
¬† ¬† ¬† дЄКдЄАзѓЗжЦЗзЂ†зЃАеНХдїЛзїНдЇЖдЄЛFlumeзЪДиГМжЩѓпЉМжО•дЄЛжЭ•жЬђжЦЗиѓіиѓіFlume NGзЪДеЖЕйГ®иЃЊиЃ°гАВж≥®жДПпЉЪжЬђжЦЗйТИеѓєзЪДжШѓFlume1.6.0зЙИжЬђгАВ
¬† ¬† ¬† дЄКдЄАзѓЗпЉЪhttp://manzhizhen.iteye.com/blog/2298150
¬† ¬† ¬† жИСдїђеЕИжЭ•зЬЛзЬЛдЄЇдїАдєИйЬАи¶БFlumeпЉМеЬ®е§ІжХ∞жНЃеИЖжЮРйҐЖеЯЯпЉМжЬАйЗНи¶БзЪДе∞±жШѓжХ∞жНЃпЉМиАМжЧ•ењЧдљЬдЄЇй¶ЦйАЙжХ∞жНЃжЭ•жЇРдєЛдЄАпЉМжЬЙзЭАдЄЊиґ≥иљїйЗНзЪДеЬ∞дљНпЉМе¶ВдїКдЉБдЄЪзЪДзЇњдЄКдЄЪеК°жЬНеК°еЩ®пЉМе∞СеИЩеЗ†еНБеП∞дЄКзЩЊеП∞пЉМе§ЪеИЩдЄКеНГеП∞пЉМињЩдєИе§ЪеП∞зЇњдЄКжЬНеК°еЩ®пЉМжМЙзЕІжѓПеП∞жѓП姩еє≥еЭЗдЇІзФЯеЗЇ50GзЪДжЧ•ењЧжЭ•зЃЧпЉМе¶ВжЮЬзЇњдЄКеЕ±жЬЙ100еП∞жЬНеК°еЩ®пЉМеИЩжѓП姩е∞±еПѓдї•дЇІзФЯеЈЃдЄНе§Ъ5TBзЪДжЧ•ењЧйЗПпЉМиАМе∞ЖдЇЫжЧ•ењЧжµБжХ∞жНЃйЂШжХИеПѓйЭ†зЪДеЖЩеЕ•hdfsпЉМжИСдїђеЇФиѓ•жАОдєИеБЪпЉЯжЬЙдЇЇдЉЪиѓіжѓПеП∞дЄЪеК°жЬНеК°еЩ®иЗ™еЈ±еЊАHDFSеЖЩеХКпЉМno,no,noпЉМињЩж†ЈеБЪзЪДиѓЭhdfsи°®з§ЇеПЧдЄНдЇЖпЉМжИСдїђдЄАеЃЪи¶БиАГиЩСеИ∞вАЬдЊЫйЬАз®≥еЃЪеТМеє≥и°°вАЭпЉМеПИжЬЙдЇЇй©ђдЄКдЉЪиѓіпЉЪзФ®KafkaпЉБзЪДз°ЃпЉМKafkaдљЬдЄЇйЂШеРЮеРРйЗПзЪДMQеЃЮзО∞дєЛдЄАпЉМжАІиГљдЄКиВѓеЃЪжШѓж≤°йЧЃйҐШпЉМиАМдЄФKafkaдљЬдЄЇApacheеП¶дЄАй°ґзЇІй°єзЫЃпЉМжЬАеИЭе∞±жШѓдљЬдЄЇжЧ•ењЧз≥їзїЯеЗЇзФЯгАВKafkaзО∞еЬ®дљЬдЄЇжµБи°МзЪДеПСеЄГ/иЃҐйШЕжґИжБѓдЄ≠йЧідїґпЉМжЬЙScalaиѓ≠и®АеЉАеПСпЉМеєњж≥ЫзЪДзФ®дЇОдљУзїЯдєЛйЧізЪДеЉВж≠•йАЪдњ°пЉМзЙєеИЂйАВеРИеЉВжЮДз≥їзїЯдєЛйЧідљњзФ®гАВеЬ®жЧ•ењЧдЉ†иЊУйҐЖеЯЯпЉМжШѓйАЙжЛ©FlumeињШжШѓKafkaпЉМе∞±еГПзЪЗй©ђжЙУеЈіиР®йВ£ж†ЈпЉМи∞БйГљж≤°жЬЙеОЛеАТжАІзЪДдЉШеКњпЉМдљЖFlumeзЇѓз≤єдЄЇжЧ•ењЧдЉ†иЊУиАМзФЯпЉМеЉАзЃ±еН≥зФ®пЉМеЗ†дєОйЫґзЉЦз®ЛпЉМиАМдЄФжПРдЊЫжЧ•ењЧињЗжї§гАБиЗ™еЃЪдєЙеИЖеПСз≠ЙеКЯиГљпЉМеєґеѓєеЖЩеЕ•HDFSз≠ЙжЬЙиЙѓе•љзЪДжФѓжМБпЉМе¶ВжЮЬжГ≥еБЈжЗТпЉМеИЩйАЙFlumeзїЭеѓєж≤°йФЩгАВдљЖзО∞е¶ВдїКпЉМKafka+Flume+HDFSз≠ЙиѓЄе§Ъе∞ЖKafkaеТМFlumeзїУеРИиµЈжЭ•дљњзФ®зЪДжЦєж°ИгАВ
