
最近对两个开源系统进行反向工程ER图生成后,对比发现一个系统其中一个表中的复合索引的列个数对查询的效率有较大的影响~~
于是上网查了下相关的资料:(关于复合索引优化的)
两个或更多个列上的索引被称作复合索引。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
如:建立 姓名、年龄、性别的复合索引。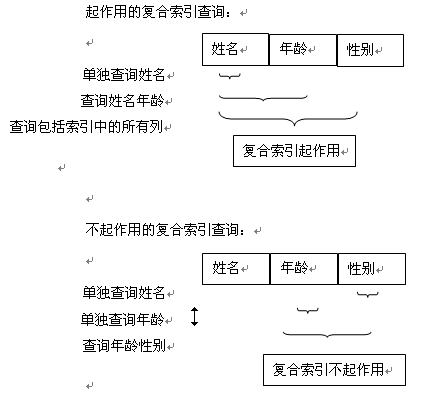
复合索引的建立原则:
如果您很可能仅对一个列多次执行搜索,则该列应该是复合索引中的第一列。如果您很可能对一个两列索引中的两个列执行单独的搜索,则应该创建另一个仅包含第二列的索引。
如上图所示,如果查询中需要对年龄和性别做查询,则应当再新建一个包含年龄和性别的复合索引。
包含多个列的主键始终会自动以复合索引的形式创建索引,其列的顺序是它们在表定义中出现的顺序,而不是在主键定义中指定的顺序。在考虑将来通过主键执行的搜索,确定哪一列应该排在最前面。
请注意,创建复合索引应当包含少数几个列,并且这些列经常在select查询里使用。在复合索引里包含太多的列不仅不会给带来太多好处。而且由于使用相当多的内存来存储复合索引的列的值,其后果是内存溢出和性能降低。
复合索引对排序的优化:
复合索引只对和索引中排序相同或相反的order by 语句优化。
在创建复合索引时,每一列都定义了升序或者是降序。如定义一个复合索引:
- CREATE INDEX idx_example
- ON table1 (col1 ASC, col2 DESC, col3 ASC)
其中 有三列分别是:col1 升序,col2 降序, col3 升序。现在如果我们执行两个查询
1:Select col1, col2, col3 from table1 order by col1 ASC, col2 DESC, col3 ASC
和索引顺序相同
2:Select col1, col2, col3 from table1 order by col1 DESC, col2 ASC, col3 DESC
和索引顺序相反
查询1,2 都可以别复合索引优化。
如果查询为:
Select col1, col2, col3 from table1 order by col1 ASC, col2 ASC, col3 ASC
排序结果和索引完全不同时,此时的查询不会被复合索引优化。
查询优化器在在where查询中的作用:
如果一个多列索引存在于 列 Col1 和 Col2 上,则以下语句:Select * from table where col1=val1 AND col2=val2 查询优化器会试图通过决定哪个索引将找到更少的行。之后用得到的索引去取值。
1. 如果存在一个多列索引,任何最左面的索引前缀能被优化器使用。所以联合索引的顺序不同,影响索引的选择,尽量将值少的放在前面。
如:一个多列索引为 (col1 ,col2, col3)
那么在索引在列 (col1) 、(col1 col2) 、(col1 col2 col3) 的搜索会有作用。
- SELECT * FROM tb WHERE col1 = val1
- SELECT * FROM tb WHERE col1 = val1 and col2 = val2
- SELECT * FROM tb WHERE col1 = val1 and col2 = val2 AND col3 = val3
2. 如果列不构成索引的最左面前缀,则建立的索引将不起作用。
如:
- SELECT * FROM tb WHERE col3 = val3
- SELECT * FROM tb WHERE col2 = val2
- SELECT * FROM tb WHERE col2 = val2 and col3=val3
3. 如果一个 Like 语句的查询条件不以通配符起始则使用索引。
如:%车 或 %车% 不使用索引。
车% 使用索引。
索引的缺点:
1. 占用磁盘空间。
2. 增加了插入和删除的操作时间。一个表拥有的索引越多,插入和删除的速度越慢。如 要求快速录入的系统不宜建过多索引。
下面是一些常见的索引限制问题
1、使用不等于操作符(<>, !=)
下面这种情况,即使在列dept_id有一个索引,查询语句仍然执行一次全表扫描
select * from dept where staff_num <> 1000;
但是开发中的确需要这样的查询,难道没有解决问题的办法了吗?
