
GateWay之路由转发和过滤
在一个Gateway项目(配置了eureka等组件)中进行配置
server:
port: 9006
spring:
application:
name: zhao-service-gateway
cloud:
gateway:
routes:
- id: service-autodeliver-router
#uri: http://127.0.0.1:8091
uri: lb://zhao-service-autodeliver
predicates:
- Path= /autodeliver/**
- id: service-resume-router
#uri: http://127.0.0.1:8081
uri: lb://zhao-service-resume
predicates:
- Path=/resume/**
filters:
- StripPrefix=1
通过第一个服务hao-service-autodeliver的配置形式,使用固定ip和服务名均可正常通过网关项目访问到服务,但是固定ip的方式不太灵活,而 lb://zhao-service-autodeliver可以实现随机的负载均衡,且不用填写固定ip也避免了不要的麻烦
第二个服务配置中 filters:- StripPrefix=1这个配置会过滤掉第一个路径配置,所以我们在最后访问的时候,除了需要加上第一个过滤掉的配置,还需要加上原本的配置。访问形式如下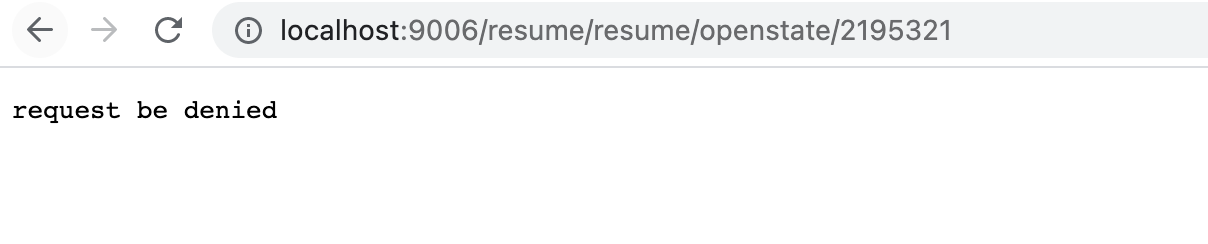
GateWay断言
上述针对路径的配置即是断言predicates的配置,而Gateway还内置了以下几种断言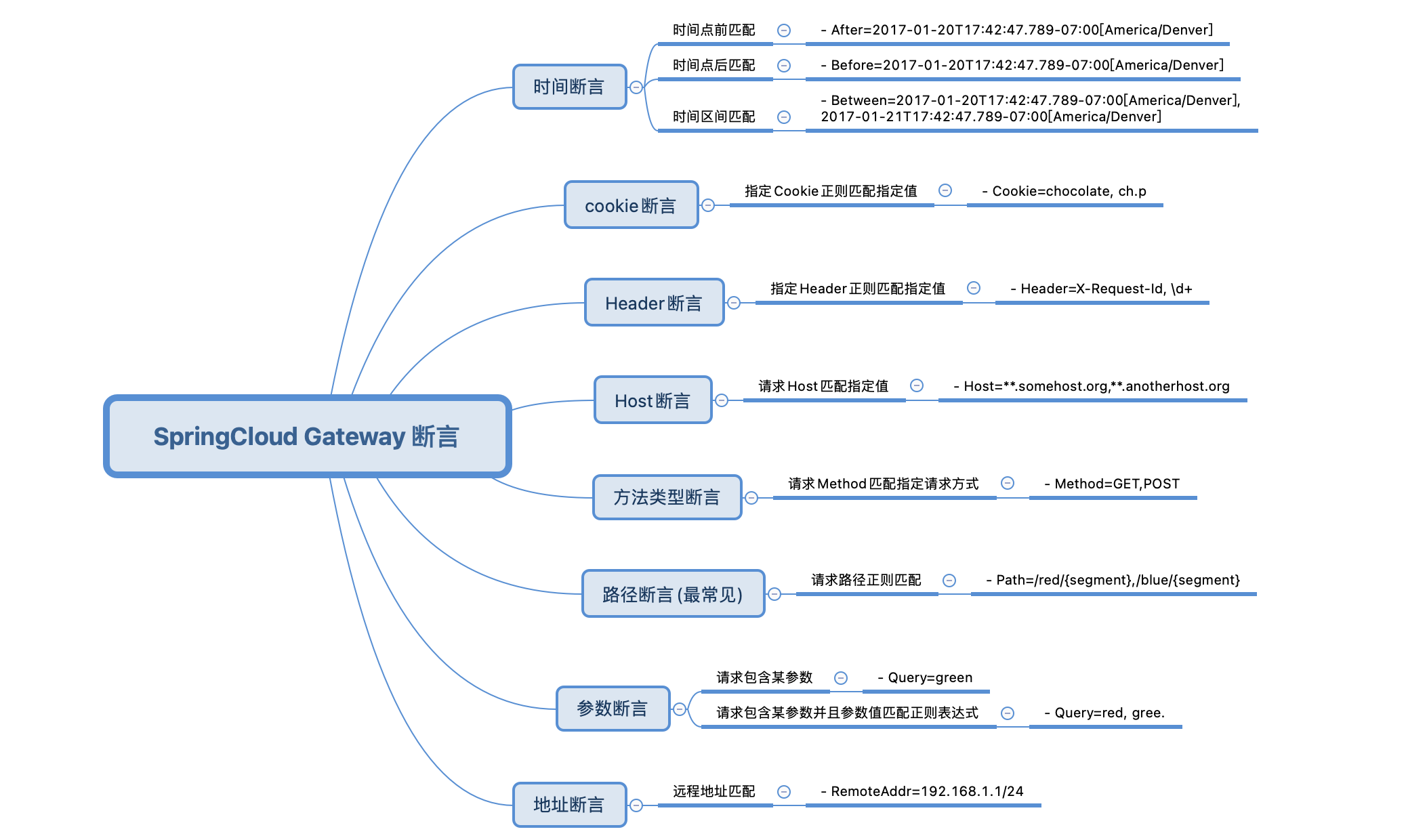
基本上上述断言都是基于请求携带的信息进行过滤的,在实际操作过程中可以综合使用这些信息来达到我们想要的操作
GateWay自定义全局过滤器
//www.fhadmin.cn
@Component
@Slf4j
public classBlackListFilterimplementsGlobalFilter, Ordered{
private static final List<String> blackList=new ArrayList<>();
static {
blackList.add("0:0:0:0:0:0:0:1");//模拟本机ip地址
}
