
Hadoop家ж—Ҹзі»еҲ—ж–Үз« пјҢ дё»иҰҒд»Ӣз»ҚHadoop家ж—Ҹдә§е“ҒпјҢеёёз”Ёзҡ„йЎ№зӣ®еҢ…жӢ¬Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, ChukwaпјҢж–°еўһеҠ зҡ„йЎ№зӣ®еҢ…жӢ¬пјҢYARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, HueзӯүгҖӮ
д»Һ2011е№ҙејҖе§ӢпјҢдёӯеӣҪиҝӣе…ҘеӨ§ж•°жҚ®йЈҺиө·дә‘ж¶Ңзҡ„ж—¶д»ЈпјҢд»ҘHadoopдёәд»ЈиЎЁзҡ„家ж—ҸиҪҜ件пјҢеҚ жҚ®дәҶеӨ§ж•°жҚ®еӨ„зҗҶзҡ„е№ҝйҳ”ең°зӣҳгҖӮејҖжәҗз•ҢеҸҠеҺӮе•ҶпјҢжүҖжңүж•°жҚ®иҪҜ件пјҢж— дёҖдёҚеҗ‘Hadoopйқ жӢўгҖӮHadoopд№ҹд»Һе°Ҹдј—зҡ„й«ҳеҜҢеё…йўҶеҹҹпјҢеҸҳжҲҗдәҶеӨ§ж•°жҚ®ејҖеҸ‘зҡ„ж ҮеҮҶгҖӮеңЁHadoopеҺҹжңүжҠҖжңҜеҹәзЎҖд№ӢдёҠпјҢеҮәзҺ°дәҶHadoop家ж—Ҹдә§е“ҒпјҢйҖҡ иҝҮвҖңеӨ§ж•°жҚ®вҖқжҰӮеҝөдёҚж–ӯеҲӣж–°пјҢжҺЁеҮә科жҠҖиҝӣжӯҘгҖӮ
дҪңдёәITз•Ңзҡ„ејҖеҸ‘дәәе‘ҳпјҢжҲ‘们д№ҹиҰҒи·ҹдёҠиҠӮеҘҸпјҢжҠ“дҪҸжңәйҒҮпјҢи·ҹзқҖHadoopдёҖиө·йӣ„иө·пјҒ
е…ідәҺдҪңиҖ…пјҡ
- еј дё№(Conan), зЁӢеәҸе‘ҳJava,R,PHP,Javascript
- weiboпјҡ@Conan_Z
- blog:В http://blog.fens.me
- email: bsspirit@gmail.com
иҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„пјҡ
http://blog.fens.me/mahout-recommendation-api

еүҚиЁҖ
з”ЁMahoutжқҘжһ„е»әжҺЁиҚҗзі»з»ҹпјҢжҳҜдёҖ件既з®ҖеҚ•еҸҲеӣ°йҡҫзҡ„дәӢжғ…гҖӮз®ҖеҚ•жҳҜеӣ дёәMahoutе®Ңж•ҙең°е°ҒиЈ…дәҶвҖңеҚҸеҗҢиҝҮж»ӨвҖқз®—жі•пјҢ并е®һзҺ°дәҶ并иЎҢеҢ–пјҢжҸҗдҫӣйқһеёёз®ҖеҚ•зҡ„APIжҺҘеҸЈпјӣеӣ°йҡҫжҳҜеӣ дёәжҲ‘们дёҚдәҶи§Јз®—жі•з»ҶиҠӮпјҢеҫҲйҡҫеҺ»ж №жҚ®дёҡеҠЎзҡ„еңәжҷҜиҝӣиЎҢз®—жі•й…ҚзҪ®е’Ңи°ғдјҳгҖӮ
жң¬ж–Үе°Ҷж·ұе…Ҙз®—жі•APIеҺ»и§ЈйҮҠMahoutжҺЁиҚҗз®—жі•еә•еұӮзҡ„дёҖдәӣдәӢгҖӮ
зӣ®еҪ•
- MahoutжҺЁиҚҗз®—жі•д»Ӣз»Қ
- з®—жі•иҜ„еҲӨж ҮеҮҶпјҡеҸ¬еӣһзҺҮдёҺеҮҶзЎ®зҺҮ
- Recommender.javaзҡ„APIжҺҘеҸЈ
- жөӢиҜ•зЁӢеәҸпјҡRecommenderTest.java
- еҹәдәҺз”ЁжҲ·зҡ„еҚҸеҗҢиҝҮж»Өз®—жі•UserCF
- еҹәдәҺзү©е“Ғзҡ„еҚҸеҗҢиҝҮж»Өз®—жі•ItemCF
- SlopeOneз®—жі•
- KNN Linear interpolation itemвҖ“basedжҺЁиҚҗз®—жі•
- SVDжҺЁиҚҗз®—жі•
- Tree Cluster-based жҺЁиҚҗз®—жі•
- MahoutжҺЁиҚҗз®—жі•жҖ»з»“
1. MahoutжҺЁиҚҗз®—жі•д»Ӣз»Қ
MahouttжҺЁиҚҗз®—жі•пјҢд»Һж•°жҚ®еӨ„зҗҶиғҪеҠӣдёҠпјҢеҸҜд»ҘеҲ’еҲҶдёә2зұ»пјҡ
- еҚ•жңәеҶ…еӯҳз®—жі•е®һзҺ°
- еҹәдәҺHadoopзҡ„еҲҶжӯҘејҸз®—жі•е®һзҺ°
1). еҚ•жңәеҶ…еӯҳз®—жі•е®һзҺ°
еҚ•жңәеҶ…еӯҳз®—жі•е®һзҺ°пјҡе°ұжҳҜеңЁеҚ•жңәдёӢиҝҗиЎҢзҡ„з®—жі•пјҢжҳҜз”ұcf.tasteйЎ№зӣ®е®һзҺ°зҡ„пјҢеғҸжҲ‘зҡ„们зҶҹжӮүзҡ„UserCF,ItemCFйғҪж”ҜжҢҒеҚ•жңәеҶ…еӯҳиҝҗиЎҢпјҢ并且еҸӮж•°еҸҜд»ҘзҒөжҙ»й…ҚзҪ®гҖӮеҚ•жңәз®—жі•зҡ„еҹәжң¬е®һдҫӢпјҢиҜ·еҸӮиҖғж–Үз« пјҡз”ЁMavenжһ„е»әMahoutйЎ№зӣ®
еҚ•жңәеҶ…еӯҳз®—жі•зҡ„й—®йўҳеңЁдәҺпјҢеҸ—йҷҗдәҺеҚ•жңәзҡ„иө„жәҗгҖӮеҜ№дәҺдёӯзӯү规模зҡ„ж•°жҚ®пјҢеғҸ1G,10Gзҡ„ж•°жҚ®йҮҸпјҢжңүиғҪеҠӣиҝӣиЎҢи®Ўз®—пјҢдҪҶжҳҜи¶…иҝҮ100Gзҡ„ж•°жҚ®йҮҸпјҢеҜ№дәҺеҚ•жңәжқҘиҜҙжҳҜдёҚеҸҜиғҪе®ҢжҲҗзҡ„д»»еҠЎгҖӮ
2). еҹәдәҺHadoopзҡ„еҲҶжӯҘејҸз®—жі•е®һзҺ°
еҹәдәҺHadoopзҡ„еҲҶжӯҘејҸз®—жі•е®һзҺ°пјҡе°ұжҳҜжҠҠеҚ•жңәеҶ…еӯҳ算法并иЎҢеҢ–пјҢжҠҠд»»еҠЎеҲҶж•ЈеҲ°еӨҡеҸ°и®Ўз®—жңәдёҖиө·иҝҗиЎҢгҖӮMahoutжҸҗдҫӣдәҶItemCFеҹәдәҺHadoop并иЎҢеҢ–з®—жі•е®һзҺ°гҖӮеҹәдәҺHadoopзҡ„еҲҶжӯҘејҸз®—жі•е®һзҺ°пјҢиҜ·еҸӮиҖғж–Үз« пјҡ
MahoutеҲҶжӯҘејҸзЁӢеәҸејҖеҸ‘ еҹәдәҺзү©е“Ғзҡ„еҚҸеҗҢиҝҮж»ӨItemCF
