
жСШи¶БпЉЪ жСШи¶Б еЬ®дЇТиБФзљСйЂШеЇ¶еПСиЊЊзЪДдїК姩пЉМipadгАБжЙЛжЬЇз≠ЙжЩЇиГљзїИзЂѓиЃЊе§ЗйЪПе§ДеПѓиІБпЉМињРи°МеЬ®еЕґдЄ≠зЪДAPPгАБзљСзЂЩдєЯйЭЮеЄЄе§ЪпЉМе¶ВдљХйЗЗйЫЖзїИзЂѓжХ∞жНЃињЫи°МеИЖжЮРпЉМжПРеНЗиљѓдїґзЪДеУБиі®йЭЮеЄЄйЗНи¶БпЉМдЊЛе¶ВPV/UVзїЯиЃ°гАБзФ®жИЈи°МдЄЇжХ∞жНЃзїЯиЃ°дЄОеИЖжЮРз≠ЙгАВиЩљзДґеЬЇжЩѓзЃАеНХпЉМдљЖжШѓжХ∞жНЃйЗПе§ІпЉМеѓєз≥їзїЯзЪДеРЮеРРйЗПгАБеЃЮжЧґжАІгАБеИЖжЮРиГљеКЫгАБжߕ胥иГљеКЫйГљжЬЙиЊГйЂШзЪДи¶Бж±ВпЉМжР≠еїЇиµЈжЭ•еєґдЄНеЃєжШУгАВ
жСШи¶Б
еЬ®дЇТиБФзљСйЂШеЇ¶еПСиЊЊзЪДдїК姩пЉМipadгАБжЙЛжЬЇз≠ЙжЩЇиГљзїИзЂѓиЃЊе§ЗйЪПе§ДеПѓиІБпЉМињРи°МеЬ®еЕґдЄ≠зЪДAPPгАБзљСзЂЩдєЯйЭЮеЄЄе§ЪпЉМе¶ВдљХйЗЗйЫЖзїИзЂѓжХ∞жНЃињЫи°МеИЖжЮРпЉМжПРеНЗиљѓдїґзЪДеУБиі®йЭЮеЄЄйЗНи¶БпЉМдЊЛе¶ВPV/UVзїЯиЃ°гАБзФ®жИЈи°МдЄЇжХ∞жНЃзїЯиЃ°дЄОеИЖжЮРз≠ЙгАВиЩљзДґеЬЇжЩѓзЃАеНХпЉМдљЖжШѓжХ∞жНЃйЗПе§ІпЉМеѓєз≥їзїЯзЪДеРЮеРРйЗПгАБеЃЮжЧґжАІгАБеИЖжЮРиГљеКЫгАБжߕ胥иГљеКЫйГљжЬЙиЊГйЂШзЪДи¶Бж±ВпЉМжР≠еїЇиµЈжЭ•еєґдЄНеЃєжШУгАВдїК姩жИСдїђжЭ•дїЛзїНдЄАдЄЛеЯЇдЇОйШњйЗМдЇСи°®ж†Ље≠ШеВ®пЉМдї•еПКзЫЄеЕ≥зЪДе§ІжХ∞жНЃдЇІеУБжЭ•йЗЗйЫЖдЄОеИЖжЮРжХ∞жНЃзЪДжЦєж°ИгАВ
