- µĄÅĶ¦ł: 1019444 µ¼Ī
- µĆ¦Õł½:

- µØźĶć¬: Õ╣┐ÕĘ×
-

µ¢ćń½ĀÕłåń▒╗
- Õģ©ķā©ÕŹÜÕ«ó (394)
- OSGI (14)
- ÕżÜń║┐ń©ŗ (10)
- µĢ░µŹ«Õ║ō (30)
- J2ME (1)
- JAVAÕ¤║ńĪĆń¤źĶ»å (46)
- Õ╝Ģńö©Õīģ (1)
- Ķ«ŠĶ«Īµ©ĪÕ╝Å (7)
- ÕĘźõĮ£µĄü (2)
- Ubuntu (7)
- µÉ£ń┤óÕ╝ĢµōÄ (6)
- QT (2)
- UbuntuõĖŗń╝¢ń©ŗ (1)
- Õ░Åń©ŗÕ║Å (2)
- UML (1)
- Servlet (10)
- spring (16)
- IM (12)
- µ¢ćµĪŻĶ¦åķóæĶĮ¼õĖ║flashµĀ╝Õ╝ÅÕ£©ń║┐µÆŁµöŠ (19)
- Maven (8)
- Ķ┐£ń©ŗĶ░āńö© (2)
- PHPRPC (1)
- EXTJSÕŁ”õ╣Ā (2)
- Hibernate (16)
- µŖƵ£»µ¢ćń½Ā (38)
- flex (5)
- µĄĘķćŵĢ░µŹ«ÕżäńÉå (5)
- FTP (8)
- JS (10)
- Struts (1)
- hibernate search (13)
- JQuery (2)
- EMail (3)
- ń«Śµ│Ģ (4)
- SVN (7)
- JFreeChart (4)
- ķØóĶ»Ģ (4)
- µŁŻĶ¦äĶĪ©ĶŠŠÕ╝Å (2)
- µĢ░µŹ«Õ║ōµĆ¦ĶāĮõ╝śÕī¢ (10)
- JVM (6)
- Http Session Cookie (7)
- ńĮæń╗£ (12)
- Hadoop (2)
- µĆ¦ĶāĮ (1)
ńżŠÕī║ńēłÕØŚ
- µłæńÜäĶĄäĶ«» ( 0)
- µłæńÜäĶ«║ÕØø ( 0)
- µłæńÜäķŚ«ńŁö ( 0)
ÕŁśµĪŻÕłåń▒╗
- 2014-03 ( 2)
- 2013-06 ( 2)
- 2013-05 ( 1)
- µø┤ÕżÜÕŁśµĪŻ...
µ£Ćµ¢░Ķ»äĶ«║
-
hy1235366’╝Ü
ĶāĮÕż¤ķÜÅõŠ┐õ╣¤ÕÅæõĖĆõĖŗ,õĮĀķĆĆńü½ń«Śµ│Ģń©ŗÕ║ÅõĮ┐ńö©ńÜäDistanceMatr ...
µ©Īµŗ¤ķĆĆńü½ń«Śµ│ĢµĆ╗ń╗ō(ÕɽõŠŗÕŁÉ)’╝łĶĮ¼’╝ē -
µóģÕ╝║Õ╝║’╝Ü
µä¤Ķ░óÕłåõ║½ŃĆéŃĆéÕĖ«Õż¦Õ┐Öõ║å
swftoolsĶĮ¼µŹóµ¢ćõ╗ȵŚČń║┐ń©ŗÕĀĄÕĪ×ķŚ«ķóśńÜäĶ¦ŻÕå│µ¢╣µ│Ģ -
wenlongsust’╝Ü
openofficeÕÆīµ¢ćõ╗ČõĖŹÕ£©ÕÉīõĖĆõĖ¬µ£ŹÕŖĪÕÖ©õĖŖ’╝īńö©Ķ┐ćÕÉŚ’╝¤
[JODConverter]wordĶĮ¼pdfÕ┐āÕŠŚÕłåõ║½’╝łĶĮ¼’╝ē -
2047699523’╝Ü
Õ”éõĮĢÕ£©java WebķĪ╣ńø«õĖŁÕ╝ĆÕÅæWebServiceµÄźÕÅŻhtt ...
Õł®ńö©Javań╝¢ÕåÖń«ĆÕŹĢńÜäWebServiceÕ«×õŠŗ -
abingpow’╝Ü
Õöē’╝īń£ŗĶĄĘµØźÕźĮÕāÅÕŠłĶ»”ń╗åÕŠłõĖŹķöÖńÜäµĀĘÕŁÉ’╝īÕÅ»µā£õĖŹµś»ń»ćķØóÕÉæÕłØÕŁ”ĶĆģńÜäµ¢ćń½Ā’╝ī ...
SpringõĖÄOSGińÜäµĢ┤ÕÉł’╝łõ║ī’╝ē’╝łĶĮ¼’╝ē
õĖĆŃĆüÕ╝ĢĶ©Ć
Õ»╣µĢ░µŹ«Õ║ōń┤óÕ╝ĢńÜäÕģ│µ│©õ╗ĵ£¬µĘĪÕć║µłæńÜäõ╗¼ńÜäĶ«©Ķ«║’╝īķéŻõ╣łµĢ░µŹ«Õ║ōń┤óÕ╝Ģµś»õ╗Ćõ╣łµĀĘńÜä’╝¤ĶüÜķøåń┤óÕ╝ĢõĖÄķØ×ĶüÜķøåń┤óÕ╝Ģµ£ēõ╗Ćõ╣łõĖŹÕÉī’╝¤ÕĖīµ£øµ£¼µ¢ćÕ»╣ÕÉäõĮŹÕÉīõ╗üµ£ēõĖĆÕ«ÜńÜäÕĖ«ÕŖ®ŃĆéµ£ēõĖŹÕ░æÕŁśń¢æńÜäÕ£░µ¢╣’╝īĶ»ÜÕ┐āÕĖīµ£øÕÉäõĮŹõĖŹÕÉØĶĄÉµĢÖµī浣Ż’╝īÕģ▒ÕÉīĶ┐øµŁźŃĆé[µ£ĆĶ┐æķ”¢ķĪĄõ╣ŗõ║ēµ▓Ėµ▓Ėµē¼µē¼’╝īõ╣¤õĖŹń¤źķüōĶ┐ÖõĖ¬µöŠÕ£©Ķ┐ÖÕÉłķĆéõ╣ł’╝īĶŗ”ÕŖ│’╝¤ÕŖ¤ÕŖ│’╝¤ŌĆ”ŌĆ”]
┬Ā
┬Ā
õ║īŃĆüB-Tree
µłæõ╗¼ÕĖĖĶ¦üńÜäµĢ░µŹ«Õ║ōń│╗ń╗¤’╝īÕģČń┤óÕ╝ĢõĮ┐ńö©ńÜäµĢ░µŹ«ń╗ōµ×äÕżÜµś»B-Treeµł¢ĶĆģB+TreeŃĆéõŠŗÕ”é’╝īMsSqlõĮ┐ńö©ńÜ䵜»B+Tree’╝īOracleÕÅŖSysbaseõĮ┐ńö©ńÜ䵜»B-TreeŃĆéµēĆõ╗źÕ£©µ£ĆÕ╝ĆÕ¦ŗ’╝īń«ĆÕŹĢÕ£░õ╗ŗń╗ŹõĖĆõĖŗB-TreeŃĆé
┬Ā
B-TreeõĖŹÕÉīõ║ÄBinary Tree’╝łõ║īÕÅēµĀæ’╝īµ£ĆÕżÜµ£ēõĖżõĖ¬ÕŁÉµĀæ’╝ē’╝īõĖƵŻĄMķśČ(ÕżÜÕ░æķśČÕ░▒µś»ÕżÜõĖ¬ķśČ[õĖ¬]ÕŁ®ÕŁÉ)ńÜäB-Treeµ╗ĪĶČ│õ╗źõĖŗµØĪõ╗Č’╝Ü
1’╝ēµ»ÅõĖ¬ń╗ōńé╣Ķć│ÕżÜµ£ēMõĖ¬ÕŁ®ÕŁÉ’╝ø
2’╝ēķÖżµĀ╣ń╗ōńé╣ÕÆīÕÅČń╗ōńé╣Õż¢’╝īÕģČÕ«āµ»ÅõĖ¬ń╗ōńé╣Ķć│Õ░æµ£ēM/2õĖ¬ÕŁ®ÕŁÉ’╝ø
