
зРЖиІ£MySQLвАФвАФ糥еЉХдЄОдЉШеМЦ
еЖЩеЬ®еЙНйЭҐпЉЪ糥еЉХеѓєжߕ胥зЪДйАЯеЇ¶жЬЙзЭАиЗ≥еЕ≥йЗНи¶БзЪДељ±еУНпЉМзРЖиІ£зіҐеЉХдєЯжШѓињЫи°МжХ∞жНЃеЇУжАІиГљи∞ГдЉШзЪДиµЈзВєгАВиАГиЩСе¶ВдЄЛжГЕеЖµпЉМеБЗиЃЊжХ∞жНЃеЇУдЄ≠дЄАдЄ™и°®жЬЙ10^6жЭ°иЃ∞ељХпЉМDBMSзЪДй°µйЭҐе§Іе∞ПдЄЇ4KпЉМеєґе≠ШеВ®100жЭ°иЃ∞ељХгАВе¶ВжЮЬж≤°жЬЙ糥еЉХпЉМжߕ胥е∞ЖеѓєжХідЄ™и°®ињЫи°МжЙЂжППпЉМжЬАеЭПзЪДжГЕеЖµдЄЛпЉМе¶ВжЮЬжЙАжЬЙжХ∞жНЃй°µйГљдЄНеЬ®еЖЕе≠ШпЉМйЬАи¶БиѓїеПЦ10^4дЄ™й°µйЭҐпЉМе¶ВжЮЬињЩ10^4дЄ™й°µйЭҐеЬ®з£БзЫШдЄКйЪПжЬЇеИЖеЄГпЉМйЬАи¶БињЫи°М10^4жђ°I/OпЉМеБЗиЃЊз£БзЫШжѓПжђ°I/OжЧґйЧідЄЇ10ms(ењљзХ•жХ∞жНЃдЉ†иЊУжЧґйЧі)пЉМеИЩжАїеЕ±йЬАи¶Б100s(дљЖеЃЮйЩЕдЄКи¶Бе•љеЊИе§ЪеЊИе§Ъ)гАВе¶ВжЮЬеѓєдєЛеїЇзЂЛB-Tree糥еЉХпЉМеИЩеП™йЬАи¶БињЫи°Мlog100(10^6)=3жђ°й°µйЭҐиѓїеПЦпЉМжЬАеЭПжГЕеЖµдЄЛиАЧжЧґ30msгАВињЩе∞±ж؃糥еЉХеЄ¶жЭ•зЪДжХИжЮЬпЉМеЊИе§ЪжЧґеАЩпЉМељУдљ†зЪДеЇФзФ®з®ЛеЇПињЫи°МSQLжߕ胥йАЯеЇ¶еЊИжЕҐжЧґпЉМеЇФиѓ•жГ≥жГ≥жШѓеР¶еσ俕忯糥еЉХгАВињЫеЕ•ж≠£йҐШпЉЪ
зђђдЇМзЂ†гАБ糥еЉХдЄОдЉШеМЦ
1гАБйАЙж˩糥еЉХзЪДжХ∞жНЃз±їеЮЛ
MySQLжФѓжМБеЊИе§ЪжХ∞жНЃз±їеЮЛпЉМйАЙжЛ©еРИйАВзЪДжХ∞жНЃз±їеЮЛе≠ШеВ®жХ∞жНЃеѓєжАІиГљжЬЙеЊИе§ІзЪДељ±еУНгАВйАЪеЄЄжЭ•иѓіпЉМеПѓдї•йБµеЊ™дї•дЄЛдЄАдЇЫжМЗеѓЉеОЯеИЩпЉЪ
(1)иґКе∞ПзЪДжХ∞жНЃз±їеЮЛйАЪеЄЄжЫіе•љпЉЪиґКе∞ПзЪДжХ∞жНЃз±їеЮЛйАЪеЄЄеЬ®з£БзЫШгАБеЖЕе≠ШеТМCPUзЉУе≠ШдЄ≠йГљйЬАи¶БжЫіе∞СзЪДз©ЇйЧіпЉМе§ДзРЖиµЈжЭ•жЫіењЂгАВ(2)зЃАеНХзЪДжХ∞жНЃз±їеЮЛжЫіе•љпЉЪжХіеЮЛжХ∞жНЃжѓФиµЈе≠Чзђ¶пЉМе§ДзРЖеЉАйФАжЫіе∞ПпЉМеЫ†дЄЇе≠Чзђ¶дЄ≤зЪДжѓФиЊГжЫіе§НжЭВгАВеЬ®MySQLдЄ≠пЉМеЇФиѓ•зФ®еЖЕзљЃзЪДжЧ•жЬЯеТМжЧґйЧіжХ∞жНЃз±їеЮЛпЉМиАМдЄНжШѓзФ®е≠Чзђ¶дЄ≤жЭ•е≠ШеВ®жЧґйЧіпЉЫдї•еПКзФ®жХіеЮЛжХ∞жНЃз±їеЮЛе≠ШеВ®IPеЬ∞еЭАгАВ
(3)е∞љйЗПйБњеЕНNULLпЉЪеЇФиѓ•жМЗеЃЪеИЧдЄЇNOT NULLпЉМйЩ§йЭЮдљ†жГ≥е≠ШеВ®NULLгАВеЬ®MySQLдЄ≠пЉМеРЂжЬЙз©ЇеАЉзЪДеИЧеЊИйЪЊињЫи°Мжߕ胥дЉШеМЦпЉМеЫ†дЄЇеЃГдїђдљњеЊЧ糥еЉХгАБ糥еЉХзЪДзїЯиЃ°дњ°жБѓдї•еПКжѓФиЊГињРзЃЧжЫіеК†е§НжЭВгАВдљ†еЇФиѓ•зФ®0гАБдЄАдЄ™зЙєжЃКзЪДеАЉжИЦиАЕдЄАдЄ™з©ЇдЄ≤дї£жЫњз©ЇеАЉгАВ
йАЙжЛ©еРИйАВзЪДж†ЗиѓЖзђ¶жШѓйЭЮеЄЄйЗНи¶БзЪДгАВйАЙжЛ©жЧґдЄНдїЕеЇФиѓ•иАГиЩСе≠ШеВ®з±їеЮЛпЉМиАМдЄФеЇФиѓ•иАГиЩСMySQLжШѓжАОж†ЈињЫи°МињРзЃЧеТМжѓФиЊГзЪДгАВдЄАжЧ¶йАЙеЃЪжХ∞жНЃз±їеЮЛпЉМеЇФиѓ•дњЭиѓБжЙАжЬЙзЫЄеЕ≥зЪДи°®йГљдљњзФ®зЫЄеРМзЪДжХ∞жНЃз±їеЮЛгАВ
(1)¬†¬† ¬†жХіеЮЛпЉЪйАЪеЄЄжШѓдљЬдЄЇж†ЗиѓЖзђ¶зЪДжЬАе•љйАЙжЛ©пЉМеЫ†дЄЇеПѓдї•жЫіењЂзЪДе§ДзРЖпЉМиАМдЄФеПѓдї•иЃЊзљЃдЄЇAUTO_INCREMENTгАВ
(2)¬†¬† ¬†е≠Чзђ¶дЄ≤пЉЪе∞љйЗПйБњеЕНдљњзФ®е≠Чзђ¶дЄ≤дљЬдЄЇж†ЗиѓЖзђ¶пЉМеЃГдїђжґИиАЧжЫіе•љзЪДз©ЇйЧіпЉМе§ДзРЖиµЈжЭ•дєЯиЊГжЕҐгАВиАМдЄФпЉМйАЪеЄЄжЭ•иѓіпЉМе≠Чзђ¶дЄ≤йГљжШѓйЪПжЬЇзЪДпЉМжЙАдї•еЃГдїђеܮ糥еЉХдЄ≠зЪДдљНзљЃдєЯжШѓйЪПжЬЇзЪДпЉМињЩдЉЪеѓЉиЗій°µйЭҐеИЖи£ВгАБйЪПжЬЇиЃњйЧЃз£БзЫШпЉМиБЪз∞З糥еЉХеИЖи£ВпЉИеѓєдЇОдљњзФ®иБЪз∞З糥еЉХзЪДе≠ШеВ®еЉХжУОпЉЙгАВ
2гАБ糥еЉХеЕ•йЧ®
еѓєдЇОдїїдљХDBMSпЉМ糥еЉХйГљжШѓињЫи°МдЉШеМЦзЪДжЬАдЄїи¶БзЪДеЫ†зі†гАВеѓєдЇОе∞СйЗПзЪДжХ∞жНЃпЉМж≤°жЬЙеРИйАВзЪД糥еЉХељ±еУНдЄНжШѓеЊИе§ІпЉМдљЖжШѓпЉМељУйЪПзЭАжХ∞жНЃйЗПзЪДеҐЮеК†пЉМжАІиГљдЉЪжА•еЙІдЄЛйЩНгАВ
е¶ВжЮЬеѓєе§ЪеИЧињЫи°М糥еЉХ(зїДеРИ糥еЉХ)пЉМеИЧзЪДй°ЇеЇПйЭЮеЄЄйЗНи¶БпЉМMySQLдїЕиÚ僺糥еЉХжЬАеЈ¶иЊєзЪДеЙНзЉАињЫи°МжЬЙжХИзЪДжЯ•жЙЊгАВдЊЛе¶ВпЉЪ
еБЗиЃЊе≠ШеЬ®зїДеРИ糥еЉХit1c1c2(c1,c2)пЉМжߕ胥иѓ≠еП•select * from t1 where c1=1 and c2=2иГље§ЯдљњзԮ胕糥еЉХгАВжߕ胥иѓ≠еП•select * from t1 where c1=1дєЯиГље§ЯдљњзԮ胕糥еЉХгАВдљЖжШѓпЉМжߕ胥иѓ≠еП•select * from t1 where c2=2дЄНиГље§ЯдљњзԮ胕糥еЉХпЉМеЫ†дЄЇж≤°жЬЙзїДеРИ糥еЉХзЪДеЉХеѓЉеИЧпЉМеН≥пЉМи¶БжГ≥дљњзФ®c2еИЧињЫи°МжЯ•жЙЊпЉМењЕйЬАеЗЇзО∞c1з≠ЙдЇОжЯРеАЉгАВ
