- 浏览: 195937 次
-

文章分类
最新评论
-
luxing44530:
你好, 关于 JDK 7中也有一个支持协程方式的实现 在那呀? ...
Java性能调优笔记 -
songgz:
你是一个会思考的人,前途无量,代码审查显然不能以风格和规则为主 ...
到底该怎么样做代码审查? -
jiaoronggui:
遇到过一模一样的问题
一条Select语句导致瓶颈 -
Leon.Wood:
写出让计算机读懂的代码很容易,写出让人读懂的只有高手才能做到. ...
到底该怎么样做代码审查? -
ajuanlove:
不经常用这玩意
对300万一张表数据,用游标进行循环,不同写法的效率比较
一:事务
首先看一下什么是事务:
通俗的理解,事务是一组原子操作单元,从数据库角度说,就是一组SQL指令,要么全部执行成功,若因为某个原因其中一条指令执行有错误,则撤销先前执行过的所有指令。更简答的说就是:要么全部执行成功,要么撤销不执行。
然后看一下事务要遵循的ISO/IEC所制定的ACID原则:
ACID是原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)的缩写。
1.事务的原子性表示事务执行过程中的任何失败都将导致事务所做的任何修改失效。
2.一致性表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。
3.隔离性表示在事务执行过程中对数据的修改,在事务提交之前对其他事务不可见。
4.持久性表示已提交的数据在事务执行失败时,数据的状态都应该正确。
看一下一些准备知识:
1.T-SQL使用下列语句来管理事务:
开始事务:BEGIN TRANSACTION
提交事务:COMMIT TRANSACTION
回滚(撤销)事务:ROLLBACK TRANSACTION
一旦事务提交或回滚,则事务结束。
2.判断某条语句执行是否出错:
使用全局变量@@ERROR
@@ERROR只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计
如: SET @errorSum=@errorSum+@@error
了解一下事务的分类:
显示事务:用BEGIN TRANSACTION明确指定事务的开始,这是最常用的事务类型
隐性事务:通过设置SET IMPLICIT_TRANSACTIONS ON 语句,将隐性事务模式设置为打开,下一个语句自动启动一个新事务。当该事务完成时,再下一个 T-SQL 语句又将启动一个新事务
自动提交事务:这是 SQL Server 的默认模式,它将每条单独的 T-SQL 语句视为一个事务,如果成功执行,则自动提交;如果错误,则自动回滚
使用事务解决经典银行转账事务问题
T-SQL语句:
- BEGIN TRANSACTION
- /*--定义变量,用于累计事务执行过程中的错误--*/
- DECLARE @errorSum INT
- SET @errorSum=0 --初始化为0,即无错误
- /*--转账:张三的账户少1000元,李四的账户多1000元*/
- UPDATE bank SET currentMoney=currentMoney-1000
- WHERE customerName='张三'
- SET @errorSum=@errorSum+@@error
- UPDATE bank SET currentMoney=currentMoney+1000
- WHERE customerName='李四'
- SET @errorSum=@errorSum+@@error --累计是否有错误
- IF @errorSum<>0 --如果有错误
- BEGIN
- print '交易失败,回滚事务'
- ROLLBACK TRANSACTION
- END
- ELSE
- BEGIN
- print '交易成功,提交事务,写入硬盘,永久的保存'
- COMMIT TRANSACTION
- END
- GO
- print '查看转账事务后的余额'
- SELECT * FROM bank
- GO
