- жөҸи§Ҳ: 473417 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

ж–Үз« еҲҶзұ»
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 5)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2011-09 ( 3)
- 2011-08 ( 20)
- 2011-07 ( 16)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
yuan_bin1990пјҡ
жӮЁеҘҪпјҢиҜ·й—®дёӢdemoеҰӮдҪ•иҝҗиЎҢе•ҠпјҢеҮҶеӨҮз ”з©¶з ”з©¶пјҢдҪҶдёҚзҹҘйҒ“е…ҘеҸЈе•ҠгҖӮ ...
ssh2(struts2+spring2.5+hibernate3.3)иҮӘеҠЁз”ҹжҲҗд»Јз ҒзЁӢеәҸ -
luyulongпјҡ
В В В В В В В В В В В В В В В [b][/b][i][/i][ ...
jQueryиҝӣеәҰжқЎжҸ’件 jQuery progressBar -
txin0814пјҡ
mark..
иҜ»еҸ–ж–Ү件зӣ®еҪ• -
vursesпјҡ
[align=center][color=red][size= ...
include дёҺ jsp:includeеҢәеҲ« -
Roshan2пјҡ
http://lijiejava.iteye.com/blog ...
Spring AOP е…Ҙй—Ёе®һдҫӢ
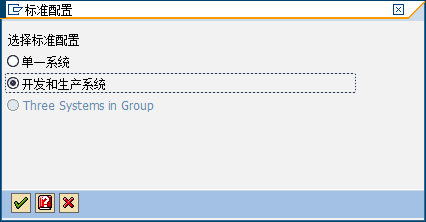
1гҖҒSM59пјҢеҲ йҷӨжүҖжңүеҢ…еҗ«STMSзҡ„иҝһжҺҘ 2гҖҒSTMSпјҢOverview-SystemпјҢеҲ йҷӨжүҖжңүй…ҚзҪ® 3гҖҒзҷ»йҷҶиҮіClient 000 В 4гҖҒSTMSпјҢж–°е»әдј иҫ“жҺ§еҲ¶еҹҹпјҢж–°е»әVisual System й…ҚзҪ®Transport RoutesпјҢ В ж Үзӯҫ:В BW7.0,В BWй…ҚзҪ® В SAP Note 18023 Jobs EU_INIT, EU_REORG, EU_PUT if you have problem, search oss note like Multiple scheduling of the jobs EU_PUT and EU_REORG SAP Note Number: 174645 Symptom What are the jobs EU_INIT (program SAPRSEUC), EU_REORG (program SAPRSLOG), and EU_PUT (program SAPRSEUT), which are automatically scheduled by the ABAP Workbench, used for? Other terms SE80 Reason and Prerequisites The EU jobs are used to reconstruct or update the indexes (where-used lists, navigation indexes, object lists) that are important for the ABAP Workbench. Solution When you start transaction SE80 for the first time, the three EU jobs are scheduled automatically: EU_INIT (single start), EU_REORG (periodically each night), and EU_PUT (periodically each night). Alternatively, You can also schedule the three jobs by manually executing program SAPRSEUJ. Short description of the individual jobs: EU_INIT: EU_INIT is used to completely rebuild the indexes and therefore has a correspondingly long runtime. It starts program SAPRSEUI. All customer-defined programs (selection according to the naming convention) are analyzed, and an index is created that is used in the EU for the where-used lists of function modules, error messages, reports, and do on. This index is automatically updated in dialog mode. The job can be repeated at any time. After a termination, the job is automatically scheduled for the next day; it then starts at the point of termination. (EU_INIT can therefore be terminated deliberately, if it disturbs other activities in the system.) EU_REORG: As mentioned above, the indexes are automatically updated online by the tools. To keep the effort for updating these indices as low as possible, only the changes are logged, which means a reorganization of the complete index for each program is required from time to time. So that this reorganization does not interfere with the online system, the EU_REORG job runs every night and performs this task. If the EU_REORG job did not run one night, this simply means that the reorganization takes place more often online. EU_PUT: The EU_PUT job also runs every night. It starts program SAPRSEUT. This program checks whether customer-defined development objects have been transported into the SAP system with the SAP transport system, and generates or updates the indexes described above whenever required. To create the indexes, the EU jobs analyze the program sources of the development objects. Faulty ABAP programs (sources with grave syntax errors, for example, a literal that is too long because a concluding inverted comma is missing) are skipped. The relevant job continued the analysis with the next program and issues the names of all programs with errors in a list. After correcting the faulty programs, you can update the object lists of the relevant programs in the Repository Browser. To do this, proceed as follows: Up to Release 6.10: Choose вҖңUpdateвҖқ. As of Release 6. 20: go to context menu вҖңOther functionsвҖқ->вҖқRebuild object listвҖқ. жәҗж–ҮжЎЈ <https://forums.sdn.sap.com/thread.jspa?messageID=2813006?> В ж Үзӯҫ:В BW7.0 В Queries RSZELTDIR Directory of the reporting component elements RSZELTTXT Texts of reporting component elements RSZELTXREF Directory of query element references RSRREPDIR Directory of all reports (Query GENUNIID) RSZCOMPDIR Directory of reporting components Workbooks RSRWBINDEX List of binary large objects (Excel workbooks) RSRWBINDEXT Titles of binary objects (Excel workbooks) RSRWBSTORE Storage for binary large objects (Excel workbooks) RSRWBTEMPLATE Assignment of Excel workbooks as personal templates RSRWORKBOOK вҖҳWhere-used listвҖҷ for reports in workbooks Web templates RSZWOBJ Storage of the Web Objects RSZWOBJTXT Texts for Templates/Items/Views RSZWOBJXREF Structure of the BW Objects in a Template RSZWTEMPLATE Header Table for BW HTML Templates BTW: There are only 26,000 tables in our small installation of BW 3.5. Posted In:В adminВ ,В bexВ ,В charВ ,В deltaВ ,В elemВ ,В eventВ ,В genuinidВ ,В globalВ ,В infopakВ ,В initВ ,В lbwq,В qrfcВ ,В queryВ ,В rsa7В ,В settingsВ ,В tablesВ ,В textВ ,В variaВ ,В variantВ ,В workbookВ . By Srinivas Neelam Custome Infoobjects Tabels: /BIC/MВ вҖ”В View of Master data Tables /BIC/PВ вҖ”В Master data Table, Time Independent attributes /BIC/QВ вҖ”В Master data Table, Time Dependent attributes /BIC/XВ вҖ”В SID Table, Time Independent /BIC/YВ вҖ”В SID Tabel, Time Dependent /BIC/TВ вҖ”В Text Table /BIC/HВ вҖ”В Heirarchy Table /BIC/KВ вҖ”В Heirarchy SID Table Standard InfoobjectsВ Tabels(Buss. Content): ReplaceВ вҖңCвҖқВ withВ вҖң0вҖіВ in above tables. Ex:В /BI0/MВ вҖ”В View of Master data Tables Standard InfoCUBE Tables : /BI0/F вҖ”В Fact Table(Before Compression) /BI0/E вҖ”В Fact Table(After Compression) /BI0/P вҖ”В Dimension Table - Data Package /BI0/T вҖ”В Dimension Table - Time /BI0/U вҖ”В Dimension Table - Unit /BI0/1, 2, 3, вҖҰвҖҰ.A,B,C,D : вҖ”В Dimension Tables BW Tables: BTCEVTJOBВ вҖ“В To check List of jobs waiting for events ROOSOURCEВ вҖ”В Control parameters for Datasource ROOSFIELDВ вҖ“В Control parameters for Datasource ROOSPRMSCВ вҖ”В Control parameters for Datasource ROOSPRMSFВ вҖ”В Control parameters for Datasource вҖ“ More info @В ROOSOURCEВ weblog RSOLTPSOURCEВ вҖ“ Replicate Table for OLTP source in BW RSDMDELTAВ вҖ“ Datamart Delta Management RSSDLINITSEL, RSSDLINITDEL вҖ“В Last valid Initialization to an OLTP Source RSUPDINFOВ вҖ” Infocube to Infosource correlation RSUPDDATВ вҖ“В Update rules key figures RSUPDENQВ вҖ“В Removal of locks in the update rules RSUPDFORMВ вҖ”В BW: Update Rules - Formulas - Checking Table RSUPDINFOВ вҖ”В Update info (status and program) RSUPDKEYВ вҖ”В Update rule: Key per key figure RSUPDROUTВ вҖ”В Update rules - ABAP routine - check table RSUPDSIMULDВ вҖ“В Table for saving simulation data update RSUPDSIMULHВ вҖ”В Table for saving simulation data header information RSDCUBEIOBJВ вҖ“ Infoobjects per Infocube RSISВ вҖ“ Infosouce Info RSUPDINFOВ вҖ” Update Rules Info RSTSВ вҖ“ Transfer Rules Info RSKSFIELDВ вҖ“ Communication Structure fields RSALLOWEDCHARВ вҖ“ Special Characters Table(T Code : RSKC, To maintain) RSDLPSELВ вҖ“ Selection Table for fields scheduler(InfpakвҖҷs) RSDLPIOВ вҖ“ Log data packet no RSMONICTABВ вҖ“ Monitor, Data Targets(Infocube/ODS) Table, request related info RSTSODSВ вҖ” Operational data store for Transfer structure RSZELTDIRВ вҖ“ Query Elements RSZGLOBVВ вҖ“ BEx Variables RXSELTXREF, RSCOMPDIRВ вҖ“ Reports/query relavent tables RSCUSTVВ вҖ“ Query settings RSDIOBJВ вҖ“ Infoobjects RSLDPSELВ вҖ” Selection table for fields scheduler(Info pak list) RSMONIPTABВ вҖ“В InfoPackage for the monitor RSRWORKBOOKВ вҖ“ Workbooks & related query genunidвҖҷs RSRREPDIRВ вҖ“ Contains Genuin id, Rep Name, author, etcвҖҰ RSRINDEXTВ вҖ“ Workbook ID & Name RSREQDONEВ вҖ“ Monitor: Saving of the QM entries RSSELDONEВ вҖ“ Monitor : Selection for exected requests RSLDTDONEВ вҖ“ Texts on the requeasted infopacks & groups RSUICDONEВ вҖ“ BIW: Selection table for user-selection update InfocubesвҖҷs RSSDBATCHВ вҖ“ Table for Batch run scheduler RSLDPDELВ вҖ“ Selection table