3’╝ēµĀ╣ń╗ōńé╣Ķć│Õ░æµ£ēõĖżõĖ¬ÕŁ®ÕŁÉ’╝łķÖżķØ×Ķ»źµĀæõ╗ģÕīģÕɽõĖĆõĖ¬ń╗ōńé╣’╝ē’╝ø
4’╝ēµēƵ£ēÕÅČń╗ōńé╣Õ£©ÕÉīõĖĆÕ▒é’╝īÕÅČń╗ōńé╣õĖŹÕīģÕɽõ╗╗õĮĢÕģ│ķö«ÕŁŚõ┐Īµü»’╝ø
5’╝ēµ£ēKõĖ¬Õģ│ķö«ÕŁŚńÜäķØ×ÕÅČń╗ōńé╣µü░ÕźĮÕīģÕɽK+1õĖ¬ÕŁ®ÕŁÉ’╝ø
ÕÅ”Õż¢’╝īÕ»╣õ║ÄõĖĆõĖ¬ń╗ōńé╣’╝īÕģČÕåģķā©ńÜäÕģ│ķö«ÕŁŚµś»õ╗ÄÕ░ÅÕł░Õż¦µÄÆÕ║ÅńÜäŃĆéõ╗źõĖŗµś»B-Tree’╝łM=4’╝ēńÜäµĀĘõŠŗ’╝Ü
┬Ā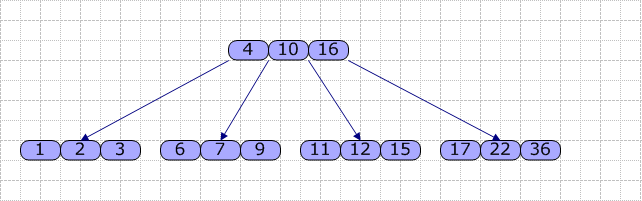 ┬Ā
┬Ā
Õ»╣õ║ĵ»ÅõĖ¬ń╗ōńé╣’╝īõĖ╗Ķ”üÕīģÕɽõĖĆõĖ¬Õģ│ķö«ÕŁŚµĢ░ń╗äKey[]’╝īõĖĆõĖ¬µīćķÆłµĢ░ń╗ä’╝łµīćÕÉæÕä┐ÕŁÉ’╝ēSon[]ŃĆéÕ£©B-TreeÕåģ’╝īµ¤źµēŠńÜ䵥üń©ŗµś»’╝ÜõĮ┐ńö©ķĪ║Õ║ŵ¤źµēŠ’╝łµĢ░ń╗äķĢ┐Õ║”ĶŠāń¤ŁµŚČ’╝ēµł¢µŖśÕŹŖµ¤źµēŠµ¢╣µ│Ģµ¤źµēŠKey[]µĢ░ń╗ä’╝īĶŗźµēŠÕł░Õģ│ķö«ÕŁŚK’╝īÕłÖĶ┐öÕø×Ķ»źń╗ōńé╣ńÜäÕ£░ÕØĆÕÅŖKÕ£©Key[]õĖŁńÜäõĮŹńĮ«’╝øÕÉ”ÕłÖ’╝īÕÅ»ńĪ«Õ«ÜKÕ£©µ¤ÉõĖ¬Key[i]ÕÆīKey[i+1]õ╣ŗķŚ┤’╝īÕłÖõ╗ÄSon[i]µēƵīćńÜäÕŁÉń╗ōńé╣ń╗¦ń╗Łµ¤źµēŠ’╝īńø┤Õł░Õ£©µ¤Éń╗ōńé╣õĖŁµ¤źµēŠµłÉÕŖ¤’╝øµł¢ńø┤Ķć│µēŠÕł░ÕÅČń╗ōńé╣õĖöÕÅČń╗ōńé╣õĖŁńÜ䵤źµēŠõ╗ŹõĖŹµłÉÕŖ¤µŚČ’╝īµ¤źµēŠĶ┐ćń©ŗÕż▒Ķ┤źŃĆé
µÄźńØĆ’╝īµłæõ╗¼õĮ┐ńö©õ╗źõĖŗÕøŠńēćµ╝öńż║Õ”éõĮĢńö¤µłÉB-Tree’╝łM=4’╝īõŠØµ¼ĪµÅÆÕģź1~6’╝ē’╝Ü
õ╗ÄÕøŠÕÅ»Ķ¦ü’╝īÕĮōµłæõ╗¼µÅÆÕģźÕģ│ķö«ÕŁŚ4µŚČ’╝īńö▒õ║ÄÕĤń╗ōńé╣ÕĘ▓ń╗ŵ╗Īõ║å’╝īµĢģĶ┐øĶĪīÕłåĶŻé’╝īÕ¤║µ£¼µīēõĖĆÕŹŖńÜäÕÄ¤ÕłÖĶ┐øĶĪīÕłåĶŻé’╝īńäČÕÉÄÕÅ¢Õć║õĖŁķŚ┤ńÜäÕģ│ķö«ÕŁŚ2’╝īÕŹćń║¦’╝łĶ┐Öķćīµś»µłÉõĖ║µĀ╣ń╗ōńé╣’╝ēŃĆéÕģČÕ«āńÜäõŠØń▒╗µÄ©’╝īÕ░▒µś»Ķ┐ÖµĀĘõĖĆõĖ¬Õż¦µ”éńÜäĶ┐ćń©ŗŃĆé
┬Ā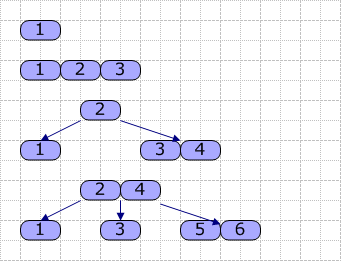 ┬Ā
┬Ā
┬Ā
õĖēŃĆüµĢ░µŹ«Õ║ōń┤óÕ╝Ģ
1’╝Äõ╗Ćõ╣łµś»ń┤óÕ╝Ģ
Õ£©µĢ░µŹ«Õ║ōõĖŁ’╝īń┤óÕ╝ĢńÜäÕɽõ╣ēõĖĵŚźÕĖĖµäÅõ╣ēõĖŖńÜäŌĆ£ń┤óÕ╝ĢŌĆØõĖĆĶ»ŹÕ╣ȵŚĀÕżÜÕż¦Õī║Õł½’╝łµā│µā│Õ░ŵŚČÕĆÖµ¤źÕŁŚÕģĖ’╝ē’╝īÕ«āµś»ńö©õ║ĵÅÉķ½śµĢ░µŹ«Õ║ōĶĪ©µĢ░µŹ«Ķ«┐ķŚ«ķƤÕ║”ńÜäµĢ░µŹ«Õ║ōÕ»╣Ķ▒ĪŃĆé
A’╝ēń┤óÕ╝ĢÕÅ»õ╗źķü┐ÕģŹÕģ©ĶĪ©µē½µÅÅŃĆéÕżÜµĢ░µ¤źĶ»óÕÅ»õ╗źõ╗ģµē½µÅÅÕ░æķćÅń┤óÕ╝ĢķĪĄÕÅŖµĢ░µŹ«ķĪĄ’╝īĶĆīõĖŹµś»ķüŹÕÄåµēƵ£ēµĢ░µŹ«ķĪĄŃĆé
B’╝ēÕ»╣õ║ÄķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īµ£ēõ║øµ¤źĶ»óńöÜĶć│ÕÅ»õ╗źõĖŹĶ«┐ķŚ«µĢ░µŹ«ķĪĄŃĆé
C’╝ēĶüÜķøåń┤óÕ╝ĢÕÅ»õ╗źķü┐ÕģŹµĢ░µŹ«µÅÆÕģźµōŹõĮ£ķøåõĖŁõ║ÄĶĪ©ńÜäµ£ĆÕÉÄõĖĆõĖ¬µĢ░µŹ«ķĪĄŃĆé
D’╝ēõĖĆõ║øµāģÕåĄõĖŗ’╝īń┤óÕ╝ĢĶ┐śÕÅ»ńö©õ║Äķü┐ÕģŹµÄÆÕ║ŵōŹõĮ£ŃĆé
┬Ā
ÕĮōńäČ’╝īõ╝ŚµēĆÕæ©ń¤ź’╝īĶÖĮńäČń┤óÕ╝ĢÕÅ»õ╗źµÅÉķ½śµ¤źĶ»óķƤÕ║”’╝īõĮåµś»Õ«āõ╗¼õ╣¤õ╝ÜÕ»╝Ķć┤µĢ░µŹ«Õ║ōń│╗ń╗¤µø┤µ¢░µĢ░µŹ«ńÜäµĆ¦ĶāĮõĖŗķÖŹ’╝īÕøĀõĖ║Õż¦ķā©ÕłåµĢ░µŹ«µø┤µ¢░ķ£ĆĶ”üÕÉīµŚČµø┤µ¢░ń┤óÕ╝ĢŃĆé
┬Ā
┬Ā
2.ń┤óÕ╝ĢńÜäÕŁśÕé©
õĖƵØĪń┤óÕ╝ĢĶ«░ÕĮĢõĖŁÕīģÕɽńÜäÕ¤║µ£¼õ┐Īµü»Õīģµŗ¼’╝Üķö«ÕĆ╝’╝łÕŹ│õĮĀÕ«Üõ╣ēń┤óÕ╝ĢµŚČµīćÕ«ÜńÜäµēƵ£ēÕŁŚµ«ĄńÜäÕĆ╝’╝ē+ķĆ╗ĶŠæµīćķÆł’╝łµīćÕÉæµĢ░µŹ«ķĪĄµł¢ĶĆģÕÅ”õĖĆń┤óÕ╝ĢķĪĄ’╝ēŃĆé
┬Ā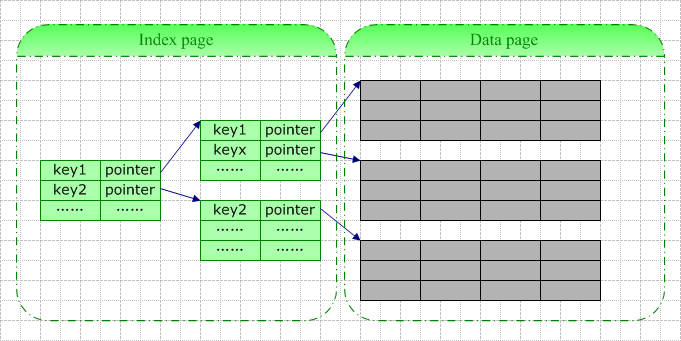 ┬Ā
┬Ā
ÕĮōõĮĀõĖ║õĖĆÕ╝Āń®║ĶĪ©ÕłøÕ╗║ń┤óÕ╝ĢµŚČ’╝īµĢ░µŹ«Õ║ōń│╗ń╗¤Õ░åõĖ║õĮĀÕłåķģŹõĖĆõĖ¬ń┤óÕ╝ĢķĪĄ’╝īĶ»źń┤óÕ╝ĢķĪĄÕ£©õĮĀµÅÆÕģźµĢ░µŹ«ÕēŹõĖĆńø┤µś»ń®║ńÜäŃĆ鵣żķĪĄµŁżµŚČµŚóµś»µĀ╣ń╗ōńé╣’╝īõ╣¤µś»ÕÅČń╗ōńé╣ŃĆéµ»ÅÕĮōõĮĀÕŠĆĶĪ©õĖŁµÅÆÕģźõĖĆĶĪīµĢ░µŹ«’╝īµĢ░µŹ«Õ║ōń│╗ń╗¤ÕŹ│ÕÉæµŁżµĀ╣ń╗ōńé╣õĖŁµÅÆÕģźõĖĆĶĪīń┤óÕ╝ĢĶ«░ÕĮĢŃĆéÕĮōµĀ╣ń╗ōńé╣µ╗ĪµŚČ’╝īµĢ░µŹ«Õ║ōń│╗ń╗¤Õż¦µŖĄµīēõ╗źõĖŗµŁźķ¬żĶ┐øĶĪīÕłåĶŻé’╝Ü