еҲҶжӯҘејҸ并иЎҢз®—жі•зҡ„й—®йўҳеңЁдәҺпјҢеҰӮдҪ•и®©еҚ•жңә算法并иЎҢеҢ–гҖӮеңЁеҚ•жңәз®—жі•дёӯпјҢжҲ‘们еҸӘйңҖиҰҒиҖғиҷ‘з®—жі•пјҢж•°жҚ®з»“жһ„пјҢеҶ…еӯҳпјҢCPUе°ұеӨҹдәҶпјҢдҪҶжҳҜеҲҶжӯҘејҸз®—жі•иҝҳиҰҒйўқеӨ–иҖғиҷ‘еҫҲеӨҡзҡ„жғ…еҶөпјҢжҜ”еҰӮеӨҡиҠӮзӮ№зҡ„ж•°жҚ®еҗҲ并пјҢж•°жҚ®жҺ’еәҸпјҢзҪ‘и·ҜйҖҡдҝЎзҡ„ж•ҲзҺҮпјҢиҠӮзӮ№е®•жңәйҮҚз®—пјҢж•°жҚ®еҲҶжӯҘејҸеӯҳеӮЁзӯүзӯүзҡ„еҫҲеӨҡй—®йўҳгҖӮ
2. з®—жі•иҜ„еҲӨж ҮеҮҶпјҡеҸ¬еӣһзҺҮ(recall)дёҺжҹҘеҮҶзҺҮ(precision)
MahoutжҸҗдҫӣдәҶ2дёӘиҜ„дј°жҺЁиҚҗеҷЁзҡ„жҢҮж ҮпјҢжҹҘеҮҶзҺҮе’ҢеҸ¬еӣһзҺҮпјҲжҹҘе…ЁзҺҮпјүпјҢиҝҷдёӨдёӘжҢҮж ҮжҳҜжҗңзҙўеј•ж“Һдёӯз»Ҹе…ёзҡ„еәҰйҮҸж–№жі•гҖӮ
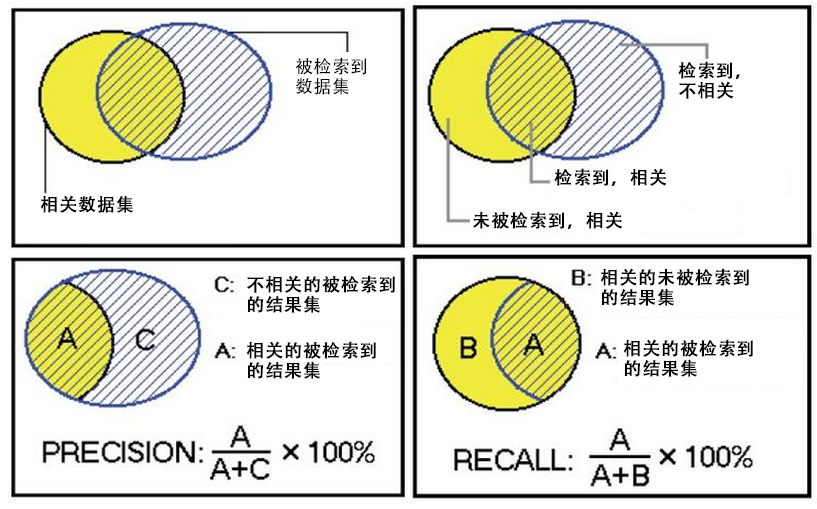
зӣёе…і дёҚзӣёе…і
жЈҖзҙўеҲ° A C
жңӘжЈҖзҙўеҲ° B D
- AпјҡжЈҖзҙўеҲ°зҡ„пјҢзӣёе…ізҡ„ пјҲжҗңеҲ°зҡ„д№ҹжғіиҰҒзҡ„пјү
- BпјҡжңӘжЈҖзҙўеҲ°зҡ„пјҢдҪҶжҳҜзӣёе…ізҡ„ пјҲжІЎжҗңеҲ°пјҢ然иҖҢе®һйҷ…дёҠжғіиҰҒзҡ„пјү
- CпјҡжЈҖзҙўеҲ°зҡ„пјҢдҪҶжҳҜдёҚзӣёе…ізҡ„ пјҲжҗңеҲ°зҡ„дҪҶжІЎз”Ёзҡ„пјү
- DпјҡжңӘжЈҖзҙўеҲ°зҡ„пјҢд№ҹдёҚзӣёе…ізҡ„ пјҲжІЎжҗңеҲ°д№ҹжІЎз”Ёзҡ„пјү
иў«жЈҖзҙўеҲ°зҡ„и¶ҠеӨҡи¶ҠеҘҪпјҢиҝҷжҳҜиҝҪжұӮвҖңжҹҘе…ЁзҺҮвҖқпјҢеҚіA/(A+B)пјҢи¶ҠеӨ§и¶ҠеҘҪгҖӮ
иў«жЈҖзҙўеҲ°зҡ„пјҢи¶Ҡзӣёе…ізҡ„и¶ҠеӨҡи¶ҠеҘҪпјҢдёҚзӣёе…ізҡ„и¶Ҡе°‘и¶ҠеҘҪпјҢиҝҷжҳҜиҝҪжұӮвҖңжҹҘеҮҶзҺҮвҖқпјҢеҚіA/(A+C)пјҢи¶ҠеӨ§и¶ҠеҘҪгҖӮ
еңЁеӨ§и§„жЁЎж•°жҚ®йӣҶеҗҲдёӯпјҢиҝҷдёӨдёӘжҢҮж ҮжҳҜзӣёдә’еҲ¶зәҰзҡ„гҖӮеҪ“еёҢжңӣзҙўеј•еҮәжӣҙеӨҡзҡ„ж•°жҚ®зҡ„ж—¶еҖҷпјҢжҹҘеҮҶзҺҮе°ұдјҡдёӢйҷҚпјҢеҪ“еёҢжңӣзҙўеј•жӣҙеҮҶзЎ®зҡ„ж—¶еҖҷпјҢдјҡзҙўеј•жӣҙе°‘зҡ„ж•°жҚ®гҖӮ
3. Recommenderзҡ„APIжҺҘеҸЈ
1). зі»з»ҹзҺҜеўғ:
- Win7 64bit
- Java 1.6.0_45
- Maven 3
- Eclipse Juno Service Release 2
- Mahout 0.8
- Hadoop 1.1.2
2). RecommenderжҺҘеҸЈж–Ү件пјҡ
org.apache.mahout.cf.taste.recommender.Recommender.java

жҺҘеҸЈдёӯж–№жі•зҡ„и§ЈйҮҠпјҡ
- recommend(long userID, int howMany): иҺ·еҫ—жҺЁиҚҗз»“жһңпјҢз»ҷuserIDжҺЁиҚҗhowManyдёӘItem
- recommend(long userID, int howMany, IDRescorer rescorer): иҺ·еҫ—жҺЁиҚҗз»“жһңпјҢз»ҷuserIDжҺЁиҚҗhowManyдёӘItemпјҢеҸҜд»Ҙж №жҚ®rescorerеҜ№з»“жһ„йҮҚж–°жҺ’еәҸгҖӮ
- estimatePreference(long userID, long itemID): еҪ“жү“еҲҶдёәз©әпјҢдј°и®Ўз”ЁжҲ·еҜ№зү©е“Ғзҡ„жү“еҲҶ
- setPreference(long userID, long itemID, float value): иөӢеҖјз”ЁжҲ·пјҢзү©е“ҒпјҢжү“еҲҶ
- removePreference(long userID, long itemID): еҲ йҷӨз”ЁжҲ·еҜ№зү©е“Ғзҡ„жү“еҲҶ
- getDataModel(): жҸҗеҸ–жҺЁиҚҗж•°жҚ®
йҖҡиҝҮRecommenderжҺҘеҸЈпјҢжҲ‘еҸҜд»ҘзҢңеҮәж ёеҝғз®—жі•пјҢеә”иҜҘдјҡеңЁеӯҗзұ»зҡ„estimatePreference()ж–№жі•дёӯиҝӣиЎҢе®һзҺ°гҖӮ
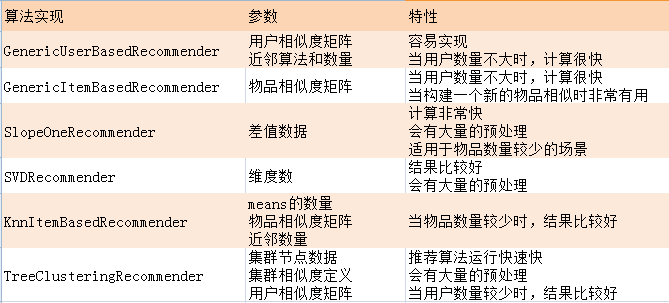
3). йҖҡиҝҮ继жүҝе…ізі»еҲ°RecommenderжҺҘеҸЈзҡ„еӯҗзұ»пјҡ

жҺЁиҚҗз®—жі•е®һзҺ°зұ»пјҡ
- GenericUserBasedRecommender: еҹәдәҺз”ЁжҲ·зҡ„жҺЁиҚҗз®—жі•
- GenericItemBasedRecommender: еҹәдәҺзү©е“Ғзҡ„жҺЁиҚҗз®—жі•
- KnnItemBasedRecommender: еҹәдәҺзү©е“Ғзҡ„KNNжҺЁиҚҗз®—жі•
- SlopeOneRecommender: SlopeжҺЁиҚҗз®—жі•
- SVDRecommender: SVDжҺЁиҚҗз®—жі•
- TreeClusteringRecommenderпјҡTreeClusterжҺЁиҚҗз®—жі•
дёӢйқўе°ҶеҲҶеҲ«д»Ӣз»ҚжҜҸз§Қз®—жі•зҡ„е®һзҺ°гҖӮ
4. жөӢиҜ•зЁӢеәҸпјҡRecommenderTest.java
жөӢиҜ•ж•°жҚ®йӣҶпјҡitem.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