¬† ¬† ¬† ¬†е¶ВжЮЬж≤°жЬЙжИРзЖЯзЪДжЧ•ењЧдЉ†иЊУжЦєж°ИпЉМжИСдїђжЭ•иЃ®иЃЇиЃ®иЃЇе¶ВжЮЬиЗ™еЈ±еБЪпЉМйЬАи¶БиІ£еЖ≥еУ™дЇЫйЧЃйҐШгАВжЬАеЃєжШУжГ≥еИ∞зЪДзђђдЄАзВєе∞±жШѓжХИзОЗеТМжАІиГљпЉМзІТзЇІзЪДеїґињЯжИСдїђеПѓдї•жО•еПЧпЉМдљЖе¶ВжЮЬиѓізЇњдЄКдЄЪеК°з≥їзїЯдЇІзФЯдЄАжЭ°жЧ•ењЧжХ∞жНЃпЉМињЗдЇЖеНБеЗ†еИЖйТЯзФЪиЗ≥дЄАдЄ™е∞ПжЧґжЙНиГљеЖЩеИ∞HDFSдЄ≠пЉМйВ£жШѓењНжЧ†еПѓењНзЪДгАВеЕґеЃЮињЩзВєдЄНйЪЊеБЪеИ∞пЉМеП™и¶БжЮґжЮДиЃЊиЃ°зЪДзЃАеНХеЃЮзФ®пЉМжХИзОЗеТМжАІиГљдЄАиИђдЄНжШѓйЧЃйҐШгАВзђђдЇМзВєе∞±жШѓеПѓйЭ†жАІпЉМеП™и¶БжШѓзїПињЗзљСзїЬдЉ†иЊУзЪДжХ∞жНЃпЉМйГље≠Шеܮ䪥姱зЪДеПѓиГљпЉМи¶БеБЪеИ∞дЄАжЭ°жЧ•ењЧдїОзФЯдЇІиАЕеПСйАБеИ∞жґИиієиАЕпЉМиАМдЄФжґИиієиАЕжЬЙдЄФдїЕдїЕжґИиієдЄАжђ°пЉМжШѓеЊИеЫ∞йЪЊзЪДпЉМеЬ®жЯРдЇЫжГЕеЖµдЄЛзФЪиЗ≥жШѓдЄНеПѓиГљзЪДпЉМе¶ВжЮЬеБЪдЄНеИ∞пЉМйВ£иЗ≥е∞СеЊЧеБЪеИ∞дњЭиѓБиЗ≥е∞СжґИиієдЄАжђ°гАВеПѓйЭ†жАІињШжґЙеПКеИ∞FailoverеТМеПѓжБҐе§НпЉМе¶ВжЮЬеПСзФЯжХЕйЪЬпЉМиГљеИЗжНҐеИ∞еЕґдїЦж≠£еЄЄжЬНеК°зЪДиКВзВєпЉМеєґдЄФеЗЇжХЕйЪЬзЪДиКВзВєиГљењЂйАЯжБҐе§НгАВзђђдЄЙзВєе∞±жШѓеПѓжЙ©е±ХжАІпЉМеПѓжЙ©е±ХжАІжШѓеИЖеЄГеЉПз≥їзїЯзЪДж†ЗйЕНдЇЖпЉМе¶ВжЮЬжЧ•ењЧйЗПеҐЮе§ІпЉМжИСдїђеПѓдї•еК®жАБзЪДжЈїеК†жЬНеК°иКВзВєпЉМжЭ•еҐЮеК†жЧ•ењЧдЉ†иЊУзЪДеРЮеРРйЗПгАВзђђеЫЫзВєпЉМеЊЧжФѓжМБеЉВжЮДжЇРпЉМжЧ•ењЧдЄНеПѓиГљеП™йЬАи¶БдЇЫеИ∞HDFSпЉМжЯРдЇЫжЧ•ењЧињШйЬАи¶БеЖЩеЕ•зЫЃзЪДеЬ∞гАВеЕґеЃЮи¶БеБЪеИ∞дї•дЄКињЩдЇЫзВєпЉМеєґдЄНеЃєжШУпЉМжИСдїђдЄНйЬАи¶БйЗНе§НйА†иљЃе≠РдЇЖпЉМеЫ†дЄЇеЈ≤зїПжЬЙFlumeдЇЖгАВ
¬† ¬† ¬† ¬†жО•дЄЛжЭ•пЉМжИСдїђзЬЛзЬЛFlumeзЪДиЃЊиЃ°пЉМFlumeжШѓдї•AgentдљЬдЄЇеЯЇжЬђзЪДжЬНеК°еНХдљНпЉМз±їдЉЉдЇОMQдЄ≠зЪДBrokerпЉМдЄАдЄ™AgentеРѓеК®еРОе∞±жШѓдЄАдЄ™JavaињЫз®ЛпЉМеЃГжЪійЬ≤дЄАдЄ™жИЦе§ЪдЄ™зЂѓеП£жЭ•жПРдЊЫжЬНеК°гАВдЇОжШѓдљ†еПѓдї•еПСзО∞пЉМеПѓдї•еП†еК†е§ЪдЄ™AgentжЭ•жПРйЂШжИСдїђзЪДжЧ•ењЧжЬНеК°иГљеКЫпЉМжѓФе¶Вдљ†еПѓдї•еЬ®дЄАдЄ™жЬНеК°еЩ®дЄКеРѓеК®е§ЪдЄ™AgentзЪДJavaињЫз®ЛпЉМжЭ•йАЪињЗжЪійЬ≤е§ЪдЄ™зЂѓеП£жЭ•еЃЮзО∞жЧ•ењЧжЬНеК°зЪДж®™еРСжЙ©е±ХпЉМеҐЮеК†жЧ•ењЧдЉ†иЊУиГљеКЫпЉМдљЖдєЯдЄНжШѓиґКе§ЪиґКе•љпЉМеЇФиѓ•ж†єжНЃCPUеЖЕж†ЄжХ∞жЭ•з°ЃеЃЪгАВжѓПдЄ™AgentйГљеѓєеЇФдЄАдЄ™йЕНзљЃжЦЗдїґпЉМйЕНзљЃжЦЗдїґдЄ≠жЬЙиѓ•AgentзЪДжЙАжЬЙзїЖиКВгАВ