A’╝ēÕłøÕ╗║õĖżõĖ¬Õä┐ÕŁÉń╗ōńé╣
B’╝ēÕ░åÕĤµĀ╣ń╗ōńé╣õĖŁńÜäµĢ░µŹ«Ķ┐æõ╝╝Õ£░µŗåµłÉõĖżÕŹŖ’╝īÕłåÕł½ÕåÖÕģźµ¢░ńÜäõĖżõĖ¬Õä┐ÕŁÉń╗ōńé╣
C’╝ēµĀ╣ń╗ōńé╣õĖŁÕŖĀõĖŖµīćÕÉæõĖżõĖ¬Õä┐ÕŁÉń╗ōńé╣ńÜäµīćķÆł
┬Ā
ķĆÜÕĖĖńŖČÕåĄõĖŗ’╝īńö▒õ║Äń┤óÕ╝ĢĶ«░ÕĮĢõ╗ģÕīģÕɽń┤óÕ╝ĢÕŁŚµ«ĄÕĆ╝’╝łõ╗źÕÅŖ4-9ÕŁŚĶŖéńÜäµīćķÆł’╝ē’╝īń┤óÕ╝ĢÕ«×õĮōµ»öń£¤Õ«×ńÜäµĢ░µŹ«ĶĪīĶ”üÕ░ÅĶ«ĖÕżÜ’╝īń┤óÕ╝ĢķĪĄńøĖĶŠāµĢ░µŹ«ķĪĄµØźĶ»┤Ķ”üÕ»åķøåĶ«ĖÕżÜŃĆéõĖĆõĖ¬ń┤óÕ╝ĢķĪĄÕÅ»õ╗źÕŁśÕ驵Ģ░ķćŵø┤ÕżÜńÜäń┤óÕ╝ĢĶ«░ÕĮĢ’╝īĶ┐ÖµäÅÕæ│ńØĆÕ£©ń┤óÕ╝ĢõĖŁµ¤źµēŠµŚČÕ£©I/OõĖŖÕŹĀÕŠłÕż¦ńÜäõ╝śÕŖ┐(µĢ░µŹ«Õ║ōńÜ䵤źµēŠńÜäķƤÕ║”ńōČķółÕ£©õ║ÄI/O’╝īĶ┐Öńé╣Ķ”üÕłćĶ«░)’╝īńÉåĶ¦ŻĶ┐ÖõĖĆńé╣µ£ēÕŖ®õ║Äõ╗ĵ£¼Ķ┤©õĖŖõ║åĶ¦ŻõĮ┐ńö©ń┤óÕ╝ĢńÜäõ╝śÕŖ┐ŃĆé
┬Ā
┬Ā
3’╝Äń┤óÕ╝ĢńÜäń▒╗Õ×ŗ
A’╝ēĶüÜķøåń┤óÕ╝Ģ’╝īĶĪ©µĢ░µŹ«µīēńģ¦ń┤óÕ╝ĢńÜäķĪ║Õ║ÅµØźÕŁśÕé©ńÜäŃĆéÕ»╣õ║ÄĶüÜķøåń┤óÕ╝Ģ’╝īÕÅČÕŁÉń╗ōńé╣ÕŹ│ÕŁśÕé©õ║åń£¤Õ«×ńÜäµĢ░µŹ«ĶĪī’╝īõĖŹÕåŹµ£ēÕÅ”Õż¢ÕŹĢńŗ¼ńÜäµĢ░µŹ«ķĪĄŃĆé
B’╝ēķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īĶĪ©µĢ░µŹ«ÕŁśÕé©ķĪ║Õ║ÅõĖÄń┤óÕ╝ĢķĪ║Õ║ŵŚĀÕģ│ŃĆéÕ»╣õ║ÄķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īÕÅČń╗ōńé╣ÕīģÕɽń┤óÕ╝ĢÕŁŚµ«ĄÕĆ╝ÕÅŖµīćÕÉæµĢ░µŹ«ķĪĄµĢ░µŹ«ĶĪīńÜäķĆ╗ĶŠæµīćķÆł’╝īĶ»źÕ▒éń┤¦ķé╗µĢ░µŹ«ķĪĄ’╝īÕģČĶĪīµĢ░ķćÅõĖĵĢ░µŹ«ĶĪ©ĶĪīµĢ░µŹ«ķćÅõĖĆĶć┤ŃĆé
┬Ā
Õ£©õĖĆÕ╝ĀĶĪ©õĖŖÕŬĶāĮÕłøÕ╗║õĖĆõĖ¬ĶüÜķøåń┤óÕ╝Ģ’╝īÕøĀõĖ║ń£¤Õ«×µĢ░µŹ«ńÜäńē®ńÉåķĪ║Õ║ÅÕŬÕÅ»ĶāĮµś»õĖĆń¦ŹŃĆéÕ”éµ×£õĖĆÕ╝ĀĶĪ©µ▓Īµ£ēĶüÜķøåń┤óÕ╝Ģ’╝īķéŻõ╣łÕ«āĶó½ń¦░õĖ║ŌĆ£ÕĀåķøåŌĆØ’╝łHeap’╝ē(Õ║öĶ»źµś»ÕĀåÕ£©õĖĆĶĄĘńÜäÕĤÕøĀĶĆīÕÅ¢ńÜäÕÉŹÕŁŚ)ŃĆéĶ┐ÖµĀĘńÜäĶĪ©õĖŁńÜäµĢ░µŹ«ĶĪīµ▓Īµ£ēńē╣Õ«ÜńÜäķĪ║Õ║Å’╝īµēƵ£ēńÜäµ¢░ĶĪīÕ░åĶó½µĘ╗ÕŖĀńÜäĶĪ©ńÜäµ£½Õ░ŠõĮŹńĮ«ŃĆé
┬Ā
┬Ā
4’╝ÄĶüÜķøåń┤óÕ╝Ģ
Õ£©ĶüÜķøåń┤óÕ╝ĢõĖŁ’╝īÕÅČń╗ōńé╣õ╣¤ÕŹ│µĢ░µŹ«ń╗ōńé╣’╝īµēƵ£ēµĢ░µŹ«ĶĪīńÜäÕŁśÕé©ķĪ║Õ║ÅõĖÄń┤óÕ╝ĢńÜäÕŁśÕé©ķĪ║Õ║ÅõĖĆĶć┤ŃĆé
┬Ā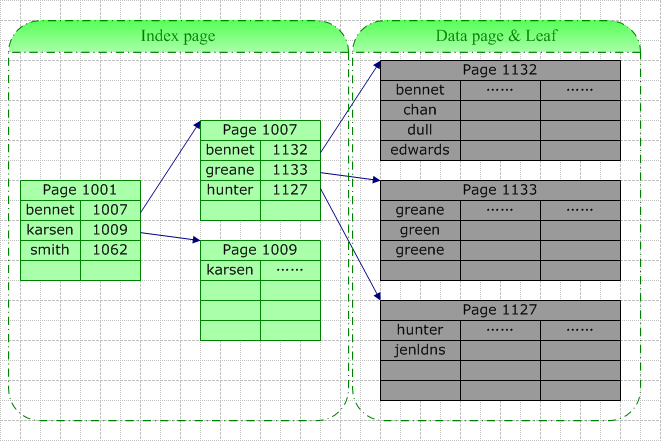 ┬Ā
┬Ā
1’╝ēĶüÜķøåń┤óÕ╝ĢõĖĵ¤źĶ»óµōŹõĮ£
Õ”éõĖŖÕøŠ’╝īµłæõ╗¼Õ£©ÕÉŹÕŁŚÕŁŚµ«ĄõĖŖÕ╗║ń½ŗĶüÜķøåń┤óÕ╝Ģ’╝īÕĮōķ£ĆĶ”üÕ£©µĀ╣µŹ«µŁżÕŁŚµ«Ąµ¤źµēŠńē╣Õ«ÜńÜäĶ«░ÕĮĢµŚČ’╝īµĢ░µŹ«Õ║ōń│╗ń╗¤õ╝ܵĀ╣µŹ«ńē╣Õ«ÜńÜäń│╗ń╗¤ĶĪ©µ¤źµēŠńÜ䵣żń┤óÕ╝ĢńÜäµĀ╣’╝īńäČÕÉĵĀ╣µŹ«µīćķÆłµ¤źµēŠõĖŗõĖĆõĖ¬’╝īńø┤Õł░µēŠÕł░ŃĆéõŠŗÕ”éµłæõ╗¼Ķ”üµ¤źĶ»óŌĆ£GreenŌĆØ’╝īńö▒õ║ÄÕ«āõ╗ŗõ║Ä[Bennet,Karsen]’╝īµŹ«µŁżµłæõ╗¼µēŠÕł░õ║åń┤óÕ╝ĢķĪĄ1007’╝īÕ£©Ķ»źķĪĄõĖŁŌĆ£GreenŌĆØõ╗ŗõ║Ä[Greane,┬ĀHunter]ķŚ┤’╝īµŹ«µŁżµłæõ╗¼µēŠÕł░ÕÅČń╗ōńé╣1133’╝łõ╣¤ÕŹ│µĢ░µŹ«ń╗ōńé╣’╝ē’╝īÕ╣ȵ£Ćń╗łÕ£©µŁżķĪĄõĖŁµēŠõ╗źõ║åńø«µĀćµĢ░µŹ«ĶĪīŃĆé
┬Ā