жөӢиҜ•зЁӢеәҸпјҡorg.conan.mymahout.recommendation.job.RecommenderTest.java
package org.conan.mymahout.recommendation.job;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.common.RandomUtils;
public class RecommenderTest {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
RandomUtils.useTestSeed();
String file = "datafile/item.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
slopeOne(dataModel);
}
public static void userCF(DataModel dataModel) throws TasteException{}
public static void itemCF(DataModel dataModel) throws TasteException{}
public static void slopeOne(DataModel dataModel) throws TasteException{}
...
жҜҸз§Қз®—жі•йғҪдёҖдёӘеҚ•зӢ¬зҡ„ж–№жі•иҝӣиЎҢз®—жі•жөӢиҜ•пјҢеҰӮuserCF(),itemCF(),slopeOne()вҖҰ.
5. еҹәдәҺз”ЁжҲ·зҡ„еҚҸеҗҢиҝҮж»Өз®—жі•UserCF
еҹәдәҺз”ЁжҲ·зҡ„еҚҸеҗҢиҝҮж»ӨпјҢйҖҡиҝҮдёҚеҗҢз”ЁжҲ·еҜ№зү©е“Ғзҡ„иҜ„еҲҶжқҘиҜ„жөӢз”ЁжҲ·д№Ӣй—ҙзҡ„зӣёдјјжҖ§пјҢеҹәдәҺз”ЁжҲ·д№Ӣй—ҙзҡ„зӣёдјјжҖ§еҒҡеҮәжҺЁиҚҗгҖӮз®ҖеҚ•жқҘи®Іе°ұжҳҜпјҡз»ҷз”ЁжҲ·жҺЁиҚҗе’Ңд»–е…ҙи¶Јзӣёдјјзҡ„е…¶д»–з”ЁжҲ·е–ңж¬ўзҡ„зү©е“ҒгҖӮ
дёҫдҫӢиҜҙжҳҺпјҡ
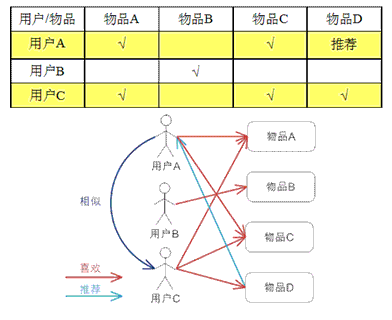
еҹәдәҺз”ЁжҲ·зҡ„ CF зҡ„еҹәжң¬жҖқжғізӣёеҪ“з®ҖеҚ•пјҢеҹәдәҺз”ЁжҲ·еҜ№зү©е“Ғзҡ„еҒҸеҘҪжүҫеҲ°зӣёйӮ»йӮ»еұ…з”ЁжҲ·пјҢ然еҗҺе°ҶйӮ»еұ…з”ЁжҲ·е–ңж¬ўзҡ„жҺЁиҚҗз»ҷеҪ“еүҚз”ЁжҲ·гҖӮи®Ўз®—дёҠпјҢе°ұжҳҜе°ҶдёҖдёӘз”ЁжҲ·еҜ№жүҖжңүзү©е“Ғзҡ„еҒҸеҘҪдҪңдёәдёҖдёӘеҗ‘йҮҸ жқҘи®Ўз®—з”ЁжҲ·д№Ӣй—ҙзҡ„зӣёдјјеәҰпјҢжүҫеҲ° K йӮ»еұ…еҗҺпјҢж №жҚ®йӮ»еұ…зҡ„зӣёдјјеәҰжқғйҮҚд»ҘеҸҠ他们еҜ№зү©е“Ғзҡ„еҒҸеҘҪпјҢйў„жөӢеҪ“еүҚз”ЁжҲ·жІЎжңүеҒҸеҘҪзҡ„жңӘж¶үеҸҠзү©е“ҒпјҢи®Ўз®—еҫ—еҲ°дёҖдёӘжҺ’еәҸзҡ„зү©е“ҒеҲ—иЎЁдҪңдёәжҺЁиҚҗгҖӮеӣҫ 2 з»ҷеҮәдәҶдёҖдёӘдҫӢеӯҗпјҢеҜ№дәҺз”ЁжҲ· AпјҢж №жҚ®з”ЁжҲ·зҡ„еҺҶеҸІеҒҸеҘҪпјҢиҝҷйҮҢеҸӘи®Ўз®—еҫ—еҲ°дёҖдёӘйӮ»еұ… вҖ“ з”ЁжҲ· CпјҢ然еҗҺе°Ҷз”ЁжҲ· C е–ңж¬ўзҡ„зү©е“Ғ D жҺЁиҚҗз»ҷз”ЁжҲ· AгҖӮ
дёҠж–ҮдёӯеӣҫзүҮе’Ңи§ЈйҮҠж–Үеӯ—пјҢж‘ҳиҮӘпјҡ https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
з®—жі•API: org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
long[] theNeighborhood = neighborhood.getUserNeighborhood(userID);
return doEstimatePreference(userID, theNeighborhood, itemID);
}
protected float doEstimatePreference(long theUserID, long[] theNeighborhood, long itemID) throws TasteException {
if (theNeighborhood.length == 0) {
return Float.NaN;
}
DataModel dataModel = getDataModel();
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
for (long userID : theNeighborhood) {
if (userID != theUserID) {
// See GenericItemBasedRecommender.doEstimatePreference() too
Float pref = dataModel.getPreferenceValue(userID, itemID);
if (pref != null) {
double theSimilarity = similarity.userSimilarity(theUserID, userID);
if (!Double.isNaN(theSimilarity)) {
preference += theSimilarity * pref;
totalSimilarity += theSimilarity;
count++;
}
}
}
}
// Throw out the estimate if it was based on no data points, of course, but also if based on
// just one. This is a bit of a band-aid on the 'stock' item-based algorithm for the moment.
