
l¬ÝÈááÈõÜÁΩëÁ´ô
【场景描述】采集房天下最新二手房信息。
【入口网址】https://tj.esf.fang.com/
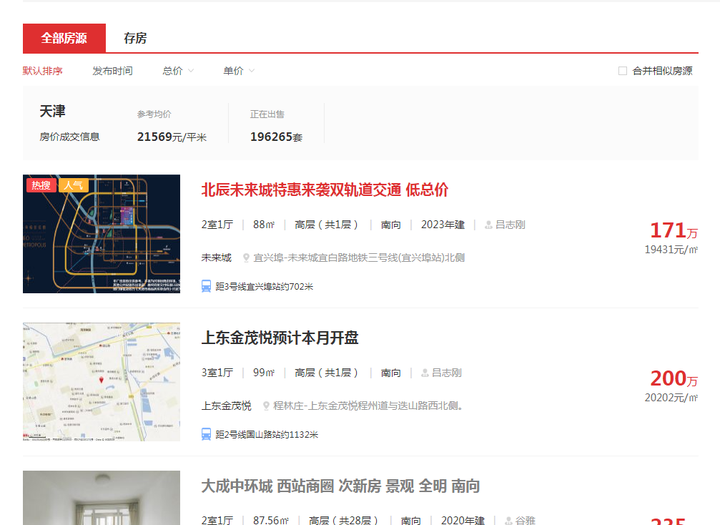
【采集内容】
ÈááÈõܧ©Ê¥•Â∏ÇÊàø§©‰∏ãÔºå‰∫åÊâãÊàøÊ®°Âùó‰∏≠ÁöÑÊâÄÊúâ‰∫åÊâãÊàøÁöÑÊÝáÈ¢ò„Äʼnª∑Êݺ„ÄÅÊà∑Âûã„ÄÅÈù¢ÁßØ„ÄÅÂç∑„ÄÅÊúùÂêë„ÄÅÊ•ºÂ±Ç„ÄÅË£Ö‰øÆ„ÄÅÂ∞èÂå∫„ÄÅÂå∫Âüü„ÄÅËÅîÁ≥ª‰∫∫„ÄÅÁîµËØù„ÄÇ
l¬ÝÊÄùË∑ØÂàÜÊûê
配置思路概览:

l¬ÝÈÖçÁΩÆÊ≠•È™§
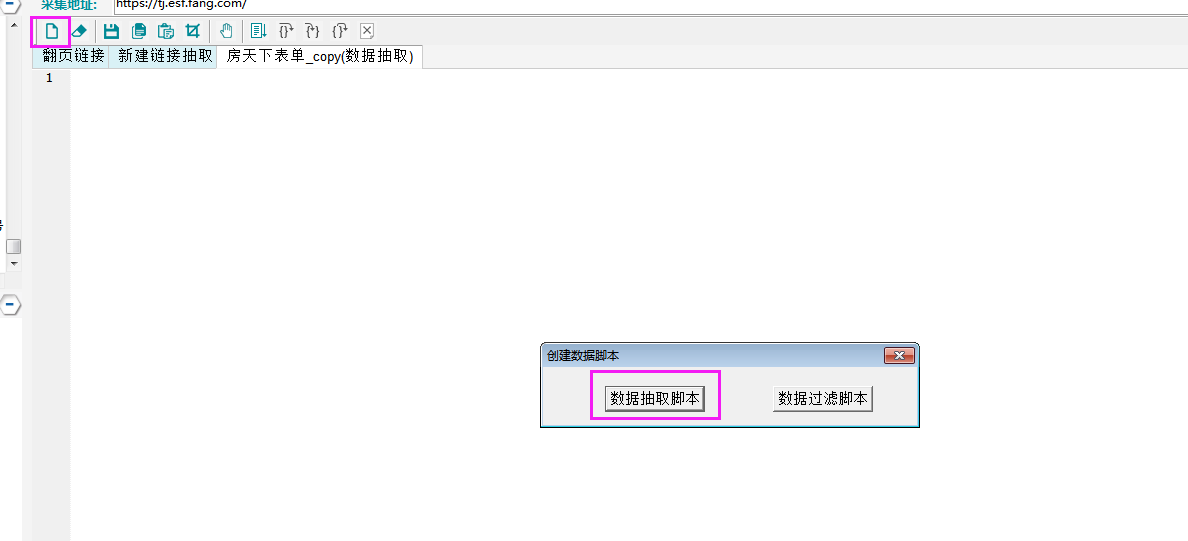
1.¬ÝÊñ∞ª∫ÈááÈõ܉ªªÂä°
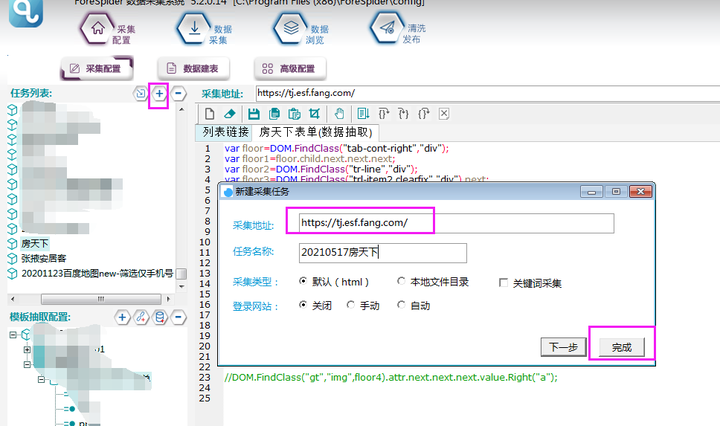
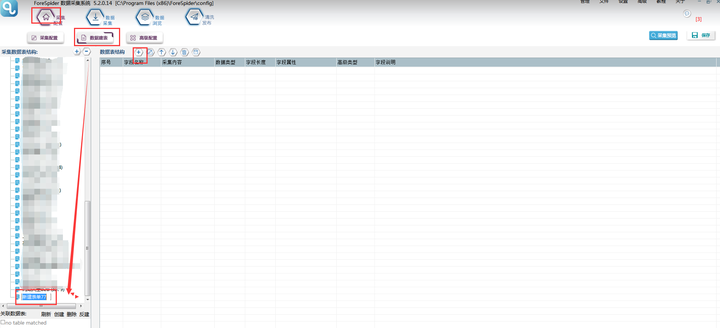
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
2.翻页配置
获取二手房页面中全部翻页链接,观察翻页链接规律发现:
https://tj.esf.fang.com/house/i32/¬ÝÁ¨¨‰∫åÈ°µÈìæÊé•
https://tj.esf.fang.com/house/i33/¬ÝÁ¨¨‰∏âÈ°µÈìæÊé•
https://tj.esf.fang.com/house/i34/¬ÝÁ¨¨ÂõõÈ°µÈìæÊé•
不难发现,翻页链接组成为:
https://tj.esf.fang.com/house/i+页数+/
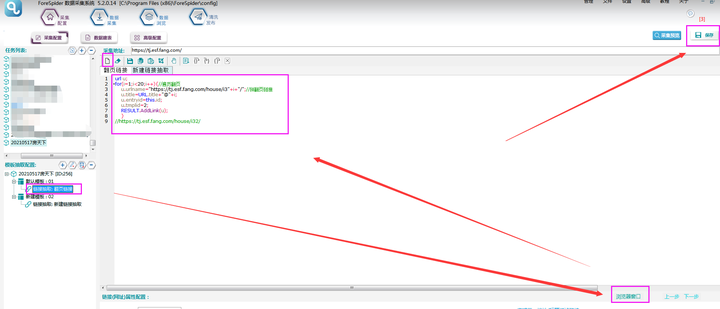
‚ëÝÊïÖÊ∑ªÂäÝËÑöÊú¨Â¶Ç‰∏ãÔºö
②采集预览
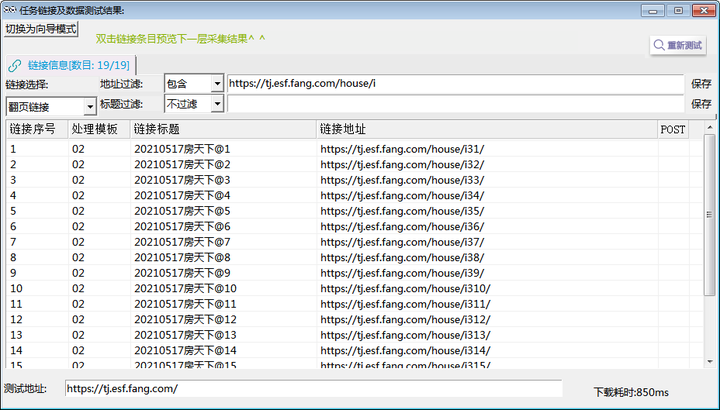
3.链接抽取
‚ëÝÊñ∞ª∫Ê®°Êùø‰∫åÔºåÂπ∂Êñ∞ª∫‰∏ĉ∏™ÈìæÊé•ÊäΩÂèñÔºåÁî®Êù•ÊäΩÂèñÊØè‰∏™ÁøªÈ°µ‰∏≠ÊâÄÊúâ‰∫åÊâãÊàøÈìæÊé•„ÄÇ
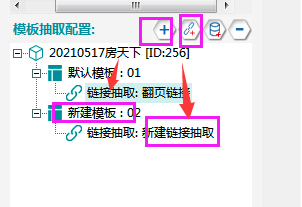
②列表链接需要脚本配置,操作如下图所示:
