
дё»йўҳ:Levenshtein Distance(LD);
зӣёе…ід»Ӣз»ҚпјҡLevenshtein distanceжҳҜз”ұдҝ„еӣҪ科еӯҰ家Vladimir LevenshteinеңЁ1965е№ҙи®ҫ计并д»Ҙд»–зҡ„еҗҚеӯ—е‘ҪеҗҚзҡ„гҖӮеҰӮжһңдёҚиғҪжӢјеҶҷжҲ–еҸ‘LevenshteinйҹіпјҢйҖҡеёёеҸҜд»Ҙз§°е®ғedit distanceпјҲзј–иҫ‘и·қзҰ»пјүпјӣ
з”ЁйҖ”пјҡиҜҘз®—жі•з”ЁдәҺеҲӨж–ӯдёӨдёӘеӯ—з¬ҰдёІзҡ„и·қзҰ»пјҢжҲ–иҖ…еҸ«жЁЎзіҠеәҰгҖӮдёӘдәәзҗҶи§Је°ұжҳҜе·®ејӮзЁӢеәҰгҖӮиҖҢе·®ејӮзҡ„ж ҮеҮҶе°ұжҳҜ1пјүеҠ дёҖдёӘеӯ—жҜҚ(Insert),2)еҲ дёҖдёӘеӯ—жҜҚ(Delete),3ж”№еҸҳдёҖдёӘеӯ—жҜҚ(Substitute)гҖӮ
В
В
з®—жі•жҸҸиҝ°пјҡ
В
|
Step |
Description |
|
1 |
Set n to be the length of s.Set m to be the length of t. |
|
2 |
Initialize the first row to 0..n. |
|
3 |
Examine each character of s (I from 1 to n). |
|
4 |
Examine each character of t (j from 1 to m). |
|
5 |
If s[i] equals t[j], the cost is 0. |
|
6 |
Set cell d[I,j] of the matrix equal to the minimum of: |
|
7 |
After the iteration steps (3, 4, 5, 6) are complete, the distance is found in cell d[n,m]. |
1гҖҒВ В еҫ—еҲ°жәҗдёІsй•ҝеәҰnдёҺзӣ®ж ҮдёІtзҡ„й•ҝеәҰmпјҢеҰӮжһңдёҖж–№дёәзҡ„й•ҝеәҰ0пјҢеҲҷиҝ”еӣһеҸҰдёҖж–№зҡ„й•ҝеәҰгҖӮ
2гҖҒВ В еҲқе§ӢеҢ–(n+1)*(m+1)зҡ„зҹ©йҳөdпјҢ第дёҖиЎҢ第дёҖеҲ—зҡ„еҖјдёә0еўһиҮіеҜ№еә”зҡ„й•ҝеәҰгҖӮ
3гҖҒВ В йҒҚеҺҶж•°з»„дёӯзҡ„жҜҸдёҖдёӘеӯ—з¬Ұ(i,jд»Һ1ејҖе§Ӣ)гҖӮеҰӮжһңs[i]дёҺt[j]зҡ„еҖјзӣёзӯүпјҢcostеҖјдёә0пјҢеҗҰеҲҷдёә1гҖӮD[i][j]зҡ„еҖјдёәd[i-1,j] + 1(е·Ұиҫ№зҡ„еҖјеҠ 1)гҖҒd[I,j-1] + 1.(дёҠиҫ№зҡ„еҖјеҠ 1)гҖҒd[i-1,j-1] + cost (ж–ңдёҠи§’зҡ„еҖјеҠ cost)В дёӯзҡ„жңҖе°ҸиҖ…гҖӮ
4гҖҒВ В зӯү第дёүжӯҘйҒҚеҺҶе®ҢеҗҺпјҢеҸідёӢи§’d[n,m]зҡ„еҖје°ұдёәдёӨдёӘеӯ—з¬ҰдёІзҡ„и·қзҰ»гҖӮ
