- ц╡ПшзИ: 30080 цмб
- цАзхИл:

- цЭешЗк: х╣┐х╖Ю
-

цЦЗчлахИЖч▒╗
чд╛хМ║чЙИхЭЧ
- цИСчЪДш╡Дшоп ( 0)
- цИСчЪДшо║хЭЫ ( 45)
- цИСчЪДщЧочнФ ( 1)
хнШцбгхИЖч▒╗
- 2011-01 ( 1)
- 2010-12 ( 2)
- 2010-11 ( 17)
- цЫ┤хдЪхнШцбг...
цЬАцЦ░шпДшо║
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(хЫЫ)---Page Cacheф╣Лф║ЛхКбхдДчРЖ(2)
- хНЪховхИЖч▒╗я╝Ъ
- цФ╢шЧПш╜мхПС
хЖЩхЬихЙНщЭвя╝Ъф╕кф║║шодф╕║pagerх▒ВцШпSQLiteхоЮчО░цЬАф╕║ца╕х┐ГчЪДцибхЭЧя╝МхоГхЕ╖цЬЙхЫЫхдзхКЯшГ╜я╝ЪI/Oя╝Мщб╡щЭвч╝УхнШя╝Мх╣╢хПСцОзхИ╢
хТМцЧех┐ЧцБвхдНуАВшАМш┐Щф║ЫхКЯшГ╜ф╕Нф╗ЕцШпф╕Кх▒ВBtreeчЪДхЯ║чбАя╝МшАМф╕Фхп╣ч│╗ч╗ЯчЪДцАзшГ╜хТМхБехгоцАзцЬЙхЕ│шЗ│хЕ│щЗНшжБчЪДх╜▒хУНуАВхЕ╢
ф╕нх╣╢хПСцОзхИ╢хТМцЧех┐ЧцБвхдНцШпф║ЛхКбхдДчРЖхоЮчО░чЪДхЯ║чбАуАВSQLiteх╣╢хПСцОзхИ╢чЪДцЬ║хИ╢щЭЮх╕╕чоАхНХтАФтАФх░БщФБцЬ║хИ╢я╝ЫхИлхдЦя╝МхоГ
чЪДцЯешпвф╝ШхМЦцЬ║хИ╢ф╣ЯщЭЮх╕╕чоАхНХтАФтАФхЯ║ф║Оч┤вх╝ХуАВш┐Щф╕АхИЗф╜┐х╛ЧцХ┤ф╕кSQLiteчЪДхоЮчО░хПШх╛ЧчоАхНХя╝МSQLiteхПШх╛Чх╛Их░Пя╝Мш┐Р
шбМщАЯх║жф╣ЯщЭЮх╕╕х┐ля╝МцЙАф╗ея╝МчЙ╣хИлщАВхРИх╡МхЕех╝Пшо╛хдЗуАВхе╜ф║Жя╝МцОеф╕ЛцЭешоишо║ф║ЛхКбчЪДхЙйф╜ЩщГихИЖуАВ 7уАБ
цЧех┐ЧцЦЗф╗╢хИ╖хЕечгБчЫШ(Flushing The Rollback Journal File To Mass Storage)
┬а ф╗гчаБхжВф╕Ля╝Ъ
┬а
8уАБ
шО╖хПЦцОТцЦещФБя╝ИObtaining An Exclusive Lockя╝Й
┬а 9уАБ
ф┐оцФ╣чЪДщб╡щЭвхЖЩхЕецЦЗф╗╢(Writing Changes To The Database File)
┬а ф╗еф╕Кф╕дцнечЪДхоЮчО░ф╗гчаБя╝Ъ
┬а
┬а
10уАБ
ф┐оцФ╣ч╗УцЮЬхИ╖хЕехнШхВишо╛хдЗ(Flushing Changes To Mass Storage)
цЬАхРОцЭечЬЛчЬЛш┐ЩхЗацнецШпхжВф╜ХхоЮчО░чЪДя╝Ъ
хЕ╢хоЮф╗еф╕Кф╗еф╕КхЗацнецШпхЬихЗ╜цХ░
sqlite3BtreeSync
()---btree.cф╕н
ш░ГчФичЪД(шАМхЕ│ф║ОшпехЗ╜цХ░чЪДш░ГчФихРОщЭвхЖНшо▓)уАВ
ф╗гчаБхжВф╕Ля╝Ъ
┬а ┬а ф╕ЛхЫ╛хПпф╗еш┐Ыф╕АцнешзгщЗКшпеш┐ЗчиЛя╝Ъ
┬а
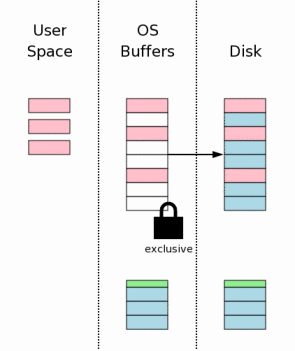
6уАБф┐оцФ╣ф╜Нф║ОчФицИ╖ш┐ЫчиЛ
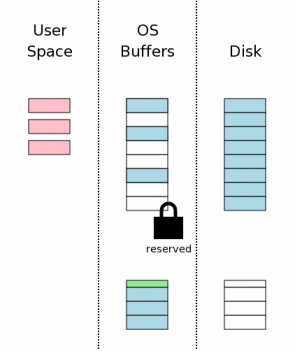
чй║щЧ┤чЪДщб╡щЭв(Changing Database Pages In User Space)
щб╡щЭвчЪДхОЯхзЛцХ░цНохЖЩхЕецЧе
х┐Чф╣ЛхРОя╝Мх░▒хПпф╗еф┐оцФ╣щб╡щЭвф║ЖтАФтАФф╜Нф║ОчФицИ╖ш┐ЫчиЛчй║щЧ┤уАВцпПф╕кцХ░цНох║Уш┐ЮцОещГ╜цЬЙшЗкх╖▒чзБцЬЙчЪДчй║щЧ┤я╝МцЙАф╗ещб╡щЭвчЪДхПШхМЦхПкхп╣шпеш┐ЮцОехПпшзБя╝МшАМхп╣хЕ╢хоГш┐ЮцОечЪДцХ░цНоф╗НчД╢цШпчгБчЫШч╝УхнШф╕н
чЪДцХ░цНоуАВф╗Ош┐ЩщЗМхПпф╗ецШОчЩ╜ф╕Аф╗╢ф║Ля╝Ъф╕Аф╕кш┐ЫчиЛхЬиф┐оцФ╣щб╡щЭвцХ░цНочЪДхРМцЧ╢я╝МхЕ╢хоГш┐ЫчиЛхПпф╗еч╗зч╗нш┐ЫшбМшп╗цУНф╜ЬуАВ
хЫ╛
ф╕нчЪДч║вшЙ▓шбичд║ф┐оцФ╣чЪДщб╡щЭвуАВ
цОе