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain){
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response =exchange.getResponse();
String clientIp = request.getRemoteAddress().getHostString();
if (blackList.contains(clientIp)){
response.setStatusCode(HttpStatus.UNAUTHORIZED);
log.error(clientIp+"在黑名单中,拒绝访问");
String data = "request be denied";
DataBuffer wrap = response.bufferFactory().wrap(data.getBytes());
return response.writeWith(Mono.just(wrap));
}
return chain.filter(exchange);
}
@Override
public int getOrder(){
return 0;
}
}
通过该过滤器拦截了黑名单中的请求(该操作在实际中可借助mysql或redis等数据存储实现),实现效果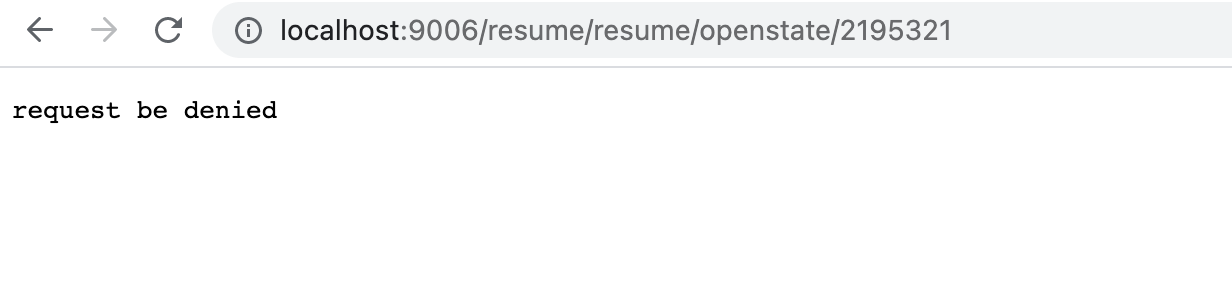
GateWay的高可用
⽹关作为⾮常核⼼的⼀个部件,如果挂掉,那么所有请求都可能⽆法路由处理,因此我们需要做GateWay的⾼可⽤。GateWay的⾼可⽤很简单:可以启动多个GateWay实例来实现⾼可⽤,在GateWay的上游使⽤Nginx等负载均衡设备进⾏负载转发以达到⾼可⽤的⽬的。启动多个GateWay实例(假如说两个,⼀个端⼝9002,⼀个端⼝9003),剩下的就是使⽤Nginx等完成负载代理即可。



相关推荐
这个名为"springcloud Gateway网关-压测用.zip"的压缩包包含了一个用于性能测试的配置,目的是评估和优化Gateway的处理能力。下面我们将深入探讨SpringCloud Gateway的相关知识点,以及如何使用性能测试工具进行压测...
而`Redis.xmind`文件可能是关于Redis缓存的思维导图,虽然不直接涉及Nacos和Spring Cloud Gateway的动态路由,但Redis作为缓存服务,常常与API网关配合使用,用于提升系统性能和减轻数据库压力。 总的来说,结合...
