
ËߣÂÜ≥ÈóÆÈ¢òÁöÑÈÄöÁî®ÊÄùË∑ØÊòØÂ∞ÜÂàÜËÄåÊ≤ª‰πãÔºàdivide-and-conquerÔºâÔºåÂ∞ܧßÈóÆÈ¢òÂà܉∏∫Ëã•Âπ≤‰∏™Â∞èÈóÆÈ¢òÔºåÂêщ∏™ÂáªÁÝ¥„ÄÇÂú®Â§ßÂûã‰∫íËÅîÁΩëÁöÑÊû∂ÊûÑÂÆûË∑µ‰∏≠ÔºåÊó݉∏ĉ∏ç‰ΩìÁé∞ËøôÁßçÊÄùÊÉ≥„ÄÇ
Êû∂ÊûÑÁõÆÊÝá
- 低成本:任何公司存在的价值都是为了获取商业利益。在可能的情况下,希望一切都是低成本的。
- È´òÊÄßËÉΩ:ÁΩëÁ´ôÊÄßËÉΩÊòØÂÆ¢ËßÇÁöÑÊåáÊÝáÔºåÂè؉ª•ÂÖ∑‰Ωì‰ΩìÁé∞Âà∞ÂìçÂ∫îÊó∂Èó¥„ÄÅÂêûÂêêÈáèÁ≠âÊäÄÊúØÊåáÊÝá„ÄÇÁ≥ªÁªüÁöÑÂìçÂ∫îª∂ËøüÔºåÊåáÁ≥ªÁªüÂÆåÊàêÊüê‰∏ÄÂäüËÉΩÈúÄ˶ʼnΩøÁî®ÁöÑÊó∂Èó¥ÔºõÁ≥ªÁªüÁöÑÂêûÂêê ÈáèÔºåÊåáÁ≥ªÁªüÂú®Êüê‰∏ÄÊó∂Èó¥Âè؉ª•Â§ÑÁêÜÁöÑÊï∞ÊçÆÊĪÈáèÔºåÈÄöÂ∏∏Âè؉ª•Áî®Á≥ªÁªüÊØèÁßí§ÑÁêÜÁöÑÊĪÁöÑÊï∞ÊçÆÈáèÊù•Ë°°ÈáèÔºõÁ≥ªÁªüÁöÑÂπ∂ÂèëËÉΩÂäõÔºåÊåáÁ≥ªÁªüÂè؉ª•ÂêåÊó∂ÂÆåÊàêÊüê‰∏ÄÂäüËÉΩÁöÑËÉΩÂäõÔºåÈÄöÂ∏∏‰πüÁî® QPS(query per second)Êù•Ë°°Èáè„ÄÇ
- 高可用:系统的可用性(availability)指系统在面对各种异常时可以正确提供服务的能力。系统的可用性可
‰ª•Áî®Á≥ªÁªüÂÅúÊúçÂä°ÁöÑÊó∂Èó¥‰∏éÊ≠£Â∏∏ÊúçÂä°ÁöÑÊó∂Èó¥ÁöÑÊØî‰æãÊù•Ë°°ÈáèÔºå‰πüÂè؉ª•Áî®ÊüêÂäüËÉΩÁöѧ±Ë¥•Ê¨°Êï∞‰∏éÊàêÂäüʨ°Êï∞ÁöÑÊØî‰æãÊù•Ë°°Èáè„ÄÇ - Êò쉺∏Áº©ÔºöÊ≥®ÈáçÁ∫øÊÄßÊâ©Â±ïÔºåÊòØÂê¶Âè؉ª•ÂÆπÊòìÈÄöËøáÂäÝÂÖ•Êú∫Âô®Êù•Â§ÑÁê܉∏çÊñ≠‰∏äÂçáÁöÑÁî®Êà∑ËÆøÈóÆÂéãÂäõ„ÄÇÁ≥ªÁªüÁöщº∏Áº©ÊÄß(scalability)ÊåáÂàÜÂ∏ɺèÁ≥ªÁªüÈÄöËøáÊâ©Â±ïÈõÜÁæ§Êú∫Âô®ËßÑÊ®°ÊèêÈ´òÁ≥ªÁªüÊÄßËÉΩÔºàÂêûÂêê„ÄŪ∂Ëøü„ÄÅÂπ∂ÂèëÔºâ„ÄÅÂ≠òÂÇ®ÂÆπÈáè„ÄÅËÆ°ÁÆóËÉΩÂäõÁöÑÁâπÊÄß„ÄÇ
- 高安全:现在商业环境中,经常出现被网站被拖库,用户账户被盗等现象。网站的安全性不言而喻。
典型实现
下面典型的一次web交互请求示意图。
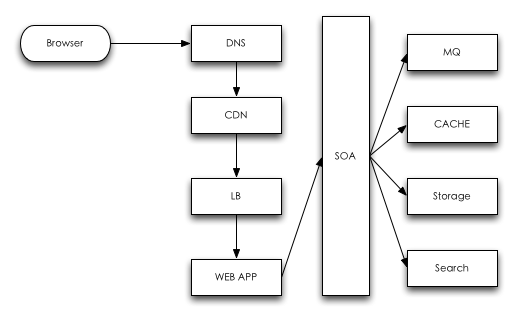
DNS
- 当用户在浏览器中输入网站地址后,浏览器会检查浏览器缓存中是否存在对应域名的解析结果。如果有,则解析过程结束;否则进入下一个步骤
- 浏览器查找操作系统缓存中是否存在这个域名的解析结果。这个缓存的内容来源就是操作系统的hosts文件。如果有,则解析过程结束;否则进入下一个步骤
- 前两个步骤都是本地查找,没有发生网络交互。在本步骤中,会使用到在网络配置的中DNS地址。这个地址我们通常称之为LDNS(Local DNS)。操作系统会把域名发送给LDNS解析。如果解析成功,则解析过程结束;否则进入下一个步骤
- LDNSÂ∞ÜËØ∑ʱÇËøîÂõûÁªôGTLDÔºàGlobal Top Level DomainÔºâÊúçÂä°Âô®ÔºåGTLDÊúçÂä°Âô®Êü•ÊâæÊ≠§ÂüüÂêçÂØπÂ∫îÁöÑName ServerÂüüÂêçÁöÑÂú∞ÂùÄ„ÄÇËøô‰∏™Name ServerÈÄöÂ∏∏Â∞±Êò؉ΩÝÁöÑÂüüÂêçÊèê‰æõÂïÜÁöÑÊúçÂä°Âô®„ÄÇName ServerÊÝπÊçÆÂÆ¢Êà∑ËØ∑ʱÇÔºåËøîÂõûËØ•ÂüüÂêçÂØπÂ∫îÁöÑIPÂú∞ÂùÄÂíåTTL(Time To Live)Âĺ„ÄÇ
- ʵèËßàÂô®ÊÝπÊçÆTTLÂĺԺåÊääËøô‰∏™ÂüüÂêçÂØπÂ∫îÁöÑIPÁºìÂ≠òÂú®Êú¨Âú∞Á≥ªÁªü‰∏≠„ÄÇÂüüÂêçËá≥Ê≠§ËߣÊûêÁªìÊùü„ÄÇ
CDN
CDN(Content Delivery Network,内容分发网络)部署在网络提供商的机房里面。在用户请求网站服务时,可以从距离自己最近的网络提供商获取数据。比如视频网站和内容网站的热点内容。
如果需要自己搭建CDN系统,有3种主流方案可以选择:
- squid是缓存服务器科班出生,自己实现了一套内存页/磁盘页的管理系统
- varnishÊòØËßâÂæósquidÊÄßËÉΩ‰∏çË°åÔºåvarnishËßâÂæólinuxÂÜÖÊÝ∏Â∑≤ÁªèÊääËôöÊãüÂÜÖÂ≠òÁÆ°ÁêÜÂÅöÂæóÂæàÂ•Ω‰∫ÜÔºåsquidÁöѧöÊ≠§‰∏ĉ∏æÂèçËÄåÂΩ±Âìç‰∫ÜÊÄßËÉΩ„ÄÇ
- nginx cache是属于不务正业,得益于nginx强大的插件机制。
LB
LB(Load BalanceÔºåË¥üËΩΩÂùáË°°)Â∞±ÊòØÂ∞ÜË¥üËΩΩÔºàÁî®Êà∑ÁöÑËØ∑ʱÇÔºâÊÝπÊçÆÊüê‰∫õÁ≠ñÁï•ÔºåÂ∞ÜË¥üËΩΩÂàÜÊëäÁªô§ö‰∏™Êìç‰ΩúÂçïÂÖÉÊâßË°å„ÄÇËØ•ÊäÄÊúØÂè؉ª•Êèê‰æõÊúçÂä°Âô®ÁöÑÂìçÂ∫îÈÄüÂ∫¶‰ª•ÂèäÂà©Áî®ÊïàÁéáÔºåÈÅøÂÖçÂá∫Áé∞ÂçïÁÇπ§±Êïà„ÄÇ
ËøôÈáåÂõûÈ°æ‰∏ãÂâçÈù¢‰ªãÁªçÁöщ∏§‰∏™Â∞èËäÇÔºåÂÖ∂ÂÆûÊú¨Ë¥®‰∏äÊääÊï∞ÊçÆÂàÜÁ±ªÔºàÊÝπÊçÆÊï∞ÊçÆÊõ¥Êñ∞È¢ëÁéáÔºåÂà܉∏∫Âä®ÊÄÅÊñቪ∂ÔºåÈùôÊÄÅÊñቪ∂ÔºâÔºåÂπ∂ÊääÊï∞ÊçÆÊîæÂú®Á¶ªË∑ùÁ¶ªÁî®Êà∑ÊúÄËøëÁöÑÂú∞Êñπ„ÄÇÂè¶Â§ñ‰∏ÄÁÇπÂ∞±ÊòØÔºåÂú®DNSÂíåCDNÂÖ∑‰ΩìÂÆûÁé∞Êó∂Ôºå‰πüÊòاßÈáè‰ΩøÁ∫ÜË¥üËΩΩÂùáË°°ÊäÄÊúØ„ÄÇ
Â∏∏ËßÅÁöÑË¥üËΩΩÂùáË°°ÁÆóÊ≥ïÁî±ÔºöRRÔºàRound RobinÔºåËΩÆËØ¢Ôºâ,WRRÔºàWeighted RRÔºåÂäÝÊùÉËΩÆËØ¢ÔºâÔºåRandomÔºàÈöèÊú∫ÔºâÔºåLCÔºàLeast ConnectionÔºåÊúÄÂ∞ëËøûÊé•ÔºâÔºåSHÔºàSource Hash,Ê∫êÂùÄÂìàÂ∏åÔºâ
Âú®Â∏∏ËßÅÁöщ∫íËÅîÁΩëÊû∂Êûщ∏≠ÔºåÈÄöÂ∏∏‰ΩøÁî®ËΩ؉ª∂Ë¥üËΩΩÔºöLVS+HAproxy+WebServerÔºàNginxÔºâ„ÄÇÂú®ÈÉ®ÁΩ≤ Êó∂ÔºåLVSÔºåHAProxyÔºåWebServerÈÉΩ‰ºöÈÉ®ÁΩ≤‰∏ĉ∏™ÈõÜÁæ§ÔºåÁî®Êù•ËøõË°åË¥üËΩΩÂùáË°°„ÄÇLVSÂ∑•‰ΩúÂú®Á¨¨4±ÇÔºåÂú®ÁΩëÁªú±ÇÂà©Áî®IPÂú∞ÂùÄËøõË°åËΩ¨Âèë„ÄÇ HAProxyÂ∑•‰ΩúÂú®Á¨¨7±ÇÔºåÊÝπÊçÆÁî®Êà∑ÁöÑHTTPËØ∑ʱÇÔºàÊØî¶ÇÊÝπÊçÆURLÔºåÊ∂àÊÅا¥ÔºâÊù•ËøõË°åËΩ¨Âèë„ÄÇ