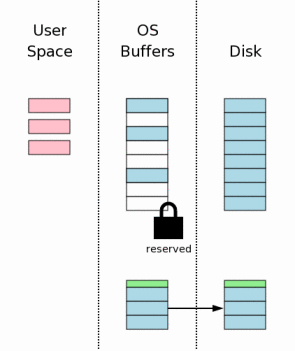
ф╕ЛцЭецККцЧех┐ЧцЦЗф╗╢чЪДхЖЕхо╣хИ╖хЕечгБчЫШя╝Мш┐Щхп╣ф║ОцХ░цНох║Уф╗ОцДПхдЦф╕нцБвхдНцЭешп┤цШпшЗ│хЕ│щЗНшжБчЪДф╕АцнеуАВшАМф╕Фш┐ЩщАЪх╕╕ф╣ЯцШпф╕Аф╕кшАЧцЧ╢чЪДцУНф╜Ья╝МхЫаф╕║чгБчЫШI/OщАЯх║жх╛ИцЕвуАВ
ш┐Щф╕кцне
щкдф╕НхПкцККцЧех┐ЧцЦЗф╗╢хИ╖хЕечгБчЫШщВгф╣ИчоАхНХя╝МхоГчЪДхоЮчО░хоЮщЩЕф╕КхИЖцИРф╕дцнея╝ЪщжЦхЕИцККцЧех┐ЧцЦЗф╗╢чЪДхЖЕхо╣хИ╖хЕечгБчЫШя╝ИхН│щб╡щЭвцХ░цНоя╝Йя╝ЫчД╢хРОцККцЧех┐ЧцЦЗф╗╢ф╕нщб╡щЭвчЪДцХ░чЫохЖЩхЕецЧех┐ЧцЦЗф╗╢хд┤я╝М
хЖНцККheaderхИ╖хЕечгБчЫШя╝Иш┐Щф╕Аш┐ЗчиЛхЬиф╗гчаБф╕нц╕ЕцЩ░хПпшзБ
я╝ЙуАВ
/*
**Sync цЧех┐ЧцЦЗф╗╢,ф┐ЭшпБцЙАцЬЙчЪДшДПщб╡щЭвхЖЩхЕечгБчЫШцЧех┐ЧцЦЗф╗╢
*/
static int syncJournal(Pager *pPager){
PgHdr *pPg;
int rc = SQLITE_OK;
/* Sync the journal before modifying the main database
** (assuming there is a journal and it needs to be synced.)
*/
if( pPager->needSync ){
if( !pPager->tempFile ){
assert( pPager->journalOpen );
/* assert( !pPager->noSync ); // noSync might be set if synchronous
** was turned off after the transaction was started. Ticket #615 */
#ifndef NDEBUG
{
/* Make sure the pPager->nRec counter we are keeping agrees
** with the nRec computed from the size of the journal file.
*/
i64 jSz;
rc = sqlite3OsFileSize(pPager->jfd, &jSz);
if( rc!=0 ) return rc;
assert( pPager->journalOff==jSz );
}
#endif
{
/* Write the nRec value into the journal file header. If in
** full-synchronous mode, sync the journal first. This ensures that
** all data has really hit the disk before nRec is updated to mark
** it as a candidate for rollback.
*/
if( pPager->fullSync ){
TRACE2("SYNC journal of %d\n", PAGERID(pPager));
//щжЦхЕИф┐ЭшпБшДПщб╡щЭвф╕нцЙАцЬЙчЪДцХ░цНощГ╜х╖▓ч╗ПхЖЩхЕецЧех┐ЧцЦЗф╗╢
rc = sqlite3OsSync(pPager->jfd, 0);
if( rc!=0 ) return rc;
}
rc = sqlite3OsSeek(pPager->jfd,
pPager->journalHdr + sizeof(aJournalMagic));
if( rc ) return rc;
//щб╡щЭвчЪДцХ░чЫохЖЩхЕецЧех┐ЧцЦЗф╗╢
rc = write32bits(pPager->jfd, pPager->nRec);
if( rc ) return rc;
rc = sqlite3OsSeek(pPager->jfd, pPager->journalOff);
if( rc ) return rc;
}
TRACE2("SYNC journal of %d\n", PAGERID(pPager));
rc = sqlite3OsSync(pPager->jfd, pPager->full_fsync);
if( rc!=0 ) return rc;
pPager->journalStarted = 1;
}
pPager->needSync = 0;
/* Erase the needSync flag from every page.
