
2гҖҒзҙўеј•дёӯз”ЁеҲ°зҡ„ж ёеҝғзұ»
еңЁLucene.Netзҙўеј•ејҖеҸ‘дёӯпјҢз”ЁеҲ°зҡ„зұ»дёҚеӨҡпјҢиҝҷдәӣзұ»жҳҜзҙўеј•иҝҮзЁӢзҡ„ж ёеҝғзұ»гҖӮе…¶дёӯAnalyzerжҳҜзҙўеј•е»әз«Ӣзҡ„еҹәзЎҖпјҢDirectoryжҳҜзҙўеј•е»әз«ӢдёӯжҲ–иҖ…е»әз«ӢеҘҪеӯҳеӮЁзҡ„д»ӢиҙЁпјҢDocumentе’ҢFieldзұ»жҳҜйҖ»иҫ‘з»“жһ„зҡ„ж ёеҝғпјҢIndexWriterжҳҜж“ҚдҪңзҡ„ж ёеҝғгҖӮе…¶д»–зұ»зҡ„дҪҝз”ЁйғҪиў«йҡҗи—ҸжҺүдәҶпјҢиҝҷд№ҹжҳҜдёәд»Җд№ҲLucene.NetдҪҝз”Ёиҝҷд№Ҳж–№дҫҝзҡ„еҺҹеӣ гҖӮ
В
2.1 Analyzer
еүҚйқўе·Із»ҸеҜ№AnalyzerиҝӣиЎҢдәҶеҫҲиҜҰз»Ҷзҡ„и®Іи§ЈпјҢAnalyzerе°ҶдјҡжҠҠдёҖж®өж–Үжң¬еҲҶжһҗз§°дёҖдёӘдёӘTokenгҖӮиҝҷдәӣTokenеҰӮдҪ•иў«IndexWriterдҪҝз”ЁпјҢиҝҷйҮҢзүөж¶үеҲ°дёҖдёӘеҫҲйҮҚиҰҒзҡ„зұ»пјҢйӮЈе°ұжҳҜDocumentsWriterгҖӮиҝҷдёӘзұ»йқһеёёе…ій”®пјҢеҸҜд»ҘиҜҙжҳҜзҙўеј•йғЁеҲҶжңҖж ёеҝғзҡ„зұ»пјҢIndexWriterеҸӘжҳҜе®ғзҡ„дёҖдёӘеҢ…иЈ…гҖӮиҝҷйҮҢдё»иҰҒд»Ӣз»Қеә”з”ЁпјҢжүҖд»Ҙе°ұдёҚеҒҡеӨӘиҜҰз»Ҷзҡ„д»Ӣз»ҚгҖӮTokenеңЁDocumentsWriterзұ»дёӯпјҢйҖҡиҝҮDocumentsWriterзҡ„жңҖйҮҚиҰҒзҡ„ж–№жі•вҖ”вҖ”InvertFieldвҖ”вҖ”жҺЁйҖҒеҲ°дәҶFieldдёӯгҖӮиҝҷж ·е°ұе®ҢжҲҗдәҶеҲҶиҜҚж·»еҠ еҲ°йҖ»иҫ‘з»“жһ„зҡ„иҝҮзЁӢгҖӮ
В
2.2 Directory
дёҘж јжқҘиҜҙпјҢDirectory并дёҚдё“еұһдәҺзҙўеј•пјҢе®ғд»ЈиЎЁзҡ„жҳҜLucene.Netзҡ„еӯҳеӮЁд»ӢиҙЁпјҢе®ғиЎЁзӨәдәҶзҙўеј•е…·дҪ“еӯҳж”ҫеҲ°д»Җд№Ҳең°ж–№гҖӮеңЁеүҚйқўзҡ„дёӨдёӘзӨәдҫӢдёӯдјјд№ҺжІЎжңүдҪҝз”ЁеҲ°е®ғпјҢйӮЈжҳҜеӣ дёәдҪ дј е…Ҙзҡ„и·Ҝеҫ„пјҢдјҡиҮӘеҠЁиҪ¬жҚўжҲҗDirectoryгҖӮDirectoryжңүдёӨдёӘеӯҗзұ»пјҢеҲҶеҲ«жҳҜRAMDirectoryвҖ”вҖ”д»ЈиЎЁзҙўеј•еӯҳж”ҫеҲ°еҶ…еӯҳдёӯпјҢе’ҢFSDirectoryвҖ”вҖ”д»ЈиЎЁзҙўеј•еӯҳж”ҫеҲ°зЎ¬зӣҳгҖӮеңЁдҪҝз”ЁFSDirectoryеӯҳж”ҫеҲ°зЎ¬зӣҳзҡ„иҝҮзЁӢдёӯпјҢиҝҳжҳҜдјҡи°ғз”ЁRAMDirectoryгҖӮIndexWriterдјҡжҠҠе»әз«Ӣзҡ„зҙўеј•е…Ҳж”ҫеҲ°RAMDirectoryпјҢ然еҗҺеҲ°дёҖе®ҡзҡ„жқЎд»¶пјҢжүҚе°Ҷиҝҷдәӣж•°жҚ®еҶҷе…ҘзЎ¬зӣҳгҖӮ
В
2.3 IndexWriter
IndexWriterжҳҜзҙўеј•дёӯиҙҹиҙЈж“ҚдҪңзҡ„ж ёеҝғпјҢе®ғиҙҹиҙЈжҠҠзҙўеј•ж–Ү件еҶҷе…ҘеӯҳеӮЁд»ӢиҙЁпјҢжҳҜжҺ§еҲ¶йҖ»иҫ‘еӯҳеӮЁиҪ¬жҚўдёәзү©зҗҶеӯҳеӮЁзҡ„зәҪеёҰгҖӮ
IndexWriterе…ұжңү10дёӘеҸҜд»ҘдҪҝз”Ёзҡ„жһ„йҖ еҮҪж•°пјҢдҪҶжҳҜ他们зҡ„еҸӮж•°зұ»еһӢжҜ”иҫғе°‘гҖӮдёҖе…ұжңүд»ҘдёӢеҮ з§Қпјҡ
В
пјҲ1пјүгҖҒDirectory dпјӣ
пјҲ2пјүгҖҒAnalyzer aпјӣ
пјҲ3пјүгҖҒbool create;
пјҲ4пјүгҖҒFileInfo pathпјӣ
пјҲ5пјүгҖҒstring pathпјӣ
пјҲ6пјүгҖҒbool autoCommitпјӣ
пјҲ7пјүгҖҒIndexDeletionPolicy deletionPolicyпјӣ
В
е…¶дёӯ6пјҢ7дёҚеёёз”ЁгҖӮиҖҢFileInfo pathе’Ңstring pathжңҖз»ҲйғҪдјҡжһ„йҖ жҲҗDirectoryпјҢеҸҲеӣ дёәиҝҷдёӨз§Қи·Ҝеҫ„йғҪжҳҜзЈҒзӣҳзҡ„и·Ҝеҫ„пјҢжүҖд»Ҙжһ„йҖ еҮәжқҘзҡ„DirectoryдёҖе®ҡжҳҜFSDrectoryгҖӮbool createиЎЁзӨәжҳҜеҗҰжҳҜеҲӣе»әпјҢеҗҰеҲҷжҳҜеўһйҮҸжӣҙж–°пјҢй»ҳи®ӨзҠ¶жҖҒжҳҜfalseгҖӮbool