
В
вҖ”вҖ”зҢ®з»ҷйӮЈдәӣеҗ‘жҲ‘иҝҷж ·еҜ№HTTPзҡ„вҖңдјӘвҖқзҶҹжӮүиҖ…гҖӮ
ж•…дәӢеҸ‘з”ҹеңЁ10жңҲд»Ҫзҡ„дёҖж¬ЎйқўиҜ•з»ҸеҺҶдёӯпјҢжң¬жқҘжҲ‘дёҚжғіиҜҙеҮәжқҘдёўдәәжҳҫзңјпјҢдҪҶжҳҜдёәдәҶиӯҰйҶ’иҮӘе·ұе’Ңе‘ҠиҜ«еҗҺдәәпјҢжҲ‘еҶіе®ҡеҶҷжҲҗеҚҡж–ҮеҸ‘еҮәжқҘгҖӮеӣ дёәеңЁйқўиҜ•иҝҮзЁӢдёӯпјҢжҲ‘и®ІеңЁ2009е№ҙеҶҷиҝҮQQеҶңеңәеҠ©жүӢпјҢеңЁиҝҷжңҹй—ҙж·ұе…ҘеӯҰд№ дәҶHTTPеҚҸи®®пјҢиҖҢдё”еңЁ2010-05-18еҶҷдәҶеҚҡж–ҮпјҡHTTPеҚҸи®®еҸҠе…¶POSTдёҺGETж“ҚдҪңе·®ејӮ & C#дёӯеҰӮдҪ•дҪҝз”ЁPOSTгҖҒGETзӯүВ гҖӮйқўиҜ•е®ҳиҜҙ既然жҲ‘зҶҹжӮүHTTPеҚҸи®®пјҢе°ұй—®вҖңеҪ“HTTPйҮҮз”ЁkeepaliveжЁЎејҸпјҢеҪ“е®ўжҲ·з«Ҝеҗ‘жңҚеҠЎеҷЁеҸ‘з”ҹиҜ·жұӮд№ӢеҗҺпјҢе®ўжҲ·з«ҜеҰӮдҪ•еҲӨж–ӯжңҚеҠЎеҷЁзҡ„ж•°жҚ®е·Із»ҸеҸ‘з”ҹе®ҢжҲҗпјҹвҖқ
иҜҙе®һиҜқпјҢеҪ“ж—¶жҲ‘жҮөдәҶпјҢдёҖзӣҙжІЎжңүе…іжіЁиҝҮkeepaliveжЁЎејҸгҖӮжҲ‘еҸӘзҹҘйҒ“пјҡHTTPеҚҸи®®дёӯе®ўжҲ·з«ҜеҸ‘йҖҒдёҖдёӘе°ҸиҜ·жұӮпјҢжңҚеҠЎеҷЁе“Қеә”д»ҘжүҖжңҹжңӣзҡ„дҝЎжҒҜпјҲдҫӢеҰӮдёҖдёӘhtmlж–Ү件жҲ–дёҖеүҜgifеӣҫеғҸпјүгҖӮжңҚеҠЎеҷЁйҖҡеёёеңЁеҸ‘йҖҒеӣһжүҖиҜ·жұӮзҡ„ж•°жҚ®д№ӢеҗҺе°ұе…ій—ӯиҝһжҺҘгҖӮиҝҷж ·е®ўжҲ·з«ҜиҜ»ж•°жҚ®ж—¶дјҡиҝ”еӣһEOFпјҲ-1пјүпјҢе°ұзҹҘйҒ“ж•°жҚ®е·Із»ҸжҺҘ收е®Ңе…ЁдәҶгҖӮВ жҲ‘е°ұиҝҷж ·иў«йқўиҜ•е®ҳеҲӨдәҶжӯ»еҲ‘пјҒпјҒпјҒиҜҙжҲ‘е®Ңе…ЁеҒңз•ҷеңЁиЎЁйқўпјҢжІЎжңүж·ұе…ҘпјҲеҪ“ж—¶зңҹзҡ„еҫҲеҸ—жү“еҮ»пјҢдёҖзӣҙиҮӘи®ӨдёәжҠҖжңҜиҝҳдёҚй”ҷпјҒпјүгҖӮжҲ‘еҪ“ж—¶зңҹзҡ„еҫҲжғіжүҫеҗ„з§ҚеҖҹеҸЈпјҡ
- д№ӢеүҚжІЎжңүз”ЁеҲ°HTTPзҡ„keepaliveжЁЎејҸпјҢжүҖд»ҘжІЎжңүж·ұе…Ҙ
- еҘҪд№…жІЎжңүз”ЁHTTPеҚҸи®®пјҢз»ҶиҠӮеҝҳдәҶ
- е®һд№ зҡ„дёңиҘҝи·ҹHTTPеҚҸи®®жІЎжңүе…ізі»пјҢз”Ёеҫ—е°‘дәҶе°ұеҝҳдәҶ
- гҖӮгҖӮгҖӮгҖӮгҖӮгҖӮ
и§үеҫ—еҗ„з§Қи§ЈйҮҠйғҪжҳҜйӮЈд№ҲиӢҚзҷҪж— еҠӣпјҒжҲ‘еҶҚж¬Ўж„ҹеҸ№д№ҰеҲ°з”Ёж—¶ж–№жҒЁе°‘пјҢд№ҹж„ҹеҸ№дёҖдёӘдәәзҡ„ж—¶й—ҙжҳҜеӨҡд№Ҳзҡ„жңүйҷҗпјҲжӣҫдёҖеәҰжғіжҲҗдёәдёҖдёӘITдё“дёҡе…ЁжүҚпјүпјҢж №жң¬жІЎжңүзІҫеҠӣйқўйқўдҝұ еҲ°пјҢиҖҢдё”еҪ“жІЎжңүзңҹжӯЈдҪҝз”ЁдёҖдёӘдёңиҘҝзҡ„ж—¶еҖҷпјҢеҫҖеҫҖдјҡеҝҪз•ҘжҺүеҫҲеӨҡз»ҶиҠӮгҖӮжңӢеҸӢеҰӮжһңдҪ д№ҹзӯ”дёҚдёҠжқҘпјҢиҜ·и®Өзңҹз»ҶзңӢдёӢж–ҮпјҢдёҚиҰҒжҖҖзқҖжө®иәҒдәҶзҡ„еҝғпјҢиҜҙдёҚе®ҡдёӢж¬Ўе°ұжңүдәәй—®дҪ иҝҷдёӘй—® йўҳгҖӮ
1гҖҒд»Җд№ҲжҳҜKeep-AliveжЁЎејҸпјҹ
жҲ‘们зҹҘйҒ“HTTPеҚҸи®®йҮҮз”ЁвҖңиҜ·жұӮ-еә”зӯ”вҖқжЁЎејҸпјҢеҪ“дҪҝз”Ёжҷ®йҖҡжЁЎејҸпјҢеҚійқһKeepAliveжЁЎејҸж—¶пјҢжҜҸдёӘиҜ·жұӮ/еә”зӯ”е®ўжҲ·е’ҢжңҚеҠЎеҷЁйғҪиҰҒж–°е»әдёҖдёӘиҝһжҺҘпјҢе®ҢжҲҗ д№ӢеҗҺз«ӢеҚіж–ӯејҖиҝһжҺҘпјҲHTTPеҚҸи®®дёәж— иҝһжҺҘзҡ„еҚҸи®®пјүпјӣеҪ“дҪҝз”ЁKeep-AliveжЁЎејҸпјҲеҸҲз§°жҢҒд№…иҝһжҺҘгҖҒиҝһжҺҘйҮҚз”Ёпјүж—¶пјҢKeep-AliveеҠҹиғҪдҪҝе®ўжҲ·з«ҜеҲ°жңҚ еҠЎеҷЁз«Ҝзҡ„иҝһжҺҘжҢҒз»ӯжңүж•ҲпјҢеҪ“еҮәзҺ°еҜ№жңҚеҠЎеҷЁзҡ„еҗҺ继иҜ·жұӮж—¶пјҢKeep-AliveеҠҹиғҪйҒҝе…ҚдәҶе»әз«ӢжҲ–иҖ…йҮҚж–°е»әз«ӢиҝһжҺҘгҖӮ
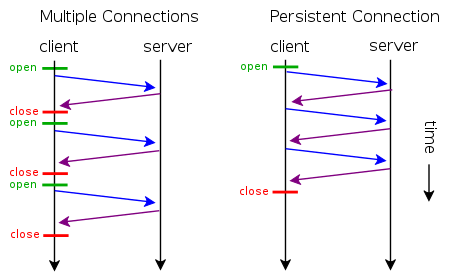
http 1.0дёӯй»ҳи®ӨжҳҜе…ій—ӯзҡ„пјҢйңҖиҰҒеңЁhttpеӨҙеҠ е…Ҙ"Connection: Keep-Alive"пјҢжүҚиғҪеҗҜз”ЁKeep-Aliveпјӣhttp 1.1дёӯй»ҳи®ӨеҗҜз”ЁKeep-AliveпјҢеҰӮжһңеҠ е…Ҙ"Connection: close "пјҢжүҚе…ій—ӯгҖӮзӣ®еүҚеӨ§йғЁеҲҶжөҸи§ҲеҷЁйғҪжҳҜз”Ёhttp1.1еҚҸи®®пјҢд№ҹе°ұжҳҜиҜҙй»ҳи®ӨйғҪдјҡеҸ‘иө·Keep-Aliveзҡ„иҝһжҺҘиҜ·жұӮдәҶпјҢжүҖд»ҘжҳҜеҗҰиғҪе®ҢжҲҗдёҖдёӘе®Ңж•ҙзҡ„Keep- AliveиҝһжҺҘе°ұзңӢжңҚеҠЎеҷЁи®ҫзҪ®жғ…еҶөгҖӮ
2гҖҒеҗҜз”ЁKeep-Aliveзҡ„дјҳзӮ№
д»ҺдёҠйқўзҡ„еҲҶжһҗжқҘзңӢпјҢеҗҜз”ЁKeep-AliveжЁЎејҸиӮҜе®ҡжӣҙй«ҳж•ҲпјҢжҖ§иғҪжӣҙй«ҳгҖӮеӣ дёәйҒҝе…ҚдәҶе»әз«Ӣ/йҮҠж”ҫиҝһжҺҘзҡ„ејҖй”ҖгҖӮдёӢйқўжҳҜRFC 2616В дёҠзҡ„жҖ»з»“пјҡ
- В
- By opening and closing fewer TCP connections, CPU time is saved in routers and hosts (clients, servers, proxies, gateways, tunnels, or caches), and memory used for TCP protocol control blocks can be saved in hosts.