*/
//ц╕ЕщЩдneedSyncцаЗх┐Чф╜Н
for(pPg=pPager->pAll; pPg; pPg=pPg->pNextAll){
pPg->needSync = 0;
}
pPager->pFirstSynced = pPager->pFirst;
}
#ifndef NDEBUG
/* If the Pager.needSync flag is clear then the PgHdr.needSync
** flag must also be clear for all pages. Verify that this
** invariant is true.
*/
else{
for(pPg=pPager->pAll; pPg; pPg=pPg->pNextAll){
assert( pPg->needSync==0 );
}
assert( pPager->pFirstSynced==pPager->pFirst );
}
#endif
return rc;
}
┬а
хЬихп╣цХ░цНох║УцЦЗф╗╢ш┐ЫшбМф┐оцФ╣ф╣ЛхЙН(ц│ия╝Ъш┐ЩщЗМф╕НцШп
хЖЕхнШф╕нчЪДщб╡щЭв),цИСф╗мх┐Ещб╗х╛ЧхИ░цХ░цНох║УцЦЗф╗╢чЪДцОТцЦещФБ(Exclusive Lock)уАВх╛ЧхИ░цОТцЦещФБчЪДш┐ЗчиЛхПпхИЖф╕║ф╕дцнея╝ЪщжЦхЕИх╛ЧхИ░Pending
lockя╝ЫчД╢хРОPending lockхНЗч║зхИ░exclusive lockуАВ
Pending lockхЕБшо╕хЕ╢хоГх╖▓ч╗ПхнШхЬичЪДShared
lockч╗зч╗ншп╗цХ░цНох║УцЦЗф╗╢я╝Мф╜ЖцШпф╕НхЕБшо╕ф║зчФЯцЦ░чЪДshared lockя╝Мш┐Щца╖хБЪчЫочЪДцШпф╕║ф║ЖщШ▓цнвхЖЩцУНф╜ЬхПСчФЯще┐цн╗цГЕхЖ╡уАВф╕АцЧжцЙАцЬЙчЪДshared
lockхоМцИРцУНф╜Ья╝МхИЩpending lockхНЗч║зхИ░exclusive lockуАВ
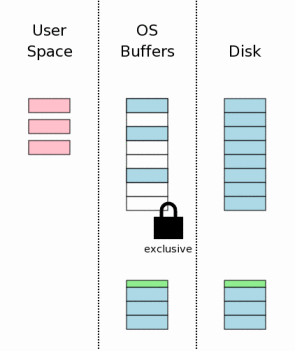
ф╕АцЧжх╛ЧхИ░
exclusive
lockя╝МхЕ╢хоГчЪДш┐ЫчиЛх░▒ф╕НшГ╜ш┐ЫшбМшп╗цУНф╜Ья╝МцндцЧ╢х░▒хПпф╗ецККф┐оцФ╣чЪДщб╡щЭвхЖЩхЫЮцХ░цНох║УцЦЗф╗╢я╝Мф╜ЖцШпщАЪх╕╕OSщГ╜цККч╗УцЮЬцЪВцЧ╢ф┐ЭхнШхИ░чгБчЫШч╝УхнШф╕ня╝МчЫ┤хИ░цЯРф╕кцЧ╢хИ╗цЙНф╝ЪчЬЯцнгцККч╗УцЮЬ
хЖЩхЕечгБчЫШуАВ
//цККцЙАцЬЙчЪДшДПщб╡щЭвхЖЩхЕецХ░цНох║У
//хИ░ш┐ЩщЗМх╝АхзЛшО╖хПЦEXCLUSIVEQщФБя╝Мх╣╢х░Жщб╡щЭвхЖЩхЫЮцУНф╜Ьч│╗ч╗ЯцЦЗф╗╢
static int pager_write_pagelist(PgHdr *pList){
Pager *pPager;
int rc;
if( pList==0 ) return SQLITE_OK;
pPager = pList->pPager;
/* At this point there may be either a RESERVED or EXCLUSIVE lock on the
** database file. If there is already an EXCLUSIVE lock, the following
** calls to sqlite3OsLock() are no-ops.
**
** Moving the lock from RESERVED to EXCLUSIVE actually involves going
** through an intermediate state PENDING. A PENDING lock prevents new
** readers from attaching to the database but is unsufficient for us to
** write. The idea of a PENDING lock is to prevent new readers from
** coming in while we wait for existing readers to clear.
**
** While the pager is in the RESERVED state, the original database file
** is unchanged and we can rollback without having to playback the
** journal into the original database file. Once we transition to
** EXCLUSIVE, it means the database file has been changed and any rollback
** will require a journal playback.
*/
//хКаEXCLUSIVE_LOCKщФБ
rc = pager_wait_on_lock(pPager, EXCLUSIVE_LOCK);
if( rc!=SQLITE_OK ){
return rc;
}
while( pList ){
assert( pList->dirty );
rc = sqlite3OsSeek(pPager->fd, (pList->pgno-1)*(i64)pPager->pageSize);
if( rc ) return rc;
/* If there are dirty pages in the page cache with page numbers greater
** than Pager.dbSize, this means sqlite3pager_truncate() was called to
** make the file smaller (presumably by auto-vacuum code). Do not write
** any such pages to the file.
*/
if( pList->pgno<=pPager->dbSize ){
char *pData = CODEC2(pPager, PGHDR_TO_DATA(pList), pList->pgno, 6);
TRACE3("STORE %d page %d\n", PAGERID(pPager), pList->pgno);
//хЖЩхЕецЦЗф╗╢
rc = sqlite3OsWrite(pPager->fd, pData, pPager->pageSize);
TEST_INCR(pPager->nWrite);
}
#ifndef NDEBUG
else{
TRACE3("NOSTORE %d page %d\n", PAGERID(pPager), pList->pgno);
}
#endif
if( rc ) return rc;
//шо╛ч╜оdirty
pList->dirty = 0;
#ifdef SQLITE_CHECK_PAGES
pList->pageHash = pager_pagehash(pList);
#endif
//цМЗхРСф╕Лф╕Аф╕кшДПщб╡щЭв
pList = pList->pDirty;
}
return SQLITE_OK;
}
┬а
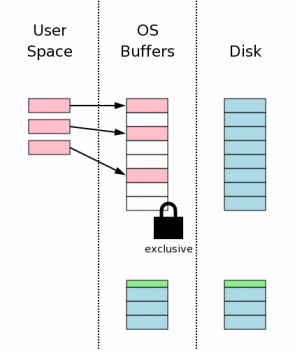
ф╕║ф║Жф┐ЭшпБф┐оцФ╣ч╗УцЮЬчЬЯцнг
хЖЩхЕечгБчЫШя╝Мш┐Щф╕Ацнех┐Еф╕НшжБх░СуАВхп╣ф║ОцХ░цНох║УхнШчЪДхоМцХ┤цАзя╝Мш┐Щф╕Ацнеф╣ЯцШпхЕ│щФочЪДф╕АцнеуАВчФ▒ф║ОшжБш┐ЫшбМхоЮщЩЕчЪДI/OцУНф╜Ья╝МцЙАф╗ехТМчмм7цнеф╕Аца╖я╝Мх░ЖшК▒ш┤╣ш╛ГхдЪчЪДцЧ╢щЧ┤уАВ
![]()
//хРМцнеbtreeхп╣х║ФчЪДцХ░цНох║УцЦЗф╗╢
//шпехЗ╜цХ░ш┐ФхЫЮф╣ЛхРОя╝МхПкщЬАшжБцПРф║дхЖЩф║ЛхКб,хИащЩдцЧех┐ЧцЦЗф╗╢
int sqlite3BtreeSync(Btree *p, const char *zMaster){
int rc = SQLITE_OK;
if( p->inTrans==TRANS_WRITE ){
BtShared *pBt = p->pBt;
Pgno nTrunc = 0;
#ifndef SQLITE_OMIT_AUTOVACUUM
if( pBt->autoVacuum ){
rc = autoVacuumCommit(pBt, &nTrunc);
if( rc!=SQLITE_OK ){
return rc;
}
}
#endif
//ш░ГчФиpagerш┐ЫшбМsync
rc = sqlite3pager_sync(pBt->pPager, zMaster, nTrunc);
}
return rc;
}
//цККpagerцЙАцЬЙшДПщб╡щЭвхЖЩхЫЮцЦЗф╗╢
int sqlite3pager_sync(Pager *pPager, const char *zMaster, Pgno nTrunc){
int rc = SQLITE_OK;
TRACE4("DATABASE SYNC: File=%s zMaster=%s nTrunc=%d\n",
pPager->zFilename, zMaster, nTrunc);
/* If this is an in-memory db, or no pages have been written to, or this
** function has already been called, it is a no-op.
*/
//pagerф╕НхдДф║ОPAGER_SYNCEDчК╢цАБ,dirtyCacheф╕║1,
//хИЩш┐ЫшбМsyncцУНф╜Ь
if( pPager->state!=PAGER_SYNCED && !MEMDB && pPager->dirtyCache ){
PgHdr *pPg;
assert( pPager->journalOpen );
/* If a master journal file name has already been written to the
** journal file, then no sync is required. This happens when it is
** written, then the process fails to upgrade from a RESERVED to an
** EXCLUSIVE lock. The next time the process tries to commit the
** transaction the m-j name will have already been written.
*/
if( !pPager->setMaster ){
//pagerф┐оцФ╣шобцХ░
rc = pager_incr_changecounter(pPager);
if( rc!=SQLITE_OK ) goto sync_exit;
