
Cloudera公司已经推出了基于Hadoop平台的查询统计分析工具Impala,只要熟悉SQL,就可以熟练地使用Impala来执行查询与分析的功能。不过Impala的SQL和关系数据库的SQL还是有一点微妙地不同的。
下面,我们设计一个表,通过该表中的数据,来将SQL查询与统计的语句,使用Solr查询的方式来与SQL查询对应。这个翻译的过程,是非常有趣的,你可以看到Solr一些很不错的功能。
用来示例的表结构设计,如图所示:
<ignore_js_op> 
下面,我们通过给出一些SQL查询统计语句,然后对应翻译成Solr查询语句,然后对比结果
查询对比
条件组合查询
SQL查询语句:
- SELECT log_id,start_time,end_time,prov_id,city_id,area_id,idt_id,cnt,net_type
- FROM v_i_event
- WHERE prov_id = 1 AND net_type = 1 AND area_id = 10304 AND time_type = 1 AND time_id >= 20130801 AND time_id <= 20130815
- ORDER BY log_id LIMIT 10;
查询结果,如图所示:
<ignore_js_op> 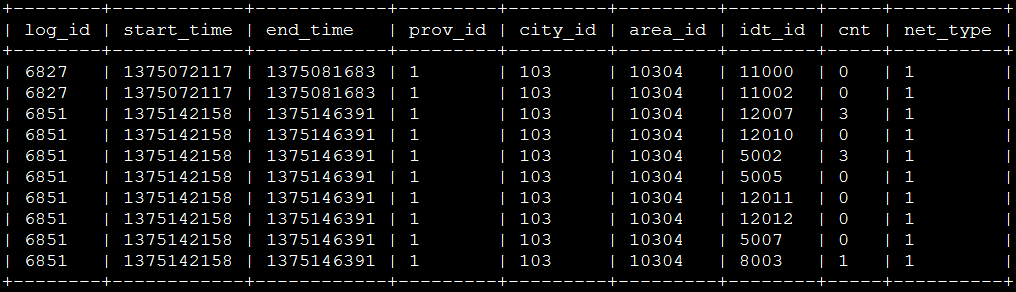
Solr查询URL:
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&fl=log_id,start_time,end_time,prov_id,city_id,area_id,idt_id,cnt,net_type&fq=prov_id:1 AND net_type:1 AND area_id:10304 AND time_type:1 AND time_id:[20130801 TO 20130815]&sort=log_id asc&start=0&rows=10
查询结果,如下所示:
- <response>
- <lst name="responseHeader">
- <int name="status">0</int>
- <int name="QTime">4</int>
- </lst>
- <result name="response" numFound="77" start="0">
- <doc>
- <int name="log_id">6827</int>
- <long name="start_time">1375072117</long>
- <long name="end_time">1375081683</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10304</int>
- <int name="idt_id">11002</int>
- <int name="cnt">0</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6827</int>
- <long name="start_time">1375072117</long>
- <long name="end_time">1375081683</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10304</int>
- <int name="idt_id">11000</int>
- <int name="cnt">0</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6851</int>
- <long name="start_time">1375142158</long>
- <long name="end_time">1375146391</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10304</int>
- <int name="idt_id">14001</int>
- <int name="cnt">5</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6851</int>
- <long name="start_time">1375142158</long>
- <long name="end_time">1375146391</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10304</int>
- <int name="idt_id">11002</int>
- <int name="cnt">23</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6851</int>
- <long name="start_time">1375142158</long>
- <long name="end_time">1375146391</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10304</int>
- <int name="idt_id">10200</int>
- <int name="cnt">55</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6851</int>
- <long name="start_time">1375142158</long>
- <long name="end_time">1375146391</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10304</int>
- <int name="idt_id">14000</int>
- <int name="cnt">4</int>
对比上面结果,除了根据idt_id排序方式不同以外(Impala是升序,Solr是降序),其他是相同的。
单个字段分组统计
SQL查询语句:
- SELECT prov_id, SUM(cnt) AS sum_cnt, AVG(cnt) AS avg_cnt, MAX(cnt) AS max_cnt, MIN(cnt) AS min_cnt, COUNT(cnt) AS count_cnt
- FROM v_i_event
- GROUP BY prov_id;
查询结果,如图所示:
<ignore_js_op> 
Solr查询URL:
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&stats=true&stats.field=cnt&rows=0&indent=true
查询结果,如下所示:
- <response>
- <lst name="responseHeader">