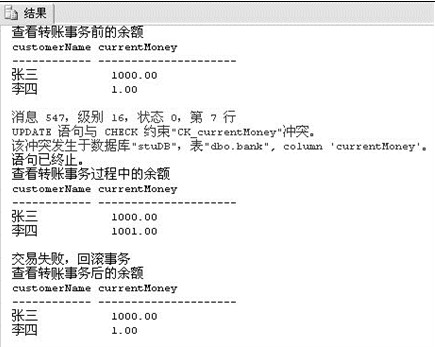
Javaj调用数据库事务方法在ava程序员从笨鸟到菜鸟之(七)一—java数据库操作
已经提到过了。在此就不在陈述了
二:索引
首先看一下什么事索引(以sqlserver为例):
SQL Server中的数据也是按页( 4KB )存放
索引:是SQL Server编排数据的内部方法。它为SQL Server提供一种方法来编排查询数据
索引页:数据库中存储索引的数据页;索引页类似于汉语字(词)典中按拼音或笔画排序的目录页
索引的作用:通过使用索引,可以大大提高数据库的检索速度,改善数据库性能
然后看一下索引的类型:
1.唯一索引:唯一索引不允许两行具有相同的索引值
2.主键索引:为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的,并且不能为空
3.聚集索引(Clustered):表中各行的物理顺序与键值的逻辑(索引)顺序相同,每个表只能有一个
4.非聚集索引(Non-clustered):非聚集索引指定表的逻辑顺序。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于249个
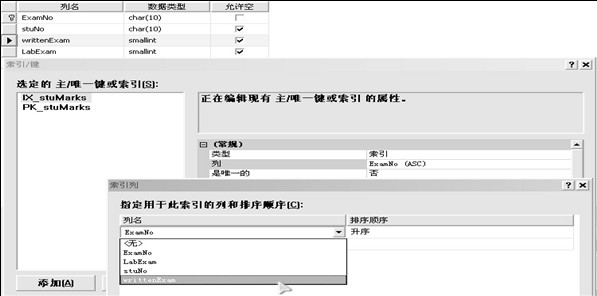
示例:利用企业管理器创建索引
使用T-SQL语句创建索引的语法:
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX index_name
ON table_name (column_name…)
[WITH FILLFACTOR=x]
注:UNIQUE表示唯一索引,可选
CLUSTERED、NONCLUSTERED表示聚集索引还是非聚集索 引,可选
FILLFACTOR表示填充因子,指定一个0到100之间的值,
该值指示索引页填满的空间所占的百分比
创建索引示例:
- USE stuDBGOIF EXISTS (SELECT name FROM sysindexes WHERE name = 'IX_writtenExam') DROP INDEX stuMarks.IX_writtenExam /*--笔试列创建非聚集索引:填充因子为30%--*/CREATE NONCLUSTERED INDEX IX_writtenExam ON stuMarks(writtenExam) WITH FILLFACTOR= 30GO/*-----指定按索引 IX_writtenExam 查询----*/SELECT * FROM stuMarks with (INDEX=IX_writtenExam) WHERE writtenExam BETWEEN 60 AND 90
索引的优缺点:
优点:1.加快访问速度2.加强行的唯一性
缺点:1.带索引的表在数据库中需要更多的存储空间
2.操纵数据的命令需要更长的处理时间,因为它们需要对索引进行更新
三:视图
首先还是先看一下什么事视图:
视图是一张虚拟表,它表示一张表的部分数据或多张表的综合数据,其结构和数据是建立在对表的查询基础上。视图中并不存放数据,而是存放在视图所引用的原始表(基表)中同一张原始表,根据不同用户的不同需求,可以创建不同的视图
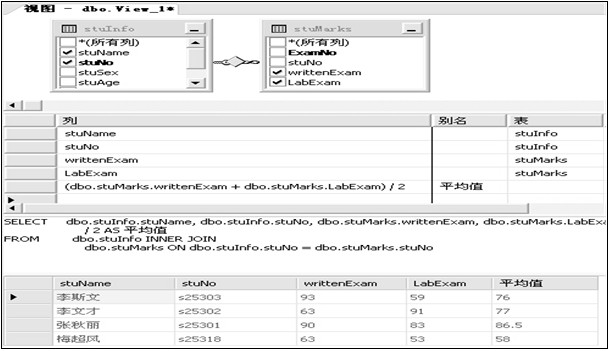
使用企业管理器创建视图:
使用T-SQL语句创建视图的语法:
CREATE VIEW view_name
AS
<select语句>
示例:创建方便教员查看成绩的视图
- <span style="color:#000000;">IF EXISTS (SELECT * FROM sysobjects WHERE
- name = 'view_stuInfo_stuMarks')
- DROP VIEW view_stuInfo_stuMarks
- GO
- CREATE VIEW view_stuInfo_stuMarks
- AS
- SELECT 姓名=stuName,学号=stuInfo.stuNo,