¬† ¬† ¬† ¬†дїїдљХжЧ•ењЧжХ∞жНЃеЬ®ињЫеЕ•AgentдєЛеЙНдЉЪ襀еМЕи£ЕжИРEventпЉМжЙАдї•пЉМеѓєдЇОAgentжЭ•иѓіпЉМзФЯеСљеС®жЬЯжЙАеЯЇз°АеИ∞зЪДжѓПдЄАи°МжЧ•ењЧпЉМеЕґеЃЮйГљжШѓдЄАдЄ™EventгАВEventдЄЛзѓЗдЉЪиѓ¶зїЖдїЛзїНпЉМжО•дЄЛжЭ•жИСдїђзЬЛзЬЛAgentзЪДеЖЕйГ®зїУжЮДпЉМе¶ВжЮЬжККAgentељУеБЪдЄАдЄ™йїСзЫТпЉМдљ†иВѓеЃЪиГљжГ≥еИ∞еЃГеЊЧжЬЙдЄ™иЊУеЕ•еТМиЊУеЗЇпЉМиЊУеЕ•жШѓEventзЪДеЕ•еП£пЉМиАМиЊУеЕ•еИЩи°®жШОжЧ•ењЧе∞ЖеПСеЊАеЕґдїЦжЯРдЄ™еЬ∞жЦєжИЦиАЕзЫіжО•еЖЩеЕ•жИСдїђзЪДз¶їзЇњжХ∞жНЃзЪДдїУеЇУHDFSгАВињЩдЄ™иЊУеЕ•е∞±жШѓAgentдЄЙе§ІзїДжИРйГ®еИЖдєЛдЄАзЪДSourceпЉМиЊУеЗЇжМЗзЪДжШѓSinkпЉМжЬАеРОдЄАдЄ™е∞±жШѓChannelпЉМChannelжШѓEventе≠ШжФЊзЪДеЬ∞жЦєгАВж≤°йФЩпЉМдЄАдЄ™Flume AgentеЃЮдЊЛе∞±жШѓзФ±е§ЪдЄ™SourceгАБе§ЪдЄ™ChannelеТМе§ЪдЄ™SinkзїДжИРзЪДпЉМдєЯе∞±жШѓиѓіпЉМдљ†еПѓдї•еЬ®AgentзЪДйЕНзљЃдљ†жЦЗдїґдЄ≠еЃЪдєЙе§ЪдЄ™SourceгАБChannelеТМSinkгАВдљЖйЬАи¶Бж≥®жДПпЉМSourceеПѓдї•жМЗеЃЪе§ЪдЄ™ChannelпЉМдљЖдЄАдЄ™SinkеЃЮдЊЛеП™иГљжМЗеЃЪдЄАдЄ™ChannelпЉМжНҐеП•иѓЭиѓіпЉМе∞±жШѓSourceиГљеРМжЧґеРСе§ЪдЄ™ChannelеЖЩеЕ•жХ∞жНЃпЉМдљЖдЄАдЄ™SinkеП™иГљдїОдЄАдЄ™ChannelдЄ≠еПЦжХ∞жНЃгАВе§ІдљУиЃЊиЃ°е¶ВдЄЛеЫЊпЉЪ
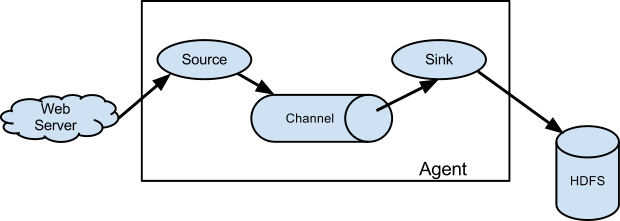
¬† ¬† ¬† ¬†SourceеЃЮдЊЛдЉЪеЬ®йЕНзљЃжЦЗдїґжМЗеЃЪзЪДзЂѓеП£жЭ•зЫСеРђжХ∞жНЃпЉМзФ®жЭ•жО•жФґеЃҐжИЈзЂѓеПСжЭ•зЪДEventеєґе∞ЖеЕґе≠ШеВ®еИ∞ChannelдєЛдЄ≠гАВFlumeжПРдЊЫдЇЖе§ЪзІНз±їеЮЛзЪДSourceпЉМзФ®жЭ•дїОдЄНеРМзЪДжЄ†йБУжЭ•жО•жФґEventпЉМжѓФе¶ВAvro SourceгАБThrift SourceгАБ Kafka SourceгАБHttp Sourceз≠ЙпЉМSourceзЪДйАЙеЮЛйЬАи¶Бж†єжНЃжЧ•ењЧеПСйАБеЃҐжИЈзЂѓжЭ•еЖ≥еЃЪпЉМе¶ВжЮЬжШѓAvroзЪДClientпЉМйВ£дєИеЃГзЪДжО•жФґжЇРеП™иГљжШѓAvro SourceпЉМиАМдЄНиГљжШѓThrift SourceгАВSourceдЄ≠жЬЙжЛ¶жИ™еЩ®пЉИinterceptorпЉЙзЪДж¶ВењµпЉМ зФ®дЇОињЗжї§жОЙдЄНзђ¶еРИи¶Бж±ВзЪДEventпЉМжИЦиАЕзїЩEventжЈїеК†ењЕи¶БзЪДдњ°жБѓпЉМжЛ¶жИ™еЩ®дєЯеПѓдї•зїДеРИжИРжЛ¶жИ™еЩ®йУЊпЉМе∞±еГПServletдЄ≠зЪДињЗжї§еЩ®йУЊдЄАж†ЈгАВеЙНйЭҐиѓіињЗпЉМдЄАдЄ™SourceиЗ≥е∞Си¶БжМЗеЃЪдЄАдЄ™жО•жФґзЪДChannelпЉМељУдЄАдЄ™SourceжМЗеЃЪе§ЪдЄ™ChannelжЧґпЉМжЬЙдЇЇиВѓеЃЪеЊЧйЧЃпЉМињЩжЧґдЄАдЄ™EventдЉЪ襀е§НеИґе§ЪдїљеИЖеИЂжФЊеЕ•ињЩдЇЫChannelеСҐпЉЯињШжШѓиіЯиљљеЭЗи°°зЪДеП™жФЊеЕ•еЕґдЄ≠дЄАдЄ™ChannelеСҐпЉЯињЩдЄ™йЧЃйҐШеЊИе•љпЉМз≠Фж°ИжШѓпЉЪйГљеПѓдї•пЉБељУдЄАдЄ™SourceзїСеЃЪе§ЪдЄ™ChannelжЧґпЉМFlumeжПРдЊЫдЇЖдЄ§зІНChannelеЖЩеЕ•з≠ЦзХ•пЉЪе§НеИґпЉИreplicatingпЉЙеТМе§НзФ®пЉИmultiplexingпЉЙпЉМељУдљњзФ®е§НеИґз≠ЦзХ•жЧґжѓПдЄ™ChannelйГљдЉЪжО•жФґеИ∞дЄАдЄ™EventзЪДеЙѓжЬђпЉМиАМеЬ®дљњзФ®е§НзФ®з≠ЦзХ•жЧґпЉМдЄАдЄ™EventеП™дЉЪдЄЛеПСеИ∞еЕґдЄ≠дЄАдЄ™еРИж†ЉзЪДChannelдЄ≠гАВFlumeдЄ≠йїШиЃ§зЪДеИЖеПСз≠ЦзХ•жШѓе§НзФ®гАВељУдљњзФ®йїШиЃ§зЪДе§НзФ®з≠ЦзХ•жЧґпЉМSourceжО•жФґеИ∞зЪДжґИжБѓдЉЪдЄНдЉЪж؃蚁胥дЄАжђ°еПСзїЩзїСеЃЪзЪДChannelжЭ•иЊЊеИ∞вАЬиіЯиљљеЭЗи°°вАЭзЪДзЫЃзЪДеСҐпЉЯеЕґеЃЮдїФзїЖжГ≥жГ≥е∞±зЯ•йБУпЉМдїОеЖЩеЕ•зЪДиІТеЇ¶жЭ•иѓіпЉМе∞ЖдЄАдїљжХ∞жНЃеЖЩеИ∞дЄАдЄ™ChannelеТМеЭЗеМАзЪДеЖЩеИ∞е§ЪдЄ™ChannelпЉМжАІиГљдЄКдЉЪжЬЙе§Ъе§ІеЈЃеИЂеРЧпЉЯжЙАдї•пЉМFlumeйЗЗзФ®зЪДдЄНжШѓзЃАеНХзЪДиіЯиљљеЭЗи°°зЪДжАЭиЈѓпЉМиАМжШѓзїЩе§НзФ®з≠ЦзХ•жЈїеК†дЇЖйАЙжЛ©еЩ®пЉИselectorпЉЙзЪДеКЯиГљпЉМеПѓдї•йАЪињЗйЕНзљЃжЭ•еБЪеИ∞ж†єжНЃEventе§ідЄ≠зЪДйФЃеАЉжЭ•еЖ≥еЃЪиѓ•EventеЖЩеЕ•еУ™дЇЫпЉИж≥®жДПпЉМињЩйЗМжШѓеУ™дЇЫпЉМеЫ†дЄЇжЬЙеПѓиГљжШѓеЖЩеЕ•е§ЪдЄ™пЉЙChannelпЉМињШеПѓдї•иЃЊзљЃдЄАдЄ™йїШиЃ§ChannelпЉМељУж≤°жЬЙеМєйЕНзЪДйФЃеАЉжЧґпЉМе∞±зЫіжО•еЖЩеЕ•иЃЊзљЃзЪДйїШиЃ§зЪДChannelдЄ≠гАВйВ£дєИйЧЃйҐШжЭ•дЇЖпЉМе¶ВжЮЬSource r1йЬАи¶БеЖЩеЕ•пЉИе§НеИґз≠ЦзХ•жИЦе§НзФ®з≠ЦзХ•пЉЙеИ∞дЄЙдЄ™Channel c1пЉМc2еТМc3дЄ≠пЉМе¶ВжЮЬеЕґдЄ≠зЪДc2еЖЩеŕ姱賕дЇЖпЉМињЩжЧґSourceдЉЪжАОдєИе§ДзРЖпЉЯе§ІеЃґиГљжГ≥еИ∞дЄ§зІНеПѓиГљзЪДе§ДзРЖжЦєж°ИпЉМзђђдЄАзІНе∞±жШѓжЙУеН∞еСКи≠¶жЧ•ењЧпЉМзДґеРОеП™еܮ姱賕зЪДc2дЄКе∞ЭиѓХйЗНжЦ∞еЖЩеЕ•гАВзђђдЇМзІНе∞±жШѓдљЬдЄЇдЄАзІНдЇЛеК°жЭ•е§ДзРЖпЉМc2зЪДеЖЩеŕ姱賕е∞ЖеѓЉиЗіиѓ•EventдЉЪйЗНжЦ∞еЖНжђ°е∞ЭиѓХеЖЩеЕ•еИ∞c1пЉМc2еТМc3дЄ≠гАВињЩйЗМпЉМељУдљњзФ®зЪДжШѓе§НзФ®з≠ЦзХ•жЧґпЉМжИСдїђеПѓдї•еЬ®SelectorдЄКйЕНзљЃеПѓйАЙпЉИ optionalпЉЙзЪДChannelпЉМж≤°жЬЙйЕНзљЃеПѓйАЙж†ЗиЃ∞зЪДйГљжШѓи¶Бж±ВпЉИrequiredпЉЙзЪДChannelпЉМеѓєдЇО襀йЕНзљЃеПѓйАЙзЪДињЩдЇЫChannelжЭ•иѓіпЉИж≥®жДПпЉМе¶ВжЮЬжЯРеПѓйАЙзЪДChannelињШеЗЇзО∞еЬ®дЇЖrequiredзЪДChannelдЄ≠пЉМйВ£дєИеЃГињШжШѓrequiredзЪДпЉЙпЉМSourceе∞ЖеЕґељУеБЪе§ЗдїљжЦєж°ИпЉМеН≥SourceеПѓдї•дЄНењЕдњЭиѓБдЄАеЃЪе∞ЖеѓєеЇФзЪДEventеЖЩеЕ•жИРеКЯпЉМSourceеП™дЉЪеРСеЕґе∞ЭиѓХеЖЩеЕ•дЄАжђ°гАВдљЖеѓєдЇОrequiredзЪДChannelпЉМSourceе∞ЖдњЭиѓБеЕґеЖЩеЕ•жИРеКЯпЉИеЕЈдљУзїЖиКВеРОйЭҐеРОйЭҐеЫЮжЭ•и°•еЕЕпЉЙгАВ
¬† ¬† ¬† ¬†ChannelзФ®жЭ•е≠ШеВ®AgentжО•жФґеИ∞зЪДEventпЉМеГПSourceдЄАж†ЈпЉМFlumeдєЯжПРдЊЫдЇЖе§ЪзІНз±їеЮЛзЪДChannelпЉМеЄЄзФ®зЪДжѓФе¶ВMemory ChannelгАБFile ChannelгАБJDBC ChannelгАБKafka ChannelгАВжХИзОЗжЬАйЂШзЪДиВѓеЃЪжШѓMemory ChannelпЉМдљЖеЃГжШѓдЄНеПѓйЭ†зЪДпЉМдЄАжЧ¶йЗНеРѓпЉМеЕ®йГ®ж≤°жЬЙжґИиієзЪДEventе∞±дЉЪ䪥姱гАВжЬАеЄЄзФ®жЬАзЃАеНХзЪДе∞±жШѓFile ChannelпЉМеЃГе∞ЖEventеЕИеЖЩеЕ•жМЗеЃЪзЪДжЦЗдїґдЄ≠пЉМжЙАдї•йЗНеРѓзЪДиѓЭе§ІйГ®еИЖж≤°жЬЙжґИиієзЪДEventињШжШѓдЉЪдњЭзХЩгАВдЄЇдЇЖдњЭиѓБзЂѓеИ∞зЂѓпЉИend to endпЉЙзЪДеПѓйЭ†жАІпЉМеП™жЬЙSinkжИРеКЯжґИиієдЇЖEventпЉМEventжЙНдЉЪдїОChannelдЄ≠еИ†йЩ§гАВ
¬† ¬† ¬† ¬†SinkзФ®дЇОе∞ЖEventеЖЩеЕ•еИ∞еЕґдїЦзЪДзЫЃзЪДеЬ∞пЉМињЩдЄ™зЫЃзЪДеЬ∞еПѓдї•жШѓHDFSгАБKafkaз≠ЙеЉАжЇРеЃЮзО∞пЉМжИЦиАЕжШѓеП¶дЄАдЄ™Flume AgentпЉМFlumeжПРдЊЫдЇЖиґ≥е§Яе§ЪзЪДSinkзЪДеЃЮзО∞пЉМиЊЊеИ∞йЕНзљЃеРОеЉАзЃ±еН≥зФ®гАВеЄЄзФ®зЪДSinkеЃЮзО∞жЬЙAvro SinkгАБHDFS SinkгАБKafka SinkгАБThrift SinkгАБNull SinkгАБLogger Sinkз≠ЙгАВе¶ВжЮЬдљњзФ®Null SinkпЉМе∞ЖзЫіжО•дЄҐеЉГдїОChannelеПЦеЗЇжЭ•зЪДEventпЉМиАМLogger SinkдЄАиИђзФ®жЭ•жµЛиѓХпЉМеЃГе∞ЖдїОChannelеПЦеЗЇжЭ•зЪДEventзЫіжО•жЙУеН∞еЬ®FlumeзЪДжЧ•ењЧжЦЗдїґдЄ≠гАВ
