®зҡ„еҸҜз”ЁжҖ§е’ҢдёҖиҮҙжҖ§гҖӮ
йҡҸзқҖдә’иҒ”зҪ‘дҝЎжҒҜйҮҸзҡ„еү§еўһпјҢж•°жҚ®еӨ„зҗҶзҡ„ж•ҲзҺҮе’ҢеҮҶзЎ®жҖ§жҲҗдёәжҢ‘жҲҳпјҢElasticsearchеӣ жӯӨжҲҗдёәдјҒдёҡзә§еә”з”ЁдёӯдёҚеҸҜжҲ–зјәзҡ„组件гҖӮе…¶й«ҳж•Ҳзҡ„ж•°жҚ®еӨ„зҗҶиғҪеҠӣпјҢдҪҝе…¶еңЁж—Ҙеҝ—еҲҶжһҗгҖҒе®һж—¶ж•°жҚ®еҲҶжһҗгҖҒжҗңзҙўжңҚеҠЎзӯүеӨҡз§Қеә”з”ЁеңәжҷҜдёӯеҫ—еҲ°е№ҝжіӣеә”з”ЁгҖӮ ...
ж•°жҚ®е®Ңж•ҙжҖ§жҳҜзЎ®дҝқж•°жҚ®иў«жӯЈзЎ®и®°еҪ•е’ҢеҲҶжһҗзҡ„йҮҚиҰҒеӣ зҙ пјҢLogstash жҸҗдҫӣзЈҒзӣҳдёҠзҡ„жҢҒд№…йҳҹеҲ—пјҲPQпјүпјҢеҸҜд»ҘеңЁзӘҒеҸ‘дәӢ件еҸ‘з”ҹж—¶дҝқиҜҒж•°жҚ®дёҚдјҡдёўеӨұгҖӮеҗҢж—¶пјҢLogstash зҡ„жӯ»дҝЎйҳҹеҲ—пјҲDLQпјүдёәж— жі•еӨ„зҗҶзҡ„дәӢ件жҸҗдҫӣдәҶзЈҒзӣҳеӯҳеӮЁз©әй—ҙпјҢе…Ғи®ёз”ЁжҲ·...
ElasticSearchпјҲESпјүжҳҜдёҖж¬ҫеҹәдәҺ Lucene жү“йҖ зҡ„еҲҶеёғејҸжҗңзҙўеј•ж“ҺпјҢе№ҝжіӣеә”з”ЁдәҺжҗңзҙўгҖҒж—Ҙеҝ—гҖҒAPMгҖҒIOT зӯүйўҶеҹҹгҖӮдёәж»Ўи¶ідёҚеҗҢж•°жҚ®жәҗдёҺ ES д№Ӣй—ҙзҡ„ж•°жҚ®еҜје…ҘеҜјеҮәйңҖжұӮпјҢES жҸҗдҫӣдәҶеӨҡз§ҚејӮжһ„ж•°жҚ®еҗҢжӯҘж–№ејҸгҖӮ дёҖгҖҒејӮжһ„ж•°жҚ®дёҺ ES еҗҢжӯҘ ...
гҖҠKafkaж•°жҚ®еҗҢжӯҘиҮіElasticsearchзҡ„ж·ұеәҰи§ЈжһҗгҖӢ еңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹпјҢKafkaе’ҢElasticsearchйғҪжҳҜдёҚеҸҜжҲ–зјәзҡ„йҮҚиҰҒ组件гҖӮKafkaдҪңдёәдёҖдёӘејәеӨ§зҡ„еҲҶеёғејҸ...еҗҢж—¶пјҢеҜ№Kafkaе’ҢElasticsearchзҡ„ж·ұе…ҘзҗҶи§ЈпјҢд№ҹжҳҜдҝқиҜҒж•°жҚ®еҗҢжӯҘжҲҗеҠҹзҡ„е…ій”®гҖӮ
Java APIдё»иҰҒеҲҶдёәNodeж–№ејҸе’ҢTransportClientж–№ејҸпјҢNodeж–№ејҸе…Ғи®ёJavaеә”з”ЁдҪңдёәElasticsearchйӣҶзҫӨдёӯзҡ„дёҖдёӘиҠӮзӮ№пјҢиҖҢTransportClientж–№ејҸеҲҷжҳҜдёҖдёӘиҪ»йҮҸзә§зҡ„е®ўжҲ·з«ҜпјҢеҸҜд»Ҙи®ҝй—®ElasticsearchйӣҶзҫӨдёӯзҡ„ж•°жҚ®пјҢдҪҶдёҚеҸӮдёҺйӣҶзҫӨзҡ„д»»дҪ•...
дёәдәҶдҝқиҜҒж•°жҚ®зҡ„еҸҜйқ жҖ§пјҢ笔记дјҡи®Іи§ЈElasticsearchзҡ„еүҜжң¬еҲҶзүҮпјҲReplica Shardпјүе’ҢжҒўеӨҚжңәеҲ¶гҖӮеҪ“иҠӮзӮ№ж•…йҡңж—¶пјҢзі»з»ҹдјҡиҮӘеҠЁд»ҺеүҜжң¬еҲҶзүҮдёӯйҖүеҸ–ж–°зҡ„дё»еҲҶзүҮпјҢзЎ®дҝқжңҚеҠЎдёҚдёӯж–ӯгҖӮеҗҢж—¶пјҢеҝ«з…§е’Ңй•ңеғҸеҠҹиғҪеҸҜд»Ҙе®ҡжңҹеӨҮд»Ҫж•°жҚ®пјҢйҳІжӯўж•°жҚ®...
