*ocean's blogпјҢ
http://www.oceanstudio.net/sps/blog
* жӯӨж–Үз« еҸ‘иЎЁж—¶й—ҙпјҡ2005е№ҙ2жңҲ25ж—Ҙ
* жӯӨж–Үз« жәҗпјҡ
http://www.cnblogs.com/ocean/archive/2005/02/25/109282.html
************************************************************************************
йҰ–е…Ҳд»Ӣз»ҚдёҖдёӢSharepointдёӯзҡ„жҗңзҙўгҖӮSharepointзҡ„з«ҷзӮ№еҸҜиғҪжҳҜдёҖдёӘй—ЁжҲ·з«ҷзӮ№пјҢд№ҹеҸҜиғҪд»…д»…жҳҜдёҖдёӘwssз«ҷзӮ№гҖӮspsзҡ„еҹәзЎҖе°ұжҳҜwssгҖӮдҪҶжҳҜжҗңзҙўдёҚеӨӘдёҖж ·гҖӮжҲ‘们е…ҲзңӢдёҖдёӢspsе’ҢwssдёӯдҪҝз”Ёзҡ„жҗңзҙўжңҚеҠЎгҖӮ
еңЁspsдёӯпјҢдҪҝз”ЁSharePointPSSearchжңҚеҠЎпјҢжҳҫзӨәеҗҚз§°дёәMicrosoft SharePointPS SearchпјҢиҝҷдёӘжңҚеҠЎзҡ„жҸҸиҝ°жҳҜвҖңMicrosoft SharePoint Portal Server Search жңҚеҠЎжҸҗдҫӣеҜ№й—ЁжҲ·е’ҢеӨ–йғЁеҶ…е®№зҡ„зҙўеј•е’ҢжҗңзҙўгҖӮвҖқгҖӮеҰӮжһңеҒңжҺүжӯӨжңҚеҠЎпјҢеңЁPortalдёӯжҗңзҙўзҡ„ж—¶еҖҷе°ұдјҡжҠҘй”ҷгҖӮдёҖиҲ¬дјҡжҠҘй”ҷвҖңжҗңзҙўйҒҮеҲ°дәҶй”ҷиҜҜгҖӮеҰӮжһңй—®йўҳ继з»ӯеӯҳеңЁпјҢиҜ·дёҺй—ЁжҲ·зҪ‘з«ҷз®ЎзҗҶе‘ҳиҒ”зі»гҖӮвҖқгҖӮspsдёӯзҡ„жҗңзҙўйқһеёёејәеӨ§пјҢеӣ дёәйҷӨдәҶжҗңзҙўз«ҷзӮ№зҡ„еҶ…е®№жң¬иә«д№ӢеӨ–пјҢиҝҳеҸҜд»Ҙжҗңзҙўе…¶е®ғз«ҷзӮ№зҡ„еҶ…е®№пјҢд№ҹеҚіеҸҜд»ҘзҲ¬зҪ‘гҖӮжҜ”еҰӮеӨ§е®¶еҲ° http://www.oceanstudio.net
дёҠжҗңзҙўдёҖдёӢпјҢе°ұдјҡеҸ‘зҺ°иғҪеӨҹжҗңеҲ°http://www.oceanstudio.net/sps
зҡ„еҶ…е®№пјҢеҗҢж—¶иҝҳиғҪжҗңhttp://www.cnblogs.com/ocean
зҡ„еҶ…е®№гҖӮжҗңзҙўзҡ„з«ҷзӮ№еҸҜд»ҘжҳҜд»»дҪ•з«ҷзӮ№иҖҢдёҚд»…д»…жҳҜwssз«ҷзӮ№гҖӮ
еҜ№дәҺwssз«ҷзӮ№е°ұдёҚз”ЁдәҶпјҢwssдҪҝз”ЁдәҶsql serverзҡ„е…Ёж–ҮжЈҖзҙўжңҚеҠЎпјҢд№ҹеҚіMSSEARCHжңҚеҠЎпјҢжҳҫзӨәеҗҚз§°дёәMicrosoft SearchжңҚеҠЎпјҢиҝҷдёӘжңҚеҠЎзҡ„жҸҸиҝ°жҳҜвҖңеҹәдәҺз»“жһ„еҢ–е’ҢеҚҠз»“жһ„еҢ–ж•°жҚ®зҡ„еҶ…е®№д»ҘеҸҠеұһжҖ§з”ҹжҲҗе…Ёж–Үзҙўеј•пјҢд»ҘдҫҝеҸҜд»ҘеҜ№ж•°жҚ®иҝӣиЎҢеҝ«йҖҹзҡ„еҚ•иҜҚжҗңзҙўвҖқгҖӮеҰӮжһңеҒңжҺүдәҶиҝҷдёӘжңҚеҠЎпјҢдҪ дјҡеҸ‘зҺ°wssзҡ„жҗңзҙўдёҚдјҡжҠҘй”ҷпјҢдҪҶжҳҜеҚҙжҗңдёҚеҲ°д»»дҪ•еҶ…е®№дәҶгҖӮ
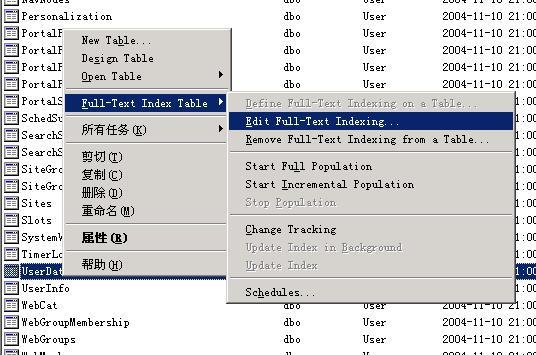