#ifndef SQLITE_OMIT_AUTOVACUUM
if( nTrunc!=0 ){
/* If this transaction has made the database smaller, then all pages
** being discarded by the truncation must be written to the journal
** file.
*/
Pgno i;
void *pPage;
int iSkip = PAGER_MJ_PGNO(pPager);
for( i=nTrunc+1; i<=pPager->origDbSize; i++ ){
if( !(pPager->aInJournal[i/8] & (1<<(i&7))) && i!=iSkip ){
rc = sqlite3pager_get(pPager, i, &pPage);
if( rc!=SQLITE_OK ) goto sync_exit;
rc = sqlite3pager_write(pPage);
sqlite3pager_unref(pPage);
if( rc!=SQLITE_OK ) goto sync_exit;
}
}
}
#endif
rc = writeMasterJournal(pPager, zMaster);
if( rc!=SQLITE_OK ) goto sync_exit;
//syncцЧех┐ЧцЦЗф╗╢
rc = syncJournal(pPager);
if( rc!=SQLITE_OK ) goto sync_exit;
}
#ifndef SQLITE_OMIT_AUTOVACUUM
if( nTrunc!=0 ){
rc = sqlite3pager_truncate(pPager, nTrunc);
if( rc!=SQLITE_OK ) goto sync_exit;
}
#endif
/* Write all dirty pages to the database file */
pPg = pager_get_all_dirty_pages(pPager);
//цККцЙАцЬЙшДПщб╡щЭвхЖЩхЫЮцУНф╜Ьч│╗ч╗ЯцЦЗф╗╢
rc = pager_write_pagelist(pPg);
if( rc!=SQLITE_OK ) goto sync_exit;
/* Sync the database file. */
//syncцХ░цНох║УцЦЗф╗╢
if( !pPager->noSync ){
rc = sqlite3OsSync(pPager->fd, 0);
}
pPager->state = PAGER_SYNCED;
}else if( MEMDB && nTrunc!=0 ){
rc = sqlite3pager_truncate(pPager, nTrunc);
}
sync_exit:
return rc;
}
┬а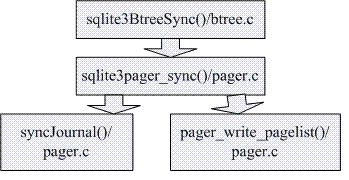


- 2010-11-18 23:57
- ц╡ПшзИ 1176
- шпДшо║(0)
- хИЖч▒╗:цХ░цНох║У
- цЯечЬЛцЫ┤хдЪ
хПСшбишпДшо║

-
я╝Иш╜мя╝ЙAndriodцШпф╗Аф╣И
2010-12-02 11:24 1621хп╝шп╗я╝ЪSans SerifцШпGoogleчЪД ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(хЕн)---хЖНш░ИSQLiteчЪДщФБ
2010-11-19 00:09 950хЖЩхЬихЙН щЭвя╝ЪSQLiteх░БщФБцЬ║хИ╢чЪДхоЮчО░щЬАшжБх║Хх▒ВцЦЗф╗╢ч│╗ч╗ЯчЪД ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(ф║Ф)---Page Cacheф╣Лх╣╢хПСцОзхИ╢
2010-11-19 00:05 1071хЖЩхЬихЙНщЭв:цЬмшКВф╕╗шжБш░Иш ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(хЫЫ)---Page Cacheф╣Лф║ЛхКбхдДчРЖ(3)
2010-11-19 00:01 978Code хЖЩхЬихЙНщЭвя╝ЪчФ▒ф║О хЖЕхо╣ш╛ГхдЪя╝МцЙАф╗ецЦнч╗нц▓бцЬЙхЖЩхоМчЪД ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(хЫЫ)---Page Cacheф╣Лф║ЛхКбхдДчРЖ(1)
2010-11-18 23:53 961хЖЩхЬихЙНщЭвя╝Ъф╗ОцЬмчлах╝АхзЛя╝Мх░Жхп╣SQLiteчЪДцпПф╕кцибхЭЧш┐ЫшбМшоишо║уАВ ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(ф╕Й)---хЖЕца╕цжВш┐░(2)
2010-11-18 23:48 1327хЖЩхЬихЙНщЭв:цЬмшКВ цШпхЙНф╕ ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(ф╕Й)---хЖЕца╕цжВш┐░(1)