有!
通过把用 or 语法替代不等号进行查询,就可以使用索引,以避免全表扫描:上面的语句改成下面这样的,就可以使用索引了。
- select * from dept shere staff_num < 1000 or dept_id > 1000;
2、使用 is null 或 is not null
使用 is null 或is nuo null也会限制索引的使用,因为数据库并没有定义null值。如果被索引的列中有很多null,就不会使用这个索引(除非索引是一个位图索引,关于位图索引,会在以后的blog文章里做详细解释)。在sql语句中使用null会造成很多麻烦。
解决这个问题的办法就是:建表时把需要索引的列定义为非空(not null)
3、使用函数
如果没有使用基于函数的索引,那么where子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。下面的查询就不会使用索引:
- select * from staff where trunc(birthdate) = '01-MAY-82';
但是把函数应用在条件上,索引是可以生效的,把上面的语句改成下面的语句,就可以通过索引进行查找。
- select * from staff where birthdate < (to_date('01-MAY-82') + 0.9999);
4、比较不匹配的数据类型
比较不匹配的数据类型也是难于发现的性能问题之一。
下面的例子中,dept_id是一个varchar2型的字段,在这个字段上有索引,但是下面的语句会执行全表扫描。
- select * from dept where dept_id = 900198;
这是因为oracle会自动把where子句转换成to_number(dept_id)=900198,就是3所说的情况,这样就限制了索引的使用。
把SQL语句改为如下形式就可以使用索引
- select * from dept where dept_id = '900198';
恩,这里还有要注意的:
来自老王的博客(http://hi.baidu.com/thinkinginlamp/blog/item/9940728be3986015c8fc7a85.html)
比方说有一个文章表,我们要实现某个类别下按时间倒序列表显示功能:
SELECT * FROM articles WHERE category_id = ... ORDER BY created DESC LIMIT ...
这样的查询很常见,基本上不管什么应用里都能找出一大把类似的SQL来,学院派的读者看到上面的SQL,可能会说SELECT *不好,应该仅仅查询需要的字段,那我们就索性彻底点,把SQL改成如下的形式:
SELECT id FROM articles WHERE category_id = ... ORDER BY created DESC LIMIT ...
我们假设这里的id是主键,至于文章的具体内容,可以都保存到memcached之类的键值类型的缓存里,如此一来,学院派的读者们应该挑不出什么毛病来了,下面我们就按这条SQL来考虑如何建立索引:
不考虑数据分布之类的特殊情况,任何一个合格的WEB开发人员都知道类似这样的SQL,应该建立一个”category_id, created“复合索引,但这是最佳答案不?不见得,现在是回头看看标题的时候了:MySQL里建立索引应该考虑数据库引擎的类型!
如果我们的数据库引擎是InnoDB,那么建立”category_id, created“复合索引是最佳答案。让我们看看InnoDB的索引结构,在InnoDB里,索引结构有一个特殊的地方:非主键索引在其BTree的叶节点上会额外保存对应主键的值,这样做一个最直接的好处就是Covering Index,不用再到数据文件里去取id的值,可以直接在索引里得到它。
如果我们的数据库引擎是MyISAM,那么建立"category_id, created"复合索引就不是最佳答案。因为MyISAM的索引结构里,非主键索引并没有额外保存对应主键的值,此时如果想利用上Covering Index,应该建立"category_id, created, id"复合索引。
唠完了,应该明白我的意思了吧。希望以后大家在考虑索引的时候能思考的更全面一点,实际应用中还有很多类似的问题,比如说多数人在建立索引的时候不从Cardinality(SHOW INDEX FROM ...能看到此参数)的角度看是否合适的问题,Cardinality表示唯一值的个数,一般来说,如果唯一值个数在总行数中所占比例小于20%的话,则可以认为Cardinality太小,此时索引除了拖慢insert/update/delete的速度之外,不会对select产生太大作用;还有一个细节是建立索引的时候未考虑字符集的影响,比如说username字段,如果仅仅允许英文,下划线之类的符号,那么就不要用gbk,utf-8之类的字符集,而应该使用latin1或者ascii这种简单的字符集,索引文件会小很多,速度自然就会快很多。这些细节问题需要读者自己多注意,我就不多说了。



相关推荐
SQL Server的复合索引,是数据库管理中一种重要的性能优化技术。复合索引,也称为组合索引,是指在一个索引中包含多个列,相比于单一索引,它可以在某些特定查询场景下提供更快的检索速度。 单一索引,顾名思义,是...
