
案例:采集“人上人”官网首页数据列表
人上人-最新资讯: http://www.gzrsr.com/news/
一. 网站内容
1. 网站截图说明
本教程通过采集“人上人”首页“最新资讯”栏目列表中的数据为例,故链接入口为:http://www.gzrsr.com/news/,如下图:
【人上人官网-“联系我们”】
2. 采集结果截图
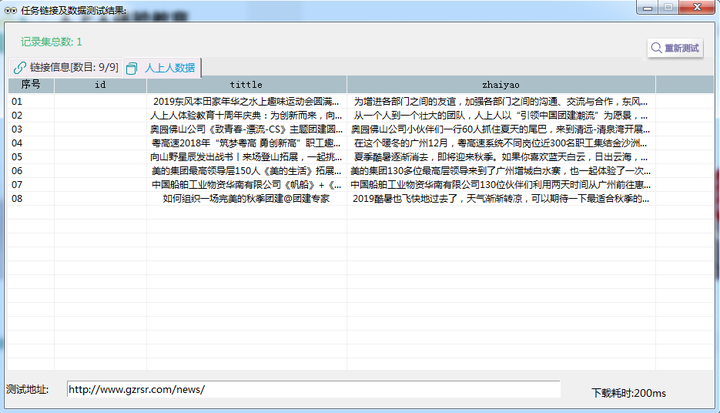
【链接列表采集预览】
一. 操作方法
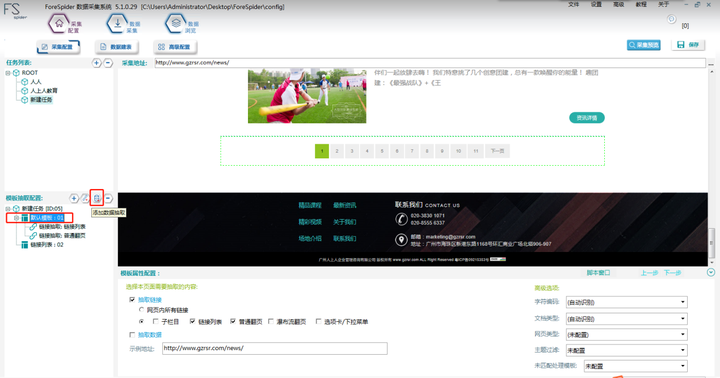
1. 新建任务
按图片数字所示,1-2-3完成新建任务的步骤

【新建任务】
Step1:点击“采集配置”
Step2:点击【任务列表】中的“+”,新建采集任务
Step3:在如图的红框中输入采集地址和任务名称(可自定义),完成后点击“下一步”。
需要采集正文数据,所以此处需要勾选【链接列表】和【普通翻页】,如图,最后点击“完成”即可。
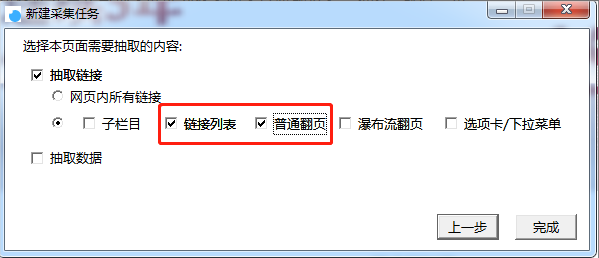
【新建采集任务】
2. 确认选区
由于我们只需要采集链接列表的数据,故需要过滤掉其他无效数据,保留最终有效数据。这里我们可以使用【确认选区】功能即可轻松筛查,操作如下图所示:
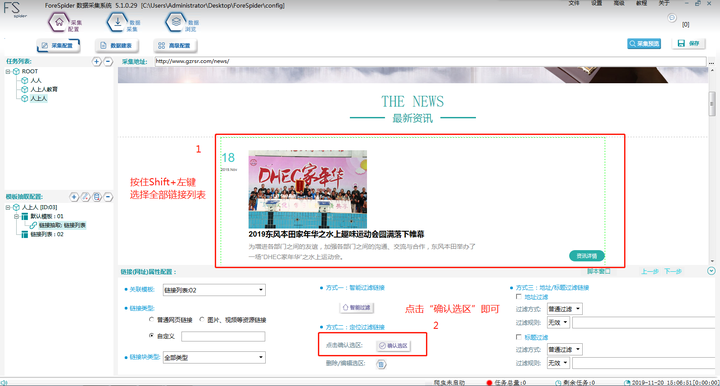
Step1:点击Shift+左键,将页面中所有的“链接列表”选中。
Step2:点击“确认选区”即可完成有效数据的筛选。
3. 链接列表 采集预览
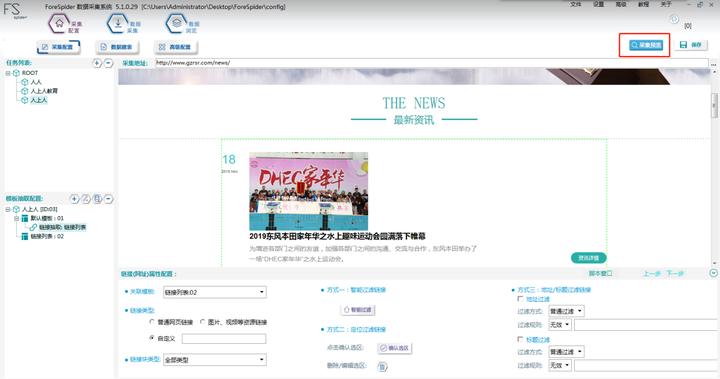
点击“采集预览”,左侧下滑列表中选择“链接列表”,最终呈现如下图所示即可表示筛选正确。
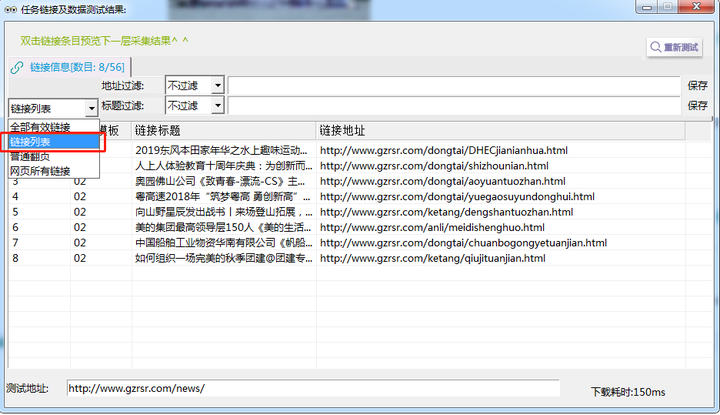
【采集预览】
4. 普通翻页配置
按图片数字所示,1-2-3完成新建任务的步骤
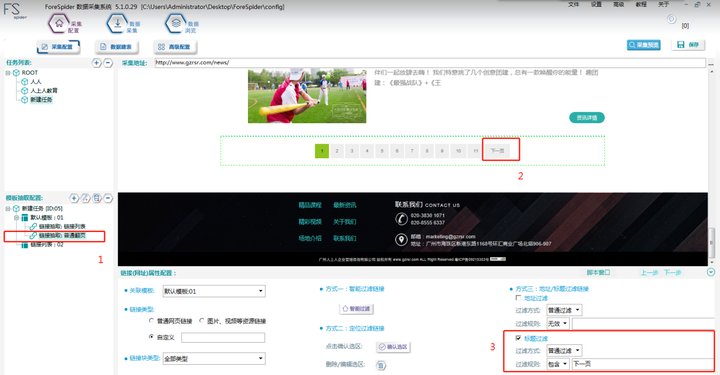
Step1:点击左侧“链接抽取-普通翻页”
Step2:这时我们将网页拉到最底部,Ctrl+左键 选择“下一页”确认选区
Step3:勾选“标题过滤”,过滤规则选择“包含”并在输入框中,手动输入“下一页”即可完成 普通翻页的配置。
注意:记得随时点击右上角的“保存”,养成良好的操作习惯。
5. 普通翻页-采集预览
完成第4步骤后,点击右上方“采集预览”,最终呈现应如下图:
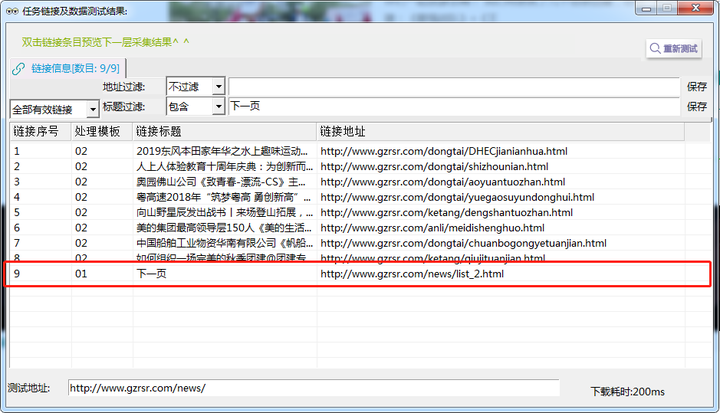