// The reason is that in this case the estimate is, simply, the user's rating for one item
// that happened to have a defined similarity. The similarity score doesn't matter, and that
// seems like a bad situation.
if (count <= 1) {
return Float.NaN;
}
float estimate = (float) (preference / totalSimilarity);
if (capper != null) {
estimate = capper.capEstimate(estimate);
}
return estimate;
}
жөӢиҜ•зЁӢеәҸ:
public static void userCF(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
зЁӢеәҸиҫ“еҮәпјҡ
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.0
Recommender IR Evaluator: [Precision:0.5,Recall:0.5]
uid:1,(104,4.333333)(106,4.000000)
uid:2,(105,4.049678)
uid:3,(103,3.512787)(102,2.747869)
uid:4,(102,3.000000)
з”ЁRиҜӯиЁҖйҮҚеҶҷUserCFзҡ„е®һзҺ°пјҢиҜ·еҸӮиҖғж–Үз« пјҡз”ЁRи§ЈжһҗMahoutз”ЁжҲ·жҺЁиҚҗеҚҸеҗҢиҝҮж»Өз®—жі•(UserCF)
6. еҹәдәҺзү©е“Ғзҡ„еҚҸеҗҢиҝҮж»Өз®—жі•ItemCF
еҹәдәҺitemзҡ„еҚҸеҗҢиҝҮж»ӨпјҢйҖҡиҝҮз”ЁжҲ·еҜ№дёҚеҗҢitemзҡ„иҜ„еҲҶжқҘиҜ„жөӢitemд№Ӣй—ҙзҡ„зӣёдјјжҖ§пјҢеҹәдәҺitemд№Ӣй—ҙзҡ„зӣёдјјжҖ§еҒҡеҮәжҺЁиҚҗгҖӮз®ҖеҚ•жқҘи®Іе°ұжҳҜпјҡз»ҷз”ЁжҲ·жҺЁиҚҗе’Ңд»–д№ӢеүҚе–ңж¬ўзҡ„зү©е“Ғзӣёдјјзҡ„зү©е“ҒгҖӮ
дёҫдҫӢиҜҙжҳҺпјҡ
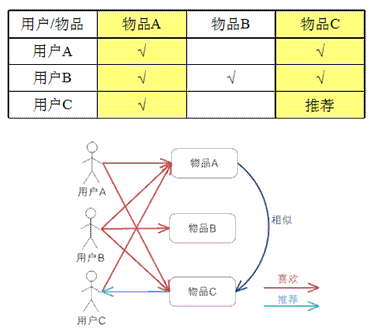
еҹәдәҺзү©е“Ғзҡ„ CF зҡ„еҺҹзҗҶе’ҢеҹәдәҺз”ЁжҲ·зҡ„ CF зұ»дјјпјҢеҸӘжҳҜеңЁи®Ўз®—йӮ»еұ…ж—¶йҮҮз”Ёзү©е“Ғжң¬иә«пјҢиҖҢдёҚжҳҜд»Һз”ЁжҲ·зҡ„и§’еәҰпјҢеҚіеҹәдәҺз”ЁжҲ·еҜ№зү©е“Ғзҡ„еҒҸеҘҪжүҫеҲ°зӣёдјјзҡ„зү©е“ҒпјҢ然еҗҺж №жҚ®з”ЁжҲ·зҡ„еҺҶеҸІеҒҸеҘҪпјҢжҺЁиҚҗзӣёдјјзҡ„зү©е“Ғз»ҷд»–гҖӮд»Һи®Ўз®— зҡ„и§’еәҰзңӢпјҢе°ұжҳҜе°ҶжүҖжңүз”ЁжҲ·еҜ№жҹҗдёӘзү©е“Ғзҡ„еҒҸеҘҪдҪңдёәдёҖдёӘеҗ‘йҮҸжқҘи®Ўз®—зү©е“Ғд№Ӣй—ҙзҡ„зӣёдјјеәҰпјҢеҫ—еҲ°зү©е“Ғзҡ„зӣёдјјзү©е“ҒеҗҺпјҢж №жҚ®з”ЁжҲ·еҺҶеҸІзҡ„еҒҸеҘҪйў„жөӢеҪ“еүҚз”ЁжҲ·иҝҳжІЎжңүиЎЁзӨәеҒҸеҘҪзҡ„ зү©е“ҒпјҢи®Ўз®—еҫ—еҲ°дёҖдёӘжҺ’еәҸзҡ„зү©е“ҒеҲ—иЎЁдҪңдёәжҺЁиҚҗгҖӮеӣҫ 3 з»ҷеҮәдәҶдёҖдёӘдҫӢеӯҗпјҢеҜ№дәҺзү©е“Ғ AпјҢж №жҚ®жүҖжңүз”ЁжҲ·зҡ„еҺҶеҸІеҒҸеҘҪпјҢе–ңж¬ўзү©е“Ғ A зҡ„з”ЁжҲ·йғҪе–ңж¬ўзү©е“Ғ CпјҢеҫ—еҮәзү©е“Ғ A е’Ңзү©е“Ғ C жҜ”иҫғзӣёдјјпјҢиҖҢз”ЁжҲ· C е–ңж¬ўзү©е“Ғ AпјҢйӮЈд№ҲеҸҜд»ҘжҺЁж–ӯеҮәз”ЁжҲ· C еҸҜиғҪд№ҹе–ңж¬ўзү©е“Ғ CгҖӮ
дёҠж–ҮдёӯеӣҫзүҮе’Ңи§ЈйҮҠж–Үеӯ—пјҢж‘ҳиҮӘпјҡ https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
з®—жі•API: org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
PreferenceArray preferencesFromUser = getDataModel().getPreferencesFromUser(userID);
Float actualPref = getPreferenceForItem(preferencesFromUser, itemID);
if (actualPref != null) {
return actualPref;
}
return doEstimatePreference(userID, preferencesFromUser, itemID);
}
protected float doEstimatePreference(long userID, PreferenceArray preferencesFromUser, long itemID)
throws TasteException {
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
double[] similarities = similarity.itemSimilarities(itemID, preferencesFromUser.getIDs());
for (int i = 0; i < similarities.length; i++) {
double theSimilarity = similarities[i];
if (!Double.isNaN(theSimilarity)) {
// Weights can be negative!
preference += theSimilarity * preferencesFromUser.getValue(i);
totalSimilarity += theSimilarity;
count++;
}
}
// Throw out the estimate if it was based on no data points, of course, but also if based on
// just one. This is a bit of a band-aid on the 'stock' item-based algorithm for the moment.