¬† ¬† ¬† ¬†иѓіеИ∞ињЩйЗМпЉМе§ІеЃґеЇФиѓ•еѓєFlume AgentжЬЙдЄАдЄ™е§ІдљУдЇЖиІ£дЇЖпЉМеРОйЭҐзЪДжЦЗзЂ†жИСеЖНжЭ•зїЩе§ІеЃґдЄАдЄАдїЛзїНеЕґеЖЕйГ®зїЖиКВгАВдЄЛдЄАзѓЗпЉЪhttp://manzhizhen.iteye.com/blog/2298394



зЫЄеЕ≥жО®иНР
### Flume 1.6.0 еЕ•йЧ®иѓ¶иІ£пЉЪеЃЙи£ЕгАБйГ®зљ≤еПКж°ИдЊЛеИЖжЮР #### дЄАгАБFlume ж¶Вињ∞ Flume жШѓ Cloudera еЉАеПСзЪДдЄАжђЊйЂШжХИгАБеПѓйЭ†дЄФжШУдЇОжЙ©е±ХзЪДжЧ•ењЧжФґйЫЖз≥їзїЯпЉМйАВзФ®дЇОе§ІжХ∞жНЃзОѓеҐГдЄЛзЪДжЧ•ењЧйЗЗйЫЖдїїеК°гАВFlume зЪДеИЭеІЛзЙИжܐ襀зІ∞дЄЇ FlumeOG...
3. FlumeењЂйАЯеЕ•йЧ®пЉЪ - **еЃЙи£ЕеЬ∞еЭА**пЉЪFlumeзЪДеЃШзљСгАБжЦЗж°£жЯ•зЬЛеТМдЄЛиљљйУЊжО•еИЖеИЂеЬ®http://flume.apache.org/гАБhttp://flume.apache.org/FlumeUserGuide.htmlеТМhttp://archive.apache.org/dist/flume/гАВ - **еЃЙи£ЕйГ®зљ≤...
дї•дЄЛжШѓеѓєFlumeеЕ•йЧ®дљњзФ®зЪДиѓ¶зїЖиѓіжШОпЉЪ 1. **Flume зїДдїґйЕНзљЃ**пЉЪ еЬ®`netcat-logger.conf`йЕНзљЃжЦЗдїґдЄ≠пЉМжИСдїђзЬЛеИ∞FlumeзЪДйЕНзљЃдЄїи¶БзФ±дЄЙйГ®еИЖзїДжИРпЉЪSourcesгАБSinks еТМ ChannelsгАВ - **Sources**пЉЪеЬ®ињЩйЗМжШѓ`r1`пЉМз±їеЮЛиЃЊзљЃдЄЇ...
Agent жШѓдЄАдЄ™ JVM ињЫз®ЛпЉМеЃГдї•дЇЛдїґзЪД嚥еЉПе∞ЖжХ∞жНЃдїОжЇРе§ійАБиЗ≥зЫЃзЪДеЬ∞пЉМжШѓ Flume жХ∞жНЃдЉ†иЊУзЪДеЯЇжЬђеНХеЕГгАВAgent дЄїи¶БжЬЙ 3 дЄ™йГ®еИЖзїДжИРпЉМSourceгАБChannel еТМ SinkгАВ 1.2.2 Source Source жШѓиіЯиі£жО•жФґжХ∞жНЃеИ∞ Flume Agent зЪДзїДдїґ...
#### дЄАгАБFlume еЕ•йЧ® ##### 1.1 Flume ж¶Вињ∞ Flume жШѓдЄАдЄ™еИЖеЄГеЉПзЪДгАБеПѓйЭ†зЪДгАБйЂШеПѓзФ®зЪДжЧ•ењЧйЗЗйЫЖз≥їзїЯпЉМдЄїи¶БзФ®дЇОжФґйЫЖгАБж±ЗжАїеТМзІїеК®е§ІйЗПзЪДжЧ•ењЧжХ∞жНЃгАВеЃГзФ± Cloudera еЕђеПЄеЉАеПСеєґеЉАжЇРпЉМзО∞еЈ≤жИРдЄЇдЇЖ Hadoop зФЯжАБз≥їзїЯдЄ≠зЪДдЄАдЄ™...
4. ењЂйАЯеЕ•йЧ®пЉЪ - FlumeзЪДеЃЙи£ЕдЄОйГ®зљ≤пЉЪеПѓдї•дїОеЃШжЦєзЂЩзВєдЄЛиљљFlumeпЉМе∞ЖеОЛзЉ©еМЕиІ£еОЛеИ∞жМЗеЃЪзЫЃељХпЉМеєґйЕНзљЃзОѓеҐГеПШйЗПгАВдЊЛе¶ВпЉМеЬ®LinuxзОѓеҐГдЄЛпЉМеПѓдї•е∞Жapache-flume-1.7.0-bin.tar.gzиІ£еОЛеИ∞/opt/module/зЫЃељХпЉМзДґеРОе∞Жflume-env.sh....