‚ë¢Êü•ÁúãÈ°µÈù¢Ê∫êÁÝÅÔºåÊâìºÄʵèËßàÂô®‰∏≠ËØ•È°µÈù¢ÔºåÁÇπÂáªF12ÔºåÁÇπÂáªÊåáÈíàÊåâÈíÆÔºå¶lj∏ãÂõæÊâÄÁ§∫ÔºåÁî®ÊåáÈíàÊåâÈíÆÈÄâ‰∏≠ÊâÄÈúÄ˶ÅÁöщ∫åÊâãÊàøÈìæÊé•ÔºåËøôÊó∂Âú®Âè≥‰æßÂá∫Áé∞ÂØπÂ∫îÊ∫êÁÝÅÂÜÖÂÆπ„ÄÇËØ¥ÊòéÈìæÊé•Âú®class‰∏∫„Äêshop_list shop_list_4„ÄëÁöÑËäÇÁÇπ‰∏ã„ÄÇ
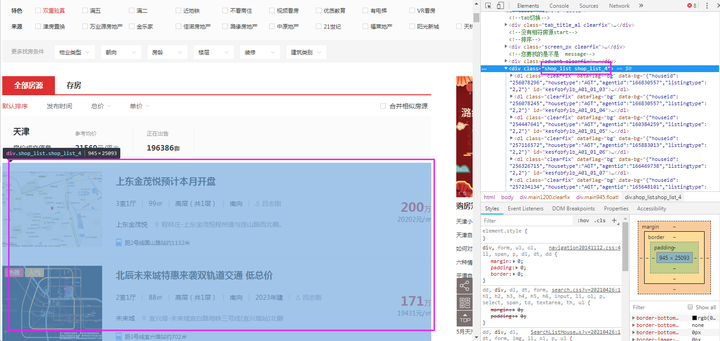
④经过观察发现,我们要找的是【shop_list shop_list_4】节点下每一个名为【dl】的节点对应一个二手房信息。

每个【dl】节点中的名为【dd】节点的子节点的子节点的href就是该二手房的链接。
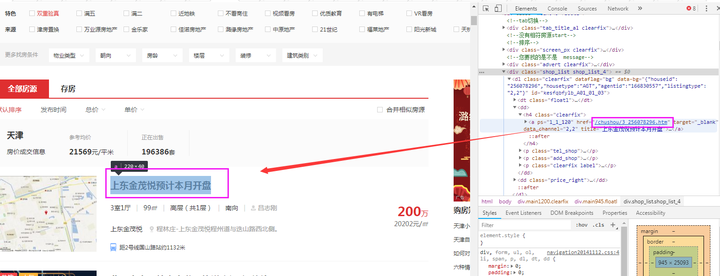
‚ë§ÊÝπÊçƉª•‰∏äÊÄùË∑ØÔºåÂÖ∑‰ΩìÈÖçÁΩÆËÑöÊú¨Â¶Ç‰∏ãÔºåÈÖçÁΩÆ•ΩËÑöÊú¨ÂêéÁÇπÂáªÂè≥‰∏äËßí„Äê‰øùÂ≠ò„Äë„ÄÇ
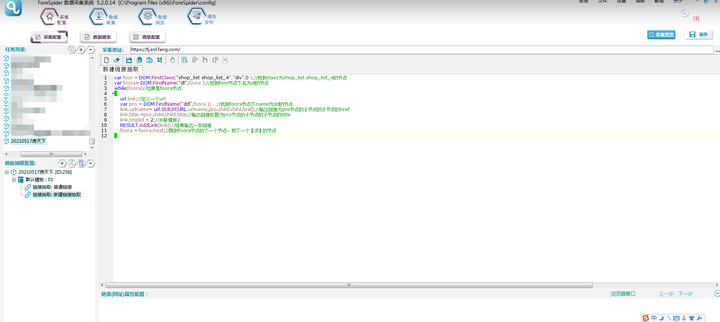
文本如下:
var foor = DOM.FindClass("shop_list shop_list_4","div",0 );//找到class为shop_list shop_list_4的节点
var foora= DOM.FindName("dl",foora );//找到foor节点下名为dl的节点
while(foora)//如果是foora节点
{
url link;//定义一个url
var pro = DOM.FindName("dd",foora ); //找到foora节点下name为dd的节点
link.urlname= url.StdUrl(URL.urlname,pro.child.child.href);//输出链接为pro节点的子节点的子节点的href
link.title =pro.child.child.title;//ËæìÂá∫ÈìæÊé•ÊÝáÈ¢ò‰∏∫proËäÇÁÇπÁöÑÂ≠êËäÇÁÇπÁöÑÂ≠êËäÇÁÇπÁöÑtitle
link.tmplid = 3;//关联模板2
RESULT.AddLink(link);//结果输出一条链接
foora = foora.next;//跳到foora节点的下一个节点,即下一个【class=listtxt】的节点
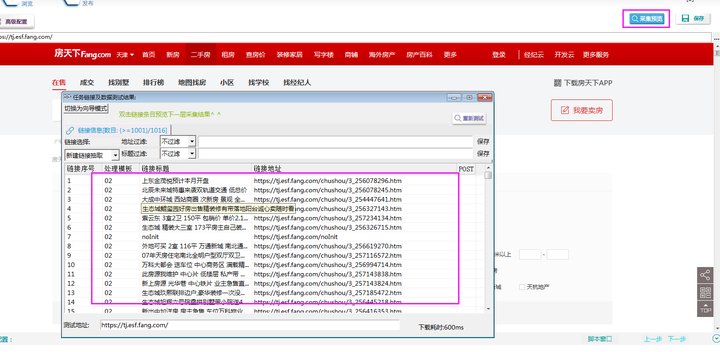
}⑥采集预览如下所示:
2.¬ÝÊï∞ÊçÆÊäΩÂèñ
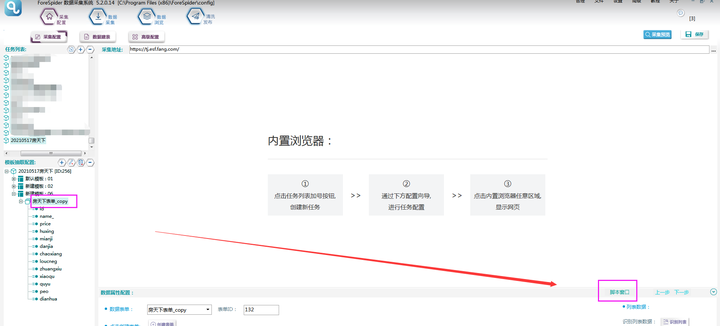
‚ëÝÈìæÊé•ÊäΩÂèñÂÆåÊàêËøõÂÖ•Êï∞ÊçÆÈ°µÔºåÂú®ÂéüÊúâÊ®°ÊùøÂü∫Á°Ä‰∏äÔºåÂè≥ÈîÆÈÄâÊã©„ÄêÊ∑ªÂäÝÊ®°Êùø„ÄëÔºåÊñ∞Ê∑ªÂäÝÁöÑÊ®°ÊùøÔºåÂè≥ÈîÆ„ÄêÊ∑ªÂäÝÊï∞ÊçÆÊäΩÂèñ„Äë„ÄÇ
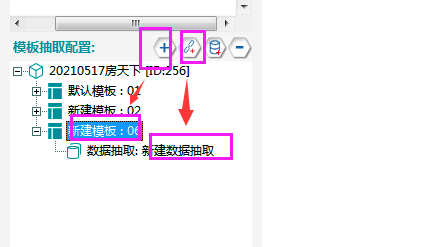
‚ë°Ê≠§Êó∂˶ÅÂÆåÊàêÊï∞Êçƪ∫Ë°®ÁöÑÂ∑•‰ΩúÔºöÈÄâÊã©„ÄêÊï∞Êçƪ∫Ë°®„ÄëÔºåÁÇπÂ᪄ÄêÈááÈõÜÊï∞ÊçÆË°®ÁªìÊûÑ„Äë‰∏≠ÁöÑ„Äê+„ÄëÔºåÂç≥ÂèØÊ∑ªÂäÝÊï∞ÊçÆË°®ÔºåÂêçÁß∞Âè؉ª•Ëá™ÂÆö‰πâÔºåÂú®Ê≠§ÂëΩÂêç‰∏∫Êàø§©‰∏ãË°®Âçï„ÄÇ
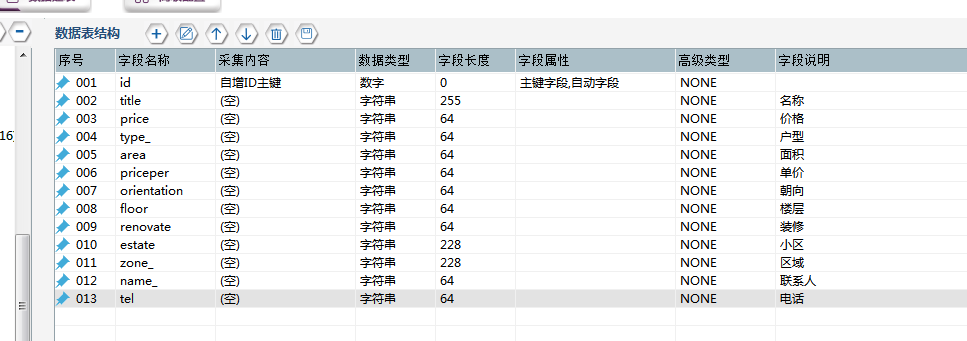
③数据表配置完成,选择【数据抽取】右侧数据属性配置,表单选择刚建立的“房天下”数据表,则可看到表单中的字段在左侧显示。
④点击脚本窗口,选择数据抽取脚本
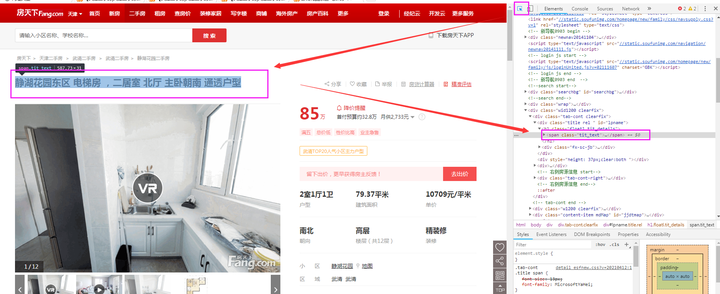
‚ë§ËßÇÂØüÊâÄÈúÄÂ≠óÊƵÂú®È°µÈù¢‰∏≠ÁöщΩçÁΩÆÔºåʵèËßàÂô®ÊâìºĉªªÊÑè‰∏ĉ∏™‰∫åÊâãÊàøËضÊÉÖÈ°µÔºåÁÇπÂáªF12ÔºåÁÇπÂáªÊåáÈíàÊåâÈíÆÔºå¶lj∏ãÂõæÊâÄÁ§∫ÔºåÁî®ÊåáÈíàÊåâÈíÆÈÄâ‰∏≠ÊâÄÈúÄ˶ÅÁöщ∫åÊâãÊàøÂ≠óÊƵ‰ø°ÊÅØÔºåËøôÊó∂Âú®Âè≥‰æßÂá∫Áé∞ÂØπÂ∫îÊ∫êÁÝÅÂÜÖÂÆπ„ÄÇ
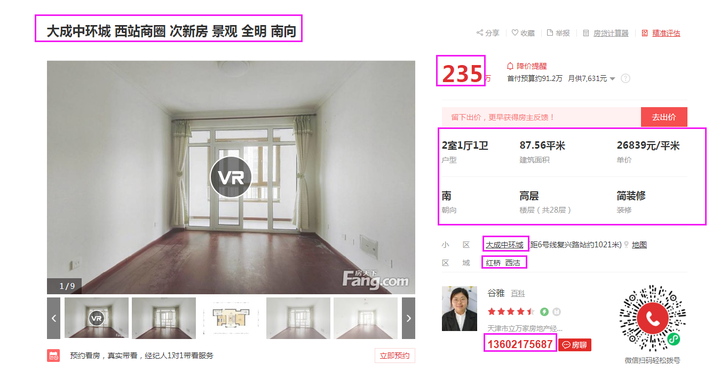
name_字段:如下图所示可知,本字段在class为【floatl tit_details】的节点下。
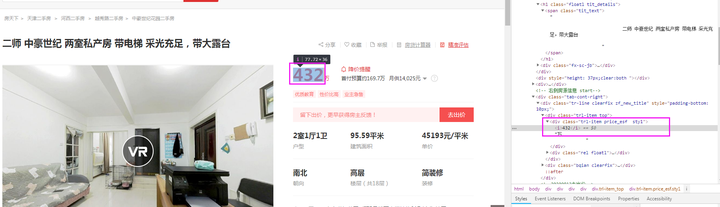
price字段:如下图所示可知,本字段在class为【trl-item price_esf sty1】的节点下。
type_字段:如下图所示可知,本字段在class为【tr-line clearfix】节点的子节点下。
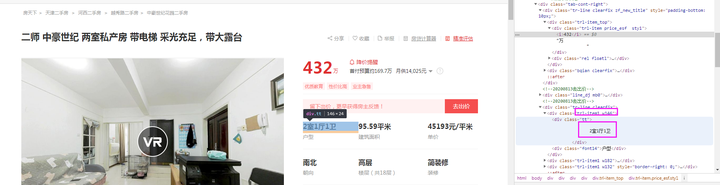
