
Úù«ÚóÿÕ»╝Þ»╗´╝Ü
1.zookeeperÕ£¿kafkaþÜäõ¢£þö¿µÿ»õ╗Çõ╣ê´╝ƒ
2.kafkaõ©¡Õçáõ╣Äõ©ìÕàüÞ«©Õ»╣µÂêµü»Þ┐øÞíîÔÇ£ÚÜŵ£║Þ»╗ÕåÖÔÇØþÜäÕăÕøáµÿ»õ╗Çõ╣ê´╝ƒ
3.kafkaÚøåþ¥ñconsumerÕÆîproducerþèµÇüõ┐íµü»µÿ»Õªéõ¢òõ┐ØÕ¡ÿþÜä´╝ƒ
4.partitionsÞ«¥Þ«íþÜäþø«þÜäþÜäµá╣µ£¼ÕăÕøáµÿ»õ╗Çõ╣ê´╝ƒ
 
õ©ÇÒÇüÕàÑÚù¿
┬á ┬á 1ÒÇüþ«Çõ╗ï
┬á ┬á Kafka is a distributed,partitioned,replicated commit logserviceÒÇéÕ«âµÅÉõ¥øõ║åþ▒╗õ╝╝õ║ÄJMSþÜäþë╣µÇº´╝îõ¢åµÿ»Õ£¿Þ«¥Þ«íÕ«×þÄ░õ©èÕ«îÕà¿õ©ìÕÉî´╝ñÕñûÕ«âÕ╣Âõ©ìµÿ»JMSÞºäÞîâþÜäÕ«×þÄ░ÒÇékafkaÕ»╣µÂêµü»õ┐ØÕ¡ÿµùµá╣µì«TopicÞ┐øÞíîÕ¢Æþ▒╗´╝îÕÅæÚÇüµÂêµü»ÞÇàµêÉõ©║Producer,µÂêµü»µÄÑÕÅùÞÇàµêÉõ©║Consumer,µ¡ñÕñûkafkaÚøåþ¥ñµ£ëÕñÜõ©¬kafkaÕ«×õ¥ïþ╗äµêÉ´╝îµ»Åõ©¬Õ«×õ¥ï(server)µêÉõ©║brokerÒÇéµùáÞ«║µÿ»kafkaÚøåþ¥ñ´╝îÞ┐ÿµÿ»producerÕÆîconsumerÚâ¢õ¥ØÞÁûõ║ÄzookeeperµØÑõ┐ØÞ»üþ│╗þ╗ƒÕÅ»þö¿µÇºÚøåþ¥ñõ┐ØÕ¡ÿõ©Çõ║ømetaõ┐íµü»ÒÇé
<ignore_js_op style="word-wrap: break-word;">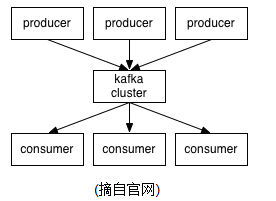  
 
  
┬á ┬á2ÒÇüTopics/logs
┬á ┬á õ©Çõ©¬TopicÕÅ»õ╗ÑÞ«ñõ©║µÿ»õ©Çþ▒╗µÂêµü»´╝îµ»Åõ©¬topicÕ░åÞó½ÕêåµêÉÕñÜõ©¬partition(Õî║),µ»Åõ©¬partitionÕ£¿Õ¡ÿÕé¿Õ▒éÚØóµÿ»append logµûçõ╗ÂÒÇéõ╗╗õ¢òÕÅæÕ©âÕê░µ¡ñpartitionþÜäµÂêµü»Úâ¢õ╝ÜÞó½þø┤µÄÑÞ┐¢ÕèáÕê░logµûçõ╗ÂþÜäÕ░¥Úâ¿´╝ŵØíµÂêµü»Õ£¿µûçõ╗Âõ©¡þÜäõ¢ìþ¢«þº░õ©║offset´╝êÕüÅþº╗ÚçÅ´╝ë´╝îoffsetõ©║õ©Çõ©¬longÕ×ïµò░Õ¡ù´╝îÕ«âµÿ»Õö»õ©ÇµáçÞ«░õ©ÇµØíµÂêµü»ÒÇéÕ«âÕö»õ©ÇþÜäµáçÞ«░õ©ÇµØíµÂêµü»ÒÇékafkaÕ╣µ▓íµ£ëµÅÉõ¥øÕàÂõ╗ûÚóØÕñûþÜäþ┤óÕ╝òµ£║ÕêµØÑÕ¡ÿÕé¿offset´╝îÕøáõ©║Õ£¿kafkaõ©¡Õçáõ╣Äõ©ìÕàüÞ«©Õ»╣µÂêµü»Þ┐øÞíîÔÇ£ÚÜŵ£║Þ»╗ÕåÖÔÇØÒÇé
 
<ignore_js_op style="word-wrap: break-word;">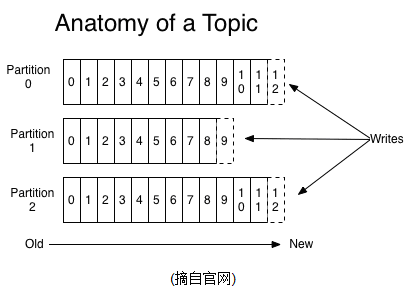  
 
  
┬á ┬á kafkaÕÆîJMS´╝êJava Message Service´╝ëÕ«×þÄ░(activeMQ)õ©ìÕÉîþÜäµÿ»:Õì│õ¢┐µÂêµü»Þó½µÂêÞ┤╣,µÂêµü»õ╗ìþäÂõ©ìõ╝ÜÞó½þ½ïÕì│ÕêáÚÖñ.µùÑÕ┐ùµûçõ╗ÂÕ░åõ╝ܵá╣µì«brokerõ©¡þÜäÚàìþ¢«Þªüµ▒é,õ┐ØþòÖõ©ÇÕ«ÜþÜäµùÂÚù┤õ╣ïÕÉÄÕêáÚÖñ;µ»öÕªélogµûçõ╗Âõ┐ØþòÖ2Õñ®,Úéúõ╣êõ©ñÕñ®ÕÉÄ,µûçõ╗Âõ╝ÜÞ󽵩àÚÖñ,µùáÞ«║ÕàÂõ©¡þÜäµÂêµü»µÿ»ÕɪÞó½µÂêÞ┤╣.kafkaÚÇÜÞ┐çÞ┐Öþºìþ«ÇÕìòþÜäµëﵫÁ,µØÑÚçèµö¥þúüþøÿþ®║Úù┤,õ╗ÑÕÅèÕçÅÕ░æµÂêµü»µÂêÞ┤╣õ╣ïÕÉÄÕ»╣µûçõ╗ÂÕåàÕ«╣µö╣Õè¿þÜäþúüþøÿIOÕ╝ǵö».
 
┬á ┬á Õ»╣õ║ÄconsumerÞÇîÞ¿Ç,Õ«âÚ£ÇÞªüõ┐ØÕ¡ÿµÂêÞ┤╣µÂêµü»þÜäoffset,Õ»╣õ║ÄoffsetþÜäõ┐ØÕ¡ÿÕÆîõ¢┐þö¿,µ£ëconsumerµØѵĺÕêÂ;Õ¢ôconsumerµ¡úÕ©©µÂêÞ┤╣µÂêµü»µùÂ,offsetÕ░åõ╝Ü"þ║┐µÇº"þÜäÕÉæÕëìÚ®▒Õè¿,Õì│µÂêµü»Õ░åõ¥Øµ¼íÚí║Õ║ÅÞó½µÂêÞ┤╣.õ║ïÕ«×õ©èconsumerÕÅ»õ╗Ñõ¢┐þö¿õ╗╗µäÅÚí║Õ║ŵÂêÞ┤╣µÂêµü»,Õ«âÕŬڣÇÞªüÕ░åoffsetÚçìþ¢«õ©║õ╗╗µäÅÕÇ╝..(offsetÕ░åõ╝Üõ┐ØÕ¡ÿÕ£¿zookeeperõ©¡,ÕÅéÞºüõ©ïµûç)
 
┬á ┬á kafkaÚøåþ¥ñÕçáõ╣Äõ©ìÚ£ÇÞªüþ╗┤µèñõ╗╗õ¢òconsumerÕÆîproducerþèµÇüõ┐íµü»,Þ┐Öõ║øõ┐íµü»µ£ëzookeeperõ┐ØÕ¡ÿ;ÕøᵡñproducerÕÆîconsumerþÜäÕ«óµêÀþ½»Õ«×þÄ░ÚØ×Õ©©Þ¢╗ÚçÅþ║º,Õ«âõ╗¼ÕÅ»õ╗ÑÚÜŵäÅþª╗Õ╝Ç,ÞÇîõ©ìõ╝ÜÕ»╣Úøåþ¥ñÚÇáµêÉÚóØÕñûþÜäÕ¢▒Õôì.
 
┬á ┬á partitionsþÜäÞ«¥Þ«íþø«þÜäµ£ëÕñÜõ©¬.µ£Çµá╣µ£¼ÕăÕøáµÿ»kafkaÕƒ║õ║ĵûçõ╗ÂÕ¡ÿÕé¿.ÚÇÜÞ┐çÕêåÕî║,ÕÅ»õ╗ÑÕ░åµùÑÕ┐ùÕåàÕ«╣ÕêåµòúÕê░ÕñÜõ©¬serverõ©è,µØÑÚü┐Õàìµûçõ╗ÂÕ░║Õ»©Þ¥¥Õê░Õìòµ£║þúüþøÿþÜäõ©èÚÖÉ,µ»Åõ©¬partitonÚâ¢õ╝ÜÞó½Õ¢ôÕëìserver(kafkaÕ«×õ¥ï)õ┐ØÕ¡ÿ;ÕÅ»õ╗ÑÕ░åõ©Çõ©¬topicÕêçÕêåÕñÜõ╗╗µäÅÕñÜõ©¬partitions,µØѵÂêµü»õ┐ØÕ¡ÿ/µÂêÞ┤╣þÜäµòêþÄç.µ¡ñÕñûÞÂèÕñÜþÜäpartitionsµäÅÕæ│þØÇÕÅ»õ╗ÑÕ«╣þ║│µø┤ÕñÜþÜäconsumer,µ£ëµòêµÅÉÕìçÕ╣ÂÕÅæµÂêÞ┤╣þÜäÞâ¢Õèø.(ÕàÀõ¢ôÕăþÉåÕÅéÞºüõ©ïµûç).
 
┬á ┬á 3ÒÇüDistribution
┬á ┬á õ©Çõ©¬TopicþÜäÕñÜõ©¬partitions,Þó½ÕêåÕ©âÕ£¿kafkaÚøåþ¥ñõ©¡þÜäÕñÜõ©¬serverõ©è;µ»Åõ©¬server(kafkaÕ«×õ¥ï)Þ┤ƒÞ┤úpartitionsõ©¡µÂêµü»þÜäÞ»╗ÕåÖµôìõ¢£;µ¡ñÕñûkafkaÞ┐ÿÕÅ»õ╗ÑÚàìþ¢«partitionsÚ£ÇÞªüÕñçõ╗¢þÜäõ©¬µò░(replicas),µ»Åõ©¬partitionÕ░åõ╝ÜÞó½Õñçõ╗¢Õê░ÕñÜÕÅ░µ£║ÕÖ¿õ©è,õ╗ѵÅÉÚ½ÿÕÅ»þö¿µÇº.
 
┬á ┬á Õƒ║õ║Äreplicatedµû╣µíê,Úéúõ╣êÕ░▒µäÅÕæ│þØÇÚ£ÇÞªüÕ»╣ÕñÜõ©¬Õñçõ╗¢Þ┐øÞíîÞ░âÕ║ª;µ»Åõ©¬partitionÚ⢵£ëõ©Çõ©¬serverõ©║"leader";leaderÞ┤ƒÞ┤úµëǵ£ëþÜäÞ»╗ÕåÖµôìõ¢£,Õªéµ×£leaderÕñ▒µòê,Úéúõ╣êÕ░åõ╝ܵ£ëÕàÂõ╗ûfollowerµØѵÄÑþ«í(µêÉõ©║µû░þÜäleader);followerÕŬµÿ»ÕìòÞ░âþÜäÕÆîleaderÞÀƒÞ┐ø,ÕÉѵÂêµü»Õì│ÕÅ»..þö▒µ¡ñÕŻ޺üõ¢£õ©║leaderþÜäserverµë┐Þ¢¢õ║åÕà¿Úâ¿þÜäÞ»Àµ▒éÕÄïÕèø,Õøᵡñõ╗ÄÚøåþ¥ñþÜäµò┤õ¢ôÞÇâÞÖæ,µ£ëÕñÜÕ░æõ©¬partitionsÕ░▒µäÅÕæ│þØǵ£ëÕñÜÕ░æõ©¬"leader",kafkaõ╝ÜÕ░å"leader"ÕØçÞííþÜäÕêåµòúÕ£¿µ»Åõ©¬Õ«×õ¥ïõ©è,µØÑþí«õ┐صò┤õ¢ôþÜäµÇºÞâ¢þ¿│Õ«Ü.
 
    Producers
┬á ┬á ProducerÕ░åµÂêµü»ÕÅæÕ©âÕê░µîçÕ«ÜþÜäTopicõ©¡,ÕÉîµùÂProducerõ╣ƒÞâ¢Õå│Õ«ÜÕ░嵡ñµÂêµü»Õ¢ÆÕ▒×õ║ÄÕô¬õ©¬partition;µ»öÕªéÕƒ║õ║Ä"round-robin"µû╣Õ╝ŵêûÞÇàÚÇÜÞ┐çÕàÂõ╗ûþÜäõ©Çõ║øþ«ùµ│òþ¡ë.
 
