
一、Spark基础知识梳理
1.Spark是什么?
Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发。Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于Hadoop MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,节省了磁盘IO耗时,号称性能比Hadoop快100倍。
2.Spark性能比Hadoop快原因分解:
(1)传统Hadoop数据抽取运算模型是:
ps:数据的抽取运算基于磁盘,中间结果也是存储在磁盘上。MR运算伴随着大量的磁盘IO。
(2)Spark 则使用内存代替了传统HDFS存储中间结果:
简述:第一代的Hadoop完全使用Hdfs存储中间结果,第二带的Hadoop加入了cache来保存中间结果。而Spark则基于内存的中间数据集存储。可以将Spark理解为Hadoop的升级版本,Spark兼容了Hadoop的API,并且能够读取Hadoop的数据文件格式,包括HDFS,Hbase等。
3.Spark架构图: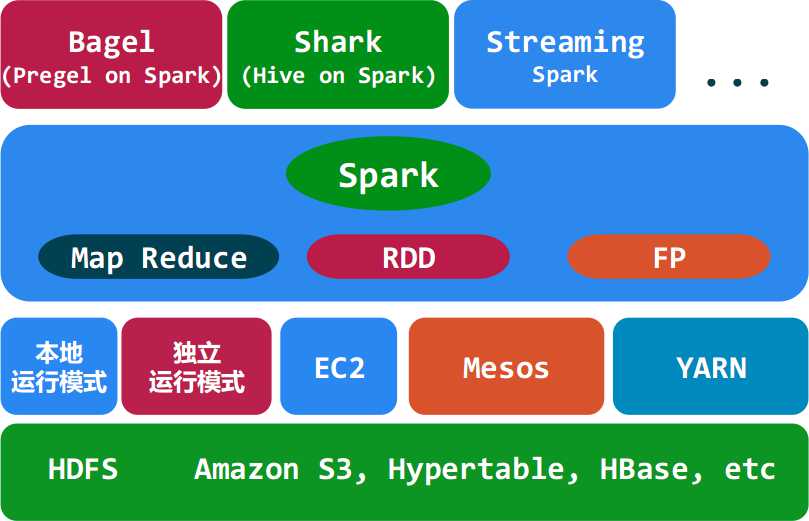
(1)Bagel(pregel on spark):Bagel是基于Spark的轻量级的Pregel(Pregel是Google鼎鼎有名的图计算框架)的实现。
(2)Shark(Hive on Spark):Shark基本上就是在Spark的框架基础上提供和Hive一样的HiveQL命令接口。可以理解为Shark On Spark,就是Hive On Hadoop,两者地位是一样的。ps:Shark可以通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析功能结合在一起(最大化RDD的重复使用)。
(3)Streaming(Spark):Spark Streaming是构建在Spark上的处理实时数据的框架。其基本原理是将Stream数据分成小的时间片段(几秒),以类似batch批处理的方式来处理小部分数据。
(4)RDD(Resilient Distributed Dataset,弹性分布式数据集):RDD是Spark操纵数据的一个高度抽象,即Spark所操作的数据集都是包装成RDD来进行操作的,例如Spark可以兼容处理Hadoop的HDFS数据文件,那么这个HDFS数据文件就是包装成Spark认识的RDD来完成数据抽取和处理的。RDD的一个英文定义是:RDDs are fault-tolerant, parallel data structures that let users explicitly persist intermediate results in memory, control their partitioning to optimize data placement, and manipulate them using a rich set of operators. 用我薄弱的英语能力翻译一下就是:RDD是一个能够让用户可以准确的将中间结果数据持久化到内存中的一个可用错的并行数据结构,可以控制(RDD数据集)分区,优化数据存储,并且有一组丰富的操作集可以操作这份数据。ps:RDD是Spark的一个核心抽象,Spark的数据操作都是基于RDD来完成。
(5)Map Reduce:MR 是Spark可以支撑的运算模式,比传统的Hadoop MR的性能更好,并且操作集更加丰富。Spark的MR计算引擎的架构图:
ps:图中的FP不知道是什么,谁知道可以告诉我一下哈!