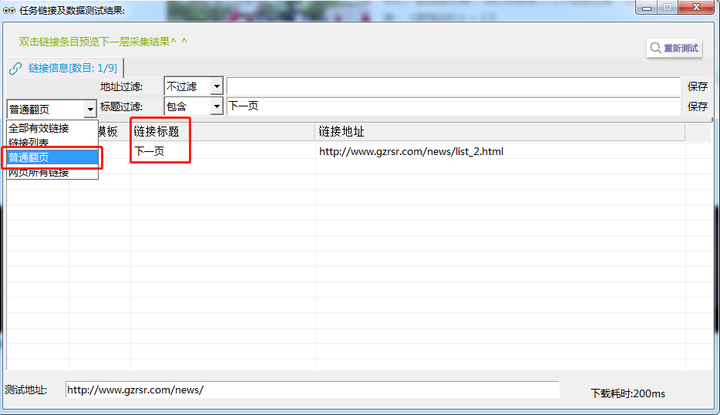
左侧下滑列表中选择“全部有效链接”和“普通翻页”如均出现【下一页】则表示配置成功,进行下一步骤。
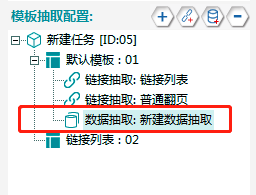
6. 添加【数据抽取】
完成链接列表和普通翻页配置后,最后我们应抽取网页中的列表数据,如下图:

点击左侧“模板抽取配置”旁边的“+”,配置数据抽取,操作如下:
最终如下:
7. 数据抽取建表
按图片数字所示,1-2-3完成新建任务的步骤
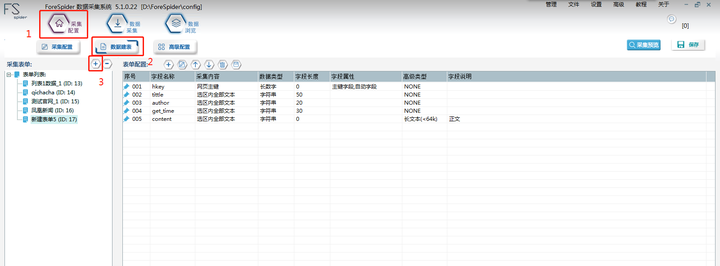
如图示点击【数据建表】:
Step1:点击“采集配置”
Step2:选择“数据建表”
Step2:点击“+”,新建表单并自定义名称,这里取“人上人数据”
根据所需内容,配置表单字段,此处配置了包括主键、标题、文章摘要等等。表单建立如下:
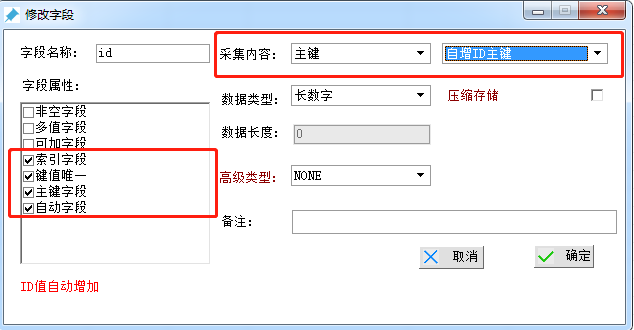
【创建主键】
字段名称:id
采集内容 选择“主键”,此处务必选“自增ID主键”。
PS:非链接内正文数据的“网页主键”
数据类型 选择“长数字”
字段属性 选择 “索引字段”、“健值唯一”、“主键字段”、“全文索引”
最后点击“确定”即可。
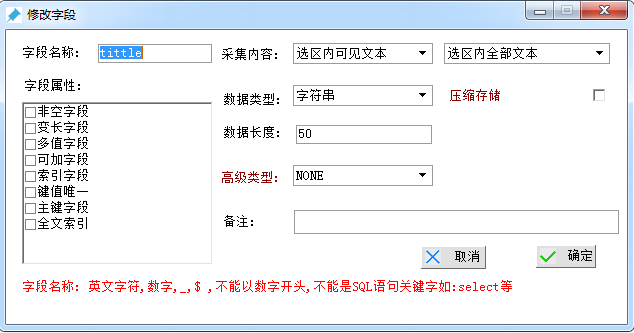
【创建字段1-标题】
字段名称:tittle
采集内容 选择“选区内可见文本”
数据类型 选择“字符串”
数据长度 选择 范围50即可,最后点击确定。(备注可随意)
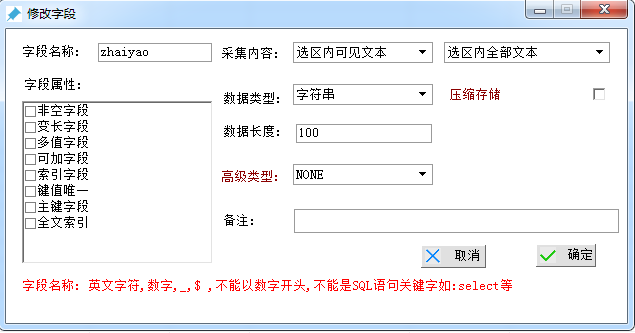
【创建字段2-摘要】
字段名称:zhaiyao
采集内容 选择“选区内可见文本”
数据类型 选择“字符串”
数据长度 选择 范围100左右即可,最后点击确定。(备注可随意)
8. 创建关联数据表
表单配置完毕后,需要进行数据关联,操作如下:

选择刚才建立的“人上人数据”,点击【创建】按钮,即可生成对应的“关联数据表”

创建表名称可随意填写,需注意 仅可使用“全英文”,最后点击 确定 即可完成。
注意:创建完成后,记得“勾选”

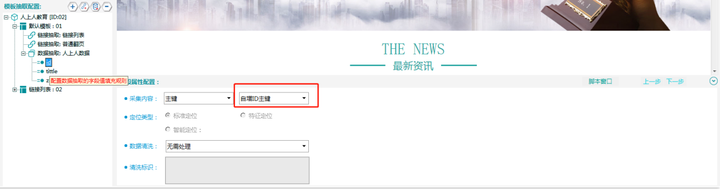
9. 数据建表 确认选区
ID字段务必保证是 “自增ID主键”,如果是“网页主键”在红框位置可选择更改。
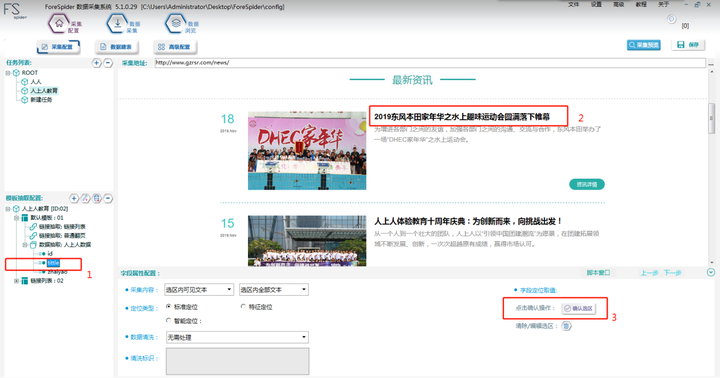
Tittle选区:
Step1:点击左侧“tittle”
Step2:Ctrl+左键选择图示2位置的标题