for deleting with full update scheduler RSADMINSVВ вҖ“ RS Administration RSSDLINITВ вҖ” Last Valid Initializations to an OLTP Source BTCEVTJOBВ вҖ“To check event status(scheduled or not) VARIВ вҖ“ ABAP Variant related Table VARIDESCВ вҖ“В Selection Variants: Description T Code : SMQ1 вҖ“> QRFC Monitor(Out Bound) T Code : SM13 вҖ“> Update Records status T Code : LBWQ вҖ“> QRFC related Tables TRFCQOUT, QREFTID, ARFCSDATA SAP Data Dictionaryз”ЁиЎЁ DD02L - SAP tables DD02T - R/3 DD: SAP table text DD03L - Table Fields DD03T - DD: Texts for fields (language dependent) EDD04L - Data elements DD04T - R/3 DD: Data element texts DD01L - Domains DD01T - R/3 DD: domain texts DD07L - R/3 DD: values for the domains DD07T - DD: Texts for Domain Fixed Values (Language-Dependent) Transparent tables can be identified using DD02L-TABCLASS = вҖҳTRANSPвҖҷ. В ж Үзӯҫ:В BW7.0,В BWж•°жҚ®еӯ—е…ё В 2 еңЁжҹҘжүҫж—¶иҰҒжіЁж„ҸжҠҖжңҜеҗҚз§°иҝҳжҳҜеҗҚз§°пјҢеӣ дёәжҹҘиҜўж—¶дјҡеңЁдёӨдёӘдёӯиҝӣиЎҢпјҢжЁЎзіҠжҹҘиҜўж—¶иҰҒз»ҶеҝғпјҢFVдёҺVйғҪеҸҜд»ҘжҹҘеҲ° 3 еӨҚеҲ¶зҡ„ж—¶еҖҷжіЁж„Ҹй•ҝеәҰпјҢиҝҮй•ҝзҡ„дјҡдёҚиғҪжҳҫзӨә 4 ејҖзқҖQueryдёҚиғҪеҲ йҷӨ 5 se01 Transport Organizer 6 иЎҢеҲ—еҸӘжҳҜз”ЁжқҘж”ҫзү№еҫҒе’Ңе…ій”®еҖј 7 иЎҢе’ҢеҲ—йғҪжҳҜжӯ»зҡ„жҳҜеӣәе®ҡжҠҘиЎЁпјҢиЎҢе’ҢеҲ—йғҪжҳҜзҒөжҙ»зҡ„жҳҜзҒөжҙ»жҠҘиЎЁпјҢиЎҢжҲ–еҲ—жңүдёҖдёӘжҳҜжӯ»зҡ„пјҢжңүдёҖдёӘжҳҜзҒөжҙ»зҡ„жҳҜеҚҠзҒөжҙ»жҠҘиЎЁ 8 SAP portalеўһйҮҸй“ҫжҺҘзҡ„ж—¶еҖҷеҲ«еҝҳи®°жү“ејҖзӣ®зҡ„ең°пјҢдёҚ然дёҚдјҡжҳҫзӨәиҸңеҚ•зҡ„ 9 PйҮҮиҙӯ purchasingпјҢIеә“еӯҳ inventory 10 дј иҫ“иҜ·жұӮзҡ„ж—¶еҖҷпјҢDSOдј иҫ“иҝҮпјҢиҪ¬жҚўдјҡеҸҳзҒ°пјҢе°ұжҳҜиҜҙеә•еұӮеҸҳпјҢдёҠеұӮдјҡжңүй—®йўҳ 11 MзүҲжң¬дёҚзӯүдәҺAзүҲжң¬пјҢеҸҜиғҪжҳҜдҝ®ж”№д»ҘеҗҺжІЎжңүжҝҖжҙ» 12 SID вҖ” Surrogate-ID 13 YTDпјҢQTDпјҢPTD е№ҙеҲқиҮід»ҠпјҢеӯЈеҲқиҮід»ҠпјҢжңҹеҲқиҮід»Ҡ 14 BOM зү©ж–ҷжё…еҚ• 15 жҠҘиЎЁе’ҢBExиҜ·жұӮиҰҒиҝӣZBW_LYHGеҢ…пјҢе…¶дҪҷзҡ„йғҪиҝӣZBWеҢ… 16 иҜ·жұӮеҮәй”ҷпјҢеҲ°иӢұж–Үзі»з»ҹзңӢжҳҺз»Ҷж—Ҙеҝ— 17 mb51пјҢ收+пјҢеҸ‘- 18 312дёәжөӢиҜ•зі»з»ҹпјҢ300-302пјҢ200-222 19 收йӣҶиҪ¬жҚўзҡ„ж—¶еҖҷиҰҒ收йӣҶдҫӢзЁӢпјҢ收йӣҶDTPзҡ„ж—¶еҖҷиҰҒеёҰдҝЎжҒҜеҢ… 20 se03 жҳҫзӨә/жӣҙж”№е‘ҪеҗҚз©әй—ҙпјҢеҸҜд»ҘзңӢеҲ°зұ»дјјдәҺ/BIO/ /BIC/зҡ„ж–Үжң¬жҸҸиҝ° /BI0/В В В В В В В В дёҡеҠЎдҝЎжҒҜд»“еә“пјҡSAP е‘ҪеҗҚз©әй—ҙВ В В В В В В В SAP AG Walldorf /BIC/В В В В В В В В дёҡеҠЎдҝЎжҒҜд»“еә“пјҡе®ўжҲ·е‘ҪеҗҚз©әй—ҙ В В В В В В В В е®ўжҲ·еҗҚз§°з©әй—ҙ 21 жңүж—¶еҖҷпјҢз»“жһңиЎҢзҡ„жҳҫзӨәдјҡжңүй”ҷиҜҜпјҢеҸҜд»ҘеҶҚQueryйҮҢе°Ҷ и®Ўз®—з»“жһң ж”№дёә еҗҲи®Ў 22 дё»й“ҫдҝ®ж”№еҗҺйңҖиҰҒи®ЎеҲ’д№ӢпјҢеҚіжү§иЎҢ 23 еҒҡе®ҢжҠҘиЎЁиҰҒдј Portalзҡ„ 24 з”ЁжҲ·еҮәеҸЈпјҡSDпјҢз»‘е®ҡз»ҷдёҖдёӘпјҢдёҚиғҪйҮҚз”Ёпјӣе®ўжҲ·еҮәеҸЈпјҢALLпјӣBTEдёҡеҠЎдәӨжҳ“дәӢ件пјҢFIпјӣBADIдёҡеҠЎйҷ„еҠ (NEW)пјҢз”ЁжҲ·еҮәеҸЈдёҺBTEзҡ„з»“еҗҲ 25 RRM_SV_VAR_WHERE_USED_LIST_GET 26 01дәӨжҳ“ж•°жҚ®пјҢ02дё»ж•°жҚ®пјҢ03еұӮж¬ЎпјҢ04з©ә 27 еҺӢзј©пјҡFдәӢе®һиЎЁеҺӢзј©иҮіEдәӢе®һиЎЁпјҢеҺӢзј©д№ӢеҗҺFиЎЁжё…з©әпјҢзӣҙжҺҘд»ҺEиЎЁеҸ–ж•°пјҢеҠ еҝ«йҖҹеәҰгҖӮеҰӮжһңжңүиҒҡйӣҶпјҢиҰҒе…ҲдёҠдј иҮіиҒҡйӣҶпјҢеҶҚеҺӢзј©гҖӮ 28 ејҖеҸ‘зұ»пјҡйҖ»иҫ‘дёҠзӣёе…ізҡ„дёҖз»„еҜ№иұЎпјҢд№ҹе°ұжҳҜиҜҙпјҢиҝҷз»„еҜ№иұЎеҝ…йЎ»дёҖиө·ејҖеҸ‘гҖҒз»ҙжҠӨе’Ңдј иҫ“ жң¬ең°еҜ№иұЎпјҡе°ҶеҜ№иұЎжҢҮжҙҫз»ҷ$TMPпјҢдёҚеҸҜдј иҫ“еҲ°е…¶д»–зі»з»ҹ иҮӘе»әејҖеҸ‘зұ»пјҡд»ҘYжҲ–иҖ…ZејҖеӨҙ 29 CCMS: Computer center Management System 30 TCODE: SSAA 31 е…ідәҺDB StatisticsпјҢи®Ўз®—з»ҹи®Ўж•°жҚ®ж—¶пјҢSAP_ANALYZE_ALL_INFOCUBES дҪҝз”Ёзҡ„дҝЎжҒҜз«Ӣж–№дҪ“ж•°жҚ®йҮҸ<=20%ж—¶пјҢBWе°ҶдјҡдҪҝз”Ё10%зҡ„дҝЎжҒҜз«Ӣж–№дҪ“ж•°жҚ®жқҘдј°и®Ўз»ҹи®Ўж•°жҚ®пјҢ еҗҰеҲҷпјҢBWе°Ҷи®Ўз®—е®һйҷ…зҡ„з»ҹи®Ўж•°жҚ®гҖӮжӯӨж—¶пјҢOracle PL/SQLеҢ…DBMS_STATSе°ұжҳҜжӣҙеҘҪзҡ„йҖүжӢ©пјҢеҰӮжһңеҸҜиғҪдјҡи°ғ用并иЎҢзҡ„жҹҘиҜўжқҘ收йӣҶз»ҹи®Ўж•°жҚ®пјӣеҗҰеҲҷи°ғз”ЁдёҖдёӘйЎәеәҸжҹҘиҜўжҲ–иҖ…ANALYZEиҜӯеҸҘгҖӮзҙўеј•з»ҹи®Ўж•°жҚ®е№¶дёҚжҳҜ并иЎҢ收йӣҶзҡ„гҖӮTCODE: DB20 32 жҜҸж¬ЎеҠ иҪҪж•°жҚ®ж—¶пјҢиҮӘеҠЁеҲ·ж–°з»ҹи®ЎдҝЎжҒҜпјҡEnvironmentвҖ“>Automatic Request Processing 33 еҲҶеҢәжҹҘзңӢпјҡSE11вҖ“>UtilitiesвҖ“>Database ObjectвҖ“>Database UtilitiesвҖ“>Storage ParametersвҖ“>Partition 34 еҲҶеҢәз®ЎзҗҶпјҡжү“ејҖCubeвҖ“>ExtrasвҖ“>DB PerformanceвҖ“>PartitioningпјҢжқҘдёӘдҫӢеӯҗпјҢеҫҲз®ҖеҚ•зҡ„и§ЈйҮҠпјҢеҫҲйҖҸеҪ» жҲ‘йҖүжӢ©йўқзҡ„жҳҜ0CALMONTHпјҢжҢүжңҲжқҘеҲҶеҢәпјҡ Example Value range for FYear/Calendar Month 6 Years * 12 Months + 2 = 74 partitions will be created (2 partitions for values that lie outside of the range, meaning <01.1998 or > 12.2003). 35 еҰӮжһңеҸҜиғҪпјҢеңЁдј иҫ“规еҲҷиҖҢдёҚжҳҜжӣҙ新规еҲҷдёӯжү§иЎҢж•°жҚ®зҡ„иҪ¬жҚўгҖӮдј иҫ“规еҲҷпјҡPSAвҖ“>DSOпјҢжӣҙ新规еҲҷпјҡDSOвҖ“>Cube 36 иҖғиҷ‘дҪҝз”Ёж•°жҚ®еә“зҡ„NOARCHIVELOGжЁЎејҸ 37 е°Ҷе®һдҫӢзҡ„жҸҸиҝ°еҸӮж•°rdisp/max_wprun_timeи®ҫзҪ®дёә0пјҢе…Ғи®ёеҜ№иҜқе·ҘдҪңиҝӣзЁӢеҚ з”Ёж— йҷҗзҡ„CPUж—¶й—ҙ 38 еҠ иҪҪдәӨжҳ“ж•°жҚ®ж—¶пјҡ 1гҖҒеҠ иҪҪжүҖжңүзҡ„дё»ж•°жҚ® 2гҖҒеҲ йҷӨдҝЎжҒҜз«Ӣж–№дҪ“еҸҠе…¶иҒҡйӣҶзҡ„зҙўеј• 3гҖҒжү“ејҖж•°еӯ—иҢғеӣҙзј“еҶІпјҲNumber range bufferingпјү 4гҖҒи®ҫзҪ®дёҖдёӘеҗҲйҖӮзҡ„ж•°жҚ®еҢ…еӨ§е°Ҹ 5гҖҒеҠ иҪҪдәӨжҳ“ж•°жҚ® 6гҖҒйҮҚе»әзҙўеј• 7гҖҒе…ій—ӯж•°еӯ—иҢғеӣҙзј“еҶІ 8гҖҒеҲ·ж–°з»ҹи®Ўж•°жҚ® 39 дәӢе®һиЎЁе‘ҪеҗҚпјҡ</BIC|/BIO>/F<дҝЎжҒҜз«Ӣж–№дҪ“еҗҚ>пјҢеҗҢзҗҶпјҢEдәӢе®һиЎЁ В 40 SIDпјҡSurrogate-IDпјҲжӣҝд»Јж ҮиҜҶпјү В з»ҙеәҰиЎЁе’ҢSIDиЎЁд№Ӣй—ҙпјҢдё»ж•°жҚ®иЎЁе’ҢSIDиЎЁд№Ӣй—ҙпјҢйғҪжҳҜиҷҡзәҝе…ізі»пјҢиҷҡзәҝе…ізі»иЎЁзӨәз”ұABAPзЁӢеәҸз»ҙжҠӨпјҢдёҚеҸ—еҲ°еӨ–й”®иЎҘе……гҖӮдҪҝеҫ—жҲ‘们иғҪеӨҹеҠ иҪҪдәӨжҳ“ж•°жҚ®пјҢеҚідҪҝж•°жҚ®еә“дёӯдёҚеӯҳеңЁд»»дҪ•дё»ж•°жҚ®д№ҹеҸҜд»ҘгҖӮAlways update data, even if no master data exists for the data! 41 BWеӨҡз§Қе»әжЁЎпјҢеҸӮз…§BW Accelerator, Multi-Dimensional Modeling with BW 42 з»ҙеәҰзү№еҫҒ or з»ҙеәҰеұһжҖ§пјҡ 1гҖҒеҰӮжһң**ж•°жҚ®еҢ…еҗ«еңЁдәӨжҳ“ж•°жҚ®дёӯпјҢйӮЈд№Ҳеә”е°Ҷ**з”ЁдҪңдёәз»ҙеәҰзү№еҫҒпјҢиҖҢдёҚиҰҒз”ЁеҒҡз»ҙеәҰеұһжҖ§гҖӮ 2гҖҒеҰӮжһң**йў‘з№Ғз”ЁдәҺеҜјиҲӘпјҢйӮЈд№Ҳеә”е°Ҷ**з”ЁеҒҡз»ҙеәҰзү№еҫҒпјҢиҖҢдёҚиҰҒз”ЁеҒҡз»ҙеәҰеұһжҖ§гҖӮ 43 з»ҙеәҰпјҡ 1гҖҒеҰӮжһңзү№еҫҒе…·жңүдёҖеҜ№еӨҡзҡ„е…ізі»пјҢйӮЈд№Ҳеә”е°Ҷе®ғ们组еҗҲеңЁеҗҢдёҖз»ҙеәҰдёӯгҖӮ 2гҖҒеҰӮжһңзү№еҫҒе…·жңүеӨҡеҜ№еӨҡзҡ„е…ізі»пјҢйӮЈд№Ҳеә”е°Ҷ他们组еҗҲеңЁдёҚеҗҢз»ҙеәҰдёӯгҖӮпјҲеҗҲ并关系еҫҲе°ҸйҷӨеӨ–пјү 44 еӨҚеҗҲеұһжҖ§пјҲз»„еҗҲеұһжҖ§ Compoundingпјүпјҡ йҷӨйқһз»қеҜ№еҝ…иҰҒпјҢдёҚиҰҒйҮҮз”ЁеӨҚеҗҲеұһжҖ§пјҢд»Јд»·жҜ”иҫғеӨ§гҖӮ зҗҶи§ЈпјҡIO_HOUSEжӢҘжңүдёҖжқЎWhite houseзҡ„и®°еҪ•пјҢдёәдәҶеҢәеҲ«жҳҜжқҘиҮӘж”ҝеәңжәҗзі»з»ҹиҝҳжҳҜ家еұ…зҪ‘з«ҷпјҢе°ҶIO_HOUSEе’Ң0SOURCESYSTEMеӨҚеҗҲиө·жқҘжҫ„жё…зү№еҫҒзҡ„е…·дҪ“еҗ«д№үгҖӮ 45 зәҝжҖ§йЎ№з»ҙеәҰпјҡ еҰӮжһңз»ҙеәҰеҸӘжңүдёҖдёӘзү№еҫҒпјҢеҸҜд»Ҙи®ҫдёәзәҝжҖ§йЎ№зү№еҫҒгҖӮеҜјиҮҙ并жңӘеҲӣе»әз»ҙеәҰиЎЁпјҢе…ій”®еӯ—жҳҜSIDиЎЁзҡ„SIDпјҢдәӢе®һиЎЁйҖҡиҝҮSIDиЎЁиҝһжҺҘеҲ°дё»ж•°жҚ®гҖҒж–Үжң¬е’ҢеұӮзә§иЎЁпјҢеҗҢж—¶еҲ йҷӨдәҶз»ҙеәҰиЎЁзҡ„дёҖдёӘдёӯй—ҙеұӮпјҢжҸҗй«ҳж•ҲзҺҮгҖӮ 46 зІ’еәҰпјҲGranularityпјүпјҡдҝЎжҒҜе…·дҪ“зҡ„зЁӢеәҰ 47 PSAпјҡж•°жҚ®д»ҘеҢ…дёәеҚ•дҪҚиҝӣиЎҢдј иҫ“ 48 IDocпјҡж•°жҚ®д»ҘIDocдёәеҚ•дҪҚиҝӣиЎҢдј иҫ“пјҢеӯ—з¬Ұж јејҸдёӯпјҢдј иҫ“з»“жһ„дёҚиғҪи¶…иҝҮ1000еӯ—иҠӮ 49 BW收йӣҶдј иҫ“ж•°жҚ®жӯҘйӘӨпјҡ 1гҖҒBWдј йҖ’дёҖдёӘеҠ иҪҪиҜ·жұӮIDocз»ҷR/3 2гҖҒеңЁеҠ иҪҪиҜ·жұӮIDocи§ҰеҸ‘ж—¶пјҢR/3е°ҶеҗҜеҠЁдёҖдёӘеҗҺеҸ°д»»еҠЎгҖӮеҗҺеҸ°д»»еҠЎд»Һж•°жҚ®еә“дёӯ收йӣҶж•°жҚ®пјҢ并дҝқеӯҳеңЁдәӢе…Ҳе®ҡд№үеҘҪеӨ§е°Ҹзҡ„еҢ…дёӯ 3гҖҒ收йӣҶдәҶ第дёҖдёӘж•°жҚ®еҢ…д»ҘеҗҺпјҢеҗҺеҸ°д»»еҠЎеҗҜеҠЁдёҖдёӘеҜ№иҜқе·ҘдҪңиҝӣзЁӢпјҲеҰӮжһңеҸҜз”ЁпјүпјҢе°Ҷ第дёҖдёӘж•°жҚ®еҢ…д»ҺR/3дј йҖ’з»ҷBW 4гҖҒеҰӮжһңйңҖиҰҒдј йҖ’жӣҙеӨҡж•°жҚ®пјҢеҗҺеҸ°е·ҘдҪңе°Ҷ继з»ӯ收йӣҶ第дәҢдёӘеҢ…зҡ„ж•°жҚ®пјҢиҖҢдёҚеҝ…зӯү第дёҖдёӘж•°жҚ®еҢ…е®ҢжҲҗе…¶дј йҖ’иҝҮзЁӢгҖӮ收йӣҶе®ҢжҜ•еҸ‘йҖҒ 5гҖҒеңЁеүҚйқўзҡ„жӯҘйӘӨиҝӣиЎҢж—¶пјҢR/3дј йҖ’дҝЎжҒҜIDocз»ҷBWпјҢйҖҡзҹҘBWж•°жҚ®жҠҪеҸ–зҡ„дј иҫ“зҠ¶жҖҒ 6гҖҒжҢүз…§дёҠйқўзҡ„ж–№ејҸиҝҮзЁӢ继з»ӯиҝӣиЎҢпјҢзӣҙеҲ°жүҖжңүиҜ·жұӮзҡ„ж•°жҚ®еҫ—д»Ҙдј иҫ“е’ҢйҖүжӢ© еӣ жӯӨпјҢдҝЎжҒҜеҢ…зҡ„еӨ§е°ҸеҫҲйҮҚиҰҒ дёҠйқўдёӨеј еӣҫпјҢдёҖдёӘжҳҜиЎЁROIDOCPRMSпјҢйҮҢйқўеӯҳеӮЁзҡ„жҳҜе…ідәҺдҝЎжҒҜеҢ…зҡ„и®ҫзҪ® и®ҫзҪ®ж–№жі•пјҡSBIWвҖ“>General SettingsвҖ“>Maintain Control Parameters for Data Transfer
еҸҰдёҖдёӘжҳҜж•°жҚ®жҠҪеҸ–зҡ„иҝҮзЁӢпјҡеҮ дёӘIDocзҡ„Info statusеҲҶеҲ«жҳҜпјҡ В иҝҷйҮҢзҡ„еҮ дёӘзҠ¶жҖҒеҲҶеҲ«дёәпјҡ В еҫҲз®ҖеҚ•зҡ„йҖ»иҫ‘пјҢ收еҲ°иҜ·жұӮпјҢејҖе§Ӣж•°жҚ®йҖүжӢ©пјҢдёҖзӣҙи·‘дёҖзӣҙи·‘пјҢдёҖзӣҙи·‘еҲ°з»“жқҹ 50 еҠ иҪҪж•°жҚ®еҲ°InfoCubeж—¶пјҢдјҡдҪҝз”Ёж•°жҚ®иҢғеӣҙзј“еҶІпјҲNumber range bufferingпјү жҳҜйҖҡиҝҮж•°жҚ®иҢғеӣҙеҜ№иұЎпјҲNumber range objectпјүжқҘе®һзҺ°зҡ„гҖӮ и®ҫзҪ®ж–№ејҸпјҡ SE37вҖ“>RSD_CUBE_GETвҖ“>I_INFOCUBEе’ҢI_BYPASS_BUFFER=XвҖ“>E_T_DIMEвҖ“>NOBJECTвҖ“>SNROвҖ“>EditвҖ“>Set-up bufferingвҖ“>Main memory д№ҹи®ёдјҡз”ЁеҲ°зҡ„жҳҜSE03вҖ“>Set System Change OptionвҖ“>General SAP name Range=Modifiable дҫӢеӯҗйҮҢи®ҫзҪ®зҡ„жҳҜ500 51 еҜ№SAPдј иҫ“пјҢиҮӘе·ұжңүдёҖзӮ№зӮ№е°Ҹзҡ„и§Ғи§Ј