2.1гАБ糥еЉХзЪДз±їеЮЛ
糥еЉХжШѓеЬ®е≠ШеВ®еЉХжУОдЄ≠еЃЮзО∞зЪДпЉМиАМдЄНжШѓеЬ®жЬНеК°еЩ®е±ВдЄ≠еЃЮзО∞зЪДгАВжЙАдї•пЉМжѓПзІНе≠ШеВ®еЉХжУОзЪД糥еЉХйГљдЄНдЄАеЃЪеЃМеЕ®зЫЄеРМпЉМеєґдЄНжШѓжЙАжЬЙзЪДе≠ШеВ®еЉХжУОйГљжФѓжМБжЙАжЬЙзЪД糥еЉХз±їеЮЛгАВ
2.1.1гАБB-Tree糥еЉХ
еБЗиЃЊжЬЙе¶ВдЄЛдЄАдЄ™и°®пЉЪ
|
CREATE TABLE People (    last_name varchar(50)    not null,    first_name varchar(50)    not null,    dob        date           not null,    gender     enum('m', 'f') not null,    key(last_name, first_name, dob) ); |
¬†еŴ糥еЉХеМЕеРЂи°®дЄ≠жѓПдЄАи°МзЪДlast_nameгАБfirst_nameеТМdobеИЧгАВеЕґзїУжЮДе§ІиЗіе¶ВдЄЛпЉЪ
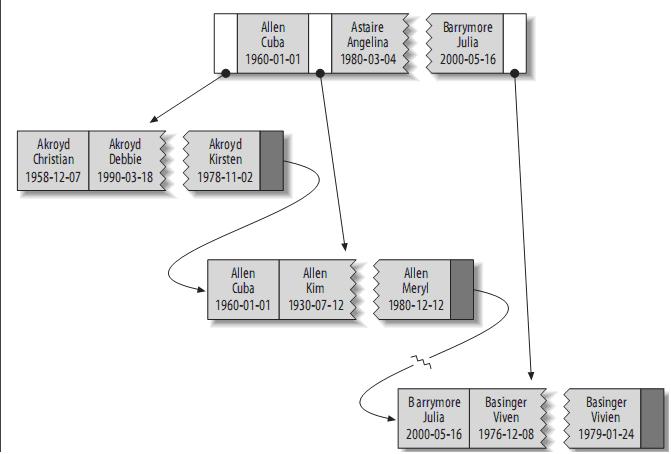  
 
¬†зіҐеЉХе≠ШеВ®зЪДеАЉжМЙ糥еЉХеИЧдЄ≠зЪДй°ЇеЇПжОТеИЧгАВеПѓдї•еИ©зФ®B-Tree糥еЉХињЫи°МеЕ®еЕ≥йФЃе≠ЧгАБеЕ≥йФЃе≠ЧиМГеЫіеТМеЕ≥йФЃе≠ЧеЙНзЉАжߕ胥пЉМељУзДґпЉМе¶ВжЮЬжГ≥дљњзԮ糥еЉХпЉМдљ†ењЕй°їдњЭиѓБжМЙ糥еЉХзЪДжЬАеЈ¶иЊєеЙНзЉА(leftmost prefix of the index)жЭ•ињЫи°Мжߕ胥гАВ
(1)еМєйЕНеЕ®еАЉ(Match the full value)пЉЪ僺糥еЉХдЄ≠зЪДжЙАжЬЙеИЧйГљжМЗеЃЪеЕЈдљУзЪДеАЉгАВдЊЛе¶ВпЉМдЄКеЫЊдЄ≠糥еЉХеПѓдї•еЄЃеК©дљ†жЯ•жЙЊеЗЇзФЯдЇО1960-01-01зЪДCuba AllenгАВ
(2)еМєйЕНжЬАеЈ¶еЙНзЉА(Match a leftmost prefix)пЉЪдљ†еПѓдї•еИ©зԮ糥еЉХжЯ•жЙЊlast nameдЄЇAllenзЪДдЇЇпЉМдїЕдїЕдљњзԮ糥еЉХдЄ≠зЪДзђђ1еИЧгАВ
(3)еМєйЕНеИЧеЙНзЉА(Match a column prefix)пЉЪдЊЛе¶ВпЉМдљ†еПѓдї•еИ©зԮ糥еЉХжЯ•жЙЊlast nameдї•JеЉАеІЛзЪДдЇЇпЉМињЩдїЕдїЕдљњзԮ糥еЉХдЄ≠зЪДзђђ1еИЧгАВ
(4)еМєйЕНеАЉзЪДиМГеЫіжߕ胥(Match a range of values)пЉЪеПѓдї•еИ©зԮ糥еЉХжЯ•жЙЊlast nameеЬ®AllenеТМBarrymoreдєЛйЧізЪДдЇЇпЉМдїЕдїЕдљњзԮ糥еЉХдЄ≠зђђ1еИЧгАВ
(5)еМєйЕНйГ®еИЖз≤Њз°ЃиАМеЕґеЃГйГ®еИЖињЫи°МиМГеЫіеМєйЕН(Match one part exactly and match a range on another part)пЉЪеПѓдї•еИ©зԮ糥еЉХжЯ•жЙЊlast nameдЄЇAllenпЉМиАМfirst nameдї•е≠ЧжѓНKеЉАеІЛзЪДдЇЇгАВ
(6)дїЕ僺糥еЉХињЫи°Мжߕ胥(Index-only queries)пЉЪе¶ВжЮЬжߕ胥зЪДеИЧйГљдљНдЇО糥еЉХдЄ≠пЉМеИЩдЄНйЬАи¶БиѓїеПЦеЕГзїДзЪДеАЉгАВ
зФ±дЇОB-ж†СдЄ≠зЪДиКВзВєйГљжШѓй°ЇеЇПе≠ШеВ®зЪДпЉМжЙАдї•еПѓдї•еИ©зԮ糥еЉХињЫи°МжЯ•жЙЊ(жЙЊжЯРдЇЫеАЉ)пЉМдєЯеПѓдї•еѓєжߕ胥зїУжЮЬињЫи°МORDER BYгАВељУзДґпЉМдљњзФ®B-tree糥еЉХжЬЙдї•дЄЛдЄАдЇЫйЩРеИґпЉЪ
(1) жߕ胥ењЕй°їдїО糥еЉХзЪДжЬАеЈ¶иЊєзЪДеИЧеЉАеІЛгАВеЕ≥дЇОињЩзВєеЈ≤зїПжПРдЇЖеЊИе§ЪйБНдЇЖгАВдЊЛе¶Вдљ†дЄНиГљеИ©зԮ糥еЉХжЯ•жЙЊеЬ®жЯРдЄА姩еЗЇзФЯзЪДдЇЇгАВ
(2) дЄНиГљиЈ≥ињЗжЯРдЄА糥еЉХеИЧгАВдЊЛе¶ВпЉМдљ†дЄНиГљеИ©зԮ糥еЉХжЯ•жЙЊlast nameдЄЇSmithдЄФеЗЇзФЯдЇОжЯРдЄА姩зЪДдЇЇгАВ
(3) е≠ШеВ®еЉХжУОдЄНиГљдљњзԮ糥еЉХдЄ≠иМГеЫіжЭ°дїґеП≥иЊєзЪДеИЧгАВдЊЛе¶ВпЉМе¶ВжЮЬдљ†зЪДжߕ胥иѓ≠еП•дЄЇWHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23'пЉМеИЩиѓ•жߕ胥еП™дЉЪдљњзԮ糥еЉХдЄ≠зЪДеЙНдЄ§еИЧпЉМеЫ†дЄЇLIKEжШѓиМГеЫіжߕ胥гАВ
2.1.2гАБHash糥еЉХ
MySQLдЄ≠пЉМеП™жЬЙMemoryе≠ШеВ®еЉХжУОжШЊз§ЇжФѓжМБhash糥еЉХпЉМжШѓMemoryи°®зЪДйїШ聧糥еЉХз±їеЮЛпЉМе∞љзЃ°Memoryи°®дєЯеПѓдї•дљњзФ®B-Tree糥еЉХгАВMemoryе≠ШеВ®еЉХжУОжФѓжМБйЭЮеФѓдЄАhash糥еЉХпЉМињЩеЬ®жХ∞жНЃеЇУйҐЖеЯЯжШѓзљХиІБзЪДпЉМе¶ВжЮЬе§ЪдЄ™еАЉжЬЙзЫЄеРМзЪДhash codeпЉМ糥еЉХжККеЃГдїђзЪДи°МжМЗйТИзФ®йУЊи°®дњЭе≠ШеИ∞еРМдЄАдЄ™hashи°®й°єдЄ≠гАВ
еБЗиЃЊеИЫеїЇе¶ВдЄЛдЄАдЄ™и°®пЉЪ
CREATE TABLE testhash (
   fname VARCHAR(50) NOT NULL,
