
写在前面一:
本文将Hive与HBase整合在一起,使Hive可以读取HBase中的数据,让Hadoop生态系统中最为常用的两大框架互相结合,相得益彰。
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
写在前面二:
使用软件说明
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
约定所有软件的存放目录:
/home/yujianxin
一、Hive整合HBase原理
Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-0.9.0.jar工具类,如下图
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
Hive与HBase通信示意图
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">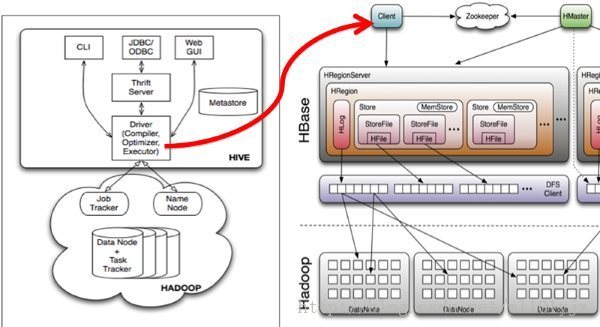
二、具体步骤
安装前说明
1、关于Hadoop、HBase、Hive集群的搭建,请参考“基于Hadoop的数据分析综合管理平台之Hadoop、HBase完全分布式集群搭建”
2、本文中Hadoop、HBase、Hive安装路径
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">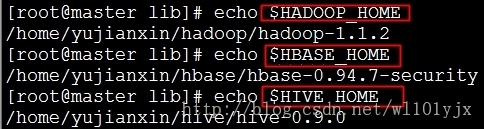
2.1、拷贝jar包
删除$HIVE_HOME/lib/下HBase、Zookeeper相关jar
重新拷贝
2.2、修改$HIVE_HOME/conf/hive-site.xml
mkdir $HIVE_HOME/logs
在尾部添加
修改
2.3、拷贝hbase-0.94.7-security.jar到所有hadoop节点(包括master)的hadoop/lib下
2.4、拷贝hbase/conf下的hbase-site.xml文件到所有hadoop节点(包括master)的hadoop/conf下
三、启动、使用配置后Hive,测试是否配置成功
3.1、启动Hive
集群方式启动
可以将此启动Hive与HBase整合的命令写成Shell脚本,设置成开机启动
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
3.2、在Hive中创建HBase识别的表
hbase.table.name 定义在hbase中的table名称
多列时,data:1,data:2
多列族时,data1:1,data2:1
hbase.columns.mapping 定义在hbase的列族,里面的:key 是固定值而且要保证在表pokes中的foo字段是唯一值
创建有分区的表
分别查看Hive、HBase中建立的表
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">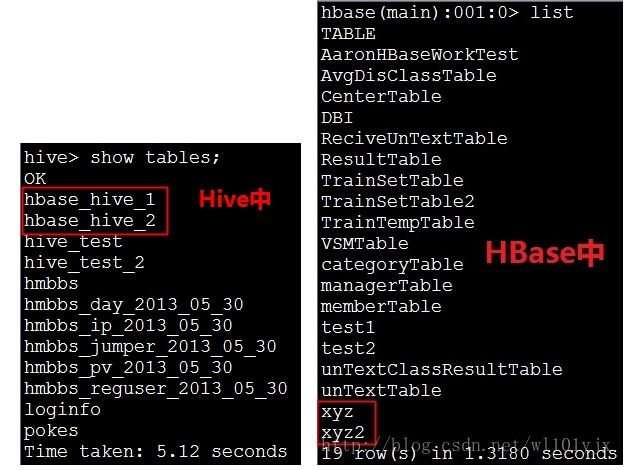
3.3、导入数据
新建hive的数据表
批量导入数据
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
