
1、HBase 简介
HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据、实现数据分布式存储提供可靠的方案。从功能上来 讲,HBase不折不扣是一个数据库,与我们熟悉的Oracle、MySQL、MSSQL等一样,对外提供数据的存储和读取服务。而从应用的角度来 说,HBase与一般的数据库又有所区别,HBase本身的存取接口相当简单,不支持复杂的数据存取,更不支持SQL等结构化的查询语言;HBase也没 有除了rowkey以外的索引,所有的数据分布和查询都依赖rowkey。所以,HBase在表的设计上会有很严格的要求。架构上,HBase是分布式数 据库的典范,这点比较像MongoDB的sharding模式,能根据键值的大小,把数据分布到不同的存储节点上,MongoDB根据 configserver来定位数据落在哪个分区上,HBase通过访问Zookeeper来获取-ROOT-表所在地址,通过-ROOT-表得到相 应.META.表信息,从而获取数据存储的region位置。
2、架构
上面提到,HBase是一个分布式的架构,除去底层存储的HDFS外,HBase本身从功能上可以分为三块:Zookeeper群、Master群和RegionServer群。
-
Zookeeper群:HBase集群中不可缺少的重要部分,主要用于存储Master地址、协调Master和RegionServer等上下线、存储临时数据等等。
-
Master群:Master主要是做一些管理操作,如:region的分配,手动管理操作下发等等,一般数据的读写操作并不需要经过Master集群,所以Master一般不需要很高的配置即可。
-
RegionServer群:RegionServer群是真正数据存储的地方,每个RegionServer由若干个region组成,而一个region维护了一定区间rowkey值的数据,整个结构如下图:
-
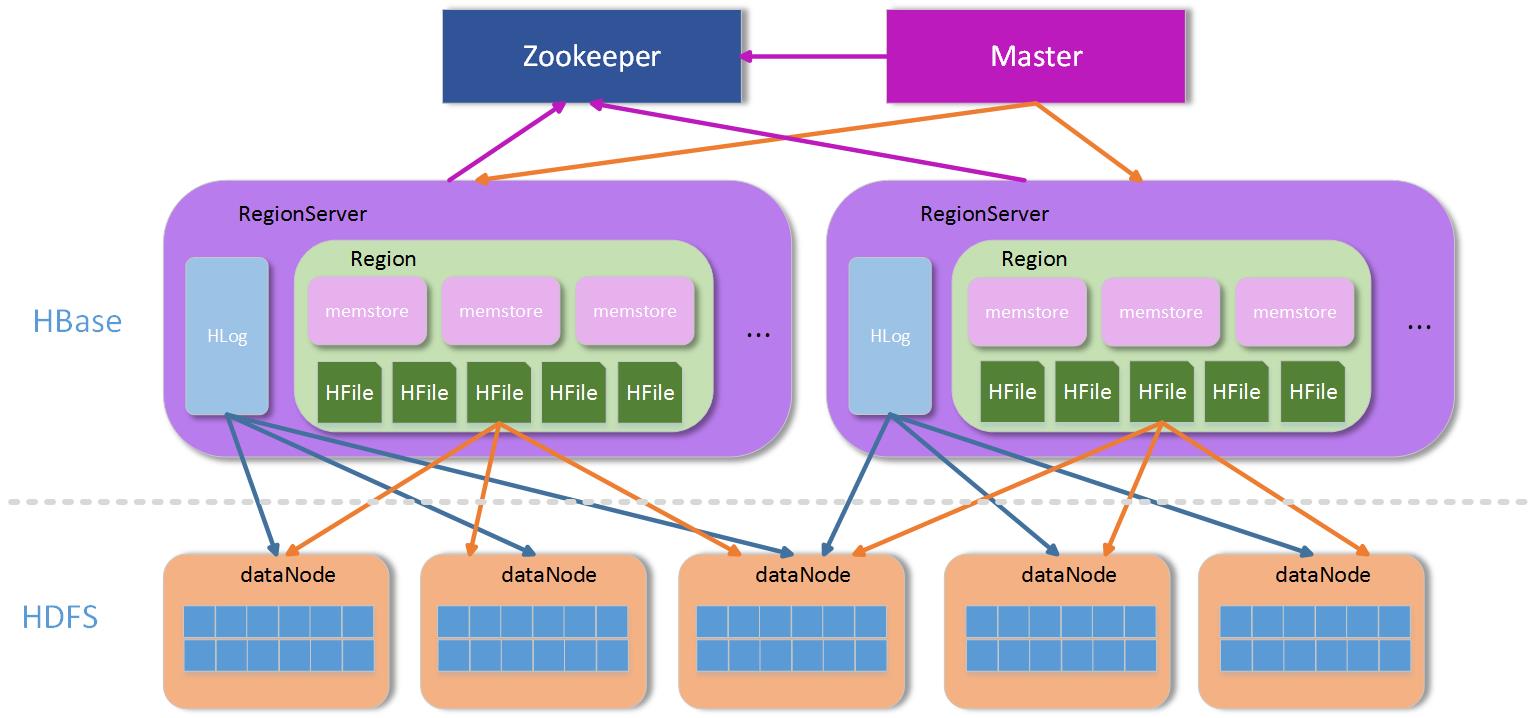
HBase结构图
上 图中,Zookeeper(简称ZK)是一个集群,通常有奇数个ZK服务组成。Master为了服务可用性,也建议部署成集群方式,因为Master是整 个管理操作的发起者,如果Master一旦发生意外停机,整个集群将会无法进行管理操作,所以Master也必须有多个,当然多个Master也有主从之 分,如何区分哪个是主,哪个是从?关键看哪个Master能竞争到ZK上对应Master目录下的锁,持有该目录锁的Master为主Master,其他 从Master轮询竞争该锁,所以一旦主Master发生意外停机,从Master很快会因为竞争到Master文件夹上的锁而接管服务。
RegionServer(简 称RS)在非Replication模式下,整个系统中都是唯一的,也就是说,在整个非Replication的HBase集群中,每台RS上保存的数据 都不一样,所以相对于前面两者,该模式下的RS并不是高可用的,至少RS可能存在单点故障的问题,但是由于HBase内部数据分region存储和 region可以迁移的机制,RS服务的单点故障可能会在极小代价下很快恢复,但是一旦停掉的RS上有-ROOT-或者.META.表的region,那 后果还是比较严重,因为数据节点的RS停机,只会在短时间内影响该台RS上的region不可访问,等到region迁移完成后即可恢复,如果是 -ROOT-、.META.所在的RS停机,整个HBase的新的求情都将受到影响,因为需要通过.META.表来路由,从而寻找到region所在RS 的地址。