µŁżµ¼Īµ¤źĶ»óńÜäIOÕīģµŗ¼3õĖ¬ń┤óÕ╝ĢķĪĄńÜ䵤źĶ»ó’╝łÕģČõĖŁµ£ĆÕÉÄõĖƵ¼ĪÕ«×ķÖģõĖŖµś»Õ£©µĢ░µŹ«ķĪĄõĖŁµ¤źĶ»ó’╝ēŃĆéĶ┐ÖķćīńÜ䵤źµēŠÕÅ»ĶāĮµś»õ╗ÄńŻüńøśĶ»╗ÕÅ¢(Physical Read)µł¢µś»õ╗Äń╝ōÕŁśõĖŁĶ»╗ÕÅ¢(Logical Read)’╝īÕ”éµ×£µŁżĶĪ©Ķ«┐ķŚ«ķóæńÄćĶŠāķ½ś’╝īķéŻõ╣łń┤óÕ╝ĢµĀæõĖŁĶŠāķ½śÕ▒éńÜäń┤óÕ╝ĢÕŠłÕÅ»ĶāĮÕ£©ń╝ōÕŁśõĖŁĶó½µēŠÕł░ŃĆéµēĆõ╗źń£¤µŁŻńÜäIOÕÅ»ĶāĮÕ░Åõ║ÄõĖŖķØóńÜäµāģÕåĄŃĆé
┬Ā
┬Ā
2’╝ēĶüÜķøåń┤óÕ╝ĢõĖĵÅÆÕģźµōŹõĮ£
µ£Ćń«ĆÕŹĢńÜäµāģÕåĄõĖŗ’╝īµÅÆÕģźµōŹõĮ£µĀ╣µŹ«ń┤óÕ╝ĢµēŠÕł░Õ»╣Õ║öńÜäµĢ░µŹ«ķĪĄ’╝īńäČÕÉÄķĆÜĶ┐ćµī¬ÕŖ©ÕĘ▓µ£ēńÜäĶ«░ÕĮĢõĖ║µ¢░µĢ░µŹ«ĶģŠÕć║ń®║ķŚ┤’╝īµ£ĆÕÉĵÅÆÕģźµĢ░µŹ«ŃĆé
┬Ā
Õ”éµ×£µĢ░µŹ«ķĪĄÕĘ▓µ╗Ī’╝īÕłÖķ£ĆĶ”üµŗåÕłåµĢ░µŹ«ķĪĄ’╝łķĪĄµŗåÕłåµś»õĖĆń¦ŹĶĆŚĶ┤╣ĶĄäµ║ÉńÜäµōŹõĮ£’╝īõĖĆĶł¼µĢ░µŹ«Õ║ōń│╗ń╗¤õĖŁõ╝ܵ£ēńøĖÕ║öńÜäµ£║ÕłČĶ”üÕ░ĮķćÅÕćÅÕ░æķĪĄµŗåÕłåńÜäµ¼ĪµĢ░’╝īķĆÜÕĖĖµś»ķĆÜĶ┐ćõĖ║µ»ÅķĪĄķóäńĢÖń®║ķŚ┤µØźÕ«×ńÄ░’╝ē’╝Ü
A’╝ēÕ£©Ķ»źõĮ┐ńö©ńÜäµĢ░µŹ«µ«Ą’╝łextent’╝ēõĖŖÕłåķģŹµ¢░ńÜäµĢ░µŹ«ķĪĄ’╝īÕ”éµ×£µĢ░µŹ«µ«ĄÕĘ▓µ╗Ī’╝īÕłÖķ£ĆĶ”üÕłåķģŹµ¢░µ«ĄŃĆé
B’╝ēĶ░āµĢ┤ń┤óÕ╝ĢµīćķÆł’╝īĶ┐Öķ£ĆĶ”üÕ░åńøĖÕ║öńÜäń┤óÕ╝ĢķĪĄĶ»╗ÕģźÕåģÕŁśÕ╣ČÕŖĀķöüŃĆé
C’╝ēÕż¦ń║”µ£ēõĖĆÕŹŖńÜäµĢ░µŹ«ĶĪīĶó½ÕĮÆÕģźµ¢░ńÜäµĢ░µŹ«ķĪĄõĖŁŃĆé
D’╝ēÕ”éµ×£ĶĪ©Ķ┐śµ£ēķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īÕłÖķ£ĆĶ”üµø┤µ¢░Ķ┐Öõ║øń┤óÕ╝ĢµīćÕÉæµ¢░ńÜäµĢ░µŹ«ķĪĄŃĆé
┬Ā
ńē╣µ«ŖµāģÕåĄ’╝Ü
A’╝ēÕ”éµ×£µ¢░µÅÆÕģźńÜäõĖƵØĪĶ«░ÕĮĢÕīģÕɽՊłÕż¦ńÜäµĢ░µŹ«’╝īÕÅ»ĶāĮõ╝ÜÕłåķģŹõĖżõĖ¬µ¢░µĢ░µŹ«ķĪĄ’╝īÕģČõĖŁõ╣ŗõĖĆńö©µØźÕŁśÕ驵¢░Ķ«░ÕĮĢ’╝īÕÅ”õĖĆÕŁśÕé©õ╗ÄÕĤķĪĄõĖŁµŗåÕłåÕć║µØźńÜäµĢ░µŹ«ŃĆé
B’╝ēķĆÜÕĖĖµĢ░µŹ«Õ║ōń│╗ń╗¤õĖŁõ╝ÜÕ░åķćŹÕżŹńÜäµĢ░µŹ«Ķ«░ÕĮĢÕŁśÕé©õ║ÄńøĖÕÉīńÜäķĪĄõĖŁŃĆé
C’╝ēń▒╗õ╝╝õ║ÄĶć¬Õó×ÕłŚõĖ║ĶüÜķøåń┤óÕ╝ĢńÜä’╝īµĢ░µŹ«Õ║ōń│╗ń╗¤ÕÅ»ĶāĮÕ╣ČõĖŹµŗåÕłåµĢ░µŹ«ķĪĄ’╝īķĪĄÕŬµś»ń«ĆÕŹĢńÜäµ¢░µĘ╗µĢ░µŹ«ķĪĄŃĆé
┬Ā
┬Ā
3’╝ēĶüÜķøåń┤óÕ╝ĢõĖÄÕłĀķÖżµōŹõĮ£
ÕłĀķÖżĶĪīÕ░åÕ»╝Ķć┤ÕģČõĖŗµ¢╣ńÜäµĢ░µŹ«ĶĪīÕÉæõĖŖń¦╗ÕŖ©õ╗źÕĪ½ÕģģÕłĀķÖżĶ«░ÕĮĢķĆĀµłÉńÜäń®║ńÖĮŃĆé
Õ”éµ×£ÕłĀķÖżńÜäĶĪīµś»Ķ»źµĢ░µŹ«ķĪĄõĖŁńÜäµ£ĆÕÉÄõĖĆĶĪī’╝īķéŻõ╣łĶ»źµĢ░µŹ«ķĪĄÕ░åĶó½Õø×µöČ’╝īńøĖÕ║öńÜäń┤óÕ╝ĢķĪĄõĖŁńÜäĶ«░ÕĮĢÕ░åĶó½ÕłĀķÖżŃĆéÕ”éµ×£Õø×µöČńÜäµĢ░µŹ«ķĪĄõĮŹõ║ÄĶʤĶ»źĶĪ©ńÜäÕģČÕ«āµĢ░µŹ«ķĪĄńøĖÕÉīńÜ䵫ĄõĖŖ’╝īķéŻõ╣łÕ«āÕÅ»ĶāĮÕ£©ķÜÅÕÉÄńÜ䵌ČķŚ┤ÕåģĶó½Õł®ńö©ŃĆéÕ”éµ×£Ķ»źµĢ░µŹ«ķĪĄµś»Ķ»źµ«ĄńÜäÕö»õĖĆõĖĆõĖ¬µĢ░µŹ«ķĪĄ’╝īÕłÖĶ»źµ«Ąõ╣¤Ķó½Õø×µöČŃĆé
┬Ā
Õ»╣õ║ĵĢ░µŹ«ńÜäÕłĀķÖżµōŹõĮ£’╝īÕÅ»ĶāĮÕ»╝Ķć┤ń┤óÕ╝ĢķĪĄõĖŁõ╗ģµ£ēõĖƵØĪĶ«░ÕĮĢ’╝īĶ┐ÖµŚČ’╝īĶ»źĶ«░ÕĮĢÕÅ»ĶāĮõ╝ÜĶó½ń¦╗Ķć│ķé╗Ķ┐æńÜäń┤óÕ╝ĢķĪĄõĖŁ’╝īÕĤń┤óÕ╝ĢķĪĄÕ░åĶó½Õø×µöČ’╝īÕŹ│µēĆĶ░ōńÜäŌĆ£ń┤óÕ╝ĢÕÉłÕ╣ČŌĆØŃĆé
┬Ā
┬Ā
5’╝ÄķØ×ĶüÜķøåń┤óÕ╝Ģ
ķØ×ĶüÜķøåń┤óÕ╝ĢõĖÄĶüÜķøåń┤óÕ╝ĢńøĖµ»ö’╝Ü
A’╝ēÕÅČÕŁÉń╗ōńé╣Õ╣ČķØ×µĢ░µŹ«ń╗ōńé╣
B’╝ēÕÅČÕŁÉń╗ōńé╣õĖ║µ»ÅõĖĆń£¤µŁŻńÜäµĢ░µŹ«ĶĪīÕŁśÕé©õĖĆõĖ¬ŌĆ£ķö«-µīćķÆłŌĆØÕ»╣
C’╝ēÕÅČÕŁÉń╗ōńé╣õĖŁĶ┐śÕŁśÕé©õ║åõĖĆõĖ¬µīćķÆłÕüÅń¦╗ķćÅ’╝īµĀ╣µŹ«ķĪĄµīćķÆłÕÅŖµīćķÆłÕüÅń¦╗ķćÅÕÅ»õ╗źÕ«ÜõĮŹÕł░ÕģĘõĮōńÜäµĢ░µŹ«ĶĪīŃĆé
D’╝ēń▒╗õ╝╝ńÜä’╝īÕ£©ķÖżÕÅČń╗ōńé╣Õż¢ńÜäÕģČÕ«āń┤óÕ╝Ģń╗ōńé╣’╝īÕŁśÕé©ńÜäõ╣¤µś»ń▒╗õ╝╝ńÜäÕåģÕ«╣’╝īÕŬõĖŹĶ┐ćÕ«āµś»µīćÕÉæõĖŗõĖĆń║¦ńÜäń┤óÕ╝ĢķĪĄńÜäŃĆé
┬Ā