иҰҒеҗҜз”Ёwssзҡ„жҗңзҙўжңҚеҠЎпјҢйҰ–е…ҲйңҖиҰҒзЎ®е®ҡMicrosoft SearchиҝҷдёӘжңҚеҠЎе·Із»ҸеҗҜеҠЁпјҢеҗҢж—¶йңҖиҰҒеңЁwssзҡ„еҗҺеҸ°з®ЎзҗҶдёӯпјҢеҗҜз”Ёе…Ёж–ҮжҗңзҙўгҖӮеҰӮдёӢеӣҫпјҡ


然еҗҺе°ұеҸҜд»ҘиҝӣиЎҢжҗңзҙўдәҶгҖӮ
spsзҡ„жҗңзҙўи®ҫзҪ®е°ұжҜ”иҫғеӨҡдәҶпјҢжҲ‘иҝҷйҮҢе°ұдёҚеҶҚд»Ӣз»ҚдәҶпјҢдё»иҰҒйғҪжҳҜе’ҢзҲ¬зҪ‘зӣёе…ізҡ„гҖӮ
жҲ‘зҡ„зҪ‘з«ҷејҖе§Ӣзҡ„ж—¶еҖҷпјҢжІЎжі•жҗңзҙўдёӯж–ҮпјҢеҗҺжқҘжүҚеҸ‘зҺ°дёҚиғҪжҗңзҙўдёӯж–ҮпјҢжңҖеҗҺжүҚеҸ‘зҺ°еҺҹжқҘж•°жҚ®еә“йҮҮз”Ёзҡ„иӢұж–ҮзүҲsql serverжңҚеҠЎеҷЁгҖӮйӮЈд№ҲжҖҺд№ҲеҠһе‘ўгҖӮжңҖеҲқжҳҜиҖғиҷ‘жӣҙж”№жҺ’еәҸ规еҲҷгҖӮ
йҮҮз”ЁвҖңalter database жө·жҙӢе·ҘдҪңе®Ө1_SITE collate Chinese_PRC_CI_ASвҖқиҜӯеҸҘжӣҙж”№жҺ’еәҸ规еҲҷпјҢеҸ‘зҺ°жҠҘй”ҷпјҡ
Server: Msg 5075, Level 16, State 1, Line 1 The object 'CK_CatDef' is dependent on database collation.
Server: Msg 5075, Level 16, State 1, Line 1 The object 'CK_CatJoint_Title' is dependent on database collation.
Server: Msg 5075, Level 16, State 1, Line 1 The object 'CK_CatKeyword_Keyword' is dependent on database collation.
Server: Msg 5075, Level 16, State 1, Line 1 The column 'Docs.LTCheckoutUserId' is dependent on database collation.
Server: Msg 5075, Level 16, State 1, Line 1 The column 'Docs.Extension' is dependent on database collation.
Server: Msg 5075, Level 16, State 1, Line 1 The object 'CK_CatPath_Depth' is dependent on database collation.
Server: Msg 5072, Level 16, State 1, Line 1 ALTER DATABASE failed. The default collation of database 'жө·жҙӢе·ҘдҪңе®Ө1_SITE' cannot be set to Chinese_PRC_CI_AS.
д№ҹеҚіжІЎжі•жӣҙж”№гҖӮеҗҺжқҘд»ҠеӨ©жІЎеҠһжі•пјҢе°ұжӣҙж”№дәҶжҜҸдёӘжңүе…Ёж–Үзҙўеј•иЎЁзҡ„еҲҶиҜҚиҜӯиЁҖгҖӮеңЁwssж•°жҚ®еә“дёӯжңү4дёӘиЎЁпјҢеҲҶеҲ«жҳҜuserinfoпјҢuserdataпјҢlistsпјҢdocsиЎЁдёҠжңүе…Ёж–Үзҙўеј•пјҢе…¶дёӯuserdataиЎЁжҳҜжңҖйҮҚиҰҒзҡ„иЎЁпјҢйҮҢйқўжңүеҮ еҚҒдёӘеӯ—ж®өйғҪжңүе…Ёж–Үзҙўеј•гҖӮжүҖд»ҘжҲ‘ж”№дәҶдёҖдёӯеҚҲпјҢз»ҲдәҺйғҪж”№е®ҢдәҶгҖӮ
第дёҖжӯҘпјҢеңЁtablesдёҠзӮ№еҮ»еҸій”®пјҢйҖүжӢ©зј–иҫ‘е…Ёж–Үзҙўеј•гҖӮ
第дәҢжӯҘпјҢе°Ҷзҙўеј•зҡ„иҜӯиЁҖе…ЁйғЁж”№жҲҗдёӯж–ҮгҖӮ
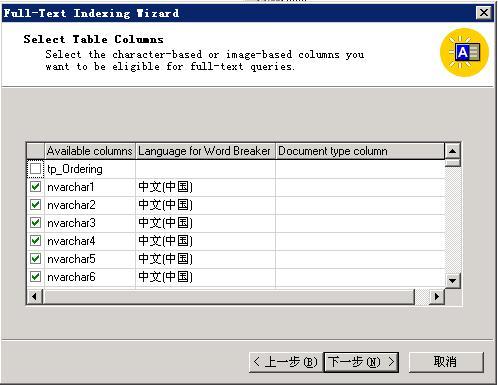
第дёүжӯҘпјҡеңЁе…Ёж–Үзӣ®еҪ•дёӯйҮҚж–°еЎ«е……гҖӮеЎ«е……еҸҜиғҪйңҖиҰҒдёҖж®өж—¶й—ҙпјҢж №жҚ®дҪ иҰҒзҙўеј•зҡ„еҶ…е®№еӨҡе°‘иҖҢе®ҡпјҢе®ҢжҜ•еҗҺе°ұеҸҜд»Ҙжҗңзҙўдёӯж–ҮдәҶгҖӮ
spsжҗңзҙўзҡ„дҫӢеӯҗеҸҜд»ҘеҲ° http://www.oceanstudio.net
дёҠзңӢгҖӮ
wssжҗңзҙўзҡ„дҫӢеӯҗеҸҜд»ҘеҲ° http://sps.oceanstudio.net
дёҠзңӢгҖӮ





зӣёе…іжҺЁиҚҗ
SAP HANAе№іеҸ°2.0зүҲжң¬зҡ„ж–°зү№жҖ§дё»иҰҒеҢ…жӢ¬дәҶд»ҘдёӢеҮ дёӘж–№йқўпјҡ 1. е®үиЈ…е’Ңжӣҙж–°пјҲInstallation and Updateпјүпјҡ - SAP HANAжңҚеҠЎеҷЁзҡ„е®үиЈ…е’Ңжӣҙж–°пјҲSAP HANA ...з”ұдәҺж–ҮжЎЈжҳҜиӢұж–ҮзүҲпјҢе…·дҪ“з»ҶиҠӮйңҖиҰҒиҝӣиЎҢзҝ»иҜ‘д»ҘдҫҝжӣҙеҘҪең°зҗҶи§Је’ҢдҪҝз”ЁгҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮжЎЈгҖҠж•°жҚ®з»“жһ„гҖӢпјҲ02331пјү第дёҖз« дё»иҰҒд»Ӣз»Қж•°жҚ®з»“жһ„зҡ„еҹәзЎҖжҰӮеҝөпјҢж¶өзӣ–ж•°жҚ®дёҺж•°жҚ®е…ғзҙ зҡ„е®ҡд№үеҸҠе…¶зү№жҖ§пјҢиҜҰз»Ҷйҳҗиҝ°дәҶж•°жҚ®з»“жһ„зҡ„дёүеӨ§иҰҒзҙ пјҡйҖ»иҫ‘з»“жһ„гҖҒеӯҳеӮЁз»“жһ„е’Ңж•°жҚ®иҝҗз®—гҖӮйҖ»иҫ‘з»“жһ„еҲҶдёәзәҝжҖ§з»“жһ„пјҲеҰӮзәҝжҖ§иЎЁгҖҒж ҲгҖҒйҳҹеҲ—пјүгҖҒж ‘еҪўз»“жһ„пјҲж¶үеҸҠж №иҠӮзӮ№гҖҒзҲ¶иҠӮзӮ№гҖҒеӯҗиҠӮзӮ№зӯүжңҜиҜӯпјүе’Ңе…¶д»–з»“жһ„гҖӮеӯҳеӮЁз»“жһ„еҜ№жҜ”дәҶйЎәеәҸеӯҳеӮЁе’Ңй“ҫејҸеӯҳеӮЁзҡ„зү№зӮ№пјҢеҢ…жӢ¬и®ҝй—®ж–№ејҸгҖҒжҸ’е…ҘеҲ йҷӨж“ҚдҪңзҡ„ж—¶й—ҙеӨҚжқӮеәҰд»ҘеҸҠз©әй—ҙеҲҶй…Қж–№ејҸпјҢ并д»Ӣз»ҚдәҶзҙўеј•еӯҳеӮЁе’Ңж•ЈеҲ—еӯҳеӮЁзҡ„жҰӮеҝөгҖӮжңҖеҗҺи®Іи§ЈдәҶжҠҪиұЎж•°жҚ®зұ»еһӢпјҲADTпјүзҡ„е®ҡд№үеҸҠе…¶з»„жҲҗйғЁеҲҶпјҢ并жҺўи®ЁдәҶз®—жі•еҲҶжһҗдёӯзҡ„ж—¶й—ҙеӨҚжқӮеәҰи®Ўз®—ж–№жі•гҖӮ йҖӮеҗҲдәәзҫӨпјҡи®Ўз®—жңәзӣёе…ідё“дёҡеӯҰз”ҹжҲ–еҲқеӯҰиҖ…пјҢеҜ№ж•°жҚ®з»“жһ„жңүдёҖе®ҡе…ҙ趣并еёҢжңӣзі»з»ҹеӯҰд№ е…¶еҹәзЎҖзҹҘиҜҶзҡ„дәәзҫӨгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ зҗҶи§Јж•°жҚ®з»“жһ„зҡ„еҹәжң¬жҰӮеҝөпјҢжҺҢжҸЎйҖ»иҫ‘з»“жһ„е’ҢеӯҳеӮЁз»“жһ„зҡ„еҢәеҲ«дёҺиҒ”зі»пјӣв‘ЎзҶҹжӮүдёҚеҗҢеӯҳеӮЁж–№ејҸзҡ„зү№зӮ№еҸҠеә”з”ЁеңәжҷҜпјӣв‘ўеӯҰдјҡеҲҶжһҗз®ҖеҚ•з®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢдёәеҗҺз»ӯж·ұе…ҘеӯҰд№ жү“дёӢеқҡе®һеҹәзЎҖгҖӮ йҳ…иҜ»е»әи®®пјҡжң¬з« иҠӮеҶ…е®№иҫғдёәзҗҶи®әеҢ–пјҢе»әи®®з»“еҗҲе®һйҷ…жЎҲдҫӢиҝӣиЎҢзҗҶи§ЈпјҢе°Өе…¶жҳҜеҜ№дәҺйҖ»иҫ‘з»“жһ„е’ҢеӯҳеӮЁз»“жһ„зҡ„зҗҶи§ЈиҰҒж·ұе…ҘеҲ°е…·дҪ“зҡ„еә”з”ЁеңәжҷҜдёӯпјҢеҗҢж—¶еҸҜд»Ҙе°қиҜ•зј–еҶҷдёҖдәӣз®ҖеҚ•зҡ„зЁӢеәҸжқҘеҠ ж·ұеҜ№жҠҪиұЎж•°жҚ®зұ»еһӢзҡ„и®ӨиҜҶгҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶж–ҪиҖҗеҫ·M580зі»еҲ—PLCзҡ„еӯҳеӮЁз»“жһ„гҖҒзі»з»ҹ硬件жһ¶жһ„гҖҒдёҠз”өеҶҷе…ҘзЁӢеәҸеҸҠCPUеҶ—дҪҷзү№жҖ§гҖӮеңЁеӯҳеӮЁз»“жһ„ж–№йқўпјҢж¶өзӣ–жӢ“жү‘еҜ»еқҖгҖҒDevice DDTиҝңзЁӢеҜ»еқҖд»ҘеҸҠеҜ„еӯҳеҷЁеҜ»еқҖдёүз§Қж–№ејҸпјҢиҜҰз»Ҷи§ЈйҮҠдәҶдёҚеҗҢзұ»еһӢзҡ„еҜ»еқҖж–№жі•еҸҠе…¶еә”з”ЁеңәжҷҜгҖӮзі»з»ҹ硬件жһ¶жһ„йғЁеҲҶпјҢйҳҗиҝ°дәҶжңҖе°Ҹзі»з»ҹзҡ„жһ„е»әиҰҒзҙ пјҢеҢ…жӢ¬CPUгҖҒжңәжһ¶е’ҢжЁЎеқ—зҡ„йҖүжӢ©дёҺй…ҚзҪ®пјҢ并д»Ӣз»ҚдәҶеёёи§Ғзҡ„зі»з»ҹжӢ“жү‘з»“жһ„пјҢеҰӮз®ҖеҚ•зҡ„жңәжһ¶й—ҙжӢ“жү‘е’ҢиҝңзЁӢеӯҗз«ҷд»ҘеӨӘзҪ‘иҸҠиҠұй“ҫзӯүгҖӮдёҠз”өеҶҷе…ҘзЁӢеәҸзҺҜиҠӮпјҢиҜҙжҳҺдәҶйҖҡиҝҮUSBе’Ңд»ҘеӨӘзҪ‘дёӨз§ҚжҺҘеҸЈиҝӣиЎҢзЁӢеәҸдёӢиҪҪзҡ„е…·дҪ“жӯҘйӘӨпјҢзү№еҲ«жҳҜй’ҲеҜ№еҲқж¬ЎдёӢиҪҪж—¶IPең°еқҖзҡ„и®ҫзҪ®ж–№жі•гҖӮжңҖеҗҺпјҢCPUеҶ—дҪҷйғЁеҲҶйҮҚзӮ№жҸҸиҝ°дәҶзғӯеӨҮеҠҹиғҪзҡ„е®һзҺ°жңәеҲ¶пјҢеҢ…жӢ¬IPйҖҡи®Ҝең°еқҖй…ҚзҪ®е’ҢзғӯеӨҮжӢ“жү‘з»“жһ„гҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢе·ҘдёҡиҮӘеҠЁеҢ–йўҶеҹҹе·ҘдҪңзҡ„жҠҖжңҜдәәе‘ҳпјҢзү№еҲ«жҳҜеҜ№PLCзј–зЁӢеҸҠзі»з»ҹйӣҶжҲҗжңүдёҖе®ҡдәҶи§Јзҡ„е·ҘзЁӢеёҲгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ её®еҠ©е·ҘзЁӢеёҲзҗҶи§Јж–ҪиҖҗеҫ·M580зі»еҲ—PLCзҡ„еҜ»еқҖжңәеҲ¶пјҢд»ҘдҫҝжӣҙеҘҪең°иҝӣиЎҢжЁЎеқ—й…ҚзҪ®е’Ңзј–зЁӢпјӣв‘ЎжҢҮеҜје·ҘзЁӢеёҲе®ҢжҲҗжңҖе°Ҹзі»з»ҹзҡ„жҗӯе»әпјҢдјҳеҢ–зі»з»ҹжӢ“жү‘з»“жһ„зҡ„и®ҫи®Ўпјӣв‘ўжҸҗдҫӣиҜҰз»Ҷзҡ„дёҠз”өеҶҷе…ҘзЁӢеәҸжҢҮеҚ—пјҢзЎ®дҝқзЁӢеәҸдёӢиҪҪйЎәеҲ©иҝӣиЎҢпјӣв‘Ји§ЈйҮҠCPUеҶ—дҪҷзҡ„е®һзҺ°ж–№ејҸпјҢжҸҗй«ҳзі»з»ҹзҡ„зЁіе®ҡжҖ§е’ҢеҸҜйқ жҖ§гҖӮ е…¶д»–иҜҙжҳҺпјҡж–Үдёӯиҝҳж¶үеҸҠдёҖдәӣзү№ж®ҠжЁЎеқ—зҡ„еҠҹиғҪд»Ӣз»ҚпјҢеҰӮе®ҡж—¶еҷЁдәӢ件е’ҢModbusдёІеҸЈйҖҡи®ҜжЁЎеқ—пјҢиҝҷдәӣеҶ…е®№жңүеҠ©дәҺз”ЁжҲ·ж·ұе…ҘдәҶи§ЈM580зі»еҲ—PLCзҡ„й«ҳзә§еә”з”ЁгҖӮжӯӨеӨ–пјҢйҷ„еҪ•йғЁеҲҶжҸҗдҫӣдәҶиҝңзЁӢеӯҗз«ҷе’ҢзғӯеӨҮеҶ—дҪҷзі»з»ҹзҡ„е®һзү©еӣҫзүҮпјҢдҫҝдәҺз”ЁжҲ·зӣҙи§ӮзҗҶи§Јзӣёе…іжҰӮеҝөгҖӮ
жҹҗеһӢиҮӘеҠЁеһӮзӣҙжҸҗеҚҮд»“еӮЁзі»з»ҹж–№жЎҲи®әиҜҒеҸҠе…ій”®йӣ¶йғЁд»¶зҡ„и®ҫи®Ў.zip
2135D3F1EFA99CB590678658F575DB23.pdf#page=1&view=fitH
еҸҜд»Ҙжҗңзҙўж–Үжң¬еҶ…зҡ„еҶ…е®№пјҢжҢҮе®ҡзӣ®еҪ•пјҢжҢҮе®ҡж–Үд»¶ж јејҸпјҢеҢ№й…ҚеӨ§е°ҸеҶҷзӯү
Windows е№іеҸ° Android Studio дёӢиҪҪдёҺе®үиЈ…жҢҮеҚ—.zip
Android Studio Meerkat 2024.3.1 Patch 1пјҲandroid-studio-2024.3.1.14-windows.zipпјүйҖӮз”ЁдәҺWindowsзі»з»ҹпјҢж–Ү件дҪҝз”Ё360еҺӢзј©иҪҜ件еҲҶеүІжҲҗдёӨдёӘеҺӢзј©еҢ…пјҢеҝ…йЎ»дёҖиө·дёӢиҪҪдҪҝз”Ёпјҡ part1: https://download.csdn.net/download/weixin_43800734/90557033 part2: https://download.csdn.net/download/weixin_43800734/90557035
еӣҪзҪ‘еҸ°еҢәз»Ҳз«ҜжңҖ新规иҢғ
еӣҪзҪ‘еҸ°еҢәз»Ҳз«ҜжңҖ新规иҢғ
1.гҖҗй”Ӯз”өжұ еү©дҪҷеҜҝе‘Ҫйў„жөӢгҖ‘Transformer-GRUй”Ӯз”өжұ еү©дҪҷеҜҝе‘Ҫйў„жөӢпјҲMatlabе®Ңж•ҙжәҗз Ғе’Ңж•°жҚ®пјү 2.ж•°жҚ®йӣҶпјҡNASAж•°жҚ®йӣҶпјҢе·Із»ҸеӨ„зҗҶеҘҪпјҢB0005з”өжұ и®ӯз»ғгҖҒB0006жөӢиҜ•пјӣ 3.зҺҜеўғеҮҶеӨҮпјҡMatlab2023bпјҢеҸҜиҜ»жҖ§ејәпјӣ 4.жЁЎеһӢжҸҸиҝ°пјҡTransformer-GRUеңЁеҗ„з§Қеҗ„ж ·зҡ„й—®йўҳдёҠиЎЁзҺ°йқһеёёеҮәиүІпјҢзҺ°еңЁиў«е№ҝжіӣдҪҝз”ЁгҖӮ 5.йўҶеҹҹжҸҸиҝ°пјҡиҝ‘е№ҙжқҘпјҢйҡҸзқҖй”ӮзҰ»еӯҗз”өжұ зҡ„иғҪйҮҸеҜҶеәҰгҖҒеҠҹзҺҮеҜҶеәҰйҖҗжёҗжҸҗеҚҮпјҢе…¶е®үе…ЁжҖ§иғҪдёҺеү©дҪҷдҪҝз”ЁеҜҝе‘Ҫйў„жөӢеҸҳеҫ—ж„ҲеҸ‘йҮҚиҰҒгҖӮжң¬д»Јз Ғе®һзҺ°дәҶTransformer-GRUеңЁиҜҘйўҶеҹҹзҡ„еә”з”ЁгҖӮ 6.