- <int name="status">0</int>
- <int name="QTime">2</int>
- </lst>
- <result name="response" numFound="4088" start="0"></result>
- <lst name="stats">
- <lst name="stats_fields">
- <lst name="cnt">
- <double name="min">0.0</double>
- <double name="max">1258.0</double>
- <long name="count">4088</long>
- <long name="missing">0</long>
- <double name="sum">32587.0</double>
- <double name="sumOfSquares">9170559.0</double>
- <double name="mean">7.971379647749511</double>
- <double name="stddev">46.69344567709268</double>
- <lst name="facets" />
- </lst>
- </lst>
- </lst>
- </response>
对比查询结果,Solr提供了更多的统计项,如标准差(stddev)等,与SQL查询结果是一致的。
IN条件查询
SQL查询语句:
[cde lang="sql"]
SELECT log_id,start_time,end_time,prov_id,city_id,area_id,idt_id,cnt,net_typ
FROM v_i_event
WHERE prov_id = 1 AND net_type = 1 ANDcity_id IN(106,103) AND idt_id IN(12011,5004,6051,6056,8002) AND time_type = 1AND time_id >= 20130801 AND time_id <= 20130815
ORDER BY log_id, start_time DESC LIMIT 10;
[/code]
查询结果,如图所示:
<ignore_js_op> 
Solr查询URL:
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&fl=log_id,start_time,end_time,prov_id,city_id,area_id,idt_id, cnt,net_type&fq=prov_id:1 AND net_type:1 AND (city_id:106 OR city_id:103) AND (idt_id:12011 OR idt_id:5004 OR idt_id:6051 OR idt_id:6056 OR idt_id:8002) AND time_type:1 AND time_id:[20130801 TO 20130815]&sort=log_id asc ,start_time desc&start=0&rows=10
或
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&fl=log_id,start_time,end_time,prov_id,city_id,area_id,idt_id, cnt ,net_type&fq=prov_id:1&fq=net_type:1&fq=(city_id:106 OR city_id:103)&fq=(idt_id:12011 OR idt_id:5004 OR idt_id:6051 OR idt_id:6056 OR idt_id:8002)&fq=time_type:1&fq=time_id:[20130801 TO 20130815]&sort=log_id asc,start_time desc&start=0&rows=10
查询结果,如下所示:
- <response>
- <lst name="responseHeader">
- <int name="status">0</int>
- <int name="QTime">6</int>
- </lst>
- <result name="response" numFound="63" start="0">
- <doc>
- <int name="log_id">6553</int>
- <long name="start_time">1374054184</long>
- <long name="end_time">1374054254</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10307</int>
- <int name="idt_id">12011</int>
- <int name="cnt">0</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6553</int>
- <long name="start_time">1374054184</long>
- <long name="end_time">1374054254</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10307</int>
- <int name="idt_id">5004</int>
- <int name="cnt">2</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6555</int>
- <long name="start_time">1374055060</long>
- <long name="end_time">1374055158</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">70104</int>
- <int name="idt_id">5004</int>
- <int name="cnt">3</int>
- <int name="net_type">1</int>
对比查询结果,是一致的。
开区间范围条件查询
SQL查询语句:
SELECTlog_id,start_time,end_time,prov_id,city_id,area_id,idt_id,cnt,net_type
FROM v_i_event
WHERE net_type = 1 AND idt_idIN(12011,5004,6051,6056,8002) AND time_type = 1 AND start_time >= 1373598465AND end_time < 1374055254
ORDER BY log_id, start_time, idt_id DESCLIMIT 30;
查询结果,如图所示:
<ignore_js_op> 