    Consumers
┬á ┬á µ£¼Þ┤¿õ©èkafkaÕŬµö»µîüTopic.µ»Åõ©¬consumerÕ▒×õ║Äõ©Çõ©¬consumer group;ÕÅìÞ┐çµØÑÞ»┤,µ»Åõ©¬groupõ©¡ÕÅ»õ╗ѵ£ëÕñÜõ©¬consumer.ÕÅæÚÇüÕê░TopicþÜäµÂêµü»,ÕŬõ╝ÜÞó½Þ«óÚÿൡñTopicþÜäµ»Åõ©¬groupõ©¡þÜäõ©Çõ©¬consumerµÂêÞ┤╣.
 
┬á ┬á Õªéµ×£µëǵ£ëþÜäconsumerÚâ¢ÕàÀµ£ëþø©ÕÉîþÜägroup,Þ┐ÖþºìµâàÕåÁÕÆîqueueµ¿íÕ╝ÅÕ¥êÕâÅ;µÂêµü»Õ░åõ╝ÜÕ£¿consumersõ╣ïÚù┤Þ┤ƒÞ¢¢ÕØçÞíí.
┬á ┬á Õªéµ×£µëǵ£ëþÜäconsumerÚâ¢ÕàÀµ£ëõ©ìÕÉîþÜägroup,ÚéúÞ┐ÖÕ░▒µÿ»"ÕÅæÕ©â-Þ«óÚÿà";µÂêµü»Õ░åõ╝ÜÕ╣┐µÆ¡þ╗Öµëǵ£ëþÜäµÂêÞ┤╣ÞÇà.
┬á ┬á Õ£¿kafkaõ©¡,õ©Çõ©¬partitionõ©¡þÜäµÂêµü»ÕŬõ╝ÜÞó½groupõ©¡þÜäõ©Çõ©¬consumerµÂêÞ┤╣;µ»Åõ©¬groupõ©¡consumerµÂêµü»µÂêÞ┤╣õ║Æþø©þï¼þ½ï;µêæõ╗¼ÕÅ»õ╗ÑÞ«ñõ©║õ©Çõ©¬groupµÿ»õ©Çõ©¬"Þ«óÚÿà"ÞÇà,õ©Çõ©¬Topicõ©¡þÜäµ»Åõ©¬partions,ÕŬõ╝ÜÞó½õ©Çõ©¬"Þ«óÚÿàÞÇà"õ©¡þÜäõ©Çõ©¬consumerµÂêÞ┤╣,õ©ìÞ┐çõ©Çõ©¬consumerÕÅ»õ╗ѵÂêÞ┤╣ÕñÜõ©¬partitionsõ©¡þÜäµÂêµü».kafkaÕŬÞâ¢õ┐ØÞ»üõ©Çõ©¬partitionõ©¡þÜäµÂêµü»Þ󽵃Éõ©¬consumerµÂêÞ┤╣µùÂ,µÂêµü»µÿ»Úí║Õ║ÅþÜä.õ║ïÕ«×õ©è,õ╗ÄTopicÞºÆÕ║ªµØÑÞ»┤,µÂêµü»õ╗ìõ©ìµÿ»µ£ëÕ║ÅþÜä.
 
┬á ┬á kafkaþÜäÞ«¥Þ«íÕăþÉåÕå│Õ«Ü,Õ»╣õ║Äõ©Çõ©¬topic,ÕÉîõ©Çõ©¬groupõ©¡õ©ìÞ⢵£ëÕñÜõ║Äpartitionsõ©¬µò░þÜäconsumerÕÉîµùµÂêÞ┤╣,ÕɪÕêÖÕ░åµäÅÕæ│þØǵƒÉõ║øconsumerÕ░åµùáµ│òÕ¥ùÕê░µÂêµü».
 
    Guarantees
┬á ┬á 1) ÕÅæÚÇüÕê░partitionsõ©¡þÜäµÂêµü»Õ░åõ╝ܵîëþàºÕ«âµÄѵöÂþÜäÚí║Õ║ÅÞ┐¢ÕèáÕê░µùÑÕ┐ùõ©¡
┬á ┬á 2) Õ»╣õ║ĵÂêÞ┤╣ÞÇàÞÇîÞ¿Ç,Õ«âõ╗¼µÂêÞ┤╣µÂêµü»þÜäÚí║Õ║ÅÕÆîµùÑÕ┐ùõ©¡µÂêµü»Úí║Õ║Åõ©ÇÞç┤.
┬á ┬á 3) Õªéµ×£TopicþÜä"replicationfactor"õ©║N,Úéúõ╣êÕàüÞ«©N-1õ©¬kafkaÕ«×õ¥ïÕñ▒µòê.
 
õ║îÒÇüõ¢┐þö¿Õ£║µÖ»
 
┬á ┬á 1ÒÇüMessaging┬á ┬á
┬á ┬á Õ»╣õ║Äõ©Çõ║øÕ©©ÞºäþÜäµÂêµü»þ│╗þ╗ƒ,kafkaµÿ»õ©¬õ©ìÚöÖþÜäÚÇëµï®;partitons/replicationÕÆîÕ«╣ÚöÖ,ÕÅ»õ╗Ñõ¢┐kafkaÕàÀµ£ëÞë»ÕÑ¢þÜäµë®Õ▒òµÇºÕÆîµÇºÞâ¢õ╝ÿÕè┐.õ©ìÞ┐çÕê░þø«Õëìõ©║µ¡ó,µêæõ╗¼Õ║öÞ»Ñե굩àµÑÜÞ«ñÞ»åÕê░,kafkaÕ╣µ▓íµ£ëµÅÉõ¥øJMSõ©¡þÜä"õ║ïÕèíµÇº""µÂêµü»õ╝áÞ¥ôµïàõ┐Ø(µÂêµü»þí«Þ«ñµ£║ÕêÂ)""µÂêµü»Õêåþ╗ä"þ¡ëõ╝üõ©Üþ║ºþë╣µÇº;kafkaÕŬÞâ¢õ¢┐þö¿õ¢£õ©║"Õ©©Þºä"þÜäµÂêµü»þ│╗þ╗ƒ,Õ£¿õ©ÇÕ«Üþ¿ïÕ║ªõ©è,Õ░ܵ£¬þí«õ┐صÂêµü»þÜäÕÅæÚÇüõ©ÄµÄѵöÂþ╗ØÕ»╣ÕÅ»ÚØá(µ»öÕªé,µÂêµü»ÚçìÕÅæ,µÂêµü»ÕÅæÚÇüõ©óÕñ▒þ¡ë)
 
┬á ┬á 2ÒÇüWebsit activity tracking
┬á ┬á kafkaÕÅ»õ╗Ñõ¢£õ©║"þ¢æþ½Öµ┤╗µÇºÞÀƒÞ©¬"þÜäµ£Çõ¢│ÕÀÑÕàÀ;ÕÅ»õ╗ÑÕ░åþ¢æÚíÁ/þö¿µêÀµôìõ¢£þ¡ëõ┐íµü»ÕÅæÚÇüÕê░kafkaõ©¡.Õ╣ÂÕ«×µùÂþøæµÄº,µêûÞÇàþª╗þ║┐þ╗ƒÞ«íÕêåµ×Éþ¡ë
 
┬á ┬á 3ÒÇüLog Aggregation
┬á ┬á kafkaþÜäþë╣µÇºÕå│Õ«ÜÕ«âÚØ×Õ©©ÚÇéÕÉêõ¢£õ©║"µùÑÕ┐ùµöÂÚøåõ©¡Õ┐â";applicationÕÅ»õ╗ÑÕ░åµôìõ¢£µùÑÕ┐ù"µë╣ÚçÅ""Õ╝鵡Ñ"þÜäÕÅæÚÇüÕê░kafkaÚøåþ¥ñõ©¡,ÞÇîõ©ìµÿ»õ┐ØÕ¡ÿÕ£¿µ£¼Õ£░µêûÞÇàDBõ©¡;kafkaÕÅ»õ╗ѵë╣ÚçŵÅÉõ║ñµÂêµü»/ÕÄïþ╝®µÂêµü»þ¡ë,Þ┐ÖÕ»╣producerþ½»ÞÇîÞ¿Ç,Õçáõ╣ĵäƒÞºëõ©ìÕê░µÇºÞâ¢þÜäÕ╝ǵö».µ¡ñµùÂconsumerþ½»ÕÅ»õ╗Ñõ¢┐hadoopþ¡ëÕàÂõ╗ûþ│╗þ╗ƒÕîûþÜäÕ¡ÿÕé¿ÕÆîÕêåµ×Éþ│╗þ╗ƒ.
 
õ©ëÒÇüÞ«¥Þ«íÕăþÉå
 
┬á ┬á kafkaþÜäÞ«¥Þ«íÕêØÞíÀµÿ»Õ©îµ£øõ¢£õ©║õ©Çõ©¬þ╗ƒõ©ÇþÜäõ┐íµü»µöÂÚøåÕ╣│ÕÅ░,Þâ¢ÕñƒÕ«×µùÂþÜäµöÂÚøåÕÅìÚªêõ┐íµü»,Õ╣ÂÚ£ÇÞªüÞâ¢Õñƒµö»µÆæÞ¥âÕñºþÜäµò░µì«ÚçÅ,õ©öÕàÀÕñçÞë»ÕÑ¢þÜäÕ«╣ÚöÖÞâ¢Õèø.
 
┬á ┬á 1ÒÇüµîüõ╣àµÇº
┬á ┬á kafkaõ¢┐þö¿µûçõ╗ÂÕ¡ÿÕ鿵Âêµü»,Þ┐ÖÕ░▒þø┤µÄÑÕå│Õ«ÜkafkaÕ£¿µÇºÞâ¢õ©èõ©ÑÚçìõ¥ØÞÁûµûçõ╗Âþ│╗þ╗ƒþÜäµ£¼Þ║½þë╣µÇº.õ©öµùáÞ«║õ╗╗õ¢òOSõ©ï,Õ»╣µûçõ╗Âþ│╗þ╗ƒµ£¼Þ║½þÜäõ╝ÿÕîûÕçáõ╣ĵ▓íµ£ëÕÅ»Þâ¢.µûçõ╗Âþ╝ôÕ¡ÿ/þø┤µÄÑÕåàÕ¡ÿµÿáÕ░äþ¡ëµÿ»Õ©©þö¿þÜäµëﵫÁ.Õøáõ©║kafkaµÿ»Õ»╣µùÑÕ┐ùµûçõ╗ÂÞ┐øÞíîappendµôìõ¢£,ÕøᵡñþúüþøÿµúÇþ┤óþÜäÕ╝ǵö»µÿ»Þ¥âÕ░ÅþÜä;ÕÉîµùÂõ©║õ║åÕçÅÕ░æþúüþøÿÕåÖÕàÑþÜäµ¼íµò░,brokerõ╝ÜÕ░åµÂêµü»µÜéµùÂbufferÞÁÀµØÑ,Õ¢ôµÂêµü»þÜäõ©¬µò░(µêûÕ░║Õ»©)Þ¥¥Õê░õ©ÇÕ«ÜÚÿÇÕÇ╝µùÂ,ÕåìflushÕê░þúüþøÿ,Þ┐ÖµáÀÕçÅÕ░æõ║åþúüþøÿIOÞ░âþö¿þÜäµ¼íµò░.
2ÒÇüµÇºÞâ¢
┬á ┬á Ú£ÇÞªüÞÇâÞÖæþÜäÕ¢▒ÕôìµÇºÞâ¢þé╣Õ¥êÕñÜ,ÚÖñþúüþøÿIOõ╣ïÕñû,µêæõ╗¼Þ┐ÿÚ£ÇÞªüÞÇâÞÖæþ¢æþ╗£IO,Þ┐Öþø┤µÄÑÕà│þ│╗Õê░kafkaþÜäÕÉ×ÕÉÉÚçÅÚù«Úóÿ.kafkaÕ╣µ▓íµ£ëµÅÉõ¥øÕñ¬ÕñÜÚ½ÿÞÂàþÜäµèÇÕÀº;Õ»╣õ║Äproducerþ½»,ÕÅ»õ╗ÑÕ░åµÂêµü»bufferÞÁÀµØÑ,Õ¢ôµÂêµü»þÜäµØíµò░Þ¥¥Õê░õ©ÇÕ«ÜÚÿÇÕÇ╝µùÂ,µë╣ÚçÅÕÅæÚÇüþ╗Öbroker;Õ»╣õ║Äconsumerþ½»õ╣ƒµÿ»õ©ÇµáÀ,µë╣ÚçÅfetchÕñܵØíµÂêµü».õ©ìÞ┐çµÂêµü»ÚçÅþÜäÕñºÕ░ÅÕÅ»õ╗ÑÚÇÜÞ┐çÚàìþ¢«µûçõ╗µØѵîçÕ«Ü.Õ»╣õ║Äkafka brokerþ½»,õ╝╝õ╣ĵ£ëõ©¬sendfileþ│╗þ╗ƒÞ░âþö¿ÕÅ»õ╗ѵ¢£Õ£¿þÜäµÅÉÕìçþ¢æþ╗£IOþÜäµÇºÞâ¢:Õ░åµûçõ╗ÂþÜäµò░µì«µÿáÕ░äÕê░þ│╗þ╗ƒÕåàÕ¡ÿõ©¡,socketþø┤µÄÑÞ»╗ÕÅûþø©Õ║öþÜäÕåàÕ¡ÿÕî║ÕƒƒÕì│ÕÅ»,ÞÇîµùáÚ£ÇÞ┐øþ¿ïÕåìµ¼ícopyÕÆîõ║ñµìó. ÕàÂÕ«×Õ»╣õ║Äproducer/consumer/brokerõ©ëÞÇàÞÇîÞ¿Ç,CPUþÜäÕ╝ǵö»Õ║öÞ»ÑÚâ¢õ©ìÕñº,ÕøᵡñÕÉ»þö¿µÂêµü»ÕÄïþ╝®µ£║Õêµÿ»õ©Çõ©¬Þë»ÕÑ¢þÜäþ¡ûþòÑ;ÕÄïþ╝®Ú£ÇÞªüµÂêÞÇùÕ░æÚçÅþÜäCPUÞÁäµ║É,õ©ìÞ┐çÕ»╣õ║ÄkafkaÞÇîÞ¿Ç,þ¢æþ╗£IOµø┤Õ║öÞ»ÑÚ£ÇÞªüÞÇâÞÖæ.ÕÅ»õ╗ÑÕ░åõ╗╗õ¢òÕ£¿þ¢æþ╗£õ©èõ╝áÞ¥ôþÜäµÂêµü»Úâ¢þ╗ÅÞ┐çÕÄïþ╝®.kafkaµö»µîügzip/snappyþ¡ëÕñÜþºìÕÄïþ╝®µû╣Õ╝Å.
 
