载自:http://tech.it168.com/o/2007-11-05/200711051415515.shtml
一、LiveJournal发展历程
LiveJournal是99年始于校园中的项目,几个人出于爱好做了这样一个应用,以实现以下功能:
- 博客,论坛
- 社会性网络,找到朋友
-
聚合,把朋友的文章聚合在一起
LiveJournal采用了大量的开源软件,甚至它本身也是一个开源软件。
在上线后,LiveJournal实现了非常快速的增长:
- 2004年4月份:280万注册用户。
- 2005年4月份:680万注册用户。
- 2005年8月份:790万注册用户。
- 达到了每秒钟上千次的页面请求及处理。
- 使用了大量MySQL服务器。
-
使用了大量通用组件。
二、LiveJournal架构现状概况
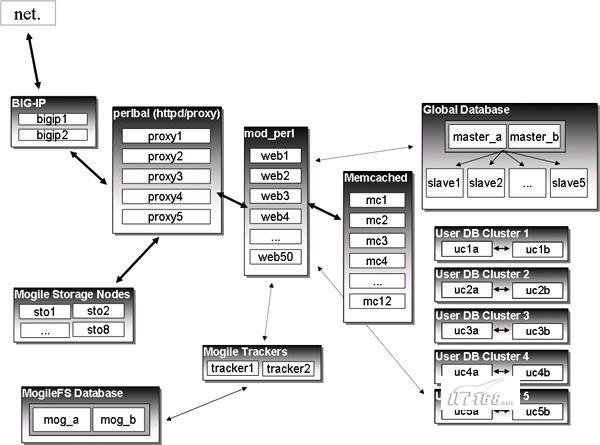
三、从LiveJournal发展中学习
LiveJournal从1台服务器发展到100台服务器,这其中经历了无数的伤痛,但同时也摸索出了解决这些问题的方法,通过对LiveJournal的学习,可以让我们避免LJ曾经犯过的错误,并且从一开始就对系统进行良好的设计,以避免后期的痛苦。
下面我们一步一步看LJ发展的脚步。
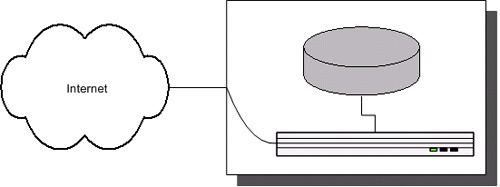
1、一台服务器
一台别人捐助的服务器,LJ最初就跑在上面,就像Google开始时候用的破服务器一样,值得我们尊敬。这个阶段,LJ的人以惊人的速度熟悉的Unix的操作管理,服务器性能出现过问题,不过还好,可以通过一些小修小改应付过去。在这个阶段里LJ把CGI升级到了FastCGI。
最终问题出现了,网站越来越慢,已经无法通过优过化来解决的地步,需要更多的服务器,这时LJ开始提供付费服务,可能是想通过这些钱来购买新的服务器,以解决当时的困境。
毫无疑问,当时LJ存在巨大的单点问题,所有的东西都在那台服务器的铁皮盒子里装着。
2、两台服务器
用付费服务赚来的钱LJ买了两台服务器:一台叫做Kenny的Dell 6U机器用于提供Web服务,一台叫做Cartman的Dell 6U服务器用于提供数据库服务。
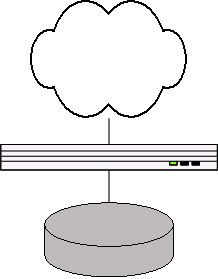
LJ有了更大的磁盘,更多的计算资源。但同时网络结构还是非常简单,每台机器两块网卡,Cartman通过内网为Kenny提供MySQL数据库服务。
暂时解决了负载的问题,新的问题又出现了:
- 原来的一个单点变成了两个单点。
- 没有冷备份或热备份。
- 网站速度慢的问题又开始出现了,没办法,增长太快了。
-
Web服务器上CPU达到上限,需要更多的Web服务器。
3、四台服务器
又买了两台,Kyle和Stan,这次都是1U的,都用于提供Web服务。目前LJ一共有3台Web服务器和一台数据库服务器。这时需要在3台Web服务器上进行负载均横。
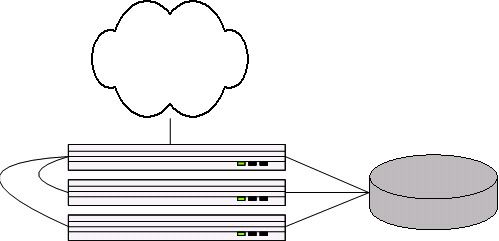
LJ把Kenny用于外部的网关,使用mod_backhand进行负载均横。
然后问题又出现了:
- 单点故障。数据库和用于做网关的Web服务器都是单点,一旦任何一台机器出现问题将导致所有服务不可用。虽然用于做网关的Web服务器可以通过保持心跳同步迅速切换,但还是无法解决数据库的单点,LJ当时也没做这个。
-
网站又变慢了,这次是因为IO和数据库的问题,问题是怎么往应用里面添加数据库呢?
