
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化。后台支持接入多种数据处理引擎,如spark,hive等。支持多种语言: Scala(Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。本文主要介绍Zeppelin中Interpreter和SparkInterpreter的实现原理。
转载请注明
http://www.cnblogs.com/shenh062326/p/6195064.html
安装与使用
参考http://blog.csdn.net/jasonding1354/article/details/46822391
原理简介
Interpreter
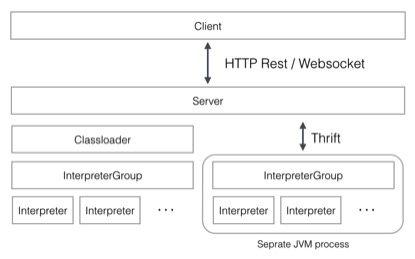
Zeppelin中最核心的概念是Interpreter,interpreter是一个插件允许用户使用一个指定的语言或数据处理器。每一个Interpreter都属于换一个InterpreterGroup,同一个InterpreterGroup的Interpreters可以相互引用,例如SparkSqlInterpreter 可以引用 SparkInterpreter 以获取 SparkContext,因为他们属于同一个InterpreterGroup。当前已经实现的Interpreter有spark解释器,python解释器,SparkSQL解释器,JDBC,Markdown和shell等。下图是Zeppelin官网中介绍Interpreter的原理图。
Interpreter接口中最重要的方法是open,close,interpert三个方法,另外还有cancel,gerProgress,completion等方法。
Open 是初始化部分,只会调用一次。
Close 是关闭释放资源的接口,只会调用一次。
Interpret 会运行一段代码并返回结果,同步执行方式。
Cancel可选的接口,用于结束interpret方法
getPregress 方法获取interpret的百分比进度
completion 基于游标位置获取结束列表,实现这个接口可以实现自动结束
SparkInterpreter
Open方法中,会初始化SparkContext,SQLContext,ZeppelinContext;当前支持的模式有:
• local[*] in local mode
• spark://master:7077 in standalone cluster
• yarn-client in Yarn client mode
• mesos://host:5050 in Mesos cluster
其中Yarn集群只支持client模式。
if (isYarnMode()) { conf.set("master", "yarn"); conf.set("spark.submit.deployMode", "client"); }
Interpret方法中会执行一行代码(以\n分割),其实会调用spark 的SparkILoop一行一行的执行(类似于spark shell的实现),这里的一行是逻辑行,如果下一行代码中以“.”开头(非“..”,“./”),也会和本行一起执行。关键代码如下:

scala.tools.nsc.interpreter.Results.Result res = null; try { res = interpret(incomplete + s); } catch (Exception e) { sc.clearJobGroup(); out.setInterpreterOutput(null); logger.info("Interpreter exception", e); return new InterpreterResult(Code.ERROR, InterpreterUtils.getMostRelevantMessage(e)); } r = getResultCode(res);
sparkInterpret的关键方法:
close 方法会停止SparkContext
cancel 方法直接调用SparkContext的cancel方法。sc.cancelJobGroup(getJobGroup(context)
getProgress 通过SparkContext获取所有stage的总的task和已经结束的task,结束的tasks除以总的task得到的比例就是进度。
问题1,是否可以存在多个SparkContext?
Interpreter支持'shared', 'scoped', 'isolated'三种选项,在scopde模式下,spark interpreter为每个notebook创建编译器但只有一个SparkContext;isolated模式下会为每个notebook创建一个单独的SparkContext。
问题2,isolated模式下,多个SparkContext是否在同一个进程中?
一个服务端启动多个spark Interpreter后,会启动多个SparkContext。不过可以用另外一个jvm启动spark Interpreter。
Zeppelin优缺点小结
优点
1.提供restful和webSocket两种接口。
2.使用spark解释器,用户按照spark提供的接口编程即可,用户可以自己操作SparkContext,不过用户3.不能自己去stop SparkContext;SparkContext可以常驻。
4.包含更多的解释器,扩展性也很好,可以方便增加自己的解释器。
5.提供了多个数据可视化模块,数据展示方便。
缺点
1.没有提供jar包的方式运行spark任务。
2.只有同步的方式运行,客户端可能需要等待较长时间。
http://www.cnblogs.com/shenh062326/p/6195064.html



相关推荐
首先上一张官方给出的Zeppelin整体架构图ApacheZeppelin的架构比较简单直观,总共分为3层:1.Zeppelin前端2.ZeppelinServer3.ZeppelinInterpreterZeppelin前端是基于AngularJS(目前社区正在升级改造前端,但是对...