ĶüÜķøåń┤óÕ╝Ģµś»õĖĆń¦Źń©Ćń¢Åń┤óÕ╝Ģ’╝īµĢ░µŹ«ķĪĄõĖŖõĖĆń║¦ńÜäń┤óÕ╝ĢķĪĄÕŁśÕé©ńÜ䵜»ķĪĄµīćķÆł’╝īĶĆīõĖŹµś»ĶĪīµīćķÆłŃĆéĶĆīÕ»╣õ║ÄķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īÕłÖµś»Õ»åķøåń┤óÕ╝Ģ’╝īÕ£©µĢ░µŹ«ķĪĄńÜäõĖŖõĖĆń║¦ń┤óÕ╝ĢķĪĄÕ«āõĖ║µ»ÅõĖĆõĖ¬µĢ░µŹ«ĶĪīÕŁśÕé©õĖƵØĪń┤óÕ╝ĢĶ«░ÕĮĢŃĆé
┬Ā
Õ»╣õ║ĵĀ╣õĖÄõĖŁķŚ┤ń║¦ńÜäń┤óÕ╝ĢĶ«░ÕĮĢ’╝īÕ«āńÜäń╗ōµ×äÕīģµŗ¼’╝Ü
A’╝ēń┤óÕ╝ĢÕŁŚµ«ĄÕĆ╝
B’╝ēRowId’╝łÕŹ│Õ»╣Õ║öµĢ░µŹ«ķĪĄńÜäķĪĄµīćķÆł+µīćķÆłÕüÅń¦╗ķćÅ’╝ēŃĆéÕ£©ķ½śÕ▒éńÜäń┤óÕ╝ĢķĪĄõĖŁÕīģÕɽRowIdµś»õĖ║õ║åÕĮōń┤óÕ╝ĢÕģüĶ«ĖķćŹÕżŹÕĆ╝µŚČ’╝īÕĮōµø┤µö╣µĢ░µŹ«µŚČń▓ŠńĪ«Õ«ÜõĮŹµĢ░µŹ«ĶĪīŃĆé
C’╝ēõĖŗõĖĆń║¦ń┤óÕ╝ĢķĪĄńÜäµīćķÆł
┬Ā
Õ»╣õ║ÄÕÅČÕŁÉÕ▒éńÜäń┤óÕ╝ĢÕ»╣Ķ▒Ī’╝īÕ«āńÜäń╗ōµ×äÕīģµŗ¼’╝Ü
A’╝ēń┤óÕ╝ĢÕŁŚµ«ĄÕĆ╝
B’╝ēRowId
┬Ā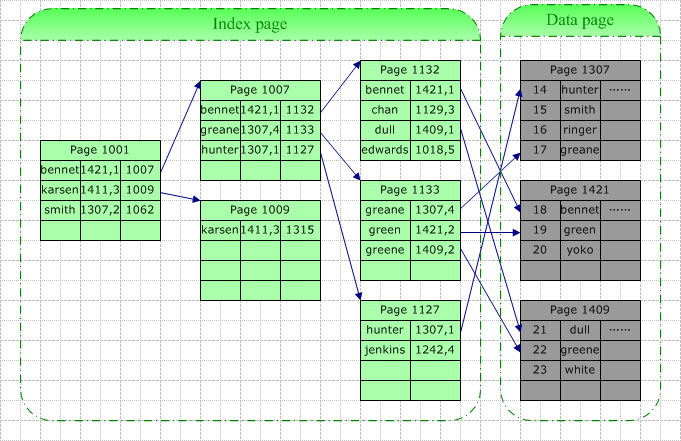 ┬Ā
┬Ā
1’╝ēķØ×ĶüÜķøåń┤óÕ╝ĢõĖĵ¤źĶ»óµōŹõĮ£
ķÆłÕ»╣õĖŖÕøŠ’╝īÕ”éµ×£µłæõ╗¼ÕÉīµĀʵ¤źµēŠŌĆ£GreenŌĆØ’╝īķéŻõ╣łõĖƵ¼Īµ¤źĶ»óµōŹõĮ£Õ░åÕīģÕɽõ╗źõĖŗIO’╝Ü3õĖ¬ń┤óÕ╝ĢķĪĄńÜäĶ»╗ÕÅ¢+1õĖ¬µĢ░µŹ«ķĪĄńÜäĶ»╗ÕÅ¢ŃĆéÕÉīµĀĘ’╝īńö▒õ║Äń╝ōÕŁśńÜäÕģ│ń│╗’╝īń£¤Õ«×ńÜäIOÕ«×ķÖģÕÅ»ĶāĮĶ”üÕ░Åõ║ÄõĖŖķØóÕłŚÕć║ńÜäŃĆé
┬Ā
┬Ā
2’╝ēķØ×ĶüÜķøåń┤óÕ╝ĢõĖĵÅÆÕģźµōŹõĮ£
Õ”éµ×£õĖĆÕ╝ĀĶĪ©ÕīģÕɽõĖĆõĖ¬ķØ×ĶüÜķøåń┤óÕ╝ĢõĮåµ▓Īµ£ēĶüÜķøåń┤óÕ╝Ģ’╝īÕłÖµ¢░ńÜäµĢ░µŹ«Õ░åĶó½µÅÆÕģźÕł░µ£Ćµ£½õĖĆõĖ¬µĢ░µŹ«ķĪĄõĖŁ’╝īńäČÕÉÄķØ×ĶüÜķøåń┤óÕ╝ĢÕ░åĶó½µø┤µ¢░ŃĆéÕ”éµ×£õ╣¤ÕīģÕɽĶüÜķøåń┤óÕ╝Ģ’╝īĶ»źĶüÜķøåń┤óÕ╝ĢÕ░åĶó½ńö©õ║ĵ¤źµēŠµ¢░ĶĪīÕ░åĶ”üÕżäõ║Äõ╗Ćõ╣łõĮŹńĮ«’╝īķÜÅÕÉÄ’╝īĶüÜķøåń┤óÕ╝ĢŃĆüõ╗źÕÅŖķØ×ĶüÜķøåń┤óÕ╝ĢÕ░åĶó½µø┤µ¢░ŃĆé
┬Ā
┬Ā
3’╝ēķØ×ĶüÜķøåń┤óÕ╝ĢõĖÄÕłĀķÖżµōŹõĮ£
Õ”éµ×£Õ£©ÕłĀķÖżÕæĮõ╗żńÜäWhereÕŁÉÕÅźõĖŁÕīģÕɽńÜäÕłŚõĖŖ’╝īÕ╗║µ£ēķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īķéŻõ╣łĶ»źķØ×ĶüÜķøåń┤óÕ╝ĢÕ░åĶó½ńö©õ║ĵ¤źµēŠµĢ░µŹ«ĶĪīńÜäõĮŹńĮ«’╝īµĢ░µŹ«ÕłĀķÖżõ╣ŗÕÉÄ’╝īõĮŹõ║Äń┤óÕ╝ĢÕÅČÕŁÉõĖŖńÜäÕ»╣Õ║öĶ«░ÕĮĢõ╣¤Õ░åĶó½ÕłĀķÖżŃĆéÕ”éµ×£Ķ»źĶĪ©õĖŖµ£ēÕģČÕ«āķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īÕłÖÕ«āõ╗¼ÕÅČÕŁÉń╗ōńé╣õĖŖńÜäńøĖÕ║öµĢ░µŹ«õ╣¤Ķ”üÕłĀķÖżŃĆé
┬Ā
Õ”éµ×£ÕłĀķÖżńÜäµĢ░µŹ«µś»Ķ»źµĢ░µēĆķĪĄõĖŁńÜäÕö»õĖĆõĖƵØĪ’╝īÕłÖĶ»źķĪĄõ╣¤Ķó½Õø×µöČ’╝īÕÉīµŚČķ£ĆĶ”üµø┤µ¢░ÕÉäõĖ¬ń┤óÕ╝ĢµĀæõĖŖńÜäµīćķÆłŃĆé
┬Ā
ńö▒õ║ĵ▓Īµ£ēĶć¬ÕŖ©ńÜäÕÉłÕ╣ČÕŖ¤ĶāĮ’╝īÕ”éµ×£Õ║öńö©ń©ŗÕ║ÅõĖŁµ£ēķóæń╣üńÜäķÜŵ£║ÕłĀķÖżµōŹõĮ£’╝īµ£ĆÕÉÄÕÅ»ĶāĮÕ»╝Ķć┤ĶĪ©ÕīģÕÉ½ÕżÜõĖ¬µĢ░µŹ«ķĪĄ’╝īõĮåµ»ÅõĖ¬ķĪĄõĖŁÕŬµ£ēÕ░æķćŵĢ░µŹ«ŃĆé
┬Ā
┬Ā
6’╝Äń┤óÕ╝ĢĶ”åńø¢
ń┤óÕ╝ĢĶ”åńø¢µś»Ķ┐ÖµĀĘõĖĆń¦Źń┤óÕ╝ĢńŁ¢ńĢź’╝ÜÕĮōµ¤ÉõĖƵ¤źĶ»óõĖŁÕīģÕɽńÜäµēĆķ£ĆÕŁŚµ«ĄńÜåÕīģÕɽõ║ÄõĖĆõĖ¬ń┤óÕ╝ĢõĖŁ’╝īµŁżµŚČń┤óÕ╝ĢÕ░åÕż¦Õż¦µÅÉķ½śµ¤źĶ»óµĆ¦ĶāĮŃĆé
┬Ā