4、五台服务器
又买了一台数据库服务器。在两台数据库服务器上使用了数据库同步(Mysql支持的Master-Slave模式),写操作全部针对主数据库(通过Binlog,主服务器上的写操作可以迅速同步到从服务器上),读操作在两个数据库上同时进行(也算是负载均横的一种吧)。
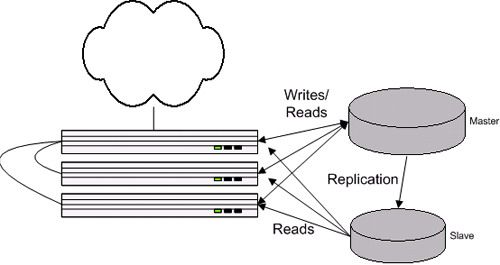
实现同步时要注意几个事项:
- 读操作数据库选择算法处理,要选一个当前负载轻一点的数据库。
- 在从数据库服务器上只能进行读操作
-
准备好应对同步过程中的延迟,处理不好可能会导致数据库同步的中断。只需要对写操作进行判断即可,读操作不存在同步问题。
5、更多服务器
有钱了,当然要多买些服务器。部署后快了没多久,又开始慢了。这次有更多的Web服务器,更多的数据库服务器,存在 IO与CPU争用。于是采用了BIG-IP作为负载均衡解决方案。
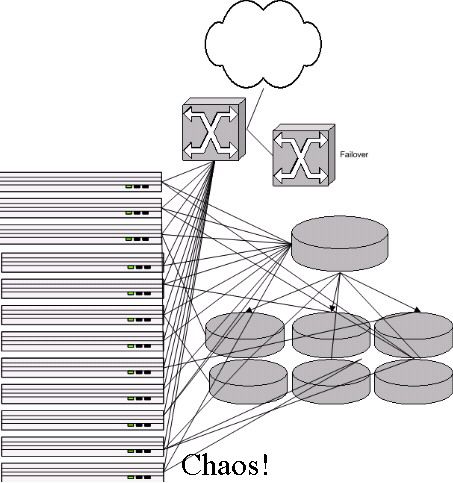
现在服务器基本上够了,但性能还是有问题,原因出在架构上。
数据库的架构是最大的问题。由于增加的数据库都是以Slave模式添加到应用内,这样唯一的好处就是将读操作分布到了多台机器,但这样带来的后果就是写操作被大量分发,每台机器都要执行,服务器越多,浪费就越大,随着写操作的增加,用于服务读操作的资源越来越少。
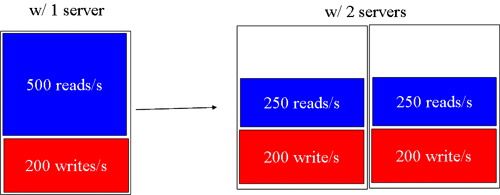
由一台分布到两台

最终效果
现在我们发现,我们并不需要把这些数据在如此多的服务器上都保留一份。服务器上已经做了RAID,数据库也进行了备份,这么多的备份完全是对资源的浪费,属于冗余极端过度。那为什么不把数据分布存储呢?