// The reason is that in this case the estimate is, simply, the user's rating for one item
// that happened to have a defined similarity. The similarity score doesn't matter, and that
// seems like a bad situation.
if (count <= 1) {
return Float.NaN;
}
float estimate = (float) (preference / totalSimilarity);
if (capper != null) {
estimate = capper.capEstimate(estimate);
}
return estimate;
}
жөӢиҜ•зЁӢеәҸ:
public static void itemCF(DataModel dataModel) throws TasteException {
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
зЁӢеәҸиҫ“еҮәпјҡ
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:0.8676552772521973
Recommender IR Evaluator: [Precision:0.5,Recall:1.0]
uid:1,(105,3.823529)(104,3.722222)(106,3.478261)
uid:2,(106,2.984848)(105,2.537037)(107,2.000000)
uid:3,(106,3.648649)(102,3.380000)(103,3.312500)
uid:4,(107,4.722222)(105,4.313953)(102,4.025000)
uid:5,(107,3.736842)
7. SlopeOneз®—жі•
иҝҷдёӘз®—жі•еңЁmahout-0.8зүҲжң¬дёӯпјҢе·Із»Ҹиў«@DeprecatedгҖӮ
SlopeOneжҳҜдёҖз§Қз®ҖеҚ•й«ҳж•Ҳзҡ„еҚҸеҗҢиҝҮж»Өз®—жі•гҖӮйҖҡиҝҮеқҮе·®и®Ўз®—иҝӣиЎҢиҜ„еҲҶгҖӮSlopeOneи®әж–ҮдёӢиҪҪ(PDF)
1). дёҫдҫӢиҜҙжҳҺпјҡ
з”ЁжҲ·XпјҢYпјҢZпјҢеҜ№дәҺзү©е“ҒA,BиҝӣиЎҢжү“еҲҶпјҢеҰӮдёӢиЎЁпјҢжұӮZеҜ№Bзҡ„жү“еҲҶжҳҜеӨҡе°‘пјҹ
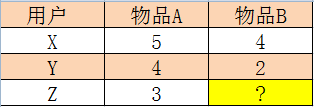
Slope oneз®—жі•и®Өдёәпјҡе№іеқҮеҖјеҸҜд»Ҙд»ЈжӣҝжҹҗдёӨдёӘжңӘзҹҘдёӘдҪ“д№Ӣй—ҙзҡ„жү“еҲҶе·®ејӮпјҢдәӢзү©AеҜ№дәӢзү©Bзҡ„е№іеқҮе·®жҳҜпјҡ((5 - 4) + (4 - 2)) / 2 = 1.5пјҢе°ұеҫ—еҲ°ZеҜ№Bзҡ„жү“еҲҶжҳҜпјҢ3-1.5 = 1.5гҖӮ
Slope oneз®—жі•е°Ҷз”ЁжҲ·зҡ„иҜ„еҲҶд№Ӣй—ҙзҡ„е…ізі»зңӢдҪңз®ҖеҚ•зҡ„зәҝжҖ§е…ізі»пјҡ
Y = mX + b2). е№іеқҮеҠ жқғи®Ўз®—пјҡ
з”ЁжҲ·XпјҢYпјҢZпјҢеҜ№дәҺзү©е“ҒA,B,CиҝӣиЎҢжү“еҲҶпјҢеҰӮдёӢиЎЁпјҢжұӮZеҜ№Aзҡ„жү“еҲҶжҳҜеӨҡе°‘пјҹ
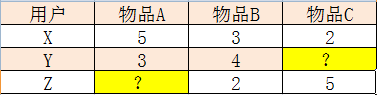
- 1. и®Ўз®—Aе’ҢBзҡ„е№іеқҮе·®, ((5-3)+(3-4))/2=0.5
- 2. и®Ўз®—Aе’ҢCзҡ„е№іеқҮе·®, (5-2)/1=3
- 3. ZеҜ№Aзҡ„иҜ„еҲҶпјҢйҖҡиҝҮABеҫ—еҲ°, 2+0.5=2.5
- 4. ZеҜ№Aзҡ„иҜ„еҲҶпјҢйҖҡиҝҮACеҫ—еҲ°пјҢ5+3=8
- 5. йҖҡиҝҮеҠ жқғе№іеқҮи®Ўз®—ZеҜ№Aзҡ„иҜ„еҲҶпјҡAе’ҢBйғҪжңүиҜ„д»·зҡ„з”ЁжҲ·ж•°дёә2,Aе’ҢCйғҪжңүиҜ„д»·зҡ„з”ЁжҲ·ж•°дёә1пјҢжқғйҮҚдёәеҲ«жҳҜ2е’Ң1пјҢ (2*2.5+1*8)/(2+1)=13/3=4.33
йҖҡиҝҮиҝҷз§Қз®ҖеҚ•зҡ„ж–№ејҸпјҢжҲ‘们еҸҜд»Ҙеҝ«йҖҹи®Ўз®—еҮәдёҖдёӘиҜ„еҲҶйЎ№пјҢе®ҢжҲҗжҺЁиҚҗиҝҮзЁӢпјҒ
з®—жі•API: org.apache.mahout.cf.taste.impl.recommender.slopeone.SlopeOneRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
return doEstimatePreference(userID, itemID);
}
private float doEstimatePreference(long userID, long itemID) throws TasteException {
double count = 0.0;
double totalPreference = 0.0;
PreferenceArray prefs = getDataModel().getPreferencesFromUser(userID);
RunningAverage[] averages = diffStorage.getDiffs(userID, itemID, prefs);
int size = prefs.length();
for (int i = 0; i < size; i++) {
RunningAverage averageDiff = averages[i];
if (averageDiff != null) {
double averageDiffValue = averageDiff.getAverage();
if (weighted) {
double weight = averageDiff.getCount();
if (stdDevWeighted) {
double stdev = ((RunningAverageAndStdDev) averageDiff).getStandardDeviation();
if (!Double.isNaN(stdev)) {
weight /= 1.0 + stdev;
}
// If stdev is NaN, then it is because count is 1. Because we're weighting by count,
// the weight is already relatively low. We effectively assume stdev is 0.0 here and
// that is reasonable enough. Otherwise, dividing by NaN would yield a weight of NaN
// and disqualify this pref entirely
// (Thanks Daemmon)
}
totalPreference += weight * (prefs.getValue(i) + averageDiffValue);
count += weight;
} else {
totalPreference += prefs.getValue(i) + averageDiffValue;
count += 1.0;
}
}
}
if (count <= 0.0) {
RunningAverage itemAverage = diffStorage.getAverageItemPref(itemID);
return itemAverage == null ? Float.NaN : (float) itemAverage.getAverage();
} else {
return (float) (totalPreference / count);
}
}
жөӢиҜ•зЁӢеәҸ:
public static void slopeOne(DataModel dataModel) throws TasteException {
RecommenderBuilder recommenderBuilder = RecommendFactory.slopeOneRecommender();
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
зЁӢеәҸиҫ“еҮәпјҡ
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.3333333333333333
Recommender IR Evaluator: [Precision:0.25,Recall:0.5]
uid:1,(105,5.750000)(104,5.250000)(106,4.500000)
uid:2,(105,2.286115)(106,1.500000)
uid:3,(106,2.000000)(102,1.666667)(103,1.625000)
uid:4,(105,4.976859)(102,3.509071)
8. KNN Linear interpolation itemвҖ“basedжҺЁиҚҗз®—жі•
иҝҷдёӘз®—жі•еңЁmahout-0.8зүҲжң¬дёӯпјҢе·Із»Ҹиў«@DeprecatedгҖӮ
з®—жі•жқҘиҮӘи®әж–Үпјҡ
This algorithm is based in the paper of Robert M. Bell and Yehuda Koren in ICDM '07.