area字段:如下图所示可知,本字段在class为【trl-item1 w182】节点的子节点下。
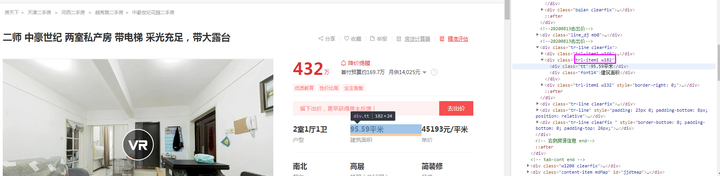
priceper字段:同理在class为【trl-item1 w132】节点的子节点下。
orientation字段:同理在class为【trl-item1 w146】节点的子节点下。
floorÂ≠óÊƵԺöËôΩÁÑ∂Êú¨Â≠óÊƵÂú®class‰∏∫„Äêtrl-item1 w182„ÄëËäÇÁÇπÁöÑÂ≠êËäÇÁÇπ‰∏ãÔºå‰ΩÜÊòضlj∏ãÂõæÊâÄÁ§∫ÔºåÊú¨È°µÊ∫êÁÝʼn∏≠‰∏çÂ虉∏ĉ∏™trl-item1 w182ÔºåÊâĉª•‰∏çËÉΩÁî®Âêå‰∏äËø∞Âá݉∏™Â≠óÊƵ‰∏ÄÊÝ∑ÁöÑÊñπÊ≥ïÊù•Ëé∑Âèñ„ÄÇ
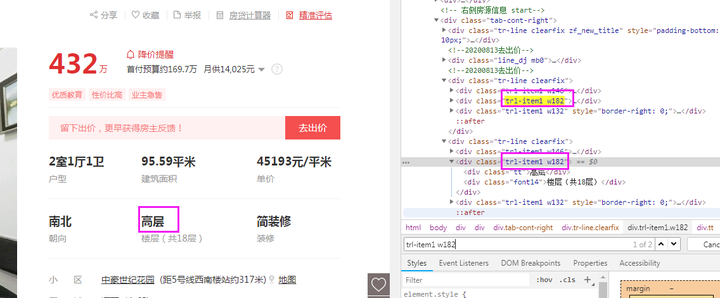
¶lj∏ãÂõæÊâÄÁ§∫ÔºåÈÄöËøáÈ°µÈù¢Ê∫êÁÝÅËßÇÂØüÂèØÂèëÁé∞ÔºåÊú¨Â≠óÊƵÂú®class‰∏∫„Äêtab-cont-right„ÄëÁöÑËäÇÁÇπÁöÑÂ≠êËäÇÁÇπÁöщ∏ã‰∏ĉ∏™Áöщ∏ã‰∏ĉ∏™Áöщ∏ã‰∏ĉ∏™ËäÇÁÇπ‰∏≠ÁöÑclass‰∏∫„Äêtrl-item1 w182„ÄëÁöÑËäÇÁÇπ‰∏≠„ÄÇ
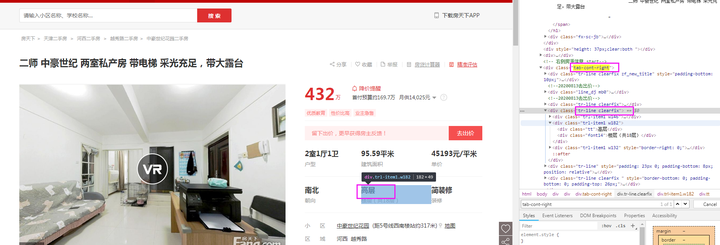
Renovate字段:由图可知,本字段在class为【tr-line clearfix】的节点下的class为【trl-item1 w132】的子节点中。
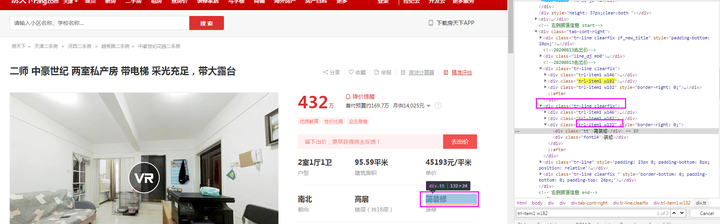
Estate字段:由图可知,本字段在class为【tr-line】的节点下的class为【rcont】的节点中的所有文本。
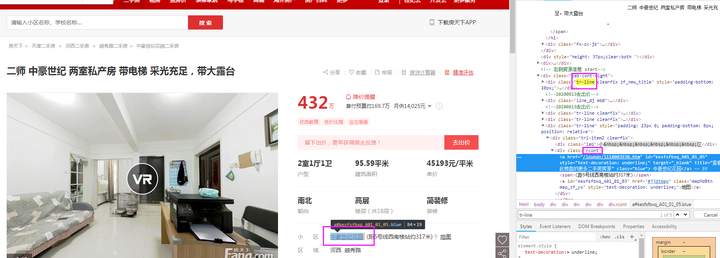
zone_字段:由图可知,本字段在class为【trl-item2 clearfix】的节点下的class为【rcont】的节点中的所有文本。
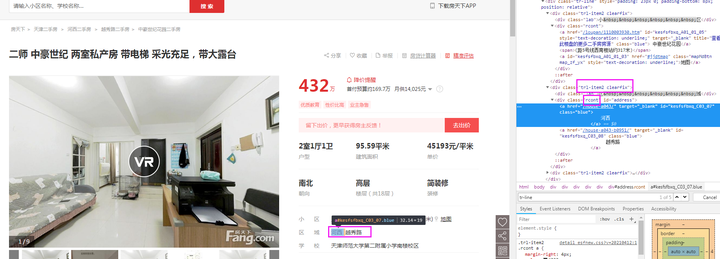
name_字段:由图可知,本字段在class为【zf_jjname】的节点中的所有文本内容。
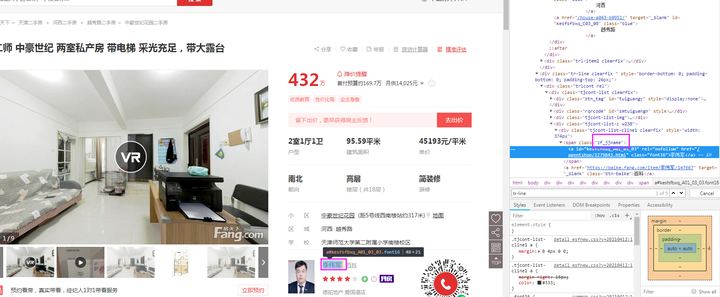
Tel字段:由图可知,本字段为classid为【AgentTel】的字段中的value属性值。
