
笔者比较推荐的中文分词器是IK分词器,在进入正式的讲解之前,我们首先对Lucene里面内置的几个分析器做个了解.
| 分析器类型 | 基本介绍 |
| WhitespaceAnalyzer | 以空格作为切词标准,不对语汇单元进行其他规范化处理 |
| SimpleAnalyzer | 以非字母符来分割文本信息,并将语汇单元统一为小写形式,并去掉数字类型的字符 |
| StopAnalyzer | 该分析器会去除一些常有a,the,an等等,也可以自定义禁用词 |
| StandardAnalyzer | Lucene内置的标准分析器,会将语汇单元转成小写形式,并去除停用词及标点符号 |
| CJKAnalyzer | 能对中,日,韩语言进行分析的分词器,对中文支持效果一般。 |
| SmartChineseAnalyzer | 对中文支持稍好,但扩展性差 |
评价一个分词器的性能优劣,关键是看它的切词效率以及灵活性,及扩展性,通常情况下一个良好的中文分词器,应该具备扩展词库,禁用词库和同义词库,当然最关键的是还得要与自己的业务符合,因为有些时候我们用不到一些自定义词库,所以选择分词器的时候就可以不考虑这一点。IK官网发布的最新版IK分词器对于Lucene的支持是不错的,但是对于solr的支持就不够好了,需要自己改源码支持solr4.x的版本。笔者使用的另一个IK包是经过一些人修改过的可以支持solr4.3的版本,并对扩展词库,禁用词库,同义词库完全支持,而且在solr里面配置很简单,只需要在schmal.xml进行简单配置,即可使用IK分词器的强大的定制化功能。不过官网上IK作者发布的IK包在lucene里面确都不支持同义词库扩展的功能,如果你想使用,得需要自己修改下源码了,不过即使自己修改扩展同义词也是非常容易的。
下面笔者给出使用官网最后一版发布的IK在Lucene中做的测试,笔者使用的已经扩展了同义词库部分,后面会给出源码。
下面先看第一个纯分词的测试
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package com.ikforlucene;
import java.io.StringReader;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class Test {
public static void main(String[] args)throws Exception {
//下面这个分词器,是经过修改支持同义词的分词器
IKSynonymsAnalyzer analyzer=new IKSynonymsAnalyzer();
String text="三劫散仙是一个菜鸟";
TokenStream ts=analyzer.tokenStream("field", new StringReader(text));
CharTermAttribute term=ts.addAttribute(CharTermAttribute.class);
ts.reset();//重置做准备
while(ts.incrementToken()){
System.out.println(term.toString());
}
ts.end();//
ts.close();//关闭流
}
} |
运行结果:
|
1
2
3
4
5
6
7
|
三劫散仙是一个菜鸟 |
第二步,测试扩展词库,使三劫为一个词,散仙为一个词,需要在同义词库里添加三劫,散仙(注意是按行读取的),注意保存的格式为UTF-8或无BOM格式即可 
添加扩展词库后运行结果如下:
|
1
2
3
4
5
|
三劫散仙是一个菜鸟 |
第三步,测试禁用词库,我们把菜鸟二个字给屏蔽掉,每行一个词,保存格式同上. 