在上述实现中,通常还会使用Keepalived+VIP(虚IP) 技术。Keepalived 提供健康检查,故障转移,提高系统的可用性。通过VIP(配置DNS 绑定域名)的形式对网站进行访问。
WEB APP
前端技术:遵循基本的Web前端优化经验,详见Web前端优化最佳实践及工具集锦
‰ªãÁªç„ÄÇÂè¶Â§ñËøòÂè؉ª•‰ΩøÁî®BigPipeÔºåÂä®ÊÄÅÈ°µÈù¢ÈùôÊÄÅÂåñÔºåÊóÝÈôêʪöÂä®ÁöÑÁøªÈ°µÊäÄÊúØÁ≠âÊäÄÊúØÊèê‰æõÊõ¥Â•ΩÁöÑÁî®Êà∑‰ΩìÈ™å„ÄÇÂè¶Â§ñ‰∏ÄÈÉ®ÂàÜÂ∞±ÊòØËÄÉËôëmobileÊäÄÊú؉∫ÜÔºåËøôÂùóÁ¨îËÄÖÊöÇÊó∂ËøòÊ≤°Ê∂âË∂≥ÔºåÂ∞±‰∏çË∞à‰∫Ü„ÄÇ
后端技术:
- HTTPÂçèËÆÆÔºöHTTPÂçèËÆƧßʶÇÂà܉∏∫ËØ∑ʱǧ¥ÔºåËØ∑ʱljΩìÔºåÂìçÂ∫ԺåÂìçÂ∫î‰Ωì„ÄÇÊóÝËÆ∫ÊòØWebServerËøòÊòØApplicationServerÔºåÂæà§öËä±ÊÝ∑ÈÉΩÊòØÂü∫‰∫éËØ∑ʱǧ¥ÁöÑËØ∑ʱÇË∑ØÂæÑÊù•Áé©ÁöÑ„ÄÇ
- APIÊé•Âè£:‰ΩøÁî®RESTFUL APIÔºåÊö¥Èú≤Êé•Â裄ÄÇÂÆÉÂÖ∑Êúâ¶lj∏ã•Ω§ÑÔºö1.ÂÖÖÂàÜÂà©Áî® HTTP ÂçèËÆÆÊú¨Ë∫´ËØ≠‰πâ„ÄÇ2.Èù¢Âêë˵ÑÊ∫êÔºå‰∏ÄÁõƉ∫ÜÁÑ∂ÔºåÂÖ∑ÊúâËá™ËߣÈáäÊÄß„ÄÇ3.ÊóÝÁä∂ÊÄÅÔºåÂú®Ë∞ÉÁ∏ĉ∏™Êé•Âè£ÔºàËÆøÈóÆ„ÄÅÊìç‰Ωú˵ÑÊ∫êÔºâÁöÑÊó∂ÂÄôÔºåÂè؉ª•‰∏çÁî®ËÄÉËôë‰∏ä‰∏ãÊñáÔºåÊûŧßÁöÑÈôç‰Ωé‰∫ܧçÊùÇÂ∫¶„ÄÇ
- Application Server:在Java中,为了保证程序能够在各个厂商的AS中兼容运行,Sun公司为制定了J2EE规范。从技术发展路径来看, Serverlet,JSP演变都是为了更好地方便程序员们编程。以典型的Tomcat为例,Connector和Container组成一个 Service,多个Service组成一个Server。Connector主要负责接受外部请求,Container负责处理请求。Server提供 了生命周期管理,如启动,停止等。
- Session Framework:在大型互联网架构中,单台机器已经存放不了用户的登录信息。同时为了支持故障转移等特性,需要一套session管理机制,支持海量用户同时在线。通常可以在遵循J2EE的容器内,使用Filter模式和分布式缓存系统来实现。
- MVCÔºöÂç≥ModelÔºåViewÂíåController„ÄÇModel‰ª£Ë°®‰∏öÂä°ÈĪËæëÔºåViewË°®Á§∫È°µÈù¢ËßÜÂõæÔºåControllerË°®Á§∫ÊÝπÊçÆÁî®Êà∑ËØ∑ ʱÇÔºåÊâßË°åÁõ∏Â∫îÁöщ∏öÂä°ÈĪËæëÔºåÂπ∂ÈÄâÊã©ÈÄÇÂΩìÁöÑÈ°µÈù¢ËßÜÂõæËøîÂõû„ÄÇÁî®ËøáRORÁöÑÂêåÂ≠¶ÈÉΩÁü•ÈÅìÔºåÈáåÈù¢ÁöÑrouterÈÖçÁΩƉ∫܉ªÄ‰πàÊÝ∑ÁöÑURLÂí剪ĉπàÊÝ∑ÁöÑactionÁõ∏ÂØπÂ∫î„ÄÇÁõ∏ Â∫îÁöÑÔºåMVCÁöÑÊú¨Ë¥®Â∞±ÊòØÊÝπÊçƉ∏çÂêåÁöÑURLÈÄâÊ㩉∏çÂêåÁöÑservletÊù•ÊâßË°å„ÄÇÂ虉∏çËøáÔºåÁªìÂêà‰∫ÜIntercepting FilterÊèê‰æõ‰∫ܺ∫§ßÁöÑÂäüËÉΩËÄåÂ∑≤„ÄÇ