Step2:点击图示3位置的“确认选区”即可完成
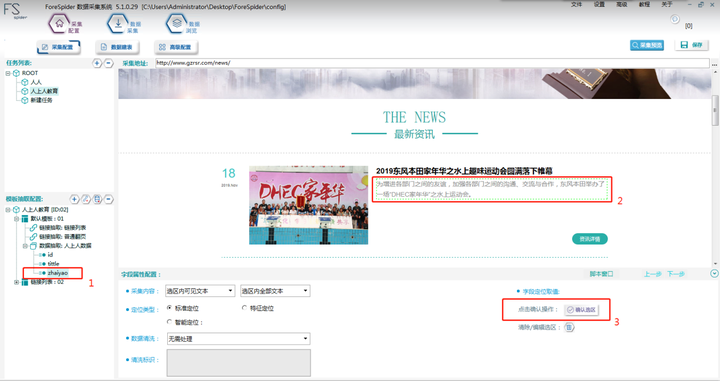
Zhaiyao选区:
Step1:点击左侧“zhaiyao”
Step2:Ctrl+左键选择图示2位置的文字部分
Step2:点击图示3位置的“确认选区”即可完成
以上步骤完成后,点击右上角的“保存”,即可完成数据建表的步骤。
三. 链接列表 数据预览
完成所有步骤后,最后点击右上方的“采集预览”即可查看“最新资讯”的链接列表数据啦~。
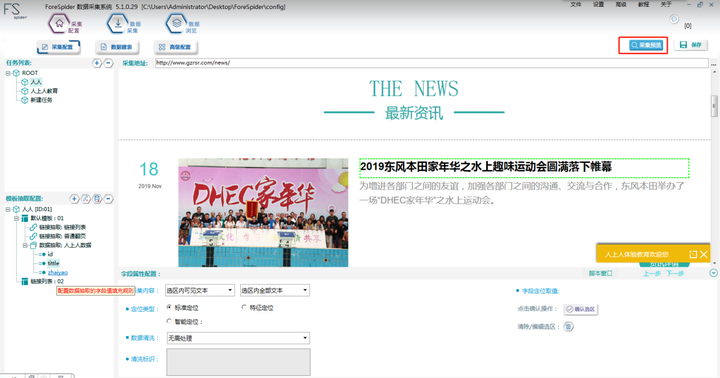
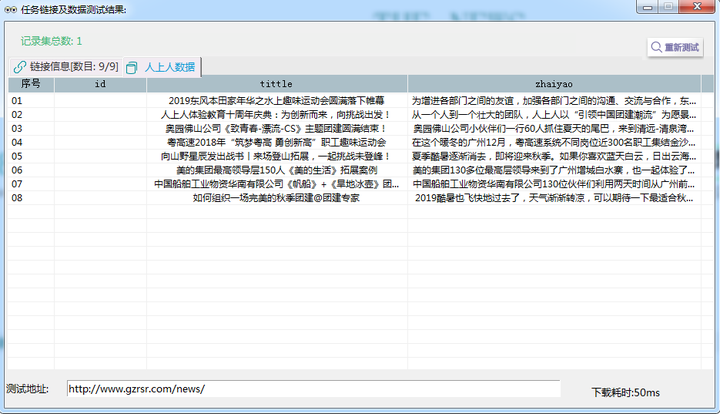
最终如下图所示,即可完成本次的操作了,你学会了吗?



相关推荐
**前嗅forespider数据采集软件详解** 在信息化时代,数据的价值不言而喻,而高效的数据采集成为企业和个人获取信息的关键。前嗅forespider数据采集软件正是为解决这一需求而生,它是一款专为非专业编程人员设计的...
内容概要:本文详细介绍了基于松下FP-XH双PLC实现的10轴摆盘系统的设计与实现。该系统采用模块化编程方法,涵盖输出与调试、报警与通信、启动与复位三个主要部分。通过PC-LINK通信协议实现双PLC间的数据交互,并结合维纶通触摸屏提供直观的操作界面。具体代码展示了轴控制、报警处理、通信数据传输等功能的实现细节,强调了程序的易维护性和高效性。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是熟悉松下PLC和维纶通触摸屏的用户。 使用场景及目标:适用于需要高精度多轴联动控制的工业应用场景,如自动化生产线、机器人控制等。目标是提高设备的稳定性和效率,减少维护难度。 其他说明:文中提供了丰富的代码示例和实际操作经验,帮助读者更好地理解和应用所介绍的技术。此外,还讨论了一些优化技巧,如通信负载管理、异常处理机制等,有助于提升项目的可靠性和性能。
k近邻算法数据集,包换鸢尾花和水果分类等
wmsj1111111111
内容概要:本文详细介绍了如何使用COMSOL Multiphysics软件进行变压器电磁场的仿真建模。主要内容涵盖了几何结构的创建、材料的选择与定义、物理场的设置以及仿真结果的分析。文中具体讲解了如何选择合适的铁磁材料(如软铁)、定义线圈材料(如铜),并设置了线圈的电流激励。通过仿真,可以得到变压器内部的磁密分布图和电路状态,从而优化变压器的设计,提升其效率和性能。 适合人群:从事电磁场仿真研究的技术人员、电力电子工程师、高校相关专业的学生。 使用场景及目标:适用于需要深入了解变压器工作原理的研究人员和技术人员,旨在通过仿真手段优化变压器设计,提高其性能和效率。 其他说明:文章提供了详细的MATLAB代码片段用于指导具体的仿真步骤,并分享了一些常见问题的解决方案,如边界条件设置不当、网格划分不合理等。同时,还强调了仿真结果的可视化展示方法,如磁密分布图和电路参数曲线的叠加显示。
