总结从MapReduce程序中的JobClient.runJob(conf)开始,给出了MapReduce执行的流程图(如下),并分析了流程图中的四个核心实体,结合实际代码介绍了MapReduce执行的详细流程。
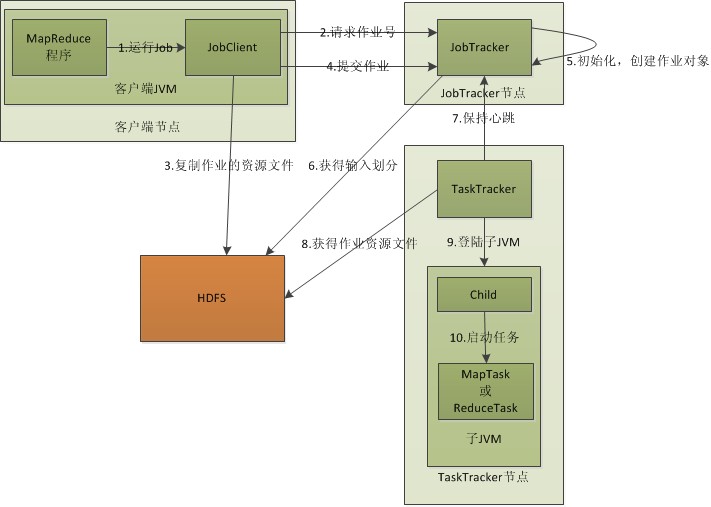
MapReduce的执行流程简单概括如下:
-
用户作业执行JobClient.runJob(conf)代码会在Hadoop集群上将其启动。
-
启动之后JobClient实例会向JobTracker获取JobId,而且客户端会将作业执行需要的作业资源复制到HDFS上,然后将作业提交给JobTracker。
-
JobTracker在本地初始化作业,再从HDFS作业资源中获取作业输入的分割信息,根据这些信息JobTracker将作业分割成多个任务,然后分配给在与JobTracker心跳通信中请求任务的TaskTracker。
-
TaskTracker接收到新的任务之后会首先从HDFS上获取作业资源,包括作业配置信息和本作业分片的输入,然后在本地启动一个JVM并执行任务。
-
任务结束后将结果写回HDFS。
介绍完MapReduce作业的详细流程后,还重点介绍了MapReduce中采用的两种机制,分别是错误处理机制和作业调度机制。在错误处理机制中,如果遇到硬件故障,MapReduce会将故障节点上的任务分配给其他节点处理。如果是任务失败,则会重新执行。在作业调度机制中,主要介绍了公平调度器。这种策略能够按照提交作业的用户数目将资源公平的分到用户的作业池中,以达到用户公平共享整个集群的目的。
最后介绍了MapReduce中两个流程的细节,分别是shuffle和任务执行。在shuffle中,从代码入手介绍了Map端和Reduce端的shuffle过程以及shuffle优化。shuffle的过程可以概括为:在Map端,当缓冲区内容达到阈值时Map写出内容。写出时按照key值对数据排序,在按照划分将数据写入文件,然后进行merge并将结果交给Reduce。在Reduce端,TaskTracker先从执行Map的TaskTracker节点上复制Map输出,然后对排序进行合并,最后进行Reduce处理。关于任务执行则主要介绍了三个任务执行的细节,分别是推测式进行、JVM重用和执行环境。推测式执行是指JobTracker在作业执行过程中,发现某个作业执行速度过慢,为了不影响整个作业的完成进度,会启动和这个作业完全相同的备份作业让TaskTracker执行,最后保留二者中较快完成的结果。JVM重用主要针对比较零碎的任务,对于新任务不是启动系的呢JVM,二是在先前执行任务完毕的JVM上执行,这样节省了启动JVM的时间。在任务执行环境中主要介绍了任务执行参数的内容和任务目录结构,以及任务临时文件夹使用情况。
转载请注明出处:http://hanlaiming.freetzi.com/?p=133
分享到:





相关推荐
#### 二、MapReduce的工作原理 MapReduce的执行流程包括以下几个关键步骤: 1. **Map任务处理** - **读取输入文件**:读取输入文件内容,并将其解析为键值对(key-value pair)的形式。 - **映射函数**:用户...
MapReduce工作流是一种在Hadoop生态系统中处理大数据的机制,它允许多个MapReduce作业(MR作业)按照特定的依赖顺序依次执行,以完成更复杂的计算任务。这些作业之间的依赖关系通常形成一个有向无环图(DAG),其中...