- 笔试成绩 =writtenExam, 机试成绩=labExam,
- 平均分=(writtenExam+labExam)/2
- FROM stuInfo LEFT JOIN stuMarks
- ON stuInfo.stuNo=stuMarks.stuNo
- GO
- SELECT * FROM view_stuInfo_stuMarks</span>
四:存储过程:
首先还是来看一下什么事存储过程:
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
存储过程(procedure)类似于Java语言中的方法
用来执行管理任务或应用复杂的业务规则
存储过程可以带参数,也可以返回结果
存储过程的有点:
执行速度更快
允许模块化程序设计
提高系统安全性
减少网络流通量
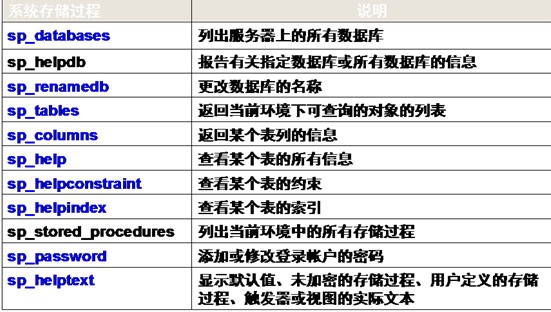
存储过程分类:
1.系统存储过程
由系统定义,存放在master数据库中,类似Java语言类库中的方法。
系统存储过程的名称都以“sp_”开头或“xp_”开头
2.用户自定义存储过程
由用户在自己的数据库中创建的存储过程,类似Java语言中用户自定义的方法
常用的系统存储过程
定义存储过程的语法
CREATE PROC[EDURE] 存储过程名
@参数1 数据类型 = 默认值 OUTPUT,
…… ,
@参数n 数据类型 = 默认值 OUTPUT
AS
SQL语句
GO
和Java语言的方法一样,参数可选
参数分为输入参数、输出参数
输入参数允许有默认值
先给出一个不带输入参数的存储过程的例子:
- CREATE PROCEDURE proc_stu //proc_stu为存储过程的名称
- AS DECLARE @writtenAvg float,@labAvg float //笔试平均分和机试平均分变量 SELECT @writtenAvg=AVG(writtenExam), @labAvg=AVG(labExam) FROM stuMarks print '笔试平均分:'+convert(varchar(5),@writtenAvg) print '机试平均分:'+convert(varchar(5),@labAvg) IF (@writtenAvg>70 AND @labAvg>70) print '本班考试成绩:优秀' ELSE print '本班考试成绩:较差' print '--------------------------------------------------' print ' 参加本次考试没有通过的学员:' SELECT stuName,stuInfo.stuNo,writtenExam,labExam FROM stuInfo INNER JOIN stuMarks ON stuInfo.stuNo=stuMarks.stuNo WHERE writtenExam<60 OR labExam<60 GO
执行存储过程的语法:
调用的语法
EXEC 过程名 [参数]
存储过程的参数分两种:1.输入参数2.输出参数
输入参数:用于向存储过程传入值,类似Java带参方法
输出参数:用于在调用存储过程后,返回结果
带输入参数的存储过程:
修改上例子:由于每次考试的难易程度不一样,每次笔试和机试的及格线可能随时变化(不再是60分),这导致考试的评判结果也相应变化
调用上面的存储过程:
- CREATE PROCEDURE proc_stu @writtenPass int, //输入参数:笔试及格线 @labPass int //输入参数:机试及格线 AS print '--------------------------------------------------' print ' 参加本次考试没有通过的学员:' SELECT stuName,stuInfo.stuNo,writtenExam, labExam FROM stuInfo INNER JOIN stuMarks ON //查询没有通过考试的学员 stuInfo.stuNo=stuMarks.stuNo WHERE writtenExam<@writtenPass OR labExam<@labPass GO