https://github.com/AlfredXiangWu/LightCNN LightCNN-v4 预训练模型
内容概要:本文详细介绍了如何利用COMSOL进行多孔介质中湿空气的传热传质仿真。首先探讨了水蒸气扩散和液态水迁移的基本原理及其数学表达,如水蒸气扩散系数随温度变化以及多孔介质渗透率随孔隙率的变化规律。接着,通过具体案例展示了如何正确设置多孔介质参数,避免常见的仿真错误,如孔隙率和曲折因子的误设。文中还提供了多个实用技巧,包括求解器配置、边界条件设置、网格划分方法等,确保仿真的稳定性和准确性。此外,强调了多物理场耦合的重要性,特别是在处理温度场和湿度场之间的相互作用时。最后,通过实例验证了模型的有效性,并给出了提高仿真精度的具体建议。 适合人群:从事多物理场仿真、传热传质研究的专业人士,尤其是使用COMSOL进行相关仿真的工程师和技术人员。 使用场景及目标:适用于需要精确模拟湿空气中传热传质过程的研究项目,帮助研究人员更好地理解和预测复杂环境下(如地下室墙面渗水、地下粮仓通风)的物理现象,从而优化设计方案并解决实际工程问题。 其他说明:本文不仅提供具体的代码片段和参数设置指导,还分享了许多实践经验,有助于读者快速掌握COMSOL仿真技巧,避免常见错误,提高仿真效率和准确性。
内容概要:本文详细介绍了用于非线性动力学分析的一系列Python代码实现,涵盖相空间重构、分形维数计算、随机微分方程求解以及智能优化算法。首先,通过互信息法和假近邻法进行相空间重构,确保时间序列数据能够在一个适当的坐标系中表示。其次,利用赫斯特指数和李雅普诺夫指数评估系统的分形特性和记忆性。然后,采用sdeint库解决带有噪声的随机微分方程,模拟复杂的动态系统。最后,比较并实现了粒子群优化(PSO)和遗传算法(GA),展示了它们在不同类型优化问题中的优势。 适合人群:具备一定编程基础的数据科学家、研究人员和技术爱好者,尤其是对非线性动力学感兴趣的读者。 使用场景及目标:适用于需要处理复杂时序数据的研究项目,如金融市场的波动分析、气象预报、生物信号处理等。目标是帮助读者掌握非线性动力学的基本概念及其Python实现,从而更好地理解和预测复杂系统的动态行为。 其他说明:文中提供了大量具体的Python代码片段,便于读者直接应用于实际问题中。同时强调了参数选择的重要性,并给出了多个实用技巧,如互信息法找延迟、假近邻法确定嵌入维数等。