- IOCÔºöËá≥‰∫é‰∏∫‰ªÄ‰πàÈúÄ˶ÅIOCÔºåÁ¨îËÄÖÂú®ËøôÁØáÊñáÁ´ÝËøõË°å‰∫ÜËÆ®ËÆ∫„ÄÇÁ©∂ÂÖ∂Êú¨Ë¥®ÂÆûÁé∞ÔºåÊóÝÈùûÊòØÂèçÂ∞Ñ+Âçï‰æãÊ®°Âºè+HashÁÆóÊ≥ï+Â≠óËäÇÁÝÅ¢ûº∫+ThreadLocal„ÄÇÂâç3ËÄÖÁî®Êù•ÂÆûÁé∞ÂØπ˱°ÁîüÂëΩÂë®ÊúüÁöÑÁÆ°ÁêÜÔºåÂêé2ËÄÖÁî®Êù•ÊîØÊåÅAOPÔºå£∞Êòéºè‰∫ãÂä°„ÄÇ
- ORMÔºöËøô‰∏™ËØçÂÆûÈôÖ‰∏äÊîæÂú®ËøôÈá剪ãÁªç‰∏秙ÂêàÈÄÇÔºå‰ΩÜÊòØÁ¨îËÄÖÁõÆÂâçÊ≤°ÊÉ≥ÊääÂÆÉÂçïÁã¨ÊãâÂá∫Á´ÝËäÇÊù•ËÆ≤„ÄÇÊÝπÊçÆÁ¨îËÄÖÁöÑÁªèÈ™åÔºåORM‰∏ªË¶ÅÂÆåÊàê‰∫ÜÁ±ªÂíåË°®ÁöÑÊòÝÂ∞ÑÔºåÂØπ˱°Âíå‰∏Ä Êù°Ë°®Êï∞ÊçÆËÆ∞ÂΩïÁöÑÊòÝÂ∞Ñ„ÄÇÂÖ∂ÊÝ∏ÂøÉÂÆûÁé∞ÊòØÈÄöËøájdbcËé∑ÂèñÊï∞ÊçÆÂ∫ìÁöÑmeta‰ø°ÊÅØÔºåÁÑ∂ÂêéÊÝπÊçÆÊòÝÂ∞ÑÂÖ≥Á≥ªÔºàËøôÈáåÂè؉ª•ÈÄöËøáCOCÔºàConversion Over ConfigurationÔºåÁ∫¶ÂÆö‰ºò‰∫éÈÖçÁΩÆÔºâÔºåÊ≥®ËߣÁ≠âÊäÄÊúØÊù•ÁÆÄÂåñÈÖçÁΩÆÔºâÊù•Âä®ÊÄÅÁîüÊàêsqlÂíåËøîÂõûÊï∞ÊçÆÂ∫ìÁöÑÊâßË°åÁªìÊûú„ÄÇ
SOA
网站架构的演进之路,从单一应用架构到垂直应用架构,分布式服务架构以及流动计算架构,越来越体现SOA框架的重要性。这里以优秀的开源实现dubbo为例,简单介绍下。
dubboÁöÑÂäüËÉΩ‰ªãÁªçËßÅÊúçÂä°Ê≤ªÁêÜËøáÁ®ãÔºåÂØπdubboÊû∂ÊûÑËضÁªÜ‰ªãÁªçÁöÑÊúâ¶ljΩïÂ≠¶‰πÝdubboÊ∫ꉪ£ÁÝÅÂíådubboÊ∫ꉪ£ÁÝÅÈòÖËت„ÄÇ
ÁÆÄËÄåˮĉπãÔºåÂ∞±Êò؉ΩøÁ∫ÜspringÁöÑschemaÁöÑÊâ©Â±ïÊú∫Âà∂ÔºåËøõËÄåÊîØÊåÅËá™ÂÆö‰πâdubboÊÝáÁ≠æÔºõÈÄöËøáÁ±ª‰ººserviceloadÊú∫Âà∂ÈÖçÁΩƧö‰∏™ÂèØÈÄâÊúçÂä°„ÄÇÈÄöËøájdkÂä®ÊÄʼnª£ÁêÜÂíåJavassistÔºå‰ΩøÊúçÂä°Ë∞ÉÁî®ÈÄèÊòéÂåñ„ÄÇÁªìÂêàZooKeeperÂÆûÁé∞È´òÂèØÁî®ÂÖÉÊï∞ÊçÆÁÆ°ÁêÜ„ÄÇ
MQ
MQÔºàMessage QueueÔºåÊ∂àÊÅØÈòüÂàóÔºâ‰ΩøÊúçÂä°Ë∞ÉÁî®ÂºÇÊ≠•ÂåñÔºåÂè؉ª•Ê∂àÈô§Âπ∂ÂèëËÆøÈóÆÊ¥™Â≥∞ÔºåÊèêÂçáÁΩëÁ´ôÂìçÂ∫îÈÄüÂ∫¶„ÄÇ Âú®MQÂÆûÁé∞‰∏≠ÔºåÁ¨îËÄÖÂÜôËøá‰∏ÄÁØቪãÁªçKafkaÁöÑÂ≠¶‰πÝÁ¨îËÆ∞ÔºåËضÁªÜ‰ªãÁªçËßÅKafka/MetaqËÆæËÆ°ÊÄùÊÉ≥Â≠¶‰πÝÁ¨îËÆ∞Ôºå‰∏çÂÜç§öˮĄÄÇ