┬á ┬á 3ÒÇüþöƒõ║ºÞÇà
┬á ┬á Þ┤ƒÞ¢¢ÕØçÞíí: producerÕ░åõ╝ÜÕÆîTopicõ©ïµëǵ£ëpartition leaderõ┐صîüsocketÞ┐×µÄÑ;µÂêµü»þö▒producerþø┤µÄÑÚÇÜÞ┐çsocketÕÅæÚÇüÕê░broker,õ©¡Úù┤õ©ìõ╝Üþ╗ÅÞ┐çõ╗╗õ¢ò"ÞÀ»þö▒Õ▒é".õ║ïÕ«×õ©è,µÂêµü»Þó½ÞÀ»þö▒Õê░Õô¬õ©¬partitionõ©è,µ£ëproducerÕ«óµêÀþ½»Õå│Õ«Ü.µ»öÕªéÕÅ»õ╗ÑÚççþö¿"random""key-hash""Þ¢«Þ»ó"þ¡ë,Õªéµ×£õ©Çõ©¬topicõ©¡µ£ëÕñÜõ©¬partitions,Úéúõ╣êÕ£¿producerþ½»Õ«×þÄ░"µÂêµü»ÕØçÞííÕêåÕÅæ"µÿ»Õ┐àÞªüþÜä.
 
┬á ┬á ÕàÂõ©¡partition leaderþÜäõ¢ìþ¢«(host:port)µ│¿ÕåîÕ£¿zookeeperõ©¡,producerõ¢£õ©║zookeeper client,ÕÀ▓þ╗ŵ│¿Õåîõ║åwatchþö¿µØÑþøæÕɼpartition leaderþÜäÕÅÿµø┤õ║ïõ╗Â.
┬á ┬á Õ╝鵡ÑÕÅæÚÇü´╝ÜÕ░åÕñܵØíµÂêµü»µÜéõ©öÕ£¿Õ«óµêÀþ½»bufferÞÁÀµØÑ´╝îÕ╣ÂÕ░åõ╗ûõ╗¼µë╣ÚçÅþÜäÕÅæÚÇüÕê░broker´╝îÕ░ŵò░µì«IOÕñ¬ÕñÜ´╝îõ╝ܵïûµàóµò┤õ¢ôþÜäþ¢æþ╗£Õ╗ÂÞ┐ƒ´╝îµë╣ÚçÅÕ╗ÂÞ┐ƒÕÅæÚÇüõ║ïÕ«×õ©èµÅÉÕìçõ║åþ¢æþ╗£µòêþÄçÒÇéõ©ìÞ┐çÞ┐Öõ╣ƒµ£ëõ©ÇÕ«ÜþÜäÚÜɵéú´╝îµ»öÕªéÞ»┤Õ¢ôproducerÕñ▒µòêµù´╝îÚéúõ║øÕ░ܵ£¬ÕÅæÚÇüþÜäµÂêµü»Õ░åõ╝Üõ©óÕñ▒ÒÇé
 
┬á ┬á 4ÒÇüµÂêÞ┤╣ÞÇà
┬á ┬á consumerþ½»ÕÉæbrokerÕÅæÚÇü"fetch"Þ»Àµ▒é,Õ╣ÂÕæèþƒÑÕàÂÞÄÀÕÅûµÂêµü»þÜäoffset;µ¡ñÕÉÄconsumerÕ░åõ╝ÜÞÄÀÕ¥ùõ©ÇիܵØíµò░þÜäµÂêµü»;consumerþ½»õ╣ƒÕÅ»õ╗ÑÚçìþ¢«offsetµØÑÚçìµû░µÂêÞ┤╣µÂêµü».
 
┬á ┬á Õ£¿JMSÕ«×þÄ░õ©¡,Topicµ¿íÕ×ïÕƒ║õ║Äpushµû╣Õ╝Å,Õì│brokerÕ░åµÂêµü»µÄ¿ÚÇüþ╗Öconsumerþ½».õ©ìÞ┐çÕ£¿kafkaõ©¡,Úççþö¿õ║åpullµû╣Õ╝Å,Õì│consumerÕ£¿ÕÆîbrokerÕ╗║þ½ïÞ┐×µÄÑõ╣ïÕÉÄ,õ©╗Õè¿ÕÄ╗pull(µêûÞÇàÞ»┤fetch)µÂêµü»;Þ┐Öõ©¡µ¿íÕ╝ŵ£ëõ║øõ╝ÿþé╣,ÚªûÕàêconsumerþ½»ÕÅ»õ╗ѵá╣µì«Þç¬ÕÀ▒þÜäµÂêÞ┤╣Þâ¢ÕèøÚÇéµùÂþÜäÕÄ╗fetchµÂêµü»Õ╣ÂÕñäþÉå,õ©öÕÅ»õ╗ѵĺÕêµÂêµü»µÂêÞ┤╣þÜäÞ┐øÕ║ª(offset);µ¡ñÕñû,µÂêÞ┤╣ÞÇàÕÅ»õ╗ÑÞë»ÕÑ¢þÜäµÄºÕêµÂêµü»µÂêÞ┤╣þÜäµò░ÚçÅ,batch fetch.
 
┬á ┬á ÕàÂõ╗ûJMSÕ«×þÄ░,µÂêµü»µÂêÞ┤╣þÜäõ¢ìþ¢«µÿ»µ£ëprodiverõ┐ØþòÖ,õ╗Ñõ¥┐Úü┐ÕàìÚçìÕñìÕÅæÚÇüµÂêµü»µêûÞÇàÕ░åµ▓íµ£ëµÂêÞ┤╣µêÉÕèƒþÜäµÂêµü»ÚçìÕÅæþ¡ë,ÕÉîµùÂÞ┐ÿÞªüµÄºÕêµÂêµü»þÜäþèµÇü.Þ┐ÖÕ░▒Þªüµ▒éJMS brokerÚ£ÇÞªüÕñ¬ÕñÜÚóØÕñûþÜäÕÀÑõ¢£.Õ£¿kafkaõ©¡,partitionõ©¡þÜäµÂêµü»ÕŬµ£ëõ©Çõ©¬consumerÕ£¿µÂêÞ┤╣,õ©öõ©ìÕ¡ÿÕ£¿µÂêµü»þèµÇüþÜäµÄºÕêÂ,õ╣ƒµ▓íµ£ëÕñìµØéþÜäµÂêµü»þí«Þ«ñµ£║ÕêÂ,ÕŻ޺ükafka brokerþ½»µÿ»þø©Õ¢ôÞ¢╗ÚçÅþ║ºþÜä.Õ¢ôµÂêµü»Þó½consumerµÄѵöÂõ╣ïÕÉÄ,consumerÕÅ»õ╗ÑÕ£¿µ£¼Õ£░õ┐ØÕ¡ÿµ£ÇÕÉĵÂêµü»þÜäoffset,Õ╣ÂÚù┤µ¡çµÇºþÜäÕÉæzookeeperµ│¿Õåîoffset.þö▒µ¡ñÕŻ޺ü,consumerÕ«óµêÀþ½»õ╣ƒÕ¥êÞ¢╗ÚçÅþ║º.
 
<ignore_js_op style="word-wrap: break-word;">  
 
┬á┬á ┬á 5ÒÇüµÂêµü»õ╝áÚÇüµ£║ÕêÂ
┬á ┬á Õ»╣õ║ÄJMSÕ«×þÄ░,µÂêµü»õ╝áÞ¥ôµïàõ┐ØÚØ×Õ©©þø┤µÄÑ:µ£ëõ©öÕŬµ£ëõ©Çµ¼í(exactly once).Õ£¿kafkaõ©¡þ¿ìµ£ëõ©ìÕÉî:
┬á ┬á 1) at most once: µ£ÇÕñÜõ©Çµ¼í,Þ┐Öõ©¬ÕÆîJMSõ©¡"ÚØ×µîüõ╣àÕîû"µÂêµü»þ▒╗õ╝╝.ÕÅæÚÇüõ©Çµ¼í,µùáÞ«║µêÉÞ┤Ñ,Õ░åõ©ìõ╝ÜÚçìÕÅæ.
┬á ┬á 2) at least once: µÂêµü»Þç│Õ░æÕÅæÚÇüõ©Çµ¼í,Õªéµ×£µÂêµü»µ£¬Þ⢵ÄÑÕÅùµêÉÕèƒ,ÕÅ»Þâ¢õ╝ÜÚçìÕÅæ,þø┤Õê░µÄѵöµêÉÕèƒ.
┬á ┬á 3) exactly once: µÂêµü»ÕŬõ╝ÜÕÅæÚÇüõ©Çµ¼í.
┬á ┬á at most once: µÂêÞ┤╣ÞÇàfetchµÂêµü»,þäÂÕÉÄõ┐ØÕ¡ÿoffset,þäÂÕÉÄÕñäþÉåµÂêµü»;Õ¢ôclientõ┐ØÕ¡ÿoffsetõ╣ïÕÉÄ,õ¢åµÿ»Õ£¿µÂêµü»ÕñäþÉåÞ┐çþ¿ïõ©¡Õç║þÄ░õ║åÕ╝éÕ©©,Õ»╝Þç┤Úâ¿ÕêåµÂêµü»µ£¬Þâ¢þ╗ºþ╗¡ÕñäþÉå.Úéúõ╣굡ñÕÉÄ"µ£¬ÕñäþÉå"þÜäµÂêµü»Õ░åõ©ìÞâ¢Þó½fetchÕê░,Þ┐ÖÕ░▒µÿ»"at most once".
┬á ┬á at least once: µÂêÞ┤╣ÞÇàfetchµÂêµü»,þäÂÕÉÄÕñäþÉåµÂêµü»,þäÂÕÉÄõ┐ØÕ¡ÿoffset.Õªéµ×£µÂêµü»ÕñäþÉåµêÉÕèƒõ╣ïÕÉÄ,õ¢åµÿ»Õ£¿õ┐ØÕ¡ÿoffsetÚÿµ«ÁzookeeperÕ╝éÕ©©Õ»╝Þç┤õ┐ØÕ¡ÿµôìõ¢£µ£¬Þ⢵ëºÞíîµêÉÕèƒ,Þ┐ÖÕ░▒Õ»╝Þç┤µÄÑõ©ïµØÑÕåìµ¼ífetchµùÂÕÅ»Þâ¢ÞÄÀÕ¥ùõ©èµ¼íÕÀ▓þ╗ÅÕñäþÉåÞ┐çþÜäµÂêµü»,Þ┐ÖÕ░▒µÿ»"at least once"´╝îÕăÕøáoffsetµ▓íµ£ëÕÅèµùÂþÜäµÅÉõ║ñþ╗Özookeeper´╝îzookeeperµüóÕñ쵡úÕ©©Þ┐ÿµÿ»õ╣ïÕëìoffsetþèµÇü.
┬á ┬á exactly once: kafkaõ©¡Õ╣µ▓íµ£ëõ©Ñµá╝þÜäÕÄ╗Õ«×þÄ░(Õƒ║õ║Ä2Úÿµ«ÁµÅÉõ║ñ,õ║ïÕèí),µêæõ╗¼Þ«ñõ©║Þ┐Öþºìþ¡ûþòÑÕ£¿kafkaõ©¡µÿ»µ▓íµ£ëÕ┐àÞªüþÜä.
┬á ┬á ÚÇÜÕ©©µâàÕåÁõ©ï"at-least-once"µÿ»µêæõ╗¼µÉ£ÚÇë.(þø©µ»öat most onceÞÇîÞ¿Ç,ÚçìÕñìµÄѵöµò░µì«µÇ╗µ»öõ©óÕñ▒µò░µì«ÞªüÕÑ¢).
 