EXEC proc_stu 60,55
--或这样调用:
EXEC proc_stu @labPass=55,@writtenPass=60
扩展:设置输入的默认值:
--或这样调用:
EXEC proc_stu
@labPass=55,
@writtenPass=60
CREATE PROCEDURE proc_stu
@writtenPass int=60,
@labPass int=60
AS
。。。。。。
调用带参数默认值的存储过程
EXEC proc_stu --都采用默认值
EXEC proc_stu 64 --机试采用默认值
EXEC proc_stu 60,55 --都不采用默认值
--错误的调用方式:希望笔试采用默认值,机试及格线55分
EXEC proc_stu ,55
--正确的调用方式:
EXEC proc_stu @labPass=55
如果希望调用存储过程后,返回一个或多个值,这时就需要使用输出(OUTPUT)参数了
- CREATE PROCEDURE proc_stu @notpassSum int OUTPUT, //输出(返回)参数:表示没有通过的人数 @writtenPass int=60, @labPass int=60 AS …… SELECT stuName,stuInfo.stuNo,writtenExam, labExam FROM stuInfo INNER JOIN stuMarks ON stuInfo.stuNo=stuMarks.stuNo WHERE writtenExam<@writtenPass OR labExam<@labPass SELECT @notpassSum=COUNT(stuNo) //统计并返回没有通过考试的学员人数 FROM stuMarks WHERE writtenExam<@writtenPass OR labExam<@labPass GO
调用带输出参数的存储过程
更多信息请查看 java进阶网 http://www.javady.com
- /*---调用存储过程----*/DECLARE @sum int EXEC proc_stu @sum OUTPUT ,64 //调用时必须带OUTPUT关键字 ,返回结果将存放在变量@sum中 print '--------------------------------------------------'IF @sum>=3 //后续语句引用返回结果 print '未通过人数:'+convert(varchar(5),@sum)+ '人, 超过60%,及格分数线还应下调'ELSE print '未通过人数:'+convert(varchar(5),@sum)+ '人, 已控制在60%以下,及格分数线适中'GO


发表评论

-
Java程序员从笨鸟到菜鸟之(三十三)大话设计模式之单例模式
2012-04-23 22:26 1077单例模式属于对象创建型模式,其意图是保证一个类仅有 ... -
Java程序员从笨鸟到菜鸟之(三十二)大话设计模式之设计模式分类和三种工厂模式
2012-04-23 22:25 1164设计模式分类 首先先简单说一下设计模式的分类设计模式可 ... -
Java程序员从笨鸟到菜鸟之(三十一)大话设计模式之设计模式遵循的七大原则
2012-04-23 22:24 795最近几年来,人们踊跃的提倡和使用设计模式,其根 ... -
Java程序员从笨鸟到菜鸟之(三十)javascript弹出框、事件、对象化编程
2012-04-23 22:24 1284一:弹出框 JavaScript ... -
Java程序员从笨鸟到菜鸟之(二十九)javascript对象的创建和继承实现
2012-04-23 22:23 705javascript对象的创建 JavaScri ... -
Java程序员从笨鸟到菜鸟之(二十四)Xml基础详解和DTD验证
2012-04-22 15:20 890Xml基础详解 Xml:可扩展标记语言 (Extens ... -
Java程序员从笨鸟到菜鸟之(二十三)常见乱码解决以及javaBean基础知识
2012-04-22 15:20 1227乱码问题应该是做javaWeb开发人员都遇到过的问题吧 ... -
Java程序员从笨鸟到菜鸟之(二十二)华山论session和cookie机制
2012-04-22 15:19 1008会话(Session)跟踪是Web程序中常用的技术,用 ... -
Java程序员从笨鸟到菜鸟之(二十一)java过滤器和监听器详解
2012-04-22 15:18 10551、Filter工作原理(� ... -
Java程序员从笨鸟到菜鸟之(二十)jsp自定义标签
2012-04-22 15:17 890一、基本概念 1、标签(Tag) 标签是一种XML元 ... -
Java程序员从笨鸟到菜鸟之(十九)EL表达式和JSTL
2012-04-21 12:55 1125一:EL表达式: 1.定义:为了计算和输出存储在标志位 ... -
Java程序员从笨鸟到菜鸟之(十八)JSP基本语法与动作指令
2012-04-21 12:54 903Jsp,通常的被大家认为是做网页的前台界面,我刚学习的时 ... -
Java程序员从笨鸟到菜鸟之(十六)CSS基础积累总结(上)
2012-04-21 12:52 834一:CSS的工作原理 1. ... -
java程序员从笨鸟到菜鸟之(七)一—java数据库操作
2012-04-19 22:48 1448更多信息请查看 java进� ... -
Java程序员从笨鸟到菜鸟之(六)I/O流操作
2012-04-19 22:47 1690在软件开发中,数� ... -
Java程序员从笨鸟到菜鸟之(十)枚举,泛型详解
2012-04-19 22:48 1167一:首先从枚举开始 ... -
Java程序员从笨鸟到菜鸟之(八)反射和代理机制
2012-04-19 22:48 877反射和代理机制是 ... -
java程序员从笨鸟到菜鸟之(七)一—java数据库操作
2012-04-18 21:14 0数据库访问几乎每一个稍微成型的程序都要用到的知识,怎么 ... -
Java程序员从笨鸟到菜鸟之(六)I/O流操作
2012-04-18 21:13 0在软件开发中,数据流和数据库操作占据了一个很重要的位置 ... -
Java程序员从笨鸟到菜鸟之(五)java开发常用类(包装,数字处理集合等)(下)
2012-04-18 00:12 849写在前面:由于前天 ...
相关推荐
曹胜欢在《JAVA程序员 从笨鸟到菜鸟.pdf》中分享了他个人学习Java的经历,从迷茫到逐渐成长的过程。他强调了自学的重要性,并鼓励初学者不要怕走弯路,同时希望自己的经验可以帮助到同样在学习Java的初学者。 2. ...
内容概要:本文详细介绍了基于松下FP-XH双PLC实现的10轴摆盘系统的设计与实现。该系统采用模块化编程方法,涵盖输出与调试、报警与通信、启动与复位三个主要部分。通过PC-LINK通信协议实现双PLC间的数据交互,并结合维纶通触摸屏提供直观的操作界面。具体代码展示了轴控制、报警处理、通信数据传输等功能的实现细节,强调了程序的易维护性和高效性。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是熟悉松下PLC和维纶通触摸屏的用户。 使用场景及目标:适用于需要高精度多轴联动控制的工业应用场景,如自动化生产线、机器人控制等。目标是提高设备的稳定性和效率,减少维护难度。 其他说明:文中提供了丰富的代码示例和实际操作经验,帮助读者更好地理解和应用所介绍的技术。此外,还讨论了一些优化技巧,如通信负载管理、异常处理机制等,有助于提升项目的可靠性和性能。
k近邻算法数据集,包换鸢尾花和水果分类等
wmsj1111111111