   lname VARCHAR(50) NOT NULL,
   KEY USING HASH(fname)
) ENGINE=MEMORY;
еМЕеРЂзЪДжХ∞жНЃе¶ВдЄЛпЉЪ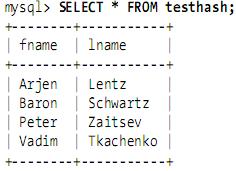
еБЗ职糥еЉХдљњзФ®hashеЗљжХ∞f( )пЉМе¶ВдЄЛпЉЪ
|
f('Arjen') = 2323 f('Baron') = 7437 f('Peter') = 8784 f('Vadim') = 2458 |
ж≠§жЧґпЉМ糥еЉХзЪДзїУжЮДе§Іж¶Ве¶ВдЄЛпЉЪ
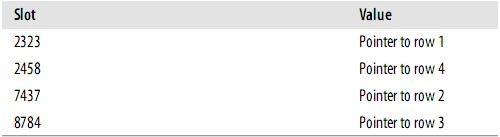  
 
¬†SlotsжШѓжЬЙеЇПзЪДпЉМдљЖжШѓиЃ∞ељХдЄНжШѓжЬЙеЇПзЪДгАВељУдљ†жЙІи°М
mysql> SELECT lname FROM testhash WHERE fname='Peter';
MySQLдЉЪиЃ°зЃЧвАЩPeterвАЩзЪДhashеАЉпЉМзДґеРОйАЪињЗеЃГжЭ•жߕ胥糥еЉХзЪДи°МжМЗйТИгАВеЫ†дЄЇf('Peter') = 8784пЉМMySQLдЉЪеܮ糥еЉХдЄ≠жЯ•жЙЊ8784пЉМеЊЧеИ∞жМЗеРСиЃ∞ељХ3зЪДжМЗйТИгАВ
еۆ䪯糥еЉХиЗ™еЈ±дїЕдїЕе≠ШеВ®еЊИзЯ≠зЪДеАЉпЉМжЙАдї•пЉМ糥еЉХйЭЮеЄЄзіІеЗСгАВHashеАЉдЄНеПЦеЖ≥дЇОеИЧзЪДжХ∞жНЃз±їеЮЛпЉМдЄАдЄ™TINYINTеИЧзЪД糥еЉХдЄОдЄАдЄ™йХње≠Чзђ¶дЄ≤еИЧзЪД糥еЉХдЄАж†Је§ІгАВ
 
Hash糥еЉХжЬЙдї•дЄЛдЄАдЇЫйЩРеИґпЉЪ
(1)зФ±дЇО糥еЉХдїЕеМЕеРЂhash codeеТМиЃ∞ељХжМЗйТИпЉМжЙАдї•пЉМMySQLдЄНиГљйАЪињЗдљњзԮ糥еЉХйБњеЕНиѓїеПЦиЃ∞ељХгАВдљЖжШѓиЃњйЧЃеЖЕе≠ШдЄ≠зЪДиЃ∞ељХжШѓйЭЮеЄЄињЕйАЯзЪДпЉМдЄНдЉЪеѓєжАІйА†жИР姙姲зЪДељ±еУНгАВ
(2)дЄНиГљдљњзФ®hash糥еЉХжОТеЇПгАВ
(3)Hash糥еЉХдЄНжФѓжМБйФЃзЪДйГ®еИЖеМєйЕНпЉМеЫ†дЄЇжШѓйАЪињЗжճ䪙糥еЉХеАЉжЭ•иЃ°зЃЧhashеАЉзЪДгАВ
(4)Hash糥еЉХеП™жФѓжМБз≠ЙеАЉжѓФиЊГпЉМдЊЛе¶ВдљњзФ®=пЉМIN( )еТМ<=>гАВеѓєдЇОWHERE price>100еєґдЄНиГљеК†йАЯжߕ胥гАВ
2.1.3гАБз©ЇйЧі(R-Tree)糥еЉХ
MyISAMжФѓжМБз©Їй׳糥еЉХпЉМдЄїи¶БзФ®дЇОеЬ∞зРЖз©ЇйЧіжХ∞жНЃз±їеЮЛпЉМдЊЛе¶ВGEOMETRYгАВ
2.1.4гАБеЕ®жЦЗ(Full-text)糥еЉХ
еЕ®жЦЗ糥еЉХжШѓMyISAMзЪДдЄАдЄ™зЙєжЃК糥еЉХз±їеЮЛпЉМдЄїи¶БзФ®дЇОеЕ®жЦЗж£А糥гАВ
3гАБйЂШжАІиГљзЪД糥еЉХз≠ЦзХ•
3.1гАБиБЪз∞З糥еЉХ(Clustered Indexes)
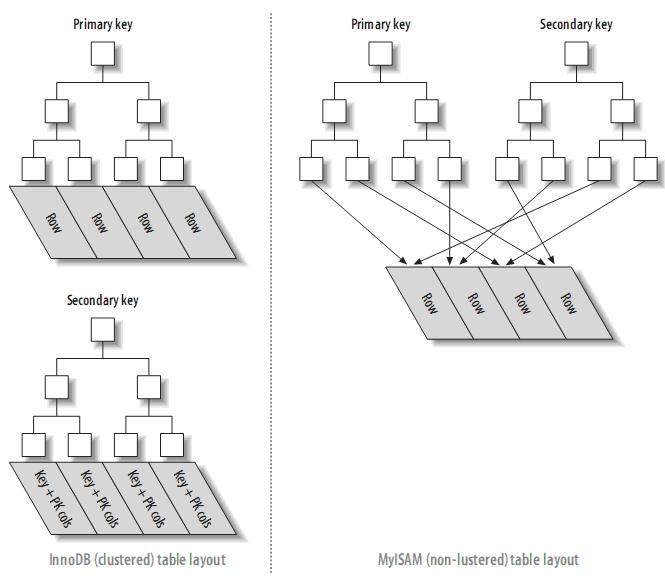
иБЪз∞З糥еЉХдњЭиѓБеЕ≥йФЃе≠ЧзЪДеАЉзЫЄињСзЪДеЕГзїДе≠ШеВ®зЪДзЙ©зРЖдљНзљЃдєЯзЫЄеРМпЉИжЙАдї•е≠Чзђ¶дЄ≤з±їеЮЛдЄНеЃЬеїЇзЂЛиБЪз∞З糥еЉХпЉМзЙєеИЂжШѓйЪПжЬЇе≠Чзђ¶дЄ≤пЉМдЉЪдљњеЊЧз≥їзїЯињЫи°Ме§ІйЗПзЪДзІїеК®жУНдљЬпЉЙпЉМдЄФдЄАдЄ™и°®еП™иГљжЬЙдЄАдЄ™иБЪз∞З糥еЉХгАВеЫ†дЄЇзФ±е≠ШеВ®еЉХжУОеЃЮзО∞糥еЉХпЉМжЙАдї•пЉМеєґдЄНжШѓжЙАжЬЙзЪДеЉХжУОйГљжФѓжМБиБЪз∞З糥еЉХгАВзЫЃеЙНпЉМеП™жЬЙsolidDBеТМInnoDBжФѓжМБгАВ
иБЪз∞З糥еЉХзЪДзїУжЮДе§ІиЗіе¶ВдЄЛпЉЪ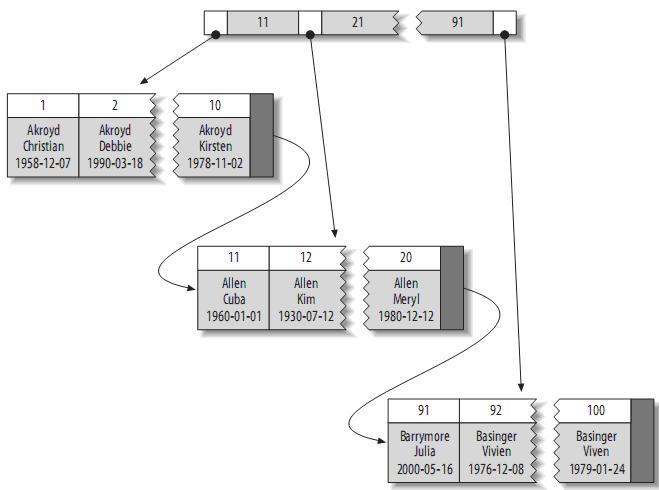
 
¬†ж≥®пЉЪеПґе≠Рй°µйЭҐеМЕеРЂеЃМжХізЪДеЕГзїДпЉМиАМеЖЕиКВзВєй°µйЭҐдїЕеМЕеЀ糥еЉХзЪДеИЧ(糥еЉХзЪДеИЧдЄЇжХіеЮЛ)гАВдЄАдЇЫDBMSеЕБиЃЄзФ®жИЈжМЗеЃЪиБЪз∞З糥еЉХпЉМдљЖжШѓMySQLзЪДе≠ШеВ®еЉХжУОеИ∞зЫЃеЙНдЄЇж≠ҐйГљдЄНжФѓжМБгАВInnoDBеѓєдЄїйФЃеїЇзЂЛиБЪз∞З糥еЉХгАВе¶ВжЮЬдљ†дЄНжМЗеЃЪдЄїйФЃпЉМInnoDBдЉЪзФ®дЄАдЄ™еЕЈжЬЙеФѓдЄАдЄФйЭЮз©ЇеАЉзЪД糥еЉХжЭ•дї£жЫњгАВе¶ВжЮЬдЄНе≠ШеЬ®ињЩж†ЈзЪД糥еЉХпЉМInnoDBдЉЪеЃЪдєЙдЄАдЄ™йЪРиЧПзЪДдЄїйФЃпЉМзДґеРОеѓєеЕґеїЇзЂЛиБЪз∞З糥еЉХгАВдЄАиИђжЭ•иѓіпЉМDBMSйГљдЉЪдї•иБЪз∞З糥еЉХзЪД嚥еЉПжЭ•е≠ШеВ®еЃЮйЩЕзЪДжХ∞жНЃпЉМеЃГжШѓеЕґеЃГдЇМ篲糥еЉХзЪДеЯЇз°АгАВ
3.1.1гАБInnoDBеТМMyISAMзЪДжХ∞жНЃеЄГе±АзЪДжѓФиЊГ
дЄЇдЇЖжЫіеК†зРЖиІ£иБЪз∞З糥еЉХеТМйЭЮиБЪз∞З糥еЉХпЉМжИЦиАЕprimary糥еЉХеТМsecond糥еЉХ(MyISAMдЄНжФѓжМБиБЪз∞З糥еЉХ)пЉМжЭ•жѓФиЊГдЄАдЄЛInnoDBеТМMyISAMзЪДжХ∞жНЃеЄГе±АпЉМеѓєдЇОе¶ВдЄЛи°®пЉЪ
 
|
CREATE TABLE layout_test (    col1 int NOT NULL,    col2 int NOT NULL,    PRIMARY KEY(col1),    KEY(col2) ); |
¬†еБЗиЃЊдЄїйФЃзЪДеАЉдљНдЇО1---10,000дєЛйЧіпЉМдЄФжМЙйЪПжЬЇй°ЇеЇПжПТеЕ•пЉМзДґеРОзФ®OPTIMIZE TABLEињЫи°МдЉШеМЦгАВcol2йЪПжЬЇиµЛдЇИ1---100дєЛйЧізЪДеАЉпЉМжЙАдї•дЉЪе≠ШеЬ®иЃЄе§ЪйЗНе§НзЪДеАЉгАВ