В йҮҠж”ҫпјҡд»ҺжҠҖжңҜи§’еәҰжқҘи®ІпјҢйҮҠж”ҫдёҖдёӘдј иҫ“иҜ·жұӮе®һйҷ…дёҠе°ұжҳҜжҠҠдј иҫ“еҜ№иұЎд»Һдј иҫ“иҜ·жұӮдёӯеҜјеҮәгҖӮ 52 зҠ¶жҖҒпјҡ В е®үиЈ…BCзҡ„ж—¶еҖҷпјҢйҖүInstallпјҢиҰҶзӣ–AзҠ¶жҖҒпјӣйҖүMatchпјҢж— ж“ҚдҪңпјӣйғҪйҖүпјҢеҗҲ并пјҲжңӘеҝ…е…ЁеҗҲ并пјү 53 STMS Transport Management System 54 InfoCube зұ»еһӢпјҡ В 55 е·ҘдҪңз°ҝеңЁж•°жҚ®еә“дёӯдҝқеӯҳдёәдәҢиҝӣеҲ¶еӨ§еҜ№иұЎпјҲBinary Large ObjectпјҢ BLOBпјүзҡ„гҖӮ 56 BWеңәжҷҜпјҡ В 57 еҜ№дәҺдё»зү№жҖ§пјҢиҒҡйӣҶдёӯиғҪйҮҮз”ЁSUMгҖҒMINе’ҢMAXиҖҢдёҚиғҪйҮҮз”ЁAVG 58 Info CubeеұӮзә§и®ҫи®Ўпјҡ дҫқиө–дәҺж—¶й—ҙзҡ„ж•ҙдҪ“еұӮзә§ з»ҙеәҰзү№еҫҒ дҫқиө–дәҺж—¶й—ҙзҡ„еҜјиҲӘеұһжҖ§ 59 DеҢ…дёҚиҰҒжҠҠзҒҜд»Һй»„иүІж”№жҲҗз»ҝиүІпјҢеҸҜжҳҜйҖӮеҪ“зҡ„ж”№жҲҗзәўиүІпјҢеҰӮжһңжІЎжңүж•°жҚ®дј иҫ“зҡ„иҜқгҖӮе°ҪйҮҸдёҚиҰҒж”№ 60 е°ҙе°¬пјҢNWDS е’Ң WASдёҖе®ҡиҰҒжҳҜеҗҢдёҖдёӘзүҲжң¬жүҚиЎҢпјҢеҫҲзғҰдәәе•ҠеҫҲзғҰдәәпјҢеҸҰеӨ–NotesеҸ·з ҒжҳҜпјҡ718949 61 DSOпјҢдёүдёӘиЎЁ В 62 DSOеҲҶдёәиҰҶзӣ–е’ҢеҗҲи®ЎдёӨз§ҚпјҢеңЁиҪ¬жҚўдёӯзӮ№DetailпјҢеҸҢеҮ»Key FigureпјҢеҸҜд»ҘйҖүгҖӮ 63 DTPпјҡ еҰӮжһңжҳҜеҚ•иҪ¬жҚўпјҢдјҡжңүпјҡ иҜӯд№үз»„пјҲй”ҷиҜҜе Ҷж Ҳе…ій”®еӯ—ж®өйҖүжӢ©пјүпјҢдјҡжңүеҢ…еӨ§е°Ҹзҡ„йҖүжӢ©пјҲдёҖиҲ¬дёә5wпјүпјҢжү§иЎҢзҡ„еӨ„зҗҶжЁЎејҸдёәиҝһз»ӯжҸҗеҸ–пјҢз«ӢеҚіе№іиЎҢеӨ„зҗҶ еҰӮжһңжңүдҝЎжҒҜжәҗпјҢеҲҷпјҡ жІЎжңүиҜӯд№үз»„пјҢеҢ…еӨ§е°ҸдёҺжәҗдёӯзҡ„еҢ…еӨ§е°ҸдёҖиҮҙ.еңЁиҝҗиЎҢж—¶й—ҙеҠЁжҖҒзЎ®е®ҡпјҢжү§иЎҢзҡ„еӨ„зҗҶжЁЎејҸдёәиҝһз»ӯжҸҗеҸ–е’ҢжәҗеҢ…зҡ„еӨ„зҗҶпјҲиҝҷдҝ©жҳҜдёҖдёӘж„ҸжҖқпјү 64 Variable Processing By: Manual Input/Default Value Replacement Path Customer exit Authorization 65 Cube<вҖ“DSO В 66 BW3.5зҡ„ж•°жҚ®еҢ…зӣҙжҺҘдёҠиҪҪпјҢжҳҜдёҚз”ҹжҲҗиҜ·жұӮзҡ„ 67 BWжҠҘиЎЁжқғйҷҗпјҡи§’иүІдёӯзҡ„дёҡеҠЎжҷәиғҪеҲҶжһҗжқғйҷҗ дёҡеҠЎжөҸи§ҲеҷЁ - дёҡеҠЎжөҸи§ҲеҷЁеҸҜйҮҚеӨҚдҪҝз”Ёзҡ„ web йЎ№зӣ® (NW 7.0+) дёҡеҠЎжөҸи§ҲеҷЁ - BEx Web жЁЎжқҝ(NW 7.0+) дёҡеҠЎжөҸи§ҲеҷЁ - 组件 дёҡеҠЎжөҸи§ҲеҷЁ - 组件: еҜ№жүҖжңүдәәзҡ„еўһејә дёҡеҠЎжөҸи§ҲеҷЁ - ж•°жҚ®и®ҝй—®жңҚеҠЎ 68 еҲ¶дҪңиҝӣзЁӢй“ҫзҡ„ж—¶еҖҷпјҢиҰҒжіЁж„Ҹ3.5зҡ„DSOпјҢ他们дјҡйҖүжӢ©иҮӘеҠЁжҝҖжҙ»е’ҢиҮӘеҠЁжӣҙж–° 69 еҮ з§ҚDSO: е…ідәҺжӣҙеӨҡдҝЎжҒҜ, иҜ·йҖҡиҝҮд»ҘдёӢи·Ҝеҫ„еҸӮйҳ… SAP еә“: http://help.sap.com/saphelp_nw04s/helpdata/en/F9/45503C242B4A67E10000000A114084/content.htm
70 еҚғдёҮдёҚиҰҒеҝҳи®°дё»ж•°жҚ®зҡ„Change Run 71 жҝҖжҙ»зҡ„ж—¶еҖҷпјҢиҰҒжұӮжңүиҝһз»ӯжҖ§пјҢе°ұжҳҜд»Һ第дёҖдёӘејҖе§ӢпјҢеҲ°жңҖеҗҺдёҖдёӘз»“жқҹпјҢеүҚзҪ®зҡ„иҜ·жұӮеҝ…йЎ»жү§иЎҢ 72 дё»ж•°жҚ®жңүжқғйҷҗзӣёе…іпјҢеҸҜд»Ҙз»ҶеҲҶжқғйҷҗпјҢжқғйҷҗTCodeпјҡRSECADMIN 73 жҝҖжҙ»зҡ„ж—¶еҖҷпјҢй»ҳи®ӨдјҡжҠҠдёҖиө·жҝҖжҙ»зҡ„ж•°жҚ®ж”ҫеңЁдёҖдёӘиҜ·жұӮйҮҢ 74 ReconstructionпјҢйҮҚж–°е»әйҖ жҳҜй’ҲеҜ№3.5зҡ„жҠҪеҸ–жқҘи®Ізҡ„пјҢиҜ·жұӮеҲ°иҫҫе…¶дёӢзә§зҡ„ж—¶еҖҷпјҢиҝҷйҮҢдјҡжҳҫзӨәдј иҫ“з»“жһ„зҠ¶жҖҒдёәжҲҗеҠҹ ж•°жҚ®зӣ®ж Үдёӯжңүж•Ҳзҡ„иҜ·жұӮдёә еӨұиҙҘпјҢзӮ№йҮҚе»әжҲ–жҸ’е…ҘпјҢеҲҷзұ»дјјдәҺжү§иЎҢDTPж“ҚдҪңпјҢеЎ«е……ж•°жҚ® 75 еҮ дёӘеӨ„зҗҶеҗҺеҸ°дәӢеҠЎзҡ„TCodeпјҡ В 76 еҮ дёӘиҙўеҠЎзҡ„TCodeпјҡ В 77 иҙ§еёҒиҪ¬жҚўжӯҘйӘӨпјҡ RSUOMи®ҫзҪ®пјҢ然еҗҺеҲ°QueryйҮҢиҝҷжҳҜConversions Unit ConversionпјҡConversion Typeе’ҢTarget UnitйҖүдёҠ 78 InfoSetзҡ„outer joinжҳҜйңҖиҰҒи°Ёж…Һж“ҚдҪңзҡ„пјҢдёҚ然дјҡеҮәеӨ§й—®йўҳ 79 е…ідәҺSAPдёҺе…¶д»–зЁӢеәҸзҡ„жҺҘеҸЈпјҢжҲ‘жңүдәҶдёҖзӮ№ж–°зҡ„зҗҶи§Јпјҡ д»ҺеӨ–йғЁеҲ°SAPпјҢеҸҜд»Ҙи°ғз”ЁBAPIпјҢеҰӮжһңеӨ–йғЁд№ҹжҳҜSAPе°ұCALL FUNCTIONпјҢеҰӮжһңеӨ–йғЁдёҚжҳҜSAPпјҢе°ұз”Ё.NETжҲ–иҖ…JAVAжқҘеҒҡ иҝҳеҸҜд»ҘеҶҷеңЁEXCELйҮҢпјҢеҒҡдёӘд»»еҠЎпјҢе®ҡжңҹжү§иЎҢ д»ҺSAPеҲ°еӨ–йғЁпјҢеҸҜд»Ҙи®©еӨ–йғЁжҺүBAPIпјҢеҸ–ж•° 80 жҹҘз”ЁжҲ·еҗҚпјҡUSER21пјҢUSR12пјҢADRP 81 RRM_SV_VAR_WHERE_USED_LIST_GET 82 RSBBSпјҢеҸҜд»Ҙи®ҫзҪ®д»ҺдёҖдёӘQueryи·іиҪ¬еҲ°еҸҰдёҖдёӘQuery 83 RSDSпјҢиҝҒ移еӣһ3.Xеҝ…еӨҮ 84 еҸ–дёҖдёӘжңҲзҡ„жңҖеҗҺдёҖеӨ©пјҢеҸҜд»ҘдҪҝз”ЁFMпјҡ SLS_MISC_GET_LAST_DAY_OF_MONTH 85 з»ҙеәҰи¶ҠеӨҡпјҢCubeеҸҜд»ҘеҗҲ并зҡ„ж•°жҚ®е°ұи¶Ҡе°‘пјҢж•ҲзҺҮе°ұи¶ҠдҪҺ 86 еҜ№дәҺеҚ•д»·иҝҷз§ҚKFпјҢеҸҜд»ҘеҒҡжҲҗзү№жҖ§пјҢеӣ дёәCubeеҜ№еҗҢж ·зҡ„ж•°жҚ®еҸӘиғҪеҒҡеҗҲи®ЎпјҢиҖҢDSOеҚҙеҸҜд»ҘиҰҶзӣ– В
96 DSOиғҪеҒҡеҲҶеҢәд№ҲпјҡеңЁSP13д»ҘеҸҠд№ӢеүҚжҳҜеҸҜд»Ҙзҡ„пјҲWrite-Optimized DSOжҳҜжҢүз…§иҜ·жұӮеҸ·пјү DSOиғҪеҒҡиҒҡйӣҶд№ҲпјҡеҰӮжһңж•°жҚ®еә“жҳҜDB2зҡ„иҜқпјҢж ҮеҮҶе’ҢзӣҙжҺҘеҶҷе…Ҙзҡ„DSOжҳҜеҸҜд»Ҙзҡ„пјҢеҶҷдјҳеҢ–зҡ„дёҚиЎҢ 97В RZ11 98В е•ҘжҳҜData Martе•ҠпјҢthe bw system can be a source to another bw system or to itself the ods/cube/infoprovider which provide data to another systm are called data martsгҖӮ 99 EventпјҡSM62 100В йғҪ100жқЎдәҶпјҢжқҘзӮ№е„ҝжңүж„ҸжҖқзҡ„гҖӮ3.xзҡ„ж—¶еҖҷпјҢmulti providerдёҚиғҪеҠ DSOпјҢеҸӘиғҪз”ЁCUBE infosetдёҚиғҪеҠ CUBEпјҢеҸӘиғҪз”ЁDSOе’ҢMaster DataпјҢзҺ°еңЁзңӢжқҘпјҢжңүзӮ№е„ҝдёҚеҸҜжҖқи®®дәҶгҖӮ
101 InfoCubeпјҡжңҖеӨ§з»ҙеәҰ16дёӘпјҢеҺ»жҺүдёүдёӘйў„е…Ҳе®ҡд№үзҡ„timeгҖҒunitгҖҒrequestпјҢжңү13дёӘеҸҜз”Ё жңҖеӨ§key figureж•°233 жңҖеӨ§characteristicж•°248 DSOпјҡ -В В В В В В В В You can create a maximum of 16 key fields (if you have more key fields, you can combine fields using a routine for a key field (concatenate).) -В В В В В В В В You can create a maximum of 749 fields -В В В В В В В В You can use 1962 bytes (minus 44 bytes for the change log) -В В В В В В В В You cannot include key figures as key fields
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/4a/e71f39488fee0ce10000000a114084/content.htm>
TABLE:
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/cf/21eb6e446011d189700000e8322d00/content.htm> В 87 е°Ҷй»„зҒҜзҠ¶жҖҒж”№жҲҗзәўзҒҜзҠ¶жҖҒпјҡиҝҗиЎҢдәӢзү©з ҒSE37пјҢжү§иЎҢеҮҪж•°RSBM_GUI_CHANGE_USTATE 88 sapж—¶й—ҙжҳҜд»Һ19910101ејҖе§Ӣзҡ„пјҲпјҹпјҹпјү 89 еҮ дёӘж–°и®ӨиҜҶзҡ„Tcode В 90 PCе»ә议并иЎҢ4жқЎ 91 CTжҳҜеҹәдәҺе°ҸжұҮжҖ»зҡ„зҷҫеҲҶжҜ”пјҢгҖҖGTжҳҜеҹәдәҺtotalзҡ„и®Ўз®—пјҢ 92 дҪ зңӢиҝҷжҳҜе•ҘпјҡData Flow Overview in BI
BW3.5
93 еҶҷдјҳеҢ–зҡ„DSOжҳҜдёҚиғҪеҒҡжҠҘиЎЁзҡ„пјҢеӣ дёәжІЎжңүSID?дёҚжҳҜзҡ„пјҢеҸҜд»ҘеҮәжҠҘиЎЁпјҢеҸӘжҳҜжІЎжңүж„Ҹд№үпјҢеӣ дёәkeyйғҪжҳҜдәӣиҜ·жұӮе•ҠпјҢж•°жҚ®зј–еҸ·д№Ӣзұ»зҡ„ 94 ж•°жҚ®жәҗдёӯпјҢйҖүжӢ©пјҡBWжҸҗеҸ–ж—¶пјҢеҸҜд»ҘеҪ“еҒҡйҖүжӢ©жқЎд»¶иҝӣиЎҢзӯӣйҖүзҡ„еӯ—ж®өгҖӮйҡҗи—ҸпјҡеңЁBWдёӯдёҚдҪ“зҺ°зҡ„еӯ—ж®ө
95В иҙ§еёҒй—®йўҳдәӢеҠЎз Ғпјҡ OX15В OX02В OX06 96 DSOиғҪеҒҡеҲҶеҢәд№ҲпјҡеңЁSP13д»ҘеҸҠд№ӢеүҚжҳҜеҸҜд»Ҙзҡ„пјҲWrite-Optimized DSOжҳҜжҢүз…§иҜ·жұӮеҸ·пјү DSOиғҪеҒҡиҒҡйӣҶд№ҲпјҡеҰӮжһңж•°жҚ®еә“жҳҜDB2зҡ„иҜқпјҢж ҮеҮҶе’ҢзӣҙжҺҘеҶҷе…Ҙзҡ„DSOжҳҜеҸҜд»Ҙзҡ„пјҢеҶҷдјҳеҢ–зҡ„дёҚиЎҢ 97В RZ11 98В е•ҘжҳҜData Martе•ҠпјҢthe bw system can be a source to another bw system or to itself the ods/cube/infoprovider which provide data to another systm are called data martsгҖӮ 99 EventпјҡSM62 100В йғҪ100жқЎдәҶпјҢжқҘзӮ№е„ҝжңүж„ҸжҖқзҡ„гҖӮ3.xзҡ„ж—¶еҖҷпјҢmulti providerдёҚиғҪеҠ DSOпјҢеҸӘиғҪз”ЁCUBE infosetдёҚиғҪеҠ CUBEпјҢеҸӘиғҪз”ЁDSOе’ҢMaster DataпјҢзҺ°еңЁзңӢжқҘпјҢжңүзӮ№е„ҝдёҚеҸҜжҖқи®®дәҶгҖӮ 101 InfoCubeпјҡжңҖеӨ§з»ҙеәҰ16дёӘпјҢеҺ»жҺүдёүдёӘйў„е…Ҳе®ҡд№үзҡ„timeгҖҒunitгҖҒrequestпјҢжңү13дёӘеҸҜз”Ё жңҖеӨ§key figureж•°233 жңҖеӨ§characteristicж•°248 DSOпјҡ -В В В В В В В В You can create a maximum of 16 key fields (if you have more key fields, you can combine fields using a routine for a key field (concatenate).) -В В В В В В В В You can create a maximum of 749 fields -В В В В В В В В You can use 1962 bytes (minus 44 bytes for the change log) -В В В В В В В В You cannot include key figures as key fields
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/4a/e71f39488fee0ce10000000a114084/content.htm>
TABLE:
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/cf/21eb6e446011d189700000e8322d00/content.htm>
102В дҪ и§үеҫ—Activate Data Automaticallyе’ҢUpdate Data AutomaticallyиғҪзңҒдәӢе„ҝд№ҲпјҢе…¶е®һдёҚжҳҜж»ҙпјҢеӣ дёәProcess ChainеҜ№иҝҷдҝ©flag ignored 103 DSOзҡ„SIDпјҹжҲ‘ејҖе§Ӣиҝҳд»ҘдёәеңЁActivation QueueйҮҢпјҢеӣ дёәйӮЈдёӘиЎЁйҮҢжңүSIDиҝҷдёӘеӯ—ж®өпјҢйҮҢйқўеЎ«зҡ„жҳҜRequest_IDпјҢ еҗҺжқҘжүҚзҹҘйҒ“ж №жң¬дёҚжҳҜиҝҷдёӘпјҢжҳҫзӨәж•°жҚ®пјҢйҮҢйқўжңүSIDзҡ„пјҢе…¶е®һе°ұжҳҜжҠҠж–Үжң¬зҡ„KeyжҚўжҲҗж•°еӯ—KeyпјҢиғҪжҸҗйҖҹгҖӮ 104В зңӢDSOзҡ„иҜ·жұӮз”ЁTCODEпјҡRSICCONT 105В жқғйҷҗпјҡInfoCube based approachВ info area, cube, dso Query name based approachВ query Dataset approachВ characteristics, key figures 106 How many fields you can assign to authorization objectВ : 10 107В жқғйҷҗеҖјвҖҳпјҡвҖҷ 1гҖҒдҪҝз”ЁжҲ·еҸҜд»Ҙи®ҝй—®дёҚеҢ…еҗ«жқғйҷҗжүҖйҷҗеҲ¶еҜ№иұЎзҡ„queryпјҢе°ұжҳҜиҜҙпјҢеҒҮеҰӮеңЁCube AйҮҢжңүIO_AпјҢеҰӮжһңQueryйҮҢдёҚеҗ«IO_AпјҢеҲҷз”ЁдёҠвҖҳпјҡвҖҷд№ӢеүҚд№ҹдёҚиғҪи®ҝй—®пјҢд№ӢеҗҺе°ұеҸҜд»ҘгҖӮ 2гҖҒеҸҜд»ҘжҹҘзңӢз»ҹи®ЎеҖјпјҢеҰӮжһңдёҚеҺ»зңӢжҳҺз»Ҷзҡ„иҜқгҖӮе°ұжҳҜиҜҙпјҢеҒҮеҰӮжҲ‘们йҷҗеҲ¶з”ЁжҲ·еҸӘиғҪзңӢе®ўжҲ·Aзҡ„иө„ж–ҷпјҢдҪҶжҳҜд»–иҝҳжҳҜеҸҜд»ҘзңӢиҜҘе…¬еҸёзҡ„е…ЁйғЁж”¶е…Ҙзҡ„гҖӮеҸӘиҰҒдёҚжҳҺз»ҶеҲ°е®ўжҲ·иҝҷдёҖеұӮгҖӮ 108В жқғйҷҗеҖјпјҡвҖҳ$вҖҷ 109 Templates of authorizationsВ : SU24 110 Archival: SARA 111 Table:RSBFILE, Open Hub Files 112 DSOдёӯеҢ…еҗ«д»ҺдёӨдёӘжЁЎеһӢйҮҢдёҠиҪҪиҝҮжқҘзҡ„иҜ·жұӮпјҢеҝ…йЎ»еҲҶејҖжҝҖжҙ» 113 BWВ еҚ•дҪҚпјҡT006пјҢиҙ§еёҒпјҡTCURR 114В д»Һ7.0 QueryиҪ¬еҲ°3.5 Query ThereвҖҷs a reversal tool you can runвҖҰ.with which you can undo the query migratie to 7.0.