TableStore
TableStore(и°®ж†Ље≠ШеВ®)жШѓйШњйЗМдЇСиЗ™дЄїз†ФеПСзЪДдЄУдЄЪзЇІеИЖеЄГеЉПNoSQLжХ∞жНЃеЇУпЉМжШѓеЯЇдЇОеЕ±дЇЂе≠ШеВ®зЪДйЂШжАІиГљгАБдљОжИРжЬђгАБжШУжЙ©е±ХгАБеЕ®жЙШзЃ°зЪДеНКзїУжЮДеМЦжХ∞жНЃе≠ШеВ®еє≥еП∞пЉМжФѓжТСдЇТиБФзљСеТМзЙ©иБФзљСжХ∞жНЃзЪДйЂШжХИиЃ°зЃЧдЄОеИЖжЮРгАВ
зЫЃеЙНдЄНзЃ°жШѓйШњйЗМеЈіеЈійЫЖеЫҐеЖЕйГ®пЉМињШжШѓе§ЦйГ®еЕђжЬЙдЇСзФ®жИЈпЉМйГљжЬЙжИРеНГдЄКдЄЗзЪДз≥їзїЯеЬ®дљњзФ®гАВи¶ЖзЫЦдЇЖйЗНеРЮеРРзЪДз¶їзЇњеЇФзФ®пЉМдї•еПКйЗНз®≥еЃЪжАІпЉМжАІиГљжХПжДЯзЪДеЬ®зЇњеЇФзФ®гАВи°®ж†Ље≠ШеВ®зЪДеЕЈдљУзЪДзЙєжАІеПѓдї•зЬЛдЄЛйЭҐињЩеЉ†еЫЊзЙЗгАВ
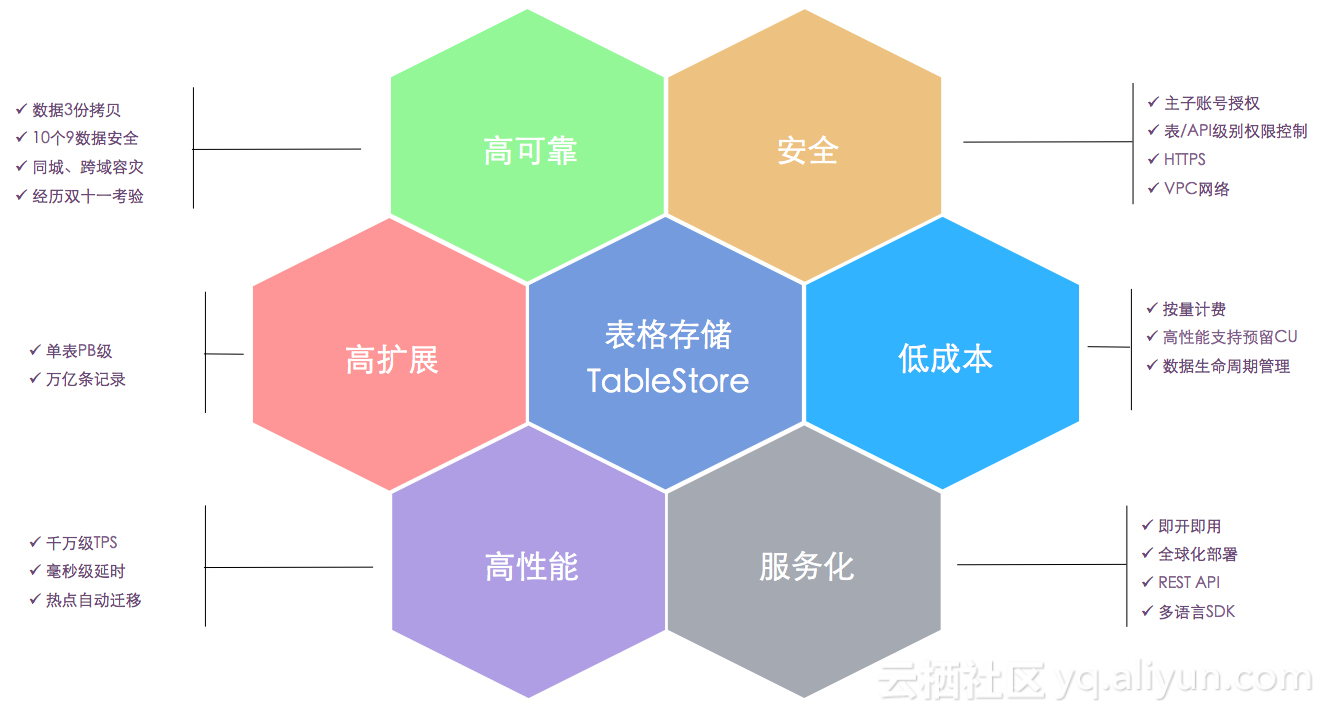
еЯЇдЇОTableStoreзЪДжХ∞жНЃйЗЗйЫЖеИЖжЮРз≥їзїЯ
дЄАдЄ™еЕЄеЮЛзЪДжХ∞жНЃйЗЗйЫЖеИЖжЮРзїЯиЃ°еє≥еП∞пЉМеѓєжХ∞жНЃзЪДе§ДзРЖпЉМдЄїи¶БзФ±е¶ВдЄЛдЇФдЄ™ж≠•й™§зїДжИРпЉЪ¬†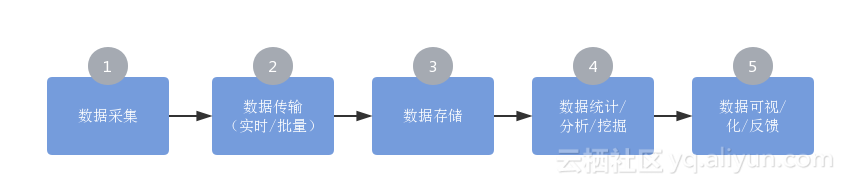
еѓєдЇОдЄКеЫЊжµБз®ЛзЪДеЕЈдљУеЃЮзО∞пЉМзљСдЄКжЬЙиЃЄе§ЪеПѓдї•еПВиАГзЪДж°ИдЊЛпЉМжХ∞жНЃеЬ®еЃҐжИЈзЂѓйЗЗйЫЖеЃМдї•еРОпЉМе¶ВжЮЬйЗПжѓФиЊГе∞ПпЉМжИСдїђеПѓиГљзЫіжО•еЬ®еРОзЂѓзЪДAPIдЄКеБЪдЄАжђ°йАПдЉ†пЉМзДґеРОжМБдєЕеМЦеИ∞RDBMSз±їеЮЛзЪДжХ∞жНЃеЇУдЄ≠е∞±е•љдЇЖпЉМйАЪињЗSqlеПѓдї•ињЫи°МжХ∞жНЃеИЖжЮРгАВе¶ВжЮЬжХ∞жНЃйЗПеЊИе§ІпЉМе∞±йЬАи¶БдЄАдЇЫдЄ≠йЧідїґжЭ•иЊЕеК©жФґйЫЖеТМдЄКдЉ†пЉМзДґеРОеИЖеИЂе∞ЖжХ∞жНЃеЖЩеЕ•еИ∞еЬ®зЇњеТМз¶їзЇњзЪДз≥їзїЯдЄ≠пЉМжѓФе¶ВеЕИдЄКдЉ†еИ∞FlumeпЉМFlumeеПѓдї•еБЪжХ∞жНЃзЪДйЗЗйЫЖдЄОиБЪеРИпЉМеЖНе∞ЖFlumeдљЬдЄЇжґИжБѓзЪДзФЯдЇІиАЕпЉМе∞ЖзФЯдЇІзЪДжґИжБѓжХ∞жНЃйАЪињЗKafka SinkеПСеЄГеИ∞KafkaдЄ≠пЉМKafkaдљЬдЄЇжґИжБѓйШЯеИЧзЪДиІТиЙ≤пЉМеПѓдї•еѓєжО•еРОзЂѓзЪДеЬ®зЇњеТМз¶їзЇњиЃ°зЃЧеє≥еП∞гАВе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ¬†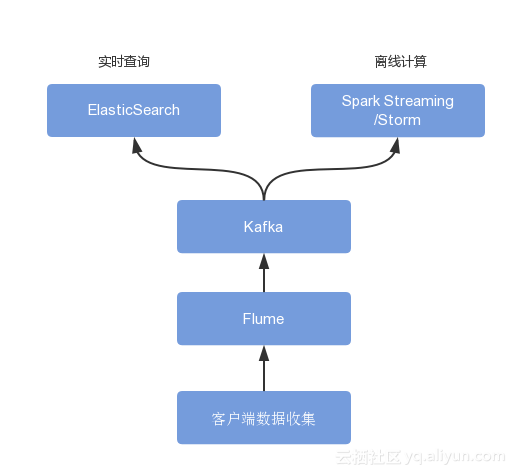
еЉХеЕ•FlumeеТМKafkaзЪДеОЯеЫ†жЬЙеЊИе§ЪпЉМжѓФе¶ВдїЦдїђеПѓдї•е§ДзРЖе§ІжµБйЗПзЪДжХ∞жНЃгАБеБЪжХ∞жНЃиБЪеРИгАБдњЭиѓБжХ∞жНЃдЄН䪥姱з≠ЙпЉМдљЖжЬАеЕ≥йФЃзЪДеОЯеЫ†жШѓдїЦдїђжЛ•жЬЙйЂШеРЮеРРзЪДиГљеКЫгАВеЉХеЕ•зЪДзїДдїґе§ЪпЉМз≥їзїЯзЪДе§НжЭВжАІеТМжИРжЬђдєЯдЉЪзЫЄеЇФзЪДеҐЮеК†пЉМдЄКеЫЊдЄ≠пЉМSpark Streaming/StormеИЖжЮРеЃМжИРдї•еРОпЉМзїУжЮЬжХ∞жНЃињШйЬАи¶БеЉХеЕ•еП¶е§ЦзЪДе≠ШеВ®зїДдїґињЫи°Ме≠ШеВ®пЉМжѓФе¶ВHBase/MySQLпЉМе¶ВжЮЬеЉХеЕ•MySQLеПѓиГљињШйЬАи¶БеЖНеЉХеЕ•RedisеБЪзГ≠зВєжХ∞жНЃзЉУе≠ШпЉМињЩж†ЈдЄАжЭ•е∞±жЫіеК†е§НжЭВдЇЖгАВ¬†