(1)¬†¬† ¬†MyISAMзЪДжХ∞жНЃеЄГе±А
еЕґеЄГе±АеНБеИЖзЃАеНХпЉМMyISAMжМЙзЕІжПТеЕ•зЪДй°ЇеЇПеЬ®з£БзЫШдЄКе≠ШеВ®жХ∞жНЃпЉМе¶ВдЄЛпЉЪ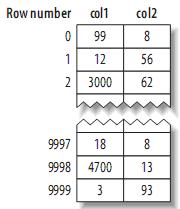
¬†ж≥®пЉЪеЈ¶иЊєдЄЇи°МеПЈ(row number)пЉМдїО0еЉАеІЛгАВеЫ†дЄЇеЕГзїДзЪДе§Іе∞ПеЫЇеЃЪпЉМжЙАдї•MyISAMеПѓдї•еЊИеЃєжШУзЪДдїОи°®зЪДеЉАеІЛдљНзљЃжЙЊеИ∞жЯРдЄАе≠ЧиКВзЪДдљНзљЃгАВ
жНЃдЇЫеїЇзЂЛзЪДprimary keyзЪД糥еЉХзїУжЮДе§ІиЗіе¶ВдЄЛпЉЪ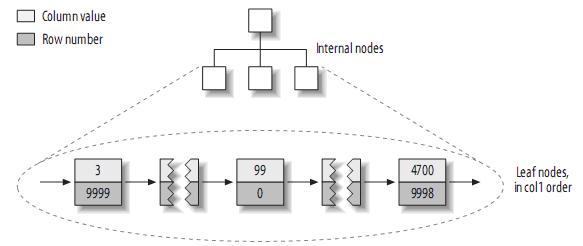
¬†ж≥®пЉЪMyISAMдЄНжФѓжМБиБЪз∞З糥еЉХпЉМ糥еЉХдЄ≠жѓПдЄАдЄ™еПґе≠РиКВзВєдїЕдїЕеМЕеРЂи°МеПЈ(row number)пЉМдЄФеПґе≠РиКВзВєжМЙзЕІcol1зЪДй°ЇеЇПе≠ШеВ®гАВ
жЭ•зЬЛзЬЛcol2зЪД糥еЉХзїУжЮДпЉЪ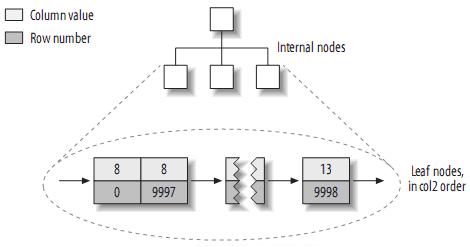
¬†еЃЮйЩЕдЄКпЉМеЬ®MyISAMдЄ≠пЉМprimary keyеТМеЕґеЃГ糥еЉХж≤°жЬЙдїАдєИеМЇеИЂгАВPrimary keyдїЕдїЕеП™жШѓдЄАдЄ™еПЂеБЪPRIMARYзЪДеФѓдЄАпЉМйЭЮз©ЇзЪД糥еЉХиАМеЈ≤гАВ
(2)¬†¬† ¬†InnoDBзЪДжХ∞жНЃеЄГе±А
InnoDBжМЙиБЪз∞З糥еЉХзЪД嚥еЉПе≠ШеВ®жХ∞жНЃпЉМжЙАдї•еЃГзЪДжХ∞жНЃеЄГе±АжЬЙзЭАеЊИе§ІзЪДдЄНеРМгАВеЃГе≠ШеВ®и°®зЪДзїУжЮДе§ІиЗіе¶ВдЄЛпЉЪ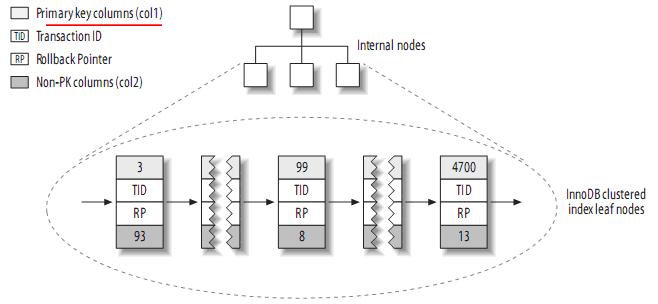
¬†ж≥®пЉЪиБЪз∞З糥еЉХдЄ≠зЪДжѓПдЄ™еПґе≠РиКВзВєеМЕеРЂprimary keyзЪДеАЉпЉМдЇЛеК°IDеТМеЫЮжїЪжМЗйТИ(rollback pointer)вАФвАФзФ®дЇОдЇЛеК°еТМMVCCпЉМеТМдљЩдЄЛзЪДеИЧ(е¶Вcol2)гАВ
зЫЄеѓєдЇОMyISAMпЉМдЇМ篲糥еЉХдЄОиБЪз∞З糥еЉХжЬЙеЊИе§ІзЪДдЄНеРМгАВInnoDBзЪДдЇМ篲糥еЉХзЪДеПґе≠РеМЕеРЂprimary keyзЪДеАЉпЉМиАМдЄНжШѓи°МжМЗйТИ(row pointers)пЉМињЩеЗПе∞ПдЇЖзІїеК®жХ∞жНЃжИЦиАЕжХ∞жНЃй°µйЭҐеИЖи£ВжЧґзїіжК§дЇМ篲糥еЉХзЪДеЉАйФАпЉМеЫ†дЄЇInnoDBдЄНйЬАи¶БжЫіжЦ∞糥еЉХзЪДи°МжМЗйТИгАВеЕґзїУжЮДе§ІиЗіе¶ВдЄЛпЉЪ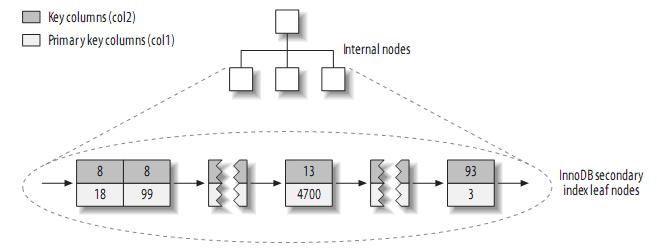
¬†иБЪз∞З糥еЉХеТМйЭЮиБЪз∞З糥еЉХи°®зЪДеѓєжѓФпЉЪ
 
¬†3.1.2гАБжМЙprimary keyзЪДй°ЇеЇПжПТеЕ•и°М(InnoDB)
е¶ВжЮЬдљ†зФ®InnoDBпЉМиАМдЄФдЄНйЬАи¶БзЙєжЃКзЪДиБЪз∞З糥еЉХпЉМдЄАдЄ™е•љзЪДеБЪж≥Хе∞±жШѓдљњзФ®дї£зРЖдЄїйФЃ(surrogate key)вАФвАФзЛђзЂЛдЇОдљ†зЪДеЇФзФ®дЄ≠зЪДжХ∞жНЃгАВжЬАзЃАеНХзЪДеБЪж≥Хе∞±жШѓдљњзФ®дЄАдЄ™AUTO_INCREMENTзЪДеИЧпЉМињЩдЉЪдњЭиѓБиЃ∞ељХжМЙзЕІй°ЇеЇПжПТеЕ•пЉМиАМдЄФиГљжПРйЂШдљњзФ®primary keyињЫи°МињЮжО•зЪДжߕ胥зЪДжАІиГљгАВеЇФиѓ•е∞љйЗПйБњеЕНйЪПжЬЇзЪДиБЪз∞ЗдЄїйФЃпЉМдЊЛе¶ВпЉМе≠Чзђ¶дЄ≤дЄїйФЃе∞±жШѓдЄАдЄ™дЄНе•љзЪДйАЙжЛ©пЉМеЃГдљњеЊЧжПТеЕ•жУНдљЬеПШеЊЧйЪПжЬЇгАВ
 
¬†3.2гАБи¶ЖзЫЦ糥еЉХ(Covering Indexes)
е¶ВжЮЬ糥еЉХеМЕеРЂжї°иґ≥жߕ胥зЪДжЙАжЬЙжХ∞жНЃпЉМе∞±зІ∞дЄЇи¶ЖзЫЦ糥еЉХгАВи¶ЖзЫЦ糥еЉХжШѓдЄАзІНйЭЮеЄЄеЉЇе§ІзЪДеЈ•еЕЈпЉМиГље§Іе§ІжПРйЂШжߕ胥жАІиГљгАВеП™йЬАи¶БиѓїеПЦ糥еЉХиАМдЄНзФ®иѓїеПЦжХ∞жНЃжЬЙдї•дЄЛдЄАдЇЫдЉШзВєпЉЪ
(1)糥еЉХй°єйАЪеЄЄжѓФиЃ∞ељХи¶Бе∞ПпЉМжЙАдї•MySQLиЃњйЧЃжЫіе∞СзЪДжХ∞жНЃпЉЫ
(2)糥еЉХйГљжМЙеАЉзЪДе§Іе∞Пй°ЇеЇПе≠ШеВ®пЉМзЫЄеѓєдЇОйЪПжЬЇиЃњйЧЃиЃ∞ељХпЉМйЬАи¶БжЫіе∞СзЪДI/OпЉЫ
(3)е§Іе§ЪжХ∞жНЃеЉХжУОиГљжЫіе•љзЪДзЉУе≠Ш糥еЉХгАВжѓФе¶ВMyISAMеП™зЉУе≠Ш糥еЉХгАВ
(4)и¶ЖзЫЦ糥еЉХеѓєдЇОInnoDBи°®е∞§еЕґжЬЙзФ®пЉМеЫ†дЄЇInnoDBдљњзФ®иБЪйЫЖ糥еЉХзїДзїЗжХ∞жНЃпЉМе¶ВжЮЬдЇМ篲糥еЉХдЄ≠еМЕеРЂжߕ胥жЙАйЬАзЪДжХ∞жНЃпЉМе∞±дЄНеЖНйЬАи¶БеЬ®иБЪйЫЖ糥еЉХдЄ≠жЯ•жЙЊдЇЖгАВ
и¶ЖзЫЦ糥еЉХдЄНиГљжШѓдїїдљХ糥еЉХпЉМеП™жЬЙB-TREE糥еЉХе≠ШеВ®зЫЄеЇФзЪДеАЉгАВиАМдЄФдЄНеРМзЪДе≠ШеВ®еЉХжУОеЃЮзО∞и¶ЖзЫЦ糥еЉХзЪДжЦєеЉПйГљдЄНеРМпЉМеєґдЄНжШѓжЙАжЬЙе≠ШеВ®еЉХжУОйГљжФѓжМБи¶ЖзЫЦ糥еЉХ(MemoryеТМFalconе∞±дЄНжФѓжМБ)гАВ