内容概要:本文详细介绍了如何使用COMSOL Multiphysics软件进行变压器电磁场的仿真建模。主要内容涵盖了几何结构的创建、材料的选择与定义、物理场的设置以及仿真结果的分析。文中具体讲解了如何选择合适的铁磁材料(如软铁)、定义线圈材料(如铜),并设置了线圈的电流激励。通过仿真,可以得到变压器内部的磁密分布图和电路状态,从而优化变压器的设计,提升其效率和性能。 适合人群:从事电磁场仿真研究的技术人员、电力电子工程师、高校相关专业的学生。 使用场景及目标:适用于需要深入了解变压器工作原理的研究人员和技术人员,旨在通过仿真手段优化变压器设计,提高其性能和效率。 其他说明:文章提供了详细的MATLAB代码片段用于指导具体的仿真步骤,并分享了一些常见问题的解决方案,如边界条件设置不当、网格划分不合理等。同时,还强调了仿真结果的可视化展示方法,如磁密分布图和电路参数曲线的叠加显示。
https://github.com/AlfredXiangWu/LightCNN LightCNN-v4 预训练模型
内容概要:本文详细介绍了如何利用COMSOL进行多孔介质中湿空气的传热传质仿真。首先探讨了水蒸气扩散和液态水迁移的基本原理及其数学表达,如水蒸气扩散系数随温度变化以及多孔介质渗透率随孔隙率的变化规律。接着,通过具体案例展示了如何正确设置多孔介质参数,避免常见的仿真错误,如孔隙率和曲折因子的误设。文中还提供了多个实用技巧,包括求解器配置、边界条件设置、网格划分方法等,确保仿真的稳定性和准确性。此外,强调了多物理场耦合的重要性,特别是在处理温度场和湿度场之间的相互作用时。最后,通过实例验证了模型的有效性,并给出了提高仿真精度的具体建议。 适合人群:从事多物理场仿真、传热传质研究的专业人士,尤其是使用COMSOL进行相关仿真的工程师和技术人员。 使用场景及目标:适用于需要精确模拟湿空气中传热传质过程的研究项目,帮助研究人员更好地理解和预测复杂环境下(如地下室墙面渗水、地下粮仓通风)的物理现象,从而优化设计方案并解决实际工程问题。 其他说明:本文不仅提供具体的代码片段和参数设置指导,还分享了许多实践经验,有助于读者快速掌握COMSOL仿真技巧,避免常见错误,提高仿真效率和准确性。
内容概要:本文详细介绍了用于非线性动力学分析的一系列Python代码实现,涵盖相空间重构、分形维数计算、随机微分方程求解以及智能优化算法。首先,通过互信息法和假近邻法进行相空间重构,确保时间序列数据能够在一个适当的坐标系中表示。其次,利用赫斯特指数和李雅普诺夫指数评估系统的分形特性和记忆性。然后,采用sdeint库解决带有噪声的随机微分方程,模拟复杂的动态系统。最后,比较并实现了粒子群优化(PSO)和遗传算法(GA),展示了它们在不同类型优化问题中的优势。 适合人群:具备一定编程基础的数据科学家、研究人员和技术爱好者,尤其是对非线性动力学感兴趣的读者。 使用场景及目标:适用于需要处理复杂时序数据的研究项目,如金融市场的波动分析、气象预报、生物信号处理等。目标是帮助读者掌握非线性动力学的基本概念及其Python实现,从而更好地理解和预测复杂系统的动态行为。 其他说明:文中提供了大量具体的Python代码片段,便于读者直接应用于实际问题中。同时强调了参数选择的重要性,并给出了多个实用技巧,如互信息法找延迟、假近邻法确定嵌入维数等。
1、文件说明: Centos8操作系统texlive-cm-super-7:20180414-23.el8.rpm以及相关依赖,全打包为一个tar.gz压缩包 2、安装指令: #Step1、解压 tar -zxvf texlive-cm-super-7:20180414-23.el8.tar.gz #Step2、进入解压后的目录,执行安装 sudo rpm -ivh *.rpm
内容概要:文档《软件测试经典面试题.docx》汇总了软件测试领域的常见面试题及其参考答案。涵盖的主题包括但不限于兼容性测试、性能测试、单元测试、集成测试、系统测试、Bug管理、测试工具(如Bugzilla、LoadRunner、QTP)、测试用例设计、测试流程、测试类型的区别与联系、测试中的沟通技巧、测试环境搭建、网络与操作系统基础知识等。文档不仅涉及具体的测试技术和工具,还包括了对测试人员职业发展的探讨,如测试工程师应具备的素质、职业规划、如何处理与开发人员的关系等。 适用人群:具备一定编程基础,尤其是有志于从事软件测试工作的人员,以及希望提升自身测试技能的专业人士。 使用场景及目标:①帮助求职者准备软件测试相关岗位的面试;②为在职测试工程师提供技术参考和职业发展建议;③为项目经理或HR提供招聘软件测试人员时的面试题目参考;④帮助理解软件测试在软件开发中的重要性及其实现方法。 阅读建议:本文内容详实,涵盖面广,建议读者根据自身需求选择性阅读。对于面试准备,重点关注面试题及其解答思路;对于技术提升,深入理解测试工具和方法;对于职业发展,思考测试人员所需素质及职业规划。同时,结合实际工作中的案例进行理解和实践,有助于更好地掌握和应用这些知识。