3、数据组织
整个架构中,ZK用于服务协调和整个集群运行过程中部分信息的保存和-ROOT-表地址定位,Master用于集群内部管理,所以剩下的RS主要用于处理数据。
RS 是处理数据的主要场所,那么在RS内部的数据是怎么分布的?其实RS本身只是一个容器,其定义了一些功能线程,比如:数据合并线程(compact thread)、storeFile分割线程(split thread)等等。容器中的主要对象就是region,region是一个表根据自身rowkey范围划分的一部分,一个表可以被划分成若干部分,也就 是若干个region,region可以根据rowkey范围不同而被分布在不同的RS上(当然也可以在同一个RS上,但不建议这么做)。一个RS上可以 包含多个表的region,也可以只包含一个表的部分region,RS和表是两个不同的概念。
这里还有一个概念——列簇。对HBase有一些了 解的人,或多或少听说过:HBase是一个列式存储的数据库,而这个列式存储中的列,其实是区别于一般数据库的列,这里的列的概念,就是列簇,列簇,顾名 思义就是很多列的集合,而在数据存储上来讲,不同列簇的数据,一定是分开存储的,即使是在同一个region内部,不同的列簇也存储在不同的文件夹中,这 样做的好处是,一般我们定义列簇的时候,通常会把类似的数据放入同一个列簇,不同的列簇分开存储,有利于数据的压缩,并且HBase本身支持多种压缩方 式。
4、原理
前面介绍了HBase的一般架构,我们知道了HBase有ZK、Master和RS等组成,本节我们来介绍下HBase的基本原理,从数据访问、RS路由到RS内部缓存、数据存储和刷写再到region的合并和拆分等等功能。
4.1 RegionServer定位
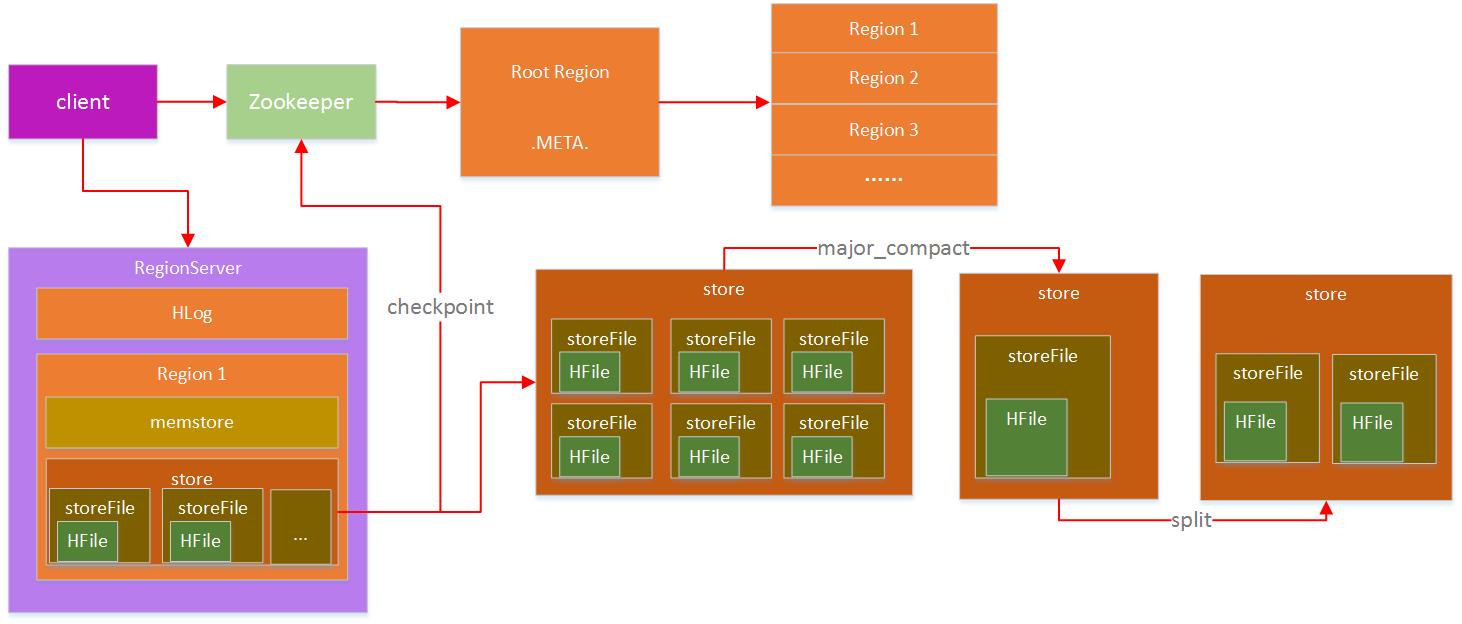
访 问HBase通过HBase客户端(或API)进行,整个HBase提供给外部的地址,其实是ZK的入口,前面也介绍了,ZK中有保存-ROOT-所在的 RS地址,从-ROOT-表可以获取.META.表信息,根据.META.表可以获取region在RS上的分布,整个region寻址过程大致如下:

RS定位过程
-
首先,Client通过访问ZK来请求目标数据的地址。
-
ZK中保存了-ROOT-表的地址,所以ZK通过访问-ROOT-表来请求数据地址。
-
同样,-ROOT-表中保存的是.META.的信息,通过访问.META.表来获取具体的RS。
-
.META.表查询到具体RS信息后返回具体RS地址给Client。
-
Client端获取到目标地址后,然后直接向该地址发送数据请求。
上述过程其实是一个三层索引结构,从ZK获取-ROOT-信息,再从-ROOT-获取.META.表信息,最后从.META.表中查到RS地址后缓存。这里有几个问题:
-
既然ZK中能保存-ROOT-信息,那么为什么不把.META.信息直接保存在ZK中,而需要通过-ROOT-表来定位?
-
Client查找到目标地址后,下一次请求还需要走ZK —> -ROOT- —> .META.这个流程么?
先 来回答第一个问题:为什么不直接把.META.表信息直接保存到ZK中?主要是为了保存的数据量考虑,ZK中不宜保存大量数据,而.META.表主要是保 存Region和RS的映射信息,region的数量没有具体约束,只要在内存允许的范围内,region数量可以有很多,如果保存在ZK中,ZK的压力 会很大。所以,通过一个-ROOT-表来转存到RS中是一个比较理想的方案,相比直接保存在ZK中,也就多了一层-ROOT-表的查询,对性能来说影响不 大。
第二个问题:每次访问都需要走ZK –> -ROOT- —> .META.的流程么?当然不需要,Client端有缓存,第一次查询到相应region所在RS后,这个信息将被缓存到Client端,以后每次访问都 直接从缓存中获取RS地址即可。当然这里有个意外:访问的region若果在RS上发生了改变,比如被balancer迁移到其他RS上了,这个时候,通 过缓存的地址访问会出现异常,在出现异常的情况下,Client需要重新走一遍上面的流程来获取新的RS地址。总体来说,region的变动只会在极少数 情况下发生,一般变动不会很大,所以在整个集群访问过程中,影响可以忽略。
4.2 Region数据写入
HBase通过ZK —> -ROOT- —> .META.的访问获取RS地址后,直接向该RS上进行数据写入操作,整个过程如下图:
RegionServer数据操作过程
Client 通过三层索引获得RS的地址后,即可向指定RS的对应region进行数据写入,HBase的数据写入采用WAL(write ahead log)的形式,先写log,后写数据。HBase是一个append类型的数据库,没有关系型数据库那么复杂的操作,所以记录HLog的操作都是简单的 put操作(delete/update操作都被转化为put进行)
4.3 HLog
4.3.1 HLog写入
HLog 是HBase实现WAL方式产生的日志信息,其内部是一个简单的顺序日志,每个RS上的region都共享一个HLog,所有对于该RS上的region 数据写入都被记录到该HLog中。HLog的主要作用就是在RS出现意外崩溃的时候,可以尽量多的恢复数据,这里说是尽量多,因为在一般情况下,客户端为 了提高性能,会把HLog的auto flush关掉,这样HLog日志的落盘全靠操作系统保证,如果出现意外崩溃,短时间内没有被fsync的日志会被丢失。
4.3.2 HLog过期
HLog的大量写入会造成HLog占用存储空间会越来越大,HBase通过HLog过期的方式进行HLog的清理,每个RS内部都有一个HLog监控线程在运行,其周期可以通过hbase.master.cleaner.interval进行配置。
HLog 在数据从memstore flush到底层存储上后,说明该段HLog已经不再被需要,就会被移动到.oldlogs这个目录下,HLog监控线程监控该目录下的HLog,当该文 件夹下的HLog达到hbase.master.logcleaner.ttl设置的过期条件后,监控线程立即删除过期的HLog。
4.4 Memstore
4.4.1 数据存储
memstore 是region内部缓存,其大小通过HBase参数hbase.hregion.memstore.flush.size进行配置。RS在写完HLog以 后,数据写入的下一个目标就是region的memstore,memstore在HBase内部通过LSM-tree结构组织,所以能够合并大量对于相 同rowkey上的更新操作。
正是由于memstore的存在,HBase的数据写入都是异步的,而且性能非常不错,写入到memstore后, 该次写入请求就可以被返回,HBase即认为该次数据写入成功。这里有一点需要说明,写入到memstore中的数据都是预先按照rowkey的值进行排 序的,这样有利于后续数据查找。
4.4.2 数据刷盘
memstore中的数据在一定条件下会进行刷写操作,使数据持久化到相应的存储设备上,触发memstore刷盘的操作有多种不同的方式如下图:

Memstore刷写流程
以上1,2,3都可以触发memstore的flush操作,但是实现的方式不同:
-
1通过全局内存控制,触发memstore刷盘操作。 memstore整体内存占用上限通过参数hbase.regionserver.global.memstore.upperLimit进行设置,当然 在达到上限后,memstore的刷写也不是一直进行,在内存下降到 hbase.regionserver.global.memstore.lowerLimit配置的值后,即停止memstore的刷盘操作。这样做, 主要是为了防止长时间的memstore刷盘,会影响整体的性能。
-
在该种情况下,RS中所有region的memstore内存占用都没达到刷盘条件,但整体的内存消耗已经到一个非常危险的范围,如果持续下去,很有可能造成RS的OOM,这个时候,需要进行memstore的刷盘,从而释放内存。
-
2手动触发memstore刷盘操作
-
HBase提供API接口,运行通过外部调用进行memstore的刷盘
-
3 memstore上限触发数据刷盘
-
前面提到memstore的大小通过hbase.hregion.memstore.flush.size进行设置,当region中memstore的数据量达到该值时,会自动触发memstore的刷盘操作。
4.4.3 刷盘影响
memstore 在不同的条件下会触发数据刷盘,那么整个数据在刷盘过程中,对region的数据写入等有什么影响?memstore的数据刷盘,对region的直接影 响就是:在数据刷盘开始到结束这段时间内,该region上的访问都是被拒绝的,这里主要是因为在数据刷盘结束时,RS会对改region做一个 snapshot,同时HLog做一个checkpoint操作,通知ZK哪些HLog可以被移到.oldlogs下。从前面图上也可以看到,在 memstore写盘开始,相应region会被加上UpdateLock锁,写盘结束后该锁被释放。
4.5 StoreFile