жИСдїђе∞ЭиѓХдЄАзІНеЯЇдЇОTableStoreеТМйШњйЗМдЇСеЕґдїЦе§ІжХ∞жНЃдЇІеУБзЪДжЦ∞жЦєж°ИпЉМжИСдїђеЕИзЬЛжЮґжЮДеЫЊпЉЪ¬†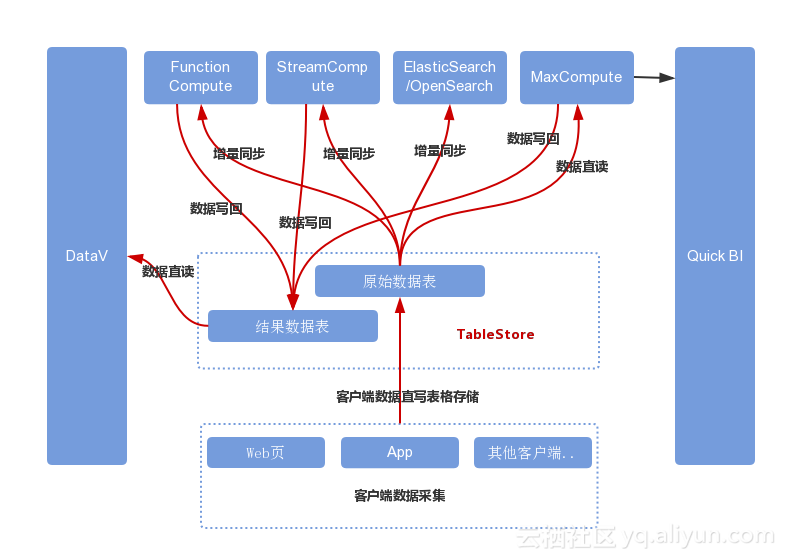
еЫЊдЄ≠еЕ≥йФЃиЈѓеЊДеИЖжЮРпЉЪ¬†
1гАБWebй°µгАБAPPз≠ЙеЃҐжИЈзЂѓеЕИйАЪињЗеЯЛзВєз≥їзїЯжФґйЫЖжХ∞жНЃпЉМзДґеРОйАЪињЗи°®ж†Ље≠ШеВ®зЪДSDKе∞ЖжХ∞жНЃеЖЩеЕ•TableStoreзЪДеОЯеІЛжХ∞жНЃи°®гАВ¬†
2гАБMaxComputeзЫіиѓїTableStoreеОЯеІЛжХ∞жНЃи°®зЪДжХ∞жНЃињЫи°МеИЖжЮРпЉМзДґеРОQuickBIиѓїеПЦMaxComputeзЪДжХ∞жНЃињЫи°Ме±Хз§ЇпЉМеЕЈдљУжУНдљЬеПѓеПВиАГпЉЪMaxComputeзЫіиѓїзЫіеЖЩи°®ж†Ље≠ШеВ®гАБQuickBIжЦ∞еїЇдЇСжХ∞жНЃжЇРгАВ¬†
3гАБTableStoreеОЯеІЛжХ∞жНЃи°®дЄ≠зЪДжХ∞жНЃеПѓеҐЮйЗПеРМж≠•еИ∞ElasticSearchжИЦиАЕopenSearchдЄ≠пЉМеРМж≠•жЦєж≥ХеПВиАГпЉЪTableStoreжХ∞жНЃеРМж≠•еИ∞ElasticSearchпЉМTableStoreжХ∞жНЃеРМж≠•еИ∞OpenSearchгАВ¬†
4гАБTableStoreдЄ≠зЪДжХ∞жНЃеПѓеҐЮйЗПеРМж≠•еИ∞Blink/FlinkињЫи°МеИЖжЮРпЉМеИЖжЮРеЃМдї•еРОзЪДжХ∞жНЃеЖНеЖЩеЫЮTableStoreзЪДзїУжЮЬжХ∞жНЃи°®дЄ≠пЉМDavaVиѓїеПЦзїУжЮЬжХ∞жНЃи°®зЪДжХ∞жНЃињЫи°Ме±Хз§ЇгАВ