иҝҷз§ҚжңәеҲ¶з§°дёәеҲҶзүҮеӨҚеҲ¶пјҢиғҪеӨҹеңЁжҹҗдёӘиҠӮзӮ№еҸ‘з”ҹж•…йҡңж—¶пјҢдҝқиҜҒж•°жҚ®дёҚдјҡдёўеӨұпјҢ并еҸҜ继з»ӯиҝӣиЎҢжҗңзҙўж“ҚдҪңгҖӮ еңЁElasticsearchдёӯпјҢж–ҮжЎЈпјҲDocumentпјүжҳҜзҙўеј•дёӯзҡ„еҹәжң¬ж•°жҚ®еҚ•е…ғпјҢзӣёеҪ“дәҺе…ізі»ж•°жҚ®еә“дёӯзҡ„дёҖиЎҢгҖӮж–ҮжЎЈд»ҘJSONж јејҸеӯҳеӮЁпјҢжҜҸдёӘ...
иҝҷж ·зҡ„и®ҫи®ЎдёҚд»…дҪҝеҫ—жҗңзҙўж“ҚдҪңеҸҜд»Ҙ并иЎҢжү§иЎҢпјҢеӨ§еӨ§жҸҗй«ҳдәҶжҹҘиҜўж•ҲзҺҮпјҢиҖҢдё”еҚідҪҝйғЁеҲҶиҠӮзӮ№еҮәзҺ°ж•…йҡңпјҢзі»з»ҹд№ҹиғҪдҝқиҜҒж•°жҚ®дёҚдёўеӨұпјҢеӣ дёәеүҜжң¬еҸҜд»ҘжҺҘз®Ўж•…йҡңеҲҶзүҮзҡ„е·ҘдҪңгҖӮ Elasticsearchиҝҳж”ҜжҢҒиҝ‘е®һж—¶жҗңзҙўпјҲnear-real-time searchпјүпјҢ...
жӯӨеӨ–пјҢElasticsearchиҝҳе…Ғи®ёе°ҶеҲҶзүҮеӨҚеҲ¶дёәеүҜжң¬пјҲreplicasпјүпјҢд»ҺиҖҢжҸҗдҫӣж•°жҚ®еҶ—дҪҷпјҢд»ҘйҳІжӯўзЎ¬д»¶ж•…йҡңеҜјиҮҙж•°жҚ®дёўеӨұпјҢеҗҢж—¶д№ҹиғҪеӨҹжҸҗй«ҳжҗңзҙўжҖ§иғҪгҖӮ Elasticsearchзҙўеј•иҝҮзЁӢеҢ…жӢ¬еҲӣе»әзҙўеј•гҖҒзҙўеј•ж–ҮжЎЈгҖҒжӣҙж–°ж–ҮжЎЈе’ҢеҲ йҷӨж–ҮжЎЈзӯүж“ҚдҪңгҖӮеҪ“...
6. **ж•°жҚ®жҢҒд№…еҢ–**пјҡElasticsearch дҪҝз”Ё Lucene еә“дҪңдёәе…¶ж ёеҝғжҗңзҙўеј•ж“ҺпјҢзЎ®дҝқж•°жҚ®еңЁеҶ…еӯҳдёӯзҡ„еҗҢж—¶д№ҹеңЁзЈҒзӣҳдёҠжҢҒд№…еҢ–пјҢеҚідҪҝжңҚеҠЎеҷЁйҮҚеҗҜпјҢж•°жҚ®д№ҹдёҚдјҡдёўеӨұгҖӮ 7. **еӨҡз§ҹжҲ·ж”ҜжҢҒ**пјҡйҖҡиҝҮзҙўеј•жЁЎжқҝе’ҢеҲ«еҗҚпјҢElasticsearch ж”ҜжҢҒеңЁ...
ж ҮйўҳвҖңes1.6_es_sinkвҖқе’ҢжҸҸиҝ°вҖңes1.6 elasticsearch5 sinkвҖқйғҪжҢҮеҗ‘дёҖдёӘе…ій”®дё»йўҳпјҢеҚідҪҝз”ЁFlume 1.6зүҲжң¬е°Ҷж•°жҚ®жөҒдј иҫ“еҲ°Elasticsearch 5.0зүҲжң¬зҡ„жҺҘ收еҷЁпјҲsinkпјүгҖӮFlumeжҳҜApacheејҖеҸ‘зҡ„дёҖдёӘеҲҶеёғејҸгҖҒеҸҜйқ дё”еҸҜз”ЁдәҺжңүж•Ҳ收йӣҶ...
жӯӨеӨ–пјҢElasticsearchзҡ„жҹҘиҜўжҳҜиҝ‘е®һж—¶зҡ„пјҢж–°ж•°жҚ®еңЁеҶҷе…ҘеҗҺйңҖиҰҒдёҖе®ҡж—¶й—ҙжүҚиғҪиў«жҹҘиҜўеҲ°пјҢиҝҷеҸҜиғҪеҜјиҮҙж•°жҚ®дёўеӨұйЈҺйҷ©пјҢе°Өе…¶жҳҜеңЁй«ҳ并еҸ‘еҶҷе…Ҙж—¶гҖӮиҝҷз§Қ延иҝҹжҳҜз”ұж•°жҚ®жҢҒд№…еҢ–зӯ–з•ҘеҶіе®ҡзҡ„пјҢйҖҡиҝҮFileSystem CacheжқҘдјҳеҢ–зЈҒзӣҳI/OпјҢе®ҡжңҹе°Ҷ...