┬á ┬á 6ÒÇüÕñìÕêÂÕñçõ╗¢
┬á ┬á kafkaÕ░åµ»Åõ©¬partitionµò░µì«ÕñìÕêÂÕê░ÕñÜõ©¬serverõ©è,õ╗╗õ¢òõ©Çõ©¬partitionµ£ëõ©Çõ©¬leaderÕÆîÕñÜõ©¬follower(ÕÅ»õ╗ѵ▓íµ£ë);Õñçõ╗¢þÜäõ©¬µò░ÕÅ»õ╗ÑÚÇÜÞ┐çbrokerÚàìþ¢«µûçõ╗µØÑÞ«¥Õ«Ü.leaderÕñäþÉåµëǵ£ëþÜäread-writeÞ»Àµ▒é,followerÚ£ÇÞªüÕÆîleaderõ┐صîüÕÉÑ.FollowerÕÆîconsumerõ©ÇµáÀ,µÂêÞ┤╣µÂêµü»Õ╣Âõ┐ØÕ¡ÿÕ£¿µ£¼Õ£░µùÑÕ┐ùõ©¡;leaderÞ┤ƒÞ┤úÞÀƒÞ©¬µëǵ£ëþÜäfollowerþèµÇü,Õªéµ×£follower"ÞÉ¢ÕÉÄ"Õñ¬ÕñܵêûÞÇàÕñ▒µòê,leaderÕ░åõ╝ܵèèÕ«âõ╗ÄreplicasÕÉÑÕêùÞí¿õ©¡ÕêáÚÖñ.Õ¢ôµëǵ£ëþÜäfollowerÚâ¢Õ░åõ©ÇµØíµÂêµü»õ┐ØÕ¡ÿµêÉÕèƒ,µ¡ñµÂêµü»µëìÞó½Þ«ñõ©║µÿ»"committed",Úéúõ╣굡ñµùÂconsumerµëìÞ⢵ÂêÞ┤╣Õ«â.Õì│õ¢┐ÕŬµ£ëõ©Çõ©¬replicasÕ«×õ¥ïÕ¡ÿµ┤╗,õ╗ìþäÂÕÅ»õ╗Ñõ┐ØÞ»üµÂêµü»þÜ䵡úÕ©©ÕÅæÚÇüÕÆîµÄѵöÂ,ÕŬުüzookeeperÚøåþ¥ñÕ¡ÿµ┤╗Õì│ÕÅ».(õ©ìÕÉîõ║ÄÕàÂõ╗ûÕêåÕ©âÕ╝ÅÕ¡ÿÕé¿,µ»öÕªéhbaseÚ£ÇÞªü"Õñܵò░µ┤¥"Õ¡ÿµ┤╗µëìÞíî)
┬á ┬á Õ¢ôleaderÕñ▒µòêµùÂ,Ú£ÇÕ£¿followersõ©¡ÚÇëÕÅûÕç║µû░þÜäleader,ÕÅ»Þ⢵¡ñµùÂfollowerÞÉ¢ÕÉÄõ║Äleader,ÕøᵡñÚ£ÇÞªüÚÇëµï®õ©Çõ©¬"up-to-date"þÜäfollower.ÚÇëµï®followerµùÂÚ£ÇÞªüÕà╝Úí¥õ©Çõ©¬Úù«Úóÿ,Õ░▒µÿ»µû░leaderserverõ©èµëÇÕÀ▓þ╗ŵë┐Þ¢¢þÜäpartition leaderþÜäõ©¬µò░,Õªéµ×£õ©Çõ©¬serverõ©èµ£ëÞ┐çÕñÜþÜäpartition leader,µäÅÕæ│þØǵ¡ñserverÕ░åµë┐ÕÅùþØǵø┤ÕñÜþÜäIOÕÄïÕèø.Õ£¿ÚÇëõ©¥µû░leader,Ú£ÇÞªüÞÇâÞÖæÕê░"Þ┤ƒÞ¢¢ÕØçÞíí".
 
┬á ┬á 7.µùÑÕ┐ù
┬á ┬á Õªéµ×£õ©Çõ©¬topicþÜäÕÉìþº░õ©║"my_topic",Õ«âµ£ë2õ©¬partitions,Úéúõ╣êµùÑÕ┐ùÕ░åõ╝Üõ┐ØÕ¡ÿÕ£¿my_topic_0ÕÆîmy_topic_1õ©ñõ©¬þø«Õ¢òõ©¡;µùÑÕ┐ùµûçõ╗Âõ©¡õ┐ØÕ¡ÿõ║åõ©ÇÕ║ÅÕêù"log entries"(µùÑÕ┐ùµØíþø«),µ»Åõ©¬log entryµá╝Õ╝Åõ©║"4õ©¬Õ¡ùÞèéþÜäµò░Õ¡ùNÞí¿þñ║µÂêµü»þÜäÚò┐Õ║ª" + "Nõ©¬Õ¡ùÞèéþÜäµÂêµü»ÕåàÕ«╣";µ»Åõ©¬µùÑÕ┐ùÚ⢵£ëõ©Çõ©¬offsetµØÑÕö»õ©ÇþÜäµáçÞ«░õ©ÇµØíµÂêµü»,offsetþÜäÕÇ╝õ©║8õ©¬Õ¡ùÞèéþÜäµò░Õ¡ù,Þí¿þñ║µ¡ñµÂêµü»Õ£¿µ¡ñpartitionõ©¡µëÇÕñäþÜäÞÁÀÕºïõ¢ìþ¢«..µ»Åõ©¬partitionÕ£¿þë®þÉåÕ¡ÿÕé¿Õ▒éÚØó,µ£ëÕñÜõ©¬log fileþ╗äµêÉ(þº░õ©║segment).segmentfileþÜäÕæ¢ÕÉìõ©║"µ£ÇÕ░Åoffset".kafka.õ¥ïÕªé"00000000000.kafka";ÕàÂõ©¡"µ£ÇÕ░Åoffset"Þí¿þñ║µ¡ñsegmentõ©¡ÞÁÀÕºïµÂêµü»þÜäoffset.
<ignore_js_op style="word-wrap: break-word;">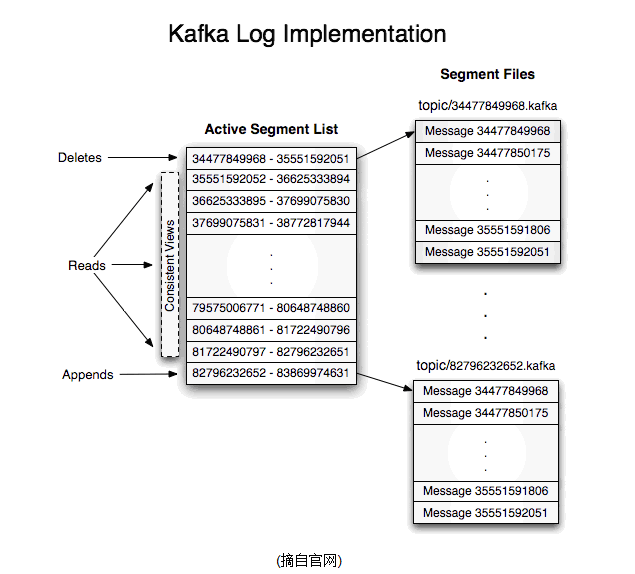  
 
 
4.png 
õ©ïÞ¢¢ÚÖäõ╗Â┬á┬áõ┐ØÕ¡ÿÕê░þø©Õåî
 
┬á ┬á ÕàÂõ©¡µ»Åõ©¬partitonõ©¡µëǵîüµ£ëþÜäsegmentsÕêùÞí¿õ┐íµü»õ╝ÜÕ¡ÿÕé¿Õ£¿zookeeperõ©¡.
┬á ┬á Õ¢ôsegmentµûçõ╗ÂÕ░║Õ»©Þ¥¥Õê░õ©ÇÕ«ÜÚÿÇÕÇ╝µùÂ(ÕÅ»õ╗ÑÚÇÜÞ┐çÚàìþ¢«µûçõ╗ÂÞ«¥Õ«Ü,Ú╗ÿÞ«ñ1G),Õ░åõ╝ÜÕêøÕ╗║õ©Çõ©¬µû░þÜäµûçõ╗Â;Õ¢ôbufferõ©¡µÂêµü»þÜäµØíµò░Þ¥¥Õê░ÚÿÇÕÇ╝µùÂÕ░åõ╝ÜÞºªÕÅæµùÑÕ┐ùõ┐íµü»flushÕê░µùÑÕ┐ùµûçõ╗Âõ©¡,ÕÉîµùÂÕªéµ×£"ÞÀØþª╗µ£ÇÞ┐æõ©Çµ¼íflushþÜäµùÂÚù┤ÕÀ«"Þ¥¥Õê░ÚÿÇÕÇ╝µùÂ,õ╣ƒõ╝ÜÞºªÕÅæflushÕê░µùÑÕ┐ùµûçõ╗Â.Õªéµ×£brokerÕñ▒µòê,µ×üµ£ëÕÅ»Þâ¢õ╝Üõ©óÕñ▒Úéúõ║øÕ░ܵ£¬flushÕê░µûçõ╗ÂþÜäµÂêµü».Õøáõ©║serverµäÅÕñûÕ«×þÄ░,õ╗ìþäÂõ╝ÜÕ»╝Þç┤logµûçõ╗µá╝Õ╝ÅþÜäþá┤ÕØÅ(µûçõ╗ÂÕ░¥Úâ¿),Úéúõ╣êÕ░▒Þªüµ▒éÕ¢ôserverÕÉ»õ©£µÿ»Ú£ÇÞªüµúǵÁïµ£ÇÕÉÄõ©Çõ©¬segmentþÜäµûçõ╗Âþ╗ôµ×äµÿ»ÕɪÕÉêµ│òÕ╣ÂÞ┐øÞíîÕ┐àÞªüþÜäõ┐«Õñì.
┬á ┬á ÞÄÀÕÅûµÂêµü»µùÂ,Ú£ÇÞªüµîçÕ«ÜoffsetÕÆîµ£ÇÕñºchunkÕ░║Õ»©,offsetþö¿µØÑÞí¿þñ║µÂêµü»þÜäÞÁÀÕºïõ¢ìþ¢«,chunk sizeþö¿µØÑÞí¿þñ║µ£ÇÕñºÞÄÀÕÅûµÂêµü»þÜäµÇ╗Úò┐Õ║ª(Úù┤µÄÑþÜäÞí¿þñ║µÂêµü»þÜäµØíµò░).µá╣µì«offset,ÕÅ»õ╗ѵë¥Õê░µ¡ñµÂêµü»µëÇÕ£¿segmentµûçõ╗Â,þäÂÕÉĵá╣µì«segmentþÜäµ£ÇÕ░ÅoffsetÕÅûÕÀ«ÕÇ╝,Õ¥ùÕê░Õ«âÕ£¿fileõ©¡þÜäþø©Õ»╣õ¢ìþ¢«,þø┤µÄÑÞ»╗ÕÅûÞ¥ôÕç║Õì│ÕÅ».
┬á ┬á µùÑÕ┐ùµûçõ╗ÂþÜäÕêáÚÖñþ¡ûþòÑÚØ×Õ©©þ«ÇÕìò:ÕÉ»Õè¿õ©Çõ©¬ÕÉÄÕÅ░þ║┐þ¿ïիܵ£ƒµë½µÅÅlog fileÕêùÞí¿,µèèõ┐ØÕ¡ÿµùÂÚù┤ÞÂàÞ┐çÚÿÇÕÇ╝þÜäµûçõ╗Âþø┤µÄÑÕêáÚÖñ(µá╣µì«µûçõ╗ÂþÜäÕêøÕ╗║µùÂÚù┤).õ©║õ║åÚü┐ÕàìÕêáÚÖñµûçõ╗µùÂõ╗ìþäµ£ëreadµôìõ¢£(consumerµÂêÞ┤╣),ÚççÕÅûcopy-on-writeµû╣Õ╝Å.
 