CACHE
CacheÂ∞±ÊòØÂ∞ÜÊï∞ÊçÆÊîæÂà∞Ë∑ùÁ¶ªËÆ°ÁÆóÊúÄËøëÁöÑÂú∞ÊñπÔºåÁî®Êù•ÂäÝÂø´Â§ÑÁêÜÈÄüÂ∫¶„ÄÇÈÄöÂ∏∏ÂØπ‰∏ÄÂÆöÊó∂Èó¥ÂÜÖÁöÑÁÉ≠ÁÇπÊï∞ÊçÆËøõË°åÁºìÂ≠ò„ÄÇ
在使用缓存时,需要注意缓存预热和缓存穿透问题。
‰∏ÄËà¨Êµ∑ÈáèÊï∞ÊçÆÁöÑÁºìÂ≠òÁ≥ªÁªü‰∏牺ö‰ΩøÁî®JavaÊù•ÂÆûÁé∞ÔºåÊòØÂõ݉∏∫JavaÊúâÈ¢ù§ñÁöÑÂØπ˱°Â§ßÂ∞èºÄÈîĉª•ÂèäGCÂéãÂäõ„ÄÇÊâĉª•‰∏ÄËà¨ÊòØÁî®ANSI CÊù•ÂÆûÁé∞„ÄÇÁõÆÂâçÁî®ÁöÑÊØîËæÉÁÅ´ÁöÑÊòØRedisÔºåÊõ¥Â§ö‰ªãÁªçËØ∑Êü•ÁúãRedis˵ÑÊñôʱáÊĪ
STORAGE
在出现NOSQL之前,一统天下的是MySQL分库分表技术。结合类似TDDL等SQL agent技术,也能够执行类似join的操作。后来,就像忽如一夜春风来,出现了很多NOSQL/分布式存储系统产品。
ÂàÜÂ∏ɺèÂ≠òÂÇ®Á≥ªÁªüÊòØÂàÜÂ∏ɺèÁ≥ªÁªü‰∏≠ÊúħçÊùÇÁöщ∏ÄÈÉ®ÂàÜÔºåÁõ∏ÊØîËæÉSOA,CACHEÁ≠âÊ°ÜÊû∂ÔºåÂÆÉÈúÄ˶ÅËߣÂÜ≥ÁöÑÈóÆÈ¢òÊõ¥ÂäݧçÊùÇ„ÄÇÂ∏∏ËßÅÁöÑÈóÆÈ¢ò¶lj∏ãÔºö
- 数据分布 在多台服务器之间保证数据分布均匀,跨服务器如何读写
- 一致性 异常情况下如何保证副本一致性
- 容错 把发生故障当成常态来设计,做到检测是否发生故障并进行故障迁移
- 负载均衡 新增、移除服务器时如何负载均衡 数据迁移如何不影响已有服务
- 事务并发控制 如何实现分布式事务,如何实现多版本并发控制
- ÂéãÁº©„ÄÅËߣÂéãÁº© ÊÝπÊçÆÊï∞ÊçÆÁâπÁÇπÈÄâÊã©ÊÅ∞ÂΩìÁÆóÊ≥ïÔºå¶ljΩïÂπ≥Ë°°Êó∂Èó¥ÂíåÁ©∫Èó¥ÁöÑÂÖ≥Á≥ª„ÄÇ
当笔者阅读完《大规模分布式存储系统原理解析与架构实战》和google的两篇存储论文后,感觉里面的实现细节太多了。如果要写的话,还是后面单独列一片把。所以这里暂且略过。
其他
还有其他方面的知识,等后面积累再多些,再重点写吧,这里仅仅是索引下,读者可以自行略过。
- 配置数据、元数据管理系统:可以查看这篇ZooKeeper和Diamond有什么不同
- ÊêúÁ¥¢Á≥ªÁªüÔºöÊú∫Âô®Â≠¶‰πÝÂàÜÊûêÁî®Êà∑Ë°å‰∏∫ÔºåÁªìÂêàÊêúÁ¥¢ËøõË°åÊé®ËçêÊéíÂêç„ÄÇ ÂêÑÁßç§ßÊï∞ÊçÆÂàÜÊûêÂ∑•ÂÖ∑„ÄÇ
- ‰∫ëËÆ°ÁÆóÔºöÁ°¨‰ª∂ËôöÊãüÂåñ„ÄÇÂàõ‰∏öÂÖ¨Âè∏Âè؉ª•Ë¥≠‰π∞‰∫ëÊúçÂä°ÔºåÈÅøÂÖçÂõ∫ÂÆö˵щ∫ߺÄÈîÄÔºåÂèØËÉΩÈó≤ÁΩÆÔºå Ë¥≠‰π∞ÔºåÁÆ°ÁêÜÔºåÂÆâË£ÖË¥πÁî® ÔºåÊóÝÊ≥ïËøÖÈÄüË¥≠‰π∞Á≠âÈóÆÈ¢òÔºå±û‰∫éʵÆÂä®Ê∂àË¥πÔºåÁ±ª‰ººÂºÄËΩ¶ÂíåÁßüËΩ¶ÁöÑÂå∫Âà´Ôºå‰ªÖÊòØÁßüÁî®ÊúçÂä°„ÄÇ ‰∫ëÂéÇÂïÜÂú®ËÉΩÊ∫êÔºåÂà∂ÂÜ∑ÔºåËøêÁª¥ÊàêÊú¨ÔºåÈáè§ßÁ°¨‰ª∂ÂÆöÂà∂ÔºåÂÖÖÂàÜÂà©Áî®Èó≤ÁΩÆ˵ÑÊ∫êÂÖ∑Êú≺òÂäø„ÄÇ