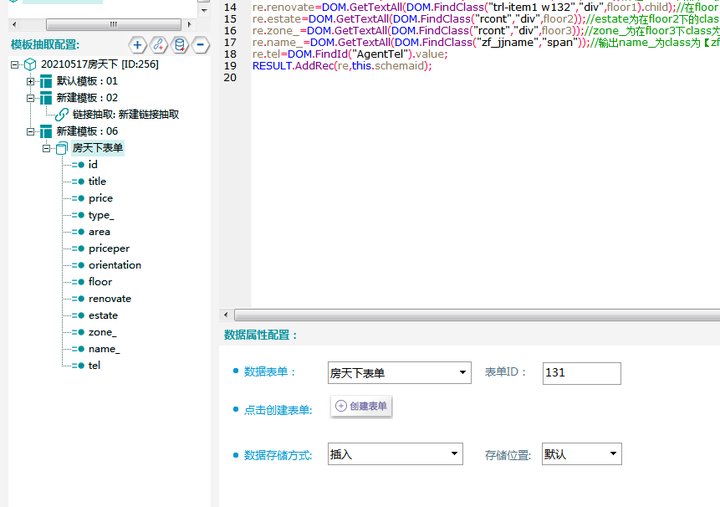
⑥综上所述,数据抽取脚本如下所示:
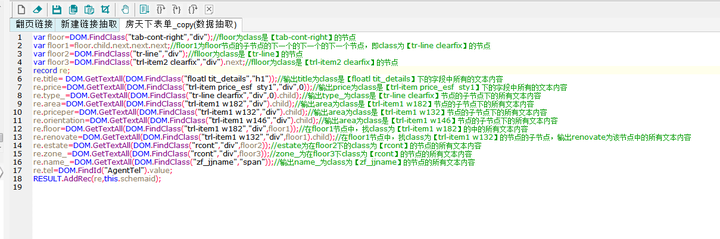
脚本文本:
var floor=DOM.FindClass("tab-cont-right","div");
var floor1=floor.child.next.next.next;
var floor2=DOM.FindClass("tr-line","div");
var floor3=DOM.FindClass("trl-item2 clearfix","div").next;
var floor4=DOM.FindClass("zf_chat_line","a");
record re;
re.id = MD5(ur);
re.title = DOM.GetTextAll(DOM.FindClass("floatl tit_details","h1"));
re.price=DOM.GetTextAll(DOM.FindClass("trl-item price_esf sty1","div",0));
re.type_=DOM.GetTextAll(DOM.FindClass("tr-line clearfix","div",0).child);
re.area=DOM.GetTextAll(DOM.FindClass("trl-item1 w182","div").child);
re.priceper=DOM.GetTextAll(DOM.FindClass("trl-item1 w132","div").child);
re.orientation=DOM.GetTextAll(DOM.FindClass("trl-item1 w146","div").child);
re.floor=DOM.GetTextAll(DOM.FindClass("trl-item1 w182","div",floor1));
re.renovate=DOM.GetTextAll(DOM.FindClass("trl-item1 w132","div",floor1).child);
re.estate=DOM.GetTextAll(DOM.FindClass("rcont","div",floor2));
re.zone_=DOM.GetTextAll(DOM.FindClass("rcont","div",floor3));
re.name_=DOM.GetTextAll(DOM.FindClass("zf_jjname","span"));