autoCommitдёҚеёёз”ЁпјҢжҳҜз”ЁжқҘжҢҮе®ҡжҳҜеҗҰеҪ“зҙўеј•еңЁcloseзҠ¶жҖҒдёӢжүҚжӣҙж–°зҡ„пјҢеҰӮжһңжҳҜfalse,еҲҷйңҖиҰҒеңЁcloseзҠ¶жҖҒдёӢжӣҙж–°гҖӮIndexDeletionPolicy deletionPolicyеҲҷжҳҜжҢҮе®ҡжҳҜеҗҰеҜ№д»ҘеүҚзҡ„жӣҙж–°иҝӣиЎҢ移йҷӨпјҢе®ғиғҪиЎЁзӨәдёәдёӨдёӘеҖјпјҢKeepOnlyLastCommitDeletionPolicyе’ҢSnapshotDeletionPolicyпјҢй»ҳи®ӨзҠ¶жҖҒдёӢжҳҜпјҢKeepOnlyLastCommitDeletionPolicyгҖӮ
В
В
2.4 Document
Documentе°ұжҳҜдёҖжқЎиҷҡжӢҹи®°еҪ•пјҢеҸҜд»ҘзҗҶи§Јдёәж•°жҚ®йҮҢзҡ„дёҖиЎҢгҖӮжӯЈжҳҜжңүдәҶе®ғпјҢжүҚдҪҝжҲ‘们еҸҜд»ҘеҫҲж–№дҫҝ并且жҳ“дәҺзҗҶи§Јең°ж“ҚдҪңзҙўеј•ж–Ү件гҖӮе®ғдёҖиҲ¬и®°еҪ•дәҶйңҖиҰҒз”ЁеҲ°зҡ„дёҖдёӘж–ҮжЎЈзҡ„еұһжҖ§пјҢеҪ“然пјҢиҝҷйңҖиҰҒе’ҢFieldиҒ”еҗҲдҪҝз”ЁгҖӮ
В
2.5 Field
Fieldзұ»е°ұжҳҜж•°жҚ®еә“йҮҢзҡ„дёҖеҲ—гҖӮдёҖдёӘж–ҮжЎЈжңүж ҮйўҳпјҢеҶ…е®№пјҢдҪңиҖ…пјҢеҲӣе»әж—¶й—ҙиҝҷеӣӣдёӘеұһжҖ§зҡ„иҜқпјҢйӮЈд№Ҳе°ұйңҖиҰҒеӣӣдёӘFieldдҝқеӯҳиҝҷдәӣеұһжҖ§пјҢ然еҗҺжҠҠеӣӣдёӘFieldеҠ е…ҘеҲ°DocumentдёӯпјҢе°ұжңүдәҶдёҖиЎҢи®°еҪ•гҖӮеңЁжҹҘиҜўзҡ„ж—¶еҖҷпјҢж— и®әжҹҘйӮЈдёӘеҲ—пјҢжҖ»иғҪеҫ—еҲ°дёҖж•ҙиЎҢи®°еҪ•пјҢжҳҜдёҚжҳҜе’Ңж•°жҚ®еә“еҫҲзӣёдјјпјҹ
Fieldжң¬иә«е…·жңүдёҖдәӣеұһжҖ§пјҢе°ұе’Ңж•°жҚ®еә“йҮҢзҡ„еҲ—дёҖж ·гҖӮе®ғзҡ„еұһжҖ§йҖҡиҝҮе®ғзҡ„дёүдёӘеҶ…еөҢзұ»и®ҫзҪ®пјҢе…¶е®һиҝҷдёӘең°ж–№е®Ңе…ЁеҸҜд»Ҙз”ЁжһҡдёҫпјҢдҪҶжҳҜеҫҲйҒ—жҶҫзҡ„жҳҜJavaйҮҢйқўжІЎжңүжһҡдёҫпјҢжүҖд»Ҙ移жӨҚиҝҮжқҘд№ҹжІЎжңүиҪ¬жҚўдёәжһҡдёҫгҖӮ