- Èπ∞ÁúºÁ≥ªÁªüÔºöÊó•ÂøóËßÑËåÉÂåñ+ÊâìÁÇπ+Êï∞ÊçÆÂàÜÊûê+ÊÝëÁä∂±ïÁé∞ÔºåËضÁªÜ‰ªãÁªçÂè؉ª•ÂèÇËÄÉ Èπ∞Áúº‰∏ãÁöÑÊ∑òÂÆù-ÂàÜÂ∏ɺèË∞ÉÁî®Ë∑üË∏™Á≥ªÁªü‰ªãÁªç
- Á≥ªÁªüËøêÁª¥Ôºö ÁõÆÊÝáÊòØËá™Âä®ÂåñËøêÁª¥„ÄÇ
- ÁõëÊéßÂêÑÁßç˵ÑÊ∫êÊåáÊÝáÔºö
- OS:(cpu,memory,disk(空间,读写次数))
- 网络流量
- 中间件: tomcat, jvm,
- MQ:ÈÄöËøáÁõëÊéßÁîü‰∫ßËÄÖÔºåbrokerÔºåÊ∂àË¥πËÄÖ‰πãÈó¥ÁöÑÈòüÂàóÊÉÖÂܵԺåÂä®ÊÄÅÂÜ≥ÂÆö¢ûÂäÝ„ÄÅÂáèÂ∞ëÊ∂àË¥πËÄÖ
- 服务框架自省(运维监控) 依赖关系统计,前台系统访问路径,
- 显示各种监控结果:Agent —》 Explorer ,Analyze,Visual,Dashboard,Share。
- 预警,运维 自动、手工降级,系统问题自动排查甚至问题自动修复,
- ÁõëÊéßÂêÑÁßç˵ÑÊ∫êÊåáÊÝáÔºö
- 能源节省:能源消耗(CPU,机柜,水冷)
- 系统安全:涉及系统的方方面面,各种脚本,sql注入,0day等等。
- ÁâàÊú¨ÂºÄÂèë„ÄÅÁâàÊú¨ÂèëÂ∏ÉÔºöºÄÂèëÁéØ¢ÉÔºåʵãËØïÁéØ¢ÉÔºåÊîØÊåźÄÈÄüÂèëÂ∏ÉÔºå‰∏çÁî®Â§ßÁöÑcycleÔºåÁÅ∞Ëâ≤ÂèëÂ∏ÉÔºåÂõûʪöÈôçÁ∫ßʵÅÁ®ãÔºåÂë®ËæπÂçèË∞É„ÄÇ Â§ß‰ºóÁÇπËØÑÁöÑÊúâ‰∏™ÂÖ≥‰∫éºÄÂèëÁéØ¢ÉÊê≠ª∫ÁöÑÔºåÊÑüÂÖ¥Ë∂£ÁöÑÂè؉ª•ÁÇπÂáªÊâìÈÄÝÈ´òÊïàÁöÑÂçïÊú∫ºÄÂèëÁéØ¢ɄÄÇ
- Êï∞ÊçƉ∏≠ÂøÉÔºöÂú®„ÄäÁ®ãÂ∫èÂëò„Äã2014Âπ¥Á¨¨‰∏ÄÊúü‰ªãÁªçÈáåÈù¢ÔºåÊèêÂà∞‰∫ÜÈòøÈáå‰ΩøÁ∫ÜZONEÁöÑʶÇÂøµÊù•ËߣÂÜ≥Ê®™ÂêëÊâ©Â±ïÁöÑÈóÆÈ¢ò„ÄÇÈòøÈáå‰∏ªË¶ÅÊò؉∏∫‰∫ÜËߣÂÜ≥Êú∫ÊàøÁΩëÁªúÁì∂È¢àÂíåË∂Ö§ßËßÑÊ®°Á≥ªÁªüÁöщº∏Áº©ÊÄßÈóÆÈ¢òÔºåÊääÂÆåÊàêÊüê‰∏ÄÁâπÂÆö‰∏öÂä°ÈúÄ˶ÅÁöÑÁ≥ªÁªü„ÄÅÊÝ∏ÂøÉÊúçÂä°„ÄÅÊï∞ÊçÆÂ∫ìÁªÑÂêàÊàê‰∏ĉ∏™‰∏öÂä°ÂçïÂÖÉ„ÄÇ
参考
- 《深入分析Java Web 技术内幕》
- 《大规模分布式存储系统原理解析与架构实战》
- „Ää§ßÂûãÁΩëÁ´ôÊäÄÊúØÊû∂ÊûÑÊÝ∏ÂøÉÂéüÁê܉∏éÊ°à‰æãÂàÜÊûê„Äã
- 《分布式系统原理介绍》
- 《大规模Web服务开发技术》
- 《程序员》2014年第一期
- google系列论文
- varnish / squid / nginx cache 有什么不同?
- RESTful的优点
¬Ý¬Ý¬Ý ËΩ¨ËΩΩËá≥http://my.oschina.net/geecoodeer/blog/202693



相关推荐
一、基础架构概述 大型网站的基础架构通常包括前端、后端、数据库、缓存、负载均衡、分布式系统等多个层面。前端负责用户交互,后端处理业务逻辑,数据库存储数据,缓存提高数据访问速度,负载均衡分发请求,分布式...