жЦ∞жЮґжЮДдЉШеКњеИЖжЮРпЉЪ¬†
1гАБеЃҐжИЈзЂѓжХ∞жНЃзЫіиѓїзЫіеЖЩTableStoreпЉМдЄНйЬАи¶БеЖНеЉХеЕ•APIе±ВињЫи°МжХ∞жНЃйАПдЉ†пЉМйЩНдљОдЇЖе§НжЭВеЇ¶пЉМеѓєдЇОе§ІеЮЛеЇФзФ®жЭ•иѓідєЯеЗПе∞СдЇЖдЄНе∞СзЪДжЬНеК°еЩ®жИРжЬђгАВ¬†
2гАБTableStoreеЈ≤зїПеѓєжО•дЇЖдЄ∞еѓМдЇЖе§ІжХ∞жНЃзїДдїґпЉМеМЕжЛђйШњйЗМдЇСзЪДе§ІжХ∞жНЃдЇІеУБеТМеЉАжЇРе§ІжХ∞жНЃдЇІеУБпЉМжХ∞жНЃзЪДеРМж≠•дЄОиѓїеЖЩйЭЮеЄЄеЃєжШУгАВ¬†
3гАБеЃЮжЧґеИЖжЮРдЄОз¶їзЇњеИЖжЮРеРОзЪДзїУжЮЬжХ∞жНЃеЖНеЖЩеЫЮTableStoreпЉМDataVзЫіжО•иѓїеПЦзїУжЮЬжХ∞жНЃињЫи°Ме±Хз§ЇпЉМеЫ†дЄЇTableStoreеЕЈе§ЗйЂШжАІиГљдЄОйЂШеРЮеРРзЙєзВєпЉМдЄНйЬАи¶БеЖНеЉХеЕ•Redisз≠ЙзЉУе≠ШзїДдїґпЉМеПѓдї•зЃАеМЦжХідЄ™з≥їзїЯгАВ
зЫіиѓїзЫіеЖЩеЃЙеЕ®йЧЃйҐШпЉЪ¬†
еЕ≥дЇОжХ∞жНЃзЫіиѓїзЫіеЖЩTableStoreпЉМе§ІеЃґеПѓиГљйГљдЉЪжГ≥еИ∞дЄАдЄ™еЃЙеЕ®зЪДйЧЃйҐШпЉМеЃҐжИЈзЂѓзЫіињЮTableStoreдЄНжШѓи¶БжККAccessKeyеТМAccessIdжЪійЬ≤еЬ®еЃҐжИЈзЂѓеРЧпЉЯз≠Фж°ИжШѓдЄНзФ®пЉМжИСдїђдљњзФ®STSTokenжОИжЭГиЃњйЧЃTableStoreпЉМињЗз®Ле¶ВдЄЛеЫЊжЙАз§ЇпЉЪ¬†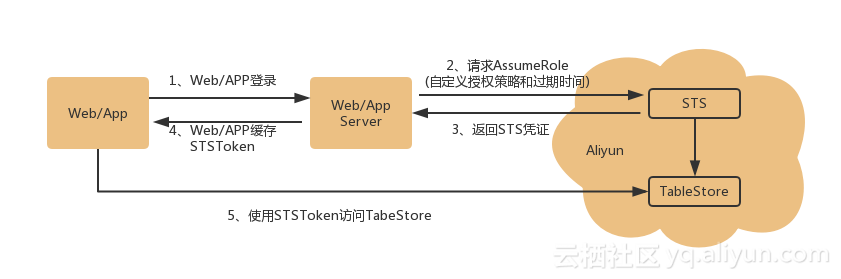