Apache FlumeжШѓдЄАдЄ™еИЖеЄГеЉПгАБеПѓйЭ†дЄФеПѓзФ®зЪДз≥їзїЯпЉМдЄїи¶БзФ®дЇОжЬЙжХИеЬ∞жФґйЫЖгАБиБЪеРИе§ІйЗПжЧ•ењЧжХ∞жНЃпЉМеєґе∞ЖеЕґдїОдЄНеРМзЪДжЇРзІїеК®еИ∞йЫЖдЄ≠еЉПжХ∞жНЃе≠ШеВ®дЄ≠гАВFlumeдЄНдїЕдїЕйАВзФ®дЇОжЧ•ењЧжХ∞жНЃзЪДиБЪеРИпЉМзФ±дЇОеЕґжХ∞жНЃжЇРзЪДеПѓеЃЪеИґжАІпЉМеЃГињШеПѓдї•зФ®дЇОдЉ†иЊУе§ІйЗП...
#### дЇМгАБFlumeеЕ•йЧ® **2.1 FlumeеЃЙи£ЕйГ®зљ≤** еЃЙи£ЕFlumeеЙНйЬАз°ЃдњЭеЈ≤еЕЈе§ЗJavaињРи°МзОѓеҐГгАВFlumeзЪДдЄЛиљљдЄОеЃЙи£Еж≠•й™§е¶ВдЄЛпЉЪ 1. **2.1.1 еЃЙи£ЕеЬ∞еЭА** - **FlumeеЃШзљСеЬ∞еЭА**: [http://flume.apache.org/]...
Flume жШѓ Apache Hadoop зФЯжАБз≥їзїЯдЄ≠зЪДдЄАдЄ™еЕ≥йФЃзїДдїґпЉМеЃГиЃЊиЃ°зФ®дЇОйЂШжХИеЬ∞жФґйЫЖгАБиБЪеРИеТМдЉ†иЊУе§ІиІДж®°жЧ•ењЧжХ∞жНЃгАВеЬ®жЬђжЦЗдЄ≠пЉМжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ® Flume зЪДеЃЙи£ЕгАБйЕНзљЃгАБжµЛиѓХдї•еПКе¶ВдљХе∞ЖеЕґеЇФзФ®дЇОеЃЮйЩЕж°ИдЊЛпЉМеН≥дїОдЄНеРМиКВзВєйЗЗйЫЖжЧ•ењЧеєґе≠ШеВ®...
### Flume NGпЉЪжЦ∞дЄАдї£жХ∞жНЃжФґйЫЖз≥їзїЯеЕ•йЧ®жМЗеНЧ #### дїАдєИжШѓFlume NGпЉЯ Flume NGпЉИNext GenerationпЉЙжЧ®еЬ®жѓФFlume OGпЉИOriginal GenerationпЉЙжЫізЃАеНХгАБжЫіе∞ПеЈІдЄФжЫіеЃєжШУйГ®зљ≤гАВдЄЇдЇЖеЃЮзО∞ињЩдЄАзЫЃж†ЗпЉМFlume NG дЄНжЙњиѓЇдЄО Flume ...
FlumeеЕ•йЧ®ж°ИдЊЛ** дї•зЫСжОІзЂѓеП£жХ∞жНЃдЄЇдЊЛпЉМFlumeеПѓдї•зЫСеРђзЙєеЃЪзЂѓеП£пЉМжФґйЫЖжµБеЕ•жХ∞жНЃеєґиЊУеЗЇеИ∞жОІеИґеП∞гАВеЃЮзО∞ж≠•й™§еМЕжЛђеЃЙи£ЕењЕи¶БзЪДеЈ•еЕЈпЉИе¶ВnetcatпЉЙпЉМйЕНзљЃFlume AgentзЪДSourceдЄЇnetcatз±їеЮЛпЉМSinkдЄЇloggerпЉМзДґеРОеРѓеК®Flumeеєґй™МиѓБ...
йАЪињЗињЩж†ЈзЪДеЯЇз°Аж°ИдЊЛпЉМжИСдїђеПѓдї•ењЂйАЯзРЖиІ£FlumeзЪДеЈ•дљЬеОЯзРЖеТМеЯЇжЬђзФ®ж≥ХпЉМдЄЇињЫдЄАж≠•жЈ±еЕ•е≠¶дє†еТМеЇФзФ®жЙУдЄЛеЯЇз°АгАВ жАїзїУжЭ•иѓіпЉМFlumeдљЬдЄЇе§ІжХ∞жНЃе§ДзРЖзЪДйЗНи¶БеЈ•еЕЈпЉМеЕґеЉЇе§ІзЪДжХ∞жНЃйЗЗйЫЖеТМдЉ†иЊУиГљеКЫпЉМдї•еПКзБµжіїзЪДжЮґжЮДиЃЊиЃ°пЉМдљњеЕґеЬ®е§ІжХ∞жНЃ...
FlumeзЪДеЕ•йЧ®ж°ИдЊЛеМЕжЛђзЫСжОІзЂѓеП£жХ∞жНЃеЃШжЦєж°ИдЊЛпЉМдљњзФ®FlumeзЫСеРђдЄАдЄ™зЂѓеП£пЉМжФґйЫЖиѓ•зЂѓеП£жХ∞жНЃпЉМеєґжЙУеН∞еИ∞жОІеИґеП∞гАВ FlumeзЪДеЇФзФ®еЬЇжЩѓйЭЮеЄЄеєњж≥ЫпЉМеМЕжЛђе§ІжХ∞жНЃйЗЗйЫЖгАБжЧ•ењЧйЗЗйЫЖгАБжХ∞жНЃдЉ†иЊУз≠ЙгАВFlumeзЪДдЉШзВєеМЕжЛђйЂШеПѓзФ®жАІгАБзБµжіїжАІгАБеПѓйЭ†...