„ÄêÊÝáÈ¢ò„ÄëÔºö‚ÄúʵÖÊûê‰∏≠§ßÂû㉺ʼn∏öÁΩëÁöщ∫íËÅîÁΩëÊû∂ÊûÑ‚Äù „ÄêÊèèËø∞„ÄëÔºöÊú¨Êñá‰∏ªË¶ÅÊé¢ËÆ®‰∫܉∏≠§ßÂû㉺ʼn∏öÁΩëÁªúÂú®Èù¢‰∏¥ÂÖ¨ÁΩëIPÂú∞ÂùÄÁü≠Áº∫ÈóÆÈ¢òÊó∂Ôºå¶ljΩïÂà©Áî®NATÔºàÁΩëÁªúÂú∞ÂùÄËΩ¨Êç¢ÔºâÊäÄÊúØÊù•ÊûѪ∫‰∫íËÅîÁΩëÊû∂ÊûÑԺ剪•Êª°Ë∂≥§ßÈáèÁî®Êà∑ÂêåÊó∂‰∏äÁΩëÁöÑÈúÄʱÇÔºåÂêåÊó∂ËÄÉËôë...
‰ª•‰∏äÂè™ÊòØ„Ää§ßÂûãÁΩëÁ´ôÊäÄÊúØÊû∂ÊûÑÊÝ∏ÂøÉÂéüÁê܉∏éÊ°à‰æãÂàÜÊûê„Äã‰∏≠ÈÉ®ÂàÜÊÝ∏ÂøÉÁü•ËØÜÁÇπÁöÑʶÇËø∞„ÄÇËøôÊú¨‰π¶ËضÁªÜËÆ®ËÆ∫‰∫ÜËøô‰∫õÊäÄÊúØÁöÑÂÆûÁé∞ÁªÜËäÇÂíåÊ°à‰æãÔºåÂØπ‰∫éÊèêÂçáÊû∂ÊûÑÂ∏àÂú®ËÆæËÆ°Âí剺òÂåñ§ßÂûãÁΩëÁ´ôÊó∂ÁöÑËÉΩÂäõÊúâÁùÄÊûŧßÁöÑÂ∏ÆÂä©„ÄÇÈÄöËøáÂØπËøô‰∫õÁü•ËØÜÁÇπÁöÑÁêÜËߣÂíåÂÆûË∑µÔºå...
1. ÁΩëÁ´ôÊû∂ÊûÑʶÇËø∞ §ßÂûãÁΩëÁ´ôÊäÄÊúØÊû∂ÊûÑÈÄöÂ∏∏ÊåáÁöÑÊò؉∏∫ʪ°Ë∂≥§ßÈáèÁî®Êà∑ËÆøÈóÆ„ÄÅÊï∞ÊçƧÑÁêÜÂíåÈ´òÂèØÁî®ÊÄß˶ÅʱÇÊâÄÈááÁî®Áöщ∏ÄÁ≥ªÂàóÊäÄÊúØÊñπÊ°àÂíåËÆæËÆ°ÂéüÂàô„Älj∏鉺ÝÁªüÁöщ∏≠Â∞èËßÑÊ®°ÁΩëÁ´ôÁõ∏ÊØîÔºå§ßÂûãÁΩëÁ´ôÂú®Áî®Êà∑Èáè„ÄÅÊï∞ÊçÆÈáè„ÄÅËÆøÈóÆÈáèÁ≠âÊñπÈù¢ÈÉΩÂëàÁé∞Âá∫Â∑®Â§ßÁöÑËßÑÊ®°...
ÂØπ‰∫é‰∏≠ÂõΩËÄåË®ÄÔºå‰∫íËÅîÁΩëÁΩëÁªúÊû∂ÊûÑÁöÑÂèë±ïÁä∂ÂܵÊòæÁ§∫ÔºåÊàëÂõΩÂü∫Á°ÄÁø°ËøêËê•ÂïÜÂíå§ßÂûã‰∫íËÅîÁΩ뉺ʼn∏öÈÉΩÂú®ÁΩëÁªúÊûѪ∫ÊñπÈù¢ÂèñÂæó‰∫ÜÊòæËëóËøõ±ï„ÄÇÊàëÂõΩÂú®ÂÖ®Áêɉ∫íËÅîÁΩë‰∏≠ÁöÑÂú∞‰Ωç‰∏çÊñ≠ÊèêÂçáÔºåÊóÝËÆ∫ÊòØÂú®ÁΩëÁªúËÉΩÂäõ„ÄÅÁΩëÁªú˵ÑÊ∫êËøòÊòØÁΩëÁªúÊÄßËÉΩÊñπÈù¢ÔºåÈÉΩÂçÝÊçƉ∫ÜÂÖ®ÁêÉ...
前后端分离系统架构概述 概述:前后端分离系统架构是指将 web 应用程序分离成前端和后端两个独立的部分,以提高开发效率、灵活性和可维护性。本文将对前后端分离系统架构进行概述,介绍前后端分离的发展历程、 MVC ...
- **微服务架构**:采用微服务架构,将大型应用分解为一组小而自治的服务,提高开发效率和系统灵活性。 - **自动化运维**:通过自动化工具实现系统的部署、监控和故障恢复,减少人工干预。 #### 技术架构变迁的全...
#### ‰∏Ä„ÄŧßÂûãÁΩëÁ´ôÊû∂ÊûÑʶÇËø∞ §ßÂûãÁΩëÁ´ôÈÄöÂ∏∏ÊòØÊåáÈÇ£‰∫õËÆøÈóÆÈáèÂ∑®Â§ß„ÄÅÊï∞ÊçƧÑÁêÜËÉΩÂäõº∫§߄ÄÅÂπ∂ÂèëÁî®Êà∑Êï∞Èáè§öÁöÑÁΩëÁ´ô„ÄÇËøôÁ±ªÁΩëÁ´ôÈù¢‰∏¥ÁùÄÂ∑®Â§ßÁöÑÊåëÊàòÔºåÂåÖÊ㨉Ω܉∏çÈôê‰∫éʵ∑ÈáèÊï∞ÊçÆÂ≠òÂÇ®„ÄÅÈ´òÂπ∂ÂèëËÆøÈóÆ„ÄÅÂàÜÂ∏ɺèËÆ°ÁÆóÁ≠âÈóÆÈ¢ò„ÄÇÂõÝÊ≠§ÔºåËÆæËÆ°ÂêàÁêÜÁöÑ...