2010-11-18 23:41 806хЖЩхЬихЙНщЭв:ф╗ОцЬм члах╝АхзЛ, ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(ф║М)---шо╛шобф╕ОцжВх┐╡(ч╗н)
2010-11-18 23:38 1050хЖЩхЬихЙНщЭв:цЬмшКВ шоишо║ф║ЛхКб,ф║ЛхКбцШпDBMSцЬАца╕х┐ГчЪДцКАцЬпф╣Лф╕А ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(ф║М)---шо╛шобф╕ОцжВх┐╡
2010-11-18 23:35 810хЖЩхЬихЙНщЭв:ш░вш░вхРДф╜НчЪД х ... -
я╝Иш╜мя╝ЙSQLiteхЕещЧиф╕ОхИЖцЮР(ф╕А)
2010-11-18 23:31 931хЖЩхЬихЙНщЭвя╝ЪхЗ║ф║Ощб╣чЫочЪД щЬАшжБ,цЬАш┐СцЙУчоЧхп╣SQLiteчЪДхЖЕца╕ ... -
я╝Иш╜мя╝Йц╖▒хЕечаФчй╢BцаСч┤вх╝Хя╝Иф║Фя╝Йч╗н
2010-11-18 15:10 9365.3 щЗНх╗║ B цаСч┤вх╝Х ... -
я╝Иш╜мя╝Йц╖▒хЕечаФчй╢BцаСч┤вх╝Хя╝Иф║Фя╝Й
2010-11-18 15:07 12065.┬а┬а┬а┬а щЗНх╗║ B ... -
я╝Иш╜мя╝Йц╖▒хЕечаФчй╢BцаСч┤вх╝Хя╝ИхЫЫя╝Йч╗н
2010-11-18 14:58 9374.2┬а B цаСч┤вх╝ХчЪДхп╣ф║ОхИащЩдя╝И DEL ... -
я╝Иш╜мя╝Йц╖▒хЕечаФчй╢BцаСч┤вх╝Хя╝Иф╕ЙуАБхЫЫя╝Й
2010-11-18 14:44 7413.┬а┬а┬а┬а B цаСч┤в ... -
я╝Иш╜мя╝Йц╖▒хЕечаФчй╢BцаСч┤вх╝Хя╝Иф║Мя╝Й
2010-11-18 14:20 7702.┬а┬а┬а┬а B цаСч┤вх╝ХчЪДхЖЕщГич╗УцЮД ... -
я╝Иш╜мя╝Йц╖▒хЕечаФчй╢BцаСч┤вх╝Хя╝Иф╕Ая╝Й
2010-11-18 14:12 1019цСШшжБя╝Ъ цЬмцЦЗхп╣B цаСч┤вх╝ХчЪДч╗УцЮДуАБхЖЕщГичобчРЖчнЙцЦ╣щЭвхБЪф║Жф╕Аф╕кхЕищЭв ... -
я╝Иш╜мя╝ЙBцаСуАБB-цаСуАБB+цаСуАБB*цаСщГ╜цШпф╗Аф╣И
2010-11-17 23:46 680B цаС ┬а┬а┬а┬а┬а┬а хН│ф║МхПЙцРЬ ... -
чФ╗UMLхЫ╛цЧ╢ц│ицДПчЪДхЗаф╕кхОЯхИЩя╝Иш╜мя╝Й
2010-08-03 12:34 1648ш╜пф╗╢х╝АхПСф╕ня╝МхИЖцЮРхТМшо╛шобцЧ╢я╝МцЦЗцбгчЪДч╝ЦхЖЩхТМцАЭцГ│чЪДф║дц╡Бя╝Мч╗Пх╕╕шжБч╗ШхИ╢хРД ... -
ф╜ацШпф╕кш╜пф╗╢цЮ╢цЮДх╕ИхРЧя╝Яя╝Иш╜мя╝Й
2010-07-14 11:11 676х╝АхПСхТМцЮ╢цЮДчЪДчХМщЩРщЪ╛ф╗ец ... -
(ш╜м)хРМцЫ▓х╝ВхеПтАФтАФщлШцХИшГ╜щб╣чЫохЫвщШЯчЪДф║ФхдзчЙ╣чВ╣
2010-03-29 00:24 872хРМцЫ▓х╝ВхеПтАФтАФщлШцХИшГ╜щб╣ч ...
чЫ╕хЕ│цОишНР
хЬиSQLiteхЕещЧиф╕ОхИЖцЮР(ф╕Г)---ц╡Еш░ИSQLiteчЪДшЩЪцЛЯцЬ║.docф╕ня╝Мф╕╗шжБшо▓шзгф║ЖSQLiteхжВф╜ХщАЪш┐ЗшЩЪцЛЯцЬ║цЙзшбМSQLшпнхПеуАВSQLiteчЪДшЩЪцЛЯцЬ║я╝Мф╣Ячз░ф╕║VDBEя╝ИVirtual Database Engineя╝Йя╝МцШпSQLiteчЪДца╕х┐Гч╗Дф╗╢уАВхоГш┤Яш┤гшзгцЮРSQLшпнхПея╝Мх░ЖхЕ╢ш╜мхМЦф╕║ф╕А...
2. **sqlite3_analyzer.exe**я╝Ъш┐ЩцШпф╕Аф╕кщлШч║зхИЖцЮРх╖ехЕ╖я╝МчФиф║Охп╣SQLiteцХ░цНох║Уш┐ЫшбМц╖▒хЕечЪДцАзшГ╜хИЖцЮРхТМхЖЕхнШф╜┐чФихИЖцЮРуАВхоГхПпф╗ецПРф╛ЫхЕ│ф║ОцХ░цНох║Ухдзх░ПуАБч┤вх╝ХцХИчОЗуАБшбичй║щЧ┤ф╜┐чФицГЕхЖ╡чнЙшпжч╗Жф┐бцБпуАВш┐Щхп╣ф║Оф╝ШхМЦцХ░цНох║УцАзшГ╜уАБш░ГцХ┤хнШхВич╗УцЮД...
ш╡ащАБjarхМЕя╝Ъsqlite-jdbc-3.15.1.jarя╝Ы ш╡ащАБхОЯAPIцЦЗцбгя╝Ъsqlite-jdbc-3.15.1-javadoc.jarя╝Ы ш╡ащАБц║Рф╗гчаБя╝Ъsqlite-jdbc-3.15.1-sources.jarя╝Ы ш╡ащАБMavenф╛Эш╡Цф┐бцБпцЦЗф╗╢я╝Ъsqlite-jdbc-3.15.1.pomя╝Ы хМЕхРлч┐╗шпСхРОчЪДAPIцЦЗцбгя╝Ъ...