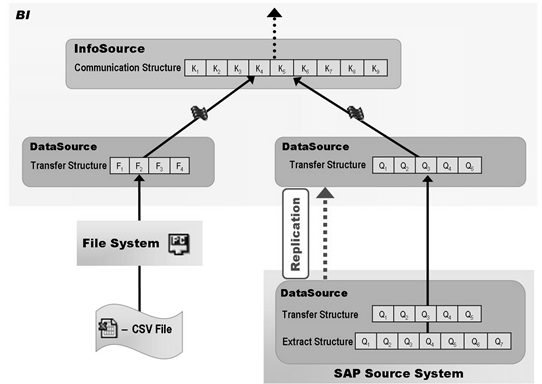
Go to SE38 and run COMPONENT_RESTORE
Not sure if itвҖҷs a custom program, but the coding can be found on OSS/SDN 115 activate master dataВ е…¶е®һжҳҜВ Change run:еӣ дёәдҪ жүӢеҠЁеҠ пјҢжҳҜMзүҲжң¬пјҲеҜ№дәҺе·Із»ҸеӯҳеңЁзҡ„пјҢеҰӮжһңжІЎжңүеӯҳеңЁпјҢе°ұзӣҙжҺҘжҳҜAзүҲжң¬пјүпјҢиҰҒactivateВ иө·AзүҲжң¬пјҢqueryВ еҸӘеҸ–AзүҲжң¬гҖӮ 116В sm66 117В зңӢдёҖдёӘиЎЁжҳҜеҗҰдҪҝз”ЁдәҶbufferпјҡSE11,然еҗҺжҠҖжңҜи®ҫзҪ® 118В еҰӮдҪ•дј иҫ“и®ҫзҪ®еҲ°$TMPзҡ„objectпјҡ 119В ж—¶й—ҙзӣёе…ізҡ„зү№жҖ§жІЎжңүPиЎЁпјҢеҸӘжңүQиЎЁ 120 SU21пјҢжҺҲжқғеҜ№иұЎ 121 System вҖ“> Status 122 ALPHAпјҢж•°еӯ—иҮӘеҠЁеЎ«0
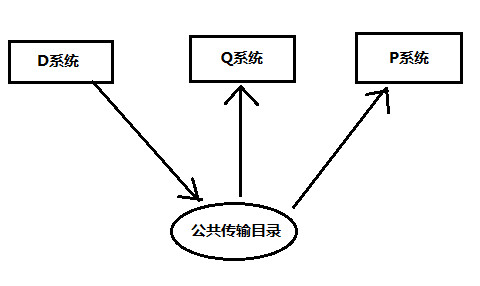
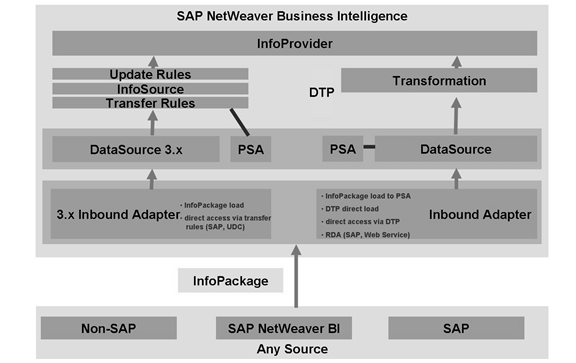
123 RSSDLINITпјҹRSREQDONEпјҹSE38вҖ“RSREQUESTпјҹ YeahпјҒжҹҘPSAзҡ„иҜ·жұӮпјҢз”ЁиҝҷдёӘе°ұйқ и°ұгҖӮ жҹҘODSе’ҢCUBEзҡ„пјҢз”ЁTableпјҡRSICCONTгҖӮ 124В SE14пјҢеҲ йҷӨеҗ„з§Қж•°жҚ®еә“иЎЁ 125 SE93пјҢжҹҘзңӢTcode 126 DSOпјҢж•°жҚ®е…ҲдёҠеҶҚеҲ°NиЎЁпјҢ然еҗҺжҝҖжҙ»еҲ°AиЎЁе’ҢLOGиЎЁ 127В дј иҫ“Tableзҡ„ж—¶еҖҷпјҢжҠҖжңҜи®ҫзҪ®иҰҒеҚ•зӢ¬иҝӣеҺ»дҝқеӯҳжүҚиғҪиҝӣиҜ·жұӮ
128В жғізңӢRequestпјҢиЎЁRSBKREQUEST 129 еҒҡж–ӯзӮ№зҡ„ж—¶еҖҷпјҢз”ЁBREAK USERNAME. 130 дҝ®еӨҚSIDпјҢRSRV 131 PSAжҹҘзңӢпјҢRSTSODS 132 RSPRECADMINпјҢйў„и®Ўз®— 133В жқғйҷҗTableпјҡ Role Authorization 134 收йӣҶдҝЎжҒҜеҜ№иұЎзҡ„ж—¶еҖҷпјҢдҝЎжҒҜиҢғеӣҙжңҖеҘҪдёҚиҰҒж”ҫйҮҢйқў 135В дјҡи®ЎдёҠпјҢжі•еҫӢе®һдҪ“дёҖе®ҡжҳҜдјҡи®Ўдё»дҪ“пјҢиҖҢдјҡи®Ўдё»дҪ“жңӘеҝ…дёҖе®ҡжҳҜжі•еҫӢдё»дҪ“гҖӮе°ұеғҸдёҠйқўзҡ„пјҢеҲҶе…¬еҸёжҳҜдјҡи®Ўдё»дҪ“пјҢеҚҙ并йқһжі•еҫӢе®һдҪ“гҖӮеӣ жӯӨпјҢдјҡи®Ўдё»дҪ“еҜ№еә”еҲ°CompanyCodeеұӮж¬ЎпјҢиҖҢжі•иҖҢжі•еҫӢе®һдҪ“еҜ№еә”еҲ°CompanyеұӮж¬ЎжҳҜеҸҜд»Ҙж»Ўи¶ідёӨдёӘеұӮж¬ЎеҲҶеҲ«еҮәе…·жҠҘиЎЁиҰҒжұӮзҡ„гҖӮ 136 收йӣҶжқғйҷҗж—¶пјҢз»„еҗҲи§’иүІдёӢзҡ„и§’иүІдјҡиў«дёҖиө·ж”¶йӣҶиҝӣеҺ» 137В жғіжҹҘиҜ·жұӮеҶ…е®№пјҢE071 138 BI ContentеҚҮзә§еҪұе“Қзҡ„жҳҜDзүҲжң¬ 139В е’ҢQueryзӣёе…ізҡ„еҮ дёӘTable RSZCOMPDIR RSZCOMPIC 140В If the number of records to be loaded is larger than 15%-20% of the targetВ table, then drop indexes. Otherwise, do not drop. 141 DSOзҡ„Secondary Index 1. Call transaction RSA1 (Administrator Workbench: Modeling вҶ’ InfoProvider). Double-click the ODS object on which you want to create a secondary index. 2. On the Edit ODS Object screen, right-click Indexes and choose Create В 142В жҹҘзңӢиҪ¬жҚўеҶ…е®№пјҢRSTRANFIELD 143В еұһжҖ§зҡ„еұӮж¬Ўз»“жһ„жңүдҝ®ж”№ж—¶пјҢеңЁchange runд№ӢеүҚеҝ…йЎ»еҠ дҝқеӯҳеұӮж¬Ўз»“жһ„ 144 BXж•°жҚ®еҸ–зҡ„жҳҜеҲқе§Ӣеә“еӯҳпјҢд№ӢеҗҺз”ЁBFе’ҢUMпјҲеЎ«Setup tableзҡ„ж—¶еҖҷиҰҒжҢүз…§е…¬еҸёпјү 145 收йӣҶеӨ„зҗҶй“ҫзҡ„ж—¶еҖҷеҸҜд»ҘжҠҠзӣёе…ізҡ„еҸҳејҸгҖҒдҝЎжҒҜеҢ…гҖҒеӨ„зҗҶй“ҫдёҖиө·ж·»еҠ иҝӣеҺ» 146 Note 750156 - Entry <XXXвҖҰ> not found in the DKF 147 T.Codes to fill up the Set Up tables for all the applications. 148 STOпјҡе…¬еҸёй—ҙй”Җе”® 149 Note 559119 - Call disconnections in the syslog or dev_rd Operating system call recv failed (error no. 73 ) Communication error, CPIC return code 020, SAP return code 223 150 WorkBookпјҡRSRWORKBOOK е…ғж•°жҚ®д»“еә“йҮҢйқўд№ҹеҸҜд»ҘзңӢеҲ°пјҢдҪҶжҳҜжІЎжңүиЎЁйҮҢеҮҶзЎ®пјҲеҸӘеҢ…еҗ«жңүж•Ҳзҡ„Queryпјү 151 AL11пјҢжҹҘзңӢжңҚеҠЎеҷЁдёҠзҡ„ж–Ү件 В 152В и§’иүІзҡ„дј иҫ“е’ҢжЁЎеһӢдёҚеҗҢпјҢдј иҫ“еҗҺпјҢжңҖеҗҺдҝ®ж”№дәәе°Ҷе’ҢејҖеҸ‘жңәдёҖиҮҙвҖҰ 153 QueryжҸҗзӨәжІЎжңүжқғйҷҗдҝ®ж”№пјҢеҸҜиғҪжҳҜеӣ дёәPatchжү“зҡ„жҜ”дёҠж¬Ўжӣҙж”№дәәзҡ„дҪҺ 154 HRз»„з»Үжңәжһ„з»ҙжҠӨВ PPOCEпјҢPPOMEпјҢPPOSE 155В еӨ„зҗҶеј№зӘ—пјҡSY-BINPTдёәз©әеҲҷеј№еҮәпјҢдёәXеҲҷдёҚеј№ 156В дј иҫ“еӨ„зҗҶй“ҫзҡ„ж—¶еҖҷпјҢеҰӮжһңжңүеҝ…иҰҒпјҢйңҖиҰҒи°ғж•ҙжәҗзі»з»ҹеҲҶй…ҚпјҢз”ҡиҮідј иҫ“жәҗзі»з»ҹ еҸҰеӨ–пјҢиҪ¬жҚўзҡ„еҜ№еә”и®ҫзҪ®еңЁпјҡRSA1пјҢе·Ҙе…·пјҢиҪ¬жҚўйҖ»иҫ‘зі»з»ҹеҗҚз§° 157 For All EntryВ д№ӢеүҚиҰҒеҲӨж–ӯжҳҜеҗҰдёәз©әпјҢеҗҰеҲҷж•ҲзҺҮеҫҲдҪҺ 158В зңӢиҷҡжӢҹCubeзҡ„FMпјҡеӨҚеҲ¶дёҖдёӢпјҢзңӢзңӢDetailйҮҢзҡ„еҮҪж•°еҗҚгҖӮ egпјҡВ RSSEM_CONSOLIDATION_INFOPROV RSSEM_CONSOLIDATION_INFOPROV3 159 OAERпјҢжӣҙжҚўexcelжЁЎжқҝ 160В д»ҺжЁЎеһӢеҲ йҷӨеӯ—ж®өзҡ„ж—¶еҖҷпјҢйңҖиҰҒжҠҠжЁЎеһӢзҡ„ж•°жҚ®жё…з©әпјҢж·»еҠ еӯ—ж®өеҚҙдёҚйңҖиҰҒ 161 IDOC WE21 162 RFC RSCUSTA 163 COPA KE24пјҢCPB1 164 AGR_HIERиЎЁеҸҜд»ҘзңӢеҲ°WorkBookеҜ№еә”зҡ„жқғйҷҗ 165 RSZELTDIR Queryе…ғзҙ жҹҘжүҫ 166В жҹҘзңӢqueryиҝҗиЎҢзҡ„ж—¶й—ҙзҡ„дәӢеҠЎд»Јз ҒжҳҜST03 167В жҖ»иҙҰ科зӣ®дҪҷйўқFBL5NпјҢFS10nиғҪжҹҘдҪҷйўқ 168 RS_VC_GET_QUERY_VIEW_DATAеҸҜд»ҘеҒҡAPDзҡ„Backup 169 SRET_TIME_DIFF_GETпјҢйҖҡиҝҮsecondsе’ҢhoursжқҘи®Ўз®—timestampзҡ„ж—¶й—ҙе·® 170В еӨ„зҗҶй“ҫзҡ„жҳҺз»Ҷи§ҶеӣҫиҝҳеҸҜд»Ҙз”ЁжқҘжҹҘзңӢеҚ•дёӘеҸҳејҸзҡ„жү§иЎҢж—¶й—ҙ В ж Үзӯҫ:В BW7.0,В BW笔记 В ABR:Forming deltas with after, before and reverse images that are updated directly in the delta queue,йҮҮз”ЁеүҚй•ңеғҸгҖҒеҗҺй•ңеғҸе’ҢеҸҚиҪ¬й•ңеғҸзҡ„жӣҙж–°жЁЎејҸпјҢж—ўж”ҜжҢҒиҰҶзӣ–еҸҲж”ҜжҢҒзҙҜеҠ пјҢжүҖд»Ҙж•°жҚ®жәҗеҸҜд»Ҙжӣҙж–°еҲ°DSOжҲ–иҖ…CUBE AIM/AIMD:Forming deltas with after image, which are updated directly in the delta queue.В йҮҮз”ЁеҗҺй•ңеғҸжЁЎејҸпјҢеҸӘж”ҜжҢҒиҰҶзӣ–пјҢдёҚж”ҜжҢҒзҙҜеҠ пјҢжүҖд»ҘиҜҘзұ»еһӢж•°жҚ®жәҗдёҚиғҪзӣҙжҺҘеҠ иҪҪеҲ°CUBEпјҢдёҖиҲ¬дјҡе…ҲеҠ иҪҪеҲ°DSO;еңЁFI-AR/APдёӯжӯӨз§ҚеўһйҮҸеӨ„зҗҶж–№ејҸеә”з”ЁиҫғеӨҡ ADDеҸӘж”ҜжҢҒзҙҜеҠ пјҢйҮҮз”Ёзҡ„жҳҜйҷ„еҠ й•ңеғҸзҡ„жӣҙж–°ж–№ејҸпјҢжүҖд»Ҙж—ўеҸҜд»Ҙжӣҙж–°еҲ°DSOеҸҲеҸҜд»Ҙжӣҙж–°еҲ°CUBE V3 Update Mode V1еҗҢжӯҘжӣҙж–°жЁЎејҸпјҢеҚіеҮӯиҜҒдә§з”ҹе°ұжӣҙж–°еўһйҮҸпјҢдёҺдёҡеҠЎж•°жҚ®еҗҢжӯҘжӣҙж–°пјӣ V2ејӮжӯҘжӣҙж–°жЁЎејҸпјҢе°ұеҰӮдёҖдёӘдёӨжӯҘзҡ„ж“ҚдҪңдёҖж ·пјҢ第дёҖжӯҘдёҡеҠЎеҮӯиҜҒжӣҙж–°дәҶпјҢ然еҗҺеҶҚжӣҙ新第дәҢжӯҘзҡ„ж•°жҚ®жәҗеўһйҮҸиЎЁ V3ејӮжӯҘжӣҙж–°жЁЎејҸпјҢдёҺV2зҡ„еҢәеҲ«еңЁдәҺд»–зҡ„жӣҙж–°ж—¶йҖҡиҝҮеҗҺеҸ°дәӢ件жқҘи§ҰеҸ‘зҡ„пјҢеҚіе®ҡдёҖдёӘд»»еҠЎе®ҡжҳҜ收йӣҶеўһйҮҸ并жӣҙж–°иҮіеўһйҮҸиЎЁ В Update Mode: Direct Delta:иҝҷе°ұжҳҜдёҖз§ҚV1жЁЎејҸпјҢжҜ”еҰӮй”Җе”®и®ўеҚ•дә§з”ҹд№ӢеҗҺпјҢи®ўеҚ•ж•°жҚ®еҗҢжӯҘжӣҙж–°еҲ°R/3зҡ„Delta QueueдёӯпјҢиҝҷз§ҚжЁЎејҸзі»з»ҹиҙҹиҚ·еҫҲйҮҚпјҢзү№еҲ«жҳҜеҜ№дәҺдёҡеҠЎйҮҸеӨ§зҡ„еҮӯиҜҒпјӣ Queued Deltaпјҡж•°жҚ®е…Ҳ被收йӣҶеҲ°дёҖдёӘ Exctraction QueueдёӯпјҲV1жЁЎејҸпјүпјҢ然еҗҺиў«йҖҒеҲ°Delta QueueпјҲV3жЁЎејҸпјү Unsterilized V3 UpdateпјҡжӯӨзұ»еһӢзҡ„жңҖеӨ§зү№еҫҒжҳҜ жІЎжңүеәҸеҲ—еҢ–пјҢе°ұжҳҜиҜҙDelta Queue дёӯй”Җе”®и®ўеҚ•жҳҜж— еәҸзҡ„пјҢиҝҷдёӘеҜ№дәҺйҮҮз”Ёoverwrite жЁЎејҸзҡ„жЁЎеһӢжқҘиҜҙжҳҜжңҖиҮҙе‘Ҫзҡ„пјҢжүҖд»ҘеҰӮжһңзӣ®ж ҮйҳҹеҲ—жҳҜDSOзҡ„иҜқпјҢиҝҳжҳҜдёҚиҰҒйҮҮз”Ёиҝҷз§ҚжЁЎејҸеҘҪгҖӮ
Check Delta QueueпјҲRSA7пјү Delta UpdateиЎЁзӨәеҪ“еүҚDelta Queueзҡ„ж•°жҚ® Delta RepetitionиЎЁзӨәзҡ„жҳҜдёҠдёҖж¬ЎжҸҗеҸ–зҡ„Deltaж•°жҚ®
Image supported by Datasource New Image:new record if no same key exit. Anafter imageshows the status after the change, abefore imagethe status before the change with a negative sign and thereverse imagealso shows the negative sign next to the record while indicating it for deletion. Delta Queue: В ж Үзӯҫ:В BW7.0,В Delta В An aggregate is a subset of an InfoCube. The objective when using aggregates is to reduce I/O volume.The BW OLAP processor selects an appropriate aggregate during a query run or a navigation step. If no appropriate aggregate exists, the BW OLAP processor retrievesВ dataВ from the original InfoCube instead. For examples, assume you may have 10 dimensions and each one have 10 value, that means you may have up to 10^10 possible records. If high level manager often access the report focus revenue inВ 2008В by customer, thatвҖҷs mean only 2 dimension are involved. You can do aggregate and it may only contain 2 dimensions with 100 records. It reduce the I/O and improve the performance. Aggregate rollup is a procedure to update aggregates with new data loads. Reference Aggregate Application components are used to organize InfoSources. They are similar to the InfoAreas used with InfoCubes. The maximum number of characters allowed for the technical name is 32. An authorization defines what a user can do, and to whichВ SAPВ objects. For example, a user with an authorization can display and execute, but not change, a query. Authorizations are defined using authorization objects. An authorization object is used to define user authorizations. It has fields with values to specify authorized activities, such as display and execution, on authorized business objects, such as queries. The maximum number of characters allowed for the technical name is 10. An authorization profile is made up of multiple authorizations. The maximum number of characters allowed for the technical name is 10. Short for Business Explorer. It includes following tools to present the reports to end user: AnalyzerВ / Web Application Designer / Report Designer / Web Analyzer. A bitmap index uses maps of bits to locate records in a table. Bitmap indices are very effective for Boolean operations of the WHERE clause of a SELECT statement. When the cardinality of a column is low, a bitmap index size will be small, thereby reducing I/O volume. Another possible choice in BW on this topic is B-tree index. Business Content is a complete set of BW objects developed by SAP to support the OLAP tasks. It contains roles, workbooks, queries, InfoCubes, key figures, characteristics, update rules, InfoSources, and extractors for SAP R/3, and other mySAP solutions. You can simply use business content directly, or take it as template for your project to speed up implementations. BW is a Data Warehousing solution from SAP. When we talking about BW, it often talking about BW3.5. The latest version is SAP Business Intelligence 7.0. BW Monitor displays data loading status and provides assistance in troubleshooting if errors occur. T-code: RSMO BW Scheduler specifies when to load data. It is based on the same techniques used for scheduling R/3 background jobs. BW Statistics is a tool for recording and reporting system activity and performance information. BWA / BIA BW/BI Accelarator is a tool that improves the performance of BW 7.x queries on InfoCubes. It enables quick access to any data with a low amount of administrative effort and is especially useful for sophisticated scenarios with unpredictable query types, high data volume and high frequency of queriesC A technology to improve the performance. Cache buffers query result data, in order to provider them for further accesses. Determines whether and in what way theВ query result and navigational states are to be saved in the OLAPВ Cache. Change run is a procedure used to activate characteristic data changes. Characteristics are descriptions of fields, such as Customer ID, Material Number, Sales Representative ID, Unit of Measure, and Transaction Date. The maximum number of characters allowed for the technical name is 9. A client is a subset of data in an SAP system. Data shared by all clients is called client-independent data, as compared with client-dependent data. When logging on to an SAP system, a user must specify which client to use. Once in the system, the user has access to both client-dependent data and client-independent data. The communication structure is the structure underlying the InfoSource. A compound attribute differentiates a characteristic to make the characteristic uniquely identifiable. For example, if the same characteristic data from different source systems mean different things, then we can add the compound attribute 0SOURSYSTEM (source system ID) to the characteristic; 0SOURSYSTEM is provided with the Business Content. Compressing will bringing data from different requests together into one single request (request ID 0) in Infocube. When you load data into Infocube, they are group with Requests ID. You can easily manage the data with Request ID. But the request ID have disadvantages cause the same data record (with same characteristics but different request ID) to appear more than once in the fact table. It waste the table space and affects query performance. You can eliminate these disadvantages by compressing data and bringing data from different requests together into one single request (request ID 0). Technically, Compress will move the data in F table to E table and aggregate the records with same char. automatically. It is widly used when you are sure that the data in InfoCube is correct and you wonвҖҷt need Request ID in the future. And be careful if you defined your own delta mechanism. For the same amount of data, the data packet size determines how work processes will be used in data loading. The smaller the data packet size, the more work processes needed.You can set it in SPRO Data mining is the process of extracting hidden patterns from data. It is one of the function provided by SAP BI. Take the most famous story вҖңbeer and diapersвҖқ as example. Wall-Mart noticed that men often bought beer at the same time they bought diapers. They mined its receipts and proved the observations. So they put diapers next to the beer coolers, and sales skyrocketed. The story is a myth, but it shows how data mining seeks to understand the relationship between different actions. Data Warehouse is a dedicated reporting and analysis environment based on the star schema (Extended) database design technique and requiring special attention to the data ETTL process. DataMart The distribution of contents of ODS or InfoCube into other BW data targets on the same or on other BW systems A DataSource is not only a structure in which source system fields are logically grouped together, but also an object that contains ETTL-related information. Four types of DataSources exist: If the source system is R/3, replicating DataSources from a source system will create identical DataSource structures in the BW system. The maximum number of characters allowed for a DataSourceвҖҷs technical name is 32. A BW functionВ that offers flexible options for extracting data directly into the BW from tables and views in database management systems that are connected to the BW in addition to the default connection. You can use tables and views from the database management systems that are supported by SAP to transfer data. DataSources are used to make data known to the BW, where it is then processed in the same way as data from all other sources. Additional requests will be read from the InfoCubeвҖҷs (F) fact table. These additional requests will be updated into the OLAP Cache. In this way, when they are changes to the data basis, the complete data for the query no longer has to be read from the database again. The Delta update option in the InfoPackage definition requests BW to load only the data that have been accumulated since the last update. Before a delta update occurs, the delta process must be initialized. A development class is a group of objects that are logically related. Dimension table Part of the Star Schema structure for InfoCubes. Dim tables contain pointers to the Fact tables & to the Master Data (SID tables). A display attribute provides supplemental information to a characteristic. Reference Navigation attribute Drill-down is a user navigation step intended to get further detailed information. For example, you can drill-down to detail report through free characteristic Short for Data Store Object. Reference ODS in BW3.5 A DataStore object serves as a storage location for consolidated and cleansed transaction data or master data on a document (atomic) level. This data can be evaluated using a BEx query. There are 3 kinds of DSO: Standard DataStore Object / Write-Optimized DataStore Objects / DataStore Objects for Direct Update. Check the definition and example at:http://help.sap.com/saphelp_nw2004s/helpdata/en/f9/45503c242b4a67e10000000a114084/frameset.htm DTP The Data Transfer Process (DTP) transfers data from source objects to target objects in BI 7.x. You can also use the data transfer process to access InfoProvider data directly. Prerequisite: a transformation to define the data flow between the source and target object. The Enterprise Data Warehouse, a comprehensive / harmonized data warehouse solution, is design to avoid isolated applications. Reference BW330. ETTL, one of the most challenging tasks in building a data warehouse, is the process of extracting, transforming, transferring, and loading data correctly and quickly. Also known as ETL. Extraction Structure The data structure used by the extraction program to extract data. Its fields are mapped to the fields of the SAP Source System DataSource. The Fact table is the central table of the InfoCube. Here key figures & pointers to the dimension tables are stored. There are two fact tables: the F-fact table and the E-fact table. If you upload data into an InfoCube, it is always written into the F-fact table. If you compress the data, the data is shifted from the F-fact table to the E-fact table. The F-fact tables for aggregates are always empty, since aggregates are compressed automatically. After a changerun, the F-fact table can have entries as well as when you use the functionality вҖҳdo not compress requestsвҖҷ for Aggregates. A free characteristic is a characteristic in a query used for drill-downs. It is not displayed in the initial result of a query run. The Full update option in the InfoPackage definition requests BW to load all data that meet the selection criteria specified via the Select data tab. Reference Delta update Filter Filter is used to restrict data to a certain business sector, product group, or time period. And these can be saved and reused in the in othercontexts.