使用sql导入hbase_table_1
导入有分区的表
往Hive中插入数据同时会插入到HBase中
3.4、分别查看Hive、HBase中的数据
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">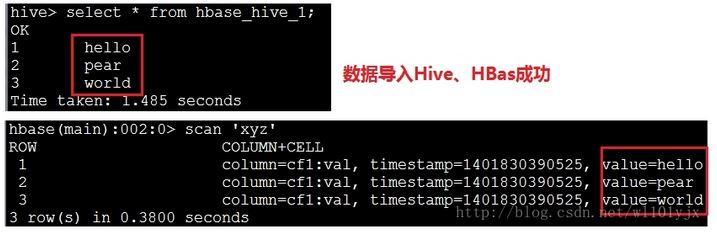
OK,到此Hive、HBase整合成功。
——————————————————————————————————————————————————————————————————
下面再给出较复杂的测试例子
情况一、对于在hbase已经存在的表,在hive中使用CREATE EXTERNAL TABLE来建立联系
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
查询gid字段中value值
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">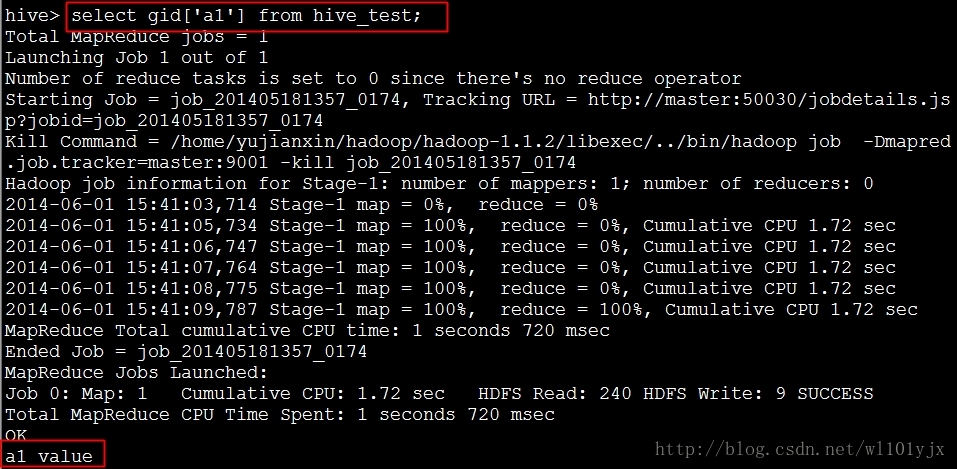
Hive成功读取到HBase中的数据
情况二、如果hbase表test2中的字段为user:gid,user:sid,info:uid,info:level
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
在hive中建表语句为
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
1.jpg
下载附件 保存到相册
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">
Hive成功读取到HBase中的数据
转自 http://www.aboutyun.com/thread-9450-1-1.html



相关推荐
这种方法适用于数据量不大的情况(小于 4TB),通过 Hive 创建一个关联 HBase 表的表,可以将数据从 Hive 导入到 HBase 中。 首先,需要创建一个 Hive 表,关联到 HBase 表,并指定 Hive schema 到 HBase schema 的...
在HBase中创建了对应的表后,可以通过Hive将数据导入到HBase。在描述中提到的命令是一个导入数据的例子: ```bash hadoop jar /usr/lib/hbase/hbase-0.90.4-cdh3u3.jar importtsv -Dimporttsv.columns=HBASE_ROW_...
被编译的hive-hbase-handler-1.2.1.jar,用于在Hive中创建关联HBase表的jar,解决创建Hive关联HBase时报FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org.apache.hadoop....
本文将围绕“Hadoop分布式搭建配置/Hive/HBase”这一主题,深入探讨Hadoop生态系统中的关键组件,并结合提供的书籍资源进行讲解。 首先,Hadoop是一个开源的分布式计算框架,它允许在大规模集群上处理和存储大量...