┬á ┬á 8ÒÇüÕêåÚàì
┬á ┬á kafkaõ¢┐þö¿zookeeperµØÑÕ¡ÿÕé¿õ©Çõ║ømetaõ┐íµü»,Õ╣Âõ¢┐þö¿õ║åzookeeper watchµ£║ÕêµØÑÕÅæþÄ░metaõ┐íµü»þÜäÕÅÿµø┤Õ╣Âõ¢£Õç║þø©Õ║öþÜäÕè¿õ¢£(µ»öÕªéconsumerÕñ▒µòê,ÞºªÕÅæÞ┤ƒÞ¢¢ÕØçÞííþ¡ë)
┬á ┬á 1) Broker node registry: Õ¢ôõ©Çõ©¬kafkabrokerÕÉ»Õè¿ÕÉÄ,ÚªûÕàêõ╝ÜÕÉæzookeeperµ│¿ÕåîÞç¬ÕÀ▒þÜäÞèéþé╣õ┐íµü»(õ©┤µùÂznode),ÕÉîµùÂÕ¢ôbrokerÕÆîzookeeperµû¡Õ╝ÇÞ┐×µÄѵùÂ,µ¡ñznodeõ╣ƒõ╝ÜÞó½ÕêáÚÖñ.
┬á ┬á µá╝Õ╝Å: /broker/ids/[0...N]┬á ┬á-->host:port;ÕàÂõ©¡[0..N]Þí¿þñ║broker id,µ»Åõ©¬brokerþÜäÚàìþ¢«µûçõ╗Âõ©¡Úâ¢Ú£ÇÞªüµîçÕ«Üõ©Çõ©¬µò░Õ¡ùþ▒╗Õ×ïþÜäid(Õà¿Õ▒Çõ©ìÕÅ»ÚçìÕñì),znodeþÜäÕÇ╝õ©║µ¡ñbrokerþÜähost:portõ┐íµü».
┬á ┬á 2) Broker Topic Registry: Õ¢ôõ©Çõ©¬brokerÕÉ»Õ迵ùÂ,õ╝ÜÕÉæzookeeperµ│¿ÕåîÞç¬ÕÀ▒µîüµ£ëþÜätopicÕÆîpartitionsõ┐íµü»,õ╗ìþäµÿ»õ©Çõ©¬õ©┤µùÂznode.
┬á ┬á µá╝Õ╝Å: /broker/topics/[topic]/[0...N]┬á┬áÕàÂõ©¡[0..N]Þí¿þñ║partitionþ┤óÕ╝òÕÅÀ.
┬á ┬á 3) Consumer and Consumer group: µ»Åõ©¬consumerÕ«óµêÀþ½»Þó½ÕêøÕ╗║µùÂ,õ╝ÜÕÉæzookeeperµ│¿ÕåîÞç¬ÕÀ▒þÜäõ┐íµü»;µ¡ñõ¢£þö¿õ©╗Þªüµÿ»õ©║õ║å"Þ┤ƒÞ¢¢ÕØçÞíí".
┬á ┬á õ©Çõ©¬groupõ©¡þÜäÕñÜõ©¬consumerÕÅ»õ╗Ñõ║ñÚöÖþÜäµÂêÞ┤╣õ©Çõ©¬topicþÜäµëǵ£ëpartitions;þ«ÇÞÇîÞ¿Çõ╣ï,õ┐ØÞ»üµ¡ñtopicþÜäµëǵ£ëpartitionsÚâ¢Þâ¢Þ󽵡ñgroupµëǵÂêÞ┤╣,õ©öµÂêÞ┤╣µùÂõ©║õ║åµÇºÞâ¢ÞÇâÞÖæ,Þ«®partitionþø©Õ»╣ÕØçÞííþÜäÕêåµòúÕê░µ»Åõ©¬consumerõ©è.
┬á ┬á 4) Consumer id Registry: µ»Åõ©¬consumerÚ⢵£ëõ©Çõ©¬Õö»õ©ÇþÜäID(host:uuid,ÕÅ»õ╗ÑÚÇÜÞ┐çÚàìþ¢«µûçõ╗µîçÕ«Ü,õ╣ƒÕÅ»õ╗Ñþö▒þ│╗þ╗ƒþöƒµêÉ),µ¡ñidþö¿µØѵáçÞ«░µÂêÞ┤╣ÞÇàõ┐íµü».
┬á ┬á µá╝Õ╝Å:/consumers/[group_id]/ids/[consumer_id]
┬á ┬á õ╗ìþäµÿ»õ©Çõ©¬õ©┤µùÂþÜäznode,µ¡ñÞèéþé╣þÜäÕÇ╝õ©║{"topic_name":#streams...},Õì│Þí¿þñ║µ¡ñconsumerþø«ÕëìµëǵÂêÞ┤╣þÜätopic + partitionsÕêùÞí¿.
┬á ┬á 5) Consumer offset Tracking: þö¿µØÑÞÀƒÞ©¬µ»Åõ©¬consumerþø«ÕëìµëǵÂêÞ┤╣þÜäpartitionõ©¡µ£ÇÕñºþÜäoffset.
┬á ┬á µá╝Õ╝Å:/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]-->offset_value
┬á ┬á µ¡ñznodeõ©║µîüõ╣àÞèéþé╣,ÕÅ»õ╗Ñþ£ïÕç║offsetÞÀƒgroup_idµ£ëÕà│,õ╗ÑÞí¿µÿÄÕ¢ôgroupõ©¡õ©Çõ©¬µÂêÞ┤╣ÞÇàÕñ▒µòê,ÕàÂõ╗ûconsumerÕÅ»õ╗Ñþ╗ºþ╗¡µÂêÞ┤╣.
┬á ┬á 6) Partition Owner registry: þö¿µØѵáçÞ«░partitionÞó½Õô¬õ©¬consumerµÂêÞ┤╣.õ©┤µùÂznode
┬á ┬á µá╝Õ╝Å:/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]-->consumer_node_idÕ¢ôconsumerÕÉ»Õ迵ùÂ,µëÇÞºªÕÅæþÜäµôìõ¢£:
┬á ┬á A) ÚªûÕàêÞ┐øÞíî"Consumer id Registry";
┬á ┬á B) þäÂÕÉÄÕ£¿"Consumer id Registry"Þèéþé╣õ©ïµ│¿Õåîõ©Çõ©¬watchþö¿µØÑþøæÕɼբôÕëìgroupõ©¡ÕàÂõ╗ûconsumerþÜä"leave"ÕÆî"join";ÕŬުüµ¡ñznode pathõ©ïÞèéþé╣ÕêùÞí¿ÕÅÿµø┤,Úâ¢õ╝ÜÞºªÕÅ浡ñgroupõ©ïconsumerþÜäÞ┤ƒÞ¢¢ÕØçÞíí.(µ»öÕªéõ©Çõ©¬consumerÕñ▒µòê,Úéúõ╣êÕàÂõ╗ûconsumerµÄÑþ«ípartitions).
┬á ┬á C) Õ£¿"Broker id registry"Þèéþé╣õ©ï,µ│¿Õåîõ©Çõ©¬watchþö¿µØÑþøæÕɼbrokerþÜäÕ¡ÿµ┤╗µâàÕåÁ;Õªéµ×£brokerÕêùÞí¿ÕÅÿµø┤,Õ░åõ╝ÜÞºªÕÅæµëǵ£ëþÜägroupsõ©ïþÜäconsumerÚçìµû░balance.
<ignore_js_op style="word-wrap: break-word;">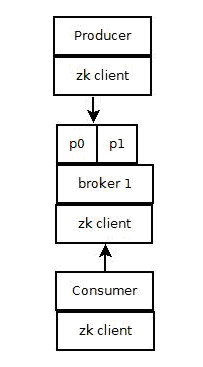  
 
┬á┬á ┬á 1) Producerþ½»õ¢┐þö¿zookeeperþö¿µØÑ"ÕÅæþÄ░"brokerÕêùÞí¿,õ╗ÑÕÅèÕÆîTopicõ©ïµ»Åõ©¬partition leaderÕ╗║þ½ïsocketÞ┐×µÄÑÕ╣ÂÕÅæÚÇüµÂêµü».
┬á ┬á 2) Brokerþ½»õ¢┐þö¿zookeeperþö¿µØѵ│¿Õåîbrokerõ┐íµü»,ÕÀ▓þ╗ÅþøæµÁïpartitionleaderÕ¡ÿµ┤╗µÇº.
┬á ┬á 3) Consumerþ½»õ¢┐þö¿zookeeperþö¿µØѵ│¿Õåîconsumerõ┐íµü»,ÕàÂõ©¡Õîàµï¼consumerµÂêÞ┤╣þÜäpartitionÕêùÞí¿þ¡ë,ÕÉîµùÂõ╣ƒþö¿µØÑÕÅæþÄ░brokerÕêùÞí¿,Õ╣ÂÕÆîpartition leaderÕ╗║þ½ïsocketÞ┐×µÄÑ,Õ╣ÂÞÄÀÕÅûµÂêµü».
 
ÕøøÒÇüõ©╗ÞªüÚàìþ¢«
 
┬á ┬á 1ÒÇüBrokerÚàìþ¢«
 
<ignore_js_op style="word-wrap: break-word;">  
 
  
┬á ┬á 2.Consumerõ©╗ÞªüÚàìþ¢«
 
<ignore_js_op style="word-wrap: break-word;">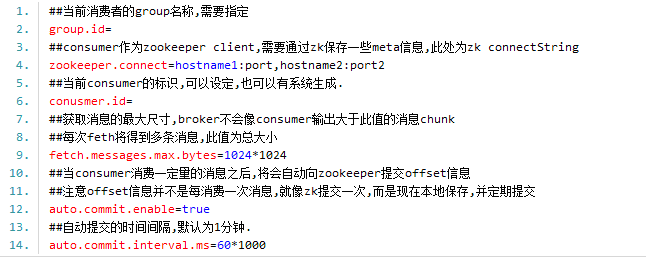  
 
  
3.Producerõ©╗ÞªüÚàìþ¢«
 
<ignore_js_op style="word-wrap: break-word;">  
 
  
 
õ╗Ñõ©èµÿ»Õà│õ║Äkafkaõ©Çõ║øÕƒ║þíÇÞ»┤µÿÄ´╝îÕ£¿ÕàÂõ©¡µêæõ╗¼þƒÑÚüôÕªéµ×£Þªükafkaµ¡úÕ©©Þ┐ÉÞíî´╝îÕ┐àÚí╗Úàìþ¢«zookeeper´╝îÕɪÕêÖµùáÞ«║µÿ»kafkaÚøåþ¥ñÞ┐ÿµÿ»Õ«óµêÀþ½»þÜäþöƒÕ¡ÿÞÇàÕÆîµÂêÞ┤╣ÞÇàÚ⢵ùáµ│òµ¡úÕ©©þÜäÕÀÑõ¢£þÜä´╝îõ╗Ñõ©ïµÿ»Õ»╣zookeeperÞ┐øÞíîõ©Çõ║øþ«ÇÕìòþÜäõ╗ïþ╗ì´╝Ü
 
õ║öÒÇüzookeeperÚøåþ¥ñ
┬á ┬á zookeeperµÿ»õ©Çõ©¬õ©║ÕêåÕ©âÕ╝ÅÕ║öþö¿µÅÉõ¥øõ©ÇÞç┤µÇºµ£ìÕèíþÜäÞ¢»õ╗´╝îÕ«âµÿ»Õ╝ǵ║ÉþÜäHadoopÚí╣þø«þÜäõ©Çõ©¬Õ¡ÉÚí╣þø«´╝îÕ╣µá╣µì«googleÕÅæÞí¿þÜäõ©Çþ»çÞ«║µûçµØÑÕ«×þÄ░þÜäÒÇézookeeperõ©║ÕêåÕ©âÕ╝Åþ│╗þ╗ƒµÅÉõ¥øõ║åÚ½ÿþ¼æõ©öµÿôõ║Äõ¢┐þö¿þÜäÕìÅÕÉîµ£ìÕèí´╝îÕ«âÕÅ»õ╗Ñõ©║ÕêåÕ©âÕ╝ÅÕ║öþö¿µÅÉõ¥øþø©Õ¢ôÕñÜþÜäµ£ìÕèí´╝îÞ»©Õªéþ╗ƒõ©ÇÕæ¢ÕÉìµ£ìÕèí´╝îÚàìþ¢«þ«íþÉå´╝îþèµÇüÕÉÑÕÆîþ╗äµ£ìÕèíþ¡ëÒÇézookeeperµÄÑÕÅúþ«ÇÕìò´╝îµêæõ╗¼õ©ìÕ┐àÞ┐çÕñÜÕ£░þ║áþ╗ôÕ£¿ÕêåÕ©âÕ╝Åþ│╗þ╗ƒþ╝ûþ¿ïÚÜ¥õ║ÄÕñäþÉåþÜäÕÉÑÕÆîõ©ÇÞç┤µÇºÚù«Úóÿõ©è´╝îõ¢áÕÅ»õ╗Ñõ¢┐þö¿zookeeperµÅÉõ¥øþÜäþÄ░µêÉ(off-the-shelf)µ£ìÕèíµØÑÕ«×þÄ░µØÑÕ«×þÄ░ÕêåÕ©âÕ╝Åþ│╗þ╗ƒÚóØÚàìþ¢«þ«íþÉå´╝îþ╗äþ«íþÉå´╝îLeaderÚÇëõ©¥þ¡ëÕèƒÞâ¢ÒÇé
┬á ┬á zookeeperÚøåþ¥ñþÜäÕ«ëÞúà,ÕçåÕñçõ©ëÕÅ░µ£ìÕèíÕÖ¿server1:192.168.0.1,server2:192.168.0.2,
    server3:192.168.0.3.
┬á ┬á 1)õ©ïÞ¢¢zookeeper
┬á ┬á Õê░http://zookeeper.apache.org/releases.htmlÕÄ╗õ©ïÞ¢¢µ£Çµû░þëêµ£¼Zookeeper-3.4.5þÜäÕ«ëÞúàÕîàzookeeper-3.4.5.tar.gz.Õ░åµûçõ╗Âõ┐ØÕ¡ÿserver1þÜä~þø«Õ¢òõ©ï
┬á ┬á 2)Õ«ëÞúàzookeeper
┬á ┬á ÕàêÕ£¿µ£ìÕèíÕÖ¿serverÕêåÕê½µëºÞíîa-cµ¡ÑÚ¬ñ
┬á ┬á a)ÞºúÕÄï┬á┬á
    tar -zxvf zookeeper-3.4.5.tar.gz
┬á ┬á ÞºúÕÄïÕ«îµêÉÕÉÄÕ£¿þø«Õ¢ò~õ©ïõ╝ÜÕÅæþÄ░ÕñÜÕç║õ©Çõ©¬þø«Õ¢òzookeeper-3.4.5,Úçìµû░Õæ¢õ╗ñõ©║zookeeper
┬á ┬á b´╝ëÚàìþ¢«
┬á ┬á Õ░åconf/zoo_sample.cfgµïÀÞ┤Øõ©Çõ╗¢Õæ¢ÕÉìõ©║zoo.cfg´╝îõ╣ƒµö¥Õ£¿confþø«Õ¢òõ©ïÒÇéþäÂÕÉĵîëþàºÕªéõ©ïÕÇ╝õ┐«µö╣ÕàÂõ©¡þÜäÚàìþ¢«´╝Ü
   