内容概要:本文详细介绍了基于信捷XC PLC和显控触摸屏的双摆头双滚头磨床自动化控制系统的设计与实现。系统采用Modbus RTU通讯协议,通过PLC控制四台变频器,实现磨床的高效稳定运行。主要内容涵盖系统总体架构、PLC配置与通讯、变频器控制逻辑、程序功能模块以及调试与优化等方面。文中还分享了一些实际开发中的技巧和经验,如变频器的负载电流用于软限位检测、通讯超时处理机制等。 适合人群:从事工业自动化控制系统的工程师和技术人员,尤其是熟悉PLC编程和Modbus通讯协议的专业人士。 使用场景及目标:适用于需要提高双摆头双滚头磨床生产效率和稳定性的制造企业。目标是通过自动化控制减少人工干预,提升设备性能和可靠性。 其他说明:文中提供的代码示例和调试经验对于类似设备的智能化改造具有重要参考价值。
第十六届蓝桥杯嵌入式官方赛点资源包
内容概要:本文详细介绍了长短期记忆神经网络(LSTM)和极限学习机(ELM)在Matlab中实现天气预测的方法,并进行了对比分析。首先,文章阐述了LSTM和ELM的基本原理,随后分别展示了它们的数据准备、预处理、网络构建、训练以及预测的具体步骤。LSTM作为一种特殊的循环神经网络,擅长处理时间序列数据中的长期依赖问题,而ELM则以其快速的训练速度著称。通过对某气象站三年数据的实际测试,LSTM在复杂天气数据预测中表现出更高的精度,特别是在长时间序列预测方面优势明显;ELM则因其简洁快速的特点适用于快速原型开发和资源受限环境。最终,文章通过对比两者的预测精度和训练效率,提出了根据不同应用场景选择合适算法的建议。 适合人群:对机器学习尤其是深度学习感兴趣的科研人员、学生以及从事气象预报工作的专业人士。 使用场景及目标:①研究和开发气象预测系统;②探索不同神经网络算法在时间序列预测中的优劣;③提高天气预测的准确性和时效性。 其他说明:文中提供了详细的Matlab代码实现,帮助读者更好地理解和复现实验结果。同时强调了特征工程的重要性,指出适当增加特征(如气压梯度)可以显著提升预测效果。此外,还提到了一些实用技巧,例如利用ELM作为LSTM的初始化器以减少训练轮数,以及在LSTM预测结果后加上滑动平均滤波以改善曲线平滑度。
内容概要:本文详细介绍了一款基于51单片机的自动浇花系统的设计与实现。该系统通过按键设置土壤湿度的上下限阈值,利用土壤湿度传感器监测土壤湿度,当湿度低于设定阈值时,触发LED报警并启动水泵浇水。主要内容涵盖硬件配置(如STC89C52主控芯片、YL-69土壤湿度传感器、ADC0832模数转换器等)、程序代码(包括端口定义、延时函数、阈值设置函数、主函数等)、Proteus仿真以及AD图(Altium Designer绘制的原理图和PCB图)。此外,文中还讨论了一些优化措施,如防抖处理、阈值保存、湿度检测精度改进、PWM控制水泵等。 适合人群:对单片机编程和硬件设计感兴趣的电子爱好者、学生及工程师。 使用场景及目标:适用于家庭或小型温室环境,旨在解决因外出或其他原因无法及时浇水的问题,确保植物始终保持适宜的水分条件。通过本项目的实践,读者可以掌握51单片机的基本应用、传感器接口技术和简单控制系统的设计方法。 其他说明:文中提供了完整的工程文件,包括Keil工程源码、Proteus仿真文件和AD原理图,便于读者快速上手实践。同时,针对可能出现的问题给出了相应的解决方案和技术细节,帮助读者更好地理解和优化系统性能。