memstore 在触发刷盘操作后会被写入底层存储,每次memstore的刷盘就会相应生成一个存储文件HFile,storeFile即HFile在HBase层的轻 量级分装。数据量的持续写入,造成memstore的频繁flush,每次flush都会产生一个HFile,这样底层存储设备上的HFile文件数量将 会越来越多。不管是HDFS还是Linux下常用的文件系统如Ext4、XFS等,对小而多的文件上的管理都没有大文件来的有效,比如小文件打开需要消耗 更多的文件句柄;在大量小文件中进行指定rowkey数据的查询性能没有在少量大文件中查询来的快等等。
4.6 Compact
大量HFile的产生,会消耗更多的文件句柄,同时会造成RS在数据查询等的效率大幅度下降,HBase为解决这个问题,引入了compact操作,RS通过compact把大量小的HFile进行文件合并,生成大的HFile文件。
RS上的compact根据功能的不同,可以分为两种不同类型,即:minor compact和major compact。
-
Minor Compact
minor compact又叫small compact,在RS运行过程中会频繁进行,主要通过参数hbase.hstore.compactionThreshold进行控制,该参数配置了 HFile数量在满足该值时,进行minor compact,minor compact只选取region下部分HFile进行compact操作,并且选取的HFile大小不能超过 hbase.hregion.max.filesize参数设置。
-
Major Compact
相 反major compact也被称之为large compact,major compact会对整个region下相同列簇的所有HFile进行compact,也就是说major compact结束后,同一个列簇下的HFile会被合并成一个。major compact是一个比较长的过程,对底层I/O的压力相对较大。
major compact除了合并HFile外,另外一个重要功能就是清理过期或者被删除的数据。前面提到过,HBase的delete操作也是通过append的 方式写入,一旦某些数据在HBase内部被删除了,在内部只是被简单标记为删除,真正在存储层面没有进行数据清理,只有通过major compact对HFile进行重组时,被标记为删除的数据才能被真正的清理。
compact操作都有特定的线程进行,一般情况下不会影响RS上 数据写入的性能,当然也有例外:在compact操作速度跟不上region中HFile增长速度时,为了安全考虑,RS会在HFile达到一定数量时, 对写入进行锁定操作,直到HFile通过compact降到一定的范围内才释放锁。
4.7 Split
compact 将多个HFile合并单个HFile文件,随着数据量的不断写入,单个HFile也会越来越大,大量小的HFile会影响数据查询性能,大的HFile也 会,HFile越大,相对的在HFile中搜索的指定rowkey的数据花的时间也就越长,HBase同样提供了region的split方案来解决大的 HFile造成数据查询时间过长问题。
一个较大的region通过split操作,会生成两个小的region,称之为Daughter,一般Daughter中的数据是根据rowkey的之间点进行切分的,region的split过程大致如下图:

region split流程
-
region先更改ZK中该region的状态为SPLITING。
-
Master检测到region状态改变。
-
region会在存储目录下新建.split文件夹用于保存split后的daughter region信息。
-
Parent region关闭数据写入并触发flush操作,保证所有写入Parent region的数据都能持久化。
-
在.split文件夹下新建两个region,称之为daughter A、daughter B。
-
Daughter A、Daughter B拷贝到HBase根目录下,形成两个新的region。
-
Parent region通知修改.META.表后下线,不再提供服务。
-
Daughter A、Daughter B上线,开始向外提供服务。
-
如果开启了balance_switch服务,split后的region将会被重新分布。
上面1 ~ 9就是region split的整个过程,split过程非常快,速度基本会在秒级内,那么在这么快的时间内,region中的数据怎么被重新组织的?
其 实,split只是简单的把region从逻辑上划分成两个,并没有涉及到底层数据的重组,split完成后,Parent region并没有被销毁,只是被做下线处理,不再对外部提供服务。而新产生的region Daughter A和Daughter B,内部的数据只是简单的到Parent region数据的索引,Parent region数据的清理在Daughter A和Daughter B进行major compact以后,发现已经没有到其内部数据的索引后,Parent region才会被真正的清理。
5、HBase设计
HBase是一个分布式数据库,其性能的好坏主要取决于内部表的设计和资源的分配是否合理。
5.1 Rowkey设计
rowkey 是HBase实现分布式的基础,HBase通过rowkey范围划分不同的region,分布式系统的基本要求就是在任何时候,系统的访问都不要出现明显 的热点现象,所以rowkey的设计至关重要,一般我们建议rowkey的开始部分以hash或者MD5进行散列,尽量做到rowkey的头部是均匀分布 的。禁止采用时间、用户id等明显有分段现象的标志直接当作rowkey来使用。
5.2 列簇设计
HBase的表设计时,根据不同需求有不同选择,需要做在线查询的数据表,尽量不要设计多个列簇,我们知道,不同的列簇在存储上是被分开的,多列簇设计会造成在数据查询的时候读取更多的文件,从而消耗更多的I/O。
5.3 TTL设计
选择合适的数据过期时间也是表设计中需要注意的一点,HBase中允许列簇定义数据过期时间,数据一旦超过过期时间,可以被major compact进行清理。大量无用历史数据的残余,会造成region体积增大,影响查询效率。
5.4 Region设计