ÕīģÕÉ½ÕżÜõĖ¬ÕŁŚµ«ĄńÜäń┤óÕ╝Ģ’╝īń¦░õĖ║ÕżŹÕÉłń┤óÕ╝ĢŃĆéń┤óÕ╝Ģµ£ĆÕżÜÕÅ»õ╗źÕīģÕɽ31õĖ¬ÕŁŚµ«Ą’╝īń┤óÕ╝ĢĶ«░ÕĮĢµ£ĆÕż¦ķĢ┐Õ║”õĖ║600BŃĆéÕ”éµ×£õĮĀÕ£©ĶŗźÕ╣▓õĖ¬ÕŁŚµ«ĄõĖŖÕłøÕ╗║õ║åõĖĆõĖ¬ÕżŹÕÉłńÜäķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īõĖöõĮĀńÜ䵤źĶ»óõĖŁµēĆķ£ĆSelectÕŁŚµ«ĄÕÅŖWhere,Order By,Group By,HavingÕŁÉÕÅźõĖŁµēƵČēÕÅŖńÜäÕŁŚµ«ĄķāĮÕīģÕɽգ©ń┤óÕ╝ĢõĖŁ’╝īÕłÖÕŬµÉ£ń┤óń┤óÕ╝ĢķĪĄÕŹ│ÕÅ»µ╗ĪĶČ│µ¤źĶ»ó’╝īĶĆīõĖŹķ£ĆĶ”üĶ«┐ķŚ«µĢ░µŹ«ķĪĄŃĆéńö▒õ║ÄķØ×ĶüÜķøåń┤óÕ╝ĢńÜäÕÅČń╗ōńé╣ÕīģÕɽµēƵ£ēµĢ░µŹ«ĶĪīõĖŁńÜäń┤óÕ╝ĢÕłŚÕĆ╝’╝īõĮ┐ńö©Ķ┐Öõ║øń╗ōńé╣ÕŹ│ÕÅ»Ķ┐öÕø×ń£¤µŁŻńÜäµĢ░µŹ«’╝īĶ┐Öń¦ŹµāģÕåĄń¦░õ╣ŗõĖ║ŌĆ£ń┤óÕ╝ĢĶ”åńø¢ŌĆØŃĆé
Õ£©ń┤óÕ╝ĢĶ”åńø¢ńÜäµāģÕåĄõĖŗ’╝īÕīģÕɽõĖżń¦Źń┤óÕ╝Ģµē½µÅÅ’╝Ü
A’╝ēÕī╣ķģŹń┤óÕ╝Ģµē½µÅÅ
B’╝ēķØ×Õī╣ķģŹń┤óÕ╝Ģµē½µÅÅ
┬Ā
1’╝ēÕī╣ķģŹń┤óÕ╝Ģµē½µÅÅ
µŁżń▒╗ń┤óÕ╝Ģµē½µÅÅÕÅ»õ╗źĶ«®µłæõ╗¼ń£üÕÄ╗Ķ«┐ķŚ«µĢ░µŹ«ķĪĄńÜ䵣źķ¬ż’╝īÕĮōµ¤źĶ»óõ╗ģĶ┐öÕø×õĖĆĶĪīµĢ░µŹ«µŚČ’╝īµĆ¦ĶāĮµÅÉķ½śµś»µ£ēķÖÉńÜä’╝īõĮåÕ£©ĶīāÕø┤µ¤źĶ»óńÜäµāģÕåĄõĖŗ’╝īµĆ¦ĶāĮµÅÉķ½śÕ░åķÜÅń╗ōµ×£ķøåµĢ░ķćÅńÜäÕó×ķĢ┐ĶĆīÕó×ķĢ┐ŃĆé
ķÆłÕ»╣µŁżń▒╗µē½µÅÅ’╝īń┤óÕ╝ĢÕ┐ģķĪ╗ÕīģÕɽµ¤źĶ»óõĖŁµČēÕÅŖńÜäńÜäµēƵ£ēÕŁŚµ«Ą’╝īÕÅ”Õż¢’╝īĶ┐śķ£ĆĶ”üµ╗ĪĶČ│’╝ÜWhereÕŁÉÕÅźõĖŁÕīģÕɽń┤óÕ╝ĢõĖŁńÜäŌĆ£Õ╝ĢÕ»╝ÕłŚŌĆØ’╝łLeading Column’╝ē’╝īõŠŗÕ”éõĖĆõĖ¬ÕżŹÕÉłń┤óÕ╝ĢÕīģÕɽA,B,C,DÕøøÕłŚ’╝īÕłÖAõĖ║ŌĆ£Õ╝ĢÕ»╝ÕłŚŌĆØŃĆéÕ”éµ×£WhereÕŁÉÕÅźõĖŁµēĆÕīģÕÉ½ÕłŚµś»BCDµł¢ĶĆģBDńŁēµāģÕåĄ’╝īÕłÖÕŬĶāĮõĮ┐ńö©ķØ×Õī╣ķģŹń┤óÕ╝Ģµē½µÅÅŃĆé
┬Ā
2’╝ēķØ×ķģŹńĮ«ń┤óÕ╝Ģµē½µÅÅ
µŁŻÕ”éõĖŖĶ┐░’╝īÕ”éµ×£WhereÕŁÉÕÅźõĖŁõĖŹÕīģÕɽń┤óÕ╝ĢńÜäÕ»╝Õ╝ĢÕłŚ’╝īķéŻõ╣łÕ░åõĮ┐ńö©ķØ×ķģŹńĮ«ń┤óÕ╝Ģµē½µÅÅŃĆéĶ┐Öµ£Ćń╗łÕ»╝Ķć┤µē½µÅÅń┤óÕ╝ĢµĀæõĖŖńÜäµēƵ£ēÕÅČÕŁÉń╗ōńé╣’╝īÕĮōńäČ’╝īÕ«āńÜäµĆ¦ĶāĮķĆÜÕĖĖõ╗ŹÕ╝║õ║ĵē½µÅŵēƵ£ēńÜäµĢ░µŹ«ķĪĄŃĆé
┬Ā
[ÕÅéĶĆā]
[1]http://manuals.sybase.com/onlinebooks/group-asarc/asg1200e/aseperf/@Generic__BookTextView/3358
[2]┬Āhttp://publib.boulder.ibm.com/infocenter/idshelp/v10/index.jsp?topic=/com.ibm.adref.doc/adref235.htm
┬Ā
Õć║Õżä’╝Ühttp://www.cnblogs.com/KissKnife/archive/2009/03/30/1425534.html
┬Ā
┬Ā


- 2011-03-23 10:00
- µĄÅĶ¦ł 1078
- Ķ»äĶ«║(0)
- Õłåń▒╗:µĢ░µŹ«Õ║ō
- µ¤źń£ŗµø┤ÕżÜ
ÕÅæĶĪ©Ķ»äĶ«║

-
SQLµ¤źĶ»óÕēŹ10µØĪĶ«░ÕĮĢ’╝łSqlServer/mysql/oracle/sybase’╝ē[Ķ»Łµ│ĢÕłåµ×É] ’╝łĶĮ¼’╝ē
2011-04-22 00:45 5531Ķ┐Öń»ćµ¢ćń½ĀõĖ╗Ķ”üµś»Õłåµ×ÉõĖŗ’ ... -
SQL Group by HavingŃĆĆÕŁ”õ╣Ā’╝łĶĮ¼’╝ē
2011-04-19 10:33 1558Õ£©select┬ĀĶ»ŁÕÅźõĖŁÕÅ»õ╗źõĮ┐ńö ... -
õĮ┐ńö©PreparedStatementķś▓µŁóSQLµ│©Õģź’╝łĶĮ¼’╝ē
2011-04-18 14:58 1846õĖƵØĪµĢłńÄćÕĘ«ńÜäsqlĶ»ŁÕÅź,Ķ ... -
JDBC Class.forNameõĮ£ńö©’╝łĶĮ¼’╝ē
2011-04-13 14:53 1246┬Ā ┬ĀõĮ┐ńö©JDBCµŚČ’╝īµłæõ╗¼ķāĮõ╝ÜÕŠłĶć¬ńäČÕŠŚõĮ┐ńö©õĖŗÕłŚĶ»ŁÕÅź’╝Ü ┬Ā ... -
Õģ│õ║ĵĢ░µŹ«Õ║ōÕåģĶ┐×µÄźÕż¢Ķ┐׵ğÕĘ”Ķ┐׵ğÕÅ│Ķ┐׵ğ(ĶĮ¼)
2011-03-26 19:04 1634ÕåģĶ┐׵ğ’╝ܵŖŖõĖżõĖ¬ĶĪ©õĖŁµĢ░µŹ«Õ»╣Õ║öńÜäµĢ░µŹ«µ¤źÕć║µØź Õż¢Ķ┐׵ğ’╝Üõ╗źµ¤ÉõĖ¬ĶĪ©õĖ║Õ¤║ńĪĆ ... -
µĢ░µŹ«Õ║ōõ║ŗÕŖĪķÜöń”╗ń║¦Õł½õĖÄķöü’╝łĶĮ¼’╝ē
2011-03-26 18:57 1310õĖĆ,õ║ŗÕŖĪńÜä4õĖ¬Õ¤║µ£¼ńē╣ÕŠü Atomic’╝łÕÄ¤ÕŁÉµĆ¦’╝ē’╝Ü õ║ŗÕŖĪõĖŁÕīģÕɽńÜä ... -
PreparedStatementµĢłńÄćõĖ║õ╗Ćõ╣łķ½ś/õĖ║õ╗Ćõ╣łĶ”üõĮ┐ńö©PreparedStatementõ╗Żµø┐Statement’╝łĶĮ¼’╝ē