    # The number of milliseconds of each tick
    tickTime=2000
    # The number of ticks that the initial
    # synchronization phase can take
    initLimit=10
    # The number of ticks that can pass between
    # sending a request and getting an acknowledgement
    syncLimit=5
    # the directory where the snapshot is stored.
    # do not use /tmp for storage, /tmp here is just
    # example sakes.
    dataDir=/home/wwb/zookeeper /data
    dataLogDir=/home/wwb/zookeeper/logs
    # the port at which the clients will connect
    clientPort=2181
    #
    # Be sure to read the maintenance section of the
    # administrator guide before turning on autopurge.
    #
    # The number of snapshots to retain in dataDir
    #autopurge.snapRetainCount=3
    # Purge task interval in hours
    # Set to "0" to disable auto purge feature
    #autopurge.purgeInterval=1
    server.1=192.168.0.1:3888:4888
    server.2=192.168.0.2:3888:4888
    server.3=192.168.0.3:3888:4888
┬á ┬á tickTime´╝ÜÞ┐Öõ©¬µùÂÚù┤µÿ»õ¢£õ©║ Zookeeper µ£ìÕèíÕÖ¿õ╣ïÚù┤µêûÕ«óµêÀþ½»õ©Äµ£ìÕèíÕÖ¿õ╣ïÚù┤þ╗┤µîüÕ┐âÞÀ│þÜäµùÂÚù┤Úù┤ÚÜö´╝îõ╣ƒÕ░▒µÿ»µ»Åõ©¬ tickTime µùÂÚù┤Õ░▒õ╝ÜÕÅæÚÇüõ©Çõ©¬Õ┐âÞÀ│ÒÇé
┬á ┬á dataDir´╝ÜÚí¥ÕÉìµÇØõ╣ëÕ░▒µÿ» Zookeeper õ┐ØÕ¡ÿµò░µì«þÜäþø«Õ¢ò´╝îÚ╗ÿÞ«ñµâàÕåÁõ©ï´╝îZookeeper Õ░åÕåÖµò░µì«þÜäµùÑÕ┐ùµûçõ╗Âõ╣ƒõ┐ØÕ¡ÿÕ£¿Þ┐Öõ©¬þø«Õ¢òÚçîÒÇé
┬á ┬á clientPort´╝ÜÞ┐Öõ©¬þ½»ÕÅúÕ░▒µÿ»Õ«óµêÀþ½»Þ┐×µÄÑ Zookeeper µ£ìÕèíÕÖ¿þÜäþ½»ÕÅú´╝îZookeeper õ╝ÜþøæÕɼÞ┐Öõ©¬þ½»ÕÅú´╝îµÄÑÕÅùÕ«óµêÀþ½»þÜäÞ«┐Úù«Þ»Àµ▒éÒÇé
┬á ┬á initLimit´╝ÜÞ┐Öõ©¬Úàìþ¢«Úí╣µÿ»þö¿µØÑÚàìþ¢« Zookeeper µÄÑÕÅùÕ«óµêÀþ½»´╝êÞ┐ÖÚçîµëÇÞ»┤þÜäÕ«óµêÀþ½»õ©ìµÿ»þö¿µêÀÞ┐×µÄÑ Zookeeper µ£ìÕèíÕÖ¿þÜäÕ«óµêÀþ½»´╝îÞÇîµÿ» Zookeeper µ£ìÕèíÕÖ¿Úøåþ¥ñõ©¡Þ┐×µÄÑÕê░ Leader þÜä Follower µ£ìÕèíÕÖ¿´╝ëÕêØÕºïÕîûÞ┐×µÄѵùµ£ÇÚò┐Þâ¢Õ┐ìÕÅùÕñÜÕ░æõ©¬Õ┐âÞÀ│µùÂÚù┤Úù┤ÚÜöµò░ÒÇéÕ¢ôÕÀ▓þ╗ÅÞÂàÞ┐ç 5õ©¬Õ┐âÞÀ│þÜäµùÂÚù┤´╝êõ╣ƒÕ░▒µÿ» tickTime´╝ëÚò┐Õ║ªÕÉÄ Zookeeper µ£ìÕèíÕÖ¿Þ┐ÿµ▓íµ£ëµöÂÕê░Õ«óµêÀþ½»þÜäÞ┐öÕø×õ┐íµü»´╝îÚéúõ╣êÞí¿µÿÄÞ┐Öõ©¬Õ«óµêÀþ½»Þ┐×µÄÑÕñ▒Þ┤ÑÒÇéµÇ╗þÜäµùÂÚù┤Úò┐Õ║ªÕ░▒µÿ» 5*2000=10 þºÆ
┬á ┬á syncLimit´╝ÜÞ┐Öõ©¬Úàìþ¢«Úí╣µáçÞ»å Leader õ©ÄFollower õ╣ïÚù┤ÕÅæÚÇüµÂêµü»´╝îÞ»Àµ▒éÕÆîÕ║öþ¡öµùÂÚù┤Úò┐Õ║ª´╝îµ£ÇÚò┐õ©ìÞâ¢ÞÂàÞ┐çÕñÜÕ░æõ©¬ tickTime þÜäµùÂÚù┤Úò┐Õ║ª´╝îµÇ╗þÜäµùÂÚù┤Úò┐Õ║ªÕ░▒µÿ»2*2000=4 þºÆ
┬á ┬á server.A=B´╝ÜC´╝ÜD´╝ÜÕàÂõ©¡ A µÿ»õ©Çõ©¬µò░Õ¡ù´╝îÞí¿þñ║Þ┐Öõ©¬µÿ»þ¼¼ÕçáÕÅÀµ£ìÕèíÕÖ¿´╝øB µÿ»Þ┐Öõ©¬µ£ìÕèíÕÖ¿þÜä ip Õ£░ÕØÇ´╝øC Þí¿þñ║þÜäµÿ»Þ┐Öõ©¬µ£ìÕèíÕÖ¿õ©ÄÚøåþ¥ñõ©¡þÜä Leader µ£ìÕèíÕÖ¿õ║ñµìóõ┐íµü»þÜäþ½»ÕÅú´╝øD Þí¿þñ║þÜäµÿ»õ©çõ©ÇÚøåþ¥ñõ©¡þÜä Leader µ£ìÕèíÕÖ¿µîéõ║å´╝îÚ£ÇÞªüõ©Çõ©¬þ½»ÕÅúµØÑÚçìµû░Þ┐øÞíîÚÇëõ©¥´╝îÚÇëÕç║õ©Çõ©¬µû░þÜä Leader´╝îÞÇîÞ┐Öõ©¬þ½»ÕÅúÕ░▒µÿ»þö¿µØѵëºÞíîÚÇëõ©¥µùµ£ìÕèíÕÖ¿þø©õ║ÆÚÇÜõ┐íþÜäþ½»ÕÅúÒÇéÕªéµ×£µÿ»õ╝¬Úøåþ¥ñþÜäÚàìþ¢«µû╣Õ╝Å´╝îþö▒õ║Ä B Ú⢵ÿ»õ©ÇµáÀ´╝îµëÇõ╗Ñõ©ìÕÉîþÜä Zookeeper Õ«×õ¥ïÚÇÜõ┐íþ½»ÕÅúÕÅÀõ©ìÞâ¢õ©ÇµáÀ´╝îµëÇõ╗ÑÞªüþ╗ÖÕ«âõ╗¼ÕêåÚàìõ©ìÕÉîþÜäþ½»ÕÅúÕÅÀ
µ│¿µäÅ:dataDir,dataLogDirõ©¡þÜäwwbµÿ»Õ¢ôÕëìþÖ╗Õ¢òþö¿µêÀÕÉì´╝îdata´╝îlogsþø«Õ¢òÕ╝ÇÕºïµÿ»õ©ìÕ¡ÿÕ£¿´╝îÚ£ÇÞªüõ¢┐þö¿mkdirÕæ¢õ╗ñÕêøÕ╗║þø©Õ║öþÜäþø«Õ¢òÒÇéÕ╣Âõ©öÕ£¿Þ»Ñþø«Õ¢òõ©ïÕêøÕ╗║µûçõ╗Âmyid,serve1,server2,server3޻ѵûçõ╗ÂÕåàÕ«╣ÕêåÕê½õ©║1,2,3ÒÇé
ÚÆêÕ»╣µ£ìÕèíÕÖ¿server2,server3ÕÅ»õ╗ÑÕ░åserver1ÕñìÕêÂÕê░þø©Õ║öþÜäþø«Õ¢ò´╝îõ©ìÞ┐çÚ£ÇÞªüµ│¿µäÅdataDir,dataLogDirþø«Õ¢ò,Õ╣Âõ©öµûçõ╗ÂmyidÕåàÕ«╣ÕêåÕê½õ©║2,3
┬á ┬á 3)õ¥Øµ¼íÕÉ»Õè¿server1´╝îserver2,server3þÜäzookeeper.
┬á ┬á /home/wwb/zookeeper/bin/zkServer.sh start,Õç║þÄ░þ▒╗õ╝╝õ╗Ñõ©ïÕåàÕ«╣
    JMX enabled by default
    Using config: /home/wwb/zookeeper/bin/../conf/zoo.cfg
    Starting zookeeper ... STARTED
┬á ┬á4) µÁïÞ»òzookeeperµÿ»Õɪµ¡úÕ©©ÕÀÑõ¢£´╝îÕ£¿server1õ©èµëºÞíîõ╗Ñõ©ïÕæ¢õ╗ñ
┬á ┬á /home/wwb/zookeeper/bin/zkCli.sh -server192.168.0.2:2181,Õç║þÄ░þ▒╗õ╝╝õ╗Ñõ©ïÕåàÕ«╣
    JLine support is enabled
    2013-11-27 19:59:40,560 - INFO      [main-SendThread(localhost.localdomain:2181):ClientCnxn$SendThread@736]- Session   establishmentcomplete on server localhost.localdomain/127.0.0.1:2181, sessionid =    0x1429cdb49220000, negotiatedtimeout = 30000
 
    WATCHER::
   
    WatchedEvent state:SyncConnected type:None path:null
    [zk: 127.0.0.1:2181(CONNECTED) 0] [root@localhostzookeeper2]#  
┬á ┬á Õì│õ╗úÞí¿Úøåþ¥ñµ×äÕ╗║µêÉÕèƒõ║å,Õªéµ×£Õç║þÄ░ÚöÖÞ»»ÚéúÕ║ö޻ѵÿ»þ¼¼õ©ëÚ⿵ùµ▓íµ£ëÕÉ»Õè¿ÕÑ¢Úøåþ¥ñ´╝î
Þ┐ÉÞíî´╝îÕàêÕê®þö¿
┬á ┬á ps aux | grep zookeeperµƒÑþ£ïµÿ»Õɪµ£ëþø©Õ║öþÜäÞ┐øþ¿ïþÜä´╝îµ▓íµ£ë޻ش╝îÞ»┤µÿÄÚøåþ¥ñÕÉ»Õè¿Õç║þÄ░Úù«Úóÿ´╝îÕÅ»õ╗ÑÕ£¿µ»Åõ©¬µ£ìÕèíÕÖ¿õ©èõ¢┐þö¿
┬á ┬á ./home/wwb/zookeeper/bin/zkServer.sh stopÒÇéÕåìõ¥Øµ¼íõ¢┐þö¿./home/wwb/zookeeper/binzkServer.sh start´╝îÞ┐ÖµùÂÕ£¿µëºÞíî4õ©ÇÞê¼µÿ»µ▓íµ£ëÚù«Úóÿ´╝îÕªéµ×£Þ┐ÿµÿ»µ£ëÚù«Úóÿ´╝îÚéúõ╣êÕàêstopÕåìÕê░binþÜäõ©èþ║ºþø«Õ¢òµëºÞíî./bin/zkServer.shstartÞ»òÞ»òÒÇé
 
µ│¿µäÅ´╝ÜzookeeperÚøåþ¥ñµù´╝îzookeeperÞªüµ▒éÕìèµò░õ╗Ñõ©èþÜäµ£║ÕÖ¿ÕÅ»þö¿´╝îzookeeperµëìÞ⢵ÅÉõ¥øµ£ìÕèíÒÇé
 
Õà¡ÒÇükafkaÚøåþ¥ñ
(Õê®þö¿õ©èÚØóserver1,server2,server3,õ©ïÚØóõ╗Ñserver1õ©║Õ«×õ¥ï)
┬á ┬á 1)õ©ïÞ¢¢kafka0.8(http://kafka.apache.org/downloads.html),õ┐ØÕ¡ÿÕê░µ£ìÕèíÕÖ¿/home/wwbþø«Õ¢òõ©ïkafka-0.8.0-beta1-src.tgz(kafka_2.8.0-0.8.0-beta1.tgz)
┬á ┬á 2)ÞºúÕÄï tar -zxvf kafka-0.8.0-beta1-src.tgz,õ║ºþöƒµûçõ╗ÂÕñ╣kafka-0.8.0-beta1-srcµø┤µö╣õ©║kafka01┬á ┬á
3)Úàìþ¢«
┬á ┬á õ┐«µö╣kafka01/config/server.properties,ÕàÂõ©¡broker.id,log.dirs,zookeeper.connectÕ┐àÚí╗µá╣µì«Õ«×ÚÖàµâàÕåÁÞ┐øÞíîõ┐«µö╣´╝îÕàÂõ╗ûÚí╣µá╣µì«Ú£ÇÞªüÞç¬ÞíîµûƒÚàîÒÇéÕñºÞç┤Õªéõ©ï´╝Ü
     broker.id=1  
     port=9091  
     num.network.threads=2  
     num.io.threads=2  
     socket.send.buffer.bytes=1048576  
    socket.receive.buffer.bytes=1048576  
     socket.request.max.bytes=104857600  
    log.dir=./logs  
    num.partitions=2  
    log.flush.interval.messages=10000  
    log.flush.interval.ms=1000  
    log.retention.hours=168  
    #log.retention.bytes=1073741824  
    log.segment.bytes=536870912  
    num.replica.fetchers=2  
    log.cleanup.interval.mins=10  
    zookeeper.connect=192.168.0.1:2181,192.168.0.2:2182,192.168.0.3:2183  
    zookeeper.connection.timeout.ms=1000000  
    kafka.metrics.polling.interval.secs=5  
    kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter  
    kafka.csv.metrics.dir=/tmp/kafka_metrics  
    kafka.csv.metrics.reporter.enabled=false
 