为了保证数据的安全性和任务的可靠性,MapReduce采用数据块的复制机制,当某个节点发生故障时,可以迅速将任务转移到其他节点继续执行。 #### 二、Hadoop及其组件 Hadoop是一个开源的分布式计算平台,它包含了两个...
8. 计数模式(Counting with Counters):计数器是MapReduce中用于记录任务执行过程中特定事件次数的机制。它可以用来监控MapReduce作业的性能,例如计算错误数据的数量或特定数据的出现频率。 9. 过滤模式...
#### 二、MapReduce的工作机制 1. **文件切片**:在MapReduce任务启动之前,首先对输入文件进行逻辑上的切片处理。每个切片对应一个独立的Map任务。切片的大小默认与HDFS块大小一致,但可以通过配置调整。 2. **Map...
#### 二、MapReduce的工作原理 MapReduce的基本思想是将大规模的数据集分割成较小的部分,通过并行处理的方式在多台计算机上进行计算。整个计算过程可以分为两个主要阶段:**Map** 和 **Reduce** 阶段。 1. **Map...
1. **理解MapReduce的工作原理**:深入学习MapReduce的工作机制,理解其分布式计算的优势。 2. **实际编程经验积累**:通过编写MapReduce程序,积累了实际编程经验,熟悉了Hadoop和MapReduce的API。 3. **分布式计算...
通过理解并动手实现这个框架,开发者不仅可以深入理解MapReduce的工作机制,还能掌握如何在实际项目中应用分布式计算解决大数据问题。对于那些关注人工智能和大数据处理的开发者,这将是一次宝贵的实践经历。
这篇文章是对Hadoop、HBase、YARN以及MapReduce进行调优的综合总结,涵盖了自动部署、配置管理、监控管理和服务监控等多个方面。首先,我们来看看Hadoop调优的关键点。 在Hadoop调优中,主要涉及到的核心配置文件...
这个压缩包文件包含了Hadoop MapReduce项目的源代码,提供了深入理解MapReduce工作原理、内部机制和优化策略的宝贵资源。以下是对MapReduce源码的一些关键知识点的详细阐述: 1. **MapReduce架构**:MapReduce将...
MapReduce的工作机制可以分为五个主要步骤: 1. **准备阶段**:首先,原始数据会被分成多个块,每个块都会被分配给不同的Map任务处理。 2. **Map阶段**:每个Map任务都会读取分配给它的数据块,并应用`Map`函数处理...
首先,Map阶段是MapReduce工作流程的第一步。在这个阶段,原始数据被分割成多个小块(split),每个split由一个map任务处理。在示例程序中,map函数会接收这些数据块,并进行预处理。为了计算平均值,我们需要统计每...
Hadoop的MapReduce还支持容错机制,当某个任务失败时,系统会自动重新调度。 **优化技巧**: 1. **Combiner**:在Map阶段后,可以使用Combiner函数局部聚合键值对,减少网络传输的数据量。 2. **Reducer数量调整**...
通过阅读这些资料,可以深入了解MapReduce的工作机制,从而在实际项目中有效地利用它来解决大数据处理问题。 总的来说,MapReduce是一个强大的工具,它简化了大规模数据处理的复杂性,使得开发者能够专注于业务逻辑...
#### 三、MapReduce的工作流程 1. **输入文件**:原始数据被分割成多个小块,每个块作为输入被传递给映射函数。 2. **映射阶段**(Map):将输入文件中的每一条记录转换为键值对形式,通常涉及一些初步的数据处理或...
总结来说,MapReduce是大数据处理的关键技术,而Hadoop是其重要的实现平台。不断研究和优化MapReduce及其在Hadoop上的应用,可以有效提升大数据处理的效率和效果,应对日益增长的数据量和复杂性。通过深入理解...
### MapReduce Online 译文PDF知识点总结 #### 摘要 本文介绍了一种改进的MapReduce体系结构,即MapReduce Online(MRO),旨在通过允许数据在操作间使用管道传输来增强传统的MapReduce编程模型。这种方法不仅简化...
在MapReduce的工作流程中,Shuffle机制扮演着至关重要的角色,它确保了数据在传递到Reducer阶段之前被正确地分区和排序。本文将深入探讨MapReduce的Shuffle机制,并讨论如何通过自定义Partitioner来满足特定的业务...
- **高容错性**: MapReduce框架内置了故障恢复机制,能够自动处理节点故障等问题。 - **高扩展性**: 可以轻松地增加更多的计算机来提高处理能力,支持PB级的大数据处理。 - **通用性强**: 适用于多种类型的数据处理...