
жң¬зҜҮд»Ҙеӯ”еӨ«еӯҗж—§д№ҰзҪ‘дёәдҫӢпјҡ
дёҖ.зҪ‘з«ҷз»“жһ„
1.зҪ‘з«ҷжҲӘеӣҫиҜҙжҳҺ
иҜҘзҪ‘з«ҷдёәеҲ—иЎЁз»“жһ„,еҸҜд»ҘйҖҡиҝҮиҜҶеҲ«еҲ—иЎЁзҡ„ж–№ејҸеҜ№е…ЁзҜҮж•°жҚ®иҝӣиЎҢжҠҪеҸ–

В
гҖҗзҪ‘з«ҷеҲ—иЎЁйЎөгҖ‘
2.йҮҮйӣҶз»“жһңжҲӘеӣҫ

В
гҖҗйҮҮйӣҶж•°жҚ®з»“жһңгҖ‘
дәҢ.й…ҚзҪ®жЁЎжқҝ
1.ж–°е»әд»»еҠЎ

В
гҖҗж–°е»әд»»еҠЎгҖ‘
зӮ№еҮ»гҖҗдёӢдёҖжӯҘгҖ‘пјҢйңҖиҰҒйҮҮйӣҶжҜҸдёҖйЎөжЈҖзҙўз»“жһң并жҠҪеҸ–ж•°жҚ®,жүҖд»ҘжӯӨеӨ„йңҖиҰҒеӢҫйҖүгҖҗжҷ®йҖҡзҝ»йЎөгҖ‘е’ҢгҖҗж•°жҚ®жҠҪеҸ–гҖ‘пјҢеҰӮеӣҫпјҡ

гҖҗж–°е»әйҮҮйӣҶд»»еҠЎгҖ‘
2.еҲӣе»ә/йҖүжӢ©иЎЁеҚ•
в‘ еҲӣе»әиЎЁеҚ•

В
гҖҗеҲӣе»әиЎЁеҚ•гҖ‘
в‘Ўй…ҚзҪ®иЎЁеҚ•
ж №жҚ®жүҖйңҖеҶ…е®№пјҢй…ҚзҪ®иЎЁеҚ•еӯ—ж®өпјҲеҚіиЎЁеӨҙпјүпјҢжӯӨеӨ„й…ҚзҪ®дәҶеҢ…жӢ¬зҪ‘йЎөдё»й”®гҖҒдҪңиҖ…еҗҚз§°гҖҒж ҮйўҳеҗҚз§°гҖҒд»·ж јзӯүеӣӣдёӘеӯ—ж®ө, д»Ҙй…ҚзҪ®еҸ‘еёғж—¶й—ҙ(pubtime)дёәдҫӢ

гҖҗй…ҚзҪ®иЎЁеҚ•гҖ‘
в‘ўж•°жҚ®жҠҪеҸ–й“ҫжҺҘе…іиҒ”иЎЁеҚ•
йҖүжӢ©еҲҡжүҚж–°еҲӣе»әзҡ„иЎЁеҚ•''еӯ”еӨ«еӯҗ''

гҖҗе…іиҒ”иЎЁеҚ•гҖ‘
3.еӯ—ж®өе®ҡдҪҚ
еҸ–еҖјж–№жі•пјҡз”ұдәҺжӯӨеӨ„жҙ»еҸ–зҡ„жҳҜеҲ—иЎЁйЎөзҡ„ж•°жҚ®пјҢжүҖд»ҘеҸҜд»Ҙеә”з”ЁвҖңиҜҶеҲ«еҲ—иЎЁвҖқеҠҹиғҪпјҢзӣҙжҺҘеҸ–еҲ°еҲ—иЎЁж•°жҚ®пјҢж“ҚдҪңж–№жі•еҰӮдёӢпјҡ
в‘ зӮ№еҮ»вҖңж•°жҚ®жҠҪеҸ–-еӯ”еӨ«еӯҗвҖқпјҢжҢүдҪҸctrl+йј ж Үе·Ұй”®зӮ№еҮ»е®ҡдҪҚж ҮйўҳеҶ…е®№