标题中的“行业分类-设备装置-用于使用源于社交媒体的数据和情绪分析来生成复合索引的方法及系统”揭示了这个主题的核心内容,它涉及到信息技术、数据分析、社交媒体和情绪分析等多个领域。这种技术通常应用于市场...
Oracle数据库在处理复合索引和空值时的行为是SQL优化中的一个重要知识点,特别是对于大型数据库系统来说,理解这些细节能够显著提升查询效率。本文将详细探讨Oracle如何处理含有空值的复合索引以及非空约束对索引...
在SQL Server中,多列复合索引是一种优化查询性能的重要工具。这种索引由两个或更多列组成,目的是为了加速对这些列组合的查询。在处理复合索引时,理解其工作原理和潜在的局限性至关重要,特别是对于大型数据表来说...
* 复合索引:包含两个或者多个字段的索引。 * 非键列:键列就是在索引中所包含的列,当然非键列就是该索引之外的列了。 摘要 1:在 SQL Server 2005 中,可以通过将非键列添加到非聚集索引的叶级别来扩展非聚集索引...
例如,如果`vtype`和`id`都经常用于查询条件,创建一个`(vtype, id)`的复合索引可能有所帮助。这样,在执行`WHERE vtype = 1`并按`id`排序的查询时,MySQL能够更快地定位到所需记录。 另外,还可以考虑使用存储过程...
MongoDB的复合索引是数据库优化的关键工具,尤其在处理多键查询时,它可以显著提升查询性能。在MongoDB中,索引是一种特殊的数据结构,它按照特定的顺序存储了集合中文档的部分或全部字段,使得数据库系统能够快速...
一、 创建主键(主键=主键索引=聚集索引) 主键是什么? 答:拿主键可以唯一确定一条数据,它和物理存储排序一致,不能为空,一个表只能有一个。 原本没有创建的主键的表在磁盘上存储为: Id=0;username=username0;sex...
一个命令行实用程序,用于为您的Firestore应用程序生成复合索引。 关于该项目 Firestore需要使用复合索引来应用排序和过滤器的组合。 在创建应用程序时,这可能意味着要为可用的排序和过滤器的每种可能组合创建一个...
此包扩展了标准 Java 集合框架以提供 IndexedCollection 类,该类提供标准对象集合的简单、自动、内存中 NoSQL 复合索引。 它为复杂的 ORM 实现提供了替代方案或更简单的补充。 例如,如果应用程序有一个名为 Book ...
以下是对复合索引、非复合索引以及不同场景下索引使用效果的实践总结。 首先,复合索引(也称为组合索引)是针对多个列创建的索引,如场景1中的IDX_TEST_01,它同时基于SEGMENT_NAME和EXTENT_ID。当查询条件包含这...
复合索引,是建立在两个或更多列上的索引,它可以提高某些特定查询的性能,减少索引数量。然而,复合索引的列必须来自同一张表,且跨表索引是不被支持的。在选择复合索引时,应综合考虑查询模式和数据分布,以避免...
3. **结构复合索引文件**(.cdx):与复合索引文件类似,但是它可以保存所有类型的索引(包括主索引和候选索引),并且其文件名通常与数据表文件名相同。结构复合索引文件同样允许指定排序方式。 #### 五、实例分析...
MySQL支持五种主要类型的索引,分别是普通索引、主键索引、唯一索引、复合索引以及全文索引。 1. 普通索引:这是最基本的索引类型,无特殊要求,用于加速查询。例如,我们可以使用`CREATE INDEX`或`ALTER TABLE`...
3. **复合索引的使用**:复合索引的顺序至关重要。在查询时,应尽量使查询条件与索引顺序一致,以充分利用索引。对于复合索引,如果只使用起始列,性能接近使用所有列,而只使用非起始列则无效。如果所有列都被用到...