(6)Spark的运行模式:apache Mesos和YARN计算两套资源管理框架,Spark最初设计就是跑在这两个资源管理框架之上的,至于Spark的本地运行模式和独立运行模式则是方便了调试。(至于图中的EC2,应该属跑在亚马逊云端的资源管理引擎上的吧,我猜?)。YARN资源管理框架也是Hadoop2.0的产物,大大优化了传统Hadoop通过JobTracker和TaskTracker来调度计算任务的方式,使集群更加平台化,可以部署多中计算引擎,比如传统的Hadoop MR和Spark都可以跑在同一个集群上,YARN这类资源管理框架出现之前是做不到的。
(7)Spark数据的存储:Spark支持多种数据底层存储,这点比Hadoop支持的数据文件格式广泛的多。Spark可以兼容HDFS,Hbase,Amazon S3等多种数据集,将这些数据集封装成RDD进行操作。
4.Spark照比传统Hadoop MR的改进点:
(1)迭代运算,一次创建数据集。多次使用,减少了IO的开销;(2)允许多种计算模型(包含map-reduce);(3)支持非OO式算法实现,对机器学习算法,图计算能力有很好的支持。
5.Spark的适用场景:
Spark立足于内存计算,从而不再需要频繁的读写HDFS,这使得Spark能更好的适用于:
(1) 迭代算法,包括大部分机器学习算法Machine Learning和比如PageRank的图形算法。
(2) 交互式数据挖掘,用户大部分情况都会大量重复的使用导入RAM的数据(R、Excel、python)
(3) 需要持续长时间维护状态聚合的流式计算。
二、Hadoop YARN 基础知识梳理
1.Yarn是什么:
Yarn (Hadoop MapReduceV2)是Hadoop 0.23.0版本后新的map-reduce框架或这更准确的说是框架容器。
架构图:
名词解释:
(1) ResourceManager:以下简称RM。YARN的中控模块,负责统一规划资源的使用。
ps:ResourceManager是YARN资源控制框架的中心模块,负责集群中所有资源的统一管理和分配。它接收来自NM的汇报,建立AM,并将资源派送给AM。
(2) NodeManager:以下简称MM。YARN中的资源结点模块,负责启动管理container。
(3) ApplicationMaster以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动container,并告诉container做什么事情。
(4) Container:资源容器。YARN中所有的应用都是在container之上运行的。AM也是在container上运行的,不过AM也是在Container上运行的,不过AM的container是向RM申请的。
简述:新一代的YARN容器框架,是传统的MR Hadoop容器框架的升级版本,之前的MR部署架构依赖于JobTracker和TaskTracker的交互模式,而新一代的YARN容器框架,则采用了ResourceManager和NodeManager的交互模式,更高层次的抽象和架构设计,是的YARN容器框架能够支撑多种计算引擎运行,包括传统的Hadoop MR和现在的比较新的SPARK。
2.Hadoop YARN产生的背景:
(1)直接源于MRv1(传统的Hadoop MR)如下几个缺陷:
受限的扩展性;单点故障;难以支持MR之外的计算; (2)多计算框架各自为战,数据共享困难。比如MR(离线计算框架),Storm实时计算框架,Spark内存计算框架很难部署在同一个集群上,导致数据共享困难。
简述:Hadoop Yarn的出现则解决了上述问题。
3.Hadoop 1.0到Hadoop 2.0(基于YARN)的演变:
简述:hadoop2.0在传统的MapReduce计算框架和存储框架HDFS之间加了一个YARN层,使得集群框架可以支撑多中计算引擎,包括上文中的SPARK。
4.以Yarn为核心的Hadoop2.0生态系统:
简述:图片简单明了,不多说了。
5.运行在YARN上的计算框架:
(1)离线计算框架:MapReduce
(2)DAG计算框架:Tez
(3)流式计算框架:Storm
(4)内存计算框架:Spark
(5)图计算框架:Giraph,Graphlib
6.Spark On Yarn的调度管理:

7.传统MapReduce 在YARN上的调度:
ps:梳理了一下Spark和YARN的基础概念,初步了解一下哈,细节部分有待深挖!
http://blog.csdn.net/lantian0802/article/details/22507525?utm_source=tuicool



相关推荐
1. **基础知识**:介绍Spark的基本概念、安装配置方法、运行模式等。 2. **实践案例**:通过具体的例子来展示如何使用Spark解决实际问题,如数据分析、机器学习模型训练等。 3. **进阶指南**:深入讲解Spark的内部...
此外,Spark还有许多扩展项目,例如Spark Streaming用于流数据分析,MLlib提供机器学习算法库,GraphX用于图形数据处理,以及SparkSQL提供了类似SQL的数据查询和分析能力。在与Hadoop的整合方面,Spark可以与Hadoop...