- HTTP requests and responses can be pipelined on a connection. Pipelining allows a client to make multiple requests without waiting for each response, allowing a single TCP connection to be used much more efficiently, with much lower elapsed time.
- Network congestion is reduced by reducing the number of packets caused by TCP opens, and by allowing TCP sufficient time to determine the congestion state of the network.
- Latency on subsequent requests is reduced since there is no time spent in TCP's connection opening handshake.
- HTTP can evolve more gracefully, since errors can be reported without the penalty of closing the TCP connection. Clients usingВ В В В future versions of HTTP might optimistically try a new feature, but if communicating with an older server, retry with oldВ В semantics after an error is reported.
RFC 2616В пјҲP47пјүиҝҳжҢҮеҮәпјҡеҚ•з”ЁжҲ·е®ўжҲ·з«ҜдёҺд»»дҪ•жңҚеҠЎеҷЁжҲ–д»ЈзҗҶд№Ӣй—ҙзҡ„иҝһжҺҘж•°дёҚеә”иҜҘи¶…иҝҮ2дёӘгҖӮдёҖдёӘд»ЈзҗҶдёҺе…¶е®ғжңҚеҠЎеҷЁжҲ–д»Јз Ғд№Ӣй—ҙеә”иҜҘдҪҝз”Ёи¶…иҝҮ2 * Nзҡ„жҙ»и·ғ并еҸ‘иҝһжҺҘгҖӮиҝҷжҳҜдёәдәҶжҸҗй«ҳHTTPе“Қеә”ж—¶й—ҙпјҢйҒҝе…ҚжӢҘеЎһпјҲеҶ—дҪҷзҡ„иҝһжҺҘ并дёҚиғҪд»Јз Ғжү§иЎҢжҖ§иғҪзҡ„жҸҗеҚҮпјүгҖӮ
3гҖҒеӣһеҲ°жҲ‘们зҡ„й—®йўҳпјҲеҚіеҰӮдҪ•еҲӨж–ӯж¶ҲжҒҜеҶ…е®№/й•ҝеәҰзҡ„еӨ§е°Ҹпјҹпјү
Keep-AliveжЁЎејҸпјҢе®ўжҲ·з«ҜеҰӮдҪ•еҲӨж–ӯиҜ·жұӮжүҖеҫ—еҲ°зҡ„е“Қеә”ж•°жҚ®е·Із»ҸжҺҘ收е®ҢжҲҗпјҲжҲ–иҖ…иҜҙеҰӮдҪ•зҹҘйҒ“жңҚеҠЎеҷЁе·Із»ҸеҸ‘з”ҹе®ҢдәҶж•°жҚ®пјүпјҹжҲ‘们已з»ҸзҹҘйҒ“ дәҶпјҢKeep-AliveжЁЎејҸеҸ‘йҖҒзҺ©ж•°жҚ®HTTPжңҚеҠЎеҷЁдёҚдјҡиҮӘеҠЁж–ӯејҖиҝһжҺҘпјҢжүҖжңүдёҚиғҪеҶҚдҪҝз”Ёиҝ”еӣһEOFпјҲ-1пјүжқҘеҲӨж–ӯпјҲеҪ“然дҪ дёҖе®ҡиҰҒиҝҷж ·дҪҝз”Ёд№ҹжІЎжңүеҠһжі•пјҢеҸҜ д»ҘжғіиұЎйӮЈж•ҲзҺҮжҳҜдҪ•зӯүзҡ„дҪҺпјүпјҒдёӢйқўжҲ‘д»Ӣз»ҚдёӨз§ҚжқҘеҲӨж–ӯж–№жі•гҖӮ
3.1гҖҒдҪҝз”Ёж¶ҲжҒҜйҰ–йғЁеӯ—ж®өConent-Length
ж•…еҗҚжҖқж„ҸпјҢConent-LengthиЎЁзӨәе®һдҪ“еҶ…е®№й•ҝеәҰпјҢе®ўжҲ·з«ҜпјҲжңҚеҠЎеҷЁпјүеҸҜд»Ҙж №жҚ®иҝҷдёӘеҖјжқҘеҲӨж–ӯж•°жҚ®жҳҜеҗҰжҺҘ收е®ҢжҲҗгҖӮдҪҶжҳҜеҰӮжһңж¶ҲжҒҜдёӯжІЎжңүConent-LengthпјҢйӮЈиҜҘеҰӮдҪ•жқҘеҲӨж–ӯе‘ўпјҹеҸҲеңЁд»Җд№Ҳжғ…еҶөдёӢдјҡжІЎжңүConent-Lengthе‘ўпјҹиҜ·з»§з»ӯеҫҖдёӢзңӢвҖҰвҖҰ
3.2гҖҒдҪҝз”Ёж¶ҲжҒҜйҰ–йғЁеӯ—ж®өTransfer-Encoding
еҪ“е®ўжҲ·з«Ҝеҗ‘жңҚеҠЎеҷЁиҜ·жұӮдёҖдёӘйқҷжҖҒйЎөйқўжҲ–иҖ…дёҖеј еӣҫзүҮж—¶пјҢжңҚеҠЎеҷЁеҸҜд»ҘеҫҲжё…жҘҡзҡ„зҹҘйҒ“еҶ…е®№еӨ§е°ҸпјҢ然еҗҺйҖҡиҝҮContent-lengthж¶ҲжҒҜйҰ–йғЁеӯ—ж®өе‘ҠиҜүе®ўжҲ·з«Ҝ йңҖиҰҒжҺҘ收еӨҡе°‘ж•°жҚ®гҖӮдҪҶжҳҜеҰӮжһңжҳҜеҠЁжҖҒйЎөйқўзӯүж—¶пјҢжңҚеҠЎеҷЁжҳҜдёҚеҸҜиғҪйў„е…ҲзҹҘйҒ“еҶ…е®№еӨ§е°ҸпјҢиҝҷж—¶е°ұеҸҜд»ҘдҪҝз”ЁTransfer-EncodingпјҡchunkжЁЎејҸжқҘдј иҫ“ ж•°жҚ®дәҶгҖӮеҚіеҰӮжһңиҰҒдёҖиҫ№дә§з”ҹж•°жҚ®пјҢдёҖиҫ№еҸ‘з»ҷе®ўжҲ·з«ҜпјҢжңҚеҠЎеҷЁе°ұйңҖиҰҒдҪҝз”Ё"Transfer-Encoding: chunked"иҝҷж ·зҡ„ж–№ејҸжқҘд»ЈжӣҝContent-LengthгҖӮ
chunkзј–з Ғе°Ҷж•°жҚ®еҲҶжҲҗдёҖеқ—дёҖеқ—зҡ„еҸ‘з”ҹгҖӮChunkedзј–з Ғе°ҶдҪҝз”ЁиӢҘе№ІдёӘChunkдёІиҝһиҖҢжҲҗпјҢз”ұдёҖдёӘж ҮжҳҺй•ҝеәҰдёә0В зҡ„chunkж ҮзӨәз»“жқҹгҖӮжҜҸдёӘChunkеҲҶдёәеӨҙйғЁе’ҢжӯЈж–ҮдёӨйғЁеҲҶпјҢеӨҙйғЁеҶ…е®№жҢҮе®ҡжӯЈж–Үзҡ„еӯ—з¬ҰжҖ»ж•°пјҲеҚҒе…ӯиҝӣеҲ¶зҡ„ж•°еӯ—В пјүе’Ңж•°йҮҸеҚ•дҪҚпјҲдёҖиҲ¬дёҚеҶҷпјүпјҢжӯЈж–ҮйғЁеҲҶе°ұжҳҜжҢҮе®ҡй•ҝеәҰзҡ„е®һйҷ…еҶ…е®№пјҢдёӨйғЁеҲҶд№Ӣй—ҙз”ЁеӣһиҪҰжҚўиЎҢ(CRLF)В йҡ”ејҖгҖӮеңЁжңҖеҗҺдёҖдёӘй•ҝеәҰдёә0зҡ„Chunkдёӯзҡ„еҶ…е®№жҳҜз§°дёәfooterзҡ„еҶ…е®№пјҢжҳҜдёҖдәӣйҷ„еҠ зҡ„HeaderдҝЎжҒҜпјҲйҖҡеёёеҸҜд»ҘзӣҙжҺҘеҝҪз•ҘпјүгҖӮ