一 般地,region不宜设计成很大,除非应用对阶段性性能要求很多,但是在将来运行一段时间可以接受停服处理。region过大会导致major compact调用的周期变长,而单次major compact的时间也相应变长。major compact对底层I/O会造成压力,长时间的compact操作可能会影响数据的flush,compact的周期变长会导致许多删除或者过期的数据 不能被及时清理,对数据的读取速度等都有影响。
相反,小的region意味着major compact会相对频繁,但是由于region比较小,major compact的相对时间较快,而且相对较多的major compact操作,会加速过期数据的清理。
当 然,小region的设计意味着更多的region split风险,region容量过小,在数据量达到上限后,region需要进行split来拆分,其实split操作在整个HBase运行过程中,是 被不怎么希望出现的,因为一旦发生split,涉及到数据的重组,region的再分配等一系列问题。所以我们在设计之初就需要考虑到这些问题,尽量避免 region的运行过程中发生split。
HBase可以通过在表创建的时候进行region的预分配来解决运行过程中region的split 产生,在表设计的时候,预先分配足够多的region数,在region达到上限前,至少有部分数据会过期,通过major compact进行清理后, region的数据量始终维持在一个平衡状态。
region数量的设计还需要考虑内存上的限制,通过前面的介绍我们知道每个region都有memstore,memstore的数量与region数量和region下列簇的数量成正比,一个RS下memstore内存消耗:
Memory = memstore大小 * region数量 * 列簇数量
如果不进行前期数据量估算和region的预分配,通过不断的split产生新的region,容易导致因为内存不足而出现OOM现象。
6、优化背景与历史现状
Datastream 一直以来在使用HBase分流日志,每天的数据量很大,日均大概在80亿条,10TB的数据。对于像Datastream这种数据量巨大、对写入要求非常 高,并且没有复杂查询需求的日志系统来说,选用HBase作为其数据存储平台,无疑是一个非常不错的选择。
HBase 是一个相对较复杂的分布式系统,并发写入的性能非常高。然而,分布式系统从结构上来讲,也相对较复杂,模块繁多,各个模块之间也很容易出现一些问题,所以 对像HBase这样的大型分布式系统来说,优化系统运行,及时解决系统运行过程中出现的问题也变得至关重要。正所谓:“你”若安好,便是晴天;“你”若有 恙,我便没有星期天。
HBase 交接到我们团队手上时,已经在线上运行有一大段时间了,期间也偶尔听到过系统不稳定的、时常会出现一些问题的言论,但我们认为:一个能被大型互联网公司广 泛采用的系统(包括Facebook,twitter,淘宝,小米等),其在性能和可用性上是毋庸置疑的,何况像Facebook这种公司,是在经过严格 选型后,放弃了自己开发的Cassandra系统,用HBase取而代之。既然这样,那么,HBase的不稳定、经常出问题一定有些其他的原因,我们所要 做的,就是找出这些HBase的不稳定因素,还HBase一个“清白”。“查案”之前,先来简单回顾一下我们接手HBase时的现状(我们运维着好几个 HBase集群,这里主要介绍问题最多那个集群的调优):
| 名称 | 数量 | 备注 |
| 服务器数量 | 17 | 配置不同,HBase、HDFS都部署在这些机器上 |
| 表数量 | 30+ | 只有部分表的数据量比较大,其他基本没多少数据 |
| Region数量 | 600+ | 基本上都是数据量较大的表划分的region较多 |
| 请求量 | 50000+ | 服务器请求分布极其不均匀 |
应用反应经常会过段时间出现数据写入缓慢,导致应用端数据堆积现象,是否可以通过增加机器数量来解决?
其 实,那个时候,我们本身对HBase也不是很熟悉,对HBase的了解,也仅仅在做过一些测试,了解一些性能,对内部结构,实现原理之类的基本上都不怎么 清楚。于是刚开始几天,各种问题,每天晚上拉着一男一起摸索,顺利的时候,晚上8,9点就可以暂时搞定线上问题,更多的时候基本要到22点甚至更晚(可能 那个时候流量也下去了),通过不断的摸索,慢慢了解HBase在使用上的一些限制,也就能逐渐解决这一系列过程中发现的问题。后面挑几个相对比较重要,效 果较为明显的改进点,做下简单介绍。
7、调优
首先根据目前17台机器,50000+的QPS,并且观察磁盘的I/O利用率和CPU利用率都相当低来判断:当前的请求数量根本没有达到系统的性能瓶颈,不需要新增机器来提高性能。如果不是硬件资源问题,那么性能的瓶颈究竟是什么?
7.1 Rowkey设计问题
7.1.1 现象
打开HBase的Web端,发现HBase下面各个RegionServer的请求数量非常不均匀,第一个想到的就是HBase的热点问题,具体到某个具体表上的请求分布如下:

HBase表请求分布
上面是HBase下某张表的region请求分布情况,从中我们明显可以看到,部分region的请求数量为0,而部分的请求数量可以上百万,这是一个典型的热点问题。
7.1.2 原因
HBase 出现热点问题的主要原因无非就是rowkey设计的合理性,像上面这种问题,如果rowkey设计得不好,很容易出现,比如:用时间戳生成rowkey, 由于时间戳在一段时间内都是连续的,导致在不同的时间段,访问都集中在几个RegionServer上,从而造成热点问题。
7.1.3 解决
知道了问题的原因,对症下药即可,联系应用修改rowkey规则,使rowkey数据随机均匀分布,效果如下:

Rowkey重定义后请求分布
7.1.4 建议
对于HBase来说,rowkey的范围划定了RegionServer,每一段rowkey区间对应一个RegionServer,我们要保证每段时间内的rowkey访问都是均匀的,所以我们在设计的时候,尽量要以hash或者md5等开头来组织rowkey。
编者注:
如果业务需求是按时间范围 scan/最左前缀 批量查询呢?此时hash或者md5虽然解决了 Region 数据热点问题,但同时查询效率下降,可以思考下这种场景如何来优化呢?