еѓєдЇО糥еЉХи¶ЖзЫЦжߕ胥(index-covered query)пЉМдљњзФ®EXPLAINжЧґпЉМеПѓдї•еЬ®ExtraдЄАеИЧдЄ≠зЬЛеИ∞вАЬUsing indexвАЭгАВдЊЛе¶ВпЉМеЬ®sakilaзЪДinventoryи°®дЄ≠пЉМжЬЙдЄАдЄ™зїДеРИ糥еЉХ(store_id,film_id)пЉМеѓєдЇОеП™йЬАи¶БиЃњйЧЃињЩдЄ§еИЧзЪДжߕ胥пЉМMySQLе∞±еПѓдї•дљњзԮ糥еЉХпЉМе¶ВдЄЛпЉЪ
|
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G *************************** 1. row ***************************            id: 1  select_type: SIMPLE         table: inventory          type: index possible_keys: NULL           key: idx_store_id_film_id       key_len: 3           ref: NULL          rows: 5007         Extra: Using index 1 row in set (0.17 sec) |
еЬ®е§Іе§ЪжХ∞еЉХжУОдЄ≠пЉМеП™жЬЙељУжߕ胥иѓ≠еП•жЙАиЃњйЧЃзЪДеИЧж؃糥еЉХзЪДдЄАйГ®еИЖжЧґпЉМ糥еЉХжЙНдЉЪи¶ЖзЫЦгАВдљЖжШѓпЉМInnoDBдЄНйЩРдЇОж≠§пЉМInnoDBзЪДдЇМ篲糥еЉХеЬ®еПґе≠РиКВзВєдЄ≠е≠ШеВ®дЇЖprimary keyзЪДеАЉгАВеЫ†ж≠§пЉМsakila.actorи°®дљњзФ®InnoDBпЉМиАМдЄФеѓєдЇОжШѓlast_nameдЄКжЬЙ糥еЉХпЉМжЙАдї•пЉМ糥еЉХиГљи¶ЖзЫЦйВ£дЇЫиЃњйЧЃactor_idзЪДжߕ胥пЉМе¶ВпЉЪ
 
|
mysql> EXPLAIN SELECT actor_id, last_name     -> FROM sakila.actor WHERE last_name = 'HOPPER'\G *************************** 1. row ***************************            id: 1  select_type: SIMPLE         table: actor          type: ref possible_keys: idx_actor_last_name           key: idx_actor_last_name       key_len: 137           ref: const          rows: 2         Extra: Using where; Using index |
 
3.3гАБеИ©зԮ糥еЉХињЫи°МжОТеЇП
MySQLдЄ≠пЉМжЬЙдЄ§зІНжЦєеЉПзФЯжИРжЬЙеЇПзїУжЮЬйЫЖпЉЪдЄАжШѓдљњзФ®filesortпЉМдЇМжШѓжМЙ糥еЉХй°ЇеЇПжЙЂжППгАВеИ©зԮ糥еЉХињЫи°МжОТеЇПжУНдљЬжШѓйЭЮеЄЄењЂзЪДпЉМиАМдЄФеПѓдї•еИ©зФ®еРМдЄА糥еЉХеРМжЧґињЫи°МжЯ•жЙЊеТМжОТеЇПжУНдљЬгАВељУ糥еЉХзЪДй°ЇеЇПдЄОORDER BYдЄ≠зЪДеИЧй°ЇеЇПзЫЄеРМдЄФжЙАжЬЙзЪДеИЧжШѓеРМдЄАжЦєеРС(еЕ®йГ®еНЗеЇПжИЦиАЕеЕ®йГ®йЩНеЇП)жЧґпЉМеПѓдї•дљњзԮ糥еЉХжЭ•жОТеЇПгАВе¶ВжЮЬжߕ胥жШѓињЮжО•е§ЪдЄ™и°®пЉМдїЕељУORDER BYдЄ≠зЪДжЙАжЬЙеИЧйГљжШѓзђђдЄАдЄ™и°®зЪДеИЧжЧґжЙНдЉЪдљњзԮ糥еЉХгАВеЕґеЃГжГЕеЖµйГљдЉЪдљњзФ®filesortгАВ
|
create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name      varchar(16) NOT NULL DEFAULT '', password        varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id),  KEY     (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
 
 
|
mysql> explain select actor_id from actor order by actor_id \G *************************** 1. row ***************************            id: 1  select_type: SIMPLE         table: actor          type: index possible_keys: NULL           key: PRIMARY       key_len: 4           ref: NULL          rows: 4         Extra: Using index 1 row in set (0.00 sec)   mysql> explain select actor_id from actor order by password \G *************************** 1. row ***************************            id: 1  select_type: SIMPLE         table: actor          type: ALL possible_keys: NULL           key: NULL       key_len: NULL           ref: NULL          rows: 4         Extra: Using filesort 1 row in set (0.00 sec)   mysql> explain select actor_id from actor order by name \G *************************** 1. row ***************************            id: 1  select_type: SIMPLE         table: actor          type: index possible_keys: NULL           key: name       key_len: 18           ref: NULL          rows: 4         Extra: Using index 1 row in set (0.00 sec) |
