
纵观业界的电商网站,我站在一个用户的角度来看,商品推荐有很多种:
一种是通过我搜索、查看的那件商品的,系统统计出搜索、查看该商品的其他用户搜索、查看其他商品的次数,把排名靠前的推荐给我,当当的一个栗子:
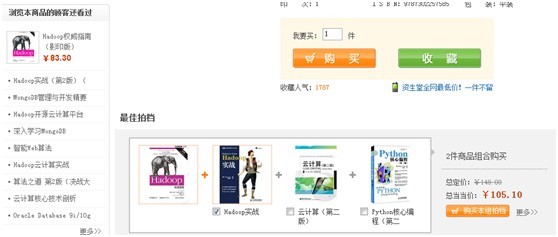
我查看了《Hadoop权威指南》,系统给我推荐了一堆其他的书:
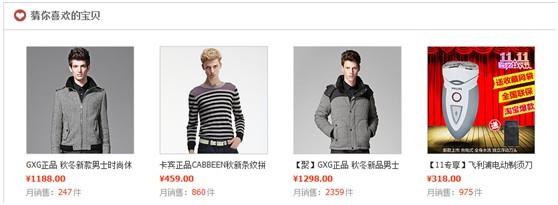
一种是通过我最近的搜索、查看过商品,系统给我推荐一些它认为我感兴趣的商品,淘宝的一个栗子:
还有几种,感觉挺有意思的:

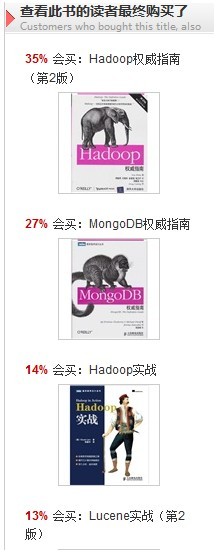

特别是这个,搜索Hadoop的用户,最终很多人都买了羽绒服,这是为什么呢?学习hadoop的筒子们都很怕冷么?还是说,北方人居多?

- 五花八门哈,别的不管了。只讨论下第一种,个人YY设计下:基于Hbase的一个简单的商品推荐系统。
- 撇开其他的流程不说,单就这个推荐而言,基于Hbase的设计,两张表就OK了。一张表user_item记录每个用户查看了的所有商品,item_user记录查看了某个商品的所有用户。
- user_item:userid作为行健,列簇和列为item:itemid,数据如下:
- user1 item:itemid timestamp=1234567891, value=item1
- user1 item:itemid timestamp=1234567892, value=item2
- user1 item:itemid timestamp=1234567893, value=item3
- user2 item:itemid timestamp=1234567894, value=item4
- user2 item:itemid timestamp=1234567895, value=item5
- user3 item:itemid timestamp=1234567881, value=item1
- user3 item:itemid timestamp=1234567832, value=item2
- user4 item:itemid timestamp=1234567843, value=item3
- user4 item:itemid timestamp=1234567854, value=item4
- user4 item:itemid timestamp=1234567895, value=item5
- ......
- item_user:itemid作为行健,列簇和列为:user:userid,数据如下:
- item1 user:userid timestamp=1234567891, value=user1
- item1 user:userid timestamp=1234567892, value=user2
- item1 user:userid timestamp=1234567893, value=user4
- item2 user:userid timestamp=1234567894, value=user3
- item3 user:userid timestamp=1234567895, value=user2
- item3 user:userid timestamp=1234567881, value=user4
- item6 user:userid timestamp=1234567832, value=user5
- item6 user:userid timestamp=1234567843, value=user6
- item8 user:userid timestamp=1234567854, value=user5
- item8 user:userid timestamp=1234567895, value=user4
- ......
- 大概的业务是:我查看《Hadoop权威指南》(item1)时,系统从item_user表中以item1作为行健查询出所有查看过item1的用户,再分别以各userid为行健,从user_item表中查询出所有查看过的商品,最后去重、统计、排序并显示。
http://f.dataguru.cn/thread-33415-1-1.html