问题发现了,开始考虑如何解决。现在要做的就是把不同用户的数据分布到不同的服务器上进行存储,以实现数据的分布式存储,让每台机器只为相对固定的用户服务,以实现平行的架构和良好的可扩展性。
为了实现用户分组,我们需要为每一个用户分配一个组标记,用于标记此用户的数据存放在哪一组数据库服务器中。每组数据库由一个master及几个slave组成,并且slave的数量在2-3台,以实现系统资源的最合理分配,既保证数据读操作分布,又避免数据过度冗余以及同步操作对系统资源的过度消耗。
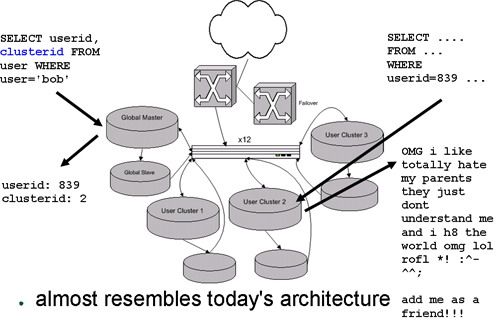
由一台(一组)中心服务器提供用户分组控制。所有用户的分组信息都存储在这台机器上,所有针对用户的操作需要先查询这台机器得到用户的组号,然后再到相应的数据库组中获取数据。
这样的用户架构与目前LJ的架构已经很相像了。
在具体的实现时需要注意几个问题:
- 在数据库组内不要使用自增ID,以便于以后在数据库组之间迁移用户,以实现更合理的I/O,磁盘空间及负载分布。
- 将userid,postid存储在全局服务器上,可以使用自增,数据库组中的相应值必须以全局服务器上的值为准。全局服务器上使用事务型数据库InnoDB。
-
在数据库组之间迁移用户时要万分小心,当迁移时用户不能有写操作。
7、现在我们在哪里
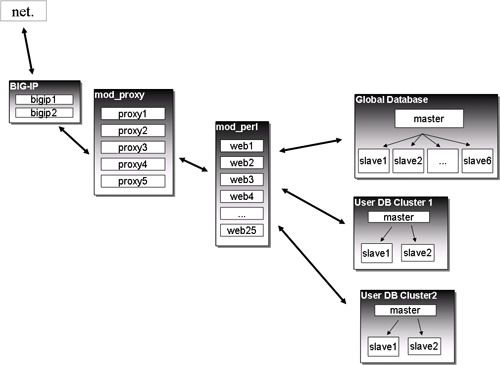
问题:
- 一个全局主服务器,挂掉的话所有用户注册及写操作就挂掉。
- 每个数据库组一个主服务器,挂掉的话这组用户的写操作就挂掉。
-
数据库组从服务器挂掉的话会导致其它服务器负载过大。
对于Master-Slave模式的单点问题,LJ采取了Master-Master模式来解决。所谓Master-Master实际上是人工实现的,并不是由MySQL直接提供的,实际上也就是两台机器同时是Master,也同时是Slave,互相同步。
Master-Master实现时需要注意:
- 一个Master出错后恢复同步,最好由服务器自动完成。
-
数字分配,由于同时在两台机器上写,有些ID可能会冲突。
解决方案:
- 奇偶数分配ID,一台机器上写奇数,一台机器上写偶数
-
通过全局服务器进行分配(LJ采用的做法)。
Master-Master模式还有一种用法,这种方法与前一种相比,仍然保持两台机器的同步,但只有一台机器提供服务(读和写),在每天晚上的时候进行轮换,或者出现问题的时候进行切换。
8、现在我们在哪里
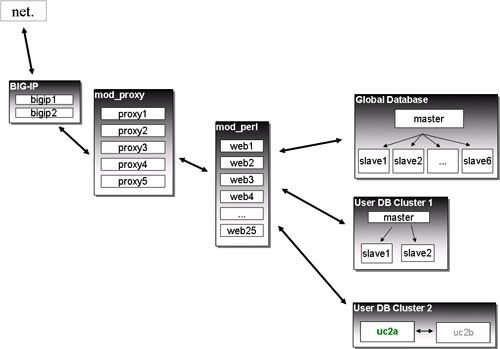
现在插播一条广告,MyISAM VS InnoDB。
使用InnoDB:
- 支持事务
-
需要做更多的配置,不过值得,可以更安全的存储数据,以及得到更快的速度。
使用MyISAM:
- 记录日志(LJ用它来记网络访问日志)
- 存储只读静态数据,足够快。
- 并发性很差,无法同时读写数据(添加数据可以)
-
MySQL非正常关闭或死机时会导致索引错误,需要使用myisamchk修复,而且当访问量大时出现非常频繁。
9、缓存
去年我写过一篇文章介绍memcached,它就是由LJ的团队开发的一款缓存工具,以key-value的方式将数据存储到分布的内存中。LJ缓存的数据:
- 12台独立服务器(不是捐赠的)
- 28个实例
- 30GB总容量
-
90-93%的命中率(用过squid的人可能知道,squid内存加磁盘的命中率大概在70-80%)
如何建立缓存策略?