В Here the data is filtered and showed in the intial result of the query. Generic data extraction is a function in Business Content that allows us to create DataSources based on database views or InfoSet queries. InfoSet is similar to a view but allows outer joins between tables. Granularity describes the level of detail in a data warehouse. It is determined by business requirements and technology capabilities. For high level reports, manager tend to high aggregated report such as by month or by BU. But operational reports always require more detail information such as by day or by product spec. means that this dimension contains a high number of attributes. This information is used to execute physical optimizations, depending on the database platform. For example, different index types from those in a standard case are used. Generally, a dimension has a high cardinality if the number of dimension entries is 20% (or more) of the number of fact table entries. IDoc (Intermediate Document) is used in SAP to transfer data between two systems. It is a specific instance of a data structure called the IDoc Type, whose processing logic is defined in the IDoc Interface. See:IDOC Basics An index is a technique used to locate needed records in a database table quickly. BW uses two types of indices: B-tree indices for regular database tables and bitmap indices for fact tables and aggregate tables. InfoAreas are used to organize InfoCubes and InfoObjects. Each InfoCube is assigned to an InfoArea. Through an InfoObject Catalog, each InfoObject is assigned to an InfoArea as well. The maximum number of characters allowed for the technical name is 30. An InfoCube is a fact table and its associated dimension tables in the star schema. The maximum number of characters allowed for the technical name is 30. InfoCube compression is a procedure used to aggregate multiple data loads at the request level. In BW, key figures and characteristics are collectively called InfoObjects. See:https://wiki.sdn.sap.com/wiki/display/BI/Characterstic+and+Key+FiguresCharacteristic and key figures InfoObject Catalogs organize InfoObjects. Two types of InfoObject Catalogs exist: one for characteristics, and one for key figures. The maximum number of characters allowed for the technical name is 30. An InfoPackage specifies when and how to load data from a given source system. BW generates a 30-digit code starting with ZPAK as an InfoPackageвҖҷs technical name. An InfoSource is a structure in which InfoObjects are logically grouped together. InfoCubes and characteristics interact with InfoSources to get source system data. The maximum number of characters allowed for the technical name is 32. In BW 3.5 it is a MUST and in BI 7.0 it is optional. The difference:http://help.sap.com/saphelp_nw2004s/helpdata/en/a4/1be541f321c717e10000000a155106/content.htm And the Recommendations for Using InfoSources in BI 7.0:http://help.sap.com/saphelp_nw2004s/helpdata/en/44/0243dd8ae1603ae10000000a1553f6/content.htm Generally, the data was generated in OLTP system such as R/3. In BW, Information Lifecycle Management includes data target management and data archiving. Reference ADK and archiving for more information. And online help:http://help.sap.com/saphelp_nw2004s/helpdata/en/d0/84e5414f070640e10000000a1550b0/frameset.htm Key figures are numeric values or quantities, such as Per Unit Sales Price, Quantity Sold, and Sales Revenue. The maximum number of characters allowed for the technical name is 9. Reference Characteristic. A line item dimension in a fact table connects directly with the SID table of its sole characteristic. When you creating a InfoCube, you have chance to use this feature on define dimension. It is only possible if exactly one characteristic in a dimension. It help to improve the performance because we do not need to join SID table when accessing the master data. A logical system is the name of a client in an SAP system. Metadata repository contains information about the metadata objects of SAP NetWeaver Business Intelligence, important object properties and their relationships with other objects. Metadata contains data about data. A multi-cube is a union of basic cubes. The multi-cube itself does not contain any data; rather, data reside in the basic cubes. To a user, the multi-cube is similar to a basic cube. When creating a query, the user can select characteristics and key figures from different basic cubes. A navigational attribute indicates a characteristic-to-characteristic relationship between two characteristics. It provides supplemental information about a characteristic and enables navigation from characteristic to characteristic during a query. The naming convention for a navigational attribute is: InfoObject_Attribute, such as 0customer_0country A number range is a range of numbers that resides in applicationВ serverВ memory for quick number assignments. ODS is a BW architectural component located between PSA and InfoCubes that allows BEx reporting. It is not based on the star schema and is used primarily for detail reporting, rather than for dimensional analysis. ODS objects do not aggregate data as InfoCubes do. Instead, data are loaded into an ODS object by inserting new records, updating existing records, or deleting old records, as specified by the 0RECORDMODE value. Reference DSO. The open hub service enables you to distribute data from an SAP BW system into external data marts, analytical applications, and other applications. Short for Online Transaction Processing / Online Analytical Processing. OLTP system are Transacton-Orientated, which means it is generally used to support the daily operation. For example, SAP R/3,В ERPВ / PDM / MES вҖҰ OLAP is generally used to analysis data. For examples, SAP BW, DDS - Decision Support System, EIS - Executive information systems. A parallel query uses multiple database processes, when available, to execute a query. A partition is a piece of physical storage for database tables and indices. If the needed data reside in one or a few partitions, then only those partitions will be selected and examined by aВ SQLВ statement, thereby significantly reducing I/O volume. It can be done in Cube or DB level. The benefit of using partition is mainly focus on: Fact table can be partitioned over a time characteristic either 0CALMONTH or 0FISCPER(Fiscal year/period). Repartition is possible in SAP BI 7.0. Seehttps://wiki.sdn.sap.com/wiki/x/N4C4AQRepartitioning For MultiProvider queries, Partitioning Type provides options for handling the data that is returned by the individual InfoProviders from the MultiProvider separately and saving it in the cache separately. A process chain is a sequence of processes that are scheduled to wait in the background for an event. You can include process chains in other process chains to manage a group of them, known as meta. chains. It is design at the implementation phase and one of the most important jobs in support and maintenance phase. More information please reference:http://help.sap.com/saphelp_nw2004s/helpdata/en/8f/c08b3baaa59649e10000000a11402f/frameset.htm Profile Generator is a tool used to create authorization profiles. The Persistent Staging Area (PSA) is a data staging area in BW. It allows us to check data in an intermediate location, before the data are sent to its destinations in BW. A BW query is a selection of characteristics and key figures for the analysis of the data in an InfoCube. A query refers to only one InfoCube, and its result is presented in a BEx Excel sheet. The maximum number of characters allowed for the technical name is 30. Read mode determines how often the OLAP processor reads data from the database during navigation. Reconstruct is a procedure used to restore load requests from PSA. A request is a data load request from BW Scheduler. Each time that BW Scheduler loads data into an InfoCube, a unique request ID is created in the data packet dimension table of the InfoCube. RFC (Remote Function Call) is a call to a function module in a system different from the callerвҖҷs usually another SAP system on the local network. In Profile Generator, an authorization profile corresponds to a role. A user assigned to that role also has the corresponding authorization profile. A user can be assigned to multiple roles. The maximum number of characters allowed for the technical name is 30. Reclustering It allows you to change the clustering of Infocubes and Data store objects that already contain data. SID (Surrogate-ID) translates a potentially long key for an InfoObject into a short four-byte integer, which saves I/O and memory during OLAP. A source system is a protocol that BW uses to find and extract data. When the source system is a non-SAP system, such as a flat file or a third-party tool, the maximum number of characters allowed for the technical name is 10. When the source system is an SAP system, either R/3 or BW, the technical name matches the logical system name. The maximum number of characters allowed for the technical name is 32. A star schema is a technique used in the data warehouse database design to help data retrieval for online analytical processing. SAP BW use extended star schema with following advantage compare to classical star schema: For a SQL statement, many execution plans are possible. The database optimizer generates the most efficient execution plan based on either the heuristic ranking of available execution plans or the cost calculation of available execution plans. Statistics is the information that the cost-based optimizer uses to calculate the cost of available execution plans and select the most appropriate one for execution. BW uses the cost-base optimizer for Oracle databases. System Administration Assistant is a collection of tools used to monitor and analyze general system operation conditions. The system landscape specifies the role of each system and the paths used in transporting objects among the various systems. A time-dependent entire hierarchy is a time-dependent hierarchy whose nodes and leaves are not time-dependent. For example, you have two hierarchy which presents organization of company in 2007 and 2008. A time-dependent hierarchy structure consists of nodes or leaves that are time-dependent, but the hierarchy itself is not time-dependent. For example, you have one hierarchy but one of his node was changed from 2007 and 2008. HR may belong to administration division before 2007 and belong to supporting division after 2008. Transfer rules specify how DataSource fields are mapped to InfoSource InfoObjects. In BI 7.0, transfer rule and update rule are replaced by transformation. A transfer structure maps DataSource fields to InfoSource InfoObjects. Transformations (TRF) An update rule specifies how data will be updated into their targets. The data target can be an InfoCube or an ODS object. If the update rule is applied to data from an InfoSource, the update ruleвҖҷs technical name will match the InfoSourceвҖҷs technical name. If the update rule is applied to data from an ODS object, the update ruleвҖҷs technical name will match the ODS objectвҖҷs technical name prefixed with number 8. In BI 7.0, transfer rule and update rule are replaced by transformation. But we still have chance to use it in BI 7.0 A variable is a query parameter. It gets its value from user input or takes a default value set by the variable creator. Variables act as placeholders for: A Virtual Provider is a type of InfoCube where the data is not managed in BI. Only the structure of the VirtualProvider is defined in BI, the data is read for reporting using an interface with another system. A BW workbook is an Excel file with a BEx query result saved in BDS. BW assigns a 25-digit ID to each workbook. Users need merely name a workbookвҖҷs title. В ж Үзӯҫ:В BW7.0,В е•ҶдёҡжҷәиғҪ,В жңҜиҜӯ В В Summary дё»иҰҒеҺҹеӣ жҳҜ3.5зҡ„datasourceдҪңдёә7.0 datasourceеҜје…ҘдәҶпјҢйңҖиҰҒе°Ҷ7.0 datasource жҒўеӨҚеҲ°3.5гҖӮSAPжҸҗдҫӣдәҶrestoreзҡ„йҖүйЎ№гҖӮ Symptom Other terms Reason and Prerequisites This problem may occur due to one of the following reasons: A (new) DataSource (R3TR RSDS) cannot be used with a transfer rule. You have to use a 3.x DataSource (R3TR ISFS) to do this. Solution If the problem is caused by the вҖңincorrect contentвҖқ, you must also reinstall the 3.x data flow from the content with object types вҖңInfoPackage, 3.x DataSource, transfer structure, transfer rules, and 3.x InfoSourceвҖқ. You cannot use program RSDS_REPL_RESET (described below) in the case of the вҖңincorrect contentвҖқ. Caution:В В Do not use this report if your system has a Support Package level lower than Support Package 07 for SAP NetWeaver 2004s BI otherwise serious inconsistences may occur. Blog ең°еқҖпјҡhttp://chenweiqin1981.spaces.live.com/?_c11_BlogPart_pagedir=Next&_c11_BlogPart_handle=cns!1675D48BEA05A462!1820&_c11_BlogPart_BlogPart=blogview&_c=BlogPart В ж Үзӯҫ:В BW7.0 В В Question 2: Question 3: Question 4: Question 5: Question 6: Question 7: Question 8: Question 9: Question 10: Question 11: Question 12: Question 13: Question 15: Question 16: Question 17: Question 18. Question 19. Question 20. Question 21. Question 22. Question 23. How and where can I control whether a repeat delta is requested? Question 24. Question 25. В ж Үзӯҫ:В Delta When you activate a master data-bearing characteristic,masterВ dataВ tables (attributes, В or time-dependent attributes. between the following types of master data: еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»