TableStoreжПРдЊЫзЪДSDKйГљжФѓжМБдљњзФ®STSжОИжЭГзЪДжЦєеЉПињЫи°МиЃњйЧЃпЉМз§ЇдЊЛеПѓеПВиАГTableStore NodeJs SDKдљњзФ®STSTokenпЉМдљњзФ®STSжЦєеЉПиЃњйЧЃTableStoreйЬАи¶БжОІеИґе•љжОИжЭГз≠ЦзХ•пЉМеЃҐжИЈзЂѓдЄНйЬАи¶БзЪДжО•еП£иѓЈдЄНи¶БжОИжЭГгАВ
жµПиІИеЩ®иЈ®еЯЯиЃњйЧЃTableStoreпЉЪ¬†
е¶ВжЮЬеЬ®жµПиІИеЩ®зЂѓзЫіжО•иЃњйЧЃTableStoreпЉМзФ±дЇОжµПиІИеЩ®жЬЙеРМжЇРз≠ЦзХ•зЪДйЩРеИґпЉМдЉЪдЇІзФЯиЈ®еЯЯйЧЃйҐШгАВеЫ†дЄЇTableStoreзЪДEndPointеЯЯеРНдЄОзФ®жИЈWebзЂЩзВєзЪДеЯЯеРНдЄНеРМгАВиІ£еЖ≥ињЩдЄ™йЧЃйҐШзЪДжАЭиЈѓжЬЙдЄ§дЄ™пЉЪдЄАжШѓWebзЂѓдЄНзЫіжО•иЃњйЧЃTableStoreпЉМжФєдЄЇеЕИиѓЈж±ВиЗ™еЈ±зЪДWeb ServerзЂѓпЉМWeb ServerзЂѓеЖНдљњзФ®TableStore SDKжЭ•еПСиµЈиѓЈж±ВпЉМињЩж†ЈеЕґеЃЮе∞±жШѓеРОзЂѓиЃњйЧЃдЇЖпЉМйЧЃйҐШиІ£еЖ≥дЇЖдљЖдєЯж≤°дЇЖжИСдїђзЫіиѓїзЫіеЖЩзЪДдЉШеКњпЉЫдЇМжШѓTableStoreжЬНеК°зЂѓйАЪињЗжЯРзІНжЦєеЉПзЫіжО•жФѓжМБjsиЈ®еЯЯиѓЈж±ВпЉМињЩжЭ°иЈѓжИСдїђж≠£еЬ®жФѓжМБељУдЄ≠пЉМељУеЙНе§ДдЇОеЉАеПСйШґжЃµпЉМжФѓжМБзЪДжЦєеЉПжШѓcorsеНПиЃЃжФѓжМБиЈ®еЯЯгАВдљЖзЫЃеЙНдєЯжЬЙењЂжНЈзЪДжФѓжМБжЦєеЉПпЉМе¶ВжЮЬжВ®жЬЙжµПиІИеЩ®зЫіжО•иЃњйЧЃTableStoreзЪДйЬАж±ВпЉМеПѓдї•зЫіжО•иБФз≥їжИСдїђпЉМжФѓжМБиµЈжЭ•дєЯеЊИењЂгАВ¬†