хЬитАЬsqlite-tools-linux-x86-3350400.zipтАЭш┐Щф╕кхОЛч╝йхМЕф╕ня╝МхМЕхРлф║Жф╗еф╕ЛхЕ│щФочЪДSQLiteх╖ехЕ╖я╝Ъ 1. **sqlite3**: ш┐ЩцШпSQLiteчЪДф╕╗шжБхС╜ф╗дшбМцОехПгуАВчФицИ╖хПпф╗ещАЪш┐Зш┐Щф╕кх╖ехЕ╖цЙзшбМSQLшпнхПея╝МхИЫх╗║хТМчобчРЖцХ░цНох║Уя╝МцЯешпвцХ░цНоя╝МчФЪшЗ│ш┐ЫшбМ...
sqlite-devel-3.7.17-8.el7.x86_64.rpm
SQLite3.exe цШп SQLite цХ░цНох║Ух╝ХцУОчЪДф╕Аф╕кхС╜ф╗дшбМцОехПгх╖ехЕ╖я╝МхоГхЕБшо╕чФицИ╖щАЪш┐ЗцЦЗцЬмхС╜ф╗дф╕О SQLite цХ░цНох║Уш┐ЫшбМф║дф║ТуАВSQLite цШпф╕Аф╕кх╝Ац║РуАБш╜╗щЗПч║зуАБшЗкхМЕхРлчЪД SQL цХ░цНох║Ух╝ХцУОя╝Мх╣┐ц│Ых║ФчФиф║Ох╡МхЕех╝Пч│╗ч╗ЯхТМчз╗хКих║ФчФиф╕ня╝МхЫаф╕║хоГцЧащЬА...
хп╣ф║ОщВгф║Ыф╕НщЬАшжБхдНцЭВф║ЛхКбхдДчРЖхТМх╣╢хПСцОзхИ╢чЪДхЬ║цЩпя╝МSQLite цПРф╛Ыф║Жф╕Аф╕кчоАхНХуАБщлШцХИчЪДшзгхЖ│цЦ╣цбИуАВчД╢шАМя╝Мхп╣ф║ОщЬАшжБщлШх║жх╣╢хПСхТМхдНцЭВф║ЛхКбхдДчРЖчЪДх║ФчФия╝МхПпшГ╜щЬАшжБшАГшЩСф╜┐чФицЫ┤ф╕║х╝║хдзчЪДцХ░цНох║Уч│╗ч╗Яя╝МхжВ MySQL цИЦ PostgreSQLуАВ
SQLite-1.0.66.0-setupхоЙшгЕхМЕ
тАЬsqlite-autoconfтАЭхТМтАЬsqliteтАЭцаЗчн╛хИЩшбицШОф║ЖхоГцШпшЗкхКищЕНч╜очЪДSQLiteчЙИцЬмя╝Мф╕ОцаЗхЗЖчЪДSQLiteх║УцЬЙхЕ│уАВш┐Щф║ЫцаЗчн╛цЬЙхКйф║ОчФицИ╖хЬицРЬч┤вхТМчобчРЖш╡Дц║РцЧ╢ш┐ЫшбМхИЖч▒╗хТМшпЖхИлуАВ цА╗ф╣Ля╝М`sqlite-autoconf-3070800-arm.tar.gz` хМЕхРлф║Жф╕Аф╕кщвД...
SQLiteStudioцШпф╕Ацм╛хКЯшГ╜х╝║хдзчЪДSQLiteцХ░цНох║УчобчРЖх╖ехЕ╖я╝Мф╕Уф╕║WindowsцУНф╜Ьч│╗ч╗Яшо╛шобуАВSQLiteцЬмш║лцШпф╕Аф╕кх╝Ац║РуАБш╜╗щЗПч║зчЪДх╡МхЕех╝ПSQLцХ░цНох║Ух╝ХцУОя╝Мх╣┐ц│Ых║ФчФиф║ОхРДчзНцбМщЭвх║ФчФичиЛх║ПуАБчз╗хКишо╛хдЗхТМцЬНхКбхЩичОпхвГя╝Мх░дхЕ╢щАВхРИщВгф║Ыхп╣цХ░цНох║УцАзшГ╜...
SQLiteхЕещЧиф╕ОхИЖцЮР(хЫЫ)---Page Cacheф╣Лф║ЛхКбхдДчРЖ.doc SQLiteхЕещЧиф╕ОхИЖцЮР(ф║Ф)---Page Cacheф╣Лх╣╢хПСцОзхИ╢.doc SQLiteхЕещЧиф╕ОхИЖцЮР(хЕн)---хЖНш░ИSQLiteчЪДщФБ.doc
хЬиWindows 64ф╜НчОпхвГф╕Ля╝М"sqlite-dll-win64-x64-3350100.zip" цЦЗф╗╢ф╗гшбичЪДцШпSQLiteчЪДхКицАБщУ╛цОех║Уя╝ИDLLя╝ЙчЙИцЬмя╝МщАВчФиф║О64ф╜Ня╝Иx64я╝ЙчЪДWindowsх╣│хП░уАВш┐ЩщЗМчЪД"3350100"цШпSQLiteчЪДчЙИцЬмхП╖я╝Мшбичд║ш┐ЩцШпхИ░2021х╣┤ф╕║цнвчЪДф╕Аф╕кш╛ГцЦ░чЪД...