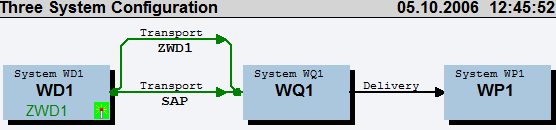
В 1 RSA1 Administrator Work Bench 2 RSA11 Calling up AWB with the IC tree 3 RSA12 Calling up AWB with the IS tree 4 RSA13 Calling up AWB with the LG tree 5 RSA14 Calling up AWB with the IO tree 6 RSA15 Calling up AWB with the ODS tree 7 RSA2 OLTP Metadata Repository 8 RSA3 Extractor Checker 9 RSA5 Install Business Content 10 RSA6 Maintain DataSources 11 RSA7 BW Delta Queue Monitor 12 RSA8 DataSource Repository 13 RSA9 Transfer Application Components 14 RSD1 Characteristic maintenance 15 RSD2 Maintenance of key figures 16 RSD3 Maintenance of units 17 RSD4 Maintenance of time characteristics 18 RSDBC DB connect 19 RSDCUBE Start: InfoCube editing 20 RSDCUBED Start: InfoCube editing 21 RSDCUBEM Start: InfoCube editing 22 RSDDV Maintaining 23 RSDIOBC Start: InfoObject catalog editing 24 RSDIOBCD Start: InfoObject catalog editing 25 RSDIOBCM Start: InfoObject catalog editing 26 RSDL DB Connect - Test Program 27 RSDMD MasterВ DataВ Maintenance w.Prev. Sel. 28 RSDMD_TEST Master Data Test 29 RSDMPRO Initial Screen: MultiProvider Proc. 30 RSDMPROD Initial Screen: MultiProvider Proc. 31 RSDMPROM Initial Screen: MultiProvider Proc. 32 RSDMWB Customer Behavior. Modeling 33 RSDODS Initial Screen: ODS Object Processng 34 RSIMPCUR Load Exchange Rates from File 35 RSINPUT Manual Data Entry 36 RSIS1 Create InfoSource 37 RSIS2 Change InfoSource 38 RSIS3 Display InfoSource 39 RSISET Maintain InfoSets 40 RSKC Maintaining the Permittd Extra Chars 41 RSLGMP Maintain RSLOGSYSMAP 42 RSMO Data Load Monitor Start 43 RSMON BW Administrator Workbench 44 RSOR BW Metadata Repository 45 RSORBCT BI Business Content Transfer 46 RSORMDR BW Metadata Repository 47 RSPC Process Chain Maintenance 48 RSPC1 Process Chain Display 49 RSPCM Monitor daily process chains 50 RSRCACHE OLAP: Cache Monitor 51 RSRT Start of the report monitor 52 RSRT1 Start of the Report Monitor 53 RSRT2 Start of the Report Monitor 54 RSRTRACE Set trace configuration 55 RSRTRACETEST Trace tool configuration 56 RSRV Analysis and Repair of BW Objects 57 SE03 Transport Organizer Tools 58 SE06 Set Up Transport Organizer 59 SE07 CTS Status Display 60 SE09 Transport Organizer 61 SE10 Transport Organizer 62 SE11 ABAP Dictionary 63 SE18 Business Add-Ins: Definitions 64 SE18_OLD Business Add-Ins: Definitions (Old) 65 SE19 Business Add-Ins: Implementations 66 SE19_OLD Business Add-Ins: Implementations 67 SE21 Package Builder 68 SE24 Class Builder 69 SE80 Object Navigator 70 RSCUSTA Maintain BW Settings 71 RSCUSTA2 ODS Settings 72 RSCUSTV* В 73 RSSM Authorizations for Reporting 74 SM04 User List 75 SM12 Display and Delete Locks 76 SM21 Online System Log Analysis 77 SM37 Overview of job selection 78 SM50 Work Process Overview 79 SM51 List of SAP Systems 80 SM58 Asynchronous RFC Error Log 81 SM59 RFC Destinations (Display/Maintain) 82 LISTCUBE List viewer for InfoCubes 83 LISTSCHEMA Show InfoCube schema 84 WE02 Display IDoc 85 WE05 IDoc Lists 86 WE06 Active IDoc monitoring 87 WE07 IDoc statistics 88 WE08 Status File Interface 89 WE09 Search for IDoc in Database 90 WE10 Search for IDoc in Archive 91 WE11 Delete IDocs 92 WE12 Test Modified Inbound File 93 WE14 Test Outbound Processing 94 WE15 Test Outbound Processing from MC 95 WE16 Test Inbound File 96 WE17 Test Status File 97 WE18 Generate Status File 98 WE19 Test tool 99 WE20 Partner Profiles 100 WE21 Port definition 101 WE23 Verification of IDoc processing 102 DB02 Tables and Indexes Monitor 103 DB14 Display DBA Operation Logs 104 DB16 Display DB Check Results 105 DB20 Update DB StatisticsBW:SAP STMSй…ҚзҪ®
UserName
SAP*
PassWord
Pass
еҪ’зұ»дәҺВ SAP BWВ |В 1 зҜҮиҜ„и®ә В»BW:EU_INIT, EU_REORG, EU_PUT Canceled
еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»
еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»1 еҗҢдёҖдёӘеҸҳйҮҸеҗҚзҡ„UIDеҸҜиғҪжңүеӨҡдёӘпјҢи®°еҫ—жіЁж„Ҹ
</BIC|/BIO>/D<дҝЎжҒҜз«Ӣж–№дҪ“еҗҚ>P
ж•°жҚ®еҢ…з»ҙеәҰ
Package
</BIC|/BIO>/D<дҝЎжҒҜз«Ӣж–№дҪ“еҗҚ>T
ж—¶й—ҙз»ҙеәҰ
Time
</BIC|/BIO>/D<дҝЎжҒҜз«Ӣж–№дҪ“еҗҚ>U
еҚ•дҪҚз»ҙеәҰ
Unit
</BIC|/BIO>/S<зү№еҫҒеҗҚ>
SIDиЎЁ
</BIC|/BIO>/P<зү№еҫҒеҗҚ>
дё»ж•°жҚ®иЎЁ
</BIC|/BIO>/T<зү№еҫҒеҗҚ>
ж–Үжң¬иЎЁ
</BIC|/BIO>/H<зү№еҫҒеҗҚ>
еұӮж¬ЎиЎЁ
</BIC|/BIO>/I<зү№еҫҒеҗҚ>
еұӮж¬ЎиЎЁI
</BIC|/BIO>/K<зү№еҫҒеҗҚ>
еұӮж¬ЎиЎЁK
</BIC|/BIO>/S<зү№еҫҒеҗҚ>
еұӮж¬ЎиЎЁS
</BIC|/BIO>/M<зү№еҫҒеҗҚ>
дё»ж•°жҚ®и§Ҷеӣҫ

0
Data request received
1
Data selection started
2
Data selection running
5
Error in data selection
6
Transfer structure obsolete, transfer rules regeneration
8
No data available, data selection ended
9
Data selection ended
Info IDoc 1
Info Idoc 2
Info Idoc 3
Info Idoc 4
Info Idoc 5
0
1
2
2
9
Dзі»з»ҹ
Development
ејҖеҸ‘зі»з»ҹ
Qзі»з»ҹ
Quality Assurance
иҙЁйҮҸдҝқйҡңзі»з»ҹ
Pзі»з»ҹ
Production
з”ҹдә§зі»з»ҹ
D
SAPдј иҫ“пјҲDeliveryпјүзҠ¶жҖҒ
A
жҙ»еҠЁпјҲActiveпјүзҠ¶жҖҒ
M
дҝ®ж”№пјҲModifiedпјүзҠ¶жҖҒ
Basic Cube
еҹәжң¬CUBE
Multi Cube
еӨҡз«Ӣж–№дҪ“
SAP Remote Cube
SAPиҝңзЁӢз«Ӣж–№дҪ“
Gen Remote Cube
дёҖиҲ¬иҝңзЁӢз«Ӣж–№дҪ“
Today-is-yesterday
ж—¶й—ҙ>еҪ“еүҚ
Yesterday-is-today
ж—¶й—ҙ<еҪ“еүҚ
Yesterday-or-today
Yesterday-and-today
AиЎЁ
жҝҖжҙ»еҗҺзҡ„ж•°жҚ®
LOGиЎЁ
еӯҳж”ҫж•°жҚ®иҜҰз»ҶеҠЁдҪңпјҢз”ЁдәҺдёҠиҪҪеҲ°CUBE
NиЎЁ
ж•°жҚ®жҠҪеҸ–еҲ°DSOеҗҺеӯҳж”ҫеңЁNиЎЁпјҢжҝҖжҙ»еҗҺжё…з©ә
DELTA
LOGиЎЁ
FULL
AиЎЁе’ҢLOGиЎЁ
SE06
е…ЁеұҖй…ҚзҪ®
SCC4
йӣҶеӣўй…ҚзҪ®
SM59
RFCй…ҚзҪ®
STMS
дј иҫ“й…ҚзҪ®
SU02
еҸӮж•°ж–Ү件пјҲжқғйҷҗпјү
SM50
еҗҺеҸ°иҝӣзЁӢжҺ§еҲ¶
SM21
зі»з»ҹж—Ҙеҝ—
ST11
иҪЁиҝ№ж—Ҙеҝ—
ST22
ABAP Runtime Error
SM37
дҪңдёҡйҖүжӢ©
ST04
еҗҺеҸ°зӣ‘жҺ§
ST06
OSзӣ‘жҺ§
ST06N
OSзӣ‘жҺ§
ST05
жү§иЎҢеҲҶжһҗпјҲиҝҪиёӘпјү
SM30
еҲқе§ӢеұҸ幕
SM64
дәӢ件еҺҶеҸІ
SM51
SAP Server
VF03
BILLINGеҮӯиҜҒ
VA43
еҗҲеҗҢ
VA03
й”Җе”®еҮӯиҜҒ
FD10N
е®ўжҲ·дҪҷйўқ
SCOT
SAP Connect
SOST
SAP
SE14
ABAP Dictionary
SM30
Maintain Table
RSPCM
Monitor of RSPC
RSMO
Monitor of All
ALRTCATDEF
ME22N
PO
ME23N
PO
ME21
PO List
ME53N
Purchasing Plan
XD03
Customer
KS03
Cost Center
FSS0
жҖ»иҙҰ科зӣ®
FB03
жҖ»иҙҰеҮӯиҜҒ
AFAB
жҠҳж—§и®°иҙҰ
FAGLL03
жҖ»иҙҰ科зӣ®иЎҢйЎ№зӣ®
CHANGERUNMONI
Change run monitor
ST01
System trace
ST05
Performance Analysis
FB03
жҳҫзӨәеҮӯиҜҒ
FD10N
е®ўжҲ·дҪҷйўқ
FAGLB03
жҖ»иҙҰдҪҷйўқ
SHDB
Transaction Recorder
SM19
BADI
RSCUR
иҙ§еёҒиҪ¬жҚў
RSZC
Query еӨҚеҲ¶
SE24
Class Builder
SE91
MSG
SNOTE
Note
SU21
Maintain Authorization Object
SE54
Generate the required maintenance dialog.


AGR_1251
RSECVAL
еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»Delta Process
Deletion:Delete
Acumulated:ADD
The delta queue is aВ dataВ store for new or changed data records for a DataSource (that have occurred since the last data request). The new or changed data records are either written to the delta queue automatically using an update process in the source system, or by means of the DataSource extractor when a data request is received from the BI system (details will be provided later).
еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»A
Aggregate
Aggregate rollup
Application component
Authorization
Authorization object
Authorization profile
B
BEx
Bitmap index
Business Content
BW
BW Monitor
BW Scheduler
BW Statistics
Cache / OLAP Cache
Cache Mode
Change run
Characteristic
Client
Communication structure
Compound attribute
Compress
D
Data packet size
Data Mining
Data Warehouse
DataSource
DB Connect
Delta Caching
Delta update
Development class
Display attribute
Drill-down
DSO
A DataStore object contains key fields (such as document number, document item) and data fields that, in addition to key figures, can also contain character fields (such as order status, customer). The data from a DataStore object can be updated with a delta update into InfoCubes (standard) and/or other DataStore objects or master data tables (attributes or texts) in the same system or across different systems.
E
EDW
ETTL
F
Fact tables
E-fact table is optimized for Reading => good for Queries. F-fact table is optimized for Writing => good for Loads
Free characteristic
Full update
G
Generic data extraction
Granularity
H
High Cardinality
I
IDoc
Index
InfoArea
InfoCube
InfoCube compression
InfoObject
InfoObject Catalog
InfoPackage
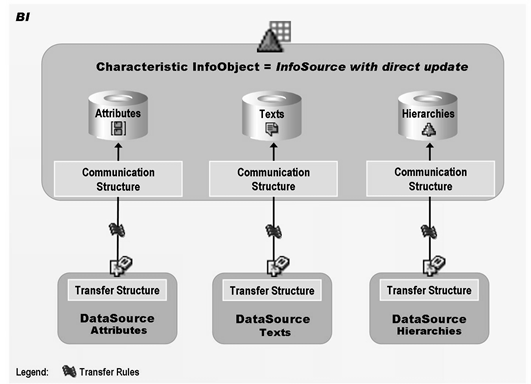
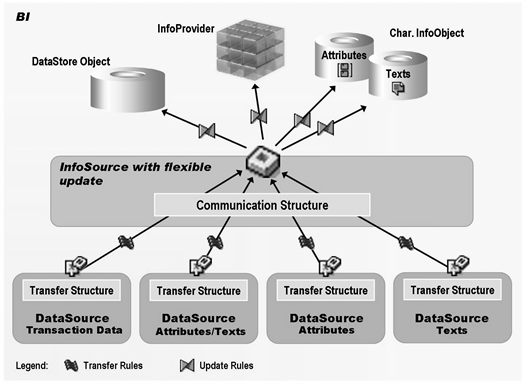
InfoSource
Information Lifecycle Mangement
K
Key figure
L
Line item dimension
Logical system
M
Metadata Repository
Multi-cube
N
Navigational attribute
Number range
O
ODS
Open Hub Service
OLTP / OLAP
P
Parallel query
Partition
Partitioning Type
Process Chain
Profile Generator
PSA
Q
Query
R
Read mode
Reconstruct
Request
RFC
Role
S
SID
Source system
Star schema
Statistics
System Administration Assistant
System landscape
T
Time-dependent entire hierarchy
Time-dependent hierarchy structure
Transfer rule
Transfer structure
TRFs connect source objects (DataSources, DSOs, InfoCubes, InfoSets) to Data Targets (InfoProviders) of a data-staging process. They replace combination of transfer rules & update rules. The TRF process allows you to consolidate, cleanse & integrate data. You must use DTP to load data to InfoProvider.
U V W X Y Z
Update rule
Variable
Virtual InfoProvider
Workbook
еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»дёәд»Җд№ҲиҰҒEmulate 3.x datasource in BW 7.0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
BW Issue Note: ETL - 3.X datasource not found
You have replicated one or more DataSources from the source system. You now want to create a mapping between a 3.x DataSource and 3.x InfoSource and then maintain the transfer rules.
However, the system does not find the 3.x DataSource.
Replication, dialog box
The object exists as a (new) DataSource (R3TR RSDS) rather than a 3.x DataSource (R3TR ISFS).
You can identify 3.x DataSources by the word вҖңemulatedвҖқ under the вҖңCompare withвҖқ button in the DataSource display and maintenance environments.
If you incorrectly replicated some of the DataSources as (new) DataSources or if the problem is caused by the вҖңincorrect contentвҖқ, proceed as follows:
Call transaction RSDS then specify the technical name of the DataSource and the source system.
Choose the вҖңRestore 3.x DataSourceвҖқ option from the вҖңDataSourceвҖқ menu.
If the problem occurs because you have replicated a large number of DataSources into the incorrect (new) DataSource object type and if you have imported at least Support Package 07 for SAP NetWeaver 2004s BI into your system, execute the report вҖңRSDS_REPL_RESETвҖқ in transaction SE38.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»Question 1:
Answer:
The вҖҳTotalвҖҷ column displays the number of LUWs that were written in the delta queue and that have not yet been confirmed. The number includes the LUWs of the last delta request (for repeating a delta request) and the LUWs for the next delta request. An LUW only disappears from the RSA7 display when it has been transferred to the BW System and a new delta request has been received from the BW System.
What is an LUW in the delta queue?
Answer:
An LUW from the point of view of the delta queue can be an individual document, a group of documents from a collective run or a wholeВ dataВ packet from an application extractor.
Why does the number in the вҖҳTotalвҖҷ column, in the overview screen of Transaction RSA7, differ from the number of data records that are displayed when you call up the detail view?
Answer:
The number on the overview screen corresponds to the total number of LUWs (see also question 1) that were written to the qRFC queue and that have not yet been confirmed. The detail screen displays the records contained in the LUWs. Both the records belonging to the previous delta request and the records that do not meet the selection conditions of the preceding delta init requests are filtered out. This means that only the records that are ready for the next delta request are displayed on the detail screen. The detail screen of Transaction RSA7 does not take into account a possibly existing customer exit.
Why does Transaction RSA7 still display LUWs on the overview screen after successful delta loading?
Answer:
Only when a new delta has been requested does the source system learn that the previous delta was successfully loaded into the BW System. The LUWs of the previous delta may then be confirmed (and also deleted). In the meantime, the LUWs must be kept for a possible delta request repetition. In particular, the number on the overview screen does not change if the first delta is loaded into the BW System.
Why are selections not taken into account when the delta queue is filled?
Answer:
Filtering according to selections takes place when the system reads from the delta queue. This is necessary for performance reasons.
Why is there a DataSource with вҖҳ0вҖІ records in RSA7 if delta exists and has been loaded successfully?
Answer:
It is most likely that this is a DataSource that does not send delta data to the BW System via the delta queue but directly via the extractor . You can display the current delta data for these DataSources using TA RSA3 (update mode =вҖҷDвҖҷ)
Do the entries in Table ROIDOCPRMS have an impact on the performance of the loading procedure from the delta queue?
Answer:
The impact is limited. If performance problems are related to the loading process from the delta queue, then refer to the application-specific notes (for example in the CO-PA area, in the logistics cockpit area, and so on).
Caution: As of PlugIn 2000.2 patch 3, the entries in Table ROIDOCPRMS are as effective for the delta queue as for a full update. Note, however, that LUWs are not split during data loading for consistency reasons. This means that when very large LUWs are written to the delta queue, the actual package size may differ considerably from the MAXSIZE and MAXLINES parameters.
Why does it take so long to display the data in the delta queue (for example approximately 2 hours)?
Answer:
With PlugIn 2001.1 the display was changed: you are now able to define the amount of data to be displayed, to restrict it, to selectively choose the number of a data record, to make a distinction between the вҖҳactualвҖҷ delta data and the data intended for repetition, and so on.
What is the purpose of the function вҖҳDelete Data and Meta. Data in a QueueвҖҷ in RSA7? What exactly is deleted?
Answer:
You should act with extreme caution when you use the delete function in the delta queue. It is comparable to deleting an InitDelta in the BW System and should preferably be executed there. Not only do you delete all data of this DataSource for the affected BW System, but you also lose all the information concerning the delta initialization. Then you can only request new deltas after another delta initialization.