7.2 Region重分布
7.2.1 现象
HBase 的集群是在不断扩展的,分布式系统的最大好处除了性能外,不停服横向扩展也是其中之一,扩展过程中有一个问题:每次扩展的机器的配置是不一样的,一般,后 面新加入的机器性能会比老的机器好,但是后面加入的机器经常被分配很少的region,这样就造成了资源分布不均匀,随之而来的就是性能上的损失,如下:
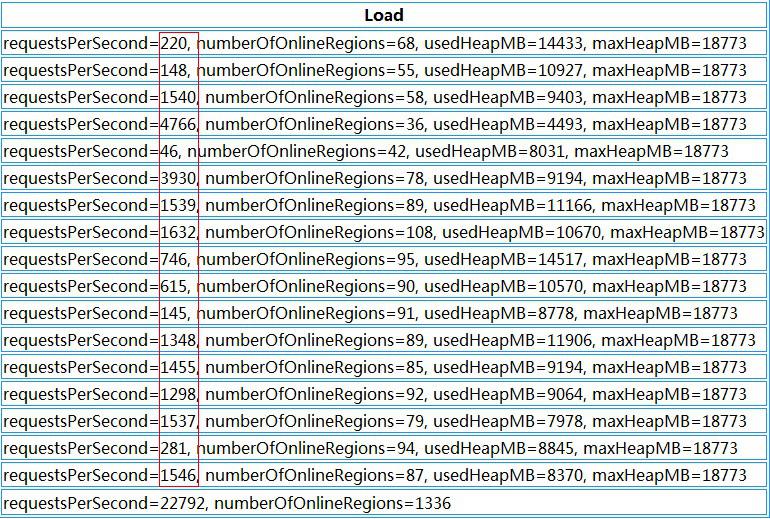
HBase各个RegionServer请求
上图中我们可以看到,每台RegionServer上的请求极为不均匀,多的好几千,少的只有几十
7.2.2 原因
资源分配不均匀,造成部分机器压力较大,部分机器负载较低,并且部分Region过大过热,导致请求相对较集中。
7.2.3 解决
迁移部分老的RegionServer上的region到新加入的机器上,使每个RegionServer的负载均匀。通过split切分部分较大region,均匀分布热点region到各个RegionServer上。
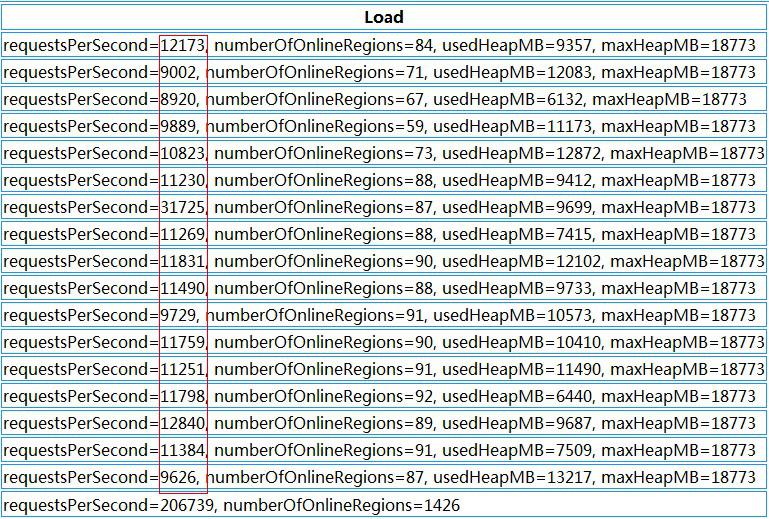
HBase region请求分布
对比前后两张截图我们可以看到,Region总数量从1336增加到了1426,而增加的这90个region就是通过split切分大的region得到的。而对region重新分布后,整个HBase的性能有了大幅度提高。
7.2.4 建议
Region 迁移的时候不能简单开启自动balance,因为balance主要的问题是不会根据表来进行balance,HBase的自动balance只会根据每 个RegionServer上的Region数量来进行balance,所以自动balance可能会造成同张表的region会被集中迁移到同一个台 RegionServer上,这样就达不到分布式的效果。
基本上,新增RegionServer后的region调整,可以手工进行,尽量使表的Region都平均分配到各个RegionServer上,另外一点,新增的RegionServer机器,配置最好与前面的一致,否则资源无法更好利用。
对于过大,过热的region,可以通过切分的方法生成多个小region后均匀分布(注意:region切分会触发major compact操作,会带来较大的I/O请求,请务必在业务低峰期进行)
7.3 HDFS写入超时
7.3.1 现象
HBase写入缓慢,查看HBase日志,经常有慢日志如下:
WARN org.apache.hadoop.ipc.HBaseServer- (responseTooSlow): {“processingtimems”:36096, “call”:”multi(org.apache.hadoop.hbase.client.MultiAction@7884377e), rpc version=1, client version=29, methodsFingerPrint=1891768260″, “client”:”xxxx.xxx.xxx.xxxx:44367″, “starttimems”:1440239670790, “queuetimems”:42081, “class”:”HRegionServer”, “responsesize”:0, “method”:”multi”}
并且伴有HDFS创建block异常如下:
INFO org.apache.hadoop.hdfs.DFSClient – Exception in createBlockOutputStream
org.apache.hadoop.hdfs.protocol.HdfsProtoUtil.vintPrefixed(HdfsProtoUtil.java:171)
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1105)
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1039)
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:487)
一般地,HBase客户端的写入到RegionServer下某个region的memstore后就返回,除了网络外,其他都是内存操作,应该不会有长达30多秒的延迟,外加HDFS层抛出的异常,我们怀疑很可能跟底层数据存储有关。
7.3.2 原因
定 位到可能是HDFS层出现了问题,那就先从底层开始排查,发现该台机器上10块盘的空间利用率都已经达到100%。按理说,作为一个成熟的分布式文件系 统,对于部分数据盘满的情况,应该有其应对措施。的确,HDFS本身可以设置数据盘预留空间,如果部分数据盘的预留空间小于该值时,HDFS会自动把数据 写入到另外的空盘上面,那么我们这个又是什么情况?