re.tel=DOM.FindId("AgentTel").value;
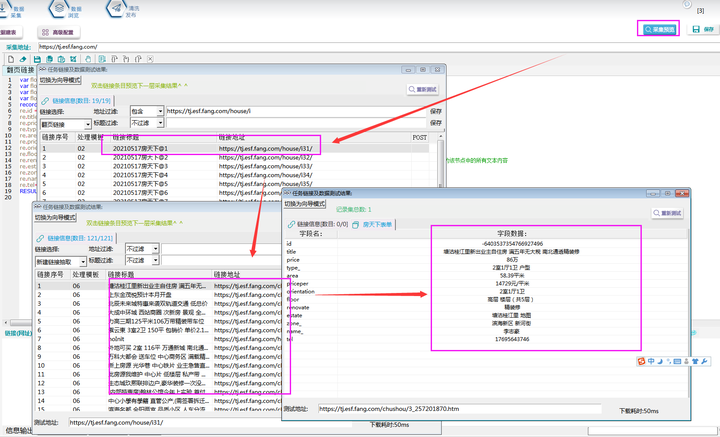
RESULT.AddRec(re,this.schemaid);⑦以上完成全部字段配置,效果预览如下:
l¬ÝÈááÈõÜÊ≠•È™§
模板配置完成,采集预览没有问题后,可以进行数据采集。
‚ëÝȶñÂÖà˶Ū∫Á´ãÈááÈõÜÊï∞ÊçÆË°®Ôºö
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为fangtianxia(注意命名不能用数字和特殊符号),点击【确定】。

创建完成,勾选数据表。
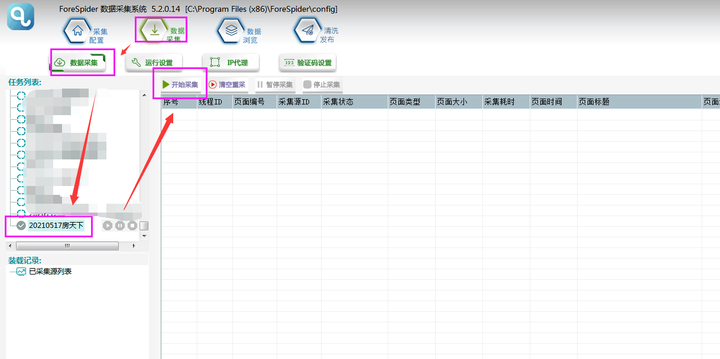
②选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
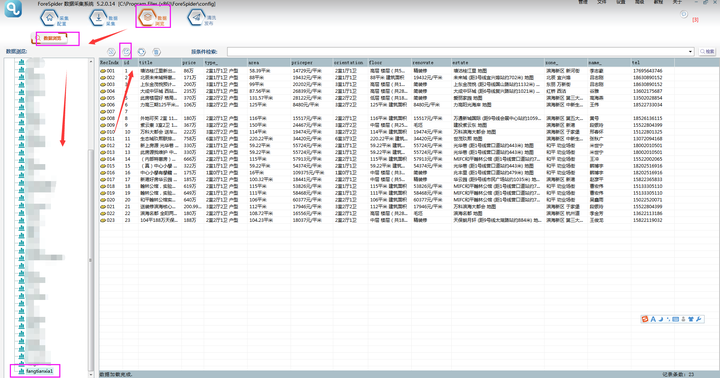
③可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
l¬ÝËØæÂêéÂõûÈ°æ
FindClass(classÂêçÔºåÊÝáÁ≠æÁ±ªÂûãÔºåºÄÂßãÊü•ÊâæÁªìÁÇπ)ÔºöÂΩìÁ¨¶ÂêàÊù°‰ª∂ÁöÑclassÂêçÁß∞Âî؉∏ÄÊó∂Ôºå‰ΩøÁî®classÂêçÊù•Êü•ÊâæÁªìÁÇπ„ÄÇ
FindName(ÊÝáÁ≠æÂêç,ºÄÂßãÊü•ÊâæÁªìÁÇπ)ÔºöÂΩìÊü•ÊâæËåÉÂõ¥ÂÜÖÔºåÁ¨¶ÂêàÊù°‰ª∂ÁöÑÊï∞ÊçÆÊÝáÁ≠æÂî؉∏ÄÊó∂ÔºåÂè؉ª•‰ΩøÁî®ÊÝáÁ≠æÂêçÁß∞Êü•ÊâæÊÝáÁ≠æÁªìÁÇπ„ÄÇ
GetTextAll(ÈúÄ˶ÅËé∑ÂèñÊñáÊú¨ÁöÑÁªìÁÇπ,‰ΩøÁî®ÁöÑÂ≠óÁ¨¶ÁºñÁÝÅ)ÔºöËé∑ÂèñËØ•htmlÊÝáÁ≠æËäÇÁÇπÂèäÊâÄÊúâÂ≠êËäÇÁÇπÁöÑÂèØËßÅÊñáÊú¨„ÄÇ
Child:孩子频道节点。
FindId(idVal)ÔºöÈÄöËøáÊÝáÁ≠æÁöÑID±ûÊÄßÂĺÊü•ÊâæÊÝáÁ≠æËäÇÁÇπÔºåÂÖ∂‰∏≠idValË°®Á§∫ÂæÖÊü•ÊâæÊÝáÁ≠æID±ûÊÄßÂĺ„ÄÇ
¬Ý
在操作中如有问题,可进入前嗅官网(http://www.forenose.com),咨询技术支持。
前嗅免费提供一对一技术支持服务。



相关推荐
Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据...
python爬虫Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫实战:数据采集、处理与分析Python爬虫...
python爬虫:Python 爬虫知识大全; python爬虫:Python 爬虫知识大全; python爬虫:Python 爬虫知识大全; python爬虫:Python 爬虫知识大全; python爬虫:Python 爬虫知识大全; python爬虫:Python 爬虫知识...
Âú®Êó•Â∏∏Â∑•‰ΩúÂíåÂ≠¶‰π݉∏≠ÂèØËÉΩ‰ºöÈÅáÂà∞ÈúÄ˶ÅÁî®PythonÊàñÂÖ∂‰ªñÂΩ¢ÂºèÁöÑÁà¨Ëô´Ëé∑Âèñ‰∫åÊâãÊàø‰ø°ÊÅØÁöÑÈúÄʱÇÔºå‰ΩÜÂèà‰ºöË㶉∫éÊ≤°ÊúâÂêàÈÄÇÁöщª£ÁÝÅÔºåÊú¨È°πÁõƉ∏∫ÂêщΩçÊèê‰æõ‰∏ĉ∏™ÂèØÁõ¥Ê镉∏äÊâãÁöÑpythonÁà¨Ëô´‰ª£ÁÝÅÔºå‰∏ãËΩΩÂç≥ÂèØËøêË°åÔºåÂèØÊÝπÊçÆÂ𥉪لÄÅÊó•Êúü„ÄÅÂú∞Âå∫„Äʼnª∑ÊݺÁ≠â‰ø°ÊÅØ...
PythonÁΩëÁªúÁà¨Ëô´Êò؉∏ÄÁßçÁ∫éËá™Âä®ÂåñÁΩëÈ°µÊï∞ÊçÆÊäìÂèñÁöÑÊäÄÊúØÔºåÂÆÉËÉΩ§üÈ´òÊïàÂú∞‰ªé‰∫íËÅîÁΩë‰∏äËé∑Âèñ§ßÈáè‰ø°ÊÅØ„ÄÇÊú¨Â•óÊïôÂ≠¶ËµÑÊñôÊ∑±ÂÖ•ËߣÊûê‰∫ÜPythonÁà¨Ëô´ÁöÑÊÝ∏ÂøÉÊäÄÊúØ„ÄÅScrapyÊ°ÜÊû∂‰ª•ÂèäÂàÜÂ∏ɺèÁà¨Ëô´ÁöÑÂÆûÁé∞ÔºåÊó®Âú®Â∏ÆÂä©Â≠¶‰πÝËÄÖÊéåÊè°Ëøô‰∏ÄÈ¢ÜÂüüÁöÑÊÝ∏ÂøÉÊäÄËÉΩ„ÄÇ...
pythonÊØï‰∏öËÆæËÆ°ÁΩëÁªúÁà¨Ëô´Áöщ∫åÊâãÊàøÊ∫êÊï∞ÊçÆÈááÈõÜÂèäÂèØËßÜÂåñÂàÜÊûêÊ∫êÁÝÅ+PPTÊñáÊ°£.zipËØ•È°πÁõÆÊò؉∏™‰∫∫È´òÂàÜÊØï‰∏öËÆæËÆ°È°πÁõÆÊ∫êÁÝÅÔºåÂ∑≤Ëé∑ÂغÂ∏àÊåáÂغËƧÂèØÈÄöËøáÔºå98ÂàÜÁöÑËØÑÂÆ°ÂàÜ„ÄÇÈÉΩÁªèËøá‰∏•ÊݺË∞ÉËØïÔºåÁ°Æ‰øùÂè؉ª•ËøêË°åÔºåÊîæÂøɉ∏ãËΩΩ‰ΩøÁÄÇ pythonÊØï‰∏öËÆæËÆ°...