1、文件说明: Centos8操作系统texlive-cm-super-7:20180414-23.el8.rpm以及相关依赖,全打包为一个tar.gz压缩包 2、安装指令: #Step1、解压 tar -zxvf texlive-cm-super-7:20180414-23.el8.tar.gz #Step2、进入解压后的目录,执行安装 sudo rpm -ivh *.rpm
内容概要:文档《软件测试经典面试题.docx》汇总了软件测试领域的常见面试题及其参考答案。涵盖的主题包括但不限于兼容性测试、性能测试、单元测试、集成测试、系统测试、Bug管理、测试工具(如Bugzilla、LoadRunner、QTP)、测试用例设计、测试流程、测试类型的区别与联系、测试中的沟通技巧、测试环境搭建、网络与操作系统基础知识等。文档不仅涉及具体的测试技术和工具,还包括了对测试人员职业发展的探讨,如测试工程师应具备的素质、职业规划、如何处理与开发人员的关系等。 适用人群:具备一定编程基础,尤其是有志于从事软件测试工作的人员,以及希望提升自身测试技能的专业人士。 使用场景及目标:①帮助求职者准备软件测试相关岗位的面试;②为在职测试工程师提供技术参考和职业发展建议;③为项目经理或HR提供招聘软件测试人员时的面试题目参考;④帮助理解软件测试在软件开发中的重要性及其实现方法。 阅读建议:本文内容详实,涵盖面广,建议读者根据自身需求选择性阅读。对于面试准备,重点关注面试题及其解答思路;对于技术提升,深入理解测试工具和方法;对于职业发展,思考测试人员所需素质及职业规划。同时,结合实际工作中的案例进行理解和实践,有助于更好地掌握和应用这些知识。
内容概要:本文详细介绍了基于信捷XC PLC和显控触摸屏的双摆头双滚头磨床自动化控制系统的设计与实现。系统采用Modbus RTU通讯协议,通过PLC控制四台变频器,实现磨床的高效稳定运行。主要内容涵盖系统总体架构、PLC配置与通讯、变频器控制逻辑、程序功能模块以及调试与优化等方面。文中还分享了一些实际开发中的技巧和经验,如变频器的负载电流用于软限位检测、通讯超时处理机制等。 适合人群:从事工业自动化控制系统的工程师和技术人员,尤其是熟悉PLC编程和Modbus通讯协议的专业人士。 使用场景及目标:适用于需要提高双摆头双滚头磨床生产效率和稳定性的制造企业。目标是通过自动化控制减少人工干预,提升设备性能和可靠性。 其他说明:文中提供的代码示例和调试经验对于类似设备的智能化改造具有重要参考价值。
第十六届蓝桥杯嵌入式官方赛点资源包