Chunkзј–з Ғзҡ„ж јејҸеҰӮдёӢпјҡ
Chunked-Body = *chunkВ
В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В "0" CRLFВ
В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В footerВ
В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В CRLFВ В
chunkВ = chunk-size [ chunk-ext ] CRLFВ
В В В В В В В В В В В В В В В В В chunk-data CRLFhex-no-zero = <HEX excluding "0">
chunk-size = hex-no-zero *HEXВ
chunk-ext = *( ";" chunk-ext-name [ "=" chunk-ext-value ] )В
chunk-ext-name = tokenВ
chunk-ext-val = token | quoted-stringВ
chunk-data = chunk-size(OCTET)footer = *entity-header
еҚіChunkзј–з Ғз”ұеӣӣйғЁеҲҶз»„жҲҗпјҡВ 1гҖҒ0иҮіеӨҡдёӘchunkеқ—В пјҢ2гҖҒ"0" CRLFВ пјҢ3гҖҒfooterВ пјҢ4гҖҒCRLFВ .В иҖҢжҜҸдёӘchunkеқ—з”ұпјҡchunk-sizeгҖҒchunk-extпјҲеҸҜйҖүпјүгҖҒCRLFгҖҒchunk-dataгҖҒCRLFз»„жҲҗгҖӮ
4гҖҒж¶ҲжҒҜй•ҝеәҰзҡ„жҖ»з»“
е…¶е®һпјҢдёҠйқў2дёӯж–№жі•йғҪеҸҜд»ҘеҪ’зәідёәжҳҜеҰӮдҪ•еҲӨж–ӯhttpж¶ҲжҒҜзҡ„еӨ§е°ҸгҖҒж¶ҲжҒҜзҡ„ж•°йҮҸгҖӮRFC 2616В еҜ№ ж¶ҲжҒҜзҡ„й•ҝеәҰжҖ»з»“еҰӮдёӢпјҡдёҖдёӘж¶ҲжҒҜзҡ„transfer-lengthпјҲдј иҫ“й•ҝеәҰпјүжҳҜжҢҮж¶ҲжҒҜдёӯзҡ„message-bodyпјҲж¶ҲжҒҜдҪ“пјүзҡ„й•ҝеәҰгҖӮеҪ“еә”з”ЁдәҶ transfer-codingпјҲдј иҫ“зј–з ҒпјүпјҢжҜҸдёӘж¶ҲжҒҜдёӯзҡ„message-bodyпјҲж¶ҲжҒҜдҪ“пјүзҡ„й•ҝеәҰпјҲtransfer-lengthпјүз”ұд»ҘдёӢеҮ з§Қжғ…еҶө еҶіе®ҡпјҲдјҳе…Ҳзә§з”ұй«ҳеҲ°дҪҺпјүпјҡ
- д»»дҪ•дёҚеҗ«жңүж¶ҲжҒҜдҪ“зҡ„ж¶ҲжҒҜпјҲеҰӮ1XXXгҖҒ204гҖҒ304зӯүе“Қеә”ж¶ҲжҒҜе’Ңд»»дҪ•еӨҙ(HEADпјҢйҰ–йғЁ)иҜ·жұӮзҡ„е“Қеә”ж¶ҲжҒҜпјүпјҢжҖ»жҳҜз”ұдёҖдёӘз©әиЎҢпјҲCLRFпјүз»“жқҹгҖӮ
- еҰӮжһңеҮәзҺ°дәҶTransfer-EncodingеӨҙеӯ—ж®ө 并且еҖјдёәйқһвҖңidentityвҖқпјҢйӮЈд№Ҳtransfer-lengthз”ұвҖңchunkedвҖқ дј иҫ“зј–з Ғе®ҡд№үпјҢйҷӨйқһж¶ҲжҒҜз”ұдәҺе…ій—ӯиҝһжҺҘиҖҢз»ҲжӯўгҖӮ
- еҰӮжһңеҮәзҺ°дәҶContent-LengthеӨҙеӯ—ж®өпјҢе®ғзҡ„еҖјиЎЁзӨәentity-lengthпјҲе®һдҪ“й•ҝеәҰпјүе’Ңtransfer-lengthпјҲдј иҫ“й•ҝ еәҰпјүгҖӮеҰӮжһңиҝҷдёӨдёӘй•ҝеәҰзҡ„еӨ§е°ҸдёҚдёҖж ·пјҲi.e.и®ҫзҪ®дәҶTransfer-EncodingеӨҙеӯ—ж®өпјүпјҢйӮЈд№Ҳе°ҶдёҚиғҪеҸ‘йҖҒContent-LengthеӨҙеӯ—ж®өгҖӮ并 дё”еҰӮжһңеҗҢ时收еҲ°дәҶTransfer-Encodingеӯ—ж®өе’ҢContent-LengthеӨҙеӯ—ж®өпјҢйӮЈд№Ҳеҝ…йЎ»еҝҪз•ҘContent-Lengthеӯ—ж®өгҖӮ
- еҰӮжһңж¶ҲжҒҜдҪҝз”ЁеӘ’дҪ“зұ»еһӢвҖңmultipart/byterangesвҖқпјҢ并且transfer-length жІЎжңүеҸҰеӨ–жҢҮе®ҡпјҢйӮЈд№Ҳиҝҷз§ҚиҮӘе®ҡз•ҢпјҲself-delimitingпјүеӘ’дҪ“зұ»еһӢе®ҡд№үtransfer-length гҖӮйҷӨйқһеҸ‘йҖҒиҖ…зҹҘйҒ“жҺҘ收иҖ…иғҪеӨҹи§ЈжһҗиҜҘзұ»еһӢпјҢеҗҰеҲҷдёҚиғҪдҪҝз”ЁиҜҘзұ»еһӢгҖӮ
- з”ұжңҚеҠЎеҷЁе…ій—ӯиҝһжҺҘзЎ®е®ҡж¶ҲжҒҜй•ҝеәҰгҖӮпјҲжіЁж„Ҹпјҡе…ій—ӯиҝһжҺҘдёҚиғҪз”ЁдәҺзЎ®е®ҡиҜ·жұӮж¶ҲжҒҜзҡ„з»“жқҹпјҢеӣ дёәжңҚеҠЎеҷЁдёҚиғҪеҶҚеҸ‘е“Қеә”ж¶ҲжҒҜз»ҷе®ўжҲ·з«ҜдәҶгҖӮпјү
дёәдәҶе…је®№HTTP/1.0еә”з”ЁзЁӢеәҸпјҢHTTP/1.1зҡ„иҜ·жұӮж¶ҲжҒҜдҪ“дёӯеҝ…йЎ»еҢ…еҗ«дёҖдёӘеҗҲжі•зҡ„Content-LengthеӨҙеӯ—ж®өпјҢйҷӨйқһзҹҘйҒ“жңҚеҠЎеҷЁе…је®№ HTTP/1.1гҖӮдёҖдёӘиҜ·жұӮеҢ…еҗ«ж¶ҲжҒҜдҪ“пјҢ并且Content-Lengthеӯ—ж®өжІЎжңүз»ҷе®ҡпјҢеҰӮжһңдёҚиғҪеҲӨж–ӯж¶ҲжҒҜзҡ„й•ҝеәҰпјҢжңҚеҠЎеҷЁеә”иҜҘз”Ёз”Ё400 (bad request) жқҘе“Қеә”пјӣжҲ–иҖ…жңҚеҠЎеҷЁеқҡжҢҒеёҢжңӣ收еҲ°дёҖдёӘеҗҲжі•зҡ„Content-Lengthеӯ—ж®өпјҢз”Ё 411 (length required)жқҘе“Қеә”гҖӮ