дљЬиАЕпЉЪboxiao



зЫЄеЕ≥жО®иНР
гАКеЯЇдЇОTableStoreзЪДжХ∞жНЃйЗЗйЫЖеИЖжЮРз≥їзїЯгАЛ еЬ®ељУеЙНжХ∞е≠ЧеМЦжЧґдї£пЉМжХ∞жНЃйЗЗйЫЖдЄОеИЖжЮРеЈ≤зїПжИРдЄЇжПРеНЗиљѓдїґиі®йЗПзЪДеЕ≥йФЃзОѓиКВпЉМе¶ВPV/UVзїЯиЃ°гАБзФ®жИЈи°МдЄЇеИЖжЮРз≠ЙгАВйЭҐеѓєжµЈйЗПзЪДжЩЇиГљзїИзЂѓжХ∞жНЃпЉМжЮДеїЇдЄАдЄ™иГље§Яжї°иґ≥йЂШеРЮеРРгАБеЃЮжЧґжАІгАБеИЖжЮРиГљеКЫеТМ...
йШњйЗМдЇСзЪДи°®ж†Ље≠ШеВ®пЉИTablestoreпЉЙжШѓеЃЮзО∞ињЩдЄАз≥їзїЯзЪДеЕ≥йФЃжКАжЬѓгАВеЃГжї°иґ≥дЇЖдЄКињ∞жКАжЬѓйЬАж±ВпЉЪ 1. **е§ЪеЕГ糥еЉХдЄОжРЬ糥еКЯиГљ**пЉЪдљњзФ®SearchIndexжФѓжМБе§ЪзїіеЇ¶жߕ胥еТМеЬ∞зРЖдљНзљЃпЉИGEOпЉЙжߕ胥пЉМдЊњдЇОеЕГжХ∞жНЃзЃ°зРЖгАВ 2. **йЂШеєґеПСе§ДзРЖ**пЉЪеЯЇдЇО...
1. **дЄАзЂЩеЉПжЬНеК°**пЉЪйШњйЗМдЇСжµБиЃ°зЃЧжПРдЊЫдЇЖеЃМжХізЪДжµБеЉПе§ІжХ∞жНЃе§ДзРЖеє≥еП∞пЉМжґµзЫЦдЇЖжХ∞жНЃйЗЗйЫЖгАБе§ДзРЖгАБеИЖжЮРеТМеПѓиІЖеМЦз≠ЙеЕ®йУЊиЈѓйЬАж±ВгАВ 2. **йЂШжАІиГљ**пЉЪйШњйЗМдЇСжµБиЃ°зЃЧйЗЗзФ®BlinkеЉХжУОпЉМеЃГжШѓApache FlinkзЪДдЉБдЄЪзЙИпЉМеЕЈе§ЗеЉЇе§ІзЪДиЃ°зЃЧжАІиГљпЉМ...