¬†ељУMySQLдЄНиГљдљњзԮ糥еЉХињЫи°МжОТеЇПжЧґпЉМе∞±дЉЪеИ©зФ®иЗ™еЈ±зЪДжОТеЇПзЃЧж≥Х(ењЂйАЯжОТеЇПзЃЧж≥Х)еЬ®еЖЕе≠Ш(sort buffer)дЄ≠еѓєжХ∞жНЃињЫи°МжОТеЇПпЉМе¶ВжЮЬеЖЕе≠Ши£ЕиљљдЄНдЄЛпЉМеЃГдЉЪе∞Жз£БзЫШдЄКзЪДжХ∞жНЃињЫи°МеИЖеЭЧпЉМеЖНеѓєеРДдЄ™жХ∞жНЃеЭЧињЫи°МжОТеЇПпЉМзДґеРОе∞ЖеРДдЄ™еЭЧеРИеєґжИРжЬЙеЇПзЪДзїУжЮЬйЫЖпЉИеЃЮйЩЕдЄКе∞±жШѓе§ЦжОТеЇПпЉЙгАВеѓєдЇОfilesortпЉМMySQLжЬЙдЄ§зІНжОТеЇПзЃЧж≥ХгАВ
(1)дЄ§йБНжЙЂжППзЃЧж≥Х(Two passes)
еЃЮзО∞жЦєеЉПжШѓеЕИе∞Жй°їи¶БжОТеЇПзЪДе≠ЧжЃµеТМеПѓдї•зЫіжО•еЃЪдљНеИ∞зЫЄеЕ≥и°МжХ∞жНЃзЪДжМЗйТИдњ°жБѓеПЦеЗЇпЉМзДґеРОеЬ®иЃЊеЃЪзЪДеЖЕе≠ШпЉИйАЪињЗеПВжХ∞sort_buffer_sizeиЃЊеЃЪпЉЙдЄ≠ињЫи°МжОТеЇПпЉМеЃМжИРжОТеЇПдєЛеРОеЖНжђ°йАЪињЗи°МжМЗйТИдњ°жБѓеПЦеЗЇжЙАйЬАзЪДColumnsгАВ
ж≥®пЉЪиѓ•зЃЧж≥ХжШѓ4.1дєЛеЙНйЗЗзФ®зЪДзЃЧж≥ХпЉМеЃГйЬАи¶БдЄ§жђ°иЃњйЧЃжХ∞жНЃпЉМе∞§еЕґжШѓзђђдЇМжђ°иѓїеПЦжУНдљЬдЉЪеѓЉиЗіе§ІйЗПзЪДйЪПжЬЇI/OжУНдљЬгАВеП¶дЄАжЦєйЭҐпЉМеЖЕе≠ШеЉАйФАиЊГе∞ПгАВ
(3)¬†¬† ¬†дЄАжђ°жЙЂжППзЃЧж≥Х(single pass)
иѓ•зЃЧж≥ХдЄАжђ°жАІе∞ЖжЙАйЬАзЪДColumnsеЕ®йГ®еПЦеЗЇпЉМеЬ®еЖЕе≠ШдЄ≠жОТеЇПеРОзЫіжО•е∞ЖзїУжЮЬиЊУеЗЇгАВ
ж≥®пЉЪдїО MySQL 4.1 зЙИжЬђеЉАеІЛдљњзФ®иѓ•зЃЧж≥ХгАВеЃГеЗПе∞СдЇЖI/OзЪДжђ°жХ∞пЉМжХИзОЗиЊГйЂШпЉМдљЖжШѓеЖЕе≠ШеЉАйФАдєЯиЊГе§ІгАВе¶ВжЮЬжИСдїђе∞ЖеєґдЄНйЬАи¶БзЪДColumnsдєЯеПЦеЗЇжЭ•пЉМе∞±дЉЪжЮБе§ІеЬ∞жµ™иієжОТеЇПињЗз®ЛжЙАйЬАи¶БзЪДеЖЕе≠ШгАВеЬ® MySQL 4.1 дєЛеРОзЪДзЙИжЬђдЄ≠пЉМеПѓдї•йАЪињЗиЃЊзљЃ max_length_for_sort_data еПВжХ∞жЭ•жОІеИґ MySQL йАЙжЛ©зђђдЄАзІНжОТеЇПзЃЧж≥ХињШжШѓзђђдЇМзІНгАВељУеПЦеЗЇзЪДжЙАжЬЙе§Іе≠ЧжЃµжАїе§Іе∞Пе§ІдЇО max_length_for_sort_data зЪДиЃЊзљЃжЧґпЉМMySQL е∞±дЉЪйАЙжЛ©дљњзФ®зђђдЄАзІНжОТеЇПзЃЧж≥ХпЉМеПНдєЛпЉМеИЩдЉЪйАЙжЛ©зђђдЇМзІНгАВдЄЇдЇЖе∞љеПѓиГљеЬ∞жПРйЂШжОТеЇПжАІиГљпЉМжИСдїђиЗ™зДґжЫіеЄМжЬЫдљњзФ®зђђдЇМзІНжОТеЇПзЃЧж≥ХпЉМжЙАдї•еЬ® Query дЄ≠дїЕдїЕеПЦеЗЇйЬАи¶БзЪД Columns жШѓйЭЮеЄЄжЬЙењЕи¶БзЪДгАВ
ељУеѓєињЮжО•жУНдљЬињЫи°МжОТеЇПжЧґпЉМе¶ВжЮЬORDER BYдїЕдїЕеЉХзФ®зђђдЄАдЄ™и°®зЪДеИЧпЉМMySQLеѓєиѓ•и°®ињЫи°МfilesortжУНдљЬпЉМзДґеРОињЫи°МињЮжО•е§ДзРЖпЉМж≠§жЧґпЉМEXPLAINиЊУеЗЇвАЬUsing filesortвАЭпЉЫеР¶еИЩпЉМMySQLењЕй°їе∞Жжߕ胥зЪДзїУжЮЬйЫЖзФЯжИРдЄАдЄ™дЄіжЧґи°®пЉМеЬ®ињЮжО•еЃМжИРдєЛеРОињЫи°МfilesortжУНдљЬпЉМж≠§жЧґпЉМEXPLAINиЊУеЗЇвАЬUsing temporary;Using filesortвАЭгАВ
 
3.4гАБ糥еЉХдЄОеК†йФБ
糥еЉХеѓєдЇОInnoDBйЭЮеЄЄйЗНи¶БпЉМеЫ†дЄЇеЃГеПѓдї•иЃ©жߕ胥йФБжЫіе∞СзЪДеЕГзїДгАВињЩзВєеНБеИЖйЗНи¶БпЉМеЫ†дЄЇMySQL 5.0дЄ≠пЉМInnoDBзЫіеИ∞дЇЛеК°жПРдЇ§жЧґжЙНдЉЪиІ£йФБгАВжЬЙдЄ§дЄ™жЦєйЭҐзЪДеОЯеЫ†пЉЪй¶ЦеЕИпЉМеН≥дљњInnoDBи°МзЇІйФБзЪДеЉАйФАйЭЮеЄЄйЂШжХИпЉМеЖЕе≠ШеЉАйФАдєЯиЊГе∞ПпЉМдљЖдЄНзЃ°жАОдєИж†ЈпЉМињШжШѓе≠ШеЬ®еЉАйФАгАВеЕґжђ°пЉМеѓєдЄНйЬАи¶БзЪДеЕГзїДзЪДеК†йФБпЉМдЉЪеҐЮеК†йФБзЪДеЉАйФАпЉМйЩНдљОеєґеПСжАІгАВ
InnoDBдїЕеѓєйЬАи¶БиЃњйЧЃзЪДеЕГзїДеК†йФБпЉМиАМ糥еЉХиГље§ЯеЗПе∞СInnoDBиЃњйЧЃзЪДеЕГзїДжХ∞гАВдљЖжШѓпЉМеП™жЬЙеЬ®е≠ШеВ®еЉХжУОе±ВињЗжї§жОЙйВ£дЇЫдЄНйЬАи¶БзЪДжХ∞жНЃжЙНиГљиЊЊеИ∞ињЩзІНзЫЃзЪДгАВдЄАж׶糥еЉХдЄНеЕБиЃЄInnoDBйВ£ж†ЈеБЪпЉИеН≥иЊЊдЄНеИ∞ињЗжї§зЪДзЫЃзЪДпЉЙпЉМMySQLжЬНеК°еЩ®еП™иГљеѓєInnoDBињФеЫЮзЪДжХ∞жНЃињЫи°МWHEREжУНдљЬпЉМж≠§жЧґпЉМеЈ≤зїПжЧ†ж≥ХйБњеЕНеѓєйВ£дЇЫеЕГзїДеК†йФБдЇЖпЉЪInnoDBеЈ≤зїПйФБдљПйВ£дЇЫеЕГзїДпЉМжЬНеК°еЩ®жЧ†ж≥ХиІ£йФБдЇЖгАВ