жүҖжңүHTTP/1.1зҡ„жҺҘ收иҖ…еә”з”ЁзЁӢеәҸеҝ…йЎ»жҺҘеҸ—вҖңchunkedвҖқ transfer-coding (дј иҫ“зј–з Ғ)пјҢеӣ жӯӨеҪ“дёҚиғҪдәӢе…ҲзҹҘйҒ“ж¶ҲжҒҜзҡ„й•ҝеәҰпјҢе…Ғи®ёдҪҝз”Ёиҝҷз§ҚжңәеҲ¶жқҘдј иҫ“ж¶ҲжҒҜгҖӮж¶ҲжҒҜдёҚеә”иҜҘеӨҹеҗҢж—¶еҢ…еҗ« Content-LengthеӨҙеӯ—ж®өе’Ңnon-identity transfer-codingгҖӮеҰӮжһңдёҖдёӘж¶ҲжҒҜеҗҢж—¶еҢ…еҗ«non-identity transfer-codingе’ҢContent-Length пјҢеҝ…йЎ»еҝҪз•ҘContent-Length гҖӮ
5гҖҒHTTPеӨҙеӯ—ж®өжҖ»з»“
жңҖеҗҺжҲ‘жҖ»з»“дёӢHTTPеҚҸи®®зҡ„еӨҙйғЁеӯ—ж®өгҖӮ
- 1гҖҒ Acceptпјҡе‘ҠиҜүWEBжңҚеҠЎеҷЁиҮӘе·ұжҺҘеҸ—д»Җд№Ҳд»ӢиҙЁзұ»еһӢпјҢ*/* иЎЁзӨәд»»дҪ•зұ»еһӢпјҢtype/* иЎЁзӨәиҜҘзұ»еһӢдёӢзҡ„жүҖжңүеӯҗзұ»еһӢпјҢtype/sub-typeгҖӮ
- 2гҖҒ Accept-Charsetпјҡ жөҸи§ҲеҷЁз”іжҳҺиҮӘе·ұжҺҘ收зҡ„еӯ—з¬ҰйӣҶВ
Accept-Encodingпјҡ жөҸи§ҲеҷЁз”іжҳҺиҮӘе·ұжҺҘ收зҡ„зј–з Ғж–№жі•пјҢйҖҡеёёжҢҮе®ҡеҺӢзј©ж–№жі•пјҢжҳҜеҗҰж”ҜжҢҒеҺӢзј©пјҢж”ҜжҢҒд»Җд№ҲеҺӢзј©ж–№жі•пјҲgzipпјҢdeflateпјүВ
Accept-LanguageпјҡжөҸи§ҲеҷЁз”іжҳҺиҮӘе·ұжҺҘ收зҡ„иҜӯиЁҖВ
иҜӯиЁҖи·ҹеӯ—з¬ҰйӣҶзҡ„еҢәеҲ«пјҡдёӯж–ҮжҳҜиҜӯиЁҖпјҢдёӯж–ҮжңүеӨҡз§Қеӯ—з¬ҰйӣҶпјҢжҜ”еҰӮbig5пјҢgb2312пјҢgbkзӯүзӯүгҖӮ - 3гҖҒ Accept-RangesпјҡWEBжңҚеҠЎеҷЁиЎЁжҳҺиҮӘе·ұжҳҜеҗҰжҺҘеҸ—иҺ·еҸ–е…¶жҹҗдёӘе®һдҪ“зҡ„дёҖйғЁеҲҶпјҲжҜ”еҰӮж–Ү件зҡ„дёҖйғЁеҲҶпјүзҡ„иҜ·жұӮгҖӮbytesпјҡиЎЁзӨәжҺҘеҸ—пјҢnoneпјҡиЎЁзӨәдёҚжҺҘеҸ—гҖӮ
- 4гҖҒ AgeпјҡеҪ“д»ЈзҗҶжңҚеҠЎеҷЁз”ЁиҮӘе·ұзј“еӯҳзҡ„е®һдҪ“еҺ»е“Қеә”иҜ·жұӮж—¶пјҢз”ЁиҜҘеӨҙйғЁиЎЁжҳҺиҜҘе®һдҪ“д»Һдә§з”ҹеҲ°зҺ°еңЁз»ҸиҝҮеӨҡй•ҝж—¶й—ҙдәҶгҖӮ
- 5гҖҒ AuthorizationпјҡеҪ“е®ўжҲ·з«ҜжҺҘ收еҲ°жқҘиҮӘWEBжңҚеҠЎеҷЁзҡ„ WWW-Authenticate е“Қеә”ж—¶пјҢз”ЁиҜҘеӨҙйғЁжқҘеӣһеә”иҮӘе·ұзҡ„иә«д»ҪйӘҢиҜҒдҝЎжҒҜз»ҷWEBжңҚеҠЎеҷЁгҖӮ
- 6гҖҒ Cache-ControlпјҡиҜ·жұӮпјҡno-cacheпјҲдёҚиҰҒзј“еӯҳзҡ„е®һдҪ“пјҢиҰҒжұӮзҺ°еңЁд»ҺWEBжңҚеҠЎеҷЁеҺ»еҸ–пјүВ
max-ageпјҡпјҲеҸӘжҺҘеҸ— Age еҖје°ҸдәҺ max-age еҖјпјҢ并且没жңүиҝҮжңҹзҡ„еҜ№иұЎпјүВ
max-staleпјҡпјҲеҸҜд»ҘжҺҘеҸ—иҝҮеҺ»зҡ„еҜ№иұЎпјҢдҪҶжҳҜиҝҮжңҹж—¶й—ҙеҝ…йЎ»е°ҸдәҺ max-stale еҖјпјүВ
min-freshпјҡпјҲжҺҘеҸ—е…¶ж–°йІңз”ҹе‘ҪжңҹеӨ§дәҺе…¶еҪ“еүҚ Age и·ҹ min-fresh еҖјд№Ӣе’Ңзҡ„зј“еӯҳеҜ№иұЎпјүВ
е“Қеә”пјҡpublic(еҸҜд»Ҙз”Ё Cached еҶ…е®№еӣһеә”д»»дҪ•з”ЁжҲ·)В
privateпјҲеҸӘиғҪз”Ёзј“еӯҳеҶ…е®№еӣһеә”е…ҲеүҚиҜ·жұӮиҜҘеҶ…е®№зҡ„йӮЈдёӘз”ЁжҲ·пјүВ
no-cacheпјҲеҸҜд»Ҙзј“еӯҳпјҢдҪҶжҳҜеҸӘжңүеңЁи·ҹWEBжңҚеҠЎеҷЁйӘҢиҜҒдәҶе…¶жңүж•ҲеҗҺпјҢжүҚиғҪиҝ”еӣһз»ҷе®ўжҲ·з«ҜпјүВ
max-ageпјҡпјҲжң¬е“Қеә”еҢ…еҗ«зҡ„еҜ№иұЎзҡ„иҝҮжңҹж—¶й—ҙпјүВ
ALL: no-storeпјҲдёҚе…Ғи®ёзј“еӯҳпјү - 7гҖҒ ConnectionпјҡиҜ·жұӮпјҡcloseпјҲе‘ҠиҜүWEBжңҚеҠЎеҷЁжҲ–иҖ…д»ЈзҗҶжңҚеҠЎеҷЁпјҢеңЁе®ҢжҲҗжң¬ж¬ЎиҜ·жұӮзҡ„е“Қеә”еҗҺпјҢж–ӯејҖиҝһжҺҘпјҢдёҚиҰҒзӯүеҫ…жң¬ж¬ЎиҝһжҺҘзҡ„еҗҺз»ӯиҜ·жұӮдәҶпјүгҖӮВ
keepaliveпјҲе‘ҠиҜүWEBжңҚеҠЎеҷЁжҲ–иҖ…д»ЈзҗҶжңҚеҠЎеҷЁпјҢеңЁе®ҢжҲҗжң¬ж¬ЎиҜ·жұӮзҡ„е“Қеә”еҗҺпјҢдҝқжҢҒиҝһжҺҘпјҢзӯүеҫ…жң¬ж¬ЎиҝһжҺҘзҡ„еҗҺз»ӯиҜ·жұӮпјүгҖӮВ
е“Қеә”пјҡcloseпјҲиҝһжҺҘе·Із»Ҹе…ій—ӯпјүгҖӮВ
keepaliveпјҲиҝһжҺҘдҝқжҢҒзқҖпјҢеңЁзӯүеҫ…жң¬ж¬ЎиҝһжҺҘзҡ„еҗҺз»ӯиҜ·жұӮпјүгҖӮВ