2011-03-25 09:28 2816Õ£©JDBCÕ║öńö©õĖŁ,Õ”éµ×£õĮĀÕ ... -
µĄģĶ░łµĢ░µŹ«Õ║ōń┤óÕ╝Ģ’╝łĶĮ¼’╝ē
2011-03-23 10:10 1231┬Ā┬Ā ┬ĀµĢ░µŹ«Õ║ōń┤óÕ╝Ģµś»õĖ║õ║åÕó×ÕŖĀµ¤źĶ»óķƤÕ║”ĶĆīÕ»╣ĶĪ©ÕŁŚµ«ĄķÖäÕŖĀńÜäõĖĆ ... -
ńö©SQLĶ»ŁÕÅźÕÄ╗µÄēķćŹÕżŹńÜäĶ«░ÕĮĢ’╝łĶĮ¼’╝ē
2011-03-23 01:25 6895µĄĘķćŵĢ░µŹ«’╝łńÖŠõĖćõ╗źõĖŖ’╝ē’ ... -
µĢ░µŹ«Õ║ōĶīāÕ╝Å’╝łĶĮ¼’╝ē
2011-03-23 01:18 1475ÕĮōÕēŹµłæõ╗¼õĮ┐ńö©ńÜäõĖ╗µĄüµĢ░µ ... -
mysqlõĖŁlimitńÜäńö©µ│ĢĶ»”Ķ¦Ż[µĢ░µŹ«ÕłåķĪĄÕĖĖńö©] ’╝łĶĮ¼’╝ē
2011-01-08 16:44 1469Õ£©µłæõ╗¼õĮ┐ńö©µ¤źĶ»óĶ»ŁÕÅźńÜ䵌ČÕĆÖ’╝īń╗ÅÕĖĖĶ”üĶ┐öÕø×ÕēŹÕćĀµØĪµł¢ĶĆģõĖŁķŚ┤µ¤ÉÕćĀĶĪīµĢ░µŹ«’╝ī ... -
µ¤źĶ»óõ╝śÕī¢ńÜäÕ┐ģĶ”üµĆ¦’╝łĶĮ¼’╝ē
2010-12-19 09:55 1525┬Ā ┬Ā┬Ā ┬Ā ┬Āµ¤źĶ»óõ╝śÕī¢ńÜäµ£Ćń╗łńø«ńÜ䵜»õĖ║õ║åµÅÉķ½śµĢ░µŹ«Õ║ōń│╗ń╗¤ńÜäµĆ¦ĶāĮ ... -
OracleÕ»╝Õć║µĢ░µŹ«’╝łĶĮ¼’╝ē
2010-12-14 15:33 15301.1┬Ā┬Ā exp┬Ā┬Ā õĮ┐ńö©µ¢╣µ│ĢÕÅŖ ... -
oracleÕłØµ¼ĪõĮ┐ńö©
2010-12-14 13:06 1129õ╗źÕēŹķāĮõ╣Āµā»õ║åõĮ┐ńö©MySQL’╝ ... -
MysqlĶ┐×µÄźÕŁŚń¼”õĖ▓Õż¦Õģ©’╝łĶĮ¼’╝ē
2010-08-15 21:25 4895┬Ā┬Ā┬Ā┬Ā┬Ā mysql JDBC ķ®▒ÕŖ©ÕĖĖńö©ńÜäµ£ēõĖżõĖ¬’╝īõĖĆõĖ¬µś»gj ... -
MysqlńÜätransactionÕ«×ńÄ░’╝łĶĮ¼’╝ē
2010-08-15 15:02 2004transactionÕ£©µĢ░µŹ«Õ║ōń╝¢ń©ŗõĖ ... -
Hibernate ÕÉäń¦ŹµĢ░µŹ«Õ║ōńÜäķģŹńĮ«’╝łĶĮ¼’╝ē
2010-07-22 20:27 16711. MySqlĶ┐׵ğķģŹńĮ«┬Ā┬Ā ┬Ā MySqlµĢ░µŹ«Õ║ōńÜähib ... -
ÕĘ”Ķ┐׵ğŃĆüÕÅ│Ķ┐׵ğŃĆüÕģ©Ķ┐׵ğÕÅŖÕī║Õł½’╝łĶĮ¼’╝ē
2010-05-16 15:23 4351õĖŖĶŖ鵳æõ╗¼õ╗ŗń╗Źõ║åĶĪ©Ķ┐׵ğ’╝īµø┤ńĪ«ÕłćńÜäĶ»┤µś»inner joinsÕģ¦Ķ┐׵ğ ... -
µ¤źĶ»óķćŹÕżŹĶ«░ÕĮĢsql ’╝łĶĮ¼’╝ē
2010-05-16 15:23 1289Ķ┐Öµś»µłæńÜäõĖƵ¼Īń¼öĶ»Ģķóś,µś»µ¤źĶ»óõĖĆõĖ¬ĶĪ©(id,name)õĖŁķćŹÕżŹńÜäĶ«░ÕĮĢ ... -
µłæńÜäķØóĶ»ĢķóśµĆ╗ń╗ōõ╣ŗõĖē’╝ܵĄĘķćŵĢ░µŹ«µ¤źĶ»óõ╝śÕī¢(ń▓Š)’╝łĶĮ¼’╝ē
2010-05-16 15:21 2461┬Ā┬Ā┬Ā┬Ā┬Ā Ķ┐Öµś»µłæķØóĶ»ĢńÜäõĖ ...
ńøĖÕģ│µÄ©ĶŹÉ
µĢ░µŹ«Õ║ōń┤óÕ╝Ģµś»µĢ░µŹ«Õ║ōń«ĪńÉåń│╗ń╗¤õĖŁńö©õ║ÄÕŖĀķƤµĢ░µŹ«µŻĆń┤óńÜäõĖĆń¦ŹµĢ░µŹ«ń╗ōµ×ä’╝īÕ«āńÜäĶ«ŠĶ«Īńø«ńÜ䵜»õĖ║õ║åµÅÉķ½śµ¤źĶ»óµĢłńÄć’╝īÕćÅÕ░æµĢ░µŹ«Ķ«┐ķŚ«ńÜ䵌ČķŚ┤ŃĆéµ£¼µ¢ćÕ░åµĘ▒ÕģźµÄóĶ«©µĢ░µŹ«Õ║ōń┤óÕ╝ĢńÜäµ”éÕ┐ĄŃĆüB-TreeµĢ░µŹ«ń╗ōµ×äõ╗źÕÅŖń┤óÕ╝ĢńÜäÕłåń▒╗ÕÆīõĮ£ńö©ŃĆé ķ”¢Õģł’╝īB-Treeµś»...
### µĢ░µŹ«Õ║ōĶ«ŠĶ«Īµ╝½Ķ░łŌĆöŌĆöÕżÜÕ╣┤ńÜäń╗Åķ¬īµĆ╗ń╗ō #### õĖĆŃĆüõ╗Ćõ╣łµś»µĢ░µŹ«Õ║ō Õ£©Õ╝ĆÕ¦ŗĶ«©Ķ«║µĢ░µŹ«Õ║ōĶ«ŠĶ«Īõ╣ŗÕēŹ’╝īķ”¢ÕģłĶ”üµśÄńĪ«ŌĆ£õ╗Ćõ╣łµś»µĢ░µŹ«Õ║ōŌĆØŃĆéķĆÜÕĖĖµØźĶ»┤’╝īµĢ░µŹ«Õ║ōµś»µīćõĖĆń¦Źń╗äń╗ćÕī¢ńÜäµĢ░µŹ«ķøåÕÉł’╝īĶ┐Öõ║øµĢ░µŹ«ķĆÜĶ┐ćńē╣Õ«ÜńÜäµ¢╣Õ╝ÅĶ┐øĶĪīÕŁśÕé©ŃĆüń«ĪńÉåÕÆīĶ«┐ķŚ«...
OracleµĢ░µŹ«Õ║ōõ╝śÕī¢Ķ«ŠĶ«Īµ¢╣µĪłµś»õĖĆõĖ¬ÕżŹµØéĶĆīÕģ©ķØóńÜäĶ┐ćń©ŗ’╝īµČēÕÅŖÕł░µĢ░µŹ«Õ║ōńÜäÕżÜõĖ¬Õ▒éķØó’╝īÕīģµŗ¼ńĪ¼õ╗ČķģŹńĮ«ŃĆüµĢ░µŹ«Õ║ōń╗ōµ×äŃĆüÕåģÕŁśń«ĪńÉåŃĆüµĢ░µŹ«Ķ¦äĶīāõĖÄÕÅŹĶ¦äĶīāŃĆüń┤óÕ╝ĢĶ«ŠĶ«Īõ╗źÕÅŖÕ╣ČĶĪīÕżäńÉåńŁēŃĆéõ╗źõĖŗµś»Õ»╣Ķ┐Öõ║øµ¢╣ķØóńÜäĶ»”ń╗åĶ¦Żµ×É’╝Ü 1. **ń¦æÕŁ”ķģŹńĮ«ķĆ╗ĶŠæ...