(TODOжңӘе®Ң)
з®—жі•API: org.apache.mahout.cf.taste.impl.recommender.knn.KnnItemBasedRecommender
@Override
protected float doEstimatePreference(long theUserID, PreferenceArray preferencesFromUser, long itemID)
throws TasteException {
DataModel dataModel = getDataModel();
int size = preferencesFromUser.length();
FastIDSet possibleItemIDs = new FastIDSet(size);
for (int i = 0; i < size; i++) {
possibleItemIDs.add(preferencesFromUser.getItemID(i));
}
possibleItemIDs.remove(itemID);
List mostSimilar = mostSimilarItems(itemID, possibleItemIDs.iterator(),
neighborhoodSize, null);
long[] theNeighborhood = new long[mostSimilar.size() + 1];
theNeighborhood[0] = -1;
List usersRatedNeighborhood = Lists.newArrayList();
int nOffset = 0;
for (RecommendedItem rec : mostSimilar) {
theNeighborhood[nOffset++] = rec.getItemID();
}
if (!mostSimilar.isEmpty()) {
theNeighborhood[mostSimilar.size()] = itemID;
for (int i = 0; i < theNeighborhood.length; i++) {
PreferenceArray usersNeighborhood = dataModel.getPreferencesForItem(theNeighborhood[i]);
int size1 = usersRatedNeighborhood.isEmpty() ? usersNeighborhood.length() : usersRatedNeighborhood.size();
for (int j = 0; j < size1; j++) {
if (i == 0) {
usersRatedNeighborhood.add(usersNeighborhood.getUserID(j));
} else {
if (j >= usersRatedNeighborhood.size()) {
break;
}
long index = usersRatedNeighborhood.get(j);
if (!usersNeighborhood.hasPrefWithUserID(index) || index == theUserID) {
usersRatedNeighborhood.remove(index);
j--;
}
}
}
}
}
double[] weights = null;
if (!mostSimilar.isEmpty()) {
weights = getInterpolations(itemID, theNeighborhood, usersRatedNeighborhood);
}
int i = 0;
double preference = 0.0;
double totalSimilarity = 0.0;
for (long jitem : theNeighborhood) {
Float pref = dataModel.getPreferenceValue(theUserID, jitem);
if (pref != null) {
double weight = weights[i];
preference += pref * weight;
totalSimilarity += weight;
}
i++;
}
return totalSimilarity == 0.0 ? Float.NaN : (float) (preference / totalSimilarity);
}
}
жөӢиҜ•зЁӢеәҸ:
public static void itemKNN(DataModel dataModel) throws TasteException {
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemKNNRecommender(itemSimilarity, new NonNegativeQuadraticOptimizer(), 10);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
зЁӢеәҸиҫ“еҮәпјҡ
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.5
Recommender IR Evaluator: [Precision:0.5,Recall:1.0]
uid:1,(107,5.000000)(104,3.501168)(106,3.498198)
uid:2,(105,2.878995)(106,2.878086)(107,2.000000)
uid:3,(103,3.667444)(102,3.667161)(106,3.667019)
uid:4,(107,4.750247)(102,4.122755)(105,4.122709)
uid:5,(107,3.833621)
9. SVDжҺЁиҚҗз®—жі•
(TODOжңӘе®Ң)
з®—жі•API: org.apache.mahout.cf.taste.impl.recommender.svd.SVDRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
double[] userFeatures = factorization.getUserFeatures(userID);
double[] itemFeatures = factorization.getItemFeatures(itemID);
double estimate = 0;
for (int feature = 0; feature < userFeatures.length; feature++) {
estimate += userFeatures[feature] * itemFeatures[feature];
}
return (float) estimate;
}
жөӢиҜ•зЁӢеәҸ:
public static void svd(DataModel dataModel) throws TasteException {
RecommenderBuilder recommenderBuilder = RecommendFactory.svdRecommender(new ALSWRFactorizer(dataModel, 10, 0.05, 10));
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
зЁӢеәҸиҫ“еҮәпјҡ
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:0.09990564982096355
Recommender IR Evaluator: [Precision:0.5,Recall:1.0]
uid:1,(104,4.032909)(105,3.390885)(107,1.858541)
uid:2,(105,3.761718)(106,2.951908)(107,1.561116)
uid:3,(103,5.593422)(102,2.458930)(106,-0.091259)
uid:4,(105,4.068329)(102,3.534025)(107,0.206257)
uid:5,(107,0.105169)
10. Tree Cluster-based жҺЁиҚҗз®—жі•
иҝҷдёӘз®—жі•еңЁmahout-0.8зүҲжң¬дёӯпјҢе·Із»Ҹиў«@DeprecatedгҖӮ
(TODOжңӘе®Ң)
з®—жі•API: org.apache.mahout.cf.taste.impl.recommender.TreeClusteringRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
buildClusters();
List topRecsForUser = topRecsByUserID.get(userID);
if (topRecsForUser != null) {
for (RecommendedItem item : topRecsForUser) {
if (itemID == item.getItemID()) {
return item.getValue();
}
}
}
// Hmm, we have no idea. The item is not in the user's cluster
return Float.NaN;
}
жөӢиҜ•зЁӢеәҸ:
public static void treeCluster(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
ClusterSimilarity clusterSimilarity = RecommendFactory.clusterSimilarity(RecommendFactory.SIMILARITY.FARTHEST_NEIGHBOR_CLUSTER, userSimilarity);
RecommenderBuilder recommenderBuilder = RecommendFactory.treeClusterRecommender(clusterSimilarity, 10);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
зЁӢеәҸиҫ“еҮәпјҡ
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:NaN
Recommender IR Evaluator: [Precision:NaN,Recall:0.0]
11. MahoutжҺЁиҚҗз®—жі•жҖ»з»“
з®—жі•еҸҠйҖӮз”ЁеңәжҷҜпјҡ
з®—жі•иҜ„еҲҶзҡ„з»“жһңпјҡ

йҖҡиҝҮеҜ№дёҠйқўеҮ з§Қз®—жі•зҡ„дёҖе№іеҲҶжҜ”иҫғпјҡitemCF,itemKNN,SVDзҡ„Rrecision,Recallзҡ„иҜ„еҲҶеҖјжҳҜжңҖеҘҪзҡ„пјҢ并且itemCFе’Ң SVDзҡ„AVERAGE_ABSOLUTE_DIFFERENCEжҳҜжңҖдҪҺзҡ„пјҢжүҖд»ҘпјҢд»Һз®—жі•зҡ„и§’еәҰзҹҘйҒ“дәҶпјҢе“ӘдёӘз®—жі•жҳҜжӣҙеҮҶзЎ®зҡ„жҲ–иҖ…дјҡзҙўеј•еҲ°жӣҙеӨҡзҡ„ж•°жҚ®йӣҶгҖӮ
еҸҰеӨ–зҡ„дёҖдәӣеӣ зҙ пјҡ
- 1. иҝҷ3дёӘжҢҮж ҮпјҢ并дёҚиғҪзӣҙжҺҘеҶіе®ҡи®Ўз®—з»“жһңдёҖе®ҡitemCF,SVDеҘҪ
- 2. еҗ„з§Қз®—жі•зҡ„еҸӮж•°жҲ‘们并没жңүи°ғдјҳ
- 3. ж•°жҚ®йҮҸе’Ңж•°жҚ®еҲҶеёғпјҢжҳҜеҪұе“Қз®—жі•зҡ„иҜ„еҲҶ
зЁӢеәҸжәҗд»Јз ҒдёӢиҪҪ
https://github.com/bsspirit/maven_mahout_template/tree/mahout-0.8/src/main/java/org/conan/mymahout/recommendation/job
иҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„пјҡ
http://blog.fens.me/mahout-recommendation-api



зӣёе…іжҺЁиҚҗ
### Mahoutз®—жі•иҜҰи§Ј #### MahoutжҺЁиҚҗз®—жі•жҰӮи§Ҳ MahoutжҳҜдёҖдёӘејҖжәҗйЎ№зӣ®пјҢдё“жіЁдәҺдёәејҖеҸ‘иҖ…жҸҗдҫӣдёҖзі»еҲ—з”ЁдәҺжһ„е»әй«ҳеәҰеҸҜдјёзј©зҡ„еӨ§ж•°жҚ®жҺЁиҚҗеј•ж“ҺгҖҒиҒҡзұ»еҲҶжһҗд»ҘеҸҠеҲҶзұ»з®—жі•еә“гҖӮе…¶ж ёеҝғз®—жі•еҢ…жӢ¬еҚҸеҗҢиҝҮж»ӨгҖҒиҒҡзұ»еҲҶжһҗеҸҠеҲҶзұ»з®—жі•пјҢе№ҝжіӣ...