Fieldзҡ„жһ„йҖ еҮҪж•°д№ҹжҜ”иҫғеӨҡпјҢжңү7дёӘд№ӢеӨҡгҖӮе…¶дёӯStoreпјҢIndexе’ҢTermVectorжҳҜйҖҡиҝҮеҶ…йғЁзұ»жҢҮе®ҡзҡ„гҖӮ
пјҲ1пјүгҖҒStore жңүдёүдёӘйҖүйЎ№пјҢField.Store.COMPRESSиЎЁзӨәиў«еҺӢзј©еӯҳеӮЁпјӣField.Store.YESиЎЁзӨәеӮЁеӯҳпјӣField.Store.NOиЎЁзӨәдёҚиў«еӯҳеӮЁгҖӮ
пјҲ2пјүгҖҒIndexзҡ„йҖүйЎ№жңүеӣӣдёӘпјҢField.Index.NOиЎЁзӨәдёҚе»әз«Ӣзҙўеј•пјӣField.Index.TOKENIZEDиЎЁзӨәеҲҶиҜҚеҗҺзҙўеј•пјӣIndex.NO_NORMSиЎЁзӨәеҖјеӯҳеӮЁеҶ…е®№пјӣField.Index.UN_TOKENIZEDиЎЁзӨәдёҚеҲҶиҜҚзҙўеј•гҖӮ
пјҲ3пјүгҖҒTermVectorиҝҷдёӘеҸӮж•°д№ҹдёҚеёёз”ЁпјҢе®ғжңүдә”дёӘйҖүйЎ№гҖӮField.TermVector.NOиЎЁзӨәдёҚзҙўеј•Tokenзҡ„дҪҚзҪ®еұһжҖ§пјӣField.TermVector.WITH_OFFSETSиЎЁзӨәйўқеӨ–зҙўеј•Tokenзҡ„з»“жқҹзӮ№пјӣField.TermVector.WITH_POSITIONSиЎЁзӨәйўқеӨ–зҙўеј•Tokenзҡ„еҪ“еүҚдҪҚзҪ®пјӣField.TermVector.WITH_POSITIONS_OFFSETSиЎЁзӨәйўқеӨ–зҙўеј•Tokenзҡ„еҪ“еүҚе’Ңз»“жқҹдҪҚзҪ®пјӣField.TermVector.YESеҲҷиЎЁзӨәеӯҳеӮЁеҗ‘йҮҸгҖӮ
В
В
В
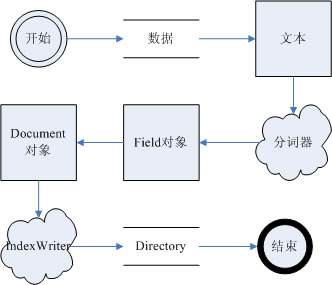
2.6 зҙўеј•ж ёеҝғзұ»е·ҘдҪңжөҒзЁӢ
В
В
еӣҫ 2.6.1
В
В
В еҰӮеӣҫ2.6.1иЎЁзӨәдәҶж•°жҚ®еңЁLucene.Netзҙўеј•иҝҮзЁӢеӨ„зҗҶзҡ„ж•ҙдёӘжөҒзЁӢгҖӮжіЁж„ҸпјҢиҝҷдёӘжөҒзЁӢеӣҫдёӯпјҢеҲҶиҜҚеҷЁе№¶дёҚзӣҙжҺҘдә§з”ҹFieldеҜ№иұЎпјҢеңЁе®һдҫӢдёӯAnalyzerжҳҜиў«иөӢдәҲIndexWriterе®һдҫӢзҡ„пјҢзӯүзӯүжү§иЎҢж·»еҠ ж–ҮжЎЈж“ҚдҪңзҡ„ж—¶еҖҷпјҢIndexWriterжүҚдјҡзңҹжӯЈең°и°ғз”ЁеҲҶиҜҚеҷЁз”ҹжҲҗFieldйңҖиҰҒзҡ„ж•°жҚ®пјҲеңЁDocumentWriterзұ»дёӯпјүгҖӮдёҠеӣҫеҸӘжҳҜеҸҚжҳ дәҶж•°жҚ®жҳҜеҰӮдҪ•жөҒеҠЁзҡ„пјҢ并дёҚжҳҜзңҹе®һзҡ„и°ғз”ЁиҝҮзЁӢгҖӮ
В
В
В



зӣёе…іжҺЁиҚҗ
Lucene.Net 2.3.1ејҖеҸ‘д»Ӣз»Қ вҖ”вҖ” дәҢгҖҒеҲҶиҜҚпјҲеӣӣпјүпјҢиҝҷжҳҜдёҖдёӘзі»еҲ—зҡ„ж–ҮжЎЈпјҢеӨӘеӨҡдәҶпјҢеҸӘеҘҪеҲҶејҖ
иҝҷдёӘж–ҮжЎЈеҜ№luceneиҝӣиЎҢдәҶд»Ӣз»Қ并且иҝӣиЎҢж·ұе…Ҙзҡ„дҪҝз”ЁпјҢж–ҮжЎЈеҲҶејҖеҸ‘дәҶпјҢзҪ‘з»ңеӨӘж…ўдәҶгҖӮгҖӮгҖӮ
lucene.net2.3.1ејҖжәҗйЎ№зӣ® luceneжҳҜдёҖдёӘејҖжәҗзҡ„е…Ёж–ҮжЈҖзҙўйЎ№зӣ®пјҢеҺҹжң¬жҳҜjavaзүҲзҡ„пјҢеҗҺжқҘе°ұжңүдәҶ.netзүҲпјҢжҲ‘дёҠдј зҡ„иҝҷдёӘжҳҜ.netзҡ„2.3.1зүҲжң¬,её®еҠ©еӨ§е®¶и§ЈеҶіе…Ёж–ҮжЈҖзҙўеј•ж“ҺгҖӮ
lucene.net2.3.1ејҖжәҗйЎ№зӣ® luceneжҳҜдёҖдёӘејҖжәҗзҡ„е…Ёж–ҮжЈҖзҙўйЎ№зӣ®пјҢеҺҹжң¬жҳҜjavaзүҲзҡ„пјҢеҗҺжқҘе°ұжңүдәҶ.netзүҲпјҢжҲ‘дёҠдј зҡ„иҝҷдёӘжҳҜ.netзҡ„2.3.1зүҲжң¬гҖӮи§ЈеҶіе…Ёж–ҮжЈҖзҙўеј•ж“ҺгҖӮжӯӨдёәдёҖйғЁеҲҶпјҢдәҢйғЁеҲҶжү“ејҖең°еқҖ...
1. **зҙўеј•еҲӣе»әдёҺз®ЎзҗҶ**пјҡLucene.Net жҸҗдҫӣдәҶй«ҳж•Ҳзҡ„зҙўеј•еҲӣе»әе·Ҙе…·пјҢеҸҜд»Ҙеҝ«йҖҹең°еҜ№еӨ§йҮҸж–Үжң¬ж•°жҚ®иҝӣиЎҢзҙўеј•пјҢж”ҜжҢҒеўһйҮҸзҙўеј•е’Ңе®һж—¶зҙўеј•гҖӮ 2. **жҹҘиҜўи§Јжһҗ**пјҡе®ғеҶ…зҪ®дәҶејәеӨ§зҡ„жҹҘиҜўиҜӯиЁҖпјҢиғҪеӨҹи§Јжһҗз”ЁжҲ·иҫ“е…Ҙзҡ„иҮӘ然иҜӯиЁҖжҹҘиҜўпјҢ并иҪ¬еҢ–дёә...