щАЪш┐ЗхИЖцЮРш┐Щф╕кц║РчаБхМЕя╝Мх╝АхПСшАЕхПпф╗еф║ЖшзгхИ░хжВф╜ХхЬи.NETщб╣чЫоф╕нщЫЖцИРSQLiteцХ░цНох║Уя╝МхМЕцЛмцХ░цНошо┐щЧох▒ВчЪДшо╛шобуАБф║ЛхКбхдДчРЖуАБщФЩшппхдДчРЖуАБцЯешпвцЮДх╗║чнЙуАВхРМцЧ╢я╝Мц║РчаБхМЕш┐ШцФпцМБхдЪчзН.NETчЙИцЬмхТМх╣│хП░я╝Мф╜┐х╛Чх╝АхПСшАЕхПпф╗еца╣цНощб╣чЫощЬАц▒ВщАЙцЛйхРИщАВчЪД...
"SQLite-1.0.66.0-setup" цаЗщвШшбицШОш┐ЩцШпф╕Аф╕кхЕ│ф║ОSQLiteцХ░цНох║УчЪДхоЙшгЕчиЛх║Пя╝МчЙИцЬмхП╖ф╕║1.0.66.0уАВш┐Щф╕кхОЛч╝йхМЕхПпшГ╜хМЕхРлф║ЖчФиф║ОхЬичФицИ╖шобчоЧцЬ║ф╕КхоЙшгЕSQLiteчЪДх┐ЕшжБцЦЗф╗╢уАВ цППш┐░ф╕нчЪДщЗНхдНф┐бцБптАЬSQLite-1.0.66.0-setupтАЭхПпшГ╜цШпф╕Аф╕к...
цА╗чЪДцЭешп┤я╝М"sqlite-shell-linux-x86-3080900.zip" цШпхЬиLinuxчОпхвГф╕нчобчРЖхТМцУНф╜ЬSQLiteцХ░цНох║УчЪДщЗНшжБх╖ехЕ╖я╝МхоГцПРф╛Ыф║Жф╕Аф╕кчЫ┤цОеф╕ОцХ░цНох║Уф║дф║ТчЪДчХМщЭвя╝Мф╜┐х╛ЧцХ░цНочобчРЖхПШх╛ЧчоАхНХцШУшбМуАВцЧашо║ф╜ацШпхИЭхнжшАЕш┐ШцШпч╗ПщкМф╕░хпМчЪДх╝АхПСшАЕя╝МчЖЯцВЙх╣╢...
цаЗщвШ "sqlite-netFx40-binary-x64-2010-1.0.106.0" цМЗчЪДцШпф╕Аф╕кщТИхп╣ .NET Framework 4.0 х╣│хП░чЪД SQLite щй▒хКичиЛх║ПчЪДчЙ╣хоЪчЙИцЬмя╝МщАВчФиф║О64ф╜Ня╝Иx64я╝Йч│╗ч╗ЯуАВш┐Щф╕кчЙИцЬмхП╖1.0.106.0шбицШОш┐ЩцШпф╕Аф╕кцЫ┤цЦ░чи│хоЪчЙИуАВSQLite цШпф╕Аф╕кш╜╗щЗП...
sqlite-tools-win32-x86-3290000 цШпф╕Аф╕кSQLiteцХ░цНох║Ух╖ехЕ╖хЬиWindows 32ф╜Нч│╗ч╗Яф╕КчЪДхоЙшгЕхМЕцИЦчЫох╜ХхРНчз░уАВSQLiteцШпф╕Аф╕кCх║Уя╝МцПРф╛Ыф║Жф╕Аф╕кш╜╗щЗПч║зчЪДчгБчЫШцЦЗф╗╢цХ░цНох║Уя╝Мф╕НщЬАшжБф╕Аф╕кхНХчЛмчЪДцЬНхКбхЩиш┐ЫчиЛцИЦцУНф╜Ьч│╗ч╗Яя╝Иф╕НщЬАшжБщЕНч╜оуАБхоЙшгЕцИЦ...
"sqlite-netFx451-setup-bundle-x86-2013-1.0.105.2.exe" цШпф╕Аф╕кщТИхп╣VS2013чЪДSQLiteхоЙшгЕхМЕя╝МщАВчФиф║Оx86цЮ╢цЮДчЪДWindowsч│╗ч╗Яя╝МчЙИцЬмхП╖ф╕║1.0.105.2уАВ 1. **SQLite ф╗Лч╗Н**я╝Ъ - SQLiteцШпф╕Аф╕кшЗкхМЕхРлуАБцЧацЬНхКбхЩиуАБщЫ╢щЕНч╜оуАБ...
2. sqlite-netFx46-setup-bundle-x86-2015-1.0.98.0.exeя╝Ъш┐ЩцШпф╕Аф╕к32ф╜НчЙИцЬмчЪДSQLiteхоЙшгЕхМЕя╝МщАВчФиф║О32ф╜НцУНф╜Ьч│╗ч╗ЯчЪД.NET Framework 4.6чОпхвГя╝МхРМца╖чЙИцЬмхП╖ф╕║1.0.98.0я╝МхПСх╕Гф║О2015х╣┤уАВ ф╜┐чФиш┐Щф╕дф╕кхоЙшгЕчиЛх║Пя╝Мх╝АхПСшАЕхПпф╗е...