Keep-AliveпјҡеҰӮжһңжөҸи§ҲеҷЁиҜ·жұӮдҝқжҢҒиҝһжҺҘпјҢеҲҷиҜҘеӨҙйғЁиЎЁжҳҺеёҢжңӣ WEB жңҚеҠЎеҷЁдҝқжҢҒиҝһжҺҘеӨҡй•ҝж—¶й—ҙпјҲз§’пјүгҖӮдҫӢеҰӮпјҡKeep-Aliveпјҡ300 - 8гҖҒ Content-EncodingпјҡWEBжңҚеҠЎеҷЁиЎЁжҳҺиҮӘе·ұдҪҝз”ЁдәҶд»Җд№ҲеҺӢзј©ж–№жі•пјҲgzipпјҢdeflateпјүеҺӢзј©е“Қеә”дёӯзҡ„еҜ№иұЎгҖӮдҫӢеҰӮпјҡContent-Encodingпјҡgzip
- 9гҖҒContent-LanguageпјҡWEB жңҚеҠЎеҷЁе‘ҠиҜүжөҸи§ҲеҷЁиҮӘе·ұе“Қеә”зҡ„еҜ№иұЎзҡ„иҜӯиЁҖгҖӮ
- 10гҖҒContent-Lengthпјҡ WEB жңҚеҠЎеҷЁе‘ҠиҜүжөҸи§ҲеҷЁиҮӘе·ұе“Қеә”зҡ„еҜ№иұЎзҡ„й•ҝеәҰгҖӮдҫӢеҰӮпјҡContent-Length: 26012
- 11гҖҒContent-Rangeпјҡ WEB жңҚеҠЎеҷЁиЎЁжҳҺиҜҘе“Қеә”еҢ…еҗ«зҡ„йғЁеҲҶеҜ№иұЎдёәж•ҙдёӘеҜ№иұЎзҡ„е“ӘдёӘйғЁеҲҶгҖӮдҫӢеҰӮпјҡContent-Range: bytes 21010-47021/47022
- 12гҖҒContent-Typeпјҡ WEB жңҚеҠЎеҷЁе‘ҠиҜүжөҸи§ҲеҷЁиҮӘе·ұе“Қеә”зҡ„еҜ№иұЎзҡ„зұ»еһӢгҖӮдҫӢеҰӮпјҡContent-Typeпјҡapplication/xml
- 13гҖҒETagпјҡе°ұжҳҜдёҖдёӘеҜ№иұЎпјҲжҜ”еҰӮURLпјүзҡ„ж Үеҝ—еҖјпјҢе°ұдёҖдёӘеҜ№иұЎиҖҢиЁҖпјҢжҜ”еҰӮдёҖдёӘ html ж–Ү件пјҢеҰӮжһңиў«дҝ®ж”№дәҶпјҢе…¶ Etag д№ҹдјҡеҲ«дҝ®ж”№пјҢжүҖд»ҘETag зҡ„дҪңз”Ёи·ҹ Last-Modified зҡ„дҪңз”Ёе·®дёҚеӨҡпјҢдё»иҰҒдҫӣ WEB жңҚеҠЎеҷЁеҲӨж–ӯдёҖдёӘеҜ№иұЎжҳҜеҗҰж”№еҸҳдәҶгҖӮжҜ”еҰӮеүҚдёҖж¬ЎиҜ·жұӮжҹҗдёӘ html ж–Ү件时пјҢиҺ·еҫ—дәҶе…¶ ETagпјҢеҪ“иҝҷж¬ЎеҸҲиҜ·жұӮиҝҷдёӘж–Ү件时пјҢжөҸи§ҲеҷЁе°ұдјҡжҠҠе…ҲеүҚиҺ·еҫ—зҡ„ ETag еҖјеҸ‘йҖҒз»ҷWEB жңҚеҠЎеҷЁпјҢ然еҗҺ WEB жңҚеҠЎеҷЁдјҡжҠҠиҝҷдёӘ ETag и·ҹиҜҘж–Ү件зҡ„еҪ“еүҚ ETag иҝӣиЎҢеҜ№жҜ”пјҢ然еҗҺе°ұзҹҘйҒ“иҝҷдёӘж–Ү件жңүжІЎжңүж”№еҸҳдәҶгҖӮ
- 14гҖҒ ExpiredпјҡWEBжңҚеҠЎеҷЁиЎЁжҳҺиҜҘе®һдҪ“е°ҶеңЁд»Җд№Ҳж—¶еҖҷиҝҮжңҹпјҢеҜ№дәҺиҝҮжңҹдәҶзҡ„еҜ№иұЎпјҢеҸӘжңүеңЁи·ҹWEBжңҚеҠЎеҷЁйӘҢиҜҒдәҶе…¶жңүж•ҲжҖ§еҗҺпјҢжүҚиғҪз”ЁжқҘе“Қеә”е®ўжҲ·иҜ·жұӮгҖӮжҳҜ HTTP/1.0 зҡ„еӨҙйғЁгҖӮдҫӢеҰӮпјҡExpiresпјҡSat, 23 May 2009 10:02:12 GMT
- 15гҖҒ Hostпјҡе®ўжҲ·з«ҜжҢҮе®ҡиҮӘе·ұжғіи®ҝй—®зҡ„WEBжңҚеҠЎеҷЁзҡ„еҹҹеҗҚ/IP ең°еқҖе’Ңз«ҜеҸЈеҸ·гҖӮдҫӢеҰӮпјҡHostпјҡrss.sina.com.cn
- 16гҖҒ If-MatchпјҡеҰӮжһңеҜ№иұЎзҡ„ ETag жІЎжңүж”№еҸҳпјҢе…¶е®һд№ҹе°ұж„Ҹе‘іи‘—еҜ№иұЎжІЎжңүж”№еҸҳпјҢжүҚжү§иЎҢиҜ·жұӮзҡ„еҠЁдҪңгҖӮ
- 17гҖҒ If-None-MatchпјҡеҰӮжһңеҜ№иұЎзҡ„ ETag ж”№еҸҳдәҶпјҢе…¶е®һд№ҹе°ұж„Ҹе‘іи‘—еҜ№иұЎд№ҹж”№еҸҳдәҶпјҢжүҚжү§иЎҢиҜ·жұӮзҡ„еҠЁдҪңгҖӮ
- 18гҖҒ If-Modified-SinceпјҡеҰӮжһңиҜ·жұӮзҡ„еҜ№иұЎеңЁиҜҘеӨҙйғЁжҢҮе®ҡзҡ„ж—¶й—ҙд№ӢеҗҺдҝ®ж”№дәҶпјҢжүҚжү§иЎҢиҜ·жұӮзҡ„еҠЁдҪңпјҲжҜ”еҰӮиҝ”еӣһеҜ№иұЎпјүпјҢеҗҰеҲҷиҝ”еӣһд»Јз Ғ304пјҢе‘ҠиҜүжөҸи§ҲеҷЁ иҜҘеҜ№иұЎжІЎжңүдҝ®ж”№гҖӮдҫӢеҰӮпјҡIf-Modified-SinceпјҡThu, 10 Apr 2008 09:14:42 GMT
- 19гҖҒ If-Unmodified-SinceпјҡеҰӮжһңиҜ·жұӮзҡ„еҜ№иұЎеңЁиҜҘеӨҙйғЁжҢҮе®ҡзҡ„ж—¶й—ҙд№ӢеҗҺжІЎдҝ®ж”№иҝҮпјҢжүҚжү§иЎҢиҜ·жұӮзҡ„еҠЁдҪңпјҲжҜ”еҰӮиҝ”еӣһеҜ№иұЎпјүгҖӮ
- 20гҖҒ If-RangeпјҡжөҸи§ҲеҷЁе‘ҠиҜү WEB жңҚеҠЎеҷЁпјҢеҰӮжһңжҲ‘иҜ·жұӮзҡ„еҜ№иұЎжІЎжңүж”№еҸҳпјҢе°ұжҠҠжҲ‘зјәе°‘зҡ„йғЁеҲҶз»ҷжҲ‘пјҢеҰӮжһңеҜ№иұЎж”№еҸҳдәҶпјҢе°ұжҠҠж•ҙдёӘеҜ№иұЎз»ҷжҲ‘гҖӮжөҸи§ҲеҷЁйҖҡиҝҮеҸ‘йҖҒиҜ·жұӮеҜ№иұЎзҡ„ ETag жҲ–иҖ… иҮӘе·ұжүҖзҹҘйҒ“зҡ„жңҖеҗҺдҝ®ж”№ж—¶й—ҙз»ҷ WEB жңҚеҠЎеҷЁпјҢи®©е…¶еҲӨж–ӯеҜ№иұЎжҳҜеҗҰж”№еҸҳдәҶгҖӮжҖ»жҳҜи·ҹ Range еӨҙйғЁдёҖиө·дҪҝз”ЁгҖӮ
- 21гҖҒ Last-ModifiedпјҡWEB жңҚеҠЎеҷЁи®ӨдёәеҜ№иұЎзҡ„жңҖеҗҺдҝ®ж”№ж—¶й—ҙпјҢжҜ”еҰӮж–Ү件зҡ„жңҖеҗҺдҝ®ж”№ж—¶й—ҙпјҢеҠЁжҖҒйЎөйқўзҡ„жңҖеҗҺдә§з”ҹж—¶й—ҙзӯүзӯүгҖӮдҫӢеҰӮпјҡLast-ModifiedпјҡTue, 06 May 2008 02:42:43 GMT