дҪҝз”Ё Lucene.NET 2.3.1 ејҖеҸ‘ еңЁејҖеҸ‘иҝҮзЁӢдёӯпјҢејҖеҸ‘иҖ…еҸҜд»ҘжҢүз…§д»ҘдёӢжӯҘйӘӨж“ҚдҪңпјҡ 1. **е®үиЈ…дёҺеј•з”Ё**пјҡйҰ–е…ҲпјҢйңҖиҰҒе°Ҷ Lucene.NET 2.3.1 еә“ж·»еҠ еҲ°йЎ№зӣ®дёӯпјҢеҸҜд»ҘйҖҡиҝҮ NuGet еҢ…з®ЎзҗҶеҷЁиҝӣиЎҢе®үиЈ…гҖӮ 2. **еҲӣе»әзҙўеј•**пјҡдҪҝз”Ё `...
йҖҡиҝҮеҲҶжһҗе…¶жәҗз ҒпјҢжҲ‘们еҸҜд»Ҙж·ұе…ҘдәҶи§Ј Lucene.Net зҡ„е·ҘдҪңеҺҹзҗҶпјҢжҸҗеҚҮеңЁжҗңзҙўе’Ңзҙўеј•йўҶеҹҹзҡ„жҠҖиғҪгҖӮ 1. **Lucene.Net.Search.TestSort.config** иҝҷдёӘж–Ү件еҸҜиғҪжҳҜжөӢиҜ•жҺ’еәҸзҡ„й…ҚзҪ®ж–Ү件пјҢз”ЁдәҺи®ҫзҪ® Lucene.Net еңЁжү§иЎҢжҗңзҙўж—¶еҰӮдҪ•еҜ№...
2. **й…ҚзҪ®еҲҶиҜҚеҷЁ**пјҡеңЁLucene.NETзҡ„зҙўеј•еҲӣе»әйҳ¶ж®өпјҢйңҖиҰҒй…ҚзҪ®Analyzerзұ»пјҢжҢҮе®ҡдҪҝз”Ёзү№е®ҡзҡ„еҲҶиҜҚеҷЁгҖӮдҫӢеҰӮпјҢдҪҝз”ЁIK AnalyzerеҸҜд»ҘеҲӣе»ә`IKAnalyzer analyzer = new IKAnalyzer();`гҖӮ 3. **еӯ—ж®өеҲҶжһҗ**пјҡеңЁеҲӣе»әDocumentеҜ№иұЎж—¶...
еңЁиҝҷдёӘе®һдҫӢдёӯпјҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁеҰӮдҪ•дҪҝз”ЁLucene.NET 2.9.2жқҘе®һзҺ°зҙўеј•зҡ„з”ҹжҲҗгҖҒдҝ®ж”№гҖҒжҹҘиҜўе’ҢеҲ йҷӨгҖӮ **дёҖгҖҒзҙўеј•з”ҹжҲҗ** йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒеҲӣе»әдёҖдёӘзҙўеј•пјҢиҝҷжҳҜе…Ёж–ҮжЈҖзҙўзҡ„еҹәзЎҖгҖӮеңЁLucene.NETдёӯпјҢжҲ‘们йҖҡеёёдјҡе®ҡд№үдёҖдёӘж–ҮжЎЈзұ»пјҢ...
ж ҮйўҳжҸҗеҲ°зҡ„"Lucene.Netзҡ„DLL"жҳҜжҢҮеҹәдәҺ.NETе№іеҸ°зҡ„е…Ёж–Үжҗңзҙўеј•ж“Һеә“вҖ”вҖ”Lucene.NetгҖӮиҝҷдёӘеә“жҳҜApache LuceneйЎ№зӣ®зҡ„дёҖдёӘ移жӨҚзүҲжң¬пјҢдё“дёә.NET Frameworkе’Ң.NET CoreејҖеҸ‘иҖ…и®ҫи®ЎпјҢжҸҗдҫӣдәҶејәеӨ§зҡ„ж–Үжң¬жЈҖзҙўе’ҢжҗңзҙўеҠҹиғҪгҖӮLucene.Net...