Âü∫‰∫éPythonÁΩëÁªúÁà¨Ëô´Áöщ∫åÊâãÊàøÊï∞ÊçÆÈááÈõÜÂèäÂèØËßÜÂåñÂàÜÊûêÈ°πÁõÆÊ∫êÁÝÅ+‰ΩøÁî®ÊïôÁ®ã+Áà¨Ëô´+Êä•ÂëäPPT.zipÂ∑≤Ëé∑ÂغÂ∏àËƧÂèØÂπ∂È´òÂàÜÈÄöËøáÁöÑÊØï‰∏öËÆæËÆ°È°πÁõÆԺ剪£ÁÝÅÂÆåÊï¥ÔºåËؕ˵ÑÊ∫ꉪ£ÁÝÅÈÉΩÊòØÁªèËøáʵãËØïËøêË°åÊàêÂäüÔºåÊ≤°Êú≪ª‰ΩïÈóÆÈ¢òÂäüËÉΩÂÆåÊï¥ÁöÑÊÉÖÂܵ‰∏ãÊâç‰∏䉺ÝÁöÑÔºå...
Êú¨ÊñáÂ∞ÜËضÁªÜËÆ≤Ëߣ‰∏é‚ÄúÊàø§©‰∏ãÊñ∞ÊàøÁà¨Ëô´excelË°®ÊݺÁªèÁ∫¨Â∫¶ÂùêÊÝáxyÂêçÁß∞‰ª∑Êݺ‚ÄùÁõ∏ÂÖ≥ÁöÑÁü•ËØÜÁÇπÔºå‰∏ªË¶ÅÊ∂âÂèäGISÔºàÂú∞Áê܉ø°ÊÅØÁ≥ªÁªüÔºâ„ÄÅWGS84ÂùêÊÝáÁ≥ªÁªü„ÄÅÊñ∞ÊàøÁà¨Ëô´ÊäÄÊú؉ª•ÂèäÊàø‰ª∑‰ø°ÊÅØÁöѧÑÁêÜ„ÄÇ È¶ñÂÖàÔºåGISÔºàÂú∞Áê܉ø°ÊÅØÁ≥ªÁªüÔºâÊò؉∏ÄÁßçÈõÜÊàê‰∫ÜÂú∞Âõæ„ÄÅ...
在本毕业设计项目中,我们将深入探讨如何使用Python编程语言构建一个网络爬虫来收集二手房源数据,并通过数据可视化技术进行深入的分析和呈现。这个项目涵盖了Python爬虫开发的关键技术和数据分析的重要步骤,旨在...
Âà©Áî®pythonÁºñÂÜô‰∫܉∏ĉ∏™Áà¨Ëô´‰ª£ÁÝÅÔºåÁà¨ÂèñÊàø§©‰∏ãÂïÜÂìÅÊàø‰ø°ÊÅØÔºåÂè؉ª•Êõ¥ÊîπÈìæÊé•Âú∞ÂùÄÔºåÁà¨ÂèñÂÖ∂‰ªñ‰ø°ÊÅØ
ÂæƉø°ÂÖ¨‰ºóÂè∑Áà¨Ëô´ÔºöÊúçÂä°Á´ØÂÖ¨‰ºóÂè∑ÊñáÁ´ÝÊï∞ÊçÆÈááÈõÜ_WechatSpider
在本项目中,我们主要探讨的是如何利用爬虫技术来获取58同城网站上的二手房信息。爬虫是一种自动化地从互联网上抓取信息的技术,它能够帮助我们批量收集和处理大量的网页数据。58同城作为中国知名的分类信息网站,其...
六、Deep Web爬虫:讲解Deep Web爬虫的基本概念、Deep Web爬虫的原理、Deep Web爬虫的应用场景等。 七、微博信息采集:讲解微博信息采集技术的基本概念、微博爬虫的原理、微博爬虫的应用场景等。 八、Web信息提取...
PythonÁà¨Ëô´ÁªÉ‰πÝÔºöbilibiliÁî®Êà∑‰ø°ÊÅØÁà¨Âèñ„Äʼn∏ãËΩΩÂ∑•ÂÖ∑„ÄÅÊàø§©‰∏ãÊñ∞Êàø‰∫åÊâãÊàøÁà¨Ëô´„ÄÅÁÆĉπ¶ÂÖ®Á´ôÊñáÁ´ÝÁà¨ÂèñÁ≠â.zip Áî≥Êòé ‰∏™‰∫∫Áöщ∏ĉ∫õpython Áà¨Ëô´ÁªÉ‰πÝ ‰ªÖÈôê‰∫éÂ≠¶‰π݉∫§ÊµÅ ÁõÆÂΩï Scrapy-Redis Êàø§©‰∏ãÊñ∞Êàø‰∫åÊâãÊàøredisÂàÜÂ∏ɺèÁà¨Ëô´ Scrapy ...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
### 基于Python Scrapy爬虫框架实现的链家二手房数据爬取系统的设计与实现 #### 一、设计背景及概括 自21世纪以来,互联网技术的飞速发展使得人们的生活方式发生了翻天覆地的变化。在房地产领域,随着城镇化进程的...