内容概要:本文详细介绍了如何利用Matlab/Simulink构建和仿真两级式光伏并网系统。系统主要由光伏板、boost变换器、LCL逆变器和电网组成。文中深入探讨了各组成部分的功能及其控制方法,包括光伏的最大功率点追踪(MPPT)、LCL逆变器的双闭环控制、锁相环及坐标变换、SVPWM调制以及观测模块的设计。此外,还提供了具体的MATLAB代码片段用于实现关键控制逻辑,确保系统能够高效稳定运行。 适用人群:适用于具有一定电力电子和控制系统基础知识的研究人员和技术人员,尤其是那些希望深入了解光伏并网系统设计与仿真的专业人士。 使用场景及目标:①帮助读者掌握光伏并网系统的基本架构和工作原理;②指导读者在Matlab/Simulink环境中搭建完整的两级式光伏并网系统仿真模型;③提供实用技巧和经验,使读者能够在实践中优化系统性能,降低谐波失真,提高并网质量。 其他说明:本文不仅涵盖了理论知识,还包括了许多实践经验,如参数选择、模块配置等方面的建议。对于想要进一步提升光伏并网系统仿真能力的人来说是非常有价值的参考资料。
内容概要:本文详细介绍了使用Abaqus进行焊接仿真的方法和技术,涵盖了热源模型、子程序编写、热力耦合分析、生死单元操作以及后处理技巧等多个方面。首先,文章讲解了如何利用Dflux子程序构建可靠的热源载荷,强调了双椭球热源模型及其Fortran代码实现的关键参数设定。接着,讨论了热力耦合分析中材料属性的正确配置,如热膨胀系数的设置。随后,深入探讨了生死单元的应用,展示了如何通过Python脚本实现单元的逐层激活,并解释了相关注意事项。此外,文章还涉及了多道焊仿真中的材料属性动态调整、搅拌摩擦焊的特殊处理方法以及后处理中的应力和应变提取技巧。最后,提供了一些实用的避坑指南,帮助用户避免常见错误并提高仿真准确性。 适合人群:从事焊接仿真研究的技术人员、工程师及高校相关专业师生。 使用场景及目标:适用于需要精确模拟焊接过程中热应力应变场的研究和工程项目,旨在提升仿真精度,减少试验成本,优化焊接工艺。 其他说明:文中提供了大量实例代码和具体操作步骤,便于读者理解和实践。同时提醒读者关注实际工况的影响因素,确保仿真结果贴近真实情况。
内容概要:本文详细介绍了DCC-GARCH模型及其在金融时间序列分析中的应用。首先,通过ADF检验确保时间序列的平稳性。接着,利用ARCH-LM检验确认是否存在条件异方差性。随后,采用GARCH模型对单个资产的波动率进行建模。最后,通过DCC-GARCH模型估计多个资产之间的动态相关系数,并对其变化进行可视化展示。文中提供了完整的Python代码实现,帮助读者理解和应用这一复杂模型。 适合人群:金融工程专业人员、量化分析师、金融研究员、数据科学家等对金融市场波动性和相关性感兴趣的从业者。 使用场景及目标:①评估金融时间序列的平稳性和波动性特征;②识别和建模时间序列中的条件异方差性;③估算多个资产之间的动态相关系数,揭示市场联动性;④为风险管理、组合优化和对冲策略提供理论支持和技术手段。 其他说明:文章强调了数据预处理的重要性,并给出了常见问题的解决方案。此外,还讨论了模型参数的经济意义及其在实际应用中的解释。
内容概要:本文介绍了基于梯度下降的改进自适应短时傅里叶变换(STFT)方法,并展示了其在Jupyter Notebook中的具体实现。传统的STFT由于固定窗口长度,在处理非平稳信号时存在局限性。改进的方法通过梯度下降策略自适应调整窗口参数,从而提高时频分辨率。文中详细解释了算法的工作原理,包括信号生成、窗函数设计、损失函数选择等方面,并给出了具体的Python代码示例。此外,文章还讨论了该方法在多个领域的广泛应用,如金融时间序列、地震信号、机械振动信号、声发射信号、电压电流信号、语音信号、声信号和生理信号等。 适合人群:从事信号处理、数据分析及相关领域研究的专业人士,尤其是对时频分析感兴趣的科研人员和技术开发者。 使用场景及目标:适用于需要处理非平稳信号的研究和应用场景,旨在提高信号处理的精度和效率。具体目标包括但不限于:改善金融市场的预测能力、提升地震监测系统的准确性、增强机械设备故障诊断的效果、优化语音识别和合成的质量等。 其他说明:该方法不仅限于特定类型的信号,而是可以通过调整参数灵活应用于不同的信号类型。文中提供的代码可以在Jupyter Notebook环境中直接运行,便于实验和验证。