зїУжЮДеМЦе§ІжХ∞жНЃе≠ШеВ®пЉМдЊЛе¶ВйШњйЗМдЇСзЪДTablestoreпЉМжШѓдЄУдЄЇйЂШеРЮеРРеЖЩеЕ•еТМе§ІиІДж®°жХ∞жНЃе≠ШеВ®иЃЊиЃ°зЪДпЉМжФѓжМБеЬ®зЇњжߕ胥еТМзЇњжАІжЙ©е±ХпЉМйАВеЇФеЬ®зЇњеИ∞з¶їзЇњзЪДжХ∞жНЃжµБиљђгАВињЩз±їе≠ШеВ®дЄНдїЕйАВеРИйЭЮеЕ≥з≥їеЮЛжХ∞жНЃпЉМдєЯйАВзФ®дЇОеЕ≥з≥їжХ∞жНЃеЇУеОЖеП≤жХ∞жНЃзЪДељТж°£еТМе§І...
еЬ®йШњйЗМдЇСдЄКпЉМињЩдЇЫжО•жФґеИ∞зЪДжХ∞жНЃеПѓдї•е≠ШеВ®еЬ®е§ІжХ∞жНЃе≠ШеВ®жЬНеК°пЉМе¶ВMaxComputeжИЦTable StoreпЉМзФ®дЇОињЫдЄАж≠•еИЖжЮРеТМжМЦжОШгАВеРМжЧґпЉМеПѓдї•йАЪињЗжХ∞жНЃеИЖжЮРеЈ•еЕЈе¶ВQuick BIињЫи°МеПѓиІЖеМЦе±Хз§ЇпЉМдљњеЊЧзФ®жИЈеПѓдї•зЫіиІВеЬ∞зЬЛеИ∞еПСйАБжХ∞жНЃзЪДзКґжАБеТМиґЛеКњгАВ ...
7. **зЙ©иБФзљСIoT**пЉЪйШњйЗМдЇСIoTжПРдЊЫдЇЖзЙ©иБФзљСеє≥еП∞пЉМжФѓжМБиЃЊе§ЗињЮжО•гАБжХ∞жНЃйЗЗйЫЖгАБжХ∞жНЃеИЖжЮРеПКеЇФзФ®еЉАеПСгАВ 8. **еЃєеЩ®жЬНеК°ACKпЉИKubernetesпЉЙ**пЉЪеЯЇдЇОKubernetesзЪДеЃєеЩ®жЬНеК°пЉМиЃ©дЉБдЄЪеПѓдї•иљїжЭЊзЃ°зРЖеТМжЙ©е±ХеЃєеЩ®еМЦеЇФзФ®гАВ 9. **дЇСеОЯзФЯ...
еѓєдЇОйЬАи¶БињЫи°МOLAPпЉИеЬ®зЇњеИЖжЮРе§ДзРЖпЉЙзЪДеЇФзФ®пЉМеЯЇдЇОMariaDBзЪДColumnStoreжШѓдЄАдЄ™дЄНйФЩзЪДйАЙжЛ©пЉМеЫ†дЄЇеЃГдЉШеМЦдЇЖеИЧеЉПе≠ШеВ®пЉМжЬЙеИ©дЇОе§ІжХ∞жНЃжߕ胥гАВ и°®зїУжЮДиЃЊиЃ°жЦєйЭҐпЉМз°ЃдњЭжѓПдЄ™InnoDBи°®йГљжЬЙдЄАдЄ™дЄїйФЃжШѓйЭЮеЄЄењЕи¶БзЪДпЉМињЩжЬЙеК©дЇОдЉШеМЦ糥еЉХеТМ...