гҖҠеҹәдәҺMahoutзҡ„MovieRecommenderз”өеҪұжҺЁиҚҗзі»з»ҹиҜҰи§ЈгҖӢ еңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢдёӘжҖ§еҢ–жҺЁиҚҗзі»з»ҹе·ІжҲҗдёәдә’иҒ”зҪ‘жңҚеҠЎдёӯзҡ„йҮҚиҰҒдёҖзҺҜпјҢзү№еҲ«жҳҜеңЁеЁұд№җйўҶеҹҹпјҢеҰӮз”өеҪұжҺЁиҚҗгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁдёҖдёӘеҹәдәҺApache Mahoutе®һзҺ°зҡ„з”өеҪұжҺЁиҚҗзі»з»ҹвҖ”вҖ”...
**Mahoutз”ЁжҲ·еҹәзЎҖжҺЁиҚҗзі»з»ҹиҜҰи§Ј** Apache MahoutжҳҜдёҖж¬ҫејҖжәҗжңәеҷЁеӯҰд№ еә“пјҢдё“дёәеӨ§ж•°жҚ®еӨ„зҗҶиҖҢи®ҫи®ЎпјҢе°Өе…¶еңЁжҺЁиҚҗзі»з»ҹгҖҒеҲҶзұ»е’ҢиҒҡзұ»ж–№йқўжңүе№ҝжіӣзҡ„еә”з”ЁгҖӮеңЁиҝҷдёӘвҖңmahoutзҡ„еҹәдәҺз”ЁжҲ·зҡ„жҺЁиҚҗDemoвҖқдёӯпјҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁеҰӮдҪ•еҲ©з”Ё...
гҖҠеҹәдәҺMahoutзҡ„еҚҸеҗҢиҝҮж»Өз®—жі•е®һзҺ°иҜҰи§ЈгҖӢ еңЁеӨ§ж•°жҚ®йўҶеҹҹпјҢжҺЁиҚҗзі»з»ҹе·ІжҲҗдёәдёҚеҸҜжҲ–зјәзҡ„дёҖйғЁеҲҶпјҢе®ғиғҪеӨҹж №жҚ®з”ЁжҲ·зҡ„еҺҶеҸІиЎҢдёәе’ҢеҒҸеҘҪпјҢдёәз”ЁжҲ·жҸҗдҫӣдёӘжҖ§еҢ–зҡ„дә§е“ҒжҲ–жңҚеҠЎжҺЁиҚҗгҖӮMahoutдҪңдёәApacheзҡ„дёҖдёӘејҖжәҗйЎ№зӣ®пјҢжҸҗдҫӣдәҶдё°еҜҢзҡ„жңәеҷЁ...
**Apache Mahout 0.5 зҹҘиҜҶзӮ№иҜҰи§Ј** Apache Mahout жҳҜдёҖдёӘејҖжәҗжңәеҷЁеӯҰд№ еә“пјҢдё“жіЁдәҺеӨ§и§„жЁЎж•°жҚ®йӣҶдёҠзҡ„з®—жі•е®һзҺ°гҖӮеңЁMahout 0.5зүҲжң¬дёӯпјҢе®ғжҸҗдҫӣдәҶеӨҡз§ҚжңәеҷЁеӯҰд№ з®—жі•пјҢеҢ…жӢ¬жҺЁиҚҗзі»з»ҹгҖҒеҲҶзұ»е’ҢиҒҡзұ»пјҢд»ҘеҸҠдёҖдәӣеҹәзЎҖзҡ„ж•°еӯҰе’Ңз»ҹи®Ў...
гҖҗз”ҳйҒ“еӨ«гҖ‘йҖҡиҝҮMahoutжһ„е»әиҙқеҸ¶ж–Ҝж–Үжң¬еҲҶзұ»еҷЁжЎҲдҫӢиҜҰи§Ј -- й…ҚеҘ—жәҗз Ғ еңЁжң¬жЎҲдҫӢдёӯпјҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁеҰӮдҪ•дҪҝз”ЁApache MahoutиҝҷдёҖејәеӨ§зҡ„жңәеҷЁеӯҰд№ еә“жқҘжһ„е»әдёҖдёӘиҙқеҸ¶ж–Ҝж–Үжң¬еҲҶзұ»еҷЁгҖӮApache MahoutжҳҜдёҖдёӘејҖжәҗйЎ№зӣ®пјҢж—ЁеңЁжҸҗдҫӣеҸҜжү©еұ•...
1. **зј–иҜ‘еҘҪзҡ„JARж–Ү件**пјҡиҝҷдәӣжҳҜиҝҗиЎҢMahoutз®—жі•жүҖйңҖзҡ„еә“ж–Ү件пјҢйҖҡеёёд»Ҙ`.jar`жү©еұ•еҗҚгҖӮ 2. **жәҗд»Јз Ғ**пјҡд»Ҙ`.java`ж–Ү件еҪўејҸеӯҳеңЁпјҢе…Ғи®ёз”ЁжҲ·жҹҘзңӢе’Ңдҝ®ж”№Mahoutзҡ„е®һзҺ°гҖӮ 3. **ж–ҮжЎЈ**пјҡеҸҜиғҪеҢ…жӢ¬READMEж–Ү件пјҢжҢҮеҜјз”ЁжҲ·еҰӮдҪ•е®үиЈ…...
Mahoutзҡ„APIи®ҫи®ЎдҪҝеҫ—з”ЁжҲ·еҸҜд»Ҙж–№дҫҝең°йӣҶжҲҗз®—жі•еҲ°иҮӘе·ұзҡ„зі»з»ҹдёӯпјҢжһҒеӨ§ең°йҷҚдҪҺдәҶејҖеҸ‘жҲҗжң¬гҖӮ 2. **HadoopйӣҶжҲҗ** Mahout 0.7зҙ§еҜҶйӣҶжҲҗдәҺHadoopпјҢиҝҷж„Ҹе‘ізқҖе®ғеҸҜд»ҘеӨ„зҗҶPBзә§еҲ«зҡ„ж•°жҚ®гҖӮйҖҡиҝҮHadoop MapReduceжЎҶжһ¶пјҢMahoutеҸҜд»ҘеңЁ...
гҖҠMahoutжөӢиҜ•ж•°жҚ®иҜҰи§ЈдёҺSparkеә”з”ЁгҖӢ Apache MahoutжҳҜдёҖдёӘеҹәдәҺApache Hadoopзҡ„жңәеҷЁеӯҰд№ еә“пјҢиҮҙеҠӣдәҺжҸҗдҫӣеҸҜжү©еұ•зҡ„гҖҒжҳ“дәҺдҪҝз”Ёзҡ„жңәеҷЁеӯҰд№ з®—жі•гҖӮеңЁеӨ§ж•°жҚ®йўҶеҹҹпјҢMahoutжү®жј”зқҖйҮҚиҰҒзҡ„и§’иүІпјҢе®ғе…Ғи®ёејҖеҸ‘иҖ…жһ„е»әеӨҚжқӮзҡ„йў„жөӢжЁЎеһӢпјҢ...