内容概要:本文详细介绍了长短期记忆神经网络(LSTM)和极限学习机(ELM)在Matlab中实现天气预测的方法,并进行了对比分析。首先,文章阐述了LSTM和ELM的基本原理,随后分别展示了它们的数据准备、预处理、网络构建、训练以及预测的具体步骤。LSTM作为一种特殊的循环神经网络,擅长处理时间序列数据中的长期依赖问题,而ELM则以其快速的训练速度著称。通过对某气象站三年数据的实际测试,LSTM在复杂天气数据预测中表现出更高的精度,特别是在长时间序列预测方面优势明显;ELM则因其简洁快速的特点适用于快速原型开发和资源受限环境。最终,文章通过对比两者的预测精度和训练效率,提出了根据不同应用场景选择合适算法的建议。 适合人群:对机器学习尤其是深度学习感兴趣的科研人员、学生以及从事气象预报工作的专业人士。 使用场景及目标:①研究和开发气象预测系统;②探索不同神经网络算法在时间序列预测中的优劣;③提高天气预测的准确性和时效性。 其他说明:文中提供了详细的Matlab代码实现,帮助读者更好地理解和复现实验结果。同时强调了特征工程的重要性,指出适当增加特征(如气压梯度)可以显著提升预测效果。此外,还提到了一些实用技巧,例如利用ELM作为LSTM的初始化器以减少训练轮数,以及在LSTM预测结果后加上滑动平均滤波以改善曲线平滑度。
内容概要:本文详细介绍了一款基于51单片机的自动浇花系统的设计与实现。该系统通过按键设置土壤湿度的上下限阈值,利用土壤湿度传感器监测土壤湿度,当湿度低于设定阈值时,触发LED报警并启动水泵浇水。主要内容涵盖硬件配置(如STC89C52主控芯片、YL-69土壤湿度传感器、ADC0832模数转换器等)、程序代码(包括端口定义、延时函数、阈值设置函数、主函数等)、Proteus仿真以及AD图(Altium Designer绘制的原理图和PCB图)。此外,文中还讨论了一些优化措施,如防抖处理、阈值保存、湿度检测精度改进、PWM控制水泵等。 适合人群:对单片机编程和硬件设计感兴趣的电子爱好者、学生及工程师。 使用场景及目标:适用于家庭或小型温室环境,旨在解决因外出或其他原因无法及时浇水的问题,确保植物始终保持适宜的水分条件。通过本项目的实践,读者可以掌握51单片机的基本应用、传感器接口技术和简单控制系统的设计方法。 其他说明:文中提供了完整的工程文件,包括Keil工程源码、Proteus仿真文件和AD原理图,便于读者快速上手实践。同时,针对可能出现的问题给出了相应的解决方案和技术细节,帮助读者更好地理解和优化系统性能。