дҪңиҖ…д»Ӣз»ҚпјҡжңәеҷЁеӯҰд№ д№ӢеҝғпјҢеҚҡ客专家и®ӨиҜҒпјҢжңәеҷЁеӯҰд№ йўҶеҹҹеҲӣдҪңиҖ…пјҢ2023еҚҡе®ўд№ӢжҳҹTOP50пјҢдё»еҒҡжңәеҷЁеӯҰд№ е’Ңж·ұеәҰеӯҰд№ ж—¶еәҸгҖҒеӣһеҪ’гҖҒеҲҶзұ»гҖҒиҒҡзұ»е’ҢйҷҚз»ҙзӯүзЁӢеәҸи®ҫи®Ўе’ҢжЎҲдҫӢеҲҶжһҗпјҢж–Үз« еә•йғЁжңүеҚҡдё»иҒ”зі»ж–№ејҸгҖӮд»ҺдәӢMatlabгҖҒPythonз®—жі•д»ҝзңҹе·ҘдҪң8е№ҙпјҢжӣҙеӨҡд»ҝзңҹжәҗз ҒгҖҒж•°жҚ®йӣҶе®ҡеҲ¶з§ҒдҝЎгҖӮ
AndroidйЎ№зӣ®еҺҹз”ҹjavaиҜӯиЁҖиҜҫзЁӢи®ҫи®ЎпјҢеҢ…еҗ«LW+ppt
еӨ§еӯҰз”ҹе…Ҙй—ЁеүҚз«Ҝ-дә”еӯҗжЈӢvueйЎ№зӣ®
иҝҷжҳҜдёҖдёӘе®Ңж•ҙзҡ„з«ҜеҲ°з«Ҝи§ЈеҶіж–№жЎҲпјҢз”ЁдәҺеҲҶжһҗе’Ңйў„жөӢйҳҝиҒ”й…ӢпјҲUAEпјүең°еҢәзҡ„дәҢжүӢиҪҰд»·ж јгҖӮж•°жҚ®йӣҶеҢ…еҗ« 10,000 жқЎдәҢжүӢиҪҰдҝЎжҒҜпјҢиҰҶзӣ–дәҶиҝӘжӢңгҖҒйҳҝеёғжүҺжҜ”е’ҢжІҷиҝҰзӯүеҹҺеёӮпјҢ并жҸҗдҫӣдәҶзІҫзЎ®зҡ„ең°зҗҶдҪҚзҪ®ж•°жҚ®гҖӮжӯӨеӨ–пјҢйЎ№зӣ®иҝҳеҢ…жӢ¬дёҖдёӘеҹәдәҺ Dash жһ„е»әзҡ„ Web еә”з”ЁзЁӢеәҸд»Јз Ғе’ҢдёҖдёӘи®ӯз»ғеҘҪзҡ„ XGBoost жЁЎеһӢпјҢеё®еҠ©з”ЁжҲ·жҺўзҙўеҢәеҹҹеёӮеңәи¶ӢеҠҝгҖҒйў„жөӢиҪҰд»·д»ҘеҸҠеҸҜи§ҶеҢ–ең°зҗҶз©әй—ҙжҙһеҜҹгҖӮ ж•°жҚ®йӣҶеҶ…е®№ йЎ№зӣ®ж–Ү件д»ҘеҺӢзј© ZIP еҪ’жЎЈеҪўејҸжҸҗдҫӣпјҢеҢ…еҗ«д»ҘдёӢеҶ…е®№пјҡ ж•°жҚ®ж–Ү件пјҡ data/uae_used_cars_10k.csvпјҡеҢ…еҗ« 10,000 жқЎдәҢжүӢиҪҰи®°еҪ•зҡ„ж•°жҚ®йӣҶпјҢж¶өзӣ–иҪҰиҫҶе“ҒзүҢгҖҒеһӢеҸ·гҖҒе№ҙд»ҪгҖҒйҮҢзЁӢж•°гҖҒеҸ‘еҠЁжңәзјёж•°гҖҒд»·ж јгҖҒеҸҳйҖҹз®ұзұ»еһӢгҖҒзҮғж–ҷзұ»еһӢгҖҒйўңиүІгҖҒжҸҸиҝ°д»ҘеҸҠй”Җе”®ең°зӮ№пјҲеҰӮиҝӘжӢңгҖҒйҳҝеёғжүҺжҜ”гҖҒжІҷиҝҰпјүгҖӮ жЁЎеһӢж–Ү件пјҡ models/stacking_model.pklпјҡи®ӯз»ғеҘҪзҡ„ XGBoost жЁЎеһӢпјҢз”ЁдәҺйў„жөӢдәҢжүӢиҪҰд»·ж јгҖӮ models/scaler.pklпјҡз”ЁдәҺж•°жҚ®йў„еӨ„зҗҶзҡ„зј©ж”ҫеҷЁгҖӮ models.pyпјҡжЁЎеһӢзӣёе…іеҠҹиғҪзҡ„е®һзҺ°гҖӮ train_model.pyпјҡи®ӯз»ғжЁЎеһӢзҡ„и„ҡжң¬гҖӮ Web еә”з”ЁзЁӢеәҸж–Ү件пјҡ app.pyпјҡDash еә”з”ЁзЁӢеәҸзҡ„дё»ж–Ү件гҖӮ callback