相关推荐
本项目是一个基于Flink和HBase的商品实时推荐系统,旨在通过实时数据处理和推荐算法,为用户提供个性化的商品推荐服务。系统通过Flink处理来自Kafka的日志数据,并将处理结果存储在HBase中,最终通过Web模块为用户...
在本项目中,"基于HBase + Spark 实现常用推荐算法(主要用于精准广告投放和推荐系统)",我们将探讨如何利用大数据处理工具Spark与分布式数据库HBase协同工作,以实现高效的推荐系统。推荐系统在现代互联网行业中...
【标题】中的“计算机课程毕设:基于hbase + spark 实现常用推荐算法(主要用于精准广告投放和推荐系统)”表明这是一个关于计算机科学与技术专业毕业设计的项目,重点在于利用HBase和Spark两种技术来实现推荐算法,...
基于Flink+SpringBoot+Hbase的商品实时推荐系统源码+全部资料齐全 flink统计商品热度,放入redis缓存,分析日志信息,将画像标签和实时记录放入Hbase在用户发起推荐请求后,根据用户画像重排序热度榜,并结合协同...
- 不懂运行,下载完可以私聊问,可远程教学 该资源内项目源码是个人的毕设,代码都测试ok,都是运行成功后才上传资源,答辩评审平均分达到96分,放心下载使用! <项目介绍> 1、该资源内项目代码都经过测试运行成功,...
商品实时推荐系统1.系统架构v2.0 1.1系统架构图 1.2...数据存储在Hbase的p_history表用户-兴趣->实现基于碱性的推荐逻辑根据用户对同一个产品的操作计算兴趣度,计算规则通过操作间隔时间(如购物-浏览实现基于标签的
总结来说,一淘搜索系统利用Hadoop和HBase的强大能力,构建了一个高可用、高性能的分布式存储和计算平台,实现了对海量电子商务数据的高效处理和检索,为用户提供优质的搜索体验。其核心在于利用HBase的分布式存储...
《基于物品的协同过滤推荐系统实现》 协同过滤推荐系统是一种广泛应用在个性化推荐中的算法,其核心思想是利用用户的历史行为数据...对于希望在推荐系统和大数据领域深化技能的开发者来说,这是一个非常有价值的资源。
基于Flink实现的商品实时推荐系统、flink统计商品热度,放入redis缓存,分析日志信息,将画像标签和实时记录放入Hbase。在用户发起推荐请求后,根据用户画像重排序热度榜,并结合协同过滤和标签两个推荐模块为新生成...
本文将深入探讨一个基于Hadoop的商品推荐算法,该算法利用MapReduce进行分布式计算,实现高效的数据处理,旨在为用户推荐最符合其兴趣的商品。 首先,我们要理解Hadoop的核心组件MapReduce。MapReduce是一种编程...
《Storm流计算项目:1号店电商实时数据分析系统——基于HBase的Dao开发》 在大数据处理领域,Storm作为实时流计算的利器,被广泛应用于实时数据处理与分析。本项目以1号店电商实时数据分析系统为例,深入探讨了如何...
1、一淘搜索系统架构 2、基于HBase的分布式存储系统 3、基于Hadoop的分布式计算平台 4、一淘全网商品离线处理系统
基于Flink实现的商品实时推荐系统。flink统计商品热度,放入...在用户发起推荐请求后,根据用户画像重排序热度榜,并结合协同过滤和标签两个推荐模块为新生成的榜单的每一个产品添加关联产品,最后返回新的用户列表。
- 根据最近评分商品与本次商品的相似度以及用户历史评分对推荐商品重新排序。 对所有时间用户评分的商品根据评分次数进行逆序排序,选出热门商品。 - flink 将 hbase `rating` 表加载到内存中,根据 productId ...
一淘搜索离线系统是大数据处理领域的一个重要应用,它主要利用了Hadoop和HBase这两个关键组件来实现大规模数据的存储、管理和检索。Hadoop是Apache基金会开发的分布式计算框架,而HBase则是一个构建在Hadoop文件系统...
项目简介:本项目为基于Flink的实时商品推荐系统,用户登录系统后,可获取实时的商品推荐、热门商品、好评商品及实时热门商品排行,对商品进行查看详细信息并评分。本项目使用了Zookeeper、Kafka、Hbase、Mysql、...
Java基于Flink实现的商品实时推荐系统。flink统计商品热度,放...在用户发起推荐请求后,根据用户画像重排序热度榜,并结合协同过滤和标签两个推荐模块为新生成的榜单的每一个产品添加关联产品,最后返回新的用户列表。
HBase是一个开源的非关系型分布式数据库(NoSQL),建立在Hadoop文件系统(HDFS)之上,是Apache Hadoop生态系统中的一部分,主要用于处理海量结构化数据的存储和实时查询。HBase的特点是它可以存储庞大的数据集,...