内容概要:本文详细介绍了如何利用Matlab/Simulink构建和仿真两级式光伏并网系统。系统主要由光伏板、boost变换器、LCL逆变器和电网组成。文中深入探讨了各组成部分的功能及其控制方法,包括光伏的最大功率点追踪(MPPT)、LCL逆变器的双闭环控制、锁相环及坐标变换、SVPWM调制以及观测模块的设计。此外,还提供了具体的MATLAB代码片段用于实现关键控制逻辑,确保系统能够高效稳定运行。 适用人群:适用于具有一定电力电子和控制系统基础知识的研究人员和技术人员,尤其是那些希望深入了解光伏并网系统设计与仿真的专业人士。 使用场景及目标:①帮助读者掌握光伏并网系统的基本架构和工作原理;②指导读者在Matlab/Simulink环境中搭建完整的两级式光伏并网系统仿真模型;③提供实用技巧和经验,使读者能够在实践中优化系统性能,降低谐波失真,提高并网质量。 其他说明:本文不仅涵盖了理论知识,还包括了许多实践经验,如参数选择、模块配置等方面的建议。对于想要进一步提升光伏并网系统仿真能力的人来说是非常有价值的参考资料。
内容概要:本文详细介绍了使用Abaqus进行焊接仿真的方法和技术,涵盖了热源模型、子程序编写、热力耦合分析、生死单元操作以及后处理技巧等多个方面。首先,文章讲解了如何利用Dflux子程序构建可靠的热源载荷,强调了双椭球热源模型及其Fortran代码实现的关键参数设定。接着,讨论了热力耦合分析中材料属性的正确配置,如热膨胀系数的设置。随后,深入探讨了生死单元的应用,展示了如何通过Python脚本实现单元的逐层激活,并解释了相关注意事项。此外,文章还涉及了多道焊仿真中的材料属性动态调整、搅拌摩擦焊的特殊处理方法以及后处理中的应力和应变提取技巧。最后,提供了一些实用的避坑指南,帮助用户避免常见错误并提高仿真准确性。 适合人群:从事焊接仿真研究的技术人员、工程师及高校相关专业师生。 使用场景及目标:适用于需要精确模拟焊接过程中热应力应变场的研究和工程项目,旨在提升仿真精度,减少试验成本,优化焊接工艺。 其他说明:文中提供了大量实例代码和具体操作步骤,便于读者理解和实践。同时提醒读者关注实际工况的影响因素,确保仿真结果贴近真实情况。
内容概要:本文详细介绍了DCC-GARCH模型及其在金融时间序列分析中的应用。首先,通过ADF检验确保时间序列的平稳性。接着,利用ARCH-LM检验确认是否存在条件异方差性。随后,采用GARCH模型对单个资产的波动率进行建模。最后,通过DCC-GARCH模型估计多个资产之间的动态相关系数,并对其变化进行可视化展示。文中提供了完整的Python代码实现,帮助读者理解和应用这一复杂模型。 适合人群:金融工程专业人员、量化分析师、金融研究员、数据科学家等对金融市场波动性和相关性感兴趣的从业者。 使用场景及目标:①评估金融时间序列的平稳性和波动性特征;②识别和建模时间序列中的条件异方差性;③估算多个资产之间的动态相关系数,揭示市场联动性;④为风险管理、组合优化和对冲策略提供理论支持和技术手段。 其他说明:文章强调了数据预处理的重要性,并给出了常见问题的解决方案。此外,还讨论了模型参数的经济意义及其在实际应用中的解释。