### MahoutжқғеЁҒжҢҮеҚ—дёӯзҡ„BigtableзҹҘиҜҶзӮ№иҜҰи§Ј #### дёҖгҖҒBigtableжҰӮиҝ° **Bigtable**жҳҜGoogleеҶ…йғЁдҪҝз”Ёзҡ„дёҖз§ҚеӨ§и§„жЁЎеҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢж—ЁеңЁеӨ„зҗҶз»“жһ„еҢ–ж•°жҚ®гҖӮж №жҚ®жҸҗдҫӣзҡ„ж–ҮжЎЈеҶ…е®№пјҢBigtableзҡ„и®ҫи®Ўзӣ®ж ҮеңЁдәҺж»Ўи¶іеӨ§и§„жЁЎж•°жҚ®...
- жҺЁиҚҗзі»з»ҹпјҡMahoutжҸҗдҫӣдәҶеҚҸеҗҢиҝҮж»ӨгҖҒеҹәдәҺеҶ…е®№зҡ„жҺЁиҚҗзӯүеӨҡз§ҚжҺЁиҚҗз®—жі•гҖӮдҫӢеҰӮпјҢеҸҜд»ҘжҹҘзңӢеҰӮдҪ•дҪҝз”ЁUserBasedRecommenderжҲ–ItemBasedRecommenderиҝӣиЎҢз”ЁжҲ·зӣёдјјеәҰи®Ўз®—е’ҢжҺЁиҚҗгҖӮ - еҲҶзұ»дёҺиҒҡзұ»пјҡеҰӮK-MeansиҒҡзұ»з®—жі•пјҢеҸҜд»Ҙз”ЁжқҘе°Ҷ...
гҖҠMahoutдёҺGuava-r09-jarеңЁж•°жҚ®жҢ–жҺҳдёӯзҡ„еә”з”ЁиҜҰи§ЈгҖӢ Apache MahoutжҳҜдёҖж¬ҫеҹәдәҺHadoopзҡ„ж•°жҚ®жҢ–жҺҳеә“пјҢе®ғдёәеӨ§и§„жЁЎжңәеҷЁеӯҰд№ жҸҗдҫӣдәҶдё°еҜҢзҡ„з®—жі•ж”ҜжҢҒпјҢеҢ…жӢ¬еҲҶзұ»гҖҒиҒҡзұ»гҖҒеҚҸеҗҢиҝҮж»ӨзӯүгҖӮеңЁMahoutзҡ„з”ҹжҖҒзі»з»ҹдёӯпјҢGuavaжҳҜдёҖдёӘдёҚеҸҜжҲ–...
еңЁJavaдёӯпјҢеҸҜд»ҘдҪҝз”ЁApache MahoutжҲ–иҖ…иҮӘиЎҢе®һзҺ°иҝҷдәӣз®—жі•гҖӮ 7. **жҖ§иғҪдјҳеҢ–** еҜ№дәҺеӨ§и§„жЁЎз”ЁжҲ·е’Ңеӣҫд№Ұзҡ„ж•°жҚ®пјҢжҺЁиҚҗзі»з»ҹйңҖиҰҒиҖғиҷ‘жҖ§иғҪдјҳеҢ–гҖӮдҫӢеҰӮпјҢйҖҡиҝҮзј“еӯҳжңәеҲ¶еҮҸе°‘ж•°жҚ®еә“жҹҘиҜўпјҢдҪҝз”ЁMapReduceжҲ–SparkиҝӣиЎҢеҲҶеёғејҸи®Ўз®—пјҢд»ҘеҸҠ...
SpringBootеә”з”ЁдёӯпјҢеҸҜд»ҘеҲ©з”ЁSpring Data JPAиҝӣиЎҢж•°жҚ®ж“ҚдҪңпјҢз»“еҗҲApache MahoutжҲ–TensorFlowзӯүе·Ҙе…·е®һзҺ°жҺЁиҚҗз®—жі•гҖӮ е…ӯгҖҒAPIжҺҘеҸЈи®ҫи®Ў дёәдәҶдёҺе…¶д»–жңҚеҠЎпјҲеҰӮеүҚз«Ҝеұ•зӨәгҖҒж•°жҚ®еҲҶжһҗпјүдәӨдә’пјҢжҺЁиҚҗзі»з»ҹйңҖжҸҗдҫӣAPIжҺҘеҸЈгҖӮSpringBoot...
дҫӢеҰӮпјҢApache Mahoutе’ҢSpark MLlibжҳҜдёӨдёӘеёёз”Ёзҡ„жңәеҷЁеӯҰд№ еә“пјҢе®ғ们жҸҗдҫӣдәҶи®ёеӨҡжҺЁиҚҗз®—жі•зҡ„е®һзҺ°гҖӮеҗҢж—¶пјҢйЎ№зӣ®еҸҜиғҪдҪҝз”ЁдәҶSpring BootжЎҶжһ¶жһ„е»әеҫ®жңҚеҠЎжһ¶жһ„пјҢе®һзҺ°й«ҳеҸҜжү©еұ•жҖ§е’Ңжҳ“з»ҙжҠӨжҖ§гҖӮж•°жҚ®еә“ж–№йқўпјҢMySQLжҲ–MongoDBеҸҜиғҪз”ЁдәҺ...
еңЁз”өеҪұжҺЁиҚҗзі»з»ҹдёӯпјҢMahoutеҸҜиғҪиў«з”ЁжқҘе®һзҺ°еҚҸеҗҢиҝҮж»ӨгҖҒеҹәдәҺеҶ…е®№зҡ„жҺЁиҚҗжҲ–иҖ…е…¶д»–жңәеҷЁеӯҰд№ з®—жі•пјҢж №жҚ®з”ЁжҲ·зҡ„и§ӮеҪұеҺҶеҸІе’Ңе–ңеҘҪпјҢдёәз”ЁжҲ·жҺЁиҚҗ他们еҸҜиғҪж„ҹе…ҙи¶Јзҡ„з”өеҪұгҖӮ йЎ№зӣ®ең°еқҖиҷҪ然没жңүз»ҷеҮәпјҢдҪҶеңЁе®һйҷ…зҡ„ејҖеҸ‘иҝҮзЁӢдёӯпјҢејҖеҸ‘иҖ…йҖҡеёёдјҡ...
**еҲҶеҢәз®—жі•иҜҰи§Јпјҡ** 1. **K-Meansз®—жі•**пјҡжҳҜжңҖеёёи§Ғзҡ„еҲҶеҢәз®—жі•д№ӢдёҖпјҢе®ғйҖҡиҝҮиҝӯд»ЈиҝҮзЁӢе°Ҷж•°жҚ®еҲҶй…ҚеҲ°жңҖиҝ‘зҡ„з°ҮдёӯеҝғгҖӮйҰ–е…ҲпјҢйҡҸжңәйҖүжӢ©KдёӘеҲқе§ӢдёӯеҝғпјҢ然еҗҺе°ҶжҜҸдёӘж•°жҚ®зӮ№еҲҶй…Қз»ҷжңҖиҝ‘зҡ„дёӯеҝғжүҖеңЁзҡ„з°ҮгҖӮжҺҘзқҖпјҢйҮҚж–°и®Ўз®—жҜҸдёӘз°Үзҡ„дёӯеҝғпјҢ...