жЭ•зЬЛдЄ™дЊЛе≠РпЉЪ
|
create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name      varchar(16) NOT NULL DEFAULT '', password        varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id),  KEY     (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
|
SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE; |
¬†иѓ•жߕ胥дїЕдїЕињФеЫЮ2---3зЪДжХ∞жНЃпЉМеЃЮйЩЕеЈ≤зїПеѓє1---3зЪДжХ∞жНЃеК†дЄКжОТеЃГйФБдЇЖгАВInnoDBйФБдљПеЕГзїД1жШѓеЫ†дЄЇMySQLзЪДжߕ胥聰еИТдїЕдљњзԮ糥еЉХињЫи°МиМГеЫіжߕ胥пЉИиАМж≤°жЬЙињЫи°МињЗжї§жУНдљЬпЉМWHEREдЄ≠зђђдЇМдЄ™жЭ°дїґеЈ≤зїПжЧ†ж≥ХдљњзԮ糥еЉХдЇЖпЉЙпЉЪ
 
|
mysql> EXPLAIN SELECT actor_id FROM test.actor     -> WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE \G *************************** 1. row ***************************            id: 1  select_type: SIMPLE         table: actor          type: index possible_keys: PRIMARY           key: PRIMARY       key_len: 4           ref: NULL          rows: 4         Extra: Using where; Using index 1 row in set (0.00 sec)   mysql> |
¬†и°®жШОе≠ШеВ®еЉХжУОдїО糥еЉХзЪДиµЈеІЛе§ДеЉАеІЛпЉМиОЈеПЦжЙАжЬЙзЪДи°МпЉМзЫіеИ∞actor_id<4дЄЇеБЗпЉМжЬНеК°еЩ®жЧ†ж≥ХеСКиѓЙInnoDBеОїжОЙеЕГзїД1гАВ
дЄЇдЇЖиѓБжШОrow 1еЈ≤зїП襀йФБдљПпЉМжИСдїђеП¶е§ЦеїЇдЄАдЄ™ињЮжО•пЉМжЙІи°Ме¶ВдЄЛжУНдљЬпЉЪ
|
SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id = 1 FOR UPDATE; |
 
¬†иѓ•жߕ胥дЉЪ襀жМВиµЈпЉМзЫіеИ∞зђђдЄАдЄ™ињЮжО•зЪДдЇЛеК°жПРдЇ§йЗКжФЊйФБжЧґпЉМжЙНдЉЪжЙІи°МпЉИињЩзІНи°МдЄЇеѓєдЇОеЯЇдЇОиѓ≠еП•зЪДе§НеИґ(statement-based replication)жШѓењЕи¶БзЪДпЉЙгАВ
е¶ВдЄКжЙАз§ЇпЉМељУдљњзԮ糥еЉХжЧґпЉМInnoDBдЉЪйФБдљПеЃГдЄНйЬАи¶БзЪДеЕГзїДгАВжЫіз≥Яз≥ХзЪДжШѓпЉМе¶ВжЮЬжߕ胥дЄНиГљдљњзԮ糥еЉХпЉМMySQLдЉЪињЫи°МеЕ®и°®жЙЂжППпЉМеєґйФБдљПжѓПдЄАдЄ™еЕГзїДпЉМдЄНзЃ°жШѓеР¶зЬЯж≠£йЬАи¶БгАВ



зЫЄеЕ≥жО®иНР
гАКOracleдЄОMySQLжХ∞жНЃеЇУ糥еЉХиЃЊиЃ°дЄОдЉШеМЦгАЛињЩжЬђдє¶жЈ±еЕ•жОҐиЃ®дЇЖдЄ§дЄ™дЄїжµБеЕ≥з≥їеЮЛжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯвАФвАФOracleеТМMySQLдЄ≠зЪД糥еЉХиЃЊиЃ°еТМдЉШеМЦз≠ЦзХ•гАВ糥еЉХжШѓжХ∞жНЃеЇУжАІиГљзЪДеЕ≥йФЃеЫ†зі†пЉМеЃГдїђиГље§ЯеК†йАЯжХ∞жНЃж£А糥пЉМжПРйЂШз≥їзїЯжХИзОЗпЉМе∞§еЕґеЬ®е§ІжХ∞жНЃйЗП...
зїУеРИжПРдЊЫзЪД"е≠ШеВ®еЯЇз°АзЯ•иѓЖвАФвАФ糥еЉХеЃЮзО∞.ppt"жЦЗдїґпЉМдљ†еПѓиГљиГљжЫізЫіиІВеЬ∞дЇЖиІ£еИ∞糥еЉХзЪДеЕЈдљУеЃЮзО∞жЦєеЉПеТМж°ИдЊЛеИЖжЮРпЉМеМЕжЛђе¶ВдљХеИЫеїЇгАБдљњзФ®еТМдЉШеМЦ糥еЉХпЉМдї•еПКеЬ®дЄНеРМеЬЇжЩѓдЄЛе¶ВдљХйАЙжЛ©еРИйАВзЪД糥еЉХз±їеЮЛгАВињЩдїљиµДжЦЩе∞ЖжЬЙеК©дЇОжЈ±еМЦ䚆僺糥еЉХжЬђиі®...
жЬђзѓЗжЦЗзЂ†е∞ЖжЈ±еЕ•жОҐиЃ®дЄ§дЄ™еЕ≥йФЃзЪДMySQLдЉШеМЦжКАжЬѓпЉЪе≠ШеВ®ињЗз®ЛдЉШеМЦеТМ糥еЉХдЉШеМЦпЉМеЕЈдљУдЄЇдљњзФ®дЄіжЧґи°®дї£жЫњжЄЄж†Здї•еПКеЈІеїЇSUM糥еЉХжЭ•жПРеНЗжХИзОЗгАВ й¶ЦеЕИпЉМжИСдїђжЭ•и∞Ии∞ИMySQLе≠ШеВ®ињЗз®ЛдЄ≠зЪДдЉШеМЦз≠ЦзХ•вАФвАФдљњзФ®дЄіжЧґи°®дї£жЫњжЄЄж†ЗгАВжЄЄж†ЗеЬ®е§ДзРЖе§НжЭВ...
дЄЇдЇЖзФЯжИРжВ®жЙАйЬАзЪДеЕ≥дЇО"йЂШжАІиГљmysqlвАФвАФйЂШжЄЕзЙИ"зЪДзЯ•иѓЖзВєпЉМжИСе∞ЖдЊЭиµЦж†ЗйҐШеТМжППињ∞йГ®еИЖжПРдЊЫзЪДдњ°жБѓпЉМдї•еПКеѓєMySQLжХ∞жНЃеЇУжАІиГљдЉШеМЦзЪДжЩЃйБНзЯ•иѓЖжЭ•ињЫи°МеЫЮз≠ФгАВ 1. MySQLж¶Вињ∞ MySQLжШѓдЄАдЄ™е§ЪзФ®жИЈгАБе§ЪзЇњз®ЛзЪДSQLжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯпЉМдљњзФ®...