Solr查询URL:
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&fl=log_id,start_time,end_time,prov_id,city_id,area_id,idt_id,cnt,net_type&fq=net_type:1 AND (idt_id:12011 OR idt_id:5004 OR idt_id:6051 OR idt_id:6056 OR idt_id:8002) AND time_type:1 AND start_time:[1373598465 TO 1374055254]&fq =-start_time:1374055254&sort=log_id asc,start_time asc,idt_id desc&start=0&rows=30
或
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&fl=log_id,start_time,end_time,prov_id,city_id,area_id,idt_id,cnt,net_type&fq=net_type:1 AND (idt_id:12011 OR idt_id:5004 OR idt_id:6051 OR idt_id:6056 OR idt_id:8002) AND time_type:1 AND start_time:[1373598465 TO 1374055254] AND -start_time:1374055254&sort=log_id asc,start_time asc,idt_id desc&start=0&rows=30
或
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&fl=log_id,start_time,end_time,prov_id,city_id,area_id,idt_id,cnt,net_type&fq=net_type:1&fq=idt_id:12011 OR idt_id:5004 OR idt_id:6051 OR idt_id:6056 OR idt_id:8002&fq =time_type:1&fq=start_time:[1373598465 TO 1374055254]&fq =-start_time:1374055254&sort=log_id asc,start_time asc,idt_id desc&start=0&rows=30
查询结果,如下所示:
- <response>
- <lst name="responseHeader">
- <int name="status">0</int>
- <int name="QTime">5</int>
- </lst>
- <result name="response" numFound="4" start="0">
- <doc>
- <int name="log_id">6553</int>
- <long name="start_time">1374054184</long>
- <long name="end_time">1374054254</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10307</int>
- <int name="idt_id">12011</int>
- <int name="cnt">0</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6553</int>
- <long name="start_time">1374054184</long>
- <long name="end_time">1374054254</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">10307</int>
- <int name="cnt">2</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6555</int>
- <long name="start_time">1374055060</long>
- <long name="end_time">1374055158</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">70104</int>
- <int name="idt_id">12011</int>
- <int name="cnt">0</int>
- <int name="net_type">1</int>
- </doc>
- <doc>
- <int name="log_id">6555</int>
- <long name="start_time">1374055060</long>
- <long name="end_time">1374055158</long>
- <int name="prov_id">1</int>
- <int name="city_id">103</int>
- <int name="area_id">70104</int>
- <int name="idt_id">5004</int>
- <int name="cnt">3</int>
- <int name="net_type">1</int>
- </doc>
- </result>
- </response>
多个字段分组统计(只支持count函数)
SQL查询语句:
SELECT city_id, area_id, COUNT(cnt) AScount_cnt
FROM v_i_event
WHERE prov_id = 1 AND net_type = 1
GROUP BY city_id, area_id;
查询结果,如图所示:
<ignore_js_op> 
Solr查询URL:
- http://slave1:8888/solr-cloud/i_event/select?q=*:*&facet=true&facet.pivot=city_id,area_id&fq=prov_id:1 AND net_type:1&rows=0&indent=true
对比上面结果,Solr查询结果,需要从上面的各组中进行合并,得到最终的统计结果,结果和SQL结果是一致的。
多个字段分组统计(支持count、sum、max、min等函数)
一次对多个字段进行独立分组统计,Solr可以很好的支持。这相当于执行两个带有GROUP BY子句的SQL,这两个GROUP BY分别只对一个字段进行汇总统计。
SQL查询语句:
- SELECT city_id, area_id, COUNT(cnt) AS count_cnt
- FROM v_i_event
- WHERE prov_id = 1 AND net_type = 1
- GROUP BY city_id;