4´╝ëÕêØÕºïÕîûÕøáõ©║kafkaþö¿scalaÞ»¡Þ¿Çþ╝ûÕåÖ´╝îÕøᵡñÞ┐ÉÞíîkafkaÚ£ÇÞªüÚªûÕàêÕçåÕñçscalaþø©Õà│þÄ»ÕóâÒÇé
    > cd kafka01  
    > ./sbt update  
    > ./sbt package  
    > ./sbt assembly-package-dependency
Õ£¿þ¼¼õ║îõ©¬Õæ¢õ╗ñµùÂÕÅ»Þâ¢Ú£ÇÞªüõ©ÇիܵùÂÚù┤´╝îþö▒õ║ÄÞªüõ©ïÞ¢¢µø┤µû░õ©Çõ║øõ¥ØÞÁûÕîàÒÇéµëÇõ╗ÑÞ»ÀÕñºÕ«Â ÞÇÉÕ┐âþé╣ÒÇé
5) ÕÉ»Õè¿kafka01
    >JMX_PORT=9997 bin/kafka-server-start.sh config/server.properties &  
a)kafka02µôìõ¢£µ¡ÑÚ¬ñõ©Äkafka01ÚøÀÕÉî´╝îõ©ìÕÉîþÜäÕ£░µû╣Õªéõ©ï
┬á ┬á õ┐«µö╣kafka02/config/server.properties
    broker.id=2
    port=9092
┬á ┬á ##ÕàÂõ╗ûÚàìþ¢«ÕÆîkafka-0õ┐صîüõ©ÇÞç┤
┬á ┬á ÕÉ»Õè¿kafka02
    JMX_PORT=9998 bin/kafka-server-start.shconfig/server.properties &  
b)kafka03µôìõ¢£µ¡ÑÚ¬ñõ©Äkafka01ÚøÀÕÉî´╝îõ©ìÕÉîþÜäÕ£░µû╣Õªéõ©ï
┬á ┬á õ┐«µö╣kafka03/config/server.properties
    broker.id=3
    port=9093
┬á ┬á ##ÕàÂõ╗ûÚàìþ¢«ÕÆîkafka-0õ┐صîüõ©ÇÞç┤
┬á ┬á ÕÉ»Õè¿kafka02
    JMX_PORT=9999 bin/kafka-server-start.shconfig/server.properties &
6)ÕêøÕ╗║Topic(ÕîàÕɽõ©Çõ©¬ÕêåÕî║´╝îõ©ëõ©¬Õ뻵£¼)
    >bin/kafka-create-topic.sh--zookeeper 192.168.0.1:2181 --replica 3 --partition 1 --topicmy-replicated-topic
7)µƒÑþ£ïtopicµâàÕåÁ
    >bin/kafka-list-top.sh --zookeeper 192.168.0.1:2181
    topic: my-replicated-topic  partition: 0 leader: 1  replicas: 1,2,0  isr: 1,2,0
8)ÕêøÕ╗║ÕÅæÚÇüÞÇà
   >bin/kafka-console-producer.sh--broker-list 192.168.0.1:9091 --topic my-replicated-topic
    my test message1
    my test message2
    ^C
9)ÕêøÕ╗║µÂêÞ┤╣ÞÇà
    >bin/kafka-console-consumer.sh --zookeeper127.0.0.1:2181 --from-beginning --topic my-replicated-topic
    ...
    my test message1
    my test message2
^C
10)µØǵÄëserver1õ©èþÜäbroker
  >pkill -9 -f config/server.properties
11)µƒÑþ£ïtopic
  >bin/kafka-list-top.sh --zookeeper192.168.0.1:2181
  topic: my-replicated-topic  partition: 0 leader: 1  replicas: 1,2,0  isr: 1,2,0
ÕÅæþÄ░topicÞ┐ÿµ¡úÕ©©þÜäÕ¡ÿÕ£¿
11´╝ëÕêøÕ╗║µÂêÞ┤╣ÞÇà´╝îþ£ïµÿ»ÕɪÞ⢵ƒÑÞ»óÕê░µÂêµü»
    >bin/kafka-console-consumer.sh --zookeeper192.168.0.1:2181 --from-beginning --topic my-replicated-topic
    ...
    my test message 1
    my test message 2
    ^C
Þ»┤µÿÄõ©ÇÕêçÚ⢵ÿ»µ¡úÕ©©þÜäÒÇé
 
OK,õ╗Ñõ©èÕ░▒µÿ»Õ»╣Kafkaõ©¬õ║║þÜäþÉåÞºú´╝îõ©ìÕ»╣õ╣ïÕñäÞ»ÀÕñºÕ«ÂÕÅèµùµîçÕç║ÒÇé
 
 
ÞíÑÕààÞ»┤µÿÄ´╝Ü
1ÒÇüpublic Map<String, List<KafkaStream<byte[], byte[]>>> createMessageStreams(Map<String, Integer> topicCountMap)´╝îÕàÂõ©¡Þ»Ñµû╣µ│òþÜäÕÅéµò░MapþÜäkeyõ©║topicÕÉìþº░´╝îvalueõ©║topicÕ»╣Õ║öþÜäÕêåÕî║µò░´╝îÞ¡¼ÕªéÞ»┤Õªéµ×£Õ£¿kafkaõ©¡õ©ìÕ¡ÿÕ£¿þø©Õ║öþÜätopicµù´╝îÕêÖõ╝ÜÕêøÕ╗║õ©Çõ©¬topic´╝îÕêåÕî║µò░õ©║value´╝îÕªéµ×£Õ¡ÿÕ£¿þÜä޻ش╝îÞ»ÑÕñäþÜävalueÕêÖõ©ìÞÁÀõ╗Çõ╣êõ¢£þö¿
 
2ÒÇüÕà│õ║Äþöƒõ║ºÞÇàÕÉæµîçÕ«ÜþÜäÕêåÕî║ÕÅæÚÇüµò░µì«´╝îÚÇÜÞ┐çÞ«¥þ¢«partitioner.classþÜäÕ▒׵ǺµØѵîçÕ«ÜÕÉæÚéúõ©¬ÕêåÕî║ÕÅæÚÇüµò░µì«´╝îÕªéµ×£Þç¬ÕÀ▒µîçÕ«ÜÕ┐àÚí╗þ╝ûÕåÖþø©Õ║öþÜäþ¿ïÕ║Å´╝îÚ╗ÿÞ«ñµÿ»kafka.producer.DefaultPartitioner,ÕêåÕî║þ¿ïÕ║ŵÿ»Õƒ║õ║ĵòúÕêùþÜäÚö«ÒÇé
 
3ÒÇüÕ£¿ÕñÜõ©¬µÂêÞ┤╣ÞÇàÞ»╗ÕÅûÕÉîõ©Çõ©¬topicþÜäµò░µì«´╝îõ©║õ║åõ┐ØÞ»üµ»Åõ©¬µÂêÞ┤╣ÞÇàÞ»╗ÕÅûµò░µì«þÜäÕö»õ©ÇµÇº´╝îÕ┐àÚí╗Õ░åÞ┐Öõ║øµÂêÞ┤╣ÞÇàgroup_idÕ«Üõ╣ëõ©║ÕÉîõ©Çõ©¬ÕÇ╝´╝îÞ┐ÖµáÀÕ░▒µ×äÕ╗║õ║åõ©Çõ©¬þ▒╗õ╝╝ÚÿƒÕêùþÜäµò░µì«þ╗ôµ×ä´╝îÕªéµ×£Õ«Üõ╣ëõ©ìÕÉî´╝îÕêÖþ▒╗õ╝╝õ©ÇþºìÕ╣┐µÆ¡þ╗ôµ×äþÜäÒÇé
 
4ÒÇüÕ£¿consumerapiõ©¡´╝îÕÅéµò░Þ«¥Þ«íÕê░µò░Õ¡ùÚâ¿Õêå´╝îþ▒╗õ╝╝Map<String,Integer>,
numStream,µîçþÜäÚ⢵ÿ»Õ£¿topicõ©ìÕ¡ÿÕ£¿þÜäµù´╝îõ╝ÜÕêøÕ╗║õ©Çõ©¬topic´╝îÕ╣Âõ©öÕêåÕî║õ©¬µò░õ©║Integer,numStream,µ│¿µäÅÕªéµ×£µò░Õ¡ùÕñºõ║ÄbrokerþÜäÚàìþ¢«õ©¡num.partitionsÕ▒׵Ǻ´╝îõ╝Üõ╗Ñnum.partitionsõ©║õ¥Øµì«ÕêøÕ╗║ÕêåÕî║õ©¬µò░þÜäÒÇé
 
5ÒÇüproducerapi´╝îÞ░âþö¿sendµù´╝îÕªéµ×£õ©ìÕ¡ÿÕ£¿topic´╝îõ╣ƒõ╝ÜÕêøÕ╗║topic´╝îÕ£¿Þ»Ñµû╣µ│òõ©¡µ▓íµ£ëµÅÉõ¥øÕêåÕî║õ©¬µò░þÜäÕÅéµò░´╝îÕ£¿Þ┐ÖÚçîÕêåÕî║õ©¬µò░µÿ»þö▒µ£ìÕèíþ½»brokerþÜäÚàìþ¢«õ©¡num.partitionsÕ▒׵ǺÕå│Õ«ÜþÜä
 