Spring Cloud Gateway 是一款基于Spring生态系统构建的API网关,它主要设计用于提供一种简单而有效的方式来路由API,并为API提供核心关注点,如安全性、监控/度量和弹性。在3.1.3版本中,它利用了Spring Boot 2.x、...
在IT行业中,Spring Cloud Gateway作为Spring Cloud生态体系中的一个关键组件,被广泛用于构建微服务架构中的API网关。这个框架允许我们集中处理各种请求,包括路由、过滤、安全等,极大地简化了服务间的通信。而...
在本文中,我们将深入探讨如何使用Spring Cloud Gateway实现网关转发功能,并整合WebSocket源码,以便在微服务架构中提供高效、灵活的数据通信。首先,让我们先了解一下Spring Cloud Gateway及其重要性。 Spring ...
在构建分布式系统时,Spring Cloud Gateway 作为微服务架构中的边缘服务或 API 网关,扮演着至关重要的角色。它负责路由请求到相应的微服务,并可以提供过滤器功能,如限流、熔断等。而Spring Security 则是 Java ...
Spring Cloud Gateway作为一款基于Spring Framework 5、Project Reactor和Spring Boot 2.0构建的云原生网关框架,它提供了强大的路由转发能力和灵活的过滤器模型,能够很好地满足微服务网关的各种需求。然而,在实际...
下面将详细介绍如何配置和使用Spring Cloud Gateway实现这一功能。 首先,我们需要了解Spring Cloud Gateway的基本结构。它是Spring Cloud生态中的一个API网关服务,提供路由、熔断、限流等能力,可以作为所有...
Spring Cloud Gateway 作为一个流行的微服务网关,提供了强大的路由功能,但是在实际生产中,基于配置文件的配置方式不能满足动态刷新、实时变更的业务需求。因此,扩展 Spring Cloud Gateway 的路由存储功能变得...
SpringCloud Zuul Gateway 服务网关是Spring Cloud生态系统中的一个重要组件,它主要负责微服务架构中的路由转发和过滤器功能。Zuul是Netflix开源的一个边缘服务,而Gateway则是Spring Cloud针对Zuul进行的升级版,...
Spring Cloud Gateway 是一款基于 Spring Framework 5 和 Spring Boot 2 设计的云原生微服务网关,它旨在提供一种简单而有效的方式来对 API 进行路由,同时提供了过滤器功能,可以进行权限验证、限流、日志记录等...
Spring Cloud Gateway 是 Spring Cloud 生态系统中的一个核心组件,主要提供 API 网关的功能。它作为系统的统一入口点,可以进行路由转发、过滤等操作,然而在处理应用响应信息时,可能会遇到乱码问题,这通常与字符...
项目中包含的SpringCloud中文文档将为开发者提供详细的指导,帮助他们理解和使用这些组件。文档通常会涵盖安装配置、基本使用、高级特性以及最佳实践等内容,是学习和实施微服务架构的重要参考资料。 总之,Spring ...
在Spring Cloud生态体系中,Spring Cloud Gateway作为新一代的API网关,被广泛应用于微服务架构中,用于统一处理请求路由、过滤器链、限流、熔断等核心功能。本篇将详细介绍Spring Cloud Gateway的配置文件相关知识...
Spring Cloud Gateway是Spring官方基于Spring 5.0、Spring Boot 2.0和Project Reactor等技术开发的网关,旨在为微服务架构提供一种简单而有效的统一的API路由管理方式。Spring Cloud Gateway的功能包括基于Spring ...
在这个名为"spring-cloud-zookeeper-master"的项目中,开发者可以深入研究如何在Spring Cloud环境中配置和使用Zookeeper作为注册中心,以及如何有效地利用Spring Cloud Gateway构建一个高效的服务网关。通过阅读源...
在使用 SpringCloudGateway2.1 使用手册中文版时,你可以找到关于如何配置路由、使用过滤器、集成服务发现、安全设置等方面的详细指导。手册中应该会包含以下内容: 1. **快速入门**:介绍如何创建基本的 Spring ...
Spring Cloud Gateway 是Spring官方推出的一款现代化的网关服务,它构建于Spring Framework 5、Project Reactor 和 Spring Boot 2之上,提供了高性能、易用的API路由管理、过滤器等功能,是Spring Cloud生态中的重要...
Predicate(谓语、断言)是路由转发的判断条件,目前 SpringCloud Gateway 支持多种方式,常见如:Path、Query、Method、Header 等。Filter(过滤器)是路由转发请求时所经过的过滤逻辑,用于修改请求、响应内容。 ...
Spring Cloud Gateway旨在提供一种简单而有效的API路由方式,并为其提供横切关注点,例如:安全,监控/指标和弹性。 特征: (1)构建于Spring Framework 5,Project Reactor 和 Spring Boot 2.0 (2)能够匹配任何...