В
В
еә”з”Ёжј”зӨәпјҡsource:wordдёҺtarget:worldжҜ”иҫғиҝҮзЁӢгҖӮ
В
В 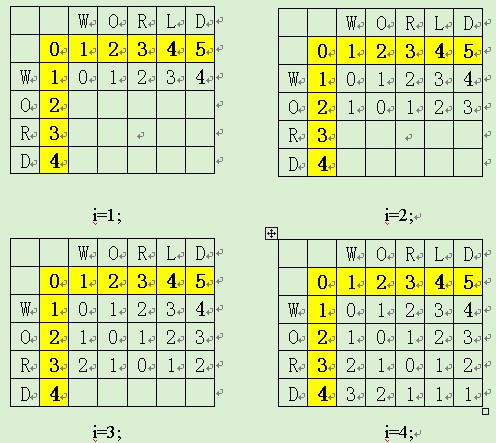
В
В
В
В
В
В
В
В
В
В
В
В
В
В
В
еә”з”ЁдёҫдҫӢпјҡжҚ®гҖҠејҖеҸ‘иҮӘе·ұзҡ„жҗңзҙўеј•ж“ҺвҖ”вҖ”Lucene 2.0+Heriterx
гҖӢи®°иҪҪP134йЎөи®°иҪҪпјҢluceneдёӯFuzzyQuery(жЁЎзіҠеҢ№й…Қ)е°ұжҳҜеә”з”ЁиҜҘз®—жі•зҡ„пјӣд№ҹеҸҜз”ЁдәҺSpell checking(жӢјеҶҷжЈҖжҹҘ),Speech recognition(иҜӯеҸҘиҜҶеҲ«),DNA analysis(DNAеҲҶжһҗ) ,Plagiarism detection(жҠ„иўӯжЈҖжөӢ)гҖӮ
еҸӮиҖғиө„ж–ҷпјҡ
http://www.merriampark.com/ld.htm
В
http://my.oschina.net/MrMichael/blog/339217



зӣёе…іжҺЁиҚҗ
`FuzzyQuery`еҹәдәҺLevenshteinи·қзҰ»з®—жі•пјҢиҜҘз®—жі•и®Ўз®—дёӨдёӘеӯ—з¬ҰдёІд№Ӣй—ҙзҡ„е·®ејӮзЁӢеәҰпјҢз”ЁдәҺиЎЎйҮҸе®ғ们зҡ„зӣёдјјжҖ§гҖӮ йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒдәҶи§ЈеҰӮдҪ•еҲӣе»әдёҖдёӘ`FuzzyQuery`гҖӮеңЁ`FuzzyQueryDemo.java`иҝҷдёӘзӨәдҫӢж–Ү件дёӯпјҢжҲ‘们еҸҜиғҪдјҡзңӢеҲ°зұ»дјј...
FuzzyQueryе…Ғи®ёи®ҫзҪ®дёҖдёӘжңҖе°Ҹзј–иҫ‘и·қзҰ»пјҲLevenshtein DistanceпјүпјҢиҝҷжҳҜиЎЎйҮҸдёӨдёӘеӯ—з¬ҰдёІд№Ӣй—ҙе·®ејӮзҡ„дёҖз§ҚеәҰйҮҸгҖӮеҪ“з”ЁжҲ·иҫ“е…ҘжҹҘиҜўж—¶пјҢLuceneдјҡиҮӘеҠЁи®Ўз®—жҹҘиҜўиҜҚдёҺе…¶д»–иҜҚжұҮзҡ„зј–иҫ‘и·қзҰ»пјҢ并иҝ”еӣһйӮЈдәӣи·қзҰ»е°ҸдәҺи®ҫе®ҡйҳҲеҖјзҡ„ж–ҮжЎЈгҖӮ йЎ№зӣ®...
дёәдәҶй«ҳж•Ҳең°еӨ„зҗҶе’ҢжЈҖзҙўеӯҳеӮЁзҡ„иҜҚйЎ№пјҲtermпјүпјҢLuceneдҪҝз”ЁдәҶFSTпјҲжңүйҷҗзҠ¶жҖҒиҪ¬жҚўеҷЁпјҢFinite State TransducerпјүиҝҷдёҖж ёеҝғз®—жі•жһ„е»әеҶ…еӯҳзҙўеј•гҖӮFSTз®—жі•дёҚд»…еҸҜд»Ҙз”ЁдәҺеҝ«йҖҹжЈҖзҙўtermдҝЎжҒҜеӯҳеӮЁзҡ„дҪҚзҪ®пјҢиҖҢдё”иҝҳж”ҜжҢҒеҲӨж–ӯдёҖдёӘtermжҳҜеҗҰ...