иө„жәҗеҶ…йЎ№зӣ®жәҗз ҒжҳҜжқҘиҮӘдёӘдәәзҡ„жҜ•дёҡи®ҫи®ЎпјҢд»Јз ҒйғҪжөӢиҜ•okпјҢеҢ…еҗ«жәҗз ҒгҖҒж•°жҚ®йӣҶгҖҒеҸҜи§ҶеҢ–йЎөйқўе’ҢйғЁзҪІиҜҙжҳҺпјҢеҸҜдә§з”ҹж ёеҝғжҢҮж ҮжӣІзәҝеӣҫгҖҒж··ж·Ҷзҹ©йҳөгҖҒF1еҲҶж•°жӣІзәҝгҖҒзІҫзЎ®зҺҮ-еҸ¬еӣһзҺҮжӣІзәҝгҖҒйӘҢиҜҒйӣҶйў„жөӢз»“жһңгҖҒж ҮзӯҫеҲҶеёғеӣҫгҖӮйғҪжҳҜиҝҗиЎҢжҲҗеҠҹеҗҺжүҚдёҠдј иө„жәҗпјҢжҜ•и®ҫзӯ”иҫ©иҜ„е®Ўз»қеҜ№дҝЎжңҚзҡ„дҝқеә•85еҲҶд»ҘдёҠпјҢж”ҫеҝғдёӢиҪҪдҪҝз”ЁпјҢжӢҝжқҘе°ұиғҪз”ЁгҖӮеҢ…еҗ«жәҗз ҒгҖҒж•°жҚ®йӣҶгҖҒеҸҜи§ҶеҢ–йЎөйқўе’ҢйғЁзҪІиҜҙжҳҺдёҖз«ҷејҸжңҚеҠЎпјҢжӢҝжқҘе°ұиғҪз”Ёзҡ„з»қеҜ№еҘҪиө„жәҗпјҒпјҒпјҒ йЎ№зӣ®еӨҮжіЁ 1гҖҒиҜҘиө„жәҗеҶ…йЎ№зӣ®д»Јз ҒйғҪз»ҸиҝҮжөӢиҜ•иҝҗиЎҢжҲҗеҠҹпјҢеҠҹиғҪokзҡ„жғ…еҶөдёӢжүҚдёҠдј зҡ„пјҢиҜ·ж”ҫеҝғдёӢиҪҪдҪҝз”ЁпјҒ 2гҖҒжң¬йЎ№зӣ®йҖӮеҗҲи®Ўз®—жңәзӣёе…ідё“дёҡ(еҰӮ计科гҖҒдәәе·ҘжҷәиғҪгҖҒйҖҡдҝЎе·ҘзЁӢгҖҒиҮӘеҠЁеҢ–гҖҒз”өеӯҗдҝЎжҒҜзӯү)зҡ„еңЁж ЎеӯҰз”ҹгҖҒиҖҒеёҲжҲ–иҖ…дјҒдёҡе‘ҳе·ҘдёӢиҪҪеӯҰд№ пјҢд№ҹйҖӮеҗҲе°ҸзҷҪеӯҰд№ иҝӣйҳ¶пјҢеҪ“然д№ҹеҸҜдҪңдёәжҜ•и®ҫйЎ№зӣ®гҖҒиҜҫзЁӢи®ҫи®ЎгҖҒеӨ§дҪңдёҡгҖҒйЎ№зӣ®еҲқжңҹз«ӢйЎ№жј”зӨәзӯүгҖӮ 3гҖҒеҰӮжһңеҹәзЎҖиҝҳиЎҢпјҢд№ҹеҸҜеңЁжӯӨд»Јз ҒеҹәзЎҖдёҠиҝӣиЎҢдҝ®ж”№пјҢд»Ҙе®һзҺ°е…¶д»–еҠҹиғҪпјҢд№ҹеҸҜз”ЁдәҺжҜ•и®ҫгҖҒиҜҫи®ҫгҖҒдҪңдёҡзӯүгҖӮ дёӢиҪҪеҗҺиҜ·йҰ–е…Ҳжү“ејҖREADME.txtж–Ү件пјҢд»…дҫӣеӯҰд№ еҸӮиҖғ, еҲҮеӢҝз”ЁдәҺе•Ҷдёҡз”ЁйҖ”гҖӮ
иө„жәҗеҶ…йЎ№зӣ®жәҗз ҒжҳҜжқҘиҮӘдёӘдәәзҡ„жҜ•дёҡи®ҫи®ЎпјҢд»Јз ҒйғҪжөӢиҜ•okпјҢеҢ…еҗ«жәҗз ҒгҖҒж•°жҚ®йӣҶгҖҒеҸҜи§ҶеҢ–йЎөйқўе’ҢйғЁзҪІиҜҙжҳҺпјҢеҸҜдә§з”ҹж ёеҝғжҢҮж ҮжӣІзәҝеӣҫгҖҒж··ж·Ҷзҹ©йҳөгҖҒF1еҲҶж•°жӣІзәҝгҖҒзІҫзЎ®зҺҮ-еҸ¬еӣһзҺҮжӣІзәҝгҖҒйӘҢиҜҒйӣҶйў„жөӢз»“жһңгҖҒж ҮзӯҫеҲҶеёғеӣҫгҖӮйғҪжҳҜиҝҗиЎҢжҲҗеҠҹеҗҺжүҚдёҠдј иө„жәҗпјҢжҜ•и®ҫзӯ”иҫ©иҜ„е®Ўз»қеҜ№дҝЎжңҚзҡ„дҝқеә•85еҲҶд»ҘдёҠпјҢж”ҫеҝғдёӢиҪҪдҪҝз”ЁпјҢжӢҝжқҘе°ұиғҪз”ЁгҖӮеҢ…еҗ«жәҗз ҒгҖҒж•°жҚ®йӣҶгҖҒеҸҜи§ҶеҢ–йЎөйқўе’ҢйғЁзҪІиҜҙжҳҺдёҖз«ҷејҸжңҚеҠЎпјҢжӢҝжқҘе°ұиғҪз”Ёзҡ„з»қеҜ№еҘҪиө„жәҗпјҒпјҒпјҒ йЎ№зӣ®еӨҮжіЁ 1гҖҒиҜҘиө„жәҗеҶ…йЎ№зӣ®д»Јз ҒйғҪз»ҸиҝҮжөӢиҜ•иҝҗиЎҢжҲҗеҠҹпјҢеҠҹиғҪokзҡ„жғ…еҶөдёӢжүҚдёҠдј зҡ„пјҢиҜ·ж”ҫеҝғдёӢиҪҪдҪҝз”ЁпјҒ 2гҖҒжң¬йЎ№зӣ®йҖӮеҗҲи®Ўз®—жңәзӣёе…ідё“дёҡ(еҰӮ计科гҖҒдәәе·ҘжҷәиғҪгҖҒйҖҡдҝЎе·ҘзЁӢгҖҒиҮӘеҠЁеҢ–гҖҒз”өеӯҗдҝЎжҒҜзӯү)зҡ„еңЁж ЎеӯҰз”ҹгҖҒиҖҒеёҲжҲ–иҖ…дјҒдёҡе‘ҳе·ҘдёӢиҪҪеӯҰд№ пјҢд№ҹйҖӮеҗҲе°ҸзҷҪеӯҰд№ иҝӣйҳ¶пјҢеҪ“然д№ҹеҸҜдҪңдёәжҜ•и®ҫйЎ№зӣ®гҖҒиҜҫзЁӢи®ҫи®ЎгҖҒеӨ§дҪңдёҡгҖҒйЎ№зӣ®еҲқжңҹз«ӢйЎ№жј”зӨәзӯүгҖӮ 3гҖҒеҰӮжһңеҹәзЎҖиҝҳиЎҢпјҢд№ҹеҸҜеңЁжӯӨд»Јз ҒеҹәзЎҖдёҠиҝӣиЎҢдҝ®ж”№пјҢд»Ҙе®һзҺ°е…¶д»–еҠҹиғҪпјҢд№ҹеҸҜз”ЁдәҺжҜ•и®ҫгҖҒиҜҫи®ҫгҖҒдҪңдёҡзӯүгҖӮ дёӢиҪҪеҗҺиҜ·йҰ–е…Ҳжү“ејҖREADME.txtж–Ү件пјҢд»…дҫӣеӯҰд№ еҸӮиҖғ, еҲҮеӢҝз”ЁдәҺе•Ҷдёҡз”ЁйҖ”гҖӮ
жӯӨдёәд»Јз Ғе®ЎжҹҘе·Ҙе…· еҸҜжҹҘ ж–Ү件数пјҢеӯ—иҠӮж•°пјҢжҖ»иЎҢж•°пјҢд»Јз ҒиЎҢж•°пјҢжіЁйҮҠиЎҢж•°пјҢз©әзҷҪиЎҢж•°пјҢжіЁйҮҠзҺҮзӯү
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮжЎЈж¶өзӣ–дәҶдёҖйЎ№е…ідәҺдјҒдёҡз ҙдә§жҰӮзҺҮзҡ„иҜҰз»ҶеҲҶжһҗд»»еҠЎпјҢеҲҶдёәд№Ұйқўеӣһзӯ”е’ҢPythonд»Јз Ғе®һзҺ°дёӨеӨ§йғЁеҲҶгҖӮ第дёҖйғЁеҲҶж¶үеҸҠеҜ№дёҡеҠЎзұ»еһӢе’Ңз ҙдә§зҠ¶жҖҒзҡ„иҫ№йҷ…еҲҶеёғгҖҒжқЎд»¶еҲҶеёғеҸҠзӣёеҜ№йЈҺйҷ©зҡ„и®Ўз®—пјҢ并з»ҳеҲ¶дәҶзӣёеә”зҡ„дәҢз»ҙжқЎеҪўеӣҫгҖӮ第дәҢйғЁеҲҶеҲ©з”ЁPythonиҝӣиЎҢдәҶж•°жҚ®еӨ„зҗҶе’ҢеҸҜи§ҶеҢ–пјҢеҢ…жӢ¬и®Ўз®—жҜ”еҖјжҜ”гҖҒиҜҶеҲ«жҠҪж ·жҠҖжңҜзұ»еһӢгҖҒеҲҶжһҗйұјзұ»ж•°жҚ®йӣҶд»ҘеҸҠжҺўи®Ёиҫӣжҷ®жЈ®жӮ–и®әгҖӮжӯӨеӨ–пјҢиҝҳжҸҗдҫӣдәҶй’ҲеҜ№йұјзұ»е’Ңж ‘жңЁж•°жҚ®зҡ„з»ҹи®ЎеҲҶжһҗж–№жі•гҖӮ йҖӮеҗҲдәәзҫӨпјҡйҖӮз”ЁдәҺжңүдёҖе®ҡж•°еӯҰе’Ңзј–зЁӢеҹәзЎҖзҡ„еӯҰд№ иҖ…пјҢе°Өе…¶жҳҜеҜ№з»ҹи®ЎеӯҰгҖҒж•°жҚ®еҲҶжһҗж„ҹе…ҙи¶Јзҡ„еӨ§еӯҰз”ҹжҲ–з ”з©¶дәәе‘ҳгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ её®еҠ©еӯҰз”ҹжҺҢжҸЎз»ҹи®ЎеӯҰжҰӮеҝөеҰӮиҫ№йҷ…еҲҶеёғгҖҒжқЎд»¶еҲҶеёғгҖҒзӣёеҜ№йЈҺйҷ©е’ҢжҜ”еҖјжҜ”зҡ„е®һйҷ…еә”з”Ёпјӣв‘Ўж•ҷжҺҲеҰӮдҪ•з”ЁPythonиҝӣиЎҢж•°жҚ®жё…жҙ—гҖҒеҲҶжһҗе’ҢеҸҜи§ҶеҢ–пјӣв‘ўжҸҗй«ҳеҜ№дёҚеҗҢзұ»еһӢжҠҪж ·жҠҖжңҜе’ҢжҪңеңЁеҒҸи§Ғзҡ„зҗҶи§ЈгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮжЎЈдёҚд»…еҢ…еҗ«дәҶзҗҶи®әзҹҘиҜҶи®Іи§ЈпјҢиҝҳжңүе…·дҪ“зҡ„д»Јз Ғе®һдҫӢдҫӣиҜ»иҖ…еҸӮиҖғе®һи·өгҖӮеҗҢж—¶жҸҗйҶ’иҜ»иҖ…еңЁе®ҢжҲҗдҪңдёҡж—¶йңҖиҰҒжіЁж„ҸжҸҗдәӨж јејҸзҡ„иҰҒжұӮгҖӮ
MCPеҝ«йҖҹе…Ҙй—Ёе®һжҲҳпјҢиҜҰз»Ҷзҡ„е®һжҲҳж•ҷзЁӢ
pythonпјҢplaywrightеҹәзЎҖ