- 22гҖҒ LocationпјҡWEB жңҚеҠЎеҷЁе‘ҠиҜүжөҸи§ҲеҷЁпјҢиҜ•еӣҫи®ҝй—®зҡ„еҜ№иұЎе·Із»Ҹ被移еҲ°еҲ«зҡ„дҪҚзҪ®дәҶпјҢеҲ°иҜҘеӨҙйғЁжҢҮе®ҡзҡ„дҪҚзҪ®еҺ»еҸ–гҖӮдҫӢеҰӮпјҡLocationпјҡhttp://i0.sinaimg.cn/dy/deco/2008/0528/sinahome_0803_ws_005_text_0.gif
- 23гҖҒ Pramgaпјҡдё»иҰҒдҪҝз”Ё Pramga: no-cacheпјҢзӣёеҪ“дәҺ Cache-Controlпјҡ no-cacheгҖӮдҫӢеҰӮпјҡPragmaпјҡno-cache
- 24гҖҒ Proxy-Authenticateпјҡ д»ЈзҗҶжңҚеҠЎеҷЁе“Қеә”жөҸи§ҲеҷЁпјҢиҰҒжұӮе…¶жҸҗдҫӣд»ЈзҗҶиә«д»ҪйӘҢиҜҒдҝЎжҒҜгҖӮProxy-AuthorizationпјҡжөҸи§ҲеҷЁе“Қеә”д»ЈзҗҶжңҚеҠЎеҷЁзҡ„иә«д»ҪйӘҢиҜҒиҜ·жұӮпјҢжҸҗдҫӣиҮӘе·ұзҡ„иә«д»ҪдҝЎжҒҜгҖӮ
- 25гҖҒ RangeпјҡжөҸи§ҲеҷЁпјҲжҜ”еҰӮ Flashget еӨҡзәҝзЁӢдёӢиҪҪж—¶пјүе‘ҠиҜү WEB жңҚеҠЎеҷЁиҮӘе·ұжғіеҸ–еҜ№иұЎзҡ„е“ӘйғЁеҲҶгҖӮдҫӢеҰӮпјҡRange: bytes=1173546-
- 26гҖҒ RefererпјҡжөҸи§ҲеҷЁеҗ‘ WEB жңҚеҠЎеҷЁиЎЁжҳҺиҮӘе·ұжҳҜд»Һе“ӘдёӘ зҪ‘йЎө/URL иҺ·еҫ—/зӮ№еҮ» еҪ“еүҚиҜ·жұӮдёӯзҡ„зҪ‘еқҖ/URLгҖӮдҫӢеҰӮпјҡRefererпјҡhttp://www.sina.com/
- 27гҖҒ Server: WEB жңҚеҠЎеҷЁиЎЁжҳҺиҮӘе·ұжҳҜд»Җд№ҲиҪҜ件еҸҠзүҲжң¬зӯүдҝЎжҒҜгҖӮдҫӢеҰӮпјҡServerпјҡApache/2.0.61 (Unix)
- 28гҖҒ User-Agent: жөҸи§ҲеҷЁиЎЁжҳҺиҮӘе·ұзҡ„иә«д»ҪпјҲжҳҜе“Әз§ҚжөҸи§ҲеҷЁпјүгҖӮдҫӢеҰӮпјҡUser-AgentпјҡMozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.8.1.14) Gecko/20080404 Firefox/2гҖҒ0гҖҒ0гҖҒ14
- 29гҖҒ Transfer-Encoding: WEB жңҚеҠЎеҷЁиЎЁжҳҺиҮӘе·ұеҜ№жң¬е“Қеә”ж¶ҲжҒҜдҪ“пјҲдёҚжҳҜж¶ҲжҒҜдҪ“йҮҢйқўзҡ„еҜ№иұЎпјүдҪңдәҶжҖҺж ·зҡ„зј–з ҒпјҢжҜ”еҰӮжҳҜеҗҰеҲҶеқ—пјҲchunkedпјүгҖӮдҫӢеҰӮпјҡTransfer-Encoding: chunked
- 30гҖҒ Vary: WEBжңҚеҠЎеҷЁз”ЁиҜҘеӨҙйғЁзҡ„еҶ…е®№е‘ҠиҜү Cache жңҚеҠЎеҷЁпјҢеңЁд»Җд№ҲжқЎд»¶дёӢжүҚиғҪз”Ёжң¬е“Қеә”жүҖиҝ”еӣһзҡ„еҜ№иұЎе“Қеә”еҗҺз»ӯзҡ„иҜ·жұӮгҖӮеҒҮеҰӮжәҗWEBжңҚеҠЎеҷЁеңЁжҺҘеҲ°з¬¬дёҖдёӘиҜ·жұӮж¶ҲжҒҜж—¶пјҢе…¶е“Қеә”ж¶ҲжҒҜзҡ„еӨҙйғЁдёәпјҡContent- Encoding: gzip; Vary: Content-EncodingйӮЈд№Ҳ Cache жңҚеҠЎеҷЁдјҡеҲҶжһҗеҗҺз»ӯиҜ·жұӮж¶ҲжҒҜзҡ„еӨҙйғЁпјҢжЈҖжҹҘе…¶ Accept-EncodingпјҢжҳҜеҗҰи·ҹе…ҲеүҚе“Қеә”зҡ„ Vary еӨҙйғЁеҖјдёҖиҮҙпјҢеҚіжҳҜеҗҰдҪҝз”ЁзӣёеҗҢзҡ„еҶ…е®№зј–з Ғж–№жі•пјҢиҝҷж ·е°ұеҸҜд»ҘйҳІжӯў Cache жңҚеҠЎеҷЁз”ЁиҮӘе·ұ Cache йҮҢйқўеҺӢзј©еҗҺзҡ„е®һдҪ“е“Қеә”з»ҷдёҚе…·еӨҮи§ЈеҺӢиғҪеҠӣзҡ„жөҸи§ҲеҷЁгҖӮдҫӢеҰӮпјҡVaryпјҡAccept-Encoding
- 31гҖҒ Viaпјҡ еҲ—еҮәд»Һе®ўжҲ·з«ҜеҲ° OCS жҲ–иҖ…зӣёеҸҚж–№еҗ‘зҡ„е“Қеә”з»ҸиҝҮдәҶе“Әдәӣд»ЈзҗҶжңҚеҠЎеҷЁпјҢ他们用д»Җд№ҲеҚҸи®®пјҲе’ҢзүҲжң¬пјүеҸ‘йҖҒзҡ„иҜ·жұӮгҖӮеҪ“е®ўжҲ·з«ҜиҜ·жұӮеҲ°иҫҫ第дёҖдёӘд»ЈзҗҶжңҚеҠЎеҷЁж—¶пјҢиҜҘжңҚеҠЎеҷЁдјҡеңЁиҮӘе·ұеҸ‘еҮәзҡ„иҜ·жұӮйҮҢйқўж·» еҠ Via еӨҙйғЁпјҢ并填дёҠиҮӘе·ұзҡ„зӣёе…ідҝЎжҒҜпјҢеҪ“дёӢдёҖдёӘд»ЈзҗҶжңҚеҠЎеҷЁж”¶еҲ°з¬¬дёҖдёӘд»ЈзҗҶжңҚеҠЎеҷЁзҡ„иҜ·жұӮж—¶пјҢдјҡеңЁиҮӘе·ұеҸ‘еҮәзҡ„иҜ·жұӮйҮҢйқўеӨҚеҲ¶еүҚдёҖдёӘд»ЈзҗҶжңҚеҠЎеҷЁзҡ„иҜ·жұӮзҡ„Via еӨҙйғЁпјҢ并жҠҠиҮӘе·ұзҡ„зӣёе…ідҝЎжҒҜеҠ еҲ°еҗҺйқўпјҢд»ҘжӯӨзұ»жҺЁпјҢеҪ“ OCS 收еҲ°жңҖеҗҺдёҖдёӘд»ЈзҗҶжңҚеҠЎеҷЁзҡ„иҜ·жұӮж—¶пјҢжЈҖжҹҘ Via еӨҙйғЁпјҢе°ұзҹҘйҒ“иҜҘиҜ·жұӮжүҖз»ҸиҝҮзҡ„и·Ҝз”ұгҖӮдҫӢеҰӮпјҡViaпјҡ1.0 236.D0707195.sina.com.cn:80 (squid/2.6.STABLE13)
===============================================================================В
HTTP иҜ·жұӮж¶ҲжҒҜеӨҙйғЁе®һдҫӢпјҡВ
Hostпјҡrss.sina.com.cnВ
User-AgentпјҡMozilla/5гҖҒ0 (Windows; U; Windows NT 5гҖҒ1; zh-CN; rv:1гҖҒ8гҖҒ1гҖҒ14) Gecko/20080404 Firefox/2гҖҒ0гҖҒ0гҖҒ14В