When you delete the data, this confirms the LUWs kept in the qRFC queue for the corresponding target system. Physical deletion only takes place in the qRFC outbound queue if there are no more references to the LUWs.
The delete function is intended for example, for cases where the BW System, from which the delta initialization was originally executed, no longer exists or can no longer be accessed.
Why does it take so long to delete from the delta queue (for example half a day)?
Answer:
Import PlugIn 2000.2 patch 3. With this patch the performance during deletion improves considerably.
Why is the delta queue not updated when you start the V3 update in the logistics cockpit area?
Answer:
It is most likely that a delta initialization had not yet run or that the the delta initialization was not successful. A successful delta initialization (the corresponding request must have QM status вҖҳgreenвҖҷ in the BW System) is a prerequisite for the application data to be written to the delta queue.
What is the relationship between RSA7 and the qRFC monitor (Transaction SMQ1)?
Answer:
The qRFC monitor basically displays the same data as RSA7. The internal queue name must be used for selection on the initial screen of the qRFC monitor. This is made up of the prefix вҖҳBW, the client and the short name of the DataSource. For DataSources whose name is shorter than 20 characters, the short name corresponds to the name of the DataSource. For DataSources whose name is longer than 19 characters (for delta-capable DataSources only possible as of PlugIn 2001.1) the short name is assigned in Table ROOSSHORTN.
In the qRFC monitor you cannot distinguish between repeatable and new LUWs. Moreover, the data of a LUW is displayed in an unstructured manner there.
Why is there data in the delta queue although the V3 update has not yet been started?
Answer:
You posted data in the background. This means that the records are updated directly in the delta queue (RSA7). This happens in particular during automatic goods receipt posting (MRRS). There is no duplicate transfer of records to the BW system. See Note 417189.
Question 14:
Why does the вҖҳRepeatableвҖҷ button on the RSA7 data details screen not only show data loaded into BW during the last delta but also newly-added data, in other words, вҖҳpureвҖҷ delta records?
Answer:
It was programmed so that the request in repeat mode fetches both actually repeatable (old) data and new data from the source system.
I loaded several delta inits with various selections. For which one
is the delta loaded?
Answer:
For delta, all selections made via delta inits are summed up. This
means a delta for the вҖҳtotalвҖҷ of all delta initializations is loaded.
How many selections for delta inits are possible in the system?
Answer:
With simple selections (intervals without complicated join conditions or single values), you can make up to about 100 delta inits. It should not be more.
With complicated selection conditions, it should be only up to 10-20 delta inits.
Reason: With many selection conditions that are joined in a complicated way, too many вҖҳwhereвҖҷ lines are generated in the generatedABAPsource code which may exceed the memory limit.
I intend to copy the source system, i.e. make a client copy. What will happen with may delta? Should I initialize again after that?
Answer:
Before you copy a source client or source system, make sure that your deltas have been fetched from the delta queue into BW and that no delta is pending. After the client copy, an inconsistency might occur between BW delta tables and the OLTP delta tables as described in Note 405943. After the client copy, Table ROOSPRMSC will probably be empty in the OLTP since this table is client-independent. After the system copy, the table will contain the entries with the old logical system name which are no longer useful for further delta loading from the new logical system. The delta must be initialized in any case since delta depends on both the BW system and the source system. Even if no dump вҖҳMESSAGE_TYPE_XвҖҷ occurs in BW when editing or creating an InfoPackage, you should expect that the delta has to be initialized after the copy.
Am I permitted to use the functions in Transaction SMQ1 to manually control processes?
Answer:
Use SMQ1 as an instrument for diagnosis and control only. Make changes to BW queues only after informing BW Support or only if this is explicitly requested in a note for Component вҖҳBC-BWвҖҷ or вҖҳBW-WHM-SAPIвҖҷ.
Despite the delta request only being started after completion of the collective run (V3 update), it does not contain all documents. Only another delta request loads the missing documents into BW. What is the cause for this вҖңsplittingвҖқ?
Answer:
The collective run submits the open V2 documents to the task handler for processing. The task handler processes them in one or several parallel update processes in an asynchronous way. For this reason, plan a sufficiently large вҖңsafety time windowвҖқ between the end of the collective run in the source system and the start of the delta request in BW. An alternative solution where this problem does not occur is described in Note 505700.
Despite deleting the delta init, LUWs are still written into the DeltaQueue
Answer:
In general, delta initializations and deletions of delta inits should always be carried out at a time when no posting takes place. Otherwise, buffer problems may occur: If you started the internal mode at a time when the delta initialization was still active, you post data into the queue even though the initialization had been deleted in the meantime. This is the case in your system.
In SMQ1 (qRFC Monitor) I have status вҖҳNOSENDвҖҷ. In the Table TRFCQOUT, some entries have the status вҖҳREADYвҖҷ, others вҖҳRECORDEDвҖҷ. ARFCSSTATE is вҖҳREADвҖҷ. What do these statuses mean? Which values in the field вҖҳStatusвҖҷ mean what and which values are correct and which are alarming? Are the statuses BW-specific or generally valid in qRFC?
Answer:
Table TRFCQOUT and ARFCSSTATE: Status READ means that the record was read once either in a delta request or in a repetition of the delta request. However, this still does not mean that the record has successfully reached the BW. The status READY in the TRFCQOUT and RECORDED in the ARFCSSTATE means that the record has been written into the delta queue and will be loaded into the BW with the next delta request or a repetition of a delta. In any case only the statuses READ, READY and RECORDED in both tables are considered to be valid. The status EXECUTED in TRFCQOUT can occur temporarily. It is set before starting a delta extraction for all records with status READ present at that time. The records with status EXECUTED are usually deleted from the queue in packages within a delta request directly after setting the status before extracting a new delta. If you see such records, it means that either a process which confirms and deletes records loaded into the BW is successfully running at the moment, or, if the records remain in the table for a longer period of time with status EXECUTED, it is likely that there are problems with deleting the records which have already been successfully been loaded into the BW. In this state, no more deltas are loaded into the BW. Every other status indicates an error or an inconsistency. NOSEND in SMQ1 means nothing (see note 378903). However the value вҖҳUвҖҷ in field вҖҳNOSENDвҖҷ of table TRFCQOUT is of concern.
The extract structure was changed when the delta queue was empty. Afterwards new delta records were written to the delta queue. When loading the delta into the PSA, it shows that some fields were moved. The same result occurs when the contents of the delta queue are listed via the detail display. Why is the data displayed differently? What can be done?
Answer:
Make sure that the change of the extract structure is also reflected in the database and that all servers are synchronized. We recommend resetting the buffers using Transaction $SYNC. If the extract structure change is not communicated synchronously to theВ serverВ where delta records are being created, the records are written with the old structure until the new structure has been generated. This may have disastrous consequences for the delta. When the problem occurs, the delta needs to be re-initialized.
Answer:
Via the status of the last delta in the BW Request Monitor. If the request is RED, the next load will be of type вҖҳRepeatвҖҷ. If you need to repeat the last load for any reason, manually set the request in the monitor to red. For the contents of the repeat, see Question 14. Delta requests set to red when data is already updated lead to duplicate records in a subsequent repeat, if they have not already been deleted from the data targets concerned.
As of PI 2003.1, the Logistic Cockpit offers various types of update methods. Which update method is recommended in logistics? According to which criteria should the decision be made? How can I choose an update method in logistics?
Answer:
See the recommendation in Note 505700.
Are there particular recommendations regarding the maximum data volume of the delta queue to avoid danger of a read failure due to memory problems?
Answer:
There is no strict limit (except for the restricted number area of the 24-digit QCOUNT counter in the LUW management table - which is of no practical importance, however - or the restrictions regarding the volume and number of records in a database table).
When estimating вҖңsoftвҖқ limits, both the number of LUWs and the average data volume per LUW are important. As a rule, we recommend bundling data (usually documents) as soon as you write to the delta queue to keep number of LUWs low (this can partly be set in the applications, for example in the Logistics Cockpit). The data volume of a single LUW should not be much larger than 10% of the memory available to the work process for data extraction (in a 32-bit architecture with a memory volume of about 1 GByte per work process, 100 MByte per LUW should not be exceeded). This limit is of rather small practical importance as well since a comparable limit already applies when writing to the delta queue. If the limit is observed, correct reading is guaranteed in most cases.
If the number of LUWs cannot be reduced by bundling application transactions, you should at least make sure that the data is fetched from all connected BWs as quickly as possible. But for other, BW-specific, reasons, the frequency should not exceed one delta request per hour.
To avoid memory problems, a program-internal limit ensures that no more than 1 million LUWs are ever read and fetched from the database per delta request. If this limit is reached within a request, the delta queue must be emptied by several successive delta requests. We recommend, however, to try not to reach that limit but trigger the fetching of data from the connected BWs as soon as the number of LUWs reaches a 5-digit value.
еҪ’зұ»дәҺВ SAP BWВ |В жІЎжңүиҜ„и®ә В»йҖҡеёёеңЁSAP BW дёӯж•°жҚ®е»әжЁЎзҡ„ж•°жҚ®еӯҳеңЁдёӢйқўзҡ„дёҖдәӣиЎЁдёӯпјҡ
з»ҙеәҰиЎЁ-Dtable
SIDиЎЁ-Stable
дё»ж•°жҚ®иЎЁпјҡеҢ…жӢ¬ж–Үжң¬иЎЁTtableпјҢ еұһжҖ§иЎЁPtable е’ҢQtableInfoCube Tables
Dimension Tables пјҲжңҖеӨҡж”ҜжҢҒ16дёӘз»ҙеәҰпјү
numbers contain the following elements: P, T, U, 1, 2, вҖҰ 9, A, B, C, D.
P DataPackage
T Time
U Unit
A (10.Dimension)
B (11.Dimension)
C (12.Dimension)
D (13.Dimension)Fact Tables
Modeling InfoObjects
settings you have made on the tab pages.
Master Data Tables
Text Table
Attribute Tables
SID Tables
You can make the following changes to a characteristic after the master data has
been loaded:
вҖў Display attribute (time-independent) вҶ’ Navigation attribute (time-independent)
вҖў Display attribute (time-independent) вҶ’ Navigation attribute (time-dependent)
вҖў Display attribute (time-independent) вҶ’ Display attribute (time-dependent)
вҖў Display attribute (time-dependent) вҶ’ Navigation attribute (time-dependent)Characteristic InfoObjects
in accordance with the concept of the enhanced star schema
characteristic values ifexternal hierarchiesare used for the characteristic.
A hierarchy is a method of displaying a characteristic structured and grouped according to individual evaluation criteria.
Structure:
a) Nodes
A hierarchy is created from nodes. The uppermost node is the root.
b) Roots
A hierarchy can have several roots. They do not have superior nodes.
c) Hierarchy Levels
All nodes on the same level of the hierarchy (nodes that are the same distance away from the root) form. a hierarchy level. The roots of a hierarchy form. level 1. The level of a node denotes the distance from the node to the root.
d) Leaves
The leaves of a hierarchy consist of characteristic values for the basic characteristic and therefore can also have entries in the fact table. A leaf cannot have any sub nodes.
e) Basic Characteristic
Hierarchies can be created only for those characteristics that do not reference other characteristics.
Properties :
A BW hierarchy has the following properties:
вҖў Hierarchies are created for basic characteristics
вҖў Hierarchies are stored in special master data tables. They behave in a similar way to master data,
вҖў and can therefore be used and modified in all Info Cubes.
вҖў You can define several hierarchies for a single characteristic.
вҖў A hierarchy can have a maximum of 98 levels.


- 2011-07-31 13:35
- жөҸи§Ҳ 6602
- иҜ„и®ә(0)
- еҲҶзұ»:иЎҢдёҡеә”з”Ё
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
еңЁ Message BrokerдёӯдҪҝз”Ё SAP JCO иҝһжҺҘ SAP зі»з»ҹ
2011-08-10 11:02 2162http://www.ibm.com/developerwor ... -
еңЁJavaдёӯи°ғз”ЁBAPIжҲ–RFC(иҪ¬)
2011-08-10 10:55 2816JCoжҳҜдёҖдёӘй«ҳжҖ§иғҪзҡ„пјҢеҹәдәҺJNIзҡ„дёӯй—ҙ件пјҢе®ғе®һзҺ°дәҶSAPзҡ„RF ... -
Javaе’ҢSAPзҡ„дёүз§Қж•°жҚ®йҖҡдҝЎж–№ејҸ RFC IDOC XI
2011-08-10 10:38 3892JAVAдёҺSAPж•°жҚ®дәӨдә’зҡ„ж–№ејҸжҖ»з»“RFCж–№ејҸпјҡJavaзЁӢеәҸзӣҙжҺҘ ... -
BWеўһйҮҸжӣҙж–°зҡ„зҗҶи§ЈпјҲж—¶й—ҙжҲіпјү
2011-08-09 17:53 1793еңЁBWдёӯпјҢеӯҳеңЁдёӨз§Қж•°жҚ®жҠҪеҸ–ж–№ејҸпјҢе®Ңе…Ёжӣҙж–°дёҺеўһйҮҸжӣҙж–°пјҢе®Ңе…Ёжӣҙ ... -
SAP BW йӮ®д»¶еҸ‘йҖҒзӣ‘жҺ§зӯ–з•Ҙ
2011-08-09 17:53 1646SAP BW йӮ®д»¶еҸ‘йҖҒзӣ‘жҺ§зӯ–з•ҘВ В В В В В В В В В В В В В ... -
BWдёҺECCзі»з»ҹиҝһжҺҘи®ҫзҪ®
2011-08-09 17:51 2415第дёҖжӯҘпјҡеҲҶй…ҚйҖ»иҫ‘зі»з»ҹ SCC4е…ҲжҹҘзңӢйҖ»иҫ‘зі»з»ҹ->S ... -
еҰӮдҪ•жҹҘжүҫDataSourceе’Ңtableзҡ„mapping?
2011-08-09 17:48 1602зӣёдҝЎпјҢеӨ§е®¶еңЁдҪҝз”ЁBI Contentзҡ„ж—¶еҖҷпјҢз»ҸеёёйңҖиҰҒжҹҘжүҫDat ... -
DeltaдёӯдёҚеҫ—дёҚзңӢзҡ„еҮ дёӘиЎЁ
2011-08-09 17:47 929DeltaдёӯдёҚеҫ—дёҚзңӢзҡ„еҮ дёӘиЎЁпјҡ RODELTAMTВ иҜҙжҳҺжҜҸ ... -
BWдёӯеҰӮдҪ•иҝӣиЎҢж•°жҚ®зӣ‘жҺ§пјҹ
2011-08-04 19:12 1141иҝҷе‘ЁиҪ®еҲ°жҲ‘еҖјзҸӯпјҢиҰҒеҮҢж ... -
жҖ»з»“InfoCubeзҡ„дјҳеҠҝеҲҶжһҗеҸҠз»ҙеәҰйҖүжӢ©жҠҖе·§
2011-08-04 17:58 809дёҖзӣҙд»ҘжқҘпјҢinfocubeйғҪжҳҜдёҖдёӘеҫҲзә з»“зҡ„дёңиҘҝгҖӮ дҪңдёә ... -
жҖ»з»“InfoCubeзҡ„дјҳеҠҝеҲҶжһҗеҸҠз»ҙеәҰйҖүжӢ©жҠҖе·§
2011-08-04 17:55 1123дёҖзӣҙд»ҘжқҘпјҢinfocubeйғҪжҳҜдёҖдёӘеҫҲзә з»“зҡ„дёңиҘҝгҖӮ дҪңдёә ... -
BW:зӣ‘жҺ§ TCODE
2011-08-04 17:38 1141SM21: жЈҖжҹҘзі»з»ҹж—ҘиӘҢ ST22: abap DUMP ... -
BW:еҜ№дәҺйқһжі•еӯ—з¬Ұзҡ„жҺ§еҲ¶
2011-08-04 17:35 1149е…¶е®һиҝҷд№ҹжҳҜдёӘиҖҒз”ҹеёёи° ... -
BWеӯҰд№ вҖ”вҖ”жқғйҷҗ
2011-08-02 21:32 1412ж №жҚ®йЎҫй—®зҡ„иҰҒжұӮпјҢеӯҰд№ дәҶBWжқғйҷҗгҖӮиҰҒзӮ№еҰӮдёӢпјҡ 1пјҢBWзҡ„жқғ ... -
еҒ¶е°”дјҡиў«дәәй—®еҲ°зҡ„Cubeзҡ„еҮ дёӘж•°еӯ—
2011-08-02 21:05 9141. дәӢе®һиЎЁ:жңҖеӨҡиғҪеӨҹе®№зәі233дёӘkeyВ figures ... -
SAPеӯҰд№ ж—Ҙеҝ—--SAPдёӯеёёз”Ёдё”йҮҚиҰҒзҡ„ж•°жҚ®еә“иЎЁ
2011-08-02 21:00 1600MARA - Material Master: General ... -
BWж•°жҚ®жәҗж·ұе…Ҙз ”з©¶гҖҗиҪ¬иҮӘWKingChenзҡ„еҚҡе®ўгҖ‘
2011-08-02 19:21 1675DataSourceжҳҜBWдёӯйқһеёёйҮҚиҰҒзҡ„йғЁеҲҶпјҢдёҖдёӘеҗҲж јзҡ„BWйЎҫй—® ... -
SAP BW дҫӢзЁӢпјҲRoutineпјүгҖҗејҖе§ӢдҫӢзЁӢгҖҒе…ій”®еҖјжҲ–зү№жҖ§зҡ„дҫӢзЁӢгҖҒз»“жқҹдҫӢзЁӢгҖ‘
2011-08-01 13:42 3951е®ҡд№ү еҸҜд»ҘдҪҝз”ЁдҫӢзЁӢе®ҡд№үе…ій”®еҖјжҲ–зү№жҖ§зҡ„еӨҚжқӮзҡ„иҪ¬жҚўи§„еҲҷ. ... -
BWд№ӢR3ж•°жҚ®жәҗеҸҠPSA
2011-07-31 15:23 2504BWж•°жҚ®жәҗдё»иҰҒжңүR3гҖҒж–Ү件 ... -
зҗҶи§ЈBWж•°жҚ®жЁЎеһӢ - DSOжЁЎеһӢ
2011-07-31 13:55 2211DSOзҡ„з”Ёжі•жңүеҫҲеӨҡпјҢжҜ”иҫ ...