内容概要:本文介绍了基于梯度下降的改进自适应短时傅里叶变换(STFT)方法,并展示了其在Jupyter Notebook中的具体实现。传统的STFT由于固定窗口长度,在处理非平稳信号时存在局限性。改进的方法通过梯度下降策略自适应调整窗口参数,从而提高时频分辨率。文中详细解释了算法的工作原理,包括信号生成、窗函数设计、损失函数选择等方面,并给出了具体的Python代码示例。此外,文章还讨论了该方法在多个领域的广泛应用,如金融时间序列、地震信号、机械振动信号、声发射信号、电压电流信号、语音信号、声信号和生理信号等。 适合人群:从事信号处理、数据分析及相关领域研究的专业人士,尤其是对时频分析感兴趣的科研人员和技术开发者。 使用场景及目标:适用于需要处理非平稳信号的研究和应用场景,旨在提高信号处理的精度和效率。具体目标包括但不限于:改善金融市场的预测能力、提升地震监测系统的准确性、增强机械设备故障诊断的效果、优化语音识别和合成的质量等。 其他说明:该方法不仅限于特定类型的信号,而是可以通过调整参数灵活应用于不同的信号类型。文中提供的代码可以在Jupyter Notebook环境中直接运行,便于实验和验证。
内容概要:本文详细介绍了利用COMSOL Multiphysics软件对N2和CO2混合气体在热-流-固(THM)三场耦合条件下增强瓦斯抽采的研究。文章首先概述了COMSOL及其在多物理场耦合分析中的应用,接着阐述了质量守恒、能量守恒和固体力学平衡三大关键方程的具体形式及其在COMSOL中的实现方法。随后,文章详细描述了模型建立、材料属性设置、边界条件设定、多物理场耦合设置以及求解与结果分析的具体步骤。此外,还分享了一些实用的经验和技术细节,如动态渗透率的定义、流固耦合边界的处理、温度场和渗流场的双向耦合、求解器配置等。 适合人群:从事煤层气抽采研究的专业人士,尤其是那些希望借助数值模拟手段优化抽采工艺的研究人员和技术人员。 使用场景及目标:适用于希望通过数值模拟深入理解N2和CO2混合气体在THM三场耦合下对瓦斯抽采的影响机制,并寻求优化抽采效率的方法。具体目标包括提高甲烷解吸量、改善渗透率、减少孔隙堵塞风险等。 其他说明:文中不仅提供了详细的数学公式和代码片段,还结合实际案例给出了许多宝贵的操作经验和注意事项,有助于读者更好地理解和应用相关技术。
初稿李雨桐-_检测报告.zip