Acceptпјҡtext/xml,application/xml,application/xhtml+xml,text/html;q=0гҖҒ9,text/plain;q=0гҖҒ8,image/png,*/*;q=0гҖҒ5В
Accept-Languageпјҡzh-cn,zh;q=0гҖҒ5В
Accept-Encodingпјҡgzip,deflateВ
Accept-Charsetпјҡgb2312,utf-8;q=0гҖҒ7,*;q=0гҖҒ7В
Keep-Aliveпјҡ300В
Connectionпјҡkeep-aliveВ
CookieпјҡuserId=C5bYpXrimdmsiQmsBPnE1Vn8ZQmdWSm3WRlEB3vRwTnRtW <-- CookieВ
If-Modified-SinceпјҡSun, 01 Jun 2008 12:05:30 GMTВ
Cache-Controlпјҡmax-age=0В
HTTP е“Қеә”ж¶ҲжҒҜеӨҙйғЁе®һдҫӢпјҡВ
StatusпјҡOK - 200 <-- е“Қеә”зҠ¶жҖҒз ҒпјҢиЎЁзӨә web жңҚеҠЎеҷЁеӨ„зҗҶзҡ„з»“жһңгҖӮВ
DateпјҡSun, 01 Jun 2008 12:35:47 GMTВ
ServerпјҡApache/2гҖҒ0гҖҒ61 (Unix)В
Last-ModifiedпјҡSun, 01 Jun 2008 12:35:30 GMTВ
Accept-RangesпјҡbytesВ
Content-Lengthпјҡ18616В
Cache-Controlпјҡmax-age=120В
ExpiresпјҡSun, 01 Jun 2008 12:37:47 GMTВ
Content-Typeпјҡapplication/xmlВ
Ageпјҡ2В
X-CacheпјҡHIT from 236-41гҖҒD07071951гҖҒsinaгҖҒcomгҖҒcn <-- еҸҚеҗ‘д»ЈзҗҶжңҚеҠЎеҷЁдҪҝз”Ёзҡ„ HTTP еӨҙйғЁВ
Viaпјҡ1.0 236-41.D07071951.sina.com.cn:80 (squid/2.6.STABLE13)В
Connectionпјҡclose
жң¬иҠӮж‘ҳиҮӘпјҡhttp://ynhu33.blog.51cto.com/412835/408801
В



{kind=link}
зӣёе…іжҺЁиҚҗ
еңЁHTTPеҚҸи®®дёӯпјҢKeep-AliveжЁЎејҸжҳҜдёҖз§Қз”ЁдәҺдјҳеҢ–зҪ‘з»ңйҖҡдҝЎзҡ„жҠҖжңҜпјҢе®ғе…Ғи®ёе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁеңЁеҗҢдёҖTCPиҝһжҺҘдёҠиҝӣиЎҢеӨҡж¬ЎиҜ·жұӮе’Ңе“Қеә”пјҢиҖҢдёҚжҳҜжҜҸж¬ЎдәӨдә’йғҪеҲӣе»әж–°зҡ„иҝһжҺҘгҖӮиҝҷз§ҚжЁЎејҸжҳҫи‘—жҸҗй«ҳдәҶж•ҲзҺҮпјҢеҮҸе°‘дәҶзҪ‘з»ң延иҝҹпјҢйҷҚдҪҺдәҶиө„жәҗж¶ҲиҖ—пјҢ...
йҮҚзӮ№и®Ёи®әдәҶHTTP1.1еј•е…Ҙзҡ„Keep-AliveгҖҒpipelineжңәеҲ¶е’ҢHTTP2.0зҡ„еӨҡи·ҜеӨҚз”ЁгҖҒеӨҙйғЁеҺӢзј©еҸҠжңҚеҠЎз«ҜжҺЁйҖҒеҠҹиғҪгҖӮжӯӨеӨ–пјҢиҝҳжҺўи®ЁдәҶQUICпјҲQuick UDP Internet ConnectionsпјүеңЁHTTP3.0дёӯзҡ„дҪңз”ЁеҸҠе…¶зӣёиҫғдәҺдј з»ҹTCPзҡ„дјҳеҠҝгҖӮ йҖӮеҗҲдәәзҫӨпјҡ...
HTTPпјҲHypertext Transfer ProtocolпјүеҚҸи®®жҳҜдә’иҒ”зҪ‘дёҠеә”з”ЁжңҖдёәе№ҝжіӣзҡ„дёҖз§ҚзҪ‘з»ңеҚҸи®®пјҢе®ғе®ҡд№үдәҶе®ўжҲ·з«ҜпјҲйҖҡеёёжҳҜWebжөҸи§ҲеҷЁпјүе’ҢжңҚеҠЎеҷЁд№Ӣй—ҙдәӨдә’ж•°жҚ®зҡ„ж јејҸе’Ң规еҲҷгҖӮHTTPеҚҸи®®еҹәдәҺTCP/IPйҖҡдҝЎеҚҸи®®жқҘдј йҖ’ж•°жҚ®пјҢе…¶и®ҫи®Ўзӣ®ж ҮжҳҜиҪ»йҮҸзә§...
4. е…ій—ӯиҝһжҺҘпјҡе®ҢжҲҗж•°жҚ®дј иҫ“еҗҺпјҢе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁйҖҡиҝҮвҖңеӣӣж¬ЎжҢҘжүӢвҖқе…ій—ӯTCPиҝһжҺҘпјҢжҲ–иҖ…еңЁKeep-AliveжңәеҲ¶дёӢдҝқжҢҒиҝһжҺҘгҖӮ дёүгҖҒHTTPиҜ·жұӮж–№жі• HTTPе®ҡд№үдәҶеӨҡз§ҚиҜ·жұӮж–№жі•пјҢеёёи§Ғзҡ„жңүпјҡ - GETпјҡиҺ·еҸ–иө„жәҗпјҢжҳҜжңҖеёёз”Ёзҡ„ж–№жі•гҖӮ - POSTпјҡ...
иӢҘдёәkeep-aliveпјҢиҝһжҺҘдҝқжҢҒдёҖж®өж—¶й—ҙд»ҘеӨ„зҗҶжӣҙеӨҡиҜ·жұӮгҖӮ 5. е®ўжҲ·з«Ҝи§Јжһҗе“Қеә”пјҢйҖҡеёёе°ҶHTMLеҶ…е®№жёІжҹ“еңЁжөҸи§ҲеҷЁзӘ—еҸЈдёӯгҖӮ HTTP/2зӣёжҜ”HTTP/1.1жңүи®ёеӨҡж”№иҝӣпјҢеҰӮдәҢиҝӣеҲ¶еҲҶеё§гҖҒеӨҡи·ҜеӨҚз”ЁгҖҒеҺӢзј©еӨҙйғЁе’ҢжңҚеҠЎеҷЁжҺЁйҖҒзӯүпјҢж—ЁеңЁжҸҗй«ҳжҖ§иғҪе’ҢйҷҚдҪҺ...
Connection:Keep-Alive Cache-Control:no-cache user=jeffrey&password=123456 ``` жӯӨеӨ–пјҢHTTP/1.1еј•е…ҘдәҶжҢҒд№…иҝһжҺҘзҡ„жҰӮеҝөпјҢе…Ғи®ёеңЁдёҖдёӘTCPиҝһжҺҘдёҠеҸ‘йҖҒеӨҡдёӘиҜ·жұӮ-е“Қеә”еҜ№пјҢеҮҸе°‘дәҶе»әз«Ӣе’Ңе…ій—ӯиҝһжҺҘзҡ„ејҖй”ҖгҖӮиҖҢHTTP/2иҝӣдёҖжӯҘ...