зӣёе…іжҺЁиҚҗ
3. иЎЁеҲҶзұ»пјҡж №жҚ®SAPжЁЎеқ—жҲ–иҖ…дёҡеҠЎеҠҹиғҪеҜ№иЎЁиҝӣиЎҢеҪ’зұ»гҖӮ 4. дё»й”®еӯ—ж®өпјҡж ҮиҜҶиЎЁдёӯе”ҜдёҖи®°еҪ•зҡ„е…ій”®еӯ—ж®өгҖӮ 5. еӯ—ж®өеҲ—иЎЁпјҡиЎЁдёӯеҢ…еҗ«зҡ„жүҖжңүеӯ—ж®өеҸҠе…¶ж•°жҚ®зұ»еһӢпјҢжҸҸиҝ°дәҶиЎЁеҸҜд»ҘеӯҳеӮЁе“Әдәӣзұ»еһӢзҡ„дҝЎжҒҜгҖӮ 6. еҸӮиҖғиЎЁпјҡеҰӮжһңжңүзҡ„иҜқпјҢеҲ—еҮә...
ж•°еӯҰе»әжЁЎеһғеңҫеҲҶзұ»еӨ„зҗҶеҪ’зұ»жҳҜе°Ҷж•°еӯҰе»әжЁЎжҠҖжңҜеә”з”ЁдәҺеһғеңҫеҲҶзұ»еӨ„зҗҶиҝҮзЁӢдёӯпјҢд»ҘжҸҗй«ҳеһғеңҫеӨ„зҗҶж•ҲзҺҮе’Ңз»ҸжөҺж•ҲзӣҠгҖӮж №жҚ®еһғеңҫеҲҶзұ»еӨ„зҗҶзҡ„зү№зӮ№пјҢж•°еӯҰе»әжЁЎеҸҜд»ҘеҲҶдёәд»ҘдёӢеҮ дёӘж–№йқўпјҡ дёҖгҖҒеһғеңҫеҲҶзұ»жЁЎеһӢ еһғеңҫеҲҶзұ»жЁЎеһӢжҳҜжҢҮж №жҚ®еһғеңҫзҡ„жҖ§иҙЁ...
еңЁжң¬иҜҫзЁӢдёӯпјҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁSAP FICOжЁЎеқ—дёӯзҡ„е…ій”®иҙўеҠЎеҠҹиғҪпјҢзү№еҲ«жҳҜвҖңARAPйҮҚеҲҶзұ»вҖқгҖҒвҖңиҮӘеҠЁж”Ҝд»ҳвҖқгҖҒвҖңеӨ–еёҒиҜ„дј°вҖқд»ҘеҸҠвҖңж ЎйӘҢе’Ңжӣҝд»ЈвҖқиҝҷеӣӣдёӘдё»йўҳгҖӮиҝҷдәӣжҰӮеҝөжҳҜSAPиҙўеҠЎдҝЎжҒҜзі»з»ҹзҡ„ж ёеҝғз»„жҲҗйғЁеҲҶпјҢеҜ№дәҺзҗҶи§Је’Ңж“ҚдҪңSAP FICO...
еңЁSAPзі»з»ҹдёӯпјҢзү©ж–ҷз»„зҡ„е®ҡд№үжҳҜдёҖдёӘжҢүз…§зү©ж–ҷзү№жҖ§иҝӣиЎҢзҡ„еҪ’зұ»гҖӮйҖҡиҝҮе®ҡд№үзү©ж–ҷз»„пјҢз”ЁжҲ·еҸҜд»Ҙе°Ҷе…·жңүзӣёдјјеұһжҖ§жҲ–зӣёеҗҢзӣ®зҡ„зҡ„зү©ж–ҷеҲҶз»„пјҢд»ҘдҫҝдәҺиҝӣиЎҢиҢғеӣҙйҷҗе®ҡзҡ„еҲҶжһҗпјҢеҰӮжҲҗжң¬гҖҒй”Җе”®гҖҒеә“еӯҳзӯүж–№йқўзҡ„з»ҹи®ЎгҖӮжӯӨеӨ–пјҢзү©ж–ҷз»„иҝҳеҸҜд»Ҙз”ЁдәҺзі»з»ҹ...
иҝҷдёӘPDFж–Ү件жҸҸиҝ°зҡ„жҳҜдёҖдёӘз®ҖеҚ•зҡ„CиҜӯиЁҖж—Ҙеҝ—и®°еҪ•зЁӢеәҸпјҢз”ЁдәҺеңЁдёҚеҗҢзҡ„зә§еҲ«пјҲеҰӮдҝЎжҒҜгҖҒй”ҷиҜҜе’Ңзі»з»ҹпјүеҲҶзұ»и®°еҪ•ж—Ҙеҝ—гҖӮж—Ҙеҝ—еҠҹиғҪеңЁи®ёеӨҡеә”з”ЁзЁӢеәҸдёӯйғҪеҫҲйҮҚиҰҒпјҢеӣ дёәе®ғеҸҜд»Ҙеё®еҠ©ејҖеҸ‘иҖ…иҝҪиёӘе’Ңи°ғиҜ•зЁӢеәҸзҡ„иЎҢдёәпјҢзү№еҲ«жҳҜеңЁеӨ„зҗҶеӨҚжқӮй—®йўҳжҲ–...
SAP зү©ж–ҷдё»ж•°жҚ®и§Ҷеӣҫ SAP зү©ж–ҷдё»ж•°жҚ®и§ҶеӣҫжҳҜ SAP зі»з»ҹдёӯжңҖйҮҚиҰҒзҡ„дё»ж•°жҚ®д№ӢдёҖпјҢеҰӮжһңдёҚзҗҶи§Јзү©ж–ҷзӣёе…іеҗ«д№үпјҢSAP е°Ҷйҡҫд»ҘжҺҢжҸЎгҖӮжң¬ж–Үе°ҶиҜҰз»Ҷд»Ӣз»Қ SAP зү©ж–ҷдё»ж•°жҚ®и§Ҷеӣҫзҡ„зҹҘиҜҶзӮ№пјҢеё®еҠ©жӮЁи§ЈејҖеҝғдёӯзҡ„и°ңеӣўгҖӮ дёҖгҖҒеҹәжң¬и§Ҷеӣҫ еҹәжң¬и§Ҷеӣҫ...
3. **дёҖз§Қзү©ж–ҷзұ»еһӢеӨҡдёӘ科зӣ®**пјҡйҖӮз”ЁдәҺйңҖиҰҒжҢүзү©ж–ҷзҡ„жҖ§иҙЁжҲ–йЎ№зӣ®иҝӣиЎҢжӣҙз»ҶзІ’еәҰеҲҶзұ»зҡ„жғ…еҶөгҖӮ ##### дёә移еҠЁзұ»еһӢе®ҡд№ү科зӣ®еҲҶз»„ 科зӣ®еҲҶз»„пјҲPosting TransactionsпјүжҳҜз”ЁдәҺе®ҡд№үзү©ж–ҷ移еҠЁж—¶иҮӘеҠЁиҝҮиҙҰиЎҢдёәзҡ„жЁЎжқҝгҖӮжҜҸдёӘ移еҠЁзұ»еһӢпјҲеҰӮ...
"IISж—Ҙеҝ—еҲҶжһҗеҪ’зұ»е·Ҙе…·"е°ұжҳҜй’ҲеҜ№иҝҷдәӣж—Ҙеҝ—иҝӣиЎҢж·ұеәҰеҲҶжһҗе’Ңж•ҙзҗҶзҡ„иҪҜ件пјҢе®ғиғҪеӨҹеё®еҠ©з®ЎзҗҶе‘ҳй«ҳж•Ҳең°зҗҶи§Је’Ңи§ЈиҜ»IISж—Ҙеҝ—ж•°жҚ®гҖӮ иҝҷж¬ҫе®Ңе…Ёе…Қиҙ№зҡ„IISж—Ҙеҝ—еҲҶжһҗиҪҜ件具еӨҮд»ҘдёӢеҮ дёӘе…ій”®еҠҹиғҪпјҡ 1. ж•°жҚ®еҜје…Ҙпјҡе·Ҙе…·иғҪеӨҹеҜје…ҘIISж—Ҙеҝ—ж–Ү件...
- **еҲҶз»„з®ЎзҗҶ**: е°ҶжүҖжңүзӣёе…ізҡ„ејҖеҸ‘йЎ№зӣ®еҪ’зұ»еҲ°еҗҢдёҖдј иҫ“еұӮдёӢпјҢж–№дҫҝз»ҹдёҖз®ЎзҗҶгҖӮ - **ж ҮеҮҶеҢ–**: жҜҸдёӘејҖеҸ‘зі»з»ҹйғҪжңүдёҖдёӘй»ҳи®Өзҡ„дј иҫ“еұӮпјҢз®ҖеҢ–дәҶйЎ№зӣ®з®ЎзҗҶжөҒзЁӢгҖӮ - **йҡ”зҰ»жҖ§**: дёҚеҗҢзҡ„дј иҫ“еұӮеҸҜд»ҘзӢ¬з«ӢиҝҗдҪңпјҢйҒҝе…ҚдәҶйЎ№зӣ®й—ҙзҡ„е№Іжү°гҖӮ...
### SAP Variant Configuration Overview #### еәҸиЁҖ SAP Variant Configuration (VC) жҳҜдёҖз§Қ...SAP Variant Configuration дёҚд»…жңүеҠ©дәҺжҸҗй«ҳдјҒдёҡзҡ„з”ҹдә§ж•ҲзҺҮпјҢиҝҳиғҪжҸҗеҚҮе®ўжҲ·ж»Ўж„ҸеәҰпјҢжҳҜзҺ°д»ЈдјҒдёҡдёҚеҸҜжҲ–зјәзҡ„ејәеӨ§е·Ҙе…·д№ӢдёҖгҖӮ
еҲқзә§жҲҗжң¬иҰҒзҙ зҡ„иҫ“е…ҘжәҗиҮӘдәҺе…¬еҸёзҡ„еӨ–йғЁдәӨжҳ“пјҢжүҖжңүзҡ„жҚҹзӣҠзұ»иҙҰжҲ·зҡ„иҙўеҠЎж•°жҚ®йғҪдјҡйҖҡиҝҮеҲқзә§жҲҗжң¬иҰҒзҙ иҫ“е…ҘеҲ°жҲҗжң¬дёӯеҝғдёӯгҖӮдҫӢеҰӮпјҢйҮҮиҙӯеҺҹжқҗж–ҷзҡ„иҙ№з”ЁгҖҒй”Җе”®дә§з”ҹзҡ„收е…ҘзӯүйғҪеұһдәҺеҲқзә§жҲҗжң¬иҰҒзҙ гҖӮ ##### 2. ж¬Ўзә§жҲҗжң¬иҰҒзҙ ж¬Ўзә§жҲҗжң¬...
3. еҲҶзұ»и§„еҲҷи®ҫе®ҡпјҡз”ЁжҲ·еҸҜд»Ҙж №жҚ®йңҖжұӮи®ҫзҪ®еҲҶзұ»и§„еҲҷпјҢжҜ”еҰӮжҢүж–Ү件зұ»еһӢгҖҒеӨ§е°ҸгҖҒж—Ҙжңҹзӯүеӣ зҙ жқҘеҪ’зұ»гҖӮдҫӢеҰӮпјҢеҸҜд»ҘеҲӣе»әдёҖдёӘ规еҲҷпјҢдҪҝеҫ—жүҖжңүеӣҫзүҮж–Ү件иҮӘеҠЁеҪ’е…ҘвҖңеӣҫзүҮвҖқж–Ү件еӨ№пјҢиҖҢж–ҮжЎЈзұ»ж–Ү件еҪ’е…ҘвҖңж–ҮжЎЈвҖқж–Ү件еӨ№гҖӮ 4. иҮӘеҠЁеҪ’жЎЈпјҡ...
#### SAP HRдёӯе·Ҙиө„зұ»еһӢзҡ„еҲҶзұ» 1. **еҹәжң¬е·Ҙиө„зұ»еһӢ**пјҡиҝҷдәӣе·Ҙиө„зұ»еһӢд»ЈиЎЁдәҶе‘ҳе·Ҙзҡ„еҹәжң¬ж”¶е…ҘжқҘжәҗпјҢеҰӮеҹәжң¬е·Ҙиө„гҖҒе°Ҹж—¶е·Ҙиө„зӯүгҖӮе®ғ们йҖҡеёёжҳҜеӣәе®ҡдёҚеҸҳзҡ„пјҢ并且жһ„жҲҗдәҶи–Әй…¬з»“жһ„зҡ„еҹәзЎҖгҖӮ 2. **еҸҳеҠЁе·Ҙиө„зұ»еһӢ**пјҡиҝҷзұ»е·Ҙиө„зұ»еһӢеҢ…жӢ¬...
еӣ жӯӨпјҢдёәдәҶиҺ·еҫ—еҮҶзЎ®зҡ„зҺ°йҮ‘жөҒйҮҸиЎЁпјҢйңҖиҰҒз»“еҗҲжҺ§еҲ¶жЁЎеқ—пјҢйҖҡиҝҮеңЁи®°иҙҰж—¶жҢҮе®ҡзҺ°йҮ‘жөҒйҮҸйЎ№зӣ®пјҢзЎ®дҝқжүҖжңүдёҺзҺ°йҮ‘жөҒзӣёе…ізҡ„йҮ‘йўқйғҪиғҪиў«жӯЈзЎ®еҪ’зұ»гҖӮ жңҲжң«е…іиҙҰж—¶пјҢиҙўеҠЎе’Ңз®ЎзҗҶдјҡи®Ўзҡ„е·ҘдҪңж¶үеҸҠеӨҡдёӘжЁЎеқ—пјҢеҢ…жӢ¬FIпјҲиҙўеҠЎдјҡи®Ўпјүзҡ„е®һйҷ…д»·ж јйҮҚ...
жҖ»еҲҶзұ»еёҗжҳҜSAP R/3иҙўдјҡеӯҗзі»з»ҹзҡ„ж ёеҝғпјҢе®ғиҝһжҺҘдәҶиҙўеҠЎдјҡи®Ўе’Ңз®ЎзҗҶдјҡи®Ўзҡ„жүҖжңүж–№йқўпјҢзЎ®дҝқж•°жҚ®зҡ„дёҖиҮҙжҖ§е’ҢеҮҶзЎ®жҖ§гҖӮ #### 9. жҖ»еҲҶзұ»еёҗеҹәжң¬жңҜиҜӯ еңЁзҗҶи§ЈжҖ»еҲҶзұ»еёҗж—¶пјҢд»ҘдёӢеҮ дёӘжңҜиҜӯйқһеёёйҮҚиҰҒпјҡ - **е…¬еҸёд»Јз Ғ**пјҡжҜҸдёӘе…¬еҸёд»Јз Ғд»ЈиЎЁ...
йҰ–е…ҲпјҢвҖңжҠҖжңҜеҪ’зұ»е§”е‘ҳдјҡ第еҚҒдә”ж¬Ўдјҡи®®вҖқеҸҜиғҪжҢҮзҡ„жҳҜдёҖдёӘеҜ№жҠҖжңҜж ҮеҮҶжҲ–иҖ…дә§е“ҒеҲҶзұ»иҝӣиЎҢ规иҢғе’Ңжӣҙж–°зҡ„жңәжһ„е®ҡжңҹеҸ¬ејҖзҡ„дјҡи®®гҖӮеңЁиҝҷдёӘдјҡи®®дёӯпјҢ委е‘ҳдјҡи®Ёи®ә并еҶіе®ҡдәҶе…ідәҺвҖңдј ж„ҹеҷЁвҖқзҡ„еҪ’зұ»и°ғж•ҙпјҢиҝҷиЎЁжҳҺдјҡи®®еҶ…е®№дёҺжҠҖжңҜж ҮеҮҶеҢ–зӣёе…ігҖӮ...
иҝҷдәӣе…ғзҙ е…ұеҗҢжһ„е»әдәҶдёҖдёӘйЎ№зӣ®зҡ„жЎҶжһ¶пјҢзЎ®дҝқжүҖжңүжҙ»еҠЁе’ҢжҲҗжң¬йғҪиў«жӯЈзЎ®еҪ’зұ»е’Ңзӣ‘жҺ§гҖӮ ### иҙ§еёҒи®ҫзҪ® SAP PSжЁЎеқ—ж”ҜжҢҒеӨҡиҙ§еёҒзҺҜеўғпјҢиҝҷж„Ҹе‘ізқҖйЎ№зӣ®еҸҜд»ҘеңЁдёҚеҗҢзҡ„иҙ§еёҒдёӢиҝӣиЎҢйў„з®—е’ҢжҲҗжң¬и®Ўз®—гҖӮиҝҷеҜ№дәҺи·ЁеӣҪдјҒдёҡе°ӨдёәйҮҚиҰҒпјҢеӣ дёәе®ғ们йңҖиҰҒ...
### SAPдёӯе’Ңи®ЎйҮҸеҚ•дҪҚжңүе…ізҡ„иЎЁ #### дёҖгҖҒеј•иЁҖ SAPзі»з»ҹдҪңдёәе…ЁзҗғйўҶе…Ҳзҡ„ERPи§ЈеҶіж–№жЎҲд№ӢдёҖпјҢеңЁеӨ„зҗҶдјҒдёҡж—ҘеёёдёҡеҠЎжөҒзЁӢдёӯиө·зқҖиҮіе…ійҮҚиҰҒзҡ„дҪңз”ЁгҖӮеҜ№дәҺд»»дҪ•ж¶үеҸҠеҲ°зү©ж–ҷз®ЎзҗҶгҖҒеә“еӯҳжҺ§еҲ¶гҖҒй”Җе”®дёҺеҲҶй”ҖзӯүжЁЎеқ—зҡ„еә”з”ЁеңәжҷҜиҖҢиЁҖпјҢи®ЎйҮҸеҚ•дҪҚ...
дәәе·ҘжҷәиғҪеҪ’зұ»з®—жі•жҳҜжңәеҷЁеӯҰд№ йўҶеҹҹдёӯзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢе®ғдё»иҰҒз”ЁдәҺеҜ№ж•°жҚ®иҝӣиЎҢеҲҶзұ»пјҢеҚіе°Ҷе…·жңүзӣёдјјзү№еҫҒзҡ„ж•°жҚ®еҜ№иұЎеҪ’еҲ°еҗҢдёҖзұ»еҲ«д№ӢдёӢгҖӮеңЁжң¬еҺӢзј©еҢ…ж–Ү件дёӯпјҢжҲ‘们еҸҜиғҪдјҡжҺўи®ЁеӨҡз§Қеёёи§Ғзҡ„дәәе·ҘжҷәиғҪеҪ’зұ»з®—жі•еҸҠе…¶еә”з”ЁеңәжҷҜгҖӮ йҰ–е…ҲпјҢи®©...