最 终通过多方面的沟通确认,发现了主要原因:我们这批机器,在上线前SA已经经过处理,每块盘默认预留100G空间,所以当通过df命令查看盘使用率为 100%时,其实盘还有100G的预留空间,而HDFS层面我们配置的预留空间是50G,那么问题就来了:HDFS认为盘还有100G空间,并且多于 50G的预留,所以数据可以写入本地盘,但是系统层面却禁止了该写入操作,从而导致数据写入异常。
7.3.3 解决
解 决的方法可以让SA释放些空间出来便于数据写入。当然,最直接有效的就是把HDFS的预留空间调整至100G以上,我们也正是这样做的,通过调整后,异常 不再出现,HBase层面的slow log也没有再出现。同时我们也开启了HDFS层面的balance,使数据自动在各个服务器之间保持平衡。
7.3.4 建议
磁盘满了导致的问题很难预料,HDFS可能会导致部分数据写入异常,MySQL可能会出现直接宕机等等,所以最好的办法就是:不要使盘的利用率达到100%。
7.4 网络拓扑
7.4.1 现象
通过rowkey调整,HDFS数据balance等操作后,HBase的确稳定了许多,在很长一段时间都没有出现写入缓慢问题,整体的性能也上涨了很多。但时常会隔一段时间出现些slow log,虽然对整体的性能影响不大,但性能上的抖动还是很明显。
7.4.2 原因
由 于该问题不经常出现,对系统的诊断带来不小的麻烦,排查了HBase层和HDFS层,几乎一无所获,因为在大多数情况下,系统的吞吐量都是正常的。通过脚 本收集RegionServer所在服务器的系统资源信息,也看不出问题所在,最后怀疑到系统的物理拓扑上,HBase集群的最大特点是数据量巨大,在做 一些操作时,很容易把物理机的千兆网卡都吃满,这样如果网络拓扑结构存在问题,HBase的所有机器没有部署在同一个交换机上,上层交换机的进出口流量也 有可能存在瓶颈。网络测试还是挺简单的,直接ping就可以,我们得到以下结果:共17台机器,只有其中一台的延迟存在问题,如下:

网络延迟测试:Ping结果
同一个局域网内的机器,延迟达到了毫秒级别,这个延迟是比较致命的,因为分布式存储系统HDFS本身对网络有要求,HDFS默认3副本存在不同的机器上,如果其中某台机器的网络存在问题,这样就会影响到该机器上保存副本的写入,拖慢整个HDFS的写入速度。
7.4.3 解决
网络问题,联系机房解决,机房的反馈也验证了我们的想法:由于HBase的机器后面进行了扩展,后面加入的机器有一台跟其他机器不在同一个交换机下,而这台机器正是我们找出的有较大ping延时这台,整个HBase物理结构如下:

HBase物理拓扑结构
跟机房协调,调整机器位置,使所有的HBase机器都位于同一个交换机下,问题迎刃而解。
7.4.4 建议
对于分布式大流量的系统,除了系统本身,物理机的部署和流量规划也相当重要,尽量使集群中所有的机器位于相同的交换机下(有容灾需求的应用除外),集群较大,需要跨交换机部署时,也要充分考虑交换机的出口流量是否够用,网络硬件上的瓶颈诊断起来相对更为困难。
7.5 JVM参数调整
解决了网络上面的不稳定因素,HBase的性能又得到进一步的提高,随之也带来了另外的问题。
7.5.1 现象
根据应用反应,HBase会阶段性出现性能下降,导致应用数据写入缓慢,造成应用端的数据堆积,这又是怎么回事?经过一系列改善后HBase的系统较之以前有了大幅度增长,怎么还会出现数据堆积的问题?为什么会阶段性出现?
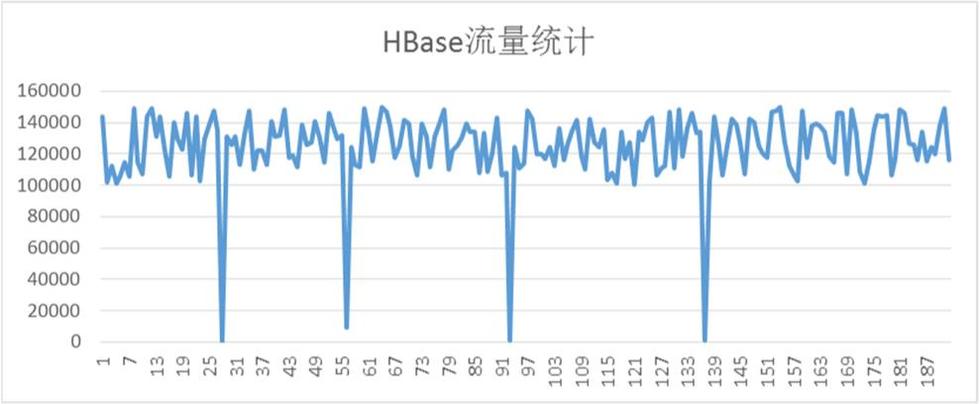
HBase流量统计
从上图看,HBase平均流量QPS基本能达到12w,但是每过一段时间,流量就会下降到接近零点,同时这段时间,应用会反应数据堆积。
7.5.2 原因
这个问题定位相对还是比较简单,结合HBase的日志,很容易找到问题所在:
org.apache.hadoop.hbase.util.Sleeper – We slept 41662ms instead of 3000ms, this is likely due to a long garbage collecting pause and it’s usually bad
通过上述日志,基本上可以判定是HBase的某台RegionServer出现GC问题,导致了服务在很长一段时间内禁止访问。
HBase通过一系列的调整后,整个系统的吞吐量增加了好几倍,然而JVM的堆大小没有进行相应的调整,整个系统的内存需求变大,而虚拟机又来不及回收,最终导致出现Full GC
7.5.3 解决
GC问题导致HBase整个系统的请求下降,通过适当调整JVM参数的方式,解决HBase RegionServer的GC问题。
7.5.4 建议
对 于HBase来说,本身不存在单点故障,即使宕掉1,2台RegionServer,也只是使剩下几台的压力有所增加,不会导致整个集群服务能力下降很 多。但是,如果其中某台RegionServer出现Full GC问题,那么这台机器上所有的访问都会被挂起,客户端请求一般都是batch发送的,rowkey的随机分布导致部分请求会落到该台 RegionServer上,这样该客户端的请求就会被阻塞,导致客户端无法正常写数据到HBase。所以,对于HBase来说,宕机并不可怕,但长时间 的Full GC是比较致命的,配置JVM参数的时候,尽量要考虑避免Full GC的出现。
8、后记
经过前面一系列的优化,目前Datastream的这套HBase线上环境已经相当稳定,连续运行几个月都没有任何HBase层面由于系统性能不稳定导致的报警,平均性能在各个时间段都比较稳定,没有出现过大幅度的波动或者服务不可用等现象。
Refer:
[1] HBase原理和设计
http://www.bitstech.net/2015/09/16/hbase-architecture/
[2] HBase优化实战
http://www.bitstech.net/2015/12/04/hbase-optmization/
[3] HBase 数据库检索性能优化策略
https://www.ibm.com/developerworks/cn/java/j-lo-HBase/
[4] 一种基于HBase表的条件查询优化方法
http://www.google.com/patents/CN103646073A?cl=zh
[5] HBase 实战(2)--时间序列检索和面检索的应用场景实战
http://www.cnblogs.com/mumuxinfei/p/3869998.html
[6] HBase性能优化方法总结(一):表的设计
http://www.cnblogs.com/panfeng412/archive/2012/03/08/hbase-performance-tuning-section1.html
[7] 日志系统之HBase日志存储设计优化
http://blog.csdn.net/yanghua_kobe/article/details/46482319
[8] Apache HBase 2015年发展回顾与未来展望
[9] HBase性能优化方法总结
http://zqhxuyuan.github.io/2015/12/16/2015-12-16-HBase-Optimize/
http://my.oschina.net/leejun2005/blog/543048#OSC_h1_4