еҗҢж—¶пјҢжҲ‘们иҝҳеӯҰд№ дәҶHTTP/1.1дёӯеј•е…Ҙзҡ„жҢҒд№…иҝһжҺҘпјҲKeep-AliveпјүжңәеҲ¶пјҢд»ҘеҮҸе°‘TCPиҝһжҺҘзҡ„еҲӣе»әдёҺй”ҖжҜҒпјҢжҸҗй«ҳжҖ§иғҪгҖӮ жӯӨеӨ–пјҢеј еӯқзҘҘиҖҒеёҲиҝҳи®Іи§ЈдәҶHTTPеҚҸи®®зҡ„зүҲжң¬иҝӯд»ЈпјҢд»ҺHTTP/1.0еҲ°HTTP/2зҡ„ж”№иҝӣпјҢеҢ…жӢ¬дәҢиҝӣеҲ¶еҲҶеё§гҖҒеӨҡи·ҜеӨҚз”Ёзӯү...
HTTP еҚҸи®®иҜҰи§Ј HTTPпјҲHypertext Transfer ProtocolпјүжҳҜдёҖз§Қеә”з”ЁеұӮеҚҸи®®пјҢжҳҜдә’иҒ”зҪ‘дёҠеә”з”ЁжңҖдёәе№ҝжіӣзҡ„дёҖз§ҚзҪ‘з»ңеҚҸи®®гҖӮе®ғе®ҡд№үдәҶе®ўжҲ·з«ҜпјҲеҰӮжөҸи§ҲеҷЁпјүдёҺжңҚеҠЎеҷЁд№Ӣй—ҙзҡ„йҖҡдҝЎж јејҸпјҢдҪҝеҫ—Webеә”з”ЁиғҪеӨҹйҖҡиҝҮHTTPеҸ‘йҖҒе’ҢжҺҘ收数жҚ®гҖӮзҗҶи§Ј...
HTTP/1.1еј•е…ҘдәҶжҢҒд№…иҝһжҺҘпјҢйҖҡиҝҮ`Connection: Keep-Alive`еӨҙйғЁеӯ—ж®өжқҘдҝқжҢҒиҝһжҺҘпјҢе…Ғи®ёеңЁеҗҢдёҖжқЎTCPиҝһжҺҘдёҠиҝһз»ӯеҸ‘йҖҒеӨҡдёӘиҜ·жұӮпјҢжҸҗй«ҳжҖ§иғҪгҖӮ жҖ»зҡ„жқҘиҜҙпјҢHTTPеҚҸи®®жҳҜдә’иҒ”зҪ‘йҖҡдҝЎзҡ„еҹәзЎҖпјҢе…¶и®ҫи®Ўзӣ®ж ҮжҳҜз®ҖеҚ•гҖҒй«ҳж•Ҳе’ҢзҒөжҙ»пјҢд»Ҙж»Ўи¶і...
### HTTPеҚҸи®®иҜҰи§Ј #### HTTPеҚҸи®®жҰӮиҝ° HTTPпјҲHyperText Transfer ProtocolпјүжҳҜдёҖз§Қеә”з”ЁеұӮеҚҸи®®пјҢз”ЁдәҺеҲҶеёғејҸи¶…еӘ’дҪ“дҝЎжҒҜзі»з»ҹпјҢеӣ е…¶з®ҖжҙҒй«ҳж•Ҳзҡ„зү№зӮ№иҖҢе№ҝжіӣеә”з”ЁдәҺдёҮз»ҙзҪ‘пјҲWorld Wide Web, WWWпјүгҖӮиҮӘ1990е№ҙиў«жҸҗеҮәд»ҘжқҘпјҢHTTP...
HTTPпјҲHypertext Transfer ProtocolпјүеҚҸи®®жҳҜдә’иҒ”зҪ‘дёҠеә”з”ЁжңҖдёәе№ҝжіӣзҡ„...йҡҸзқҖжҠҖжңҜзҡ„еҸ‘еұ•пјҢHTTP/2е’ҢHTTP/3пјҲеҹәдәҺQUICеҚҸи®®пјүзӣёз»§еҮәзҺ°пјҢеёҰжқҘдәҶжӣҙеӨҡдјҳеҢ–пјҢеҰӮеӨҡи·ҜеӨҚз”ЁгҖҒеӨҙйғЁеҺӢзј©е’Ңжӣҙеҝ«зҡ„иҝһжҺҘе»әз«ӢпјҢиҝӣдёҖжӯҘжҸҗеҚҮдәҶWebйҖҡдҝЎзҡ„ж•ҲзҺҮгҖӮ
HTTPпјҲHypertext Transfer ProtocolпјүеҚҸи®®жҳҜдә’иҒ”зҪ‘дёҠеә”з”ЁжңҖдёәе№ҝжіӣзҡ„дёҖз§ҚзҪ‘з»ңеҚҸи®®пјҢе®ғе®ҡд№үдәҶе®ўжҲ·з«ҜпјҲйҖҡеёёжҳҜWebжөҸи§ҲеҷЁпјүе’ҢжңҚеҠЎеҷЁд№Ӣй—ҙйҖҡдҝЎзҡ„ж•°жҚ®ж јејҸе’ҢдәӨдә’规еҲҷгҖӮиҝҷдёӘеҚҸи®®жҳҜеҹәдәҺTCP/IPйҖҡдҝЎеҚҸи®®жқҘдј иҫ“ж•°жҚ®зҡ„пјҢдё»иҰҒз”ЁдәҺеңЁ...
然иҖҢпјҢдёәдәҶе®һзҺ°жҢҒд№…иҝһжҺҘпјҢHTTP/1.1еј•е…ҘдәҶ"Connection: keep-alive"еӨҙйғЁпјҢе…Ғи®ёеңЁеҗҢдёҖTCPиҝһжҺҘдёҠиҝһз»ӯеҸ‘йҖҒеӨҡдёӘиҜ·жұӮе’Ңе“Қеә”пјҢд»ҺиҖҢеҮҸе°‘дәҶе»әз«Ӣе’Ңе…ій—ӯиҝһжҺҘзҡ„ејҖй”ҖгҖӮ HTTPеҚҸи®®иҝҳжңүе…¶д»–зү№зӮ№пјҡ 1. ж”ҜжҢҒеҹәжң¬и®ӨиҜҒе’Ңе®үе…Ёи®ӨиҜҒпјҲеҰӮ...
### HTTP 1.1еҚҸи®®иҜҰи§Ј #### дёҖгҖҒжҰӮиҝ°дёҺиғҢжҷҜ HTTPпјҲHyperText Transfer ProtocolпјүдҪңдёәдә’иҒ”зҪ‘дёҠеә”з”ЁжңҖе№ҝжіӣзҡ„дёҖз§ҚзҪ‘з»ңеҚҸи®®пјҢдё»иҰҒз”ЁдәҺ规иҢғе®ўжҲ·з«ҜдёҺжңҚеҠЎеҷЁд№Ӣй—ҙзҡ„ж•°жҚ®дәӨжҚўиҝҮзЁӢгҖӮйҡҸзқҖдә’иҒ”зҪ‘зҡ„еҸ‘еұ•пјҢHTTPеҚҸи®®д№ҹеңЁдёҚж–ӯиҝӣеҢ–...
**ж¶ҲжҒҜжҠҘеӨҙ**еҢ…еҗ«йўқеӨ–дҝЎжҒҜпјҢеҰӮAcceptпјҲжҢҮе®ҡе®ўжҲ·з«ҜжҺҘ收зҡ„зұ»еһӢпјүгҖҒHostпјҲжҢҮе®ҡжңҚеҠЎеҷЁең°еқҖпјүгҖҒConnectionпјҲеҰӮKeep-AliveдҝқжҢҒиҝһжҺҘпјүзӯүгҖӮ HTTPе“Қеә”з”ұзҠ¶жҖҒиЎҢпјҲзҠ¶жҖҒз ҒгҖҒеҺҹеӣ зҹӯиҜӯпјүгҖҒе“Қеә”еӨҙйғЁе’Ңе“Қеә”дҪ“з»„жҲҗпјҢзҠ¶жҖҒз ҒиЎЁжҳҺиҜ·жұӮ...
- жңҚеҠЎеҷЁеңЁе“Қеә”еӨҙйғЁдёӯж·»еҠ `Connection: keep-alive`жҲ–еңЁHTTP 1.1дёӯй»ҳи®ӨдҝқжҢҒиҝһжҺҘгҖӮ - еҶ…е®№й•ҝеәҰжҺ§еҲ¶пјҡжңҚеҠЎеҷЁеңЁе“Қеә”дёӯеҝ…йЎ»еҢ…еҗ«`Content-Length`еӨҙпјҢд»Ҙдҫҝе®ўжҲ·з«ҜзҹҘйҒ“жҺҘ收数жҚ®зҡ„й•ҝеәҰпјҢд»ҺиҖҢеҶіе®ҡдҪ•ж—¶е…ій—ӯиҝһжҺҘжҲ–иҜ»еҸ–дёӢдёҖжқЎ...