4. **й«ҳж•ҲеӯҳеӮЁ**пјҡLucene.NetдҪҝз”ЁеҖ’жҺ’зҙўеј•жҠҖжңҜпјҢжһҒеӨ§ең°жҸҗй«ҳдәҶжҗңзҙўйҖҹеәҰгҖӮеҗҢж—¶пјҢе®ғиҝҳж”ҜжҢҒеҺӢзј©пјҢд»ҘеҮҸе°‘зЈҒзӣҳз©әй—ҙеҚ з”ЁгҖӮ 5. **еҶ…еӯҳдјҳеҢ–**пјҡLucene.NetеңЁеҶ…еӯҳз®ЎзҗҶе’Ңзј“еӯҳзӯ–з•ҘдёҠиҝӣиЎҢдәҶдјҳеҢ–пјҢиғҪеңЁеӨ§и§„жЁЎж•°жҚ®йӣҶдёҠдҝқжҢҒиүҜеҘҪзҡ„...
йҰ–е…ҲпјҢжҲ‘们иҰҒзҗҶи§ЈLucene.Net.dllзҡ„ж ёеҝғ组件д№ӢдёҖвҖ”вҖ”зҙўеј•гҖӮеңЁLucene.NetдёӯпјҢзҙўеј•жҳҜж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўзҡ„еҹәзЎҖгҖӮе®ғйҖҡиҝҮеҲҶиҜҚгҖҒе»әз«ӢеҖ’жҺ’зҙўеј•зӯүиҝҮзЁӢпјҢе°ҶеҺҹе§Ӣж–Үжң¬иҪ¬еҢ–дёәеҸҜеҝ«йҖҹжҹҘиҜўзҡ„ж•°жҚ®з»“жһ„гҖӮеҲҶиҜҚеҷЁпјҲAnalyzerпјүиҙҹиҙЈе°Ҷж–Үжң¬еҲҶи§Ј...
**дәҢгҖҒLucene.netжәҗз ҒеҲҶжһҗ** жәҗз ҒеҲҶжһҗжҳҜеӯҰд№ Lucene.netзҡ„йҮҚиҰҒзҺҜиҠӮгҖӮйҖҡиҝҮйҳ…иҜ»жәҗз ҒпјҢдҪ еҸҜд»ҘдәҶи§Је…¶еҶ…йғЁе·ҘдҪңеҺҹзҗҶпјҢеҢ…жӢ¬еҲҶиҜҚеҷЁпјҲTokenizerпјүеҰӮдҪ•е°Ҷж–Үжң¬еҲҶеүІжҲҗиҜҚе…ғпјҢзҙўеј•еҷЁпјҲIndexWriterпјүеҰӮдҪ•жһ„е»әзҙўеј•пјҢд»ҘеҸҠжҗңзҙўеҷЁ...
еҹәдәҺLucene.netзҡ„еӣӣдёӘзүҲжң¬пјҲжӣҙж–°иҮі2018.1.26 пјү ------------------------------- Lucene.Net.2.9.2.2-ж”ҜжҢҒ.net2.0е’Ң4.0пјӣ Lucene.Net.2.9.4.1 д»…ж”ҜжҢҒ.net4.0; Lucene.Net.3.0.3 zж”ҜжҢҒ3.5е’Ң4.0пјӣ Lucene.Net.4.8.0-...
гҖҠеҹәдәҺLucene.NetејҖеҸ‘зҡ„дёӘдәәзҹҘиҜҶеә“гҖӢ еңЁдҝЎжҒҜжҠҖжңҜйўҶеҹҹпјҢй«ҳж•Ҳзҡ„дҝЎжҒҜжЈҖзҙўе’Ңз®ЎзҗҶжҳҜиҮіе…ійҮҚиҰҒзҡ„гҖӮLucene.NetпјҢдҪңдёәApache LuceneйЎ№зӣ®зҡ„дёҖдёӘ.NETзүҲжң¬пјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶејәеӨ§зҡ„е…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢдҪҝеҫ—ејҖеҸ‘иҖ…иғҪеӨҹиҪ»жқҫжһ„е»әиҮӘе·ұзҡ„...