- 启动Hive服务,创建所需的Hive表,例如`user_action`表,并确认数据文件在HDFS中正确生成。 **2. 使用Sqoop将数据从Hive导入MySQL**: - 使用Sqoop连接到Hive并指定要导出的表。 - 设置目标MySQL数据库的连接...
Hadoop Hive与Hbase整合是大数据处理中一个重要的话题。Hbase是一个分布式、面向列的NoSQL数据库,擅长处理大规模数据,而Hive则是一个基于Hadoop的数据仓库工具,擅长处理复杂的查询操作。通过整合Hive和Hbase,...
通过创建外表,HIVE可以直接访问HBASE中的数据,并且可以使用类SQL和各种函数来操作数据。创建外表时,需要指定HBASE的ZooKeeper集群、HBASE表的名称和字段映射关系。 在HIVE中使用HBASE外表,可以实现以下几个方面...
jdk1.8.0_131、apache-zookeeper-3.8.0、hadoop-3.3.2、hbase-2.4.12 mysql5.7.38、mysql jdbc驱动mysql-connector-java-8.0.8-dmr-bin.jar、 apache-hive-3.1.3 2.本文软件均安装在自建的目录/export/server/下 ...
整合的关键在于Hive的外部表功能,通过创建指向HBase表的外部表,我们可以用Hive的HQL查询HBase中的数据。 整合步骤如下: 1. **环境准备**:确保已经安装了Hadoop、Hive和HBase,并且它们都在同一环境中正常运行...
配置hive-0.9.0和hbase-0.94.1结合使用,部分内容如下: 1.拷贝hbase-0.94.1.jar和zookeeper-3.4.3.jar到hive/lib下。 注意:如hive/lib下已经存在这两个文件的其他版本,建议删除后使用hbase下的相关版本。 //...
Hive 的核心设计是让用户能够通过类似 SQL 的查询语言(称为 HiveQL)来处理存储在 HDFS(Hadoop 分布式文件系统)中的数据。 **1.2 特点** - **数据抽象层**:Hive 不直接存储数据,而是依赖 HDFS 和 MapReduce ...
总之,Java在Hive和HBase的数据交互中起到桥梁作用,通过精心设计的数据处理流程和合理的利用HBase的Bulk Load特性,可以高效地将Hive中的大量数据导入到HBase,满足实时查询的需求。在大数据场景下,这种方案具有很...
Hive与Hbase的整合,集中两者的优势,使用HiveQL语言,同时具备了实时性
实施迁移时,需确保兼容性,因为Hive的表结构、分区和元数据都需要精确地在新环境中复现。此外,对于大规模数据,可能需要分批迁移,同时监控数据完整性与一致性。 其次,**Kudu迁移方案**:Kudu是一种列式存储系统...
"HIVE和HBASE区别" HIVE和HBASE是两种基于Hadoop的不同...就像用Google来搜索,用Facebook进行社交一样,HIVE可以用来进行统计查询,HBASE可以用来进行实时查询,数据也可以从HIVE写到HBASE,设置再从HBASE写回HIVE。
该文档保护了目前比较流行的大数据平台的原理过程梳理。Hadoop,Hive,Hbase,Spark,MapReduce,Storm
Scala、Hive与HBase是大数据处理领域中的关键组件,它们在Java开发环境中扮演着重要角色。...开发者可以通过解压并分析其中的代码,学习如何在Java和Scala环境中有效地利用Hive和HBase进行大数据处理。
- **创建映射表**:在Hive中创建一个与HBase表相对应的外部表。例如: ```sql CREATE EXTERNAL TABLE h2h( rowkey string, f1 map,string>, f2 map,string> ) STORED BY 'org.apache.hadoop.hive.hbase....
这样,Hive查询可以通过HBase的表获取数据,反之亦然。映射的关键在于定义正确的SerDe(序列化/反序列化)类和配置参数,以确保Hive能理解HBase的行键和列族结构。 接下来,Spark作为一个分布式计算框架,提供了一...