1. **жЇРпЉИSourcesпЉЙ**пЉЪжЇРжШѓFlumeжХ∞жНЃйЗЗйЫЖзЪДиµЈзВєпЉМиіЯиі£дїОеРДзІНжХ∞жНЃжЇРпЉИе¶ВWebжЬНеК°еЩ®жЧ•ењЧгАБз≥їзїЯжЧ•ењЧгАБз§ЊдЇ§е™ТдљУжµБз≠ЙпЉЙжО•жФґжХ∞жНЃгАВFlumeжПРдЊЫдЇЖе§ЪзІНеЖЕзљЃжЇРпЉМе¶ВзЃАеНХзЪДHTTPжЇРгАБAvroжЇРгАБThriftжЇРз≠ЙпЉМдєЯеПѓдї•ж†єжНЃйЬАи¶БзЉЦеЖЩиЗ™еЃЪдєЙ...
гАКSpark2.xењЂйАЯеЕ•йЧ®жХЩз®Л-еЖЕеРЂжЇРз†Бдї•еПКиЃЊиЃ°иѓіжШОдє¶гАЛжШѓдЄАдЄ™еЕ®йЭҐзЪДжХЩз®ЛпЉМжЧ®еЬ®еЄЃеК©еИЭе≠¶иАЕењЂйАЯжОМжП°Spark2.xзЪДж†ЄењГзЙєжАІеТМеЇФзФ®гАВжЬђжХЩз®ЛжґµзЫЦдЇЖе§ЪдЄ™еЕ≥йФЃзЯ•иѓЖзВєпЉМеМЕжЛђSpark SQLгАБStructured StreamingгАБHive on Sparkдї•еПКе§ЪзІН...
#### Flume ењЂйАЯеЕ•йЧ® ##### еЃЙи£ЕйГ®зљ≤ Flume зЪДеЃЙи£ЕйГ®зљ≤ињЗз®ЛзЫЄеѓєзЃАеНХпЉМдЄїи¶БеМЕжЛђдї•дЄЛеЗ†дЄ™ж≠•й™§пЉЪ 1. **иОЈеПЦ Flume**пЉЪ - иЃњйЧЃ Flume еЃШжЦєзљСзЂЩпЉЪ[http://flume.apache.org/](http://flume.apache.org/) - жЯ•зЬЛжЦЗж°£...
еЬ®иІ£еЖ≥ Flume еЕ•йЧ®ж°ИдЊЛзЪДињЗз®ЛдЄ≠пЉМеПѓиГљдЉЪйБЗеИ∞дЄАдЇЫйЪЊзВєпЉМе¶ВйЕНзљЃжЦЗдїґзЪДзЉЦеЖЩгАБйФЩиѓѓжОТжЯ•з≠ЙгАВжХЩеЄИеПѓдї•йАЪињЗз§ЇиМГжХЩе≠¶пЉМжПРдЊЫе≠¶дє†иІЖйҐСпЉМжМЗеѓЉе≠¶зФЯйАРж≠•иІ£еЖ≥йЧЃйҐШгАВе≠¶зФЯеЬ®йБЗеИ∞еЫ∞йЪЊжЧґпЉМеПѓдї•еАЯеК©жХЩе≠¶иµДжЇРпЉМе¶ВеЬ®зЇњеє≥еП∞гАБе§ІжХ∞жНЃжКАжЬѓеЃЮ...
### е§ІжХ∞жНЃењЂйАЯеЕ•йЧ® еЬ®ељУдїКзЪДдњ°жБѓжЧґдї£пЉМе§ІжХ∞жНЃеЈ≤жИРдЄЇдЉБдЄЪеЖ≥з≠ЦеТМжКАжЬѓеИЫжЦ∞зЪДйЗНи¶Бй©±еК®еКЫгАВжЬђжЦЗжЧ®еЬ®дЄЇеИЭе≠¶иАЕжПРдЊЫдЄАдЄ™ењЂйАЯеЕ•йЧ®жМЗеНЧпЉМеЄЃеК©зРЖиІ£е§ІжХ∞жНЃзЪДеЯЇжЬђж¶ВењµеТМжКАжЬѓж†ИпЉМеМЕжЛђHadoopгАБSparkгАБRedisгАБHiveз≠Йж†ЄењГеЈ•еЕЈгАВ ##...
еЬ®ењЂйАЯеЕ•йЧ®дЄ≠пЉМй¶ЦеЕИдљ†йЬАи¶БдЇЖиІ£CamelзЪДеЯЇжЬђж¶ВењµпЉМе¶ВEndpointпЉИзЂѓзВєпЉЙгАБRouteпЉИиЈѓзФ±пЉЙеТМDSLпЉИйҐЖеЯЯзЙєеЃЪиѓ≠и®АпЉЙз≠ЙгАВEndpointжШѓCamelиЈѓзФ±зЪДиµЈзВєеТМзїИзВєпЉМеПѓдї•жШѓдїїдљХCamelжФѓжМБзЪДзїДдїґгАВRouteеИЩеЃЪдєЙдЇЖжХ∞жНЃе¶ВдљХдїОдЄАдЄ™Endpoint...