1. **FuzzyQuery**пјҡйҖҡиҝҮи®ҫзҪ®жЁЎзіҠеәҰеҸӮж•°`fuzziness`пјҢеҰӮ`new FuzzyQuery(new Term("field", "keyword"), Fuzziness.AUTO)`пјҢе…Ғи®ёжҹҘиҜўиҜҚдёҺзҙўеј•иҜҚд№Ӣй—ҙжңүдёҖе®ҡзҡ„зј–иҫ‘и·қзҰ»гҖӮ 2. **WildcardQuery**пјҡдҪҝз”ЁйҖҡй…Қз¬Ұ`?`пјҲд»ЈиЎЁ...
жҖ»зҡ„жқҘиҜҙпјҢ`luceneејҖеҸ‘дёӯз”ЁеҲ°зҡ„jarеҢ…`ж¶үеҸҠеҲ°зҡ„ж ёеҝғжҰӮеҝөжҳҜж–Ү件解жһҗе’Ңе…Ёж–ҮжҗңзҙўгҖӮ`htmlparser.jar`е’Ң`htmllexer.jar`з”ЁдәҺеӨ„зҗҶHTMLпјҢ`pdfbox-0.8.0-incubating.jar`еҲҷжңҚеҠЎдәҺPDFж–ҮжЎЈзҡ„и§ЈжһҗгҖӮдәҶ解并зҶҹз»ғжҺҢжҸЎиҝҷдәӣе·Ҙе…·пјҢе°Ҷжңү...
гҖҠж•ҷдҪ иҝҗз”ЁLuceneз®—жі•гҖӢ LuceneжҳҜдёҖж¬ҫејәеӨ§зҡ„е…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢе®ғжҸҗдҫӣдәҶдё°еҜҢзҡ„дҝЎжҒҜжЈҖзҙўеҠҹиғҪпјҢеҢ…жӢ¬ж–Үжң¬еҲҶжһҗгҖҒзҙўеј•жһ„е»әгҖҒжҗңзҙўд»ҘеҸҠз»“жһңжҺ’еҗҚзӯүгҖӮеңЁж·ұе…ҘзҗҶи§ЈLuceneзҡ„е·ҘдҪңеҺҹзҗҶж—¶пјҢжҲ‘们йҰ–е…ҲиҰҒе…іжіЁзҡ„жҳҜе…¶ж ёеҝғз®—жі•гҖӮ дёҖгҖҒеҚ•дёӘ...
гҖҠж·ұе…ҘзҗҶи§ЈLuceneд№Ӣеӣӣпјҡдё»иҰҒз®—жі•д»Ӣз»ҚгҖӢ LuceneжҳҜдёҖдёӘејәеӨ§зҡ„ејҖжәҗе…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢе®ғеңЁдҝЎжҒҜжЈҖзҙўйўҶеҹҹе…·жңүе№ҝжіӣзҡ„еә”з”ЁгҖӮжң¬иө„ж–ҷж—ЁеңЁд»Ӣз»ҚLuceneеңЁжһ„е»әзҙўеј•гҖҒеўһйҮҸеҪ’并гҖҒжҹҘжүҫе®ҡдҪҚзӯүж–№йқўзҡ„е…ій”®з®—жі•пјҢеё®еҠ©иҜ»иҖ…жӣҙж·ұе…Ҙең°зҗҶи§Је…¶...
ж·ұе…ҘдәҶи§Ј Lucene д№ӢдёүжҺ’еәҸз®—жі• Lucene жҺ’еәҸз®—жі•жҳҜжҗңзҙўеј•ж“Һдёӯзҡ„ж ёеҝғ组件д№ӢдёҖпјҢиҙҹиҙЈе°Ҷжҗңзҙўз»“жһңжҢүз…§зӣёе…іеәҰжҺ’еәҸд»Ҙдҫҝз”ЁжҲ·еҝ«йҖҹжүҫеҲ°жүҖйңҖдҝЎжҒҜгҖӮ Lucene зҡ„жҺ’еәҸз®—жі•дё»иҰҒеҹәдәҺ tf-idf жЁЎеһӢпјҢд»ҘдёӢжҳҜ Lucene жҺ’еәҸз®—жі•зҡ„иҜҰз»Ҷд»Ӣз»Қ...
### Lucene дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸ #### зҹҘиҜҶзӮ№жҰӮи§Ҳ 1. **Luceneз®Җд»Ӣ** 2. **жӯЈеҲҷиЎЁиҫҫејҸ(regex)еңЁLuceneдёӯзҡ„еә”з”Ё** 3. **regexQueryиҜҰи§Ј** 4. **зӨәдҫӢд»Јз Ғи§Јжһҗ** 5. **зҙўеј•еҲӣе»әдёҺжҹҘиҜўжөҒзЁӢ** 6. **жӯЈеҲҷиЎЁиҫҫејҸзҡ„иҜӯжі•** #### ...