### µĢ░µŹ«Õ║ōĶ«ŠĶ«Īµ╝½Ķ░ł’╝łń¼¼2ńēł’╝ē2011 #### 1. µĢ░µŹ«Õ║ōÕ¤║ńĪĆń¤źĶ»å **1.1 µĢ░µŹ«Õ║ōńÜäÕ«Üõ╣ē** µĢ░µŹ«Õ║ōµś»µīćķĆÜĶ┐ćńē╣իܵ¢╣Õ╝Åń╗äń╗ćĶĄĘµØźÕ╣ČÕŁśÕé©õ║ÄĶ«Īń«Śµ£║õĖŁńÜäÕż¦ķćŵĢ░µŹ«ķøåÕÉłŃĆéĶ┐Öõ║øµĢ░µŹ«ĶāĮÕż¤Ķó½Ķ┐ģķĆ¤Õ£░µŻĆń┤óŃĆüµø┤µ¢░õ╗źÕÅŖµē®Õ▒ĢŃĆéµĢ░µŹ«Õ║ōõĖŹõ╗ģõ╗ģÕīģµŗ¼...
ńÉåĶ¦Żń┤óÕ╝ĢńÜäÕĘźõĮ£ÕĤńÉå’╝īÕÉłńÉåõĮ┐ńö©ĶüÜķøåń┤óÕ╝ĢÕÆīķØ×ĶüÜķøåń┤óÕ╝Ģ’╝īõ╗źÕÅŖõĮĢµŚČõĮ┐ńö©Õö»õĖĆń┤óÕ╝ĢÕÆīķØ×Õö»õĖĆń┤óÕ╝Ģ’╝īĶāĮµśŠĶæŚµÅÉķ½śµĢ░µŹ«Õ║ōµĆ¦ĶāĮŃĆé 8. **õ║ŗÕŖĪÕżäńÉå**’╝ÜSQL Serverµö»µīüACID’╝łÕÄ¤ÕŁÉµĆ¦ŃĆüõĖĆĶć┤µĆ¦ŃĆüķÜöń”╗µĆ¦ÕÆīµīüõ╣ģµĆ¦’╝ēõ║ŗÕŖĪ’╝īńĪ«õ┐صĢ░µŹ«µōŹõĮ£ńÜä...
Õ«īÕģ©µüóÕżŹÕÅ»õ╗źµüóÕżŹµĢ┤õĖ¬µĢ░µŹ«Õ║ō’╝īÕīģµŗ¼µēƵ£ēµĢ░µŹ«ŃĆüĶĪ©ń╗ōµ×äÕÆīń┤óÕ╝ĢŃĆé õĖŹÕ«īÕģ©µüóÕżŹµś»µīćõ╗ÄÕżćõ╗ĮõĖŁµüóÕżŹķā©ÕłåµĢ░µŹ«’╝īķĆÜÕĖĖÕ£©ķā©ÕłåµĢ░µŹ«õĖóÕż▒µł¢µŹ¤ÕØŵŚČõĮ┐ńö©ŃĆéõĖŹÕ«īÕģ©µüóÕżŹÕÅ»õ╗źµüóÕżŹķā©ÕłåµĢ░µŹ«’╝īõŠŗՔ鵤ÉõĖ¬ĶĪ©µł¢µ¤ÉõĖ¬ÕłåÕī║ŃĆé ÕĮƵĪŻõĖÄķØ×ÕĮƵĪŻ Oracle ...
### µ╝½Ķ░łńł¼ĶÖ½µŖƵ£»õĖÄń╗ŵĄÄµĢ░µŹ«µöČķøå #### õĖĆŃĆüń╗ŵĄÄÕŁ”Õ«×Ķ»üńĀöń®ČõĖŁńÜäńĮæń╗£µĢ░µŹ«ÕÅŖńē╣ńé╣ Õ£©µĢ░ÕŁŚÕī¢µŚČõ╗Ż’╝īÕż¦µĢ░µŹ«ÕĘ▓ń╗ŵłÉõĖ║õ║åń╗ŵĄÄÕŁ”ńĀöń®ČńÜäķćŹĶ”üń╗䵳Éķā©ÕłåŃĆéķÜÅńØĆõ║ÆĶüöńĮæµŖƵ£»ńÜäĶ┐ģńīøÕÅæÕ▒Ģ’╝īń╗ŵĄÄµ┤╗ÕŖ©õ║¦ńö¤ńÜäµĢ░µŹ«ķćÅÕæłµīćµĢ░ń║¦Õó×ķĢ┐ŃĆéõŠŗÕ”é’╝ī...
ŃĆɵɣń┤óÕ╝Ģµōĵ╝½Ķ░łŃĆæ µÉ£ń┤óÕ╝Ģµōĵś»õ║ÆĶüöńĮæµŚČõ╗ŻńÜäµĀćÕ┐ŚµĆ¦õ║¦ńē®’╝īÕ«āµ×üÕż¦Õ£░µö╣ÕÅśõ║åõ║║õ╗¼ĶÄĘÕÅ¢õ┐Īµü»ńÜäµ¢╣Õ╝ÅŃĆéõ╗Äõ╝Āń╗¤ńÜäÕøŠõ╣”ķ”åµŻĆń┤óń│╗ń╗¤Õł░ńÄ░õ╗ŻńÜäńĮæń╗£µÉ£ń┤óÕ╝ĢµōÄ’╝īµŖƵ£»ńÜäµ╝öĶ┐øõĮ┐ÕŠŚõ┐Īµü»µŻĆń┤óńÜäµĢłńÄćÕÆīń▓ŠÕ║”Õż¦Õ╣ģµÅÉÕŹćŃĆé õ╝Āń╗¤µÉ£ń┤óÕ╝ĢµōÄ’╝īÕ”éµāģµŖźµŻĆń┤ó...
µ╝½Ķ░łÕłåÕĖāÕ╝ŵ×ȵ×ä ÕłØĶ»åÕłåÕĖāÕ╝ŵ×ȵ×äõĖĵäÅõ╣ē Õ”éõĮĢµŖŖÕ║öńö©õ╗ÄÕŹĢµ£║µē®Õ▒ĢÕł░ÕłåÕĖāÕ╝Å Õż¦Õ×ŗÕłåÕĖāÕ╝ŵ×ȵ×äµ╝öĶ┐øĶ┐ćń©ŗ ÕłåÕĖāÕ╝ŵ×ȵ×äĶ«ŠĶ«Ī õĖ╗µĄüµ×ȵ×䵩ĪÕ×ŗ-SOAµ×ȵ×äÕÆīÕŠ«µ£ŹÕŖĪµ×ȵ×ä ķóåÕ¤¤ķ®▒ÕŖ©Ķ«ŠĶ«ĪÕÅŖõĖÜÕŖĪķ®▒ÕŖ©Ķ¦äÕłÆ ÕłåÕĖāÕ╝ŵ×ȵ×äńÜäÕ¤║µ£¼ńÉåĶ«║CAPŃĆüBASE...
- **Õ║öńö©Õ£║µÖ»**’╝ܵɣń┤óÕ╝ĢµōÄŃĆüµĢ░µŹ«Õ║ōń┤óÕ╝Ģõ╝śÕī¢ńŁēŃĆé - **ń¼¼õ║īÕŹüõ║öń½Ā’╝Üõ║īÕłåµ¤źµēŠÕ«×ńÄ░** - **ń¤źĶ»åńé╣**’╝Üõ║īÕłåµ¤źµēŠń«Śµ│ĢŃĆé - **Õ║öńö©Õ£║µÖ»**’╝ܵ£ēÕ║ŵĢ░ń╗äõĖŁńÜäÕģāń┤Āµ¤źµēŠŃĆüń«Śµ│ĢµĢÖÕŁ”ńŁēŃĆé - **ń¼¼õ║īÕŹüÕģŁń½Ā’╝ÜÕ¤║õ║Äń╗ÖÕ«ÜńÜäµ¢ćµĪŻńö¤µłÉÕĆƵÄÆ...
3.2.2 Õå£Õ£║õ╣ŗBLOCKµ╝½Ķ░ł89 3.2.3 Õå£Õ£║õ╣ŗÕī║õĖĵ«Ą 91 3.2.4 Õå£Õ£║õ╣ŗĶĪ©ń®║ķŚ┤ńÜäÕłåń▒╗ 93 3.2.4.1 ĶĪ©ń®║ķŚ┤õĖÄń│╗ń╗¤Õå£Õ£║93 3.2.4.2 ĶĪ©ń®║ķŚ┤õĖÄõĖ┤µŚČÕå£Õ£║93 3.2.4.3 ĶĪ©ń®║ķŚ┤õĖÄÕø×µ╗ÜÕå£Õ£║94 3.2.5 ķĆ╗ĶŠæń╗ōµ×äõ╣ŗÕłØµ¼ĪõĮōõ╝Ü 94 3.2.5.1 ķĆ╗ĶŠæń╗ōµ×ä...
3. **ķĆÜÕÉæµ×ȵ×äÕĖłńÜäķüōĶĘ»(ń¼¼ÕģŁÕż®)õ╣ŗµ╝½Ķ░łÕ¤║õ║ĵĢ░µŹ«Õ║ōńÜäµØāķÖÉń│╗ń╗¤ńÜäĶ«ŠĶ«Ī.docx** µØāķÖÉń│╗ń╗¤µś»õ╗╗õĮĢÕż¦Õ×ŗÕ║öńö©ńÜäÕ¤║ńĪĆń╗äõ╗Č’╝īńĪ«õ┐صĢ░µŹ«ńÜäÕ«ēÕģ©Ķ«┐ķŚ«ŃĆ鵣żµ¢ćµĪŻÕÅ»ĶāĮĶ«©Ķ«║õ║åÕ”éõĮĢĶ«ŠĶ«ĪÕÆīÕ«×ńÄ░õĖĆõĖ¬Õ¤║õ║ĵĢ░µŹ«Õ║ōńÜäµØāķÖÉµÄ¦ÕłČµ©ĪÕ×ŗ’╝īµČĄńø¢õ║åńö©µłĘĶ¦ÆĶē▓...