гҖҠж·ұе…Ҙеү–жһҗLucene.NET 2.9.1пјҡжәҗз Ғи§ЈжһҗдёҺеә”з”ЁејҖеҸ‘гҖӢ Lucene.NET 2.9.1жҳҜејҖжәҗжҗңзҙўеј•ж“Һеә“Luceneзҡ„.NETзүҲжң¬пјҢе®ғдёә.NETејҖеҸ‘иҖ…жҸҗдҫӣдәҶејәеӨ§зҡ„е…Ёж–ҮжЈҖзҙўе’Ңзҙўеј•еҠҹиғҪгҖӮиҝҷдёӘзүҲжң¬зҡ„жәҗз ҒжҸҗдҫӣдәҶдёҖдёӘе®қиҙөзҡ„иө„жәҗпјҢеё®еҠ©жҲ‘们зҗҶи§Је…¶еҶ…йғЁ...
2. зҙўеј•пјҲIndexпјүпјҡзҙўеј•жҳҜLucene.Netзҡ„ж ёеҝғпјҢе®ғе°Ҷж–ҮжЎЈеҶ…е®№иҪ¬еҢ–дёәеҖ’жҺ’зҙўеј•з»“жһ„пјҢдҫҝдәҺеҝ«йҖҹжҹҘжүҫеҢ…еҗ«зү№е®ҡиҜҚжұҮзҡ„ж–ҮжЎЈгҖӮзҙўеј•иҝҮзЁӢеҢ…жӢ¬еӯ—ж®өеҲ’еҲҶгҖҒеҲҶжһҗгҖҒе»әз«ӢиҜҚе…ёе’ҢеҖ’жҺ’иЎЁзӯүжӯҘйӘӨгҖӮ 3. ж–ҮжЎЈпјҲDocumentпјүпјҡж–ҮжЎЈжҳҜзҙўеј•зҡ„еҹәжң¬...
еңЁVS2012зҺҜеўғдёӢејҖеҸ‘Lucene.Net + зӣҳеҸӨеҲҶиҜҚзҡ„жҗңзҙўеј•ж“ҺпјҢйҰ–е…ҲйңҖиҰҒе®үиЈ…Lucene.Netзҡ„NuGetеҢ…пјҢ并确дҝқдёҺйЎ№зӣ®зҡ„.NETзүҲжң¬е…је®№гҖӮ然еҗҺпјҢеҜје…ҘзӣҳеҸӨеҲҶиҜҚеә“пјҢеҸҜд»ҘйҖҡиҝҮдёӢиҪҪжәҗз Ғзј–иҜ‘жҲ–еҜ»жүҫйў„зј–иҜ‘зҡ„DLLж–Ү件гҖӮеңЁйЎ№зӣ®дёӯпјҢдҪ йңҖиҰҒеҲӣе»ә...
Lucene.net жҳҜ Lucene жЎҶжһ¶й’ҲеҜ№ .NET е№іеҸ°зҡ„移жӨҚзүҲжң¬пјҢжҳҜдёҖдёӘй«ҳеәҰеҸҜжү©еұ•зҡ„е…Ёж–ҮжЈҖзҙўеј•ж“ҺејҖеҸ‘е·Ҙе…·еҢ…гҖӮе®ғ并дёҚзӣҙжҺҘжҸҗдҫӣдёҖдёӘе®Ңж•ҙзҡ„е…Ёж–ҮжЈҖзҙўжңҚеҠЎпјҢиҖҢжҳҜдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶдёҖеҘ—жһ„е»әй«ҳж•ҲгҖҒзҒөжҙ»зҡ„жҗңзҙўеј•ж“Һзҡ„еҹәзЎҖжһ¶жһ„гҖӮйҖҡиҝҮ Lucene...