添加禁用词库后运行结果如下:
|
1
2
3
4
|
三劫散仙是一个 |
最后我们再来测试下,同义词部分,现在笔者把河南人,洛阳人作为"一个"这个词的同义词,添加到同义词库中(笔者在这里仅仅是做一个测试,真正生产环境中的同义词肯定是正式的),注意同义词,也是按行读取的,每行的同义词之间使用逗号分割。
http://my.oschina.net/MrMichael/blog/220771
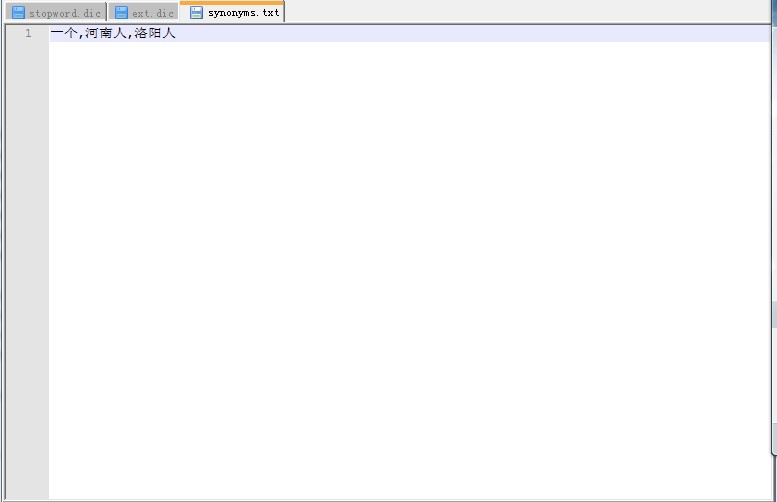
添加同义词库后运行结果如下:
|
1
2
3
4
5
6
|
三劫散仙是一个河南人洛阳人 |
至此,使用IK在Lucene4.3中大部分功能都已测试通过,下面给出扩展同义词部分的源码,有兴趣的道友们,可以参照借鉴下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package com.ikforlucene;
import java.io.IOException;
import java.io.Reader;
import java.util.HashMap;
import java.util.Map;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.synonym.SynonymFilterFactory;
import org.apache.solr.core.SolrResourceLoader;
import org.wltea.analyzer.lucene.IKTokenizer;
/** * 可以加载同义词库的Lucene
* 专用IK分词器
*
*
* */
public class IKSynonymsAnalyzer extends Analyzer {
@Override
protected TokenStreamComponents createComponents(String arg0, Reader arg1) {
Tokenizer token=new IKTokenizer(arg1, true);//开启智能切词
Map<String, String> paramsMap=new HashMap<String, String>();
paramsMap.put("luceneMatchVersion", "LUCENE_43");
paramsMap.put("synonyms", "E:\\同义词\\synonyms.txt");
SynonymFilterFactory factory=new SynonymFilterFactory(paramsMap);
SolrResourceLoader loader= new SolrResourceLoader("");
try {
factory.inform(loader);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return new TokenStreamComponents(token, factory.create(token));
}
} |
关于同义词部分的使用,各位道友,可以先去官网上下载源码,然后将此同义词扩展部分放进去即可,非常简单方便。



相关推荐
【Lucene4.7+IK Analyzer中文分词入门教程】 Lucene是一个开源的全文检索库,它提供了文本分析、索引和搜索的核心工具。在这个入门教程中,我们将使用Lucene 4.7版本,结合IK Analyzer,一个专门针对中文分词的开源...
《Lucene 4.7:官方完整包详解》 Lucene是一个开源的全文搜索引擎库,由Apache软件基金会开发并维护。作为Java平台上的一个高性能、可扩展的信息检索库,Lucene为开发者提供了强大的文本搜索功能。本文将深入探讨...
三、Lucene4.7在Web应用中的集成步骤 1. 配置依赖:首先,需要在项目中引入Lucene4.7的相关jar包,如`lucene-core`, `lucene-analyzers-common`, `lucene-queryparser`等,这些可以从提供的"依赖的Jar包截图.png"中...
5. **更强大的分析器**:4.7版本提供更多的预配置分析器和过滤器,适应不同语言和文本类型的处理需求,如中文分词。 在`LuceneTest`这个测试案例中,你可以体验以下操作步骤: 1. **创建索引**:首先,你需要使用...
在这个“ssh集成Lucene4.7demo”项目中,开发者将SSH框架与Lucene 4.7版本的全文搜索引擎进行了整合,同时还引入了IKAnalyzer作为中文分词器,以支持对中文文本的处理。这个示例项目不仅包含了基本的整合工作,还...