想缓存所有的东西?那是不可能的,我们只需要缓存已经或者可能导致系统瓶颈的地方,最大程度的提交系统运行效率。通过对MySQL的日志的分析我们可以找到缓存的对象。
缓存的缺点?
- 没有完美的事物,缓存也有缺点:
- 增大开发量,需要针对缓存处理编写特殊的代码。
- 管理难度增加,需要更多人参与系统维护。
-
当然大内存也需要钱。
在数据包级别使用BIG-IP,但BIG-IP并不知道我们内部的处理机制,无法判断由哪台服务器对这些请求进行处理。反向代理并不能很好的起到作用,不是已经够快了,就是达不到我们想要的效果。
所以,LJ又开发了Perlbal。特点:
- 快,小,可管理的http web 服务器/代理
- 可以在内部进行转发
- 使用Perl开发
- 单线程,异步,基于事件,使用epoll , kqueue
- 支持Console管理与http远程管理,支持动态配置加载
- 多种模式:web服务器,反向代理,插件
-
支持插件:GIF/PNG互换?
11、MogileFS
LJ使用开源的MogileFS作为分布式文件存储系统。MogileFS使用非常简单,它的主要设计思想是:
- 文件属于类(类是最小的复制单位)
- 跟踪文件存储位置
- 在不同主机上存储
- 使用MySQL集群统一存储分布信息
-
大容易廉价磁盘
到目前为止就这么多了,更多文档可以在http://www.danga.com/words/找到。Danga.com和LiveJournal.com的同学们拿这个文档参加了两次MySQL Con,两次OS Con,以及众多的其它会议,无私的把他们的经验分享出来,值得我们学习。在web2.0时代快速开发得到大家越来越多的重视,但良好的设计仍是每一个应用的基础,希望web2.0们在成长为Top500网站的路上,不要因为架构阻碍了网站的发展。
分享到:





相关推荐
从LiveJournal后台发展看大规模网站性能优化方法 一、LiveJournal发展历程与背景 LiveJournal,一个始于1999年的校园项目,最初是由一群技术爱好者为了实现博客、论坛、社交网络以及文章聚合等功能而创立的。它的...
从LiveJournal后台发展看大规模网站性能优化方法 70 中国顶级门户网站架构分析1 116 中国顶级门户网站架构分析 2 118 服务器的大用户量的承载方案 120 YouTube Scalability Talk 121 资料收集:...
一、 web2.0网站常用可用性功能模块分析 二、 Flickr的幕后故事 三、 YouTube 的架构扩展 四、 mixi.jp:使用开源...七、 从LiveJournal后台发展看大规模网站性能优化方法 八、 说说大型高并发高负载网站的系统架构
- 文档《从LiveJournal后台发展看大规模网站性能优化方法》和其续篇深入分析了LiveJournal如何通过数据库优化、缓存策略、负载均衡以及代码重构来处理大规模用户流量。这涉及到数据库查询优化、分布式缓存如...
从LiveJournal后台发展看大规模网站性能优化方法 70 一、LiveJournal发展历程 70 二、LiveJournal架构现状概况 70 三、从LiveJournal发展中学习 71 1、一台服务器 71 2、两台服务器 72 3、四台服务器 73 4...
6. **从LiveJournal后台发展看大规模网站性能优化方法**:LiveJournal是一个早期的大型社交平台,其发展历程提供了许多关于处理高并发和大数据量的教训。文档可能包含内存缓存、异步处理、数据库优化等方面的经验...
使用memcached可以显著提高大规模互联网应用的性能,尤其是在处理高并发读写操作时。它降低了数据库的负载,减少了网络延迟,提供了更佳的响应时间。然而,memcached不适合长期存储数据,因为它会在内存耗尽时丢失...
为了解决这些问题,LiveJournal采用了Gearman来优化其后台架构。 1. **架构概览**: - **Web服务器**:通过Perlbal负载均衡器接收外部请求,并转发至后端的web服务器。 - **代理服务器**:用于缓存和加速请求响应...
- **小规模应用**:对于规模较小的应用程序,Memcached带来的性能提升可能不明显,反而可能因网络连接的开销而降低整体效率。 ##### 2.2 适用场合 - **作为数据库前端缓存**:Memcached最适合用于数据库前端的缓存...