### LuceneжЈҖзҙўз®—жі•зҡ„ж”№иҝӣ #### жЈҖзҙўзі»з»ҹйҮҮз”Ёзҡ„жҠҖжңҜ еңЁгҖҠLuceneжЈҖзҙўз®—жі•зҡ„ж”№иҝӣгҖӢдёҖж–ҮдёӯпјҢдҪңиҖ…们д»Ӣз»ҚдәҶ他们жүҖйҮҮз”Ёзҡ„дёҖзі»еҲ—жҠҖжңҜжқҘж”№иҝӣеҹәдәҺLuceneзҡ„жЈҖзҙўзі»з»ҹгҖӮе…·дҪ“иҖҢиЁҖпјҢиҝҷдәӣжҠҖжңҜеҢ…жӢ¬пјҡ 1. **ејҖж”ҫжәҗд»Јз Ғзҡ„ж–Үжң¬жЈҖзҙў...
3. **зә й”ҷз®—жі•**: Lucene5дҪҝз”ЁдәҶзј–иҫ‘и·қзҰ»з®—жі•пјҲеҰӮLevenshteinи·қзҰ»пјүжқҘи®Ўз®—еҚ•иҜҚй—ҙзҡ„зӣёдјјеәҰпјҢжүҫеҲ°жңҖжҺҘиҝ‘зҡ„жӯЈзЎ®жӢјеҶҷгҖӮ 4. **е»әи®®жҺ’еәҸдёҺиҝ”еӣһ**: ж №жҚ®зӣёдјјеәҰеҫ—еҲҶеҜ№зә жӯЈе»әи®®иҝӣиЎҢжҺ’еәҸпјҢ然еҗҺиҝ”еӣһеүҚеҮ дёӘжңҖеҸҜиғҪзҡ„жӯЈзЎ®жӢјеҶҷгҖӮ *...
3. **иҝ‘дјјжҗңзҙў**пјҡйҖҡиҝҮзј–иҫ‘и·қзҰ»пјҲLevenshtein DistanceпјүжҲ–дҪҷејҰзӣёдјјеәҰзӯүз®—жі•пјҢжҹҘжүҫдёҺжҹҘиҜўиҜҚзӣёиҝ‘зҡ„жңҜиҜӯгҖӮ 4. **й«ҳдә®жҳҫзӨә**пјҡжҗңзҙўз»“жһңдёӯеҢ№й…Қзҡ„жҹҘиҜўиҜҚеҸҜд»Ҙиў«й«ҳдә®жҳҫзӨәпјҢдҪҝз”Ё`Highlighter`зұ»е®һзҺ°гҖӮ 5. **жӣҙж–°е’ҢеҲ йҷӨзҙўеј•...
жҖ»д№ӢпјҢLuceneзҡ„BM25зӨәдҫӢжҳҜдёҖдёӘжһҒеҘҪзҡ„еӯҰд№ иө„жәҗпјҢе®ғж¶өзӣ–дәҶд»Һзҙўеј•жһ„е»әеҲ°жҹҘиҜўжү§иЎҢзҡ„е…ій”®жӯҘйӘӨпјҢ并йҖҡиҝҮе®һйҷ…еҜ№жҜ”еұ•зӨәдәҶеҰӮдҪ•дҪҝз”Ёжӣҙе…Ҳиҝӣзҡ„зӣёдјјеәҰз®—жі•жҸҗеҚҮжҗңзҙўж•ҲжһңгҖӮеҜ№дәҺеёҢжңӣеңЁж–Үжң¬жЈҖзҙўйўҶеҹҹж·ұе…Ҙз ”з©¶жҲ–еә”з”ЁLuceneзҡ„ејҖеҸ‘иҖ…жқҘиҜҙпјҢ...
npm install lucene-query-string-builder --save зү№еҫҒ еҲӣе»әжңҜиҜӯеӯ—з¬ҰдёІж—¶иҪ¬д№үluceneзү№ж®Ҡеӯ—з¬Ұ еҢ…еҗ«жүҖжңүluceneз”ЁйҖ”зҡ„иҝҗз®—з¬Ұ з®ҖеҚ•зҡ„lucene.builderеҮҪж•°пјҢз”ЁдәҺе®ҡд№үluceneжҹҘиҜўжһ„е»әеҷЁ з”Ёжі• и®©жҲ‘们зңӢзңӢеҰӮдҪ•дҪҝз”ЁLuceneжҹҘиҜў...