- SELECT city_id, area_id, COUNT(cnt) AS count_cnt
- FROM v_i_event
- WHERE prov_id = 1 AND net_type = 1
- GROUP BY area_id;
查询结果,不再显示。
Solr查询URL:
- >http://slave1:8888/solr-cloud/i_event/select?q=*:*&stats=true&stats.field=cnt&f.cnt.stats.facet=city_id&&f.cnt.stats.facet=area_id&fq=prov_id:1 AND net_type:1&rows=0&indent=true
查询结果,如下所示:
- <response>
- <lst name="responseHeader">
- <int name="status">0</int>
- <int name="QTime">72</int>
- </lst>
- <result name="response" numFound="1171" start="0"></result>
- <lst name="facet_counts">
- <lst name="facet_queries" />
- <lst name="facet_fields" />
- <lst name="facet_dates" />
- <lst name="facet_ranges" />
- <lst name="facet_pivot">
- <arr name="city_id,area_id">
- <lst>
- <str name="field">city_id</str>
- <int name="value">103</int>
- <int name="count">678</int>
- <arr name="pivot">
- <lst>
- <str name="field">area_id</str>
- <int name="value">10307</int>
- <int name="count">298</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">10315</int>
- <int name="count">120</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">10317</int>
- <int name="count">86</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">10304</int>
- <int name="count">67</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">10310</int>
- <int name="count">49</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">70104</int>
- <int name="count">48</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">10308</int>
- <int name="count">6</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">0</int>
- <int name="count">2</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">10311</int>
- <int name="count">2</int>
- </lst>
- </arr>
- </lst>
- <lst>
- <str name="field">city_id</str>
- <int name="value">0</int>
- <int name="count">463</int>
- <arr name="pivot">
- <lst>
- <str name="field">area_id</str>
- <int name="value">0</int>
- <int name="count">395</int>
- </lst>
- <lst>
- <str name="field">area_id</str>
- <int name="value">10307</int>
- <int name="count">68</int>
对比上面结果,Solr查询结果,需要从上面的各组中进行合并,得到最终的统计结果,结果和SQL结果是一致的。
多个字段联合分组统计(支持count、sum、max、min等函数)
SQL查询语句:
SELECT city_id, area_id, SUM(cnt) ASsum_cnt, AVG(cnt) AS avg_cnt, MAX(cnt) AS max_cnt, MIN(cnt) AS min_cnt,COUNT(cnt) AS count_cnt
FROM v_i_event
WHERE prov_id = 1 AND net_type = 1
GROUP BY city_id, area_id;
查询结果,如图所示:
<ignore_js_op> 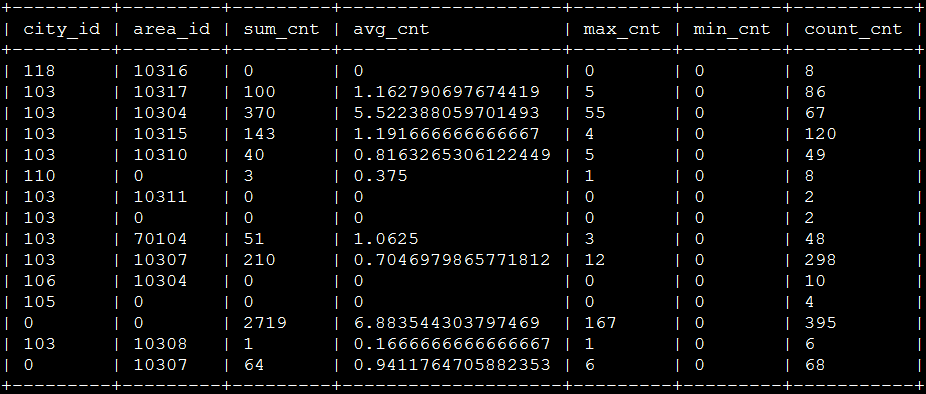
Solr目前不能简单的支持这种查询,如果想要满足这种查询统计,需要在schema的设计上,将一个字段设置为多 值,然后通过多个值进行分组统计。如果应用中查询统计分析的模式比较固定,预先知道哪些字段会用于联合分组统计,完全可以在设计的时候,考虑设置多值字段 来满足这种需求。
感兴趣的读者,还可以看看这里:基于Solr DIH实现MySQL表数据全量索引和增量索引



相关推荐
在本篇文章中,我们将深入探讨如何使用Java API来与Solr 7.1.0进行交互,并了解Solr最新支持的SQL查询功能。 首先,让我们来讨论如何通过Java API与Solr 7.1.0进行通信。Solr提供了一个名为SolrJ的客户端库,它允许...
在企业级应用中,常常需要将SQL查询的结果映射到Solr的索引中,以便实现高效的全文搜索和数据分析。 Solr的主要特点包括: 1. **全文搜索**:Solr支持复杂的全文搜索功能,可以对文本内容进行模糊匹配、短语搜索和...
- **查询优化**:利用Solr的查询过滤器(Filter Queries)和查询结果缓存,减少不必要的文档扫描,提高查询效率。 - **数据预处理**:在索引阶段,预先计算join结果并存储在Solr文档中,查询时直接读取,避免运行时...
它提供了高效、可扩展的搜索与分析能力。在电商领域,搜索结果的排序和打分对于用户体验至关重要,因为它直接影响到商品的展示顺序,进而影响到销售。本篇文章将详细介绍如何利用Solr实现电商自定义打分机制。 首先...