гҖҗе®ҡдҪҚж ҮйўҳгҖ‘
в‘ЎжҢүдҪҸShift+йј ж Үе·Ұ键继з»ӯзӮ№еҮ»пјҢзӣҙеҲ°зӮ№еҮ»еҲ°йҖүдёӯж•ҙдёӘ第дёҖжқЎж•°жҚ®

гҖҗе®ҡдҪҚ第дёҖжқЎж•°жҚ®гҖ‘
в‘ўеңЁиҪҜ件зҡ„еҸідёӢи§’еҸҜд»ҘзңӢеҲ°вҖңиҜҶеҲ«еҲ—иЎЁвҖқжҢүй’® пјҢжӯӨж—¶зӮ№еҮ»вҖңиҜҶеҲ«еҲ—иЎЁвҖқпјҢеҰӮдёӢеӣҫпјҢжӯӨж—¶еҲ—иЎЁдёӯзҡ„еҶ…е®№йғҪе·Із»ҸйҖүдёӯгҖӮ

гҖҗе®ҡдҪҚе…Ёж•°жҚ®гҖ‘
в‘ЈеҜ№жҜҸдёӘеӯ—ж®өиҝӣиЎҢеҸ–еҖј,ж–№жі•дҫқ然жҳҜпјҡжҢүдҪҸCtrl+йј ж Үе·Ұй”®пјҢиҝӣиЎҢеҢәеҹҹйҖүжӢ©пјҢжҢүдҪҸShift+йј ж Үе·Ұй”®пјҢжү©еӨ§йҖүжӢ©еҢәеҹҹгҖӮеҰӮпјҡpriceеӯ—ж®ө,и§ҒдёӢеӣҫ:

гҖҗеӯ—ж®өе®ҡдҪҚгҖ‘
4.жЁЎжқҝйў„и§Ҳ
йј ж ҮеҸій”®зӮ№еҮ»вҖңеӯ”еӨ«еӯҗвҖқпјҢ然еҗҺзӮ№еҮ»вҖңжЁЎжқҝйў„и§ҲвҖқ

В
гҖҗжЁЎжқҝйў„и§ҲгҖ‘
5.иҝҮж»Өзҝ»йЎөй“ҫжҺҘ
еӢҫйҖүж ҮйўҳиҝҮж»Ө,иҝҮж»Ө规еҲҷйҖүжӢ©еҢ…еҗ«,еЎ«е…Ҙ''дёӢдёҖйЎө''

гҖҗиҝҮж»Өзҝ»йЎөгҖ‘
дёү.ж•°жҚ®йҮҮйӣҶ

1.иҝһжҺҘж•°жҚ®еә“
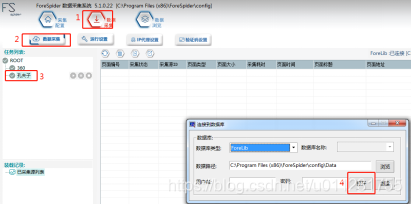
В
гҖҗиҝһжҺҘж•°жҚ®еә“гҖ‘
2.еҲӣе»әж•°жҚ®иЎЁ