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗеЕ®йЭҐиЃ≤иІ£дЇЖ MySQL 糥еЉХзЪДеЯЇз°Аж¶ВењµгАБз±їеЮЛгАБеЇХе±ВзїУжЮДдї•еПКдЉШеМЦжКАеЈІгАВй¶ЦеЕИдїЛзїНдЇЖ糥еЉХдљЬдЄЇжХ∞жНЃеЇУвАШзЫЃељХвАЩзЪДдљЬзФ®пЉМеЗПе∞Сз£БзЫШI/OеєґжПРйЂШжߕ胥йАЯеЇ¶гАВжО•зЭАиѓ¶зїЖиІ£йЗКдЇЖдЄНеРМз±їеЮЛзЪД糥еЉХпЉМеМЕжЛђжЩЃйАЪ糥еЉХгАБеФѓдЄА糥еЉХгАБдЄїйФЃ...
MySQLжШѓдЄАзІНжµБи°МзЪДеЉАжЇРеЕ≥з≥їеЮЛжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯпЉМеЃГдї•еЕґйЂШжХИгАБеПѓйЭ†еТМ...жОМжП°ињЩдЇЫеЯЇз°АзЯ•иѓЖпЉМиГљеЄЃеК©жИСдїђжЈ±еЕ•зРЖиІ£MySQLзЪДеЈ•дљЬеОЯзРЖпЉМжЫіе•љеЬ∞иЃЊиЃ°еТМдЉШеМЦжХ∞жНЃеЇУз≥їзїЯгАВжЧ†иЃЇжШѓеЉАеПСгАБињРзїіињШжШѓжХ∞жНЃеЇУзЃ°зРЖпЉМињЩдЇЫзЯ•иѓЖйГљжШѓењЕдЄНеПѓе∞СзЪДгАВ
MySQLжПРдЊЫдЇЖиЃЄе§ЪжАІиГљдЉШеМЦжЙЛжЃµпЉМе¶Вжߕ胥дЉШеМЦпЉИйАЪињЗEXPLAINеИЖжЮРжߕ胥聰еИТпЉЙгАБйЕНзљЃеПВжХ∞и∞ГжХігАБInnoDBе≠ШеВ®еЉХжУОзЪДзЉУеЖ≤汆гАБ糥еЉХдЉШеМЦдї•еПКдљњзФ®жЕҐжߕ胥жЧ•ењЧеИЖжЮРжАІиГљйЧЃйҐШгАВ 12. **еЃЙеЕ®жАІ**пЉЪ MySQLжФѓжМБзФ®жИЈжЭГйЩРзЃ°зРЖпЉМйАЪињЗGRANT...
MySQL жߕ胥дЉШеМЦзЪДзЩЊзІСеЕ®дє¶ вАФвАФ Explain иѓ¶иІ£ MySQL жШѓжАОж†ЈињРи°МзЪДпЉЯдїОж†єеДњдЄКзРЖиІ£ MySQL зЪДжߕ胥дЉШеМЦжШѓдЄАдїґе§НжЭВзЪДдЇЛжГЕпЉМдљЖдЇЖиІ£ Explain иѓ≠еП•иЊУеЗЇзЪДеРДдЄ™еИЧзЪДжДПжАЭжШѓйЭЮеЄЄйЗНи¶БзЪДгАВжЬђзЂ†е∞ЖзїІзї≠еФ†еП® Explain иѓ≠еП•иЊУеЗЇзЪДеРДдЄ™...
гАРзЗХеНБеЕЂ е∞БзђФдєЛдљЬвАФвАФMySQLдЉШеМЦгАС зЗХеНБеЕЂпЉМдЄАдљНеЬ®ITи°МдЄЪеЖЕдЇЂжЬЙзЫЫеРНзЪДдЄУеЃґпЉМдї•еЕґжЈ±еЕ•жµЕеЗЇзЪДиЃ≤иІ£й£Ож†ЉеТМдЄ∞еѓМзЪДеЃЮжИШзїПй™МеЬ®MySQLдЉШеМЦйҐЖеЯЯзХЩдЄЛдЇЖжЈ±еИїзЪДеН∞иЃ∞гАВдїЦзЪДвАЬе∞БзђФдєЛдљЬвАЭиБЪзД¶дЇОMySQLжХ∞жНЃеЇУзЪДжАІиГљжПРеНЗпЉМжЧ®еЬ®еЄЃеК©...
гАКжґВжКєMySQLпЉЪиЈЯзЭАдЄЙжАЭдЄАж≠•дЄАж≠•е≠¶MySQLгАЛжШѓдЄАжЬђжЧ®еЬ®еЄЃеК©еИЭе≠¶иАЕеТМдЄ≠зЇІзФ®жИЈжЈ±еЕ•зРЖиІ£MySQLжХ∞жНЃеЇУз≥їзїЯзЪДжХЩз®ЛгАВињЩжЬђдє¶йАЪињЗжЄЕжЩ∞зЪДиІ£йЗКеТМеЃЮдЊЛпЉМйАРж≠•еЉХеѓЉиѓїиАЕжОМжП°MySQLзЪДж†ЄењГж¶ВењµеТМжКАжЬѓгАВMySQLжШѓдЄАзІНеєњж≥ЫдљњзФ®зЪДеЉАжЇРеЕ≥з≥їеЮЛ...
- **糥еЉХдЉШеМЦ**: йАЪињЗеѓєжߕ胥殰еЉПзЪДзРЖиІ£пЉМеПѓдї•жЫіжЬЙжХИеЬ∞职聰糥еЉХпЉМдїОиАМжФѓжМБжЫіе§Ъз±їеЮЛзЪДжߕ胥гАВ #### дЇФгАБйБњеЕНдљњзФ®ORињЮжО•жЭ°дїґ **ж†ЗйҐШ:** еЇФе∞љйЗПйБњеЕНеЬ®whereе≠РеП•дЄ≠дљњзФ®orжЭ•ињЮжО•жЭ°дїґпЉМеР¶еИЩе∞ЖеѓЉиЗіеЉХжУОжФЊеЉГдљњзԮ糥еЉХиАМињЫи°МеЕ®...
- ж≠£з°ЃдљњзФ®EXPLAINеИЖжЮРжߕ胥聰еИТпЉМзРЖиІ£MySQLе¶ВдљХдљњзԮ糥еЉХжЭ•жЙІи°Мжߕ胥пЉМдї•дЊњињЫи°МдЉШеМЦгАВ йЩ§дЇЖдЄКињ∞жЦєж≥ХпЉМињШжЬЙеЕґдїЦзЪДдЉШеМЦжЙЛжЃµпЉМдЊЛе¶ВеРИзРЖдљњзФ®еИЖеМЇи°®гАБйАЙжЛ©еРИйАВзЪДе≠ШеВ®еЉХжУОгАБзЫСжОІеТМи∞ГжХізЇњз®Л汆姲е∞ПгАБеЃЪжЬЯеИЖжЮРеТМдЉШеМЦи°®зїУжЮДз≠Й...
ж†єжНЃдєЛеЙНзЪДMYSQLе≠¶дє†зђФиЃ∞(2)зЪДе≠¶дє†пЉМйАЪињЗдЄАдЇЫе∞ПзїГдє†жЭ•еʆ棱僺糥еЉХзЪДзРЖиІ£гАВ еїЇдЄЛи°®еєґжПТеЕ•жХ∞жНЃжЬАеРОеїЇзЂЛзЫЄеЕ≥糥еЉХпЉЪ CREATE TABLE IF NOT EXISTS `test`( id int PRIMARY KEY auto_increment, c1 char(10), c2 char(10), ...
жАїзЪДжЭ•иѓіпЉМзРЖиІ£еєґеРИзРЖдљњзԮ糥еЉХжШѓдЉШеМЦMySQLжߕ胥жАІиГљзЪДеЕ≥йФЃпЉМйЬАи¶Бж†єжНЃеЃЮйЩЕжГЕеЖµжЭГ谰糥еЉХеЄ¶жЭ•зЪДеҐЮзЫКеТМзїіжК§жИРжЬђгАВеЬ®иЃЊиЃ°жХ∞жНЃеЇУжЧґпЉМеЇФиАГиЩСжߕ胥殰еЉПпЉМжЬЙйТИеѓєжАІеЬ∞еИЫеїЇеТМдљњзԮ糥еЉХпЉМеРМжЧґж≥®жДПйБњеЕНдЄКињ∞еПѓиГљеѓЉиdz糥еЉХ姱жХИзЪДжУНдљЬгАВ...