Õà│õ║ÄkafkaÞ»┤µÿÄÕÅ»õ╗ÑÕÅéÞÇâ´╝Ühttp://kafka.apache.org/documentation.html
 
http://www.aboutyun.com/thread-9341-1-1.html



þø©Õà│µÄ¿ÞìÉ
kafkaÕ»╣µÂêµü»õ┐ØÕ¡ÿµùµá╣µì«TopicÞ┐øÞíîÕ¢Æþ▒╗´╝îÕÅæÚÇüµÂêµü»ÞÇàµêÉõ©║Producer,µÂêµü»µÄÑÕÅùÞÇàµêÉõ©║Consumer,µ¡ñÕñûkafkaÚøåþ¥ñµ£ëÕñÜõ©¬kafkaÕ«×õ¥ïþ╗äµêÉ´╝îµ»Åõ©¬Õ«×õ¥ï(server)µêÉõ©║brokerÒÇéµùáÞ«║µÿ»kafkaÚøåþ¥ñ´╝îÞ┐ÿµÿ»producerÕÆîconsumerÚâ¢õ¥ØÞÁûõ║Äzookeeper...
õ©ïÚØóÕ░åÞ»ªþ╗åõ╗ïþ╗ìKafkaÕàÑÚù¿þÜäþø©Õà│þƒÑÞ»åþé╣ÒÇé **Kafkaþ«Çõ╗ï** Kafkaµÿ»õ©Çõ©¬ÕêåÕ©âÕ╝ŵÁüÕñäþÉåÕ╣│ÕÅ░´╝îÕ«âþÜäµá©Õ┐âÕèƒÞ⢵ÿ»µÂêµü»ÚÿƒÕêùþ│╗þ╗ƒ´╝îþö¿õ║ÄÕñäþÉåÕñºÚçÅÕ«×µùµò░µì«þÜäÕÅæÕ©âÕÆîÞ«óÚÿàÒÇéÕ«âÞó½Þ«¥Þ«íõ©║Õ£¿ÕêåÕ©âÕ╝ÅþÄ»Õóâõ©¡Þ┐ÉÞíî´╝îÕÅ»õ╗ÑÕñäþÉåÚ½ÿÕ╣ÂÕÅæþÜäÞ»╗ÕåÖÞ»Àµ▒é´╝î...
### KafkaÕàÑÚù¿þƒÑÞ»åþé╣Þ»ªÞºú #### õ©ÇÒÇüµªéÞ┐░õ©Äþ│╗þ╗ƒþÄ»Õóâ Kafkaµÿ»õ©Çµ¼¥Õ╝║ÕñºþÜäÕêåÕ©âÕ╝ŵÂêµü»þ│╗þ╗ƒ´╝îõ©╗ÞªüÕ║öþö¿õ║ÄÕ«×µùµò░µì«ÕñäþÉåÕ£║µÖ»ÒÇéÕàÂÚ½ÿµòêþÜäµò░µì«õ╝áÞ¥ôÞâ¢ÕèøÕÆîÚ½ÿÕÉ×ÕÉÉÚçÅþë╣µÇºõ¢┐ÕàÂÕ£¿Õñºµò░µì«ÚóåÕƒƒÕÅùÕê░Õ╣┐µ│øÚØÆþØÉÒÇé - **þ│╗þ╗ƒþÄ»Õóâ**´╝ܵ£¼µûçµíú...
- **þÄ»ÕóâµÉ¡Õ╗║**´╝ܵîçÕ»╝Õªéõ¢òÕ«ëÞúàÚàìþ¢«KafkaÚøåþ¥ñÒÇé - **Õƒ║µ£¼µôìõ¢£**´╝ÜÕîàµï¼ÕêøÕ╗║topicÒÇüÕÅæÕ©âµÂêµü»ÒÇüµÂêÞ┤╣µÂêµü»þ¡ëÕƒ║µ£¼Õæ¢õ╗ñþÜäõ¢┐þö¿ÒÇé - **µòàÚÜ£µÄƵƒÑ**´╝ÜÕ©©ÞºüÚù«ÚóÿÕÅèÞºúÕå│µû╣µ│òµ▒çµÇ╗ÒÇé - **Ú½ÿþ║ºþë╣µÇº**´╝ÜÕªéõ║ïÕèíµö»µîüÒÇüµÁüÕñäþÉåþ¡ëÚ½ÿþ║ºþë╣µÇºþÜä...
- ÕìܵûçµÄ¿ÞìÉ´╝ÜÒÇèZookeeperÚøåþ¥ñµÉ¡Õ╗║ÒÇï´╝Ühttps://www.cnblogs.com/ysocean/p/9860529.html µ¡ñÕñû´╝îÕ«×ÞÀÁµÿ»µúÇÚ¬îþÉåÞ«║þÜäµ£ÇÕÑ¢µû╣Õ╝Å´╝îÕÅ»õ╗ÑÚÇÜÞ┐çÕêøÕ╗║þ«ÇÕìòþÜäKafkaþöƒõ║ºÞÇàÕÆîµÂêÞ┤╣ÞÇàÕ║öþö¿µØÑþ僵éëAPI´╝îÕ╣ÂÚÇɵ¡ÑµÄóþ┤óµø┤ÕñìµØéþÜäÕ£║µÖ»´╝îÕªéÕ«╣ÚöÖ...
#### õ©ëÒÇüÞ«¥Þ«íÕăþÉå **1ÒÇüµîüõ╣àµÇº** KafkaÕ░åµò░µì«Õ¡ÿÕé¿Õ£¿þí¼þøÿõ©è´╝îÕ╣Âõ©öÚççþö¿õ║åÚóäÕåÖÕ╝ŵùÑÕ┐ù(WAL)µ£║ÕêµØÑþí«õ┐صò░µì«þÜäµîüõ╣àµÇºÒÇéÞ┐ÖµäÅÕæ│þØǵëǵ£ëµò░µì«ÕåÖÕàÑõ╣ïÕëìÚâ¢õ╝ÜÕàêÕåÖÕàÑÕê░µùÑÕ┐ùõ©¡´╝îþí«õ┐ØÕì│õ¢┐Õ£¿þ│╗þ╗ƒÕ┤®µ║âþÜäµâàÕåÁõ©ïõ╣ƒõ©ìõ╝Üõ©óÕñ▒µò░µì«ÒÇé **2...
### KafkaÕ¡ªõ╣áÞ»ªþ╗åµûçµíúþ¼öÞ«░ #### õ©ÇÒÇüÕàÑÚù¿ **1ÒÇüþ«Çõ╗ï** Kafkaµÿ»þö▒LinkedInÕ╝ǵ║ÉþÜäõ©Çµ¼¥ÕêåÕ©âÕ╝ÅþÜäµÁüÕñäþÉåÕ╣│ÕÅ░´╝îÕàµá©Õ┐âÕèƒÞâ¢Õ£¿õ║ĵÂêµü»...ÚÇÜÞ┐çµÀ▒ÕàÑþÉåÞºúÕàÂÞ«¥Þ«íÕăþÉåÕÆîÕ║öþö¿Õ£║µÖ»´╝îÕÅ»õ╗ÑÕ©«Õè®Õ╝ÇÕÅæÞÇàµø┤ÕÑ¢Õ£░Õê®þö¿KafkaÞºúÕå│Õ«×ÚÖàÚù«ÚóÿÒÇé
Kafkaµÿ»õ©Çõ©¬Ú½ÿµÇºÞâ¢ÒÇüÕêåÕ©âÕ╝ÅþÜäµÁüÕñäþÉåÕ╣│ÕÅ░´╝îõ©╗ÞªüÞ«¥Þ«íþø«µáçµÿ»µÅÉõ¥øÕ«×µùÂþÜäµò░µì«ÕñäþÉåÞâ¢ÕèøÒÇéÕ«âþö▒ApacheÞ¢»õ╗ÂÕƒ║Úçæõ╝ÜÕ╝ÇÕÅæ´╝îõ¢┐þö¿ScalaÕÆîJavaþ╝ûÕåÖ´╝îµö»µîüÚ½ÿÕÉ×ÕÉÉÚçÅþÜäµÂêµü»õ╝áÚÇÆ´╝îÕ©©þö¿õ║ÄÕñäþÉåþ¢æþ½Öþö¿µêÀÞíîõ©║µò░µì«ÒÇüµùÑÕ┐ùÞüÜÕÉêÒÇüµÁüÕ╝ŵò░µì«ÕñäþÉåþ¡ë...
µ£¼µûçÕ░åõ╗ÄÕìíÕñ½ÕìíÚøåþ¥ñþÜ䵪éÕ┐ÁÒÇüÕƒ║µ£¼ÕăþÉåÒÇüµÂêÞ┤╣ÞÇà´╝êConsumer´╝ëõ╗ÑÕÅèÕªéõ¢òÕ«ëÞúàÕÆîõ¢┐þö¿ÕìíÕñ½ÕìíÚøåþ¥ñþ¡ëµû╣ÚØóÞ┐øÞíîÞ»ªþ╗åõ╗ïþ╗ìÒÇé ÚªûÕàê´╝îÕìíÕñ½ÕìíÚøåþ¥ñµÿ»þö▒ÕñÜõ©¬ÕìíÕñ½Õìíõ╗úþÉå´╝êBroker´╝ëµ×äµêÉþÜä´╝îµ»Åõ©¬õ╗úþÉåÚ⢵ÿ»õ©Çõ©¬þï¼þ½ïþÜäµ£ìÕèíÕÖ¿Þèéþé╣ÒÇéõ╗úþÉåõ╣ïÚù┤...
1. **Úâ¿þ¢▓õ©ÄÚàìþ¢«**´╝ÜKafkaÚøåþ¥ñþÜäµÉ¡Õ╗║ÒÇüÞèéþé╣µë®Õ▒òÒÇüÚàìþ¢«õ╝ÿÕîûþ¡ëÒÇé 2. **þøæµÄºõ©ÄÞ░âÞ»ò**´╝ÜÚÇÜÞ┐çKafkaþÜäþ«íþÉåÕÀÑÕàÀ´╝îÕªéKafka-topics.shÒÇüKafka-console-consumer.shþ¡ë´╝îþøæµÄºÚøåþ¥ñþèµÇü´╝îµÄƵƒÑÚù«ÚóÿÒÇé 3. **Õ«ëÕ࿵ĺÕêÂ**´╝ÜKafkaµö»µîü...
õ╗Äþ╗ÖÕç║þÜäÕåàÕ«╣µØÑþ£ï´╝îµ£¼õ╣ªµÅÉõ¥øõ║åÕ»╣KafkaþÜäÕà¿ÚØóõ╗ïþ╗ì´╝îõ©ìõ╗àÕîàµï¼Õƒ║þíǵªéÕ┐ÁÕÆîÕ«ëÞúàµîçÕìù´╝îÞ┐ÿÞ»ªþ╗åÞ«▓Þºúõ║åKafkaÚøåþ¥ñþÜäµÉ¡Õ╗║ÒÇüÞ«¥Þ«íÕăþÉåÒÇüþ╝ûþ¿ïµÄÑÕÅúõ╗ÑÕÅèõ©ÄÕàÂõ╗ûþ│╗þ╗ƒþÜäÚøåµêɵû╣µ│òÒÇ鵡ñÕñû´╝îµ£¼õ╣ªÞ┐ÿµÅÉõ¥øõ║åÕà│õ║ÄKafkaþöƒõ║ºÞÇàÕÆîµÂêÞ┤╣ÞÇàþ╝ûþ¿ïÕ«×ÞÀÁþÜä...
- þÄ»ÕóâµÉ¡Õ╗║´╝ÜÕ£¿Õ¡ªõ╣áHadoopõ╣ïÕëì´╝îÚªûÕàêÚ£ÇÞªüÕçåÕñçõ©Çõ©¬ÕÉêÚÇéþÜäþÄ»ÕóâÒÇéÞ┐ÖÕîàµï¼ÚÇëµï®µôìõ¢£þ│╗þ╗ƒ´╝êÚÇÜÕ©©µÿ»Linux´╝ëÒÇüÕ«ëÞúàJavaþ¡ëÕ┐àÞªüÞ¢»õ╗ÂÒÇé - Úàìþ¢«Õìòµ£║µ¿íÕ╝Å´╝ܵ£Çþ«ÇÕìòþÜäHadoopÚâ¿þ¢▓µû╣Õ╝ŵÿ»Õ£¿Õìòõ©¬Þèéþé╣õ©èÞ┐øÞíî´╝îÞ┐Öþºìµû╣Õ╝ÅÚÇéÕÉêÕêØÕ¡ªÞÇàþÉåÞºúÕƒ║µ£¼...
2. **Õ┐½ÚǃÕàÑÚù¿**´╝ܵÅÉõ¥øÕ┐½ÚǃµÉ¡Õ╗║ÕÆîõ¢┐þö¿þÜäµîçÕ»╝ÒÇé 3. **Õ£║µÖ»µòÖþ¿ï**´╝ÜÚÆêÕ»╣Õà©Õ×ïÕ║öþö¿Õ£║µÖ»þ╗ÖÕç║Þ»ªþ╗åþÜäµôìõ¢£µ¡ÑÚ¬ñÒÇé 4. **Õà¿ÚØóÕ╝ÇÕÅæ**´╝ܵÀ▒ÕàѵÄóÞ«¿Ú½ÿþ║ºÕèƒÞâ¢ÕÆîµ£Çõ¢│Õ«×ÞÀÁÒÇé **3.2 MapReduce** **3.2.1 MapReduceþ«Çõ╗ï** MapReduceµÿ»...
- **Úàìþ¢«µûçõ╗Â**´╝Üõ¢┐þö¿ HOCON µá╝Õ╝ÅÞ┐øÞíîÚàìþ¢«ÒÇé - **Õ迵ÇüÚàìþ¢«**´╝ÜÞ┐ÉÞíîµùÂõ┐«µö╣Úàìþ¢«ÒÇé - **Ú╗ÿÞ«ñÚàìþ¢«**´╝ÜAkka µÅÉõ¥øõ║åõ©Çþ│╗ÕêùÚ╗ÿÞ«ñÚàìþ¢«ÕÇ╝ÒÇé #### õ©ëÒÇüActor þø©Õà│µªéÕ┐Á ##### 3.1 Actors - **Õƒ║µ£¼µªéÕ┐Á**´╝ÜActor µÿ» Akka þÜäµá©Õ┐â...
4´╝îõ¢┐þö¿þ╗╝ÕÉêµíêõ¥ïµØÑÕèáÕ╝║Úçìþé╣þƒÑÞ»å´╝îþö¿ÕêçÕ«×þÜäÕ║öþö¿Õ£║µÖ»µÅÉÕìçþ╝ûþ¿ïÞâ¢Õèø´╝îÕààÕêåÕÀ®Õø║ÕÉäõ©¬þƒÑÞ»åþé╣þÜäÕ║öþö¿ÒÇé 5´╝îµò┤õ©¬Þ»¥þ¿ïþÜäÞ«▓ÞºúµÇØÞÀ»µÿ»ÕàêµÅÉÕç║Úù«Úóÿ´╝îþäÂÕÉÄÕêåµ×ÉÚù«Úóÿ´╝îÕ╣Âþ╝ûþ¿ïÞºúÕå│ÞºúÚóÿÒÇé ÚÇéþö¿õ║║þ¥ñ 1ÒÇüÕ»╣Õñºµò░µì«µäƒÕà┤ÞÂúþÜäÕ£¿µáíþöƒÕÅèÕ║öÕ▒èµ»òõ©Ü...
þÉåÞºúÞ┐Öõ║øþ▒╗þÜäÕÀÑõ¢£ÕăþÉåÒÇüÕåàÚâ¿þ╗ôµ×äõ╗ÑÕÅèõ¢┐þö¿Õ£║µÖ»Õ»╣õ║Äþ╝ûÕåÖÚ½ÿµòêõ╗úþáüÞç│Õà│ÚçìÞªüÒÇé - **ÚØóÞ»òµèÇÕÀº**´╝ÜÚÇÜÞ┐çÕ«×õ¥ïÕêåµ×ÉÚØóÞ»òõ©¡Õ©©ÞºüþÜäMapþø©Õà│Úù«Úóÿ´╝îµ»öÕªéÕªéõ¢òÚÇëµï®ÕÉêÚÇéþÜäMapÕ«×þÄ░þ▒╗ÒÇüÞºúÕå│ÕôêÕ©îÕå▓þ¬üþÜäµû╣µ│òþ¡ëÒÇé ##### 2.JavaÚØóÞ»òõ©ôÚóÿÞ»¥ -...
10-hadoopÚøåþ¥ñµÉ¡Õ╗║þÜäµùáÕ»åþÖ╗ÚÖåÚàìþ¢«.avi þ¼¼õ║îÕñ® hdfsþÜäÕăþÉåÕÆîõ¢┐þö¿µôìõ¢£ÒÇüþ╝ûþ¿ï 01-NNÕàâµò░µì«þ«íþÉåµ£║ÕêÂ.avi 02-NNÕÀÑõ¢£µ£║ÕêÂ2.avi 03-DNÕÀÑõ¢£ÕăþÉå.avi 04-HDFSþÜäJAVAÕ«óµêÀþ½»þ╝ûÕåÖ.avi 05-filesystemÞ«¥Þ«íµÇصâ│µÇ╗þ╗ô.av i ...