В
гҖҗеҲӣе»әж•°жҚ®иЎЁгҖ‘
3.йҖүдёӯж•°жҚ®иЎЁ

гҖҗе…іиҒ”ж•°жҚ®иЎЁгҖ‘
4.ејҖе§ӢйҮҮйӣҶ

гҖҗејҖе§ӢйҮҮйӣҶгҖ‘
5.йҮҮйӣҶз»“жһң

В
В
В
гҖҗйҮҮйӣҶз»“жһңгҖ‘



зӣёе…іжҺЁиҚҗ
еүҚе—…forespiderж•°жҚ®йҮҮйӣҶиҪҜ件жӯЈжҳҜдёәи§ЈеҶіиҝҷдёҖйңҖжұӮиҖҢз”ҹпјҢе®ғжҳҜдёҖж¬ҫдё“дёәйқһдё“дёҡзј–зЁӢдәәе‘ҳи®ҫи®Ўзҡ„еҸҜи§ҶеҢ–ж•°жҚ®йҮҮйӣҶе·Ҙе…·пјҢдҪҝеҫ—еҚідҪҝжҳҜжІЎжңүзј–зЁӢеҹәзЎҖзҡ„з”ЁжҲ·д№ҹиғҪиҪ»жқҫиҝӣиЎҢзҪ‘йЎөж•°жҚ®зҡ„жҠ“еҸ–гҖӮ **дёҖгҖҒforespiderиҪҜ件жҰӮиҝ°** forespider...
ForeSpiderзҲ¬иҷ«е·Ҙе…·иҪҜ件дҪҝз”Ёж•ҷзЁӢ дҪҝз”ЁForeSpiderзҲ¬иҷ«иҪҜ件жү№йҮҸйҮҮйӣҶдјҒдёҡдҝЎжҒҜе…¬зӨәзі»з»ҹ.zip
еңЁеҪ“д»ҠдҝЎжҒҜеҢ–ж—¶д»ЈпјҢж•°жҚ®иҺ·еҸ–жҳҜж•°жҚ®еӨ„зҗҶе’ҢеҲҶжһҗзҡ„йҰ–иҰҒжӯҘйӘӨпјҢеҜ№дәҺеӨ§ж•°жҚ®жҠҖжңҜеӯҰд№ иҖ…иҖҢиЁҖпјҢжҺҢжҸЎжңүж•Ҳзҡ„ж•°жҚ®иҺ·еҸ–ж–№жі•е°ӨдёәйҮҚиҰҒгҖӮжң¬ж–Ү件еҶ…е®№ж¶үеҸҠзҡ„вҖңеӣҪејҖ-еӨ§ж•°жҚ®жҠҖжңҜеҜји®ә-е®һйӘҢ3 зҪ‘йЎөж•°жҚ®иҺ·еҸ–вҖқпјҢиҜҰз»Ҷд»Ӣз»ҚдәҶеҰӮдҪ•йҖҡиҝҮзҪ‘з»ңзҲ¬иҷ«...
зҪ‘дёҠзҡ„дҫҝжҚ·зҲ¬иҷ«иҪҜ件пјҢеҸҜзӣҙжҺҘеңЁи®ёеӨҡзҪ‘з«ҷдёҠиҝӣиЎҢж•°жҚ®зҲ¬еҸ–
JavaиҜӯиЁҖеҹәзЎҖ** JavaжҳҜдёҖз§Қйқўеҗ‘еҜ№иұЎзҡ„гҖҒи·Ёе№іеҸ°зҡ„зј–зЁӢиҜӯиЁҖпјҢд»Ҙе…¶ејәеӨ§зҡ„зұ»еә“е’ҢиүҜеҘҪзҡ„еҸҜ移жӨҚжҖ§иў«е№ҝжіӣеә”з”ЁдәҺеҗ„з§ҚйўҶеҹҹпјҢеҢ…жӢ¬зҪ‘з»ңзҲ¬иҷ«зҡ„ејҖеҸ‘гҖӮеңЁиҝҷдёӘйЎ№зӣ®дёӯпјҢ`mySpider.java`жҳҜдё»зЁӢеәҸж–Ү件пјҢ`.bak`жү©еұ•еҗҚиЎЁзӨәе®ғжҳҜиҜҘж–Ү件зҡ„...
еңЁITиЎҢдёҡдёӯпјҢзҪ‘з»ңзҲ¬иҷ«пјҲSpiderпјүжҳҜдёҖз§ҚиҮӘеҠЁеҢ–зЁӢеәҸпјҢз”ЁдәҺд»Һдә’иҒ”зҪ‘дёҠжҠ“еҸ–еӨ§йҮҸж•°жҚ®пјҢд»ҘдҫҝеҲҶжһҗгҖҒеӯҳеӮЁжҲ–еҶҚеҲ©з”ЁгҖӮеңЁиҝҷдёӘзү№ж®Ҡзҡ„йЎ№зӣ®дёӯпјҢвҖңweibo_spider_spiderвҖқжҢҮзҡ„жҳҜдёҖдёӘй’ҲеҜ№еҫ®еҚҡе№іеҸ°е®ҡеҲ¶зҡ„зҲ¬иҷ«зЁӢеәҸпјҢе®ғиғҪжңүж•Ҳең°зҲ¬еҸ–еҫ®еҚҡ...