相关推荐
### 阿里云HBase备份恢复的原理及实践 #### 背景与选型考量 在审计行业中,为了高效地处理大规模的财务数据,选择合适的数据存储系统至关重要。HBase作为Apache Hadoop生态系统中的一个分布式、可伸缩的大规模表...
在当前的大数据时代,数据量的爆发性增长和业务需求的多样性,对...文档中涉及的知识点涵盖了云数据库、大数据存储与处理、分布式系统设计等多个IT领域的关键技术和最佳实践,是深入研究和应用云HBase的宝贵资源。
书中详细阐述了Hbase的核心原理、生态环境以及在实际项目中的架构设计与性能优化策略,旨在帮助读者全面理解并掌握Hbase的运用。 Hbase作为Apache Hadoop生态系统的一部分,是一款开源的、非关系型的分布式数据库,...
HBase是一种分布式、高性能、基于列族的NoSQL数据库,...记住,理论知识与实践相结合是掌握HBase的关键,通过实际操作和项目经验,你会对HBase有更深入的理解。提供的“hbase 培训”资料应该能帮助你开始这段学习之旅。
在HBase这样的分布式列式数据库中,读性能的优化至关重要,因为它直接影响到应用程序的响应速度和用户体验。本文主要探讨了HBase服务器端的读性能优化策略,这些策略可以帮助解决读延迟大、资源消耗高和负载不均衡等...
2. **高性能**:HBase设计为面向列的存储,允许快速访问特定列族或列,这在处理大量稀疏数据时非常有效。其使用了LSM树(Log-Structured Merge Tree)数据结构,优化了写入性能,同时通过MemStore和StoreFile的管理...
**HBase实验报告** 在本实验中,我们主要聚焦于HBase,这是一个基于谷歌Bigtable设计的开源...在后续的学习和实践中,应深入研究HBase的其他高级特性,如Region Split、Compaction等,以便更好地应用到实际项目中。
### HBase原理简介 HBase是一种分布式的、面向列的开源数据库,其设计灵感来源于Google的Bigtable论文。HBase提供了高性能的随机读写能力,适用于海量非结构化/半结构化数据存储。 #### 数据模型 HBase的数据模型...
总结,安装配置HBase涉及多个步骤,包括下载安装、环境配置、权限设置、模式配置、服务启动与停止,以及后续的实践和优化。掌握这些知识,对于在互联网环境中进行大数据管理和处理是非常有价值的。通过实践,你可以...
《HBase架构设计基础》 HBase,全称为Hadoop Base,是建立在Apache Hadoop文件系统(HDFS)之上的分布式列式数据库,专为处理大规模...理解和掌握HBase的原理和实践,对于构建高性能的分布式数据存储系统至关重要。
本项目作为HBase数据库设计的源码解析,不仅为Java开发者提供了学习和实践HBase的机会,也为数据库设计与优化提供了宝贵的参考。通过对项目的深入研究,开发者将能够更好地理解HBase的工作原理,掌握在Java环境下...
总之,HBase的Schema设计与关系型数据库有较大差异,需要从其独特的数据模型和存储原理出发,通过合理规划行键、列族、压缩策略和版本控制等,来设计出能够高效支持大规模数据随机访问需求的表结构。在实践过程中,...
《HBase应用架构》则侧重于HBase在大数据架构中的定位和作用,讨论了HBase与其他大数据组件(如Hadoop、Spark)的整合策略,以及如何构建和优化HBase为基础的大数据平台。 总的来说,这些书籍覆盖了HBase的各个方面...
《HBase in Action》是一本由Nick Dimiduk和Amandeep Khurana撰写的关于HBase实践的书籍,该书旨在帮助读者深入理解HBase的工作原理及其实战应用。 **章节概述**: - **第一部分:HBase基础** - **第1章:介绍...
源文件中,不仅有对HBase核心操作的封装,还包括了对数据读写的优化、对数据模型的设计,以及与其他Java应用组件的集成等关键内容。 除了Java源文件,系统中还包括了5个XML配置文件。XML文件在系统配置和数据交换...
总之,"HBase应用场景原理与基本架构"这一主题涵盖了HBase的核心要素,包括它的设计理念、架构组件、工作流程以及在不同领域的实践应用。深入理解和掌握这些知识,对于从事大数据处理、实时分析或云存储等相关工作的...
本分享将深入探讨阿里在搜索领域如何利用HBase这一NoSQL数据库进行设计与实践,旨在揭示大数据解决方案的核心原理和实际应用。 首先,Hadoop作为开源的分布式计算框架,其核心由HDFS(Hadoop Distributed File ...