#### 一、大型分布式网站概述 大型分布式网站是指那些处理海量用户访问、存储和处理大量数据的网站系统。随着互联网技术的发展,越来越多的企业和服务依赖于这类系统来满足用户需求。这些系统通常需要具备高可用性...
### 大型应用软件架构的变迁 #### 一、引言 随着信息技术的快速发展和应用场景的不断拓展,大型应用软件的架构也在经历着显著的变化。本文将深入探讨由杨钢先生分享的“大型应用软件架构的变迁”这一主题,重点分析...
#### ‰∏Ä„ÄŧßÂûãÁΩëÁ´ôÊû∂ÊûÑʶÇËø∞ §ßÂûãÁΩëÁ´ôÊû∂ÊûÑÊòØÊåáÈíàÂØπÈ´òÂπ∂Âèë„ÄŧßʵÅÈáèÂú∫Êô؉∏ãÁöÑÁΩëÁ´ôÁ≥ªÁªüÊâÄËÆæËÆ°ÁöÑÂü∫Á°ÄÊû∂ÊûÑ„ÄÇËøôÁ±ªÊû∂ÊûÑÈÄöÂ∏∏ÂÖ∑§áÈ´òÂ∫¶ÂèØÈùÝÊÄß„ÄÅÂÆâÂÖ®ÊÄß„ÄÅÂèØÊâ©Â±ïÊÄßÂíåÊòì‰∫éÁª¥Êä§Á≠âÁâπÁÇπÔºåÊó®Âú®Á°Æ‰øùÁΩëÁ´ôÂú®Èù¢ÂØπʵ∑ÈáèÁî®Êà∑ËÆøÈóÆÊó∂‰æùÁÑ∂ËÉΩ§ü...
ÁΩëÁªúÊúçÂä°Âô®Êû∂ÊûÑʶÇËø∞ ÁΩëÁªúÊúçÂä°Âô®Êû∂ÊûÑʶÇËø∞ÊòØÊåáÂú®ÊÝ°Âõ≠ÊúçÂä°Âô®‰∏≠ÔºåÁªèËøáÈïøÊó∂Èó¥ÁöÑËøêË°åÔºåÊúçÂä°Âô®‰∏≠ÁöÑÂêÑÁßçÁ≥ªÁªüÂ∑≤ÁªèÁ¥ä‰π±ÔºåÈúÄ˶ÅÈáçÊñ∞ÂÆâË£ÖÊìç‰ΩúÁ≥ªÁªüÊàñÂ∫îÁî®ËΩ؉ª∂„ÄÇËøôÁØáÊñáÁ´ÝÂ∞ÜËÆ≤ËߣËΩ؉ª∂Áª¥Êä§ËøáÁ®ã‰∏≠ÊâÄÈúÄÊ≥®ÊÑèÁöщ∏ĉ∫õÈóÆÈ¢ò„ÄÇ ‰∏Ä„ÄÅÂÆâË£ÖÂâçÁöÑ...
云原生架构广泛应用于互联网、金融科技、零售、医疗等多个行业,帮助企业快速构建和调整业务系统,应对市场变化。例如,通过微服务架构,企业可以快速响应客户需求,推出新的功能或服务;借助容器和Kubernetes,可以...
‰∏≠Âè∞ÊäÄÊúØÊû∂Êûщ∏∫‰ºÅ‰∏öÊèê‰æõ‰∫ÜÊõ¥ÂäÝÁŵʥªÂíåÈ´òÊïàÁöÑITÂü∫Á°ÄËÆæÊñΩÔºåÊúâÂ䩉∫鉺ÝÁªü‰ºÅ‰∏öËΩ¨ÂûãÂíå‰∫íËÅîÁΩ뉺ʼn∏öÂàõÊñ∞„ÄÇÁÑ∂ËÄåÔºåÂÆûÊñΩ‰∏≠Âè∞Âπ∂ÈùûÊòì‰∫ãÔºåÈúÄ˶ÅÂÖÖÂàÜÁêÜËߣ‰∏öÂä°ÈúÄʱÇÔºåÂêàÁêÜËßÑÂàíԺ剪•ÂèäÂØπÁé∞ÊúâÁ≥ªÁªüËøõË°åÈÄÇÈÖçÂíåÊîπÈÄÝ„ÄÇÊ≠£Á°ÆÁêÜËߣÂíåËøêÁ∏≠Âè∞ÔºåÂè؉ª•‰∏∫...
一、网站架构概述 大型网站的技术架构是支撑其高并发、高性能、高可用和可扩展性的重要基石。它涉及到多个层次,包括硬件、操作系统、网络、数据库、缓存、分布式系统等。李智慧先生在书中详细讲解了这些层次的设计...
【Windows网络服务器架构概述】 Windows网络服务器架构是一个复杂而精细的体系,主要涉及操作系统安装、维护、网络服务配置以及各种应用系统的部署。本专题将详细阐述这个过程。 首先,安装前的准备工作至关重要。...
随着互联网技术的快速发展与用户需求的日益增长,大型门户网站面临着前所未有的挑战。如何构建一个高效、稳定且可扩展的架构成为了众多技术人员关注的重点。本文将围绕“大型门户网站架构心得”这一主题,深入探讨其...