综上所述,这个项目展示了如何在Java Web环境中利用SSM框架与Spring Data Solr进行数据库与Solr的整合,实现高效、便捷的全文搜索功能。对于希望在项目中加入高级搜索功能的开发者来说,这是一个非常有价值的参考...
Solr-SQL为Solr Cloud提供了SQL接口,开发人员可以通过JDBC协议在Solr Cloud上运行。同时,solr-sql是用于solr的Apache Calcite(见 http://calcite.apache.org)适配器。solr-sql 是用 Scala 编写的,它可以生成像 ...
- SQL查询错误:确保查询语句符合SQL语法,且返回的数据类型与Solr字段类型匹配。 对于Oracle,还需要注意兼容性问题,因为`ojdbc6.jar`适用于Oracle 11g,如果使用的是更高版本的Oracle数据库,可能需要更新到相应...
在Windows或Linux环境下,Solr的搭建主要包括以下步骤:下载Solr二进制包,解压,配置Solr核心,启动Solr服务器,并通过Web界面管理索引和查询。 **Spring**: Spring是一个全面的Java企业级应用开发框架,它简化了...
首先,理解Hive-Solr集成的核心意义在于,它允许我们将经过Hive处理后的大量结构化数据直接导入到Solr中,利用Solr的高效索引和查询能力,实现对大数据集的快速检索。这对于需要实时分析和查询大规模数据的业务场景...
2. 数据导入配置文件:这些文件(通常是XML格式)定义了Solr如何与MySQL数据库通信,包括连接参数、SQL查询、数据类型映射等。 3. 可能还有示例脚本或者文档,指导如何配置和启动定时任务。 要使用这个插件,你需要...
- 编辑`db-data-config.xml`文件,配置数据源连接、SQL查询语句等。 **3.3 编辑managed-schema** - `managed-schema`文件定义了索引的字段和数据类型。 - 根据实际需求修改`managed-schema`文件中的字段定义。 ##...
3. **基于Compass+Lucene实现站内搜索**:适合于数据库驱动的应用场景,尤其是用于替代传统的SQL查询方式,例如使用`LIKE '%expression%'`来进行模糊匹配。 **1.2 Solr的特性** - **1.2.1 Solr使用Lucene并且进行...
3. **数据导入处理器(DIH)**:文件`apache-solr-dataimportscheduler-1.4.jar`表明了Solr 7.5 包含数据导入调度器,它能够定时从数据库或其他数据源导入数据,支持多种数据库驱动,如`sqljdbc4.jar`(用于与SQL ...
《Solr In Action 2013》是一本专注于Solr搜索引擎应用与实践的书籍,它详细介绍了如何使用Solr进行企业级搜索应用的开发。Solr是基于Apache Lucene的开源搜索服务器,它能够提供强大的全文搜索功能,多样的查询解析...
3. **基于Compass+Lucene实现**:该方案适用于数据库驱动的应用数据索引,尤其适用于替代传统的SQL查询方式来实现对文本字段的高效检索。然而,在分布式处理和接口封装方面仍需额外开发工作。 4. **基于Solr实现**:...
Solr的学习和实践不仅需要理解其核心原理,还要掌握如何与数据库交互、如何优化查询性能,以及如何根据实际需求选择和配置合适的分词器。通过深入学习和实践,你可以搭建出强大的搜索引擎,为企业或项目提供高效的...
在本文中,我们将详细介绍如何配置Solr 5.3.1与MySQL数据库的集成,以便实现高效的数据搜索功能。Solr是一款高性能、可伸缩的企业级搜索引擎,它是Apache Lucene的分布式应用实例,广泛应用于各种需要全文搜索的应用...
这是一个非常重要的配置文件,用于定义数据源、SQL查询语句以及如何将数据映射到Solr索引中。 #### 三、添加中文分词和同义词支持 **1. 中文分词器配置** 要支持中文分词,首先需要在Solr中启用相应的分词器。这...
通过SolrJ库,我们可以方便地与Solr服务器进行交互,实现数据的导入、更新和查询。 2. **Spring**: Spring是Java应用开发中最广泛使用的轻量级框架,它提供了依赖注入(DI)和面向切面编程(AOP)等功能。在本框架...