《Lucene 4.7 开发简单实例详解》 Lucene 是一款强大的全文搜索引擎库,广泛应用于各种信息检索系统中。在本实例中,我们将深入探讨Lucene 4.7版本,涵盖索引的创建、修改、删除,以及查询时的排序、分页、优化和...
Lucene包含了一系列分词器(Tokenizers)和过滤器(Filters),可以处理各种语言和格式的文本,确保搜索的准确性。索引过程则是将这些分词结果转化为可快速查询的数据结构,比如倒排索引,这大大提高了搜索速度。...
3. **lucene-queryparser-4.7.x.jar**:包含了查询解析器,将用户输入的查询字符串转换为可执行的Lucene查询对象。 4. **lucene-sandbox-4.7.x.jar**(可能):包含一些实验性的或者不稳定的特性。 5. **lucene-...
lucene4.7相关jar包 以及IKAnalyzer分词jar包
8. **paoding-analysis.jar**:这是 Paoding 分词器的 JAR 包,一个专为中文设计的开源分词工具,它提供了高效的中文分词能力,是 lucene-analyzers-smartcn-4.7.0.jar 中可能用到的一个外部依赖。 通过这些组件,...
1. **分词与索引**:Lucene使用高效的分词器将文档内容分解成独立的词汇项(tokens),然后建立倒排索引。倒排索引是一种数据结构,它将每个词汇项映射到包含该词汇项的文档列表,极大地加速了搜索过程。 2. **搜索...
4. **自然语言处理**:Lucene集成了多种文本分析工具,如分词器、词干提取器和停用词过滤器,以适应不同语言的文本处理需求。4.7版本可能对这些工具进行了优化,提高了分析速度和效果。 5. **更新和删除文档**:在...
IKAnalyzer是一个基于Lucene的中文分词器,特别适合处理中文文本。它的全名是“智能狂飙分词系统”,在2012年的FF版本中,HF1代表了该版本的一个小更新,可能包括性能提升或新特性。使用IKAnalyzer可以更好地处理...
开发者可以通过Analyzer类来处理输入的文本,进行分词、去除停用词等预处理步骤。然后,使用Document类表示要索引的数据,Field类用于定义字段及其类型,最后通过IndexWriter类将文档写入索引。 在索引管理方面,...
目前比较好用的分词器 是IK 2012年停更 只支持到 Lucene4.7 ,但是有些程序需要使用Lucene高版本,比如,Solr5.5就需要Lucene5.5.4来支持
solr的lucene的新版本接口都进行了修改,除非修改实现不然就没法向下兼容,但是我们也有办法的,我们可以利用他的分词工具自己封装一个TokenizerFactory,通过实现最新的接口就可以让solr新版本用上ik了。
Solr 4.7 是一个基于 Lucene 的全文检索服务器,它提供了强大的搜索功能和配置灵活性。IK Analyzer 2012FF_hf1 是一个针对中文的分词器,专为处理中文文本而设计,旨在提高中文文本的索引和搜索效率。这个组合在描述...
### Apache Solr Guide 4.7 知识点解析 #### 一、Apache Solr 概述 **Apache Solr** 是一个高性能、基于 Lucene 的全文检索...在实际应用中,还需要根据具体场景选择合适的分析器、分词器和过滤器来提高搜索质量。
1. **Lucene的基本概念**:包括倒排索引、分词器(Analyzer)、文档(Document)、字段(Field)、索引(Index)、查询(Query)等基本元素。倒排索引是Lucene的核心,它允许快速定位到包含特定词项的文档。 2. **...
lucene-solr-4.7所有Jar包 tika包 IK包 mmseg4j包 包括索引、高亮、IK分词及MMSEG分词 其中MMSEG中的BUG: TokenStream contract violation: reset()/close() call missing, reset() called multiple times, or ...