ж”ҜжҢҒи®ёеӨҡејәеӨ§зҡ„жҹҘиҜўзұ»еһӢпјҢжҜ”еҰӮ PhraseQueryгҖҒWildcardQueryгҖҒRangeQueryгҖҒFuzzyQueryгҖҒBooleanQuery зӯүгҖӮ ж”ҜжҢҒи§Јжһҗдәә们иҫ“е…Ҙзҡ„дё°еҜҢжҹҘиҜўиЎЁиҫҫејҸгҖӮ е…Ғи®ёз”ЁжҲ·дҪҝз”Ёе®ҡеҲ¶жҺ’еәҸгҖҒиҝҮж»Өе’ҢжҹҘиҜўиЎЁиҫҫејҸи§Јжһҗжү©еұ•жҗңзҙўиЎҢдёәгҖӮ дҪҝз”ЁеҹәдәҺ...
luceneпјҢluceneж•ҷзЁӢпјҢluceneи®Іи§ЈгҖӮ дёәдәҶеҜ№ж–ҮжЎЈиҝӣиЎҢзҙўеј•пјҢLucene жҸҗдҫӣдәҶдә”дёӘеҹәзЎҖзҡ„зұ» public class IndexWriter org.apache.lucene.index.IndexWriter public abstract class Directory org.apache.lucene.store....
гҖҠж·ұе…Ҙеү–жһҗLuceneдёӯзҡ„дёӯж–ҮеҲҶиҜҚз®—жі•жәҗз ҒгҖӢ еңЁдҝЎжҒҜжЈҖзҙўйўҶеҹҹпјҢLuceneдҪңдёәдёҖж¬ҫејәеӨ§зҡ„е…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢиў«е№ҝжіӣеә”з”ЁдәҺеҗ„з§Қж•°жҚ®жЈҖзҙўзі»з»ҹгҖӮиҖҢдёӯж–ҮеҲҶиҜҚжҳҜLuceneеӨ„зҗҶдёӯж–Үж–Үжң¬ж—¶зҡ„е…ій”®жӯҘйӘӨпјҢе®ғеҶіе®ҡдәҶжҗңзҙўзҡ„еҮҶзЎ®жҖ§е’Ңж•ҲзҺҮгҖӮжң¬ж–Үе°Ҷ...
1. **й«ҳжҖ§иғҪ**пјҡLuceneйҮҮз”ЁдәҶй«ҳж•Ҳзҡ„зҙўеј•е’Ңжҗңзҙўз®—жі•пјҢиғҪеӨҹеңЁжө·йҮҸж•°жҚ®дёӯиҝ…йҖҹжүҫеҲ°еҢ№й…Қзҡ„ж–ҮжЎЈгҖӮ 2. **еҲҶиҜҚеӨ„зҗҶ**пјҡLuceneж”ҜжҢҒеӨҡз§ҚеҲҶиҜҚеҷЁпјҢеҸҜд»ҘеҜ№ж–Үжң¬иҝӣиЎҢеҲҶжһҗпјҢе°ҶеҸҘеӯҗжӢҶеҲҶжҲҗеҸҜжҗңзҙўзҡ„е…ій”®иҜҚгҖӮ 3. **еҖ’жҺ’зҙўеј•**пјҡLucene...
гҖҠAnnotated Lucene дёӯж–ҮзүҲ Luceneжәҗз Ғеү–жһҗгҖӢжҳҜдёҖжң¬ж·ұе…ҘжҺўи®ЁApache Luceneзҡ„д№ҰзұҚпјҢдё“жіЁдәҺжәҗз Ғи§ЈжһҗпјҢеё®еҠ©иҜ»иҖ…зҗҶи§ЈиҝҷдёӘејәеӨ§зҡ„е…Ёж–Үжҗңзҙўеј•ж“Һеә“зҡ„е·ҘдҪңеҺҹзҗҶгҖӮLuceneжҳҜдёҖж¬ҫејҖжәҗзҡ„Javaеә“пјҢе®ғжҸҗдҫӣдәҶй«ҳж•Ҳзҡ„ж–Үжң¬жҗңзҙўеҠҹиғҪпјҢиў«...