通过深入研究这些源码,开发者可以更好地理解Zeppelin的内部工作原理,并根据自己的需求进行定制或改进。 总的来说,Zeppelin是一款结合了C++高性能特性和NoSQL数据库灵活性的分布式KV存储平台,由奇虎360精心打造...
Apache Zeppelin 是一个开源的交互式数据分析平台,主要用于大数据处理和...通过"zeppelin.zip"中的"zeppelin-master",开发者可以深入了解其内部工作原理,定制自己的数据分析环境,或是参与到项目的开发和改进中。
在Kubernetes上部署Apache ... 基本上,整个过程基于简单的原理:有一个Web服务器作为Kubernetes部署引入。 在与Zeppelin笔记进行交互时,服务器会以惰性方式为每个口译员创建窗格。 口译员窗格均使用相同的图像。 建立
一、Helium架构与原理 1. 软件包存储库:标题中的"helium-packages"指的是一个存储库,其中包含了各种可供Zeppelin使用的Helium应用程序。这个存储库就像是一个市场,用户可以在其中挑选并安装适合自己的插件,以...
Spark基本原理 Spark的核心设计理念是快速、通用且可扩展的大数据处理框架。它通过内存计算提高了数据处理速度,支持批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)和机器学习(MLlib)等多种...
"glZepa" 是一个专门为 GarageLab...同时,理解硬件设备的工作原理以及如何通过软件与其交互也是非常关键的。通过阅读和分析 glZepa-master 中的源代码,可以学习到实际的移动应用开发流程,对提升个人技能非常有帮助。
1. **源代码**:如果文件包括源代码,这将允许开发者对Zeppelin进行自定义和扩展,了解其内部工作原理。 2. **配置文件**:安装过程中会用到的配置文件,如`zeppelin-env.sh`或`zeppelin-site.xml`,这些文件用于...
标题中的"collectibleClaim"指的是一个项目,它与ERC721标准有关,该标准是用于...为了深入学习这个项目,你需要掌握以上提及的技术,并熟悉以太坊开发环境,理解NFTs的工作原理以及如何通过智能合约实现所有权的转移。
- **Zeppelin 架构简介**:Zeppelin 是一个开源的数据分析和可视化工具。 - **Kylin Interpreter 的工作原理**:通过 Zeppelin 的 Interpreter 插件执行 Kylin 查询。 - **如何使用 Zeppelin 访问 Kylin**:配置 ...
**标题含义**:“Telecommunication Breakdown”这个标题本身可能让人有些困惑,但作者们在其注释中解释说,这是对Led Zeppelin乐队经典歌曲“Communication Breakdown”的一种幽默改编。这里的“Breakdown”并非指...
理解HDFS的数据模型、副本策略以及MapReduce的工作原理是必不可少的。MapReduce将大任务分解为小任务在集群中并行处理,而Reduce阶段则负责整合结果。 接着,Apache Spark是一个流行的快速大数据处理框架,它提供了...
实验4主要关注基于Spark MLlib的开源软件项目流行度预测,这个实验旨在让学生深入理解GitHub软件项目的流行度预测背景,熟悉Spark的基本原理和运行模式,同时掌握特征工程、SparkSQL的使用、Spark Pipeline的操作...
接下来,我们将详细介绍这些组件的原理和应用。 在数据采集方面,Flume和Kafka是常用的两种工具。Flume是一个分布式、可靠且可用的系统,用于有效地从多个源收集、聚合和移动大量日志数据。它的核心组件包括source...
在大数据架构技术中,吉首大学的资料涵盖了多个关键领域,包括Hadoop生态系统中的核心组件以及实时大数据处理的原理和应用。以下是对这些知识点的详细阐述: 1. **HDFS(Hadoop Distributed File System)**:HDFS...
ApacheCN组织不仅翻译了本书,还提供了其他相关文档如TensorFlow R1.2的中文文档、Spark、Zeppelin、Pytorch等工具的中文介绍,为读者提供了丰富的学习材料。同时,ApacheCN还建立了一个学习机器学习的微信群,读者...
查询和可视化部分讲述了如何通过Web界面、RestAPI、ODBC、JDBC、Tableau和Zeppelin等多种方式来访问Kylin,并进行数据分析和可视化展示。 Cube优化是Kylin核心功能之一。通过剪枝优化可以有效减少存储空间,提高...