在《AI人工智能课程 机器学习技术分享 Spark大数据编程基础(Scala版)》这门课程中,第九章主要介绍了Spark机器学习的基础知识及其在大数据处理中的应用。Spark是一个开源的大规模数据处理框架,它提供了高级API...
分享课程——Spark 2.x + Python 大数据机器学习实战课程,完整版视频课程下载。 本课程系统讲解如何在Spark2.0上高效运用...适合于学习大数据基础知识的初学者,更适合正在使用机器学习想结合大数据技术的人员;
对于初学者来说,理解并掌握以上知识点,可以为深入学习Spark打下坚实基础。通过IDEA这样的集成开发环境,可以更方便地编写、运行和调试Spark程序。在实践中,结合提供的代码示例,逐步熟悉和掌握Spark的API和编程...
本文将从“大数据Spark技术分享 推荐系统的深度学习 共31页.pdf”这一文档出发,详细解析其中涉及的关键知识点。 #### 二、推荐系统概述 推荐系统是一种信息过滤系统,旨在通过预测用户可能感兴趣的内容来提高用户...
这个压缩包中的PPT文件,虽然以英文为主,但它们提供了深入理解Spark框架的关键知识点,对于想要提升Spark技能或研究Spark最新动态的学习者来说,具有极高的学习价值。以下是一些可能涵盖的关键知识点: 1. **Spark...
### 大数据Spark技术分享——面向库开发人员的Apache Spark ...总之,《大数据Spark技术分享——面向库开发人员的Apache Spark》涵盖了从基础知识到高级实践的全面内容,是学习和应用Apache Spark不可或缺的一份指南。
根据提供的文件信息,我们可以归纳出以下关键知识点,主要聚焦于大数据技术、Spark 技术以及在混合云环境下的应用。 ### 大数据技术背景 在当前的信息时代,数据量呈指数级增长,如何高效地存储、处理这些海量数据...
大数据技术分享与Apache Spark调整Spark的知识点主要包括以下几个方面: 1. Spark简介与背景 Apache Spark是一个强大的开源大数据处理引擎,支持大规模数据处理的快速编程。它构建在Hadoop的生态系统之上,可以用来...
首先,官方文档是学习任何技术的基础,Spark的官方文档详细介绍了Spark的核心概念、架构以及API的使用。它涵盖了以下几个主要部分: 1. **Spark概述**:解释了Spark的基本理念,如弹性分布式数据集(RDD)和...
**一、Spark基础知识** Spark是一个快速、通用且可扩展的大数据处理框架,它提供了统一的API用于批处理、交互式查询、流处理和机器学习任务。Spark SQL是Spark的一个模块,允许用户使用SQL或DataFrame API对数据进行...
在《Learning Spark SQL》中,作者Aurobindo Sarkar不仅将介绍Spark SQL的基础,还会带领读者深入了解如何使用Spark SQL构建架构,实现流式分析和机器学习解决方案。读者将学习到如何在不同的大数据应用场景下,有效...
涉及到Spark内核原理、Spark基础知识及应用、Spark基于DataFrame的Sql应用、机器学习等内容。由浅到深的带大家深入学习大数据领域最火的项目Spark。帮助大家进入大数据领域,抓住大数据浪潮的尾巴。
1. **Spark基础知识**:介绍Spark的核心概念,如弹性分布式数据集(RDD)、DataFrame和Dataset,以及Spark的计算模型——弹性分布式计算(Spark Core)。 2. **Spark MLlib库**:讲解Spark的机器学习库MLlib,包括...
总的来说,Bright Spark 1.10是一个全面且实用的电子教育工具,它涵盖了电子学的基础知识,同时通过直观的交互方式,使理论知识与实践操作相结合,降低了学习门槛,提升了学习兴趣。对于想要踏入电子世界的人来说,...
### 大数据Spark技术分享:在规模上使用Spark-Solr为搜索生成Spark #### 关键知识点概述 本文档主要围绕大数据环境下如何有效利用Apache Spark与Apache Solr结合的技术进行大规模搜索系统的构建展开讨论。主要内容...
在"资源达人分享计划"的标签下,这门课程旨在共享高质量的学习资源,鼓励知识的传播和交流。无论你是想提升技能,还是寻求职业发展,这都是一个不容错过的学习机会。记得检查压缩包内的“赚钱项目”文件,它可能包含...